Relevance-driven Decision Making for Safer and More Efficient Human Robot Collaboration
Abstract
Human intelligence possesses the ability to effectively focus on important environmental components, which enhances perception, learning, reasoning, and decision-making. Inspired by this cognitive mechanism, we introduced a novel concept termed relevance for Human-Robot Collaboration (HRC). Relevance is defined as the importance of the objects based on the applicability and pertinence of the objects for the human objective or other factors. In this paper, we further developed a novel two-loop framework integrating real-time and asynchronous processing to quantify relevance and apply relevance for safer and more efficient HRC. The asynchronous loop leverages the world knowledge from an LLM and quantifies relevance, and the real-time loop executes scene understanding, human intent prediction, and decision-making based on relevance. In decision making, we proposed and developed a human robot task allocation method based on relevance and a novel motion generation and collision avoidance methodology considering the prediction of human trajectory. Simulations and experiments show that our methodology for relevance quantification can accurately and robustly predict the human objective and relevance, with an average accuracy of up to 0.90 for objective prediction and up to 0.96 for relevance prediction. Moreover, our motion generation methodology reduces collision cases by 63.76% and collision frames by 44.74% when compared with a state-of-the-art (SOTA) collision avoidance method. Our framework and methodologies, with relevance, guide the robot on how to best assist humans and generate safer and more efficient actions for HRC.
I Introduction
Robots and automation systems are becoming increasingly critical in enhancing productivity, efficiency, and precision in industry [1, 2, 3] and daily human life [4, 5]. However, they still struggle to match the exceptional cognitive capabilities of human beings. Among all cognitive mechanisms in human brains, humans are extraordinary at selectively focusing on important components within the environment, which guide our perception, learning, reasoning, and decision-making in daily life. It enables us to focus on relevant stimuli while filtering out irrelevant information in our environment, thus playing a crucial role in more efficient spatial perception, scene understanding, and decision-making [6, 7].
To empower the robot with similar capabilities, in [8], we defined a new and important concept and scene understanding approach, termed relevance, and developed methodologies for quantifying relevance with a novel event-based framework and a probabilistic methodology based on a new scene representation. Relevance is defined as the pertinence of objects in the scene based on the human objective or other factors. An example of relevance is shown in Fig. 1.

Relevance offers three key benefits in human-robot collaboration (HRC). First, accurately determined relevance enables the robot to better understand object applicability to the scene and potential interaction sequences, enhancing the efficiency, safety, and fluency of HRC. Second, focusing on relevant objects allows the robot to optimize its computational resources, improving speed and safety [9]. Third, relevance unites human, task, and scene models, facilitating more accurate predictions and reasoning by leveraging improvements from various areas.
Building on the work in [8], this paper further develops and presents a framework for determining relevance and applying it to a novel real-time decision-making component that enhances safety in HRC. In this framework, two loops are running asynchronously, namely the async loop and the real-time loop. The real-time loop performs continuous real-time computation, including scene understanding, human intent prediction, and decision-making. The asynchronous loop leverages the world knowledge from Large Language Models (LLM) to predict the potential human objective and relevance. The real-time loop utilizes those results for decision-making to achieve proactive and safe HRC. Although the loop operates asynchronously, its execution rate dynamically adjusts based on the scene’s conditions.
In the decision-making module, we developed a real-time methodology with human-robot task allocation and a novel motion planning methodology. With relevance, the traditional Artificial Potential Field (APF) methods for motion planning and collision avoidance are enhanced by a virtual obstacle constructed based on the future projection of the human motion and associated repulsive force formulation. In this way, the robot can behave in a proactive manner for safer and more efficient HRC. Simulation results demonstrate that our decision making module reduces the collision cases and frames by 63.76% and 44.74 %, respectively.
In summary, the paper’s contributions are as follows: (1) We proposed and developed a novel methodology to quantify relevance with human objective prediction and relevant object prediction based on LLMs. (2) We proposed and developed a novel two-loop framework to integrate LLM inference and relevance quantification into a real-time application by leveraging the asynchronous frameworks based on different inference requirements of different components. (3) We proposed and developed a novel methodology of decision making based on relevance. Simulations and experiments validate enhanced safety and lower collision probability with our Relevance-based Artificial Potential Field (RAPF).
II Related Works
This work is unique to the best of our knowledge and exceptionally contributes to the area of robotics in the following manners.
II-A Saliency and Attention
Relevance fundamentally differs from previous works that aim to identify and underline the important regions in the scene, such as attention and saliency. Saliency focuses on identifying the visually prominent and conspicuous features in the image [10, 11, 12], while attention focuses on current short-term, reactive, and simple tasks without considering the future projection [13, 14]. Relevance fundamentally differs from those works in that relevance represents the inherent relationship between objects because of the human objective and the applicability of objects to achive the objective. Relevance considers the interconnection among environmental understanding, human models, task models, etc.
II-B LLMs for Robotics
Large Language Models (LLMs) are revolutionizing robotics by enabling multi-modality reasoning [15], general prediction without transfer learning [16], and flexible connections between modules in robotic frameworks [17]. In this paper, we utilized LLMs for a dramatically different and novel application, i.e., relevance determination. Moreover, the current inference time of LLMs is longer than that of real-time computation requirements. Existing works with LLMs in robotics mainly apply to non-real-time policy generation in a static or pre-defined environment. Our unique two-loop design enables knowledge retrieval of LLMs in real-time applications by leveraging asynchronous computation.
II-C Artificial Potential Fields
APF is an intuitive and efficient real-time robot motion planning method by simulating attractive forces toward goals and repulsive forces away from obstacles, enabling smooth and collision-free navigation [18]. Song et al. proposed a methodology called Predictive APF to anticipate obstacles based on the robot’s velocity and the relative positions of obstacles to adjust the path before potential collisions [19]. However, their goal of incorporating prediction into APF is to smooth the path considering the dynamic constraints of the agent, which is dramatically different from ours. Moreover, their methodology is limited to environments with static obstacles. Our Relevance-based APF (RAPF) is to improve HRC safety by predicting the motion of the human and dynamically updating the path proactively in a highly dynamic environment.
III Problem Definition and Methodology
In this section, we introduce the problem definition and methodology for quantifying relevance and applying it to sensorimotor policy generation for safer and more efficient HRC.
III-A Problem definition
Let be a set of class of objects in a visual scene, where each represents a class of objects and is the number of classes of objects in the scene. The set of relevant elements , which contains all the relevant elements to the human’s objective and associated tasks, is predicted and determined with the available information. Based on , the robot generates actions to assist the human to achieve the human’s objective.
III-B Framework overview
An overview of the framework is shown in Fig. 2. Our framework for relevance quantification and safer HRC consists of two loops. The first loop fulfills the function of perceiving the world, understanding the scene, and decision making based on relevance for safer HRC. The second loop is an asynchronous loop that leverages LLMs and quantifies relevance. By optimally coordinating the two loops, the world knowledge of the LLM can be incorporated into real-time operation of the robots.
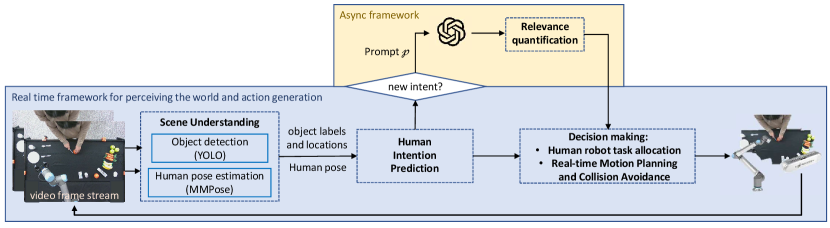
III-C Scene understanding
III-D Human intention prediction
The module of human intention prediction determines current human actions and aggregates them into a history record. Here, we implement an algorithm that leverages Bayesian networks to fuse three modalities of human information: head orientation, hand orientation, and hand movement. By fusing three modalities for human intention recognition, the accuracy and precision of the prediction are dramatically increased because different modality provides valuable information in different stages of the actions.
III-E Relevance Quantification with LLMs
In the original relevance formulation and quantification methodology, the scene is represented as classes and elements. The relevance of each class and element is determined in a sequential and hierarchical manner. In this paper, we adopted a direct prediction based on LLMs on the element level for simplicity. The goal of the LLMs in this paper is to predict the human objective and the set of relevant elements , reflecting potential future object interactions and human motion.
The first step in quantifying relevance with LLM is contextualizing the scene. Currently, this is achieved with a fixed prompt designed and optimized specifically for the setup and the problem of HRC. However, in the future, automatic scene contextualization and prompt construction can be considered and developed. In the prompt , the environment, the objects in the scene, and the action history of the human are automatically generated from the scene understanding and human intention prediction modules.
The outputs of the LLM module are the prediction of the human objective and the set of relevant elements . The relevance of each element is quantified to be
| (1) |
With this method, world knowledge of an LLM can be extracted for a general environment and setup without any training and transfer learning.
III-F Decision making - task allocation
Our framework’s decision-making can be decomposed into two components: human task allocation and real-time motion generation with collision avoidance.
For the sake of simplicity, we assume that humans need all the relevant elements predicted for the objective. A more detailed inquiry method to derive the necessary and preferred elements can be found in [8]. The human-robot task allocation is formulated as an optimization problem and solved with an optimization solver.
In the problem definition, we define the subscript representing the index of elements such that . We define the position vector of element in the world coordiante as , the position of the common destination of relevant elements as , the initial location of the robot as , the velocity of the robot as , the velocity of human as , the start-up delay for the human to finish the current task as . We consider because there is a temporal delay between the time the robot and the human start to fulfill the allocated tasks. We further define and as the time durations for the robot or the human to finish the assigned tasks, which can be computed as:
| (2) | ||||
and
| (3) |
We define the decision variable as the maximum time taken to complete all tasks, and the optimization problem is formulated as:
| Minimize | (4) | ||||
| Subject to: | (5) | ||||
| (6) | |||||
| (7) | |||||
| (8) | |||||
| (9) |
where is a binary decision variable where if the robot moves , and otherwise, and is a binary variable where if is the first task done by the robot, and otherwise. (5) ensures that exactly one object is designated as the initial task performed by the robot. (6) specifies that an object can only be the first task executed by the robot if that object is assigned to the robot, as indicated by . After the relevant objects are allocated to the robot or the human, the robot will execute the assigned tasks, generate the motion, and avoid obstacles dynamically in real time.
III-G Decision making - motion planning
For dynamic motion planning and obstacle avoidance, our methodology is based on an APF formulation in [23]. The major contribution of our work, as shown in Fig. 3, is that we build a virtual obstacle from the current human hand based on the predicted human motion and update the repulsive force based on the virtual obstacle for proactive and safer motion generation.
In our APF, the attractive force is modeled as:
| (10) |
where is the magnitude of the attractive force, is the distance between the robot and its goal, is the constant that controls how the attractive force decreases with distance, and is the unit vector from the robot to the goal.
The repulsive force by obstacles other than the human’s hand is constructed as:
| (11) |
where is the number of elements in the scene, is the magnitude of the repulsive force, is the distance between the robot and the obstacle , and is the unit vector from the obstacle to the robot location. and are two factors defining the shape and decreasing rate of the repulsive force as the distance increases, respectively.
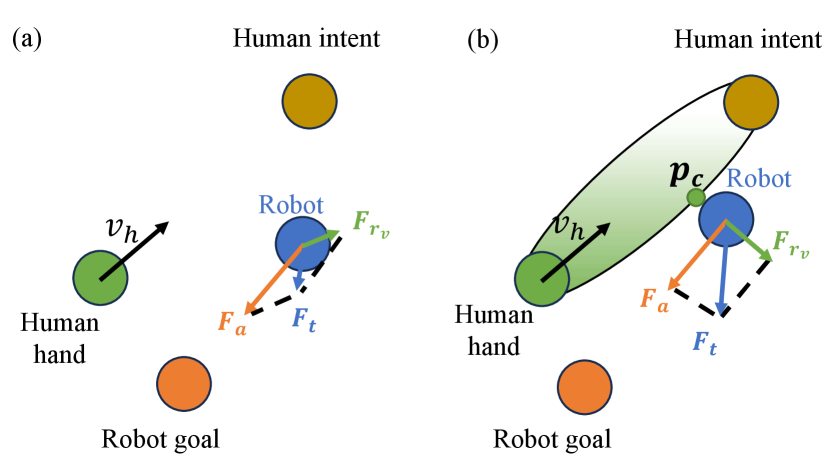
To consider the future motion of the human hand, we developed a novel methodology to construct an ellipsoid virtual obstacle as shown in Fig. 3. The two endpoints of the major axis of the ellipsoid are the current position of the human hand and the position of the predicted hand destination . The semi-axes , , and of the ellipsoid are given by:
| (12) |
| (13) |
| (14) |
where and are two factors controlling the shape of the ellipsoid. The repulsive force from this virtual obstacle is updated to
| (15) |
Where is the distance from the robot to the closest point on the ellipsoid , represents the unit normal vector at the closest point on the ellipsoid, and is a new factor we proposed representing a scale factor on the force magnitude based on the proximity to the human. In this paper, is computed as:
| (16) |
where represents the unit vector from to , and is a time factor we proposed in the unit of reflecting the available safety buffer in terms of time. decreases as becomes farther away from . Without , will consider the virtual obstacle too early and conservatively, which will result in unnecessary detour and a longer robot trajectory.
The total force acting on the robot is the sum of the attractive force and repulsive forces from both the physical obstacles and the virtual obstacle:
| (17) |
This total force determines the direction and magnitude of the robot’s motion, allowing it to avoid both physical and virtual obstacles while moving towards its goal.
IV Evaluation Setup
In this section, we introduce the evaluation setup for our proposed methodologies on leveraging LLMs for objective and relevance prediction and relevance in decision making for safer and more efficient HRC.
IV-A Dataset
The performance of human objective prediction and relevance prediction is assessed via the Breakfast Actions Dataset [24], which comprises a variety of typical human activities performed during breakfast time (e.g., preparing coffee, cooking pancakes, and making hot chocolate, etc.). For each test, ground truth data provides the ground truth objective (GTO), and the ground truth plan (GTP), which describes the sequence of actions performed by an individual in the execution of the objective. In our evaluation, a step ratio of segments from the GTP is contextualized and input into LLM to predict the human objective and the set of relevant elements. Three distinct ratio step values: 0.25, 0.5, and 0.75 are employed. The objective prediction is evaluated through a manual assessment process. The predicted relevant objects are evaluated automatically with word matching. The metrics for the evaluation are percentages of tests with correct prediction of the objective and the relevant elements.
IV-B Simulation Development and Setup
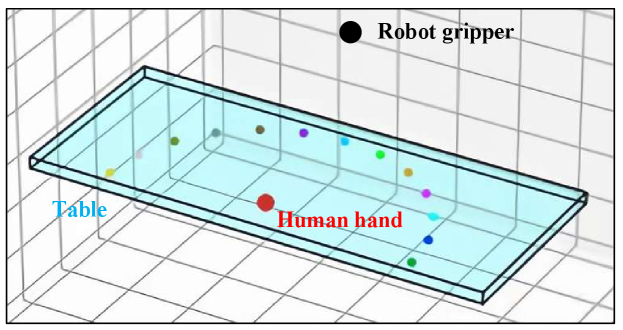
To verify the effectiveness of relevance for safer HRC, we developed a simulator as shown in Fig. 4. In the simulator, we constructed the environment with a table (the cyan cuboid) and objects on top of the table. The height of the table is set to be 73 cm. The table size is 180 cm in the direction, 6 cm in the direction, and 76 cm in the direction. The objects on the table consist of two parts: the necessary objects for the objective and randomly added objects from a list of kitchen objects. The locations for each objects on the tabletop are randomly selected from a collection of locations uniformly distributed on a half circle with a radius of 60 cm. The diameter of each object is 8 cm.
A human’s hand (the red dot) is added to the simulator to simulate the human’s motion. A UR5 robot is mounted on the other end of the table, reasoning about the human objective and the relevant objects and generating safe actions to best assist the human by accomplishing the human’s objective with minimum time. The initial locations of the human and the robot are shown in Fig. 4. To take the inference time of LLM into consideration, the simulation runs and progresses in real time with a frequency of 30 Hz. The velocities of the human’s hand and the end gripper are set to be 0.4 .
To test the effectiveness of relevance and our decision-making methodology, we focus on comparing two methods. The first method uses relevance and our decision-making with virtual obstacles, as described in Section III. For the comparison, we built a baseline test without virtual obstacles but with relevance. It’s worth noticing that, without relevance, the robot has no idea about its tasks to assist the human. Thus, we assign the same tasks as the relevance test cases to the robot. And the robot starts to move with exactly the same frame index as the relevance cases. Without loss of generality and for simplicity, we test on the objective of making cereals, and the relevant objects are cereal, bowl, milk, and spoon.
V Evaluation Results
In this section, we present the evaluation results of our proposed methodologies, demonstrating their effectiveness.
V-A Accurate Objective and Relevance Prediction
Our evaluation results are depicted in Table. I, confirming the effectiveness of our methodology for objective and relevance prediction across various scenarios. At a step ratio of 0.75 with more human actions contextualized and fed into LLM, our methodology achieves a high objective prediction accuracy of 0.90 and a relevance prediction accuracy of 0.96.
| Step Ratio | Average | Objectives | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cereals | Coffee | Friedegg | Chocolate | Juice | Pancake | Salad | Sandwich | Scrambledegg | Tea | |||
| Objective prediction | 0.25 | 0.69 | 0.93 | 0.96 | 0.16 | 0.76 | 0.72 | 0.43 | 0.92 | 0.65 | 0.42 | 0.92 |
| 0.5 | 0.82 | 1.00 | 1.00 | 0.13 | 1.00 | 0.96 | 0.95 | 1.00 | 0.32 | 0.84 | 0.96 | |
| 0.75 | 0.90 | 1.00 | 1.00 | 0.28 | 1.00 | 0.92 | 1.00 | 1.00 | 0.88 | 0.95 | 1.00 | |
| Relevance Prediction | 0.25 | 0.77 | 0.78 | 0.56 | 0.66 | 1.00 | 1.00 | 0.67 | 1.00 | 0.88 | 0.68 | 0.50 |
| 0.5 | 0.94 | 0.96 | 0.96 | 0.88 | 1.00 | 1.00 | 0.81 | 1.00 | 1.00 | 1.00 | 0.75 | |
| 0.75 | 0.96 | 1.00 | 0.88 | 0.88 | 1.00 | 1.00 | 0.95 | 1.00 | 0.97 | 0.95 | 0.96 | |
We first analyze the performance of objective prediction using our methodology, upon which relevance determination depends. Upon further examination of individual objectives, certain objectives, such as the preparation of cereal, coffee, hot chocolate, juice, salad, and tea, exhibit consistently high predictive accuracy across all evaluated ratio steps. The prediction accuracy for those objectives is high even at a low step ratio of 0.25, demonstrating our methodology can accurately identify the human’s objective at an early stage of the human action and motion. Consistent with expectations, an increase in the “ratio steps” parameter correlates positively with enhanced prediction accuracy. The contextualization of the scene with a higher step ratio will contain more indicative cues about the objectives and thus improve the objective prediction accuracy. The inaccuracy for fried eggs is attributed to the inherent similarity between the objectives involving eggs, such as omelettes and scrambled eggs. However, the relevance for those objectives are very similar.
Next, we analyze the performance of relevance prediction using our methodology based on the predicted objective. The relevance prediction performs extraordinarily for specific objectives, including hot chocolate, juice, and salad, which achieves a 100% accuracy at the step ratio of 0.25. The prediction accuracy of all other objectives achieves at least 0.85 at the step ratio of 0.75. For the relevance prediction, the accuracy also increases with the step ratio. It’s worth noting that the relevance prediction for the objectives predicted with low accuracy can still be accurate. This is attributed to the fact that similar objectives, such as omelettes and scrambled eggs, share the same relevance, which bolster the relevance prediction despite inaccuracies in objective identification.
V-B Real-time and Safer Decision Making
Through all the test cases, our methodology of relevance determination robustly and correctly predicts the human’s objective and the set of relevant elements for making cereals as bowl, spoon, milk, and cereal. Our human robot task allocation module robustly solves the optimization problem in real-time to generate the tasks for the robot. Thus, we focus on the evaluation of the virtual obstacle and collision avoidance. The test results of our real-time and safe decision making methodology are shown in Table II.
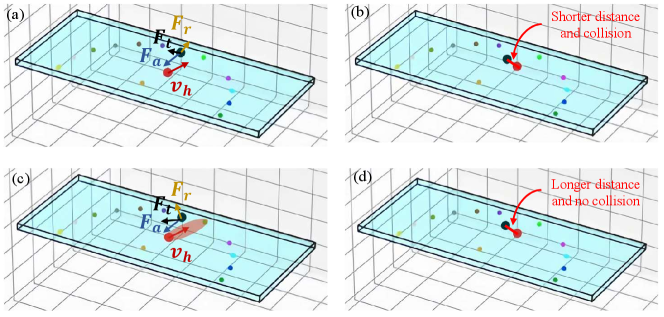
With our RAPF, the robot actions generated are much safer, with the rate of collided cases decreasing by 63.76% and the rate of collided frames decreasing by 44.74%. A visual comparison between the two methods is shown in Fig. 5. The frames at are the frames before the collision. With the relevance and the virtual obstacle, the repulsive force (shown with a gold arrow) is more perpendicular to the hand trajectory and thus pushes the gripper further from the hand smoothly. At , the gripper and the human collide in the baseline test because there is not enough duration of repulsive force to push the gripper farther away from the hand trajectory. However, with the virtual obstacle, no collision happens because of the proactive repulsive force generated by the virtual obstacle. Those results demonstrate the effectiveness of relevance and RAPF in informing the robot how to best assist humans and generate safer and more efficient actions.
| Baseline | RAPF | Percentage decrease | |
|---|---|---|---|
| Rate of collided cases | 0.149 | 0.054 | 63.76% |
| Rate of collided frames | 0.010 | 0.006 | 44.74% |
VI Conclusions and Future Works
Relevance is a novel concept inspired by the human cognitive abilities to evaluate the pertinence of objects based on the human’s objective or other factors. In this paper, we developed a novel two-loop framework that robustly, efficiently, and accurately quantifies relevance and applies relevance to improve the effectiveness and safety of HRC. This framework integrates an asynchronous loop to leverage world knowledge from an LLM and quantify relevance, as well as a real-time loop to execute scene understanding, human intention prediction, and decision-making. Moreover, we proposed and developed a decision making methodology based on relevance, integrating human robot task allocation and real-time motion generation. In motion generation, we developed a methodology to construct a virtual obstacle and formulate the associated repulsive force. Simulations and experiments verify that our framework performs well for relevance quantification, with an objective prediction accuracy of 0.90 and a relevance prediction accuracy of 0.96. Simulations further verify our novel motion generation methodology dramatically decreases the cases with a collision by 63.76% and the frames with a collision by 44.74%. The robot is comprehensively informed about how to best assist the human with relevance, and our decision making module generates safe actions to achieve the assistance.
References
- [1] X. Zhang and K. Youcef-Toumi, “Magnetohydrodynamic energy harvester for low-power pipe instrumentation,” IEEE/ASME Transactions on Mechatronics, vol. 27, no. 6, pp. 4718–4728, 2022.
- [2] X. Zhang, A. Al Alsheikh, and K. Youcef-Toumi, “Systematic evaluation and analysis on hybrid strategies of automatic agent last-mile delivery,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 2733–2740.
- [3] X. Zhang, “Design and optimization of an mhd energy harvester for intelligent pipe systems,” Ph.D. dissertation, Massachusetts Institute of Technology, 2019.
- [4] A. Kothari, T. Tohme, X. Zhang, and K. Youcef-Toumi, “Enhanced human-robot collaboration using constrained probabilistic human-motion prediction,” arXiv preprint arXiv:2310.03314, 2023.
- [5] F. Xia, J. Quigley, X. Zhang, C. Yang, Y. Wang, and K. Youcef-Toumi, “A modular low-cost atomic force microscope for precision mechatronics education,” Mechatronics, vol. 76, p. 102550, 2021.
- [6] C. Bundesen, “A theory of visual attention.” Psychological review, vol. 97, no. 4, p. 523, 1990.
- [7] K. Yoo, M. D. Rosenberg, Y. H. Kwon, Q. Lin, E. W. Avery, D. Sheinost, R. T. Constable, and M. M. Chun, “A brain-based general measure of attention,” Nature human behaviour, vol. 6, no. 6, pp. 782–795, 2022.
- [8] X. Zhang, D. Huang, and K. Youcef-Toumi, “Relevance for human robot collaboration,” 2024. [Online]. Available: https://arxiv.org/abs/2409.07753
- [9] X. Zhang, J. Chong, and K. Youcef-Toumi, “How does perception affect safety: New metrics and strategy,” in 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 13 411–13 417.
- [10] L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual attention for rapid scene analysis,” IEEE Transactions on pattern analysis and machine intelligence, vol. 20, no. 11, pp. 1254–1259, 1998.
- [11] D. Meger, P.-E. Forssén, K. Lai, S. Helmer, S. McCann, T. Southey, M. Baumann, J. J. Little, and D. G. Lowe, “Curious george: An attentive semantic robot,” Robotics and Autonomous Systems, vol. 56, no. 6, pp. 503–511, 2008.
- [12] D. Chung, R. Hirata, T. N. Mundhenk, J. Ng, R. J. Peters, E. Pichon, A. Tsui, T. Ventrice, D. Walther, P. Williams, et al., “A new robotics platform for neuromorphic vision: Beobots,” in Biologically Motivated Computer Vision: Second International Workshop, BMCV 2002 Tübingen, Germany, November 22–24, 2002 Proceedings 2. Springer, 2002, pp. 558–566.
- [13] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [14] C. Devin, P. Abbeel, T. Darrell, and S. Levine, “Deep object-centric representations for generalizable robot learning,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 7111–7118.
- [15] Y. Yang, T. Zhou, K. Li, D. Tao, L. Li, L. Shen, X. He, J. Jiang, and Y. Shi, “Embodied multi-modal agent trained by an llm from a parallel textworld,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 275–26 285.
- [16] L. Chen, O. Sinavski, J. Hünermann, A. Karnsund, A. J. Willmott, D. Birch, D. Maund, and J. Shotton, “Driving with llms: Fusing object-level vector modality for explainable autonomous driving,” in 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 14 093–14 100.
- [17] Z. Zhou, J. Song, K. Yao, Z. Shu, and L. Ma, “Isr-llm: Iterative self-refined large language model for long-horizon sequential task planning,” in 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 2081–2088.
- [18] O. Khatib, “Real-time obstacle avoidance for manipulators and mobile robots,” The international journal of robotics research, vol. 5, no. 1, pp. 90–98, 1986.
- [19] J. Song, C. Hao, and J. Su, “Path planning for unmanned surface vehicle based on predictive artificial potential field,” International Journal of Advanced Robotic Systems, vol. 17, no. 2, p. 1729881420918461, 2020.
- [20] P. Jiang, D. Ergu, F. Liu, Y. Cai, and B. Ma, “A review of yolo algorithm developments,” Procedia computer science, vol. 199, pp. 1066–1073, 2022.
- [21] M. Contributors, “Openmmlab pose estimation toolbox and benchmark,” https://github.com/open-mmlab/mmpose, 2020.
- [22] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [23] J.-H. Chen and K.-T. Song, “Collision-free motion planning for human-robot collaborative safety under cartesian constraint,” in 2018 IEEE International Conference on Robotics and Automation (ICRA), 2018, pp. 4348–4354.
- [24] H. Kuehne, A. B. Arslan, and T. Serre, “The language of actions: Recovering the syntax and semantics of goal-directed human activities,” 2014 IEEE Conference on Computer Vision and Pattern Recognition, pp. 780–787, 2014. [Online]. Available: https://api.semanticscholar.org/CorpusID:9621856