(eccv) Package eccv Warning: Package ‘hyperref’ is loaded with option ‘pagebackref’, which is *not* recommended for camera-ready version
{haobin.jiang,zongqing.lu}@pku.edu.cn
Reinforcement Learning Friendly Vision-Language Model for Minecraft
Abstract
One of the essential missions in the AI research community is to build an autonomous embodied agent that can achieve high-level performance across a wide spectrum of tasks. However, acquiring or manually designing rewards for all open-ended tasks is unrealistic. In this paper, we propose a novel cross-modal contrastive learning framework architecture, CLIP4MC, aiming to learn a reinforcement learning (RL) friendly vision-language model (VLM) that serves as an intrinsic reward function for open-ended tasks. Simply utilizing the similarity between the video snippet and the language prompt is not RL-friendly since standard VLMs may only capture the similarity at a coarse level. To achieve RL-friendliness, we incorporate the task completion degree into the VLM training objective, as this information can assist agents in distinguishing the importance between different states. Moreover, we provide neat YouTube datasets based on the large-scale YouTube database provided by MineDojo. Specifically, two rounds of filtering operations guarantee that the dataset covers enough essential information and that the video-text pair is highly correlated. Empirically, we demonstrate that the proposed method achieves better performance on RL tasks compared with baselines. The code and datasets are available at https://github.com/PKU-RL/CLIP4MC.
Keywords:
Dataset Multimodal model Reinforcement learning1 Introduction
Training reinforcement learning (RL) agents to perform complex tasks in a vision-based and open-ended world can be difficult. One main challenge is that manually specifying reward functions in all open-ended tasks is unrealistic [21, 3], especially when we cannot access the internal configuration of the environment. In addition, learning a reward model from human feedback is typically expensive. To this end, MineDojo [8] has proposed an internet-scale, multi-modal knowledge base of YouTube videos to facilitate learning in an open-ended world. With the advent of a such large-scale database, agents are able to harvest practical knowledge encoded in large amounts of media like human beings. Moreover, a vision-language model (VLM), MineCLIP [8], is proposed to utilize the internet-scale domain knowledge. In more detail, the learned correlation score between the visual observation and the language prompt can be used effectively as an open-vocabulary, massively multi-task reward function for RL training. Therefore, no further task-specific reward design is needed for open-ended tasks.
However, the autonomous embodied agent requires the vision-language model to provide a more instructive correlation score. Given the partial observations, e.g., video snippet, and the language prompt that describes the task, the agent needs to figure out two non-trivial matters to better evaluate the current state. On the one hand, whether the target entities are present within its field of vision? MineCLIP tried to address this question. However, the alignment of texts and videos in the YouTube database is totally a catastrophe, which impedes the learning of VLM. On the other hand, what is the relationship between each video snippet and the degree of completion of the task? Normally, in an open-ended world, e.g. Minecraft, the agent explores first, then approaches and interacts with the target object. In other words, the agent requires approaching the target object before it takes trial-and-error, even for the target that needs to be kept away. Therefore, it is reasonable to make an assumption, namely, that the higher the level of completion of the task, the closer the agent is to the targets in the video snippet. We also argue it is important to incorporate the level of completion of the task into the reward function.
In this paper, we first construct neat YouTube datasets to facilitate the learning of basic game concepts, mainly the correspondence between the videos and texts. Though a large-scale database is provided by MineDojo, it contains significant noise due to its nature as an online resource. In addition, MineDojo only claims the training dataset is randomly sampled from the database, making it hard to reproduce. To overcome the catastrophic misalignment of video-text pairs in the original database, we have done four steps of dataset processing to guarantee the dataset is clean. Firstly, transcript cleaning enhances the accuracy of transcripts and ensures they are complete sentences. Secondly, keyword filtering ensures that the content of clips is relevant to the key entities in Minecraft, thereby facilitating the learning of basic game concepts. Thirdly, video partitioning and selection can handle the issue of scene transitions and thereby mitigate interference from other extraneous information. Lastly, correlation filtering can effectively address the issue of mismatch between video clips and transcripts.
We also propose an upgraded vision-language model, CLIP4MC, to provide a more RL-friendly reward function. In RL, simply utilizing the similarity between the video snippet and the language prompt is not RL-friendly since MineCLIP tends to only capture the similarity at the entity level. In other words, VLM can hardly reflect the relationship between each video snippet and the degree of completion of the task. However, this information can better help agents distinguish the importance between similar states. To achieve this, we incorporate the degree of task completion into the VLM training objective. In more detail, CLIP has exhibited remarkable segmentation capabilities without fine-tuning. After we extend pre-trained MineCLIP with modifications inspired by MaskCLIP [35], it can segment the specified object from the image and label the size of the target shown in the corresponding video. Intuitively, the closer the agent is to the target, the larger the target size becomes. During the learning procedure, we dynamically control the degree of contrasting positive and negative pairs of instances based on the target size in this positive video sample. Thus, CLIP4MC can render a more RL-friendly reward signal that instructs the agent to learn tasks faster. Our proposed method is trained on our YouTube dataset and evaluated on MineDojo Programmatic tasks, including harvest, hunt, and combat tasks. Empirically, our results show that CLIP4MC can provide a more friendly reward signal for the RL training procedure.
To summarize, our contributions are as follows:
-
•
Open-sourced datasets: We provide two high-quality datasets. The first one undergoes data cleaning (Sections 4.1, 4.2 and 4.3) and global-level correlation filtering (Section 4.4). The VLM trained on this dataset matches the performance of the officially released MineCLIP, which lacks a publicly available training set.
-
•
RL-friendly dataset: Our second dataset further incorporates local-level correlation filtering (Section 4.4), making it more suited for RL. The VLM trained on this dataset outperforms that on the first dataset.
-
•
RL-friendly VLM: To better evaluate and leverage the advantages of our more RL-friendly dataset, we introduce CLIP4MC, a novel method to train a VLM that could improve downstream RL performance (Section 5.2).
2 Related Work
Video-Text Retrieval. Video-text retrieval plays an essential role in multi-modal research and has been widely used in many real-world web applications. Recently, the pre-trained models have dominated this line of research with noticeable results on both zero-shot and fine-tuned retrieval. Especially, BERT [5], ViT [6], and CLIP [25], are used as the backbones to extract the text or video embedding. The cross-modal embeddings are then matched with specific fusion networks to find the correct video-text pair.
In more detail, CLIP4Clip [20] proposes three different similarity modules to calculate the correlation between video and text embeddings. HiT [19] performs hierarchical matching at two different levels, i.e. semantic level and feature level. Note that semantic level and feature level features are from the transformer network’s higher and lower feature layers, respectively. Frozen [1] proposes a dual encoder architecture that utilizes the flexibility of a transformer visual encoder to train from images or video clips with text captions. Moreover, MDMMT [7] adopts several pre-training models as encoders and it shows the CLIP-based model performs the best. Therefore, our model follows this line of research by using the pre-trained model, CLIP [25], to extract the feature embeddings.
Minecraft for AI Research. As an open-ended video game with an egocentric vision, Minecraft is a noticeable and important domain in RL due to the nature of the sparse reward, large exploration space, and long-term episodes. Since the release of the Malmo simulator [14] and later the MineDojo simulator [8], various methods have attempted to train agents to complete tasks in Minecraft [31, 30, 10, 18, 12]. Approaches such as model-based RL, hierarchical RL, goal-based RL, and reward shaping have been adopted to alleviate the sparse reward and exploration difficulty for the agent in this environment.
Recently, with the development of large language models (LLM) like GPT-4 [24], a series of methods leveraging LLMs for high-level planning in Minecraft have been proposed [16, 22, 34, 32, 36]. These methods have demonstrated remarkable capabilities in guiding the agent to complete multiple complicated, long-horizon tasks, such as mining diamonds. These LLMs play a crucial role in decision-making, determining the sequence of basic skills required to accomplish specific tasks. Their effectiveness is due to their extensive knowledge about Minecraft, learned from the Internet, and their ability to reflect on real-time feedback from the game environment.
In addition to the use of LLMs, recent research attempts to incorporate Internet visual data into basic skill learning in Minecraft, beyond the traditional RL methods. MineRL [11] collected 60M player demonstrations with action labels, motivating some methods [29, 16] based on behavior cloning. As well-labeled data is limited in quantity, MineCLIP [8] instead uses over 730K narrated Minecraft videos without action labels from YouTube. It aims to learn a vision-language model providing auxiliary reward signals, utilizing the vast and diverse data available on the Internet. Different from MineCLIP, VPT [2] uses action-labeled data to train an inverse dynamic model to label 70K hours of Internet videos and then conduct behavior cloning.
Unlike the existing approaches, which incorporate the human experience and require a large number of demonstrations with action labels to train the agent, our work follows the line of MineCLIP [8] and focuses on only using the data without action labels to assist agent learning in Minecraft, which is more friendly with data collection and has the potential to scale in the future.
3 Background
MineDojo tasks. MineDojo [8] provides thousands of benchmark tasks, which can be used to develop generally capable agents in Minecraft. These tasks can be divided into two categories, Programmatic and Creative tasks. The former has ground-truth simulator states to assess whether the task has been completed. The latter, however, do not have well-defined success criteria and tend to be more open-ended, but have to be evaluated by humans.
We mainly focus on Programmatic tasks since they can be automatically assessed. Specifically, MineDojo provides 4 categories of programmatic tasks, including Harvest, Combat, Survival, and Tech Tree, with 1581 template-generated natural language goals to evaluate the agent’s different capabilities. Among these tasks, Survival and Tech Tree tasks are harder than Harvest and Combat tasks. Currently, MineCLIP [8] only expresses promising potential in some Harvest and Combat tasks. Harvest means finding, obtaining, cultivating, or manufacturing hundreds of materials and objects. Combat means fighting various monsters and creatures that require fast reflexes and martial skills.
POMDP. We model the programmatic task as a partially observable Markov decision process (POMDP) [15]. At each timestep , the agent obtains the partial observation from the global state and a language prompt , takes action following its policy , and receives a reward , where is the fixed-length sequence of observations till (thus a video snippet) and maps and to a scalar value. Then the environment transitions to the next state given the current state and action according to transition probability function . The agent aims to maximize the expected return , where is the discount factor and is the episode time horizon.
4 YouTube Dataset

The Internet is rich in Minecraft-related data, containing a wealth of weakly labeled or even unlabeled Minecraft knowledge, including crucial entities, plausible actions, and common-sense event processes. With these multi-modal data, it is possible to create dense language-conditioned rewards, making open-ended long-term task learning feasible. MineDojo [8] collected over 730K YouTube videos and their corresponding transcripts, totaling 33 years of video content and 2.2B words in transcripts. Around 640K video clips are selected using keyword-based filtering from these videos, and these clips are used to train MineCLIP. However, MineDojo open-sourced a 13.8M dataset, and the 640K video clips were randomly sampled in their paper. However, as illustrated in Figure 1, most videos feature irrelevant game content that is not conducive to learning basic game concepts. Meanwhile, the alignment between the transcripts and videos may not always be precise, leading to temporal or content discrepancies that could hinder the learning of retrieval and RL tasks. Given the low quality of the data, we found it necessary to provide a neat 640k dataset to the community for the training usage. To address these issues, we adopt the following few steps to acquire a clean dataset with high quality.
4.1 Transcript Cleaning
Downloading YouTube’s automatic transcripts directly can lead to several issues. Firstly, transcript blocks may overlap, resulting in overlapping timestamps in the transcript. Additionally, the caption quality is typically mediocre, with a higher occurrence of misidentifications, especially in non-English videos. Moreover, the transcript lacks punctuation, making it less friendly for understanding semantics. Based on the aforementioned issues, we implement a pipeline to construct high-quality transcripts as follows: (1) Extract audio from the videos and use Whisper [26] to obtain high-quality, temporally non-overlapping transcripts. (2) Employ FullStop [9] to generate punctuation, resulting in complete sentences of 10-35 words in length.
4.2 Keyword Filtering
Following MineDojo [8], we also implement keyword-based filtering to ensure that the content in our dataset is pertinent to the key entities in Minecraft, thereby facilitating the learning of basic game concepts. As essential components of Minecraft, the key entities, such as stones, trees, and sheep, are common across multiple tasks in MineDojo and videos from YouTube. Specifically, we identify entity keywords in the transcripts using a keyword list from MineDojo and extract transcript clips formed into sentences to encompass as many keywords as possible. These extracted transcript clips then serve as the textual component of our dataset, determining the location of corresponding video clips.
4.3 Video Partition and Selection
After completing the previous two steps, we obtain transcript clips relevant to the keywords. For each transcript clip, we calculate the central timestamp that corresponds to the clip based on the transcript timestamps and then use this central timestamp to extract a video clip with a duration of seconds from the video. This process allows us to obtain temporally-aligned video clips. However, the video clips obtained in this manner still exhibit some issues, including scene transitions and discrepancies between video content and transcripts. We handle the former problem through video partition and filtering, while the latter problem is addressed in Section 4.4.
Owing to the informal nature of YouTube content, there is often a lack of semantic congruence between the video clips and their corresponding transcriptions, as noted in VideoCLIP [33]. Moreover, video clips frequently contain a few different behaviors which cause scene transitions, e.g. Chopping down the tree first, then suddenly switching the inventory bar. Since some scene transitions lead to irrelevant information, we partition the video content into several semantically coherent segments based on the semantic structure of the video. Then we select the segment that aligns best with the transcript.
To achieve semantic partition of video content, we employ the Bellman -segmentation algorithm [13]. This algorithm divides a sequence of data points into distinct and constant-line segments, providing a piece-wise constant approximation of the data. To process the video, we first use the officially released MineCLIP [8] video encoder to obtain the embedding of each frame, since MineCLIP can capture video semantics to some extent. Subsequently, we partition these embeddings into segments and select the segment with the highest similarity score, as calculated in MineCLIP.
4.4 Correlation Filtering



We employ correlation filtering techniques to address disparities that persist between video content and transcripts. The correlation filtering is done at two levels, the global and the local levels. From the global level, we calculate the cosine similarities between video embeddings and text embeddings via the original MineCLIP and then select clips based on these similarities.
Recent research [35, 17] has demonstrated that CLIP [25], though trained on whole images, can generate meaningful local features. Inspired by this and following MaskCLIP [35], we make modifications to the original MineCLIP visual encoder, empowering it with the ability to estimate and label the size of the key entity, which is mentioned in the corresponding transcript, in each frame of a video clip without fine-tuning. Then the correlations between video clips and transcripts are calculated as the summation of the sizes across all frames in each video clip. We consider this correlation at the local level.
Based on these two criteria, we select the top of clips, resulting in the final training set. We provide an elaboration on our implementation in Appendix 0.A and illustrate some examples in Figure 2.
The aforementioned four-step approach creates a dataset consisting of 640K video-text clip pairs, with an additional 4K pairs extracted for validation of video-text retrieval. Regarding the constants of the approach, and are set to 16 and 50, respectively. Therefore, our dataset comprises videos with a total duration of one week and approximately 0.16B words, significantly smaller in scale compared to the original low-quality 13.8M dataset. Importantly, we will open-source our entire YouTube dataset, serving as an upgraded version of the unreleased MineCLIP training data.
5 CLIP4MC
Given a video snippet and a language prompt , the vision-language model outputs a correlation score, , that measures the similarity between the video snippet and the language prompt. Ideally, if the agent performs behaviors following the description of the language prompt, the vision-language model will generate a higher correlation score, leading to a higher reward. Otherwise, the agent will be given a lower reward.
5.1 Architecture
We follow the same architecture design as MineCLIP [8], including a video encoder, a text encoder, and a similarity calculator. All the video frames first go through the spatial transformer to obtain a sequence of frame features. The temporal transformer is then utilized to summarize the sequence of frame features into a single video embedding. An adapter further processes the video embedding for better features. Refer to Appendix 0.B for more details about the architecture.
Empirically, we found that the video encoder (essentially MineCLIP) can provide a bond between the entities and the language prompts and give a similar high reward as long as the target entities are present in the video frames, similar to observations in [4]. However, such a reward is not instructive enough for RL tasks since it does not reflect the behavioral trends of agents.
5.2 Contrastive Training
We aim to minimize the sum of the multi-modal contrastive losses [23], including video-to-text, and text-to-video:
| (1) |
where is the batch containing sampled video-text pairs, and is the contrastive loss that calculates the similarity of two inputs. To illustrate, the video-to-text contrastive loss is given by
| (2) |
where is a temperature hyperparameter, is the positive text embedding matching with the video embedding , and are negative text embeddings that are implicitly formed by other text clips in the training batch. Contrastive loss of text-to-video is defined in the same way.
In addition, we also need to incorporate the degree of task completion into the training objective. Specifically, we hope the similarity score between video clip and text embeddings could reflect the task completion degree, i.e., higher completion leads to higher similarity. The sizes of key entities provided by the local correlation filtering serve as a surrogate for the task completion degree. Initially, we try to dynamically adjust the weight of the positive pairs based on the size of the target object. However, it did not work. Essentially, positive and negative pairs will still be separated, even with smaller sample weights.
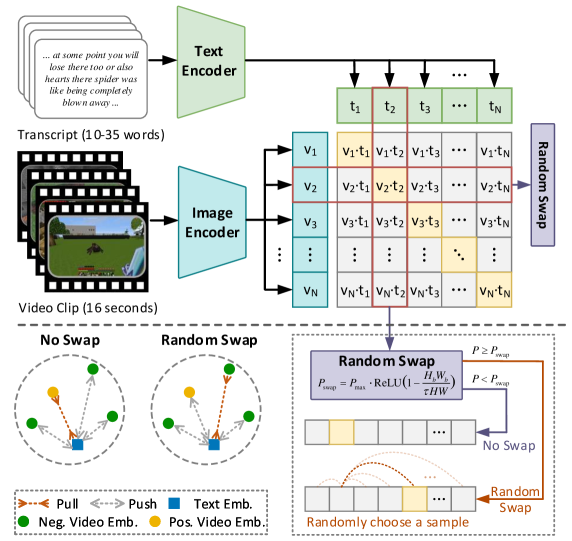
Therefore, we instead forcibly change the labels of the positive and negative video samples, as illustrated in Figure 3, thereby reducing the model’s confidence in certain positive pairs. Specifically, during training, a positive video sample is swapped with a random negative video sample from the based on probability . This swap only occurs when the labeled target size in the positive video sample is below a certain threshold , and the smaller the size, the greater the probability,
| (3) |
where represents the size of the image.
Since contrastive learning brings positive samples closer and pushes negative samples away, converting a positive pair to a negative one with a certain probability, i.e., the aforementioned random swap, during training will lower the similarity score. As the decrease in similarity is directly proportional to the swapping probability, we set to be inversely related to task completion, ensuing similarity score increases as completion increases.
In addition, the upper limit in Equation 3 is set to 0.5, as the swap should not disrupt severely the normal distinction between positive and negative pairs in most cases. This constraint enables CLIP4MC to preserve the understanding capability of MineCLIP for general behaviors that may lack explicit target entities in Minecraft, as discussed in Appendix 0.F.
5.3 RL Training
For RL training, the first step is reward generation. At timestep , we concatenate the agent’s latest 16 egocentric RGB frames in a temporal window to form a video snippet, . CLIP4MC outputs the probability that calculates the similarity of to the task prompt, , against all other negative prompts. To compute the reward, we further process the raw probability as previous work [8] , where is the number of prompts passed to CLIP4MC. Note that CLIP4MC can handle unseen language prompts without any further fine-tuning due to the open-vocabulary ability of CLIP [25].
The ultimate goal is to train a policy network that takes as input raw pixels and other structural data and outputs discrete actions to accomplish the task that is described by the language prompt, . We use PPO [28] as our RL training backbone and the policy is trained on the CLIP4MC reward together with the sparse task reward if any. The policy input contains several modality-specific components and more details can be found in Appendix 0.D.
6 Experiments
In this section, we comprehensively evaluate and analyze our proposed model CLIP4MC, utilizing the open-ended platform MineDojo [8], which comprises thousands of diverse, open-ended Minecraft tasks designed for embodied agents.
We compare CLIP4MC against two baselines: (1) MineCLIP [official], the officially released MineCLIP model [8]. (2) MineCLIP [ours], using the same architecture as MineCLIP [official] but trained on our cleaned YouTube dataset. It also serves as the ablation of CLIP4MC without the swap operation. We train CLIP4MC and MineCLIP [ours] for 20 epochs and select the models with the highest performance on RL tasks. Please refer to Appendix 0.C for more training details. All results are presented in terms of the mean and standard error of four runs with different random seeds.
6.1 Environment Settings
We conduct experiments on eight Programmatic tasks, comprising two harvest tasks: milk a cow and shear wool, two combat tasks: combat a spider and combat a zombie, and four hunt tasks: hunt a cow, hunt a sheep, hunt a pig, and hunt a chicken. These tasks are all built-in tasks in the MineDojo benchmark.
Harvest. Milk a cow requires the agent to obtain milk from a cow with an empty bucket. Similarly, shear wool requires the agent to obtain wool from a sheep with shears. A harvest task is terminated and considered completed when the target item is obtained by the agent with a specified quantity. The prompts used to calculate the reward is “obtain milk from a cow in plains with an empty bucket”; for shear wool, it is “shear a sheep in plains with shears”.
Combat. In these tasks, target animals, spiders, and zombies, are hostile and will actively approach and attack the agent. The agent’s goal is to fight and kill the target animal. The prompt for each combat task is “combat a spider/zombie in plains with a diamond sword”.
Hunt. Hunt tasks consist of hunt a cow, hunt a sheep, hunt a pig, and hunt a sheep. For each task, the agent’s goal is to kill the target animal as indicated in the task name. Different from combat tasks, the target animals will flee from the agent after being attacked. Therefore, these tasks require the agent to keep chasing and attacking the target, making them challenging. As noted in [4], the original MineCLIP reward fails in these tasks since it cannot consistently increase when the agent approaches the agent. This observation aligns with our assertion that the original MineCLIP model can hardly capture the degree of task completion. The prompt for each task is “hunt a {target} in plains with a diamond sword” where {target} is replaced with the corresponding animal name.
More elaborated introduction of the Minecraft environment and settings of these tasks are available in Appendix 0.D. To guarantee a fair comparison, we adopt the same RL hyperparameters for all models and tasks. These hyperparameters are listed in Appendix 0.E.
6.2 RL Results
| Models | Harvest | Combat | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| milk a cow | shear wool | combat a spider | combat a zombie | |||||||
| CLIP4MC | 84.5±2.0 | 74.6±2.1 | 85.8±0.9 | 70.4±8.3 | ||||||
| MineCLIP[ours] | 84.4±1.1 | 71.6±3.5 | 75.4±10.1 | 63.6±8.7 | ||||||
| MineCLIP[official] | 84.1±0.5 | 73.2±1.8 | 82.7±2.5 | 57.4±3.7 | ||||||
| Models | Hunt | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| hunt a cow | hunt a sheep | hunt a pig | hunt a chicken | |||||||
| CLIP4MC | 39.8±2.5 | 45.9±7.2 | 30.6±8.4 | 26.1±3.5 | ||||||
| MineCLIP[ours] | 17.3±10.6 | 33.0±18.1 | 14.1±10.6 | 15.3±10.6 | ||||||
| MineCLIP[official] | 11.6±11.1 | 28.5±16.7 | 1.5±0.6 | 0.0±0.0 | ||||||
Through our evaluation of CLIP4MC, MineCLIP [ours], and MineCLIP [official] across eight Minecraft tasks, we want to answer two key questions:
(1) Whether the YouTube dataset we constructed enables MineCLIP, when trained on it, to provide a more effective reward signal for task learning?
(2) Whether our upgraded model, CLIP4MC, based on our YouTube dataset, offers a reward signal that is further friendly for the RL training procedure?
These questions are central to verifying the effectiveness of our dataset and CLIP4MC model in Minecraft. Table 1 shows the success rates of all methods on the eight Minecraft tasks.
It is noticeable that, in four hunt tasks, three models demonstrate varying performance on RL. Firstly, MineCLIP [ours] consistently achieves better results compared to MineCLIP [official] across all hunt tasks. The superior performance of MineCLIP [ours] provides a positive answer to our first question, suggesting that the YouTube dataset we construct indeed enhances the effectiveness of the reward signal in MineCLIP for task learning. Note that this is the dataset we plan to release for better training the VLM model for RL tasks on Minecraft. Secondly, CLIP4MC shows significantly higher success rates on hunt tasks compared to both MineCLIP [ours] and MineCLIP [official], meaning that the answer to the second question is also positive. As CLIP4MC provides a reward signal taking into account a surrogate for the degree of task completion, i.e., the size of the target object in our implementation, it becomes more RL-friendly in these challenging tasks.
In addition, we notice a practical example of misalignment in the officially released MineCLIP model. Specifically, we observe that in hunt a chicken, the agent trained with MineCLIP [official] tends to keep looking at the sky, indicating such behavior can provide a high intrinsic reward. This phenomenon suggests that the officially released MineCLIP indeed suffers from the misalignment problem in the YouTube dataset. In contrast, our MineCLIP [official] shows promising behaviors on this task, demonstrating that our dataset processing improves the alignment between the transcripts and videos.
In contrast to hunt tasks, these methods perform comparably on harvest tasks and combat tasks, while CLIP4MC still shows marginal advantage over the other two methods. This finding aligns with the results reported in [8], where the MineCLIP reward already achieves saturated performance on these easy tasks. Therefore, further enhancements in the reward signal, like MineCLIP [ours] and CLIP4MC, do not significantly improve performance. Unlike hunt tasks, neither harvest nor combat tasks require the agent to take multiple rounds of chasing. This result does not detract from the superiority of CLIP4MC, evidenced by its performance on hunt tasks, which are considered more difficult [2].
6.3 Reward Analysis
To quantitatively verify that CLIP4MC captures the size of the target entity specified in the language prompt, we collect 5000 steps in task hunt a cow and apply the method described in Appendix 0.A to estimate the maximal size of the cow in consecutive 16 frames. Then we use CLIP4MC, MineCLIP [ours], and MineCLIP [official] to calculate intrinsic rewards respectively. Before calculating the correlation between the size and intrinsic rewards, we transform the size value using , focusing on smaller values. The relationship between the transformed size and intrinsic rewards is visualized in Figure 4. The corresponding Pearson correlation coefficients from left to right are 0.81, 0.66, and 0.62, indicating that CLIP4MC reward has a higher correlation with the size, especially when it is relatively small. This is crucial in RL, as the agent needs dense and distinguishing reward signals to guide the learning process, particularly when the target is distant. Such characteristic is the essential benefit of CLIP4MC in RL.



6.4 Ablation on Dataset Filtering
| Models | milk a cow | shear wool | hunt a cow | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5e5 | 1e6 | 5e5 | 1e6 | 5e5 | 1e6 | |||||||||
| ours | 73.1±0.9 | 84.4±1.1 | 47.5±6.3 | 71.6±3.5 | 15.6±8.7 | 17.3±10.6 | ||||||||
| w/o LCF | 71.3±1.8 | 80.7±1.1 | 53.8±3.3 | 73.6±1.5 | 0.7±0.7 | 12.1±12.0 | ||||||||
| RS | 65.1±3.9 | 81.7±1.0 | 21.7±6.5 | 68.5±3.6 | 1.0±0.5 | 4.0±2.6 | ||||||||
| official | 69.8±1.3 | 84.1±0.5 | 47.0±13.5 | 73.2±1.8 | 2.7±1.1 | 11.6±11.1 | ||||||||
To evaluate the influence of the dataset quality on RL training and verify the effectiveness of our proposed correlation filter at the local level, we compare MineCLIP [ours] with two ablations: (1) MineCLIP [w/o LCF] is trained on the dataset processed with only global correlation filtering, omitting the local correlation filtering. (2) MineCLIP [RS] is trained on 640K video clips randomly sampled from the MineDojo released database, consistent with their stated dataset construction method [8]. Note that methods evaluated here do not apply random swap introduced in Section 5.2 since these datasets cannot provide entity size. The results are presented in Table 2. Given the overall performance across all three presented tasks, firstly, [RS] does not perfectly reproduce the performance of [official], suggesting that misalignment in the original database hinders the reproduction of [official]. Secondly, part of our proposed data filtering makes the model, [w/o LCF], comparable to [official]. In addition, with all of our proposed data filtering techniques, [ours] outperforms [official].
6.5 Video-Text Retrieval Results
| Models | R@1 | R@5 | R@10 |
|---|---|---|---|
| ours | 12.4/13.1 | 27.5/27.8 | 35.3/35.9 |
| w/o LCF | 12.7/14.1 | 29.4/29.7 | 37.9/37.5 |
| RS | 11.1/11.6 | 24.8/25.0 | 32.4/32.2 |
Table 3 shows the results of video-to-text retrieval and text-to-video on the test set with the same MineCLIP model for a fair comparison. We train these models for 20 epochs and select the models with the highest R@1 value on the test set, respectively. From the results, the model trained on the randomly sampled dataset gets the worst performance than those trained on our YouTube dataset. The results demonstrate that our neat dataset indeed can facilitate the learning of basic game concepts. A notable observation is that [ours] achieves higher success rates on RL tasks but lower performance on retrieval tasks compared to [w/o LCF], suggesting that the video-text alignment objective does not fully align with RL requirements. [w/o LCF] is trained on the dataset filtered only by global-level correlation, which is directly conducted at the video level. In contrast, [ours] is trained on the dataset further filtered by local-level correlation, which is object-centric designing for RL training. Note that [w/o LCF] is the dataset we plan to release for better training the VLM model for video-text retrieval tasks on Minecraft.
7 Conclusion
We construct a neat YouTube dataset based on the large-scale YouTube database provided by MineDojo. Moreover, we introduce a novel cross-modal contrastive learning framework architecture, CLIP4MC, to learn an RL-friendly VLM that serves as an intrinsic reward function for open-ended tasks. Our findings suggest that our dataset enhances the acquisition of fundamental game concepts and CLIP4MC delivers a more effective reward signal for RL training.
Acknowledgements
This work was supported by NSFC under grant 62250068. The authors would like to thank the anonymous reviewers for their valuable comments.
References
- [1] Bain, M., Nagrani, A., Varol, G., Zisserman, A.: Frozen in time: A joint video and image encoder for end-to-end retrieval. In: IEEE/CVF International Conference on Computer Vision (ICCV) (2021)
- [2] Baker, B., Akkaya, I., Zhokhov, P., Huizinga, J., Tang, J., Ecoffet, A., Houghton, B., Sampedro, R., Clune, J.: Video pretraining (VPT): learning to act by watching unlabeled online videos. arXiv preprint arXiv:2206.11795 (2022)
- [3] Baumli, K., Baveja, S., Behbahani, F., Chan, H., Comanici, G., Flennerhag, S., Gazeau, M., Holsheimer, K., Horgan, D., Laskin, M., et al.: Vision-language models as a source of rewards. arXiv preprint arXiv:2312.09187 (2023)
- [4] Cai, S., Wang, Z., Ma, X., Liu, A., Liang, Y.: Open-world multi-task control through goal-aware representation learning and adaptive horizon prediction. arXiv preprint arXiv:2301.10034 (2023)
- [5] Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
- [6] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations (ICLR) (2021)
- [7] Dzabraev, M., Kalashnikov, M., Komkov, S., Petiushko, A.: MDMMT: multidomain multimodal transformer for video retrieval. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (2021)
- [8] Fan, L., Wang, G., Jiang, Y., Mandlekar, A., Yang, Y., Zhu, H., Tang, A., Huang, D.A., Zhu, Y., Anandkumar, A.: Minedojo: Building open-ended embodied agents with internet-scale knowledge. In: Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track (2022)
- [9] Guhr, O., Schumann, A.K., Bahrmann, F., Böhme, H.J.: Fullstop: Multilingual deep models for punctuation prediction (June 2021), http://ceur-ws.org/Vol-2957/sepp_paper4.pdf
- [10] Guss, W.H., Codel, C., Hofmann, K., Houghton, B., Kuno, N., Milani, S., Mohanty, S., Liebana, D.P., Salakhutdinov, R., Topin, N., et al.: Neurips 2019 competition: the minerl competition on sample efficient reinforcement learning using human priors. arXiv preprint arXiv:1904.10079 (2019)
- [11] Guss, W.H., Houghton, B., Topin, N., Wang, P., Codel, C., Veloso, M., Salakhutdinov, R.: Minerl: A large-scale dataset of minecraft demonstrations. In: International Joint Conference on Artificial Intelligence (IJCAI) (2019)
- [12] Hafner, D., Pasukonis, J., Ba, J., Lillicrap, T.P.: Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104 (2023)
- [13] Haiminen, N., Gionis, A., Laasonen, K.: Algorithms for unimodal segmentation with applications to unimodality detection. Knowledge and information systems 14, 39–57 (2008)
- [14] Johnson, M., Hofmann, K., Hutton, T., Bignell, D.: The malmo platform for artificial intelligence experimentation. In: International Joint Conference on Artificial Intelligence (IJCAI) (2016)
- [15] Kaelbling, L.P., Littman, M.L., Cassandra, A.R.: Planning and acting in partially observable stochastic domains. Artificial intelligence 101(1-2), 99–134 (1998)
- [16] Kanervisto, A., Milani, S., Ramanauskas, K., Topin, N., Lin, Z., Li, J., Shi, J., Ye, D., Fu, Q., Yang, W., Hong, W., Huang, Z., Chen, H., Zeng, G., Lin, Y., Micheli, V., Alonso, E., Fleuret, F., Nikulin, A., Belousov, Y., Svidchenko, O., Shpilman, A.: Minerl diamond 2021 competition: Overview, results, and lessons learned. arXiv preprint arXiv:2202.10583 (2022)
- [17] Li, Y., Wang, H., Duan, Y., Li, X.: Clip surgery for better explainability with enhancement in open-vocabulary tasks. arXiv preprint arXiv:2304.05653 (2023)
- [18] Lin, Z., Li, J., Shi, J., Ye, D., Fu, Q., Yang, W.: Juewu-mc: Playing minecraft with sample-efficient hierarchical reinforcement learning. arXiv preprint arXiv:2112.04907 (2021)
- [19] Liu, S., Fan, H., Qian, S., Chen, Y., Ding, W., Wang, Z.: Hit: Hierarchical transformer with momentum contrast for video-text retrieval. In: IEEE/CVF International Conference on Computer Vision (ICCV) (2021)
- [20] Luo, H., Ji, L., Zhong, M., Chen, Y., Lei, W., Duan, N., Li, T.: Clip4clip: An empirical study of CLIP for end to end video clip retrieval and captioning. Neurocomputing 508, 293–304 (2022)
- [21] Ma, Y.J., Liang, W., Wang, G., Huang, D.A., Bastani, O., Jayaraman, D., Zhu, Y., Fan, L., Anandkumar, A.: Eureka: Human-level reward design via coding large language models. arXiv preprint arXiv:2310.12931 (2023)
- [22] Nottingham, K., Ammanabrolu, P., Suhr, A., Choi, Y., Hajishirzi, H., Singh, S., Fox, R.: Do embodied agents dream of pixelated sheep?: Embodied decision making using language guided world modelling. arXiv preprint arXiv:2301.12050 (2023)
- [23] Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018)
- [24] OpenAI: Gpt-4 technical report (2023)
- [25] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning, ICML (2021)
- [26] Radford, A., Kim, J.W., Xu, T., Brockman, G., McLeavey, C., Sutskever, I.: Robust speech recognition via large-scale weak supervision (2022). https://doi.org/10.48550/ARXIV.2212.04356, https://arxiv.org/abs/2212.04356
- [27] Schulman, J., Moritz, P., Levine, S., Jordan, M., Abbeel, P.: High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438 (2015)
- [28] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
- [29] Shah, R., Wang, S.H., Wild, C., Milani, S., Kanervisto, A., Goecks, V.G., Waytowich, N.R., Watkins-Valls, D., Prakash, B., Mills, E., Garg, D., Fries, A., Souly, A., Chan, J.S., del Castillo, D., Lieberum, T.: Retrospective on the 2021 minerl BASALT competition on learning from human feedback. In: Neural Information Processing Systems (NeurIPS) Competitions and Demonstrations Track (2021)
- [30] Shu, T., Xiong, C., Socher, R.: Hierarchical and interpretable skill acquisition in multi-task reinforcement learning. In: International Conference on Learning Representations (ICLR) (2018)
- [31] Tessler, C., Givony, S., Zahavy, T., Mankowitz, D., Mannor, S.: A deep hierarchical approach to lifelong learning in minecraft. In: AAAI conference on artificial intelligence (AAAI) (2017)
- [32] Wang, G., Xie, Y., Jiang, Y., Mandlekar, A., Xiao, C., Zhu, Y., Fan, L., Anandkumar, A.: Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291 (2023)
- [33] Xu, H., Ghosh, G., Huang, P.Y., Okhonko, D., Aghajanyan, A., Metze, F., Zettlemoyer, L., Feichtenhofer, C.: Videoclip: Contrastive pre-training for zero-shot video-text understanding. arXiv preprint arXiv:2109.14084 (2021)
- [34] Yuan, H., Zhang, C., Wang, H., Xie, F., Cai, P., Dong, H., Lu, Z.: Plan4mc: Skill reinforcement learning and planning for open-world minecraft tasks. arXiv preprint arXiv:2303.16563 (2023)
- [35] Zhou, C., Loy, C.C., Dai, B.: Extract free dense labels from clip. In: European Conference on Computer Vision. pp. 696–712. Springer (2022)
- [36] Zhu, X., Chen, Y., Tian, H., Tao, C., Su, W., Yang, C., Huang, G., Li, B., Lu, L., Wang, X., et al.: Ghost in the minecraft: Generally capable agents for open-world enviroments via large language models with text-based knowledge and memory. arXiv preprint arXiv:2305.17144 (2023)
Appendix 0.A Dataset Details
0.A.1 Key Entity Size Estimation
MaskCLIP [35] has shown notable zero-shot segmentation ability of CLIP [25] without fine-tuning. Given that the architecture and training loss of MineCLIP [8] are similar to those of CLIP, we hypothesize that MineCLIP could also achieve zero-shot segmentation. Therefore, we modify the vision transformer in MineCLIP following MaskCLIP, replacing the output of CLS token with value-embeddings of all patches in the final self-attention block. This change enables the vision transformer to output embedding vectors for each image patch rather than a single vector for the entire image. Since there is an additional temporal transformer in MineCLIP visual encoder compared to CLIP, we pass the patch embedding vectors through this temporal transformer individually, ensuring the patch embeddings are aligned with MineCLIP’s embedding space. With an image input, we now acquire embedding vectors for each patch in MineCLIP’s embedding space. We also generate text embedding vectors for all entities in the MineDojo keyword list using the MineCLIP text encoder. The cosine similarities between each patch embedding vector and the text embedding vectors are then calculated.




As our goal is to estimate the size of the key entity mentioned in the corresponding transcript, we extract the similarity scores of the key entity on each image patch and create a heatmap for it. For instance, Figure 5(b) shows a heatmap generated for the entity “horse”. To refine this heatmap, we apply two filtering criteria: firstly, a patch is retained only if the key entity’s similarity score on it is higher than that of any other entity in the keyword list; secondly, we ignore patches with similarity scores below a threshold, , to reduce noise. After filtering, we find the maximum connected region in the filtered heatmap and compute the minimum bounding box that covers this region, as depicted in Figure 5(d). This bounding box allows us to estimate the size of the key entity within the image, calculated as the area of the bounding box .
0.A.2 Construction Process
The construction steps of the dataset are as follows:
-
1.
Obtain YouTube videos along with their transcripts and the keywords list from the MineDojo database††https://github.com/MineDojo/MineDojo.
-
2.
Use Transcript Cleaning (Section 4.1) to enhance the accuracy of transcripts and ensure they are complete sentences.
-
3.
For each video with a transcript, annotate all keywords (including different forms of keywords such as combined words, plural forms, etc.) appearing in the transcript.
-
4.
Use Keyword Filtering (Section 4.2) to find all transcript sentences containing keywords. The length of sentences is adjusted to 10-35 words.
-
5.
Extract all non-overlapping transcript clips from each video with a transcript following step 4.
-
6.
For each transcript clip, calculate the central timestamp corresponding to the clip based on the transcript timestamps. Use this central timestamp to extract a video clip of duration seconds from the video.
-
7.
From all the video-clip pairs extracted in the previous steps, extract pairs. Utilize Video Partition and Selection (Section 4.3) to select one from partitions, in order to handle the issue of scene transitions and thereby mitigate interference from other extraneous information.
-
8.
Use Correlation Filtering (Section 4.4) to select the top pairs with the highest correlation from the pairs as the training set. Specifically, we firstly select pairs following the local correlation filtering criteria, i.e., the size of target entity. If the number of video clips with explicit target entities is less than , we select the remaining training pairs based on the global correlation filtering criteria, i.e., the cosine similarity calculated via MineCLIP.
-
9.
Randomly select pairs in addition to the pairs as the test set.
The parameters used in the above process are listed in Table 4. Following this process, we construct a training set of size 640K and a test set of size 4096. This is the dataset for better training the VLM for RL tasks on Minecraft. Our other dataset for better training the VLM for video-text retrieval tasks on Minecraft is only filtered by the global correlation filtering criteria to select the top pairs in step 8. We have released the two datasets by specifying the transcript clips and the corresponding timestamps of the videos in the original database. The link is https://huggingface.co/datasets/AnonymousUserCLIP4MC/CLIP4MC.
| Parameter | Value |
|---|---|
| 16 | |
| 1,280,000 | |
| 3 | |
| 50 | |
| 4,096 |
| Hyperparameter | Value |
|---|---|
| warmup steps | 320 |
| learning rate | 1.5e-4 |
| lr schedule | cosine with warmup |
| weight decay | 0.2 |
| layerwise lr decay | 0.65 |
| batch size per GPU | 100 |
| parallel GPUs | 4 |
| video resolution | 160 × 256 |
| number of frames | 16 |
| image encoder | ViT-B/16 |
| swap threshold | 0.02 |
Appendix 0.B Architecture
Input Details. The length of each transcript clip is 25 words, while the length of the video is 16 seconds. The resolution of the video stream is 160 × 256, with 5 fps. In other words, the video stream is 80 frames. As for the video snippet, we further equidistantly sample it to 16 frames for fewer computing resources.
Text Encoder Details. Referring to the design of MineCLIP [8], the text encoder is a 12-layer 512-width GPT model, which has 8 attention heads. The textual input is tokenized via the tokenizer used in CLIP and is padded/truncated to 77 tokens. The initial weights of the model use the public checkpoint of CLIP and only finetune the last two layers during training.
Spatial Encoder Details. The Spatial encoder is a frame-wise image encoder referred to the design of MineCLIP [8], which uses the ViT-B/16 architecture to compute a 512-D embedding for each frame. The initial weights of the model use the public checkpoint of OpenAI CLIP, and only the last two layers are finetuned during training.
Temporal Transformer Details. The temporal Transformer is used to aggregate the temporal information from the spatial encoder, which is a 2-depth 8-head Transformer module whose input dimension is 512 and maximum sequence length is 32.
Adapter Details. In order to get better embedding, we use an adapter to map video embedding and text embedding. The adapter models are 2-layer MLP, except the text adapter which is an identity.
Appendix 0.C CLIP4MC Training
The training process for CLIP4MC is adapted from the training processes for CLIP4Clip [20] and MineCLIP [8]. We trained all models on the 640K training set. For each video-text clip pair, we obtain 16 frames of RGB image through equidistant sampling and normalize each channel separately. During training, we use random resize crops for data augmentation. We use cosine learning rate annealing with 320 gradient steps of warming up. We only fine-tune the last two layers of pre-trained CLIP encoders, and we apply a module-wise learning rate decay (learning rate decays along with the modules) for better fine-tuning. Training is performed on 1 node of 4 × A100 GPUs with FP16 mixed precision via the PyTorch native amp module. All hyperparameters are listed in Table 5.
Appendix 0.D Environment Details
0.D.1 Environment Initialization
Table 6 outlines how we set up and initialize the environment for each task in our RL experiments. SR denotes the spawn range of animals, and Length represents the length of one episode. All tasks are in the biome plains.
| Task | Mob | SR | Length | Tool | Prompt |
|---|---|---|---|---|---|
| milk a cow | cow | 10 | 200 | empty_bucket | obtain milk from a cow in plains with a bucket |
| shear wool | sheep | 10 | 200 | shears | shear a sheep in plains with shears |
| combat a spider | spider | 7 | 500 | diamond_sword | combat a spider in plains with a diamond sword |
| combat a zombie | zombie | 7 | 500 | diamond_sword | combat a zombie in plains with a diamond sword |
| hunt a cow | cow | 7 | 500 | diamond_sword | hunt a cow in plains with a diamond sword |
| hunt a sheep | sheep | 7 | 500 | diamond_sword | hunt a sheep in plains with a diamond sword |
| hunt a pig | pig | 7 | 500 | diamond_sword | hunt a pig in plains with a diamond sword |
| hunt a chicken | chicken | 7 | 500 | diamond_sword | hunt a chicken in plains with a diamond sword |
0.D.2 Observation Space
To enable the creation of multi-task and continually learning agents that can adapt to new scenarios and tasks, MineDojo provides unified observation and action spaces [8]. Table 7 provides detailed descriptions of the observation space adopted in our experiments.
| Observation | Descriptions |
|---|---|
| Egocentric RGB frame | RGB frames provide an egocentric view of the running Minecraft client; The shape height (H) and width (W) are specified by argument image_size. In our experiment, it is (160, 256). |
| Voxels | Voxels observation refers to the 3x3x3 surrounding blocks around the agent. This type of observation is similar to how human players perceive their surrounding blocks. It includes names and properties of blocks. |
| Location Statistics | Location statistics include information about the terrain the agent currently occupies. It also includes the agent’s location and compass. |
| Biome ID | Index of the environmental biome where the agent spawns. |
0.D.3 Action Space
We simplify the original action space of MineDojo [8] into a two-dimensional multi-discrete action space. The first dimension consists of 12 discrete actions: NO_OP, forward, backward, left, right, jump, sneak, sprint, camera pitch +30, camera pitch -30, camera yaw +30, and camera yaw -30. The second dimension contains NO_OP, attack, and use.
Appendix 0.E RL Training
0.E.1 Agent Network
Like MineAgent [8], our policy framework is also composed of three components: an encoder for input features, a policy head, and a value head. In order to deal with cross-modal observations, the feature extractor includes a variety of modality-specific components:
RGB frame. To optimize for computational efficiency and equip the agent with strong visual representations from scratch, we use the fixed frame-wise image encoder from CLIP4MC to process RGB frames.
Goal of the task. The text embedding of the natural language task objective (prompt) is computed by from CLIP4MC.
Yaw and Pitch. We first compute sin(·) and cos(·) features respectively, then pass them through CompassMLP as described in Table 8.
GPS. The position coordinates are normalized and passed through GPSMLP as described in Table 8.
Voxels. To process the 3 × 3 × 3 voxels surrounding the agent, we embed discrete block names as dense vectors, flatten them, and pass them through VoxelEncoder as described in Table 8.
Previous action. Our agent relies on its immediate previous action, which is embedded and processed through Prev Action Emb as described in Table 8, which is a conditioning factor.
BiomeID. To perceive the discrepancy in different environments, we embed BiomeID as a vector through an MLP named BiomeIDEmb as described in Table 8.
The features from each modality are combined by concatenation, passed through an additional feature fusion network as described in Table 8, and then fed into a GRU to integrate historical information. The output of GRU serves as the input for both the policy head and the value head. The policy head is modeled using an MLP, as described in Table 8 for Actor & Critic Network, which transforms the input feature vectors into an action probability distribution. Similarly, value MLP is used to estimate the value function, conditioned on the same input features.
| Network | Details |
|---|---|
| Actor & Critic Net | hidden_dim: 256, hidden_depth: 2 |
| GRU | hidden_dim: 256, layer_num: 1 |
| CompassMLP | hidden_dim: 128, output_dim: 128, hidden_depth: 2 |
| GPSMLP | hidden_dim: 128, output_dim: 128, hidden_depth: 2 |
| VoxelEncoder | embed_dim: 8, hidden_dim: 128, output_dim: 128, hidden_depth: 2 |
| BiomeIDEmb | embed_dim: 8 |
| PrevActionEmb | embed_dim: 8 |
| ImageEmb | output_dim: 512 |
| FeatureFusion | output_dim: 512, hidden_depth: 0 |
0.E.2 Algorithm
In our experiments, we implement Proximal Policy Optimization (PPO) [28] as our base RL algorithm. In detail, PPO updates policies via
Here, is defined as
where is a clip value that limits the deviation between the new policy and the old . is the advantage function for the current policy and estimated via Generalized Advantage Estimation (GAE) [27]. Unlike MineDojo [8], our implementation does not include additional self-imitation learning and action smoothing techniques as we found that our adopted PPO is already able to achieve high performance. The hyperparameters of our PPO implementation are listed in Table 9 and shared across all experiments.
| Hyperparameter | Value |
|---|---|
| num steps | 1000 |
| num envs | 4 |
| num minibatches | 4 |
| num epochs | 8 |
| GAE lambda | 0.95 |
| discounted gamma | 0.99 |
| entropy coef | 0.005 |
| clip epsilon | 0.02 |
| learning rate | 1e-4 |
| optimizer | Adam |
| GRU data chunk length | 10 |
| gradient norm | 10.0 |
0.E.3 Coefficient of MineCLIP Reward
In our experiments, the agent is trained with the shaped reward defined as . Specifically, represents the sparse reward provided by the environment. The environment will provide a +100 reward only when the agent successfully accomplishes the task; otherwise, the environment reward is zero. The other component, , denotes the MineCLIP reward introduced in Section 5.3. The coefficient controls the weight of the MineCLIP reward. For RL algorithms in sparse-reward environments, the coefficient of the intrinsic reward has a significant influence on the final performance of algorithms. Therefore, we conduct preliminary experiments to decide a suitable coefficient of MineCLIP reward for our experiments in the paper. We choose two tasks, milk a cow and hunt a cow, as our testbed. As shown in Figures 6 and 7, three values, , , and , are evaluated on CLIP4MC, MineCLIP [ours], and MineCLIP [official]. The results demonstrate that achieves the best performance in 5 out of 6 experiments. Based on this observation, we set for all experiments in this paper.






0.E.4 Learning Curves
Figure 8 shows the learning curves of all methods on eight Minecraft tasks. The results in Table 1 are averaged on the last five checkpoints in Figure 8.








Appendix 0.F Creative Tasks
As defined in MineDojo [8], Creative Tasks is a unique task suite, distinct from Programmatic Tasks due to the lack of success criteria. MineCLIP demonstrates its effectiveness in learning Creative Tasks, such as dig a hole and lay the carpet, and serving as a reliable success classifier. It is noticeable that Creative Tasks often lack clear indicators of task completion progress, unlike Programmatic Tasks. In other words, our adopted approach, where the size of the key entity serves as a surrogate for task completion progress, is ineffective. For example, in dig a hole, it is not feasible to detect a hole and estimate its size before the agent completes this task. Therefore, the swap operation in CLIP4MC would bring no benefit to Creative Tasks. However, due to the upper bound of swap probability we set, CLIP4MC is expected to preserve the ability of MineCLIP to understand these creative behaviors without an explicit target entity that exists in the Minecraft world in advance.
To validate our hypothesis regarding the effectiveness of CLIP4MC in Creative Tasks, we conduct experiments on dig a hole. We train agents using PPO with intrinsic rewards calculated by CLIP4MC or MineCLIP [official]. At the beginning of each episode, the agent is spawned in the biome plains with an iron shovel. The prompt is “dig a hole” and each episode lasts 200 steps. Due to the lack of success criteria for dig a hole, we run each agent for 100 episodes and record the average reward per step within each episode, calculated by MineCLIP [official]. The resulting reward distributions are shown in Figure 9. The result shows that the mean MineCLIP reward of the agent trained with CLIP4MC reward is lower than that of the agent trained with MineCLIP reward. This is consistent with expectations, as the agent trained with MineCLIP reward should overfit it and thus achieve higher rewards. In addition, the MineCLIP reward of the agent trained with CLIP4MC is significantly higher than that taking random actions, indicating that CLIP4MC successfully guides agents in learning behaviors relevant to dig a hole.
The original MineCLIP paper proposes a successful classifier based on the average MineCLIP reward. In detail, a trajectory with a average MineCLIP reward greater than the threshold is classified as successful. However, the specific threshold values for each task are not provided. Therefore, we evaluate success rates at various reward thresholds, as depicted in Figure 9. Considering the high success rate (91.6%) reported for dig a hole in the original paper, we speculate that the agent trained with CLIP4MC would also achieve high success rates. This is supported by the narrow performance gap between the agent trained with MineCLIP and CLIP4MC rewards when the former’s success rate is high (around 90%), as shown in Figure 9.
