REHRSeg: Unleashing the Power of Self-Supervised Super-Resolution for Resource-Efficient 3D MRI Segmentation
Abstract
High-resolution (HR) 3D magnetic resonance imaging (MRI) can provide detailed anatomical structural information, enabling precise segmentation of regions of interest for various medical image analysis tasks. Due to the high demands of acquisition device, collection of HR images with their annotations is always impractical in clinical scenarios. Consequently, segmentation results based on low-resolution (LR) images with large slice thickness are often unsatisfactory for subsequent tasks. In this paper, we propose a novel Resource-Efficient High-Resolution Segmentation framework (REHRSeg) to address the above-mentioned challenges in real-world applications, which can achieve HR segmentation while only employing the LR images as input. REHRSeg is designed to leverage self-supervised super-resolution (self-SR) to provide pseudo supervision, therefore the relatively easier-to-acquire LR annotated images generated by 2D scanning protocols can be directly used for model training. The main contribution to ensure the effectiveness in self-SR for enhancing segmentation is three-fold: (1) We mitigate the data scarcity problem in the medical field by using pseudo-data for training the segmentation model. (2) We design an uncertainty-aware super-resolution (UASR) head in self-SR to raise the awareness of segmentation uncertainty as commonly appeared on the ROI boundaries. (3) We align the spatial features for self-SR and segmentation through structural knowledge distillation to enable a better capture of region correlations. Experimental results demonstrate that REHRSeg achieves high-quality HR segmentation without intensive supervision, while also significantly improving the baseline performance for LR segmentation.
keywords:
Magnetic resonance imaging , High-resolution segmentation , Self-supervised super-resolution , Uncertainty awareness , Knowledge distillation[1]organization=School of Biomedical Engineering,addressline=Shanghai Jiao Tong University, city=Shanghai, postcode=200030, country=China
[2]organization=Department of Data Science AI, Faculty of Information Technology, addressline=Monash University, country=Australia
[3]organization=Department of Radiology, addressline=Shanghai Ninth People’s Hospital, Shanghai Jiao Tong University School of Medicine, city=Shanghai, postcode=200011, country=China
[4]organization=School of Biomedical Engineering, addressline=ShanghaiTech University, city=Shanghai, postcode=201210, country=China
1 Introduction
Magnetic resonance imaging (MRI) is widely used for diagnosis and monitoring due to its high precision in distinguishing between different types of soft tissue, while avoiding the risks associated with ionizing radiation exposure [1]. A critical task in computer-assisted diagnosis and intervention in MRI is the high-resolution (HR) 3D segmentation and reconstruction of regions of interest (ROI) within complex anatomical structures, which can facilitate subsequent procedures such as 3D printing and surgical planning [2]. In recent years, deep learning techniques have emerged as the leading approach in MRI segmentation, with 3D-based neural networks becoming the predominant method to achieve voxel-wise segmentation, as opposed to treating slices independently [3]. Moreover, transformer-based techniques, which inherently capture global dependencies, have shown competitive performance, albeit at the cost of increased model complexity [4]. However, current methods for 3D MRI segmentation face challenges in clinical applications, where 2D scanning protocols are frequently employed to reduce acquisition time. Such protocols result in MR images with high in-plane resolution but lower inter-plane resolution, which cannot be directly processed by current segmentation models to achieve HR segmentation.
Recently, several works have explored HR segmentation from low-resolution (LR) images [5, 6, 7, 8], presenting a potential solution to the aforementioned issues. These methods typically use downsampled images as the main input while producing HR segmentation directly, thereby avoiding the need for HR images during inference. Some approaches also leverage image super-resolution as a proxy task to assist in capturing fine-grained features and ensuring that high-frequency details are preserved in the segmentation results [5, 6, 9]. However, these methods still rely on the availability of HR images and corresponding annotations for training, which are costly to obtain. On the one hand, prolonged scanning times for HR acquisition may cause patient discomfort and increase the risk of motion artifacts [10]; on the other hand, annotating HR images is considerably more labor-intensive and time-consuming. A potential solution to obtain HR segmentation with only LR images for training is to upsample the acquired LR images and interpolate the labels using morphology-based operators [11]. This strategy has been adopted in some datasets [12], but it can lead to misaligned labels, particularly on the ROI boundaries.

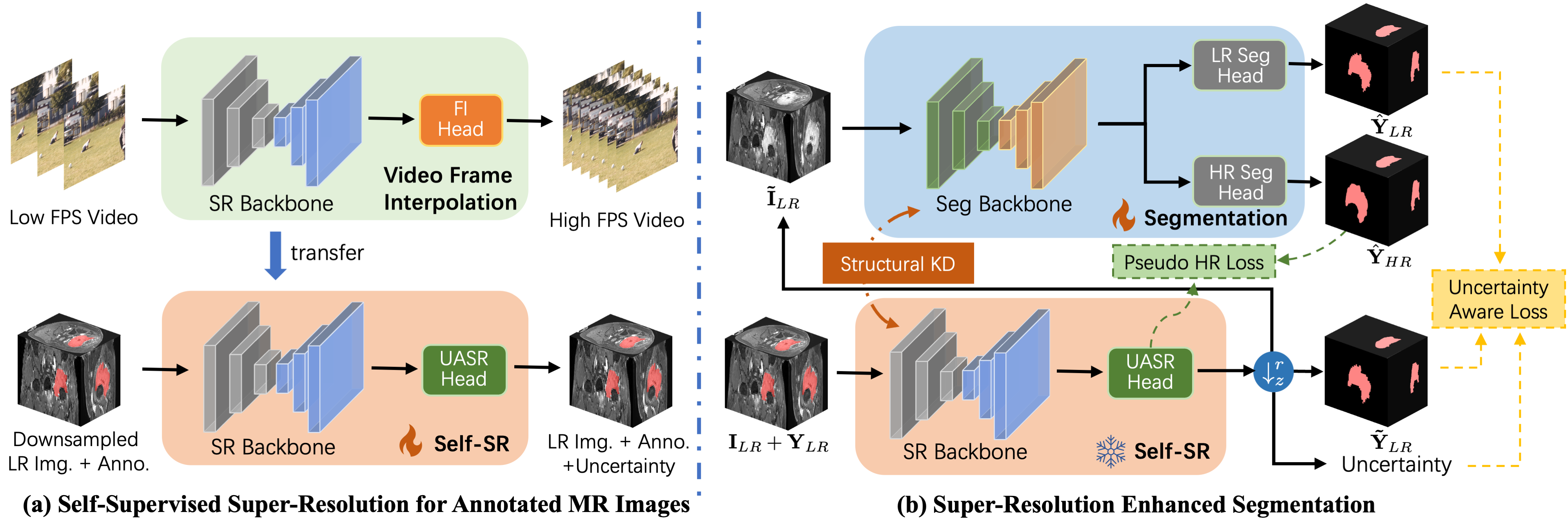
In this paper, we rethink current methods for HR segmentation from LR images and propose a novel Resource-Efficient High-Resolution Segmentation framework (REHRSeg) for real-world clinical applications. As illustrated in Fig 1, conventional methods require HR annotated data, which are resource-intensive to collect. In contrast, REHRSeg replaces the supervision from real images with pseudo-HR data and addresses misalignment issues through a self-supervised super-resolution technique for annotated images. This strategy only requires LR data for training, making it more resource-efficient for practical use.
Furthermore, REHRSeg takes a step further in exploring super-resolution-assisted segmentation by investigating the capability of self-supervised super-resolution (self-SR) to enhance segmentation. This exploration begins by addressing data scarcity using pseudo-HR data generated by self-SR to expand the dataset for the segmentation task. Additionally, REHRSeg incorporates uncertainty-aware learning to improve ROI boundary recognition by utilizing the uncertainty map extracted from uncertainty-aware super-resolution (UASR) head, which highlights regions that are difficult to reconstruct. Moreover, REHRSeg aligns deep features in self-SR to capture correlated regions for segmentation. The key contributions of this work is as follows:
-
1.
We introduce a novel framework for high-resolution segmentation that can be trained without the need for high-resolution data.
-
2.
We integrate a super-resolution prior to improve segmentation performance. Specifically, we:
-
(a)
Employ super-resolution as a data generator to expand the training data for the segmentation task;
-
(b)
Introduce an uncertainty-aware super-resolution (UASR) head within the super-resolution process to improve boundary recognition of segmentation task;
-
(c)
Propose a distillation strategy to help the segmentation network capture deep correlations.
-
(a)
-
3.
We conduct extensive experiments on both synthetic and real-world datasets, demonstrating that REHRSeg not only produces high-quality high-resolution segmentation but also significantly improves segmentation performance on low-resolution data.
2 Related Work
2.1 3D MRI Segmentation
MRI segmentation aims to identify and delineate ROI in acquired MR images, playing a crucial role in computer-aided diagnosis and disease progression monitoring [13]. Recent advancements in deep learning technologies have led to significant breakthroughs in automatic MRI segmentation. Among the most widely adopted architectures are U-shaped CNN-based networks [14, 15, 16, 17], with nnUNet [18] emerging as a leading model. nnUNet automatically configures various datasets and focuses on dataset preprocessing and inference strategies, currently dominating the field of medical image segmentation. Furthermore, vision transformer (ViT) techniques have been applied to MRI segmentation, leveraging the transformer’s ability to capture global and long-range dependencies [19, 20, 21, 22, 23].
Despite the high performance of these methods, they often require substantial computational resources for whole-volume segmentation of HR MRI images. Consequently, several approaches have aimed to develop efficient 3D MRI segmentation models with reduced resource demands by designing lightweight architectures. For example, ADHDC-Net [24] uses decoupled convolution, dilated convolution, and attention-based refinement to minimize the number of parameters and operations in brain tumor segmentation. Similarly, UNETR++ [21] employs efficient paired attention to reduce the complexity of self-attention computations and constrains the number of parameters by sharing weights between queries and keys. MISSU [25] incorporates a self-distillation mechanism to refine local 3D features with multi-scale fusion blocks, which are removed during inference to ease computational burdens. However, these lightweight models often struggle to capture rich features, limiting segmentation performance. Our approach addresses this limitation by utilizing the priors embedded in super-resolution models to enhance segmentation performance without increasing computational costs during inference.
2.2 HR Segmentation from LR Image
Recently, several studies [26, 6, 27, 8, 9] have focused on achieving high-resolution (HR) segmentation from low-resolution (LR) images, primarily designed to efficiently capture global information and further reduce the computational cost, especially during inference. For example, AR-Seg [8] reduces computational costs for video semantic segmentation by lowering the resolution for non-keyframes, while employing a cross-resolution fusion module to prevent accuracy degradation. GDN [7] replaces conventional down-sampling with a learnable procedure to reduce image resolution for real-time segmentation. UHRSNet [28] fuses local features extracted from image patches with global features from downsampled images.
Super-resolution techniques have also been employed in this context to improve segmentation performance by capturing fine-grained details and providing richer semantic information. Lei et al. [29] propose a framework for remote sensing images that simultaneously performs quadruple super-resolution and segmentation. PFSeg [26] integrates super-resolution as an auxiliary task for patch-free 3D medical image segmentation, and incorporates a fusion module for joint optimization. ISDNet [27] introduces super-resolution tasks as guides in the coarse-grained branches of the network, and fuses this information into fine-grained branches. DS2F [9] redesigns the segmentation and super-resolution framework by proposing a shared feature extraction module and a proxy loss for ROI recognition.
While these methods achieve HR segmentation from LR images, they still rely on resource-intensive HR annotations during training. In contrast, our proposed REHRSeg framework only requires LR annotations for training, significantly reducing the annotation burden. Additionally, REHRSeg does not depend on HR images for super-resolution assistance, making it more practical for clinical applications where 2D scanning protocols are commonly employed.
2.3 Self-supervised Super-resolution of MR Images
Due to limitations in medical resources and scanning time, the acquisition of MR images employs a 2D scanning protocol in many clinical settings, resulting in low inter-plane resolution with large slice thickness [30, 31]. Therefore, super-resolution technology has been employed to enhance the resolution of such images, particularly in the inter-plane direction. Deep learning methods, especially CNN-based architectures, have become the dominant approach for MRI super-resolution. Conventional deep learning methods typically rely on fully supervised training [32, 33, 34], requiring paired HR and simulated LR images. However, collecting HR images in real-world clinical scenarios is significantly more challenging and costly than acquiring LR images, making it difficult to obtain sufficient paired training samples.
To address this, self-supervised training methods have been increasingly applied to super-resolution tasks. These methods achieve super-resolution of MR images using only LR images for training. For example, Xuan et al. [35] propose a VAE-based generative model trained on LR images, and synthesizes HR images from interpolated latent space to train the super-resolution model. SMORE [36] uses HR and LR data inherent in the high-resolution plane for training, restoring image quality by improving resolution and reducing aliasing. Wang et al. [37] extend SMORE by introducing video frame interpolation as a preliminary task, and design an architecture based on implicit neural representation with a three-stage training protocol to refine the results. TSCTNet [38] incorporates a cycle-consistency constraint to enable self-supervised learning for reducing the slice gap for MR images.
In this work, we explore the capacity of self-supervised learning from annotated LR images in the field of MRI super-resolution to enhance and provide supervision for segmentation tasks, a direction not yet explored in prior super-resolution studies.
3 Method
3.1 Overview
The overall framework of REHRSeg is designed to produce high-resolution (HR) segmentation , with an inter-plane resolution that is times higher than the original low-resolution (LR) image and its annotation . As illustrated in Fig. 2, we begin by applying self-supervised super-resolution (self-SR) on the annotated MR images, generating coarse HR annotations alongside the HR MR images . Next, the self-SR model and the pseudo HR data are leveraged to enhance the segmentation model, enabling simultaneous generation of both refined LR segmentation and HR segmentation . This is achieved through three key components: 1) utilizing self-SR as a pseudo-data generator for segmentation, 2) incorporating an uncertainty-aware super-resolution (UASR) head in self-SR for additional boundary guidance, and 3) applying structural knowledge distillation from the self-SR model.
3.2 Self-SR for Annotated MR images
We introduce a self-supervised super-resolution (self-SR) method as a preliminary task in REHRSeg. This approach is built upon the principles of the most recent self-supervised MRI super-resolution method [37], with modifications to support the super-resolution of annotated MR images. Given a LR image and its corresponding annotation , both with a spatial resolution of , we assume that the frequency- and phase-encoding directions have identical spatial resolution. The super-resolution process is applied with a scaling factor of , generating HR images with a spatial resolution of in two main steps: First, both the image and annotation are interpolated to achieve isotropic voxel spacing, so that the spatial consistency can be ensured between training and inference stages. Our experiments show that the utilization of SMORE [36] as an alternative to traditional interpolation techniques, such as B-spline interpolation for images and nearest-neighbor interpolation for annotations, can further improve the final results.
In the second step, we generate the LR-HR pairs required for self-SR training by simulating slice separation along the axes. Specifically, the interpolated images are convoluted with a 1D Gaussian filter as the slice profile with FWHM equal to , followed by downsampling by a factor of along with the annotations. Unlike SMORE, we avoid introducing aliasing artifacts, as our self-SR model directly operates on instead of the interpolated one to reduce computational cost. Additionally, the slice gap is not considered in our self-SR method, as many segmentation datasets lack this information. Notably, several SR methods such as SMORE[36], DeepResolve[32], and SAINR[34] also neglect the slice gap without experiencing significant performance degradation. In this scenario, the task can be considered as slice interpolation and deblurring for 3D data.
To accelerate training and ensure faster convergence, we leverage a pretrained model from the domain of video frame interpolation. This strategy has been previously shown to be effective in self-supervised super-resolution [37]. Here we use the FLAVR [39] model pretrained on Vimeo-90K [40] to initialize the backbone of our self-SR model. By applying the trained model to and , we obtain the estimated pseudo HR image and its annotation . The pseudo data and the self-SR model are then used to enhance the segmentation model in the subsequent stage.
3.3 Self-SR as Pseudo-data Generator
We propose to utilize the self-SR model as a data generator to create pseudo-data for the MRI segmentation task, which is implemented in two distinct ways: data augmentation for LR segmentation and pseudo supervision for HR segmentation. Given the HR image and its annotation produced by self-SR, we can simulate the LR data and with a large slice thickness that matches the spatial resolution of the segmentation dataset, by blurring and downsampling the synthesized data as follows:
| (1) |
where denotes 1D convolution along the axes, and represents the downsampling operator along the axes by a factor of . This process creates the amount of LR data compared to the original dataset, as the improved resolution in the synthesized data allows for additional data generation. This is accomplished by applying the downsampling operator while adjusting the corresponding starting index of the target image. Note that this can also be considered a novel form of data augmentation for LR segmentation, and the prior knowledge embedded within the self-SR process can be leveraged to further improve the segmentation performance with this additional data.
Furthermore, by generating the pseudo - pair via self-SR, the segmentation model is enabled to perform HR segmentation in parallel with LR segmentation task. This is achieved by using an additional HR segmentation head consisting of a upsampling layer to the segmentation backbone, just before the original LR segmentation head. During training, both tasks share the same input , allowing for multi-task learning of LR and HR segmentation using pseudo-supervision from self-SR.
3.4 Uncertainty-aware Learning with Self-SR Guidance
We further utilize the self-SR model to provide uncertainty guidance for the segmentation task, with the goal of enhancing its performance with uncertainty-aware segmentation. It is widely recognized that the tissues in medical images often overlap and blurriness occur on their boundaries, leading to high uncertainty in the delineation of these regions [41]. This issues not only lead to unreliable segmentation region, but also cause poorly reconstructed regions for the super-resolution tasks. Therefore, we propose to estimate uncertainty in the self-SR model by designing an uncertainty-aware super-resolution (UASR) head, which identifies the regions with high reconstruction error and provides guidance for the segmentation task.
The first step of uncertainty estimation with UASR involves the generation of intermediate results. We extract the 3D feature map from the backbone of the self-SR model, where , , represent the slice depth, height, and width of the input LR images, respectively. The features along the depth dimension are concatenated into a 2D feature map, which is then processed to generate intermediate features via Leaky ReLU activation and convolution. These features are split along the channel dimension and merged back into the depth dimension, yielding intermediate images and annotations . The whole procedure can be expressed as:
| (2) |
where and are the 3D convolutional filters applied to the intermediate features. The operators and denote the merging of features along dimension into dimension , and the splitting of features along dimension into dimension , respectively. Next, we obtain multiple attention maps by applying another set of convolutions, followed by a channel-wise softmax function:
| (3) |

Then, the attention maps are used to perform channel-wise selection for the intermediate images and annotations, and the final results are obtained via:
| (4) |
where denotes element-wise multiplication. Similarly, the uncertainty map is also generated from the intermediate attention maps via:
| (5) |
where denotes concatenation along the channel dimension, and is the sigmoid activation function. The modified loss function for the super-resolution task is used to ensure that the uncertainty map accurately reflects regions with high reconstruction error:
| (6) |
where is the original pixel-level loss function for the super-resolution task, which is defined as loss for the image. This modification ensures that the uncertainty map is automatically learned to represent the reconstruction error. Note that we do not use the uncertainty map to regularize the super-resolution of annotations, which uses cross entropy and dice loss, to stabilize the learning process.
Since regions with high reconstruction error often correspond to boundaries of anatomical structures, we incorporate the uncertainty map to guide the segmentation task by introducing a segmentation loss regularization term:
| (7) |
where the uncertainty map extracted from UASR is first normalized to have its intensity range of before employed as the weight map for the pixel-level segmentation loss.

3.5 Structural Knowledge Distillation
We also propose to leverage knowledge distillation from the self-SR model to further enhance MRI segmentation. Given the disparity between image reconstruction and segmentation tasks, traditional distillation methods that constrain features with pixel-wise alignment only provide limited benefits. Instead, the structural correlation between regions shares similar patterns between the feature map produced by different tasks, which have also been confirmed in the previous work [42]. Therefore, the segmentation task has potential to benefit from the self-SR task by distilling the correlation patterns from it. Here the feature maps and are extracted from the trained self-SR model and current segmentation model. The shape of is aligned with with bilinear interpolation, resulting in feature maps of . We model the spatial correlation between regions using a fully-connected affinity graph, where the nodes represent different spatial locations, and the edges denote their similarity. In this graph, we aggregate the voxels in a local patch to represent the feature of each node, setting the granularity of the graph to . Consequently, the affinity graph comprises fully connected nodes. We compute the similarity between the -th and -th nodes by:
| (8) |
where average pooling is applied to aggregate features before calculating similarity. This process is performed for both the self-SR and segmentation models, with and denoting the similarities from the self-SR and segmentation models, respectively. The loss for correlation distillation is defined as the squared difference between these similarity measures:
| (9) |
Additionally, we align spatial features to highlight critical regions and improve segmentation performance. This is achieved through a cosine distance loss between the features from the self-SR model and the adapted segmentation features, as described in the previous work [43]:
| (10) |
where is the student adaptor for feature vectors with parameters .
3.6 Optimization
The overall loss for training our segmentation model is composed of an uncertainty-aware segmentation loss, a pseudo HR segmentation loss, and a knowledge distillation loss:
| (11) | ||||
where is used to balance the losses for segmentation and distillation. is implemented with cross entropy loss weighted with uncertainty map, and is implemented with cross entropy loss with dice loss.
4 Experiments
4.1 Datasets
Our experiments are conducted on a public dataset with HR images and their annotations, as well as an in-house dataset with only LR labeled images. Due to the difference in data availability, we calculate quantitative metrics on the public dataset for HR results, while providing only qualitative HR results for the in-house dataset. Both datasets undergo 5-fold cross-validation to ensure a robust and unbiased evaluation.
4.1.1 Synthetic Public Dataset
We first generate a synthetic LR MRI dataset from the publicly available Meningioma-SEG-CLASS dataset [44], which contains pre-operative T1-CE (HR) and T2-FLAIR (LR) MR images from patients with pathologically confirmed Grade I or Grade II meningiomas. For our experiments, we extract 76 near-isotropic T1-CE images, each containing manually contoured tumors. Following standard practices in super-resolution techniques [32, 31, 45], all images are first Gaussian-filtered before resampling to simulate the acquisition of thicker slices produced by 2D scanning protocols. A downsampling factor of 4 is applied, and our method is completely blind to the original HR images and their annotations during training.
4.1.2 In-house Dataset
We also collect an internal dataset to evaluate the real-world application of our method. The dataset contains 91 patients that underwent pelvic MRI exams using contrast-enhanced, fat-suppressed T1WI. The MR images are reconstructed with in-plane spatial resolution ranging from 0.42 to 0.74 and slice thickness between 3 and 6. The MR images were manually labeled to generate the gold standard for training and validation, which were performed by two radiologists using an annotation tool in the SenseCare research platform [46]. To standardize the data for segmentation model training, the in-plane resolution is resampled to 0.75, while the original thickness is kept unchanged during training, similar to [47].
| Method | Meningioma-SEG-CLASS | In-house | |||||
|---|---|---|---|---|---|---|---|
| DSC (LR) | HD95 (LR) | DSC (HR) | HD95 (HR) | DSC (LR) | HD95 (LR) | ||
| 2D-based methods | |||||||
| SegFormer [48] | 0.74160.0846 | 29.0122.13 | 0.68500.0879 | 42.529.80 | 0.61500.0966 | 125.4578.35 | |
| Mask2Former [49] | 0.81870.0546 | 21.0518.91 | 0.80430.0606 | 23.4913.84 | 0.84440.0544 | 27.7227.62 | |
| nnUNet-2D [18] | 0.81370.0449 | 6.783.16 | 0.80770.0499 | 17.505.82 | 0.80570.0528 | 28.5512.41 | |
| TransUNet-2D [22] | 0.76700.0743 | 18.9416.28 | 0.77010.0696 | 21.766.84 | 0.75890.0858 | 40.3335.50 | |
| 3D-based methods | |||||||
| nnFormer [19] | 0.81440.0274 | 14.3112.91 | - | - | 0.79570.0510 | 66.3224.00 | |
| TransUNet-3D [22] | 0.80670.0510 | 6.513.26 | - | - | 0.76700.0723 | 33.0123.41 | |
| UNETR++ [21] | 0.79210.0650 | 17.6115.57 | - | - | 0.87610.0390 | 24.8517.35 | |
| nnUNet-3D [18] | 0.81550.0342 | 7.223.62 | - | - | 0.88520.0456 | 15.0010.10 | |
| REHRSeg | 0.83060.0330 | 5.042.93 | 0.81860.0498 | 6.572.38 | 0.90410.0308 | 9.416.00 | |

4.2 Implementation Details
We utilize a downsampling factor (DSF) of 4 for both datasets, and initialize our self-SR backbone with the FLAVR model pretrained on video frame interpolation. To stabilize the training of the UASR head, we only include the uncertainty-guided loss during the final 20,000 iterations, following an initial fine-tuning phase of 130,000 iterations with the batch size of 64. For structural distillation, we aggregate only in-plane features with a granularity set to . The spatial distillation process employs a convolution layer following the previous work [50], since experiments show that more complex distillers, such as those in [43], do not improve segmentation performance in this context. The segmentation network is initialized using the default setting of nnUNet-3D [18], and its data augmentation strategy is applied throughout our experiments. To allow the segmenter to produce HR results, we interpolate the features before the last layer and use two convolution with a ReLU activation in between, which is light-weighted to produce the final results. All the experiments are performed on an NVIDIA RTX A6000 GPU.
4.3 Enhanced LR Segmentation
In this section, we evaluate whether the self-SR model can provide effective guidance for the segmentation model, by inspecting whether its performance is improved for LR segmentation. We also conduct experiments for HR segmentation on the Meningioma-SEG-CLAS dataset, as 2D-based segmentation methods can be directly applied to cross-sectional slices extracted from HR volumes. It is important to note that these 2D-based methods use HR images as inputs, whereas our method operates on LR images in the inference stage. Quantitative results presented in Table 1 indicate that 2D-based methods generally underperform 3D-based methods for MRI segmentation, particularly in terms of the HD95 metric. Notably, nnUNet remains a strong baseline and outperforms several transformer-based methods, especially for the in-house dataset where the complex data distribution poses challenges for these methods to achieve satisfactory results. This can be attributed to the limited amount of training data, which prevents transformer-based methods from fully leveraging their advantages.
Despite these challenges, REHRSeg significantly improves performance over baseline ( 0.05, HD95) and outperforms all the alternatives for both LR and HR segmentation. Visualization results in Fig. 5 also demonstrate that REHRSeg excels in both tumor types, and notably enhances the nnUNet baseline in boundary recognition. Moreover, REHRSeg shows strong performance in difficult cases where other methods fail to accurately capture the tumor shapes, as illustrated in the fourth row of Fig. 5.
| Methods | PSNR | SSIM | DSC |
|---|---|---|---|
| B-spline | 25.120.41 | 0.91530.0120 | 0.90050.0689 |
| SMORE [36] | 29.730.63 | 0.96160.0070 | 0.93020.0379 |
| FLAVR [39] from scratch | 29.150.53 | 0.95320.0090 | 0.93400.0361 |
| REHRSeg | 29.860.56 | 0.95830.0083 | 0.93570.0356 |

4.4 Reconstructing HR Results Using LR Data
Although REHRSeg is trained on LR images and their corresponding annotations, it allows the acquisition of coarse HR results via the proposed self-SR model. Additionally, the segmentation model is enhanced using these self-SR results to produce HR segmentation outputs. The evaluation of these results are further illustrated in the following sections.
4.4.1 Super-resolution Results for Annotated Images
We first evaluate the quality of our method for self-supervised super-resolution. As there are no existing methods for the super-resolution of both images and labels, we implement three baseline methods, including: 1) B-spline interpolation for image and morphology-based interpolation for label [11] commonly used for producing spatially standardized data [12], 2) a modified version of SMORE (2D) [36] with an auxiliary segmentation head, and 3) our model trained from scratch (i.e., without pretraining on video frame interpolation).
Quantitative results demonstrate that our method achieves the highest Peak Signal-to-Noise Ratio (PSNR) and Dice Score (DSC), although the Structural Similarity Index (SSIM) metric is slightly lower compared to SMORE. It is noteworthy that pretraining on a video frame-interpolation task significantly improves the performance of the self-SR model (from 29.15 to 29.86 in PSNR), which is also consistent with findings from previous work [37]. The qualitative results shown in Fig. 6 illustrate the super-resolution outcomes for labels overlaid on the super-resolved images. Simple B-spline interpolation results in blurred images and misaligned labels. While SMORE offers notable improvements over B-spline interpolation, it still exhibits issues such as discontinuities on the surface of the pallium (sagittal view) and blurriness on the ROI boundaries (axial and coronal views). In contrast, our proposed self-SR method can preserve image-label correspondence with clear boundaries. Although some serration remains along the borders, further refinement is possible using a video-pretrained model. These precise super-resolution results serve as the foundation that the knowledge gained from our model can guide and enhance the following segmentation process.
| Methods | HR input | HR label | DSC | HD95 |
|---|---|---|---|---|
| PFSeg [26] | ✗ | ✓ | 0.72790.0664 | 15.259.23 |
| DS2F [9] | ✗ | ✓ | 0.75180.0538 | 12.889.09 |
| ISDNet [27] | ✓ | ✓ | 0.70900.0771 | 18.538.72 |
| nnUNet [18] | ✗ | ✗ | 0.80350.0453 | 9.383.64 |
| REHRSeg | ✗ | ✗ | 0.81860.0498 | 6.572.38 |
| Fully Supervised | ✓ | ✓ | 0.84810.0414 | 8.922.65 |
4.4.2 HR Segmentation from LR Image
We evaluate the performance of REHRSeg for HR segmentation from LR image in this section. In addition to the previous works with 3D-based [26, 9] or 2D-based [27] methods for HR segmentation, we also compare with the training protocol that uses the B-spline interpolated data defined in the previous section, which enables the trained model to produce HR segmentation results using upsampled LR images as inputs. This will consume considerably more computational resources during training and inference due to the enlarged input size. Quantitative results in Table 3 indicate that REHRSeg achieves top-ranked performance without any HR ground truth. It is also noteworthy to find that our HD95 metric is even better than fully supervised method, which can be explained by our effective super-resolution assisted segmentation design. The qualitative results for three different subjects in Fig. 7 also support the reported metrics. For instance, 2D-based methods such as ISDNet exhibit better results in the sagittal view compared to other views, but their overall performance is inferior to 3D-based methods like PFSeg. Furthermore, training with interpolated data using a powerful segmentation framework provides a strong baseline for this task. However, the boundaries in these interpolated results are less precise, likely due to misalignment between the interpolated images and labels. In contrast, REHRSeg provides the segmentation results whose boundaries are closest to the ground truth, even in challenging cases such as those from the coronal view, where other methods struggle to achieve satisfactory results.
| DSC (LR) | HD95 (LR) | DSC (HR) | HD95 (HR) | |
| Baseline | 0.81550.0342 | 7.223.62 | - | - |
| +Pseudo SR Data | 0.82130.0302 | 7.043.77 | 0.80070.0403 | 7.072.19 |
| +Uncertainty Guidance | 0.82310.0281 | 6.960.87 | 0.80270.0468 | 7.111.52 |
| +Knowledge Distillation | 0.83060.0330 | 5.042.93 | 0.81860.0498 | 6.572.38 |
4.5 Ablation Study
4.5.1 Effectiveness of Our Architecture
We conduct an ablation study of each component of REHRSeg to evaluate their effectiveness, and report the quantitative results in Table 4. The experiments start by the incorporation of pseudo data generated by our self-SR model to assist the segmentation model with extra data and an auxiliary task. We can observe an improvement of the LR segmentation performance, and more importantly the availability of HR segmentation. Next, the introduction of uncertainty guidance refines the segmentation model to be aware of the boundaries of ROI, indicated by more advanced segmentation results. Our knowledge distillation strategy achieves the best performance, which significantly surpasses the baseline. This trend is also reflected in HR segmentation, although the addition of uncertainty guidance results in a slight decrease on the HD95 metric.
| DSC (LR) | HD95 (LR) | DSC (HR) | HD95 (HR) | |
| B-spline | 0.81050.0421 | 7.523.69 | 0.78770.0590 | 7.212.21 |
| SMORE | 0.82260.0301 | 7.752.55 | 0.80680.0410 | 7.111.87 |
| FLAVR from scratch | 0.82160.0306 | 7.033.73 | 0.80830.0421 | 6.962.17 |
| REHRSeg | 0.83060.0330 | 5.042.93 | 0.81860.0498 | 6.572.38 |
4.5.2 Comparison of Different Self-SR Methods
We further assess the impact of replacing our self-SR model with alternative methods for reducing slice thickness. Specifically, we evaluate the B-spline interpolation and SMORE, using their super-resolution results solely as pseudo-data to assist the segmentation model, as these methods do not provide uncertainty maps or 3D feature maps. It is evident that B-spline interpolation negatively affects segmentation performance, as the morphology-based interpolation of labels does not accurately reflect the actual boundaries of the B-spline interpolated images, leading to sub-optimal segmentation results. Although SMORE yields a slight improvement on the DSC scores, they fail to enhance the HD95 metric. In contrast, our method improves both metrics and achieves even better performance when the self-SR model is pretrained on video frame interpolation.
| DSC (LR) | HD95 (LR) | DSC (HR) | HD95 (HR) | |
| MIMIC [51] | 0.82020.0319 | 6.133.13 | 0.80850.0485 | 7.032.36 |
| IFVD [52] | 0.82690.0270 | 5.902.75 | 0.82220.0386 | 6.752.08 |
| Correlation Only | 0.83210.0278 | 5.983.39 | 0.80480.0533 | 6.752.46 |
| REHRSeg (=0.01) | 0.82340.0332 | 7.996.19 | 0.80760.0514 | 6.892.26 |
| REHRSeg (=0.1) | 0.83270.0355 | 5.292.55 | 0.81640.0576 | 6.772.27 |
| REHRSeg (=1.0) | 0.83060.0330 | 5.042.93 | 0.81860.0498 | 6.572.38 |
| REHRSeg (=10.0) | 0.82000.0500 | 6.163.19 | 0.81600.0472 | 7.012.35 |
4.5.3 Comparison of Different Knowledge Distillation Methods
We also evaluate the effect of incorporating different knowledge distillation methods in REHRSeg. For comparison, we include the established distillation techniques for dense prediction tasks: MIMIC [51] with pixel-wise distillation, IFVD with cosine similarity distillation, and REHRSeg using only correlation distillation (i.e., without cosine similarity). We further evaluate the effect of changing the distillation intensity, which is reflected by the weight of distillation loss during training. Quantitative results in Table 6 demonstrate that all methods effectively distill some useful knowledge from self-SR model, especially for the HR segmentation compared with the third row in Table 4. The cosine similarity and correlation-based distillation methods are generally better than pixel-wise distillation using MSE loss, while the proposed distillation strategy using the combination of these methods can further improve the performance. We also find that setting the distillation intensity yields optimal overall results, with too large deviations from this value resulting in performance degradation.
5 Conclusion and Discussion
HR MRI segmentation has been extensively studied to provide accurate and detailed delineation of ROI, while encountering real-world application issues with only LR images in hand. Although existing methods have explored using LR images as inputs for HR segmentation in the inference stage, they still require HR images and their annotations for training, which are both expensive to acquire in clinical scenarios. In this paper, we propose a novel resource-efficient 3D HR segmentation framework, REHRSeg, that can be trained without the need of HR data. By further investigating the self-supervised super-resolution framework, we take advance of its capacities in enhancing the segmentation model from three different aspects. Experimental results for both the synthetic and real-world datasets are promising, as REHRSeg can obtain high-quality HR segmentation, while also achieving superior LR segmentation results in conventional settings.
Despite the inspiring results as mentioned above, there are still potential extensions that can be explored. For example, more advanced uncertainty-guided strategy [41] can be used to refine the predicted ROI boundaries, and deeper integration of feature interaction between super-resolution and segmentation [9] may further improve the performance, albeit with an increase in computational cost. Moreover, the proposed REHRSeg method is anticipated to enhance other segmentation protocols such as few-shot learning and domain adaptation, which can further contribute to the developments of resource-efficient medical image segmentation.
References
- [1] G. Katti, S. A. Ara, A. Shireen, Magnetic resonance imaging (mri)–a review, Int. J. Dent. Clin. 3 (1) (2011) 65–70.
- [2] Y. Qu, et al., Surgical planning of pelvic tumor using multi-view cnn with relation-context representation learning, Med. Image Anal. 69 (2021) 101954.
- [3] N. Siddique, S. Paheding, C. P. Elkin, V. Devabhaktuni, U-net and its variants for medical image segmentation: A review of theory and applications, IEEE Access 9 (2021) 82031–82057.
- [4] F. Shamshad, et al., Transformers in medical imaging: A survey, Med. Image Anal. 88 (2023) 102802.
- [5] H. Wang, et al., Adaptive decomposition and shared weight volumetric transformer blocks for efficient patch-free 3d medical image segmentation, IEEE J. Biomed. Health. Inf. 27 (10) (2023) 4854–4865.
- [6] Y. Wang, et al., Rose: Multi-level super-resolution-oriented semantic embedding for 3d microvasculature segmentation from low-resolution images, Neurocomputing 599 (2024) 128038.
- [7] D. Luo, H. Kang, J. Long, J. Zhang, X. Liu, T. Quan, Gdn: Guided down-sampling network for real-time semantic segmentation, Neurocomputing 520 (2023) 205–215.
- [8] Y. Hu, et al., Efficient semantic segmentation by altering resolutions for compressed videos, in: Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 22627–22637.
- [9] Z. Qiu, Y. Hu, X. Chen, D. Zeng, Q. Hu, J. Liu, Rethinking dual-stream super-resolution semantic learning in medical image segmentation, IEEE Trans. Pattern Anal. Mach. Intell. 46 (1) (2024) 451–464.
- [10] K. Krupa, M. Bekiesińska-Figatowska, Artifacts in magnetic resonance imaging, Polish J. Radiol. 80 (2015) 93.
- [11] A. B. Albu, T. Beugeling, D. Laurendeau, A morphology-based approach for interslice interpolation of anatomical slices from volumetric images, IEEE Trans. Biomed. Eng. 55 (8) (2008) 2022–2038.
- [12] B. H. Menze, et al., The multimodal brain tumor image segmentation benchmark (brats), IEEE Trans. Med. Imag. 34 (10) (2015) 1993–2024.
- [13] L. Clarke, et al., Mri segmentation: Methods and applications, Magn. Reson. Imag. 13 (3) (1995) 343–368.
- [14] O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in: Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent, 2015, pp. 234–241.
- [15] L. Yu, et al., Automatic 3d cardiovascular mr segmentation with densely-connected volumetric convnets, in: Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent, 2017, pp. 287–295.
- [16] F. Milletari, N. Navab, S.-A. Ahmadi, V-net: Fully convolutional neural networks for volumetric medical image segmentation, in: Proc. 4th Int. Conf. 3D Vis., Ieee, 2016, pp. 565–571.
- [17] S. Roy, et al., Mednext: Transformer-driven scaling of convnets for medical image segmentation, in: Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent, 2023, pp. 405–415.
- [18] F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, K. H. Maier-Hein, nnu-net: a self-configuring method for deep learning-based biomedical image segmentation, Nat. Methods 18 (2) (2021) 203–211.
- [19] H.-Y. Zhou, et al., nnformer: Volumetric medical image segmentation via a 3d transformer, IEEE Trans. Image Process. 32 (2023) 4036–4045.
- [20] Y. He, V. Nath, D. Yang, Y. Tang, A. Myronenko, D. Xu, Swinunetr-v2: Stronger swin transformers with stagewise convolutions for 3d medical image segmentation, in: Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent, 2023, pp. 416–426.
- [21] A. M. Shaker, M. Maaz, H. Rasheed, S. Khan, M.-H. Yang, F. S. Khan, Unetr++: Delving into efficient and accurate 3d medical image segmentation, IEEE Trans. Med. Imag. (2024) 1–1.
- [22] J. Chen, et al., Transunet: Rethinking the u-net architecture design for medical image segmentation through the lens of transformers, Med. Image Anal. 97 (2024) 103280.
- [23] J. Ma, Y. He, F. Li, L. Han, C. You, B. Wang, Segment anything in medical images, Nat. Commun. 15 (1) (2024) 654.
- [24] H. Liu, G. Huo, Q. Li, X. Guan, M.-L. Tseng, Multiscale lightweight 3d segmentation algorithm with attention mechanism: Brain tumor image segmentation, Expert Syst. Appl. 214 (2023) 119166.
- [25] N. Wang, et al., Missu: 3d medical image segmentation via self-distilling transunet, IEEE Trans. Med. Imag. 42 (9) (2023) 2740–2750.
- [26] H. Wang, et al., Patch-free 3d medical image segmentation driven by super-resolution technique and self-supervised guidance, in: Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent, 2021, pp. 131–141.
- [27] S. Guo, et al., Isdnet: Integrating shallow and deep networks for efficient ultra-high resolution segmentation, in: Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 4361–4370.
- [28] L. Shan, et al., Uhrsnet: A semantic segmentation network specifically for ultra-high-resolution images, in: Proc. 25th Int. Conf. Pattern Recognit., IEEE, 2021, pp. 1460–1466.
- [29] S. Lei, Z. Shi, X. Wu, B. Pan, X. Xu, H. Hao, Simultaneous super-resolution and segmentation for remote sensing images, in: Proc. IEEE Int. Geosci. Remote Sens. Symp., 2019, pp. 3121–3124.
- [30] J. E. Iglesias, et al., Joint super-resolution and synthesis of 1 mm isotropic mp-rage volumes from clinical mri exams with scans of different orientation, resolution and contrast, Neuroimage 237 (2021) 118206.
- [31] Z. Song, et al., Alias-free co-modulated network for cross-modality synthesis and super-resolution of mr images, in: Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent., 2023, pp. 66–76.
- [32] A. S. Chaudhari, et al., Super-resolution musculoskeletal mri using deep learning, Magn. Reson. Med. 80 (5) (2018) 2139–2154.
- [33] C. Peng, W.-A. Lin, H. Liao, R. Chellappa, S. K. Zhou, Saint: Spatially aware interpolation network for medical slice synthesis, in: Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2020, pp. 7747–7756.
- [34] X. Wang, et al., Spatial attention-based implicit neural representation for arbitrary reduction of mri slice spacing, Med. Image Anal. (2024) 103158.
- [35] K. Xuan, et al., Reducing magnetic resonance image spacing by learning without ground-truth, Pattern Recognit. 120 (2021) 108103.
- [36] C. Zhao, B. E. Dewey, D. L. Pham, P. A. Calabresi, D. S. Reich, J. L. Prince, Smore: A self-supervised anti-aliasing and super-resolution algorithm for mri using deep learning, IEEE Trans. Med. Imag. 40 (3) (2021) 805–817.
- [37] X. Wang, et al., Inter-slice super-resolution of magnetic resonance images by pre-training and self-supervised fine-tuning, in: Proc. IEEE Int. Symp. Biomed. Imag., 2024, pp. 1–5.
- [38] Z. Lu, et al., Two-stage self-supervised cycle-consistency transformer network for reducing slice gap in mr images, IEEE J. Biomed. Health. Inf. 27 (7) (2023) 3337–3348.
- [39] T. Kalluri, D. Pathak, M. Chandraker, D. Tran, Flavr: Flow-agnostic video representations for fast frame interpolation, in: Proc. IEEE Winter Conf. Appl. Comput. Vis., 2023, pp. 2071–2082.
- [40] T. Xue, B. Chen, J. Wu, D. Wei, W. T. Freeman, Video enhancement with task-oriented flow, Int. J. Comput. Vis. 127 (2019) 1106–1125.
- [41] P. Tang, P. Yang, D. Nie, X. Wu, J. Zhou, Y. Wang, Unified medical image segmentation by learning from uncertainty in an end-to-end manner, Knowl.-Based Syst. 241 (2022) 108215.
- [42] M. Fei, et al., Distillation of multi-class cervical lesion cell detection via synthesis-aided pre-training and patch-level feature alignment, Neural Networks 178 (2024) 106405.
- [43] M. Ranzinger, G. Heinrich, J. Kautz, P. Molchanov, Am-radio: Agglomerative vision foundation model reduce all domains into one, in: Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 12490–12500.
- [44] A. Vassantachart, et al., Automatic differentiation of grade i and ii meningiomas on magnetic resonance image using an asymmetric convolutional neural network, Sci. Rep. 12 (1) (2022) 3806.
- [45] Z. Song, et al., Uni-coal: A unified framework for cross-modality synthesis and super-resolution of mr images, arXiv preprint arXiv:2311.08225 (2023).
- [46] Q. Duan, et al., Sensecare: A research platform for medical image informatics and interactive 3d visualization, arXiv preprint arXiv:2004.07031 (2020).
- [47] Y. Qu, et al., Surgical planning of pelvic tumor using multi-view cnn with relation-context representation learning, Med. Image Anal. 69 (2021) 101954.
- [48] E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, P. Luo, Segformer: Simple and efficient design for semantic segmentation with transformers, in: Proc. Adv. Neural Inf. Process. Syst., Vol. 34, 2021, pp. 12077–12090.
- [49] B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, R. Girdhar, Masked-attention mask transformer for universal image segmentation, in: Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 1290–1299.
- [50] M. Li, J. Lin, Y. Ding, Z. Liu, J.-Y. Zhu, S. Han, Gan compression: Efficient architectures for interactive conditional gans, IEEE Trans. Pattern Anal. Mach. Intell. 44 (12) (2022) 9331–9346.
- [51] Q. Li, S. Jin, J. Yan, Mimicking very efficient network for object detection, in: Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2017.
- [52] Y. Wang, W. Zhou, T. Jiang, X. Bai, Y. Xu, Intra-class feature variation distillation for semantic segmentation, in: Proc. Eur. Conf. Comput. Vis., 2020, pp. 346–362.