Regulating stochastic clocks
This version: )
Abstract
Stochastic clocks represent a class of time change methods for incorporating trading activity into continuous-time financial models, with the ability to deal with typical asymmetrical and tail risks in financial returns. In this paper we propose a significant improvement of stochastic clocks for the same objective but without decreasing the number of trades or changing the trading intensity. Our methodology targets any Lévy subordinator, or more generally any process of nonnegative independent increments, and is based on various choices of regulating kernels motivated from repeated averaging. By way of a hyperparameter linked to the degree of regulation, arbitrarily large skewness and excess kurtosis of returns can be easily achieved. Generic-time Laplace transforms, characterizing triplets, and cumulants of the regulated clocks and subsequent mixed models are analyzed, serving purposes ranging from statistical estimation and option price calibration to simulation techniques. Under specified jump–diffusion processes and tempered stable processes, a robust moment-based estimation procedure with profile likelihood is developed and a comprehensive empirical study involving S&P500 and Bitcoin daily returns is conducted to demonstrate a series of desirable effects of the proposed methods.
MSC2020 Classifications: 60E07; 60G51; 60H30
JEL Classifications: C13; C65; G12
Keywords: Asymmetrical and tail risks; Lévy subordinators; regulating kernels; tempered stable processes; moment-based estimation; profile likelihood
1 Introduction
Financial returns have long been documented to have excessive skewness and kurtosis relative to those of an (un)conditional Gaussian distribution, leading to asymmetrical and tail risks; see, among others, [Bollerslev, 1987] [16], [Mittnik et al., 2000] [49], [Jondeau and Rockinger, 2003] [35], and [Ornthanalai, 2014] [51]. This phenomenon appears to be even more salient in the recently burgeoning cryptocurrency market which exhibits very high volatility due to its heavy reliance on supply and demand and market attention; see [Troster et al., 2019] [63], [Gkillas and Katsiampa, 2018] [30], [Chaim and Laurini, 2019] [20], and [Liu and Tsyvinski, 2021] [42], e.g., for the major cryptocurrencies including Bitcoin.
In continuous-time modeling, a well-known method for incorporating distributional asymmetry and heavy tails is to replace the usual, constantly forward-moving clock under which the underlying stochastic process is monitored with a generally independent nondecreasing stochastic process. The latter process is termed a “stochastic clock” and can be linked to trading volumes or the number of trades (see [Clark, 1973] [23], [Ané and Geman, 2000] [5], [Geman et al., 2001] [29], and [Geman, 2008] [28]). Stemming from the celebrated Dambis–Dubins–Schwarz theorem of time change, [Monroe, 1978] [50] first gave the possibility to represent any semimartingale as a time-changed Brownian motion. When the stochastic clock is modeled by a nonnegative process with independent and stationary increments, namely a Lévy subordinator, such a representation has had striking consequences in generating a variety of purely discontinuous Lévy processes as mixed models, which have flourished for the last two decades in time series econometrics, option pricing, and portfolio management, some recent contributions including [Madan et al., 2019] [47], [Aguilar et al., 2020] [2], and [Fallahgoul and Loeper, 2021] [27].
The key idea behind using stochastic clocks in the absence of a drift component in producing large skewness and kurtosis is rather comprehensible: Pure-jump stochastic clocks progress in a staircase-like manner and are less active – and less uniform – than the usual “sloped” clock of calendar time, and hence possess relatively slower local speed, representing trading activity that does not take place in a perfectly continuous manner, which enables them to adequately tell apart periods of intensive trading and other relatively calmer ones. Perhaps the two most predominant clocks of this type are the gamma process and the inverse Gaussian process, which were studied in [Madan et al., 1998] [46] and [Barndorff-Nielsen, 1997] [7], respectively, to time-change a drifted Brownian motion for building discontinuous models in dealing with skewed and leptokurtic financial returns.111The same processes also play an important role in many nonfinancial fields, especially in reliability engineering to model the degradation phenomena of structural components (see the overview by [Ye and Xie, 2015] [70]).
Noteworthily, when working with ordinary stochastic clocks under Lévy subordinators, the asymmetrical and tail risks of returns are largely controlled by the number of trades occurring for a significant period of time (i.e., the aggregate level of trading activity) through an infinite-divisibility (i.e., time-multiplicative) parameter (as mentioned in the overview in [Schoutens, 2003, Chap. 4] [59]), or the long-term trading intensity (equivalently, the variation of trading volumes) via an -stability index (in the case of the stable family; see [Samorodnitsky and Taqqu, 1994] [57] e.g.). More specifically, the matching of a high empirical kurtosis level will require decreasing the value of the infinite-divisibility parameter which is a direct measurement of the amount of jumps,222The intuition is that as such a parameter tends to zero in value, the corresponding distribution becomes degenerate. or altering the stability index which is heavily tied to the microstructure or the local regularity of sample paths. Such an operation seems totally innocuous when return distributions are analyzed statically, after imposing assumptions of i.i.d. samples. However, in reality, the aggregate number of trades cannot be expected to be unlimitedly small, or close to zero, leading effectively to degeneracy, or trading halts; on the other hand, the long-term trading intensity is generally specified a priori without being optimized and may be estimated in a dynamical fashion using techniques of empirical power variations (see, e.g., [Aït-Sahalia and Jacod, 2009] [3], [Todorov and Tauchen, 2011] [62], [Jing et al., 2012] [34], and [Todorov, 2021] [61]), which of course varies with the frequencies at which data are observed. With restrictions on these two important dimensions, nearly all the noticed Lévy models will not function well in coping with diverse asymmetrical and tail risks of returns.
In connection with this, we are motivated to consider yet another possibility for the same purpose, by changing the size of local movements of a stochastic clock instead of decreasing their amount or adjusting the corresponding activity level. From the perspective of trading activity, this would mean that the spread of trade sizes may be enlarged at will without having to alter the level of trading intensity or stick to an implausibly small number of trades. In doing so, we prefer to operate in a continuous-time environment because discrete-time analogies are easy to develop subsequently, whereas it will be understandably difficult to go in the opposite direction, e.g., to ensure infinite divisibility in finite dimensions.
Besides, consideration of such a possibility will be beneficial in unraveling the microstructure of returns from low-frequency data via a connection to phenomena that trigger abnormal trading volumes, with ample empirical evidence. For instance, the goal to increase the sparsity of trade size distributions is in agreement with the presence of large speculators in traditional and cryptocurrency markets (mentioning, e.g., [Chang et al., 1997] [21] and [Blau, 2017] [14], respectively) or the prevalence of trade-size clustering (referring to [Alexander and Peterson, 2008] [4] and [Chen, 2019] [22]). In this regard, the linkage between skewed and leptokurtic returns and the theoretical moments of the driving stochastic clock is simply embodied by the famous price–volume relationship (see, e.g., [Karpoff, 1987] [37] and [Richardson and Smith, 1994] [55]).
With the foregoing aspects in mind, in this paper we aim to propose a unified approach towards regulating any existing stochastic clock without impairing important fundamental properties. In this context, the act of “regulating” can be understood in the ordinary sense – a stochastic clock is continually adjusted with the intent of achieving a desirable local speed, making it more reliable for capturing the differences in trading activity over time. As a starting point, however, our methodology is concentrated on the aforesaid Lévy subordinators but will be easily extendable to processes of independent but time-inhomogeneous increments, or Sato processes (see [Sato, 2006] [58] and [Eberlein and Madan, 2009] [26]), all of which can be subsequently applied to build structurally more complex stochastic clocks with mean-reverting acceleration and continuous movements that can deal with volatility clustering (see [Carr and Wu, 2004] [19]). The regulated stochastic clocks have essentially the same functionalities as the originals, and can be used to time-change diffusion processes to spawn multifarious semimartingales with discontinuities, albeit with much larger capacity in dealing with asymmetrical and tail risks.
That being said, our approach can also be exploited to generate a rich class of unexplored Lévy processes comfortable for financial modeling. As expected, this newfound dimension is encoded into a hyperparameter representing the degree of regulation, i.e., how much slower the regulated clock is compared with the unregulated one, and kept as independent as possible from the roles of other shape parameters. The resultant processes are shown to be analytically tractable whether it be statistical estimation or risk-neutral valuation of options that is of interest.
The remainder of this paper is structured as follows. In Section 2 we present our main methodology in three recipes, all of which serve to regulate a stochastic clock to any intended degrees. The effect of clock regulation on the jump behaviors depicting corresponding evolution of trading activity is analyzed (Theorem 1, Theorem 2, and Corollary 1) and the impact on asymmetry and tail heaviness of the original distribution is examined in detail (Corollary 2). Then, we present in Section 3 two simple ways for utilizing the (un)regulated stochastic clocks in order to construct real-valued mixed models. In Section 4, we demonstrate clock regulation on two important special cases featuring jump–diffusion models and purely discontinuous models and discuss their potential applications in finance as well as other fields. Section 5 outlines two possible candidates for optimizing the degree of regulation: one employing a robust moment-based estimation procedure combined with profile log-likelihood and the other using option price calibration with numerical Fourier inversion techniques, which underlie our empirical study in Section 6 concerning S&P500 and Bitcoin returns and Bitcoin options. Conclusions are drawn in Section 7 along with a summary of the properties of the three recipes and highlights on future research directions. All mathematical proofs are presented at the end of the paper, in Appendix A.
2 Regulated stochastic clocks
As already noted, we shall develop our methodology using Lévy processes exclusively. By having independent and stationary increments, such processes are easy to manage and sit at the core of statistical estimation with i.i.d. temporal data. To begin with, we outline some basic intuition.
Let be a Lévy subordinator (nondeterministic by default), acting as a stochastic clock. The objective of regulation lies in properly compressing the amplitude of its moderate jumps (for moderate values the jump component ), and an attendant consequence is that the finite-dimensional distribution of will tend to have greater asymmetry and a heavier right tail, as measured by the skewness and kurtosis. Thus, suppose that is the Laplace transform (LT) of the random variable for generic , assumed to be definable in a neighborhood of the origin (in ), and then with the canonical expansion
| (2.1) |
in terms of corresponding cumulants , (with ), the objective is converted to finding, for a fixed , a linear functional such that, from (2.1),
where the time-invariant factors ’s satisfy and , . These relations will immediately render cumulants of larger (up to four) orders more reduced. Although there are obviously infinitely many possible ways to construct such a functional, should be conceptually matched with a recipe operating on the sample paths to which the collection of LTs correspond; otherwise temporal structures represented by path properties will be difficult to justify if possible at all. In what follows we are going to present three utterly simple and closely related recipes of this nature, by exploiting continuous temporal averaging.
2.1 Repeated averaging-induction: Three recipes
We design our first recipe as follows. Set and, for any , repeatedly define the running averages
| (2.1.1) |
For each , is a stochastic process having -a.s. continuous sample paths, where continuity at 0 follows by the dominated convergence theorem. More specifically, the sample paths belong to the class of ()th-order differentiable functions for , -a.s., as a result of repeated integration.
Since (2.1.1) operates a linear functional, it is clear that for every and fixed the random variable has an infinitely divisible distribution, which induces a unique Lévy process that is also nonnegative, which we denote as
| (2.1.2) |
By nonnegativity every can be used as a different stochastic clock, and will be referred to as the type-I regulated -clock of degree .
The intuition behind the first recipe is rather clear: Averaging in time has a natural effect of contracting moderate values of the sample paths and continuing to do so will tend to enlarge such an effect. To give some remarks, in the special case , the process is precisely the running average of , which is heavily tied to linear integral functionals of Lévy processes; such integrals have been widely applied to trace the cumulative patterns of various stochastic systems; some notable examples include the total cost of random epidemics (see, e.g., [Downton, 1972] [25] and [Pollett, 2003] [54]), cumulation of count data generalized to non-integer values ([Orsingher and Polito, 2013] [52]) or count data with overdispersion ([Xia, 2019] [67]), and the modeling of structural degradation phenomena in the presence of memory effects (see [Tseng and Peng, 2004] [64] and [Xia, 2021, Sect. 4.1] [68]).
Note that the averaging–induction procedure also works for any integer , and hence it is intuitive to consider inducing a Lévy process for each using (2.1.2), before initiating a subsequent averaging step (2.1.1). In this way the integrand in the averaging step can be made a Lévy process even for , and each resultant averaged process will correspond to the linear functional of a certain Lévy process. Such an idea leads to our second recipe. Likewise, set , and then repeatedly utilize the first recipe for every in the following fashion:
| (2.1.3) |
where ’s are induced Lévy processes such that
It is clear that the averaged processes and are indistinguishable, and so are the induced processes and , but for they are different with dissimilar path properties – the sample paths will remain in the class (-a.s.) for .
It can be shown (see the proof of Theorem 1 in Appendix A) that the second recipe can be essentially thought to average the log-LT, while in comparison the first recipe, by construction, has the averaging effect on the sample paths. We will refer to the process , , as the type-II regulated -clock of degree .
In the averaging step (2.1.1), if we stack up the time scale () outside of the integral operators for every , the averaging procedure becomes a folded cumulation with a one-time power scaling, and we shall have our third recipe. Set and define the quasi-averages
| (2.1.4) |
which has an infinitely divisible distribution for the same reason as in (2.1.1), and induce a unique nonnegative Lévy process,
referred to as the type-III regulated -clock of degree .
It is obvious that the processes and have the same degree of path smoothness but are guaranteed to coincide (up to indistinguishability) only if . Besides, the distribution of is also infinitely divisible for every and fixed .
We present some general formulae for the LTs of the three types of regulated stochastic clocks in Theorem 1, which are naturally extended to non-integer-valued as well. This aspect hints at the extension of the three recipes to the sense of averaging of fractional degrees and will be considered in the optimization of the regulation degree .
Theorem 1.
For generic and any , the LTs of , , and , are given by
| (2.1.5) |
respectively, where and symbolize, respectively, the usual gamma function and the (upper) incomplete gamma function.
In any case, the recipes have given rise to three families of stochastic clocks, controlled by the degree of regulation. The effect of operating the three recipes on the unregulated clock is twofold – on path properties and distributional properties, as we are bound to investigate next.
2.2 Characterizing triplets
From their primary motivation, the three recipes are all supposed to compress the jumps of into extreme values. To confirm such effects, it is necessary to derive the characterizing triplets of the regulated clocks ’s, ’s, and ’s governing their sample path properties. Doing so will also be helpful for developing simulation methods, the main reason being that the LTs that we have obtained in (1), having exponentiated integrals, are generally difficult to invert analytically, thus circumventing the implementation of inverse sampling methods.
First, there is no Brownian component in ’s, ’s or ’s and we assume without loss of generality that there is no drift as well, so that we can concentrate on the corresponding Lévy measure. More specifically, suppose that the LT takes the following general form due to the Lévy–Khintchine representation:
with the characterizing triplet , for some Lévy measure333The notation will occasionally be used for the Lévy measure of in the mathematical proofs (Appendix A) to avoid ambiguity. imposed on such that and . Then, the characterizing triplets of , , and , given , are denoted as , , and respectively, which make the representations
| (2.2.1) |
Theorem 2.
For any , we have
| (2.2.2) |
where is the inverse regularized (upper) incomplete gamma function.444It is understood as the unique solution to the transcendental equation for ; see [DiDonato and Morris, 1986] [24].
Furthermore, if is absolutely continuous with respect to Lebesgue measure, then
| (2.2.3) |
with .
We remark that the Lévy measures ’s, ’s, and ’s from (2), for , are all absolutely continuous because of integration, and thus their associated Lévy densities on the left-hand side of (2) exist unconditionally. More importantly, we have the following equalities among their Blumenthal–Getoor indices ([Blumenthal and Getoor, 1961] [15]).
Corollary 1.
For any , it holds that
| (2.2.4) |
and similarly .
Corollary 1 means that none of the three recipes alters the path regularity of , which is beyond doubt a very desirable property as there is never an intention of changing the jump activity of the underlying models connected with trading intensities (recalling Section 1). On the other hand, all of the induced Lévy measures govern jumps of arbitrarily large amplitudes, whereas their actual weights (namely likelihood) will depend on the functional form of (or that of the LT), subject to further adjustment of its parameters, and through the foregoing relations. This aspect will be clearer as we move to specific distribution families of interest in Section 4.
To gain additional insight into how the three recipes distort the Lévy measures , , and from a comparative angle, it is first observed from (2) in Theorem 2 that these Lévy measures do coincide if and only if . Upon the substitution , they can be viewed as fractional integrals of the Lévy measure of under different kernels, which with fixed boil down to the functions , , and , respectively, defined for . Interestingly, we then observe that the first two functions are precisely the derivatives in magnitude of and , respectively, which happen to be inverses of each other. Put differently, the effects on the (average-induced) Lévy measures from the first two recipes are perfectly complementary, in the sense that neither dominates the other. Differently, the third function integrates in magnitude to , which is not in direct comparison with the others, for the third recipe, strictly speaking, does not embody a running average for . This discussion is further illustrated in Figure 1, with five integer degrees of regulation. We see that the first recipe, which averages the sample paths, has a larger impact (distortion) when is concentrated on small values of , relative to the second, which at bottom averages the log-LT. In addition, the larger the regulation degree, the faster the impact differences are reflected.

2.3 Asymmetry and tail heaviness
The static effect from operating the three recipes is to enlarge the asymmetry and (right) tail heaviness of the distribution of the unregulated clock for any fixed . With the LTs in (1) at hand, computation of the statistics of the corresponding regulated clocks ’s and ’s is straightforward. More particularly, we shall focus on the impact of regulation on skewness and excess kurtosis. Let us restate from (2.1) that the corresponding cumulants are defined to be the series coefficients and in
with . The next corollary explains how the cumulants vary with the regulation degree .
Corollary 2.
For any , we have the cumulant reduction relations
| (2.3.1) |
with the sequence
| (2.3.2) |
which is rational for .
Using Corollary 2, the relations for the mean, variance, skewness and excess kurtosis of the type-I -degree regulated -clocks are given by
| (2.3.3) |
Since the integrand in (2.3.2) admits the series representation ([Abramowitz and Stegun, 1972, Eq. 6.5.29] [1])
carrying out the integral over gives
| (2.3.4) |
and hence the sequence decays exponentially as increases for and (strictly) faster for . This indicates that the first recipe shrinks the cumulants of with acceleration – more aggressively so as regulation continues with . Note that for the exponential decay is in fact an equality . Looking at (2.3) and (2.3.4) we can also claim that the type-I regulated clocks have at least exponentially decaying mean and variance but faster-than-exponentially increasing skewness and excess kurtosis, with respect to the degree of regulation, other things (e.g., parameter values) held equal.
In the case of the type-II regulated clocks, the counterpart of (2.3) for is
| (2.3.5) |
Intuitively, this signifies that the cumulant-reduction effect of the second recipe is uniform, in the sense that for each additional round of regulation, the mean and variance are reduced by fixed proportions ( and , respectively) while the skewness and excess kurtosis are simultaneously enlarged by fixed proportions ( and , respectively). In consequence, for the type-II regulated -clocks the mean and variance decay exactly exponentially and so do the skewness and excess kurtosis increase, other things equal.
As for the type III, we have similarly from Corollary 2 the quotient , , and subsequently the following moment relations for :
| (2.3.6) |
Upon comparing the above quotient with (2.3.4), with as it is seen that the third recipe generates an even severer cumulant-reduction effect than the first recipe does. However, the skewness and excess kurtosis are enlarged with deceleration, noted that and , as . Put together, the type-III regulated -clocks have mean and variance of faster-than-exponential decay whereas the skewness and excess kurtosis exhibit slower-than-linear growth, which properties are in stark contrast with those of the first two types.
On paper, if we do not alter the parameter (if any) values of , then all three recipes are able to effectively enlarge the asymmetry and tail heaviness of its distribution, with the first having the most significant effect, whereas the downside is that the mean and variance are reduced at the same time. The latter effect is, of course, undesirable for applications, and eluding it will require at least two independent parameters so that the mean and variance can be held constant across the regulation degree . More specifically, when a real-valued model is to be constructed from (see Section 3), with the aid of an additional location parameter the mean can be readily fixed by way of centralization, and so the other parameter will most likely (and ideally) be a scale parameter, to which the standard deviation is proportional and the skewness and excess kurtosis are immune. Such a requirement becomes rather standard in statistical inference, and in consequence the skewness and excess kurtosis relations stated in (2.3), (2.3.5), and (2.3) provide useful implications. We remark, however, that if the mean is to be kept invariant to regulation by way of a shape parameter of (oftentimes existent for one-sided distributions) then changing its value is likely to enlarge skewness and excess kurtosis at rates different from those in (2.3) and (2.3.5), despite exponential growth rates. Such a situation cannot be analyzed from a universal viewpoint and will again depend on the functional form of the LT , with respect to the shape parameter. More details are provided in Section 4.
Similarly, the results for the statistics stated in this section can be naturally extended for fractional degrees of regulation. In Figure 2 we give a joint plot of the enlargement effect on asymmetry and tail heaviness for the two recipes with real regulation degrees , by using (2.3), (2.3.5), and (2.3) in sequence.

3 Time-changed processes
As aforementioned, the functionality of the regulated clocks ’s, ’s, and ’s is meant to be the same as that of – mathematically, to adjust the time underlying a (continuous) base process and generate a wide class of models for real-valued temporal data such as financial returns. In the following we shall consider two well-known base processes for the mixture, which are also shown to retain, leastways in part, the enlargement effect on asymmetry and tail heaviness through the clock regulation.
3.1 Constant mixtures
The simplest base process is beyond doubt a (deterministic) drift up to positive scaling, and time-changing it by the clock gives none but itself. Then, in order to create a real-valued random variable from it suffices to take the difference of two of its independent copies. Specifically, let be an independent copy of , and then define the difference process
| (3.1.1) |
where is a location parameter and are additional scale parameters. Then is a purely discontinuous real-valued Lévy process admitting the LT (fixing )
| (3.1.2) |
where the domain of can be extended to a neighborhood of provided that (2.1) holds.
Note that since the integral operator is for every a linear isometry over the space of bounded functions, considering such independent differences under the -degree regulated clocks is no different from operating the three recipes on the initial difference process . As a result, we can define the corresponding difference processes under each , , and , denoted , , and , respectively, in the same way as in (3.1.1).
Corollary 3.
For generic and any , the LTs of the constant mixtures subject to clock regulation are given by
| (3.1.3) |
Besides, by independence the th cumulant of for fixed is nothing but and similarly for and . If the mean and variance of and are kept constant by adjusting, respectively, the location parameter and a scale parameter of , then the skewness and excess kurtosis increase at precisely the same rates as those of stated in (2.3), (2.3.5), and (2.3), respectively. Therefore, the constant mixture approach also preserves enlargement effects on asymmetry and tail heaviness of the constituent subordinator , regardless of the additional parameters , , and .
Simplicity notwithstanding, a major drawback of this approach, due to linearity, is that it inevitably inherits the path regularity of into the processes ’s, ’s, and ’s, as the next corollary shows.
Corollary 4.
For any , we have .
3.2 Gaussian mixtures
Alternatively, one can construct a real-valued random variable by using it as a scale parameter for an independent Gaussian random variable – a technique called “Gaussian mixture,” which is implemented here by way of using to time-change a Brownian motion with drift (see, e.g., [Barndorff-Nielsen, 1997, Sect. 3.1] [7] and [Madan et al., 1998, Sect. 2] [46]). To be precise, let be a standard Brownian motion independent of , and define the mixed process
| (3.2.1) |
where is a location parameter and is a Brownian drift parameter representing signed random momenta. The dispersion of the Brownian motion can be fixed at for simplicity as long as has a scale parameter, which is already able to capture jump volatility. Then, is also a purely discontinuous real-valued Lévy process. Upon applying the tower property of conditional expectations, the LT of for fixed is found to be
| (3.2.2) |
Again, a partial domain extension into is possible with (2.1).
In a similar fashion, we can time-change the Brownian motion with drift by the regulated clocks, though this would not be equivalent to operating the two recipes on . The resultant processes are denoted as, respectively, , , and , with the LTs () states as follows.
Corollary 5.
For generic and any , the LTs of the Gaussian mixtures subject to clock regulation are given by
| (3.2.3) |
From Corollary 5, an application of Faà di Bruno’s formula yields the cumulants of in terms the finite sums
where ’s are partial Bell polynomials. In particular, by the order of the first four cumulants are: , , , and , in order. Similar results hold for and . Notably, the elegance of the Gaussian mixture (3.2.1) lies in that the additional parameter in its own right acts as a scaling factor on , so that scaling is fundamentally linked to doing , making it a feasible task to control the variance of (and that of and ) to be invariant to clock regulation, while the invariance of the mean is taken care of by the location parameter . The consequence is that the skewness and kurtosis relations in (2.3), (2.3.5), and (2.3) set the upper bounds for those (lower-bounded by 1) of the Gaussian-mixed processes, whose exact rates of increase are subject to the value of .
The main reason to consider Gaussian mixtures is that they allow for processes with infinite-variation sample paths. Indeed, it can be shown (see Appendix A) that the Blumenthal-Getoor indices of the Gaussian mixtures are precisely double that of .
Corollary 6.
For any we have .
Therefore, as long as , , and hence , , and , , on the regulated clocks, will all have jumps of infinite variation. The same idea goes for the Gaussian mixtures on the regulated clocks. This property overcomes the limitation of the constant mixtures and is particularly attractive when flexibility to include highly active jumps in asset returns is required for model formulation.
4 Some important special cases
We now consider two specific distributions of the unregulated clock for practical interests. By infinite divisibility we fix time at unless otherwise specified. Explicit formulae will be presented for the distributions of all three types of regulated clocks, as well as their time-changed processes.
4.1 Poisson process
Let the LT of be given by with shape parameter (Poisson intensity). Then we have the following specialized formulae.
Proposition 1.
If is a Poisson process with intensity , then for any ,
| (4.1.1) |
where denotes the generalized hypergeometric function (see [Slater, 1966] [60]); also,
| (4.1.2) |
It is an easy implication from Proposition 1 that the type-I regulated clock is of compound Poisson type: In light of the discussion in Subsection 2.2 and with inverse sampling in mind,
| (4.1.3) |
where is a sequence of i.i.d. standard uniform random variables. The transformed variable representing the jump amplitudes reduces to the standard uniform for and takes values in for all values of . In particular, is a compound Poisson-uniform process, which result has been discovered as a special case of fractionally integrated Poisson processes in [Orsingher and Polito, 2013] [52].
The first LT (1) cannot be evaluated explicitly555Apparently, this is caused by the lack of an explicit antiderivative of the function , . Even so, one can always derive alternative series representations for the log-LT. except for , in which case it is . Nonetheless, the first integral in (1) is very amenable to numerical computations using a standard Gauss–Kronrod quadrature rule because the integrand is an increasing function (of ) with values in for any .
Likewise, under the second recipe, the following representation exists for :
| (4.1.4) |
which is also a compound Poisson process. Similar to the type I, the jump amplitudes are all valued in , and are standard uniformly distributed for .
For the same reason as the first, the second LT in (1) can be efficiently carried out as a numerical integral thanks to the monotonicity and boundedness of the integrand, while an explicit expression has been given for integer regulation degrees. Only for two degree values can it be expressed in terms of more elementary functions. Of course, if , we have the compound Poisson-uniform LT . If , one can consult [Bateman, 1954, Eq. 4.6.1 and Eq. 4.6.2] [10] to obtain
where is known as the Euler–Mascheroni constant.
Due to simplicity, the third LT in (1) (under the third recipe) permits explicit evaluation for any real regulation degree, from which we have the representation
| (4.1.5) |
showing that is a compound Poisson process with -scaled beta()-distributed jumps. Unlike the other two types, due to such scaling the support of the jump amplitudes of shrinks with , and converges to the origin in its lower limit.
According to (4.1.3), (4.1.4), and (4.1.5), we conclude that when is a Poisson process, all three types of regulated clocks follow compound Poisson processes with bounded jumps. These representations provide easy ways for conducting simulations. Also, the two corresponding transformations under the first two recipes form inverse functions of each other, in line with the demonstration by Figure 1.
In financial applications, compound Poisson processes with finite jump amplitudes, coupled with an independent Brownian motion, form adequate jump–diffusion models for log-price dynamics when sudden movements in returns are believed not to be arbitrarily large in reality; see [Yan and Hanson, 2006] [69] and also [Baustian et al., 2017] [12]. These models are built from uniform distributions and are deemed to enlarge the tail heaviness of Gaussian distributions to an extent comparable to normally or double-exponentially distributed jumps (e.g., [Kou, 2002] [40]). Noted that is a compound Poisson-uniform process, they can be simply expressed in terms of
| (4.1.6) |
for a rate (reciprocal scale) parameter and a Brownian dispersion parameter . Since the continuous part is immune to regulation by the stability of the Gaussian distribution, clock regulation can still be understood on the entire jump–diffusion process . Viewing from the representations (4.1.3), (4.1.4), and (4.1.5), the effect of regulation is then to assign greater (probabilistic) weights to smaller price jumps, and the consequent jump amplitude distribution, which possesses a strictly decreasing density over a finite domain, is a “give-and-take” between the uniform and the exponential family.
To give an example, let us consider the scaled clock , where is for every a rate parameter (assuming for simplicity), and derive from it the regulated clocks , , and accordingly, whose constant mixtures are constructed following Subsection 3.1, with and . Then the processes , , and are centered symmetric compound Poisson processes with intensity and positive and negative jumps equally distributed in magnitude. To fix the variance of (at generic time) over , it suffices to set , for , , and for , . Then, as increases, the domain of jump amplitudes spreads out, albeit bounded, and the probability of smaller jumps also rises, as Figure 3 shows. Therefore, , , and all constitute a rich class of desirable models, when return jumps are known to be bounded in size but unevenly distributed.



Moreover, if and are two independent Poisson processes with possibly different intensities, say , the modified constant mixture666The superscript is expanded to include the process because here it is not an exact copy of . with parameters , , and is seen to be a scaled Skellam process which has jumps of fixed amplitude (equal to ). This type of discrete-valued processes have gained popularity in modeling tick-by-tick price changes with high-frequency data, as pioneered in [Barndorff-Nielsen et al., 2011] [9]. Recent developments have dealt with stochastic-volatility extensions for memory effects; see, e.g., [Kerss et al., 2014] [38], and [Gupta et al., 2020] [33], the latter also having studied associated running average processes beside discussing natural applications to scoring in ball sports. In connection with this, the process (), up to scaling by a positive number, defines exactly the -degree running average of (by linearity) and enables analysis of arbitrarily long-term behaviors of such phenomena (tick price changes versus scoring gaps). On the other hand, the scaled Lévy processes , , and of possibly fractional degrees , when applied for the same modeling purposes, allow for imprecision (e.g., ambiguity between change versus no change) in possible outcomes, by assigning positive probability to jumps of amplitudes strictly less than . In consequence, these possible outcomes are extended to real values to balance out false judgments, but still cannot fall out of their constructional range (tick sizes or score scales). In particular, the extent of imprecision is directly related to – if , ambiguity in favor of no change stays minor. Obviously, in the limit as the original discrete-valued processes are restored.
4.2 Tempered stable subordinators
Tempered stable distributions are an infinitely divisible family that was initially introduced in [Koponen, 1995] [39] from a procedure incorporating the finite moments property of Gaussian processes into Lévy stable processes, where it bore the name “truncated Lévy flights.” It is most commonly known in its one-sided form, characterized by up to three parameters (shape), (rate) and (family), with which the corresponding Lévy processes are often called tempered stable subordinators and so are readily usable as stochastic clocks. We refer to [Schoutens, 2003, Sect. 5.3.6] [59], [Rosiński, 2007] [56], and [Küchler and Tappe, 2013] [41] for a comprehensive treatment of these processes; see also [Grabchak, 2021] [31] for their discrete-valued analogy. The tempered stable family includes several commonly used subordinators as special cases, such as the gamma process () and the inverse Gaussian process (). If is a tempered stable subordinator with parametrization , its LT (at ) is given by
which is right-continuous at . The Lévy density of exists and equals , .
For , the indistinguishable order-1 regulated clocks , , and have been studied in depth in [Xia, 2021] [68], by the name of “average-tempered stable subordinators.” For all other values of , in the presence of the gamma-related functions, for the type I it does not seem possible to further write the corresponding formulae in (1) and (2) explicitly, whereas both in the present form can be computed numerically with high efficiency thanks to the positivity and boundedness of the integrands.
In contrast, the formulae in (1) and (2) for the type-II clocks are reducible to some closed-form expressions provided , by exploiting series representations of the integrands; further, due to the constructional simplicity of the type III, its corresponding formulae readily permit explicit evaluation, even for fractional degrees, which results are given in Proposition 2.
Proposition 2.
If is a tempered stable subordinator with with parametrization , then for any ,
| (4.2.1) |
where the poly-logarithm, and where analytic continuation is understood in each slit region and , , respectively, and
| (4.2.4) | ||||
| (4.2.5) |
where denotes the Meijer G-function (see the proof in Appendix A).
Note that if , then with and the elementary formulae follow:
as were initially obtained in [Xia, 2021, Thm. 1 and Corol. 2] [68]. For rational values of the family parameter , it is possible to rewrite (2) in terms of multiply nested sums of poly-logarithms; see, e.g., [Kalmykov and Kniehl, 2009] [36]. However, it is our preference not to straggle into those representations which are extremely lengthy in general, as interest is more for computational efficiency. For example, the following elementary formula applies to in the special case , corresponding to the inverse Gaussian process:
It can be easily verified using the antiderivative of in ; see [Gradshteyn and Ryzhik, 2007, Eq. 2.725] [32].
Also, we note that none of the Lévy densities given in (4.2.4) is integrable on , meaning that the processes ’s all have essentially infinite jump activity, as discussed earlier; in particular, for the tempered stable subordinator . In the special case , the first formula in (4.2.4) reduces to
corresponding to the Lévy density derived in [Xia, 2021, Corol. 1] [68], while for , the formula (4.2.4) stands and cannot be simplified to more elementary functions.777The first formula (4.2.4) is not really useful beyond deciphering the functional form of the induced Lévy densities; more specifically, because the G-function is defined through complex line integration by most computer algebra systems, its implementation is understandably much less computationally efficient relative to its numerical counterpart (via (2) by the quadrature rule), which also accommodates fractional values of .
Unlike the other two, the third recipe benefits by having no effect of increasing the computational complexity of the LT when operating on a tempered stable subordinator,888Numerical computations through the formulae (2) and (4.2.4) still intensify with the regulation degree which controls the dimensionality of the hypergeometric functions. and by this advantage the formulae (2) can be confidently applied to characteristic function-based optimization problems such as calibrating the parameters of a market model on strings of derivatives prices using numerical Fourier transforms.
Because the LTs , , and (fixing ) are all analytic in the complex plane except for a branch point on the negative real axis, the corresponding inverses (i.e., (a posteriori existent) density functions) can be found via a standard deformation argument employing a counterclockwise keyhole contour avoiding the cut extending to . Consequently, we obtain the following formulae:
| (4.2.6) |
for , where the real and imaginary parts are efficiently computable according to Theorem 1.999From a computational viewpoint, the formulae in (4.2) are stabler than performing a numerical inverse Fourier transform and allow the density functions to evaluated (or plotted) on a fine grid. In particular, for we have, after the substitution
| (4.2.7) |
and for any , with ,
| (4.2.8) |
Despite stability, implementation of (4.2) will require some effort for since the hypergeometric functions need to be computed by analytic continuation of the definitional series which are only convergent within , while there is no such issue for (4.2) because of fixed dimensionality of the hypergeometric functions.
With its overall flexibility and explicitness, processes with marginal tempered stable distributions are of great applicability in operations research, especially in the fields of reliability engineering and mathematical finance; we mention [van Noortwijk, 2009] [65], [Wang and Xu, 2015] [66], and [Ye and Xie, 2015] [70] for résumés on related structural degradation models and [Boyarchenko and Levendorskii, 2000] [17] and [Carr et al., 2002] [18] for derivatives pricing theory. For Gaussian mixtures, the path regularity is directly captured by the family parameter . Recalling that , for any (by Corollary 6), if , then the mixed processes , , and all have sample paths of finite variation, while the paths are of infinite variation for . In the special cases and , becomes the variance gamma process and the normal inverse Gaussian process, respectively.101010In [Carr et al., 2002] [18], two-sided tempered stable processes were studied under the name “CGMY,” which include the variance gamma process as a special case. However, for such processes cannot be interpreted as Gaussian mixtures of tempered stable subordinators. With the sample paths of the variance gamma process are of finite variation while with those of the normal inverse Gaussian process have infinite variation. In such cases, the processes , , and derived from stochastic clock regulation are natural extensions of the foregoing models with arbitrarily large skewness and kurtosis, the mean and variance fixed and path regularity unchanged.
Subject to the addition parameters , the density function of can be written either with (3.2.2) as the Fourier inverse
| (4.2.9) |
or, after applying the Bayes theorem to (4.2), as the marginalization
| (4.2.10) |
where the use of Fubini’s theorem in the second equality is under the condition that ;111111It can be shown that the polarity of with being a tempered stable subordinator exactly equals that of , which feature is also unaffected by regulation (). similar results hold for the densities and in terms of and , respectively.
It is straightforward to keep the mean and variance of the Gaussian mixture invariant to with the parametrization . One can for example adjust the location and Brownian drift parameters and according to the rules and ;121212Since we know from Subsection 3.2 that the value of directly controls the skewness, this approach can very quickly result in abnormally large asymmetry as increases. to maintain the moderate enlargement effects in (2.3.5), one can as well adjust the location and (tempered stable) rate parameters and by the rules and , where has unit scale; alternatively, disregarding the additional parameters and one can change the shape and rate parameters and of the unregulated clock , as discussed in Subsection 3.2.131313In contrast to the first, this one tends to give milder-than-moderate enlargement effects and so can fit in with a wide range of values of , hence also more manageable; see Appendix B for details. Along these lines one can come up with many hybrid methods for fixing the mean and variance, e.g., by changing , and powers of simultaneously. Similar arguments go for and .
5 Optimal degrees of regulation
It is time to consider the problem of finding an optimal degree of regulation with available data. Optimization may be accomplished by many different rules, depending on various aspects of the resultant distributions and data types. Instead of a comprehensive analysis, the aim of this section is to discuss two popular and comfortable methods that can justify values significantly deviating from zero (unregulated case) with due contrast control. The methods by themselves accommodate both the constant mixture and the Gaussian mixture .
5.1 Moment-based estimation
In financial modeling, it is a standard assumption that a probability distribution of asset returns can be defined by the knowledge of their first several (usually four) moments; see, e.g., [Ané and Geman, 2000] [5]. This suggests that one can use the first sample moments – in particular the sample mean, variance, skewness, and excess kurtosis – to retrieve certain model parameters, and underlies our moment-based estimation procedure, which goes as follows.
We start by fixing a truncated and discretized domain of degrees of regulation, and conduct moment-based estimation of the model parameters for each , with corresponding to the unregulated case. Recall that regulation leads to simple cumulant reduction relations (Corollary 2), with regulation type-specific coefficients
| (5.1.1) |
so it is most convenient to construct corresponding moment conditions from the model cumulants; for similar estimation procedures in the literature we refer to [Beckers, 1981] [13] and [Bandi and Nguyen, 2003] [6]. After experimenting with every member in , the optimal value of is identified (a posteriori) based on the maximal profile likelihood as a criterion for model selection. The reason behind choosing moment-based estimation over maximum likelihood estimation is twofold: It is much more computationally efficient because the density function of Lévy models are generally difficult to obtain in closed form (e.g., see [Schoutens, 2003, Chap. 4] [59]), with or without clock regulation; it is also more robust by making fewer assumptions for the underlying data-generating mechanism as only a finite number of moments are utilized.
Suppose that we have obtained an i.i.d. sample of some log-returns , with being the sample size, at a uniform frequency in fractions of a year; from now on we shall write as , , , and the sample mean, variance, skewness, and excess kurtosis, respectively, and , for , the mixed model cumulants with regulation degrees . Then, the four moment conditions can be written
| (5.1.2) |
First, we take to be a Poisson process and its constant mixture plus an independent Brownian motion, as discussed in Subsection 4.1. From (4.1.3), (4.1.4), and (4.1.5) we know that in this case the model is of jump–diffusion type with bounded (distorted uniform) jumps. For convenience, we shall focus on downside jumps, in view of excessive tail risk, by imposing the auxiliary parameter values and in (3.1.1). Note that the mixed model with clock regulation has a total of four parameters to be estimated, including an infinite-divisibility parameter , a rate parameter , a location parameter , and a Brownian dispersion parameter , all of which are subscripted by the corresponding degree of regulation, .
Proposition 3.
In terms of the above estimates, the profile likelihood function under the mixed model (with an -degree regulated clock) can be directly computed using the Bernoulli approximation technique in [Kou, 2002, Eq. (5)] [40] as
provided that is small – e.g., as in the case of daily data, where the Lévy density represents any one of , , and (with scaling factor ) in Proposition 1 according to the type of regulation. Whichever model yields the largest value of is taken as the best.
Second, we let be a tempered stable subordinator and construct its Gaussian mixture . The family parameter is fixed a priori for its special connection to local path regularity, which leaves us with also four parameters to be estimated – (with regulation degree subscripts) the infinite-divisibility parameter , rate parameter , location parameter , and the Brownian drift parameter . In this case, the moment-based estimators can be shown to be generally unique under the conditions in (5.1.2).
Proposition 4.
Given any regulation degree , under the Gaussian-mixed tempered stable model with and parametrization , the moment-based estimators are given by the conditions
| (5.1.4) |
where and solves the rational equation
| (5.1.5) |
with
5.2 Model calibration on option prices
Alternatively, instead of estimating parameters from sample moments, one can recover them by model calibration on option price data. With the assumption of no-arbitrage, such an exercise will require that the LT be evaluated under some risk-neutral probability measure (other than ) under which the asset price is discounted at some (supposedly) constant risk-free rate . Allowing for calibration efficiency, here we concentrate on the type-II and type-III regulated clocks which permit some explicit formulae when acting on Gaussian mixtures of tempered stable subordinators (recall Subsection 4.2). By way of the “mean-correcting measure” outlined in [Schoutens, 2003, Sect. 6.2.2] [59], we can then directly assume that the LT of the log asset price at time under the measure is given by
provided that the denominator in the power is finite, where is the constant risk-free rate in the associated money market and is the same select domain of the regulation degree for experiments.
Then, the no-arbitrage price of a European-style call option written on at time with strike price and maturity fixed is given by
| (5.2.1) |
where is the (constant) dividend yield and
are associated risk-neutralized in-the-money probabilities.
Suppose that we have obtained contemporaneous market quotes of call options on for various strike prices and maturities, denoted as . Focusing on the Gaussian mixed model where is the tempered stable subordinator with a fixed family parameter , then after mean correction there will be only three parameters, , , and (with degree subscripts as before), whose (locally) optimal values can be found by solving the following minimization problem:
| (5.2.2) |
where the objective function is the mean absolute percentage error (MAPE) measuring average pricing errors and the summation runs over all available strikes and maturities. The best model is then characterized by imposing the criterion on the right side of (5.2.2). A similar exercise using put options is immediate by applying a standard parity argument to (5.2.1). Nevertheless, compared with moment-based estimation, calibration is expected to be less robust because it generally constitutes a highly non-convex optimization problem which must be solved numerically.
6 Empirical modeling
In this section we demonstrate the effect of clock regulation on real financial returns. We focus on the equity market and the cryptocurrency market; in particular, we have collected S&P500 index and Bitcoin price data on the daily basis over the 2020 calendar year (data source: Yahoo Finance) and have computed corresponding log-returns. The two data sets hence have sample sizes () of 252 and 366, respectively, with .
In accordance with the moment-based estimation procedures discussed in Subsection 5.1, our empirical study will feature two exercises, one using the constant mixture of a Poisson process augmented by an independent Brownian motion and the other using the Gaussian mixture of a tempered stable subordinator, respectively. We highlight that the first exercise is interesting for modeling (presumably) bounded jumps in asset returns ([Yan and Hanson, 2006] [69] and [Baustian et al., 2017] [12]) and aims to compare the distorted jump distributions with commonly used uniform distributions; the second, on the other hand, is especially significant for possible improvement of tempered stable processes ([Rosiński, 2007] [56] and [Küchler and Tappe, 2013] [41]) in terms of flexibility, by investigating how the degree of regulation affects the model fit subject to moment matching for different choices of the family parameter .
First, we report the four sample statistics of the collected return data in Table 1. Relative to the S&P500, Bitcoin returns have clearly exhibited a much larger (absolute) skewness and excess kurtosis, speaking to high asymmetrical and tail risk.
| Data set | mean | variance | skewness | excess kurtosis |
|---|---|---|---|---|
| S&P500 | 0.000564705 | 0.00047912 | 8.46843 | |
| Bitcoin | 0.00384156 | 0.00160601 | 50.8679 |
In both exercises, the choice of the degree domain is with fixed modulus to ease comparison. In the first exercise, the exponential jump–diffusion model ([Kou, 2002] [40]) is also included as a contrast model because the distorted uniform distributions due to regulation have exponential shapes. In the second exercise, we experiment with four values of : 0 (variance gamma), 0.25, 0.5 (normal inverse Gaussian), and 0.75. Estimation results are presented in ten (sub)tables – Table 2, Table 3, Table 4, Table 5, Table 6, Table 7, Table 8, Table 9, Table 10, and Table 11, and are comprised of parameter estimates and the profile log-likelihood (PLL), , for every . In each model setting (including each chosen value of ), the model with the highest PLL value for a certain regulation type is marked “” and that with the highest PLL value taking into account all three types is marked “.” To enhance visual impact, changes in the PLL are plotted separately in Figure 4, Figure 6, and Figure 7.
Furthermore, we provide Figure 5, Figure 8, and Figure 9 to compare the estimated density functions of the best fit model (namely the one with the highest PLL value across all three types) and the original model () against the empirical kernel density function which is estimated using the Gaussian kernel, i.e.,
the optimal bandwidth is determined by the Silverman rule of thumb:
where is the interquartile range (the difference between the third and the first quartiles).
*
| type I | PLL | |||||
|---|---|---|---|---|---|---|
| 0 | 0.228049 | 4.64498 | 0.191402 | 0.331917 | 605.28 | |
| 1 | 0.467045 | 3.71599 | 0.205148 | 0.330853 | 620.36 | |
| 2 | 1.03524 | 3.37102 | 0.219081 | 0.330044 | 621.566 | |
| 3 | 2.27627 | 3.11901 | 0.233531 | 0.329334 | 622.22 | |
| 4 | 4.98085 | 2.91283 | 0.249179 | 0.328666 | 622.669 | |
| 5 | 10.8658 | 2.73578 | 0.266423 | 0.328018 | 623.007 | |
| 6 | 23.6553 | 2.5796 | 0.285589 | 0.327377 | 623.276 | |
| 7 | 51.4231 | 2.43945 | 0.306992 | 0.326739 | 623.496 | |
| 8 | 111.664 | 2.31218 | 0.330954 | 0.326099 | 623.68 | |
| 9 | 242.275 | 2.19558 | 0.357827 | 0.325455 | 623.837 | |
| 10 | 525.314 | 2.08804 | 0.387992 | 0.324803 | 623.972 | |
| type II | PLL | |||||
| 0 | 0.228049 | 4.64498 | 0.191402 | 0.331917 | 605.28 | |
| 1 | 0.467045 | 3.71599 | 0.205148 | 0.330853 | 620.36 | |
| 2 | 0.956508 | 2.97279 | 0.222744 | 0.329716 | 621.973 | |
| 3 | 1.95893 | 2.37823 | 0.245267 | 0.328497 | 622.917 | |
| 4 | 4.01189 | 1.90259 | 0.274096 | 0.327193 | 623.557 | |
| 5 | 8.21634 | 1.52207 | 0.310998 | 0.325796 | 624.018 | |
| 6 | 16.8271 | 1.21765 | 0.358232 | 0.3243 | 624.359 | |
| 7 | 34.4618 | 0.974124 | 0.418691 | 0.322695 | 624.612 | |
| 8 | 70.5779 | 0.779299 | 0.496079 | 0.320976 | 624.798 | |
| 9 | 144.543 | 0.623439 | 0.595135 | 0.319131 | 624.935 | |
| 10 | 296.025 | 0.498751 | 0.721927 | 0.317151 | 625.046 | |
| type III | PLL | |||||
| 0 | 0.228049 | 4.64498 | 0.191402 | 0.331917 | 605.28 | |
| 1 | 0.467045 | 3.71599 | 0.205148 | 0.330853 | 620.36 | |
| 2 | 0.751093 | 1.80638 | 0.211606 | 0.330498 | 620.954 | |
| 3 | 1.038 | 0.595511 | 0.214933 | 0.330338 | 621.161 | |
| 4 | 1.32573 | 0.148002 | 0.216952 | 0.330247 | 621.267 | |
| 5 | 1.6138 | 0.029492 | 0.218306 | 0.330189 | 621.33 | |
| 6 | 1.90206 | 0.00490304 | 0.219277 | 0.330148 | 621.373 | |
| 7 | 2.19041 | 0.000699163 | 0.220007 | 0.330118 | 621.404 | |
| 8 | 2.47883 | 0.000087275 | 0.220576 | 0.330095 | 621.427 | |
| 9 | 2.7673 | 0.221031 | 0.330077 | 621.445 | ||
| 10 | 3.05579 | 0.221404 | 0.330062 | 621.459 | ||
| exponential | - | 2.43253 | 18.5799 | 0.273228 | 0.326566 | 624.048 |
PLL: profile log-likelihood
| type I | PLL | |||||
|---|---|---|---|---|---|---|
| 0 | 0.766746 | 1.99897 | 1.78958 | 0.62922 | 641.506 | |
| 1 | 1.5703 | 1.59918 | 1.89698 | 0.618971 | 736.065 | |
| 2 | 3.48068 | 1.45072 | 2.00583 | 0.611076 | 736.11 | |
| 3 | 7.65327 | 1.34227 | 2.11873 | 0.604087 | 736.174 | |
| 4 | 16.7466 | 1.25354 | 2.24098 | 0.597444 | 736.2 | |
| 5 | 36.533 | 1.17735 | 2.3757 | 0.590935 | 736.171 | |
| 6 | 79.5338 | 1.11014 | 2.52544 | 0.584454 | 736.08 | |
| 7 | 172.894 | 1.04982 | 2.69265 | 0.577936 | 735.924 | |
| 8 | 375.437 | 0.995048 | 2.87986 | 0.571337 | 735.702 | |
| 9 | 814.575 | 0.944869 | 3.08981 | 0.564624 | 735.414 | |
| 10 | 1766.21 | 0.89859 | 3.32547 | 0.557771 | 735.063 | |
| type II | PLL | |||||
| 0 | 0.766746 | 1.99897 | 1.78958 | 0.62922 | 641.506 | |
| 1 | 1.5703 | 1.59918 | 1.89698 | 0.618971 | 736.065 | |
| 2 | 3.21597 | 1.27934 | 2.03445 | 0.607849 | 736.076 | |
| 3 | 6.5863 | 1.02347 | 2.21041 | 0.595756 | 736.101 | |
| 4 | 13.4887 | 0.81878 | 2.43565 | 0.582581 | 735.963 | |
| 5 | 27.6249 | 0.655024 | 2.72395 | 0.568191 | 735.511 | |
| 6 | 56.5759 | 0.524019 | 3.09297 | 0.552428 | 734.623 | |
| 7 | 115.867 | 0.419215 | 3.56532 | 0.535103 | 733.21 | |
| 8 | 237.297 | 0.335372 | 4.16992 | 0.515982 | 731.201 | |
| 9 | 485.983 | 0.268298 | 4.94382 | 0.494772 | 728.473 | |
| 10 | 995.294 | 0.214638 | 5.9344 | 0.471097 | 724.378 | |
| type III | PLL | |||||
| 0 | 0.766746 | 1.99897 | 1.78958 | 0.62922 | 641.506 | |
| 1 | 1.5703 | 1.59918 | 1.89698 | 0.618971 | 736.065 | |
| 2 | 2.52532 | 0.777379 | 1.94743 | 0.615517 | 736.092 | |
| 3 | 3.48997 | 0.256279 | 1.97342 | 0.613954 | 736.116 | |
| 4 | 4.45737 | 0.0636928 | 1.9892 | 0.613067 | 736.131 | |
| 5 | 5.42592 | 0.0126919 | 1.99977 | 0.612496 | 736.141 | |
| 6 | 6.39508 | 0.00211003 | 2.00736 | 0.612097 | 736.148 | |
| 7 | 7.36459 | 0.000300886 | 2.01306 | 0.611803 | 736.153 | |
| 8 | 8.33432 | 0.0000375589 | 2.01751 | 0.611578 | 736.157 | |
| 9 | 9.30419 | 2.02107 | 0.611399 | 736.16 | ||
| 10 | 10.2742 | 2.02398 | 0.611254 | 736.162 | ||
| exponential | - | 8.17863 | 7.9959 | 2.42886 | 0.576157 | 735.574 |
PLL: profile log-likelihood




*
| (VG) | ||||||
| type I | PLL | |||||
| 0 | 94.8367 | 811.158 | 0.744442 | 654.012 | ||
| 1 | 128.456 | 549.545 | 0.752422 | 662.425 | ||
| 2 | 203.096 | 434.589 | 0.760763 | 666.79 | ||
| 3 | 334.145 | 357.634 | 0.7691 | 668.065 | ||
| 4 | 561.015 | 300.338 | 0.777794 | 667.986 | ||
| 5 | 954.266 | 255.534 | 0.787051 | 667.252 | ||
| 6 | 1638.64 | 219.491 | 0.797029 | 666.333 | ||
| 7 | 2835.01 | 189.959 | 0.807875 | 665.136 | ||
| 8 | 4935.86 | 165.446 | 0.81974 | 662.129 | ||
| 9 | 8641.45 | 144.906 | 0.832792 | 662.009 | ||
| 10 | 15206.5 | 127.574 | 0.847223 | 660.34 | ||
| type II | PLL | |||||
| 0 | 94.8367 | 811.158 | 0.744442 | 654.012 | ||
| 1 | 128.456 | 549.545 | 0.752422 | 662.425 | ||
| 2 | 174.38 | 373.157 | 0.761651 | 666.218 | ||
| 3 | 237.339 | 254.059 | 0.772375 | 667.676 | ||
| 4 | 324.016 | 173.515 | 0.784904 | 667.625 | ||
| 5 | 443.949 | 118.945 | 0.799644 | 666.73 | ||
| 6 | 610.907 | 81.8998 | 0.817127 | 665.336 | ||
| 7 | 845.057 | 56.6956 | 0.838074 | 663.626 | ||
| 8 | 1176.48 | 39.5076 | 0.863484 | 661.708 | ||
| 9 | 1651.07 | 27.7586 | 0.894794 | 659.645 | ||
| 10 | 2340.97 | 19.7109 | 0.93414 | 657.469 | ||
| type III | PLL | |||||
| 0 | 94.8367 | 811.158 | 0.744442 | 654.012 | ||
| 1 | 128.456 | 549.545 | 0.752422 | 662.425 | ||
| 2 | 174.86 | 249.402 | 0.756665 | 665.585 | ||
| 3 | 223.022 | 79.5317 | 0.758921 | 666.776 | ||
| 4 | 271.766 | 19.384 | 0.760309 | 667.32 | ||
| 5 | 320.774 | 3.81341 | 0.761249 | 667.615 | ||
| 6 | 369.923 | 0.628261 | 0.761926 | 667.795 | ||
| 7 | 419.157 | 0.0889868 | 0.762437 | 667.915 | ||
| 8 | 468.446 | 0.0110503 | 0.762836 | 667.999 | ||
| 9 | 517.773 | 0.0012214 | 0.763157 | 668.061 | ||
| 10 | 567.126 | 0.000121622 | 0.76342 | 668.108 | ||
VG: variance gamma — PLL: profile log-likelihood
| type I | PLL | |||||
| 0 | 11.8708 | 621.521 | 0.755058 | 668.251 | ||
| 1 | 17.7616 | 422.34 | 0.764691 | 668.672 | ||
| 2 | 29.8475 | 335.05 | 0.774806 | 668.277 | ||
| 3 | 51.6775 | 276.597 | 0.784966 | 667.305 | ||
| 4 | 90.8543 | 233.057 | 0.795618 | 666.07 | ||
| 5 | 161.326 | 198.997 | 0.807023 | 664.739 | ||
| 6 | 288.564 | 171.591 | 0.819393 | 661.032 | ||
| 7 | 519.198 | 149.132 | 0.832928 | 652.583 | ||
| 8 | 938.875 | 130.495 | 0.847844 | 660.391 | ||
| 9 | 1705.49 | 114.887 | 0.864387 | 659.088 | ||
| 10 | 3111.25 | 101.731 | 0.882844 | 657.695 | ||
| type II | PLL | |||||
| 0 | 11.8708 | 621.521 | 0.755058 | 668.251 | ||
| 1 | 17.7616 | 422.34 | 0.764691 | 668.672 | ||
| 2 | 26.6293 | 287.789 | 0.775895 | 668.241 | ||
| 3 | 40.0192 | 196.745 | 0.789001 | 667.224 | ||
| 4 | 60.311 | 135.026 | 0.804439 | 665.812 | ||
| 5 | 91.1977 | 93.0987 | 0.82278 | 664.09 | ||
| 6 | 138.465 | 64.553 | 0.844796 | 662.253 | ||
| 7 | 211.286 | 45.0713 | 0.871567 | 660.317 | ||
| 8 | 324.434 | 31.744 | 0.904647 | 657.45 | ||
| 9 | 502.195 | 22.6087 | 0.946369 | 655.531 | ||
| 10 | 785.628 | 16.3417 | 1.0004 | 655.78 | ||
| type III | PLL | |||||
| 0 | 11.8708 | 621.521 | 0.755058 | 668.251 | ||
| 1 | 17.7616 | 422.34 | 0.764691 | 668.672 | ||
| 2 | 29.4917 | 191.979 | 0.769827 | 668.582 | ||
| 3 | 50.086 | 61.2722 | 0.772562 | 668.423 | ||
| 4 | 86.8967 | 14.9415 | 0.774248 | 668.29 | ||
| 5 | 154.046 | 2.94048 | 0.775389 | 668.186 | ||
| 6 | 278.893 | 0.484571 | 0.776211 | 668.103 | ||
| 7 | 515.191 | 0.0686477 | 0.776833 | 668.038 | ||
| 8 | 970.033 | 0.00852589 | 0.777318 | 667.985 | ||
| 9 | 1859.66 | 0.000942492 | 0.777708 | 667.941 | ||
| 10 | 3626.32 | 0.0000938585 | 0.778028 | 667.904 | ||
PLL: profile log-likelihood
| (NIG) | ||||||
| type I | PLL | |||||
| 0 | 1.3704 | 432.849 | 0.777245 | 667.041 | ||
| 0.5 | 1.72512 | 343.139 | 0.783233 | 666.37 | ||
| 1 | 2.26522 | 296.003 | 0.790516 | 665.447 | ||
| 1.5 | 3.01643 | 262.598 | 0.797581 | 664.544 | ||
| 2 | 4.04629 | 236.4 | 0.804581 | 663.674 | ||
| 2.5 | 5.45309 | 214.807 | 0.811644 | 662.832 | ||
| 3 | 7.37333 | 196.483 | 0.818859 | 662.016 | ||
| 3.5 | 9.99496 | 180.635 | 0.826291 | 661.22 | ||
| 4 | 13.5762 | 166.743 | 0.833993 | 660.442 | ||
| 4.5 | 18.472 | 154.447 | 0.842012 | 659.68 | ||
| 5 | 25.17 | 143.48 | 0.850391 | -6.08376 | 658.933 | |
| type II | PLL | |||||
| 0 | 1.3704 | 432.849 | 0.777245 | 667.041 | ||
| 0.5 | 1.76152 | 357.786 | 0.783616 | 666.261 | ||
| 1 | 2.26522 | 296.003 | 0.790516 | 665.447 | ||
| 1.5 | 2.9143 | 245.126 | 0.797999 | 664.604 | ||
| 2 | 3.75125 | 203.209 | 0.806132 | 663.738 | ||
| 2.5 | 4.83121 | 168.655 | 0.814989 | 662.853 | ||
| 3 | 6.22584 | 140.155 | 0.824658 | 661.951 | ||
| 3.5 | 8.02838 | 116.634 | 0.835242 | 661.036 | ||
| 4 | 10.3604 | 97.2105 | 0.846859 | 660.108 | ||
| 4.5 | 13.3806 | 81.1608 | 0.859651 | 659.17 | ||
| 5 | 17.2969 | 67.8906 | 0.87379 | 658.222 | ||
| type III | PLL | |||||
| 0 | 1.3704 | 432.849 | 0.777245 | 667.041 | ||
| 0.5 | 1.68675 | 371.306 | 0.784277 | 666.26 | ||
| 1 | 2.26522 | 296.003 | 0.790516 | 665.447 | ||
| 1.5 | 3.173 | 210.414 | 0.7947 | 664.868 | ||
| 2 | 4.58808 | 135.007 | 0.797632 | 664.453 | ||
| 2.5 | 6.81669 | 79.3114 | 0.799788 | 664.144 | ||
| 3 | 10.3757 | 43.1666 | 0.801435 | 663.907 | ||
| 3.5 | 16.1436 | 21.9721 | 0.802734 | 663.719 | ||
| 4 | 25.6301 | 10.5381 | 0.803784 | 663.567 | ||
| 4.5 | 41.459 | 4.7913 | 0.804649 | 663.442 | ||
| 5 | 68.2414 | 2.07545 | 0.805375 | 663.337 | ||
NIG: normal inverse Gaussian — PLL: profile log-likelihood
| type I | PLL | |||||
| 0 | 0.127463 | 248.604 | 0.852286 | 654.027 | ||
| 0.1 | 0.134541 | 233.914 | 0.853433 | 653.976 | ||
| 0.2 | 0.142421 | 222.685 | 0.855778 | 653.863 | ||
| 0.3 | 0.151034 | 213.54 | 0.858568 | 653.721 | ||
| 0.4 | 0.160364 | 205.785 | 0.861531 | 653.566 | ||
| 0.5 | 0.170423 | 199.021 | 0.864556 | 653.405 | ||
| 0.6 | 0.181235 | 193.002 | 0.867597 | 653.242 | ||
| 0.7 | 0.192836 | 187.563 | 0.870632 | 653.079 | ||
| 0.8 | 0.205268 | 182.593 | 0.873656 | 652.917 | ||
| 0.9 | 0.218579 | 178.007 | 0.876666 | 652.757 | ||
| 1 | 0.232824 | 173.745 | 0.879663 | 652.599 | ||
| type II | PLL | |||||
| 0 | 0.127463 | 248.604 | 0.852286 | 654.027 | ||
| 0.1 | 0.135368 | 239.776 | 0.854794 | 653.885 | ||
| 0.2 | 0.143766 | 231.278 | 0.857349 | 653.743 | ||
| 0.3 | 0.152687 | 223.097 | 0.859953 | 653.601 | ||
| 0.4 | 0.162164 | 215.22 | 0.862607 | 653.458 | ||
| 0.5 | 0.172233 | 207.637 | 0.865313 | 653.316 | ||
| 0.6 | 0.182929 | 200.335 | 0.868072 | 653.173 | ||
| 0.7 | 0.194293 | 193.306 | 0.870884 | 653.03 | ||
| 0.8 | 0.206367 | 186.537 | 0.873753 | 652.887 | ||
| 0.9 | 0.219194 | 180.02 | 0.876679 | 652.743 | ||
| 1 | 0.232824 | 173.745 | 0.879663 | 652.599 | ||
| type III | PLL | |||||
| 0 | 0.127463 | 248.604 | 0.852286 | 654.027 | ||
| 0.1 | 0.132234 | 240.172 | 0.853793 | 653.96 | ||
| 0.2 | 0.13829 | 233.905 | 0.856772 | 653.818 | ||
| 0.3 | 0.14551 | 228.168 | 0.86014 | 653.65 | ||
| 0.4 | 0.153881 | 222.222 | 0.863506 | 653.475 | ||
| 0.5 | 0.163442 | 215.729 | 0.86672 | 653.305 | ||
| 0.6 | 0.174271 | 208.561 | 0.869727 | 653.143 | ||
| 0.7 | 0.186477 | 200.706 | 0.872516 | 652.991 | ||
| 0.8 | 0.200194 | 192.219 | 0.875092 | 652.85 | ||
| 0.9 | 0.21558 | 183.194 | 0.877469 | 652.72 | ||
| 1 | 0.232824 | 173.745 | 0.879663 | 652.599 | ||
PLL: profile log-likelihood
*
| (VG) | ||||||
| type I | PLL | |||||
| 0 | 27.7898 | 56.0074 | 3.00165 | 455.411 | ||
| 1 | 39.9891 | 40.7099 | 3.10861 | 524.494 | ||
| 2 | 67.5402 | 34.7769 | 3.23098 | 601.924 | ||
| 3 | 119.117 | 31.0558 | 3.36652 | 655.587 | ||
| 4 | 215.901 | 28.5552 | 3.52426 | 691.131 | ||
| 5 | 400.41 | 26.9375 | 3.71367 | 715.837 | ||
| 6 | 759.406 | 26.0819 | 3.94698 | 729.963 | ||
| 7 | 1474.97 | 25.9914 | 4.24121 | 737.741 | ||
| 8 | 2941.94 | 26.7808 | 4.62072 | 741.75 | ||
| 9 | 6047.17 | 28.7032 | 5.12027 | 742.155 | ||
| 10 | 12850.6 | 32.2046 | 5.78719 | 740.616 | ||
| type II | PLL | |||||
| 0 | 27.7898 | 56.0074 | 3.00165 | 455.411 | ||
| 1 | 39.9891 | 40.7099 | 3.10861 | 524.494 | ||
| 2 | 58.4843 | 30.162 | 3.24722 | 591.811 | ||
| 3 | 87.4167 | 22.9374 | 3.43303 | 645.474 | ||
| 4 | 134.707 | 18.1054 | 3.69371 | 691.284 | ||
| 5 | 217.137 | 15.123 | 4.08334 | 717.942 | ||
| 6 | 375.668 | 13.859 | 4.72003 | 730.62 | ||
| 7 | 730.375 | 14.9641 | 5.89275 | 730.654 | ||
| 8 | 1689.11 | 21.4225 | 8.28461 | 716.365 | ||
| 9 | 4447.82 | 42.7097 | 12.7363 | 675.673 | ||
| 10 | 11431.1 | 114.716 | 19.1751 | 558.882 | ||
| type III | PLL | |||||
| 0 | 27.7898 | 56.0074 | 3.00165 | 455.411 | ||
| 1 | 39.9891 | 40.7099 | 3.10861 | 524.494 | ||
| 2 | 56.2539 | 19.1976 | 3.16875 | 573.498 | ||
| 3 | 73.0303 | 6.24998 | 3.20178 | 598.04 | ||
| 4 | 89.9752 | 1.543 | 3.22249 | 613.948 | ||
| 5 | 106.996 | 0.306219 | 3.23666 | 623.336 | ||
| 6 | 124.059 | 0.05077 | 3.24696 | 630.002 | ||
| 7 | 141.146 | 0.00722557 | 3.25478 | 635.146 | ||
| 8 | 158.249 | 0.000900634 | 3.26092 | 639.394 | ||
| 9 | 175.363 | 0.0000998491 | 3.26587 | 642.235 | ||
| 10 | 192.485 | 3.26994 | 644.439 | |||
VG: variance gamma — PLL: profile log-likelihood
| type I | PLL | |||||
| 0 | 7.17612 | 47.0281 | 3.1418 | 641.25 | ||
| 1 | 11.3467 | 35.0184 | 3.28923 | 674.554 | ||
| 2 | 20.2654 | 30.7629 | 3.46274 | 703.597 | ||
| 3 | 37.443 | 28.3513 | 3.66136 | 722.383 | ||
| 4 | 70.7801 | 27.0578 | 3.90086 | 734.063 | ||
| 5 | 136.543 | 26.7025 | 4.19975 | 740.223 | ||
| 6 | 268.857 | 27.3237 | 4.5831 | 743.733 | ||
| 7 | 541.024 | 29.136 | 5.08604 | 744.02 | ||
| 8 | 1113.88 | 32.5598 | 5.756 | 741.869 | ||
| 9 | 2344.96 | 38.2747 | 6.65067 | 737.46 | ||
| 10 | 5028.11 | 47.2474 | 7.82714 | 730.984 | ||
| type II | PLL | |||||
| 0 | 7.17612 | 47.0281 | 3.1418 | 641.25 | ||
| 1 | 11.3467 | 35.0184 | 3.28923 | 674.554 | ||
| 2 | 18.2308 | 26.8011 | 3.48754 | 701.452 | ||
| 3 | 29.9485 | 21.3312 | 3.76679 | 721.23 | ||
| 4 | 50.8037 | 18.0118 | 4.18535 | 733.655 | ||
| 5 | 90.4781 | 16.731 | 4.86847 | 737.997 | ||
| 6 | 173.503 | 18.2688 | 6.10689 | 734.271 | ||
| 7 | 364.579 | 25.7088 | 8.51289 | 718.548 | ||
| 8 | 795.808 | 47.4225 | 12.7543 | 682.923 | ||
| 9 | 1616.39 | 110.052 | 18.8531 | 606.713 | ||
| 10 | 2565.25 | 544.578 | 26.6876 | 320.315 | ||
| type III | PLL | |||||
| 0 | 7.17612 | 47.0281 | 3.1418 | 641.25 | ||
| 1 | 11.3467 | 35.0184 | 3.28923 | 674.554 | ||
| 2 | 19.4167 | 16.7381 | 3.37351 | 692.703 | ||
| 3 | 33.5171 | 5.48975 | 3.42025 | 701.522 | ||
| 4 | 58.7421 | 1.36161 | 3.44971 | 706.549 | ||
| 5 | 104.855 | 0.271079 | 3.46994 | 709.757 | ||
| 6 | 190.782 | 0.0450476 | 3.48468 | 711.971 | ||
| 7 | 353.758 | 0.00642237 | 3.49589 | 713.587 | ||
| 8 | 668.049 | 0.000801617 | 3.5047 | 714.816 | ||
| 9 | 1283.77 | 0.0000889697 | 3.51181 | 715.782 | ||
| 10 | 2508.23 | 3.51766 | 716.56 | |||
PLL: profile log-likelihood
| (NIG) | ||||||
|---|---|---|---|---|---|---|
| type I | PLL | |||||
| 0 | 1.69903 | 40.2719 | 3.4866 | 741.57 | ||
| 0.5 | 2.18658 | 34.0606 | 3.60284 | 744.017 | ||
| 1 | 2.95041 | 31.8517 | 3.75372 | 746.459 | ||
| 1.5 | 4.037 | 30.6647 | 3.91344 | 748.356 | ||
| 2 | 5.56725 | 30.0464 | 4.08646 | 749.25 | ||
| 2.5 | 7.72111 | 29.8558 | 4.27762 | 749.903 | ||
| 3 | 10.7581 | 30.0452 | 4.49173 | 747.875 | ||
| 3.5 | 15.0512 | 30.61 | 4.73399 | 750.611 | ||
| 4 | 21.1362 | 31.5722 | 5.01006 | 749.197 | ||
| 4.5 | 29.7841 | 32.9755 | 5.32626 | 747.685 | ||
| 5 | 42.1034 | 34.8824 | 5.68939 | 745.767 | ||
| type II | PLL | |||||
| 0 | 1.69903 | 40.2719 | 3.4866 | 741.57 | ||
| 0.5 | 2.23523 | 35.6267 | 3.60867 | 744.468 | ||
| 1 | 2.95041 | 31.8517 | 3.75372 | 746.459 | ||
| 1.5 | 3.90955 | 28.8422 | 3.92845 | 748.107 | ||
| 2 | 5.20409 | 26.5277 | 4.14219 | 748.78 | ||
| 2.5 | 6.96431 | 24.8739 | 4.40824 | 748.142 | ||
| 3 | 9.37804 | 23.891 | 4.74579 | 746.481 | ||
| 3.5 | 12.7184 | 23.648 | 5.18271 | 747.08 | ||
| 4 | 17.3826 | 24.2981 | 5.75891 | 743.584 | ||
| 4.5 | 23.9386 | 26.1153 | 6.52903 | 739.578 | ||
| 5 | 33.1604 | 29.5378 | 7.56059 | 731.809 | ||
| type III | PLL | |||||
| 0 | 1.69903 | 40.2719 | 3.4866 | 741.57 | ||
| 0.5 | 2.14646 | 37.2922 | 3.62438 | 743.909 | ||
| 1 | 2.95041 | 31.8517 | 3.75372 | 746.459 | ||
| 1.5 | 4.19843 | 23.7357 | 3.84507 | 748.233 | ||
| 2 | 6.13874 | 15.7484 | 3.9114 | 748.608 | ||
| 2.5 | 9.19582 | 9.4846 | 3.96141 | 749.061 | ||
| 3 | 14.0854 | 5.26192 | 4.00036 | 749.327 | ||
| 3.5 | 22.0249 | 2.71928 | 4.03151 | 749.486 | ||
| 4 | 35.1087 | 1.32035 | 4.05697 | 749.581 | ||
| 4.5 | 56.9807 | 0.606458 | 4.07815 | 749.634 | ||
| 5 | 94.0523 | 0.264957 | 4.09606 | 749.657 | ||
NIG: normal inverse Gaussian — PLL: profile log-likelihood
| type I | PLL | |||||
| 0 | 0.304774 | 50.5501 | 5.21772 | 752.733 | ||
| 0.1 | 0.321949 | 48.3428 | 5.26152 | 752.507 | ||
| 0.2 | 0.341336 | 47.5163 | 5.34882 | 752.06 | ||
| 0.3 | 0.362624 | 47.2887 | 5.4522 | 751.546 | ||
| 0.4 | 0.385726 | 47.3793 | 5.56273 | 750.975 | ||
| 0.5 | 0.410649 | 47.664 | 5.67699 | 750.398 | ||
| 0.6 | 0.437445 | 48.0803 | 5.79359 | 749.811 | ||
| 0.7 | 0.466199 | 48.594 | 5.91194 | 749.224 | ||
| 0.8 | 0.497011 | 49.1848 | 6.03186 | 748.614 | ||
| 0.9 | 0.530001 | 49.8404 | 6.1533 | 748.005 | ||
| 1 | 0.565299 | 50.5528 | 6.27632 | 747.39 | ||
| type II | PLL | |||||
| 0 | 0.304774 | 50.5501 | 5.21772 | 752.733 | ||
| 0.1 | 0.324226 | 50.3274 | 5.30404 | 752.302 | ||
| 0.2 | 0.344917 | 50.1521 | 5.39414 | 751.851 | ||
| 0.3 | 0.366924 | 50.0249 | 5.48823 | 751.379 | ||
| 0.4 | 0.39033 | 49.9464 | 5.5865 | 750.885 | ||
| 0.5 | 0.41522 | 49.9176 | 5.68916 | 750.367 | ||
| 0.6 | 0.441685 | 49.9393 | 5.79643 | 749.825 | ||
| 0.7 | 0.469821 | 50.0124 | 5.90855 | 749.257 | ||
| 0.8 | 0.499731 | 50.1382 | 6.02574 | 748.663 | ||
| 0.9 | 0.531519 | 50.3179 | 6.14824 | 748.041 | ||
| 1 | 0.565299 | 50.5528 | 6.27632 | 747.39 | ||
| type III | PLL | |||||
| 0 | 0.304774 | 50.5501 | 5.21772 | 752.733 | ||
| 0.1 | 0.316506 | 49.8956 | 5.27563 | 752.433 | ||
| 0.2 | 0.331647 | 50.6222 | 5.38789 | 751.857 | ||
| 0.3 | 0.349699 | 51.6632 | 5.51481 | 751.21 | ||
| 0.4 | 0.370556 | 52.6039 | 5.64265 | 750.562 | ||
| 0.5 | 0.394296 | 53.2529 | 5.76595 | 749.939 | ||
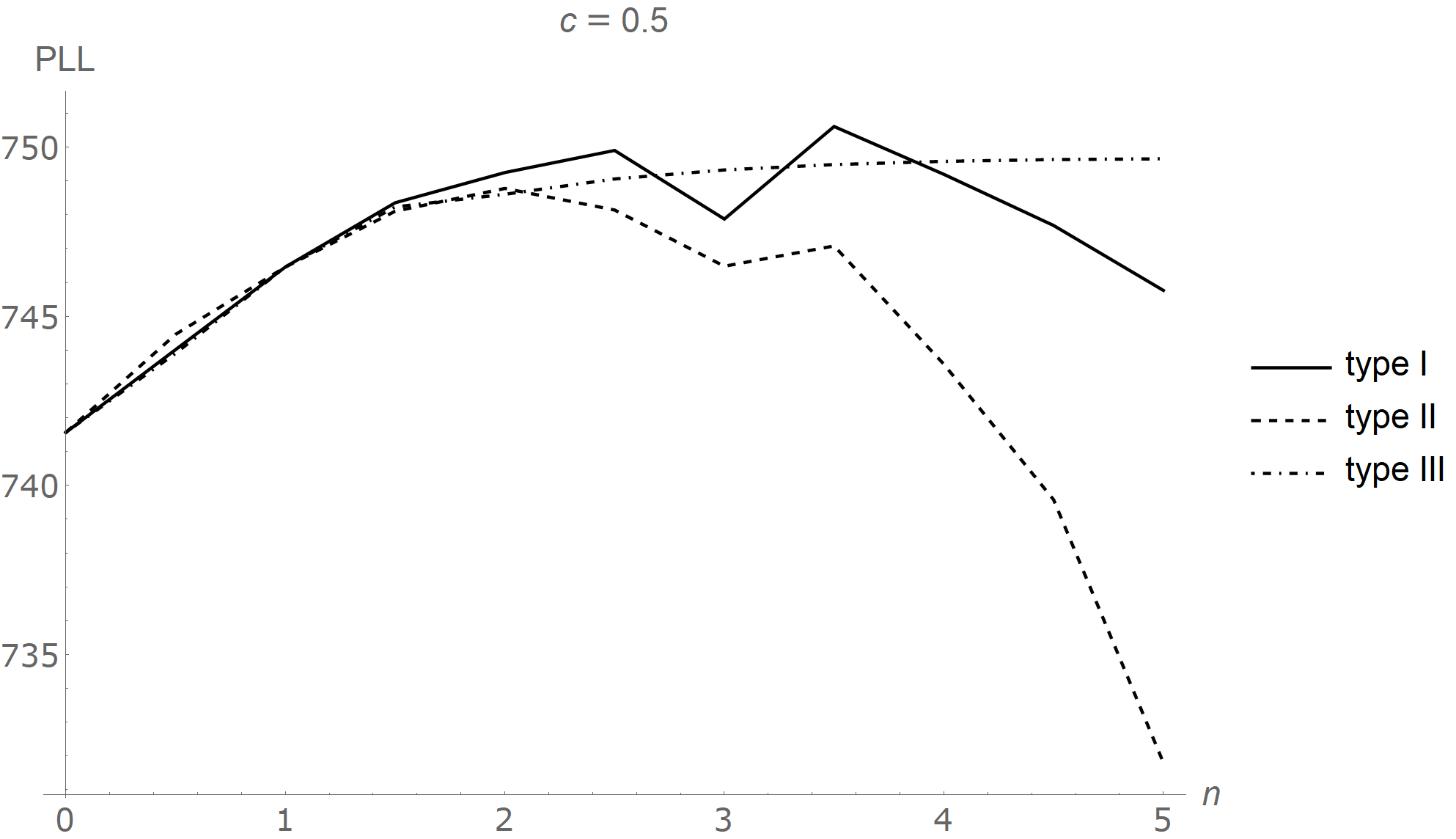
| 0.6 | 0.421103 | 53.5212 | 5.88255 | 749.352 | ||
| 0.7 | 0.451243 | 53.3751 | 5.99177 | 748.805 | ||
| 0.8 | 0.485048 | 52.815 | 6.09357 | 748.297 | ||
| 0.9 | 0.522912 | 51.8624 | 6.18827 | 747.826 | ||
| 1 | 0.565299 | 50.5528 | 6.27632 | 747.39 | ||
PLL: profile log-likelihood
*







*








For the first exercise involving jump–diffusion models, from Table 2 and Table 3, the steady changes in the parameter values are clear for both data sets, which show robustness of the moment-based estimation. Specifically, while the estimate of the drift parameter, , has only marginally increased and that of the Brownian dispersion parameter, , remains fairly stable, the infinite-divisibility parameter estimate has increased geometrically with the degree regardless of the regulation type. This is in keeping with our original motivation to not reduce the measure of the number of trades. While decreasing, the rate of change of the rate parameter estimate , on the other hand, does depend on the regulation type, and is the lowest under the type I, moderate under the type II, and the highest (actually in orders of reciprocal factorials) under the type III. This is because the rate parameter plays the role of adjusting the local movement sizes of stochastic clocks in consonance with the decreasing effect from regulation. Speaking of the profile log-likelihood, we see that any type of regulation has resulted in a notable improvement for some . While the first two types tend to achieve a maximal value relatively quickly for , the type III seems to be increasing the likelihood much more slowly. A simple explanation is that the third type has the mildest enlargement effect on distributional asymmetry and tail heaviness among the three. Besides, for both data sets the best models (with a “”) have all outperformed their counterparts with exponentially distributed jumps, also implying that jump–diffusion models with distorted uniformly distributed jump amplitudes can be used as an ideal replacement of the widely accepted exponential jump–diffusion models in most applications. The density plots in Figure 5 mainly show that despite closeness of the three estimated model densities, the peak of the one of the best fit model tends to lie between those of the models with uniform or exponential jumps, confirming its balancing characteristic mentioned in Subsection 4.1.
For the second exercise with Gaussian-mixed tempered stable models, it is seen from Table 4, Table 5, Table 6, Table 7, Table 8, Table 9, Table 10, and Table 11 that the parameter estimates also change steadily with the regulation degree, for all regulation types and both data sets. For any chosen value of the family parameter and any regulation type, apart from marginal increases in the location parameter estimate and the absolute Brownian drift estimate , the conspicuous value increase of the estimate of the infinite-divisibility parameter shows that clock regulation is indeed able to cater to a large number of trades while maintaining a significant level of asymmetry and tail heaviness. In the meantime, the interpretation of the value change of the rate parameter estimate is the same as in the jump–diffusion case in the first exercise. Viewing from the profile log-likelihood, the effect of regulation deteriorates rapidly as increases, with the variance gamma case () undergoing the greatest improvement. This phenomenon is within expectation, because in the limit as the tempered stable subordinator will approach the usual drift clock of calendar time, which is by no means affected by regulation (or path averaging); equivalently, its Gaussian mixture will tend to a drifted Brownian motion, by the central limit theorem.141414When minute-level data are employed, the value of will probably be near 1 for liquid assets (see [Todorov and Tauchen, 2011, Table 5] [62]), in which case the underlying stochastic clock is close to the calendar time. This in turn shows that clock regulation is particularly useful for daily or lower-frequency data, making up their deficiency relative to the high-frequency counterparts which inevitably come at additional costs. Such a trend is more salient for the S&P500 returns than for the Bitcoin returns, depending on the relative extent of asymmetrical and tail risks. To be fair, an intriguing observation is that by increasing the degree of regulation the same level of log-likelihood (distributional information) has been achieved, whichever -value is being used. Since has an important dynamical meaning in terms of the local regularity of sample paths, and hence long-term trading intensity (recalling Section 1), clock regulation has therefore introduced a useful dimension for parameter estimation of a tempered stable model for any fixed value of the family parameter . The fundamental difference, as we shall restate, is that the regulation degree only changes the sizes of local movements and does not affect the Blumenthal–Getoor index (Corollary 1). The density plots in Figure 8 and Figure 9 further confirm the benefits of increasing the value of (a large number of trades), as the original model density without clock regulation seems overly “peaked” (almost degenerate, or near trading halts) when its moments are matched to the empirical, while proper clock regulation helps get rid of such degeneracy tendency.
To demonstrate the method outlined in Subsection 5.2, we also do a calibration exercise on Bitcoin options using the Gaussian-mixed tempered stable models. The data set is directly taken from [Xia, 2021, Sect. 4.2] [68] and consists of Bitcoin call option prices quoted as of July 11th, 2020. The strike prices range from $3,000 to $32,000 and there are four maturities: days. At the time of quoting, the Bitcoin price stood at . We have for digital assets. To keep the demonstration concise, we also only consider four values of the family parameter and choose the domain of regulation degrees (with ), which already give rise to 48 independent models. Each model is calibrated according to (5.2.2).
*
| type II | ||||||
|---|---|---|---|---|---|---|
| (VG) | MAPE (%) | CPU time (sec) | ||||
| 0 | 52.8148 | 97.315 | 1.00541 | 24.7965 | 213.984 | |
| 1 | 69.312 | 63.5709 | 0.835575 | 24.423 | 221.781 | |
| 2 | 79.9247 | 34.5063 | 24.368 | 1208.5 | ||
| 3 | 99.9403 | 21.5024 | 24.2491 | 1011.41 | ||
| 4 | 99.8584 | 10.7058 | 23.7375 | 2647.44 | ||
| 5 | 99.9986 | 5.30486 | 23.3089 | 3961.56 | ||
| MAPE (%) | CPU time (sec) | |||||
| 0 | 5.29036 | 24.9255 | 22.5461 | 347.219 | ||
| 1 | 5.55635 | 9.93689 | 20.484 | 501.266 | ||
| 2 | 6.89235 | 5.1679 | 21.5499 | 3029.7 | ||
| 3 | 2.81083 | 0.476929 | 19.065 | 13629.9 | ||
| 4 | - | - | - | - | - | |
| 5 | - | - | - | - | - | |
| (NIG) | MAPE (%) | CPU time (sec) | ||||
| 0 | 0.485557 | 1.37746 | 19.2856 | 135.625 | ||
| 1 | 0.664932 | 0.572124 | 19.2146 | 378.313 | ||
| 2 | 1.03635 | 0.343634 | 19.1939 | 618.609 | ||
| 3 | - | - | - | - | - | |
| 4 | - | - | - | - | - | |
| 5 | - | - | - | - | - | |
| MAPE (%) | CPU time (sec) | |||||
| 0 | 0.288703 | 9.88632 | 23.3422 | 164.516 | ||
| 1 | 0.331241 | 0.608326 | 20.6779 | 304.75 | ||
| 2 | - | - | - | - | - | |
| 3 | - | - | - | - | - | |
| 4 | - | - | - | - | - | |
| 5 | - | - | - | - | - | |
MAPE: mean absolute percentage error — VG: variance gamma — NIG: normal inverse Gaussian
| type III | ||||||
|---|---|---|---|---|---|---|
| (VG) | MAPE (%) | CPU time (sec) | ||||
| 0 | 52.8148 | 97.315 | 1.00541 | 24.7965 | 213.984 | |
| 1 | 69.312 | 63.5709 | 0.835575 | 24.423 | 221.781 | |
| 2 | 25.7893 | 7.01917 | 21.9319 | 1386.55 | ||
| 3 | 80.8854 | 5.83995 | 23.9882 | 1071.81 | ||
| 4 | 90.3674 | 1.28759 | 23.8168 | 968.281 | ||
| 5 | 97.9971 | 0.232557 | 23.6565 | 764.641 | ||
| MAPE (%) | CPU time (sec) | |||||
| 0 | 5.29036 | 24.9255 | 22.5461 | 347.219 | ||
| 1 | 5.55635 | 9.93689 | 20.484 | 501.266 | ||
| 2 | 4.40503 | 1.49887 | 18.5857 | 1442.34 | ||
| 3 | 7.26858 | 0.477655 | 19.6144 | 673.453 | ||
| 4 | 9.61409 | 0.0816453 | 18.9021 | 681.328 | ||
| 5 | 9.94952 | 0.0053706 | 24.8041 | 1469.98 | ||
| (NIG) | MAPE (%) | CPU time (sec) | ||||
| 0 | 0.485557 | 1.37746 | 19.2856 | 135.625 | ||
| 1 | 0.664932 | 0.572124 | 19.2146 | 378.313 | ||
| 2 | 1.30094 | 0.242459 | 19.1893 | 492.594 | ||
| 3 | 3.02094 | 0.0752527 | 19.2294 | 1282.11 | ||
| 4 | 9.89913 | 0.0457464 | 19.9204 | 815.641 | ||
| 5 | 9.95359 | 0.0000857145 | 23.4282 | 1602.34 | ||
| MAPE (%) | CPU time (sec) | |||||
| 0 | 0.288703 | 9.88632 | 23.3422 | 164.516 | ||
| 1 | 0.331241 | 0.608326 | 20.6779 | 304.75 | ||
| 2 | 0.978496 | 0.728833 | 22.117 | 762.734 | ||
| 3 | 1.82492 | 0.00378187 | 19.4049 | 750.078 | ||
| 4 | 6.33734 | 0.000522405 | 19.43 | 708.563 | ||
| 5 | 27.7777 | 0.000615278 | 19.8326 | 903.156 | ||
MAPE: mean absolute percentage error — VG: variance gamma — NIG: normal inverse Gaussian
As discussed in Subsection 5.2, the optimal parameter values are subject to minor instability with joint calibration. For this reason, the main goal of this calibration exercise is to demonstrate that tempered stable models with clock regulation can be used with high efficiency and well expected to outperform the originals with unregulated clocks for financial derivatives valuation. The calibration results are summarized in Table 12 and Table 13, along with (locally) minimal pricing error and CPU time (with only a quad-core processor). Notably, under type-II regulated clocks, since the computational complexity of the formula (2) can increase rapidly with the degree of regulation, some models for and have not been successfully calibrated within a reasonable time limit (24 hours), and hence their results have been deliberately left out for comparability, while the remaining results are sufficient to serve our conclusions. Likewise, for each chosen value of , the model with the best fit is marked “.”
From Table 12 and Table 13 we can see that adopting regulated clocks has significantly improved the calibration results, regardless of the value of . More specifically, for type-II regulation, better performance is generally produced by increasing , though the computation time grows drastically simultaneously. The latter feature is especially notable if , when one is forced to apply (2) outside the unit disk, whereas for the variance gamma model with , the more elementary formula (4.2.4) is used instead. In contrast, under type-III regulation, computation time does not scale with the degree of regulation, but there is oftentimes an optimal value that gives a best fit.
Speaking of the optimized parameter values, we observe that, for each fixed value of , usually increases with while decreases, which is similar to the results of statistical estimation. Besides, seems to be very stable in general, implying, yet again, that the Brownian drift parameter is largely uninfluenced by clock regulation. From Table 12 and Table 13 we identify the best fit model as the one with and under type-III regulation, whose implied prices are further visually compared with the market prices in Figure 10.

Furthermore, we compare in Figure 11 the risk-neutral densities (namely the -densities) of annualized Bitcoin log-returns (driven by for ) to further illustrate the static effect of clock regulation, though for succinctness the illustration is only done for the subcase “type III, ” of which the best fit model is a special case. The formula (4.2) is applied because , along with the choice .

7 Concluding remarks
In this paper we have studied the regulation of stochastic clocks built from Lévy subordinators for the purpose of tackling asymmetrical and tail risks typically observed in financial returns without making undesirable changes on parameters linked to important aspects of the trading activity. These parameters are those measuring infinite divisibility or -stability and so making such an improvement has potential not only in enhancing capacity of the original processes but in balancing various modeling emphases involving the microstructure of data as well. From the viewpoint of static distributions, a direct effect is to arbitrarily enlarge skewness and (excess) kurtosis, while being able to fix the mean and variance and not decrease the jump intensity (or approach degeneracy).
The methodology comes in three concrete recipes. Despite a common motivation from repeated continuous-time averaging, the recipes vary in their impact on the original distributional asymmetry and tail heaviness as well as the computational complexity of resultant distribution formulae, which properties are summarized and compared in Table 14 for the convenience of the reader.
| Category | type I | type II | type III | ||||||
| induction nature | average of sample paths | average of log-LT |
|
||||||
| regulating kernel | incomplete gamma | inverse gamma | Riemann-Liouville | ||||||
| Lévy measure distortion | severe | moderate | mild | ||||||
| Skew/EKurt enlargement | faster than exponential | exponential |
|
||||||
|
|
|
LT and LM: any | ||||||
|
LT and LM : only | LT and LM: | LT and LM: any |
LT: Laplace transform — LM: Lévy measure
Generally speaking, stochastic clock regulation works well on any Lévy subordinator as long as the prerequisite (2.1) of generic-time log-LT analyticity is satisfied and can be utilized to obtain a good number of newfangled Lévy models for financial modeling and other uses. It is only futile for processes whose generic-time log-LT is linear or undefined in the neighborhood of zero.151515Note that the log-LT cannot be a finite-order polynomial of degree greater than two; see [Lukacs, 1970, Thm. 7.3.5] [45]. Clearly, in the former case the subordinator is degenerate and effectively identical to the clock of calendar time, and in the latter it does not have a finite third-order cumulant. The resultant mixed models then have skewness and excess kurtosis either equal to zero or undefined (including infinity) – obviously, both zero and infinity cannot be further “enlarged” by multiplication.
When applied to a Poisson process, the regulated clocks have led to compound Poisson processes with bounded jumps having a truncated exponential-like distribution and hence corresponding jump–diffusion models inheriting the advantages of both the uniform distribution ([Yan and Hanson, 2006] [69]) and the (usual) exponential distribution ([Kou, 2002] [40]). As our empirical study on S&P500 and Bitcoin returns has shown, when moment-based estimation is employed to match the empirical skewness and kurtosis, the profile likelihood for the new models with regulation degree is indeed improved relative to the uniform and the pure-exponential, which signifies that the distorted uniform distributions are suitable for modeling downside risks in a jump–diffusion framework.
Secondly, operating the regulated clocks on the Gaussian-mixed tempered stable models generates a series of modified processes with unchanged path regularity but enhanced distributional asymmetry and tail heaviness. The empirical results imply that the effect of regulation is most conspicuous when the family parameter is small, close to the case of variance gamma processes, while it gradually diminishes as approaches the upper limit 1, when the mixed model tends to Gaussianity. More importantly, by varying the degree of regulation, one can expect to easily take account of empirical skewness and kurtosis of returns without losing essential information on the actual distribution, regardless of which value of is in use. Put differently, in the presence of the hyperparameter , the value of can be confidently fixed for a certain data frequency or taken from other sources of estimation, since , benignly, has no effect on the local regularity of the stochastic process.
The methodology that the present paper has put forward is a jump-off point and so can be advanced in various directions. For instance, as we have mentioned since Section 1, it can be extended to subordinators of the Sato type (with non-stationary increments) with reasonable effort as well as the establishment of mean-reverting time changes of Ornstein–Uhlenbeck type ([Carr and Wu, 2004] [19]) for stochastic volatility. Also, an ongoing research is concerned with developments into a multidimensional setting, especially for the Gaussian mixed models, which will be conducive to portfolio analysis and derived optimization problems. We note that multivariate subordination of Brownian motion via tempered stable subordinators has received much attention in the literature; see, e.g., [Luciano and Semeraro, 2010a] [43], [Luciano and Semeraro, 2010b] [44], [Pérez-Abreu and Stelzer, 2014] [53], and [Mandoza-Arriaga and Linetsky, 2016] [48]. Of course, the two special cases discussed in Section 4 are also far from exhaustive, and it is possible to consider operating the regulating kernels on other choices of Lévy subordinators, e.g., compound Poisson-exponential processes or generalized inverse Gaussian processes ([Barndorff-Nielsen and Halgreen, 1977] [8]), and derive the moment-based estimation procedures in the same spirit as in Subsection 5.1. Last but not least, the empirical aspect may be strengthened by studying other kinds of financial time series, such as individual stocks, exchange rates, volatility indices, etc., in order to explore how the degree of clock regulation is fundamentally reflected in trading volumes or relative illiquidity and its variation with different levels of asymmetrical and tail risks.
References
- [1] Abramowitz, M., Stegun, I.A. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, 10th Printing, U.S. National Bureau of Standards, Washington, D.C., 1972.
- [2] Aguilar, J-P., Kirkby, J.L., Korbel, J. (2020). Pricing, risk and volatility in subordinated market models. Risks, 8: No. 124.
- [3] Aït-Sahalia, Y., Jacod, J. (2009). Testing for jumps in a discretely observed process. Annals of Statistics, 37: 184–222.
- [4] Alexander, G.J., Peterson, M.A. (2007). An analysis of trade-size clustering and its relation to stealth trading. Journal of Financial Economics, 84: 435–471.
- [5] Ané, T., Geman, H. (2000). Order flow, transaction clock, and normality of asset returns. Journal of Finance, 55: 2259–2284.
- [6] Bandi, F.M., Nguyen, T.H. (2003). On the functional estimation of jump–diffusion models. Journal of Econometrics, 116: 293–328.
- [7] Barndorff-Nielsen, O.E. (1997). Normal inverse Gaussian distributions and stochastic volatility models. Scandinavian Journal of Statistics, 24: 1–13.
- [8] Barndorff-Nielsen, O.E., Halgreen, C. (1977). Infinitely divisibility of the hyperbolic and generalized inverse Gaussian distributions. Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete, 38: 309–311.
- [9] Barndorff-Nielsen, O.E., Pollard, D.G., Shephard, N. (2011). Integer-valued Lévy processes and low latency financial econometrics. Quantitative Finance, 12: 587–605.
- [10] Bateman, H. Tables of Integral Transforms, 1st Vol., McGraw-Hill, New York–Toronto–London, 1954.
- [11] Bateman, H., Erdélyi, A. Higher Transcendental Functions, 2nd Vol., McGraw-Hill, New York, 1954.
- [12] Baustian, F., Mrázek, M., Pospíšil, J., Sobotka, T. (2017). Unifying pricing formula for several stochastic volatility models with jumps. Applied Stochastic Models in Business and Industry, 33: 422–442.
- [13] Beckers, S. (1981). A note on estimating the parameters of the diffusion–jump model of stock returns. Journal of Financial and Quantitative Analysis, 16: 127–140.
- [14] Blau, B.M. (2017). Price dynamics and speculative trading in bitcoin. Research in International Business and Finance, 41: 493–499.
- [15] Blumenthal, R.M., Getoor, R.K. (1961). Sample functions of stochastic processes with stationary independent increments. Journal of Mathematics and Mechanics, 10: 493–516.
- [16] Bollerslev, T. (1987). A conditionally heteroskedastic time series model for speculative prices and rates of return. Review of Economics and Statistics, 69: 542–547.
- [17] Boyarchenko, S.I., Levendorskii, S.Z. (2000). Option pricing for truncated Lévy processes. International Journal of Theoretical and Applied Finance, 3: 549–552.
- [18] Carr, P., Gemen, H., Madan, D.B., Yor, M. (2002). The fine structure of asset returns: An empirical investigation. The Journal of Business, 75: 305–332.
- [19] Carr, P., Wu, L. (2004). Time-changed Lévy processes and option pricing. Journal of Financial Economics, 71: 113–141.
- [20] Chaim, P., Laurini, M.P. (2019). Nonlinear dependence in cryptocurrency markets. North American Journal of Economics and Finance, 48: 32–47.
- [21] Chang, E.C., Pinegar, J.M., Schachter, B. (1997). Interday variations in volume, variance and participation of large speculators. Journal of Banking and Finance, 21: 797–810.
- [22] Chen, T. (2019). The price impact of trade-size clustering: Evidence from an intraday analysis. Journal of Business Research, 101: 300–314.
- [23] Clark, P.K. (1973). A subordinated stochastic process model with finite variance for speculative prices. Econometrica, 41: 135–155.
- [24] DiDonato, A.R., Morris, A.H. (1986). Computation of the incomplete gamma function ratios and their inverse. ACM Transactions on Mathematical Software, 12: 377–393.
- [25] Downton, F. (1972). The area under the infectives trajectory of the general stochastic epidemic. Journal of Applied Probability, 9: 414–417.
- [26] Eberlein, E., Madan, D.B. (2009). Sato processes and the valuation of structured products. Quantitative Finance, 9: 27–42.
- [27] Fallahgoul, H., Loeper, G. (2021). Modelling tail risk with tempered stable distributions: An overview. Annals of Operations Research, 299: 1253–1280.
- [28] Geman, H. Stochastic clock and financial markets. In: Aspects of Mathematical Finance, Springer, Berlin, Heidelberg, 37–52, 2008.
- [29] Geman, H., Madan, D.B., Yor, M. (2001). Time changes for Lévy processes. Mathematical Finance, 11: 79–96.
- [30] Gkillas, K., Katsiampa, P. (2018). An application of extreme value theory to cryptocurrencies. Economics Letters, 164: 109–111.
- [31] Grabchak, M. (2021). Discrete tempered stable distributions. Methodology and Computing in Applied Probability, Online First, 1–14.
- [32] Gradshteyn, I.S., Ryzhik, I.M. Table of Integrals, Series, and Products, 7th Ed. Academic Press, Elsevier, Burlington, 2007.
- [33] Gupta, N., Kumar, A., Leonenko, N.N. (2020). Skellam type processes of order and beyond. Entropy, 22: 1193.
- [34] Jing, B-Y., Kong, X-B., Liu, Z., Mykland, P. (2012). On the jump activity index for semimartingales. Journal of Econometrics, 166: 213–223.
- [35] Jondeau, E., Rockinger, M. (2003). Conditional volatility, skewness, and kurtosis: Existence, persistence, and comovements. Journal of Economic Dynamics and Control, 27: 1699–1737.
- [36] Kalmykov, M.Y., Kniehl, B.A. (2009). Towards all-order Laurent expansion of generalised hypergeometric functions about rational values of parameters. Nuclear Physics B, 809 [PM]: 365–405.
- [37] Karpoff, J.M. (1987). The relation between price changes and trading volume: A survey. Journal of Financial and Quantitative Analysis, 22: 109–126.
- [38] Kerss, A., Leonenko, N.N., Sikorskii, A. (2014). Fractional Skellam processes with applications to finance. Fractional Calculus & Applied Analysis, 17: 532-551.
- [39] Koponen, I. (1995). Analytic approach to the problem of convergence of truncated Lévy flights towards the Gaussian stochastic process. Physical Review E, 52: 1197–1199.
- [40] Kou, S. (2002). A jump-diffusion model for option pricing. Management Science, 48: 1086–1101.
- [41] Küchler, U., Tappe, S. (2013). Tempered stable distributions and processes. Stochastic Processes and their Applications, 123: 4256–4293.
- [42] Liu, Y., Tsyvinski, A. (2021). Risks and returns of cryptocurrency. The Review of Financial Studies, 34: 2689–2727.
- [43] Luciano, E., Semeraro, P. (2010a). A generalized normal mean–variance mixture for return processes in finance. International Journal of Theoretical and Applied Finance, 13: 415–440.
- [44] Luciano, E., Semeraro, P. (2010b). Multivariate time changes for Lévy asset models: Characterization and calibration. Journal of Computational and Applied Mathematics, 233: 1937–1953.
- [45] Lukacs, E. Characteristic Functions, 2nd Ed., Griffin, London, 1970.
- [46] Madan, D.B., Carr, P., Chang, E.C. (1998). The variance gamma process and option pricing. European Finance Review, 2: 79–105.
- [47] Madan, D.B., Reyners, S., Schoutens, W. (2019). Advanced model calibration on bitcoin options. Digital Finance, 1: 117–137.
- [48] Mandoza-Arriaga, R., Linetsky, V. (2016). Multivariate subordination of Markov processes with financial applications. Mathematical Finance, 26: 699–747.
- [49] Mittnik, S., Paolella, M.S., Rachev, S.T. (2000). Diagnosing and treating the fat tails in financial returns data. Journal of Empirical Finance, 7: 389–416.
- [50] Monroe, I. (1978). Processes that can be embedded in Brownian motion. Annals of Probability, 6: 42–56.
- [51] Ornthanalai, C. (2014). Lévy jump risk: Evidence from options and returns. Journal of Financial Economics, 112: 69–90.
- [52] Orsingher, E., Polito, F. (2013). On the integral of fractional Poisson processes. Statistics and Probability Letters, 83: 1006–1017.
- [53] Pérez-Abreu, V., Stelzer, R. (2014). Infinitely divisible multivariate and matrix gamma distributions. Journal of Multivariate Analysis, 130: 155–175.
- [54] Pollett, P.K. (2003). Integrals for continuous-time Markov chains. Mathematical Biosciences, 182: 213–225.
- [55] Richardson, M., Smith, T. (1994). A direct test of mixture distribution hypothesis: Measuring the daily flow of information. Journal of Financial and Quantitative Analysis, 29: 101–116.
- [56] Ronsiński, J. (2007). Tempering stable processes. Stochastic Processes and their Applications, 117: 677–707.
- [57] Samorodnitsky, G., Taqqu, M.S. Stable Non-Gaussian Random Processes: Stochastic Models with Infinite Variance. Chapman & Hall / CRC, New York, 1994.
- [58] Sato, K-I. (2006). Additive processes and stochastic integrals. Illinois Journal of Mathematics, 50: 825–851.
- [59] Schoutens, W. Lévy Processes in Finance: Pricing Financial Derivatives. The Atrium, Southern Gate, Chichestor: John Wiley & Sons Ltd, 2003.
- [60] Slater, L.J. Generalized Hypergeometric Functions, Cambridge University Press, Cambridge, UK, 1966.
- [61] Todorov, V. (2021). Nonparametric jump variation measures from options. Journal of Econometrics, Online First.
- [62] Todorov, V., Tauchen, G. (2011). Volatility jumps. Journal of Business and Economic Statistics, 29: 356–371.
- [63] Troster, V., Tiwari, A.K., Shahbaz, M., Macedo, D.N. (2019). Bitcoin returns and risk: A general GARCH and GAS analysis. Finance Research Letters, 30: 187–193.
- [64] Tseng, S-P., Peng, C-Y. (2004). Optimal burn-in policy by using an integrated Wiener process. IIE Transactions, 36: 1161–1170.
- [65] Van Noortwijk, J.M. (2009). A survey of the application of gamma processes in maintenance. Reliability Engineering & System Safety, 94: 2–21.
- [66] Wang, X., Xu, D. (2010). An inverse Gaussian process model for degradation data. Technometrics, 52: 188–197.
- [67] Xia, W. (2019). The average of a negative-binomial Lévy process and a class of Lerch distributions. Communications in Statistics - Theory and Methods, 49: 1008–1024.
- [68] Xia, W. (2021). Average-tempered stable subordinators with applications. Applied Stochastic Models in Business and Industry, 37: 1097–1122.
- [69] Yan, G., Hanson, F.B. Option pricing for a stochastic-volatility jump–diffusion model with log-uniform jump-amplitude. In: Proceedings of American Control Conference, Minneapolis, MI, USA, June, 14–16, 2006.
- [70] Ye, Z-S., Xie, M. (2015). Stochastic modelling and analysis of degradation for highly reliable products. Applied Stochastic Models in Business and Industry, 31: 16–32.
Appendix Appendix A Mathematical proofs
Theorem 1
Proof..
Let be fixed. By applying integration-by-parts to (2.1.1) times we have the fractional integral representation
| (A.1) |
where the second equality follows from the substitution .161616The first recipe generalizes the fractional integration of nonnegative processes to logarithmic kernels, as for every and the integrand in (A.1) constitutes a nonnegative stochastic process. The representation (A.1) together with the fact that is a Lévy process allows to write
where is the geometric integral sign and which leads to the first formula in (1) with the substitution .
For the other two formulae it suffices to identify the corresponding fractional integral representations. For (2.1.3), observe that for each , is the running average of the given Lévy process , so that the LT of at generic time satisfies the recurrence relation
| (A.2) |
due to the independent increments property of . The recurrence can be resolved easily via integration-by-parts, given the initial condition , in the same vein as (A.1), yielding the second formula in (1).
Also, since the integrals in (2.1.4) are simply iterated, an application of Cauchy’s repeated integration formula immediately gives
which result shows that each can be treated as a (times-scaled) usual fractional Lévy process under the Riemann–Liouville kernel. ∎
Theorem 2
Proof..
Comparing the first formula in (1) with the first formula in (2.2), we obtain the following Fredholm integral equation:
but as for all and , the substitution together with the Fubini–Tonelli theorem yields
| (A.3) |
Since forms a strictly increasing function for each , we can apply the further substitution to obtain the first formula in (2), after some rearrangement.
Then, for each fixed , comparing the second formula in (1) with the second formula in (2.2) and interchanging integrals gives the following integral equation:
which is equivalent, on rearranging the right-hand side, to
It leaves us with no choice but
This is yet another recurrence equation similar to the ones solved before, subject to the initial condition . Upon integration-by-parts we obtain the second formula in (2).
It is straightforward to obtain the third formula in (2) by mimicking the steps taken for the first.
With absolute continuity with respect to Lebesgue measure, the corresponding formulae for Lévy densities in (2) follow from direct calculations. ∎
Corollary 1
Proof..
According to the definition of the Blumenthal–Getoor index, it suffices to observe that the relations in (2) (or (2)) entail integration over domains bounded away from zero. Then the sigma-finiteness of the Lévy measures along with the Fubini–Tonelli theorem implies that the finiteness of the integrals , , and , for any , are all equivalent to that of , for any . ∎
Corollary 2
Proof..
Fix . The construction of the coefficients and , , for the type I and type III, respectively, is a direct result of Theorem 1, or the fractional integral representations (A.1) and (A.2). For the type II, since induction takes place for each , the coefficients , , are obtained by noting that .
The rationality of ’s is seen from the fact that, for every , and the finite series representation , and for any . ∎
Corollary 3
Proof..
The formulae follow immediately by replacing with its regulated counterparts in (3.1.2). ∎
Corollary 4
Proof..
According to Corollary 1, it is enough to consider the constant mixture based on the Lévy subordinator . Suppose . Following (3.1.2) and the Lévy–Khintchine representation, the Lévy measure of is given by
Thus, it follows from the inequalities
that , as required. If either or is zero the result is immediate. ∎
Corollary 5
Proof..
The formulae follow immediately by replacing with its regulated counterparts in (3.2.2). ∎
Corollary 6
Proof..
Again, with Corollary 1 we only consider the Gaussian mixture based on . By construction, the Lévy measure of satisfies
where , for , represents the Gaussian measure with mean and variance , that is, the probability measure of the drifted Brownian motion . For every , by the Fubini–Tonelli theorem we have
being a standard normal random variable and . From the fact that
the finiteness of is the same as that of . Towards that end, we first apply the -inequality to obtain for every
so that . Second, for every , observe that
where the second equality uses the substitution and which implies that . It is therefore concluded that , as required. ∎
Proposition 1
Proof..
For the type I, plugging the stated LT of into the first formula in (1) and applying substitution as in (A.3) the LT of reads for
| (A.4) |
which is clearly an entire function.
The general formula for the type II is immediate from the second formula in (1). If , then with we have that
where the second equality follows from the proof of Corollary 2 and which is also entire.
For the type III, note that
applies to non-integer values of as well. The integral can be directly evaluated with the substitution , leading to the third formula in (1).
Proposition 2
Proof..
Given , starting with the LT of , we have using binomial expansion and the proof of Corollary 2 that for ,
where in the first equality the interchange of integration and summation for is justified by analytic continuation.
The limiting case (corresponding to the gamma process) cannot be immediately gleaned from the last result. Similarly, by performing a separate computation we have
Thus, after some rearrangement we arrive at the first formula in (2).
Explicit computation of the Lévy density () is subtler because the integral inside (2) is concentrated on the tail behavior of , which obstructs direct expansion. Alternatively, observe that the recurrence relation leading to it, i.e.,
| (A.5) |
is nothing but an Euler integral equation for the G-function (documented in [Bateman and Erdélyi, 1954, Eq. 20.5.2] [11]), or
to be precise, where and are all integers and is linear. By employing an induction argument the general solution to (A.5) reads
for some yet-to-be-determined numbers and . Given the initial condition that , , we are forced to choose and , with , in which case the G-function specializes for to
from where it remains to set and .
The formulae for the type III are easily obtained by adapting the binomial expansion argument used for the type II. ∎
Proposition 3
Proof..
Let be a Poisson process and consider its constant mixture plus an independent Brownian motion. From Subsection 3.1 and Subsection 4.1 we know that the model cumulants (with regulation degrees) over the time period of are given by
where recall that is the truncated and discretized -domain for experimentation, and ’s are specified in (5.1.1). We then immediately have the following quotient relation:
which combined with the four moment conditions in (5.1.2) pins down the rate parameter estimate , and subsequently the other estimates in (5.1.3). ∎
Proposition 4
Proof..
Consider the case of the Gaussian mixture of being a tempered stable subordinator. Using the results obtained in Subsection 3.2 and Subsection 4.2 we have the following model cumulants:
where
are the first four cumulants of with regulation degree-subscripted parameters. From here one can deduce the following cumulant quotient relations:
which define a rational system for and . Note that the latter two conditions in (5.1.2) can be equivalently written as and ; from the first condition the sign of is seen to be determined by that of , and then using the second the equation (5.1.5) governing its absolute value can be easily derived. Notice that, as long as the condition
is fulfilled, a real solution of (5.1.5) always exists and can be easily located numerically; otherwise, the equation may not admit a real solution. Upon rearranging terms we obtain the estimates in (4) as desired. ∎
Appendix Appendix B Alternative skewness and excess kurtosis enlargement for tempered stable subordinators
For each (including zero), let be a tempered stable subordinator with parametrization , and ( and ). We know from [Küchler and Tappe, 2013, Eq. 2.19] [41] that the mean and variance at fixed are respectively
We stick to writing as a placeholder for any type of regulated stochastic clocks, whose th cumulant is times that of (see (5.1.1)). Then, from the quotient relation and the first two formulae in (2.3), (2.3.5), and (2.3) we have
Following is understood to be -clocks with parameters , , and , as opposed to -clocks. If we keep the mean and variance of to be invariant across , we need
It then follows that
Therefore, according to the last two formulae in (2.3), (2.3.5), and (2.3) we obtain for any
which as well apply to any non-integer values of . Specifying the last results for according to (5.1.1) delivers the results.