Regularized OFU: an Efficient UCB Estimator for Non-linear Contextual Bandit
Abstract
Balancing exploration and exploitation (EE) is a fundamental problem in contextual bandit. One powerful principle for EE trade-off is Optimism in Face of Uncertainty (OFU), in which the agent takes the action according to an upper confidence bound (UCB) of reward. OFU has achieved (near-)optimal regret bound for linear/kernel contextual bandits. However, it is in general unknown how to derive efficient and effective EE trade-off methods for non-linear complex tasks, such as contextual bandit with deep neural network as the reward function. In this paper, we propose a novel OFU algorithm named regularized OFU (ROFU). In ROFU, we measure the uncertainty of the reward by a differentiable function and compute the upper confidence bound by solving a regularized optimization problem. We prove that, for multi-armed bandit, kernel contextual bandit and neural tangent kernel bandit, ROFU achieves (near-)optimal regret bounds with certain uncertainty measure, which theoretically justifies its effectiveness on EE trade-off. Importantly, ROFU admits a very efficient implementation with gradient-based optimizer, which easily extends to general deep neural network models beyond neural tangent kernel, in sharp contrast with previous OFU methods. The empirical evaluation demonstrates that ROFU works extremely well for contextual bandits under various settings.
1 Introduction
Contextual bandit langford2007epoch ; bubeck2012regret is a basic sequential decision-making problem which is extensively studied and widely applied in machine learning. At each time step in contextual bandit, an agent is presented with a context and the agent chooses an action according to the context. After that the agent will receive a reward conditioned on the context and the selected action. The goal of the agent is to maximize its cumulative reward. One key challenge in contextual bandit is exploration and exploitation (EE) trade-off. In order to maximize cumulative reward, the agent exploits collected data to take the action with high estimated reward while it also explores the undiscovered areas to learn knowledge.
Optimism in Face of Uncertainty (OFU) is a powerful principle for EE trade-off. When facing uncertainty, OFU first optimistically guesses how good each action could be and then takes the action with highest guess. In philosophy, it exploits collected knowledge by estimating the expected reward and enforces exploration of the areas with large uncertainty via optimism. OFU algorithms can be divided into two categories, i.e., confidence bonus method auer2002finite and confidence set method jaksch2010near . In confidence bonus method, the uncertainty of each action is measured according to its historical frequency, which is added to its mean value as the estimated reward; in confidence set method, the reward function is constrained to a subset with high confidence and the maximum value over the confidence set is taken as the estimated value. These OFU algorithms have been proved to achieve the (near-)optimal regret bounds on tabular and linear problems, including multi-armed bandit (MAB) auer2002finite , linear contextual bandit (LCB) chu2011contextual and kernel contextual bandit (KCB) valko2013finite , and have also been successfully applied in practice.
However, the representation power of the tabular and linear models often becomes insufficient when facing many real-world contextual bandit problems where the scale of the underlying problem is huge or even infinite, and the reward mechanism is complex. Therefore, in practice, non-linear deep neural networks (DNN) are used to approximate the reward functions. While DNN models work well to fit training data, it remains challenging to quantify its uncertainty on new data. Therefore, existing OFU methods cannot be efficiently applied to non-linear contextual bandit. For confidence set method, it is difficult to compute the confidence set of the non-linear deep neural networks and hence hard to obtain the optimal action. For the confidence bound method, it is unclear how to design the frequency for non-linear reward functions. Overall, estimating uncertainty of the reward function approximated by non-linear functions, e.g., DNN, becomes a major obstacle when applying OFU algorithms to real-world applications.
There are several works zhou2020neural ; filippi2010parametric ; zahavy2019deep ; gu2021batched that attempt to generalize OFU to non-linear contextual bandit. One is NeuralUCB zhou2020neural that takes the gradient of each observation as the random feature and constructs the upper confidence bound accordingly. It has been shown that NeuralUCB achieves sublinear regret on neural tangent kernel contextual bandit (NTKCB). However, at each time step, NeuralUCB requires to compute an inversion of a matrix where is the number of model parameters. As the time complexity of matrix inversion is davie2013improved , the computational cost is prohibited for large-scale DNN models. Therefore, it is still largely under-explored to develop OFU algorithms that are able to achieve good EE trade-off with reasonable computational cost for non-linear contextual bandit.
Motivated by these challenges, in this paper, we propose a novel and general OFU method, called Regularized OFU (ROFU). In ROFU, we measure the uncertainty of the reward function by a differentiable regularizer, and then we calculate the optimistic estimation by maximizing the reward function with the regularizer penalizing its uncertainty. We prove that ROFU enjoys near-optimal regret on many contextual bandit problems with relatively simple reward mechanism, including MAB, LCB, KCB and NTKCB. Importantly, in contrast to existing OFU algorithms, ROFU admits an efficient implementation with gradient-based optimizer as the optimization problem in ROFU is unconstrained and differentiable, which has a time complexity linear to . Moreover, our algorithm easily extends to general deep neural network models.
We summarize our contributions as follows:
-
•
We show that ROFU achieves (near-)optimal regret on contextual bandits with simple reward functions, including MAB, LCB, KCB and NTK bandit. These results theoretically justify the efficiency of ROFU on EE trade-off.
-
•
We propose an algorithm which can efficiently approximate the upper confidence bound with standard gradient-based optimizer.
-
•
We empirically evaluate ROFU on complex contextual bandits with reward functions beyond linear, kernel and NTK. We show that ROFU also provides efficient UCB estimation for popular DNN architectures including MLP, CNN and ResNet. Moreover, our algorithm enjoys a smaller regret than strong baselines on real-world non-linear contextual bandit problems introduced by deep_bayesian_bandit_showdown .
2 Preliminary
In this work, we consider contextual bandit with general reward functions.
Definition 1 (Contextual bandit).
Contextual bandit is a sequential decision-making problem where the agent has a set of actions . At each time step , the agent first observes a context , then selects an action based on the context. After taking the action, the agent receives a (random) reward with where is a function with unknown groundtruth parameters . The agent aims to maximize its expected cumulative reward which is equivalent to minimizing the regret .
The most studied contextual bandit is linear contextual bandit, where the reward is generated from a linear function, i.e., where is a known feature map. For more complex problems, we have to use non-linear models, such as DNN, to represent the reward function.
In practice, given dataset , we can estimate by minimizing a loss function, i.e., . In this work, we focus on the mean squared loss and its variants,
| (1) |
This is because MSE is a natural choice for regression tasks. Generally speaking, OFU algorithms trade off exploration and exploitation with an optimistic estimation on the reward for each action, and then select . In the literature, OFU algorithms can be divided into two categories. The first one optimistically estimates the reward by adding a confidence bonus to , i.e.,
| (2) |
We call this OFU method Bonus-OFU. In simple cases, the bonus can be constructed using concentration bounds. For example, at time step , in UCB1 for MAB auer2002finite , the bonus is , where is the number of pulls on action ; in LinUCB for LCB chu2011contextual , the bonus is . Both UCB1 and LinUCB are proved to have (near-)optimal regret bounds.
The second kind of OFU algorithms optimistically estimates the reward by the best possible value over a confidence set of the reward functions, i.e.,
| (3) |
where and is the likelihood of given . We call this OFU method Set-OFU.
For convenience, we suppose is a -dimensional vector. Both Bonus-OFU and Set-OFU can effectively trade-off EE, however, they require a lot of computational resources when is a complex neural network: firstly, existing Bonus-OFU algorithms, such as NeuralUCB zhou2020neural , need to calculate the inversion of a matrix, which is expensive especially for large DNN models; secondly, it is also hard to efficiently compute the confidence set of DNN parameters and even harder to maximize the value over it to compute the . The computational cost significantly limits the application of OFU methods for complex tasks.
In the next section, we will propose a new OFU method, named Regularized OFU, which achieves a near-optimal regret bound on simple tasks, and more importantly, admits a very efficient implementation with a gradient-based optimizer.
3 Method
Different from Bonus-OFU and Set-OFU, we measure the uncertainty of reward with a (differentiable) function, and compute the optimistic reward estimation under the regularization of the uncertainty measure function. We call the reward estimation regularized OFU (ROFU) and take action accordingly. In round , given context and action pair , ROFU is defined as follows and the algorithm is presented in Alg. 1:
| (4) | ||||
| (5) |
where is the set of collected data in first rounds, is a regularizer, is the weight of the regularizer, is a monotonically increasing function with and is trained by minimizing some objective function, i.e., . We simply take action to interact with the environment.
In Eq. (4), we first solve an unconstrained optimization problem to calculate . Then, in Eq. (5), we add a bonus to according to the difference between and . From Eq. (4) and (5), we can see that , while ROFU still adds a bonus on as Bonus-OFU, it does not need to explicitly construct the upper confidence bound via concentration inequalities. Instead, we construct the upper confidence bound by solving a regularized optimization problem which is more general. In comparison to Set-OFU, our optimization problem is unconstrained, so Eq. (4) can be efficiently computed by standard gradient-based optimizers. In Sec. 3.2, we will propose an algorithm which can efficiently approximate with a few steps of gradient descent.
An important question is whether selecting action with maximum achieves good EE trade-off, or whether is a reasonable upper confidence bound over . To provide more insights, consider the case where . It is easy to see that . Thus, given is monotonically increasing and , we have is an upper bound of . Intuitively, if we can find a parameter that increases the value of without significantly increasing , then the uncertainty on the reward of would be large. Consequently, a large bonus would be added to such an action by Eq. (5). Moreover, and cooperatively control the scale of the confidence bonus: the difference between and increases as decreases and controls the contribution of such difference to the final bonus. In Section 3.1, we show that with proper and we can achieve near-optimal regret bound on contextual bandit when the reward function is simple.
Remark 1.
It is noteworthy that the choices of and are crucial to the performance on EE trade-off. For example, if we select which is used in Set-OFU, then . Then our method would uniformly sample actions.
3.1 Regret analysis
The regret bounds for ROFU are developed by drawing connections between ROFU with existing near-optimal algorithms. Then the regret of ROFU in these cases is also near-optimal. More specifically, we show that for MAB, LCB and KCB, the exact solution of Eq. (5) is equivalent to UCB1, LinUCB and KernelUCB respectively. For NTKCB, has similar properties to the upper confidence bound in NeuralUCB. We summarize these results in Table 1.
| MAB | Linear/Kernel-CB | NTK CB | |
| See Eq. (8) | |||
| See Eq. (7) | |||
| Equivalent/Related to | UCB1 | Lin/KernelUCB | NeuralUCB |
| Regret |
Equivalence to UCB1, LinUCB and KernelUCB
Specifically, we use MSE-variants for both and and , henceforth. After fixing , and , we can tune to make the solution of Eq. (5) equal to the upper confidence bound in UCB1, LinUCB or KernelUCB. Recall . The following theorem shows the equivalence between ROFU and LinUCB.
Theorem 1.
With , , and . We have is identical to the upper confidence bound used in LinUCB.
The derivation in Thm 1 can be directly used to show that is identical to upper confidence bound used in KernelUCB as well. And the equivalence between ROFU and UCB1 can be proved by similar techniques. We postpone the derivation into Appendix.
Remark 2.
From the derivation in Thm 1, it is easy to see that when , we can also tune to make ROFU identical to LinUCB. However, for , is a complex function depending on and . Thus, we only consider .
Connection to NeuralUCB and sublinear regret for NTK contextual bandit.
The NeuralUCB zhou2020neural uses a neural network to learn the reward function and constructs a UCB by using the DNN-based random feature mappings. For learning the reward function, NeuralUCB exploits the recent progress of optimizing a DNN in the Neural Tangent Kernel (NTK) regime allen2018convergence ; du2019gradient ; zou2019improved , which shows that gradient descent can find global minima of a loss for a finite set of training samples if the network is sufficiently wide and the learning rate is sufficiently small.
Intuitively, NeuralUCB takes the gradient as a random feature to represent the observation . Then, it constructs a UCB as in a linear bandit, i.e., , where is some predefined constant, is the network width and is a matrix with the contextual information. Specifically, NeuralUCB achieves regret.
We next show that ROFU can also achieve a similar regret in the NTK regime by carefully choosing the regularizer . To hide the technical exposure of NTK regime, we adopt the same assumptions and the same model setup as those in zhou2020neural . We bound the difference between ROFU and NeuralUCB in the NTK regime, and then show that ROFU can achieve a similar regret bound to NeuralUCB.
At the start, we assume that the network takes the following form
| (6) |
where is composed of , the is the point-wise activation function, is the network depth and is the network width. Furthermore, for and collects all these matrices into a long vector with dimension .
To see the connection with NeuralUCB, in Algorithm 1 we choose the loss as
| (7) |
where is the network parameter at initialization, is the network width. Here, the MSE loss is penalized by the distance between and its initialization because the analysis technique for NTK bandit requires that the network parameters stay within a neighborhood around the initialization zhou2020neural . We note that the penalizing coefficient written as is for proof convenience and the comparison with NeuralUCB. We further choose the regularizer as
| (8) |
where is the last iterate that minimizes the loss on . Moreover, and are the first order Taylor expansions of and at , respectively. Then equivalently, is calculated by
| (9) |
where and are defined as above.
We assume that the network is trained in the NTK regime with learning rate (see details in Algorithm 3 of Appendix B). Then if choosing in Eq. (5) and where is a factor same as the one used in NeuralUCB, we have a regret bound for ROFU as follows.
Theorem 2.
For convenience, let denote the network depth, denote the time horizon, denote the action set and denote the minimal eigenvalue of the neural tangent kernel matrix at initialization. If the loss and regularizer are chosen as Eq. (7) and Eq. (8) and the network width satisfies and the learning rate , then with high probability, the regret of ROFU satisfies that where hides the terms, the dependence on the problem dimension and other factors that are irrelevant with .
The idea of proof is to connect the formula of ROFU with the NeuralUCB and then bound their difference such that the order of the regret bound is not affected. We leave the full proof into Appendix B. This justifies that the ROFU can also achieve a near optimal regret bound in the NTK regime. Nonetheless, in sharp contrast with NeuralUCB where computing the inverse of a large matrix is necessary in each step, ROFU admits a very efficient implementation as shown below.
3.2 An efficient algorithm to compute
In order to apply ROFU, we have to efficiently solve or approximate Eq. (4). In cases of MAB, KCB, we can calculate closed-form solutions for Eq. (4). When is a deep neural network, it is time-consuming to exactly solve Eq. (4). Naturally, one can use gradient descent methods to approximately solve Eq. (4). However, it is still not manageable to optimize from scratch for every . We propose that the optimization starts from for .
More specifically, when is a neural network and is differentiable, we can optimize the parameters with gradient ascent. We approximately solve Eq. (4) by executing a few steps of gradient ascent starting from . That is, with , where is the step size. The above implementation is summarized in Alg. 2.
Alg. 2 essentially performs a local search around . Indeed it brings extra benefit for the optimization by starting from in this case. This is because intuitively often gets closer to when is larger. For example, in MAB, where is the empirical mean of action and where is the number of pulls on . Thus, is close to when is large.
It is easy to see that the time complexity of Alg. 2 is . In Sec. 5, we can see that the regret of ROFU is low in practice with very small .
Remark 3.
For MAB, linear/kernel bandit and NTK bandit, is strongly convex and smooth. Assuming that it is strongly convex and smooth, by Thm 2.1 in needell2014stochastic , we have , where is over the randomness of SGD, is the learning rate and is the expected gradient norm square at .
We note that the convex and smooth property for NTK bandit is due to the choice of in Eq. (8). Based on Remark 3, we can expect Alg. 2 converges fast for these cases, especially, which can leverage the property that gets smaller as gets larger. When is general and complex, there is no theoretical guarantee on the convergence rate, but in practice, stochastic gradient descent with a good initialization usually converges fast. We note that NeuralUCB can have a fast implementation by approximating with its diagonal elements, which, however, can significantly compromise the regret in practice. Please see Sec. 5.2 for empirical evaluations.
4 Related work
The contextual bandit problem has been extensively studied and applied in machine learning. Besides OFU, the most used and studied contextual bandit algorithms can be mainly divided into two categories: -greedy sutton2018reinforcement and Thompson sampling thompson1933likelihood .
-greedy greedily selects the action with probability and randomly selects an action to explore with probability . While being sub-optimal on EE trade-off, -greedy is simple, general and computationally efficient. Thus, -greedy is the most widely used algorithm in complex tasks.
The basic idea of Thompson sampling thompson1933likelihood is to maintain a posterior over parameters and make decisions according to the samples from the posterior. However, Thompson sampling can be applied only if we can access the posterior and use approximate inference methods which can be computationally inefficient and may significantly hurt the performance of regret deep_bayesian_bandit_showdown ; phan2019thompson .
There are several works extending OFU and Thompson sampling to the case of non-linear contextual bandits. NeuralUCB zhou2020neural and Neural-TS zhang2021neural extend OFU and TS to NTK bandits and they provide regret bounds in the order of . Our analysis for NTK bandit is largely inspired by their work. However, as mentioned in Sec. 2, both NeuralUCB and NeuralTS need to calculate the inversion of a matrix with dimension equal to the number of parameters in DNN, which is computationally inefficient for large DNN models. Moreover, the neural-linear model is studied in zahavy2019deep ; deep_bayesian_bandit_showdown , where they take the output of the second last layer of a DNN as feature map. These algorithms sometimes work well, but have no theoretical guarantee on regret.
5 Experiment
We now empirically evaluate ROFU. For simplicity, in all our experiments, we set , and . That is, is trained to minimize with standard optimizer 111We train with stochastic gradient descent starting from in all the experiments. and is trained to maximize using Alg. 2.

5.1 Analysis on MLP and ResNet bandits
As discussed in Sec. 1, a contextual bandit algorithm should be efficient in trading off EE when reward is generated from a complex function while keeping a low cost on computational resources. From Alg. 2, we can see that the time complexity of ROFU is determined by the training step . Thus, we here evaluate the regret of ROFU when is small.
To evaluate the performance of ROFU in Alg. 2 on complex tasks, we consider two contextual bandits with a DNN as the simulator. That is, is generated by a DNN model. We consider two popular DNN architectures to generate rewards: 2-layer MLP and 20-layer ResNet with CNN blocks and Batch Normalization as in he2016deep . We summarize other information of the two tested bandits in Table. 2.
Bandit Layer Context Dim # Arms NN Parameters Context Distribution Noise MLP Random Gaussian ResNet Train on Cifar10 Uniform
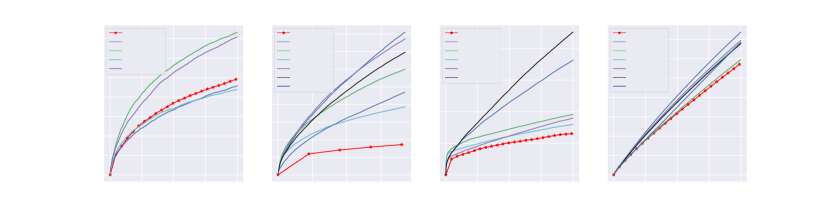
We use DNNs with larger size for training in Alg. 2. More specifically, for MLP-bandit, is chosen as a 3-layer MLP and for ResNet20-bandit, is chosen as ResNet32. Each experiment is repeated for 16 times. We present the regret and confidence bonus in Fig. 1. From Fig. 1, we can see that (1) ROFU can achieve a small regret on both tasks with a considerably small even for very large DNN model; (2) The confidence bonus monotonically increases with . For each , the confidence bonus converges to as expected. Moreover, while the regret seems sensitive to the value of , the regrets of ROFU with are much smaller than the case of and -greedy.


5.2 Performance comparison on real-world datasets
To evaluate ROFU against powerful baselines, we conduct experiments on contextual bandits which are created from real-world datasets, following the setting in deep_bayesian_bandit_showdown . For example, suppose that is a -classification dataset where is the feature vector and is the label. We create a contextual bandit problem as follows: at time step , the agent observes context , and then takes an action . The agent receives high reward if it successfully predicts the label of . For non-classification dataset, we can turn it into contextual bandit in similar ways. For the details of these bandits, please refer to deep_bayesian_bandit_showdown .
For baselines, we consider NeuralUCB zhou2020neural and Thompson sampling variants from deep_bayesian_bandit_showdown . It is noteworthy that we only evaluate the algorithms in deep_bayesian_bandit_showdown with relatively small regrets. We directly run the code provided by the authors. For ROFU, we fix for all experiments. For other hyper-parameters, please see Appendix C. We repeat each algorithm for times on each dataset.
We report the regret where and is the parameter trained on the dataset. For hyperparameters tuning and more details, please see Appendix C. The results are presented in Fig. 2 and Table 3. We found that the regret of NeuralUCB is occasionally linear. This might be because that NeuralUCB uses a diagonal matrix to approximate to accelerate. Moreover, we can see that ROFU significantly outperforms these baselines in terms of regret.
Mean Census Jester Adult Covertype Statlog Financial Mushroom Dropout Bootstrap ParamNoise NeuralLinear Greedy NeuralUCB ROFU (ours)
Conclusion and future work
In this work, we propose an OFU variant, called ROFU, which can be applied to non-linear contextual bandit. We show that the regret of ROFU is (near-)optimal on various contextual bandit models. Moreover, we propose an efficient algorithm to approximately compute the upper confidence bound. Thus, ROFU is efficient in both computation and EE trade-off, which are empirically verified by our experimental results.
EE trade-off is a fundamental problem that lies in the heart of sequential decision making. However, the huge computational cost of (near-)optimal EE trade-off algorithms significantly limits the application, especially on complex domain. We hope our method could inspire more algorithms to efficiently trade-off EE for sequential decision-making tasks beyond contextual bandit, such as deep reinforcement learning.
References
- (1) Z. Allen-Zhu, Y. Li, and Z. Song. A convergence theory for deep learning via over-parameterization. arXiv preprint arXiv:1811.03962, 2018.
- (2) Z. Allen-Zhu, Y. Li, and Z. Song. On the convergence rate of training recurrent neural networks. In Advances in Neural Information Processing Systems, 2019.
- (3) P. Auer, N. Cesa-Bianchi, and P. Fischer. Finite-time analysis of the multiarmed bandit problem. Machine Learning, 2002.
- (4) S. Bubeck and N. Cesa-Bianchi. Regret analysis of stochastic and nonstochastic multi-armed bandit problems. arXiv preprint arXiv:1204.5721, 2012.
- (5) Y. Cao and Q. Gu. A generalization theory of gradient descent for learning over-parameterized deep ReLU networks. arXiv preprint arXiv:1902.01384, 2019.
- (6) W. Chu, L. Li, L. Reyzin, and R. Schapire. Contextual bandits with linear payoff functions. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 2011.
- (7) A. M. Davie and A. J. Stothers. Improved bound for complexity of matrix multiplication. Proceedings. Section A, Mathematics-The Royal Society of Edinburgh, 143(2):351, 2013.
- (8) S. S. Du, X. Zhai, B. Poczos, and A. Singh. Gradient descent provably optimizes over-parameterized neural networks. In International Conference on Learning Representations (ICLR), 2019.
- (9) S. Filippi, O. Cappe, A. Garivier, and C. Szepesvári. Parametric bandits: The generalized linear case. In NIPS, volume 23, pages 586–594, 2010.
- (10) Q. Gu, A. Karbasi, K. Khosravi, V. Mirrokni, and D. Zhou. Batched neural bandits. arXiv preprint arXiv:2102.13028, 2021.
- (11) K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- (12) T. Jaksch, R. Ortner, and P. Auer. Near-optimal regret bounds for reinforcement learning. Journal of Machine Learning Research, 2010.
- (13) D. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- (14) J. Langford and T. Zhang. The epoch-greedy algorithm for contextual multi-armed bandits. Advances in neural information processing systems, 20(1):96–1, 2007.
- (15) D. Needell, R. Ward, and N. Srebro. Stochastic gradient descent, weighted sampling, and the randomized kaczmarz algorithm. Advances in neural information processing systems, 27:1017–1025, 2014.
- (16) M. Phan, Y. Abbasi-Yadkori, and J. Domke. Thompson sampling with approximate inference. arXiv preprint arXiv:1908.04970, 2019.
- (17) C. Riquelme, G. Tucker, and J. Snoek. Deep bayesian bandits showdown: An empirical comparison of bayesian deep networks for thompson sampling. 2018.
- (18) R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
- (19) W. R. Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 1933.
- (20) M. Valko, N. Korda, R. Munos, I. Flaounas, and N. Cristianini. Finite-time analysis of kernelised contextual bandits. arXiv preprint arXiv:1309.6869, 2013.
- (21) T. Zahavy and S. Mannor. Deep neural linear bandits: Overcoming catastrophic forgetting through likelihood matching. arXiv preprint arXiv:1901.08612, 2019.
- (22) W. Zhang, D. Zhou, L. Li, and Q. Gu. Neural thompson sampling. In International Conference on Learning Representations, 2021.
- (23) D. Zhou, L. Li, and Q. Gu. Neural contextual bandits with ucb-based exploration. In International Conference on Machine Learning, 2020.
- (24) D. Zou and Q. Gu. An improved analysis of training over-parameterized deep neural networks. In Advances in Neural Information Processing Systems, 2019.
Appendix A Analysis on multi-armed bandit
The following theorem presents the equivalence between ROFU and UCB1 auer2002finite .
Appendix B Analysis on neural tangent kernel bandit
See 2
The step 6 in Algorithm 1 is accomplished by running gradient descent for iterations with learning rate to minimize the loss, as given by Algorithm 3. In the following analysis, we assume that satisfies the first order optimality of minimizing for the ease of the derivation and is the randomly initialized starting point.
By choosing the regularizer as Eq. (8), the procedure of searching (Eq. (4)) is equivalent to
| (10) |
where
are the first order Taylor expansions of and at , respectively. We note that the special choice of regularizer Eq. (8) is to derive a simple form of .
In the following analysis, we first connect ROFU with NeuralUCB via an informal argument. Then we bound the approximations in the informal argument and show they will not affect to establish the sublinear regret in the order sense. We use notation to denote .
An intuitive procedure.
With the above choices, we can see that the procedure Eq. (10) is equivalent to
| (11) |
where
| (12) |
by assuming that satisfies the first-order optimality condition of minimizing the .
Solving the problem Eq. (11), we obtain
Hence if the function in Eq. (5) is given by , then the becomes
| (13) |
where the approximation is because of using the first order Taylor approximation of at to replace .
Similar to the formula of (13), one uses
| (14) |
as the upper confidence bound in NeuralUCB (zhou2020neural, , Algorithm 1). One difference is that they zhou2020neural use
| (15) |
We next bound the differences between ROFU and NeuralUCB, and then show that the differences won’t affect the regret bound on the order of .
Bound the approximations in above derivation
We first introduce some existing bounds on how the function value is approximated by the first order Taylor expansion in the NTK regime.
Lemma 1 (Lemma 4.1& Theorem B.3, cao2019generalization ).
There exist constants such that for any , if satisfies that , then with probability at least , for all with , and for all and all , we have
| (16) | |||
| (17) |
We also introduce a bound on the difference between the gradient at and the gradient at initial point when is not far from as required and satisfied in the NTK regime.
Lemma 2 (Theorem 5, allen2019convergence ).
There exist constants such that for any , if satisfies that , then with probability at least , for all with ,and for all and all , we have
| (18) |
With these existing bounds, we next show that (Eq. (12)) enjoys the same property as (Eq. (15)) as follows. We introduce another sequence . In (zhou2020neural, , Lemma B.3), they showed that is close to . Similarly, we have the following lemma on the distance on .
Lemma 3.
With probabililty where , for any , we have
| (19) |
if the network width satisfies that
| (20) |
with some constants .
Proof.
The proof can be adapted from that of Lemma B.3 in zhou2020neural with the fact that is bounded because of Lemma 2. ∎
We note that Lemma 3 plays the same role as Lemma B.3 in zhou2020neural . Hence with Lemma 3 we can establish a similar result as Lemma 5.2 in zhou2020neural that with high probability, the optimal lies in the sequence of confidence sets, i.e., an ellipsoid defined with the new matrix .
Next we show that the first-order Taylor approximation in Eq. (11) does not affect the achievable regret bound either. By the proof of Lemma 5.3 in zhou2020neural , in order to prove a similar result, we only need to bound
| (21) |
where and is given by Algorithm 1 in zhou2020neural . The derivation is as follows,
| (22) |
where is a constant and the last inequality is due to Lemma 1 and the choice of such that . Hence we show the shares the same property as the in Algorithm 1 of zhou2020neural . The left proof follows a similar procedure.
Appendix C Experimental details
Hyperparameters: We tune the hyper-parameters of ROFU on statlog and directly apply the hyperparameters on statlog to other datasets except mushroom. This is because the reward scale of mushroom is much larger than other datasets. For baselines, we directly use the best reported hyper-parameters.
For convenience, we suppose context is sampled from some distribution for all . And we define a virtual dataset as well as a parameter trained by minimizing MSE on the virtual dataset where MinimizeMSE is a gradient-based optimizer, e.g., SGD or Adam kingma2014adam .
To alleviate the influence of regret injected by neural network training and generalization error, we decompose the regret into two parts:
| (23) |
where and is selected by agent.
It is noteworthy that in practice, is usually an upper bound of as is trained on data points while and are trained on no more than data points. And the regret I is caused by MinimizeMSE and generalization power of function . So, regret I is independent with the algorithm for EE trade-off. Thus, we only report regret II in Fig. 2 to give a clearer evaluation on ROFU’s ability for EE trade-off. We also present the full regret in Fig. 3. The running time is in Table. 4.
ROFU Neural-UCB Dropout ParamNoise Greedy Bootstrap Neural Linear Runing time (s) 5259 1589 525 306 771 729 3612