Regularized Flexible Activation Function Combinations for Deep Neural Networks
Abstract
Activation in deep neural networks is fundamental to achieving non-linear mappings. Traditional studies mainly focus on finding fixed activations for a particular set of learning tasks or model architectures. The research on flexible activation is quite limited in both designing philosophy and application scenarios. In this study, three principles of choosing flexible activation components are proposed and a general combined form of flexible activation functions is implemented. Based on this, a novel family of flexible activation functions that can replace sigmoid or tanh in LSTM cells are implemented, as well as a new family by combining ReLU and ELUs. Also, two new regularisation terms based on assumptions as prior knowledge are introduced. It has been shown that LSTM models with proposed flexible activations P-Sig-Ramp provide significant improvements in time series forecasting, while the proposed P-E2-ReLU achieves better and more stable performance on lossy image compression tasks with convolutional auto-encoders. In addition, the proposed regularization terms improve the convergence, performance and stability of the models with flexible activation functions. The code for this paper is available at https://github.com/9NXJRDDRQK/Flexible_Activation.
I Introduction
Deep learning is one of the most powerful techniques in modern artificial intelligence [1]. One reason is its ability in approximating complex functions with a large but limited number of parameters [2, 3], while the regular layer structures make it possible to be trained with efficient back propagation algorithms [4].
In a deep neural network, the weights and bias take account of linear transformation of the data flow, while the activation functions bring in non-linearity. It is remarked in [3] that activation functions do not perform equally well if we take minimal redundancy or computational efficiency into account. Thus the selection of activation function for different tasks is a critical issue in a sense. Traditionally, people train the weights of linear transformations between layers while keeping the activation functions fixed, and usually one identical activation function is used for all the neurons on each single layer. For example, the rectifier linear units (ReLU) are used as the default choice for the activation in hidden units for feed forward neural networks and in a large proportion of convolutional neural networks [5], while sigmoid and tanh functions are used where output values are bounded, such as in output layers for classification problems and the gate activations in recurrent cells [6, 7].
The drawback of ReLU activation is the issue of dead unit when the input is negative, which motivated the introduction of functions with non-zero values in the negative range, including leaky-ReLU and exponential linear units (ELU) [8, 9]. By considering other properties that could be helpful in training, such as dropout or self-regularization effects, more types of activation functions such as GeLu and Mish are proposed [10, 11]. There are also activation functions designed for particular learning tasks such as reinforcement learning [12], where the activation functions used for neural network function approximation are computed by the sigmoid function multiplied by its input. Moreover, reinforcement learning can be implemented for searching activation functions with an RNN controller [13]. Beyond properly choosing the activation functions, techniques such as clipping and batch normalization can be implemented to make activations robust to explosion or vanishing gradients[14, 15]. Traditionally, explosion or vanishing gradients in back propagation are also issues that harm the performance of model largely due to the shape of activations [16, 17, 18]. Beyond properly choosing the activation functions, techniques such as clipping and batch normalization can be implemented to alleviate these issues to some extent [14, 15].
With a large enough neural network and sufficient training time, the model can effectively learn the patterns from data with possible high accuracy, however it is not straightforward to confirm that learning process is the most efficient and the results are the most accurate. One possible solution for accelerating model training is to introduce flexible or trainable activation functions [19, 20, 21]. Even though this requires higher computing and storing cost that is proportional to the number of neurons, the performance of models can be improved in a more efficient manner than increasing the number of basic model parameters or the number of neurons. For example, as the leaky-ReLU function has a hyper-parameter to be optimized, which is the slope of its negative part, parameterized Relu (PReLU) was proposed to make this slope adapt to the data within specific neurons and to be learned during the training process [20]. Meanwhile, [22] proposes the parameterized version of ELU activation, which introduces two parameters to control the shape of exponential curve in the negative region.
It can also be a blending of different commonly used activations, where the trainable parameters are the weights for the combination components [23, 24]. Since different activation functions can have very similar behavior in some specific regions, a more generative way is to consider their Taylor expansions at point and use a weighted combination of polynomial functions with different orders instead [21]. For containing those functions that are not centered at , one choice is to train a piece-wise function adaptively [19]. The similar effect can be achieved by Maxout activation, which is quite helpful in promoting the efficiency of models with dropout [25]. Beyond that, there are also studies on making the most of the non-linear properties by introducing adaptation mechanism on the Softmax layers [26], which achieve the former state-of-the-art results on several natural language processing (NLP) tasks.
The limitation of existing studies can be illustrated as follows. First, most of existing work focus on some specific forms of parameterized activation functions rather than a more general form, or consider each component of the combination as a fixed activation function. Second, there is a lack of study on flexible activations with bounded domain such as sigmoid and tanh. Third, existing works rarely discuss the regularization on activations parameters, which have different nature from normal model parameters. In this study, we consider the activation function as a combination of a set of trainable functions following the constraints of several principles. Based on these principles, we develop two flexible activation functions that can be implemented for bounded or unbounded domain. In addition, layer-wise regularization on activation parameters is introduced to reduce the variance caused by activation functions.
Section II is an introduction of the main idea and methodology of this paper with initial theoretical analysis. Section III is the experimental results of our methods, in which we compare the performances of models with newly proposed flexible activation functions and baseline models on several datasets. Also we check the effect of regularization on activation parameters. Section IV is the discussion on number of parameters and computational complexity. Section V is the conclusion.
II Methodology
Existing studies on trainable activation function mainly focus on the case where the output is unbounded. However, activation functions with bounded domain, such as sigmoid and tanh, are implemented in a large number of models. One scenario is recurrent neural networks, such as LSTM, whose cell has the functional mapping as follows:
| (1) |
where the cell structure includes multiple sigmoid and tanh activation functions. If we want to introduce trainable ones in the same positions, the output domains of the newly introduced flexible activation functions should be the same with the original fixed ones.
II-A Parameterized Activation Function Combinations
In this study, we implement a general form of parameterized activation functions linearly combined by different activation functions as components[23, 24]. We further extend the existing works by introducing trainable parameters in each component, which is essential for building trainable activations with bounded domain. We assume that the parameters in the combined activation functions can be different for each neuron, which can be trained during the main training process of the model parameters with back propagation.
| (2) |
where indexes the neuron, and is the input of the activation layer indexed by . This means that, at each neuron , it is possible to have its own set of parameters and where is the combination weights and is the activation parameter vector for the -th component activation , respectively. Thus Eq. (2) defines a form of activation function as a linear combination of a set of basic parameterized non-linear activation functions with the same input to the neuron. Normally, we require for all and to ensure that the output is strictly bounded between 0 and 1. This setting will take advantage of the low computational costs of existing activation functions, while it will be much easier to implement weights normalization when we need a bounded activation function.
Since the specific activation function corresponding to each neuron only depends on its own activation parameters, the back propagation of these activation parameters by stochastic gradient descent can be done as follows:
| (3) |
where is the loss function of all parameters of the model, is the index of the hidden neuron with output and is the index of combined flexible activation functions. Here we use a simplified expression that does not include the indices of layer and training examples in each mini-batch. is the learning rate of gradient descent for all the parameters in activation functions. With the gradients given by , adaptive optimizers such as AdaGrad, Adam and RMSProp can also be applied. In general, gradient descent approach and its derivatives can push the activation parameters toward the direction that minimizes the empirical risk of the model on training data.
To build effective combinations with the general form given by Eq. (2), we introduce the following three principles for selecting the components:
-
•
Principle 1: Each component should have the same domain as the baseline activation function.
-
•
Principle 2: Each component should have an equal range as the baseline activation function.
-
•
Principle 3: Each component activation functions should be expressively independent of other component functions with the following definition.
Definition 1: If a component activation function is expressively independent of a set of other component functions: , there does not exist a set of combination coefficients ,…,, inner activation parameters ,…, parameters of the previous linear layers , such that for any input , activation parameters , and parameters of the previous linear layer , , the following equation holds:
| (4) |
Proposition 1: For a single-layer network with neurons, if a component activation function , which is not expressively independent of other components, is excluded, we need at most neurons to express the same mapping exactly.
Proof: For any original combined activation function: . Assume that is not expressively independent. If we exclude from the combination and get , then for any input , parameters of the previous linear layer: , , and activation parameters: of a specific neuron, we have:
| (5) |
and there exist , and such that:
| (6) |
which can be expressed by two neurons with function with corresponding weights and bias in the previous linear layer. Therefore, for a single-layer network with neurons, we need at most neurons without to express the any mappings by the original function.
The first two principles are aiming at keeping the same ranges and domains of the information flow with the mapping in each layer. The third principle is aiming at reducing the redundant parameters that do not contribute to the model expressiveness even with limited number of units. For example, is not expressively independent with since when , we have . Therefore, the combined activation will not be a good choice. Based on this, we can then design the combined trainable activation functions for both bounded or unbounded domains.
II-B P-Sig-Ramp : Sigmoid/Tanh Function substitute with bounded domain
Sigmoid and Tanh activation functions are widely used in recurrent neural networks, including basic recurrent nets and recurrent nets with cell structure such as LSTMs and GRUs. For the sigmoid function, the output should be in the domain of , while for tanh the output should be in . In the first case, one basic choice is:
| (7) |
where and
| (8) |
In Eq. (7), can be considered as a combination of two Ramp functions bounded between 0 and 1 with parameter . The shapes of a sample of combined activation with Eq. (7) are shown in Fig. 1. Similarly, we can build a function with the same boundary as function, and use the corresponding combination to replace in the LSTM cell. Consequently, for each combined flexible activation function, there are two parameters to be optimized during the training process. By combining the original activation function with another function with the same boundary using normalized weights, the model can be trained with flexible gates and have the potential to achieve better generalization performance.

II-C P-E2-ReLU: ReLU Function substitute with unbounded domain
The outputs of ReLU function is unbounded on both sides, while the derivative with respect to the inputs is a step function. To build more flexible activation in the condition when ReLU function is used, we can make a weighted combination between ReLU and other non-linear functions with unbounded ends. Considering the goodness of candidate components as well as the principles proposed in Section II-A, we introduce the following combined form:
| (9) |
This is actually a weighted combination of ReLU function and two ELU-family functions, which introduces non-linear functions with different shapes in both positive and negative region. If we bound all the wights between 0 and 1, each of the three components , or can not be fully expressed by the combination of the others with certain model parameters. Figrue 7 demonstrates the examples of P-E2-ReLU given by Equation (9) with different activation parameters.

In addition, if we set , the combined two ELU-family terms will be symmetric with respect to point , which is similar to the combination of and ReLU proposed in [24] but can be more naturally implemented for unbounded domains. Also, we can consider other combinations such as , and , where “Id” represent identity functions, and is the trainable parameter of ELU (default is 1.0). We categorize them all as in “P-E2-X” family. In this study we will focus on the form provided by Equation (9), while the others could achieve even better performances in some tasks.
II-D Layer-wise Regularisation for Activation Parameters
Similar to the weights decay regularisation for model weights in NN models, we introduce regularisation terms for parameters in activation functions to avoid over-parameterization during learning process. When we set the summation of each component’s weights in each flexible activation function to 1, it is not suitable to implement a L1 or L2 norm on the absolute value of activation weights. Instead, we use the L2 norm for the absolute difference between each specific activation parameter and the mean of corresponding parameters in the same layer. In addition, we introduce another L2 regularisation term controlling the difference between the trained parameters and the initial parameters of benchmark activation function. This can make sure that the benchmark is actually a specific case of flexible activation, while the variations can be learned to adapt to the training dataset and controlled by these regularisation effects. Thus, the cost function can be given by Equation (10), where is the predictive loss, refers to the th activation parameter for th element in th layer, is the average value of in th layer, is the combination coefficient of th component in basic or standard activation functions (e.g. Sigmoid).
| (10) |
In the first regularization term, is the number of neurons in th layer, while is the layer-wise regularisation coefficients, and is mutual regularization coefficient. and are the regularization coefficients for the second and third regularization terms, and is the number of units in the whole network architecture. We can consider the first two regularization terms as prioris. For the first one, we consider that in the layer structure of deep neural networks, usually different layer is learning different level of patterns, which could be in favor of using similar activation functions in each layer. we call it as “towards-mean regularization”. Meanwhile, the second regularization terms can be considered as another priori in assuming that the initial activation functions are good enough and the learned activation parameters should not differ too much from the initial values. We call this as “towards-default regularization”. In addition, the third regularization term is introduced to ensure the combination parameters are bounded between 0 and 1, where is a small number. We set to be a relatively large value (e.g. ) to make this as a strong constraint. The regularization coefficients and can be implemented for controlling the flexibility in activation parameter space. The effects of these two regularization terms can be summarized as follows:
-
•
Small , small : The activation functions can be trained independently for different neurons in different layers with high flexibility.
-
•
Large , small : The activation functions in the same layer will be constraint to be close to each other, while the activation in different layers can be different.
-
•
Large : The activation function will be constraint to be close to the default fixed ones.
Therefore, with optimized activation coefficients, the models can achieve performances at least no worse than models with fixed default activation. Moreover, gradient-based methods may also be applied in optimizing these regularization coefficients [27, 28].
II-E Initialization
Since we introduced a set of new trainable parameters, the way to initialize them could make a difference. The default choice is to set the coefficients of benchmark activation functions to 1 and train the other terms from 0. However, this setting could suffer from the risk of being trapped in local optimal. Other solutions include the following:
-
•
Treat the initialization values as hyper-parameters, and use hyper-parameter searching algorithms to find the optimal setting.
-
•
Use random initialization following certain types of distributions with mode close 1 for the default activation.
The advantage of treating initialization values of activation parameters as hyper-parameters is that we can search for the optimal solution based on the final validation performance of model, while the drawback is higher computational cost for extra hyper-parameter optimizations. Alternatively, by using random initialization for each training, an ensemble of activation functions with different shapes are used at the beginning of model training, which can be more flexible in explore larger region in search space. In this study, to avoid tunning too many hyper-parameters, we initialized the parameters of activation function as standard activation functions such as sigmoid and ReLu, which corresponds to in Eq. (7) and Eq. (9).
III Experiments
All the experiments were conducted in the environment of Pytorch 1.3.1, we implemented the embedded functions of sigmoid, ReLU and pReLU in the baseline models and manually created the proposed flexible functions with backward path in the flexible models. The experiments are conducted with a cloud Intel Xeon 8-Core CPU.
III-A Experiment with Recurrent Neural Networks on multi-variate time series forecasting
For testing the performance of the model with flexible activation in recurrent neural networks, we build a multiple-layer LSTM model. We change the three sigmoid functions in Eq. (1) to the parameterized combined function as shown in Eq. (7), then compare the model performances in the cases with or without flexible activations.
The datasets being experimented on is a combination of daily stock returns of G7 countries, which is a multi-variate time series [29, 30]. The returns of each day can be considered as an input vector to the corresponding hidden layer, while the output is one-step ahead forecast given a sequence of historical data. Instead of using random sampling, we directly split the set of sequences with 10 lagging vectors into training set (64%), validation set (16%) and test set (20%), while the learning curves on training and validation sets can be obtained. The loss is selected as the average of mean squared errors of all forecasted values with respect to the true values for each example. For the hyper-parameter setting, the batch size was set to be 50, the window size is 10 time steps as is recommended by related papers[31], while the optimizer implemented in training is Adam optimizer with the same learning rate of 0.001 on both weights, bias and activation parameters. The initialization of the flexible activation parameters in replacing sigmoid function is and , which means that we train them from baseline settings. On the other hand, four stacked LSTM models with different layer configurations are implemented, then we compare the validation and test performances of these models with (a) fixed activations, (b) flexible activations without regularization, (c) flexible activation with a toward-mean regularization using a same default regularization coefficient of 0.025. We perform 50 trials for each setting with different random initialization for each of them.
For BRICS indices forecasting, we test the model performances with 4 stacked LSTM configurations, including models with layer structures: , , and . For example, in the first layer structure, we have 5 input units for each time step, and a LSTM layer with a hidden state of length 8 for each time step. The results are provided in Fig. 3, where we use error bars to show the sample standard errors of each method in each time step.

As we can see, for all the four cases, generally the learning curves of models with flexible activation and regularized flexible activation (with fixed towards-mean regularization) lie below the learning curves of models with fixed sigmoid activations. For G7 indices forecasting, we exam the performances on stacked-LSTM models with layer structures: , , and . The results on training set are provided in Fig. 4. The curves are plotted from the 5th epoch to focus on the comparison in later stage.

We can see that in Fig. 4, for all the four cases, the learning curves of model with flexible activation functions (denoted as “flexible models”) on training set lie below the corresponding curves of models with fixed activation functions (denoted as “fixed models”) during most of training time. In addition, towards-mean regularization on activation parameters can further improve the convergence performance. Meanwhile, the error bars of population means demonstrate that the improvement of flexible models in terms of validation performance is significant in general.

Similarly, we can see that in Fig. 5, for all the four cases, the learning curves of flexible models on validation set lie below the corresponding curves of fixed models during most of training time. Moreover, the error bars of population means demonstrate that the improvement of flexible models in terms of validation performance is significant in general. To make a further investigation, we use optimized learning rates instead of the default ones in each case. First, we perform grid searches for both models without flexible activation functions and model with flexible activation functions in the range of on logarithm scale. Also, for models with flexible activation, we perform another grid search in the range of on logarithm scale for the optimal activation regularization coefficients defined in Section II-D, while the searching is based on the optimal learning rate in each case. Then for each architecture, we compare the models with four settings: (a) Models without flexible activation on the corresponding optimal learning rate; (b) Models with flexible activation function on the corresponding optimal learning rate, without regularization on the activation function; (c) Models with flexible activation function on the corresponding optimal learning rate, with regularization on the activation function on the default value of 0.025; (d) Models with flexible activation function on the corresponding optimal learning rate, with optimal regularization on the activation function in each case. The results of 50 runs with corresponding error bars are shown in Fig. 6.

We can learn from Fig. 6 that with optimized learning rates and Adam optimizer, LSTM models with flexible activation functions perform better in terms of convergence compared with fixed models for all the four architectures. By introducing regularization on flexible activation towards the mean, the convergence can be further improved. To investigate the effect of two types of regularization, we conduct a simulation and plot the relationship between the minimum validation model performance and the values of regularization coefficients. We use a default learning rate of 0.001. For regularization coefficients, we take 20 discrete grid points in the logarithm scale of 0.001 to 0.2. At each point, we plot the average of 30 trials with corresponding error bars for the standard error of sample means.
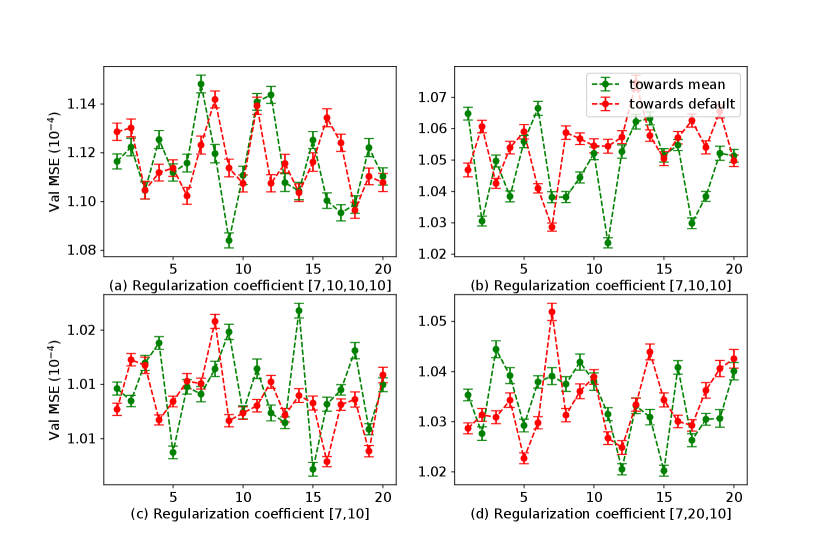
.
It is shown in Fig. 7, the minimum validation model performance is not constant under different regularization coefficients for both the two types of regularization of flexible activation functions. By referring to the error bars for 30 trials, we can learn that the change is not random, but with statistical significance. Generally, the minimum validation performances are obtained by regularization towards the mean with a intermediate regularization coefficient. Also, we have had a similar investigation based on the minimum validation loss in each setting. We use the test set of G7 for testing and all training and validation samples for training, with a default learning rate of 0.001. At each point, we plot the average of 20 trials with corresponding error bars for the standard error of sample means.

.
As is shown in Fig. 8, the test model performance is not constant under different regularization coefficients for both the two types of regularization of flexible activation functions. By referring to the error bars for 20 trials, we can learn that the change of test performance is not random, but with statistical significance. Generally, the best performances are obtained with a intermediate regularization coefficient. This demonstrates that a better test performance can be achieved by optimizing the towards-mean or towards default regularization of flexible activation function given the architectures unchanged.
III-B Experiment with convolutional autoencoder
The second experiment is conducted with autoencoder models for lossy image compression on several benchmark datasets including MNIST and FMNIST [4]. The architecture used in this experiment can be shown as follows:
Convolutional Autoencoder 1 (CAE 1):
Convolutional Autoencoder 2 (CAE 2):
Convolutional Autoencoder 3 (CAE 3):
CAE 1 and CAE 2 compress images of size 28*28 to 16 filters with size 2*2 for each. For each trial, we randomly sample 5,000 examples from the original training datasets of MNIST and FMNIST as the training data, another randomly sampled example from the remaining of the training set as the validation set, and use the original test sets as the test sets in our experiment. We then compare the performances of following activation functions in replacing the ReLU activation functions in the original architectures of CAE 1 and CAE 2: (a) ReLU function; (b) PReLU function; (c) ELU function; (d) Gelu function; (e) Newly proposed P-E2-ReLU function, which is initialized as . The learning rate of each model with different activation function is optimized with a grid-search in the range between 0.001 and 0.1 on logarithmic scale. In addition, we run four more models in each trials with P-E2-ReLU on the optimized learning rates for other four candidates activation functions. After 50 trials, we can compare the learning curves of these five activation functions. The validation curves are given in Fig. 9, while the training curves are given in Fig. 10.
We noticed that models with the newly proposed P-E2-Relu activation function outperform all the other activation function in terms of the both validation and training performance with statistical significance during the whole learning process after a small amount of initial steps. Meanwhile, the standard ReLU activation function perform the worst, and the other three activation functions including PReLU, ELU and Gelu get similar performances in general. Moreover, even with the learning rates optimized under models with other activation functions, the proposed P-E2-ReLU activation function still outperform other activation functions in this task. To make a further investigation, we perform experiments on CIFAR10 and SVHN with another convolutional auto-encoder architecture given by CAE 3, where the encoder compress each image of size 32*32*3 to 48 filters with size 4*4. In addition, we introduced other two flexible activation functions proposed in Section II-C, which are combinations of and . The initialization of the two combination weights for these two activation functions are both 0.5. The learning rate is set to be the default value of 0.001 for all activation functions.



As is shown in Fig. 11, the experiment with CAE 3 architecture show the advantage of bounded P-E2-ReLU and P-E2-Id activation functions over other state-of-the-art activation functions in the image compression tasks on CIFAR10 and SVHN. For both two datasets, the model with the proposed P-E2-Id activation function perform the best, although the performance is close to ELU and PReLU. Further, we made one-tail two sample t-test for the difference of population means on test set. The results are given in Table I, where the null hypothesis means the population mean test loss of bounded P-E2-ReLU () is worse or equal to that of ELU (. The test statistics demonstrate that P-E2-ReLU significantly outperforms PReLU and ELU in terms of test reconstruction MSE in both cases, with very small p-values, while P-E2-Id performs even better.
| Activation | Dataset | ||
| CIFAR10 | SVHN | ||
| Model 1 | P-E2-Id | 1.01E-2 (2.4E-4) | 1.25E-3 (3.9E-5) |
| Model 2 | ELU | 1.27E-2 (1.6E-4) | 1.84E-3 (2.7E-5) |
| Model 3 | PReLU | 1.35E-2 (1.5E-4) | 2.24E-3 (9.3E-5) |
| Model 4 | P-E2-ReLU | 1.05E-2 (2.8E-4) | 1.38E-3 (6.3E-5) |
| Null Hypothesis | p-value | ||
| Test 1 | H0: | 3.64E-09 | 3.96E-14 |
| Test 2 | H0: | 1.73E-13 | 3.97E-11 |
| Test 3 | H0: | 2.05E-06 | 4.86E-7 |
| Test 4 | H0: | 4.77E-10 | 2.03E-7 |
Again, to check the effect of regularization on flexible activations, we train and evaluate flexible models under different regularization coefficients. The learning rate is optimized for P-E2-ReLU. We take 20 discrete grid points from 0.001 to 0.2 in logarithm scale. The result is shown in Fig. 12.

.
As we can see in Fig. 12, for towards-default regularization, the models achieve the best performances under the smallest regularization coefficients. This indicates that model performance can be significantly improved by introducing the proposed flexible activating function. On the other hand, for towards-mean regularization, in half of the cases the minimum validation errors are obtained when the regularization coefficients are 0, while in the other two cases, the minimum validation errors are obtained at intermediate points. In addition, we notice that the curves representing towards-mean regularization are below the curves of towards-default regularization in most of the time. In (c) and (d), a strong towards-mean regularization does not harm the model performance but a strong towards-default regularization does, which indicates that the models can be improved by sharing different activations functions in different layers without variation across each same layer, and we may only need two more parameters in each layer to achieve this improvement with layer-wise learned activation functions.
IV Number of model parameters and space complexity
IV-A Number of parameters and model performances
When batch-normalization is not implemented, the number of parameters in each deep neural network is equal to the number of weighs plus the number of bias. For an FFNN, , where is the number of layers including input layer, hidden layer and output layer, while is the number of units in th layer. If flexible activations are introduced in all hidden and output units, with two independent extra parameters in each unit, the total number of model parameters will increase by . The number of parameters in basic RNN models is depend on the type of hidden cells used, in general it is , where is the number of weight matrices in each cell. For basic RNN, , for GRU, , and for LSTM, . Meanwhile, the extra number of parameters needed for RNNs with flexible activations is , where is the number of activation functions replaced by flexible ones in th layer.
Following this derivation, in the LSTM models used in Section III-A, we can make a summary table for the increasing ratio of model parameters in each case.
| model | layer size | basic model | flexible activation | ratio of increase |
|---|---|---|---|---|
| 1 | [5, 8] | 448 | 48 | 10.7% |
| 2 | [5, 8, 8] | 992 | 96 | 9.6% |
| 3 | [5, 8, 8, 8] | 1536 | 144 | 9.3% |
| 4 | [5, 16, 8] | 2208 | 144 | 6.5% |
| model | layer size | basic model | flexible activation | ratio of increase |
|---|---|---|---|---|
| 1 | [7, 10] | 720 | 60 | 8.3% |
| 2 | [7, 10, 10] | 1560 | 120 | 7.6% |
| 3 | [7, 10, 10, 10] | 2400 | 180 | 7.5% |
| 4 | [7, 20, 10] | 3480 | 180 | 5.1% |
As shown in Table II and Table III, we can see that the models with flexible activations have about 5% to 10% increase in the number of parameters. However, it is shown in Section III-A that model 1, model 3 and model 4 have very similar validation performances during training even though their number of parameters varies in much higher (even more than 100%) proportions, while the corresponding validation performances for models with flexible activations are better than all the models with fixed activations.
In Table II, the best performed model with layer size has a single hidden layer and the number of parameters is smaller than the other models with layer sizes , and . Similarly, in Table III, the best performed model with layer size has a single hidden layer and the number of parameters is smaller than the other models with layer sizes , and . Therefore, the number of parameters does not really matters in this range when we consider the minimum validation performance in a long training time, and the improvement of model performance can be explained by the advantage of introducing flexible activation with trainable parameters.
| model | layer size | basic model | flexible activation | ratio of increase |
|---|---|---|---|---|
| 1 | CAE 1 | 3401 | 50 | 1.47% |
| 2 | CAE 2 | 5729 | 66 | 1.15% |
| 3 | CAE 3 | 47355 | 168 | 0.35% |
| model | layer size | basic model | flexible activation | ratio of increase |
|---|---|---|---|---|
| 1 | CAE 1 | 3401 | 25 | 0.73% |
| 2 | CAE 2 | 5729 | 33 | 0.57% |
| 3 | CAE 3 | 47355 | 84 | 0.17% |
For the three Convolutional auto-encoder models in Section III-B, the basic model parameters include those in convolutional layers. The number of parameters of each convolutional neural layer is: , where is the filter size, while and represent the numbers of input and output channels. For filter-shared flexible activation functions with activation parameters, the extra number of parameters is , where for P-ReLU-Id and P-ReLU-E2-1, and for P-ReLU-E2. The summary table showing the numbers of basic model parameters as well as extra activation parameters for three CAE models are given in Table IV and V. We can see that although the experimental results shown in Fig. 10 and Fig. 11 demonstrate that the proposed P-E2-ReLU achieves a significant improvement compared with fixed activation such as ReLU and GeLU, the extra number of parameter introduced only a quite small proportion of the total number of parameters in each architecture. Moreover, as is indicated in Fig. 12, when layer-wise flexible activation are applied, the model performance can be improved with even smaller number of extra activation parameters.
To sum up, the results at least show that we can achieve a quite significant performance improvement with only a small proportion of extra parameters in the flexible activation functions. Although the same mapping may be learned without flexible activation functions, it may need much more number of parameters or much larger effort of hyper-parameter searching with a bunch of different model architectures.
IV-B Time complexity
LSTM is local in space and time [32]. Its computational complexity per time step and weight is , while the overall complexity of an LSTM per time step is equal to , where is the number of weights [33]. Therefore, theoretically the computational complexity is proportion to the number of parameters in LSTM models. For activation functions, each of them will include 2 parameters, and will process one input for either forward or backward path. Therefore, the extra computational complexity will still be proportional to the number of activation parameters, which corresponds to the ratios shown in Table II and III.
For convolutional neural networks, we have learned that the total time complexity of all convolutional layers is [34]:
| (11) |
where is the index of a convolutional layer, and is the depth (number of convolutional layers). is the number of filters (also known as “width”) in the -th layer, while is known as the number of input channels of the -th layer. is the spatial size (length) of the filter. is the spatial size of the output feature map. For the whole training process we have:
| (12) |
where is the input length and the number of iterations. When flexible activation function is implemented, there will be extra computational cost in both forward and backward propagations: In forward propagation, when flexible activation is added after a convolutional layer, the number of different activations in this layer equals to the number of channels in that convolutional layer. Therefore, we need to do more element-wise operations that is proportional to the number of the input elements to each flexible activation function. It depends on the number of input channels and input filter size to the activation layer, but does not depend on the number of output filters and corresponding filter size. This is because after the input mapping and activation function, each element will become a single value before multiplying with filters in the next layer. The extra computational cost can be written as:
| (13) |
where we start from since the first activation layer comes after the first convolutional layer rather than the input layer of data. On the other hand, in backward propagation, the updating in Eq. (3) will require extra computation that is proportional to the number of input element as well as the number of activation parameters, also we need to pass the gradients through flexible activation functions, which requires extra element-wise operations that proportional to the number of elements of the input to each flexible activation function. Notice that the gradients of the loss with respect to the output of activation are stored in cache and shared for calculating other gradients. Therefore, the theoretical extra computational cost is at least one-order smaller than that of the baseline model with fixed activation functions. This will not add a heavy burden for model training from the theoretical prospective.
V Conclusion
In this study, we proposed a set of principles for designing flexible activation functions in a weighted combination form. Based on these principles, we built two novel flexible activation functions: The first can be implemented to replace sigmoid and tanh functions in the RNN cells with bounded domains. The second is a combined form of ReLU and ELU family, which can be used as a substitute for activations with unbounded domain. In addition, two regularization terms considering the nature of layer-wise feature extraction and goodness of original activation functions are proposed, which is essential in controlling the model flexibility and achieving stable improvement of the models.
Experiments on multivariate time series forecasting show that, with replacing sigmoid activation by the flexible combination proposed in this study, stacked LSTMs can achieve significant improvement in terms of convergence as well as validation performance for forecasting G7 Indices returns. On the other hand, the newly proposed P-E2-ReLU and P-E2-Id can stably outperform existing state-of-the-art activation functions including PReLU and ELU in image compression tasks with convolutional auto-encoder. In addition, we show that the towards-mean regularization on the flexible activation functions outperform the towards-default ones in general, and optimized regularization coefficients can further improve model performance on validation set.
Theoretically, by introducing combined flexible activation functions in a general form, it is not necessary to consider the types of single activation function in each layer as a hyper-parameter to be searched given the boundary of the output of each layer, and the shape of activation functions can be trained with back-propagation. In practice, the findings in this study provide a novel aspect to be considered in designing and improving deep learning architecture. The proposed flexible activation function in RNN cells could be a powerful tool in financial time series forecasting, which can also be used in combination with other advanced forecasting approaches.
In future study, different types of combined activation functions following the principles proposed in this study can be investigated on a variety of learning tasks. It can be implemented along with other methods in both meta-learning and manually designed architectures. Since we can have arbitrary number of components and activation parameters in the combined activation functions, this can be considered as another dimension of parameters in training deep neural networks. The corresponding approaches of learning the shapes of activations other than back-propagation can also be explored.
References
- [1] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, p. 436, 2015.
- [2] G. Cybenko, “Approximation by superpositions of a sigmoidal function,” Mathematics of control, signals and systems, vol. 2, no. 4, pp. 303–314, 1989.
- [3] K. Hornik, “Approximation capabilities of multilayer feedforward networks,” Neural Networks, vol. 4, no. 2, pp. 251–257, 1991.
- [4] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT Press, 2016.
- [5] V. Nair and G. E. Hinton, “Rectified linear units improve restricted Boltzmann machines,” in Proceedings of the 27th International Conference on Machine Learning (ICML), 2010, pp. 807–814.
- [6] F. A. Gers, J. Schmidhuber, and F. Cummins, “Learning to forget: Continual prediction with lstm,” Neural Computation, vol. 12, no. 10, pp. 2451–2471, 2000.
- [7] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,” arXiv:1412.3555, 2014.
- [8] A. L. Maas, A. Y. Hannun, and A. Y. Ng, “Rectifier nonlinearities improve neural network acoustic models,” in ICML Workshop on Deep Learning for Audio, Speech and Language Processing, 2013.
- [9] D.-A. Clevert, T. Unterthiner, and S. Hochreiter, “Fast and accurate deep network learning by exponential linear units (elus),” arXiv:1511.07289, 2015.
- [10] D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),” arXiv:1606.08415, 2016.
- [11] D. Misra, “Mish: A self regularized non-monotonic neural activation function,” arXiv:1908.08681, 2019.
- [12] S. Elfwing, E. Uchibe, and K. Doya, “Sigmoid-weighted linear units for neural network function approximation in reinforcement learning,” Neural Networks, vol. 107, pp. 3–11, 2018.
- [13] P. Ramachandran, B. Zoph, and Q. V. Le, “Searching for activation functions,” arXiv:1710.05941, 2017.
- [14] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” arXiv:1502.03167, 2015.
- [15] Y. Lin, S. Han, H. Mao, Y. Wang, and W. J. Dally, “Deep gradient compression: Reducing the communication bandwidth for distributed training,” arXiv:1712.01887, 2017.
- [16] Y. Bengio, P. Simard, P. Frasconi et al., “Learning long-term dependencies with gradient descent is difficult,” IEEE Transactions on Neural Networks, vol. 5, no. 2, pp. 157–166, 1994.
- [17] S. Hochreiter, “The vanishing gradient problem during learning recurrent neural nets and problem solutions,” International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, vol. 6, no. 02, pp. 107–116, 1998.
- [18] R. Pascanu, T. Mikolov, and Y. Bengio, “Understanding the exploding gradient problem,” arXiv: 1211.5063, vol. 2, 2012.
- [19] F. Agostinelli, M. Hoffman, P. Sadowski, and P. Baldi, “Learning activation functions to improve deep neural networks,” arXiv:1412.6830, 2014.
- [20] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1026–1034.
- [21] H. Chung, S. J. Lee, and J. G. Park, “Deep neural network using trainable activation functions,” in International Joint Conference on Neural Networks (IJCNN). IEEE, 2016, pp. 348–352.
- [22] Y. Li, C. Fan, Y. Li, Q. Wu, and Y. Ming, “Improving deep neural network with multiple parametric exponential linear units,” Neurocomputing, vol. 301, pp. 11–24, 2018.
- [23] L. R. Sütfeld, F. Brieger, H. Finger, S. Füllhase, and G. Pipa, “Adaptive blending units: Trainable activation functions for deep neural networks,” arXiv:1806.10064, 2018.
- [24] F. Manessi and A. Rozza, “Learning combinations of activation functions,” in 24th International Conference on Pattern Recognition (ICPR). IEEE, 2018, pp. 61–66.
- [25] I. Goodfellow, D. Warde-Farley, M. Mirza, A. Courville, and Y. Bengio, “Maxout networks,” in International Conference on Machine Learning, 2013, pp. 1319–1327.
- [26] S. Flennerhag, H. Yin, J. Keane, and M. Elliot, “Breaking the activation function bottleneck through adaptive parameterization,” in Advances in Neural Information Processing Systems, 2018, pp. 7739–7750.
- [27] D. Maclaurin, D. Duvenaud, and R. Adams, “Gradient-based hyperparameter optimization through reversible learning,” in International Conference on Machine Learning, 2015, pp. 2113–2122.
- [28] L. Franceschi, M. Donini, P. Frasconi, and M. Pontil, “Forward and reverse gradient-based hyperparameter optimization,” in Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017, pp. 1165–1173.
- [29] S. Selvin, R. Vinayakumar, E. Gopalakrishnan, V. K. Menon, and K. Soman, “Stock price prediction using lstm, rnn and cnn-sliding window model,” in 2017 international conference on advances in computing, communications and informatics (icacci). IEEE, 2017, pp. 1643–1647.
- [30] T. Fischer and C. Krauss, “Deep learning with long short-term memory networks for financial market predictions,” European Journal of Operational Research, vol. 270, no. 2, pp. 654–669, 2018.
- [31] Y. Qin, D. Song, H. Cheng, W. Cheng, G. Jiang, and G. W. Cottrell, “A dual-stage attention-based recurrent neural network for time series prediction,” in Proceedings of the 26th International Joint Conference on Artificial Intelligence, 2017, pp. 2627–2633.
- [32] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [33] E. Tsironi, P. Barros, C. Weber, and S. Wermter, “An analysis of convolutional long short-term memory recurrent neural networks for gesture recognition,” Neurocomputing, vol. 268, pp. 76–86, 2017.
- [34] K. He and J. Sun, “Convolutional neural networks at constrained time cost,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 5353–5360.