Regret Bounds for Gaussian-Process Optimization in Large Domains
Abstract
The goal of this paper is to characterize Gaussian-Process optimization in the setting where the function domain is large relative to the number of admissible function evaluations, i.e., where it is impossible to find the global optimum. We provide upper bounds on the suboptimality (Bayesian simple regret) of the solution found by optimization strategies that are closely related to the widely used expected improvement (EI) and upper confidence bound (UCB) algorithms. These regret bounds illuminate the relationship between the number of evaluations, the domain size (i.e. cardinality of finite domains / Lipschitz constant of the covariance function in continuous domains), and the optimality of the retrieved function value. In particular, we show that even when the number of evaluations is far too small to find the global optimum, we can find nontrivial function values (e.g. values that achieve a certain ratio with the optimal value).
1 Introduction
In practice, nonconvex, gradient-free optimization problems arise frequently, for instance when tuning the parameters of an algorithm or optimizing the controller of a physical system (see e.g. Shahriari et al. (2016)) for more concrete examples). Different versions of this problem have been addressed e.g. in the multi-armed-bandit and the Bayesian-optimization literature (which we review below). However, the situation where the number of admissible function evaluations is too small to identify the global optimum has so far received little attention, despite arising frequently in practice. For instance, when optimizing the hyper-parameters of a machine-learning method or the controller-parameters of a physical system, it is typically impossible to explore the domain exhaustively. We take first steps towards a better understanding of this setting through a theoretical analysis based on the adaptive-submodularity framework by Golovin and Krause (2011). It is not the purpose of the present paper to propose a novel algorithm with better performance (we modify the EI and UCB strategies merely to facilitate the proof), but rather to gain an understanding of how GP-optimization performs in the aforementioned setting, as a function of the number of evaluations and the domain size.
As is done typically, we model the uncertainty about the underlying function as a Gaussian Process (GP). The question is how close we can get to the global optimum with function evaluations, where is small relative to the domain of the function (i.e., it is impossible to identify the global optimum with high confidence with only evaluations). As a performance measure, we use the Bayesian simple regret, i.e., the expected difference between the optimal function value and the value attained by the algorithm. For the discrete case with domain size , we derive a problem-independent regret bound (i.e., it only depends on and is worst-case in terms of the GP prior) for two optimization algorithms that are closely related to the well-known expected improvement (EI, Jones et al. (1998)) and the upper confidence bound (UCB, Auer et al. (2002); Srinivas et al. (2010)) methods. In contrast to related work, our bounds are non-vacuous even when we can only explore a small fraction of the function. We extend this result to continuous domains and show that the resulting bound scales better with the size of the function domain (equivalently, the Lipschitz constant of the covariance function) than related work (Grünewälder et al. (2010)).
1.1 Related Work
The multi-armed bandit literature is closest to the present paper. In the multi-armed bandit problem, the agent faces a row of slot machines (also called one-armed bandits, hence the name). The agent can decide at each of rounds which lever (arm) to pull, with the objective of maximizing the payoff. This problem was originally proposed in Robbins (1952) to study the trade-off between exploration and exploitation in a generic and principled way. Since then, this problem has been studied extensively and important theoretical results have been established.
Each of the arms has an associated reward distribution, with a fixed but unknown mean . When pulling arm at round , we obtain a payoff where the noise is zero mean , independent across time steps and arms, and identically distributed for a given arm across time steps. Let us denote the arm pulled at time by . Performance is typically analyzed in terms of the regret, which is defined as the difference between the mean payoff of the optimal arm and the one pulled at time
| (1) |
Here, we are interested in the setting where is small or even zero and we are allowed to pull only few arms . We classify related work according to the information about the mean and the noise that is available to the agent.
1.1.1 No Prior Information
Traditionally, most authors considered the case where only very basic information about the payoff is available to the agent, e.g. that its distribution is a member of a given family of distributions or that it takes values in an interval, typically .
In a seminal paper, Lai and Robbins (1985) showed that the cumulative regret grows at least logarithmically in and proposed a policy that achieves this rate asymptotically. Later, Auer et al. (2002) proposed an upper confidence bound (UCB) strategy and proved that it achieves logarithmic cumulative regret in uniformly in time, not just asymptotically. Since then, many related results have been obtained for UCB and other strategies, such as Thompson sampling Agrawal and Goyal (2011); Kaufmann et al. (2012). A number of similar results have also been obtained for the objective of best arm identification Madani et al. (2004); Bubeck et al. (2009); Audibert and Bubeck (2010), where we do not care about the cumulative regret, but only about the lowest regret attained.
However, all of these bounds are nontrivial only when the number of plays is larger than the number of arms . This is not surprising, since no algorithm can be guaranteed to perform well with a low number of plays with such limited information. To see this, consider an example where and . Since the agent has no prior information about which is the right arm , the best it can do is to randomly try out one after the other. Hence it is clear that to obtain meaningful bounds for we need more prior knowledge about the reward distributions of the arms.
1.1.2 Structural Prior Information
In Dani et al. (2008) the authors consider the problem where the mean rewards at each bandit are a linear function of an unknown, -dimensional vector. However, similarly to the work above, the difficulty addressed in this paper is mainly the noise, i.e. the fact that the same arm does not always yield the same reward. For , the cumulative regret bounds derived in this paper are trivial, since with evaluations we can simply identify the linear function.
1.1.3 Gaussian Prior
More closely related to our work, a number of authors have considered Gaussian priors. Bull (2011) for instance provides asymptotic convergence rates for the EI strategy with Gaussian-process priors on the unknown function.
Srinivas et al. (2010) propose a UCB algorithm for the Gaussian-process setting. The authors give finite-time bounds on the cumulative regret. However, these bounds are intended for a different setting than the one we consider here: 1) They allow for noisy observations and 2) they are only meaningful if we are allowed to make a sufficient number of evaluations to attain low uncertainty over the entire GP. Please see Appendix B for more details on the second point.
Russo and Van Roy (2014) use a similar analysis to derive bounds for Thompson sampling, which are therefore subject to similar limitations. In contrast, the bounds in Russo and Van Roy (2016) do not depend on the entropy of the entire GP, but rather on the entropy of the optimal action. However, our goal here is to derive bounds that are meaningful even when the optimal action cannot be found, i.e. its entropy remains large.
De Freitas et al. (2012) complement the work in (Srinivas et al., 2010) by providing regret bounds for the setting where the function can be observed without noise. However, these are asymptotic and therefore not applicable to the setting we have in mind.
Similarly to the present paper, Grünewälder et al. (2010) analyze the Bayesian simple regret of GP optimization. They provide a lower and an upper bound on the regret of the optimal policy for GPs on continuous domains with covariance functions that satisfy a continuity assumption. Here, we build on this work and derive a bound with an improved dependence on the Lipschitz constant of the covariance function, i.e., our bound scales better with decreasing length-scales (and, equivalently, larger domains). Unlike (Grünewälder et al., 2010), we also consider GPs on finite domains without any restrictions on the covariance.
1.1.4 Adaptive Submodularity
The adaptive-submodularity framework of Golovin and Krause (2011) is in principle well suited for the kind of analysis we are interested in. However, we will show that the problem at hand is not adaptively submodular, but our proof is inspired by that framework.
2 Problem Definition
2.1 The Finite Case
In this section we specify the type of bandit problem we are interested in more formally. The goal is to learn about a function with domain (we will use to denote the set and co-domain . We represent the function as a sequence . Our prior belief about the function is assumed to be Gaussian
| (2) |
At each of the iterations, we pick an action (arm) from at which we evaluate the function. After each action, an observation is returned to the agent
| (3) |
Note that here we restrict ourselves to the case where the function can be evaluated without noise.
For convenience, we introduce some additional random variables, based on which the optimization algorithm will pick where to evaluate the function next. We denote the posterior mean and covariance at time by
| (4) | ||||
| (5) |
In addition, we will need the maximum and minimum observations up to time
| (6) | ||||
| (7) |
Furthermore, we will make statements about the difference between the smallest and the largest observed value
| (8) |
Finally, for notational convenience we define
| (9) |
Analogously, let us define the function minimum , maximum and difference .
2.1.1 Problem Instances
A problem instance is defined by the tuple , i.e. the domain size , the number of rounds and the prior 2 with mean and covariance , where we use to denote the set of positive semidefinite matrices of size .
2.2 The Continuous Case
The definitions in the continuous case are analogous. A problem instance here is defined by , i.e. the function domain , the number of rounds , a mean function and a positive semi-definite kernel .
3 Results
In this section we provide bounds on the Bayesian simple regret that hold for the two different optimization algorithms we describe in the following.
3.1 Optimization Algorithms
Two of the most widely used GP-optimization algorithms are the expected improvement (EI) (Jones et al. (1998)) and the upper confidence bound (UCB) (Auer et al. (2002); Srinivas et al. (2010)) methods. In the following, we define two optimization policies that are closely related:
Definition 1.
The expected improvement Bull (2011) is defined as
| (10) |
where is the standard normal density function and is the complementary cumulative density function of a standard normal distribution. Furthermore, we use the notation
| (11) |
Definition 2 (EI2).
An agent follows the EI2 strategy when it picks its actions according to
| (12) |
with the expected improvement as defined in Definition 1.
Definition 3 (UCB2).
An agent follows the UCB2 strategy when it picks its actions according to
| (13) |
The main difference to the standard versions of these methods (see Definition 6 and Definition 7) is that the algorithms here are symmetrical in the sense that they are invariant to flipping the sign of the GP. They maximize and minimize at the same time by picking the point which we expect to either increase the observed maximum or decrease the observed minimum the most. This symmetry is important for our proof, whether the same bound also holds for following the standard, one-sided EI or UCB strategies is an open question, we discuss this point in detail in Section 4.
3.2 Upper Bound on the Bayesian Simple Regret for the Extremization Problem
Here, we provide a regret bound for function extremization (i.e. the goal is to find both the minimum and the maximum) from which the regret bound for function maximization will follow straightforwardly. Note that the bound is problem-independent in the sense that it does not depend on the prior .
Theorem 1.
For any instance of the problem defined in Section 2.1 with , if we follow either the EI2 (Definition 2) or the UCB2 (Definition 3) strategy, we have
| (14) |
This guarantees that the expected difference between the maximum and minimum retrieved function value achieves a certain ratio with respect to the expected difference between the global maximum and the global minimum.
Proof.
The full proof can be found in the supplementary material in Appendix G, here we only give an outline. The proof is inspired by the adaptive submodularity framework by Golovin and Krause (2011). The problem at hand can be understood as finding the policy (optimization algorithm) which maximizes an expected utility. Finding this optimal policy would require solving a partially observable Markov decision process (POMDP), which is intractable in most relevant situations. Instead, a common approach is to use a greedy policy which maximizes the expected single-step increase in utility at each time step , which is in our case
| (15) |
This corresponds to the EI2 (Definition 2) strategy. The task now is to show that the greedy policy will not perform much worse than the optimal policy. Golovin and Krause (2011) show that this holds for problems that are adaptively submodular (among some other conditions). In the present problem, we can roughly translate this condition to: The progress we make at a given time step has to be proportional to how far the current best value is from the global optimum. While our problem is not adaptively submodular (see Appendix A), we show that a similar condition holds (which leads to similar guarantees). ∎
3.3 Upper and Lower Bound on the Bayesian Simple Regret for the Maximization Problem
For maximization, the goal is to minimize the Bayesian simple regret, i.e. the expected difference between the globally maximal function value and the best value found by the optimization algorithm
| (16) |
As is often done in the literature (see e.g. Srinivas et al. (2010)), we restrict ourselves here to centered GPs (i.e. zero prior mean; naturally, the mean will change during the optimization). To be invariant to scaling of the prior distribution, we normalize the regret with the expected global maximum:
| (17) |
3.3.1 Upper Regret Bound for the EI2 and UCB2 Policies
We obtain the following upper bound on this normalized Bayesian simple regret:
Corollary 1.
For any instance of the problem defined in Section 2.1 with zero mean and , if we follow either the EI2 (Definition 2) or the UCB2 (Definition 3) strategy, we have
| (18) |
This implies a bound on the ratio between the expected maximum found by the algorithm and the expected global maximum.
Proof.
The Gaussian prior is symmetric about , as the mean is everywhere (i.e. the probability density satisfies ). Since also both the EI2 and the UCB2 policies are symmetric, we have and hence
| (19) |
and similarly . Substituting this in Theorem 1, Corollary 1 follows.∎
In Figure 2, we plot this bound, and we observe that we obtain nontrivial regret bounds even when evaluating the function only at a small fraction of its domain.

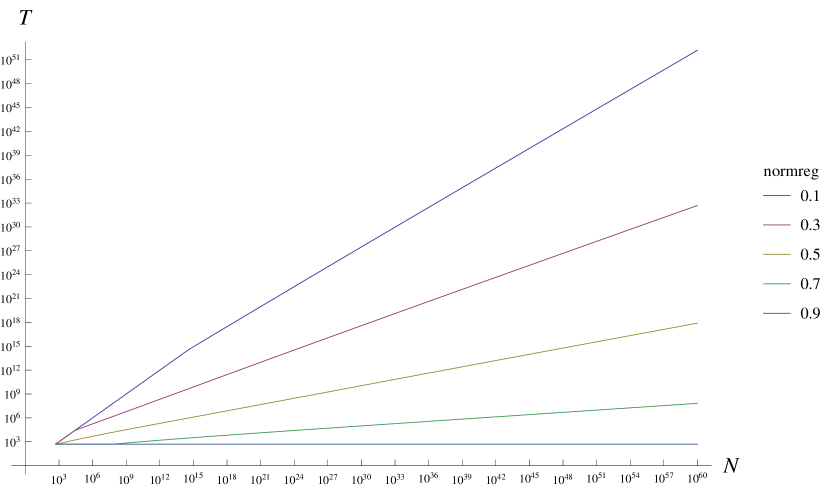
For instance, if we pick the curve that corresponds to (the rightmost curve), and we choose , we achieve a regret of about , as indicated in the figure. This means that we can expect to find a function value of about of the expected global maximum by evaluating the function at only a fraction of of its domain, and this holds for any prior covariance .
In Figure 2, we plot the upper bound on the required number of evaluations , implied by Corollary 1, as a function of the domain size . We observe that seems to scale polynomially with (i.e. linearly in log space) with an order that depends on the regret we want to achieve. Indeed, it is easy to see from Corollary 1 that
| (20) |
which implies that
| (21) |
This means for instance that, if we accept to achieve only of the global maximum, the required number of evaluations grows very slowly with about , but still polynomially.
3.3.2 Lower Regret Bound for the Optimal Policy
The upper bound from Corollary 1 is tight, as we can see by comparing 20 to the following result:
Lemma 1 (Lower Bound).
For the instance of the problem defined in Section 2.1 with and , the following lower bound on the regret holds for the optimal strategy:
| (22) |
Proof.
Here, sampling without replacement is an optimal strategy, which yields the bound above, see Appendix I for the full proof. ∎
It follows from Lemma 1 that
| (23) |
Hence, for a given regret, the required number of evaluations grows polynomially in the domain size , even for the optimal policy, albeit with low degree. This means that if the domain size grows exponentially in the problem dimension, we will inherit this exponential growth also for the necessary number of evaluations. However, since our bounds are problem independent and hence worst-case in terms of the prior covariance , this result does not exclude the possibility that for certain covariances we might be able to obtain polynomial scaling of the required number of evaluations in the dimension of the problem.
3.3.3 Lower Regret Bound for Prior-Independent Policies
It is important to note that a uniform random policy will not achieve the bound from Corollary 1 in general. In fact, despite the bound from Corollary 1 being independent of the prior , it cannot be achieved by any policy that is independent of the prior:
Lemma 2.
For any optimization policy which does not depend on the prior , there exists an instance of the problem defined in Section 2.1 where
| (24) |
which is clearly worse for than the bound in Corollary 1.
Proof.
Suppose we construct a function that is zero everywhere except in one location. Since the policy has no knowledge of that location, it is possible to place it such that the policy will perform no better than random selection, which yields the regret above. See Appendix J for the full proof. ∎
3.4 Extension to Continuous Domains
For finite domains, we looked at the setting where the cardinality of the domain is much larger than the number of admissible evaluations . The notion of domain size is less obvious in the continuous case, in the following we clarify this point before we discuss the results.
3.4.1 Problem Setting
In the continuous setting, we characterize the GP by and , which are properties of the kernel :
| (25) | ||||
| (26) |
where is the -dimensional unit cube (note that to use a domain other than the unit cube we can simply rescale). The setting we are interested in is
| (27) |
As we discuss in more detail in Appendix C, corresponds to the number of points we would require to cover the domain such that we could acquire nonzero information about any point in the domain. Naturally, to guarantee that we can find the global optimum we would require at least that number of evaluations . Here, in contrast, we consider the setting where is much smaller and only a small fraction of the GP can be explored.
3.4.2 Results
Here, we adapt Corollary 1 to continuous domains. The bound we propose in the following is based on a result from (Grünewälder et al., 2010), which states that for a centered Gaussian Process with domain being the -dimensional unit cube and a Lipschitz-continuous kernel
| (28) |
the regret of the optimal policy is bounded by
| (29) |
Note that Grünewälder et al. (2010) state the bound for the more general case of Hölder-continuous functions, for simplicity of exposition we limit ourselves here to the case of Lipschitz-continuous kernels. Grünewälder et al. (2010) complement this bound with a matching lower bound (up to log factors). However, as we shall see, we can improve substantially on this bound in terms of its dependence on the Lipschitz constant if we assume that the variance is bounded, i.e., . This is particularly relevant for GPs with short length scales (or, equivalently, large domains) and hence large .
Interestingly, Grünewälder et al. (2010) obtain 29 using a policy that selects the actions a priori (by placing them on a grid), without any feedback from the observations made. Here, we will refine 29 by using this strategy for preselecting a large set of admissible actions offline and then selecting actions from this set using EI2 (Definition 2) or UCB2 (Definition 3) online. A reasoning along these lines yields the following bound:
Theorem 2.
For any centered Gaussian Process , where is the -dimensional unit cube, with kernel such that
| (30) | ||||
| (31) |
we obtain the following bound on the regret, if we follow the EI2 (Definition 2) or the UCB2 (Definition 3) strategy:
| (32) |
This bound also holds when restricting EI2 or UCB2 to a uniform grid on the domain , where each side is divided into segments. Finally, this bound converges to as .
Proof.
The idea here is to pre-select a set of points at locations on a grid and then sub-select points from this set during runtime using EI2 (Definition 2) or UCB2 (Definition 3). We bound the regret of this strategy by combining Theorem 1 with the main result from (Grünewälder et al., 2010), the full proof can be found in Appendix K. ∎
The important point to note here is that in Theorem 2 the bound grows logarithmically in , as opposed to the bound 29 from Grünewälder et al. (2010), which grows with . This means that for Gaussian Processes with high , i.e. high variability, 32 is much lower than 29 (note that cuboid domains can be rescaled to the unit cube by adapting the Lipschitz constant accordingly, hence a large domain is equivalent to a large Lipschitz constant). This allows for meaningful bounds even when the number of allowed evaluations is small relative to the domain-size of the function. We illustrate this in Figure 3. Consider for instance the case of , where the number of evaluations is far too low to explore the GP (). We see from Figure 3(a) that our regret bounds (second-darkest cyan) remain low while the ones from Grünewälder et al. (2010) (second-darkest magenta) explode.
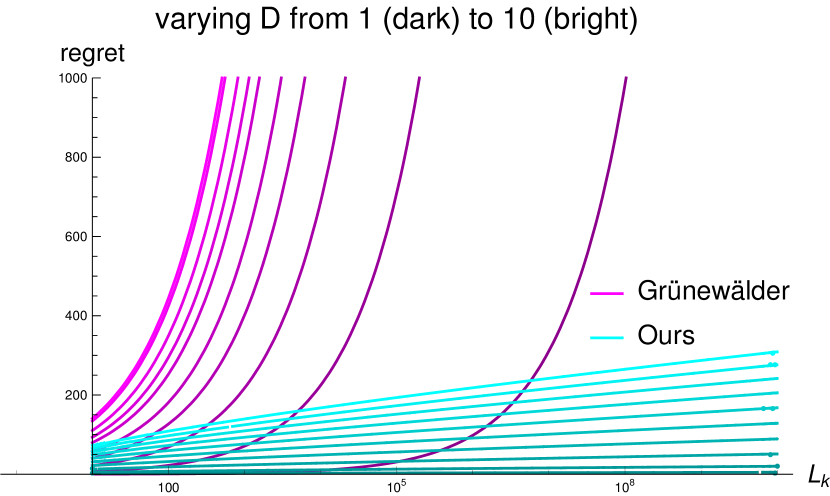
.
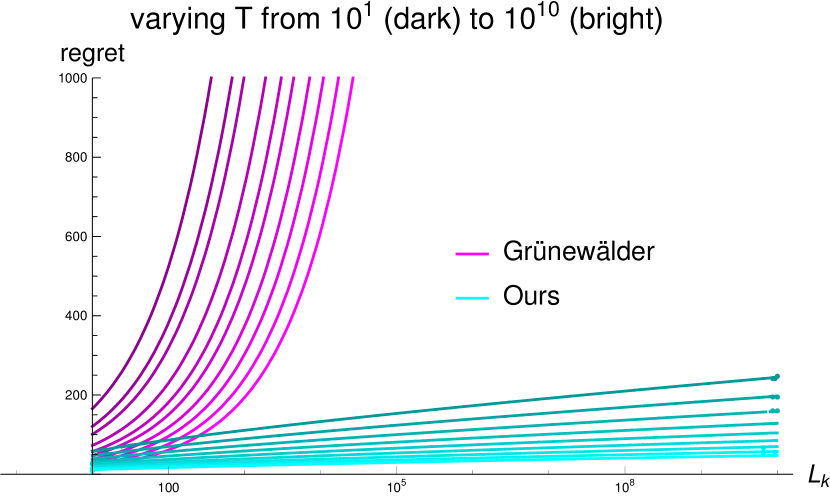
.
4 Relation to Standard EI and UCB
An empirical comparison (Appendix F) indicates EI2/UCB2 require more evaluations than EI/UCB to attain a given regret, but not more than twice as many. This matches our intuition: We would expect standard EI/UCB to perform better because i) any given step, evaluating at a potential maximizer instead of a minimizer will clearly lead to a larger immediate reduction in expected regret and ii) we would not expect an evaluation at a potential minimizer to provide any more useful information than an evaluation at a potential maximizer. Further, we would not expect EI2/UCB2 to perform much worse because a substantial fraction of its evaluations (in expectation half, for a centered GP) will be maximizations.
If we could prove that EI/UCB performs better than EI2/UCB2 for maximization, this would imply that the regret bounds presented above apply to EI/UCB. Unfortunately, proving this formally appears to be nontrivial. Nevertheless, we are able to give weaker regret bounds for standard EI/UCB which we discuss in the following.
4.1 Upper Bound on the Bayesian Simple Regret for Standard EI and UCB
Let us now consider the standard, one-sided versions of EI (Definition 6) and UCB (Definition 7), which are identical to EI2 (Definition 2) and UCB2 (Definition 3) except that we drop the second term in the . We obtain the following version of Theorem 1:
Theorem 3.
For any instance of the problem defined in Section 2.1 with , if we follow either the EI (Definition 6) or the UCB strategy (Definition 7) we have
| (33) |
Proof.
The proof is very similar to the one of Theorem 1 and can be found in Appendix H. ∎
Note that we marked the changes in bold. Now, instead of a guarantee on , we provide a guarantee on , i.e. the difference between the best obtained value and the function minimum. We can then derive from that a version of Corollary 1:
Corollary 2.
For any instance of the problem defined in Section 2.1 with zero mean and , if we follow either standard EI (Definition 6) or UCB strategy (Definition 7), we have
| (34) |
5 Limitations
While we believe that the results above are insightful, there are a number of limitations one should be aware of:
As discussed in Section 4, the regret bounds we derive for standard EI and UCB are weaker than the ones for EI2 and UCB2, despite the intuition and empirical evidence that EI/UCB most likely perform no worse for maximization than EI2/UCB2. It would be interesting to close this gap.
Another limitation is that the bounds only hold for the noise-free setting. We believe that this limitation is acceptable because the problem of noisy observations is mostly orthogonal to the problem studied herein. Furthermore, the naive solution of reducing the noise by evaluating multiple times at each point leads to qualitatively similar regret bounds, see Appendix D for a more detailed discussion.
Further, the bounds from Corollary 1, Theorem 2, and Corollary 2 only hold for zero prior mean (equivalently, constant prior mean). This assumption is not uncommon in the GP optimization literature (see e.g. Srinivas et al. (2010)) but it may be limiting if one has prior knowledge about where good function values lie. It is likely possible to extend the results in this article to arbitrary prior means.
Finally, there are limitations that hold generally for the GP optimization literature: 1) In a naive implementation, the computational cost is cubic in the number of evaluations and 2) the assumption that the true function is drawn from a Gaussian Process is typically not realistic and only made for analytical convenience. It is hence not clear whether the relations we uncovered herein apply to realistic optimization settings or if they are mostly an artifact of the GP assumption.
Summarizing, it is clear that the results in the present paper have little direct practical relevance. Instead, the intention is to develop a theoretical understanding of the problem setting.
6 Conclusion
We have characterized GP optimization in the setting where finding the global optimum is impossible because the number of evaluations is too small with respect to the domain size. We derived regret-bounds for the finite-arm setting which are independent of the prior covariance, and we showed that they are tight. Further, we derived regret-bounds for GP optimization in continuous domains that depend on the Lipschitz constant of the covariance function and the maximum variance. In contrast to previous work, our bounds are non-vacuous even when the domain size is very large relative to the number of evaluations. Therefore, they provide novel insights into the performance of GP optimization in this challenging setting. In particular, they show that even when the number of evaluations is far too small to find the global optimum, we can find nontrivial function values (e.g. values that achieve a certain ratio with the optimal value).
References
- Agrawal and Goyal [2011] Shipra Agrawal and Navin Goyal. Analysis of thompson sampling for the multi-armed bandit problem. CoRR, abs/1111.1797, 2011. URL http://arxiv.org/abs/1111.1797.
- Audibert and Bubeck [2010] Jean-Yves Audibert and Sébastien Bubeck. Best Arm Identification in Multi-Armed Bandits. In COLT - 23th Conference on Learning Theory - 2010, page 13 p., Haifa, Israel, June 2010. URL https://hal-enpc.archives-ouvertes.fr/hal-00654404.
- Auer et al. [2002] Peter Auer, Nicolò Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem. Mach. Learn., 47(2-3):235–256, May 2002. ISSN 0885-6125. doi: 10.1023/A:1013689704352. URL https://doi.org/10.1023/A:1013689704352.
- Bubeck et al. [2009] Sébastien Bubeck, Rémi Munos, and Gilles Stoltz. Pure exploration in multi-armed bandits problems. In Proceedings of the 20th International Conference on Algorithmic Learning Theory, ALT’09, pages 23–37, Berlin, Heidelberg, 2009. Springer-Verlag. ISBN 3-642-04413-1, 978-3-642-04413-7. URL http://dl.acm.org/citation.cfm?id=1813231.1813240.
- Bull [2011] Adam D. Bull. Convergence rates of efficient global optimization algorithms. Journal of Machine Learning Research, 12:2879–2904, 2011. URL http://dblp.uni-trier.de/db/journals/jmlr/jmlr12.html#Bull11.
- Dani et al. [2008] Varsha Dani, Thomas P. Hayes, and Sham M. Kakade. Stochastic linear optimization under bandit feedback. In In submission, 2008.
- De Freitas et al. [2012] Nando De Freitas, Alex J. Smola, and Masrour Zoghi. Exponential regret bounds for gaussian process bandits with deterministic observations. In Proceedings of the 29th International Coference on International Conference on Machine Learning, ICML’12, pages 955–962, USA, 2012. Omnipress. ISBN 978-1-4503-1285-1. URL http://dl.acm.org/citation.cfm?id=3042573.3042697.
- Golovin and Krause [2011] Daniel Golovin and Andreas Krause. Adaptive submodularity: Theory and applications in active learning and stochastic optimization. Journal of Artificial Intelligence Research (JAIR), 42:427–486, 2011.
- GPy [since 2012] GPy. GPy: A gaussian process framework in python. http://github.com/SheffieldML/GPy, since 2012.
- Grünewälder et al. [2010] Steffen Grünewälder, Jean-yves Audibert, Manfred Opper, and John Shawe-Taylor. Regret Bounds for Gaussian Process Bandit Problems. In Yee Whye Teh and Mike Titterington, editors, Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, volume 9 of Proceedings of Machine Learning Research, pages 273–280, Chia Laguna Resort, Sardinia, Italy, 2010. PMLR.
- Jones et al. [1998] Donald R. Jones, Matthias Schonlau, and William J. Welch. Efficient global optimization of expensive black-box functions. Journal of Global Optimization, 13(4):455–492, Dec 1998. ISSN 1573-2916. doi: 10.1023/A:1008306431147. URL https://doi.org/10.1023/A:1008306431147.
- Kaufmann et al. [2012] Emilie Kaufmann, Nathaniel Korda, and Rémi Munos. Thompson sampling: An asymptotically optimal finite-time analysis. In Proceedings of the 23rd International Conference on Algorithmic Learning Theory, ALT’12, pages 199–213, Berlin, Heidelberg, 2012. Springer-Verlag. ISBN 978-3-642-34105-2. doi: 10.1007/978-3-642-34106-9˙18. URL http://dx.doi.org/10.1007/978-3-642-34106-9_18.
- Krause and Golovin [2014] Andreas Krause and Daniel Golovin. Submodular function maximization. In Tractability: Practical Approaches to Hard Problems. Cambridge University Press, February 2014.
- Lai and Robbins [1985] T.L Lai and Herbert Robbins. Asymptotically efficient adaptive allocation rules. Adv. Appl. Math., 6(1):4–22, March 1985. ISSN 0196-8858. doi: 10.1016/0196-8858(85)90002-8. URL http://dx.doi.org/10.1016/0196-8858(85)90002-8.
- Madani et al. [2004] Omid Madani, Daniel J. Lizotte, and Russell Greiner. Active model selection. In Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, UAI ’04, pages 357–365, Arlington, Virginia, United States, 2004. AUAI Press. ISBN 0-9749039-0-6. URL http://dl.acm.org/citation.cfm?id=1036843.1036887.
- Massart [2007] Pascal Massart. Concentration Inequalities and Model Selection. Springer, June 2007. URL https://market.android.com/details?id=book-LmErAAAAYAAJ.
- Nemhauser et al. [1978] G. L. Nemhauser, L. A. Wolsey, and M. L. Fisher. An analysis of approximations for maximizing submodular set functions—i. Mathematical Programming, 14(1):265–294, 1978.
- Pedregosa et al. [2011] Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. Scikit-learn: Machine Learning in Python. Journal of machine learning research: JMLR, 12(null):2825–2830, November 2011. URL https://dl.acm.org/doi/10.5555/1953048.2078195.
- Robbins [1952] Herbert Robbins. Some aspects of the sequential design of experiments. Bulletin of the American Mathematical Society, 58(5):527–535, 1952. URL http://www.projecteuclid.org/DPubS/Repository/1.0/Disseminate?view=body&id=pdf_1&handle=euclid.bams/1183517370.
- Russo and Van Roy [2016] D Russo and B Van Roy. An information-theoretic analysis of thompson sampling. Journal of machine learning research: JMLR, 2016.
- Russo and Van Roy [2014] Daniel Russo and Benjamin Van Roy. Learning to Optimize via Posterior Sampling. Mathematics of Operations Research, 39(4):1221–1243, April 2014.
- Shahriari et al. [2016] B. Shahriari, K. Swersky, Z. Wang, R. P. Adams, and N. de Freitas. Taking the human out of the loop: A review of bayesian optimization. Proceedings of the IEEE, 104(1):148–175, Jan 2016. ISSN 0018-9219. doi: 10.1109/JPROC.2015.2494218.
- Srinivas et al. [2010] Niranjan Srinivas, Andreas Krause, Sham M Kakade, and Matthias Seeger. Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), 2010. URL https://arxiv.org/abs/0912.3995.
Appendix A Relation to Adaptive Submodularity
Submodularity is a property of set functions with far-reaching implications. Most importantly here, it allows for efficient approximate optimization Nemhauser et al. [1978], given the additional condition of monotonicity. This fact has been exploited in many information gathering applications, see Krause and Golovin [2014] for an overview.
In Golovin and Krause [2011], the authors extend the notion of submodularity to adaptive problems, where decisions are based on information acquired online. This is precisely the setting we consider in the present paper. However, as we will show shortly, our function maximization problem is not submodular. Nevertheless, our proof is inspired by the notion of adaptive sumodularity.
Consider the following definitions, which we adapted to the notation in the present paper:
Definition 4.
(Golovin and Krause [2011]) The Conditional Expected Marginal Benefit with respect to some utility function is defined as
| (37) |
Definition 5.
(Golovin and Krause [2011]) Adaptive submodularity holds if for any , any and any we have
| (38) |
Intuitively, in an adaptively submodular problem the expected benefit of any given action decreases the more information we gather. Golovin and Krause [2011] show that if a problem is adaptively submodular (along with some other condition), then the greedy policy will converge exponentially to the optimal policy.
A.1 Gaussian-Process Optimization is not Adaptively Submodular
In the following we make a simple argument why GP optimization is not generally adaptively submodular. It is not entirely clear what is the right utility function , but our argument holds for any plausible choice.
Consider a function with all values mutually independent, except for and which are negatively correlated. Further, suppose that we made an observation which is far larger than the upper confidence bounds on and . Any reasonable choice of utility function would yield an extremely small conditional expected marginal benefit for , since we would not expect this to give us any information about the optimum. Now suppose we evaluate the function at and observe a such that the posterior mean of is approximately equal to . Now, the conditional expected marginal benefit of evaluating at should be substantial for any reasonable utility, since the maximum might lie at that point. More generally, through unlikely observations the GP landscape can change completely and points which seemed uninteresting before can become interesting, which violates the diminishing-returns property of adaptive submodularity Definition 5.
Appendix B Relation to GP-UCB
The bounds from Srinivas et al. [2010] are only meaningful if we are allowed to make a sufficient number of evaluations to attain low uncertainty over the entire GP. The reason is that these bounds depend on a term called the information gain , which represents the maximum information that can be acquired about the GP with evaluations. As long as the GP still has large uncertainty in some areas, each additional evaluation may add a substantial amount of information (there is no saturation) and , and hence the cumulative regret, will keep growing.
To see this, consider Lemma 5.3 in Srinivas et al. [2010] (we use a slightly different notation here): The information gain of a set of points can be expressed as
| (39) |
where is the predictive variance after evaluating at and is the variance of the observation noise111Note that the information gain goes to infinity as the observation noise goes to zero, which is in fact another reason why the results from Srinivas et al. [2010] are not directly applicable to our setting. However, this is a technicality that can be resolved (in the most naive way, one could add artificial noise).. Hence, we can write the information gain for points as
| (40) |
Now let be the points that maximize the information gain. By definition (see equation 7 in Srinivas et al. [2010]), we have
| (41) |
that is, is the maximum information that can be acquired using points. For points we have
| (42) | ||||
| (43) |
where the inequality follows from the fact that maximizing over jointly will at least yield as high a value as just picking from the previous optimization and optimizing only over . Plugging in 40, we have
| (44) |
and hence
| (45) |
This means that if is not large enough to explore the GP reasonably well everywhere (i.e., there are still such that is large), then adding an observation can add substantial information, i.e. is substantially larger than (which means the regret grows substantially).
As a more concrete case, suppose we have a GP which a priori has a uniform variance . In addition, suppose that the GP domain is large with respect to , in the sense that it is not possible to reduce the variance everywhere substantially by observing (or less) points, i.e. we have . We hence have
| (46) | ||||
| (47) |
This linear growth will continue until is large enough such that the uncertainty of the GP can be reduced substantially everywhere.
Since the bound on the cumulative regret is of the form (see Theorem 1 in Srinivas et al. [2010]) it will hence also grow linearly in . Srinivas et al. [2010] then bound the suboptimality of the optimization by the average regret (see the paragraph on regret in Section 2 of Srinivas et al. [2010]), which does not decrease as long as grows linearly in .
Appendix C The Continuous-Domain Setting
In the continuous setting, we characterize the GP by and , which are properties of the kernel :
| (48) | ||||
| (49) |
where is the -dimensional unit cube (note that to use a domain other than the unit cube we can simply rescale). The setting we are interested in is
| (50) |
which implies that a large part of the GP may remain unexplored, as will become clear in the following comparison to related work:
As discussed in the introduction and in Appendix B, the results from Srinivas et al. [2010] only apply when we can reduce the maximum variance of the GP using evaluations. This would require that we can acquire information on each point that has maximum prior variance . In order to ensure that we gather nonzero information on such a point , we have to make sure to evaluate at least one point such that (or, more realistically, , which would lead to a qualitatively similar result), which is equivalent to the condition
| (51) |
which we can ensure by
| (52) |
or equivalently by
| (53) |
This statement says that has to be within a cube centered at with sidelength . To ensure that this holds for all (since in the worst case they all have prior variance , which is typical), we need to cover the domain with
| (54) |
cubes and hence evaluations.
Appendix D A Note on Observation Noise
Our goal here was to focus on the issue of large domains, without the added difficulty of noisy observations, such as to allow a clearer view of the core problem. Interestingly, the proofs apply practically without any changes to the setting with observation noise. The caveat is that the regret bounds are on the largest noisy observation rather than the largest retrieved function value (the two are identical in the noise-free setting).
As a naive way of obtaining regret bounds on , one could simply evaluate each point times and use the average observation as a pseudo observation. Choosing large enough, all pseudo observations will be close to their respective function values with high probability. To guarantee that all pseudo observations are within of the true function values with probability , we would need (this follows from union bound over observations), where is some function that is not relevant here and is the noise standard deviation. We can now simply replace with in all the theorems (to be precise, we would also have to add to the regret, but it can be made arbitrarily small). While this solution is impractical, it is interesting to note that the dependence of the resulting regret-bounds on the domain size and Lipschitz constant does not change. The dependence on is also identical, up to a factor. This suggests that the relations we uncovered in this paper between the regret, the number of evaluations , the domain size , the Lipschitz constant remain qualitatively the same in the presence of observation noise.
Appendix E Definitions of Standard EI/UCB
Definition 6 (EI).
An agent follows the EI strategy when it picks its actions according to
| (55) |
with the expected improvement as defined in Definition 1.
Definition 7 (UCB).
An agent follows the UCB strategy when it picks its actions according to
| (56) |
Appendix F Empirical Comparison between EI/UCB and EI2/UCB2
We conducted a number of within-model experiments, where the ground-truth function is a sample drawn from the GP. The continuous-domain experiments use the GPy [since 2012] library and the discrete-domain experiments use scikit-learn (Pedregosa et al. [2011]). The code for all the experiments is publicly accessible222https://github.com/mwuethri/regret-Bounds-for-Gaussian-Process-Optimization-in-Large-Domains.
F.1 Continuous Domain
We defined a GP on a -dimensional unit cube with a squared-exponential kernel with length scale . The smaller the length-scale and the larger the dimensionality, the harder the problem. For the experiments that follow, we chose the ranges of such that we cover the classical setting (where the global optimum can be identified) as well as the large-domain setting (where this is not possible). To make this scenario computationally tractable, we discretize the domain using a grid with points, and we allow the algorithm to evaluate at points.
The true expected regret
| (57) |
is a function of the length-scale , the dimension , and the number of function evaluations . We compute this quantity empirically using samples (i.e. randomly-drawn ground-truth functions). In Figure 4, for instance, we plot this empirical expected regret as a function of the number of evaluations .
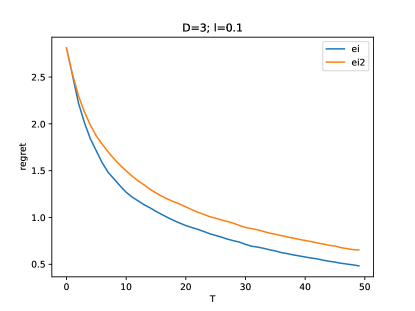
In this example, EI performs slightly better than EI2. To gain a more quantitative understanding, it is instructive to look at how many evaluations are required to attain a given regret :
| (58) |
We can then compare the required number of steps for EI and EI2:
| (59) |
which we report in Table 1.
| 2.5 | 2.0 | 1.5 | 1.0 | 0.5 | ||
|---|---|---|---|---|---|---|
| D | l | |||||
| 1 | 0.003 | 1.00 | 1.00 | 0.87 | 0.84 | NaN |
| 0.010 | 1.00 | 1.00 | 0.80 | 0.80 | 0.74 | |
| 0.030 | 1.00 | 1.00 | 1.00 | 1.00 | 0.78 | |
| 0.100 | 1.00 | 1.00 | 1.00 | 1.00 | 0.75 | |
| 0.300 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| 2 | 0.003 | 1.00 | 1.00 | 1.00 | 1.00 | NaN |
| 0.010 | 1.00 | 0.86 | 1.00 | NaN | NaN | |
| 0.030 | 0.67 | 1.00 | 0.91 | 0.71 | NaN | |
| 0.100 | 1.00 | 1.00 | 0.80 | 0.78 | 0.75 | |
| 0.300 | 1.00 | 1.00 | 1.00 | 1.00 | 0.83 | |
| 3 | 0.003 | 1.00 | 1.00 | 1.00 | 1.00 | NaN |
| 0.010 | 1.00 | 1.00 | 1.00 | NaN | NaN | |
| 0.030 | 1.00 | 1.00 | 1.06 | NaN | NaN | |
| 0.100 | 1.00 | 1.00 | 0.73 | 0.69 | NaN | |
| 0.300 | 1.00 | 1.00 | 0.75 | 0.86 | 0.73 | |
| 4 | 0.003 | 1.00 | 1.00 | 1.00 | NaN | NaN |
| 0.010 | 1.00 | 1.00 | 1.00 | NaN | NaN | |
| 0.030 | 1.00 | 1.00 | 1.00 | NaN | NaN | |
| 0.100 | 1.00 | 1.00 | 0.84 | NaN | NaN | |
| 0.300 | 1.00 | 0.75 | 0.86 | 0.71 | 0.70 |
In one entry EI2 appears to perform slightly better, we have . This is may be due to the variance of the empirical estimation. In all other entries, we have , which means that EI always reaches the given expected regret faster than EI2, but not more than twice as fast. This is what we intuitively expected: EI should do better than EI2, because it does not waste evaluations on minimization, but not much better, since in expectation every second evaluation of EI2 is a maximization. Note that the entries which are , i.e. both algorithms perform equally well, correspond to i) particularly simple settings (large , low ) where both algorithms find good values in just a handful of evaluations or ii) particularly hard settings where there is no essentially no correlation between different points in the discretized domain.
For UCB and UCB2 (where we used a fixed confidence level) we obtain similar results, see Table 2.
| 2.5 | 2.0 | 1.5 | 1.0 | 0.5 | ||
|---|---|---|---|---|---|---|
| D | l | |||||
| 1 | 0.003 | 1.00 | 1.00 | 0.89 | 0.86 | NaN |
| 0.010 | 1.00 | 1.00 | 0.80 | 0.90 | 0.81 | |
| 0.030 | 1.00 | 1.00 | 1.00 | 1.00 | 0.90 | |
| 0.100 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| 0.300 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| 2 | 0.003 | 1.00 | 1.00 | 1.00 | 1.00 | NaN |
| 0.010 | 1.00 | 0.86 | 1.00 | NaN | NaN | |
| 0.030 | 0.67 | 0.83 | 0.83 | 0.77 | NaN | |
| 0.100 | 1.00 | 1.00 | 0.80 | 0.73 | 0.78 | |
| 0.300 | 1.00 | 1.00 | 1.00 | 1.00 | 0.83 | |
| 3 | 0.003 | 1.00 | 1.00 | 1.00 | 1.00 | NaN |
| 0.010 | 1.00 | 1.00 | 1.00 | NaN | NaN | |
| 0.030 | 1.00 | 1.00 | 1.00 | NaN | NaN | |
| 0.100 | 1.00 | 0.83 | 0.75 | 0.76 | NaN | |
| 0.300 | 1.00 | 1.00 | 0.75 | 1.00 | 0.71 | |
| 4 | 0.003 | 1.00 | 1.00 | 1.00 | NaN | NaN |
| 0.010 | 1.00 | 1.00 | 1.00 | NaN | NaN | |
| 0.030 | 1.00 | 1.00 | 1.00 | NaN | NaN | |
| 0.100 | 1.00 | 0.86 | 0.83 | NaN | NaN | |
| 0.300 | 1.00 | 0.75 | 0.87 | 0.75 | 0.66 |
F.2 Band Covariance Matrices
Next, we compare EI/UCB with EI2/UCB2 in the discrete setting with . We use band covariance matrices, where the diagonal elements are equal to and there are a number of nonzero elements to the right and the left of the diagonal. We vary width of this band and the value the off-diagonal elements take, we report the results in Table 3 for EI vs EI2 and in Table 4 for UCB vs UCB2. Similarly to the case of continuous domains, we see that (and the equivalent for UCB).
| 2.00 | 1.55 | 1.10 | 0.65 | 0.20 | ||
|---|---|---|---|---|---|---|
| band_size | band_corr | |||||
| 0 | 0.00 | 1.0 | 1.00 | 1.00 | NaN | NaN |
| 2 | -0.20 | 1.0 | 0.75 | 0.86 | 0.82 | NaN |
| 3 | 0.20 | 1.0 | 1.00 | 0.87 | 0.89 | NaN |
| 5 | -0.10 | 1.0 | 1.00 | 1.00 | 0.94 | NaN |
| 0.20 | 1.0 | 1.00 | 1.00 | 0.88 | NaN | |
| 10 | 0.10 | 1.0 | 1.00 | 1.00 | 0.94 | NaN |
| 40 | 0.05 | 1.0 | 1.00 | 0.87 | 0.94 | NaN |
| 2.00 | 1.55 | 1.10 | 0.65 | 0.20 | ||
|---|---|---|---|---|---|---|
| band_size | band_corr | |||||
| 0 | 0.00 | 1.0 | 1.0 | 1.00 | NaN | NaN |
| 2 | -0.20 | 1.0 | 1.0 | 0.86 | 0.87 | NaN |
| 3 | 0.20 | 1.0 | 1.0 | 0.87 | 0.89 | NaN |
| 5 | -0.10 | 1.0 | 1.0 | 1.00 | 0.88 | NaN |
| 0.20 | 1.0 | 1.0 | 1.00 | 0.88 | NaN | |
| 10 | 0.10 | 1.0 | 1.0 | 1.00 | 0.83 | NaN |
| 40 | 0.05 | 1.0 | 1.0 | 1.00 | 1.00 | NaN |
F.3 Randomly-Sampled Covariance Matrices
Finally, we sample covariances (of size ) randomly from an inverse Wishart distribution (with degrees of freedom and identity scale matrix). We report the results in Table 5 for EI vs EI2 and in Table 6 for UCB vs UCB2. As in the previous experiments, we see that (and the equivalent for UCB).
| 0.20 | 0.15 | 0.10 | 0.05 | 0.00 | |
|---|---|---|---|---|---|
| wishart_seed | |||||
| 1 | 1.0 | 0.67 | 0.83 | 0.78 | NaN |
| 2 | 1.0 | 1.00 | 0.83 | 0.87 | NaN |
| 3 | 1.0 | 1.00 | 0.83 | 0.83 | NaN |
| 4 | 1.0 | 1.00 | 1.00 | 0.82 | NaN |
| 5 | 1.0 | 1.00 | 1.00 | 0.82 | NaN |
| 0.20 | 0.15 | 0.10 | 0.05 | 0.00 | |
|---|---|---|---|---|---|
| wishart_seed | |||||
| 1 | 1.0 | 1.0 | 0.83 | 0.82 | NaN |
| 2 | 1.0 | 1.0 | 0.83 | 0.87 | NaN |
| 3 | 1.0 | 1.0 | 0.83 | 0.88 | NaN |
| 4 | 1.0 | 1.0 | 1.00 | 0.87 | NaN |
| 5 | 1.0 | 1.0 | 1.00 | 0.81 | NaN |
Appendix G Proof of Theorem 1
In this section we prove Theorem 1. As we have seen in the previous section, our problem is not adaptively submodular. Nevertheless, the following proof is heavily inspired by the proof in Golovin and Krause [2011]. We derive a less strict condition than adaptive submodularity which is applicable to our problem and implies that we converge exponentially to the optimum:
Lemma 3.
For any problem of the type defined in Section 2.1, we have for any
| (60) | ||||
| (61) |
i.e. the first inequality implies the second inequality.
Proof.
The proof is closely related to the adaptive submodularity proof by Golovin and Krause [2011]. Defining , we can rewrite the first inequality as
Since the function is convex, we have . Using this fact, we obtain the inequality
Now we can substitute and (since :
∎
G.1 Specialization for the Extremization Problem
Lemma 4.
For any problem of the type defined in Section 2.1 we have for any
| (62) | ||||
| (63) |
Proof.
To prove that 62 holds, we will derive a lower bound for the right-hand side and an upper bound for the left-hand side.
G.2 Lower Bound for the Right-Hand Side
Lemma 5.
For any instance of the problem defined in Section 2.1, if we follow either the EI2 (Definition 2) or the UCB2 (Definition 3) strategy, we have
| (66) | ||||
with as defined in Definition 1 and
| (67) |
for any .
Proof.
Developing the expectation on the left hand side of 62 we have
| (68) | ||||
| (69) | ||||
| (70) | ||||
| (71) |
where we have used Definition 1, and the inequality follows from the fact that the expected improvement () is always . The action is a function of . If we follow the EI2 strategy (Definition 2), we have
| 71 | (72) |
and if we follow the UCB2 (Definition 3) strategy, we have
| (73) |
Clearly we have , hence for both strategies it holds that which concludes the proof.
∎
G.3 Upper Bound for the Left-Hand Side
In analogy with Definition 1, we define
Definition 8 (Multivariate Expected Improvement).
For a family of jointly Gaussian distributed RVs with mean and covariance and a threshold , we define the multivariate expected improvement as
| (74) | ||||
| (75) |
Lemma 6.
For any instance of the problem defined in Section 2.1, if we follow either the EI2 (Definition 2) or the UCB2 (Definition 3) strategy, we have for any
| (76) | ||||
for any .
Proof.
We have
| (77) | ||||
| (78) | ||||
| (79) | ||||
| (80) | ||||
| (81) | ||||
| (82) |
where by we mean that the scalar is subtracted from each element of the vector .
∎
G.4 Upper Bound on the Regret
Theorem 4.
For any instance of the problem defined in Section 2.1, if we follow either the EI2 (Definition 2) or the UCB2 (Definition 3) strategy, we have for any and any
| (83) | ||||
| (84) |
i.e. the first line implies the second.
Proof.
According to Lemma 4, we have
| (85) |
In the following, we will find a simpler expression which implies 85 and therefore 84. Then we will simplify the new expression further, until we finally arrive at 83 through an unbroken chain of implications.
Using the lower bound from Lemma 5 and the upper bound from Lemma 6 we can write
| (86) | |||
where we have dropped the time indices, since they are irrelevant here. It is easy to see that all terms in 86 are invariant to a common shift in and . Hence, we can impose a constraint on these variables, without changing the condition. We choose the constraint to simplify the expression
| (87) | |||
Clearly, the denominator is invariant with respect to any sign flips in the elements of . The numerator is maximized if all elements of have the same sign, no matter if positive or negative. Hence, we can restrict the above conditions to with positive entries, which means in all maximum operators the left term is active
| (88) |
Inserting the bound from Lemma 12 we have
| (89) | |||
| (90) |
It holds for any that and
from which it follows that
| (91) |
Using this fact we can write
| (92) |
For any we have
| (93) |
According to Definition 1, we have
Using this fact, we obtain
| (94) |
Defining we can simplify this condition as
| (95) |
For any the numerator of the left hand side is negative
| (96) | ||||
| (97) | ||||
| (98) | ||||
| (99) |
and since and the denominator are both positive, 95 is satisfied. Hence, we only need to consider the case where and can therefore write
| (100) |
From this chain of implications and Lemma 4 the result of Theorem 4 follows.∎
Finally, using the previous results, we can obtain the desired bound on the regret (Theorem 1), which we restate here for convenience:
See Theorem 1
Proof.
We can rewrite Theorem 4 as
| (101) | ||||
where we have restricted the inequality to , a condition we need later . What is left to be done is to simplify this bound, such that it becomes interpretable. We can rewrite the above as
| (102) | ||||
Choosing a
We choose
| (103) |
where is the derivative of ei, and
| (104) |
Before we can continue, we need to show that this satisfies the condition in 102. First of all, from 104 and the conditions in 102 we can derive some relations which will be useful later on
| (105) |
It is easy to see that holds, it remains to be shown that
| (106) |
Inserting the definition of 103 and simplifying we have
| (107) | ||||
| (108) |
Using Definition 1 and the lower bound in Lemma 10, we obtain a sufficient condition
| (109) |
Since we have (see 105) we obtain the sufficient condition
| (110) |
From (see 105) it follows that , and hence we can further simplify to obtain a sufficient condition
| (111) |
Given 105 it is easy to see that both sides are positive, hence we can square each side to obtain
| (112) |
Now we will show that this condition is satisfied by 104. We have from 105
| (113) | ||||
| (114) |
and since , we have
| (115) |
This implies 112, to see this we use the above inequality to bound in 112
| (116) | ||||
| (117) |
It is easy to verify that for any , the left-hand side is decreasing and the right-hand side is increasing. Hence, it is sufficient to show that it holds for which is easily done by evaluating at that value. This concludes the proof that our choice of 103 satisfies the conditions in 102. We can now insert this value to obtain
| (118) | ||||
Optimizing for
Here we show that
| (119) |
We have
| (120) | ||||
| (121) |
Since the ei function is convex, we have . Using this and the fact that the denominator is positive (since ei is always positive and is always negative), we have
| (122) |
Inserting this result into 118, we obtain
| (123) | ||||
Simplifying the bound further
Now, all that is left to do is to simplify this bound a bit further.
Bounding the left factor
First of all, we show that the left factor satisfies
| (124) |
Using Definition 1 and the lower bound from Lemma 10, we obtain
| (125) | ||||
| (126) |
where the second inequality is easily seen to hold true, since we have . Inserting 104, and bounding further we obtain
| (127) | ||||
| (128) | ||||
| (129) |
from which 124 follows.
Bounding the right factor
Now we will show that the right factor from 123 satisfies
| (130) |
Using Definition 1 and the upper bound from Lemma 10, we obtain
| (131) |
Now, to lower bound this further, we show that
| (132) |
Equivalently, we can show that
| (133) |
Since , we have , and hence
| (134) |
is a sufficient condition. The derivative of the left-hand side
| (135) | ||||
| (136) |
is always negative (since ). Hence, it is sufficient to show that 134 holds for the minimal , which can easily be verified to hold true for any . Hence, we have shown that 132 holds, and inserting it into 131, we obtain
| (137) | ||||
| (138) | ||||
| (139) |
Final bound
This implies straightforwardly the bound on the regret
| (141) |
∎
Appendix H Proof of Theorem 3
The proof of Theorem 3 is very similar to the one of Theorem 1 in Appendix G. Here we discuss the parts that are different.
Lemma 7.
For any problem of the type defined in Section 2.1, we have for any
| (142) | ||||
| (143) |
i.e. the first inequality implies the second inequality.
Proof.
This result is obtained from Lemma 3 by replacing with . It is easy to see that the proof of Lemma 3 goes through with this change.
∎
Hence, if for some we can show that 142 holds, Lemma 7 yields a lower bound on the expected utility.
Lemma 8.
For any problem of the type defined in Section 2.1 we have for any
| (144) | ||||
| (145) |
Theorem 5.
For any instance of the problem defined in Section 2.1, if we follow either the EI (Definition 6) or the UCB (Definition 7) strategy, we have for any and any
| (146) | ||||
| (147) |
i.e. the first line implies the second.
Proof.
According to Lemma 8, we have
| (148) |
Rearranging terms and plugging in the known variable we have
| (149) | |||
| (150) |
Since the expected minimum function value is no larger than the smallest mean , we have
| (151) | |||
| (152) |
Since these terms are invariant to a common shift in all variables, we can assume without loss of generality, and hence
| (153) | |||
| (154) |
We have
| (155) | ||||
| (156) | ||||
| (157) |
with mei as defined in Definition 8. In addition, we have
| (158) | ||||
| (159) |
with ei as defined in Definition 1. The equality follows from the fact that we know that . The inequality follows due to a similar argument as the one in the proof of Lemma 5.
Finally, using the previous results, we can obtain the desired bound on the regret (Theorem 3), which we restate here for convenience:
See Theorem 3
Proof.
The proof is identical to the one from Theorem 1. We simply substitute with and the proof goes through unchanged otherwise. ∎
Appendix I Proof of Lemma 1
Proof.
Since the bandits are i.i.d., an optimal strategy is to select arms uniformly at random (without replacement), which means that at each step we observe an i.i.d. sample. It is known that for i.i.d. standard normal random variables , we have asymptotically
| (162) |
see e.g. Massart [2007] page 66. It follows that
| (163) |
from which the desired result follows straightforwardly. ∎
Appendix J Proof of Lemma 2
Proof.
Suppose we have an optimization policy, and the prior mean and covariance are both zero, i.e. the GP is zero everywhere. This will induce a distribution over the actions taken by the policy. Since there are possible actions and the policy is allowed to pick of them, there is at least one action which has a probability of no more than of being chosen. Now suppose that we set the prior covariance to a nonzero value, while maintaining everything else zero. Note that this will not change the distribution over the actions taken by the policy unless it happens to pick , hence the probability of action being selected does not change. Since the observed maximum is if action is selected by the policy and zero otherwise, we have
| (164) |
from which 24 follows straightforwardly. ∎
Appendix K Proof of Theorem 2
Proof.
The idea here is to pre-select a set of points at locations on a grid and then sub-select points from this set during runtime using EI2 (Definition 2) or UCB2 (Definition 3). The regret of this strategy can be bounded by
| (165) |
A bound on the first term is given by the main result in Grünewälder et al. [2010]:
| (166) |
A bound on the second term can be derived straightforwardly from Corollary 1:
| (167) | ||||
| (168) |
where we have used the inequality (see Massart [2007], Lemma 2.3).
Choosing we obtain
| (169) | ||||
| (170) |
So far, we have only shown that 32 holds when preselecting a grid as proposed in Grünewälder et al. [2010] and then restricting our optimization policies to this preselected domain. However, it is easy to show that the result also holds when allowing EI2 (Definition 2) or the UCB2 (Definition 3) to select from the entire domain . The proof of Corollary 1 is based on bounding the expected increment of the observed maximum at each time step 60. It is clear that by allowing the policy to select from a larger set of points, the expected increment cannot be smaller.
Convergence
In the following, we show that the bound converges to 0 as . Clearly, the first term in 32 converges to zero. The second term can be written (without the factor , as it is irrelevant) as
| (172) |
Clearly, the last of these terms converges to zero. For the other two terms we have
| (173) | |||
| (174) | |||
| (175) | |||
| (176) |
The numerator grows with , while the denominator grows faster, with , which means that these terms also converge to 0.
∎
Appendix L Some Properties of Expected Improvement and Related Functions
Here we prove some properties of the expected improvement (Definition 1) and related functions, such that we can use them in the rest of the proof.
Lemma 9 (Convexity of expected improvement).
The standard expected improvement function (Definition 1) is convex on .
Proof.
This is easy to see since the second derivative
| (177) |
is positive everywhere.
∎
Lemma 10 (Bounds on normal CCDF).
We have the following bounds on the complementary cumulative density function (CCDF) of the standard normal distribution
| (178) |
The normal CCDF is defined as
| (179) |
Proof.
Using integration by parts, we can write for any
| (180) | ||||
| (181) | ||||
| (182) | ||||
| (183) |
From this the bounds straightforwardly follow
∎
Lemma 11 (Bounds on the expected improvement).
We have the following bound for the expected improvement (Definition 1)
| (184) |
Proof.
From Definition 1 we have that
| (185) |
The desired result follows straightforwardly using the bounds from Lemma 10.
∎
Lemma 12 (Upper bound on the multivariate expected improvement).
For a family of jointly Gaussian distributed RVs with mean and covariance and a threshold , we can bound the multivariate expected improvement (Definition 8) as follows
| (186) | ||||
| (187) |
Proof.
Defining , we can write
| (188) | ||||
| (189) | ||||
| (190) | ||||
| (191) | ||||
| (192) | ||||
| (193) | ||||
| (194) |
Since for any , we can bound this as
| 194 | (195) | |||
| (196) | ||||
| (197) | ||||
| (198) |
where we have used the fact that the event is identical to the event . Using the union bound we can now write
| 198 | (199) | |||
| (200) | ||||
| (201) |
Noticing that the summands in the above term match the definition of expected improvement (Definition 1), we can write
| 201 | (202) | |||
| (203) | ||||
| (204) |
where we have used 11 in the last line. Using Lemma 11 we obtain for any
| 204 | (205) |
This inequality hence holds for any which satisfies and (from 191). We pick the following value which clearly satisfies these conditions
| (206) |
from which it follows that
| (207) |
Given this fact it is easy to see that
| 205 | (208) | |||
| (209) | ||||
| (210) |
It is easy to see that , which concludes the proof. ∎