Registration between Point Cloud Streams and Sequential Bounding Boxes via Gradient Descent
Abstract
In this paper, we propose an algorithm for registering sequential bounding boxes with point cloud streams. Unlike popular point cloud registration techniques, the alignment of the point cloud and the bounding box can rely on the properties of the bounding box, such as size, shape, and temporal information, which provides substantial support and performance gains. Motivated by this, we propose a new approach to tackle this problem. Specifically, we model the registration process through an overall objective function that includes the final goal and all constraints. We then optimize the function using gradient descent. Our experiments show that the proposed method performs remarkably well with a 40% improvement in IoU and demonstrates more robust registration between point cloud streams and sequential bounding boxes
I INTRODUCTION
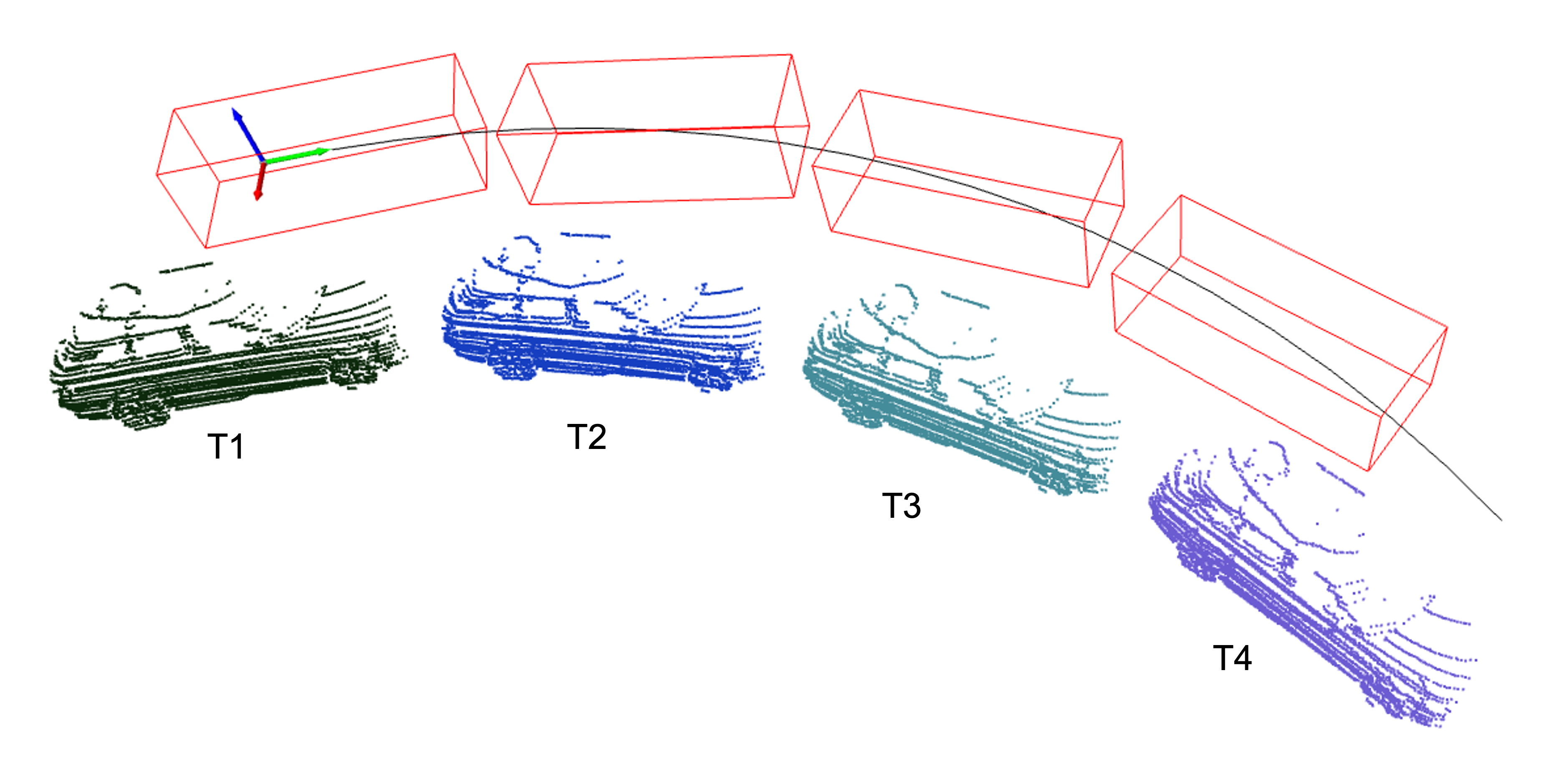
Point clouds are three-dimensional datasets that accurately represent the geometric location and structure of objects or surroundings. Due to their precise nature, they have become widely used across various industries, including mining, agriculture, and autonomous driving [1, 2, 3, 4, 5]. The registration between point cloud sets, which describe the same object from different points of view, has been an active research topic for a while and is typically solved using iterative closest points (ICP) and its variants. However, beyond the surface details captured by the point cloud, bounding boxes focus more on representing object instances, as they are low-dimensional and can accurately represent objects’ key high-level information. Given the initial sequential bounding boxes, accurately registering and aligning them with point cloud streams, as shown in Fig. 1, is still an open and new question to ask. Accurate registration between point clouds and bounding boxes is important for many real-world applications, such as path-planning tasks [6, 7, 8] in the context of autonomous driving, object detection [9, 10, 11, 12], and 3D auto-labeling systems [3, 13].
One current strategy to tackle this problem is to design a multi-stage network to refine the initial bounding boxes with point clouds [3, 13]. However, this approach is limited by the availability of large, high-quality annotated training datasets, which are expensive to obtain. Moreover, its performance significantly decreases when there is a domain gap between the training and deployment scenarios, and accurate alignment or registration is challenging to explain and control. Another approach is to apply the ICP algorithm by sampling points from the bounding boxes and converting this problem into the registration between point clouds. However, points sampled from bounding boxes do not have the structure of the target objects and are difficult to register accurately with the object’s point set. In this paper, we propose a novel approach that borrows ideas from classical ICP algorithms and generates the solution through modeling and optimization instead of labeling and training. Similar to the ICP algorithm, we first define the final objective function and its constraints, design and verify each term in the objective function and constraints, and then combine all terms into a differentiable objective function with Lagrange multipliers. Finally, we optimize the objective function using Newton’s method (second-order gradient descent). In the experimental section, we show that our approach is effective and accurate in solving the registration between point cloud streams and sequential bounding boxes.
As for as we know, this is the first approach to solve this problem via conventional methods without requiring annotated dataset. Compared with learning-based methods, the proposed method is more flexible, explained, and controllable, since we can easily change the final objective function or add extra constraints to make it adapt to different scenarios. To sum up, our main contribution is to propose a new method for solving the registration between point cloud streams and sequential bounding boxes and verifying its effectiveness and accuracy with empirical experiments.
II RELATED WORK
There are two main categories of algorithms for handling registration: those that use learning techniques [3, 13] to train registration models, and those that use an optimization-based approach [14, 15, 16, 17, 18, 19] to build an objective function and optimize the distance between two registered targets. In this section, we will briefly review both approaches.
II-A Registration with learning
Registration methods that use learning techniques usually employ specialized networks to gradually register bounding boxes with point clouds. For instance, in [3], two separate branches were proposed to refine different attributes of 3D bounding boxes: size and dynamic pose. The first branch is designed for the size of each object, as the size will be used to crop the point clouds and is important for subsequent tasks. The second branch aims to recover and refine the pose of the object for each time point in the trajectory, given the temporal states of the entire trajectory and the point cloud (cropped with the refined size). In contrast, [13] proposed two separate networks, based on PointNet [20], for the static and dynamic objects, respectively. The network takes sequential point clouds and sequential bounding boxes as inputs and directly refines all attributes of 3D bounding boxes. Both methods serve as auto-labeling systems for 3D autonomous driving. These modules require higher quality training annotations than the end-to-end 3D detectors [21, 22], as they target an intersection over union (IoU) of 0.9 with the ground truth rather than the 0.7 IoU targeted by other detectors. Furthermore, the annotation rules in the 3D auto-labeling system can only be implicitly encoded into the labeled training samples and cannot be explicitly added into these specialized models. In comparison, our proposed method has the advantage of not requiring labeled training samples, easily embedding annotation rules, and being explainable with respect to the refined 3D bounding boxes.
II-B Optimization-based registration
The most popular optimization-based registration methods are the ICP [14] and their variants [15, 23, 16], which minimize the distance between corresponding points in two point clouds to register them. The algorithm iteratively selects matched points, estimates the transformation parameters by minimizing the distance between corresponding points, and transforms the one of point sets. This process is repeated until the transformation parameters converge to a stable value. However, conventional ICP is computationally expensive, and several ICP variants [15, 23] have been proposed to speed up the algorithm. For example, [15] optimized the speed by using uniform sampling of the space of normals, and [23] applied stochastic gradient descent to remove inefficient iterative steps. Additionally, Colored ICP [16] design a photometric objective function to aligns RGB-D images to point clouds by locally parameterizing the point cloud with a virtual camera. The ICP cannot be directly applied for the registration between point cloud streams and sequential bounding boxes. The bounding box has first been converted into point set via surface sampling, then the sampled points can be registered with object’s point cloud. However, sampled points lack of object’s structure and geometrical information, which leads to poor performance. Our proposed method is inspired by ICP but optimizes the parameters of sequential bounding boxes directly without the need for point sampling.
III Problem definition
We first review the ICP algorithm [14], which is a widely-used approach for the registration of point clouds. Assume that there are two corresponding sets, i.e. source points X and target points Y. , , in which . The objective of the ICP algorithm is to estimate the optimal translation and rotation matrix that minimize the distance error between two point sets, as given in Equ.1, where is the index set of matched point pairs. The first step is to find the matched pairs or correspondence between two point clouds, and then Equ.1 can be solved with the least square to find the R and T given the matched points. The ICP algorithm iteratively implements these two steps to estimate the optimal R and T.
| (1) |
In contrast to ICP, our approach aims to align point cloud streams with their sequential bounding boxes. The source sequential bounding boxes represent the bounding boxes of a rigid object moving over a certain period. These bounding boxes have the same size (i.e. length, width, and height) but different poses (i.e. and ), and the trajectory of the central point in sequential bounding boxes should be smooth without any zigzag, as shown in Fig. 1. The target point cloud streams represent the corresponding points of this rigid object at different temporal timestamps. The number of points can vary, and these points may reveal different parts of the object due to movement and occlusion.
Let’s assume the sequential bounding boxes are , where denotes the central point location of the , is its size, and indicates the orientation (roll, pitch, yaw). Given these parameters, the six planes and eight corner points of can be easily calculated. The point cloud streams can be described as , where each represents the j-th 3-dim point in i-th point cloud. Our aim for the registration between point cloud streams and sequential bounding boxes is to make initial sequential bounding boxes well-aligned with the point cloud streams so that each bounding box can enclose its point clouds tightly, and simultaneously, the trajectory of all bounding boxes should be smooth. The objective of our problem is to optimize the and for each bounding box to minimize the distance between the points and bounding box, as Equ. 2.
| (2) |
where the objective is constrained by the condition that the sequential bounding boxes BOX have a smooth trajectory, and the heading of each is consistent with trajectory as well. Furthermore, given the initial box state , the final state of can be estimated with optimized and . Instead of finding and as the intermediate state, we can optimize each variable of (i.e. , , , , , ) directly for simplicity. Therefore, we can get our final objective function, as Equ. 3. The function Dist and each constraint will be thoroughly explained in the upcoming section.
| (3) |
IV Registration
In order to optimize the variables (, , , , , ), we need to properly encode them in a continuous function so that they are differentiable. The modeling of the objective function and each constraint and its optimization will be explained in detail.
IV-A Modelling
The main objective function (Equ. 3) aims to align bounding box with its corresponding points as closely as possible while ensuring that these points are enclosed within . Hence, it can be decomposed into two terms: closeness and enclosure . The closeness measures the distance between BOX and SEQ, while the enclosure ensures that all points lie inside their corresponding boxes. However, the term may not always be zero due to the constraints imposed by the smooth trajectory on the pose (location and orientation) of , and like when the objects are occluded and their point clouds are located inside the bounding box without touching any of its surfaces.
The objective function is constrained by the condition that all have a smooth trajectory, and the heading of each is consistent with the trajectory as well. The constraints can be depicted with two additional terms: smoothness and alignment . The smoothness is used to represent how smooth the trajectory is, while alignment is used to evaluate how well each aligns with the trajectory. These four terms will be elaborated on comprehensively in the rest of the section.
IV-A1 Closeness
The main idea of the term is to keep the in close proximity to its corresponding point cloud. To achieve this, we assume that the front/back face of the bounding box is perpendicular along the x-axis, the left/right side is perpendicular along the y-axis, and the top/bottom side is perpendicular along the z-axis. The distance between point and the front/back face of can be denoted as 111 refers to the distance between point and plane and can be easily calculated with equation , in which is the parameters for the plane function of one face of . Given the , the plane function of its six faces can be easily calculated with rigid geometry transformation. The whole calculation chain is differentiable., similarly, we can calculate the and . Observed from a certain point of view, the object has at most one visible face along each axis, and there are usually three visible faces. The point clouds should stay near these visible faces. The visible side can be decided by comparing the mass center of the point cloud and the geometrical center of the box, which is simple but feasible given the assumption that the initial bounding boxes are coarsely close to their corresponding point cloud. The top -th closest points are selected to estimate the Closeness instead of using all points, as only boundary points matter. In the end, the function can be defined as the following Equ. 4.
| (4) | ||||
IV-A2 Enclosure
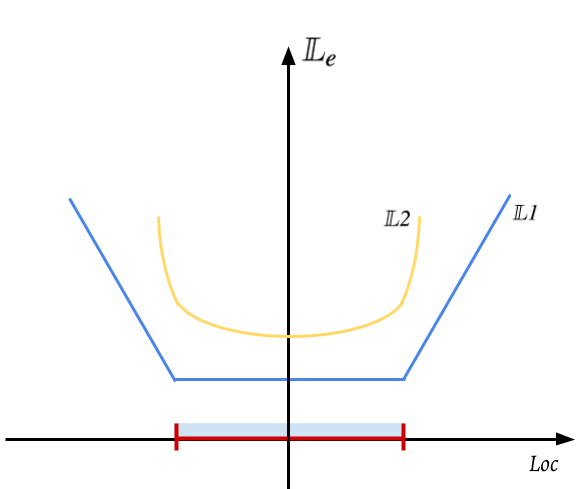
A should include points inside, i.e. , but it actually only encloses points. Therefore, the enclosure can be defined as the ratio between and , i.e. . However, this definition is not differentiable with respect to the optimized values (, , , , , ). To make the enclosure term gradient-traceable to the target values, we represent it as L1-norm distance between points and six faces of the bounding box, as shown in Equ. 5. The reason why we choose L1-norm rather than L2-norm can be well-explained with their loss landscape, as depicted in Fig. 2. With the L1-norm, the is constant and optimal, when the points are located inside the , so the gradient is thereby zero. As the points move out the , the start to increase, accompanied by a non-zero gradient. However, the optimal solution for with L2-norm is when points are located in the center of the bounding box, which is not desired towards our objective.
| (5) |
IV-A3 Smoothness
The sequential bounding boxes have a smooth trajectory with an unknown degree of a polynomial. To model the smoothness , we assume that the change in the box’s location and orientation is similar between neighboring timestamps, which is similar to a constant-velocity motion model. Therefore, the smoothness can be defined as Equation 6.
| (6) |
where the describe the pose change between neighbouring timestamps.
IV-A4 Alignment
The heading of the object or is along its x-axis (forward/backward) and it should align with the direction of the trajectory. The orientation vector unit should be close to the movement vector unit of the object . The heading alignment can be defined as the following Equ. 7. Before we calculate the , each is wrapped into
| (7) |
where the = 222The is calculated with the Euler angles-based rotation matrix, for example, a roll about the x-axis is defined as , simliarly, we can calculate the and , and , and = [, , , ().
IV-A5 Total loss function
We form the total loss function as a sum of all the above loss terms with an augmented Lagrange multiplier, seen in Equ. 8. Here, the , , , and are the weights and multiplier for each term.
| (8) |
IV-B Optimization
Newton’s optimization method [24] can be used to find our solution, as our final loss function (Equ. 8) is differentiable to each optimized variable, and the gradient descent is also proved to be more efficient than classical ICP [23]. The optimization iteration step is shown as Equ. 9. The starting values for iteration are the initial pose of 3D bounding boxes.
| (9) |
IV-C Speeding-up
The computation of involves going through each point in the point cloud streams, and given that there could be a large number of points in one bounding box, the optimization process can be quite slow. To speed up the computation, we first down-sample the point clouds using farthest point sampling [25], which can significantly reduce the number of points while preserving the structure of the object. Newton’s iteration with the second-order gradient can find the optimal iteration step in Equ. 9, but the second-order gradient requires a lot of extra computation. Therefore, we use quasi-Newton methods, specifically, the LM-BFGS algorithm [26], for computing and updating the gradients to save computation time.
V Experimental results
V-A Setup details
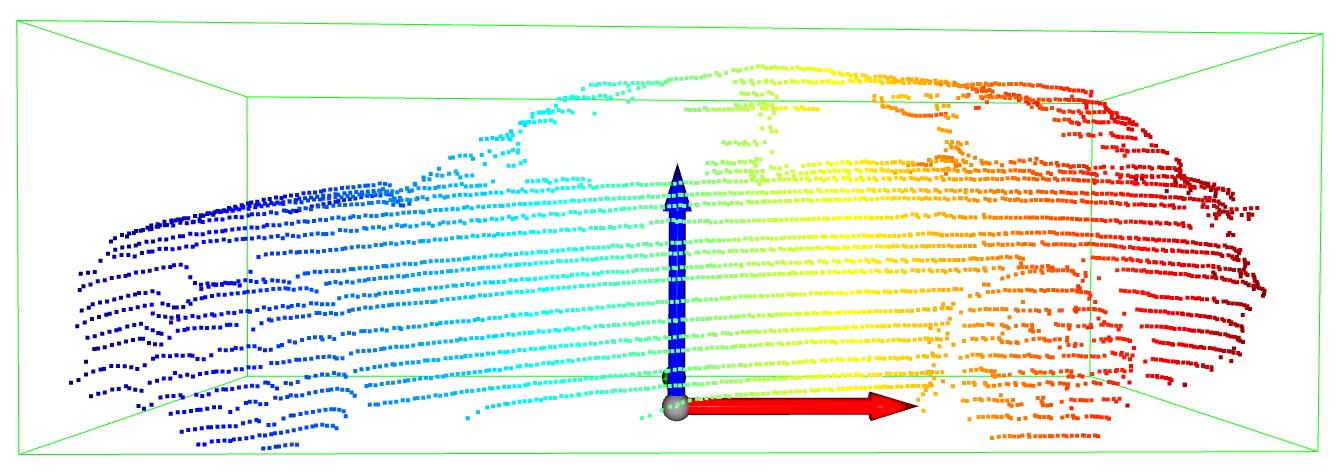
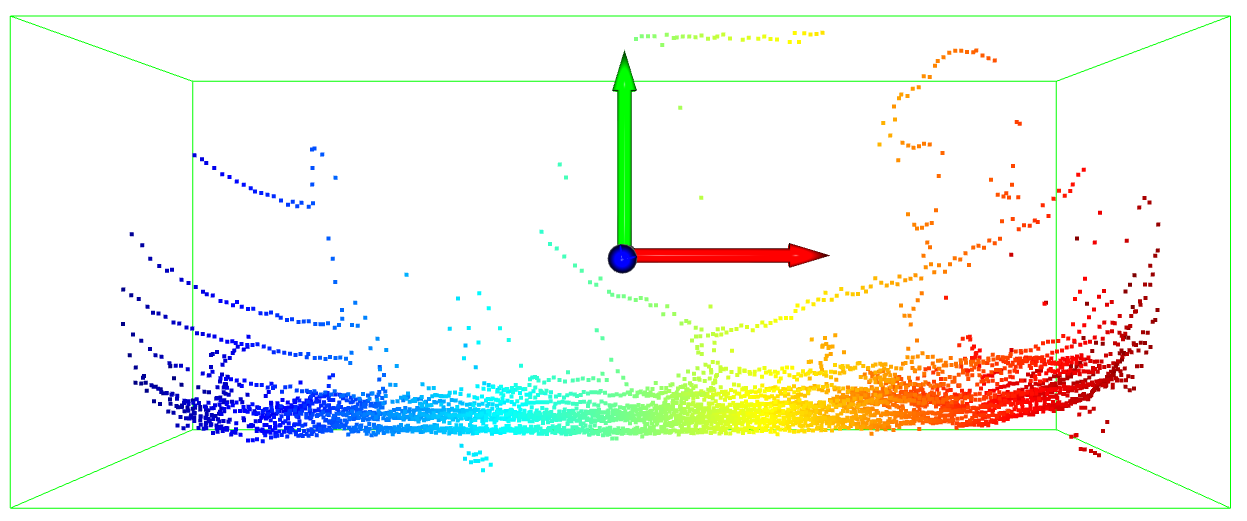
We validate our approach with a simulated point cloud, 3D bounding box, and controlled trajectory. The point cloud and bounding box can be seen in Fig. 5, which is an SUV scanned by a LiDAR from a side view. The experiment is conducted in two experimental settings. One is for sequential 3D bounding boxes registration, and we assume that the vehicle is constantly moving forward, and keep turning (yawing) in a half cycle around with rolling and pitching simultaneously, like a vehicle driving on a mountainous and uneven road. The trajectory function is as Equ. 10. The other setting is for sequential 2D bounding boxes registration and it is a simplified scenario with the assumption that the vehicle is moving on a flat area and detected from bird-eye view (BEV), and (no rolling) (no pitching). This is a common assumption in the context of autonomous driving [27]. For both experiments, we randomly block some areas of the SUV point cloud during the vehicle’s movement, as if it were occluded by other vehicles in the real world.
| (10) |
V-B 3D bounding boxes
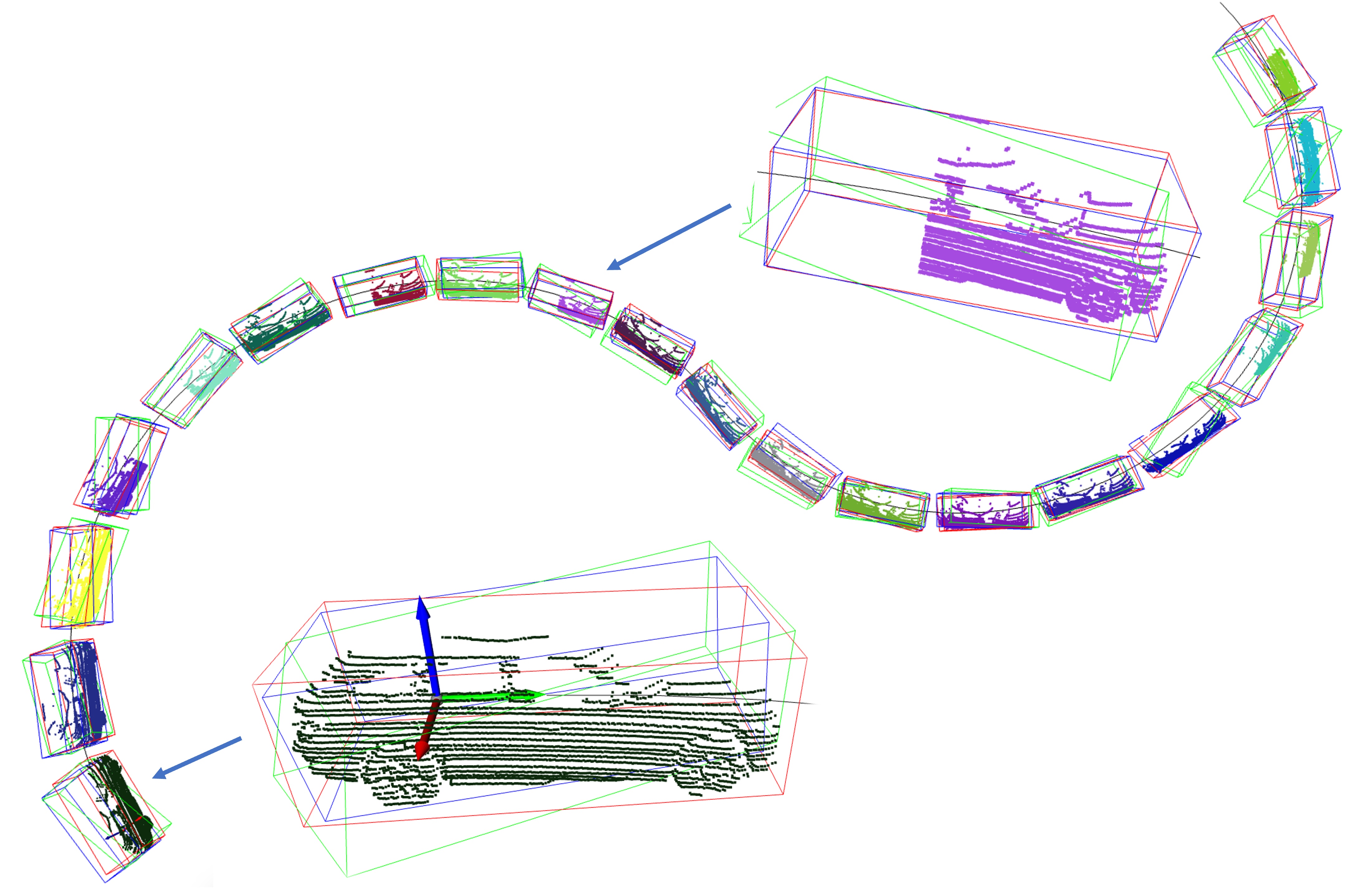
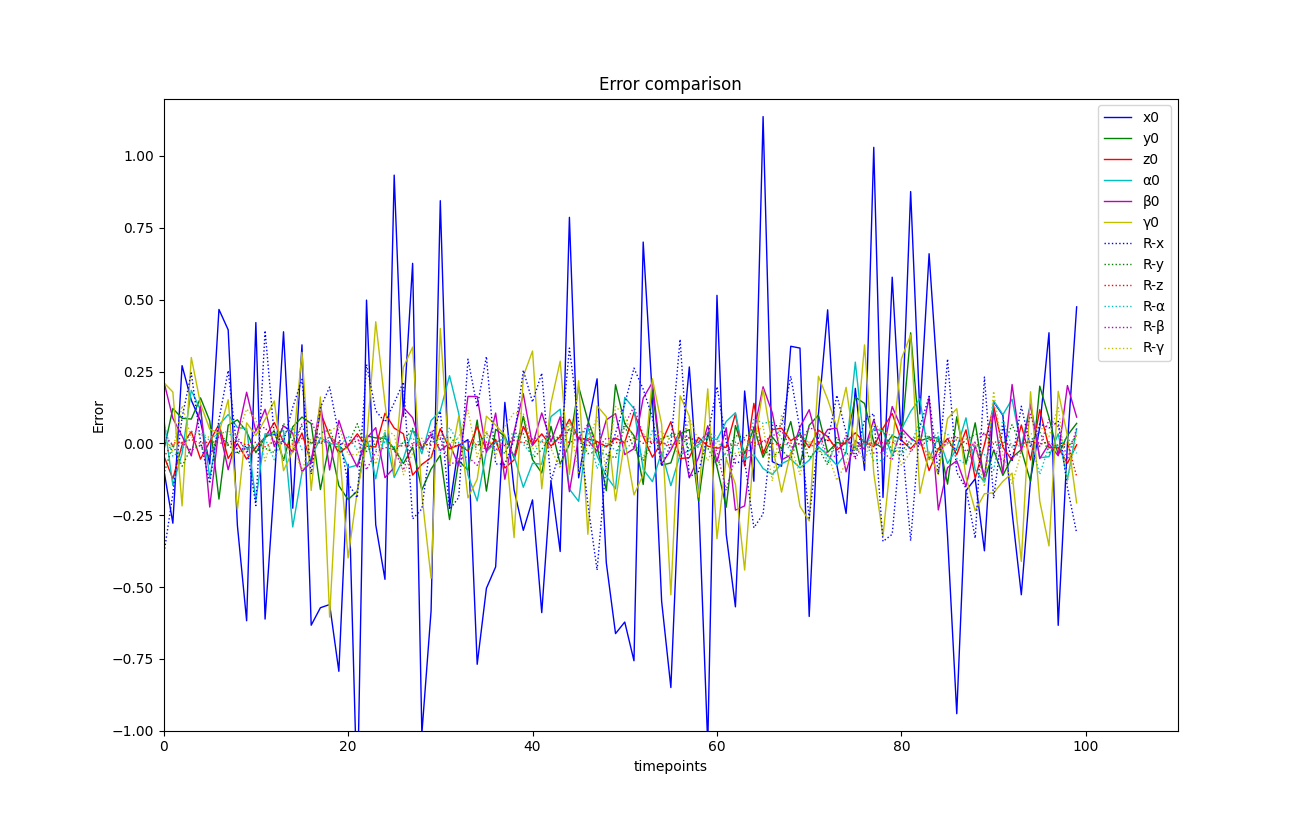
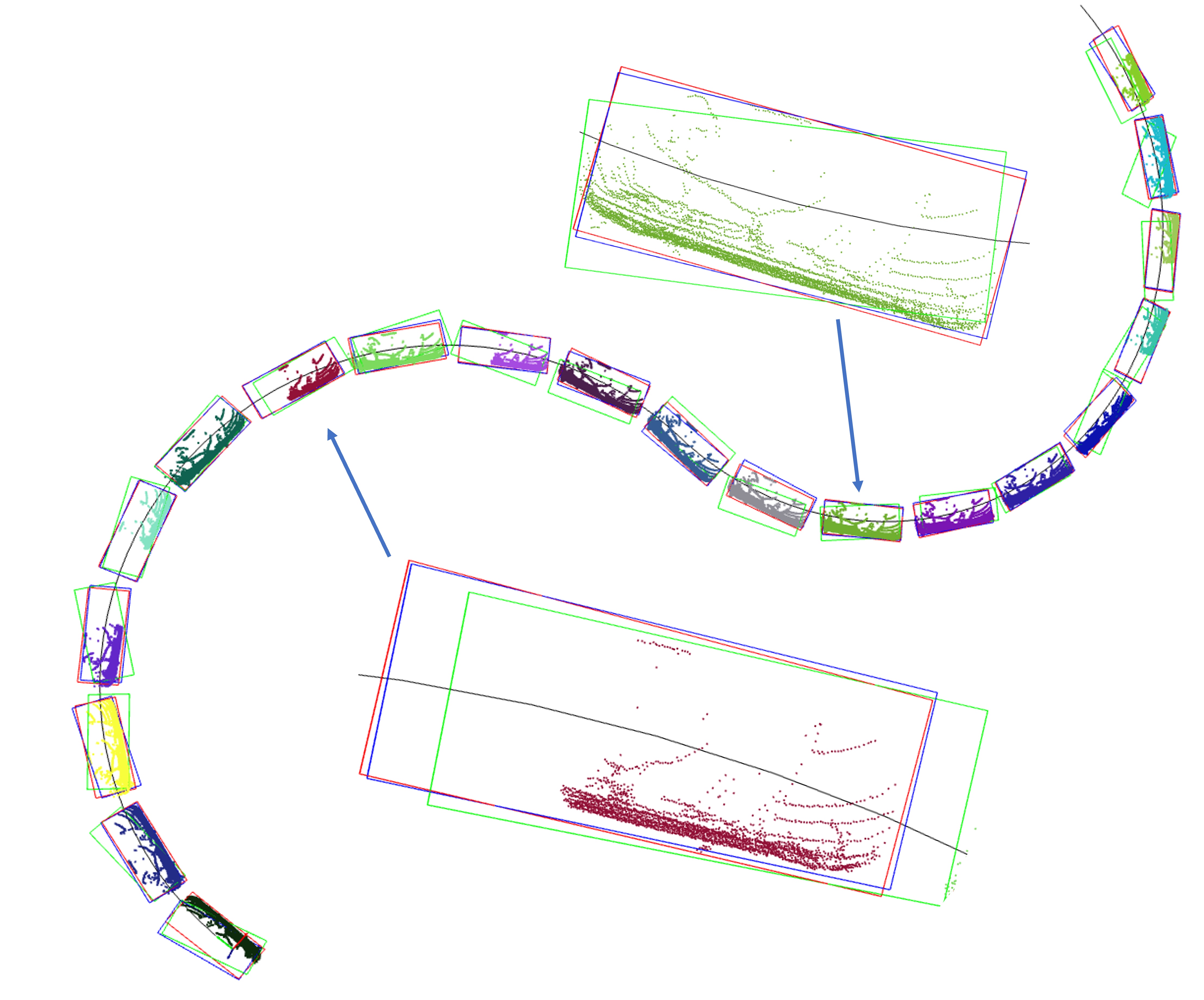
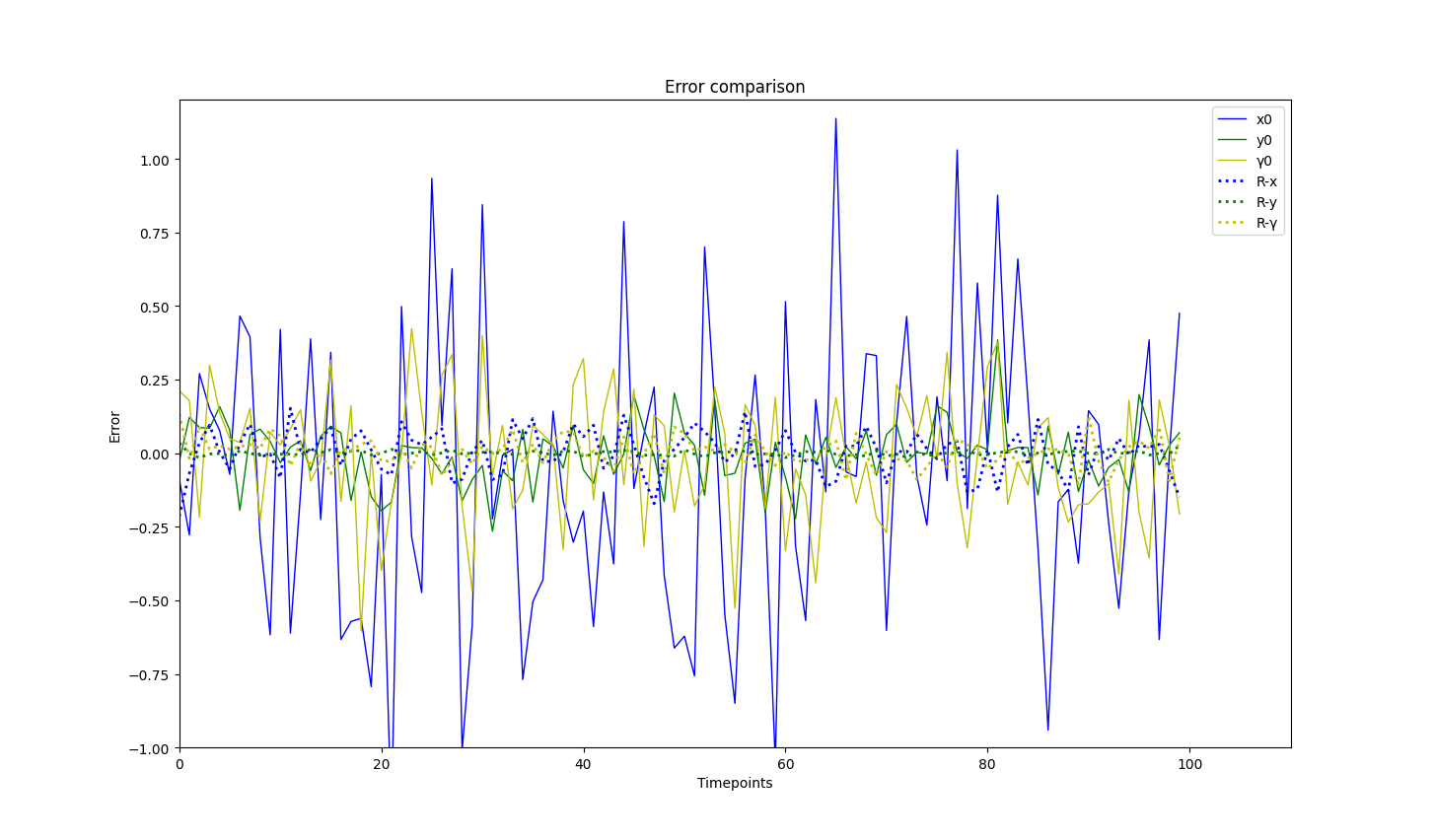
The trajectory of 3D object’s movement can be found in Fig. 3(a), and each state within the trajectory includes the six degrees of freedom. The error comparison before and after registering sequential bounding boxes with the point cloud streams can be found in Fig. 3(b). The experimental results show that our optimized bounding boxes in green color are much closer to the ground truth (red), given poor initial boxes in green color, especially for these bounding boxes in the middle. However, for the box at the very beginning and the last end, our approach fails (seeing the zoomed bounding box at the bottom of Fig. 3(a)). This is because there is no historical information for the first time point, and no future information for the last time point, which means that Smoothness (Equ. 6) and Alignment (Equ. 7) are not available for generating gradients, and there are no sufficient constraints enforced on optimizing them. From Fig. 3(b), we can observe that the dotted lines are more concentrated around zero than solid lines, which indicates that our approach can significantly reduce the error between initial bounding boxes and ground truth. The error difference can also be found in Table I, from which we infer that our approach can effectively optimize each variable and reduce error to 30% and improve the average IoU from 0.573 to 0.816. Each 3D bounding box has seven parameters for optimization, and as the trajectory increases, the dimensions increase as well, making the optimization more challenging, especially for the roll , which has only one loss term imposed on it. Sliding window techniques can be adapted to alleviate high-dimensional issues, and fixed-length windows with a low number of optimized parameters allow for stable optimization.
| Item | x | y | z | IoU | |||
|---|---|---|---|---|---|---|---|
| Initial | 0.392 | 0.124 | 0.082 | 0.083 | 0.1 | 0.18 | 0.573/0.618 |
| 3D | 0.121 | 0.049 | 0.012 | 0.031 | 0.034 | 0.053 | 0.816 |
| 2D | 0.054 | 0.006 | n/a | n/a | n/a | 0.032 | 0.896 |
V-C 2D bounding boxes in BEV
2D object detection from BEV is also an important topic and has been widely used for autonomous driving [27]. We applied our approach to this simplified scenario as well. The problem becomes the registration between 2d bounding boxes (no rolling, pitch, and height) and 2D point cloud (no z value), and our optimized variables change from 6 (, , , , , and ) to 3 (, , ). We used a similar trajectory as in the previous part, shown in Fig. 4 (a). We can visually tell that the blue bounding boxes are very close to the red ones and our approach can achieve better performance in the 2D tasks than the 3D task. From the table I, we can see that mean errors for three variables (, , ) in 2D bounding boxes are much smaller than the previous task, and the proposed approach can increase the IoU from 0.618 to 0.896 (40% improvement). The reason why our approach performs better is mainly due to the low dimensionality of variables. This task has only half of the total parameters in previous tasks, and each variable can be optimized by multiple loss terms with strong constraints.
VI Conclusion
Overall, the paper proposes a new approach to solve the problem of registration between sequential bounding boxes and point cloud streams. The approach treats registration as an optimization problem and builds an objective function that encodes the registration goal and constraints. The experimental results with simulated data show that the approach can achieve accurate registration with a 40% gain in IoU for 2D bounding boxes and 3D bounding boxes. However, the approach’s performance decreases as the dimension of parameters increases, and testing on real-world datasets is left for future work. The paper focuses on explaining the approach’s idea and demonstrating its effectiveness with simulated data.
References
- [1] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
- [2] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” in CVPR, 2020.
- [3] B. Yang, M. Bai, M. Liang, W. Zeng, and R. Urtasun, “Auto4d: Learning to label 4d objects from sequential point clouds,” CoRR, vol. abs/2101.06586, 2021. [Online]. Available: https://arxiv.org/abs/2101.06586
- [4] X. Li, N. Kwok, J. E. Guivant, K. Narula, R. Li, and H. Wu, “Detection of imaged objects with estimated scales.” in VISIGRAPP (5: VISAPP), 2019, pp. 39–47.
- [5] X. Li and J. E. Guivant, “Efficient and accurate object detection with simultaneous classification and tracking under limited computing power,” IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 6, pp. 5740–5751, 2023.
- [6] C. Liu, S. Lee, S. Varnhagen, and H. E. Tseng, “Path planning for autonomous vehicles using model predictive control,” in 2017 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2017, pp. 174–179.
- [7] W. Schwarting, J. Alonso-Mora, and D. Rus, “Planning and decision-making for autonomous vehicles,” Annual Review of Control, Robotics, and Autonomous Systems, vol. 1, no. 1, pp. 187–210, 2018.
- [8] S. Khan, J. Guivant, and X. Li, “Design and experimental validation of a robust model predictive control for the optimal trajectory tracking of a small-scale autonomous bulldozer,” Robotics and Autonomous Systems, vol. 147, p. 103903, 2022.
- [9] S. Shi, C. Guo, L. Jiang, Z. Wang, J. Shi, X. Wang, and H. Li, “Pv-rcnn: Point-voxel feature set abstraction for 3d object detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 529–10 538.
- [10] Y. Chen, Y. Li, X. Zhang, J. Sun, and J. Jia, “Focal sparse convolutional networks for 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5428–5437.
- [11] X. Li, J. Guivant, and S. Khan, “Real-time 3d object proposal generation and classification using limited processing resources,” Robotics and Autonomous Systems, vol. 130, p. 103557, 2020.
- [12] X. Li, “Object detection for intelligent robots in urban contexts,” Ph.D. dissertation, UNSW Sydney, 2020.
- [13] C. R. Qi, Y. Zhou, M. Najibi, P. Sun, K. Vo, B. Deng, and D. Anguelov, “Offboard 3d object detection from point cloud sequences,” 2021.
- [14] P. Besl and N. D. McKay, “A method for registration of 3-d shapes,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 14, no. 2, pp. 239–256, 1992.
- [15] S. Rusinkiewicz and M. Levoy, “Efficient variants of the icp algorithm,” in Proceedings Third International Conference on 3-D Digital Imaging and Modeling, 2001, pp. 145–152.
- [16] J. Park, Q.-Y. Zhou, and V. Koltun, “Colored point cloud registration revisited,” in 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 143–152.
- [17] C. Kerl, J. Sturm, and D. Cremers, “Robust odometry estimation for rgb-d cameras,” in 2013 IEEE International Conference on Robotics and Automation, 2013, pp. 3748–3754.
- [18] P. Li, J. Shi, and S. Shen, “Joint spatial-temporal optimization for stereo 3d object tracking,” 2020.
- [19] F. J. Lawin, M. Danelljan, F. Khan, P.-E. Forssén, and M. Felsberg, “Density adaptive point set registration,” in IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: Computer Vision Foundation, June 2018. [Online]. Available: https://github.com/felja633/DARE
- [20] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” CoRR, vol. abs/1612.00593, 2016. [Online]. Available: http://arxiv.org/abs/1612.00593
- [21] Y. Zhou, P. Sun, Y. Zhang, D. Anguelov, J. Gao, T. Ouyang, J. Guo, J. Ngiam, and V. Vasudevan, “End-to-end multi-view fusion for 3d object detection in lidar point clouds,” CoRR, vol. abs/1910.06528, 2019. [Online]. Available: http://arxiv.org/abs/1910.06528
- [22] X. Li, J. E. Guivant, N. Kwok, and Y. Xu, “3d backbone network for 3d object detection,” CoRR, vol. abs/1901.08373, 2019. [Online]. Available: http://arxiv.org/abs/1901.08373
- [23] F. A. Maken, F. Ramos, and L. Ott, “Speeding up iterative closest point using stochastic gradient descent,” CoRR, vol. abs/1907.09133, 2019. [Online]. Available: http://arxiv.org/abs/1907.09133
- [24] J. Nocedal and S. J. Wright, Numerical Optimization, 2nd ed. New York, NY, USA: Springer, 2006.
- [25] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” arXiv preprint arXiv:1706.02413, 2017.
- [26] D. C. Liu and J. Nocedal, “On the limited memory bfgs method for large scale optimization.” Math. Program., vol. 45, no. 1-3, pp. 503–528, 1989. [Online]. Available: http://dblp.uni-trier.de/db/journals/mp/mp45.html#LiuN89
- [27] Y. Ma, T. Wang, X. Bai, H. Yang, Y. Hou, Y. Wang, Y. Qiao, R. Yang, D. Manocha, and X. Zhu, “Vision-centric bev perception: A survey,” 2022. [Online]. Available: https://arxiv.org/abs/2208.02797