ReFRS: Resource-efficient Federated Recommender System for Dynamic and Diversified User Preferences
Abstract.
Owing to its nature of scalability and privacy by design, federated learning (FL) has received increasing interest in decentralized deep learning. FL has also facilitated recent research on upscaling and privatizing personalized recommendation services, using on-device data to learn recommender models locally. These models are then aggregated globally to obtain a more performant model, while maintaining data privacy. Typically, federated recommender systems (FRSs) do not take into account the lack of resources and data availability at the end-devices. In addition, they assume that the interaction data between users and items is i.i.d. and stationary across end-devices (i.e., users), and that all local recommender models can be directly averaged without considering the user’s behavioral diversity. However, in real scenarios, recommendations have to be made on end-devices with sparse interaction data and limited resources. Furthermore, users’ preferences are heterogeneous and they frequently visit new items. This makes their personal preferences highly skewed, and the straightforwardly aggregated model is thus ill-posed for such non-i.i.d. data. In this paper, we propose Resource Efficient Federated Recommender System (ReFRS) to enable decentralized recommendation with dynamic and diversified user preferences. On the device side, ReFRS consists of a lightweight self-supervised local model built upon the variational autoencoder for learning a user’s temporal preference from a sequence of interacted items. On the server side, ReFRS utilizes a scalable semantic sampler to adaptively perform model aggregation within each identified cluster of similar users. The clustering module operates in an asynchronous and dynamic manner to support efficient global model update and cope with shifting user interests. As a result, ReFRS achieves superior performance in terms of both accuracy and scalability, as demonstrated by comparative experiments on real datasets.
1. Introduction
In the era of big data, recommender systems (RSs) play a pivotal role in handling information overload. Users of online services, such as e-commerce and video streaming, demand that relevant items to be recommended upfront. In order to provide each user with personalized recommendations, users’ personal information and behavioral footprints are collected and then hosted at a central server to facilitate user preference modelling. Typically, such data consists of user ID, age, gender, demographics, likes, dislikes and other interactions with items. As those attributes are highly personal and even sensitive, most users tend to be reluctant to share such sensitive information with their service provider (Leon et al., 2013). Furthermore, laws such as the General Data Protection Regulation (GDPR) (Voigt and Von dem Bussche, 2017) prohibit service providers from accessing unconsented user data.
Consequently, handling a massive volume of data and promising each user on data privacy introduces a dilemma for the current centralized RSs (Yang et al., 2020), as users cannot enjoy accurate personalized recommendation without handing over their data to the server for analysis. In centralized systems, this trade-off between privacy and personalization (Awad and Krishnan, 2006) is ineluctable, as they require both users’ personal information as well as large-scale user-item interactions in order to facilitate training. Additionally, as user-item interaction datasets easily exceed billion-scale, training RS on a central server raises scalability and efficiency issues, especially for state-of-the-art models that are commonly deep learning-based.
Recent advances in computational hardware of edge devices have given rise to the possibility of distributed machine learning paradigms, where a typical representative is federated learning (FL). In FL, user models are trained collaboratively on their local devices by exchanging only the local model parameters, without disclosing any raw user data to the server. The submitted local models are aggregated into a global model on the server side (Karimireddy et al., 2020; Konečnỳ et al., 2016; Lin et al., 2020), and this global model is then re-distributed to the edge devices. Owing to FL’s decentralized nature, it offers two advantages. First, FL relieves the burden of computational dependencies on servers and second, it ensures user privacy by design because the data is fully retained by the users.
Given the high privacy sensitivity and resource-intensive characteristics of recommendation services, FL has attracted an increasing amount of research attention in the field of RSs (Ammad-Ud-Din et al., 2019; Chai et al., 2020; Chen et al., 2018; Niu et al., 2020). Current federated recommender systems (FRSs) adopt different collaborative filtering methods as their local recommenders, and perform FL via variants of the model averaging algorithm (McMahan et al., 2017), in order to obtain an expressive global recommender. The FRSs (Ammad-Ud-Din et al., 2019; Niu et al., 2020; Chai et al., 2020; Jia and Lei, 2021; Wang et al., 2021a) train the local models with the users’ on-device data and collaborate with the federated server (FS) to iteratively improve the local model with the global context. Despite the decentralization and privacy guarantees provided, in what follows, we point out several shortcomings of existing FRSs that remain unsolved and inevitably hinder their usability in practice.
Currently, FL-based architectures for RS (Wang et al., 2021b; Ali et al., 2021; Ammad-Ud-Din et al., 2019; Niu et al., 2020; Chai et al., 2020; Jia and Lei, 2021; Wang et al., 2021a) are primarily focused on generating an accurate recommender model on users’ devices. However, they fail to consider the fact that end-devices are usually limited in computational power and memory. For example, in federated MF, a device must store all item embeddings and (at least) one user embedding to facilitate model training and inference. The embeddings become a major memory bottleneck due to the large number of possible items in a dataset (Chen et al., 2021; Li et al., 2021). The 128-dim embedding of a single item takes approximately 10.2KB, and the embedding of just 10000 items takes more than 100MB memory. Hence, storing embedded representations of more than a million items on a single device would be infeasible. On the other hand, the parameters of a very simple General Matrix Factorization (GMF) model with 21,009 parameters take approximately 1.352 MB, on 32-bit systems accepting 128-dim input. Secondly, processing models with large size becomes computationally expensive. On edge devices with limited resources, such models become impractical as the number of items and model complexity increases.
Additionally, current FRS frameworks typically consider a scenario in which complete user interaction history is already available on the end-device, neglecting sequential nature of user-item interactions (Chen et al., 2019; Sun et al., 2020; Zhao et al., 2020). In the real-world, most user devices have sparse data (especially those with new users) (Tam et al., 2017), which limits the ability of local and global models to capture users’ changing preferences or demands. Lastly, each user demonstrates strictly non-i.i.d interactions, revealing preferences that vary across cultures, genders, age groups, demographics, and so on. As a result, a single global model may not be enough to accurately reflect the heterogeneity in user behavior distributions. As shown in the evaluation section, the federated model experiences reduced performance due to an inability to cater to both data sparsity and diverse user behavior/preference distributions.
Motivation.
Overall, existing FRS are challenged by 1) poor quality of learned models due to data sparsity, 2) weak ability to model dynamic preferences, 3) limited personalization due to traditional FL’s single global aggregation of models, and 4) significant memory consumption. In light of these challenges, we aim to develop an FRS that is lightweight, handles data sparsity, captures dynamics of user interests, and considers heterogeneity of users during the global update. These challenges motivate use to design a more practical paradigm for learning distributed recommender models. To capture the dynamic user interests, we learn temporal representations of a user’s preferences via her/his sequential interactions with items. For the diverse personal preferences and the resulted non-i.i.d on-device data, we dynamically cluster and aggregate models from semantically similar users instead of all users. Since each device shares model parameters with the server, we group users based upon these parameters rather than sharing users’ personal information.
Our Contribution.
To this end, we propose Resource-efficient Federated Recommender System (ReFRS), an FRS that can effectively manage dynamic and diversified user preferences, even when the edge device is resource-constrained and subject to sparse user interactions. The framework of ReFRS is comprised primarily of two components, namely a decentralized client module and a semantic server.
Based on the sequential on-device interactions generated by the user, the locally deployed client module learns dynamic user interests. To avoid storing all item information on the edge device for recommendation, we use a sequential approach where interactions are processed in sessions. These sessions are kept small to fit into limited memory efficiently, and old sessions are swapped out to maximize memory utilization. This module consists of three parts. An interaction sampler in the client module collects and organizes the user’s interactions into chunks of stacked sequences. Each of these chunks is converted into a low-dimensional vector representation by an embedding model. The embedding model is a lightweight generative model based on a self-supervised variational autoencoder (VAE) (Imran et al., 2020), which condenses continuous vectors into discrete vectors using vector quantization (VQ) (Jin et al., 2020). A hidden representation of each interaction sequence is extracted from the VQ layer as an embedded vector. It reflects the most distinct characteristics of user’s temporal interactions and is fed as an input to the recommender model. The model parameters of the encoder layer are shared with the federated server, which enriches the local models with high-order information. It allows faster convergence of the local models and is communication efficient since we only have to share a single layer’s parameters. A major advantage of our client model is that it can effectively handle sparse data and convert it into a size-constrained discrete vector representation.
To overcome the non-i.i.d. nature of individual user data, we propose an efficient grouping scheme which only aggregates client models that are semantically similar. Rather than grouping clients by requesting and comparing all users’ sensitive information like demographic data (Muhammad et al., 2020), we utilize a neural approach to efficiently capture user affinity by simply looking at the model parameters submitted by each client. This is accomplished via a federated server, which is composed of a semantic sampler, a clustering unit, and an aggregator. Semantic samplers contain a VAE, which encodes every user’s model parameters into a compact vector representation, maintaining close affinity among semantically similar user models in the embedding space. A dynamic clustering mechanism is then used to group these low-level vector representations of clients’ models. Based on the low-level representation of clients’ model parameters, the clustering unit is able to generate discriminative and dynamic clusters. The aggregator then aggregates all the clients’ models within each cluster and then distributes the cluster-wise global model to all the clients in the same cluster. This approach aggregates users with similar interests. All three components of the federated server are scalable and communicate asynchronously. The dynamic nature of our clustering unit allows for the adaptive increase and decrease in the number of clusters based on the variance in the incoming user models. As the cluster formation is asynchronous, the communication bandwidth is not affected.
One of the advantages of FL is that no amount of user information or generated data is shared during the model federation. However, the shared model parameters are very vulnerable to membership inference attacks (Zhang et al., 2021a; Shokri et al., 2017) and attribute inference attacks (Carlini et al., 2019; Yeom et al., 2018) on the server. This may lead to the leakage of sensitive or private information. For this reason, we adopt Differential Privacy (DP) (Wei et al., 2020) and Homomorphic Encryption (HP) (Jiang et al., 2021) to showcase the strong compatibility of ReFRS with these privacy schemes. Our main contributions are summarised as follows:
-
•
We design a lightweight generative model that learns discrete item representations conditioned on the temporal context, and is able to fully capture the dynamic user preferences for sequential recommendation.
-
•
We propose an asynchronous and scalable model aggregation approach for the federated server, allowing for grouping semantically similar user models into clusters. The global models are aggregated cluster-wise to support quicker local model convergence and better personalized recommendation in the presence of non-i.i.d. data.
-
•
We validate the advantageous effectiveness and scalability of ReFRS by conducting extensive experiments with real-world datasets of different sizes and state-of-the-art baselines.
2. Related Work
2.1. Recommender Systems (RS)
A RS gathers information about the preferences of its users for a set of items e.g., movies, songs, books, jokes, gadgets, applications, websites, etc. The information can be collected either explicitly (typically from the ratings of users) or implicitly (typically by monitoring the users’ actions, such as the songs they hear, the applications they download, or the websites they visit). RS may also use demographic information such as age, nationality, and gender, as well as social information, like followers, followed, tweets, and posts, that is commonly used in Web 2.0, to predict users’ interests. As a general rule, recommender systems are programs that attempt to predict an individual or business’ interest in an item based on information about the item, the user, and their interactions with the item.
In the mid-1990s, researchers began to focus on recommendation problems based on explicit ratings, and recommender systems emerged as an independent research area (Adomavicius and Tuzhilin, 2005; Goldberg et al., 1992). The most common recommendation techniques are collaborative filtering (CF) (Schafer et al., 2007), the content-based approach (CB) (Pazzani and Billsus, 2007) and knowledge-based approach (KB) (Burke, 2000). In addition to its strengths and weaknesses, each recommendation method has advantages and disadvantages; e.g., CF suffers from sparseness, scalability, and cold-start problems (Adomavicius and Tuzhilin, 2005; Schafer et al., 2007), while CB offers overspecialized recommendations (Adomavicius and Tuzhilin, 2005; Goldberg et al., 1992). Many advanced recommendation approaches have been proposed to solve these problems, including social network-based recommender systems (He and Chu, 2010), fuzzy recommender systems (Zhang et al., 2013), context-aware recommender systems (Adomavicius and Tuzhilin, 2011), group recommender systems (Masthoff, 2011), session based recommender systems (Qiu et al., 2020) and sequential recommender systems (Tang and Wang, 2018).
2.2. Sequential Recommender Systems (SRS)
In Sequential Recommender Systems (SRS), each user is associated with a number of interaction sequences with some items. Its goal is to recommend each user the most probable next item by considering that user’s general tastes as well as short-term intention (Tang and Wang, 2018). Most of the early research on SRS adopts the Markov Chain (MC) (Mobasher et al., 2002; Rendle et al., 2010; Shani et al., 2005) method to model sequential behavior by estimating an item-item transition probability, and predicting the next item. The introduction of neural networks paved way for learning based RS, with the adoption of Gated Recurrent Units (GRU) (Hidasi et al., 2015) to the session-based recommendation. Modifications of GRU based methods soon followed, by adopting pair-wise loss functions (Hidasi et al., 2016), memory networks (Huang et al., 2019, 2018), hierarchical structures (Quadrana et al., 2017), copy mechanism (Ren et al., 2019) and reinforcement learning (Zhou et al., 2020), etc.
Recently generative model have generated increased interest in SRS, that captures user behavior and time dependencies in those preferences. One such approach is developed by SVAE (Sachdeva et al., 2019), which utilizes variational autoencoders for modeling a user’s preferences by incorporating latent variables and temporal dependencies. It models latent dependencies by using recurrent neural networks, before feeding them into the VAE model for prediction. Another popular approch is To generate high-quality latent variables, ACVAE (Xie et al., 2021) adopts the Adversarial Variational Bayes (AVB) (Mescheder et al., 2017) framework. Then, it applies a contrastive loss (Inoue and Goto, 2020) to compare the latent variables between different users. Contrary to the use of multi-user single models in these proposed models, ReFRS follows a federated setting, where each user only has access to their own data. As part of the embedding model, ReFRS takes in a window of recently interacted items and learns their temporal representation using a generative model. The vector quantization (VQ) layer and the multi-head attention between the encoder latents and the quantized latent help preserve the salient temporal features and interaction dependencies.
2.3. Federated Learning (FL)
FL is an online architecture where under the coordination of a central aggregator, multiple clients can collaborate to solve machine learning (ML). FL allows the training to be carried out on a local device, in a decentralized fashion, to ensure the data privacy of each device (Zhang et al., 2021b). The main contribution of FL is preserving user privacy while allowing multiple users to collaborate. FL architecture can be divided into three categories, horizontal FL, vertical FL and federated transfer learning (Yang et al., 2019). Horizontal FL is suitable for a scenario where the items that are interacted by the users overlap but not the users themselves (Bonawitz et al., 2017; Smith et al., 2017). In Vertical FL, the items being interacted with only overlap a little (if any). However, the users (or user interactions) have a high degree of overlap (Cheng et al., 2021). Finally, in federated transfer learning, both the users and the user-item interactions rarely overlap. In this case, rather than segmenting the data, we adopt transfer learning for the lack of data or tags (Liu et al., 2020). Model aggregation is one of the main components in FL, which trains the global model by summarizing the model parameters from all participating clients (Zhang et al., 2021b).
2.4. Federated Recommender System(FRS)
RSs are primarily data-driven systems, where the common case is that the more data it uses, the better it performs. However, due to privacy and security constraints, directly sharing user data between parties is undesired (Tan et al., 2020). FRS builds up a stronger recommender model without compromising user privacy or data security. Recently, Ammad et al. (Ammad-Ud-Din et al., 2019) introduced the first FL-based collaborating filtering (CF) method, that utilizes stochastic gradient descent (SGD) to update the local model and the FedAvg mechanism is adopted to update the global model. Improving on data security and potential leakages in (Ammad-Ud-Din et al., 2019), (Chai et al., 2020) introduces FedMF, which enhances the distributed matrix factorization (MF) framework to the FL setting and apply homomorphic encryption on the gradient information before sharing the information. FedMeta (Chen et al., 2018) is a federated meta-learning framework, where a parameterized algorithm is shared as compared to a global model using FedAvg, adopted in a typical FL setting. SFSL (Niu et al., 2020) observe that clients interact with a subspace of items rather than complete feature space. To cater effective utilization of bandwidth and ensure model anonymity, they design a secure federated sub-model learning mechanism coupled with a private set union protocol. FedFast (Muhammad et al., 2020) accelerates federated recommendation tasks by applying an active aggregation method that propagates the updated models to similar clients. However, FedFast (Muhammad et al., 2020) relies on user grouping based upon profile similarity. This similarity is computed by sharing user’s personal demographic information with the central server, leaving users vulnerable to identity leakage (Kendzierskyj et al., 2019).
Some clustering based FL approaches have been proposed that support users’ behavioral heterogeneity without sharing/leaking any user data. Iterative Federated Cluster Algorithm (IFCA) (Ghosh et al., 2020) attempts to minimize the loss function of each FL client while also assigning the client to a cluster. Two variants are proposed for model aggregation in IFCA, i.e., model and gradient averaging. IFCA applies random initialization and multiple restarts to cluster clients and reach optimal results. However, IFCA estimates each client’s cluster by iteratively finding the best performing model parameters on the local device. Consequently, this will incur additional communication and computational costs on resource-constrained user devices like cellphones or tablets. A more recent clustering-based FL approach, DistFL (Liu et al., 2021), extracts and compares distribution knowledge from uploaded models to perform clustering based on the data generated from uploaded models, but its practicality is also constrained by the high communication overhead. Furthermore, in IFCA, each user device participating in federated clustering has to be synchronously on the same training step. In the real world, this is infeasible, especially in recommendation systems where user devices are constantly connecting and disconnecting from the server.
3. PRELIMINARIES
In this section, for the ease of understanding, we formally define some key technical terms, followed by problem formulation and system overview. The notations adopted to describe key technical elements are listed in Table 1.
| Notation | Description | |
|---|---|---|
| Set of users | ||
|
||
| Set of items | ||
| Number of users in | ||
| Feature set of item | ||
| Number of dimensions | ||
| Sequence , representing number of items interacted with within a window | ||
| Consective number of items | ||
| Session, contains a collection of consective sequences | ||
| Input feature vector, of items in | ||
| Latent representation of | ||
| Embedding vector of an interaction |
Term 1: Edge Device is the digital hardware used by the user for streaming and other services. It could be a desktop computer, laptop, tablet, etc. We also refer to the user’s device as a client in this work.
Term 2: Global Epoch represents a full iteration in which all the participating clients have interacted with the global server.
Term 3: Asynchronous Clustering represents the computation of client clusters based on their local models’ parameters, which happens when the uploaded local models are being aggregated into the global model and then transmitted back to local devices.
Term 4: Aggregated Global Models are the aggregation of all client models within each cluster. The total number of aggregated models are determined by the number of clusters, which changes automatically with each asynchronous clustering commit.

3.1. Problem Formulation
Let a set of users interact independently with a set of items , and each has features , where is the number of dimensions. Each user accumulates various sessions on her/his local machine over time, where a session is a sequence of interacted items in a short time period. Note that we use numbered subscripts for items mainly to indicate their orders in a sequence. Our sequential recommendation task is session-based, where the model predicts the next item for every given . Due to multi-faceted user preferences, the distribution of is highly skewed across users. Also, compared with the centralized setting where all users’ data is available, in FRS, each user has a highly limited amount of interactions for learning her/his preference. To fully capture such data heterogeneity, we perform asynchronous clustering to help generate aggregated global models, so as to achieve better personalized recommendation accuracy in an effective and efficient way.
3.2. System Overview
ReFRS follows the standard FL client-server architecture, as illustrated in Section 1. Each client corresponds to a personal device that holds a single user’s interaction data and trains a lightweight recommender model. A client hosts an interaction sampler, an embedding model and a recommender model. The server identifies client groups based on their model parameters and keeps a copy of the aggregated recommender model for each group. Overall the server is responsible for: 1) identifying, grouping and asynchronously updating client groups based on their parameter similarity; 2) aggregating and disseminating model parameters within each user cluster. The detailed designs of both the client and server are presented in Section 4 and Section 5.
4. Client-side Dynamic Preference Modelling
We start the description of ReFRS with the locally deployed model on end-devices, which learns each user’s dynamic preferences via sequential interactions . The client module consists of three parts: 1) user interaction sampler, 2) an embedding model and 3) a recommender model. We assume that each client device holds a single user’s data. The objective of user preference embedding is to aggregate historical user-item interactions in order to determine the user’s preferences. The ReFRS client comprises a self-supervised embedding module that encodes these preferences i.e., the relation between the items. The embedded vectors computed by the self-supervised embedding module are then fed into a recommender model that predicts the next item.
4.1. User Interactions Sampler
In the federated setting, each client holds only its own user’s interaction sequences . These sequences are first broken down into smaller sessions in order to train the user model. To simulate sequential behavior, these sessions are fed to the embedding model as batches. Since the same item may recur over time in a sequential system, it is important to take note of how this item co-occurs with its neighbors over time (Chorney et al., 2010). This results in different representations of an item in different sessions, reflecting changes in the user’s behavior. For this reason we define an interaction window , which represents the interaction history of an item . Taking into account that consists of items and leads to the item, we model the input to our embedding model using sequential feature vectors of items in , used to estimate the latent representation of item .

An example of aforementioned sequence sampling is given in Figure 2. User 1 interacts with multiple music tracks over a period of time. In order to get the user interaction behavior for Track 4 at time interval , we define (of size 4 for the purpose of this example) and stack the feature vectors of tracks falling under the window . Note that the generation of Track 4’s embedding is conditioned on (i.e., stacked features of Tracks 7, 1, 1, and 8 in this case). The embedding of items in such sampling is influenced by their sequential context and temporal positioning. As such, the same item will have a different temporal embedding when different temporal contexts are given. The main advantage of our approach is that it captures the user’s interest in an item at time when it is followed by sampled items , grouped temporally. This change of user interest and variation in grouping persist in SRS setting, so it is beneficial to encode each item based on the latest context, when predicting the next item. In our work we define the best after experimentation (using and ). In the first session (i.e. batch), 16 interactions are sampled as for , for , and so on.
4.2. Embedding Model
Given a session, the embedding model learns informative item representations by incorporating the dynamic context carried by other recently interacted items. In other words, we need to learn a compact vector representation (i.e., embedding) of item from the interaction window . The window groups semantically similar items together to capture the temporal and contextual relationships between the interacted items. As a result of this representation, item-sequence relationships should be effectively captured and items that are contextually and temporally similar should be grouped together. Since an item can be repeatedly interacted with over time, it is important to fully incorporate such dynamic context into an item’s embedding. Hence, in ReFRS, instead of using a fixed embedding for every item, each item’s embedding is dynamically conditioned on its predecessors within the same session. In order to meet these requirements, we propose to utilize the sequential variational autoencoders (VAE) (Shao et al., 2021) to capture the relationship among the input feature vector. The VAE will try to capture the dependencies among the temporally stacked item sequence (as described in Section 4.1), by enforcing a probabilistic prior to the latent space of the autoencoder (Zhu et al., 2020). That is, instead of mapping the session to a point in the embedding space, VAE maps it to a normal distribution, making the representation learned from similar sources close, compact and smooth to interpolate between. VAE uses Kullback-Leibler (KL) divergence to measure the information discrepancy between the approximated true posterior of the latent variables and the variational posterior :
| (1) |
where denotes posteriors approximated by the neural network encoder, and is the reconstruction approximated by the decoder, which is also a neural network.
However, in federated settings where there is only one user’s data (a small amount of data that grows slowly), the training objective of VAE (i.e., KL divergence) quickly reaches local maxima (Lucas et al., 2019). As a result, the continuous latent representation learned by VAE suffers from issues like high variance and posterior collapse (Dai et al., 2020). Furthermore, the continuous vector representation produced by VAE requires a large embedding representation to accurately represent the feature vector. However, the limited memory of the end-device, makes storing large embedding vectors counterproductive.
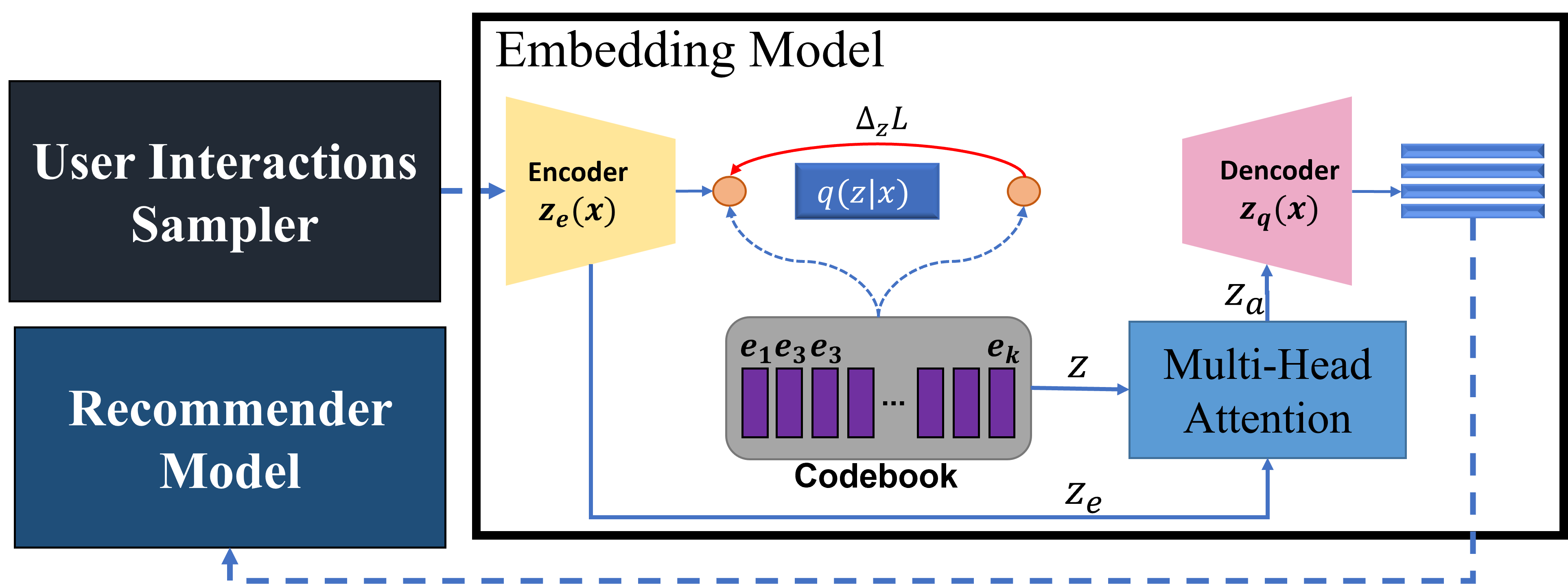
We propose to use the vector quantization (VQ) (Jin et al., 2020) technique to discretize the latent variable space into numerous sub-spaces, and further adopt self-supervision to drive the learning of discrete latent variables. This technique effectively projects each interaction window in a separate sub-space. VQ transforms continuous vectors into finite sets of ”code” vectors. In essence, it works the same way as k-nearest neighbors (KNN), in that a sample is mapped to a centroid code vector with the minimum Euclidean distance. The resultant discrete latent representations are also more constricted and space-efficient.
As shown in Figure 3, an encoder layer converts the input into latents and the VQ layer then convert into discrete latents by calculating nearest neighbour look-up. Before feeding to the decoder, we perform multi-head attention (Vaswani et al., 2017) on and , yielding , which is converted back in by the decoder. As a result, the model can jointly attend to information from different representation from the latent sub-spaces at different positions.
| (2) | ||||
The discrete latents, fed into the attention network are the sampled distributions indexed by an embedding table (van den Oord et al., 2017). Overall the embedding model can be viewed as a VAE where is bounded by the evidence lower bound (ELBO) (Yang, 2017), as given in Eq. (3):
| (3) |
where denotes the output from the encoder given by , which is discretized by mapping to the nearest element of embedding , with given as:
| (4) |
where each embedding vector is drawn from the VQ’s embedding table (a.k.a. codebook) consisting of discrete values. The objective function of our embedding model is then to minimize the flipped ELBO (Jin et al., 2020) assuming degenerate approximate posteriors:
| (5) |
In Eq.(5), the first term is the reconstruction loss from the decoder. While both the second and third terms use error to move towards , in the second term we adopt the stop-gradient operator (Jin et al., 2020) to encourage the encoder output to commit as much as possible to its closest codebook vector. is a hyperparameter controlling the effect of the third term. Note that, once we obtain a well-trained embedding model, its parameters will stay fixed and we use the learned encoder followed by the vector quantization described in Eq.(4) to directly generate the temporal embeddings for observed items. With embeddings generated for all items in , we further use a sequential recommender model to capture the dynamic preferences of the user. Note that, every time an item is visited, its feature vector is obtained from the server and a unique embedding is calculated based on its temporal position. As a result, all item embeddings are private and specific to the device.
4.3. Recommender Model
Both models for item embedding and next-item recommendation are trained independently. We follow the commonly used recommendation strategy here, i.e., predicting the next most likely item to be interacted with. Given our primary contribution was obtaining meaningful temporal embeddings, we test its effectiveness by feeding learned embedding to state-of-the-art sequential recommender models. The sequence representation (where, ) and the item embedding matrix are used to compute the predictive score as:
| (6) |
In our work we use GRU4Rec (Hidasi et al., 2016) and SASRec (Kang and McAuley, 2018) since they are the most widely adopted SRSs. In addition the learning mechanism proposed by these frameworks i.e., GRU and the transformer, are widely adopted in different variations by other state-of-the-art SRSs.
5. Server-side Adaptive Model Aggregation
The model presented in Section 4 is locally deployed on each client and is subject to data sparsity issues. In order to better generalize the local models and better capture the interaction context while reducing the communication cost for model aggregation, we only share the parameters of the encoder (of client embedding model) with the server. In order to maintain users’ privacy, the user information, interaction data, item embeddings and model hyperparameters for the decoder and the codebook are strictly not shared. Since the embedding model essentially maps each user’s interaction behavior into the target item’s embedding, it benefits the federated server by helping to identify similar user patterns. However, as described earlier, notwithstanding data heterogeneity and user preference diversity, most FRSs (Ammad-Ud-Din et al., 2019; Niu et al., 2020; Chai et al., 2020; Jia and Lei, 2021; Wang et al., 2021a) simply assume that the parameters of all user models can be directly aggregated. To overcome the non-i.i.d. nature of individual user data, we propose an efficient grouping scheme that only aggregates client models that are semantically similar. Rather than grouping clients by requesting and comparing all users’ sensitive information like demographic data (Muhammad et al., 2020), we utilize a neural approach to efficiently capture user affinity by simply looking at the model parameters submitted by each client. We also enable the server to asynchronously update client groupings as the user interaction behavior changes over time. Our sever-side design has three parts, namely a semantic sampler, a clustering unit and a model aggregator, which we will describe below.
5.1. Semantic Sampler
In FRSs where the main objective is to provide users with suggested items based on their historical interactions with a collection of items, the issue of non-i.i.d. data arises. For example, music streaming clients may be interested in different categories of music due to personal interests, demographics, moods etc. Thus, leveraging the heterogeneity in user behavior is of utmost interest. FL facilitates aggregating models for learning user preferences while maintaining each user’s privacy, however by straightforwardly treating interactions from all the users as i.i.d., it inevitably harms the personalization characteristics of a recommender model.
In light of this, we tackle the dilemma of interaction scarcity at the user level and non-i.i.d. data at the server level by investigating communities consisting of similar users. Intuitively, it would be beneficial to perform model aggregation within each of the user groups, such that each client model can be enhanced using only the knowledge from users with similar preferences. Though similar users can be easily identified via their interaction records or personal attributes, it will void the privacy guarantees provided by FRSs. So, we propose a semantic sampler that utilizes the shared model parameters to generate user clusters. More precisely, the semantic sampler treats the encoder model parameters of each client as its respective features, and embeds them into a low-dimensional vector representation via a stand-alone VAE model. The input to this VAE are the shared encoder model parameters (obtained in Section 4.2) of each client, obtained from encoder layer. By obtaining low-dimensional vectors withholding client-wise similarity information, we are able to avoid heavy computation cost of directly clustering the high-dimensional model parameters.
Using VAE, latent variables of a client are drawn from a prior , where is the embedding vector of the client’s shared model parameters . Here are flattened encoder layer parameters of client . VAE defines a joint probability distribution over the input data and latent variables, with the goal of inferring the latent variables (i.e., client’s model embedding) given observed data (i.e., the client’s model parameters):
| (7) |
where the optimization goal can be formulated analogously to Eq.(1) using Kullback-Leibler (KL) divergence:
| (8) |
As such, the server is able to compute low-dimensional vector representations using model parameters shared by clients. In addition to reduced dimensionality, the VAE also maps similar models closer in the embedding space.
5.2. Clustering Unit
The semantic sampler computes a low-dimensional vector representation of each client’s model parameters, as soon as they arrive at the server side. Note that in Section 5.1, vector embeddings are computed in such a way that semantically similar models will have close representations in the vector space and dissimilar clients will be mapped far apart. Such placement of model parameters in the embedding space fulfils both clustering properties (Bateni et al., 2017; Hung et al., 2017), i.e. intra-cluster maximization and inter-cluster minimization. Making use of -Means (Jin and Han, 2010) algorithm to compute effective clusters, we group together similar client models. However, directly applying -Means clustering incurs the following overheads: 1) the optimal value of is unknown; 2) it needs to be recomputed every time a new client has to be added; and 3) it is inefficient to synchronously update for each incoming client model.
Our asynchronous clustering module effectively addresses these challenges via a dynamic setting. After the first global epoch, using a small pool of sampled initial clients, the server trains the VAE-based semantic sampler and also generates initial client embeddings. With these initial embeddings, we run the Elbow method (Syakur et al., 2018) that uses -Means clustering on the dataset, and then compute an average silhouette score (De Amorim and Hennig, 2015) for all the clusters. Subsequently, the server obtains the incoming client’s model embeddings by feeding its model parameters to the trained semantic sampler. For the subsequent epochs, we compute the Euclidean distance between cluster centroids and the embedded vector to efficiently assign/update the clustering outcome. Since the computation of the optimal clustering coefficient and the assignment of an incoming client model to an existing group are performed asynchronously to the model aggregation, the communication bandwidth of the federated server is not affected. This live computation of client's cluster, given in Algorithm 1, simultaneously supports model scalability and efficiency.
Finally, the asynchronous capability of the server allows us to update the semantic sampler model and recompute the effective number of clusters. This is achieved completely independently without incurring any overhead on communication bandwidth between the server and the clients. The dynamic nature of ReFRS architecture enables any clustering algorithm to be substituted.
5.3. Aggregator
Each client model at the server side is assigned a specific cluster by the clustering unit. The aggregator is responsible for aggregating all the model parameters on each individual cluster and sending the respective aggregated model to the client upon request. When the server receives a client’s model parameters, it processes them as explained in Section 5.2. Once the cluster id is obtained, the model parameter and cluster id is fed as input to the aggregator.
Model parameters, received by the server are aggregated via lines 3-5 of Algorithm 2 and distributed back to the respective clients. In order to asynchronously update clusters on the server side, we keep a copy of the last shared client models. The server updates the clusters after every two global epochs.
6. Privacy Protection
FL assures users some level of privacy since the data is not directly sent to the central server (McMahan et al., 2017). However, it is still possible to infer some information from the shared model parameters by the client. Therefore, a privacy mechanism is still needed to protect user information. In our work, we discuss and demonstrate the compatibility of ReFRS with two widely adopted privacy mechanisms i.e., Differentially Private (DP) Stochastic Gradient Descent SGD and Homomorphic Encryption (HE).
6.1. Differentially Private (DP) SGD
As a result of its strong privacy guarantees, DP has been widely adopted in FL settings as a privacy mechanism. If some information from a dataset is publicly available, DP can address the privacy leakage of data belonging to an individual. To provide privacy, most DP mechanisms add an independent random noise component to available data (Kim et al., 2021). By working only on the final parameters, it is possible to protect the privacy of training data. Unfortunately, it may not be possible to directly determine how these parameters are dependent on the training data; if the parameters are overly noisy, the worst-case analysis would undermine the usefulness of the learned model. We take the sophisticated approach of attempting to control the influence of the training data during the training process, specifically in the SGD computation. Several previous works have adopted this approach (e.g., (Song et al., 2013; Bassily et al., 2014)). To compute the SGD-DP, each step of the procedure computes the gradient for a random subset of examples, clips the norm of each gradient, computes the average, adds noise for privacy, and takes a step in the opposite direction of the average noisy gradient.
6.2. Homomorphic Encryption (HE)
As opposed to traditional cryptographic schemes, HE allows certain operations like addition, multiplication, and so forth to be performed directly over encrypted data without the need for decryption. When decrypted, computations produce the same results as if performed on unencrypted data. A homomorphic scheme is one that satisfies the following equation:
| (9) |
here, and are the model parameters from client 1 and 2 at the server side, represents the mathematical operation performed between the parameters and represents encryption algorithm. The most commonly are partially homomorphic encryption (PHE) (Morris, 2013), somewhat homomorphic (SHE) (Boneh et al., 2013), and fully homomorphic (FHE) (Brakerski et al., 2014). As we need to aggregate encrypted models with a federated setting, we use a fully homomorphic HE scheme (FHE) that offers support for an unbounded number of additive and multiplicative operations. To construct FHE structures, we apply Cheon-Kim-Kim-Song’s (CKKS) (Cheon et al., 2017) algorithm, which depends on the hardness of Learning-With-Error (LWE) (Regev, 2009). With CKKS, we can approximate arithmetic on real and floating point numbers.
7. Evaluation
In this section, we evaluate the proposed ReFRS framework in terms of recommendation quality and scalability. Particularly, we aim to investigate the following research questions (RQs) :
-
RQ1:
How effective ReFRS is compared with state-of-the-art federated recommenders?
-
RQ2:
Can ReFRS protect user privacy while offering accurate recommendations?
-
RQ3:
How is the recommendation quality of ReFRS compared with fully centralized counterparts?
-
RQ4:
What are the contributions of the key components of ReFRS?
-
RQ5:
How well the asynchronous clustering adjusts to scalability, as more clients are introduced?
-
RQ6:
What are the memory and computation requirements of ReFRS?
7.1. Datasets
We leverage large-scale datasets where each user would have multiple interactions with items for experimentation. Hence we adopted two publicly available datasets ”MovieLens 20M” (ML 20M) (Harper and Konstan, 2015) and ”Last.fm 360K” (FM 2306K) (Celma, 2010). MovieLens 20M contains 20 million interaction records for 162,000 users with a rating density of 0.52%. Here rating density means ”how many items in the dataset were rated by each user”. Last.fm dataset contains 17,559,530 interactions (tracks played) by 359,347 users, with a track played density of 0.016%. Smaller subsets of these datasets have been widely adopted by centralized recommendation literature/research (Kang and McAuley, 2018; Craw et al., 2015). The key characteristics of both datasets are summarized in Table 2. Using a smaller sample of the original dataset, we evaluate our client’s embedding model against state-of-the-art embedding models in a centralized setting. Detailed information about the smaller subsets can be found in Table 6, where MovieLens dataset is limited to 100,000 interactions, and Last.fm to 52,551. We first split the datasets into temporally sequential chunks in order to simulate sequential recommendations. Because the models must be deployed on resource-constrained end-devices, we build small sessions, each consisting of 50 interactions.
| Dataset | Interactions | Users | Items | Density | Domain |
|---|---|---|---|---|---|
| ML 20M | 20,000,263 | 138,493 | 27,278 | 0.52% | film |
| FM 360K | 17,559,530 | 359,347 | 17,632 | 0.016% | music |
7.2. Evaluation Criteria
To efficiently evaluate the performance in our experimentation, we use the widely adopted ”leave-one-out” (Deshpande and Karypis, 2004) strategy. The latest interaction sequences of each user are held-out for testing, while all previous interaction sequences are used for training. The performance of ranked items is evaluated using Hit Ratio @10 (HR@10) and Normalized Discounted Cumulative Gain @10 (NDCG@10) (Wang et al., 2010; Yu et al., 2019; Sun et al., 2020; Chen et al., 2020). In sequential RS settings, HR@10 (Equation 10) is simply the number of times that the ground truth item appears among the top-10 recommendations.
| (10) |
where is the correct number of hits among ten predictions. NDCG (Equation 13) is simply the normalization of DCG@10 (Equation 11) score with IDCG@10 (Equation 12) score. DCG penalizes relevant items being placed at the bottom and IDCG is the ideal ranking of items in descending order, according their relevance up to position 10.
| (11) |
| (12) |
| (13) |
where is the relevance score for item and represents the ideal list of items. We calculate both metrics for each client’s test data and report the average score among them.
7.3. Implementation Details
Our implementation generally consists of the clients and a central server. The structure of client models is similar for each user and the embedding dimension for each client is set to 16. The VAE of the client’s embedding model consists of two convolution layers (Tang and Wang, 2018) with filter sizes of 32, 16 and the kernel size of 2. We restrict the approximation of the posterior using independent gaussians distribution. We test our model by setting the sequence window of multiple sizes, however since the number of interactions available for most users were low, we keep and the session size is kept at 100. For the recommender at the client side, any state-of-the-art model can be adopted. In our work we used GRU4Rec (Hidasi et al., 2016) and SASRec (Kang and McAuley, 2018) for two reasons. Firstly, they are the most widely adopted SRSs, Secondly, the technologies suggested by these frameworks i.e., GRU and the transformer, are widely adopted in variations by other state-of-the-art SRSs.
The VAE model used by the semantic sampler, at the server side, consists of two convolution layers (64,32) and three dense layers (16 units each). On the server side standard Gaussian distribution is used. Using the Elbow method, we determine the optimal number of clusters by setting between 1 and 100. Initially, 1,000 users were used to train the semantic sampler.
7.4. Baselines
We evaluate the performance of ReFRS against three main baselines, using the large-scale datasets. Hyper-parameter settings for these federated baselines frameworks, including ReFRS are given in Table 3.
| Model | #Clusters | Client Epoch | Optimization | ||
|---|---|---|---|---|---|
| FedAvg | 1 | 50 | 10 | 0.01 | SGD |
| FedFast | 10 | 50 | 10 | 0.01 | SGD |
| FRS-1 | 0 | 50 | 0 | 0.01 | SGD |
| FRS-2 | 1 | 50 | 10 | 0.01 | SGD |
| ReFRS-GRU4Rec | dynamic | 50 | 10 | 0.01 | SGD |
| ReFRS-SASRec | dynamic | 50 | 10 | 0.01 | SGD |
- •
-
•
FedFast (Muhammad et al., 2020): This method accelerates FRS tasks by applying an active aggregation method that propagates the updated models to similar clients. Each client contains multiple users, which are clustered based upon user similarity information. GMF (He et al., 2017) is used for the client model.
-
•
Federated Recommendation System-1 (FRS-1) : FRS-1 is the basic setting of ReFRS. It consists of a client model, using GRU4Rec as a recommender. Here, the client learns recommendations for each user separately, without the guidance of a federated server.
-
•
Federated Recommendation System-2 (FRS-2) : FRS-2 is the second basic setting of ReFRS, in which the federated server adopts FedAvg to aggregate shared models into a single global model. The client uses GRU4Rec as a recommender in FRS-2.
-
•
FedAvg-GRU4Rec : This setting adopts FedAvg algorithm to enable decentralized learning of GRU4Rec (Hidasi et al., 2015) algorithm. GRU4Rec utilizes GRU layers to model user interaction sequences per session.
-
•
FedAvg-SASRec : This setting adopts FedAvg algorithm to enable decentralized learning of SASRec (Kang and McAuley, 2018) algorithm. SASRec uses multi-head attention in order to recommend the next item.
-
•
FedFast-GRU4Rec : This setting of FedFast adopts GRU4Rec as the recommender model.
-
•
FedFast-SASRec : This setting of FedFast adopts SASRec as the recommender model.
-
•
ReFRS-GRU4Rec : This setting of ReFRS adopts GRU4Rec to compute next item recommendation.
-
•
ReFRS-SASRec : This setting of ReFRS adopts SASRec as the recommender model.
To show the effectiveness of ReFRS’s client module, we also compare it against the following state-of-the-art centralized sequential recommender models, using smaller datasets. All hyper-parameters are set following the original papers.
-
•
AutoInt (Song et al., 2019) learns feature interactions using the multi-head self-attentive neural network
-
•
GRU4Rec (Hidasi et al., 2015) utilizes GRU layers to model user interaction sequences per session.
-
•
Caser (Tang and Wang, 2018) uses horizontal and vertical convolutional to capture high-order Markov Chains.
-
•
SASRec (Kang and McAuley, 2018) uses multi-head attention in order recommend next item, for sequential recommendation task.
-
•
BERT4Rec (Sun et al., 2019) adopts a Cloze objective loss, on top of bidirectional self-attention mechanism, for sequential recommendation task.
-
•
HGN (Ma et al., 2019) uses hierarchical gated networks for capturing both long-term and short-term user interests.
-
•
FDSA (Zhang et al., 2019) generates feature sequences and model’s feature transition patterns using a feature level self-attention block.
-
•
-Rec (Zhou et al., 2020) utilize the intrinsic data correlation to derive self-supervision signals and enhance the data representations via per-training. All hyper-parameters are set following the suggestions from the original papers.
7.5. RQ-1: Performance Comparison on Large-scale Datasets
| FedAvg | FedFast | FedAvg | FedFast | ReFRS | |||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | GMF | GMF | GRU4Rec | SASRec | GRU4Rec | SASRec | GRU4Rec | SASRec | |
| ML-10% | HR@10 | 0.4526 | 0.5612 | 0.4930 | 0.5298 | 0.5733 | 0.6160 | 0.6164 | 0.6624 |
| NDCG@10 | 0.2716 | 0.3404 | 0.3017 | 0.4047 | 0.3508 | 0.4706 | 0.3772 | 0.5060 | |
| ML-20% | HR@10 | 0.3998 | 0.5520 | 0.4488 | 0.4856 | 0.5219 | 0.5647 | 0.5612 | 0.6072 |
| NDCG@10 | 0.1811 | 0.2576 | 0.2796 | 0.3605 | 0.3251 | 0.4192 | 0.3496 | 0.4508 | |
| ML-30% | HR@10 | 0.3168 | 0.4784 | 0.3973 | 0.4341 | 0.4620 | 0.5048 | 0.4968 | 0.5428 |
| NDCG@10 | 0.1433 | 0.2116 | 0.2281 | 0.2943 | 0.2652 | 0.3422 | 0.2852 | 0.3680 | |
| ML-40% | HR@10 | 0.1735 | 0.3220 | 0.3017 | 0.3458 | 0.3508 | 0.4021 | 0.3772 | 0.4324 |
| NDCG@10 | 0.0830 | 0.1288 | 0.1913 | 0.2649 | 0.2225 | 0.3080 | 0.2392 | 0.3312 | |
| ML-50% | HR@10 | 0.0905 | 0.1932 | 0.2207 | 0.2649 | 0.2567 | 0.3080 | 0.2760 | 0.3312 |
| NDCG | 0.0528 | 0.0920 | 0.1104 | 0.1619 | 0.1283 | 0.1882 | 0.1380 | 0.2024 | |
| ML-100% | HR@10 | 0.0604 | 0.1564 | 0.1692 | 0.1987 | 0.1968 | 0.2310 | 0.2116 | 0.2484 |
| NDCG@10 | 0.0075 | 0.0460 | 0.0662 | 0.0957 | 0.0770 | 0.1112 | 0.0828 | 0.1196 | |
| FM-10% | HR@10 | 0.4602 | 0.5704 | 0.4562 | 0.5077 | 0.5305 | 0.5904 | 0.5704 | 0.6348 |
| NDCG@10 | 0.3093 | 0.4140 | 0.3311 | 0.4121 | 0.3850 | 0.4791 | 0.4140 | 0.5152 | |
| FM-20% | HR@10 | 0.2490 | 0.3588 | 0.3900 | 0.4341 | 0.4535 | 0.5048 | 0.4876 | 0.5428 |
| NDCG@10 | 0.1358 | 0.2116 | 0.2649 | 0.3017 | 0.3080 | 0.3508 | 0.3312 | 0.3772 | |
| FM-30% | HR@10 | 0.1961 | 0.2944 | 0.3753 | 0.4047 | 0.4364 | 0.4706 | 0.4692 | 0.5060 |
| NDCG@10 | 0.1132 | 0.1564 | 0.2428 | 0.2870 | 0.2823 | 0.3337 | 0.3036 | 0.3588 | |
| FM-40% | HR@10 | 0.1811 | 0.2576 | 0.2796 | 0.3017 | 0.3251 | 0.3508 | 0.3496 | 0.3772 |
| NDCG@10 | 0.0453 | 0.1012 | 0.1545 | 0.1692 | 0.1797 | 0.1968 | 0.1932 | 0.2116 | |
| FM-50% | HR@10 | 0.1282 | 0.1932 | 0.2281 | 0.2428 | 0.2652 | 0.2823 | 0.2852 | 0.3036 |
| NDCG@10 | 0.0075 | 0.0552 | 0.1104 | 0.1472 | 0.1283 | 0.1711 | 0.1380 | 0.1840 | |
| FM-100% | HR@10 | 0.0604 | 0.1380 | 0.1251 | 0.1324 | 0.1455 | 0.1540 | 0.1564 | 0.1656 |
| NDCG@10 | 0.0000 | 0.0092 | 0.0589 | 0.0809 | 0.0684 | 0.0941 | 0.0736 | 0.1012 | |
We evaluate the performance of ReFRS in federated settings against FedAvg and FedFast. In order the effectiveness of our embedding method we upscale the basic General Matrix Factorization (GMF) based recommender approch adopted by FedFast and FedAvg. We replace basic GMF model by state-of-the-art GRU4Rec (Hidasi et al., 2015) and SASRec (Kang and McAuley, 2018) models. In our work we use GRU4Rec and SASRec since they are most widely adopted SRSs. In addition the learning mechanism proposed by these frameworks i.e., GRU and the transformer, are widly adopted in different variations by other state-of-the-art SRS.
In contrast to the FedFast paper, (Muhammad et al., 2020), which uses a small-scale dataset to evaluate their semantic models, in our work we use datasets that are over 200 percent larger. This approach tests the scalability of the proposed frameworks and simulates the real world better. This experiment evaluates the performance of all baselines as the number of client devices are increased. We divide ML and FM datasets into subsets containing 10%, 20%, 30%, 40%, 50% and 100% of the actual users. These subsets are generated at random. The HR@10 and NDCG@10 scores of ReFRS against all the base lines are given in Table 4.
In Table 4 all settings of the FedAvg algorithm constantly under performs our proposed approach. This is because, a large number of users in our datasets do not have enough interactions for the RS to effectively predict user’s long term interests and change in interaction patterns. This lack of interaction data in a large number of users causes lower performance of the global model as all user models are aggregated together. Global generalization of models improves the performance in the case of FedFast. However, since their model generalization is based upon aggregating models of users with similar Bios, they fail to outperform both settings ReFRS which groups users based upon model parameters. This shows that the semantic sampler in ReFRS maps similarly behaving user models close in the embedding space. ReFRS with SASRec performs better than GRU4Rec, indicating that attention-based techniques more accurately synthesize user behavior from embeddings, than recurrent neural networks. Note, shared model gradients do not provide any information regarding user behavior, rather each gradients only carry some effect on the input sequence (Sundararajan et al., 2017) (models with similar gradients will have the same effect). Hence, no personal information is leaked at the server side.
7.6. RQ-2: Effects of Privacy on Performance
FL assures users some level of privacy since the data is not directly sent to the central server (McMahan et al., 2017). However, it is still possible to infer some information from the shared model parameters by the client. This may lead to the leakage of sensitive or private information. For this reason, to the effect of different privacy mechanisms on ReFRS, we adopt two widely used privacy mechanisms i.e., Differentially Private (DP) Stochastic Gradient Descent SGD and Homomorphic Encryption (HE). The DP noise multiplier is adjusted to regulate the amount of noise added during training. As a general rule, more noise corresponds to better privacy and less utility. In our experiments and to obtain rigorous privacy guarantees (Balle and Wang, 2018), the value is set to 0.3. We evaluate the performance of ReFRS-GRU4Rec and ReFRS-SASRec using both encryption mechanisms.
| DP-SGD | HE | ||||
|---|---|---|---|---|---|
| Dataset | Matrices | ReFRS-GRU4Rec | ReFRS-SASRec | ReFRS-GRU4Rec | ReFRS-SASRec |
| ML-10% | HR@10 | 0.4095 | 0.4459 | 0.6164 | 0.6624 |
| NDCG@10 | 0.2366 | 0.2821 | 0.3772 | 0.5060 | |
| ML-20% | HR@10 | 0.3640 | 0.4186 | 0.5612 | 0.6072 |
| NDCG@10 | 0.2912 | 0.3367 | 0.3496 | 0.4508 | |
| ML-30% | HR@10 | 0.3185 | 0.3549 | 0.4968 | 0.5428 |
| NDCG@10 | 0.2366 | 0.2639 | 0.2852 | 0.3680 | |
| ML-40% | HR@10 | 0.3003 | 0.3458 | 0.3772 | 0.4324 |
| NDCG@10 | 0.1729 | 0.1911 | 0.2392 | 0.3312 | |
| ML-50% | HR@10 | 0.2275 | 0.2548 | 0.2760 | 0.3312 |
| NDCG | 0.0819 | 0.1001 | 0.1380 | 0.2024 | |
| ML-100% | HR@10 | 0.1911 | 0.1911 | 0.2116 | 0.2484 |
| NDCG@10 | 0.0455 | 0.0637 | 0.0828 | 0.1196 | |
| FM-10% | HR@10 | 0.5005 | 0.5278 | 0.5704 | 0.6348 |
| NDCG@10 | 0.3094 | 0.3367 | 0.4140 | 0.5152 | |
| FM-20% | HR@10 | 0.4277 | 0.4641 | 0.4876 | 0.5428 |
| NDCG@10 | 0.2548 | 0.2912 | 0.3312 | 0.3772 | |
| FM-30% | HR@10 | 0.3731 | 0.3913 | 0.4692 | 0.5060 |
| NDCG@10 | 0.2093 | 0.2275 | 0.3036 | 0.3588 | |
| FM-40% | HR@10 | 0.3003 | 0.3367 | 0.3496 | 0.3772 |
| NDCG@10 | 0.1274 | 0.1638 | 0.1932 | 0.2116 | |
| FM-50% | HR@10 | 0.2366 | 0.2639 | 0.2852 | 0.3036 |
| NDCG@10 | 0.0728 | 0.1183 | 0.1380 | 0.1840 | |
| FM-100% | HR@10 | 0.1183 | 0.1365 | 0.1564 | 0.1656 |
| NDCG@10 | 0.0546 | 0.0637 | 0.0736 | 0.1012 | |
Table 5 shows the effect of DP-SGD and HE on our framework. The results show degradation in the results when DP-SGD is used. This is because the inclusion of noise during training of the client model in DP-SGD, makes the reconstruction task inaccurate. In addition, the noisy model parameter makes the semantic server improperly group client models. Therefore, the model fails to capture valuable client interaction patterns. However, in the case of HE a secure message is sent to the server, on which mathematical operations can be performed precisely. This does not effect either the client model or the semantic server. Hence, we suggest HE should be adopted as encryption mechanism when semantic sampling is evolved at the server side. The key sharing strategy adopted here is the same as in federated learning literature i.e. the private key distributed to each client is the same, distributed by a third party (unknown by the server and top-level clients).
7.7. RQ-3: Effectiveness against Centralized Models
ReFRS is designed for federated settings, where the central server has no user interaction data available. However, in order to further demonstrate the effectiveness of ReFRS’s client model, we compare it against state-of-the-art centralized SRSs. For this experiment we test the recommendation performance of ReFRS using SASRec as the recommender model of our client model. We select two smaller subsets of the previously adopted datasets i.e., MovieLens 100K (ML 100K) and Last.fm 1K (FM 1K) and evaluate performance of ReFRS against state state-of-the-art centralized SRSs. ML 100K contains 100,000 interactions of 1,682 users on 943 items, while FM 1K have 52,551 interactions of 1,090 users on 3,646 items.
The statistics of the datasets are given in Table 6.
| Dataset | Users | Items | Interactions |
|---|---|---|---|
| MovieLens 100K | 1,682 | 943 | 100,000 |
| Last.fm 1k | 1,090 | 3,646 | 52,551 |
| Datasets | Matrix | AutoInt | GRU4Rec | Caser | SASRec | BERT4Rec | HGN | FDSA | -Rec | ReFRS | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ML 100K | HR@1 | 0.0731 | 0.2092 | 0.2194 | 0.2351 | 0.2863 | 0.2428 | 0.2198 | 0.2091 | 0.3001 | |
| HR@5 | 0.2249 | 0.5103 | 0.5353 | 0.5434 | 0.5876 | 0.5768 | 0.5728 | 0.5885 | 0.5897 | ||
| HR@10 | 0.3367 | 0.6351 | 0.6692 | 0.6629 | 0.697 | 0.7411 | 0.7555 | 0.6725 | 0.7565 | ||
| NDCG@5 | 0.1501 | 0.3705 | 0.3832 | 0.398 | 0.4454 | 0.4162 | 0.4014 | 0.3401 | 0.4522 | ||
| NDCG@10 | 0.186 | 0.4064 | 0.4268 | 0.4368 | 0.4818 | 0.4695 | 0.4607 | 0.3934 | 0.4851 | ||
| FM 1k | HR@1 | 0.0349 | 0.0642 | 0.0899 | 0.1211 | 0.122 | 0.0908 | 0.0936 | 0.1743 | 0.1753 | |
| HR@5 | 0.155 | 0.1817 | 0.2982 | 0.3385 | 0.3569 | 0.2872 | 0.2624 | 0.4523 | 0.4530 | ||
| HR@10 | 0.2596 | 0.2817 | 0.4431 | 0.4706 | 0.4991 | 0.4193 | 0.4055 | 0.5535 | 0.5447 | ||
| NDCG@5 | 0.0946 | 0.1228 | 0.196 | 0.233 | 0.2409 | 0.1896 | 0.1766 | 0.3156 | 0.3174 | ||
| NDCG@10 | 0.1285 | 0.155 | 0.2428 | 0.2755 | 0.2871 | 0.2324 | 0.2225 | 0.3583 | 0.3566 |
Table 7 shows that our model performs comparably to state-of-the-art centralized SRSs. This is because the recommender model on each mobile device is personalized, which can effectively address the issues of biases in the centralized models. Central models are often critiqued as being “single thought” models that favors only the users with rich interaction data, leading to unsatisfactory performance for the long-tail users. Traditional centralized machine learning relies mainly on generic models: models tuned to an average target population. However, the ’good’ performance by these generic models does not necessarily translate to each individual. For MovieLens dataset, BERT4Rec performs comparably to our model. This shows that our model can also capture repeated behaviours (rating similar genre movies) of users in the ML dataset. For the Last.fm dataset, where the users’ interest evolve over time, ReFRS along with -Rec are able to effectively capture higher-order interaction behaviors.
7.8. RQ-4: Ablation Study of the key components of ReFRS
7.8.1. Ablation Study of Client Module
This study aims to demonstrate how the ablation of the client model affects the accuracy and size of the model. We perform the ablation study of our proposed embedding (client) module by removing various layers from the proposed generative model and testing the Hit@10 ratio. For this study, we compare the embedding model of our proposed ReFRS, which has VQ-VAE reinforced by a multi-head attention layer, against a simple VAE model and VQ-VAE model. For consistent experimentation, we test all models on both MovieLens and Last.fm datasets and report the ablated models’ performance as their average.



As depicted in Figure 4(a) and Figure 4(b), our proposed attention guided embedding method outperforms simple VAE and VQ-VAE. This is because our method produces guided embeddings, which enhance similar and repeated interactions and diminish arbitrary ones. Figure 4(a) and Figure 4(b) also show that the Hit@10 starts to stabilize when the embedding size reaches 16. As a result, our model’s embedding size was set to 16 to meet the resource-efficient requirement. We can see from the Figure 4(c) that adding VQ and attention layers with (16) embedding size does not lead to a considerable memory overhead, as compared to baselines.
7.8.2. Ablation Study of Server Module
Note that unlike GMF-based FedFast or FedAvg, ReFRS operates in a sequential fashion. Hence, we divide the input streams into sessions of new interactions, added every global epoch. To verify the effectiveness and efficiency of the federated component at each global epoch, we carry out ablation study of ReFRS, on the same large-scale datasets.

We test the effectiveness and efficiency of our proposed semantic similarity based grouping against FRS-1, which is the basic setting of ReFRS with federated component removed and FRS-2 which aggregates all the client models using simple FedAvg.
To show comparability of neural federated system of ReFRS in efficiency, against FRS-1 and FRS-2, we train each framework for four global epochs, on four sessions of data. Global updates in Figure 5 represent the time taken by the slowest worker to converge for five local training session, updating to the federated server and receiving the aggregated model back on the client. For each user, this involves feature sampling, embedding client models, recommending times, and server aggregation.
For FRS-1, global update represents convergence of the slowest local model for five local training session. In Figure 5 we can see that after the first global update, where the global model is trained from scratch, the time efficiency for all there epochs is comparable with FRS-2. This is because the global model is updated asynchronously after its initialization during the first epoch. We also compare the quality of these settings by altering the number of users in training. As shown in Table 4 and Figure 6, although FRS-1 has a quicker training time, ReFRS outperforms both FRS-1 and FRS-2 for recommendation quality. These results clearly indicate the importance of diversity in the recommendation process, which is key objective of ReFRS. FM dataset takes more training time because of the larger amount of input features of items.

7.9. RQ-5: Server Scalability
In real-time simulation settings, input into the client model are the next stream of user interactions. With the inclusion of new user interactions or new user clients, global groupings of client models are updated. Figure 7 shows the dynamic update of user grouping as the latest sequences of interactions for each user are added. Changes in the number of clusters over time by the ReFRS server depicts its adaptability to change and acceptance to scalability. ReFRS dynamically caters new interactions, as well as introduction of new clients.

7.10. RQ-6: Memory and Computation Requirements of ReFRS
| FedAvg | FedFast | ReFRS | |
| Number of Embedded Vectors Stored | 18K-28K | 18K-28K | 100 |
| Avg. Size of embedding File | 2.43MB-3.78MB | 2.43MB-3.78MB | 270KB |
| Total Number of Model Parameters | 35,564 | 35,564 | 50,239 |
| Avg. Computation Time (for Single Batch) | 45 min | 45 min | 3s |
| Embedding Dimensions | 8 | 8 | 16 |
An end-device’s memory and computation power must be taken into account when running a deep learning model. Apart from battery consumption, there are three aspects to consider here: the amount of space the model takes up in your app bundle (number of items to be stored at a time and the space taken by their embedded vectors), the amount of memory it uses at runtime (total number of parameters), and how fast the model runs. Table 8 shows the average on device memory consumption of ReFRS against GMF based FRS. The computation time represents the time taken by the client embedding module for a single batch training. Simulations of our experiments used CPUs with 2.2 GHz processing power, which is equal to any CPU found on most common android devices. Since ReFRS actively swaps in new interaction sessions with the old ones and does not require a full list of embedded items to update the client model, its memory consumption is far less than any other GMF-based federated model.
8. Discussion
In this paper we proposed a federated recommendation system for end-user device that trains local models on user behavior, aggregates those models in a federated settings while taking into account user’s behavioral diversity. There are two main parts to our proposed architecture, a decentralized client module and a semantic server. Using a federated server, the ReFRS client model aims to learns the user’s interests and interaction behaviors. The federated server helps in accelerating the convergence of the client model using semantically aggregated user models.
The ReFRS client model capture users’ interaction behavior by developing such a generative model that mimics users’ interactions and builds interpretable vector representations. The goal of the client model is to learn compact vector representations (i.e., embeddings) of the interaction window in the latent space, that group semantically similar items together to capture the temporal and contextual relationships between the interacted items. As a result of this representation, item-sequence relationships should be effectively captured and items that are contextually and temporally similar should be grouped together. To avoid storing all item information on the edge device for recommendation, we use a sequential approach where interactions are processed in sessions. These sessions are kept small to fit into limited memory efficiently, and old sessions are swapped out to maximize memory utilization. As we generate meaningful lightweight vectors, in this work we make use of state-of-the-art recommender models for the next item suggestion. A major advantage of our client model is that it can effectively handle sparse data and convert it into a size constrained discrete vector representation.
To overcome the non-i.i.d. nature of individual user data, we propose a semantic server that utilizes an efficient grouping scheme that only aggregates semantically similar client models. Rather than grouping clients by requesting and comparing all users’ sensitive information like demographic data (Muhammad et al., 2020), our proposed method utilize a neural approach to efficiently capture user affinity by simply looking at the model parameters submitted by each client. We also enable the server to asynchronously update client groupings as the user interaction behavior changes over time. Our sever-side design has three parts, namely a semantic sampler, a clustering unit and a model aggregator, which we will describe below.
We conducted extensive experiments to demonstrate the effectiveness of our proposed method in both federated and centralized settings. In addition, we show the effects of applying Differentially Private Stochastic Gradient Descent and Homomorphic Encryption on the shared parameters and recommend using Homomorphic Encryption to support semantic grouping.
ReFRS solves the cold start, single-user client, and privacy issues with FedFast, but it incurs some security overheads. In particular, the client’s model parameter does convey an idea about grouping when viewed with others. Grouping clients with known information will provide insight into other members of the group. For future work, we focus on a more web 3.0 friendly SRS i.e. server-less architecture. Rather than being supported by a central server, Web 3.0 apps are built on blockchain, completely decentralized networks of peer-to-peer nodes, or a combination of both. Hence, the client is no longer reliant on a central party to decide on grouping. In the future, it is vital to explore strategies that can link the proposed decentralized to a server-less architecture.
9. Conclusion
We conclude that ReFRS is a promising federated recommendation system that provides user diversity, while preserving user privacy. Unlike other existing methods, ReFRS is highly effective even when dealing with single user-client recommendations. ReFRS is an FRS designed for edge devices with limited resources that capture diversified user behavior in a decentralized manner. Its main advantages are that it is lightweight, handles data sparsity, captures changes in user behavior, and considers heterogeneity in local models during the global update. This is a more practical paradigm for learning distributed recommender models. Due to asynchronicity and neural nature of its federated server, ReFRS is highly efficient and scaleable to accommodate heterogeneous clients.
Acknowledgement
This work is supported by Australian Research Council (Grant No. FT210100624 and DP190101985) and The University of Queensland (Grant No. NS-2103).
References
- (1)
- Adomavicius and Tuzhilin (2005) Gediminas Adomavicius and Alexander Tuzhilin. 2005. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE transactions on knowledge and data engineering 17, 6 (2005), 734–749.
- Adomavicius and Tuzhilin (2011) Gediminas Adomavicius and Alexander Tuzhilin. 2011. Context-aware recommender systems. In Recommender systems handbook. Springer, 217–253.
- Ali et al. (2021) Waqar Ali, Rajesh Kumar, Zhiyi Deng, Yansong Wang, and Jie Shao. 2021. A Federated Learning Approach for Privacy Protection in Context-Aware Recommender Systems. Comput. J. (2021).
- Ammad-Ud-Din et al. (2019) Muhammad Ammad-Ud-Din, Elena Ivannikova, Suleiman A Khan, Were Oyomno, Qiang Fu, Kuan Eeik Tan, and Adrian Flanagan. 2019. Federated collaborative filtering for privacy-preserving personalized recommendation system. arXiv preprint arXiv:1901.09888 (2019).
- Awad and Krishnan (2006) Naveen Farag Awad and Mayuram S Krishnan. 2006. The personalization privacy paradox: an empirical evaluation of information transparency and the willingness to be profiled online for personalization. MIS quarterly (2006), 13–28.
- Balle and Wang (2018) Borja Balle and Yu-Xiang Wang. 2018. Improving the Gaussian mechanism for differential privacy: Analytical calibration and optimal denoising. In International Conference on Machine Learning. PMLR, 394–403.
- Bassily et al. (2014) Raef Bassily, Adam Smith, and Abhradeep Thakurta. 2014. Private empirical risk minimization: Efficient algorithms and tight error bounds. In 2014 IEEE 55th Annual Symposium on Foundations of Computer Science. IEEE, 464–473.
- Bateni et al. (2017) Mohammad Hossein Bateni, Soheil Behnezhad, Mahsa Derakhshan, Mohammad Taghi Hajiaghayi, Raimondas Kiveris, Silvio Lattanzi, and Vahab Mirrokni. 2017. Affinity clustering: Hierarchical clustering at scale. In Proceedings of the 31st International Conference on Neural Information Processing Systems. 6867–6877.
- Bonawitz et al. (2017) Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. 2017. Practical secure aggregation for privacy-preserving machine learning. In proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. 1175–1191.
- Boneh et al. (2013) Dan Boneh, Craig Gentry, Shai Halevi, Frank Wang, and David J Wu. 2013. Private database queries using somewhat homomorphic encryption. In International Conference on Applied Cryptography and Network Security. Springer, 102–118.
- Brakerski et al. (2014) Zvika Brakerski, Craig Gentry, and Vinod Vaikuntanathan. 2014. (Leveled) fully homomorphic encryption without bootstrapping. ACM Transactions on Computation Theory (TOCT) 6, 3 (2014), 1–36.
- Burke (2000) Robin Burke. 2000. Knowledge-based recommender systems. Encyclopedia of library and information systems 69, Supplement 32 (2000), 175–186.
- Carlini et al. (2019) Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. 2019. The secret sharer: Evaluating and testing unintended memorization in neural networks. In 28th USENIX Security Symposium (USENIX Security 19). 267–284.
- Celma (2010) O. Celma. 2010. Music Recommendation and Discovery in the Long Tail. Springer.
- Chai et al. (2020) Di Chai, Leye Wang, Kai Chen, and Qiang Yang. 2020. Secure Federated Matrix Factorization. IEEE Intelligent Systems (2020), 1–1. https://doi.org/10.1109/MIS.2020.3014880
- Chen et al. (2018) Fei Chen, Mi Luo, Zhenhua Dong, Zhenguo Li, and Xiuqiang He. 2018. Federated meta-learning with fast convergence and efficient communication. arXiv preprint arXiv:1802.07876 (2018).
- Chen et al. (2019) Tong Chen, Hongzhi Yin, Hongxu Chen, Rui Yan, Quoc Viet Hung Nguyen, and Xue Li. 2019. Air: Attentional intention-aware recommender systems. In 2019 IEEE 35th International Conference on Data Engineering (ICDE). IEEE, 304–315.
- Chen et al. (2020) Tong Chen, Hongzhi Yin, Quoc Viet Hung Nguyen, Wen-Chih Peng, Xue Li, and Xiaofang Zhou. 2020. Sequence-aware factorization machines for temporal predictive analytics. In 2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 1405–1416.
- Chen et al. (2021) Tong Chen, Hongzhi Yin, Yujia Zheng, Zi Huang, Yang Wang, and Meng Wang. 2021. Learning elastic embeddings for customizing on-device recommenders. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 138–147.
- Cheng et al. (2021) Kewei Cheng, Tao Fan, Yilun Jin, Yang Liu, Tianjian Chen, Dimitrios Papadopoulos, and Qiang Yang. 2021. Secureboost: A lossless federated learning framework. IEEE Intelligent Systems (2021).
- Cheon et al. (2017) Jung Hee Cheon, Andrey Kim, Miran Kim, and Yongsoo Song. 2017. Homomorphic encryption for arithmetic of approximate numbers. In International Conference on the Theory and Application of Cryptology and Information Security. Springer, 409–437.
- Chorney et al. (2010) Jill MacLaren Chorney, Abbe Marrs Garcia, Kristoffer S Berlin, Roger Bakeman, and Zeev N Kain. 2010. Time-window sequential analysis: An introduction for pediatric psychologists. Journal of pediatric psychology 35, 10 (2010), 1061–1070.
- Craw et al. (2015) Susan Craw, Ben Horsburgh, and Stewart Massie. 2015. Music recommenders: user evaluation without real users?. In Twenty-Fourth International Joint Conference on Artificial Intelligence.
- Dai et al. (2020) Bin Dai, Ziyu Wang, and David Wipf. 2020. The usual suspects? Reassessing blame for VAE posterior collapse. In International Conference on Machine Learning. PMLR, 2313–2322.
- De Amorim and Hennig (2015) Renato Cordeiro De Amorim and Christian Hennig. 2015. Recovering the number of clusters in data sets with noise features using feature rescaling factors. Information sciences 324 (2015), 126–145.
- Deshpande and Karypis (2004) Mukund Deshpande and George Karypis. 2004. Item-based top-n recommendation algorithms. ACM Transactions on Information Systems (TOIS) 22, 1 (2004), 143–177.
- Ghosh et al. (2020) Avishek Ghosh, Jichan Chung, Dong Yin, and Kannan Ramchandran. 2020. An efficient framework for clustered federated learning. Advances in Neural Information Processing Systems 33 (2020), 19586–19597.
- Goldberg et al. (1992) David Goldberg, David Nichols, Brian M Oki, and Douglas Terry. 1992. Using collaborative filtering to weave an information tapestry. Commun. ACM 35, 12 (1992), 61–70.
- Harper and Konstan (2015) F Maxwell Harper and Joseph A Konstan. 2015. The movielens datasets: History and context. Acm transactions on interactive intelligent systems (tiis) 5, 4 (2015), 1–19.
- He and Chu (2010) Jianming He and Wesley W Chu. 2010. A social network-based recommender system (SNRS). In Data mining for social network data. Springer, 47–74.
- He et al. (2017) Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative filtering. In Proceedings of the 26th international conference on world wide web. 173–182.
- Hidasi et al. (2015) Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2015. Session-based recommendations with recurrent neural networks. arXiv preprint arXiv:1511.06939 (2015).
- Hidasi et al. (2016) Balázs Hidasi, Massimo Quadrana, Alexandros Karatzoglou, and Domonkos Tikk. 2016. Parallel recurrent neural network architectures for feature-rich session-based recommendations. In Proceedings of the 10th ACM conference on recommender systems. 241–248.
- Huang et al. (2019) Jin Huang, Zhaochun Ren, Wayne Xin Zhao, Gaole He, Ji-Rong Wen, and Daxiang Dong. 2019. Taxonomy-aware multi-hop reasoning networks for sequential recommendation. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining. 573–581.
- Huang et al. (2018) Jin Huang, Wayne Xin Zhao, Hongjian Dou, Ji-Rong Wen, and Edward Y Chang. 2018. Improving sequential recommendation with knowledge-enhanced memory networks. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 505–514.
- Hung et al. (2017) Nguyen Quoc Viet Hung, Huynh Huu Viet, Nguyen Thanh Tam, Matthias Weidlich, Hongzhi Yin, and Xiaofang Zhou. 2017. Computing crowd consensus with partial agreement. IEEE Transactions on Knowledge and Data Engineering 30, 1 (2017), 1–14.
- Imran et al. (2020) Mubashir Imran, Hongzhi Yin, Tong Chen, Yingxia Shao, Xiangliang Zhang, and Xiaofang Zhou. 2020. Decentralized embedding framework for large-scale networks. In International Conference on Database Systems for Advanced Applications. Springer, 425–441.
- Inoue and Goto (2020) Nakamasa Inoue and Keita Goto. 2020. Semi-supervised contrastive learning with generalized contrastive loss and its application to speaker recognition. In 2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 1641–1646.
- Jia and Lei (2021) Junjie Jia and Zhipeng Lei. 2021. Personalized Recommendation Algorithm for Mobile Based on Federated Matrix Factorization. In Journal of Physics: Conference Series, Vol. 1802. IOP Publishing, 032021.
- Jiang et al. (2021) Zhifeng Jiang, Wei Wang, and Yang Liu. 2021. FLASHE: Additively Symmetric Homomorphic Encryption for Cross-Silo Federated Learning. arXiv preprint arXiv:2109.00675 (2021).
- Jin et al. (2020) Shuning Jin, Sam Wiseman, Karl Stratos, and Karen Livescu. 2020. Discrete Latent Variable Representations for Low-Resource Text Classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020. 4831–4842.
- Jin and Han (2010) Xin Jin and Jiawei Han. 2010. K-Means Clustering. Springer US, Boston, MA, 563–564. https://doi.org/10.1007/978-0-387-30164-8_425
- Kang and McAuley (2018) Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE International Conference on Data Mining (ICDM). IEEE, 197–206.
- Karimireddy et al. (2020) Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. 2020. SCAFFOLD: Stochastic controlled averaging for federated learning. In International Conference on Machine Learning. PMLR, 5132–5143.
- Kendzierskyj et al. (2019) Stefan Kendzierskyj, Hamid Jahankhani, Arshad Jamal, and Jaime Ibarra Jimenez. 2019. The transparency of big data, data harvesting and digital twins. In Blockchain and Clinical Trial. Springer, 139–148.
- Kim et al. (2021) Muah Kim, Onur Günlü, and Rafael F Schaefer. 2021. Federated Learning with Local Differential Privacy: Trade-Offs Between Privacy, Utility, and Communication. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2650–2654.
- Konečnỳ et al. (2016) Jakub Konečnỳ, H Brendan McMahan, Felix X Yu, Peter Richtárik, Ananda Theertha Suresh, and Dave Bacon. 2016. Federated learning: Strategies for improving communication efficiency. arXiv preprint arXiv:1610.05492 (2016).
- Leon et al. (2013) Pedro Giovanni Leon, Blase Ur, Yang Wang, Manya Sleeper, Rebecca Balebako, Richard Shay, Lujo Bauer, Mihai Christodorescu, and Lorrie Faith Cranor. 2013. What matters to users? factors that affect users’ willingness to share information with online advertisers. In Proceedings of the ninth symposium on usable privacy and security. 1–12.
- Li et al. (2021) Yang Li, Tong Chen, Peng-Fei Zhang, and Hongzhi Yin. 2021. Lightweight self-attentive sequential recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 967–977.
- Lin et al. (2020) Yujie Lin, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Dongxiao Yu, Jun Ma, Maarten de Rijke, and Xiuzhen Cheng. 2020. Meta Matrix Factorization for Federated Rating Predictions. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 981–990.
- Liu et al. (2021) Bingyan Liu, Yifeng Cai, Ziqi Zhang, Yuanchun Li, Leye Wang, Ding Li, Yao Guo, and Xiangqun Chen. 2021. DistFL: Distribution-aware Federated Learning for Mobile Scenarios. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 5, 4 (2021), 1–26.
- Liu et al. (2020) Yang Liu, Yan Kang, Chaoping Xing, Tianjian Chen, and Qiang Yang. 2020. A secure federated transfer learning framework. IEEE Intelligent Systems 35, 4 (2020), 70–82.
- Lucas et al. (2019) James Lucas, George Tucker, Roger B Grosse, and Mohammad Norouzi. 2019. Don’t blame the Elbo! a linear Vae perspective on posterior collapse. Advances in Neural Information Processing Systems 32 (2019), 9408–9418.
- Ma et al. (2019) Chen Ma, Peng Kang, and Xue Liu. 2019. Hierarchical gating networks for sequential recommendation. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 825–833.
- Masthoff (2011) Judith Masthoff. 2011. Group recommender systems: Combining individual models. In Recommender systems handbook. Springer, 677–702.
- McMahan et al. (2017) Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep networks from decentralized data. In AISTATS. 1273–1282.
- Mescheder et al. (2017) Lars Mescheder, Sebastian Nowozin, and Andreas Geiger. 2017. Adversarial variational bayes: Unifying variational autoencoders and generative adversarial networks. In International Conference on Machine Learning. PMLR, 2391–2400.
- Mobasher et al. (2002) Bamshad Mobasher, Honghua Dai, Tao Luo, and Miki Nakagawa. 2002. Using sequential and non-sequential patterns in predictive web usage mining tasks. In 2002 IEEE International Conference on Data Mining, 2002. Proceedings. IEEE, 669–672.
- Morris (2013) Liam Morris. 2013. Analysis of partially and fully homomorphic encryption. Rochester Institute of Technology (2013), 1–5.
- Muhammad et al. (2020) Khalil Muhammad, Qinqin Wang, Diarmuid O’Reilly-Morgan, Elias Tragos, Barry Smyth, Neil Hurley, James Geraci, and Aonghus Lawlor. 2020. Fedfast: Going beyond average for faster training of federated recommender systems. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1234–1242.
- Niu et al. (2020) Chaoyue Niu, Fan Wu, Shaojie Tang, Lifeng Hua, Rongfei Jia, Chengfei Lv, Zhihua Wu, and Guihai Chen. 2020. Billion-scale federated learning on mobile clients: a submodel design with tunable privacy. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking. 1–14.
- Pazzani and Billsus (2007) Michael J Pazzani and Daniel Billsus. 2007. Content-based recommendation systems. In The adaptive web. Springer, 325–341.
- Qiu et al. (2020) Ruihong Qiu, Zi Huang, Jingjing Li, and Hongzhi Yin. 2020. Exploiting cross-session information for session-based recommendation with graph neural networks. ACM Transactions on Information Systems (TOIS) 38, 3 (2020), 1–23.
- Quadrana et al. (2017) Massimo Quadrana, Alexandros Karatzoglou, Balázs Hidasi, and Paolo Cremonesi. 2017. Personalizing session-based recommendations with hierarchical recurrent neural networks. In Proceedings of the Eleventh ACM Conference on Recommender Systems. 130–137.
- Regev (2009) Oded Regev. 2009. On lattices, learning with errors, random linear codes, and cryptography. Journal of the ACM (JACM) 56, 6 (2009), 1–40.
- Ren et al. (2019) Pengjie Ren, Zhumin Chen, Jing Li, Zhaochun Ren, Jun Ma, and Maarten De Rijke. 2019. Repeatnet: A repeat aware neural recommendation machine for session-based recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 4806–4813.
- Rendle et al. (2010) Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th international conference on World wide web. 811–820.
- Sachdeva et al. (2019) Noveen Sachdeva, Giuseppe Manco, Ettore Ritacco, and Vikram Pudi. 2019. Sequential variational autoencoders for collaborative filtering. In Proceedings of the twelfth ACM international conference on web search and data mining. 600–608.
- Sattler et al. (2019) Felix Sattler, Simon Wiedemann, Klaus-Robert Müller, and Wojciech Samek. 2019. Robust and communication-efficient federated learning from non-iid data. IEEE transactions on neural networks and learning systems 31, 9 (2019), 3400–3413.
- Schafer et al. (2007) J Ben Schafer, Dan Frankowski, Jon Herlocker, and Shilad Sen. 2007. Collaborative filtering recommender systems. In The adaptive web. Springer, 291–324.
- Shani et al. (2005) Guy Shani, David Heckerman, Ronen I Brafman, and Craig Boutilier. 2005. An MDP-based recommender system. Journal of Machine Learning Research 6, 9 (2005).
- Shao et al. (2021) Huajie Shao, Zhisheng Xiao, Shuochao Yao, Dachun Sun, Aston Zhang, Shengzhong Liu, Tianshi Wang, Jinyang Li, and Tarek Abdelzaher. 2021. ControlVAE: Tuning, Analytical Properties, and Performance Analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021).
- Shokri et al. (2017) Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Membership inference attacks against machine learning models. In 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 3–18.
- Smith et al. (2017) Virginia Smith, Chao-Kai Chiang, Maziar Sanjabi, and Ameet Talwalkar. 2017. Federated multi-task learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems. 4427–4437.
- Song et al. (2013) Shuang Song, Kamalika Chaudhuri, and Anand D Sarwate. 2013. Stochastic gradient descent with differentially private updates. In 2013 IEEE Global Conference on Signal and Information Processing. IEEE, 245–248.
- Song et al. (2019) Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. Autoint: Automatic feature interaction learning via self-attentive neural networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 1161–1170.
- Sun et al. (2019) Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
- Sun et al. (2020) Ke Sun, Tieyun Qian, Tong Chen, Yile Liang, Quoc Viet Hung Nguyen, and Hongzhi Yin. 2020. Where to go next: Modeling long-and short-term user preferences for point-of-interest recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 214–221.
- Sundararajan et al. (2017) Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic attribution for deep networks. In International Conference on Machine Learning. PMLR, 3319–3328.
- Syakur et al. (2018) MA Syakur, BK Khotimah, EMS Rochman, and Budi Dwi Satoto. 2018. Integration k-means clustering method and elbow method for identification of the best customer profile cluster. In IOP Conference Series: Materials Science and Engineering, Vol. 336. IOP Publishing, 012017.
- Tam et al. (2017) Nguyen Thanh Tam, Matthias Weidlich, Duong Chi Thang, Hongzhi Yin, and Nguyen Quoc Viet Hung. 2017. Retaining data from streams of social platforms with minimal regret. In Proceedings of the 26th International Joint Conference on Artificial Intelligence. 2850–2856.
- Tan et al. (2020) Ben Tan, Bo Liu, Vincent Zheng, and Qiang Yang. 2020. A federated recommender system for online services. In Fourteenth ACM Conference on Recommender Systems. 579–581.
- Tang and Wang (2018) Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommendation via convolutional sequence embedding. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining. 565–573.
- van den Oord et al. (2017) Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. 2017. Neural discrete representation learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems. 6309–6318.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems. 5998–6008.
- Voigt and Von dem Bussche (2017) Paul Voigt and Axel Von dem Bussche. 2017. The eu general data protection regulation (gdpr). A Practical Guide, 1st Ed., Cham: Springer International Publishing 10 (2017), 3152676.
- Wang et al. (2010) Fengxia Wang, Huixia Jin, and Xiao Chang. 2010. Relevance Vector Ranking for Information Retrieval. J. Convergence Inf. Technol. 5, 9 (2010), 118–125.
- Wang et al. (2021b) Qinyong Wang, Hongzhi Yin, Tong Chen, Junliang Yu, Alexander Zhou, and Xiangliang Zhang. 2021b. Fast-adapting and Privacy-preserving Federated Recommender System. arXiv preprint arXiv:2104.00919 (2021).
- Wang et al. (2021a) Shuai Wang, Richard Cornelius Suwandi, and Tsung-Hui Chang. 2021a. Demystifying Model Averaging for Communication-Efficient Federated Matrix Factorization. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 3680–3684.
- Wei et al. (2020) Kang Wei, Jun Li, Ming Ding, Chuan Ma, Howard H Yang, Farhad Farokhi, Shi Jin, Tony QS Quek, and H Vincent Poor. 2020. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Transactions on Information Forensics and Security 15 (2020), 3454–3469.
- Xie et al. (2021) Zhe Xie, Chengxuan Liu, Yichi Zhang, Hongtao Lu, Dong Wang, and Yue Ding. 2021. Adversarial and contrastive variational autoencoder for sequential recommendation. In Proceedings of the Web Conference 2021. 449–459.
- Yang et al. (2020) Liu Yang, Ben Tan, Vincent W Zheng, Kai Chen, and Qiang Yang. 2020. Federated Recommendation Systems. In Federated Learning. Springer, 225–239.
- Yang et al. (2019) Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. 2019. Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST) 10, 2 (2019), 1–19.
- Yang (2017) Xitong Yang. 2017. Understanding the variational lower bound.
- Yeom et al. (2018) Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. 2018. Privacy risk in machine learning: Analyzing the connection to overfitting. In 2018 IEEE 31st Computer Security Foundations Symposium (CSF). IEEE, 268–282.
- Yu et al. (2019) Junliang Yu, Min Gao, Hongzhi Yin, Jundong Li, Chongming Gao, and Qinyong Wang. 2019. Generating reliable friends via adversarial training to improve social recommendation. In 2019 IEEE International Conference on Data Mining (ICDM). IEEE, 768–777.
- Zhang et al. (2021b) Chen Zhang, Yu Xie, Hang Bai, Bin Yu, Weihong Li, and Yuan Gao. 2021b. A survey on federated learning. Knowledge-Based Systems 216 (2021), 106775.
- Zhang et al. (2021a) Minxing Zhang, Zhaochun Ren, Zihan Wang, Pengjie Ren, Zhunmin Chen, Pengfei Hu, and Yang Zhang. 2021a. Membership Inference Attacks Against Recommender Systems. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security. 864–879.
- Zhang et al. (2019) Tingting Zhang, Pengpeng Zhao, Yanchi Liu, Victor S Sheng, Jiajie Xu, Deqing Wang, Guanfeng Liu, and Xiaofang Zhou. 2019. Feature-level Deeper Self-Attention Network for Sequential Recommendation.. In IJCAI. 4320–4326.
- Zhang et al. (2013) Zui Zhang, Hua Lin, Kun Liu, Dianshuang Wu, Guangquan Zhang, and Jie Lu. 2013. A hybrid fuzzy-based personalized recommender system for telecom products/services. Information Sciences 235 (2013), 117–129.
- Zhao et al. (2020) Kangzhi Zhao, Yong Zhang, Hongzhi Yin, Jin Wang, Kai Zheng, Xiaofang Zhou, and Chunxiao Xing. 2020. Discovering Subsequence Patterns for Next POI Recommendation.. In IJCAI. 3216–3222.
- Zhou et al. (2020) Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 1893–1902.
- Zhu et al. (2020) Yizhe Zhu, Martin Renqiang Min, Asim Kadav, and Hans Peter Graf. 2020. S3VAE: Self-supervised sequential VAE for representation disentanglement and data generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6538–6547.