Refining Automatic Speech Recognition System for older adults
Abstract
Building a high quality automatic speech recognition (ASR) system with limited training data has been a challenging task particularly for a narrow target population. Open-sourced ASR systems, trained on sufficient data from adults, are susceptible on seniors’ speech due to acoustic mismatch between adults and seniors. With 12 hours of training data, we attempt to develop an ASR system for socially isolated seniors (80+ years old) with possible cognitive impairments. We experimentally identify that ASR for the adult population performs poorly on our target population and transfer learning (TL) can boost the system’s performance. Standing on the fundamental idea of TL, tuning model parameters, we further improve the system by leveraging an attention mechanism to utilize the model’s intermediate information. Our approach achieves absolute improvements over the TL model.
Index Terms— automatic speech recognition, small training data, senior population, transfer learning, attention mechanism
1 Introduction
Recently, in cognitive research, analyzing everyday conversation has received increasing attention as it opens a window toward to individuals’ personal world and could potentially reveal their cognitive and behavioral characteristics [1]. This analysis relies on high-fidelity transcription which is labor intensive and costly. A high-quality ASR system could potentially serve as an alternative solution to facilitate the analyzing process. The ASR systems have been widely used in medical applications such as clinical documentation [2] and healthcare systems [3]. The ASR systems have also been adopted in medical researches, such as cognitive tests in Alzheimer’s research [4].
Nowadays, deploying deep neural networks (DNN) in key components of the ASR engine, the acoustic and language models, has significantly boosted the performance. On the other hand, ASR systems inherit DNN’s hunger for target-domain data [5] and the susceptibility to domain mismatch. Although training a domain-specific model with sufficient data is ideal, collecting training data is a challenging task in the medical field especially when facing a narrow target population [6].
This challenge can be caused by multiple factors, such as target population size, financial limitations or policy concerns. Current publicly available ASR systems, which are trained on large amounts of data from adults, perform well on their training domain. However, their performance degrades in clinical applications for seniors as the acoustic characteristics of the target speakers deviate from those used in training examples. This is a crucial limitation in our proposed study as the age range of our participants (seniors above 80 years old) imposes a strong acoustic mismatch leading to an inaccurate recognition. Seniors’ vocal characteristics are different from adults. Age-related speech deterioration begins around 60 years old [7] resulting in significantly different voice characteristics in comparison to the younger generation [8]. Enriching seniors’ training dataset with adult’s recordings cannot ease the data restriction. Moreover, plausible influence of impaired cognitive functioning on acoustic features of MCI subjects [9] may serve as an additional source of acoustical mismatch.
Our training dataset contains 12 hours of transcribed recordings collected from above 80 years old seniors with possible cognitive impairments. To train a end-to-end ASR system, we propose using transfer learning (TL) to address the data limitation. Based on the idea of transfer learning, we design a conditional-independent attention mechanism to leverage the intermediate outputs from the base model. Our method gains a lower word error rate (WER) score than weight transfer learning (WTL).
The remainder of this paper is organized as follows. Section 2 presents backgrounds of transfer learning and the attention mechanism. Section 3 describes the conditional-independent attention mechanism and its application. Section 4 present the detail of our experimental data. Section 5 describes the experimental setup and presents testing results.
2 Background
2.1 Transfer Learning
TL is a type of adaptation widely used in data-scarce scenarios aiming to reuse the learned knowledge of a base DNN model on a related target domain. The fundamental idea is tuning the weights of a pre-trained model. WTL and hidden linear TL (HLTL) are two well-studied ones. WTL initializes the target model with a pre-trained base model where both models share the exact same DNN architecture. Then, tune the entire or a portion of the DNN with a small learning rate [10]. HLTL builds upon a hypothesis where similar tasks share common low-level features. It considers the base model as part of the target model by using the base model as a feature extractor that makes the first process on the input data [11]. Other than these well-studied methods, Factorized Hidden Layer (FHL) models the pre-trained parameters with a linear interpolation of a set of bases [12, 13]. A key ingredient to a successful model adaptation is a well-trained base model from a similar task that has learned from a relatively large and yet diverse training samples [14].
2.2 Attention Mechanism
Researchers utilized the attention mechanism to manage long sequence memory without forgetting [15]. Given an input vector, the mechanism aligns the input to each memory cell, and outputs the summarized memory. The following equations are the general operations of the mechanism:
where is the th column of matrix . The vectors and are the th columns in matrices and , respectively. These two matrices represent the identity and the content of the memory. The symbols, and , represent linear layers. The left graph in Figure 1 describes the general structure of this mechanism. The alignment is conditional to the input . Although the conditional alignment shows its power in multiple researches [15, 16], a small dataset is not sufficient to train these additional layers in TL. In Section 3, we will introduce our conditional-independent attention mechanism which only requires a limited amount of additional parameters.
2.3 DeepSpeech2
DS2 [17] is an end-to-end ASR system that leverages a recurrent neural network (RNN) for modeling the spectrogram to the sequence of 26 English letters. This architecture utilized convolution (Conv) layers for low-level information processing and uses bidirectional gate recurrent unit (bi-GRU) layers for high-level processing. The output layer is a linear layer. In the decoding process, the DS2 [17] utilizes a beam search approach [18] to search for the transcription with the highest probability based on the combination of probabilities from the DS2 model and a n-gram language model. The left graph of Fig 2 is the architecture that we used in our experiments.


3 Conditional-independent Attention Mechanism
Based on the fundamental idea of TL, we focus on leveraging intermediate information from the base model. FTL utilizes these information to interpolate trained model parameters in speaker adaptation [12] and domain adaptation [13]. We assume hidden output loss part of useful information which can be retrieved from intermediate outputs. Moreover, we also extend the use case of attention mechanism. We still consider it as a control unit. Instead of long-term memory management, we utilize the mechanism to summarize useful information for target domain. The right graph in Fig 1 shows the backbone of our mechanism. Theoretically, we can use it in any network and the use case is not limited to TL. But, we focus our research on the data-scarce problem. The right graph in Fig 2 is the modified DS2 architecture where we add an Attention layer (AttenL) to summarize bi-GRU layers’ outputs. Although all examples takes three inputs, the mechanism does not limit to this number. We modified the standard attention into the conditional-independent version: (1) the manual attention and (2) the learnable attention.
3.1 Manual Unconditional Attention
We remove the alignment function from the standard attention mechanism and manually assign the attention to the outputs of GRU layers based on our knowledge about the model. The following equation is the operations of manual attention:
where is the output of GRUn and is the attention that we manually assign to it. This format is the same as the weighted average of GRU outputs. This does not have additional parameters. Therefore it is ideal for evaluating the effectiveness of utilizing intermediate information. We name this mechanism as the manual attention mechanism (MAM).
3.2 Learnable Attention
To learn the attention from the target dataset, we apply a function to learn assigning attention in a conditional-independent fashion. The learnable attention mechanism can be described with following operations:
where is a one-by-three matrix and is GRUn’s output. The matrix is an one-by- non-negative matrix and is the additional parameter matrix. , and are partitioned matrices of . Each represents the importance of the output of the GRU layer with the identical subscript ID. Matrix , which is a -by-three binary matrix, summarize each partitioned matrix by summing up its elements. This matrix is fixed once we set the column sizes for all where . If contains more elements than others, it is more likely that GRUn’s output receives higher attention than others. Thus, we view matrix as the matrix of representatives and matrix as the matrix of tally. By setting the column size of ’s partitioned matrices, we can gently encourage the mechanism to assign extra attention on layers which are important in our prior knowledge. For example, if we think GRU1 should receive more attention, we can define the column sizes for , and to be 2, 1 and 1, respectively. The and should be the following format:
where is a scaler for all . We name this mechanism as the learnable attention mechanism (LAM).
4 Data
The data comes from a long-term behavioral research project that uses internet-based social interactions as a tool to enhance seniors’ cognitive reserve. This project, titled as I-CONECT, conducted at Oregon health & Science University (OHSU), University of Michigan, and Wayne State University. Socially isolated older adults with above 80 years old are mainly recruited from the local Meals on Wheels program in Portland, Oregon and in Detroit, Michigan (with recruitment of African American subjects). Conversations are semi-structured, in which participants freely talk about a predefined topic, i.e. picnic, summer time, swimming and so on, with a moderator online. The corpus includes 30-minute recordings of 61 older adults (29 diagnosed with MCI, 25 normal controls, and 7 without clinical diagnosis) along with their professionally annotated transcriptions.
4.1 Preprocess
As our target speakers are seniors, we remove moderators’ utterances based on the given speaker labels of utterances in the manual transcription. We extract word-level timestamps using a force-alignment algorithm available in Gentle111https://github.com/lowerquality/gentle, which is an open-source software, for each senior’s utterance. We segment long utterances into multiple pieces that are less than 7 seconds long by utilizing the word-level timestamps. Finally, we removed all utterances that are less than 3 seconds.
4.2 Data Splitting
For both validation and testing sets, we randomly select 2 MCI and 2 healthy participants from both genders and leave 53 participants for the training set. With 14 hours of transcribed speech, this splitting leaves about hours of audio recordings for the training purpose. The total recording duration in the validation set and testing set are and hours, respectively. We use the validation set to select hyperparameters (i.e., learning rate) and the testing set is only used for assessing the model performance.
5 Attention Over GRU Outputs
Our base model is an open-sourced DS2 model222https://github.com/PaddlePaddle/DeepSpeech, which is trained on Baidu’s 8000 hours internal data, as well as the corresponding n-gram language model. The language model is fixed throughout all experiments. We have two base lines. We test the original model on our testing set. Also, we tune the entire model with our training set for 40 epochs and evaluate its performance. The tuned model’s nickname is Plain WTL model (PTM).
5.1 Manual Attention Layer
We use the MAM at the AttenL and define the basic attention unit to be . All s must be an integral multiple of the unit. We use M--- to present the setting of attention in an experiment. For example, if we assign all attention to GRU1, the attention setting is M-6/6-0/6-0/6. In train process, we fine tune the modified model for 40 epochs.
In Fig 3, the PTM completely outperforms the base mode on senior domain. The top 5 settings, where we assign more than half attention to GRU1’s output, outperform PTM. The M--- achieves absolute improvements over the PTM. Since we use the pre-trained Linear1, who used to receive GRU1’s output only, GRU1 is naturally strongly related to Linear1. On the other hand, unreasonable settings, assigning small attention to the output of GRU1, perform worse than PTM. This experiment brings us confidence on utilizing intermediate information.
5.2 Learnable Attention Layer
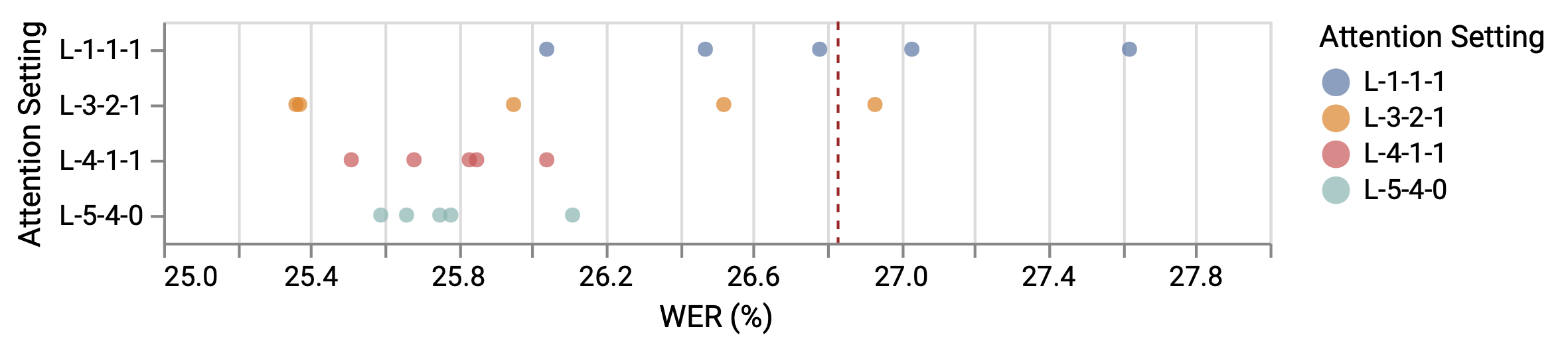
We adopt the LAM at the AttenL to learn the attention from the target dataset. We use L--- to specify the column sizes of partitioned matrices in . We evaluate four settings: L-1-1-1, L-4-1-1, L-3-2-1 and L-5-4-0. We use the first one to evaluate LAM’s learning ability. The other settings are designed to assign more attention to GRU1’s output. All experiments first train the AttenL for epochs while freezing other layers. Then, we reverse the freezing status and train the model for epochs. We try each setting for times to evaluate the influence of randomly initialization on additional parameters.
In Fig 4, random initialization dramatically influences L-1-1-1’s final outcome. On the contrary, we achieve more stable performance when applying prior knowledge through the column setting. This proves that setting the column sizes, based on prior knowledge, positively influences a tuned model’s performance. Another evidence comes from the comparison between L-4-1-1 and L-3-2-1. Although the total column size of s are the same, models with L-4-1-1 perform more stable than the other. Both L-4-1-1 and L-5-4-0 outperform PTM. Our results are marginally worse than the optimal WER in Section 5.1, but we cannot exclude the negative influence from the small training set. Moreover, LAM can be transformed to conditional-dependent form, which is a flexibility that MAM does not have.

6 Conclusion And Future Work
We propose a conditional-independent attention mechanism to leverage a pre-trained model’s intermediate information for model adaptation on the senior domain. We experimentally identify the domain mismatch between the pre-trained DS2 model and seniors and the benefit of applying TL. Our method, which stands on the shoulder of TL, can further reduce the mismatch. Also, our experiments support that guild the training direction with prior knowledge reduces the negative influence caused by random initialization. We will analysis how the size of training data influences the performance of learnable attention mechanism.
7 Acknowledgements
This work was supported by Oregon Roybal Center for Aging and Technology Pilot Program award P30 AG008017-30 in addition to NIH-NIA awards R01-AG051628, and R01-AG056102.
References
- [1] Ali Khodabakhsh, Fatih Yesil, Ekrem Guner, and Cenk Demiroglu, “Evaluation of linguistic and prosodic features for detection of alzheimer’s disease in turkish conversational speech,” EURASIP Journal on Audio, Speech, and Music Processing, vol. 2015, no. 1, pp. 9, 2015.
- [2] Li Zhou, Suzanne V Blackley, Leigh Kowalski, Raymond Doan, Warren W Acker, Adam B Landman, Evgeni Kontrient, David Mack, Marie Meteer, David W Bates, et al., “Analysis of errors in dictated clinical documents assisted by speech recognition software and professional transcriptionists,” JAMA network open, vol. 1, no. 3, pp. e180530–e180530, 2018.
- [3] Ahmed Ismail, Samir Abdlerazek, and Ibrahim M El-Henawy, “Development of smart healthcare system based on speech recognition using support vector machine and dynamic time warping,” Sustainability, vol. 12, no. 6, pp. 2403, 2020.
- [4] Alexandra König, Aharon Satt, Alexander Sorin, Ron Hoory, Orith Toledo-Ronen, Alexandre Derreumaux, Valeria Manera, Frans Verhey, Pauline Aalten, Phillipe H Robert, et al., “Automatic speech analysis for the assessment of patients with predementia and alzheimer’s disease,” Alzheimer’s & Dementia: Diagnosis, Assessment & Disease Monitoring, vol. 1, no. 1, pp. 112–124, 2015.
- [5] Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta, “Revisiting unreasonable effectiveness of data in deep learning era,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 843–852.
- [6] Richard J Holden, Amanda M McDougald Scott, Peter LT Hoonakker, Ann S Hundt, and Pascale Carayon, “Data collection challenges in community settings: Insights from two field studies of patients with chronic disease,” Quality of Life Research, vol. 24, no. 5, pp. 1043–1055, 2015.
- [7] Fred D Minifie, Introduction to communication sciences and disorders, Singular Publishing Group, Incorporated, 1994.
- [8] Sue Ellen Linville, “Source characteristics of aged voice assessed from long-term average spectra,” Journal of Voice, vol. 16, no. 4, pp. 472–479, 2002.
- [9] Jonathan D Rodgers, Kris Tjaden, Lynda Feenaughty, Bianca Weinstock-Guttman, and Ralph HB Benedict, “Influence of cognitive function on speech and articulation rate in multiple sclerosis,” Journal of the International Neuropsychological Society, vol. 19, no. 2, pp. 173–180, 2013.
- [10] Prashanth Gurunath Shivakumar and Panayiotis Georgiou, “Transfer learning from adult to children for speech recognition: Evaluation,” Analysis and Recommendations, 2018.
- [11] Bo Li and Khe Chai Sim, “Comparison of discriminative input and output transformations for speaker adaptation in the hybrid nn/hmm systems,” in Eleventh Annual Conference of the International Speech Communication Association, 2010.
- [12] Lahiru Samarakoon and Khe Chai Sim, “Factorized hidden layer adaptation for deep neural network based acoustic modeling,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 12, pp. 2241–2250, 2016.
- [13] Khe Chai Sim, Arun Narayanan, Ananya Misra, Anshuman Tripathi, Golan Pundak, Tara N Sainath, Parisa Haghani, Bo Li, and Michiel Bacchiani, “Domain adaptation using factorized hidden layer for robust automatic speech recognition.,” in Interspeech, 2018, pp. 892–896.
- [14] Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson, “How transferable are features in deep neural networks?,” in Advances in neural information processing systems, 2014, pp. 3320–3328.
- [15] Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka Grabska-Barwińska, Sergio Gómez Colmenarejo, Edward Grefenstette, Tiago Ramalho, John Agapiou, et al., “Hybrid computing using a neural network with dynamic external memory,” Nature, vol. 538, no. 7626, pp. 471–476, 2016.
- [16] Minh-Thang Luong, Hieu Pham, and Christopher D Manning, “Effective approaches to attention-based neural machine translation,” in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 2015, pp. 1412–1421.
- [17] Dario Amodei, Sundaram Ananthanarayanan, Rishita Anubhai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Qiang Cheng, Guoliang Chen, et al., “Deep speech 2: End-to-end speech recognition in english and mandarin,” in International conference on machine learning, 2016, pp. 173–182.
- [18] Sam Wiseman and Alexander M Rush, “Sequence-to-sequence learning as beam-search optimization,” in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2016, pp. 1296–1306.