[table]capposition=top
ReEvo: Large Language Models as Hyper-Heuristics with Reflective Evolution
Abstract
The omnipresence of NP-hard combinatorial optimization problems (COPs) compels domain experts to engage in trial-and-error heuristic design. The long-standing endeavor of design automation has gained new momentum with the rise of large language models (LLMs). This paper introduces Language Hyper-Heuristics (LHHs), an emerging variant of Hyper-Heuristics that leverages LLMs for heuristic generation, featuring minimal manual intervention and open-ended heuristic spaces. To empower LHHs, we present Reflective Evolution (ReEvo), a novel integration of evolutionary search for efficiently exploring the heuristic space, and LLM reflections to provide verbal gradients within the space. Across five heterogeneous algorithmic types, six different COPs, and both white-box and black-box views of COPs, ReEvo yields state-of-the-art and competitive meta-heuristics, evolutionary algorithms, heuristics, and neural solvers, while being more sample-efficient than prior LHHs.
1 Introduction
NP-hard combinatorial optimization problems (COPs) pervade numerous real-world systems, each characterized by distinct constraints and objectives. The intrinsic complexity and heterogeneity of these problems compel domain experts to laboriously develop heuristics for their approximate solutions [23]. Automation of heuristic designs represents a longstanding pursuit.
Classic Hyper-Heuristics (HHs) automate heuristic design by searching for the best heuristic (combination) from a set of heuristics or heuristic components [64]. Despite decades of development, HHs are limited by heuristic spaces predefined by human experts [64]. The rise of large language models (LLMs) opens up new possibilities for HHs. This paper introduces the general concept of Language Hyper-Heuristics (LHH) to advance beyond preliminary attempts in individual COP settings [68, 46]. LHH constitutes an emerging variant of HH that utilizes LLMs for heuristic generations. It features minimal human intervention and open-ended heuristic spaces, showing promise to comprehensively shift the HH research paradigm.
Pure LHH (e.g., LLM generations alone) is sample-inefficient and exhibits limited inference capability for black-box COPs. This work elicits the power of LHH with Reflective Evolution (ReEvo). ReEvo couples evolutionary search for efficiently exploring heuristic spaces, with self-reflections to boost the reasoning capabilities of LLMs. It emulates human experts by reflecting on the relative performance of two heuristics and gathering insights across iterations. This reflection approach is analogous to interpreting genetic cues and providing "verbal gradient" within search spaces. We introduce fitness landscape analysis and black-box prompting for reliable evaluation of LHHs. The dual-level reflections are shown to enhance heuristic search and induce verbal inference for black-box COPs, enabling ReEvo to outperform prior state-of-the-art (SOTA) LHH [47].
We introduce novel applications of LHHs and yield SOTA solvers with ReEvo: (1) We evolve penalty heuristics for Guided Local Search (GLS), which outperforms SOTA learning-based [52, 24, 75] and knowledge-based [1] (G)LS solvers. (2) We enhance Ant Colony Optimization (ACO) by evolving its heuristic measures, surpassing both neural-enhanced heuristics [94] and expert-designed heuristics [71, 6, 72, 17, 39]. (3) We refine the genetic algorithm (GA) for Electronic Design Automation (EDA) by evolving genetic operators, outperforming expert-designed GA [63] and the SOTA neural solver [31] for the Decap Placement Problem (DPP). (4) Compared to a classic HH [15], ReEvo generates superior constructive heuristics for the Traveling Salesman Problem (TSP). (5) We enhance the generalization of SOTA neural combinatorial optimization (NCO) solvers [37, 51] by evolving heuristics for attention reshaping. For example, we improve the optimality gap of POMO [37] from 52% to 29% and LEHD [51] from 3.2% to 3.0% on TSP1000, with negligible additional time overhead and no need for tuning neural models.
We summarize our contributions as follows. (1) We propose the concept of Language Hyper-Heuristics (LHHs), which bridges emerging attempts using LLMs for heuristic generation with a methodological group that enjoys decades of development. (2) We present Reflective Evolution (ReEvo), coupling evolutionary computation with humanoid reflections to elicit the power of LHHs. We introduce fitness landscape analysis and black-box prompting for reliable LHH evaluations, where ReEvo achieves SOTA sample efficiency. (3) We introduce novel applications of LHHs and present SOTA COP solvers with ReEvo, across five heterogeneous algorithmic types and six different COPs.
2 Related work
Traditional Hyper-Heuristics.
Traditional HHs select the best performing heuristic from a predefined set [13] or generate new heuristics through the combination of simpler heuristic components [15, 104]. HHs offer a higher level of generality in solving various optimization problems [109, 96, 19, 44, 103, 58], but are limited by the heuristic space predefined by human experts.
Neural Combinatorial Optimization.
Recent advances of NCO show promise in learning end-to-end solutions for COPs [2, 93, 3]. NCO can be regarded as a variant of HH, wherein neural architectures and solution pipelines define a heuristic space, and training algorithms search within it. A well-trained neural network (NN), under certain solution pipelines, represents a distinct heuristic. From this perspective, recent advancements in NCO HHs have led to better-aligned neural architectures [28, 51, 34, 73] and advanced solution pipelines [32, 52, 42, 89, 95, 12, 5] to define effective heuristic spaces, and improved training algorithms to efficiently explore heuristic spaces [33, 27, 14, 76, 18, 90, 79, 35], while targeting increasingly broader applications [9, 107, 54, 77]. In this work, we show that ReEvo-generated heuristics can outperform or enhance NCO methods.
LLMs for code generation and optimization.
The rise of LLMs introduces new prospects for diverse fields [88, 82, 105, 25, 50, 99]. Among others, code generation capabilities of LLMs are utilized for code debugging [10, 49], enhancing code performance [55], solving algorithmic competition challenges [41, 70], robotics [38, 43, 81], and general task solving [92, 102]. Interleaving LLM generations with evaluations [74] yields powerful methods for prompt optimization [108, 83, 20], reinforcement learning (RL) reward design [53], algorithmic (self-)improvement [98, 48, 45], neural architecture search [8], and general solution optimization [91, 4, 80], with many under evolutionary frameworks [57, 87, 21, 7, 40]. Most related to ReEvo, concurrent efforts by Liu et al. [47] and Romera-Paredes et al. [68] leverage LLMs to develop heuristics for COPs. We go beyond and propose generic LHH for COPs, along with better sample efficiency, broader applications, more reliable evaluations, and improved heuristics. In addition, ReEvo contributes to a smoother fitness landscape, showing the potential to enhance other tasks involving LLMs for optimization. We present further discussions in Appendix A.
Self-reflections of LLMs.
Shinn et al. [70] propose to reinforce language agents via linguistic feedback, which is subsequently harnessed for various tasks [56, 84]. While Shinn et al. [70] leverage binary rewards indicating passing or failing test cases in programming, ReEvo extends the scope of verbal RL feedback to comparative analysis of two heuristics, analogous to verbal gradient information [66] within heuristic spaces. Also, ReEvo incorporates reflection within an evolutionary framework, presenting a novel and powerful integration.
3 Language Hyper-Heuristics for Combinatorial Optimization
HHs explore a search space of heuristic configurations to select or generate effective heuristics, indirectly optimizing the underlying COP. This dual-level framework is formally defined as follows.
Definition 3.1 (Hyper-Heuristic).
For COP with solution space and objective function , a Hyper-Heuristic (HH) searches for the optimal heuristic in a heuristic space such that a meta-objective function is minimized, i.e., .
Depending on how the heuristic space is defined, traditional HHs can be categorized into selection and generation HHs, both entailing manually defined heuristic primitives. Here, we introduce a novel variant of HHs, Language Hyper-Heuristics (LHH), wherein heuristics in are generated by LLMs. LHHs dispense with the need for predefined , and instead leverage LLMs to explore an open-ended heuristic space. We recursively define LHHs as follows.
Definition 3.2 (Language Hyper-Heuristic).
A Language Hyper-Heuristic (LHH) is an HH variant where heuristics in are generated by LLMs.
In this work, we define the meta-objective function as the expected performance of a heuristic for certain COP. It is estimated by the average performance on a dataset of problem instances.
4 Language Hyper-Heuristic with ReEvo
LHH takes COP specifications as input and outputs the best inductive heuristic found for this COP. Vanilla LHH can be repeated LLM generations to randomly search the heuristic space, which is sample-inefficient and lacks reasoning capabilities for complex and black-box problems (see § 6). Therefore, we propose Reflective Evolution (ReEvo) to interpret genetic cues of evolutionary search and unleash the power of LHHs.
ReEvo is schematically illustrated in Fig. 1. Under an evolutionary framework, LLMs assume two roles: a generator LLM for generating individuals and a reflector LLM for guiding the generation with reflections. ReEvo, as an LHH, features a distinct individual encoding, where each individual is the code snippet of a heuristic. Its evolution begins with population initialization, followed by five iterative steps: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. We evaluate the meta-objective of all heuristics, both after crossover and mutation. Our prompts are gathered in Appendix B.
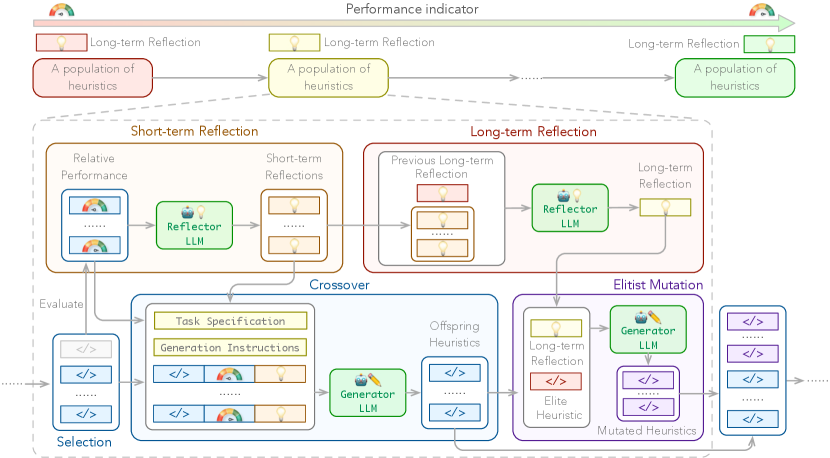
Individual encoding.
ReEvo optimizes toward best-performing heuristics via an evolutionary process, specifically a Genetic Programming (GP). It diverges from traditional GPs in that (1) individuals are code snippets generated by LLMs, and (2) individuals are not constrained by any predefined encoding format, except for adhering to a specified function signature.
Population initialization.
ReEvo initializes a heuristic population by prompting the generator LLM with a task specification. A task specification contains COP descriptions (if available), heuristic designation, and heuristic functionality. Optionally, including seed heuristics, either trivial or expertly crafted to improve upon, can provide in-context examples that encourage valid heuristic generation and bias the search toward more promising directions.
A ReEvo iteration contains the following five sequential steps.
Selection.
ReEvo selects parent pairs from successfully executed heuristics at random, while avoiding pairing heuristics with an identical meta-objective value .
Short-term reflection.
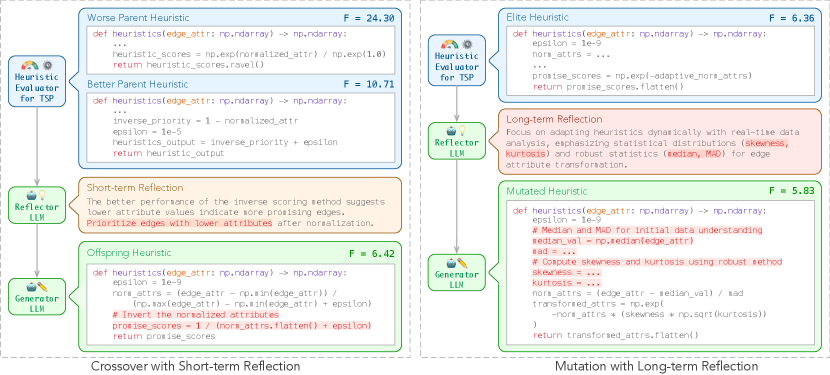
For each pair of heuristic parents, the reflector LLM reflects upon their relative performance and gives hints accordingly for improved design. Unlike prior work [70], ReEvo integrates the reflections into evolutionary search and reflects by performing comparative analyses. Our proposed approach is analogous to interpreting genetic cues and providing verbal gradients within search spaces, which leads to smoother fitness landscapes and better search results (see § 6.1).
Crossover.
ReEvo prompts the generator LLM to generate an offspring heuristic, given task specifications, a pair of parent heuristics, explicit indications of their relative performance, short-term reflections over the pair, and generation instructions.
Long-term reflection.
ReEvo accumulates expertise in improving heuristics via long-term reflections. The reflector LLM, given previous long-term reflections and newly gained short-term ones, summarizes them and gives hints for improved heuristic design.
Elitist mutation.
ReEvo employs an elitist mutation approach. Based on long-term reflections, the generator LLM samples multiple heuristics to improve the current best one. A mutation prompt consists of task specifications, the elite heuristic, long-term reflections, and generation instructions.
Viewing ReEvo from the perspective of an LLM agentic architecture [88], short-term reflections interpret the environmental feedback from each round of interaction. Long-term reflections distill accumulated experiences and knowledge, enabling them to be loaded into the inference context without causing memory blowups.
5 Heuristic generation with ReEvo
This section presents novel applications of LHH across heterogeneous algorithmic types and diverse COPs. With ReEvo, we yield state-of-the-art and competitive meta-heuristics, evolutionary algorithms, heuristics, and neural solvers.
Hyperparameters of ReEvo and detailed experimental setup are given in Appendix C. We apply ReEvo to different algorithmic types across six diverse COPs representative of different areas: Traveling Salesman Problem (TSP), Capacitated Vehicle Routing Problem (CVRP), and Orienteering Problem (OP) for routing problems; Multiple Knapsack Problem (MKP) for subset problems; Bin Packing Problem (BPP) for grouping problems; and Decap Placement Problem (DPP) for electronic design automation (EDA) problems. Details of the benchmark COPs are given in Appendix D. The best ReEvo-generated heuristics are collected in Appendix E.
5.1 Penalty heuristics for Guided Local Search
We evolve penalty heuristics for Guided Local Search (GLS) [1]. GLS interleaves local search with solution perturbation. The perturbation is guided by the penalty heuristics to maximize its utility. ReEvo searches for the penalty heuristic that leads to the best GLS performance.
We implement the best heuristic generated by ReEvo within KGLS [1] and refer to such coupling as KGLS-ReEvo. In Table 1, we compare KGLS-ReEvo with the original KGLS, other GLS variants [24, 75, 47], and SOTA NCO method that learns to improve a solution [52]. The results show that ReEvo can improve KGLS and outperform SOTA baselines. In addition, we use a single heuristic for TSP20 to 200, while NCO baselines require training models specific to each problem size.
| Method | Type | TSP20 | TSP50 | TSP100 | TSP200 | ||||
|---|---|---|---|---|---|---|---|---|---|
| Opt. gap (%) | Time (s) | Opt. gap (%) | Time (s) | Opt. gap (%) | Time (s) | Opt. gap (%) | Time (s) | ||
| NeuOpt* [52] | LS+RL | 0.000 | 0.124 | 0.000 | 1.32 | 0.027 | 2.67 | 0.403 | 4.81 |
| GNNGLS [24] | GLS+SL | 0.000 | 0.116 | 0.052 | 3.83 | 0.705 | 6.78 | 3.522 | 9.92 |
| NeuralGLS† [75] | GLS+SL | 0.000 | 10.005 | 0.003 | 10.01 | 0.470 | 10.02 | 3.622 | 10.12 |
| EoH [47] | GLS+LHH | 0.000 | 0.563 | 0.000 | 1.90 | 0.025 | 5.87 | 0.338 | 17.52 |
| KGLS‡ [1] | GLS | 0.004 | 0.001 | 0.017 | 0.03 | 0.002 | 1.55 | 0.284 | 2.52 |
| KGLS-ReEvo‡ | GLS+LHH | 0.000 | 0.001 | 0.000 | 0.03 | 0.000 | 1.55 | 0.216 | 2.52 |
| *: All instances are solved in one batch. D2A=1; T=500, 4000, 5000, and 5000 for 4 problem sizes, respectively. | |||||||||
| †: The results are drawn from the original literature. ‡: They are based on our own GLS implementation. | |||||||||
5.2 Heuristic measures for Ant Colony Optimization
Solutions to COPs can be stochastically sampled, with heuristic measures indicating the promise of solution components and biasing the sampling. Ant Colony Optimization (ACO), which interleaves stochastic solution sampling with pheromone update, builds on this idea. We generate such heuristic measures for five different COPs: TSP, CVRP, OP, MKP, and BPP.
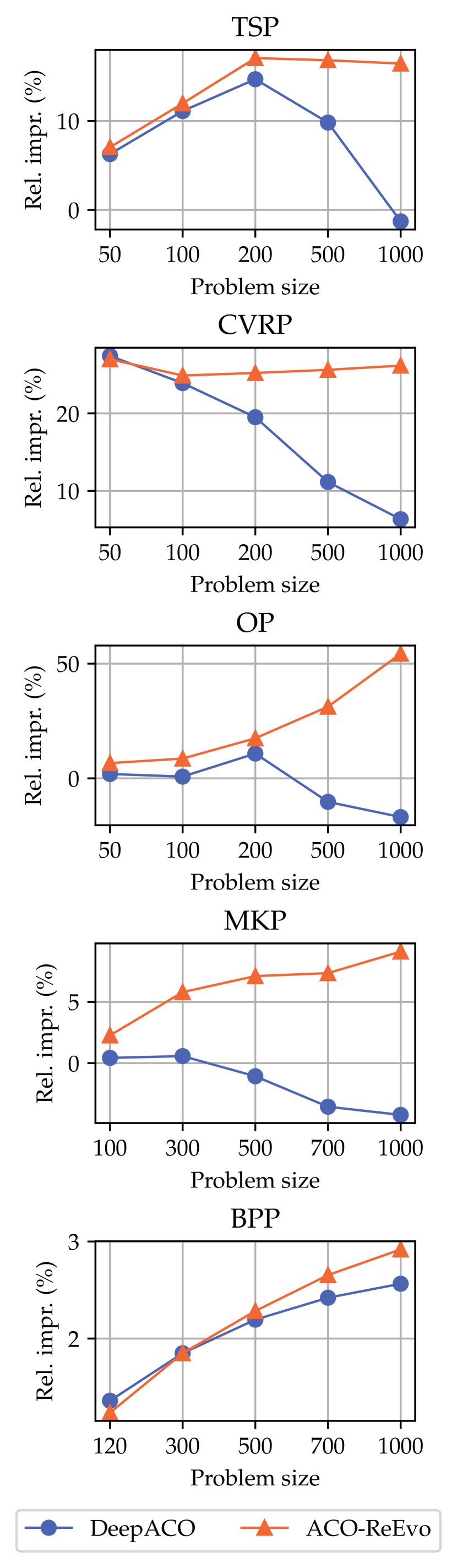
Under the ACO framework, we evaluate the best ReEvo-generated heuristics against the expert-designed ones and neural heuristics specifically learned for ACO [94]. The evolution curves displayed in Fig. 2 verify the consistent superiority of ReEvo across COPs and problem sizes. Notably, on 3 out of 5 COPs, ReEvo outperforms DeepACO [94] even when the latter overfits the test problem size (TSP50, OP50, and MKP100). We observe that most ReEvo-generated heuristics show consistent performance across problem sizes and distributions. Hence, their advantages grow as the distributional shift increases for neural heuristics.
5.3 Genetic operators for Electronic Design Automation
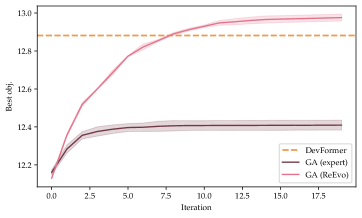
Expert-designed GAs are widely adopted in EDA [69, 97, 11, 26]. Besides directly solving EDA problems, GA-generated solutions can be used to train amortized neural solvers [31]. Here, we show that ReEvo can improve the expert-designed GAs and outperform DevFormer [31], the SOTA solver for the DPP problem. We sequentially evolve with ReEvo the crossover and mutation operators for the GA expert-designed by Park et al. [63]. Fig. 3 compares online and offline learned methods, DevFormer, the original expert-designed GA, and the GA with ReEvo-generated operators, showing that the ReEvo-designed GA outperforms previous methods and, importantly, both the expert-designed GA and DevFormer.
| Method | # of shots | Obj. |
|---|---|---|
| Pointer-PG [30] | 10,000 | 9.66 0.206 |
| AM-PG [60] | 10,000 | 9.63 0.587 |
| CNN-DQN [61] | 10,000 | 9.79 0.267 |
| CNN-DDQN [100] | 10,000 | 9.63 0.150 |
| Pointer-CRL [30] | Zero Shot | 9.59 0.232 |
| AM-CRL [62] | Zero Shot | 9.56 0.471 |
| DevFormer-CSE [31] | Zero Shot | 12.88 0.003 |
| GA-expert [63] | 400 | 12.41 0.026 |
| GA-ReEvo (ours) | 400 | 12.98 0.018 |
5.4 Constructive heuristics for the Traveling Salesman Problem
Heuristics can be used for deterministic solution construction by sequentially assigning values to each decision variable. We evaluate the constructive heuristic for TSP generated by ReEvo on real-world benchmark instances from TSPLIB [67] in Table 2. ReEvo can generate better heuristics than GHPP [15], a classic HH based on GP.
| Instance | Nearest Neighbour | GHPP [15] | ReEvo |
|---|---|---|---|
| ts225 | 16.8 | 7.7 | 6.6 |
| rat99 | 21.8 | 14.1 | 12.4 |
| rl1889 | 23.7 | 21.1 | 17.5 |
| u1817 | 22.2 | 21.2 | 16.6 |
| d1655 | 23.9 | 18.7 | 17.5 |
| bier127 | 23.3 | 15.6 | 10.8 |
| lin318 | 25.8 | 14.3 | 16.6 |
| eil51 | 32.0 | 10.2 | 6.5 |
| d493 | 24.0 | 15.6 | 13.4 |
| kroB100 | 26.3 | 14.1 | 12.2 |
| kroC100 | 25.8 | 16.2 | 15.9 |
| Instance | Nearest Neighbour | GHPP [15] | ReEvo |
|---|---|---|---|
| ch130 | 25.7 | 14.8 | 9.4 |
| pr299 | 31.4 | 18.2 | 20.6 |
| fl417 | 32.4 | 22.7 | 19.2 |
| d657 | 29.7 | 16.3 | 16.0 |
| kroA150 | 26.1 | 15.6 | 11.6 |
| fl1577 | 25.0 | 17.6 | 12.1 |
| u724 | 28.5 | 15.5 | 16.9 |
| pr264 | 17.9 | 24.0 | 16.8 |
| pr226 | 24.6 | 15.5 | 18.0 |
| pr439 | 27.4 | 21.4 | 19.3 |
| Avg. opt. gap | 25.4 | 16.7 | 14.6 |
5.5 Attention reshaping for Neural Combinatorial Optimization
Autoregressive NCO solvers suffer from limited scaling-up generalization [29], partially due to the dispersion of attention scores [85]. Wang et al. [85] design a distance-aware heuristic to reshape the attention scores, which improves the generalization of NCO solvers without additional training. However, the expert-designed attention-reshaping can be suboptimal and does not generalize across neural models or problem distributions.
Here we show that ReEvo can automatically and efficiently tailor attention reshaping for specific neural models and problem distributions of interest. We apply attention reshaping designed by experts [85] and ReEvo to two distinct model architectures: POMO with heavy encoder and light decoder [37], and LEHD with light encoder and heavy decoder [51]. On TSP and CVRP, Table 3 compares the original NCO solvers [37, 51], those with expert-designed attention reshaping [85], and those with ReEvo-designed attention reshaping. The results reveal that the ReEvo-generated heuristics can improve the original models and outperform their expert-designed counterparts. Note that implementing ReEvo-generated attention reshaping takes negligible additional time; e.g., solving a CVRP1000 with LEHD takes 50.0 seconds with reshaping, compared to 49.8 seconds without.
| Method | |||||||
|---|---|---|---|---|---|---|---|
| Obj. | Opt. gap (%) | Obj. | Opt. gap (%) | Obj. | Opt. gap (%) | ||
| TSP | POMO [37] | 11.16 | 4.40 | 22.21 | 34.43 | 35.19 | 52.11 |
| POMO + DAR [85] | 11.12 | 3.98 | 21.63 | 30.95 | 33.32 | 44.05 | |
| POMO + ReEvo [75] | 11.12 | 4.02 | 20.54 | 24.32 | 29.86 | 29.08 | |
| LEHD [51] | 10.79 | 0.87 | 16.78 | 1.55 | 23.87 | 3.17 | |
| LEHD + DAR [85] | 10.79 | 0.89 | 16.79 | 1.62 | 23.87 | 3.19 | |
| LEHD + ReEvo | 10.77 | 0.74 | 16.78 | 1.55 | 23.82 | 2.97 | |
| CVRP | POMO [37] | 22.39 | 10.93 | 50.12 | 33.76 | 145.40 | 289.48 |
| POMO + DAR [85] | 22.36 | 10.78 | 50.23 | 34.05 | 144.24 | 286.37 | |
| POMO + ReEvo | 22.30 | 10.48 | 47.10 | 25.70 | 118.80 | 218.22 | |
| LEHD [51] | 20.92 | 3.68 | 38.61 | 3.03 | 39.12 | 4.79 | |
| LEHD + DAR [85] | 21.13 | 4.67 | 39.16 | 4.49 | 39.70 | 6.35 | |
| LEHD + ReEvo | 20.85 | 3.30 | 38.57 | 2.94 | 39.11 | 4.76 | |
6 Evaluating ReEvo
6.1 Fitness landscape analysis
The fitness landscape of a searching algorithm depicts the structure and characteristics of its search space [59]. This understanding is essential for designing effective HHs. Here we introduce this technique to LHHs and evaluate the impact of reflections on the fitness landscape.
Traditionally, the neighborhood of a solution is defined as a set of solutions that can be reached after a single move of a certain heuristic. However, LHHs feature a probabilistic nature and open-ended search space, and we redefine its neighborhood as follows.
Definition 6.1 (Neighborhood).
Let denote an LHH move, a specific prompt, and the current heuristic. Given and , the neighborhood of is defined as a set , where each element represents a heuristic that can mutate into, in response to :
| (1) |
Here, denotes the probability of generating after prompting with and , and is a small threshold value. In practice, the neighborhood can be approximated by sampling from the distribution for a large number of times.
We extend the concept of autocorrelation to LHHs under our definition of neighborhood. Autocorrelation reflects the ruggedness of a landscape, indicating the difficulty of a COP [59, 22].
Definition 6.2 (Autocorrelation).
Autocorrelation measures the correlation structure of a fitness landscape. It is derived from the autocorrelation function of a time series of fitness values, which are generated by a random walk on the landscape via neighboring points:
| (2) |
where is the mean fitness of the points visited, is the size of the random walk, and is the time lag between points in the walk.
Based on the autocorrelation function, correlation length is defined below [86].
Definition 6.3 (Correlation Length).
Given an autocorrelation function , the correlation length is formulated as for . It reflects the ruggedness of a landscape, and smaller values indicate a more rugged landscape.
To perform autocorrelation analysis for ReEvo, we conduct random walks based on the neighborhood established with our crossover prompt either with or without short-term reflections. In practice, we set the population size to 1 and skip invalid heuristics; the selection always picks the current and last heuristics for short-term reflection and crossover, and we do not implement mutation.
| Correlation length | Objective | |
|---|---|---|
| w/o reflection | 0.28 0.07 | 12.08 7.15 |
| w/ reflection | 1.28 0.62 | 6.53 0.60 |
Table 4 presents the correlation length and the average objective value of the random walks, where we generate ACO heuristics for TSP50. The correlation length is averaged over 3 runs each with 40 random walk steps, while the objective value is averaged over all heuristics. The results verify that implementing reflection leads to a less rugged landscape and better search results. As discussed in § 4, reflections can function as verbal gradients that lead to better neighborhood structures.
6.2 Ablation studies
In this section, we investigate the effects of the proposed components of ReEvo with both white and black-box prompting.
Black-box prompting.
We do not reveal any information related to the COPs and prompt LHHs in general forms (e.g., in place of ). Black-box settings allow reliable evaluations of LHHs in designing effective heuristics for novel and complex problems, rather than merely retrieving code tailored for prominent COPs from their parameterized knowledge.
| Method | White-box | Black-box |
|---|---|---|
| LLM | 8.64 0.13 | 9.74 0.54 |
| w/o long-term reflections | 8.61 0.21 | 9.32 0.71 |
| w/o short-term reflections | 8.46 0.01 | 9.05 0.83 |
| w/o crossover | 8.45 0.02 | 9.47 1.40 |
| w/o mutation | 8.83 0.09 | 9.34 0.96 |
| ReEvo | 8.40 0.02 | 8.96 0.82 |
We evaluate sampling LLM generations without evolution (LLM) and ReEvo without long-term reflections, short-term reflections, crossover, or mutation on generating ACO heuristics for TSP100. Table 5 shows that ReEvo enhances sample efficiency, and all its components positively contribute to its performance, both in white-box and black-box prompting.
6.3 Comparative evaluations
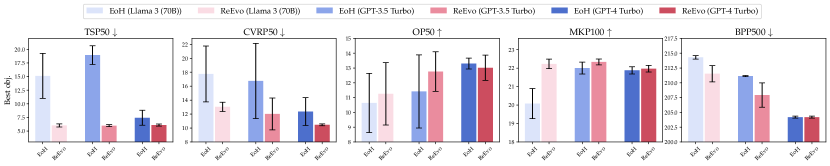
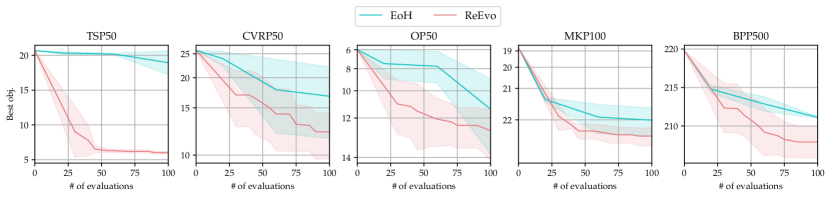
This section compares ReEvo with EoH [47], a recent SOTA LHH that is more sample-efficient than FunSearch [68]. We adhere to the original code and (hyper)parameters of EoH. Our experiments apply both LHHs to generate ACO heuristics for TSP, CVRP, OP, MKP, and BPP, using black-box prompting and three LLMs: GPT-3.5 Turbo, GPT-4 Turbo, and Llama 3 (70B).
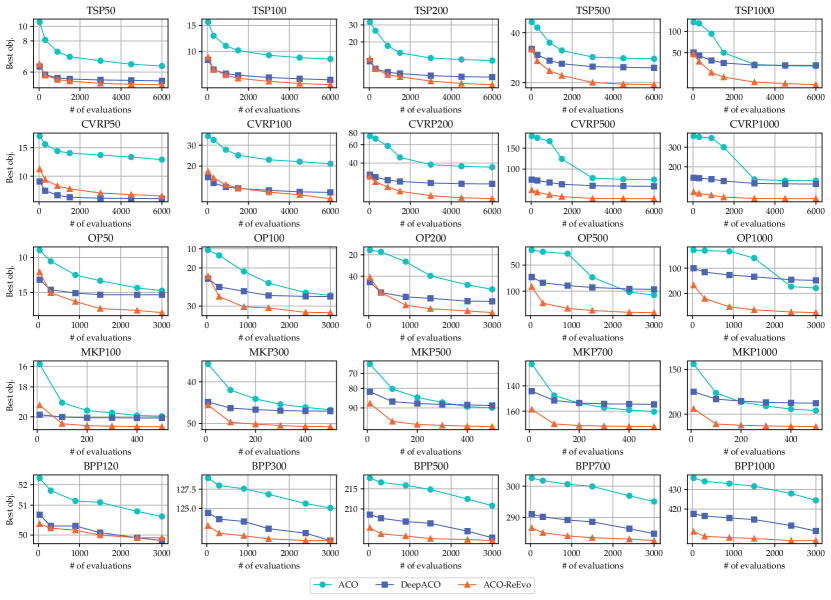
Fig. 4 compares EoH and ReEvo, and shows that ReEvo demonstrates superior sample efficiency. Besides the better neighborhood structure (§ 6.1), reflections facilitate explicit verbal inference of underlying black-box COP structures; we depict an example in Fig. 1 (b). The enhanced sample efficiency and inference capabilities of ReEvo are particularly useful for complex real-world problems, where the objective function is usually black-box and expensive to evaluate.
7 Discussions and limitations
When to use ReEvo as an LHH.
Our experiments limit the number of heuristic evaluations to 100 shots and the results do not necessarily scale up. ReEvo is designed for scenarios where sample efficiency is crucial, such as real-world applications where heuristic evaluation can be costly. Allowing a large number of heuristic evaluations could obscure the impact of reflection or other prompting techniques, as reported by Zhang et al. [101].
When to use ReEvo as an (alternative to) NCO/ML4CO method.
LHH can be categorized as an NCO/ML4CO method. However, to facilitate our discussion, we differentiate LHHs from "traditional" NCO methods that usually train NN-parameterized heuristics via parameter adjustment. In § 5, we demonstrate that ReEvo can either outperform or enhance NCO methods. Below, we explore the complementary nature of LHH and NCO methods.
-
•
Rule-based v.s. NN-parameterized policies. LHHs generate interpretable and rule-based heuristics (code snippets), while NCO generates black-box NN-parameterized policies. Interpretable heuristics offer insights for human designers and can be more reliable in practice when faced with dynamic environments, limited data, distributional shifts, or adversarial attacks. However, they may not be as expressive as neural networks and may underfit in complex environments.
-
•
Evolution and training. LHHs require only less than 100 heuristic evaluations and about 5 minutes to evolve a strong heuristic, while many NCO methods usually require millions of samples and days of training. LHHs are more practical when solution evaluation is expensive.
-
•
Inference. LHHs generate heuristics that are less demanding in terms of computational resources, as they do not require GPU during deployment. NCO methods require GPU for training and deployment, but they can also leverage the parallelism of GPU to potentially speed up inference.
-
•
Engineering efforts and inductive biases. LHHs only need some text-based (and even black-box) explanations to guide the search. NCO requires the development of NN architectures, hyperparameters, and training strategies, where informed inductive biases and manual tuning are crucial to guarantee performance.
The choice of LLMs for ReEvo.
Reflection is more effective when using capable LLMs, such as GPT-3.5 Turbo and its successors, as discussed by Shinn et al. [70]. Currently, many open-source LLMs are not capable enough to guarantee statistically significant improvement of reflections [101]. However, as LLM capabilities improve, we only expect this paradigm to get better over time [70]. One can refer to [101] for extended evaluations based on more LLMs and problem settings.
Benchmarking LHHs based on heuristic evaluations.
We argue that benchmarking LHHs should prioritize the number of heuristic evaluations rather than LLM query budgets [101] due to the following reasons.
-
•
Prioritizing scenarios where heuristic evaluations are costly leads to meaningful comparisons between LHHs. The performance of different LHH methods becomes nearly indistinguishable when a large number of heuristic evaluations are allowed [101].
-
•
The overhead of LLM queries is negligible compared to real-world heuristic evaluations. LLM inference—whether via local models or commercial APIs—is highly cost-effective nowadays, with expenses averaging around $0.0003 per call in ReEvo using GPT-3.5-turbo, and response times of under one second on average for asynchronous API calls or batched inference. These costs are negligible compared to real-world heuristic evaluations, which, taking the toy EDA problem in this paper as an example, exceeds 20 minutes per evaluation.
-
•
Benchmarking LHHs based on LLM inference costs presents additional challenges. Costs and processing time are driven by token usage rather than the number of queries, complicating the benchmarking process. For instance, EoH [47] requires heuristic descriptions before code generation, resulting in higher token usage. In contrast, although ReEvo involves more queries for reflections, it is more token-efficient when generating heuristics.
8 Conclusion
This paper presents Language Hyper-Heuristics (LHHs), a rising variant of HHs, alongside Reflective Evolution (ReEvo), an evolutionary framework to elicit the power of LHHs. Applying ReEvo across five heterogeneous algorithmic types, six different COPs, and both white-box and black-box views of COPs, we yield state-of-the-art and competitive meta-heuristics, evolutionary algorithms, heuristics, and neural solvers. Comparing against SOTA LHH [47], ReEvo demonstrates superior sample efficiency. The development of LHHs is still at its emerging stage. It is promising to explore their broader applications, better dual-level optimization architectures, and theoretical foundations. We also expect ReEvo to enrich the landscape of evolutionary computation, by showing that genetic cues can be interpreted and verbalized using LLMs.
Acknowledgments and disclosure of funding
We are very grateful to Yuan Jiang, Yining Ma, Yifan Yang, AI4CO community, anonymous reviewers, and the area chair for valuable discussions and feedback. This work was supported by the National Natural Science Foundation of China (Grant No. 62276006); Wuhan East Lake High-Tech Development Zone National Comprehensive Experimental Base for Governance of Intelligent Society; the National Research Foundation, Singapore under its AI Singapore Programme (AISG Award No: AISG3-RP-2022-031); the Institute of Information & Communications Technology Planning & Evaluation (IITP)-Innovative Human Resource Development for Local Intellectualization program grant funded by the Korea government (MSIT) (IITP-2024-RS-2024-00436765).
References
- Arnold and Sörensen [2019] F. Arnold and K. Sörensen. Knowledge-guided local search for the vehicle routing problem. Computers & Operations Research, 105:32–46, 2019.
- Bengio et al. [2021] Y. Bengio, A. Lodi, and A. Prouvost. Machine learning for combinatorial optimization: a methodological tour d’horizon. European Journal of Operational Research, 290(2):405–421, 2021.
- Berto et al. [2023] F. Berto, C. Hua, J. Park, M. Kim, H. Kim, J. Son, H. Kim, J. Kim, and J. Park. RL4CO: a unified reinforcement learning for combinatorial optimization library. In NeurIPS 2023 Workshop: New Frontiers in Graph Learning, 2023.
- Brooks et al. [2023] E. Brooks, L. A. Walls, R. Lewis, and S. Singh. Large language models can implement policy iteration. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Bu et al. [2024] F. Bu, H. Jo, S. Y. Lee, S. Ahn, and K. Shin. Tackling prevalent conditions in unsupervised combinatorial optimization: Cardinality, minimum, covering, and more. arXiv preprint arXiv:2405.08424, 2024.
- Cai et al. [2022] J. Cai, P. Wang, S. Sun, and H. Dong. A dynamic space reduction ant colony optimization for capacitated vehicle routing problem. Soft Computing, 26(17):8745–8756, 2022.
- Chao et al. [2024] W. Chao, J. Zhao, L. Jiao, L. Li, F. Liu, and S. Yang. A match made in consistency heaven: when large language models meet evolutionary algorithms, 2024.
- Chen et al. [2023a] A. Chen, D. M. Dohan, and D. R. So. Evoprompting: Language models for code-level neural architecture search. arXiv preprint arXiv:2302.14838, 2023a.
- Chen et al. [2023b] J. Chen, J. Wang, Z. Zhang, Z. Cao, T. Ye, and C. Siyuan. Efficient meta neural heuristic for multi-objective combinatorial optimization. In Advances in Neural Information Processing Systems, 2023b.
- Chen et al. [2023c] X. Chen, M. Lin, N. Schärli, and D. Zhou. Teaching large language models to self-debug. arXiv preprint arXiv:2304.05128, 2023c.
- de Paulis et al. [2020] F. de Paulis, R. Cecchetti, C. Olivieri, and M. Buecker. Genetic algorithm pdn optimization based on minimum number of decoupling capacitors applied to arbitrary target impedance. In 2020 IEEE International Symposium on Electromagnetic Compatibility & Signal/Power Integrity (EMCSI), pages 428–433. IEEE, 2020.
- Dernedde et al. [2024] T. Dernedde, D. Thyssens, S. Dittrich, M. Stubbemann, and L. Schmidt-Thieme. Moco: A learnable meta optimizer for combinatorial optimization. arXiv preprint arXiv:2402.04915, 2024.
- Drake et al. [2020] J. H. Drake, A. Kheiri, E. Özcan, and E. K. Burke. Recent advances in selection hyper-heuristics. European Journal of Operational Research, 285(2):405–428, 2020.
- Drakulic et al. [2023] D. Drakulic, S. Michel, F. Mai, A. Sors, and J.-M. Andreoli. Bq-nco: Bisimulation quotienting for efficient neural combinatorial optimization. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Duflo et al. [2019] G. Duflo, E. Kieffer, M. R. Brust, G. Danoy, and P. Bouvry. A gp hyper-heuristic approach for generating tsp heuristics. In 2019 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 521–529. IEEE, 2019.
- Erdin and Achar [2019] I. Erdin and R. Achar. Multi-objective optimization of decoupling capacitors for placement and component value. IEEE Transactions on Components, Packaging and Manufacturing Technology, 9(10):1976–1983, 2019.
- Fidanova [2020] S. Fidanova. Hybrid ant colony optimization algorithm for multiple knapsack problem. In 2020 5th IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE), pages 1–5. IEEE, 2020.
- Gao et al. [2023] C. Gao, H. Shang, K. Xue, D. Li, and C. Qian. Towards generalizable neural solvers for vehicle routing problems via ensemble with transferrable local policy. arXiv preprint arXiv:2308.14104, 2023.
- Guerriero and Saccomanno [2023] F. Guerriero and F. P. Saccomanno. A hierarchical hyper-heuristic for the bin packing problem. Soft Computing, 27(18):12997–13010, 2023.
- Guo et al. [2023] Q. Guo, R. Wang, J. Guo, B. Li, K. Song, X. Tan, G. Liu, J. Bian, and Y. Yang. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. arXiv preprint arXiv:2309.08532, 2023.
- Hemberg et al. [2024] E. Hemberg, S. Moskal, and U.-M. O’Reilly. Evolving code with a large language model, 2024.
- Hordijk [1996] W. Hordijk. A measure of landscapes. Evolutionary computation, 4(4):335–360, 1996.
- Hromkovič [2013] J. Hromkovič. Algorithmics for hard problems: introduction to combinatorial optimization, randomization, approximation, and heuristics. Springer Science & Business Media, 2013.
- Hudson et al. [2022] B. Hudson, Q. Li, M. Malencia, and A. Prorok. Graph neural network guided local search for the traveling salesperson problem. In International Conference on Learning Representations, 2022.
- Ji et al. [2023] J. Ji, T. Qiu, B. Chen, B. Zhang, H. Lou, K. Wang, Y. Duan, Z. He, J. Zhou, Z. Zhang, et al. Ai alignment: A comprehensive survey. arXiv preprint arXiv:2310.19852, 2023.
- Jiang et al. [2024] L. Jiang, L. Zhang, S. Tan, D. Li, C. Hwang, J. Fan, and E.-P. Li. A novel physics-assisted genetic algorithm for decoupling capacitor optimization. IEEE Transactions on Microwave Theory and Techniques, 2024.
- Jiang et al. [2023] Y. Jiang, Z. Cao, Y. Wu, W. Song, and J. Zhang. Ensemble-based deep reinforcement learning for vehicle routing problems under distribution shift. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Jin et al. [2023] Y. Jin, Y. Ding, X. Pan, K. He, L. Zhao, T. Qin, L. Song, and J. Bian. Pointerformer: Deep reinforced multi-pointer transformer for the traveling salesman problem. arXiv preprint arXiv:2304.09407, 2023.
- Joshi et al. [2020] C. K. Joshi, Q. Cappart, L.-M. Rousseau, and T. Laurent. Learning the travelling salesperson problem requires rethinking generalization. arXiv preprint arXiv:2006.07054, 2020.
- Kim et al. [2021a] H. Kim, H. Park, M. Kim, S. Choi, J. Kim, J. Park, S. Kim, S. Kim, and J. Kim. Deep reinforcement learning framework for optimal decoupling capacitor placement on general pdn with an arbitrary probing port. In 2021 IEEE 30th Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), pages 1–3. IEEE, 2021a.
- Kim et al. [2023a] H. Kim, M. Kim, F. Berto, J. Kim, and J. Park. Devformer: A symmetric transformer for context-aware device placement. In International Conference on Machine Learning, pages 16541–16566. PMLR, 2023a.
- Kim et al. [2021b] M. Kim, J. Park, et al. Learning collaborative policies to solve np-hard routing problems. Advances in Neural Information Processing Systems, 34:10418–10430, 2021b.
- Kim et al. [2022] M. Kim, J. Park, and J. Park. Sym-nco: Leveraging symmetricity for neural combinatorial optimization. Advances in Neural Information Processing Systems, 35:1936–1949, 2022.
- Kim et al. [2023b] M. Kim, T. Yun, E. Bengio, D. Zhang, Y. Bengio, S. Ahn, and J. Park. Local search gflownets. arXiv preprint arXiv:2310.02710, 2023b.
- Kim et al. [2024] M. Kim, S. Choi, J. Son, H. Kim, J. Park, and Y. Bengio. Ant colony sampling with gflownets for combinatorial optimization. arXiv preprint arXiv:2403.07041, 2024.
- Kool et al. [2019] W. Kool, H. van Hoof, and M. Welling. Attention, learn to solve routing problems! In International Conference on Learning Representations, 2019.
- Kwon et al. [2020] Y.-D. Kwon, J. Choo, B. Kim, I. Yoon, Y. Gwon, and S. Min. Pomo: Policy optimization with multiple optima for reinforcement learning. Advances in Neural Information Processing Systems, 33:21188–21198, 2020.
- Lehman et al. [2023] J. Lehman, J. Gordon, S. Jain, K. Ndousse, C. Yeh, and K. O. Stanley. Evolution through large models. In Handbook of Evolutionary Machine Learning, pages 331–366. Springer, 2023.
- Levine and Ducatelle [2004] J. Levine and F. Ducatelle. Ant colony optimization and local search for bin packing and cutting stock problems. Journal of the Operational Research society, 55(7):705–716, 2004.
- Li et al. [2024] P. Li, J. Hao, H. Tang, X. Fu, Y. Zheng, and K. Tang. Bridging evolutionary algorithms and reinforcement learning: A comprehensive survey, 2024.
- Li et al. [2022] Y. Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lago, et al. Competition-level code generation with alphacode. Science, 378(6624):1092–1097, 2022.
- Li et al. [2023] Y. Li, J. Guo, R. Wang, and J. Yan. T2t: From distribution learning in training to gradient search in testing for combinatorial optimization. In Advances in Neural Information Processing Systems, 2023.
- Liang et al. [2023] J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9493–9500. IEEE, 2023.
- Lim et al. [2023] K. C. W. Lim, L.-P. Wong, and J. F. Chin. Simulated-annealing-based hyper-heuristic for flexible job-shop scheduling. Engineering Optimization, 55(10):1635–1651, 2023.
- Liu et al. [2023a] F. Liu, X. Lin, Z. Wang, S. Yao, X. Tong, M. Yuan, and Q. Zhang. Large language model for multi-objective evolutionary optimization. arXiv preprint arXiv:2310.12541, 2023a.
- Liu et al. [2023b] F. Liu, X. Tong, M. Yuan, and Q. Zhang. Algorithm evolution using large language model. arXiv preprint arXiv:2311.15249, 2023b.
- Liu et al. [2024] F. Liu, X. Tong, M. Yuan, X. Lin, F. Luo, Z. Wang, Z. Lu, and Q. Zhang. Evolution of heuristics: Towards efficient automatic algorithm design using large language mode. In ICML, 2024. URL https://arxiv.org/abs/2401.02051.
- Liu et al. [2023c] S. Liu, C. Chen, X. Qu, K. Tang, and Y.-S. Ong. Large language models as evolutionary optimizers. arXiv preprint arXiv:2310.19046, 2023c.
- Liventsev et al. [2023] V. Liventsev, A. Grishina, A. Härmä, and L. Moonen. Fully autonomous programming with large language models. arXiv preprint arXiv:2304.10423, 2023.
- Lu et al. [2023] Y. Lu, X. Liu, Z. Du, Y. Gao, and G. Wang. Medkpl: a heterogeneous knowledge enhanced prompt learning framework for transferable diagnosis. Journal of Biomedical Informatics, page 104417, 2023.
- Luo et al. [2023] F. Luo, X. Lin, F. Liu, Q. Zhang, and Z. Wang. Neural combinatorial optimization with heavy decoder: Toward large scale generalization. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Ma et al. [2023a] Y. Ma, Z. Cao, and Y. M. Chee. Learning to search feasible and infeasible regions of routing problems with flexible neural k-opt. In Advances in Neural Information Processing Systems, 2023a.
- Ma et al. [2023b] Y. J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Jayaraman, Y. Zhu, L. Fan, and A. Anandkumar. Eureka: Human-level reward design via coding large language models. arXiv preprint arXiv:2310.12931, 2023b.
- Ma et al. [2023c] Z. Ma, H. Guo, J. Chen, Z. Li, G. Peng, Y.-J. Gong, Y. Ma, and Z. Cao. Metabox: A benchmark platform for meta-black-box optimization with reinforcement learning. In Advances in Neural Information Processing Systems, volume 36, 2023c.
- Madaan et al. [2023a] A. Madaan, A. Shypula, U. Alon, M. Hashemi, P. Ranganathan, Y. Yang, G. Neubig, and A. Yazdanbakhsh. Learning performance-improving code edits. arXiv preprint arXiv:2302.07867, 2023a.
- Madaan et al. [2023b] A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, et al. Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651, 2023b.
- Meyerson et al. [2023] E. Meyerson, M. J. Nelson, H. Bradley, A. Gaier, A. Moradi, A. K. Hoover, and J. Lehman. Language model crossover: Variation through few-shot prompting. arXiv preprint arXiv:2302.12170, 2023.
- Mohammad Hasani Zade et al. [2023] B. Mohammad Hasani Zade, N. Mansouri, and M. M. Javidi. A new hyper-heuristic based on ant lion optimizer and tabu search algorithm for replica management in cloud environment. Artificial Intelligence Review, 56(9):9837–9947, 2023.
- Ochoa et al. [2009] G. Ochoa, R. Qu, and E. K. Burke. Analyzing the landscape of a graph based hyper-heuristic for timetabling problems. In Proceedings of the 11th Annual conference on Genetic and evolutionary computation, pages 341–348, 2009.
- Park et al. [2020a] H. Park, M. Kim, S. Kim, S. Jeong, S. Kim, H. Kang, K. Kim, K. Son, G. Park, K. Son, et al. Policy gradient reinforcement learning-based optimal decoupling capacitor design method for 2.5-d/3-d ics using transformer network. In 2020 IEEE Electrical Design of Advanced Packaging and Systems (EDAPS), pages 1–3. IEEE, 2020a.
- Park et al. [2020b] H. Park, J. Park, S. Kim, K. Cho, D. Lho, S. Jeong, S. Park, G. Park, B. Sim, S. Kim, et al. Deep reinforcement learning-based optimal decoupling capacitor design method for silicon interposer-based 2.5-d/3-d ics. IEEE Transactions on Components, Packaging and Manufacturing Technology, 10(3):467–478, 2020b.
- Park et al. [2022] H. Park, M. Kim, S. Kim, K. Kim, H. Kim, T. Shin, K. Son, B. Sim, S. Kim, S. Jeong, et al. Transformer network-based reinforcement learning method for power distribution network (pdn) optimization of high bandwidth memory (hbm). IEEE Transactions on Microwave Theory and Techniques, 70(11):4772–4786, 2022.
- Park et al. [2023] H. Park, H. Kim, H. Kim, J. Park, S. Choi, J. Kim, K. Son, H. Suh, T. Kim, J. Ahn, et al. Versatile genetic algorithm-bayesian optimization (ga-bo) bi-level optimization for decoupling capacitor placement. In 2023 IEEE 32nd Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), pages 1–3. IEEE, 2023.
- Pillay and Qu [2018] N. Pillay and R. Qu. Hyper-heuristics: theory and applications. Springer, 2018.
- Popovich et al. [2007] M. Popovich, A. Mezhiba, and E. G. Friedman. Power distribution networks with on-chip decoupling capacitors. Springer Science & Business Media, 2007.
- Pryzant et al. [2023] R. Pryzant, D. Iter, J. Li, Y. T. Lee, C. Zhu, and M. Zeng. Automatic prompt optimization with" gradient descent" and beam search. arXiv preprint arXiv:2305.03495, 2023.
- Reinelt [1991] G. Reinelt. Tsplib—a traveling salesman problem library. ORSA journal on computing, 3(4):376–384, 1991.
- Romera-Paredes et al. [2023] B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. Ruiz, J. S. Ellenberg, P. Wang, O. Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, pages 1–3, 2023.
- Shibasaka et al. [2013] K. Shibasaka, K. Kanazawa, and M. Yasunaga. Decoupling-capacitor allocation problem solved by genetic algorithm. In 2013 IEEE Electrical Design of Advanced Packaging Systems Symposium (EDAPS), pages 225–228. IEEE, 2013.
- Shinn et al. [2023] N. Shinn, F. Cassano, A. Gopinath, K. R. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Skinderowicz [2022] R. Skinderowicz. Improving ant colony optimization efficiency for solving large tsp instances. Applied Soft Computing, 120:108653, 2022.
- Sohrabi et al. [2021] S. Sohrabi, K. Ziarati, and M. Keshtkaran. Acs-ophs: Ant colony system for the orienteering problem with hotel selection. EURO Journal on Transportation and Logistics, 10:100036, 2021.
- Son et al. [2023] J. Son, M. Kim, S. Choi, and J. Park. Solving np-hard min-max routing problems as sequential generation with equity context. arXiv preprint arXiv:2306.02689, 2023.
- Song et al. [2024] X. Song, Y. Tian, R. T. Lange, C. Lee, Y. Tang, and Y. Chen. Position paper: Leveraging foundational models for black-box optimization: Benefits, challenges, and future directions. arXiv preprint arXiv:2405.03547, 2024.
- Sui et al. [2023] J. Sui, S. Ding, B. Xia, R. Liu, and D. Bu. Neuralgls: learning to guide local search with graph convolutional network for the traveling salesman problem. Neural Computing and Applications, pages 1–20, 2023.
- Sun and Yang [2023] Z. Sun and Y. Yang. Difusco: Graph-based diffusion solvers for combinatorial optimization. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Tang et al. [2024] H. Tang, F. Berto, Z. Ma, C. Hua, K. Ahn, and J. Park. Himap: Learning heuristics-informed policies for large-scale multi-agent pathfinding. arXiv preprint arXiv:2402.15546, 2024.
- Voudouris and Tsang [1999] C. Voudouris and E. Tsang. Guided local search and its application to the traveling salesman problem. European Journal of Operational Research, 113(2):469–499, Mar. 1999. ISSN 03772217. doi: 10.1016/S0377-2217(98)00099-X.
- Wang et al. [2024a] C. Wang, Z. Yu, S. McAleer, T. Yu, and Y. Yang. Asp: Learn a universal neural solver! IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024a.
- Wang et al. [2023a] H. Wang, S. Feng, T. He, Z. Tan, X. Han, and Y. Tsvetkov. Can language models solve graph problems in natural language? arXiv preprint arXiv:2305.10037, 2023a.
- Wang et al. [2023b] L. Wang, Y. Ling, Z. Yuan, M. Shridhar, C. Bao, Y. Qin, B. Wang, H. Xu, and X. Wang. Gensim: Generating robotic simulation tasks via large language models. arXiv preprint arXiv:2310.01361, 2023b.
- Wang et al. [2023c] L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y. Lin, et al. A survey on large language model based autonomous agents. arXiv preprint arXiv:2308.11432, 2023c.
- Wang et al. [2023d] X. Wang, C. Li, Z. Wang, F. Bai, H. Luo, J. Zhang, N. Jojic, E. P. Xing, and Z. Hu. Promptagent: Strategic planning with language models enables expert-level prompt optimization. arXiv preprint arXiv:2310.16427, 2023d.
- Wang et al. [2023e] Y. Wang, Z. Liu, J. Zhang, W. Yao, S. Heinecke, and P. S. Yu. Drdt: Dynamic reflection with divergent thinking for llm-based sequential recommendation. arXiv preprint arXiv:2312.11336, 2023e.
- Wang et al. [2024b] Y. Wang, Y.-H. Jia, W.-N. Chen, and Y. Mei. Distance-aware attention reshaping: Enhance generalization of neural solver for large-scale vehicle routing problems. arXiv preprint arXiv:2401.06979, 2024b.
- Weinberger [1990] E. Weinberger. Correlated and uncorrelated fitness landscapes and how to tell the difference. Biological cybernetics, 63(5):325–336, 1990.
- Wu et al. [2024] X. Wu, S. hao Wu, J. Wu, L. Feng, and K. C. Tan. Evolutionary computation in the era of large language model: Survey and roadmap, 2024.
- Xi et al. [2023] Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhou, et al. The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864, 2023.
- Xiao et al. [2023] Y. Xiao, D. Wang, H. Chen, B. Li, W. Pang, X. Wu, H. Li, D. Xu, Y. Liang, and Y. Zhou. Reinforcement learning-based non-autoregressive solver for traveling salesman problems. arXiv preprint arXiv:2308.00560, 2023.
- Xiao et al. [2024] Y. Xiao, D. Wang, B. Li, M. Wang, X. Wu, C. Zhou, and Y. Zhou. Distilling autoregressive models to obtain high-performance non-autoregressive solvers for vehicle routing problems with faster inference speed. In Proceedings of the AAAI Conference on Artificial Intelligence, 2024.
- Yang et al. [2023a] C. Yang, X. Wang, Y. Lu, H. Liu, Q. V. Le, D. Zhou, and X. Chen. Large language models as optimizers. arXiv preprint arXiv:2309.03409, 2023a.
- Yang et al. [2023b] J. Yang, A. Prabhakar, K. Narasimhan, and S. Yao. Intercode: Standardizing and benchmarking interactive coding with execution feedback. arXiv preprint arXiv:2306.14898, 2023b.
- Yang and Whinston [2023] Y. Yang and A. Whinston. A survey on reinforcement learning for combinatorial optimization. In 2023 IEEE World Conference on Applied Intelligence and Computing (AIC), pages 131–136. IEEE, 2023.
- Ye et al. [2023] H. Ye, J. Wang, Z. Cao, H. Liang, and Y. Li. Deepaco: Neural-enhanced ant systems for combinatorial optimization. In Advances in Neural Information Processing Systems, 2023.
- Ye et al. [2024] H. Ye, J. Wang, H. Liang, Z. Cao, Y. Li, and F. Li. Glop: Learning global partition and local construction for solving large-scale routing problems in real-time. In Proceedings of the AAAI Conference on Artificial Intelligence, 2024.
- Zambrano-Gutierrez et al. [2023] D. Zambrano-Gutierrez, J. Cruz-Duarte, and H. Castañeda. Automatic hyper-heuristic to generate heuristic-based adaptive sliding mode controller tuners for buck-boost converters. In Proceedings of the Genetic and Evolutionary Computation Conference, pages 1482–1489, 2023.
- Zebulum et al. [2018] R. S. Zebulum, M. A. Pacheco, and M. M. B. Vellasco. Evolutionary electronics: automatic design of electronic circuits and systems by genetic algorithms. CRC press, 2018.
- Zelikman et al. [2023] E. Zelikman, E. Lorch, L. Mackey, and A. T. Kalai. Self-taught optimizer (stop): Recursively self-improving code generation. arXiv preprint arXiv:2310.02304, 2023.
- Zhang et al. [2023a] C. Zhang, K. Yang, S. Hu, Z. Wang, G. Li, Y. Sun, C. Zhang, Z. Zhang, A. Liu, S.-C. Zhu, et al. Proagent: Building proactive cooperative ai with la rge language models. arXiv preprint arXiv:2308.11339, 2023a.
- Zhang et al. [2020] L. Zhang, W. Huang, J. Juang, H. Lin, B.-C. Tseng, and C. Hwang. An enhanced deep reinforcement learning algorithm for decoupling capacitor selection in power distribution network design. In 2020 IEEE International Symposium on Electromagnetic Compatibility & Signal/Power Integrity (EMCSI), pages 245–250. IEEE, 2020.
- Zhang et al. [2024] R. Zhang, F. Liu, X. Lin, Z. Wang, Z. Lu, and Q. Zhang. Understanding the importance of evolutionary search in automated heuristic design with large language models. In International Conference on Parallel Problem Solving from Nature, pages 185–202. Springer, 2024.
- Zhang et al. [2022] S. Zhang, Z. Chen, Y. Shen, M. Ding, J. B. Tenenbaum, and C. Gan. Planning with large language models for code generation. In The Eleventh International Conference on Learning Representations, 2022.
- Zhang et al. [2023b] Z.-Q. Zhang, F.-C. Wu, B. Qian, R. Hu, L. Wang, and H.-P. Jin. A q-learning-based hyper-heuristic evolutionary algorithm for the distributed flexible job-shop scheduling problem with crane transportation. Expert Systems with Applications, 234:121050, 2023b.
- Zhao et al. [2023a] Q. Zhao, Q. Duan, B. Yan, S. Cheng, and Y. Shi. A survey on automated design of metaheuristic algorithms. arXiv preprint arXiv:2303.06532, 2023a.
- Zhao et al. [2023b] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023b.
- Zhong et al. [2024] T. Zhong, Z. Liu, Y. Pan, Y. Zhang, Y. Zhou, S. Liang, Z. Wu, Y. Lyu, P. Shu, X. Yu, et al. Evaluation of openai o1: Opportunities and challenges of agi. arXiv preprint arXiv:2409.18486, 2024.
- Zhou et al. [2023] J. Zhou, Y. Wu, Z. Cao, W. Song, J. Zhang, and Z. Chen. Learning large neighborhood search for vehicle routing in airport ground handling. IEEE Transactions on Knowledge and Data Engineering, 2023.
- Zhou et al. [2022] Y. Zhou, A. I. Muresanu, Z. Han, K. Paster, S. Pitis, H. Chan, and J. Ba. Large language models are human-level prompt engineers. arXiv preprint arXiv:2211.01910, 2022.
- Zhu et al. [2023] L. Zhu, Y. Zhou, S. Sun, and Q. Su. Surgical cases assignment problem using an efficient genetic programming hyper-heuristic. Computers & Industrial Engineering, 178:109102, 2023.
Appendix A Extended discussions
A.1 Comparisons with EoH
Our work is developed concurrently with Evolution of Heuristics (EoH) [47], which establishes the groundwork for this emerging field. Nonetheless, our work extends the boundaries of LHH through three primary lenses: (1) the search algorithm, (2) the downstream CO applications, and (3) the evaluation methodologies.
-
•
Search Algorithm: We introduce the Reflective Evolution, demonstrating its superior sample efficiency.
-
•
Applications: Our work broadens the scope by applying LHH to five heterogeneous algorithmic types and six different COPs, advancing the state-of-the-art in GLS, EDA, ACO, and NCO.
-
•
Evaluation Methodologies: We employ fitness landscape analysis to explore the underlying mechanisms of our proposed method; we establish black-box experimental settings to ensure reliable comparisons and practical relevance to real-world applications.
A.2 Extended applications
ReEvo is generally applicable to other string-based optimization scenarios [57] as long as reflecting the relative performance of strings is meaningful. Preliminary experiments on prompt tuning verify the advantage of ReEvo over random search and vanilla genetic programming. Furthermore, we identify in reasoning-capable LLM approaches released after ReEvo such as OpenAI o1 [106] an interesting avenue of future works and experimentation that could yield even better sample efficiency and performance.
Appendix B Prompts
We gather prompts used for ReEvo in this section. Our prompt structure is flexible and extensible. To adapt ReEvo to a new problem setting, one only needs to define its problem description, function description, and function signature.
B.1 Common prompts
The prompt formats are given below. They are used for all COP settings.
The user prompt used for short-term reflection in black-box COPs is slightly different from the one used for white-box COPs. We explicitly ask the reflector LLM to infer the problem settings and to give hints about how the node and edge attributes correlate with the black-box objective value.
The function signature variables here are used to adjust function names with their versions, which is similar to the design in [68]. For example, when designing “heuristics”, the worse code is named “heuristics_v0” while the better code “heuristics_v1”. In LABEL:lst:_user_prompt_for_elitist_mutation, the elitist code is named “heuristic_v1”.
B.2 Problem-specific prompt components
Problem-specific prompt components are given below.
-
•
Problem descriptions of all COP settings are given in Table 6.
-
•
The function descriptions of all COP settings are presented in LABEL:tab:_function_descriptions. The descriptions crafted for black-box settings avoid disclosing any information that could link to the original COP.
-
•
The function signatures are gathered in LABEL:lst:_function_signatures_used_in_reevo.
-
•
The seed functions are shown in LABEL:lst:_seed_heuristics_used_for_reevo. The seed function used for TSP_constructive is drawn from [46]. The seed functions used for black-box ACO settings are expert-designed heuristics [71, 6, 72, 17, 39], while those used for while-box ACO settings are trivial all-ones matrices.
-
•
The initial long-term reflections for some COP settings are presented in LABEL:lst:_initial_long-term_reflections, while are left empty for the others.
| Problem | Problem description |
|---|---|
| TSP_NCO | Assisting in solving the Traveling Salesman Problem (TSP) with some prior heuristics. TSP requires finding the shortest path that visits all given nodes and returns to the starting node. |
| CVRP_NCO | Assisting in solving Capacitated Vehicle Routing Problem (CVRP) with some prior heuristics. CVRP requires finding the shortest path that visits all given nodes and returns to the starting node. Each node has a demand and each vehicle has a capacity. The total demand of the nodes visited by a vehicle cannot exceed the vehicle capacity. When the total demand exceeds the vehicle capacity, the vehicle must return to the starting node. |
| DPP_GA | Assisting in solving black-box decap placement problem with genetic algorithm. The problem requires finding the optimal placement of decaps in a given power grid. |
| TSP_GLS | Solving Traveling Salesman Problem (TSP) via guided local search. TSP requires finding the shortest path that visits all given nodes and returns to the starting node. |
| TSP_ACO | Solving Traveling Salesman Problem (TSP) via stochastic solution sampling following "heuristics". TSP requires finding the shortest path that visits all given nodes and returns to the starting node. |
| TSP_ACO_black-box | Solving a black-box graph combinatorial optimization problem via stochastic solution sampling following "heuristics". |
| CVRP_ACO | Solving Capacitated Vehicle Routing Problem (CVRP) via stochastic solution sampling. CVRP requires finding the shortest path that visits all given nodes and returns to the starting node. Each node has a demand and each vehicle has a capacity. The total demand of the nodes visited by a vehicle cannot exceed the vehicle capacity. When the total demand exceeds the vehicle capacity, the vehicle must return to the starting node. |
| CVRP_ACO_black-box | Solving a black-box graph combinatorial optimization problem via stochastic solution sampling following "heuristics". |
| OP_ACO | Solving Orienteering Problem (OP) via stochastic solution sampling following "heuristics". OP is an optimization problem where the goal is to find the most rewarding route, starting from a depot, visiting a subset of nodes with associated prizes, and returning to the depot within a specified travel distance. |
| OP_ACO_black-box | Solving a black-box graph combinatorial optimization problem via stochastic solution sampling following "heuristics". |
| MKP_ACO | Solving Multiple Knapsack Problems (MKP) through stochastic solution sampling based on "heuristics". MKP involves selecting a subset of items to maximize the total prize collected, subject to multi-dimensional maximum weight constraints. |
| MKP_ACO_black-box | Solving a black-box combinatorial optimization problem via stochastic solution sampling following "heuristics". |
| BPP_ACO | Solving Bin Packing Problem (BPP). BPP requires packing a set of items of various sizes into the smallest number of fixed-sized bins. |
| BPP_ACO_black-box | Solving a black-box combinatorial optimization problem via stochastic solution sampling following "heuristics". |
| TSP_constructive | Solving Traveling Salesman Problem (TSP) with constructive heuristics. TSP requires finding the shortest path that visits all given nodes and returns to the starting node. |
| Problem | Function description |
|---|---|
| TSP_NCO | The ‘heuristics‘ function takes as input a distance matrix and returns prior indicators of how bad it is to include each edge in a solution. The return is of the same shape as the input. The heuristics should contain negative values for undesirable edges and positive values for promising ones. Use efficient vectorized implementations. |
| CVRP_NCO | The ‘heuristics‘ function takes as input a distance matrix (shape: n by n) and a vector of customer demands (shape: n), where the depot node is indexed by 0 and the customer demands are normalized by the total vehicle capacity. It returns prior indicators of how promising it is to include each edge in a solution. The return is of the same shape as the distance matrix. The heuristics should contain negative values for undesirable edges and positive values for promising ones. Use efficient vectorized implementations. |
| DPP_GA_crossover | The ‘crossover‘ function takes as input a 2D NumPy array parents and an integer n_pop. The function performs a genetic crossover operation on parents to generate n_pop offspring. Use vectorized implementation if possible. |
| DPP_GA_mutation |
The ‘mutation‘ function modifies a given 2D population array to ensure exploration of the genetic algorithm. You may also take into account the feasibility of each individual. An individual is considered feasible if all its elements are unique and none are listed in the prohibited array or match the probe value. Use a vectorized implementation if possible.
The function takes as input the below arguments: - population (np.ndarray): Population of individuals; shape: (P, n_decap). - probe (int): Probe value; each element in the population should not be equal to this value. - prohibit (np.ndarray): Prohibit values; each element in the population should not be in this set. - size (int): Size of the PDN; each element in the population should be in the range [0, size). |
| TSP_GLS | The ‘heuristics‘ function takes as input a distance matrix, and returns prior indicators of how bad it is to include each edge in a solution. The return is of the same shape as the input. |
| TSP_ACO | The ‘heuristics‘ function takes as input a distance matrix, and returns prior indicators of how promising it is to include each edge in a solution. The return is of the same shape as the input. |
| TSP_ACO_black-box | The ‘heuristics‘ function takes as input a matrix of edge attributes with shape ‘(n_edges, n_attributes)‘, where ‘n_attributes=1‘ in this case. It computes prior indicators of how promising it is to include each edge in a solution. The return is of the shape of ‘(n_edges,)‘. |
| CVRP_ACO | The ‘heuristics‘ function takes as input a distance matrix (shape: n by n), Euclidean coordinates of nodes (shape: n by 2), a vector of customer demands (shape: n), and the integer capacity of vehicle capacity. It returns prior indicators of how promising it is to include each edge in a solution. The return is of the same shape as the distance matrix. The depot node is indexed by 0. |
| CVRP_ACO_black-box | The ‘heuristics‘ function takes as input a matrix of edge attributes (shape: n by n) and a vector of node attributes (shape: n). A special node is indexed by 0. ‘heuristics‘ returns prior indicators of how promising it is to include each edge in a solution. The return is of the same shape as the input matrix of edge attributes. |
| OP_ACO | Suppose ‘n‘ represents the number of nodes in the problem, with the depot being the first node. The ‘heuristics‘ function takes as input a ‘prize‘ array of shape (n,), a ‘distance‘ matrix of shape (n,n), and a ‘max_len‘ float which is the constraint to total travel distance, and it returns ‘heuristics‘ of shape (n, n), where ‘heuristics[i][j]‘ indicates the promise of including the edge from node #i to node #j in the solution. |
| OP_ACO_black-box | The ‘heuristics‘ function takes as input a vector of node attributes (shape: n), a matrix of edge attributes (shape: n by n), and a constraint imposed on the sum of edge attributes. A special node is indexed by 0. ‘heuristics‘ returns prior indicators of how promising it is to include each edge in a solution. The return is of the same shape as the input matrix of edge attributes. |
| MKP_ACO | Suppose ‘n‘ indicates the scale of the problem, and ‘m‘ is the dimension of weights each item has. The constraint of each dimension is fixed to 1. The ‘heuristics‘ function takes as input a ‘prize‘ of shape (n,), a ‘weight‘ of shape (n, m), and returns ‘heuristics‘ of shape (n,). ‘heuristics[i]‘ indicates how promising it is to include item i in the solution. |
| MKP_ACO_black-box | Suppose ‘n‘ indicates the scale of the problem, and ‘m‘ is the dimension of some attributes each involved item has. The ‘heuristics‘ function takes as input an ‘item_attr1‘ of shape (n,), an ‘item_attr2‘ of shape (n, m), and returns ‘heuristics‘ of shape (n,). ‘heuristics[i]‘ indicates how promising it is to include item i in the solution. |
| BPP_ACO | Suppose ‘n‘ represents the number of items in the problem. The heuristics function takes as input a ‘demand‘ array of shape (n,) and an integer as the capacity of every bin, and it returns a ‘heuristics‘ array of shape (n,n). ‘heuristics[i][j]‘ indicates how promising it is to put item i and item j in the same bin. |
| BPP_ACO_black-box | Suppose ‘n‘ represents the scale of the problem. The heuristics function takes as input an ‘item_attr‘ array of shape (n,) and an integer as a certain constraint imposed on the item attributes. The heuristics function returns a ‘heuristics‘ array of shape (n, n). ‘heuristics[i][j]‘ indicates how promising it is to group item i and item j. |
| TSP_constructive | The select_next_node function takes as input the current node, the destination node, a set of unvisited nodes, and a distance matrix, and returns the next node to visit. |
Appendix C Detailed experimental setup
Hyperparameters for ReEvo.
Unless otherwise stated, we adopt the parameters in Table 8 for ReEvo runs. During initialization, the LLM temperature is added by 0.3 to diversify the initial population.
Heuristic generation pipeline.
We perform 3 ReEvo runs for each COP setting. Unless otherwise stated, the heuristic with the best validation performance is selected for final testing on 64 held-out instances.
Cost and hardware.
When the hardware permits, heuristics from the same generation are generated, reflected upon, and evaluated in parallel. The duration of a single ReEvo run can range from approximately two minutes to hours, depending on the evaluation runtime and the hardware used. Each run costs about $0.06 when using GPT3.5 Turbo. When conducting runtime comparisons, we employ a single core of an AMD EPYC 7742 CPU and an NVIDIA GeForce RTX 3090 GPU.
| Parameter | Value |
| LLM (generator and reflector) | gpt-3.5-turbo |
| LLM temperature (generator and reflector) | 1 |
| Population size | 10 |
| Number of initial generation | 30 |
| Maximum number of evaluations | 100 |
| Crossover rate | 1 |
| Mutation rate | 0.5 |
C.1 Penalty heuristics for Guided Local Search
Guided Local Search (GLS) explores solution space through local search operations under the guidance of heuristics. We aim to use ReEvo to find the most effective heuristics to enhance GLS. In our experimental setup, we employed a variation of the classical GLS algorithm [78] that incorporated perturbation phases [1], wherein edges with higher heuristic values will be prioritized for penalization. In the training phase, we evaluate each heuristic with TSP200 using 1200 GLS iterations. For generating results in Table 1, we use the parameters in Table 9. The iterations stop when reaching the predefined threshold or when the optimality gap is reduced to zero.
| Problem | Perturbation moves | Number of iterations | Scale parameter |
| TSP20 | 5 | 73 | 0.1 |
| TSP50 | 30 | 175 | |
| TSP100 | 40 | 1800 | |
| TSP200 | 40 | 800 |
C.2 Heuristic measures for Ant Colony Optimization
Ant Colony Optimization is an evolutionary algorithm that interleaves solution samplings with the update of pheromone trails. Stochastic solution samplings are biased toward more promising solution space by heuristics, and ReEvo searches for the best of such heuristics. For more details, please refer to [94].
Table 10 presents the ACO parameters used for heuristic evaluations during LHH evolution. They are adjusted to maximize ACO performance while ensuring efficient evaluations. Instance generations and ACO implementations follow Ye et al. [94]. To conduct tests in Fig. 2, we increase the number of iterations to ensure full convergence.
| Problem | Population size | Number of iterations |
|---|---|---|
| TSP | 30 | 100 |
| CVRP | 30 | 100 |
| OP | 20 | 50 |
| MKP | 10 | 50 |
| BPP | 20 | 15 |
C.3 Genetic operators for Electronic Design Automation
Here we briefly introduce the expert-design GA for DPP. Further details can be found in [31, Appendix B].
The GA designed by Kim et al. [31] is utilized as an expert policy to collect expert guiding labels for imitation learning. The GA is a widely used search heuristic method for the Decoupling Capacitor Placement Problem (DPP), which aims to find the optimal placement of a given number of decoupling capacitors (decaps) on a Power Distribution Network (PDN) with a probing port and 0-15 keep-out regions to best suppress the impedance of the probing port.
Key aspects of the designed GA include:
-
•
Encoding and initialization. The GA generates an initial population randomly, and each solution consists of a set of numbers representing decap locations on the PDN. The population size is fixed to 20, and each solution is evaluated and sorted based on its objective value.
-
•
Elitism. After the initial population is formulated, the top-performing solutions (elite population) are kept for the next generation. The size of the elite population is predefined as 4.
-
•
Selection. The better half of the population is selected for crossover.
-
•
Crossover. This process generates new population candidates by dividing each solution from the selected population in half and performing random crossover.
-
•
Mutation. After crossover, solutions with overlapping numbers are replaced with random numbers while avoiding locations of the probing port and keep-out regions.
In this work, we sequentially optimize the crossover and mutation operators using ReEvo. When optimizing crossover, all other components of the GA pipeline remain identical to the expert-designed one. When optimizing mutation, we additionally set the crossover operator to the best one previously generated by ReEvo.
C.4 Attention reshaping for Neural Combinatorial Optimization
For autoregressive NCO solvers, e.g. POMO [37] and LEHD [51], the last decoder layer outputs the logits of the next node to visit. Then, the attention-reshaping heuristic values are added to the logits before masking, logit clipping, and softmax operation.
For the autoregressive NCO models with a heavy encoder and a light decoder, the last decoder layer computes logits using [36]
| (3) |
Here, is the compatibility between current context and node , a constant for logit clipping, the query embedding of the current context, the key embedding of node , and the query/key dimensionality. For each node already visited, i.e. , is masked.
We reshape the attention scores by using
| (4) |
is computed via attention-reshaping heuristics. In practice, for TSP and CVRP, , where is the heuristic matrix and is simplified to the current node.
For the autoregressive NCO models with a light encoder and a heavy decoder [51], or only a decoder [14], the last decoder layer computes logits using:
| (5) |
where is a learnable matrix at the output layer and node is among the available nodes. We reshape the logits with
| (6) |
where node is the current node.
For evaluations in Table 3, we generalize the models trained on TSP100 and CVRP100 to larger instances with 200, 500, and 1000 nodes. For TSP, we apply the same ReEvo-generated heuristic across all sizes, whereas for the CVRP, we use distinct heuristics for each size due to the observed variations in desirable heuristics.
Appendix D Benchmark problems
D.1 Traveling Salesman Problem
Definition.
The Traveling Salesman Problem (TSP) is a classic optimization challenge that seeks the shortest possible route for a salesman to visit each city in a list exactly once and return to the origin city.
Instance generation.
Nodes are sampled uniformly from unit for the synthetic datasets.
D.2 Capacitated Vehicle Routing Problem
Definition.
The Capacitated Vehicle Routing Problem (CVRP) extends the TSP by adding constraints on vehicle capacity. Each vehicle can carry a limited load, and the objective is to minimize the total distance traveled while delivering goods to various locations.
Instance generation.
For § 5.2, We follow DeepACO [94]. Customer locations are sampled uniformly in the unit square; customer demands are sampled from the discrete set ; the capacity of each vehicle is set to 50; the depot is located at the center of the unit square. For § 5.5, we use the test instances provided by LEHD [51].
D.3 Orienteering Problem
Definition.
In the Orienteering Problem (OP), the goal is to maximize the total score collected by visiting nodes while subject to a maximum tour length constraint.
Instance generation.
The generation of synthetic datasets aligns with DeepACO [94]. We uniformly sample the nodes, including the depot node, from the unit . We use a challenging prize distribution [36]: , where is the distance between the depot and node . The maximum length constraint is also designed to be challenging. As suggested by Kool et al. [36], we set it to 3, 4, 5, 8, and 12 for OP50, OP100, OP200, OP500, and OP1000, respectively.
D.4 Multiple Knapsack Problem
Definition.
The Multiple Knapsack Problem (MKP) involves distributing a set of items, each with a given weight and value, among multiple knapsacks to maximize the total value without exceeding the capacity of any knapsack.
Instance generation.
Instance generation follows DeepACO [94]. The values and weights are uniformly sampled from . To make all instances well-stated, we uniformly sample from .
D.5 Bin Packing Problem
Definition.
The Bin Packing Problem requires packing objects of different volumes into a finite number of bins or containers of a fixed volume in a way that minimizes the number of bins used. It is widely applicable in manufacturing, shipping, and storage optimization.
Instance generation.
Following Levine and Ducatelle [39], we set the bin capacity to 150, and item sizes are uniformly sampled between 20 and 100.
D.6 Decap Placement Problem
Definition.
The Decap Placement Problem (DPP) is a critical hardware design optimization issue that involves finding the optimal placement of decoupling capacitors (decap) within a power distribution network (PDN) to enhance power integrity (PI) [65, 69, 16, 63]. Decoupling capacitors are hardware components that help reduce power noise and ensure a stable supply of power to the operating integrated circuits within hardware devices such as CPUs, GPUs, and AI accelerators [65]. The DPP is formulated as a black-box contextual optimization problem, where the goal is to determine the best positions for a set of decaps to maximize the PI objective. This objective is contextualized by the target hardware’s feature vectors, with the constraint of a limited number of decaps. Interested readers can refer to [31] for more details.
Instance generation.
Appendix E Generated heuristics
This section presents the best heuristics generated by ReEvo for all problem settings.
LABEL:lst:_heuristic_for_TSPACO presents the best heuristic found for TSP_ACO, which is generated when viewing TSP as a black-box COP. ‘edge_attr’ represents the distance matrix.
LABEL:lst:_heuristic_for_MKPACO presents the best heuristic found for MKP_ACO, which is generated when viewing MKP as a black-box COP. ‘item_attr1’ and ‘item_attr2’ represent the prizes and multi-dimensional weights of items, respectively.
LABEL:lst:_heuristic_for_TSPconstructive gives the best-ReEvo generated constructive heuristic for TSP. We used the best heuristic found in AEL [46] as the seed for ReEvo. As a result, our heuristic closely mirrors the one in AEL, scoring each node mostly using a weighted combination of the four factors.
Appendix F Licenses for used assets
Table 11 lists the used assets and their licenses. Our code is licensed under the MIT License.
| Type | Asset | License | Usage |
| Code | NeuOpt [52] | MIT License | Evaluation |
| GNNGLS [24] | MIT License | Evaluation | |
| EoH [47] | MIT License | Evaluation | |
| DeepACO [94] | MIT License | Evaluation | |
| DevFormer [31] | Apache-2.0 license | Evaluation | |
| POMO [37] | MIT License | Evaluation | |
| LEHD [51] | MIT License | Evaluation | |
| Dataset | TSPLIB [67] | Available for any non-commercial use | Testing |
| DPP PDNs [63] | Apache-2.0 license | Testing |