Redundancy-Free Self-Supervised Relational Learning for Graph Clustering
Abstract
Graph clustering, which learns the node representations for effective cluster assignments, is a fundamental yet challenging task in data analysis and has received considerable attention accompanied by graph neural networks in recent years. However, most existing methods overlook the inherent relational information among the non-independent and non-identically distributed nodes in a graph. Due to the lack of exploration of relational attributes, the semantic information of the graph-structured data fails to be fully exploited which leads to poor clustering performance. In this paper, we propose a novel self-supervised deep graph clustering method named Relational Redundancy-Free Graph Clustering (R2FGC) to tackle the problem. It extracts the attribute- and structure-level relational information from both global and local views based on an autoencoder and a graph autoencoder. To obtain effective representations of the semantic information, we preserve the consistent relation among augmented nodes, whereas the redundant relation is further reduced for learning discriminative embeddings. In addition, a simple yet valid strategy is utilized to alleviate the over-smoothing issue. Extensive experiments are performed on widely used benchmark datasets to validate the superiority of our R2FGC over state-of-the-art baselines. Our codes are available at https://github.com/yisiyu95/R2FGC.
Index Terms:
Deep Clustering, Graph Representation Learning, Relation Preservation, Redundancy Reduction.I Introduction
Clustering, as one of the most classical and fundamental components in machine learning and data mining communities, has attracted significant attention. It serves as a critical preprocessing step in a variety of real-world applications such as community detection [1], anomaly detection [2], domain adaptation [3], and representation learning [4, 5, 6]. The underlying idea of clustering is to assign the samples to different groups such that similar samples are pulled into the same cluster while dissimilar samples are pushed into different clusters. Hence, clustering intuitively reflects the characteristics of the whole dataset, which could provide a priori information for various downstream domains, including computer vision and natural language processing.
Among many challenges therein, how to effectively partition the whole dataset into different clusters remains a fundamental yet open challenge such that the intrinsic distribution information of the dataset can be well preserved. To achieve this goal, a large number of advanced approaches have been developed over the past decades [7, 8]. Traditional clustering methods such as subspace clustering [8] and spectral clustering [7] aim at projecting the data samples into a low-dimensional space coupled with additional constraint information so that the samples in the latent space can be clearly separated. However, the two-stage training paradigm of the traditional methods is typically sub-optimal since the representation learning and clustering are dependent on each other that should be jointly optimized. Moreover, traditional algorithms have limited model capacity that unavoidably limits their applicability and potential. Recently, benefiting from the strong representation capability of deep learning, massive deep clustering algorithms are proposed to show great potential and advantages over traditional approaches [9, 10, 11, 12, 13]. The core essence of deep clustering is to group the data samples into different clusters through deep neural networks in an end-to-end fashion. In this way, clustering and representation learning are jointly optimized to learn clustering-friendly representations without manual feature extraction. For example, CC [9] jointly learned effective representations and cluster assignments by leveraging the power of instance- and cluster-level contrastive learning in an end-to-end manner.
With the prevalence of graph-structured data, Graph Neural Networks (GNNs) have been extensively studied and achieved remarkable progress for many promising graph-related tasks and applications [14, 15, 16]. One fundamental problem therein is graph clustering, which divides nodes in a graph into different clusters. GNNs can be well utilized for enhancing graph clustering performance to learn effective cluster assignments [17, 18, 19, 20, 21, 22, 23, 24, 25, 26]. Recently, there has been an increasing body of approaches on graph clustering. For example, SDCN [18] firstly incorporated the topological structure knowledge into deep clustering accompanied by autoencoder (AE) [27] and GNN. To better combine node attributes and structure information, DFCN [21] improved the graph autoencoder (GAE) [28] and developed a fusion mechanism to dynamically integrate both sides for robust target distribution generation. Based on AE, AGCC [24] incorporated the attention mechanism to fuse learned node representations and leveraged a self-supervised mechanism to guide the clustering optimization procedure.
Despite the promising achievements of previous methods, a vast majority of existing graph clustering approaches still suffer from two key limitations: (i) Neglect the exploration of relational information. Most existing GNN-based methods only use message passing to aggregate neighboring information of the nodes in a graph. The high-order attributive and structural relationships of the non-IID graph-structured data are not well exploited, which leads that the underlying distribution information cannot be well revealed for meaningful representations; (ii) Fail to reduce redundant information. Many clustering methods mainly focus on exploring graph information from multiple perspectives, unavoidably incorporating much redundant information into the learned representations, while the redundancy reduction is not taken into account, which prevents obtaining discriminative representations and excellent clustering performance. As such, it is highly promising to develop an approach that can fully explore the intrinsic relational information among nodes and decrease the redundant information for effective cluster assignments.
Towards this end, this paper proposes a novel deep clustering method called Relational Redundancy-Free Graph Clustering (R2FGC). The key idea of R2FGC is to exploit attribute- and structure-level relational information among the nodes from both global and local views in a redundancy-free manner. To achieve the goal effectively, R2FGC first learns compact representations from an AE and a GAE to explore the attributive and structural information from complementary perspectives. Then, the relational information is extracted based on the learned representations from global and local views. Moreover, to fully benefit from the extracted relations, we preserve the consistent relationship such that the relational information for the same node is invariant to augmentations, whereas the correlations of the relational distribution for different nodes are reduced for learning discriminative representations. Further, R2FGC combines the redundancy-free relational learning from both attribute and structure levels with an augmentation-based fusion mechanism to optimize the embedded representations in a self-supervised fashion. Comprehensive experiments are conducted to show that the proposed method can greatly improve the clustering performance compared with the existing state-of-the-art approaches over multiple benchmark datasets. To summarize, the main contributions of our work are as follows:
-
•
General Aspects: This paper studies the inherent relational learning for non-IID graph-structured data and explores redundancy-free representations based on relational information for the graph clustering task.
-
•
Novel Methodologies: We propose a novel approach to exploit attribute- and structure-level relational information among the nodes, which aims to extract augmentation-invariant relationships for the same node and decrease the redundant correlations between different nodes. Our R2FGC is beneficial to obtain effective and discriminative representations for clustering.
-
•
Multifaceted Experiments: We perform extensive experiments on various commonly used datasets to demonstrate the effectiveness of the proposed approach.
II Related Work
II-A Graph Neural Networks
Recent years have witnessed great progress in Graph Neural Networks (GNNs) and achieved state-of-the-art performance. The concept of GNNs was proposed [29] before 2010 and has become an ever-increasing theme. A general paradigm of GNNs is to iteratively update node representations by aggregating neighboring information based on message-passing [30]. Representative method Graph Convolutional Network (GCN) [31] extended the classical convolutional neural networks to the case of graph-structured data. Subsequent work Graph Attention Network (GAT) [32] further leveraged the attention mechanism [33] to dynamically aggregate the features of neighbors. With the powerful capability of GNNs, the learned graph representations can be used to serve a variety of downstream tasks, such as node classification [31, 34], graph classification [35, 36, 37], and graph clustering [18, 38].
II-B Deep Clustering
The goal of deep clustering focus on utilizing the excellent representation ability of deep learning to serve the clustering process, which has achieved remarkable progress. Existing methods can be categorized into three main groups based on the training objectives: (i) reconstruction based methods, (ii) self-augmentation based methods, and (iii) spectral clustering based methods. The first group uses the AE to reconstruct the original input, which incorporates desired constraints on feature embeddings in the latent space. For instance, DEC [39] iteratively conducted the process of representation learning and clustering assignments via minimizing the Kullback-Leibler divergence. To preserve important data structure, IDEC [40] introduced AE to improve the clustering so that the local structure of data generating distribution can be maintained. The second group aims to encourage the consistency between original samples and their augmented samples by optimizing the networks. For example, IIC [41] sought to achieve the consistency of assignment probabilities by maximizing the mutual information of paired samples. The third group aims at constructing a robust affinity matrix for effective data partitioning. For instance, RCFE [42] utilized the idea of rank constraints and clusters data points in a low-dimensional subspace. Li et al. [43] utilized multiple features to construct affinity graphs for spectral clustering.
Benefiting from the breakthroughs of GNNs on graph-structured data, GNNs are capable of organically integrating node attributes and graph structures in a united way, and have emerged as a promising way for graph clustering. The basic idea is to group the nodes in the graph into several disjoint clusters. Similar to the deep clustering methods, a vast majority of existing graph clustering approaches [44, 45, 23, 24, 46, 47, 18, 22] also continue the paradigm of AE, in which the GAE and the variational GAE (VGAE) are leveraged to operate on graph-structured data. For example, to dynamically learn the importance of the neighboring nodes to the center node, DAEGC [45] employed the GAE to capture a compact representation by encoding the graph structures and node attributes. EGAE [23] learned the explainable representations based on the GAE that can be also used for various tasks. Compared with previous methods, our work further explores graph clustering by simultaneously preserving the relational similarity and reducing the redundancy of the learned representations based on both AE and GAE.
II-C Self-supervised Learning
Recently, self-supervised learning (SSL) revitalizes and has achieved superior performance across numerous domains. This technique is completely free of the need for explicit labels [48], due to its powerful capability in learning effective representations from unlabeled data. The core procedure of SSL is first designing a domain-specific pretext task and training the networks on the pretext task, such that the learned representations can be more discriminative and applicable. Recently, many SSL approaches have been proposed to marry the power of SSL and deep learning [49, 50, 51, 52], and have shown competitive performance in various downstream application [53, 54, 55, 56, 57]. For example, SimCLR [49] employed multiple data augmentations and a learnable nonlinear transformation to train an encoder, such that the model can pull the feature representations from the same samples together. To alleviate the issue of the large batch size of SimCLR, MoCo [50] introduced a moving-averaged encoder to set up a dynamic dictionary for SSL. Furthermore, our proposed R2FGC inherits the advantages of SSL to preserve the consistent relation and reduce the redundant information among nodes from global and local views for graph clustering.
III Notations and problem definition
In this section, we first briefly give the basic notations and formal terminologies in a graph. Then we introduce the concept of Graph Convolutional Network (GCN) and the problem formalization of graph clustering.
Notations. Let denote an arbitrary undirected graph, where is the vertex set with nodes, is the edge set, is the node attribute matrix with corresponding to node for , and is the dimensionality of the node attributes. denote the adjacency matrix which is generated according to the adjacency relationships in , and if , i.e., there is an edge from node to node , otherwise . The adjacency matrix can be normalized by , where , is the identify matrix for adding self-connections, and is the corresponding degree matrix with .
Graph Convolutional Network. GCN generalizes the classical Convolutional Neural Networks to the case of graph-structured data. It utilizes the graph directly and learns new representations by aggregating the information of a node and its neighbors. In general, a layer of GCN has the form
where is the input data, is an activation function, such as Tanh and ReLU, and are the learned embedded representation and the trainable weight matrix in the -th () layer, respectively.
Graph Clustering. Given an unlabeled graph with nodes, the target of the graph clustering task is to divide these unlabeled nodes into disjoint clusters based on a well-learned embedding matrix , where is the number of dimension of the latent embeddings. The nodes in the same cluster are highly similar and cohesive, while the nodes in different clusters are discriminative and separable.
IV The proposed method

In this section, we introduce our proposed method named Relational Redundancy-Free Graph Clustering (R2FGC). R2FGC mainly contains four parts, i.e., attribute- and structure-level representation learning module, relation preservation and de-redundancy module, augmentation-based representation fusion module, and joint optimization module for graph clustering. Figure 1 shows the framework overview of the proposed R2FGC. In the following, we present the four components and the complexity analysis for R2FGC.
IV-A Attribute- and Structure-level Learning Module
AE can reasonably explore the node attribute information, whereas the GAE can effectively capture the topological structure information. To gain a more comprehensive embedding and a better performance on downstream tasks, we consider both AE and GAE to reconstruct the input and learn fusional representation.
The AE module feeds the attribute information into the multi-layer perceptrons and extracts the latent representations by minimizing the reconstruction loss between the input raw data and the reconstructed data. The corresponding optimization objective is formalized as
| (1) | ||||
where is the input attribute matrix and is the reconstructed data, is the Frobenius norm, is the learned latent representation in AE, and are the encoder and decoder networks, respectively.
In the GAE module, following the improved version in [21], a multi-layer GCN is adopted to reconstruct the adjacency matrix and the attribute information. The corresponding reconstruction loss is formalized as
| (2) | ||||
where is a pre-defined hyper-parameter, is the normalized adjacency matrix, is the reconstructed adjacency matrix produced by fusing respective inner products of the learned latent representation resulting from the graph encoder and the attribute representations (i.e., the reconstructed weighted attribute matrix) resulting from the graph decoder, and are the layer-specific trainable weight matrices in the -th graph encoder and decoder layers, respectively. The detailed fusion mechanism is discussed in the following Section IV-C, which unites the embedded representations from both AE and GAE to promote latent presentation learning in the graph augmentation fashion.
IV-B Relation Preservation and De-redundancy Module
In this module, we learn the inherent relational information among the nodes based on augmentations on a given graph. One of the basic ideas is to preserve the similarity of the relational information from two augmented views, while the latent representation of the same node can vary after graph augmentation. Hence, we aim to increase the consistency of the relational information in each positive pair. It allows fine-grained mining of the node relationship. On the other hand, it is necessary to improve the discriminative capability of the resulting representations for graph clustering, thus we also decrease the correlation of the relational information in each negative pair. In the following, we first introduce the adopted graph augmentation strategies and relation extraction methods. Then, we describe the details of the subsequent relation preservation and relation de-redundancy.
Based on the given graph, we first construct two different graph views through augmentations, including
-
•
Attribute perturbation. For each value in the attribute matrix, we disturb it by multiplying a Gaussian random number with a small variance. This strategy performs a slight disturbance on the node features, which would not essentially change the semantic information.
-
•
Edge deletion. We remove some edges based on the node similarity obtained from the pre-learned latent embeddings. For each node, the edges that connect the nodes with low similarity are dropped in a certain proportion. Compared with random deletion, more semantic information can be preserved by referring to the node similarity.
-
•
Graph diffusion. We transform the adjacency matrix to a diffusion matrix by leveraging graph diffusion [58], which contributes to providing additional local information. Technically, given the transition matrix , the graph diffusion matrix is formulated as
where is the weight coefficient. We adopt the personalized PageRank [59] to characterize graph diffusion, which is a special case. Specifically, is chosen as the normalized adjacency matrix and with teleport probability . Then, the resulting diffusion matrix has the form
(3)
After obtaining two augmented graph views and , we perform AE and GAE on and , which generates the attribute-level latent representations and the structure-level latent representations . To meticulously characterize the relational information, we explore the similarities of each node to some anchor nodes from both global and local perspectives based on these representations.
Extraction of Global Anchors. For capturing the global relationship of a query node , the target is to sample diverse anchors from the whole graph nodes. Due to the neighborhood aggregation mechanism in GNNs, we argue that the high-degree nodes may receive more information when passing messages, while the low-degree nodes would receive less information. This may result in poor representations for the nodes with low degrees. Hence, we perform non-uniform sampling on the nodes to balance the qualities of the representations for low- and high-degree nodes. Specifically, we adopt an inverse degree-weighted distribution for sampling anchors, which puts a larger sampling probability on a lower-degree node. The sampling weight and probability for each node, respectively, are as follows,
where is a hyper-parameter to control the skewness of the distribution, and is the degree of node . Moreover, quasi-Monte Carlo (QMC) sampling methods usually can achieve a higher convergence rate than Monte Carlo (MC) methods [60]. Hence, based on the defined discrete distribution, we perform multinomial sampling in the QMC fashion [61, 62]. Instead of the uniform random number (the MC fashion), we leverage the randomized one-dimensional low-discrepancy point set to do multinomial sampling on the discrete distribution in each training epoch. Randomization is used to avoid the same sample in different epochs and increase the randomness for extracting more diverse anchors. For each node , we denote the index set of the sampled anchors from the global view as and .
Extraction of Local Anchors. To fully explore the relational information, besides the global anchor sampling, we also concentrate on the local relational information. Graph diffusion removes the restriction of using only the direct neighbors and alleviates the problem of noisy and often arbitrarily defined edges. It leads that the diffusion matrix in (3) can acquire richer structural information in the local view compared with traditional GNNs. Hence, we leverage graph diffusion to generate the local anchors according to the scores in . Specifically, the values in the -th row of can reflect the influence between node and all the other nodes. We select the nodes with the largest scores in the -th row of as the local anchors of node . It makes that the local anchors of share similar semantic information to , which allows us to extract more effective local relations. For each node , we denote the index set of the local anchors as and .
Based on these global- and local-view anchor sets , we extract the relational information of the nodes in the sense of similarity. We use the AE latent representations to illustrate the detailed process. Specifically, given a query node , we calculate the similarities between the embedded representation of in and the embeddings of these anchors in by
Similarly, we also calculate the similarities between the embedding of in and those of the anchors in by
Hereafter, let be the relation vector composed by with traversing the whole index set of node , and be the relation matrix for any .
Relation Preservation. To make the relational information invariant to augmentation, we maximize the proximity of and from both global and local views, i.e., we maximize the attribute-level relational similarities of all the positive pairs under augmentation, which are formulated by
and
We can similarly obtain the structure-level relational similarities and corresponding to GAE from both views. This operation helps to learn representations that are more reflective of the relationships between the attribute and topological information of all the nodes.
Relation De-redundancy. In addition, besides preserving the relational similarity under augmentations, the discriminative capability of the latent representation is also important for the downstream graph clustering task. Hence, we decrease the correlations of the relation vectors for different nodes from both global and local views. It contributes to filtering redundant information and improving the separating capability for better clustering performance. Specifically, we minimize the attribute-level relational correlations of all the negative pairs, which are formulated as follows,
and
In like manner, we can obtain the corresponding structure-level loss under GAE from global and local views, denoted by and , respectively.
Based on the above discussion, we can capture the augmentation-invariant relational information and conduct redundancy-free relational learning by minimizing the total relation loss with
| (4) | ||||
The loss takes into account both efficient representation learning and reduction of redundant information upon the relation extraction of the nodes, which allows for better guidance of downstream tasks.
IV-C Augmentation-based Representation Fusion Module
In this section, to obtain fine-grained representations of the nodes, we discuss the fusion mechanism of the attribute- and structure-level latent representations based on augmentations. First, we take a weighted summation of the four parts to fuse the embedded representations from the two levels as follows,
where are trainable weight matrices to control the importance of the two types of representations and is the Hadamard product. Based on , we further blend the embeddings from both global and local views to refine the fused information. From the local view, we adopt the neighborhood aggregation operation on to enhance the local information, whereas, from the global view, we utilize the self-correlation matrix of the nodes characterized by to improve the exploitation of the global information, which is normalized by the softmax function. Specifically, the final formula of the fused representation is
| (5) |
where is a trainable weight parameter. With , we can obtain the reconstructed attribute matrix in (1) and weighted attribute matrix in (2) by feeding into the decoders of AE and GAE, respectively. The reconstructed adjacency matrix is calculated by fusing the self-correlations of the learned representations in GAE, which is formulated as
The above fusion process is similar to [21].
In addition, under the neighbor aggregation mechanism, GCN updates node representations by aggregating information from the neighbors. However, when stacking multiple layers, the learned representations would become indistinguishable, seriously degrading the performance, which is the so-called over-smoothing issue [63, 64]. Hence, it is important to balance the message aggregation ability and over-smoothing issue. To alleviate the problem in GAE, we incorporate a novel propagation-regularization loss to enhance information capturing while alleviating over-smoothing defined as
where contains the embedding matrix in each layer of both the encoder and decoder in GAE and is the metric function, such as the cross entropy, Kullback-Leibler (KL) divergence, and the Jensen-Shannon divergence. Propagation regularization simulates a deep GCN by supervision at a low cost, which enables current embeddings to capture further information contained in the deeper layer. Compared with directly increasing the GCN layers, we can more finely balance the information capture ability and the over-smoothing problem by adjusting the weight of the loss.
IV-D Joint Optimization Module for Graph Clustering
Graph clustering is essentially an unsupervised task with no feedback available as reliable guidance. To this end, we perform a clustering layer on the fused representation in (5) and use the soft labels derived by a probability distribution as a self-supervised signal to jointly optimize the redundancy-free relational learning framework for graph clustering.
First, by using the student’s -distribution as a kernel, we calculate the soft cluster assignment probabilities upon the latent embeddings , respectively, to measure the similarities between the latent representations and cluster centroids, i.e., each value indicates the probability of assigning the th node to the th cluster. For example, is computed as follows,
where and ’s are the cluster centroids. The and can be calculated similarly. The ’s are initialized by performing -Means on the pre-trained fused representation. When the network is well trained, we adopt the fusion-based assignment matrix to measure the cluster assignment probability of all the nodes, i.e.,
| (7) |
where is the predicted cluster of node for .
Next, we introduce an auxiliary confident probability distribution to improve the confidence of the soft assignment, which is derived from and formulated as
To make the data representation close to cluster centroids and improve cluster cohesion, we minimize the KL divergence loss between and as follows,
| (8) |
By utilizing the confident distribution , the process self-supervises the cluster assignment without any label guidance. We integrate the latent representations from AE, GAE, and the fusion mechanism in the self-supervised clustering procedure to obtain more accurate clustering results.
To sum up, the total loss in the whole framework of R2FGC is composed of the relation loss, the reconstruction loss, and the self-supervised clustering loss, i.e.,
| (9) |
where is a pre-defined hyper-parameter to balance the weight of the clustering loss. The training process of our proposed R2FGC is summarized in Algorithm 1.
IV-E Computational Complexity Analysis
For the scalability of large-scale datasets, we adopt the mini-batch stochastic gradient descent to optimize our method. Assume that the batch size is and the dimensions of each layer of AE and GAE are and , respectively. Given a graph with nodes and edges, the dimension of the original attributes is . The time complexities of AE and GAE are and with , respectively. For each batch, the complexity of the relation learning module is based on -dimensional latent representations. Moreover, we perform the representation fusion and propagation regularization in time and conduct the self-supervised clustering in time with classes in the task. Hence, the total computational complexity of our method R2FGC is , which is linearly related to the numbers of nodes and edges.
V Experiments
In this section, we first introduce the experimental settings and then conduct experiments to validate the effectiveness of R2FGC. We aim to answer the following research questions.
-
•
RQ1: Compared with state-of-the-art methods, does our method R2FGC achieve better performance for self-supervised graph clustering?
-
•
RQ2: How do different components of the proposed method contribute to the clustering performance?
-
•
RQ3: How do the hyper-parameters in R2FGC affect the final clustering performance?
-
•
RQ4: How is the convergence of the proposed model under different datasets?
-
•
RQ5: Is there any supplementary analysis that can illustrate the superiority of R2FGC?
V-A Experimental Settings
Datasets. For comparison, we perform the proposed method R2FGC on five commonly used benchmark datasets. Four of them are graph datasets, including a paper network ACM111http://dl.acm.org/, a shopping network AMAP222https://github.com/shchur/gnn- benchmark/raw/master/data/npz/
amazon_electronics photo.npz, a citation network CITE333http://citeseerx.ist.psu.edu/index, and an author network DBLP444https://dblp.uni-trier.de; another is a non-graph dataset, i.e., a record dataset HHAR[65]. Following [18], for the non-graph data, the adjacency matrix is generated by the undirected -nearest neighbor graph. Table I briefly summarizes the information of these benchmark datasets.
| Dataset | Type | Samples | Dimension | Classes |
|---|---|---|---|---|
| ACM | Graph | 3025 | 1870 | 3 |
| AMAP | Graph | 7650 | 745 | 8 |
| CITE | Graph | 3327 | 3703 | 6 |
| DBLP | Graph | 4057 | 334 | 4 |
| HHAR | Record | 10299 | 561 | 6 |
Compared Methods. To illustrate the superiority of our proposed R2FGC, we compare its clustering performance with some state-of-the-art clustering methods, which are divided into four categories, i.e., the classical shallow clustering method -means, the AE-based methods, the GCN-based methods, and the combination of AE and GCN. The AE-based methods contains AE[27], DEC[39], and IDEC[40]. They convert the raw data to low-dimensional codes to learn feature representations by AE and then perform clustering over the learned latent embeddings. The GCN-based methods include GAE, VGAE[28], DAEGC[45], and ARGA[46]. They adopt the GCN encoder to learn the node content and topological information for clustering. In addition, some methods combine AE and GCN to boost the embedded representations for clustering, which contains SDCN [18], DFCN[21] and AGCC [24]. These methods integrate GCN with AE from different perspectives to jointly train the clustering network.
Training Procedure. The training of our method R2FGC includes two phases. First, following [21], the AE and GAE are pre-trained independently for 30 epochs to minimize their respective reconstruction loss functions. Both sub-networks are integrated into a united framework for another 100 epochs to obtain the initial representations and cluster centroids. Then, we train the whole network for at least 300 epochs until convergence to minimize the total loss in (9). Following the compared methods, to alleviate the adverse influence of the randomness, we repeat the experiment 10 times to evaluate our method and report the mean values and the standard deviations (i.e., mean±std) of the considered metric values. We implement our method using PyTorch 1.8.0 and Pytorch Geometric 1.7.2, which can easily train GNNs for a variety of applications associated with graph-structured data.
| Dataset | Metric | -Means | AE | DEC | IDEC | GAE | VGAE | DAEGC | ARGA | SDCN | DFCN | AGCC | R2FGC (Ours) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | 67.31±0.71 | 81.83±0.08 | 84.33±0.76 | 85.12±0.52 | 84.52±1.44 | 84.13±0.22 | 86.94±2.83 | 86.29±0.36 | 90.45±0.18 | 90.90±0.20 | 90.38±0.38 | 92.43±0.18 | |
| NMI | 32.44±0.46 | 49.30±0.16 | 54.54±1.51 | 56.61±1.16 | 55.38±1.92 | 53.20±0.52 | 56.18±4.15 | 56.21±0.82 | 68.31±0.25 | 69.40±0.40 | 68.34±0.89 | 72.42±0.53 | |
| ARI | 30.60±0.69 | 54.64±0.16 | 60.64±1.87 | 62.16±1.50 | 59.46±3.10 | 57.72±0.67 | 59.35±3.89 | 63.37±0.86 | 73.91±0.40 | 74.90±0.40 | 73.73±0.90 | 78.72±0.47 | |
| ACM | F1 | 67.57±0.74 | 82.01±0.08 | 84.51±0.74 | 85.11±0.48 | 84.65±1.33 | 84.17±0.23 | 87.07±2.79 | 86.31±0.35 | 90.42±0.19 | 90.80±0.20 | 90.39±0.39 | 92.45±0.18 |
| ACC | 27.22±0.76 | 48.25±0.08 | 47.22±0.08 | 47.62±0.08 | 71.57±2.48 | 74.26±3.63 | 76.44±0.01 | 69.28±2.30 | 53.44±0.81 | 76.88±0.80 | 75.25±1.21 | 81.28±0.05 | |
| NMI | 13.23±1.33 | 38.76±0.30 | 37.35±0.05 | 37.83±0.08 | 62.13±2.79 | 66.01±3.40 | 65.57±0.03 | 58.36±2.76 | 44.85±0.83 | 69.21±1.00 | 68.37±1.39 | 73.88±0.17 | |
| ARI | 5.50±0.44 | 20.80±0.47 | 18.59±0.04 | 19.24±0.07 | 48.82±4.57 | 56.24±4.66 | 59.39±0.02 | 44.18±4.41 | 31.21±1.23 | 58.98±0.84 | 58.32±2.38 | 66.25±0.36 | |
| AMAP | F1 | 23.96±0.51 | 47.87±0.20 | 46.71±0.12 | 47.20±0.11 | 68.08±1.76 | 70.38±2.98 | 69.97±0.02 | 64.30±1.95 | 50.66±1.49 | 71.58±0.31 | 70.04±1.63 | 75.29±0.32 |
| ACC | 39.32±3.17 | 57.08±0.13 | 55.89±0.20 | 60.49±1.42 | 61.35±0.80 | 60.97±0.36 | 64.54±1.39 | 61.07±0.49 | 65.96±0.31 | 69.50±0.20 | 68.08±1.44 | 70.60±0.45 | |
| NMI | 16.94±3.22 | 27.64±0.08 | 28.34±0.30 | 27.17±2.40 | 34.63±0.65 | 32.69±0.27 | 36.41±0.86 | 34.40±0.71 | 38.71±0.32 | 43.90±0.20 | 40.86±1.45 | 45.39±0.37 | |
| ARI | 13.43±3.02 | 29.31±0.14 | 28.12±0.36 | 25.70±2.65 | 33.55±1.18 | 33.13±0.53 | 37.78±1.24 | 34.32±0.70 | 40.17±0.43 | 45.50±0.37 | 41.82±2.03 | 47.07±0.30 | |
| CITE | F1 | 36.08±3.53 | 53.80±0.11 | 52.62±0.17 | 61.62±1.39 | 57.36±0.82 | 57.70±0.49 | 62.20±1.32 | 58.23±0.31 | 63.62±0.24 | 64.30±0.20 | 60.47±1.57 | 65.28±0.12 |
| ACC | 38.65±0.65 | 51.43±0.35 | 58.16±0.56 | 60.31±0.62 | 61.21±1.22 | 58.59±0.06 | 62.05±0.48 | 64.83±0.59 | 68.05±1.81 | 76.00±0.80 | 73.45±2.16 | 80.95±0.20 | |
| NMI | 11.45±0.38 | 25.40±0.16 | 29.51±0.28 | 31.17±0.50 | 30.80±0.91 | 26.92±0.06 | 32.49±0.45 | 29.42±0.92 | 39.50±1.34 | 43.70±1.00 | 40.36±2.81 | 50.82±0.32 | |
| ARI | 6.97±0.39 | 12.21±0.43 | 23.92±0.39 | 25.37±0.60 | 22.02±1.40 | 17.92±0.07 | 21.03±0.52 | 27.99±0.91 | 39.15±2.01 | 47.00±1.50 | 44.40±3.79 | 56.34±0.42 | |
| DBLP | F1 | 31.92±0.27 | 52.53±0.36 | 59.38±0.51 | 61.33±0.56 | 61.41±2.23 | 58.69±0.07 | 61.75±0.67 | 64.97±0.66 | 67.71±1.51 | 75.70±0.80 | 71.84±2.02 | 80.54±0.19 |
| ACC | 59.98±0.02 | 68.69±0.31 | 69.39±0.25 | 71.05±0.36 | 62.33±1.01 | 71.30±0.36 | 76.51±2.19 | 63.30±0.80 | 84.26±0.17 | 87.10±0.10 | 86.54±1.79 | 88.91±0.05 | |
| NMI | 58.86±0.01 | 71.42±0.97 | 72.91±0.39 | 74.19±0.39 | 55.06±1.39 | 62.95±0.36 | 69.10±2.28 | 57.10±1.40 | 79.90±0.09 | 82.20±0.10 | 82.21±1.78 | 83.39±0.07 | |
| ARI | 46.09±0.02 | 60.36±0.88 | 61.25±0.51 | 62.83±0.45 | 42.63±1.63 | 51.47±0.73 | 60.38±2.15 | 44.70±1.00 | 72.84±0.09 | 76.40±0.10 | 75.58±1.85 | 78.52±0.08 | |
| HHAR | F1 | 58.33±0.03 | 66.36±0.34 | 67.29±0.29 | 68.63±0.33 | 62.64±0.97 | 71.55±0.29 | 76.89±2.18 | 61.10±0.90 | 82.58±0.08 | 87.30±0.10 | 85.79±2.48 | 89.23±0.06 |
Parameter Settings. For a fair comparison, we adopt the same parameter setting for AE and GAE as [21], i.e., the layers of the encoder (/decoder) for AE and GAE are set to 4 and 3, respectively; the dimensions of the encoder (/decoder) for AE are set to 128, 256, 512, 20 in turn; the dimensions of the encoder (/decoder) for GAE are set to 128, 256, 20 in turn. The network is trained with the Adam optimizer. The learning rate is set to 5e-5 for ACM, 1e-4 for DBLP, and 1e-3 for AMAP, CITE, and HHAR. The hyper-parameters and are set to 256, 8. Moreover, the parameters are set to 0.1, 0.2, 0.8, 5e3, 10, respectively. The optimization stops when the validation loss comes to a plateau.
Evaluation Metrics. To evaluate the clustering performance of each compared method, we adopt four widely used evaluation metrics following [18], i.e., Accuracy (ACC), Normalized Mutual Information (NMI), Average Rand Index (ARI), and Macro F1-score (F1). For each metric, a larger value implies a better clustering result.
V-B Performance Comparison (RQ1)
The experimental results of our method and eleven compared methods on five benchmark datasets are reported in Table II, in which the bold and underlined values indicate the best results in all the methods and all the baselines, respectively. From these results, we have the following observations.
| Dataset | Model | ACC | NMI | ARI | F1 |
|---|---|---|---|---|---|
| ACM | R2FGC w/o gloRE | 92.39±0.14 | 72.39±0.44 | 78.72±0.37 | 92.40±0.14 |
| R2FGC w/o locRE | 92.21±0.16 | 72.17±0.53 | 78.53±0.43 | 92.19±0.16 | |
| R2FGC w/o REpre | 92.13±0.23 | 71.88±0.67 | 78.09±0.56 | 92.27±0.21 | |
| R2FGC w/o REder | 92.35±0.17 | 72.34±0.55 | 78.62±0.46 | 92.41±0.18 | |
| R2FGC w/o REpre & REder | 92.05±0.16 | 71.31±0.49 | 77.81±0.41 | 92.11±0.16 | |
| R2FGC w/o PR | 91.93±0.18 | 71.01±0.51 | 77.44±0.47 | 91.95±0.18 | |
| R2FGC (Ours) | 92.43±0.18 | 72.42±0.53 | 78.72±0.47 | 92.45±0.18 | |
| AMAP | R2FGC w/o gloRE | 81.21±0.07 | 73.79±0.18 | 66.04±0.45 | 75.14±0.45 |
| R2FGC w/o locRE | 81.23±0.06 | 73.81±0.22 | 66.15±0.51 | 75.03±0.48 | |
| R2FGC w/o REpre | 81.24±0.06 | 73.81±0.19 | 66.20±0.42 | 75.21±0.33 | |
| R2FGC w/o REder | 80.85±0.45 | 73.06±0.69 | 66.00±0.43 | 74.88±0.46 | |
| R2FGC w/o REpre & REder | 80.75±0.07 | 72.87±0.23 | 65.83±0.36 | 74.51±0.40 | |
| R2FGC w/o PR | 80.39±0.61 | 72.50±0.82 | 65.53±0.67 | 74.35±0.82 | |
| R2FGC (Ours) | 81.28±0.05 | 73.88±0.17 | 66.25±0.36 | 75.29±0.32 | |
| CITE | R2FGC w/o gloRE | 69.84±0.53 | 44.47±0.32 | 45.61±0.41 | 64.77±0.32 |
| R2FGC w/o locRE | 70.25±0.51 | 44.99±0.40 | 46.65±0.37 | 64.93±0.43 | |
| R2FGC w/o REpre | 70.03±0.58 | 44.37±0.64 | 46.03±0.57 | 64.73±0.48 | |
| R2FGC w/o REder | 68.84±0.45 | 43.06±0.47 | 44.59±0.51 | 64.37±0.38 | |
| R2FGC w/o REpre & REder | 68.20±0.41 | 42.97±0.32 | 44.29±0.41 | 64.30±0.29 | |
| R2FGC w/o PR | 69.70±0.57 | 44.36±0.43 | 45.89±0.39 | 64.97±0.29 | |
| R2FGC (Ours) | 70.60±0.45 | 45.39±0.37 | 47.07±0.30 | 65.28±0.12 | |
| DBLP | R2FGC w/o gloRE | 80.15±0.40 | 49.74±0.52 | 55.34±0.26 | 79.73±0.37 |
| R2FGC w/o locRE | 80.72±0.27 | 50.73±0.41 | 56.23±0.52 | 80.21±0.25 | |
| R2FGC w/o REpre | 80.82±0.25 | 50.56±0.40 | 56.04±0.52 | 80.31±0.24 | |
| R2FGC w/o REder | 79.63±0.44 | 49.41±0.49 | 55.65±0.68 | 79.69±0.30 | |
| R2FGC w/o REpre & REder | 78.95±0.23 | 48.77±0.40 | 55.27±0.32 | 79.65±0.22 | |
| R2FGC w/o PR | 80.73±0.14 | 49.59±0.26 | 55.88±0.25 | 80.23±0.16 | |
| R2FGC (Ours) | 80.95±0.20 | 50.82±0.32 | 56.34±0.42 | 80.54±0.19 | |
| HHAR | R2FGC w/o gloRE | 88.82±0.05 | 83.38±0.04 | 78.43±0.07 | 89.13±0.05 |
| R2FGC w/o locRE | 88.87±0.05 | 83.32±0.06 | 78.45±0.07 | 89.18±0.05 | |
| R2FGC w/o REpre | 88.87±0.05 | 83.32±0.07 | 78.45±0.08 | 89.18±0.05 | |
| R2FGC w/o REder | 88.83±0.05 | 83.37±0.04 | 78.44±0.06 | 89.15±0.05 | |
| R2FGC w/o REpre & REder | 88.79±0.04 | 83.01±0.04 | 78.05±0.05 | 88.85±0.04 | |
| R2FGC w/o PR | 87.98±0.03 | 82.84±0.08 | 77.45±0.05 | 88.30±0.03 | |
| R2FGC (Ours) | 88.91±0.05 | 83.39±0.07 | 78.52±0.08 | 89.23±0.06 |
-
•
Compared with shallow clustering method -means, these deep graph clustering methods clearly show preferable performance. It indicates that the strong capability for learning representation of deep neural network methods enables exploit more meaningful information from graph-structured data for clustering.
-
•
The purely AE-based methods (AE, DEC, and IDEC) perform worse than the methods combining AE and GCN (SDCN, DFCN, and AGCC) in most cases. The reason may be that the AE-based methods only leverage the attribute information to learn the latent representation, which overlooks the structure-level semantic information. Similarly, the purely GCN-based methods (GAE, VGAE, DAEGC, and ARGA) also show inferior performance than SDCN, DFCN, and AGCC in most circumstances. It indicates that integrating AE into GCN can capture the attribute and structure information more effectively from complementary views.
-
•
Our method R2FGC achieves the best clustering performance compared with all the baselines in terms of the four considered metrics over all the datasets. For both graph and non-graph data, our approach represents a significant improvement over the baselines. For example, compared with the best results among all the baselines, for the ACM dataset, our method relatively improves 1.68%, 4.35%, 5.10%, 1.82% on ACC, NMI, ARI, F1; for the AMAP dataset, our method improves 5.72%, 6.75%, 11.55%, 5.18% on ACC, NMI, ARI, F1; for the DBLP dataset, our method improves 6.51%, 16.29%, 19.87%, 6.39% on ACC, NMI, ARI, F1, respectively.
-
•
The reasons for the superiority of our method R2FGC are that a) R2FGC extracts the inherent relational information based on AE and GAE from both local and global views under augmentation, which allows for better exploration of both attribute and structure information; b) Under augmentation, R2FGC preserves the consistent relationship among the nodes but not the latent representations, which expects to learn more essential representations of the semantic information; c) R2FGC decreases the redundant relation among the nodes for learning discriminative and meaningful representations, which can better serve the graph clustering; d) R2FGC couples AE and GAE together in the representation fusion mechanism to fully integrate and refine the attribute and structure information; e) R2FGC also brings the propagation regularization to mitigate the possible over-smoothing problem caused by GAE to promote the clustering performance. With the addition of relation extraction, relation preservation and de-redundancy strategies, R2FGC outperforms all the baselines upon the fusion mechanism of AE and GAE and the regularization method of alleviating over-smoothing.
V-C Ablation Study (RQ2)
In this section, to further investigate the validity of our proposed method, we conduct some ablation experiments to study the contribution of each component of R2FGC. We mainly focus on the influence of global-view relation extraction (gloRE), local-view relation extraction (locRE), relation preservation (REpre), relation de-redundancy(REder), and propagation regularization (PR). In addition, we make some discussion on the proposed global sampling strategy.
Effects of gloRE and locRE. In the relation extraction module, we explore the inherent relation from both global and local views. The former view learns the global relation of the nodes and the latter concerns the neighbor relation. We perform some ablation experiments to verify the respective effectiveness of the global- and local-view strategies. Specifically, we consider the following two cases:
-
•
R2FGC w/o gloRE: R2FGC without considering the global-view relation extraction;
-
•
R2FGC w/o locRE: R2FGC without considering the local-view relation extraction;
The corresponding results are displayed in Table III. From the comparison of R2FGC w/o gloRE and R2FGC w/o locRE, for the ACM dataset, local-view relation extraction has a greater effect than the global-view one on clustering in terms of ACC, NMI, ARI, and F1, while for the CITE and DBLP datasets, the global-view relation extraction may have a more prominent contribution. As for the AMAP and HHAR datasets, R2FGC w/o gloRE and R2FGC w/o locRE show close metric values, which indicates that global- and local-view extractions almost play equal roles. Moreover, R2FGC consistently shows better performance than R2FGC w/o gloRE and R2FGC w/o locRE over the five considered datasets. Hence, these results illustrate that both views are necessary and important for achieving good clustering performance.
Effects of gloRE, locRE, and PR. Additionally, relation preservation is used to learn the effective representations by preserving the consistent relation information, whereas the relation de-redundancy conduces to reduce the confusing information, which benefits obtaining discriminative embeddings. Moreover, we adopt propagation regularization to relieve the over-smoothing issue. Hence, we also explore their respective efficiencies in the ablation experiments, i.e., four cases are considered as follows:
-
•
R2FGC w/o REpre: R2FGC without considering the relation preservation;
-
•
R2FGC w/o REder: R2FGC without considering the relation de-redundancy;
-
•
R2FGC w/o REpre & REder: R2FGC without both relation preservation and de-redundancy;
-
•
R2FGC w/o PR: R2FGC without adopting the propagation-regularization trick.
The corresponding results are also shown in Table III. Comparing R2FGC w/o REpre with R2FGC w/o REder, it is observed that relation preservation outperforms relation de-redundancy for the ACM dataset; relation de-redundancy shows more significant power to improve the clustering performance for the AMAP, CITE, and DBLP datasets; these two strategies have almost equal impact on the HHAR dataset. Moreover, by contrasting with R2FGC w/o REpre & REder, both R2FGC w/o REpre and R2FGC w/o REder give better clustering results with higher metric values, which implies that both relation preservation and relation de-redundancy possess the capability to promote the effect of graph clustering. In addition, by comparing R2FGC w/o PR and R2FGC w/o REpre & REder, for the ACM, AMAP, and HHAR datasets, the over-smoothing issue has a more significant impact on clustering performance, whereas, for the CITE and DBLP datasets, the relation extraction is more important for good performance. For example, R2FGC on the ACM dataset has 1.99% relative improvement over R2FGC w/o PR in terms of NMI; R2FGC on the CITE dataset obtains 6.28% improvement over R2FGC w/o REpre & REder in terms of ARI. Hence, these results demonstrate that all of the proposed components in R2FGC are efficient for reaching informative representation and good performance for graph clustering.




Discussion on Global Sampling Strategy. To further illustrate the effectiveness of the QMC inverse degree-weighted distribution sampling for extracting global anchors, we perform experiments to compare it with two MC cases on the AMAP, DBLP, and HHAR datasets, i.e., we consider the following three cases:
-
•
R2FGC with QMC global sampling (Ours): R2FGC with considering QMC inverse degree-weighted distribution sampling, i.e., the low-discrepancy point set is used in the multinomial sampling;
-
•
R2FGC with MC global sampling: R2FGC with considering MC inverse degree-weighted distribution sampling, i.e., the uniform random numbers are used;
-
•
R2FGC with SRS: R2FGC with considering simple random sampling for drawing global anchors.
The results are depicted in Figure 2. Comparing the three strategies, R2FGC with QMC global sampling shows better performance over the three considered datasets in terms of the average ACC, NMI, ARI, and F1 scores. Moreover, R2FGC with MC global sampling outperforms R2FGC with SRS, which implies that inverse degree-weighted distribution sampling is indeed effective to avoid poor representations. In addition, from the error bars in Figure 2, we can also find that R2FGC with QMC global sampling leads to smaller variances for the metric values, which benefits from the high convergence rate of the QMC sampling strategy. The sampled global anchor set is a better representation of the target distribution, which motivates the subsequent representation learning to have a better and more stable performance. In this way, our proposed sampling method guarantees good robustness to relation extraction and thus to clustering performance.











V-D Parameter Sensitivity Analysis (RQ3)
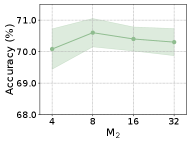
In this section, we examine the sensitivity of the proposed R2FGC to the hyper-parameters. For the global- and local-view relation extraction in Section IV-B, we need to pre-define the numbers of the global and local anchors and for sampling. Hence, we investigate the effect of varying and on ACM, AMAP, CITE, and HHAR datasets. For each dataset, we consider and . When is varied, we fix to its optimal setting as in Section V-A, and vice versa. Additionally, we explore the impact of two loss weight parameters and on ACM, AMAP, CITE, and DBLP datasets. We vary across and across . The results are depicted in Figures 3 and 4, respectively.
Performance of Different Amounts of Global Anchors. From Figure 3, it can be seen that the average accuracies for the considered datasets are relatively stable as changes. It may be due to that with the QMC multinomial sampling, the drawn anchors can well mimic the defined inverse degree-weighted distribution even if is small. It helps to solve the problem caused by varying qualities of the learned representations for the nodes with different degrees. On the other hand, we draw different samples in different training epochs based on the randomization strategy, which increases the diversity of the samples to catch a broad relationship, even with a small number of global anchors. Therefore, the clustering performance is robust to the number of global anchors based on the proposed sampling strategy.
Performance of Different Amounts of Local Anchors. As for , it can be found that on the four datasets, as increases, it promotes the clustering performance first and then shows a weakening tendency. The possible reason may be that small cannot well collect the neighboring information, whereas large may absorb nodes involved in other clusters, which can disturb the extraction of local relation. Hence, a moderate number of local anchors is preferable and a well-designed deterministic sampling is desirable to avoid the intake of inconsistent information from other nodes.
Performance of Different Amounts of Loss Weights. As shown in Figure 4, when is small, increasing leads to a decrease in model performance. This is because large enhances the information aggregation ability of the nodes, which is equivalent to a deep GCN and thus increases the risk of over-smoothing, while small means a low self-supervision ability, which results in poor cohesion and insufficient discrimination in node representations. As the increase of , better representation cohesion achieves, and increasing appropriately is promising to improve the performance by balancing the strength of neighbor aggregation in GCN and the weakness of over-smoothness. However, when becomes excessively large, there may be a slight decline in performance due to the over-smoothing issue on some datasets. In addition, when is fixed, increasing results in an increasing trend in model performance on ACM and AMAP datasets. However, on CITE and DBLP datasets, excessively large leads to a decreasing trend. One possible reason is that CITE and DBLP represent citation networks and author networks, respectively, where different articles and individuals may belong to distinct disciplines or communities. Forcing strong cohesion in these cases may lead to suboptimal results. Overall, we recommend to set around 10 and around 5e3 for satisfying performance. When dealing with a new dataset, a small-scale hyper-parameter tuning around the recommended values is needed due to the dataset’s specific characteristics.
V-E Empirical Convergence Analysis (RQ4)


In this section, we analyze the convergence of our proposed method R2FGC, the curves of the training losses are shown in the Figure 5. It can be observed that our method demonstrates graceful convergence across different datasets AMAP and HHAR. The reason behind this can be attributed to our pre-training learning based on AE and GAE, which provides us with a well-initialized representation. As a result, the initial loss optimization has the correct gradient direction, leading to a rapid decrease in loss. Additionally, our method effectively maintains the relational similarity between nodes in the graph while reducing the redundancy of learned representations. This allows the learned representations to possess highly rich semantic information and strong discriminative capabilities. It enables similar nodes closer to each other while better distinguishing unrelated nodes, facilitating the formation of clusters. This also motivates the training objective to converge to lower value, leading to better clustering performance.
V-F Analysis of Over-smoothing Issue (RQ5)




To verify the superiority of the proposed propagation-regularization loss in alleviating over-smoothing issue, we compare the effects of different GCN layers in GAE encoder and different values of by mean average distance (MAD) and clustering performance (i.e., accuracy). MAD reflects the smoothness of node representations by calculating the mean of the average cosine distance between the nodes and other nodes [64]. A smaller MAD indicates a higher global smoothness. The analysis results are shown in Figure 6.
It can be observed that as the number of GCN layers in GAE encoder increases, indicated by the dashed line in the figure, both MAD and accuracy exhibit a decreasing trend. It implies that larger GCN layers cause nodes to immensely absorb information from farther neighbors and thus can lead to indistinguishable node representations, exacerbating the over-smoothing issue and resulting in performance degradation. On the other hand, our proposed propagation-regularization loss shows a slight decrease in MAD and a gradual increase in clustering performance as increases to a certain value (e.g., 2e3 for AMAP, 1e4 for DBLP). This suggests that our propagation-regularization loss is equivalent to simulating a GCN of a fractional layer, which possesses the capability to ease the increase of smoothness and meanwhile enhance the expressive power of node representations, thereby promoting the clustering performance. However, when is particularly large, both MAD and accuracy decrease sharply. This is because excessively large amplifies the risk of over-smoothness. Therefore, selecting an appropriate weight is crucial in balancing node expressiveness and the over-smoothing issue.
V-G Visualization of Clustering Results (RQ5)












To visually verify the validity of our proposed R2FGC, we plot 2D -distributed stochastic neighbor embedding (-SNE) visualizations[66] for the learned representations on the ACM, CITE, DBLP, and HHAR datasets. We compare the -SNE visualizations of the embeddings resulting from R2FGC with those from the raw data and DFCN (the best method among the baselines in Section V-B) to enable a visual comparison. The plots are shown in Figure 7. The results of -SNE on the four raw data clearly have poor separability for different clusters. Compared with the raw data, more distinguishing visualizations in R2FGC and DFCN demonstrate that deep graph clustering methods indeed make great performance improvements. Comparing R2FGC with DFCN, the latent representations obtained by our method R2FGC show better separability for different clusters, where the samples from the same cluster have better aggregation and those from different clusters have a bigger gap. Such a phenomenon illustrates that our proposed method learns more discriminative representations and produces more effective cluster assignments compared with state-of-the-art methods.
VI Conclusion
In this paper, we study self-supervised deep graph clustering and propose a novel method termed R2FGC. R2FGC introduces the relational learning for the graph-structured data, in which the attribute- and structure-level relation information among nodes are extracted based on AE and GAE. To achieve effective representations, R2FGC preserves consistent relations among the nodes under augmentation, whereas the redundancy relation is filtered for discriminative representations. R2FGC also cooperates a representation fusion mechanism with the relational learning to instruct downstream self-supervised clustering tasks jointly. Experimental results on various benchmark datasets demonstrate the validity and superiority of the proposed method. In the future, we aim to extend relational learning to other scenarios including multi-view graph clustering, interpretable clustering, and other promising applications such as face clustering and text clustering.
Acknowledgments
The authors are grateful to the anonymous reviewers for critically reading the manuscript and for giving important suggestions to improve their paper.
References
- [1] F. Liu, S. Xue, J. Wu, C. Zhou, W. Hu, C. Paris, S. Nepal, J. Yang, and P. S. Yu, “Deep learning for community detection: progress, challenges and opportunities,” arXiv preprint arXiv:2005.08225, 2020.
- [2] X.-R. Sheng, D.-C. Zhan, S. Lu, and Y. Jiang, “Multi-view anomaly detection: Neighborhood in locality matters,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 4894–4901.
- [3] H. Tang, K. Chen, and K. Jia, “Unsupervised domain adaptation via structurally regularized deep clustering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 8725–8735.
- [4] M. Xu, H. Wang, B. Ni, H. Guo, and J. Tang, “Self-supervised graph-level representation learning with local and global structure,” in International Conference on Machine Learning. PMLR, 2021, pp. 11 548–11 558.
- [5] W. Ju, Y. Gu, X. Luo, Y. Wang, H. Yuan, H. Zhong, and M. Zhang, “Unsupervised graph-level representation learning with hierarchical contrasts,” Neural Networks, vol. 158, pp. 359–368, 2023.
- [6] X. Luo, W. Ju, M. Qu, Y. Gu, C. Chen, M. Deng, X.-S. Hua, and M. Zhang, “Clear: Cluster-enhanced contrast for self-supervised graph representation learning,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [7] A. Ng, M. Jordan, and Y. Weiss, “On spectral clustering: Analysis and an algorithm,” in Advances in Neural Information Processing Systems, vol. 14, 2001.
- [8] R. Vidal, “Subspace clustering,” IEEE Signal Processing Magazine, vol. 28, no. 2, pp. 52–68, 2011.
- [9] M. Caron, P. Bojanowski, A. Joulin, and M. Douze, “Deep clustering for unsupervised learning of visual features,” in Proceedings of the European Conference on Computer Vision, 2018, pp. 132–149.
- [10] S. Mukherjee, H. Asnani, E. Lin, and S. Kannan, “Clustergan: Latent space clustering in generative adversarial networks,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 4610–4617.
- [11] Y. Li, P. Hu, Z. Liu, D. Peng, J. T. Zhou, and X. Peng, “Contrastive clustering,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 10, 2021, pp. 8547–8555.
- [12] H. Zhong, J. Wu, C. Chen, J. Huang, M. Deng, L. Nie, Z. Lin, and X.-S. Hua, “Graph contrastive clustering,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9224–9233.
- [13] C. Liu, R. Li, S. Wu, H. Che, D. Jiang, Z. Yu, and H.-S. Wong, “Self-guided partial graph propagation for incomplete multiview clustering,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
- [14] Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and S. Y. Philip, “A comprehensive survey on graph neural networks,” IEEE transactions on neural networks and learning systems, vol. 32, no. 1, pp. 4–24, 2020.
- [15] S. Ji, S. Pan, E. Cambria, P. Marttinen, and S. Y. Philip, “A survey on knowledge graphs: Representation, acquisition, and applications,” IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 2, pp. 494–514, 2021.
- [16] W. Ju, Z. Fang, Y. Gu, Z. Liu, Q. Long, Z. Qiao, Y. Qin, J. Shen, F. Sun, Z. Xiao et al., “A comprehensive survey on deep graph representation learning,” arXiv preprint arXiv:2304.05055, 2023.
- [17] D. Shi, L. Zhu, Y. Li, J. Li, and X. Nie, “Robust structured graph clustering,” IEEE transactions on neural networks and learning systems, vol. 31, no. 11, pp. 4424–4436, 2019.
- [18] D. Bo, X. Wang, C. Shi, M. Zhu, E. Lu, and P. Cui, “Structural deep clustering network,” in Proceedings of The Web Conference, 2020, pp. 1400–1410.
- [19] Z. Peng, H. Liu, Y. Jia, and J. Hou, “Attention-driven graph clustering network,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 935–943.
- [20] H. Zhao, X. Yang, Z. Wang, E. Yang, and C. Deng, “Graph debiased contrastive learning with joint representation clustering,” in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, 2021, pp. 3434–3440.
- [21] W. Tu, S. Zhou, X. Liu, X. Guo, Z. Cai, E. Zhu, and J. Cheng, “Deep fusion clustering network,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 11, 2021, pp. 9978–9987.
- [22] P. Zhu, J. Li, Y. Wang, B. Xiao, S. Zhao, and Q. Hu, “Collaborative decision-reinforced self-supervision for attributed graph clustering,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [23] H. Zhang, P. Li, R. Zhang, and X. Li, “Embedding graph auto-encoder for graph clustering,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [24] X. He, B. Wang, Y. Hu, J. Gao, Y. Sun, and B. Yin, “Parallelly adaptive graph convolutional clustering model,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [25] Y. Liu, W. Tu, S. Zhou, X. Liu, L. Song, X. Yang, and E. Zhu, “Deep graph clustering via dual correlation reduction,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2022.
- [26] X. Peng, J. Cheng, X. Tang, J. Liu, and J. Wu, “Dual contrastive learning network for graph clustering,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
- [27] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507, 2006.
- [28] T. N. Kipf and M. Welling, “Variational graph auto-encoders,” arXiv preprint arXiv:1611.07308, 2016.
- [29] F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini, “The graph neural network model,” IEEE Transactions on Neural Networks, vol. 20, no. 1, pp. 61–80, 2008.
- [30] J. Gilmer, S. S. Schoenholz, P. F. Riley, O. Vinyals, and G. E. Dahl, “Neural message passing for quantum chemistry,” in International Conference on Machine Learning. PMLR, 2017, pp. 1263–1272.
- [31] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [32] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, “Graph attention networks,” arXiv preprint arXiv:1710.10903, 2017.
- [33] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, vol. 30, 2017.
- [34] J. Yuan, X. Luo, Y. Qin, Y. Zhao, W. Ju, and M. Zhang, “Learning on graphs under label noise,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- [35] Z. Ying, J. You, C. Morris, X. Ren, W. Hamilton, and J. Leskovec, “Hierarchical graph representation learning with differentiable pooling,” in Advances in Neural Information Processing Systems, vol. 31, 2018.
- [36] W. Ju, X. Luo, M. Qu, Y. Wang, C. Chen, M. Deng, X.-S. Hua, and M. Zhang, “Tgnn: A joint semi-supervised framework for graph-level classification,” arXiv preprint arXiv:2304.11688, 2023.
- [37] W. Ju, J. Yang, M. Qu, W. Song, J. Shen, and M. Zhang, “Kgnn: Harnessing kernel-based networks for semi-supervised graph classification,” in Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, 2022, pp. 421–429.
- [38] W. Ju, Y. Gu, B. Chen, G. Sun, Y. Qin, X. Liu, X. Luo, and M. Zhang, “Glcc: A general framework for graph-level clustering,” arXiv preprint arXiv:2210.11879, 2022.
- [39] J. Xie, R. Girshick, and A. Farhadi, “Unsupervised deep embedding for clustering analysis,” in International Conference on Machine Learning. PMLR, 2016, pp. 478–487.
- [40] X. Guo, L. Gao, X. Liu, and J. Yin, “Improved deep embedded clustering with local structure preservation.” in Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, 2017, pp. 1753–1759.
- [41] X. Ji, J. F. Henriques, and A. Vedaldi, “Invariant information clustering for unsupervised image classification and segmentation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 9865–9874.
- [42] Z. Li, F. Nie, X. Chang, L. Nie, H. Zhang, and Y. Yang, “Rank-constrained spectral clustering with flexible embedding,” IEEE transactions on neural networks and learning systems, vol. 29, no. 12, pp. 6073–6082, 2018.
- [43] Z. Li, F. Nie, X. Chang, Y. Yang, C. Zhang, and N. Sebe, “Dynamic affinity graph construction for spectral clustering using multiple features,” IEEE transactions on neural networks and learning systems, vol. 29, no. 12, pp. 6323–6332, 2018.
- [44] C. Wang, S. Pan, G. Long, X. Zhu, and J. Jiang, “Mgae: Marginalized graph autoencoder for graph clustering,” in Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, 2017, pp. 889–898.
- [45] C. Wang, S. Pan, R. Hu, G. Long, J. Jiang, and C. Zhang, “Attributed graph clustering: A deep attentional embedding approach,” arXiv preprint arXiv:1906.06532, 2019.
- [46] S. Pan, R. Hu, S.-F. Fung, G. Long, J. Jiang, and C. Zhang, “Learning graph embedding with adversarial training methods,” IEEE Transactions on Cybernetics, vol. 50, no. 6, pp. 2475–2487, 2019.
- [47] S. Fan, X. Wang, C. Shi, E. Lu, K. Lin, and B. Wang, “One2multi graph autoencoder for multi-view graph clustering,” in Proceedings of the Web Conference, 2020, pp. 3070–3076.
- [48] X. Liu, F. Zhang, Z. Hou, L. Mian, Z. Wang, J. Zhang, and J. Tang, “Self-supervised learning: Generative or contrastive,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 1, pp. 857–876, 2021.
- [49] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in International Conference on Machine Learning. PMLR, 2020, pp. 1597–1607.
- [50] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9729–9738.
- [51] X. Chen, H. Fan, R. Girshick, and K. He, “Improved baselines with momentum contrastive learning,” arXiv preprint arXiv:2003.04297, 2020.
- [52] J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar et al., “Bootstrap your own latent-a new approach to self-supervised learning,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 21 271–21 284.
- [53] D. Yuan, X. Chang, P.-Y. Huang, Q. Liu, and Z. He, “Self-supervised deep correlation tracking,” IEEE Transactions on Image Processing, vol. 30, pp. 976–985, 2020.
- [54] C. Yan, X. Chang, Z. Li, W. Guan, Z. Ge, L. Zhu, and Q. Zheng, “Zeronas: Differentiable generative adversarial networks search for zero-shot learning,” IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 12, pp. 9733–9740, 2021.
- [55] W. Ju, Y. Qin, Z. Qiao, X. Luo, Y. Wang, Y. Fu, and M. Zhang, “Kernel-based substructure exploration for next poi recommendation,” arXiv preprint arXiv:2210.03969, 2022.
- [56] N. Lee, D. Hyun, J. Lee, and C. Park, “Relational self-supervised learning on graphs,” in Proceedings of the 31st ACM International Conference on Information & Knowledge Management, 2022, pp. 1054–1063.
- [57] W. Ju, Z. Liu, Y. Qin, B. Feng, C. Wang, Z. Guo, X. Luo, and M. Zhang, “Few-shot molecular property prediction via hierarchically structured learning on relation graphs,” Neural Networks, vol. 163, pp. 122–131, 2023.
- [58] J. Klicpera, S. Weißenberger, and S. Günnemann, “Diffusion improves graph learning,” arXiv preprint arXiv:1911.05485, 2019.
- [59] L. Page, S. Brin, R. Motwani, and T. Winograd, “The pagerank citation ranking: Bringing order to the web.” Stanford InfoLab, Tech. Rep., 1999.
- [60] C. Lemieux, Monte Carlo and Quasi-Monte Carlo Sampling. New York: Springer, 2009.
- [61] S.-Y. Yi, Z. Liu, M.-Q. Liu, and Y.-D. Zhou, “Global likelihood sampler for multimodal distributions,” Journal of Computational and Graphical Statistics, pp. 1–20, 2023.
- [62] S.-Y. Yi and Y.-D. Zhou, “Model-free global likelihood subsampling for massive data,” Statistics and Computing, vol. 33, no. 1, p. 9, 2023.
- [63] K. Oono and T. Suzuki, “Graph neural networks exponentially lose expressive power for node classification,” arXiv preprint arXiv:1905.10947, 2019.
- [64] D. Chen, Y. Lin, W. Li, P. Li, J. Zhou, and X. Sun, “Measuring and relieving the over-smoothing problem for graph neural networks from the topological view,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 04, 2020, pp. 3438–3445.
- [65] A. Stisen, H. Blunck, S. Bhattacharya, T. S. Prentow, M. B. Kjærgaard, A. Dey, T. Sonne, and M. M. Jensen, “Smart devices are different: Assessing and mitigatingmobile sensing heterogeneities for activity recognition,” in Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, 2015, pp. 127–140.
- [66] L. Van der Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of Machine Learning Research, vol. 9, no. 11, 2008.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a80fcf8e-9660-4499-bea7-59679f081bcd/Yi.jpeg) |
Siyu Yi is currently a Ph.D. candidate in statistics from Nankai University, Tianjin, China. She received the B.S. and M.S. degrees in Mathematics from Sichuan University, Sichuan, China, in 2017 and 2020, respectively. Her research interests focus on graph representation learning, design of experiments, and subsampling in big data. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a80fcf8e-9660-4499-bea7-59679f081bcd/Ju.jpg) |
Wei Ju is currently a postdoc research fellow in Computer Science at Peking University. Prior to that, he received his Ph.D. degree in Computer Science from Peking University, Beijing, China, in 2022. He received the B.S. degree in Mathematics from Sichuan University, Sichuan, China, in 2017. His current research interests lie primarily in the area of machine learning on graphs including graph representation learning and graph neural networks, and interdisciplinary applications such as knowledge graphs, drug discovery and recommender systems. He has published more than 30 papers in top-tier venues and has won the best paper finalist in IEEE ICDM 2022. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a80fcf8e-9660-4499-bea7-59679f081bcd/x36.jpg) |
Yifang Qin is an graduate student in School of Computer Science, Peking University, Beijing, China. Prior to that, he received the B.S. degree in school of EECS, Peking University. His research interests include graph representation learning and recommender systems. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a80fcf8e-9660-4499-bea7-59679f081bcd/Luo.jpg) |
Xiao Luo is a postdoctoral researcher in Department of Computer Science, University of California, Los Angeles, USA. Prior to that, he received the Ph.D. degree in School of Mathematical Sciences from Peking University, Beijing, China and the B.S. degree in Mathematics from Nanjing University, Nanjing, China, in 2017. His research interests includes machine learning on graphs, image retrieval, statistical models and bioinformatics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a80fcf8e-9660-4499-bea7-59679f081bcd/Liu.jpg) |
Luchen Liu is currently a post-doctoral research fellow in Computer Science at Peking University. He received the Ph.D. degree in Computer Science from Peking University in 2020. His current research interests lie primarily in the area of deep learning for temporal graph data and interdisciplinary applications such as intelligent healthcare and quantitative investment. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a80fcf8e-9660-4499-bea7-59679f081bcd/x37.png) |
Yongdao Zhou received his B.S. degree in Mathematics, M.S. and Ph.D. degree in Statistics from Sichuan University, China, in 2002, 2005, and 2008, respectively. After graduation, he joined Sichuan University and was a professor after 2015. In 2017, he then joined Nankai University, where he is presently a professor in Statistics. His research agenda focuses on design of experiments and big data analysis. He published more than 60 papers and 5 monographs. His research publications have won best paper awards in WCE 2009 and Sci Sin Math in 2023. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a80fcf8e-9660-4499-bea7-59679f081bcd/Zhang.jpeg) |
Ming Zhang received her B.S., M.S. and Ph.D. degrees in Computer Science from Peking University respectively. She is a full professor at the School of Computer Science, Peking University. Prof. Zhang is a member of Advisory Committee of Ministry of Education in China and the Chair of ACM SIGCSE China. She is one of the fifteen members of ACM/IEEE CC2020 Steering Committee. She has published more than 200 research papers on Text Mining and Machine Learning in the top journals and conferences. She won the best paper of ICML 2014 and best paper nominee of WWW 2016. Prof. Zhang is the leading author of several textbooks on Data Structures and Algorithms in Chinese, and the corresponding course is awarded as the National Elaborate Course, National Boutique Resource Sharing Course, National Fine-designed Online Course, National First-Class Undergraduate Course by MOE China. |