ReDFeat: Recoupling Detection and Description for Multimodal Feature Learning
Abstract
Deep-learning-based local feature extraction algorithms that combine detection and description have made significant progress in visible image matching. However, the end-to-end training of such frameworks is notoriously unstable due to the lack of strong supervision of detection and the inappropriate coupling between detection and description. The problem is magnified in cross-modal scenarios, in which most methods heavily rely on the pre-training. In this paper, we recouple independent constraints of detection and description of multimodal feature learning with a mutual weighting strategy, in which the detected probabilities of robust features are forced to peak and repeat, while features with high detection scores are emphasized during optimization. Different from previous works, those weights are detached from back propagation so that the detected probability of indistinct features would not be directly suppressed and the training would be more stable. Moreover, we propose the Super Detector, a detector that possesses a large receptive field and is equipped with learnable non-maximum suppression layers, to fulfill the harsh terms of detection. Finally, we build a benchmark that contains cross visible, infrared, near-infrared and synthetic aperture radar image pairs for evaluating the performance of features in feature matching and image registration tasks. Extensive experiments demonstrate that features trained with the recoulped detection and description, named ReDFeat, surpass previous state-of-the-arts in the benchmark, while the model can be readily trained from scratch.
Index Terms:
Detection and description, multimodal feature learning, mutual weighting strategy, image matching.I Introduction
Feature detection and description are fundamental steps in many computer vision tasks, such as visual localization [42, 42], Structure-from-Motion (SfM) [29], and Simultaneous-Localization-and-Mapping (SLAM) [14]. Nowadays, increasing attention has been attracted onto the multimodal feature extraction and matching in special scenarios, such as autonomous drive and remote sensing, because different modalities provide complementary information [40]. Although several modal-invariant features, e.g., OS-SIFT [38] and RIFT [18] emerge endlessly, the role SIFT [21] playing in visual image matching cannot be found for multimodal images. Therefore, it is imperative to study a more general and robust solution.
Modeling invariance is the key to feature extraction [15]. Benefiting from the great potential of Deep Neural Network (DNN), the features learned on big data dispense with heuristic designs to acquire invariance and significantly outperform their traditional counterparts on both visual-only [23, 41, 33, 32, 22, 12, 27, 34] and cross-modal [2, 19, 10, 9] images. Deep learning methods can be mainly divided into two categories: the two-stage and the one-stage frameworks. The efforts [23, 33, 22, 2, 19] belonging to the former category are based on the manual detector and then encode the patches centered at detected interest points with DNN. Undoubtedly, those descriptors are limited by the detected scale, orientation and so on. To fill the gap between the detection and the description, the one-stage pipeline [11, 12, 27, 6, 34, 20, 9, 10, 36, 31] that learns to output dense detection scores and descriptors is proposed and further improvements are achieved.
The joint framework seems alluring, however, its training would be unstable without a proper definition of detection. To address the problem, SuperPoint [11] generates synthetic corner data to give the detection clear supervision. A SIFT-like non-maximum suppression is performed on the final feature map in D2-Net [12]. R2D2 [27] proposes a slack constraint, in which detection scores are encouraged to peak locally and repeat among various images so that more dense points can be detected. Furthermore, to increase the reliability of the detected features, the detection is always coupled with the description in the optimization. For example, D2-Net tries to suppress the detection scores of the descriptors that are not distinct enough to match. Similarly, R2D2 learns an extra reliability mask to filter out those points. Additionally, the probabilistic model introduced in ReinforcedPoint [6] and DISK [34] can be also seen as a coupling strategy that shares the same motivation with D2-Net and R2D2.
Compared with the synthetic supervision and the non-maximum suppression, the constraints of local peaking and repeatability are more feasible for detection, because of their flexibility in the training and practical significance in the test. Based on these properties, the detection scores should be also linked to the probability of correctly matching of corresponding descriptors, i.e., the detection should be coupled with the description as mentioned above. However, the modal-invariant descriptors are always hard to learn and match. Naive suppression on the detected probability of those descriptors that are likely to be wrongly matched would fall into the local minimum where the detected probabilities are all zeros. Additionally, those hard descriptors are the key to gaining promotions, so simply ignoring them would not be a wise choice. Therefore, the coupling of detection and description should be more cautiously designed.
In this paper, we firstly absorb the experience from related works and reformulate independent basic loss functions that are more effective and stable for multimodal feature learning, including a contrastive loss for description, a local peaking loss and a repeatability loss for detection. Different from the direct multiplication in previous efforts, we recouple the detection and the description in the mutual weighting strategy as briefly illustrated in Fig. 1. As for the detection, while an edge-based priori guides the detector to pay attention around edges, the detection scores of the reliable descriptors are further forced to peak by weighting the peaking loss with the matching risk of descriptors. Moreover, the repeatability loss is weighted by the similarity of corresponding descriptors. As for the description, the constrictive loss is weighted with the detection scores so that those descriptors with high detected probability are prioritized in the optimization. Note that, the weights in our recoupling strategy are ‘stopped gradients’, i.e., detached from back propagation, which makes the detection and the description would not be disturbed by the gradients of the weights. Finally, the features constrained by the recoupled detection and description loss functions, named ReDFeat, can be readily trained from scratch.

Moreover, to fulfill those harsh terms of the detection, Super Detector is proposed. The prior probability that a point is a keypoint and the conditional probability that a keypoint is extracted from the image are modeled by a fully connected network and a deep convolutional network with a large receptive field, respectively. Particularly, the deep convolution network is equipped with learnable local non-maximum suppression layers to stick out the keypoints. Finally, the posterior detected probability that a detected point is a keypoint is computed by the multiplication of outputs from two networks. To evaluate the features systematically, we collect several kinds of cross-modal image pairs, including cross visible (VIS), near-infrared (NIR), infrared (IR) and synthetic aperture radar (SAR), and build a benchmark in which the performances of features are strictly evaluated. Extensive experiments on this benchmark confirm the applicability of our ReDFeat.
Our contributions can be summarized as follows:
-
1)
We recouple detection and description with the mutual weighting strategy, which can increase the training stability and performance of the learned cross-modal features.
-
2)
We propose Super Detector that possesses a large receptive field and learnable local non-maximum suppression blocks to improve the ability and the discreteness of the detection.
-
3)
We build a benchmark that contains three kinds of cross-modal image pairs for multimodal feature learning. Extensive experiments on the benchmark demonstrate the superiority of our method.
II Related Works
Handcrafted Methods. Although visible deep learning features have sprung up in recent years, their handcrafted counterparts, such as SIFT [21], ORB [24] and SURF [5] still maintain popular in common scenes due to their robustness and cheapness [16, 15]. Their cross-modal counterparts, such as MFP [1], SR-SIFT [30], PCSD [13], OS-SIFT [38], RIFT [18] and KAZE-SAR [26], still receive a large number of attention from the community of multimodal image processing due to the scarcity of well registered data that can support the deep learning methods. Both the visible and the handcrafted multimodal features focus on corner or edge detection and description, which are believed to contain information that is invariant to geometric and radiant distortion. Their successes motivate many deep learning methods [11, 20, 4] and us to inject edge-based priori into the training.
Two-stage Deep Methods. In recent years, the deep learning ‘revolution’ has swept across the whole field of computer vision including local feature extraction. However, due to the lack of strong supervision of detection, deep local descriptors [23, 33, 22, 2, 19] had been stuck in a two-stage pipeline, in which the keypoints are extracted by classical detectors, e.g., Difference of Gaussian (DOG) [21], and then patches centered in those points are encoded into descriptors by DNN. This pipeline restricts the room for modifications so that most methods devote to modifying the loss functions for descriptors [33, 41, 32, 22]. Additionally, Key.Net [4] takes the early effort to learn keypoint extraction with repeatability as a constraint, which is a minority of two-stage methods. Despite of the isolation between detection and description in this kind of methods, DNN still reveals strong potential for local feature extraction [16]. Moreover, the independent constraints of detection and description in the two-stage pipeline pave the way to the joint frameworks, which are also the bases of our formulation.
One-stage Deep Methods. An obvious limitation, that detection and description cannot reinforce each other, exists in the two-stage pipeline. To tackle this problem, SuperPoint [11] firstly proposes a joint detection and description framework, in which the detection and the description are trained with the synthetic supervision and the contrastive learning, respectively.
To further enhance the interaction between these two steps, a framework for joint training with a semi-handcrafted local maximum mining as the detector, i.e., D2-Net [12] is proposed. The detection and description of D2-Net are not only optimized in the meantime, but also tangled for the mutual guide. However, its non-maximum suppression detector is unexplainable. Based on D2-Net, SAFeat [31] designs a multi-scale fusion network to extract scale-invariant features. CMMNet [9] applies D2-Net to multimodal scenario. So, both SAFeat and CMMNet inherit the weakness of D2Net.
R2D2 [27] proposes a fully learnable detector with feasible constraints and further introduces an extra learnable mask to filter out some unreliable detection. But it is unclear why the reliability should be additionally learned rather than fused into one detector. TransFeat [36] introduces transformer [35] to capture global information for local feature learning. It has been aware of the flaw of D2-Net’s detection and drawn on the local peaking loss from R2D2 to remedy the fault.
Furthermore, ReinforcedPoint [6] and DISK [34], model the matching probability in a differential form, in which the detection and description are concisely coupled, and employ Reinforcement Learning (RL) to construct and optimize the matching loss. Undoubtedly, the matching performance of DISK would significantly benefit from direct optimization on matching loss, but RL is hungry for computation and data, which might not be feasible in multimodal scenario.
To the best of our knowledge, besides CMMNet, MAP-Net [10] is the only joint detection and description method customized for multimodal images. However, it draws on the pipeline from DELG [8], whose features are specific for the image retrieval task instead of the accurate image matching task that we focus on. Therefore, we tend to conduct a further study on more feasible joint detection and description methods for cross-modal image matching.
III Method
III-A Background of Coupled Constraints
The joint detection and description framework of local feature learning aims to employ DNN to extract a dense descriptor map and a detection score map for an input image , where , , denote the parameters of adapter, encoder and detector, respectively. Let represent a correspondence in a pair of overlapping images and , represent the descriptor of th point with detected probability .
To constrain the learning of an individual descriptor , a matching risk function is constructed within descriptor maps and . Since the reliability of the descriptor can be estimated by to some extent, many related works couple the corresponding detection scores and to guide the optimization of in a general loss:
| (1) |
where denotes the expectation calculation (averaging in batch). While the descriptors with larger detection score would play more important roles during the optimization, the detection scores of points with large would tend to be zeros. In this way, problems come up: firstly, the zero detection score map is one of a local minimum of this loss, which is not our desire. Secondly, the hard descriptors with large are the key for improvement, so they deserve more attention instead of being treated as distractors. The two problems are magnified in multimodal feature learning, in which the correspondences suffer from the extreme variance of imaging.
Although D2-Net [12] and CMMNet [9] conduct normalization onto detection score so that would not be the minimum of the loss, the normalization breaks the convexity of detection and the balance between the learning of detection and description would be hard to hold, which finally leads to failed optimization. Reliability loss of R2D2 [27] also contains a term similar to Eqn. (1), which would suffer from the first problem mentioned before. The failures of CMMNet and R2D2 prove our hypothesis as shown in Section VI. Moreover, the formulation of probabilistic matching loss introduced in ReinforcedPoint [6] and DISK [34] is also similar to Eqn. (1), so it is likely to get stuck in the two problems. Therefore, we devote ourselves to recoupling detection and description in a more elaborated way for better training.
III-B Basic Constraints
The basic constraints of detection and description should be determined before coupling them. To satisfy the nearest neighbor matching principle, the distance between an anchor and its nearest non-matching neighbor should be maximized, while the distance to its correspondence should be minimized. Therefore, we sample pairs of corresponding descriptors and their detection scores . The set of samples is denoted by . For a pair corresponding cross-modal descriptors , we mine two intra-modal nearest non-matching neighbor and two inter-modal non-matching neighbor in as:
| (2) | ||||
| (3) | ||||
| (4) | ||||
| (5) |
where is the angular distance. Although the nearest neighbor matching request distinction between an anchor and its inter-modal nearest neighbor, we believe maximizing and in the meantime is hazardous for acquiring the modal invariance. Thus we tend to maximize , and , while minimizing in contrastive learning behavior. As a result, our basic loss function of description is:
| (6) | ||||
| (7) | ||||
The angular distance is employed for distance measure because it could balance the optimization of matching and non-matching pairs [22]. Moreover, the quadratic matching risk makes the hard samples obtain larger gradients to be optimized. In this way, is expected to increase the cross-modal robustness of descriptors.
As mentioned above, repeatability and local peaking should be the primary properties of detection. To guarantee the repeatability, the detection score of the first image should be similar to the warped of the other image. Moreover, the detection score should be salient so that a unique point can be extracted in a local area. Thus, we follow R2D2 [27] to primarily constrain the detection with basic repeatability loss and peaking loss as:
| (8) | ||||
| (9) |
where is a flattened patch of coordinate, which is extracted on full coordinate by shifted windows with kernel size of and stride of ; denotes the flattened and normalized vector of detection score, which is indexed by ; AP and MP denote the average pooling and the max pooling with kernel size of and stride of , respectively. Note that, the kernel size and the strides are all adopted from R2D2 empirically.
III-C Recoupled Constraints
Successes of the related works [12, 27, 34] suggest that coupling detection and description can improve the feature learning, however, inappropriate coupling strategies bring up problems as mentioned in Section III-A. To tackle problems, we recouple them with a mutual weighting strategy, in which the gradients of weights are ‘stopped’ as illustrated in Fig. 1. Specifically, we again sample pair of corresponding descriptors and their detection scores . For detection, a weight that is negatively correlated to matching risk would encourage the more reliable descriptor to be detected in a higher probability. Furthermore, learning from the handcrafted cross-modal features which focus on modal-invariant texture extraction, we introduce an edge-based prior to prevent the interest points from laying on smooth areas. So the recoupled peaking loss can be formulated as:
| (10) | ||||
| (11) | ||||
| (12) | ||||
where denotes the rectified linear unit (ReLU); denotes the ‘stop gradient equality’; the edge of image is computed as with Laplacian operator. The weights and are visualized in Fig. 2 (b) and (c), respectively.

There are several key differences between our peaking constraints and previous works. Firstly, the recoupling weight is detached from back propagation, which would not directly affect the learning of description [12, 9, 27, 34]. Secondly, only constrains the peaking of the detection, which would not suppress any detected probability of hard descriptors with large and solve the problems mentioned above [12, 9, 27, 34]. Thirdly, edge-based priori is introduced to balance the peaking constraint, instead of forcing the model to detect corners or edges [11, 20, 4]. Moreover, the weights are normalized by the expectation dynamically, so the weights would not be zeros and keep functioning. In this way, while the detection turns explainable and reliable, it can be more stably trained without risks of falling into sub-optimum, i.e., trivial solution.
Multimodal sensors may display the same object in totally different forms, which means requesting repeatability in such areas is exactly irrational. Thus, the repeatability also needs guides from the description. For two corresponding patches of detection score, we compute the average cosine similarity of their descriptors to estimate the local similarity. Then, the local similarity is used as a weight to modulate the recoupled repeatability loss as:
| (13) | ||||
| (14) | ||||
where denotes the warped dense descriptors. Note that the detached would also not affect the optimization of description. And in the weight is visualized in Fig. 2 (e).
As discussed before, since the flattening and peaking of detection are safely defined and hold a balance in the recoulped peaking loss, the detection would slip into trivial solution, e.g., zeros. Therefore, it is worth recoupling the detection to the description. In other words, the matching risk can be weighted with the detection score so that the descriptors with high detected probability would attract more attention in the optimization. The recoupled description loss with detached weights can be formulated as:
| (15) | ||||
| (16) |
where is shown in Fig. 1 (f).
Finally, the total loss function of our RedFeat can be formulated in the sum of Eqns. (9), (12) and (14) with only one hyperparameter :
| (17) | ||||
While the weights and are generated by description and recoulped to the detection, the weight takes a converse effect in the loss. This loss based on the mutual weighting strategy would stabilize and boost the feature learning.
III-D Network Architecture
Architecture. Most joint detection and description methods share similar architectures which include an encoder and a detector. R2D2 proposes a lightweight encoder that contains only convolution layers and a naive linear detector to output 128-dimensional dense descriptors and a score map, which is cheap in time and memory. Therefore, we adopt this architecture as our raw architecture. The shallow layers are divided as the adapter that is unshared for eliminating the variance of modals. The raw encoder in our architecture consists of the last convolutional layers and the raw detector keeps the same with R2D2. Note that, the encoder and detector are weight sharing.
Super Detector. Our recoupling constraints mainly embrace the detection. limited by the small receptive field, the raw linear detector cannot capture the neighborhood and global information to fulfill peaking loss. Therefore, we propose a super detector, which has two branches like R2D2. One branch is the raw detector that models the prior probability that the point is a keypoint as ; The structure of the other branch needs to model the conditional probability that a keypoint can be detected globally.

Since is related to global information, the branch should possess a larger receptive field by stacking more convolutional layers. Moreover, the score of the detected point should be the local maximum, so we propose learnable non-maximum suppression layer (LNMS) as shown in Fig. 3. In the LMNS, features are firstly transformed by a learnable convolutional layer. Then, local maximums in the transformed feature map are detected by the local softmax operation, i.e., Eqn. (18). At last, statistical maximums in batch and channel are further mined by BN and IN with ReLU. Briefly, for an input feature map , the forward propagation in LNMS can be described as:
| (18) | ||||
where AP3 denotes average pooling with a kernel size of . BN and IN represent batch normalization and instance normalization, respectively. Finally, the branch is constructed by cascading convolutional layers and several LNMS as shown in Fig. 3, and it outputs a two-channel feature. After channel softmax activation, the first channel in the final feature map is maintained as . The posterior probability that the detected point is an interest point, i.e., , can be approximately computed as .
IV Benchmark
The lack of benchmark is one of the major reasons for the slow development of multimodal feature learning. Therefore, building a benchmark might be even more imperative than a robust algorithm. In this paper, we collect three kinds of cross-modal images, including RGB-NIR, VIS-IR and VIS-SAR to build a benchmark for cross-modal feature learning. The features can be evaluated in feature matching and image registration pipelines. Basic information of the collected data is shown Table I.
IV-A Dataset
VIS-NIR. Visible and near-infrared (NIR) image pairs in the average size of are collected from the RGB-NIR scene dataset [7]. The dataset covers various scenes, including country, field, forest, indoor, mountain, old building, street, urban, and water. And most image pairs are photographed in special conditions and can be well registered. We randomly split the images from scenes into the training set and the test set with a ratio of , which results in a training set of pairs of images. The ground truths of the test set are manually validated and filtered for more reliable evaluation. Finally, there are pairs of images left in the test set.
VIS-IR. We collect roughly registered 265 pairs of visible and long-wave infrared (IR) images in the average size of . static image pairs from RGB-LWIR [3] are mainly shot on buildings during the day. The other pairs of video frames come from RoadScene [39], in which more complex objects, e.g., cars and people, are captured both day and night. We randomly select images as the test set and leave the rest as the training set. Since the overlapping image pairs cannot be registered with the homography matrix due to the greatly varying depth of objects, we manually mark about landmarks per image pair for reprojection error estimation.
VIS-SAR. Optical-SAR [37] provides aligned gray level and synthetic aperture radar image pairs in the uniform size of , which are remotely sensed by the satellite and cover field and town scenes. There are 2011 and 424 image pairs in the training set and test set, respectively. The dataset and its split are gathered into our benchmark without changes. Note that, it is hard to validate the ground truth or label landmarks for this subset due to the fuzziness of SAR images.
| Number | Channel | Size | Character | |||
| Train | Test | VIS | * | |||
| VIS-NIR | 345 | 128 | 3 | 1 | Multiple scenes | |
| VIS-IR | 221 | 47 | 3 | 1 | Road video at night | |
| VIS-SAR | 2011 | 424 | 1 | 1 | Satellite remote sensing | |
IV-B Evaluation Protocol
Random Transform. Cross-modal features should carry both geometric and modal invariance. Thus, we generate homography transforms by cascading random perspective with distortion scale , random rotation and random scaling . And then, the transforms are conducted on the aligned raw test set to generate the warped test set.
Feature Matching. To generate sufficient matches, the detected keypoints should be repeatable and the extracted descriptors should be robust. To evaluate the repeatability of the keypoints, we compute the number of correspondences (Corres) of image pairs and the repeatable rate (RR), i.e., the ratio of the number of correspondences over the detected keypoints. Furthermore, we match the descriptors with the bidirectional nearest neighbor matching and calculate the number of correct matches. Following the definition in [11, 27], we report matching score (MS), that the ratio of the number of correct matches over the number of the detected keypoints in the overlap, to evaluate the robustness of descriptors. Note that, the metrics are validated at different thresholds of pixels. And RR and MS are computed symmetrically across the pair of images and averaged.
Image Registration. The image registration is the destination of local feature learning. The matched features are used to estimate homography transform with RanSAC from OpenCV libraries, where the reprojection threshold is set to pixels and the iterations to K. Since the ground-truth transform is provided, we compute the reprojection error as:
| (19) |
where denotes the flatten vector of . However, this metric would be not indicative for VIS-IR subset, because the raw test image pairs are not well aligned. Therefore, we introduce another method to estimate reprojection error with the landmarks as:
| (20) |
where and denote the set of landmarks on two images; represents the reprojected point of . The registration is successful, if RE is smaller than a threshold. The successfully registered images (SR) are counted and the successful registration rate (SRR) is calculated on each subset.
V Experiments
V-A Implementation
We implement our ReDFeat in PyTorch [25] and Kornia [28]. The training data in a size of is achieved by cropping, normalization and random perspective transform mentioned above. The network is trained in about 10000 iterations with a batch size of 2 on an NVIDIA RTX3090 GPU. Adam optimizer [17] with weight decay of is employed to optimize the loss. Its learning rate is initialized at and decays to at the last epoch. The last checkpoint of training would be used for evaluation.
Our ReDFeat is compared to several counterparts in our benchmark, including SIFT [21], RIFT [18], DOG+HN [23], R2D2 [27] and CMMNet [9]. SIFT and RIFT are extracted with the open-source codes and default settings. HardNet and R2D2, which are deep learning features for visible images, are modified to multimodal scenario by specializing parameters of the first convolutional layers for individual modal images. CMMNet, which is not open-source, is implemented on the codebase of D2Net [12].
| # Matches (MS) | R2D2 | CMMNet | ReDFeat |
|---|---|---|---|
| Pre-trained | 36 (3%) | 42 (4%) | 171 (16%) |
| Scratch | 0 (0%) | 1 (0%) | 160 (15%) |










R2D2 +\scriptsize1⃝ +\scriptsize1⃝+\scriptsize2⃝ +\scriptsize1⃝+\scriptsize2⃝+\scriptsize3⃝
V-B Ablation Study
Training Stability. Since the training stability is the key problem that our recoupling strategy aims to tackle, we try to train the CMMNet, R2D2 and our method from scratch or pre-trained models to confirm our motivation. CMMNet adopts the VGG-16 pre-trained on ImageNet as the initialization. For comparison, we use the official pre-trained model for visible images to initialize R2D2 for cross-modal images. For ReDFeat, we just employ self-supervised learning [11], which is fed with augmented visible images, to obtain a pre-trained model. The mean number of correct matches and MS of keypoints on VIS-IR subset are shown in Table II. As we can see, CMMNet and R2D2 fail to learn discriminative features without pre-trained models, because the joint optimization of their naive coupled constraints is ill-posed. By contrast, our ReDFeat can be readily trained from scratch while also achieving a tiny improvement from the self-supervised pre-trained, which demonstrates the solidity of our formulation. Therefore, while we keep initializing the training of CMMNet and R2D2 with pre-trained models in subsequent experiments, our ReDFeat would be always trained from scratch.
Impact of . The weight of , , is the only hyperparameter of ReDFeat, which plays a crucial role in balancing detection and description in our recoupling strategy. To investigate the impact of , we train ReDFeat with different values and report relevant metrics of keypoints on VIS-IR in Table III. Totally, lager than brings out desirable registration performance that the community focuses on. It demonstrates that the repeatability constrained by and weighted by impose a strong impact on the registration performance. However, the repeatability not only forces the detection to be similar but also narrows the gap between two descriptor maps and decreases the distinction of descriptors, which can be proved by the decrease of the correct matches. Therefore, the image registration performance peaks at and the setting would be kept in subsequent experiments.
| 0.01 | 4 | 8 | 12 | 16 | 20 | 24 | |
| # Matches | 154 | 163 | 160 | 135 | 126 | 132 | 129 |
| MS (%) | 15 | 16 | 14 | 13 | 13 | 13 | 13 |
| REM | 4.22 | 3.63 | 2.75 | 2.77 | 3.31 | 2.75 | 3.13 |
| # SR | 36 | 44 | 46 | 44 | 45 | 43 | 44 |
Proposed Components. We propose three novel modifications: \scriptsize1⃝ basic constraints, \scriptsize2⃝ recoupled constraints and \scriptsize3⃝ new networks for multimodal feature learning. To evaluate the efficiency of our proposals, we choose R2D2, which provides the raw network architecture for losses, as the baseline, and the modifications are successively executed in this framework. As we can see in Table IV, our basic loss is more suitable for multimodal feature learning and remarkably improves the baseline on all metrics. The recoupled constraints obtain further improvements on feature matching tasks, while the registration performance is comparable to the former. After the new network, i.e., Super Detector, is equipped, state-of-the-art results are achieved. So far, the proposed components are proved to take positive effects.
| # Corrs | RR(%) | # Matches | MS(%) | REM | # SR | |
|---|---|---|---|---|---|---|
| R2D2 | 213 | 16 | 36 | 4 | 3.30 | 41 |
| +\scriptsize1⃝ | 307 | 30 | 83 | 8 | 2.81 | 45 |
| +\scriptsize1⃝+\scriptsize2⃝ | 346 | 33 | 112 | 11 | 2.93 | 46 |
| +\scriptsize1⃝+\scriptsize2⃝+\scriptsize3⃝ | 415 | 40 | 160 | 15 | 2.75 | 46 |
To gain an insight into the impacts of our proposals, we visualize the detection score maps, what we discuss throughout our formulation, under different configurations in Fig. 4. As shown in the second and the third columns of images, while the local peaking loss guides R2D2 to generate discrete detection score, it leads to bulks of detection basic constraints. It can be explained that moderates the impact of local peaking in basic constraints. These lumped detected features intend to repeat and be matched within an acceptable error so that the matching performance is improved. After recoupling the constraints, the edge-based priori makes the detection gather in areas with rich textures, which is expected to obtain further improvements. Finally, the Super Detector equipped with learnable local non-maximum suppression blocks introduces a strong inductive bias to discretize the detection score. The discrete detection score must tighten weighted description loss and repeatability loss, which is believed to help the joint learning and improve the accuracy of keypoint location.




































SIFT RIFT DOG+HN R2D2 CMMNet ReDFeat


(a) Matching Performance on VIS-NIR

(b) Matching Performance on VIS-IR
(c) Matching Performances on VIS-SAR
V-C Feature Matching Performance
The feature matching performance of 1024 keypoints of SIFT, RIFT, HN, R2D2, CMMNet, and our RedFeat on three subsets is quantified in Fig. 5, in which RR and MS are selected as the primary metrics and calculated at varying thresholds. As we can see, we achieve the state-of-the-art RR and MS at all thresholds on three subsets, which demonstrates that we obtain more robust descriptors while detecting more precise and repeatable keypoints. As for MS, we gain large margins on all subsets at varying thresholds. Especially on the most challenging subset, VIS-SAR, our MS seems to be several times higher than the second place CMMNet. It is worth mentioning that R2D2 employing pre-trained models for initialization still fails to optimize the description on VIS-SAR, which confirms the significance of our recoupling strategy.
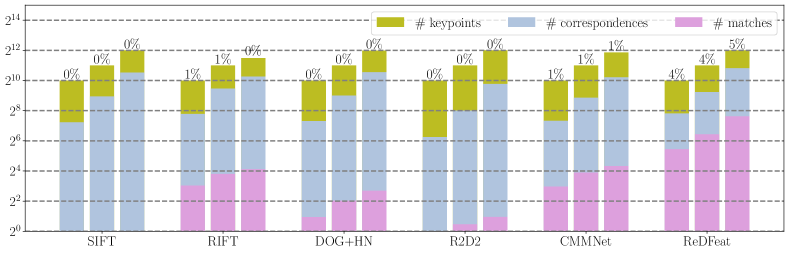
More quantitative performance of 1024, 2048 and 4096 keypoints at a threshold of 3px is shown in Fig. 6. The matching score that is key index for feature matching performance is deliberately highlighted on the bars. Except for the number of correspondences on VIS-IR and VIS-SAR, our ReDFeat achieve the best scores on all metrics at 3px. Note that, the handcrafted local-maximums-searching-based detector might fail to extract large numbers of keypoints for some image pairs, which demonstrates the superiority and the flexibility of the learnable detection.
Qualitative performance is shown in Fig. 7. Compared to R2D2 and CMMNet, our detected points seem to be more rationally distributed in the textured area, i.e., intensely but not too intensely. However, traditional detectors employed by SIFT, RIFT, and DOG-HN seemingly generate more interpretable results that strictly attach to the edges or corners. Especially, RIFT detects scattered corner points, which are proved by RR shown in Fig. 5 and the number of correspondences shown in Fig. 6, in not so salient regions. The weakness of the deep learning detector can be attributed to the flaws of the training set, which cannot provide strict correspondences so that the keypoints are not precisely located. Despite the advantages of traditional detectors, the deep learning one-stage and two-stage methods show the superiority of deep learning on the feature description. In our method that the description and detection are mutually guided in our recoupling strategy, the hard descriptors are better optimized, which makes significant progress in matching performance.
V-D Image Registration Performance
Successful registration rates of 1024 keypoints of those algorithms are drawn in Fig. 8. Note that, we use two measures of projection error (RE) on the three subsets according to the quality of the ground truths. Nevertheless, our ReDFeat obtains more successfully registered images pairs in each case. And the margin is more prominent on VIS-SAR that is the most challenging. Moreover, the weak performance of CMMNet on VIS-NIR highlights the important of keypoint location, i.e., the registration performance depends on MS at low thresholds. The problem is well tackled by recoupled constraints and Super Detector in our method, as proved in ablation study.

The distributions of reprojection errors of 1024, 2048 and 4096 keypoints are illustrated in Fig. 9. Except on the VIS-NIR with and keypoints, our method achieves the most SR and the lowest mean RE. Particularly, while greatly boosting SR on VIS-SAR, our method gets the mostly precise image registration performance. As for the tiny disparity of RE among SIFT, DOG-HN, and ReDFeat on VIS-NIR, it can be explained by the small discrepancy between visible and near-infrared images and the accuracy of handcrafted keypoint location as mentioned above.
Some examples, in which only our ReDFeat succeeds, are shown in Fig. 10. Although RIFT, R2D2 and CMMNet estimate approximate transforms in some cases from VIS-NIR and VIS-IR, the accuracy of registration does not meet the expectations. On samples of VIS-SAR, the other alternatives even fail to receive a rough result, which is consistent with the feature matching performance. Generally, with the help of recoupled constraints and Super Detector, our method can learn robust cross-modal features that indeed boost the performance of cross-modal image registration.

(a) Reprojection Errors on VIS-NIR

(b) Reprojection Errors on VIS-IR

(c) Reprojection Errors on VIS-SAR
| Time (ms) | SIFT | RIFT | DOG+HN | R2D2 | CMMNet | ReDFeat | ||
|---|---|---|---|---|---|---|---|---|
|
236 | 3186 | 351 | 59 | 1790 | 94 | ||
|
68 | 1984 | 229 | 54 | 458 | 74 | ||
|
97 | 2530 | 263 | 56 | 675 | 85 |


















SIFT RIFT DOG+HN R2D2 CMMNet ReDFeat
V-E Runtime
Time consumption is important for feature extraction. Because SIFT, RIFT, DOG+HN and CMMNet employ handcrafted detectors, their computation complexities are hard to calculate. And we just report the average runtime in three test sets in Table V. All of them are implemented in Python, except RIFT which is implemented in Matlab. All methods are run on an Intel Xeon Silver 4210R CPU and an NVIDIA RTX3090 GPU. As we can see, R2D2 consumes the least time to extract features for each image. And benefiting from the parallel computation on GPU, its runtime is not sensitive to the image size. Because of the complex operations in Super Detector, ReDFeat takes more time to finish the extraction. However, the improvements of our method are believed to be worth the increased runtime. All methods seem to be time-consuming except SIFT which takes the same order of magnitude of time as R2D2 and ReDFeat. Generally, we significantly improve the performance of features with few extra costs.
VI Conclusion
In this paper, we take the ill-posed detection in joint detection and description framework as the start point, and propose the recoupled constraints for multimodal feature learning. Firstly, based on the efforts from related works, we reformulate the repeatability loss and the local peaking loss for detection, as well as the contrastive loss for description in multimodal scenario. Then, to recouple the constraints of the detection and description, we propose the mutual weighting strategy, in which the robust features are forced to achieve desired detected probabilities that are locally peaking and consistent for different modals, and the features with high detected probability are emphasized during the optimization. Different from previous works, the weights are detached from back propagation so that the detected probability of an indistinct feature would not be directly suppressed and the training would be more stable. In this way, our ReDFeat can be readily trained from scratch and adopted in cross-modal image registration. To fulfill the harsh terms of detection in the recoupled constraints and achieve further improvements, we propose the Super Detector that possesses a large receptive field and learnable local non-maximum suppression blocks. Finally, we collect visible and near-infrared, infrared, and synthetic aperture radar image pairs to build a benchmark. Extensive experiments on this benchmark prove the superiority of our ReDFeat and the effectiveness of all proposed components.
References
- [1] Cristhian Aguilera, Fernando Barrera, Felipe Lumbreras, Angel D Sappa, and Ricardo Toledo. Multispectral image feature points. J. Sens., 12(9):12661–12672, 2012.
- [2] Cristhian A Aguilera, Angel D Sappa, Cristhian Aguilera, and Ricardo Toledo. Cross-spectral local descriptors via quadruplet network. J. Sens., 17(4):873–887, 2017.
- [3] Cristhian A Aguilera, Angel D Sappa, and Ricardo Toledo. Lghd: A feature descriptor for matching across non-linear intensity variations. In Proc. IEEE Int. Conf. Image Process., pages 178–181, 2015.
- [4] Axel Barroso-Laguna, Edgar Riba, Daniel Ponsa, and Krystian Mikolajczyk. Key. net: Keypoint detection by handcrafted and learned cnn filters. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pages 5836–5844, 2019.
- [5] Herbert Bay, Tinne Tuytelaars, and Luc Van Gool. Surf: Speeded up robust features. In Proc. Europ. Conf. Comput. Vis., pages 404–417, 2006.
- [6] Aritra Bhowmik, Stefan Gumhold, Carsten Rother, and Eric Brachmann. Reinforced feature points: Optimizing feature detection and description for a high-level task. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pages 4948–4957, 2020.
- [7] Matthew Brown and Sabine Süsstrunk. Multi-spectral sift for scene category recognition. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pages 177–184, 2011.
- [8] Bingyi Cao, Andre Araujo, and Jack Sim. Unifying deep local and global features for image search. In Proc. Europ. Conf. Comput. Vis., pages 726–743, 2020.
- [9] Song Cui, Ailong Ma, Yuting Wan, Yanfei Zhong, Bin Luo, and Miaozhong Xu. Cross-modality image matching network with modality-invariant feature representation for airborne-ground thermal infrared and visible datasets. IEEE Trans. Geosci. Remote Sens., 60:5606414, 2022.
- [10] Song Cui, Ailong Ma, Liangpei Zhang, Miaozhong Xu, and Yanfei Zhong. Map-net: Sar and optical image matching via image-based convolutional network with attention mechanism and spatial pyramid aggregated pooling. IEEE Trans. Geosci. Remote Sens., 60:1000513, 2022.
- [11] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superpoint: Self-supervised interest point detection and description. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops, pages 224–236, 2018.
- [12] Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Pollefeys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-net: A trainable cnn for joint description and detection of local features. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pages 8092–8101, 2019.
- [13] Jianwei Fan, Yan Wu, Ming Li, Wenkai Liang, and Yice Cao. Sar and optical image registration using nonlinear diffusion and phase congruency structural descriptor. IEEE Trans. Geosci. Remote Sens., 56(9):5368–5379, 2018.
- [14] Qiang Fu, Hongshan Yu, Xiaolong Wang, Zhengeng Yang, Yong He, Hong Zhang, and Ajmal Mian. Fast orb-slam without keypoint descriptors. IEEE Trans. Image Process., 31:1433–1446, 2021.
- [15] Xingyu Jiang, Jiayi Ma, Guobao Xiao, Zhenfeng Shao, and Xiaojie Guo. A review of multimodal image matching: Methods and applications. Inf. Fusion, 73:22–71, 2021.
- [16] Yuhe Jin, Dmytro Mishkin, Anastasiia Mishchuk, Jiri Matas, Pascal Fua, Kwang Moo Yi, and Eduard Trulls. Image matching across wide baselines: From paper to practice. Int. J. Comput. Vis., 129(2):517–547, 2021.
- [17] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Proc. Int. Conf. Learn. Represent., 2014.
- [18] Jiayuan Li, Qingwu Hu, and Mingyao Ai. Rift: Multi-modal image matching based on radiation-invariant feature transform. IEEE Trans. Image Process., 29:3296–3310, 2019.
- [19] Weiquan Liu, Xuelun Shen, Cheng Wang, Zhihong Zhang, Chenglu Wen, and Jonathan Li. H-net: Neural network for cross-domain image patch matching. In Proc. Int. Jt. Conf. Artif. Intell., pages 856–863, 2018.
- [20] Xiaotao Liu, Chen Meng, Fei-Peng Tian, and Wei Feng. Dgd-net: Local descriptor guided keypoint detection network. In Proc. IEEE Int. Conf. Multimed. Expo., pages 1–6, 2021.
- [21] David G Lowe. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis., 60(2):91–110, 2004.
- [22] Jiayi Ma and Yuxin Deng. Sdgmnet: Statistic-based dynamic gradient modulation for local descriptor learning. arXiv preprint arXiv:2106.04434, 2021.
- [23] Anastasiya Mishchuk, Dmytro Mishkin, Filip Radenovic, and Jiri Matas. Working hard to know your neighbor’s margins: Local descriptor learning loss. In Adv. Neural Inf. Process. Syst., pages 4829–4840, 2017.
- [24] Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. Orb-slam: a versatile and accurate monocular slam system. IEEE Trans. Robot., 31(5):1147–1163, 2015.
- [25] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. pages 1–12, 2019.
- [26] Mohammadreza Pourfard, Tahmineh Hosseinian, Roghayeh Saeidi, Sayed Ahmad Motamedi, Mohammad Javad Abdollahifard, Reza Mansoori, and Reza Safabakhsh. Kaze-sar: Sar image registration using kaze detector and modified surf descriptor for tackling speckle noise. IEEE Trans. Geosci. Remote Sens., 60:5207612, 2022.
- [27] Jerome Revaud, Cesar De Souza, Martin Humenberger, and Philippe Weinzaepfel. R2d2: Reliable and repeatable detector and descriptor. pages 1–11, 2019.
- [28] Edgar Riba, Dmytro Mishkin, Daniel Ponsa, Ethan Rublee, and Gary Bradski. Kornia: an open source differentiable computer vision library for pytorch. In Proc. IEEE Winter Conf. Appl. Comput. Vis., pages 3674–3683, 2020.
- [29] Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pages 4104–4113, 2016.
- [30] Amin Sedaghat and Hamid Ebadi. Distinctive order based self-similarity descriptor for multi-sensor remote sensing image matching. J. Photogramm. Remote Sens, 108:62–71, 2015.
- [31] Xuelun Shen, Cheng Wang, Xin Li, Yifan Peng, Zijian He, Chenglu Wen, and Ming Cheng. Learning scale awareness in keypoint extraction and description. Pattern Recognit., 121:108221–108233, 2022.
- [32] Yurun Tian, Axel Barroso Laguna, Tony Ng, Vassileios Balntas, and Krystian Mikolajczyk. Hynet: Learning local descriptor with hybrid similarity measure and triplet loss. In Adv. Neural Inf. Process. Syst., pages 7401–7412, 2020.
- [33] Yurun Tian, Xin Yu, Bin Fan, Fuchao Wu, Huub Heijnen, and Vassileios Balntas. Sosnet: Second order similarity regularization for local descriptor learning. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pages 11016–11025, 2019.
- [34] Michał Tyszkiewicz, Pascal Fua, and Eduard Trulls. Disk: Learning local features with policy gradient. pages 14254–14265, 2020.
- [35] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. page 6000–6010, 2017.
- [36] Zihao Wang, Xueyi Li, and Zhen Li. Local representation is not enough: Soft point-wise transformer for descriptor and detector of local features. In Int. Jt. Conf. Artif. Intell., pages 1150–1156, 2021.
- [37] Yuming Xiang, Rongshu Tao, Feng Wang, Hongjian You, and Bing Han. Automatic registration of optical and sar images via improved phase congruency model. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., 13:5847–5861, 2020.
- [38] Yuming Xiang, Feng Wang, and Hongjian You. Os-sift: A robust sift-like algorithm for high-resolution optical-to-sar image registration in suburban areas. IEEE Trans. Geosci. Remote Sens., 56(6):3078–3090, 2018.
- [39] Han Xu, Jiayi Ma, Zhuliang Le, Junjun Jiang, and Xiaojie Guo. Fusiondn: A unified densely connected network for image fusion. In Proc. AAAI Conf. Artif. Intell., pages 12484–12491, 2020.
- [40] Hao Zhang, Han Xu, Xin Tian, Junjun Jiang, and Jiayi Ma. Image fusion meets deep learning: A survey and perspective. Inf. Fusion, 76:323–336, 2021.
- [41] Linguang Zhang and Szymon Rusinkiewicz. Learning local descriptors with a cdf-based dynamic soft margin. In Proc. IEEE Int. Conf. Comput. Vis., pages 2969–2978, 2019.
- [42] Zichao Zhang, Torsten Sattler, and Davide Scaramuzza. Reference pose generation for long-term visual localization via learned features and view synthesis. Int. J. Comput. Vis., 129(4):821–844, 2021.