Recursive Reasoning in Minimax Games: A Level Gradient Play Method
Abstract
Despite the success of generative adversarial networks (GANs) in generating visually appealing images, they are notoriously challenging to train. In order to stabilize the learning dynamics in minimax games, we propose a novel recursive reasoning algorithm: Level Gradient Play (Lv. GP) algorithm. In contrast to many existing algorithms, our algorithm does not require sophisticated heuristics or curvature information. We show that as increases, Lv. GP converges asymptotically towards an accurate estimation of players’ future strategy. Moreover, we justify that Lv. GP naturally generalizes a line of provably convergent game dynamics which rely on predictive updates. Furthermore, we provide its local convergence property in nonconvex-nonconcave zero-sum games and global convergence in bilinear and quadratic games. By combining Lv. GP with Adam optimizer, our algorithm shows a clear advantage in terms of performance and computational overhead compared to other methods. Using a single Nvidia RTX3090 GPU and 30 times fewer parameters than BigGAN on CIFAR-10, we achieve an FID of 10.17 for unconditional image generation within 30 hours, allowing GAN training on common computational resources to reach state-of-the-art performance.
1 Introduction
In recent years, there has been a surge of powerful models that require simultaneous optimization of several objectives. This increasing interest in multi-objective optimization arises in various domains - such as generative adversarial networks [21, 27], adversarial attacks and robust optimization [37, 7], and multi-agent reinforcement learning [36, 55] - where several agents aim at minimizing their objectives simultaneously. Games generalize this optimization framework by introducing different objectives for different learning agents, known as players.

The generative adversarial network is a widely-used method of this type, which has demonstrated state-of-the-art performance in a variety of applications, including image generation [28, 52], image super-resolution [32], and image-to-image translation [10]. Despite their success at generating visually appealing images, GANs are notoriously challenging to train [40, 39]. Naive application of the gradient-based algorithm in GANs often leads to poor image diversity (sometimes manifesting as "mode collapse") [40], Poincare recurrence [39], and subtle dependency on hyperparameters [18]. An immense corpus of work is devoted to exploring and enhancing the stability of GANs, including techniques as diverse as the use of optimal transport distance [1, 22], critic gradient penalties [54], different neural network architectures [26, 6], feature matching [50], pre-trained feature space [51], and minibatch discrimination [50]. Nevertheless, architectural modifications (e.g., StyleGANs [27]) require extensive computational resources, and many theoretically appealing methods (Follow-the-ridge [56], CGD[53]) require Hessian inverse operations, which is infeasible for most GAN applications.
To stabilize the learning dynamics in GANs, many recent efforts rely on sophisticated heuristics that allow the agents to anticipate each other’s next move [16, 53, 23]. This anticipation is an example of a recursive reasoning procedure in cognitive science [12]. Similar to how humans think, recursive reasoning represents the belief reasoning process where each agent considers the reasoning process of other agents, based on which it expects to make better decisions. Importantly, it enables the use of opponents that reason about the learning agent, rather than assuming fixed opponents; the process can therefore be nested in a form as ’I believe that you believe that I believe…’. Based on this intuition, we introduce a novel recursive reasoning algorithm that utilizes only gradient information to optimize GANs. Our contributions can be summarized as follows:
(i) We propose a novel algorithm: level gradient play (Lv. GP), which is capable of reasoning about players’ future strategy. In a game, agents at Lv. adjust their strategies in accordance with the strategies of Lv. agents. We justify that, while typical GANs optimizers, such as Learning with Opponent Learning Awareness (LOLA) and Symplectic Gradient Adjustment (SGA), approximate Lv. and Lv. GP, our algorithm permits higher levels of strategic reasoning. In addition, the proposed algorithm is amenable to neural network optimizers like Adam [29].
(ii) We show that, in smooth games, Lv. GP converges asymptotically towards an accurate prediction of agents’ next move. Under mutual opponent shaping, two Lv. agents will naturally have a consistent view of one another if the Lv. GP converges as increases. Based on this idea, we provide a closed-form solution for Lv. GP: the Semi-Proximal Point Method (SPPM).
(iii) We prove the local convergence property of Lv. GP in nonconvex - nonconcave zero-sum games and its global convergence in bilinear and quadratic games. The theoretical analysis we present indicates that strong interactions between competing agents can increase the convergence rate of Lv. GP agents in a zero-sum game.
(iv) By combining Lv. GP with Adam optimizer, our algorithm shows a clear advantage in terms of performance and computational overhead compared to other methods. Using a single 3090 GPU with 30 times fewer parameters and 16 times smaller mini-batches than BigGAN [6] on CIFAR-10, we achieve an FID score [24] of 10.17 for unconditional image generation within 30 hours, allowing GAN training on common computing resources to reach state-of-the-art performance.
2 Related Works
In recent years, minimax problems have attracted considerable interest in machine learning in light of their connection with GANs. Gradient descent ascent (GDA), a generalization of gradient descent for minimax games, is the principal approach for training GANs in applications. GDA alternates between a gradient descent step for the min-player and a gradient ascent step for the max-player. The convergence of GDA in games is far from as well understood as gradient descent in single-objective problems. Despite the impressive image quality generated by GANs, GDA fails to converge even in bilinear zero-sum games. Recent research on GDA has established a unified picture of its behavior in bilinear games in continuous and discrete-time [39, 46, 13, 41, 20]. First, [39] revealed that continuous-time GDA dynamics in zero-sum games result in Poincare recurrence, where agents return arbitrarily close to their initial state infinitely many times. Second, [3, 58] examined the discrete-time GDA dynamics, showing that simultaneous update of two players results in divergence while the agents’ strategies remain bounded and cycle when agents take turns to update their strategies.
The majority of existing approaches to stabilizing GDA follow one of three lines of research. The essence of the first method is that the discriminator is trained until convergence while the generator parameters are frozen. As long as the generator changes slowly enough, the discriminator still converges in the presence of small generator perturbations. The two-timescale update rule proposed by [21, 24, 42] aims to keep the discriminator’s optimality while updating the generator at an appropriate step size. [25, 14] proved that this two-timescale GDA with finite timescale separation converges towards the strict local minimax/Stackelberg equilibrium in differentiable games. [15, 56] explicitly find the local minimax equilibrium in games with secon-order optimization algorithms.
The second line of research overcomes the failure of GDA in games with predictive updates. Extra-gradient method (EG) [30] and optimistic gradient descent (OGD) [13] use the predictability of the agents’ strategy to achieve better convergence property. Their variants are developed to improve the training performance of GANs [8, 19, 43]. [45] provided a unified analysis of EG and OGD, showing that they approximate the classical proximal point methods. Competitive gradient descent [53] models the agents’ next move by solving a regularized bilinear approximation of the underlying game. Learning with opponent learning awareness (LOLA) and consistent opponent learning awareness (COLA) [16, 57] introduced opponent shaping to this problem by explicitly modeling the learning strategy of other agents in the game. LOLA models opponents as naive learners rather than LOLA agents, while COLA utilizes neural networks to predict opponents’ next move. Lookahead-minimax [9] stabilizes GAN training by ‘looking ahead’ at the sequence of future states generated by an inner optimizer. In the game theory literature, recent work has proposed Clairvoyant Multiplicative Weights Update (CMWU) for regret minimization in general games [47]. Although CMWU is proposed to solve finite normal form games, which are different from unconstrained continuous games that Lv. GP aims to solve, both CMWU and Lv. GP share the same motivation of enabling the learning agent to update their strategy based on the opponent’s future strategy. From this aspect, Lv. GP can be viewed as a specialized variant of CMWU that is specific to the problem of two-player zero-sum games, but adapted for unconstrained continuous kernel games.
Other methods directly modify the GDA algorithm with ad-hoc modifications of game dynamics and introduction of additional regularizers. Consensus optimization (CO) [40] and gradient penalty [22, 54] improve convergence by directly minimizing the magnitude of players’ gradients. Symplectic gradient adjustment (SGA) [33, 4, 17] improves convergence by disentangling convergent potential components from rotational Hamiltonian components of the vector field.
3 Preliminaries
3.1 Notation
In this paper, vectors are lower-case bold letters (e.g. ), matrices are upper-case bold letters (e.g. ). For a function , we denote its gradient by . For functions of two vector arguments we use to denote its partial gradients. We use to denote its Hessian. A stationary point of denotes the point where . We use to denote the Euclidean norm of vector . We refer to the largest and smallest eigenvalues of a matrix by and , respectively. Moreover, we denote the spectral radius of matrix by , i.e., the eigenvalue with largest absolute value.
3.2 Problem Definition
In order to justify the effectiveness of recursive reasoning procedure, in this paper, we consider the problem of training Generative Adversarial Networks (GANs)[21]. The GANs training strategy defines a two-player game between a generative neural network and a discriminative neural network . The generator takes as input random noise sampled from a known distribution , e.g., , and outputs a sample . A discriminator takes as input a sample (either sampled from the true distribution or from the generator) and attempts to classify it as real or fake. The goal of the generator is to fool the discriminator. The optimization of GAN is formulated as a two-player differentiable game where the generator with parameter , and the discriminator with parameters , aim at minimizing their own cost function and respectively, as follows:
| (1) |
where the two function . When the corresponding optimization problem is called a two-player zero-sum game and it becomes a minimax problem:
| (Minimax) |
In this work, we assume the cost functions have Lipschitz continuous gradients with respect to all model parameters :
Assumption 3.1.
The gradient , is Lipschitz with respect to and Lipschitz with respect to and the gradient , is Lipschitz with respect to and Lipschitz with respect to , i.e.,
We define .
4 Level Gradient Play
In this section, we propose a novel recursive reasoning algorithm, Level Gradient Play (Lv. GP), that allows the agents to discover self-interested strategies while taking into account other agents’ reasoning processes. In Lv. GP, steps of recursive reasoning is applied to obtain an anticipated future state , and the current states are then updated as follows:
| (Lv.k GP) |
We define the current state , to be the starting point , of the reasoning process. Learning agents that adopt Lv. GP strategy are then called Lv. agents. Lv. agents act naively in response to the current state using GDA dynamics and Lv. agents act in response to Lv. agents by assuming its opponent as a naive learner. Therefore, Lv. GP allows for higher levels of strategic reasoning. The inspiration comes from how humans collaborate: humans are great at anticipating how their actions will affect others, so they frequently find out how to collaborate with other people to reach a "win-win" solution. The key to human collaboration is their ability to understand how other humans think which helps them develop strategies that benefit their collaborators. One of our main theoretical results is the following theorem, which demonstrates that agents adopting Lv. GP can precisely predict other players’ next move and reach a consensus on their future strategies:
Theorem 4.1.
Suppose Assumption 3.1 holds. Let us define , and . Assume lie in a complete subspace of . Then for Lv.k GP we have:
| (2) |
Suppose the learning rate satisfies: , then the sequence is a Cauchy sequence. That is, given , there exists such that, if then:
| (3) |
Moreover, the sequence converges to a limit : .
In accordance with Theorem 4.1, if we define , then Lv. GP is equivalent to the following implicit algorithm where we call it Semi-Proximal Point Method:
| (SPPM) |
4.1 Algorithms as an Approximation of SPPM
SPPM players arrive at a consensus by knowing precisely what their opponents’ future strategies will be. Existing algorithms are not able to offer this kind of agreement. For instance, consensus optimization[40] forces the learning agents to cooperate regardless of their own benefits. Agents employ extra-gradient method[30], SGA[4], and LOLA[16] consider their opponents as naive learners, ignoring their strategic reasoning ability. CGD[53] takes into account the reasoning process of learning agents; however, it leads to an inaccurate prediction of agents in games that have cost functions with non-zero higher order derivatives () [57]. In this section, we consider a subset of provably convergent variants of GDA in the Minimax setting, showing that, for specific choice of hyperparameters, the mentioned algorithms either approximate SPPM or approximate the approximations of SPPM:
| Algorithm | Update Rule | Precision |
| SGA [4] | —— | |
| LOLA [16] | —— | |
| Lv.2 GP | ||
| LEAD† [23] | —— | |
| CGD [53] | ||
| Lv.3 GP | ||
| SPPM (Lv. GP) |
In Table 1, we compare the orders of precision of different algorithms as an approximation of SPPM in Minimax games with infinitely differentiable objective functions. In accordance with Equation (3) of Theorem 4.1, Lv.k GP is an approximation of SPPM. In order to analyze how well existing algorithms approximate SPPM, we consider the first-order Taylor approximation to SPPM:
Under-brace terms correspond to the first-order Taylor approximation of Lv. GP. For an appropriate choice of hyperparameters, SGA () and LOLA () are identical to the first-order Taylor approximation of Lv.2 GP, where each agent models their opponent as a naive learner. Hence, we list them above the Lv.2 GP, which approximates SPPM up to . CGD exactly recovers the first-order Taylor approximation of SPPM.111The CGD update for the max player is . If we substitute into ’s update (and substitute into ’s update, respectively), we arrive at the first-order approximation of SPPM. See A.5 for derivation details. In games with cost functions that have non-negative higher order derivatives (), the remaining term in SPPM’s first-order approximation is an error of magnitude , which means that CGD’s accuracy is in the same range as that of Lv. GP. In bilinear and quadratic games where the objective function is at most twice differentiable, CGD is equivalent to SPPM. The distinction between LEAD () and CGD can be understood by considering their update rules. LEAD is an explicit method where opponents’ potential next strategies are anticipated based on their most recent move . On the contrary, CGD accounts for this anticipation in an implicit manner, , where the future states appear in current states’ update rules. Therefore, the computation of CGD updates requires solving an function involving additional Hessian inverse operations. A numerical justification is also provided in Table 2, showing that the approximation accuracy of Lv. GP improves as increases.
5 Convergence Property
In Theorem 4.1, we have analytically proved that Lv. GP convergences asymptotically towards SPPM, we will use this result to study the convergence property of Lv. GP in games based on our analysis of SPPM. The local convergence of SPPM in a non convex - non concave game can be analyzed via the spectral radius of the game Jacobian around a stationary point:
Theorem 5.1.
Consider the (Minimax) problem under Assumption 3.1 and Lv. GP. Let be a stationary point. Suppose not in kernel of , not in kernel of and . There exists a neighborhood of such that if SPPM started at , the iterates generated by SPPM satisfy:
where . Moreover,for any satisfying:
| (4) |
SPPM converges asymptotically to .
Remark 5.1.

We assume that the difference between the trajectory and the stationary point is not in the kernel of and for the sake of simplicity. Detailed proofs without this assumption are provided in Appendix A.4. Following the same setting as Theorem 4.1, we have , which ensures that . Therefore, as , and in Remark 5.1, and as such Lv. GP has similar local convergence properties to SPPM. Figure 2 illustrates this property in a quadratic game. Lv. GP may behave differently than SPPM at lower values of , but as increases, both max step size and distance to equilibrium for a fixed number of iterations under converges to that of SPPM. Thus, we observe that Lv. GP is empirically similar to SPPM at higher values of .
We study the global convergence property of SPPM by analyzing its behavior in bilinear and quadratic games. Consider the following bilinear game:
| (Bilinear game) |
where is a full rank matrix. The following theorem summarizes SPPM’s convergence property:
Theorem 5.2.
Consider the Bilinear game and the SPPM method. Further, we define . Then, for any , the iterates generated by SPPM satisfy
| (5) |
It is worth noting that the convergence property of Lv. GP in bi-linear game has been studied in [2]. Furthermore, we study the convergence property of SPPM in the Quadratic game:
| (Quadratic game) |
where is symmetric and positive definite, is symmetric and negative definite and the interaction term is full rank. SPPM in quadratic games converges with the following rate:
Theorem 5.3.
Consider the Quadratic game and the SPPM. Then, for any , the iterates generated by SPPM satisfy
| (6) |
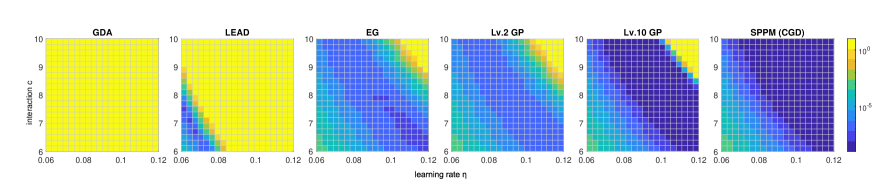
Theorem 5.1,5.2 and 5.3 indicate that stronger interaction improve the convergence rate towards the stationary points. By contrast, in existing modifications of GDA, the step size is chosen in inversely proportional to the interaction term [40, 13, 34]. In Figure 3, we showcase the effect of interaction on different algorithms in the Quadratic game setup with dimension and the interaction matrix is defined as . Stronger interaction corresponds to higher values of . A key difference between SPPM and Lv. GP in the experiments is that, SPPM converges with any step size - and so arbitrarily fast - while it is not the case for Lv. GP. In order to approximate SPPM, one needs Lv. GP to be a contraction and so have . This result implies an additional bound on step sizes for Lv. GP. As long as the constraint on is satisfied, stronger interaction only improves convergence for higher order Lv. GP while all other algorithms quickly diverge as and increase.
6 Experimental Results
In this section, we discuss our implementation of Lv. GP algorithm for training GANs. Its performance is evaluated on 8-Gaussians and two representative datasets CIFAR-10 and STL-10.
6.1 Level Adam
We propose to combine Lv. GP with the Adam optimizer [29]. Preliminary experiments find that Lv. Adam to converge much faster than Lv. GP, see A.8 for experiment results. A detailed pseudo-code for Level Adam (Lv. Adam) on GAN training with loss functions and is given in Algorithm 1. For the Adam optimizer, there are several possible choices on how to update the moments. This choice can lead to different algorithms in practice. Unlike [19] where the moments are updated on the fly, in Algorithm 1, we keep the moments fixed in the reasoning steps and update it together with model parameters. In Table 2, our experiment result suggests that the proposed Lv. Adam algorithm converges asymptotically as the number of reasoning steps increases.
6.2 8-Gaussians
In our first experiment, we evaluate Lv. Adam on generating a mixture of 8-Gaussians with standard deviations equal to and modes uniformly distributed around the unit circle. We use a two layer multi-layer perceptron with ReLU activations, latent dimension of and batch size of . The generated distribution is presented in Figure 4.
| Lv. Adam | |||||
|---|---|---|---|---|---|
| Lv. GP |

In addition to presenting the mode coverage of the generated distribution after training, we also study the convergence of the reasoning steps of Lv. Adam and Lv. GP. Let us define the difference between the states of Lv. and Lv. agents at time as:
| (7) |
We measure the difference averaged over the first 100 iterations, , for Lv. Adam () and Lv. GP (). The result presented in Table2 demonstrates that both Lv. GP and Lv. Adam are converging as increases. Moreover, the estimation precision of Lv. GP improves rapidly and converges to within finite steps, making it an accurate estimation for SPPM.
| Algorithm | Architecture | FID | IS |
|---|---|---|---|
| Adam [29] | BigGAN [6] | 14.73 | |
| Adam [29] | StyleGAN2 [59] | 11.07 | 9.18 |
| Adam [29] | SN-GAN [44] | ||
| Unrolled GAN [42, 9] | SN-GAN [44] | —— | |
| Extra-Adam [19, 38, 9] | SN-GAN [44] | —— | |
| LEAD† [23] | SN-GAN [44] | —— | |
| LA-AltGAN [9] | SN-GAN [44] | ||
| ODE-GAN(RK4) [48] | SN-GAN [44] | ||
| Lv. Adam | SN-GAN [44] |

6.3 Image Generation Experiments
We evaluate the effectiveness of our Lv. Adam algorithm on unconditional generation of CIFAR-10 [31]. We use the Inception score (the higher the better) [50] and the Fréchet Inception distance (the lower the better) [24] as performance metrics for image synthesis. For architecture, we use the SN-GAN architecture based on [44]. For baselines, we compare the performance of Lv. Adam to that of other first-order and second-order optimization algorithms with the same SN-GAN architecture, and to state-of-the-art models trained with Adam. For Lv. Adam, we use and for all experiments. We use different learning rates for the generator () and the discriminator (). We train Lv. Adam with batch size for epochs. For testing, we use an exponential moving average of the generator’s parameters with averaging factor .
In table 3, we present the performance of our method and baselines. The best FID score and Inception score, and , on SN-GAN are obtained with our Lv. Adam. We also outperform BigGAN and StyleGAN2 in terms of FID score. Notably, our model has 5.1M parameters in total, and is trained with a small batch size of 128, whereas BigGAN uses 158.3M parameters and a batch size of 2048.
The effect of and losses: We evaluate values of on non-saturated loss [21] (non-zero-sum formulation) and hinge loss [35] (zero-sum formulation). The result is presented in Table 4.
| Lv. Adam | Lv. Adam | Lv. Adam | |
|---|---|---|---|
| Non-saturated loss | |||
| Hinge loss |
Remarkably, our experiments demonstrate that few steps of recursive reasoning can result in significant performance gain comparing to existing GAN optimizers. The gradual improvements in the FID scores justify the idea that better estimation of opponents’ next move improves performance. Moreover, we observe performance gains in both zero-sum and non-zero-sum formulations which supplement our theoretical convergence guarantees in zero-sum games.
Experiment results on STL-10: To test whether the proposed Lv. Adam optimizer works on higher resolution images, we evaluate its performance on the STL-10 dataset [11] with resolutions. In our experiments, Lv. Adam obtained an averaged FID of which outperforms that of the Adam optimizer, , using the same SN-GAN architecture.
Memory and computation cost: Compared to SGD, Lv. Adam requires the same extra memory as the EG method (one additional set of parameters per player). The relative cost of one iteration versus SGD is a factor of and the computational cost increases linearly as increases, we illustrate this relationship in Figure 5 (right). We provide an accelerated version of Lv. Adam in A.8 which reduces the computation cost by half for . In Figure 5 (top-left), we compare the FID scores obtained by Lv. Adam, Adam, and LEAD on CIFAR-10 over the same number of gradient computations. LEAD, Lv4 Adam, and Lv6 Adam all outperform Adam in this experiment. Lv4 Adam outperforms LEAD after gradient computations. Our method is also compared with different algorithms on the 8-Gaussian problem in terms of its computational cost. On the same architecture with different widths, Figure 5 (bottom-left) illustrates the wall-clock time per computation for different algorithms. We observe that the computational cost of Lv. Adam while being much lower than CGD, is similar to LEAD, SGA and CO which involve JVP operations. Each run on CIFAR-10 dataset takes hours on a Nvidia RTX3090 GPU. Each experiment on STL-10 takes hours on a Nvidia RTX3090 GPU.
7 Conclusion and Future Work
This paper proposes a novel algorithm: Level gradient play, capable of reasoning about players’ future strategies. We achieve an average FID score of 10.17 for unconditional image generation on CIFAR-10 dataset, allowing GAN training on common computing resources to reach state-of-the-art performance. Our results suggest that Lv. GP is a flexible add-on that can be easily attached to existing GAN optimizers (e.g., Adam) and provides noticeable gains in performance and stability. In future work, we will examine the effectiveness of our approach on more complicated GAN designs, such as Progressive GANs [26] and StyleGANs [27], where optimization plays a more significant role. Additionally, we intend to examine the convergence property of Lv. GP in games with more than two player in the future.
Broader Impact
Our work introduces a novel optimizer that improves the performance of GANs and may reduce the amount of hyperparameter tuning required by practitioners of generative modeling. Generative models have been used to create illegal content(a.k.a. deepfakes [5]). There is risk of negative social impact resulting from malicious use of the proposed methods.
Acknowledgement
This work was supported by a funding from a NSERC Alliance grant and Huawei Technologies Canada. ZL would like to thank Tianshi Cao for insightful discussions on algorithm and experiment design. We are grateful to Bolin Gao and Dian Gadjov for their support.
References
- Arjovsky et al. [2017] Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In International conference on machine learning, pages 214–223. PMLR, 2017.
- Azizian et al. [2020] Waïss Azizian, Ioannis Mitliagkas, Simon Lacoste-Julien, and Gauthier Gidel. A tight and unified analysis of gradient-based methods for a whole spectrum of differentiable games. In International Conference on Artificial Intelligence and Statistics, pages 2863–2873. PMLR, 2020.
- Bailey et al. [2020] James P Bailey, Gauthier Gidel, and Georgios Piliouras. Finite regret and cycles with fixed step-size via alternating gradient descent-ascent. In Conference on Learning Theory, pages 391–407. PMLR, 2020.
- Balduzzi et al. [2018] David Balduzzi, Sebastien Racaniere, James Martens, Jakob Foerster, Karl Tuyls, and Thore Graepel. The mechanics of n-player differentiable games. In International Conference on Machine Learning, pages 354–363. PMLR, 2018.
- Brandon [2018] John Brandon. Terrifying high-tech porn: Creepy ’deepfake’ videos are on the rise. Fox News, 2018.
- Brock et al. [2018] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018.
- Carlini and Wagner [2017] Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In 2017 ieee symposium on security and privacy (sp), pages 39–57. IEEE, 2017.
- Chavdarova et al. [2019] Tatjana Chavdarova, Gauthier Gidel, François Fleuret, and Simon Lacoste-Julien. Reducing noise in GAN training with variance reduced extragradient. Advances in Neural Information Processing Systems, 32, 2019.
- Chavdarova et al. [2020] Tatjana Chavdarova, Matteo Pagliardini, Sebastian U Stich, François Fleuret, and Martin Jaggi. Taming GANs with lookahead-minmax. arXiv preprint arXiv:2006.14567, 2020.
- Choi et al. [2018] Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8789–8797, 2018.
- Coates et al. [2011] Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 215–223. JMLR Workshop and Conference Proceedings, 2011.
- Corballis [2007] Michael C Corballis. The uniqueness of human recursive thinking: the ability to think about thinking may be the critical attribute that distinguishes us from all other species. American Scientist, 95(3):240–248, 2007.
- Daskalakis et al. [2017] Constantinos Daskalakis, Andrew Ilyas, Vasilis Syrgkanis, and Haoyang Zeng. Training GANs with optimism. arXiv preprint arXiv:1711.00141, 2017.
- Fiez and Ratliff [2021] Tanner Fiez and Lillian J Ratliff. Local convergence analysis of gradient descent ascent with finite timescale separation. In Proceedings of the International Conference on Learning Representation, 2021.
- Fiez et al. [2019] Tanner Fiez, Benjamin Chasnov, and Lillian J Ratliff. Convergence of learning dynamics in Stackelberg games. arXiv preprint arXiv:1906.01217, 2019.
- Foerster et al. [2017] Jakob N Foerster, Richard Y Chen, Maruan Al-Shedivat, Shimon Whiteson, Pieter Abbeel, and Igor Mordatch. Learning with opponent-learning awareness. arXiv preprint arXiv:1709.04326, 2017.
- Gemp and Mahadevan [2018] Ian Gemp and Sridhar Mahadevan. Global convergence to the equilibrium of gans using variational inequalities. arXiv preprint arXiv:1808.01531, 2018.
- Gemp and McWilliams [2019] Ian Gemp and Brian McWilliams. The Unreasonable Effectiveness of Adam on Cycles. In NeurIPS Workshop on Bridging Game Theory and Deep Learning, 2019.
- Gidel et al. [2018] Gauthier Gidel, Hugo Berard, Gaëtan Vignoud, Pascal Vincent, and Simon Lacoste-Julien. A variational inequality perspective on generative adversarial networks. arXiv preprint arXiv:1802.10551, 2018.
- Gidel et al. [2019] Gauthier Gidel, Reyhane Askari Hemmat, Mohammad Pezeshki, Rémi Le Priol, Gabriel Huang, Simon Lacoste-Julien, and Ioannis Mitliagkas. Negative momentum for improved game dynamics. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 1802–1811. PMLR, 2019.
- Goodfellow et al. [2014] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014.
- Gulrajani et al. [2017] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. Improved training of Wasserstein GANs. Advances in neural information processing systems, 30, 2017.
- Hemmat et al. [2020] Reyhane Askari Hemmat, Amartya Mitra, Guillaume Lajoie, and Ioannis Mitliagkas. Lead: Least-action dynamics for min-max optimization. arXiv preprint arXiv:2010.13846, 2020.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Jin et al. [2020] Chi Jin, Praneeth Netrapalli, and Michael Jordan. What is local optimality in nonconvex-nonconcave minimax optimization? In International Conference on Machine Learning, pages 4880–4889. PMLR, 2020.
- Karras et al. [2017] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of GANs for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196, 2017.
- Karras et al. [2019] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019.
- Karras et al. [2020] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of StyleGAN. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8110–8119, 2020.
- Kingma and Ba [2014] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Korpelevich [1976] Galina M Korpelevich. The extragradient method for finding saddle points and other problems. Matecon, 12:747–756, 1976.
- Krizhevsky et al. [2009] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- Ledig et al. [2017] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4681–4690, 2017.
- Letcher et al. [2019] Alistair Letcher, David Balduzzi, Sébastien Racaniere, James Martens, Jakob Foerster, Karl Tuyls, and Thore Graepel. Differentiable game mechanics. The Journal of Machine Learning Research, 20(1):3032–3071, 2019.
- Liang and Stokes [2019] Tengyuan Liang and James Stokes. Interaction matters: A note on non-asymptotic local convergence of generative adversarial networks. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 907–915. PMLR, 2019.
- Lim and Ye [2017] Jae Hyun Lim and Jong Chul Ye. Geometric gan. arXiv preprint arXiv:1705.02894, 2017.
- Lowe et al. [2017] Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. Advances in neural information processing systems, 30, 2017.
- Madry et al. [2017] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017.
- Mertikopoulos et al. [2018a] Panayotis Mertikopoulos, Bruno Lecouat, Houssam Zenati, Chuan-Sheng Foo, Vijay Chandrasekhar, and Georgios Piliouras. Optimistic mirror descent in saddle-point problems: Going the extra (gradient) mile. arXiv preprint arXiv:1807.02629, 2018a.
- Mertikopoulos et al. [2018b] Panayotis Mertikopoulos, Christos Papadimitriou, and Georgios Piliouras. Cycles in adversarial regularized learning. In Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 2703–2717. SIAM, 2018b.
- Mescheder et al. [2017] Lars Mescheder, Sebastian Nowozin, and Andreas Geiger. The numerics of GANs. Advances in neural information processing systems, 30, 2017.
- Mescheder et al. [2018] Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for GANs do actually converge? In International conference on machine learning, pages 3481–3490. PMLR, 2018.
- Metz et al. [2016] Luke Metz, Ben Poole, David Pfau, and Jascha Sohl-Dickstein. Unrolled generative adversarial networks. arXiv preprint arXiv:1611.02163, 2016.
- Mishchenko et al. [2020] Konstantin Mishchenko, Dmitry Kovalev, Egor Shulgin, Peter Richtárik, and Yura Malitsky. Revisiting stochastic extragradient. In International Conference on Artificial Intelligence and Statistics, pages 4573–4582. PMLR, 2020.
- Miyato et al. [2018] Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957, 2018.
- Mokhtari et al. [2020] Aryan Mokhtari, Asuman Ozdaglar, and Sarath Pattathil. A unified analysis of extra-gradient and optimistic gradient methods for saddle point problems: Proximal point approach. In International Conference on Artificial Intelligence and Statistics, pages 1497–1507. PMLR, 2020.
- Papadimitriou and Piliouras [2018] Christos Papadimitriou and Georgios Piliouras. From Nash equilibria to chain recurrent sets: An algorithmic solution concept for game theory. Entropy, 20(10):782, 2018.
- Piliouras et al. [2021] Georgios Piliouras, Ryann Sim, and Stratis Skoulakis. Optimal no-regret learning in general games: Bounded regret with unbounded step-sizes via clairvoyant mwu. arXiv preprint arXiv:2111.14737, 2021.
- Qin et al. [2020] Chongli Qin, Yan Wu, Jost Tobias Springenberg, Andy Brock, Jeff Donahue, Timothy Lillicrap, and Pushmeet Kohli. Training generative adversarial networks by solving ordinary differential equations. Advances in Neural Information Processing Systems, 33:5599–5609, 2020.
- Rockafellar [1976] R Tyrrell Rockafellar. Monotone operators and the proximal point algorithm. SIAM journal on control and optimization, 14(5):877–898, 1976.
- Salimans et al. [2016] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training GANs. Advances in neural information processing systems, 29, 2016.
- Sauer et al. [2021] Axel Sauer, Kashyap Chitta, Jens Müller, and Andreas Geiger. Projected GANs converge faster. Advances in Neural Information Processing Systems, 34, 2021.
- Sauer et al. [2022] Axel Sauer, Katja Schwarz, and Andreas Geiger. StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets. arXiv preprint arXiv:2202.00273, 2022.
- Schäfer and Anandkumar [2019] Florian Schäfer and Anima Anandkumar. Competitive gradient descent. Advances in Neural Information Processing Systems, 32, 2019.
- Thanh-Tung et al. [2019] Hoang Thanh-Tung, Truyen Tran, and Svetha Venkatesh. Improving generalization and stability of generative adversarial networks. arXiv preprint arXiv:1902.03984, 2019.
- Vinyals et al. [2019] Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature, 575(7782):350–354, 2019.
- Wang et al. [2019] Yuanhao Wang, Guodong Zhang, and Jimmy Ba. On solving minimax optimization locally: A follow-the-ridge approach. arXiv preprint arXiv:1910.07512, 2019.
- Willi et al. [2022] Timon Willi, Johannes Treutlein, Alistair Letcher, and Jakob Foerster. COLA: Consistent Learning with Opponent-Learning Awareness. arXiv preprint arXiv:2203.04098, 2022.
- Zhang et al. [2021] Guodong Zhang, Yuanhao Wang, Laurent Lessard, and Roger Grosse. Near-optimal Local Convergence of Alternating Gradient Descent-Ascent for Minimax Optimization. arXiv preprint arXiv:2102.09468, 2021.
- Zhao et al. [2020] Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu, and Song Han. Differentiable augmentation for data-efficient gan training. Advances in Neural Information Processing Systems, 33:7559–7570, 2020.
Appendix A Appendix
A.1 Proof of Theorem 4.1
Proof.
To begin with, let us consider Lv. GP:
The differences between and are:
Recall our definition of we have:
| (8) |
Then, with and , the differences between Lv. agents and Lv. agents are:
Recall that , using Equation (8) we have:
| (9) |
Similarly, we can derive the differences between Lv. and Lv. agents:
| (10) |
Consequently, the difference between any two consecutive states and are upper bounded by:
| (11) |
Since we have:
| (12) |
Suppose , such that the difference between any two consecutive states is a contraction, then we consider the difference, , where . We can rewrite it as:
| (13) |
Since , we have that and for any , we can solve for such that . Therefore the sequence is a Cauchy sequence. Moreover, in a complete space, every Cauchy sequence has a limit: ∎
A.2 Proof of Theorem 5.1
Theorem A.1.
Consider the (Minimax) problem under Assumption 3.1 and Lv. GP. Let be a stationary point. Suppose not in kernel of , not in kernel of and . There exists a neighborhood of such that if SPPM started at , the iterates generated by SPPM satisfy:
where . Moreover, for any satisfying:
| (14) |
SPPM converges asymptotically to .
Proof.
Consider the learning dynamics:
Let us define
It follows immediately by linearizing the system about the stationary point that
Let us denote the Jacobian by
| (15) |
Then we can rewrite the dynamics around the stationary point as
| (16) |
Similarly, for the other player we have
| (17) |
Let us define the symmetric matrices , and , . Further we define . Based on these definitions, and the expressions in (52) and (53) we have
| (18) |
To simplify the expression in (54) we use the following lemma:
Lemma A.1.
The matrices , satisfy the following properties:
| (19) | ||||
| (20) |
Using this lemma, we can show that
where the intermediate equality holds as . Hence, the expression in (54) can be simplified as
| (21) |
We simplify equation (57) as follows. Consider the term involving . We have
| (22) |
where the last equality follows by replacing by its definition. The same procedure follows for the term involving which leads to the expression
| (23) |
Substitute and in (57) with the expressions in (22) and (23), respectively, to obtain
| (24) |
Note that, we assume that the trajectory is not in the kernel of and , thus and . Now using the expression in (60) and the fact that , and and have the same set of non-zero eigenvalues, if we denote the minimum non-zero eigenvalues by and , we can write
Replacing and with and we have:
Recall that , and , therefore for any satisfying that:
| (25) |
we have . Since we linearize the system about the stationary point , there exists a neighborhood around the stationary point, such that, SPPM started at converges asymptotically to . ∎
A.3 Proof of Remark 5.1
Proof.
To prove the local convergence of Lv. GP in non-convex non-concave games, we first consider the update rule of Lv. GP:
Similar to Section A.2 let us denote
and we define the difference between states and stationary points as
Linearizing the dynamical system induced by Lv. GP about the stationary point we get:
Note, in Lv. GP, we define and , thus for Lv. GP, we have:
For Lv. GP, we have:
Substituting and into the update rule above we get:
Similarly, for Lv. and Lv. GP we have:
and
Summarizing the equations above we have that for Lv. GP, its update can be written as:
Similar to Appendix A.2, let us define , and , . Further, we define , and , .
Since , we have that:
and
| (26) | |||
| (27) |
Also, from Lemma A.1 and the definition of the error terms, it can be verified that
| (28) | ||||
| (29) |
Then we can rewrite the update rule of Lv. GP:
Let us consider the following sum:
| (30) |
The R.H.S. of Eq.(30) can be written as:
| (31) |
Now, before adding all terms in Eq.(31), note that all of the cross terms in Eq.(31) cancel out.
For instance, using Lemma A.1 and Eq.(28), Eq.(29) we can show that
By using similar arguments it can be shown that terms in Eq.(31) leads to:
| (32) |
Similar to Eq.(22) we have the following simplification:
Now we can further simplify Eq.(31) as:
Using Eq.(26) and Eq.(27) and definition of and we have:
Similarly, we have that
Thus we simplify the R.H.S. of Eq.(30) as
| (33) |
Let us consider the L.H.S. of Eq.(30)
| (34) |
Substituting Eq.(34) and Eq.(33) into L.H.S. and R.H.S. of Eq.(30) respectively we get:
Now we have the following equation:
Note that
| (35) | ||||
| (36) |
Similarly
| (37) | ||||
| (38) |
Summing everything together we have:
Note that, we assume that the trajectory is not in the kernel of and , thus and . Now using the expression in (60) and the fact that , and and have the same set of non-zero eigenvalues, if we denote the minimum non-zero eigenvalues by and , we can write
Let us define the distance as:
| (40) | ||||
| (41) |
Then we have
| (42) |
where
and
| (43) |
∎
A.3.1 Proof of Lemma A.1
Let be the singular value decomposition of . Here and are orthonormal matrices and is a rectangular diagonal matrix. Then we have:
Here we used the fact that and are orthonormal matrices. Now, we simplify the other side to get:
Now we consider the following equation:
| (44) |
which indicates that . Multiplying both sides of this equation by and we have:
Therefore, we have . Using a similar argument, we can also prove the equality in Equation (20).
A.4 Theorem 5.1 without kernel assumption
Theorem A.2.
Proof.
Following the same setting and procedure as in Appendix A.2, we have that
| (46) |
Now using the fact that , , we can write
For any that satisfying
| (47) |
we have that
| (48) |
i.e., SPPM converges asymptotically towards . ∎
A.5 Proof of Theorem 5.2
Proof.
In order to proof the convergence of SPPM in bilinear games, we first show that the SPPM update rule is equivalent to that of the following Proximal Point Method:
| (49) |
In the Bilinear game, the SPPM update is:
and the PPM update is:
Thus SPPM and PPM are equivalent in the Bilinear game. The convergence result of PPM in bilinear games has been proved in Theorem 2 of [49]:
Theorem A.3.
Consider the Bilinear game and the PPM method. Further, we define . Then, for any , the iterates generated by SPPM satisfy
| (50) |
Therefore, SPPM and PPM have the same convergence property in bilinear games. ∎
A.6 Proof of Theorem 5.3
Proof.
Consider the learning dynamics:
In the Quadratic game, the SPPM update rule can be written as:
| (51) |
Then we can rewrite the learning dynamics:
| (52) |
Similarly, for the other player we have
| (53) |
Let us define the symmetric matrices , and , . Further we define . Based on these definitions, and the expressions in (52) and (53) we have
| (54) |
To simplify the expression in (54) we use Lemma A.1 to obtain the following equations:
| (55) | ||||
| (56) |
Using this lemma, we can show that
where the intermediate equality holds as . Hence, the expression in (54) can be simplified as
| (57) |
We simplify equation (57) as follows. Consider the term involving . We have
| (58) |
where the last equality follows by replacing by its definition. The same procedure follows for the term involving which leads to the expression
| (59) |
Substitute and in (57) with the expressions in (58) and (59), respectively, to obtain
| (60) |
Now using the expression in (60) and the fact that , and , we can write
∎
A.7 Competitive Gradient Descent as an Approximation of SPPM
In this section, we justify our results in Section 4.1 that Competitive Gradient Descent is a first order Taylor approximation of SPPM. Firstly, we consider the standard definition of CGD:
Rewriting the update rules we can get:
Similarly, we have:
Therefore, CGD is a first order approximation of SPPM. Then we prove that the standard definition of CGD is equivalent to the update rule in Table 1. Consider the update rule in Table 1 and its footnote, we have:
| (61) |
Substituting into the first equation of (61) we get:
Substituting into the second equation of (61) and applying similar arguments we get:
Thus the update rule in Table 1 is equivalent to the standard definition of CGD and it is equivalent to the first order Taylor approximation of SPPM.
A.8 Experiments on Bilinear and Quadratic Games
Bilinear Game
Consider the following bilinear game:
| (62) |
the example presented in Figure 1 is an example of using different algorithms to solve the bilinear game above with coefficient . For sake of completeness, we also provide a grid of experiment results for different algorithms with different coefficients and learning rates , starting from the same point . The result is presented in Figure 6.

The experiment demonstrates that, in a bilinear game, Lv. GP is equivalent to the extra-gradient method, and higher level Lv. GP performs better with increased coefficient and learning rate as long as it remains a contraction (i.e., ).
Quadratic Game
For the quadratic game presented in Figure 3, we randomly initialize the matrices and :
where is symmetric and positive definite and is symmetric and negative definite. The interaction matrix is defined as:
where represents the strength of the interaction between the two players. The starting point and are and respectively.

A.9 Experiments on 8-Gaussians
Dataset
The target distribution is a mixture of 8-Gaussians with standard deviation equal to and modes uniformly distributed around a unit circle.
Experiment
For our experiments, we used the PyTorch framework. Furthermore, the batch size we used is .
A.10 Experiments on CIFAR-10 and STL-10
For our experiments, we used the PyTorch222https://pytorch.org/ framework. For experiments on CIFAR-10 and STL-10, we compute the FID and IS metrics using the provided implementations in Tensorflow333https://tensorflow.org/ for consistency with related works.
Lv. GP vs Lv. Adam

In experiments, we compare the performance of Lv. GP and Lv. Adam on the task of CIFAR-10 image generation. The experiment results is presented in Figure 8. The experiments on Lv. GP and Lv. Adam use the same initialization and hyperparameters. According to our experiments, Lv. Adam converges much faster than Lv. GP for the same choice of and learning rates.
Adam vs Lv. Adam

We also present a comparison between the performance of Adam and Lv. Adam optimizers on the task of STL-10 image generation. The experiment results is presented in Figure 9. Under the same choice of hyperparameters and identical model parameter initialization, Lv. Adam consistently outperforms the Adam optimizer in terms of FID score.
Accelerated Lv. Adam
In this section, we propose an accelerated version of Lv. Adam. The intuition is that we update the min player and the max player in an alternating order. The corresponding Lv. GP algorithm can be writen as:
| (Alt-Lv. GP) |
Instead of responding to , in Alt-Lv. GP, the max player acts in response to the min player’s current action, . A Lv. min player in Alt-Lv. GP is equivalent to a Lv. player in the Lv. GP, and a Lv. max player in Alt-Lv. GP is equivalent to a Lv. player in the Lv. GP, respectively. Therefore, it is easy to verify that Alt-Lv. GP converges two times faster than Lv. GP and the corresponding Alt-Lv. Adam algorithm is provided in Algorithm 2.
Architecture
In this section, we describe the model we used to evaluate the performance of Lv. Adam for generating CIFAR-10444CIFAR10 is released under the MIT license. and STL-10 datasets. With ’conv’ we denote a convolutional layer and ’transposed conv’ a transposed convolution layer. The models use Batch Normalization and Spectral Normalization. The model’s parameters are initialized with Xavier initialization.
| G-ResBlock |
|---|
| Shortcut: |
| Upsample() |
| Residual: |
| Batch Normalization |
| ReLU |
| Upsample() |
| conv (ker:, ; stride: ; pad: ) |
| Batch Normalization |
| ReLU |
| conv (ker:, ; stride: ; pad: ) |
| D-ResBlock (th block) |
| Shortcut: |
| AvgPool (ker: ), if |
| conv (ker: , ; stride: ) |
| Spectral Normalization |
| AvgPool (ker: , stride: ), if |
| Residual: |
| ReLU, if |
| conv (ker: , ; stride: ; pad: ) |
| Spectral Normalization |
| ReLU |
| conv (ker: , ; stride: ) |
| Spectral Normalization |
| AvgPool (ker: ) |
| Generator | Discriminator |
|---|---|
| Input: | Input: |
| Linear() | D-ResBlock |
| G-ResBlock | D-ResBlock |
| G-ResBlock | D-ResBlock |
| G-ResBlock | D-ResBlock |
| Batch Normalization | ReLU |
| ReLU | AvgPool(ker:) |
| conv (ker:, ; stride: ; pad: ) | Linear() |
| Tanh | Spectral Normalization |
| Generator | Discriminator |
|---|---|
| Input: | Input: |
| Linear() | D-ResBlock down |
| G-ResBlock up | D-ResBlock down |
| G-ResBlock up | D-ResBlock down |
| G-ResBlock up | D-ResBlock down |
| Batch Normalization | D-ResBlock |
| ReLU | ReLU, AvgPool (ker: ) |
| conv (ker: , ; stride: ; pad: ) | Linear() |
| Tanh | Spectral Normalization |
Images generated on CIFAR-10 and STL-10
In this section, we present sample images generated by the best performing trained generators on CIFAR-10 and STL-10.

