Recommending with Recommendations
Abstract
Recommendation systems are a key modern application of machine learning, but they have the downside that they often draw upon sensitive user information in making their predictions. We show how to address this deficiency by basing a service’s recommendation engine upon recommendations from other existing services, which contain no sensitive information by nature. Specifically, we introduce a contextual multi-armed bandit recommendation framework where the agent has access to recommendations for other services. In our setting, the user’s (potentially sensitive) information belongs to a high-dimensional latent space, and the ideal recommendations for the source and target tasks (which are non-sensitive) are given by unknown linear transformations of the user information. So long as the tasks rely on similar segments of the user information, we can decompose the target recommendation problem into systematic components that can be derived from the source recommendations, and idiosyncratic components that are user-specific and cannot be derived from the source, but have significantly lower dimensionality. We propose an explore-then-refine approach to learning and utilizing this decomposition; then using ideas from perturbation theory and statistical concentration of measure, we prove our algorithm achieves regret comparable to a strong skyline that has full knowledge of the source and target transformations. We also consider a generalization of our algorithm to a model with many simultaneous targets and no source. Our methods obtain superior empirical results on synthetic benchmarks.
1 Introduction
Recommendation engines enable access to a range of products by helping consumers efficiently explore options for everything from restaurants to movies. But these systems typically rely on fine-grained user data—which both necessitates users’ sharing such data, and makes it difficult for platforms without existing data sources to enter the space. In this paper, we propose a new approach to recommendation system design that partially mitigates both of these challenges: basing recommendations on existing recommendations developed by other services. We call the new service’s recommendation task the target, and call the prior recommendations we rely on the source. Source recommendations are always available to the user, and are sometimes even public. We show that as long as the source and target recommendation tasks are sufficiently related, users can enable services to make high-quality recommendations for them without giving away any new personal data. Thus our method offers a middle ground between consumers’ current options of either giving platforms personal data directly or receiving low-quality recommendations: under our system, consumers can receive high-quality recommendations while only sharing existing recommendations based on data that other services already possess.
For intuition, consider the following example which we use throughout the paper for illustration: There is an existing grocery delivery service, which has become effective at recommending grocery items to its users. A new takeout delivery service is seeking to recommend restaurants to the same set of users. Users’ preferences over groceries and restaurant food rely on many of the same underlying user characteristics: for example, a user who loves pasta will buy it at grocery stores and patronize Italian restaurants; meanwhile, a user who is lactose intolerant will prefer not to buy milk products and prefer to avoid ice cream parlors. Thus, high-quality grocery recommendations provide valuable data upon which we could base restaurant recommendations.
From the user perspective, a restaurant recommendation system based on existing grocery recommendations would be able to provide high-quality restaurant suggestions immediately, rather than needing to learn the user’s preferences over time. And yet the user would not need to share any data with the restaurant recommendation system other than the grocery recommendations themselves—which by nature contain (weakly) less user private information than they were derived from. Crucially, the user’s food preferences might theoretically be driven by a health condition like lactose intolerance, but they could also just be a matter of taste (not liking milk). In this case, the grocery delivery platform’s recommendations reflect that preference information in a way that is useful for extrapolating restaurant recommendations, without directly revealing the potentially sensitive underlying source of the user’s preferences.
And while these food recommendation instances are a bit niche, there are many settings in which recommendations built on personal data may be available, even if we do not have access to the personal data itself. Search engines, for example, utilize user data to serve advertisements, and at least two notable projects—the Ad Observatory project [1] and the Citizen Browser [2]—have automatically logged social media advertisements that were served to users. Such advertisements could be used as contextual input for a variety of recommendation problems.
In our framework, we consider an agent that aims to make recommendations for a collection of users over a collection of target tasks. Each task takes the form of a standard stochastic linear bandit problem, where the reward parameter for user is given by a task-specific linear transformation of ’s high-dimensional personal data vector. We think of these transformations as converting the personal data into some lower-dimensional features that are relevant for the task at hand. These transformations and the personal data vectors are unknown to the agent. However, the agent is given access to the optimal arms (and its final reward) for each of the users on a source task. No other “white-box” information about the source task (e.g., the reward history for the agent that solved the task) is known. That is, only the recommendations themselves—which are served to (and thus may be captured by) the user—in addition to the final reward (which may also be captured by asking the user to rate the recommendation) are accessible to the agent.
We describe algorithms that allow the agent to effectively make use of this information to reduce regret, so long as the source and target task transformations make use of segments of the high-dimensional personal data similar to those used in the source task. Notably, such a recommendation system functions without the user providing any personal information to the agent directly—and moreover, to the extent that the source task abstracts from sensitive data, all of the target task recommendations do as well.
Formally, we set up two related contextual bandit problems for the recommendation problem. When we have one target and many users, we can decompose each user’s reward parameter into idiosyncratic components, which are unique to each user, and systematic components, which are shared among all users. If the source and target tasks utilize similar segments of the users’ personal data, the idiosyncratic component is low-dimensional. As a result, if is the shared information between the subspaces, our regret bounds improve upon the LinUCB baseline [3] by a factor of .
In our second iteration, we consider the general problem of having many targets and many users, but no sources. We show that if we perform what is essentially an alternating minimization algorithm to solve for a few tasks at first, use the solutions to solve for all the users, and then use those to solve for all the tasks, we obtain strong experimental performance. We call our collective methods Rec2, for recommending with recommendations.
In both analyses, we make a crucial user growth assumption, which states that in several initial phases, we have beta groups where only some subset of the tasks and some subset of the users can appear. This assumption enables us to estimate systematic parameters accurately, as there are fewer idiosyncratic parameters. It also reflects how a web platform grows.
Section 2 introduces our formal model and compares it to prior work. In Section 3, we describe our approach for inferring the relationship between the source and target tasks when we have source recommendations for multiple users. We then develop and analyze an algorithm that uses this approach to reduce regret. In Section 4, we generalize our algorithm from Section 3 to our second setting where we have multiple target tasks. In Section 5, we demonstrate our methods in synthetic experiments. Finally, Section 6 concludes.
2 Preliminaries
2.1 Framework
In our setup, we aim to solve target tasks for users. We are also given the optimal arms (and corresponding expected reward) for each user on a source task.
Formally, we associate to each user a vector denoting all of the user’s data, some of which is potentially sensitive. We think of this space as being extremely high-dimensional—i.e., —and encapsulating all of the salient attributes about the user. We associate to the source task a matrix and similarly associate to each target task a matrix . The parameters denote the dimensionality of the source target tasks, respectively.111The assumption that all target tasks have the same dimensionality is made for expositional simplicity and can be relaxed. We assume that the task matrices and do not contain any redundant information, and thus have full row rank. These task matrices transform a user’s personal data into the reward parameter for the task. For example, if a takeout delivery service (given by target task ) aims to make recommendations for some user , the task matrix transforms ’s personal data into the space of possible restaurants in such a way that the vector essentially denotes ’s ideal restaurant choice.
We now consider a multi-armed bandit problem with finite horizon . At each time , the agent observes a context consisting of a user-task pair , and subsequently chooses an arm from a finite and time-dependent decision set . We then observe the reward
| (1) |
where are i.i.d., mean-, independent -subgaussian random variables. We assume that the decision sets are well-conditioned, such that for any arm , for all . We also assume , so each arm has -norm at most , and that for all .
Crucially, in our setup, the agent is not given access to any of the personal data vectors , or any of the source/task matrices or . The agent is, however, given access to each of the optimal arms and corresponding reward for an agent that solved the source task. These quantities can be used to approximate the source reward parameter under reasonable assumptions on the source agent’s arm space. Namely, we assume that the source agent’s arm space is a net of some ball of radius , whence we may write . The corresponding expected reward, as per (1), is then approximately given by . We may then approximate ; in the remainder of this paper we assume, for simplicity, that this approximation is exact.
As usual, the objective of the agent is to maximize the expected cumulative reward , or equivalently minimize the expected regret
| (2) |
Our central contribution in this paper is demonstrating how knowledge of the optimal arms for the each of the source tasks may be used to significantly reduce regret relative to the naive approach solving each of the contexts separately. Using the popular LinUCB algorithm [4], we obtain the following baseline regret bound. (All proofs are in Appendix A.)
Theorem 2.1 (LinUCB Bound).
A LinUCB agent that naively solves each of the tasks separately has regret bounded by
An interpretation of Theorem 2.1 is that on average, each user receives an arm with reward at most worse than the best, meaning that the problem is harder when there are more tasks, more users, and higher dimension, but becomes easier with time.
2.2 Related Work
Recommendation Systems
Recommendation systems—which recommend items to users, given data on users, items, and/or their pairwise interactions—have been one of the most impactful applications of modern machine learning [5]. Moreover, the study of recommendation systems has led to a number of foundational methodological breakthroughs [6, 7].
Contextual Bandits
Our framework is an example of a setting with contextual bandits [8], i.e., one in which bandits are allowed to draw upon information beyond the arms themselves—the context—to help make their decisions. Moreover, our framework follows that of a linear bandit. However, our framework differs from the standard model of contextual linear bandits [9, Equation 19.1], which represents the rewards as where is a known feature map and is an unknown reward parameter. While our question can be fit into that standard framework by using
such a setup does not allow for us to easily incorporate our information about into the problem, as it merely views as an unrolling of a vector. In particular, the direct bounds obtained through the standard contextual bandits formulation (without further assumptions) are weak relative to ours, as has dimension .
Explore and Refine Approaches
Our algorithm in Section 3 is methodologically similar to the algorithm of [10], which also explores to obtain a subspace containing the solution, and imposes a soft penalty to make the estimated reward parameter close to that subspace. Indeed, our approach draws upon their LowOFUL algorithm. However, the problem we seek to solve is quite different from that of [10]—we have either multiple tasks or side information in each of our models.
Cross-Domain Recommendations
Cross-Domain recommendations (see [11] for a survey) is an area where data from other recommendation domains is used to inform recommendations in a new domain. Here we highlight works in cross-domain recommendations that we find particularly relevant.
[12] makes a low-rank assumption on the tensor of item-user-domain, which is similar to but differs from our assumption, as our assumption does not make any assumptions regarding the quantity of items, and hence about rank constraints along that axis. Furthermore, those works recommend items, whereas our work chooses from a set of arms—the featurizations in our model are provided ahead of time, whereas in [12] they are learnt.
[13] uses a similar cross-domain recommendation idea; but they use explicit relationships between items as hinted by the title (i.e. aficionados of the book "The Devil Wears Prada" should also enjoy the movie "The Devil Wears Prada"), which our work does not depend on. Our work makes purely low-rank based assumptions, making it more general than [13].
Meta-Learning
In addition, our setup resembles the standard meta-learning [14, 15] setup, as we have several interrelated tasks (namely, each (service, user) pair can be viewed as a separate task). In [16], the authors address a meta-learning task by assuming that the task matrices come from a simple distribution, which are then learnt. One way to think of this work is that it corresponds to ours in the case where . As such, it cannot share parameters across users, and thus must make distributional assumptions on the tasks to get nontrivial guarantees.
Transfer Learning and Domain Adaptation
Our setup also resembles that of transfer learning, as we use parameters from one learned task directly in another task, as well as domain adaptation, because we use similar models across two different settings. Transfer learning has commonly used in the bandit setting [17, 18, 19, 20].
Most relevant to our work, the model we present in Section 3 is similar to the setting of [21], in which the target features are a linear transformation away from the source features, and the bandit has access to historical trajectories of the source task. One way to interpret this in our model is that the work assumes knowledge of the full set of features (as opposed to merely a projection), and thus strives to solve for . It then solves for by applying linear regression to align the contexts, obtaining a nontrivial regret guarantee. However, the result is not directly comparable, because the model contains substantially more information than ours, namely access to the full instead of simply a view as well as past trajectories on a bandit problem.
The paper [22] uses domain adaptation to approach cross-domain recommendation and shows that it can achieve superior performance to certain baselines. However, it is not clear how to implement this in a bandit-based framework.
User-similarity for recommendation
In works like [23, 24, 25, 26], the authors address recommendation problems by using information about similar users, like users in a social network. They assume that people who are connected on social media have similar parameter vectors. However, this assumption may potentially violate privacy by assuming access to a user’s contacts, and by using many tasks (as these works effectively have ) and many users we can obtain similar results without using social data.
3 One Target, One Source, Many Users
In this section, we consider the case where we have target task. We show that source recommendations can be used to generate target recommendations in two phases. We first show how an agent with full knowledge of the source and target matrices can reduce regret using the source recommendations by reducing the dimensionality of target recommendation problem. We then show that agent without knowledge of the source and target matrices can still reduce regret under a realistic assumption on the ordering of the contexts by learning the underlying relationship between the source and target matrices from observed data. One quantity that relates to the success of our approach is the common information, which we define as
| (3) |
This quantity can be thought of as the fraction of information about the underlying reward parameter that can be possibly be explained given the source information . Referring back to Figure 1, we can see that if , then the target task uses segments of the user’s information that are almost all contained by the segments used by the source task – a situation that arises often in practice. Stated differently, this implies that the source and target matrices and have a low rank structure. To see this, observe that the rank of the block matrix is given by
In our running example, the matrix represents a grocery recommendation task and the matrix represents a restaurant recommendation task. Our algorithm finds the minimal set of information needed to predict both tasks, and then predicts the user’s restaurant preferences by looking at all possibilities that are consistent with the user’s grocery preferences.
Skyline Regret Bound
We now show how an agent that was given the source and target matrices and may use this structure to reduce regret. By the above, we may write the compact singular value decomposition of the stacked matrix as , where and . Projecting onto the principal components, we can create a low-dimensional generative model
where . Letting denote the orthogonal projector onto the first components and denote the orthogonal projector onto the last components, we have that , whence we may write . Here, denotes the Moore-Penrose pseudo-inverse. Substituting in, we may write
| (4) |
We call the transformer, as it transforms the known reward parameter from the source domain into the target domain. From the above, we have that the residual lies in , which is a space of dimension . Choosing an orthogonal basis for this space, it follows that we may write
| (5) |
where has orthogonal columns given by the basis elements, and gives the corresponding weights. We call the generator, as it generates the second term in the above expression from a lower dimensional vector . Together and give a useful decomposition of the target reward parameter into a systematic component that can be inferred from the source reward parameter, and an idiosyncratic component that must be learned independently for each user. An agent with full knowledge of the source and task matrices can compute and as given above, and thus needs only solve for each of the that lie in a -dimensional subspace. As a result, it attains a lower skyline regret bound.
Theorem 3.1 (Skyline Regret).
An agent with full knowledge of the source and target matrices and may attain regret
Comparing to Theorem 2.1, we see that we obtain an identical bound, but with a factor of in front. Thus, as alluded to earlier, the improvement depends on how large is. If is close to one, then we obtain a significant improvement, corresponding to being able to use a substantial amount of information from the source recommendations. This result only applies when the agent is given the source and target matrices.
Learning from Observed Data
We now return to our original setup, where the source and target matrices are unknown. We show how the transformer and the generator may be learned from observed data under a realistic assumption on the ordering of the contexts. We assume that some subset of the users belongs to a beta group, and are the only users requesting recommendations for the first iterations. After the first iterations, all users are allowed to request recommendations for the target task. This assumption makes learning the transformer and generator easier as it reduces the number of idiosyncratic parameters we must fully learn in order to understand the relationship between the two tasks.
Our approach is briefly summarized as follows. In the first iterations, we use some exploration policy that independently pulls arms for each user. In practice, this policy could be adaptive, like the baseline LinUCB algorithm. To keep our analysis tractable, we instead assume that the exploration policy is oblivious. That is, we assume that arms pulled in the first iterations do not depend on any observed rewards, and that the arms are randomly drawn from . We further assume that the same oblivious policy is used across users. This is essentially equivalent to using different oblivious strategies for different users, as we have no prior information on the reward parameters. In our experiments, we show that this obliviousness assumption does not appear necessary to achieve good performance. We find that adaptive policies (namely LinUCB) are just as, if not more effective at learning the model relating the two tasks, while achieving performance equivalent to the baseline during the exploration phase.
Immediately after iteration , we run least-squares for each user on the arm-reward history we have observed thus far to obtain estimates for each user . Observe by Equation 4 that the transformer is determined by the left singular vectors . As , may also be computed given . We compute the singular value decomposition
| (6) |
we then use , which corresponds to the first columns of the decomposition, as a proxy for .
Note that in the skyline, we showed that lies in the subspace
By substituting for , and subsequently computing and as in Equation 4, we obtain the approximation to given by
Although is an affine space, it is a subset of the linear space . If is close to the space (i.e. if our approximation is close) then in the coordinates of some orthogonal basis for , where is a basis for , is approximately sparse (i.e. components of that lie outside of have small magnitude). We invoke an algorithm known as LowOFUL [10], which works in precisely this setting to select arms for all iterations . We give a full description of our algorithm in Algorithm 1. More concretely, the regret for our approach may be decomposed as
where is the number of times user requests a recommendation. Our approach achieves regret comparable to the skyline agent that has knowledge of the source and target matrices. Each term is bounded in terms of the magnitude of the “almost sparse” components . With methods from perturbation theory, we show:
Lemma 3.2.
With probability , we have that for all ,
where ; ; ; is some absolute constant; and we assume that .
We now apply the original LowOFUL [10, Corollary 1] regret bound to show:
Theorem 3.3.
With an oblivious exploration policy that draws identical arms for each user from , assuming that each user appears equally many times, with probability at least , we have
Observe that the first sum term in this bound essentially matches the skyline bound (Theorem 3.1), and has regret scaled by . We pick up an additional penalty term given by the second summand that comes from the approximation error in . Looking more closely at the term , our bound predicts that we obtain more regret when the number of users in the beta group increases as we have to learn more idiosyncratic components, justifying the user growth assumption, and less regret as the time we have to learn the idiosyncratic components increases, Finally, when for some constant and while holding fixed, the second term is times the first term.
4 No Sources, Many Targets, Many Users
The previous section showed that we can obtain learning guarantees from a source. In this section, we address that case where we have no sources but many targets – the reward at time is given by , where and index the task and user respectively. As before, we compare to a LinUCB baseline (Theorem 2.1) that uses one bandit for each of the contexts. In the previous section, we found that source tasks with low rank (or equivalently high common information ) were effective in producing recommendations for the target task. We similarly assume in this setting that there exist user-specific vectors of dimension along with matrices such that for all and .
In our running example, the matrices represent many different food delivery apps, perhaps focused on different food sources. Our low-rank assumption posits that there is substantial redundancy between the different tasks (in the example: user-specific food preferences are consistent across apps). One benefit is that after many users has been solved for, solving new tasks is very easy because we have data on a large set of users.
Skyline Regret Bound
In the skyline, we assume full access to the task matrices – we show that in this case, we obtain a reduction to separate dimension- bandit problems, one for each user.
Lemma 4.1 (Skyline Bound).
With access to all task matrices, we obtain a regret of
An Algorithm based on User and Task Growth
Our algorithm in the previous section required the existence of a beta group of users to learn the relationship between the source and target. In this multitask setting, we additionally require a a beta group of tasks. We first apply an exploration strategy as in Section 3 to make estimates for a small number of users and tasks . We subsequently compute a singular value decomposition, as in Equation 6, to produce estimates for . Next, we let all users request recommendations on the tasks, and use the to make estimates for the low rank latent parameters for all . We accomplish this by running least-squares on the arm-reward history, noting that for any arm ,
In the last phase, we let all users request recommendations on all tasks, and again use these approximations, in conjunction with the reward history, to learn all for all by least squares
Observe that the sample complexity of learning the is greatly reduced as we make use of all estimates to estimate each . That is, no matter which user appears for a given task context , we are able to collect some sample that helps in approximating , as we have access to a quality estimate of the low rank latent parameter for the user . Although we do not give a theoretical analysis of this algorithm (for barriers described in Appendix D) we show in synthetic experiments that our approach offers a clear advantage over the baseline approach of solving each of the contexts separately. We give a full description of the algorithm in Algorithm 2.
5 Simulation Experiments
In this section, we present several simulation experiments to benchmark our approach.222 Ideally, we would also perform an experimental evaluation on real-world data. To accomplish this, however, we would need to obtain data on user behavior for the same collection of users over multiple services. The closest matches to this requirement are datasets such as Douban [27] that show the action-reward history for a real cross-domain recommendation service. Unfortunately, although the Douban dataset does record user behavior over multiple services, the only actions that we know rewards for are those that were executed by the service. That is, each user only gave feedback for items recommended to them by the service, which in practice is a very small fraction of the total action space. Thus, this dataset cannot be used to assess our algorithms, since the recommendations our algorithms would make would not coincide with those that received feedback in Douban. We tested Rec2’s regret, using a LinUCB implementation following that of [28].333 Each run of our algorithms takes at most five seconds on a 8-core 2.3GHz Intel Core i9 processor. We provide the full experimental setup in Appendix C, only highlighting the most important details here.
Experiment with One Source, One Target, Many Users
In this experiment, we choose , , , , , and , and . We generate and by letting be random -dimensional vectors, where , and , are random and -dimensional matrices. As we can see, the results of our Rec2 approaches greatly improve upon the baselines. Notably, while we only have bounds on the excess regret after exploration for the oblivious exploration policy, it appears that similar bounds hold for both the oblivious exploration policy and the LinUCB exploration policy.
Experiment with No Sources, Many Targets and Many Users
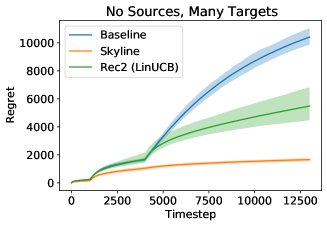
In this experiment, we choose , , , , , and , . We choose random vectors , and each task matrix is a matrix. Actions are random vectors of length . We run Algorithm 2 for timesteps in the first phase, timesteps in the second phase, and timesteps in the third phase and see that the results of Rec2 strongly outperform the baseline in the third phase.

6 Conclusion
We introduced a contextual multi-armed bandit recommendation framework under which existing recommendations serve as input for new recommendation tasks. We show how to decompose the target problem into systematic and idiosyncratic components. The systematic component can be extrapolated from the source recommendations; the idiosyncratic component must be learned directly but has significantly lower dimensionality than the original task. The decomposition itself can be learned and utilized by an algorithm that that executes a variant of LinUCB in a low-dimensional subspace, achieving regret comparable to a strong skyline bound. Our approach extends to a setting with simultaneous targets but no source, and the methods perform well in simulation.
We believe that recommending with recommendations should make it possible to reduce recommendation systems’ reliance on sensitive user data. Indeed, there are already large corpora of recommendations (in the form of advertisements) produced by search engines and social media platforms that have access to tremendous amounts of user information; these span a wide range of domains and thus could be used as source input in many different target tasks.444Ironically, in this sense, advertisements effectively act as a privacy filter – they can actually serve as a fairly complete profile of a person, while abstracting from much of the underlying sensitive data. Moreover, individual platforms such as grocery delivery services are developing expertise in recommending products within specific domains; these could naturally be extrapolated to target tasks with some degree of overlap, such as the restaurant recommendation service in our running example.
Operationalizing the approach we provide here just requires a way for users to share the recommendations from one service with another. There are already public data sets for this in advertising domains, but in the future it could be accomplished more robustly either through a third-party tool that users can use to scrape and locally store their recommendations, or through direct API integrations with existing recommendation engines. But in any event, once a given user’s existing recommendations are available, they can be loaded into a new service (with the user’s consent) and then can instantaneously learn the systematic component and provide valuable recommendations using the approach we described here.
In addition to the overall privacy benefits of basing recommendations on existing recommendation sources rather than the underlying user data, our method lowers barriers to entry by creating a way for new services to bootstrap off of other platforms’ recommendations. Moreover, this approach to some extent empowers users by giving them a way to derive additional value from the recommendations that platforms have already generated from their data.
References
- [1] NYU. Ad Observatory by NYU Tandon School of Engineering, 2018.
- [2] The Markup. Citizen Browser - The Markup, 2021.
- [3] Wei Chu, Lihong Li, Lev Reyzin, and Robert Schapire. Contextual bandits with linear payoff functions. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, pages 208–214. JMLR Workshop and Conference Proceedings, 2011.
- [4] Lihong Li, Wei Chu, John Langford, and Robert E Schapire. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th international conference on World wide web, pages 661–670, 2010.
- [5] Jesús Bobadilla, Fernando Ortega, Antonio Hernando, and Abraham Gutiérrez. Recommender systems survey. Knowledge-based systems, 46:109–132, 2013.
- [6] Emmanuel J Candès and Benjamin Recht. Exact matrix completion via convex optimization. Foundations of Computational mathematics, 9(6):717–772, 2009.
- [7] Yehuda Koren, Robert Bell, and Chris Volinsky. Matrix factorization techniques for recommender systems. Computer, 42(8):30–37, 2009.
- [8] Naoki Abe, Alan W Biermann, and Philip M Long. Reinforcement learning with immediate rewards and linear hypotheses. Algorithmica, 37(4):263–293, 2003.
- [9] Tor Lattimore and Csaba Szepesvári. Bandit algorithms. Cambridge University Press, 2020.
- [10] Kwang-Sung Jun, Rebecca Willett, Stephen Wright, and Robert Nowak. Bilinear bandits with low-rank structure. In International Conference on Machine Learning, pages 3163–3172. PMLR, 2019.
- [11] Feng Zhu, Yan Wang, Chaochao Chen, Jun Zhou, Longfei Li, and Guanfeng Liu. Cross-domain recommendation: Challenges, progress, and prospects. arXiv preprint arXiv:2103.01696, 2021.
- [12] Liang Hu, Jian Cao, Guandong Xu, Longbing Cao, Zhiping Gu, and Can Zhu. Personalized recommendation via cross-domain triadic factorization. In Proceedings of the 22nd international conference on World Wide Web, pages 595–606, 2013.
- [13] Pinata Winoto and Tiffany Tang. If you like the devil wears prada the book, will you also enjoy the devil wears prada the movie? a study of cross-domain recommendations. New Generation Computing, 26(3):209–225, 2008.
- [14] Jürgen Schmidhuber. Evolutionary principles in self-referential learning, or on learning how to learn: the meta-meta-… hook. PhD thesis, Technische Universität München, 1987.
- [15] Y Bengio, S Bengio, and J Cloutier. Learning a synaptic learning rule. In IJCNN-91-Seattle International Joint Conference on Neural Networks, volume 2, pages 969–vol. IEEE, 1991.
- [16] Leonardo Cella, Alessandro Lazaric, and Massimiliano Pontil. Meta-learning with stochastic linear bandits. In International Conference on Machine Learning, pages 1360–1370. PMLR, 2020.
- [17] Mohammad Gheshlaghi Azar, Alessandro Lazaric, and Emma Brunskill. Sequential transfer in multi-armed bandit with finite set of models. In NIPS, 2013.
- [18] Daniele Calandriello, Alessandro Lazaric, and Marcello Restelli. Sparse multi-task reinforcement learning. In NIPS-Advances in Neural Information Processing Systems 26, 2014.
- [19] Junzhe Zhang and Elias Bareinboim. Transfer learning in multi-armed bandit: a causal approach. In Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems, pages 1778–1780, 2017.
- [20] Aniket Anand Deshmukh, Ürün Dogan, and Clayton Scott. Multi-task learning for contextual bandits. In NIPS, 2017.
- [21] Bo Liu, Ying Wei, Yu Zhang, Zhixian Yan, and Qiang Yang. Transferable contextual bandit for cross-domain recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- [22] Heishiro Kanagawa, Hayato Kobayashi, Nobuyuki Shimizu, Yukihiro Tagami, and Taiji Suzuki. Cross-domain recommendation via deep domain adaptation. In European Conference on Information Retrieval, pages 20–29. Springer, 2019.
- [23] Nicolò Cesa-Bianchi, Claudio Gentile, and Giovanni Zappella. A gang of bandits. Advances in Neural Information Processing Systems, 26, 2013.
- [24] Kaige Yang, Laura Toni, and Xiaowen Dong. Laplacian-regularized graph bandits: Algorithms and theoretical analysis. In International Conference on Artificial Intelligence and Statistics, pages 3133–3143. PMLR, 2020.
- [25] Marta Soare, Ouais Alsharif, Alessandro Lazaric, and Joelle Pineau. Multi-task linear bandits. In NIPS2014 Workshop on Transfer and Multi-task Learning: Theory meets Practice, 2014.
- [26] Claudio Gentile, Shuai Li, and Giovanni Zappella. Online clustering of bandits. In International Conference on Machine Learning, pages 757–765. PMLR, 2014.
- [27] Feng Zhu, Yan Wang, Chaochao Chen, Guanfeng Liu, Mehmet Orgun, and Jia Wu. A deep framework for cross-domain and cross-system recommendations. arXiv preprint arXiv:2009.06215, 2020.
- [28] Huazheng Wang, Qingyun Wu, and Hongning Wang. Factorization bandits for interactive recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 31, 2017.
- [29] T Tony Cai, Anru Zhang, et al. Rate-optimal perturbation bounds for singular subspaces with applications to high-dimensional statistics. The Annals of Statistics, 46(1):60–89, 2018.
- [30] Roman Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018.
Supplementary Material
Appendix A Proofs Omitted from the Main Text
A.1 Proof of Theorem 2.1
Theorem (LinUCB Bound).
A LinUCB agent that naively solves each of the tasks separately has regret bounded by
We first restate the LinUCB regret bound.
Lemma A.1 ( [9, Corollary 19.3]).
Suppose that a LinUCB agent aims to solve a stochastic linear bandit problem with reward parameter . If the agent’s decision sets for satisfy
then the regret at time is bounded by
In our setup, there are contexts, corresponding to each user-task pair. We define to be the regret of a LinUCB agent that runs for iterations for the reward parameter . We further define
to be the number of times that the agent encountered the user-task pair . Observe that by our assumptions on the decision set in Section 2.1, the assumptions of Lemma A.1 have been met. As the LinUCB algorithm is anytime (i.e. it does not require advance knowledge of the horizon), we can decompose the regret as
where the second inequality follows by Jensen’s inequality: the quantity is maximized when all contexts are observed an equal number of times.
A.2 Proof of Theorem 3.1
Theorem (Skyline Regret).
An agent with full knowledge of the source and target matrices and may attain regret
To reduce regret given the decomposition (5), we consider a modification of the standard LinUCB algorithm. Observe that we may rewrite the reward (as given in (1)) for a given action as
| (7) |
The generator transforms the action to a lower-dimensional space . To attain low regret in this “affine” variant of the standard stochastic linear bandit problem, we compute confidence sets for in the style of LinUCB using the transformed actions and translated rewards . We then select the action
| (8) |
where (with high probability) denotes the upper confidence bound for the action at time . We show that this agent achieves lower regret.
We first prove the regret bound in the case in which we only have one user with reward parameter . Observe that as has orthogonal rows, for any action ,
We then make use of the following lemma.
Lemma A.2 ([9, Theorems 19.2 and 20.5]).
Let denote the instantaneous regret in round . If . where , then,
with failure probability .
We first show that is indeed bounded above by . To see this, we first note that by our choice of ,
where the third line follows from our definition (8). We may then compute
Applying Lemma A.2, we obtain a single-user regret bound
The desired regret bound then follows by applying Jensen’s inequality, as in the proof of Theorem 2.1.
A.3 Proof of Lemma 3.2
Lemma.
With probability , we have that for all ,
where ; ; ; is some absolute constant; and we assume that .
This proof has two parts: first showing that there exists a point in which is close to , and then showing that this implies the result.
A crucial step in the proof is considering the sin-theta matrix between two orthogonal columns and . Suppose that the singular values of are . Then we call .
Lemma A.3.
With probability , there exists for all so that
Proof.
Note that we have
for a certain orthogonal matrix (by the first equation under the third statement of [29, Lemma 1]). Then note that if , we have
which we set to be .
Now observe that
The next result shows that is close to , which we show later is enough to show that is close to .
Lemma A.4.
With probability , we have
Proof.
Since the matrix formed by stacking the arms together is fixed across users, we have that
where is a matrix of i.i.d. -subgaussian random variables. We seek to bound the value of .
Claim.
With probability , we have
where is an absolute constant.
Proof.
Let be an -net of the -ball of size with radius , which exists by [30, Corollary 4.2.13]. Then note that by [30, Lemma 4.4.1]. Letting , note that
with probability at most – where is an absolute constant – from properties of subgaussian random variables. Thus, by a union bound, with probability at least we have
Claim.
With probability , we have
Proof.
We can see that
By [30, Theorem 4.6.1], since is times a matrix whose entries are uniform Gaussian, we have
with probability . ∎
By the second claim, we have that
with probability at least . By the first claim, we have that with probability at least ,
Thus, by the union bound, both inequalities are true with probability at least , in which case we have we have
as desired.
∎
Suppose now that . We show that the inequality
follows, which suffices for the main claim.
By the remark under subsection 2.3 in [29], we have that
Note that by Weyl’s inequality on singular values, so
so we have
Then note that
Recall that by the first equation under the third statement of [29, Lemma 1] there exists an orthogonal square matrix so that
Thus,
where the second line follows from Weyl’s Inequality.
Finally, we have
and we may now conclude. ∎
From the lemma, we have shown that with probability , there exists for all so that
It remains to show that for all . Note that is an element of . Thus it suffices to show that is the distance between and the closest element in , which is given by . Thus the distance is given by
and we may conclude.
A.4 Proof of Theorem 3.3
Theorem.
With an oblivious exploration policy that draws identical arms for each user from , assuming that each user appears equally many times, with probability at least , we have
Here, we first give the LowOFUL algorithm in Algorithm 3. We note here that we use a generalization of the LowOFUL algorithm where the action sets are allowed to vary with time obliviously; we note that the argument in the proof does not change.
Note that we can break up the total regret into two terms, which are
and
We give our bound in terms of , and then substitute our bound from Lemma 3.2 to conclude. Note that each user gets timesteps in the second phase, which is less than .
From [10, Appendix D(c)] (and using their notation) we have that (for )
Now, we can bound , and
Finally, by the main result of [10] we obtain that the regret, with probability at least , for a particular user, is
By a union bound, with probability at least , we have that is small and that all of these regrets are small, which results in an overall regret given by the above expression. Multiplying by and dividing by now yields the desired result.
A.5 Proof of Lemma 4.1
Lemma.
With access to all task matrices, we obtain a regret of
Once given access to the task matrices , the problem reduces to a contextual bandit problem with just contexts, instead of contexts. Using the task matrices, we first compute the
By the definition of , we may write for all , where . Noting that
we consider a LinUCB agent that runs one bandit per user, transforming the action space by , where denotes the task context at time . From here, we obtain regret in a manner similar to the argument presented in the proof of Theorem 2.1 where the number of contexts is replaced with , and the dimensionality is replaced with . This yields the desired bound
Appendix B Pseudocode for Algorithms
B.1 Algorithm for One Source, One Target, Many Users
B.2 Algorithm for No Source, Many Targets, Many Users
B.3 The LowOFUL Algorithm
For completeness, we overview the LowOFUL Algorithm [10] here.
Appendix C Full Experimental Details
Actions are isotropic Gaussian random vectors of length and respectively.
Lemma C.1.
The run-time of the first algorithm is in total
and the run-time of the second algorithm is
Experiments with One Source, One Target, Many Users
In this experiment, we choose , , , , , with a choice between actions. We also have and . We generate and by letting be unit isotropic dimension- Gaussians, where , and letting , , be times arbitrary and -dimensional elementwise Gaussian matrices. In addition, we let be comprised of dimension- isotropic Gaussian vectors, and use Gaussian noise for .
The only remaining issue is the order in which users arrive. First, we have the users come in order for entries, and then the users arrive in random order.
In LowOFUL, we take and , again following [10].
Experiments with No Sources, Many Targets and Many Users
In this experiment, we choose , , , , actions, and , tasks and users in the reduced phase, where the matrices and vectors are all given by isotropic standard Gaussian matrices and vectors. Moreover, the are each standard isotropic Gaussian, and each task matrix is times an arbitrary elementwise uniform matrix. We run Algorithm 2 for actions in the first phase, steps in the second phase, and actions in the third phase.
Appendix D Difficulties in the Analysis of Algorithm 2
The intuition and motivation behind algorithm 2 (the proposed algorithm in section 4) mirrors that of algorithm 1 (our solution to the setup in section 3). However, the analysis becomes intractable due to a dependence structure that arises in this setting that is not present in the setting of section 3. Whereas we had access to the true optimal arms on the source tasks for members of the beta group in section 3, we only have access to confidence sets for the true optimal arms for the other target tasks in this setting. These confidence sets are stochastically determined by the algorithm in a way that depends on the action history. This, in and of itself, is not a problem so long as one can make distance guarantees on the diameter of the confidence set. However, the axes of these confidence sets are not of equal length (i.e. the confidence sets are anisotropic), and the lengths themselves are dependent on the action history. Thus, although the algorithm is well-motivated given the analysis of section 3, and the fundamental ideas remain the same, we believe the analysis of the second case to be intractable. We were, however, able to demonstrate the success of the method experimentally.