Real World Large Scale Recommendation Systems Reproducibility and Smooth Activations
Abstract.
Real world recommendation systems influence a constantly growing set of domains. With deep networks, that now drive such systems, recommendations have been more relevant to the user’s interests and tasks. However, they may not always be reproducible even if produced by the same system for the same user, recommendation sequence, request, or query. This problem received almost no attention in academic publications, but is, in fact, very realistic and critical in real production systems. We consider reproducibility of real large scale deep models, whose predictions determine such recommendations. We demonstrate that the celebrated Rectified Linear Unit (ReLU) activation, used in deep models, can be a major contributor to irreproducibility. We propose the use of smooth activations to improve recommendation reproducibility. We describe a novel family of smooth activations; Smooth ReLU (SmeLU), designed to improve reproducibility with mathematical simplicity, with potentially cheaper implementation. SmeLU is a member of a wider family of smooth activations. While other techniques that improve reproducibility in real systems usually come at accuracy costs, smooth activations not only improve reproducibility, but can even give accuracy gains. We report metrics from real systems in which we were able to productionalize SmeLU with substantial reproducibility gains and better accuracy-reproducibility trade-offs. These include click-through-rate (CTR) prediction systems, content, and application recommendation systems.
1. Introduction
Machine learned recommendation systems are appearing in more and more domains. Examples include systems for search engines, content recommendation, online shopping, online ads, and diagnostic. Deep models, that have grown to dominate and drive such systems, can recommend how to find answers to questions, what movie to watch, what product to buy, which ads are shown, how to fix one’s car, and how to diagnose one’s medical condition. Similar models are the backbone of language translation and understanding, speech recognition, image understanding, video processing, and other applications.
Consider a situation where a user queried for a job recommendations and two attractive results were shown. The user chose one, and deferred the other for later, without saving the details. Later, the user queries again to find the second job recommendation, but the system showes a different recommendation list. The user is unable to find the job they want. This scenario is very realistic and common. An identical query to the same system gives a different set of recommendations, and no matter how hard one tries, they cannot reproduce a result set they had found before. For the user, this can be frustrating. There may be serious consequences in other applications, like medical diagnosis. Irreproducibility in deep models is a critical factor in causing situations like this. Unlike the crisis of lack of replicability (Pineau et al., 2021) in published results due to missing information, much less attention has been given to this problem.
While deep models provide astonishing results on many tasks, they appear to unveil model irreproducibility. The problem manifests as multiple models with the same configuration and training data generate predictions with deviations far beyond classical statistical deviations. The scenario we described is one example. This problem has become very obvious in practical large scale systems. Despite its importance, it received very little attention in academic publications. Only recently, a series of empirical works (Chen et al., 2020; D’Amour et al., 2020; Dusenberry et al., 2020; Shamir and Coviello, 2020a, b; Snapp and Shamir, 2021; Summers and Dinneen, 2021; Yu et al., 2021) demonstrated it. An initial theoretical framework for reproducibility in optimization only appears in very recent work (Ahn et al., 2022) and demonstrates the problem for the much simpler case of convex optimization. Generalizing such results to deep learning, with highly non-convex loss landscape, is even more challenging.
In real systems, two models that are supposedly the same, may behave very differently when deployed in production. For some applications this may be acceptable. However, for some recommendation systems, providing different recommendations for the same request is undesirable, specifically in cases where a typical user would expect equal results. Irreproducibilty is exacerbated if the current recommendations and their user engagements become the training data for future recommendations, as in reinforcement learning systems. Divergence of the training data gradually expands model and future recommendation differences. Practical systems often retrain models and redeploy new versions, use continuous (online) training, update models with fresh new data, or replace models by new generations. Different recommendations may be unavoidable if new generations or new data change model predictions, but one would expect fresh versions or a small amount of new data not to cause substantial deviations.
Irreproducibility affects not only the user, but also the engineering development cycle. It can lead to arbitrary model evaluations, and invalid A/B testing results. Model developers usually use aggregate prediction accuracy metrics on either validation or progressive validation (Blum et al., 1999) (in online models) data to judge experimental models. With huge training datasets, training is expensive, timely, and resource intensive. Model developers attempt to fail fast based on training performance, to only deploy promising models for live recommendations. Without taking reproducibility into consideration, a model can be deployed in experimental stage, show favorable metrics, but then, when retrained to be deployed in production, produce unfavorable results. This can be expensive to diagnose and address. An example of large scale recommendation is click-through-rate (CTR) prediction in sponsored advertising (McMahan et al., 2013). The signal produced by the model is used as part of an auction process to determine ads to show. Shown ads choices affect other system metrics. Two models that are irreproducible tend to show significant divergence in these system metrics, and also end up pushing different examples to the training data. Irreproducibility is thus a source of concern to the engineering development cycle. The problem is not unique to CTR systems, and can interfere with development cycles of other recommendation systems in a similar fashion.
Unlike overfitting, duplicate models that produce different recommendations may have identical average loss or accuracy metrics, but they can exhibit potentially very large Prediction Differences (PDs) on individual examples (Chen et al., 2020; Dusenberry et al., 2020; Yu et al., 2021). PDs do not diminish with more training examples (unlike epistemic/model uncertainty). We may observe PDs in orders of magnitude of 20% or more of the predicted positive engagement rates. Specifically, we observed that PDs are very correlated to system irreproducibility. Thus they can be used to measure the level of irreproducibility (Shamir and Coviello, 2020a) in a training model prior to its deployment, saving resources. In large scale, we also observed that it is sufficient to measure PDs between only two models. This is very suitable for cutting costs in such scale.
1.1. Our Contributions
Our main contributions are:
-
•
We expose how critical irreproducibility can be to real world large scale systems, specifically recommendation systems, both to a user as well as to the development engineer. As such, it is important to study and understand this problem theoretically and empirically, as well as develop methods that are able to mitigate it to reasonable levels.
-
•
We demonstrate how smooth activations can be useful to mitigate irreproducibility in large scale production systems.
-
•
We propose using Smooth reLU (SmeLU) as a smooth activation to mitigate irreproducibility. SmeLU has a much simpler mathematical form than other smooth activations. This can lead to cheaper implementations, yet it gives trade-offs on reproducibility-accuracy comparable to or even favorable over much more mathematically complex smooth activations.
-
•
We report results from a range of production recommendation systems (including content and application recommendation, and CTR prediction) in which we were able to deploy SmeLU in production with both reproducibility and accuracy gains. This led to substantial simplifications, as well as training speed improvements of these systems, cutting down resource usage, and development times.
-
•
We report results in which we were able to productionalize smooth activations from the wider family of generalized SmeLU (gSmeLU) activations (that includes SmeLU) with accuracy gains over other activations, specifically in a distillation (Hinton et al., 2015) pipeline.
1.2. Related Work and Productionalization
Reproducibility: Many factors contribute to irreproducibility in deep models (D’Amour et al., 2020; Fort et al., 2020; Frankle et al., 2020; Shallue et al., 2018; Snapp and Shamir, 2021; Summers and Dinneen, 2021; Zhuang et al., 2021). The highly non-convex objective (Fort et al., 2020), combined with nondterminism in training (Summers and Dinneen, 2021) and underspecificaiton (D’Amour et al., 2020) of over-parameterized deep networks, can lead training models to optima at different locations in a manifold or sets of optima. Nondeterminism can emerge from the highly parallelized, highly distributed training pipelines, quantization errors, hardware types (Zhuang et al., 2021) and more. Slight deviations early in training due to these can lead to very different models (Achille et al., 2017)). A fixed initialization does not mitigate the problem. Neither do standard methods like regularization, learning rates, or other hyper-parameter tuning, dropout, and data augmentation. Among the techniques, some may reduce PDs. However, that comes at the expense of degraded validation accuracy. Degraded accuracy makes these methods undesirable in production systems. Warm starting models to solutions of previously trained models may not be a good idea, because without any guidance, a solution that leads to unfavorable metrics may be the one we anchor to. Moreover, in a production development cycle, new models, architectures, and algorithms are being developed. A new model may not always be aligned with a previous generation, and it may not be possible to warm start its now different parameters to those of a previous model. With huge datasets in practical systems, enforcing determinism (Nagarajan et al., 2018) in training is also not an option.
A natural approach to improve reproducibility is using ensembles (Dietterich, 2000), and specifically self ensembles (Allen-Zhu and Li, 2020), where multiple duplicates of the model are trained, and the final prediction is the average prediction of the duplicate components. Ensembles have also been proposed and studied in the context of model prediction uncertainty (see e.g., (Lakshminarayanan et al., 2017) and references therein). Each component converges to a different optimum, and the average reduces the prediction variance. Ensembles also reduce PD levels, and with different initialization of the parameters of each component, PD of the overall ensemble reduces even more. However, in real world scale practical recommendation systems this can come at the expense of other costs. Unlike images, recommendation systems implement sparse machine learning problems, as we discuss in Section 2. A huge set of input features are learned, but every training example consists only of an insignificant fraction of the feature set. Those features are mapped to embedding vectors that are concatenated as the input to the deep network. Embeddings constitute the dominating fraction of model parameters. Moreover, many models we consider train online with single visit per example, as opposed to batch learning with multiple visits of each example. In this production regime, ensembles are, in fact, inferior in their prediction accuracy to single networks with the same number of parameters or with the same complexity. For keeping equal complexity, a network component of an ensemble will have narrower embedding vectors and hidden layers than a single network counterpart. Thus in a production system with limited parameter complexity, using ensembles may improve reproducbility, but at the expense of accuracy (which directly effects important downstream metrics). This is unlike image models (Kondratyuk et al., 2020; Lobacheva et al., 2020; Wang et al., 2021) where the model learned parameters are dominated by internal link weights and biases. Ensembles may make production models more complex and harder to maintain. Production models may include various parts with special handling of various special cases. Interactions of such parts with multiple duplicates as well as with their ensemble can build up to a substantial technical debt (see, e.g., (Sculley et al., 2014)). Finally, as we have observed in real cases, having multiple sets of the same sparse input features, as required with ensembles, creates a bottleneck that can slow training substantially.
Compression of deep networks into smaller networks that attempt to describe the same information is the emerging area of distillation (Hinton et al., 2015). Predictions of a strong teacher train a weaker student model. The student is then deployed. This approach is very common if there are ample training resources, but deployment is limited, as for mobile network devices. Co-distillation (Anil et al., 2018) (see also (Zhang et al., 2018)) embraces training ensembles and distillation to address irreproducibility. Instead of unidirectional transfer of knowledge, several models in an ensemble distill information between each other, attempting to agree on a solution. The method requires more training resources to co-train models, but deployment only requires a single model (which can be an ensemble by itself). The deployed model follows the PD levels of the training ensemble, but may exhibit some degradation in accuracy due to forcing the components to agree on a solution they may not prefer.
A somewhat opposite approach; Anti-Distillation was proposed in (Shamir and Coviello, 2020a), again, embracing ensembles, with an additional (decorrelation) loss that forces their components away from one another. Each component is forced to capture a (more) different part of the objective space, and as a whole, the predictions of the ensemble are more reproducible. This may still come at the expense of accuracy. However, we were able to deploy anti-distillation models with reproducibility improvements and without any accuracy loss. In such models, different components, such as linear components of the model, were able to compensate for the accuracy loss caused by the anti-distillation decorrelation loss.
Distillation from the same teacher can reduce PDs. However, like warm starting to the same solution, it may not necessarily be a desired solution, as it may anchor predictions to an unfavorable teacher. Unlike warm starting, distillation does not need to align parameters to those of the teacher. Using ensemble teachers trained to be reproducible (potentially with anti-distillation) (Shamir and Coviello, 2020b) with a more accurate student and/or teacher can improve reproducibility of a deployed model forcing it towards a more reproducible solution, which may not be just that of a disfavored teacher. This method can give a deployed model with the accuracy of a single component model, and reproducibility of the ensemble teacher. An ensemble does not need to be deployed, but must be trained and maintained as a distillation teacher model. Other recent approaches to address the irreproducibility problem attempted to anchor the a solution to some constraint (Bhojanapalli et al., 2021; Shamir, 2018) but also degrade performance by constraining the model’s ability to converge to a better solution.
Activations: The Rectified Linear Unit (ReLU) activation (Nair and Hinton, 2010) has been instrumental to deep networks in recent years. With back-propagation it gives simple updates, accompanied with superior accuracy. Due to its non-smoothness, ReLU imposes an extremely non-convex objective surface. With such surface, the order in which updates are applied is a dominant factor in determining the optimization trajectory, providing a recipe for irreproducibility.
Various recent works started challenging the dominance of ReLU, exploring alternatives. Overviews of various activations were reported in (Nwankpa et al., 2018; Pedamonti, 2018). Variations on ReLU were studied in (Jin et al., 2015). Activations like SoftPlus (Zheng et al., 2015), Exponential Linear Unit (ELU) (Clevert et al., 2015), Scaled Exponential Linear Unit (SELU) (Klambauer et al., 2017; Sakketou and Ampazis, 2019; Wang et al., 2017), or Continuously differentiable Exponential Linear Unit (CELU) (Barron, 2017) were proposed, as well as the Gaussian Error Linear Unit (GELU) (Hendrycks and Gimpel, 2016). The Swish activation (Ramachandran et al., 2017) (approximating GELU) was found through automated search to achieve accuracy superior to ReLU. Additional GELU like activations; Mish (Misra, 2019), and TanhExp (Liu and Di, 2020), were recently proposed. Unlike ReLU, many of these activations are smooth with continuous gradients. Recent work (Bresler and Nagaraj, 2020) smoothed ReLU taking only initial coefficients of its Fourier series. Studies (Mhaskar, 1997) (see also (Du, 2019; Lokhande et al., 2020)) suggested potential advantages to smooth activations, where recent work (Xie et al., 2020), inspired by our results, applied smooth activations to adversarial training.
2. System Overview
We consider a supervised learning problem in recommendation systems. Logs of past recommendation sets constitute the training dataset. A recommendation set can be a stream of past recommendations that a user engaged with, or it can be an outcome set provided for a specific query issued by the user. A recommended item is assigned a label based on the user response or engagement with the item. In the simplest binary case, which we focus on, the label is either positive, i.e., the user engaged with the item, or negative, the user did not engage with the item.
Many such systems are in the sparse regime. There is a huge selection of items the user can engage with, and a huge set of features that can describe the request as well as the items themselves. Features can be properties of the request, the item, the combination of the two, the user, the recommendation user interface, the recommendation rendering, and more. A single recommendation item, represented as a labeled example in the training dataset, will have only an insignificant portion of features present. Using standard notation, the example is the pair , with being a feature value vector and the label. In such sparse problems, most entries in are 0. Some features are binary; either the th feature is present, with the respective component of taking value , or absent, with . Some features are categorical, i.e., from a group of features, only one can be present, although for some categories, multiple ones can be in a given example.
Models for such systems can train on the training dataset with multiple epochs, where in each epoch, all or a subset of the currently available training dataset is (re)visited. A trained model is then deployed to provide recommendations to live user requests. These recommendations are ordered by engagement rates predicted by the model, or joined with other signals, such as bids in CTR, and shown to the user based on combination of the predicted engagement rates and the other signals. The requests, their outcomes, and users’ engagements with the outcomes produce more training examples that can be fed into the training dataset, and used to refresh models. Models can be retrained from scratch on refreshed datasets, or trained continuously when additional data is available.
For some recommendation systems, such as device application installation recommendations, except in special cases, current world trends may have smaller effects on engagement rates. However, in others, such trends can affect which content a user is engaged with, or which ads users tend to click on. Trend as well as other temporal nonstationarities justify online learning, where models train with a single visit to each data point, and examples are ordered in a roughly chronological order. With ample training data, which many such systems have, this reduces overfitting to the training data. (Some of the real systems we consider train online, although, others, for which the time is not as critical, may use data shuffling with different schedules.) For efficiency, production systems have to be mini-batched, parallelized and distributed. Thus even with online systems, training is not per-example online, and model update ordering is only roughly chronological. Training accuracy (and other training metrics) can (still) be evaluated with progressive validation (Blum et al., 1999), where prediction on each example is evaluated relative to the true label before the model trains on the example. We focus the exposition on online learning production systems, but the methods described also apply to batch training systems. Specifically, some results reported in Section 6 did not use an online schedule.
Recommender deep neural networks can be fully connected or of other architectures. Due to the extreme sparsity, models can train mainly on individual item engagement label rates, although other losses can also be introduced for various purposes. Numerical input features act as inputs to the network. Categorical features are mapped into embedding vectors, each vector representing a category. All features/embeddings are concatenated into an input layer of the deep network. The embeddings constitute the majority of the model parameters, but as described, only an insignificant portion of the stored embedding vectors is present in any training example. Embeddings are stored in highly distributed systems, and the correct vector must be fetched for any training example. Hence, fetching embeddings can be costly. This cost scales with ensembles that store multiple copies of embedding vectors for the same feature, all of which must be fetched for a given example. This can substantially slow ensemble training (unless model components are shared).
Taking the embedding layer as inputs, a network of several hidden layers is used to produce an engagement rate output. Since the sparse parameter space is dominated (by far) by embeddings, deep networks can be rather shallow with single digit layer count. Let denote the activation output of layer . The embeddings constitute layer . Starting with layer , a nonlinearity is applied on the output of the previous layer. Then, the layer produces an output where and are link weight matrices and bias vectors, respectively, that are learned by the network. For the output layer, , can have a single row (although if multiple losses or outputs are needed, it can have more rows). For binary labeled models, we use logistic regression with logarithmic cross entropy loss. The output of layer is converted to probability of positive engagement with the logistic (Sigmoid) function . The positive engagement probability predicted by the model is . It is compared against the true label producing loss whose gradients propagate to the network. Some form of Stochastic Gradient Descent (SGD) can be used to train the models, including the embeddings, and the weights and biases. Because of the problem sparsity, per-coordinate learning schedules as those in AdaGrad (Duchi et al., 2011) are used, especially for training the embeddings. Actual production models may be a lot more complex with additional architecture, factorization, constraints and components, as well as use more complex optimizers. However, such complications are beyond the scope of this paper, and do not change the results and conclusions.
Hidden layer activations are clipped within some range to ensure numerical stability. Together with capping, some form of normalization should be applied to limit the range of the signal. Without such normalization, an extremely non-smooth objective surface is attained, which at the very least encourages model irreproducbility. Weight normalization (Salimans and Kingma, 2016), layer normalization (Ba et al., 2016), or batch normalization (Ioffe and Szegedy, 2015) can be applied. For shallow networks with sparse embedding inputs, batch normalization may not be ideal. Layer norm and a slightly different form of weight normalization have shown beneficial to our production systems. With this form of weight norm, an norm of a row of , constituting the matrix weights incoming to some output neuron of the layer, is kept at a fixed value . Specifically, with , let denote the th row of . Then, is replaced by . One advantage of this weight norm is that in deployment, normalization can be computed once for all weights, whereas with layer norm, normalization must be computed on the activations for every inference.
A very important trait of mature large scale production recommendation systems is that they have been highly optimized. From our experience, even very small accuracy improvements of small fractions of a percent of the training loss can make a huge difference to the application system’s overall performance. For binary-labeled models, in addition to training loss, ranking loss, commonly computed as Area Under the Curve (AUC) loss is also important.
| (1) |
where is the indicator function, and is the total number of positive-negative label pairs in the validation corpus. Such a loss can also be computed per query (or request) (PQAUC). Training and ranking accuracy tend to be well correlated with many of the practical system’s objectives. Therefore, resources can be saved by eliminating models with bad accuracy metrics without need for live deployment.







Deployed production models may be constrained in complexity, amount of training data, and other system considerations. As such, they may not be able to produce metrics that can be produced without these limitations. Unconstrained teacher models can be trained and used with distillation (Hinton et al., 2015) to transfer such gains to the student to be deployed. Distillation can be advantageous for reproducibility beyond the methods described in Section 1. Some techniques trade off reproducibility to accuracy. We can train more accurate models, with degraded reproducibility, and use distillation to distill the accuracy of these models to more reproducible student models. This approach has been used with gSmeLU to improve production model performance, as we report in Section 6.
3. Prediction Difference
Engagement rate Prediction Difference (PD) for individual examples is correlated with system level reproducibility performance metrics. For content recommendations, such differences can lead to different or swapped recommendation sets. When predictions are used for auctions, PDs affect the auction outcomes. Unlike classification applications that focus on the final label, in recommendation systems, the exact predicted engagement probabilities can make a difference. Theoretically, we can use different statistics averaged over multiple models (Chen et al., 2020; Shamir and Coviello, 2020a; Yu et al., 2021) such as standard deviations or KL divergences. In (Shamir and Coviello, 2020a), various norms relative to an average prediction of a set of models were considered. However, training multiple models is expensive in large scale production systems. Thus a metric with minimal training costs is desirable. PDs between two models in our large scale systems tend to settle to roughly the same values for different pairs of the same model. Thus it is (usually) sufficient to train one pair of models and measure PD between them. We also want a metric that is not sensitive to actual predicted engagement rates. We define the relative PD for example as the absolute difference between predictions and of models and normalized by their average prediction. Then, the model relative PD, averaged on all examples, is given by
| (2) |
4. Smooth Activations
Several forms of smooth activations have been recently proposed, all attempting to preserve ReLU’s shape with a smooth form. Many can be parameterized with a single parameter, denoted as . Let be the standard error function and the standard normal CDF. Functional forms of some smooth activations are:
| (3) | |||||
| (4) | |||||
| (5) |
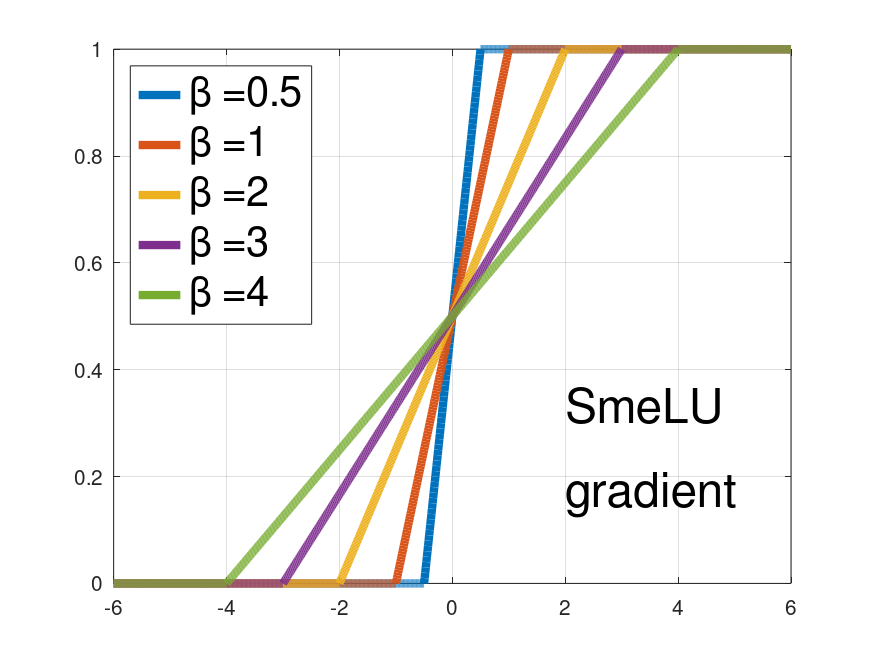
Activations such as Mish and TanhExp are similar to GELU and Swish, and did not add benefit to accuracy-reproducibilty trade-offs in our systems. Others, such as SELU did not perform as well. GELU can be approximated by Swish with . Fig. 1 shows the different activations and their gradients for different values of . The parameter controls the width of a transition region from approaching on the left towards a slope on the right. For activations in (3)-(5), a smaller gives a wider region, and a larger , a narrower one. When , the activation resembles ReLU, and when , it is close to linear. Activations like GELU and Swish are not monotonic, and have a region in which they change the direction of the gradients. Also, they do not have a stop region, i.e, strictly , and a clear slope region. Activations, such as GELU must be either numerically computed or approximated by other functions. Such activations require more complex hardware implementation, especially with cheaper, simplified hardware that supports only a limited number of operations. These properties can make deployment error-prone, expensive, or slow.












ReLU’s noncontinuous gradient partitions the parameter space into regions with multiple local minima. Some equal, but may provide different model predictions. Training randomness leads the model into a region, and converges to its local minimum. Sudden jumps in gradient, like in ReLU, may lock some hidden units at some states, requiring others to compensate by moving towards their nearest optima. If this happens early in training, it determines the trajectory of the optimization. Different examples and update orders thus lead to different trajectories. Smoother activations give a model fewer opportunities to diverge. Wider transition regions allow gradients to change more slowly, and units in the network to gradually adjust. Wider transition regions are closer to more reproducible linear functions. However, a good activation must also retain good accuracy. Softplus, for example, may not achieve accuracy as good as other activations. Roughly, reproducibility improves by widening activations’ transition regions, but accuracy moves in the opposite direction. However, as observed on our datasets, there exist tuning points where smooth activations outperform ReLU on both accuracy and reproducibility. This is demonstrated in Section 6. Smooth activations thus provide a tuning knob (the parameter ) to trade off between accuracy and reproducibility. Trade-offs as we described are usually dataset, model architecture, and model configuration dependent.
5. Smooth reLU - SmeLU
As mentioned above, there are several disadvantages to activations in (3)-(5) and others alike. In this section, we introduce a new, simple smooth activation SmeLU, that gives competitive accuracy-reproducibility trade-offs. We then generalize the methodology to describe a larger family of activations.

5.1. SmeLU
Using linear and quadratic pieces (Huber, 1992) but asymmetrically (unlike (Huber, 1992)), we design SmeLU to keep ReLU’s functional form, including monotonicity, complete stop on the left, and gradient of 1 on the right. Multiple pieces are joined with smoothness, continuous gradient, constraints. We match both sides of ReLU with a middle quadratic region. Let to be the half-width of a symmetric transition region around . Reciprocally to (3)-(5), a smaller gives a narrower transition region, and a larger a wider one. With constraints: a) to the left of the transition; b) to the right of the transition; c) continuous gradient at the transition boundaries:
| (6) |
we arrive at the SmeLU activation function:
| (7) |
The 3rd column in Fig. 1 shows SmeLU and its gradient as function of . SmeLU is a convolution of ReLU with a box of magnitude in . Its gradient is a hard Sigmoid. As we report in Section 6, despite its simplicity, SmeLU’s accuracy-reproducibility trade-offs in real systems are competitive with the more complex smooth activations. A greater tends to produce better PD and a smaller better accuracy. Using larger values in layers closer to input features and smaller ones closer to the output may allow lowering PDs, because of better smoothness closer to most model parameters (the embeddings) with compensation for accuracy closer to the output. While this approach interacted well with weight normalization, it did not with layer normalization.
Figs. 2 and 3 demonstrate loss landscapes vs. inputs with deep networks whose weights and biases were fixed to random values and a single input is fed into the network (Fig. 2) or two inputs are fed into the network (Fig. 3). Different loss functions and different normalization strategies are shown. Activations are clipped within a predefined range. Curves and surfaces are shown for ReLU, and SmeLU with different values. The ReLU networks exhibit multiple local (and global) optima, and very non-smooth overall curves or surfaces. Even with very small , smoothing of the curves or surfaces from SmeLU is clear, as well as reduction of the quantities of optima. The objectives appear smoother as we increase . The second row in Fig. 3 illustrates the changing of the manifold surrounding a local maximum, which gradually disappears with increasing giving a single global minimum when . Smoothing reduces the opportunities of the optimization to end up in a different minimum. However, too much smoothing also reduces the ability of the model to distinguish between parameters. For example, while the loss for at the top of Fig. 2 is clearly different for different inputs for ReLU and SmeLU with , with larger this distinction disappears. Thus models with large may not be able to distinguish inputs that produce high and low engagement rates. While it can be more reproducible, its reproducible predictions will have unacceptable accuracy. Using smaller , such as , on the other hand, may have, in addition to better reproducibility, better accuracy than ReLU because the model is less likely to fall into false local minima.
The surfaces of Fig. 3 also demonstrate that the reproducibility improvements of smooth activations do not carry over if initializations are very different between models, or if training example shuffling is too aggressive. While we see reduction in the quantity of different minima, the surface is still highly non-convex when model accuracy is kept on-par. If the model starts in different locations, it may not be able to converge to the same minimum. Aggressive shuffling can affect the trajectory leading to a different region with a different minimum as well. Thus, smooth activations improve PDs under some locality constraints on the objective surface, as demonstrated in (Snapp and Shamir, 2021). Normalization helps to keep activations within the clipping range. Otherwise, clipping can destroy the smoothness imposed by the activations.
5.2. Generalized SmeLU
The constraints in (6) can be generalized by allowing for asymmetry, shifts, and different gradients to the left and to the right of the quadratic transition region. Using
| (8) |
generalized SmeLU (gSmeLU) is defined by . To cross the origin, , and . For a leaky and monotonic activation, . Enforcing (8) and continuity at and leads to
| (9) |
with
| (10) |
Examples of gSmeLU (with ) are shown on the right column of Fig. 1. SmeLU is obtained with , , and . Hyper-parameters of generalized SmeLU can be learned in training of a deep network together with the model parameters, per network, layer, or unit. In real systems that optimize for accuracy, layers closer to inputs often learn negative , suggesting some level of sparsity regularization. Closer to the output, closer to is learned. The method of constructing gSmeLU can be extended to use any functions and multiple segments. We refer to such an activation as REctified Smooth Continuous Unit (RESCU). (Multiple-piece non-smooth ReLU extensions were considered in (Chen and Ho, 2018; Montufar et al., 2014)).
6. Large-Scale Production Systems
SmeLU was deployed in multiple recommendation production systems for multiple products, with a wide range of architectures and objectives, where irreproducibility was a critical concern. For sponsored advertising CTR prediction, using SmeLU allowed replacing costly ensembles by a single network in several products. In one system, PDs of were observed with single-network ReLU models. A three component ensemble lowered PD to . SmeLU with a single component network lowered production PDs to ( reduction) with no accuracy degradation relative to the ensemble, reducing ensemble complexity and technical debt. Tuning to narrower , keeping PD equal to that of the ensemble, gave PQAUC loss improvements, giving substantial system metrics improvements. In another system, SmeLU gave over PQAUC loss improvements in production, keeping PDs equal to those of an ensemble, but also providing training speed improvements due to elimination of multiple embedding lookups. In a different system, PDs were reduced from to . In a content recommendation system, SmeLU provided decrease of recommendation swapping rate, with other additional positive metrics. In an application installation recommendation system, SmeLU gave up to decrease of PDs.
For a clean comparison of accuracy-reproducibility trade-offs of smooth activations and SmeLU, we also tested them on a “toy” simple model on real CTR prediction data for sponsored advertisement. We constructed a simple layer fully connected network with dimensions with informative features that were learned as embedding vectors, providing a total of inputs. Models were identically initialized, trained with data-shuffling on billions of examples with the system described in Section 2. Fig. 4 reports relative PD against PQAUC ranking loss relative movements. Losses are expressed as percentage change from a baseline ReLU model. Moving left implies better accuracy, and down implies better reproducibility. For smooth activations, the different points are the result of different . Moving from the left down to the right described increasing for SmeLU (and decreasing for other activations). ReLU has PD. All smooth activations have points to the left and below ReLU, showing they can be tuned to have both better accuracy and PD. Differences among smooth activations are subtle. Swish can reach better accuracy, but with worse PD, and Softplus can have better PD, but with bad accuracy. SmeLU allows lower PDs ( on this example) with improved accuracy over ReLU.

Generalized SmeLU gives an additional degrees of freedom over SmeLU. Training the activation together with the model (per layer or unit) led to prediction accuracy improvements. However, when trained for accuracy, gSmeLU does not give good PDs. Accuracy improvements can still be leveraged on a teacher model in a distillation set up. In one system, gSmeLU gave about PQAUC loss reduction to the teacher model, which was leveraged to speed up convergence of the student, reducing training time by .
7. Conclusions
We unveiled the importance of irreproducibility in real world large scale recommendation systems. We demonstrated how ReLU exacerbates this problem, and described using smooth activations as an approach to mitigate it. We presented SmeLU, which is a simple smooth activation that can be used to improve reproducibility, and reported production launches in real recommendation systems that were able to benefit from SmeLU to improve reproducibility, accuracy, and efficiency. We also described a generalization of SmeLU that can improve model accuracy, and reported how it was productionalized, gaining efficiency without harming reproducibility.
Acknowledgement
The authors acknowledge Sergey Ioffe for early discussions, and Lorenzo Coviello for help in experimentation and launches.
References
- (1)
- Achille et al. (2017) Alessandro Achille, Matteo Rovere, and Stefano Soatto. 2017. Critical learning periods in deep neural networks. arXiv preprint arXiv:1711.08856 (2017).
- Ahn et al. (2022) Kwangjun Ahn, Prateek Jain, Ziwei Ji, Satyen Kale, Praneeth Netrapalli, and Gil I. Shamir. 2022. Reproducibility in optimization: Theoretical framework and Limits. arXiv preprint arXiv:2202.04598 (2022).
- Allen-Zhu and Li (2020) Zeyuan Allen-Zhu and Yuanzhi Li. 2020. Towards understanding ensemble, knowledge distillation and self-distillation in deep learning. arXiv preprint arXiv:2012.09816 (2020).
- Anil et al. (2018) Rohan Anil, Gabriel Pereyra, Alexandre Passos, Robert Ormandi, George E Dahl, and Geoffrey E Hinton. 2018. Large scale distributed neural network training through online distillation. arXiv preprint arXiv:1804.03235 (2018).
- Ba et al. (2016) Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. 2016. Layer normalization. arXiv preprint arXiv:1607.06450 (2016).
- Barron (2017) Jonathan T Barron. 2017. Continuously differentiable exponential linear units. arXiv (2017), arXiv–1704.
- Bhojanapalli et al. (2021) Srinadh Bhojanapalli, Kimberly Jenney Wilber, Andreas Veit, Ankit Singh Rawat, Seungyeon Kim, Aditya Krishna Menon, and Sanjiv Kumar. 2021. On the Reproducibility of Neural Network Predictions.
- Blum et al. (1999) Avrim Blum, Adam Kalai, and John Langford. 1999. Beating the hold-out: Bounds for k-fold and progressive cross-validation. In Proceedings of the twelfth annual conference on Computational learning theory. 203–208.
- Bresler and Nagaraj (2020) Guy Bresler and Dheeraj Nagaraj. 2020. A Corrective View of Neural Networks: Representation, Memorization and Learning. In COLT 2020 (Proceedings of Machine Learning Research, Vol. 125), Jacob Abernethy and Shivani Agarwal (Eds.). PMLR, 848–901.
- Chen and Ho (2018) Zhi Chen and Pin-han Ho. 2018. Deep Global-Connected Net With The Generalized Multi-Piecewise ReLU Activation in Deep Learning. arXiv preprint arXiv:1807.03116 (2018).
- Chen et al. (2020) Zhe Chen, Yuyan Wang, Dong Lin, Derek Cheng, Lichan Hong, Ed Chi, and Claire Cui. 2020. Beyond point estimate: Inferring ensemble prediction variation from neuron activation strength in recommender systems. arXiv preprint arXiv:2008.07032 (2020).
- Clevert et al. (2015) Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. 2015. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289 (2015).
- D’Amour et al. (2020) Alexander D’Amour, Katherine Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen, Jonathan Deaton, Jacob Eisenstein, Matthew D. Hoffman, Farhad Hormozdiari, Neil Houlsby, Shaobo Hou, Ghassen Jerfel, Alan Karthikesalingam, Mario Lucic, Yian Ma, Cory McLean, Diana Mincu, Akinori Mitani, Andrea Montanari, Zachary Nado, Vivek Natarajan, Christopher Nielson, Thomas F. Osborne, Rajiv Raman, Kim Ramasamy, Rory Sayres, Jessica Schrouff, Martin Seneviratne, Shannon Sequeira, Harini Suresh, Victor Veitch, Max Vladymyrov, Xuezhi Wang, Kellie Webster, Steve Yadlowsky, Taedong Yun, Xiaohua Zhai, and D. Sculley. 2020. Underspecification Presents Challenges for Credibility in Modern Machine Learning. arXiv:2011.03395 [cs.LG]
- Dietterich (2000) T. G. Dietterich. 2000. Ensemble methods in machine learning. Lecture Notes in Computer Science (2000), 1–15.
- Du (2019) Simon Du. 2019. Gradient Descent for Non-convex Problems in Modern Machine Learning. Ph. D. Dissertation. Carnegie Mellon University.
- Duchi et al. (2011) J. Duchi, E. Hazan, and Y. Singer. 2011. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research 12 (Feb. 2011), 2121–2159.
- Dusenberry et al. (2020) Michael W Dusenberry, Dustin Tran, Edward Choi, Jonas Kemp, Jeremy Nixon, Ghassen Jerfel, Katherine Heller, and Andrew M Dai. 2020. Analyzing the role of model uncertainty for electronic health records. In Proceedings of the ACM Conference on Health, Inference, and Learning. 204–213.
- Fort et al. (2020) Stanislav Fort, Huiyi Hu, and Balaji Lakshminarayanan. 2020. Deep Ensembles: A Loss Landscape Perspective. arXiv:1912.02757 [stat.ML]
- Frankle et al. (2020) Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. 2020. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning. PMLR, 3259–3269.
- Hendrycks and Gimpel (2016) Dan Hendrycks and Kevin Gimpel. 2016. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415 (2016).
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015).
- Huber (1992) Peter J Huber. 1992. Robust estimation of a location parameter. In Breakthroughs in statistics. Springer, 492–518.
- Ioffe and Szegedy (2015) Sergey Ioffe and Christian Szegedy. 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 (2015).
- Jin et al. (2015) Xiaojie Jin, Chunyan Xu, Jiashi Feng, Yunchao Wei, Junjun Xiong, and Shuicheng Yan. 2015. Deep learning with s-shaped rectified linear activation units. arXiv preprint arXiv:1512.07030 (2015).
- Klambauer et al. (2017) Günter Klambauer, Thomas Unterthiner, Andreas Mayr, and Sepp Hochreiter. 2017. Self-normalizing neural networks. In Advances in neural information processing systems. 971–980.
- Kondratyuk et al. (2020) Dan Kondratyuk, Mingxing Tan, Matthew Brown, and Boqing Gong. 2020. When ensembling smaller models is more efficient than single large models. arXiv preprint arXiv:2005.00570 (2020).
- Lakshminarayanan et al. (2017) Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in neural information processing systems. 6402–6413.
- Liu and Di (2020) Xinyu Liu and Xiaoguang Di. 2020. TanhExp: A Smooth Activation Function with High Convergence Speed for Lightweight Neural Networks. arXiv preprint arXiv:2003.09855 (2020).
- Lobacheva et al. (2020) Ekaterina Lobacheva, Nadezhda Chirkova, Maxim Kodryan, and Dmitry Vetrov. 2020. On power laws in deep ensembles. arXiv preprint arXiv:2007.08483 (2020).
- Lokhande et al. (2020) Vishnu Suresh Lokhande, Songwong Tasneeyapant, Abhay Venkatesh, Sathya N Ravi, and Vikas Singh. 2020. Generating Accurate Pseudo-Labels in Semi-Supervised Learning and Avoiding Overconfident Predictions via Hermite Polynomial Activations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11435–11443.
- McMahan et al. (2013) H Brendan McMahan, Gary Holt, David Sculley, Michael Young, Dietmar Ebner, Julian Grady, Lan Nie, Todd Phillips, Eugene Davydov, Daniel Golovin, et al. 2013. Ad click prediction: a view from the trenches. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 1222–1230.
- Mhaskar (1997) HN Mhaskar. 1997. On smooth activation functions. In Mathematics of Neural Networks. Springer, 275–279.
- Misra (2019) Diganta Misra. 2019. Mish: A self regularized non-monotonic neural activation function. arXiv preprint arXiv:1908.08681 (2019).
- Montufar et al. (2014) Guido F Montufar, Razvan Pascanu, Kyunghyun Cho, and Yoshua Bengio. 2014. On the number of linear regions of deep neural networks. In Advances in neural information processing systems. 2924–2932.
- Nagarajan et al. (2018) Prabhat Nagarajan, Garrett Warnell, and Peter Stone. 2018. Deterministic implementations for reproducibility in deep reinforcement learning. arXiv preprint arXiv:1809.05676 (2018).
- Nair and Hinton (2010) Vinod Nair and Geoffrey E Hinton. 2010. Rectified linear units improve restricted boltzmann machines. In ICML.
- Nwankpa et al. (2018) Chigozie Nwankpa, Winifred Ijomah, Anthony Gachagan, and Stephen Marshall. 2018. Activation functions: Comparison of trends in practice and research for deep learning. arXiv preprint arXiv:1811.03378 (2018).
- Pedamonti (2018) Dabal Pedamonti. 2018. Comparison of non-linear activation functions for deep neural networks on MNIST classification task. arXiv preprint arXiv:1804.02763 (2018).
- Pineau et al. (2021) Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vincent Larivière, Alina Beygelzimer, Florence d’Alché Buc, Emily Fox, and Hugo Larochelle. 2021. Improving reproducibility in machine learning research: a report from the NeurIPS 2019 reproducibility program. Journal of Machine Learning Research 22 (2021).
- Ramachandran et al. (2017) Prajit Ramachandran, Barret Zoph, and Quoc V Le. 2017. Searching for activation functions. arXiv preprint arXiv:1710.05941 (2017).
- Sakketou and Ampazis (2019) Flora Sakketou and Nicholas Ampazis. 2019. On the Invariance of the SELU Activation Function on Algorithm and Hyperparameter Selection in Neural Network Recommenders. In IFIP International Conference on Artificial Intelligence Applications and Innovations. Springer, 673–685.
- Salimans and Kingma (2016) Tim Salimans and Durk P Kingma. 2016. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In Advances in neural information processing systems. 901–909.
- Sculley et al. (2014) David Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, and Michael Young. 2014. Machine learning: The high interest credit card of technical debt. (2014).
- Shallue et al. (2018) Christopher J Shallue, Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Frostig, and George E Dahl. 2018. Measuring the effects of data parallelism on neural network training. arXiv preprint arXiv:1811.03600 (2018).
- Shamir (2018) Gil I. Shamir. 2018. Systems and Methods for Improved Generalization, Reproducibility, and Stabilization of Neural Networks via Error Control Code Constraints.
- Shamir and Coviello (2020a) Gil I Shamir and Lorenzo Coviello. 2020a. Anti-Distillation: Improving Reproducibility of Deep Networks. Preprint (2020).
- Shamir and Coviello (2020b) Gil I. Shamir and Lorenzo Coviello. 2020b. Distilling from Ensembles to Improve Reproducibility of Neural Networks.
- Snapp and Shamir (2021) Robert R Snapp and Gil I Shamir. 2021. Synthesizing Irreproducibility in Deep Networks. arXiv preprint arXiv:2102.10696 (2021).
- Summers and Dinneen (2021) Cecilia Summers and Michael J. Dinneen. 2021. On Nondeterminism and Instability in Neural Network Optimization.
- Wang et al. (2017) Tianyang Wang, Zhengrui Qin, and Michelle Zhu. 2017. An ELU network with total variation for image denoising. In International Conference on Neural Information Processing. Springer, 227–237.
- Wang et al. (2021) Xiaofang Wang, Dan Kondratyuk, Eric Christiansen, Kris M. Kitani, Yair Alon, and Elad Eban. 2021. Wisdom of Committees: An Overlooked Approach To Faster and More Accurate Models. arXiv preprint arXiv:2012.01988 (2021).
- Xie et al. (2020) Cihang Xie, Mingxing Tan, Boqing Gong, Alan Yuille, and Quoc V Le. 2020. Smooth adversarial training. arXiv preprint arXiv:2006.14536 (2020).
- Yu et al. (2021) Haichao Yu, Zhe Chen, Dong Lin, Gil Shamir, and Jie Han. 2021. Dropout Prediction Variation Estimation Using Neuron Activation Strength. arXiv preprint arXiv:2110.06435 (2021).
- Zhang et al. (2018) Ying Zhang, Tao Xiang, Timothy M Hospedales, and Huchuan Lu. 2018. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4320–4328.
- Zheng et al. (2015) Hao Zheng, Zhanlei Yang, Wenju Liu, Jizhong Liang, and Yanpeng Li. 2015. Improving deep neural networks using softplus units. In 2015 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–4.
- Zhuang et al. (2021) Donglin Zhuang, Xingyao Zhang, Shuaiwen Leon Song, and Sara Hooker. 2021. Randomness in neural network training: Characterizing the impact of tooling. arXiv preprint arXiv:2106.11872 (2021).