Real-time Human Activity Recognition Using Conditionally Parametrized Convolutions on Mobile and Wearable Devices
Abstract
Recently, deep learning has represented an important research trend in human activity recognition (HAR). In particular, deep convolutional neural networks (CNNs) have achieved state-of-the-art performance on various HAR datasets. For deep learning, improvements in performance have to heavily rely on increasing model size or capacity to scale to larger and larger datasets, which inevitably leads to the increase of operations. A high number of operations in deep leaning increases computational cost and is not suitable for real-time HAR using mobile and wearable sensors. Though shallow learning techniques often are lightweight, they could not achieve good performance. Therefore, deep learning methods that can balance the trade-off between accuracy and computation cost is highly needed, which to our knowledge has seldom been researched. In this paper, we for the first time propose a computation efficient CNN using conditionally parametrized convolution for real-time HAR on mobile and wearable devices. We evaluate the proposed method on four public benchmark HAR datasets consisting of WISDM dataset, PAMAP2 dataset, UNIMIB-SHAR dataset, and OPPORTUNITY dataset, achieving state-of-the-art accuracy without compromising computation cost. Various ablation experiments are performed to show how such a network with large capacity is clearly preferable to baseline while requiring a similar amount of operations. The method can be used as a drop-in replacement for the existing deep HAR architectures and easily deployed onto mobile and wearable devices for real-time HAR applications.
Index Terms:
Human activity recognition, deep learning, convolutional neural networks, conditionally parametrized convolution, wearable devices, mobile phone.I Introduction
Human activity recognition (HAR) has become an important research area in ubiquitous computing and human computer interaction, which has a variety of applications including health care, sports, interactive gaming, and monitoring systems for general purposes. With the rapid technical advancement of mobile phones and other wearable devices, various motion sensors have been placed at different body positions in order to collect data and infer human activity details [1]. Unlike video or wireless signals based method, mobile phone and wearable devices are more popular, which are not location dependent, easy to deploy and have no any health hazard caused by radiation. As we have known, mobile phones have become an important part of human’s daily life and can be carried around almost every day. Therefore, the use of data generated by mobile phones and other wearable sensors has dominated the research landscape in HAR, which provides obvious advantages over other sensor modalities [2]. On the whole, mobile and wearable sensor based methods provide a better alternative to real-time implementation of HAR applications [3].
On the other hand, sensor based HAR mainly lies in the assumption that specific body movement can be translated into characteristic sensor signal pattern, which may be further classified using machine learning technique [4]. Recently, deep learning technique outperformed many conventional machine learning methods, which has represented an important research trend in HAR [5]. In particular, deep convolutional neural networks (CNNs) have achieved state-of-the-art performance on various HAR tasks [6]. For deep learning, improvements in performance have to heavily rely on increasing model size or capacity to scale to larger and larger datasets [7]. However, increasing model size or capacity inevitably leads to the increase of operations or computation cost. Building larger CNN may result in higher performance, but lead to the need for more resources such as computational power that is expensive for mobile and wearable devices. Therefore, deploying optimal deep models for mobile and wearable HAR applications are often impractical, which limits their wide use for real-time HAR applications with strict latency constraints. Therefore, it deserves further research to develop computation efficient CNN to perform real-time HAR using mobile and wearable sensors.
Without loss of generality, there is two ways to design computation efficient CNN for mobile and wearable HAR applications. For the first case, using fewer convolutional layers or decreasing the size of existing convolutions may lead to the decrease of computation cost. Thus, current computationally efficient models often are smaller, which have suboptimal performance with fewer parameters on mobile deployment [8], [9]. For the second case, decreasing the size of the input to convolution also can proportionally decrease computation cost. Actually, HAR using mobile phones and wearable sensors can be seen as a classic multivariate time series classification problem, which makes use of sliding window [10] to segment time series sensor signals and extracts discriminative features from them to be able to recognize activities by utilizing a classifier. Intuitively, using smaller sliding window can yield faster inference. However, in this case it often is hard to obtain most suitable size for feature extraction of HAR, which make CNNs be not able to offer best results. Therefore, as indicated in both cases, current computationally efficient models often are suboptimal for HAR [9]. Recently, there has been rising research interest in conditional computation [11], [12], whose goal is to increase model capacity or performance without a proportional increase in computation cost. In particular, Yang et al. [13] proposed an idea of conditionally parameterized convolution (CondConv), which can easily be optimized by gradient descent. According to our research motivation, replacing conventional convolutions with CondConv could be one feasible step to realize efficient inference for mobile and wearable HAR applications without compromising computation cost.
In this paper, we propose a new CNN using the idea of CondConv for HAR applications with strict latency constraints, which aims to increase model capacity or performance while maintaining efficient inference to better serve these real-time HAR applications on mobile and wearable devices. To the best of our knowledge, building high-performance CNN for HAR without compromising computation cost has seldom been explored, and this paper is the first try to develop computation efficient CNN for real-time HAR on ubiquitous and wearable computing area. To be specific, we replace the standard convolution with CondConv which is a linear combination of experts, where , …, are weight functions of the input learned through gradient descent. The standard convolution requires expensive computation cost as it needs to be computed at many different positions within the input. In comparison with standard convolution, increasing the number of experts in the CondConv can greatly enhance the representing ability of CNN without compromising computation cost, as all the experts are combined only once per input. Thus, we can increase model capacity or performance via increasing the number of experts, which require only an expensive convolution with a very small increase in computation cost. We evaluate our method on four public benchmark HAR datasets, namely WISDM dataset [14], PAMAP2 dataset [15], UNIMIB-SHAR dataset [16], and OPPORTUNITY dataset [17]. We also evaluate the actual inference speed of our model on a smartphone with an Android platform. By various ablation experiments, we show how increasing the number of experts improves model performance across the benchmark HAR datasets while maintaining efficient inference. The experimental results indicate the advantage of the HAR applications using CondConv with regard to typical challenges for real-time HAR in ubiquitous and wearable computing scenarios.
The rest of this paper is organized as follows. Section II presents the related works in activity recognition and conditional computation. Section III details the proposed framework for HAR. In Section IV, we first describe the HAR dataset used and experimental setup, and then present the experimental result comparison and analysis from several aspects. The last section concludes this study with a brief summary and points out future research work.
II Related Works
In recent years, deep learning has become popular in mobile and wearable sensors based HAR, due to their superior performance. In particular, CNN is one of the most researched deep learning techniques which can automatically extract features and identify the hidden or unknown activity patterns from raw time series sensor data. A number of CNN architectures for the use of HAR have been developed by researchers. For example, Zeng et al. [18] firstly proposed a shallow CNN based approach to recognize activities, which has achieved state-of-the-art performance in three public HAR datasets. Yang et al. [6] developed a new architecture of CNN, in which the convolution filters are applied along the temporal dimension for each sensor and all feature maps for different sensors are unified as an input for a classifier. CNNs that combine other fusion techniques were also proposed. Ordóñezet al. [19] proposed an architecture of DeepConvLSTM, which replaced the fully connected layer of CNN with Long Short Term Memory (LSTM) to capture temporal relationship contained in time series sensor data. Wang et al. [20] proposed an attention-based CNN which is able to enhance interesting activity in the weakly supervised learning scenarios. Ignatov et al. [21] proposed a CNN which combines local feature extraction with simple statistical features that preserve global information about the time series sensor data. Teng et al. [22] developed a layer wise training CNN for HAR with local loss, which is able to achieve remarkable performance with less parameters on various HAR application domains. On the whole, deep CNNs have yielded excellent results in terms of recognition accuracy, but often need a lot of computation cost, which is infeasible for mobile and wearable HAR applications that have strict latency constraints.
Due to the growing number of hyper-parameters, designing computation efficient CNN for HAR applications becomes increasingly difficult. In another line of research, recent research effort on visual recognition or natural language processing has been shifting to conditional computation, which aims to increase model capacity or performance without a proportional increase in computation cost. For example, Wu et al. [23] proposed BlockDrop method which uses reinforcement learning to dynamically learn discrete routing functions, in order to best reduce computation cost without decreasing model accuracy. Mullapudi et al. [24] developed HydraNet model which uses unsupervised clustering method to choose proper subset of the entire network architecture to run most efficient inference on a given input. Shazeer et al. [25] proposed a trainable gating network by introducing a sparsely-gated mixture-of-experts layer, which is able to determine a sparse combination of different experts to use for each example. However, these aforementioned approaches in conditional computation often require to learn discrete routing decisions of different experts across every example, which is hard to train using gradient descent and not suitable for CNN based HAR applications. Recently, Yang et al. [13] proposed CondConv to challenge the fundamental assumption that the same convolutional kernels should be shared for each example, which enables different expert convolution kernels to focus on their specialized examples. In particular, the CondConv can easily be trained with gradient descent without requiring access to discrete routing of each example. Despite the success of conditional computation, their primary use mainly lies in imagery or natural language processing tasks, which has never been used to perform HAR. The increasing demands for running efficient deep neural networks for HAR on mobile and wearable devices encourage our current study. In the next section, we will describe the CondConv and then present the entire architecture of deep HAR applications using CondConv.

III Proposed Scheme
In this section, we will discuss our new CNN architecture using CondConv to handle the unique challenges existed in mobile and wearable HAR applications. An overview of the proposed HAR system is presented in Fig.1. For sensor based HAR, we have to firstly deal with multiple channels of time series sensor signals, in which the convolution need to be applied along temporal dimension and then be shared or unified among multiple different sensors. Due to implementational simplicity and no need of preprocessing, the sliding window technique is ideally suitable for real-time HAR applications, which has been widely used to segment time series sensor signal into a collection of smaller data pieces as an input for CNN. Hence an instance handled by CNN typically corresponds to a two-dimensional matrix with r raw samples representing the number of samples per window, in which each sample contains multiple sensor attributes recorded at time t. Though in any case the sensor signal stream must be segmented into data windows, they can be of a continuous nature. Thus, an overlap between adjacent windows is tolerated to preserve the continuity of activities. Intuitively, decreasing the size of sliding window leads to a faster activity inference, as well as a reduced need for computation cost. To make fair comparison, we still select the same window size that is preferably used in previous state-of-the-art works.
Our main research motivation is to realize computation efficient CNN using CondConv for the practical use of HAR on mobile and wearable devices. Without loss of generality, the baseline CNN is typically comprised of four units: (i) a convolution layer with a set of learned kernels that convolve the input along temporal dimension or the previous layer’s output; (ii) a ReLU layer with activation function max(x,0) that maps the previous layer’s output; (iii) a max pooling layer that subsamples via finding the maximum feature map across a range of local temporal neighborhood; (iv) a Batch Normalization(BN) [26] layer used to normalize the values of different feature maps from the previous layer. Following the settings of Yang et al. [13], we replace the standard convolution kernels used in convolutional layers with a linear combinations of experts:
| (1) |
in which is ReLU activation function and is the number of experts. The dimension of each kernel is still the same to that in original convolution. Obviously, if the scalar weight is constant for all examples, a CondConv layer has almost the same capacity with a standard convolutional layer. To avoid the case, the weight can be computed using a routing function (x):
| (2) |
in which is Sigmoid activation function, and GlobalAveragePool is global average pooling layer. is a dense layer that maps the pooled inputs to expert weights with the parameters learned across lots of training examples. Therefore, the weights of experts are example-dependent, which enable different experts to specialize in their interesting examples. That is to say, the weights of experts are different across all examples, in which each individual example can be processed with different weights.
From the perspective of matrix theory, a CondConv layer can be equally expressed as:
| (3) |
which is more computationally expensive. As a comparison, the CondConv for each example can be computed as a linear combination of experts, and then only one expensive convolution needs to be computed. To be specific, each additional expert requires only one additional multiply-add operation, which suggests that we can increase model capacity or performance via increasing the number of experts, with only a very small increase in computation cost. Though increasing the number of experts inevitably requires more memory resource, it is often affordable due to the rapid technical advancement of mobile phones and other wearable devices. Hence the CondConv is able to achieve higher inference performance without compromising computation cost, which provides a better alternative to serve mobile and wearable HAR that has strict latency constrains. With the increase in the number of experts, the CondConv is able to increase model capacity, which is also prone to overfitting. To avoid overfitting, we additionally introduce data augmentation via improving the overlapping rate of sliding windows, as well as randomly dropping out to ensure sufficient regularization.
IV Experiments and Results
We evaluate the proposed method on four public benchmark HAR datasets consisting of WISDM dataset [14], PAMAP2 dataset [15], UNIMIB-SHAR dataset [16], and OPPORTUNITY dataset [17], which are recorded with different sampling rates, number of sensors and kinds of activities. In terms of accuracy and FLOPs, we compare our method against the baseline CNN, as well as other state-of-the-art techniques that have been widely used in the HAR tasks. To make fair comparison, we restrain the baseline CNN with the same hyperparameters and regularization methods as the CondConv model. For each baseline architecture, we replace standard convolution layer with CondConv Layer to evaluate CondConv via increasing the number of experts per layer. To be specific, model performance is evaluated via varying the number of experts in the CondConv layer from 1, 2, 4, 8, 16. To fully exert the effect of CondConv, we additionally replace the fully connected layer with a 1x1 CondConv layer in some cases. For each CondConv layer, the BN layer is inserted right after a convolutional layer, but before feeding into ReLU activation [27]. To determine the routing weight functions, we experiment with different activation functions including Tanh, Sigmoid, Softmax, LReLU, ELU and ReLU, in which the results suggest that Sigmoid significantly outperforms other activation functions. Various ablation experiments are performed to further analyze the effect of CondConv layer across different examples at different depths in the network.
Models are trained in a supervised way, and the model parameters are optimized by minimizing the cross-entropy loss function with mini-batch gradient descent using an Adam optimizer. Training is done for at least 400 epochs. The epoch that achieves the best performance is selected and the corresponding model is applied to test set. For the CondConv, increasing the number of experts will inevitably lead to the increase of parameter count, which requires enough examples to train the model. The data augmentation and dropout technique are used for the CondConv model with large capacity, which aims to ensure sufficient regularization. First, data augmentation technique is added via improving the overlapping rate of sliding time windows. We use smaller sliding step length to segment time series sensor signal, which is able to generate more training examples. Second, dropout technique is applied to avoid overfitting during the training stage. However, normal combination of dropout and BN technique often lead to worse results unless some conditioning is done to prevent the risk of variance shifts. As suggested by Li et al. [28], the worse performance caused by the variance shift only happens when there exists a dropout layer before a BN layer. Thus, we insert only one dropout layer right before the final Softmax layer. All the experiment in this paper are implemented in Python using TensorFlow backend on a machine with an Intel i7-6850K CPU, 64GB RAM and NVIDIA RTX 2080 Ti GPU. In addition, we test the actual inference speed on a smartphone with an Android platform.
IV-A Experiment Results and Performance Comparison
IV-A1 The WISDM dataset [14]
The WISDM dataset used for the experiment is provided by the Wireless Sensor Data Mining(WISDM) Lab, which contains various human activities with 6 attributes: user, activity, timestamp, x-acceleration, y-acceleration, z-acceleration. The smartphones were placed in a front leg pocket of each dominant, in which one triaxial accelerometer embedded in smartphones with an Android platform was used to generate time series data at a constant sampling rate of 20Hz. The activities were collected from 29 subjects and each subject performed 6 distinctive human activities consisting of walking, jogging, walking upstairs, walking downstairs, sitting and standing .
In the experiment, the sliding window technique is utilized to segment the time series accelerometer signals. The size of sliding time window is set to 10s and a 95 overlapping rate is used, which equals to 0.5s of the sliding step length. The whole WISDM dataset is partitioned into two parts, in which 70 is randomly selected to generate training examples and the rest test examples. The shorthand description of the baseline CNN architecture is C(64)-C(128)-C(384)-FC-Sm, which consists of three convolutional layers and one fully connected layer. To be specific, each convolution begins with Conv-BN-ReLU and then another one. We use a 1x1 CondConv layer to replace the fully connected classification layer. The model will be trained using mini-batches with a size of 210. Adam is used for optimization. The initial learning rate is set as 0.0001, which will be reduced by a factor of 0.1 after each 50 epochs.

In Fig.2, we evaluate model performance using CondConv via varying the number of experts. As can be seen in the figure, there is a steady increase in performance on test data with increasing the number of experts. During training stage, increasing the number of experts makes the model converge faster. In terms of accuracy and FLOPs, Table I demonstrates the performance of our model compared with the baseline and state-of-the-arts. The number of experts that achieve the best performance on test set are =1 (98.12), =2 (98.94), =4 (99.12) and =8 (99.60). From the results, we see that the models with CondConv () consistently perform better than the counterparts without CondConv ( =1). As a reference, the baseline has 98.12 accuracy at the cost of 30.01 MFLOPs. The CondConv model has 99.60 classification accuracy with a computation complexity of 31.69 MFLOPs. There is an improvement of 1.48 in accuracy with a very small increase in FLOPs. To the best of our knowledge, the best performance on the dataset was 98.82 using CNN with local loss (Teng et al. [22]). The second best result was 98.20 using a temporal convolution on the spectrogram domain of the time series signal (Ravi et al. [29]). Our result with CondConv is best reported, which surpasses the state-of-the-art results. The results imply that the proposed model demonstrates state-of-the-art performance using CNN while requiring almost the same computation cost.
IV-A2 The PAMAP2 dataset [15]
The physical activity monitoring dataset is an open source dataset available at UCI repository, which contains extensive physical activities: both everyday household and sports performed by 9 participants wearing 3 inertial measurement units (IMUs) and a heart rate monitor. The IMU sensors were placed over the chest, wrist and side’s ankle on the dominant. The participants were asked to perform 12 protocol activities such as stand, sit, ascend stairs, descend stairs, rope jumping and run. In addition, some of them performed 6 optional activities such as watching TV, car driving, house cleaning and playing soccer. The sampling rate of heart rate monitor is 9Hz, and the sampling rate of IMUs is 100Hz; i.e. data is recorded 100 times per second. For the use of HAR, we subsample the IMU signals from 100Hz to 33.3Hz.
As indicated, HAR is typically computed over a sliding window. The sliding window length is usually fixed. Different window lengths are selected by authors in various studies. To compare the result with other works, we selecte window size of 512 (5.12 seconds) to slide one instance at a time, which leads to a 78 overlap with around 473k samples. All samples are normalized into zero mean and unit variance. We randomly select 70 of the data in each class for training, the rest for test. The shorthand description of the baseline CNN is described as C(64)-C(128)-C(256)-FC-Sm, which consists of three convolutional layers and one fully connected layer. BN is applied before ReLU activation.
The batch size is set to 204 and Adam optimization [30] is used for training. The learning rate is set to 0.001, 0.0005 and 0.00001 during 12.5, 25 and 62.5 of the total training time.

Keeping all hyper-parameters except the number of experts identical, we train the best performing model using CondConv to see if it could improve the result further. Fig.3 shows the effect of increasing number of experts on the performance using the CondConv architectures with =1,=2,=4,=8 and =16. It can be seen that the model performance consistently increases when the number of experts is greater than 1. Under a variety of , we compare classification accuracy and FLOPs with the baseline of =1, as well as the state-of-the-arts on the dataset. From the results in Table II, the number of experts that achieves the best results on test set are =1(89.97), =2(91.8), =4(92.7), =8(93.79) and =16(94.01). Our method using CondConv with =16 surpasses the baseline by 4.04, accompanied by a very small increase in computation cost. As can be seen in Table II, the best published result on this dataset using CNN is to our knowledge 91.4(Yang et al. [31]). The proposed method surpasses the state-of-the-art result by a large margin. This implies that we can exploit this CondConv as a drop-in replacement of standard convolutions to achieve better results with only a small increase in computation cost.
| Model | Test Acc | FLOPs |
|---|---|---|
| CondConv(with =1) | 89.97 | 31.57M |
| CondConv(with =2) | 91.80 | 31.81M |
| CondConv(with =4) | 92.70 | 32.31M |
| CondConv(with =8) | 93.79 | 33.25M |
| CondConv(with =16) | 94.01 | 35.17M |
| Yang et al.2018 [31] | 91.40 | |
| Zeng et al.2018 [32] | 89.96 | |
| Khan et al.2016 [33] | 86.00 |
IV-A3 The UNIMIB-SHAR dataset [16]
UNIMiB-SHAR is a new dataset including 11771 samples designed for the use of HAR and fall detection. In a supervised condition, the 30 subjects of ages ranging from 18 to 60 years wearing a Samsung Galaxy Nexus I9250 smartphone were instructed to perform activities. Each activity was performed 2 or 6 times. The half of all participants placed the smartphone in their left pocket, and the other half in their right pocket. An embedded Bosh BMA220 3D accelerometer was used to generate examples. The whole dataset is composed of 17 fine grained classes which is further grouped into two coarse grained classes: one containing samples of 9 types of activities of daily living(ADLs) and the other containing samples of 8 types of falls.
For fair comparison, the sliding window with a fixed length T=151 is selected, which equals to approximately 3s. Since the accelerometer signals are recorded at a constant sampling rate of 50 Hz, for each activity, the accelerometer signal is comprised of 3 vectors of 151 values, one for each acceleration direction. Thus, the whole dataset contains 11,771 windows of size 151*3 in total, which describes both ADLs (7759) and falls (4192) unequally distributed across activity types. The architecture of the baseline CNN is C(128)-C(256)-C(384)-FC-Sm, which contains three convolutional layers and one fully connected layer. At the last, we use a 1x1 CondConv layer to replace the final fully connected classification layer. The samples are split into 70 training and 30 test set. Adam optimizer [30] is used to train with batch size of 203. The learning rate is set to 0.0004, 0.00001 and 0.000001 during 12.5, 25 and 62.5 of the total training time.

We evaluate the performance of our proposed method with various number of experts on the dataset. Fig.4 shows that the accuracy will increase as the number of experts grows, which is consistent with our motivation. The CNN that utilizes CondConv always performs better than that without CondConv. Table III demonstrates the performance of our model compared with the baseline and other state-of-the-arts in terms of accuracy and FLOPs. It can be seen that our method achieves 1.32, 2.74 and 3.16 improvements over baseline with =2, =4 and =8 respectively for this task. There is only a small increase in computation cost. In addition, our model using CondConv outperforms other state-of-the-arts. When compared to the best result obtained by Li et al. [34] using CNN, our method with =8 achieves 2.34 improvement. Our CondConv also surpasses the Long et al’s method [35] by 1.28, which uses dual residual networks. Under same parameter configurations, by increasing the number of experts, the CondConv with sufficient regulation is able to enhance the expression ability of CNN by a large margin.
IV-A4 The OPPORTUNITY dataset [17]
The OPPORTUNITY dataset is publicly available on the UCI Machine Learning repository, which comprises both static/periodic and sporadic activities collected with sensors of different modalities integrated into the environment and on the subjects, in a daily living scenario. The samples were recorded from four subjects performing morning activities, in which each subject was asked to perform one ADL session and one drill session. During the ADL session, without any strict restriction, subjects performed a session five times with activities such as preparing and drinking a coffee, preparing and eating a sandwich, cleaning up, and so on. During the drill session, subjects were instructed to perform 20 repetitions of a predefined sorted set of 17 activities.

The dataset has been used in numerous activity recognition challenges. In this paper, we evaluate our method on the same subset employed in previous OPPORTUNITY challenge, which contains the samples collected from 4 subjects with only on-body sensors. The sensor signals are recorded at a sampling rate of 30Hz from 12 locations on the dominant and annotated with 18 mid-level gesture annotations. ADL1, ADL2 and ADL3 from subject 1, 2 and 3 are used as training set. ADL4 and ADL5 from subject 4 and 5 are used as test set. The size of sliding time window and sliding step length are set to 64 and 8 respectively, which generates approximately 650k samples. The baseline model is a deep CNN, whose shorthand description is presented as C(64)-C(64)-C(128)-C(128)-C(256)-Fc-Sm, that contains five convolutional layers and one fully connected layer. For this experiment, The initial learning rate is set as 0.0001, which will be reduced by a factor of 0.1 after each 50 epochs using Adam with default parameters. Initial batch size is set to 204.
We characterize the effect of the number of experts employed to increase model capacity or performance. Fig.5 shows that with sufficient regulation increasing the number of experts tends to increase the performance on the OPPORTUNITY dataset. The results of the proposed method are shown in Table IV, which also includes a comprehensive list of past published deep learning techniques employed on the dataset. Among deep architectures, the CondConv systematically performs best on the dataset. It can be seen that the results of the baseline CNN are close to those obtained previously by Zeng et al. [18] using CNN on raw signal data. The CondConv with the number of experts greater than 1 consistently outperforms our baseline, with a very small increase in computation cost. We also reproduce the state-of-the-art DeepConvLSTM using our experiment setup. The CondConv systematically performs better than the DeepConvLSTM, improving the performance by 2.28 on average on the OPPORTUNITY dataset.
| Model | Test Acc | FLOPs |
|---|---|---|
| CondConv(with =1) | 77.5 | 114.23M |
| CondConv(with =2) | 78.7 | 115.57M |
| CondConv(with =4) | 80.9 | 117.43M |
| CondConv(with =8) | 81.18 | 121.56M |
| Zeng et al.2014 [18] | 76.83 | |
| Ordóñez et al.2016 [19] | 78.90 | |
| Hammerla et al.2016 [36] | 74.50 |
IV-B The Ablation studies
To better understand model design with the CondConv block, we conduct several ablation studies to further explore why the CondConv with larger model capacity is able to improve accuracy while maintaining efficient inference. Our ablation experiments are performed on the UNIMIB-SHAR dataset, and all hyper-parameters are exactly the same as used above. Finally, we also evaluate the actual inference time of our model on an Android smartphone.



First, we study the influence of routing weights across different classes of activities at three different depths in the network. As mentioned above, if all the experts have the same routing weight for each example, the CondConv will degenerate into standard convolutions. Thus, all the experts are example-dependent, and each individual example can yield different activation weights. We apply the CondConv in all convolutional layers as well as the final fully connected classification layer. Results are shown in Fig.6. It can be seen that the value discrepancy is increased layer by layer. For shallow layers, the distributions of routing weights of different experts are very close across classes, while in deep layers they are diverse. That is to say, the experts are more class specific or sensitive to high-level features, which suggests that there is no significant performance improvement if the CondConv layer is applied near the input of the network. In particular, we also find that the examples from the similar activities such as StandingUpFL and StandingUpFS tend to follow very close distribution.
Next, to demonstrate the superiority of our method, we use the CondConv to compute the confusion matrices on the UNIMIB-SHAR dataset. As can be seen in Fig.7, for the similar activities such as StandingUpFL and StandingUpFS, the baseline CNN made 31 errors, while the CondConv in case of misclassified only 17 activities. Though the experts activated by the similar activities follow almost the same distribution, their combination is still able to offer better results, which indicates that multiple experts are often more useful than one. The CondConv is able to enhance the expression ability of CNN by a large margin via increasing the number of experts.


Next, we evaluate the distribution of routing weights activated by all the examples in the UNIMIB-SHAR test set in the final CondConv layer. The main purpose of this evaluation is to disentangle the influence of different experts at deeper layers. Fig.8 shows the routing weights follow a bi-modal distribution, and most of them approximately equal to 0 or 1. Without using any L1 regularization technique, most experts are sparsely activated. That is to say, for each individual example, only a small portion of the entire network is activated, which suggests an explanation why the CondConv is able to realize efficient inference with larger model capacity.

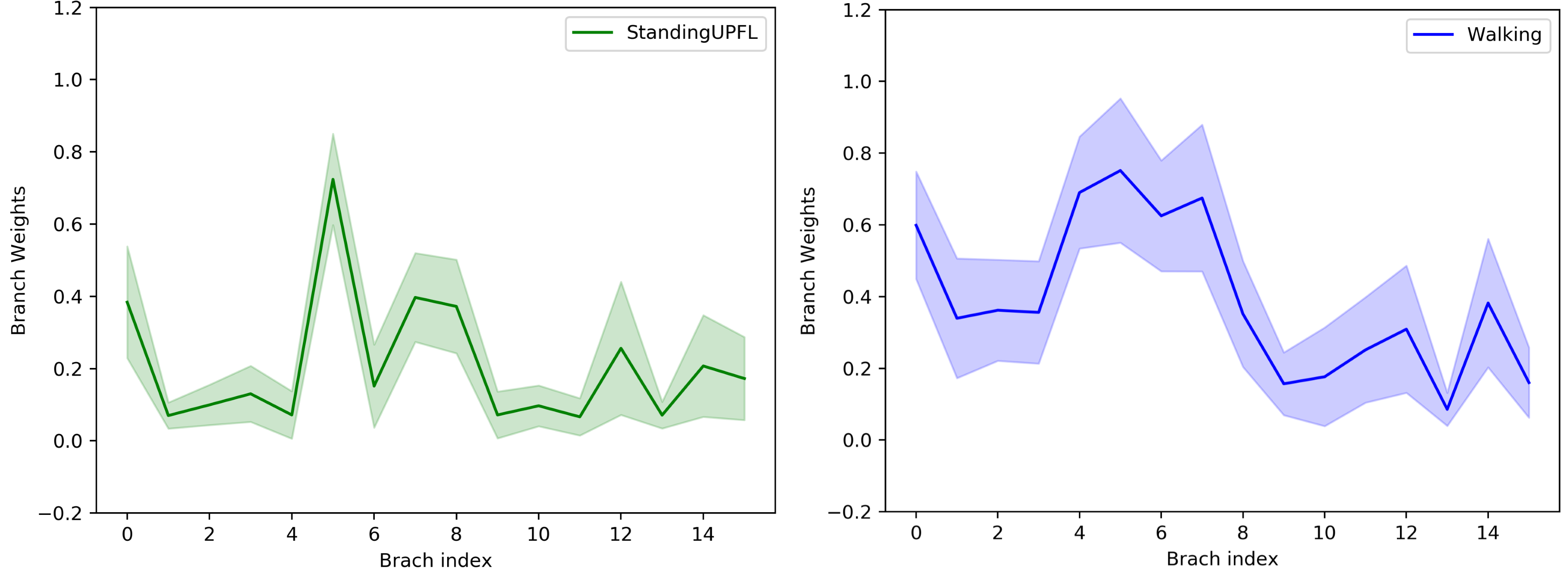
We then study the variation of routing weights within one class in the final CondConv layer. Results are shown in Fig.9. We find that even within one class the routing weights between examples show much higher variance. In addition, to gain a better understanding of experts in the final CondConv layer, we visualize several typical activity examples of top 4 classes with highest activated values on 8 difference experts, as shown in Fig.10.

Finally, we evaluate the actual inference time of the CondConv models on a smartphone. The open source APP introduced in [37] is directly utilized for the evaluation, which is a smartphone-based application for mobile HAR. A screenshot of the APP’s user interface is shown in Fig.11. The CondConv models with and are trained on the WISDM dataset. We convert the models into .pb file, which are deployed to build an Android application. Our experiment is implemented on a Huawei Mate 30 device with the Android OS(10.0.0). As shown in Table V, it can be seen that the CondConv with has almost the same inference speed with baseline in the real implementation.

| Model | Inference Time(ms/window) |
|---|---|
| CNN(Baseline) | 228-272ms |
| CondConv(=8) | 241-292ms |
V Conclusion
Recently, deep CNNs have achieved state-of-the-art performance on various mobile and wearable HAR tasks. However, this technique is severely hampered by the computation power in current mobile and wearable devices. A high number of computations in deep leaning increases computational time and is not suitable for real-time HAR on mobile and wearable devices. Shallow and conventional machine learning methods could not achieve good performance. Therefore, deep learning methods that can balance the trade-off between accuracy and computation cost is highly needed. In this paper, we have presented an efficient solution for HAR on mobile and wearable devices via replacing conventional convolutions with CondConv. The proposed CondConv method is evaluated in on four public HAR benchmark datasets, WISDM dataset, PAMAP2 dataset, UNIMIB-SHAR dataset, and OPPORTUNITY dataset, achieving state-of-the-art accuracy without compromising inference speed. We have also performed various ablation experiments to show how such a larger network is clearly preferable to the baseline while requiring a similar amount of operations. On the whole, with efficient regulation, the proposed method can greatly improve recognition accuracy of the existing HAR using CNN without compromising computation cost, which is very suitable for HAR that has strict latency constrains. By combining the efficient architecture design with any existing CNN based HAR method, we are able to perform real-time HAR tasks on mobile and wearable devices.
References
- [1] A. Bulling, U. Blanke, and B. Schiele, “A tutorial on human activity recognition using body-worn inertial sensors,” ACM Computing Surveys (CSUR), vol. 46, no. 3, pp. 1–33, 2014.
- [2] F. Demrozi, G. Pravadelli, A. Bihorac, and P. Rashidi, “Human activity recognition using inertial, physiological and environmental sensors: a comprehensive survey,” arXiv preprint arXiv:2004.08821, 2020.
- [3] O. D. Lara and M. A. Labrador, “A survey on human activity recognition using wearable sensors,” IEEE communications surveys & tutorials, vol. 15, no. 3, pp. 1192–1209, 2012.
- [4] D. Anguita, A. Ghio, L. Oneto, X. Parra, and J. L. Reyes-Ortiz, “Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine,” in International workshop on ambient assisted living. Springer, 2012, pp. 216–223.
- [5] J. Wang, Y. Chen, S. Hao, X. Peng, and L. Hu, “Deep learning for sensor-based activity recognition: A survey,” Pattern Recognition Letters, vol. 119, pp. 3–11, 2019.
- [6] J. Yang, M. N. Nguyen, P. P. San, X. L. Li, and S. Krishnaswamy, “Deep convolutional neural networks on multichannel time series for human activity recognition,” in Twenty-Fourth International Joint Conference on Artificial Intelligence, 2015.
- [7] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [8] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [9] Y. Tang, Q. Teng, L. Zhang, F. Min, and J. He, “Efficient convolutional neural networks with smaller filters for human activity recognition using wearable sensors,” arXiv preprint arXiv:2005.03948, 2020.
- [10] O. Banos, J.-M. Galvez, M. Damas, H. Pomares, and I. Rojas, “Window size impact in human activity recognition,” Sensors, vol. 14, no. 4, pp. 6474–6499, 2014.
- [11] Y. Bengio, N. Léonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,” arXiv preprint arXiv:1308.3432, 2013.
- [12] K. Cho and Y. Bengio, “Exponentially increasing the capacity-to-computation ratio for conditional computation in deep learning,” arXiv preprint arXiv:1406.7362, 2014.
- [13] B. Yang, G. Bender, Q. V. Le, and J. Ngiam, “Condconv: Conditionally parameterized convolutions for efficient inference,” in Advances in Neural Information Processing Systems, 2019, pp. 1305–1316.
- [14] J. R. Kwapisz, G. M. Weiss, and S. A. Moore, “Activity recognition using cell phone accelerometers,” ACM SigKDD Explorations Newsletter, vol. 12, no. 2, pp. 74–82, 2011.
- [15] A. Reiss and D. Stricker, “Introducing a new benchmarked dataset for activity monitoring,” in 2012 16th International Symposium on Wearable Computers. IEEE, 2012, pp. 108–109.
- [16] D. Micucci, M. Mobilio, and P. Napoletano, “Unimib shar: A dataset for human activity recognition using acceleration data from smartphones,” Applied Sciences, vol. 7, no. 10, p. 1101, 2017.
- [17] R. Chavarriaga, H. Sagha, A. Calatroni, S. T. Digumarti, G. Tröster, J. d. R. Millán, and D. Roggen, “The opportunity challenge: A benchmark database for on-body sensor-based activity recognition,” Pattern Recognition Letters, vol. 34, no. 15, pp. 2033–2042, 2013.
- [18] M. Zeng, L. T. Nguyen, B. Yu, O. J. Mengshoel, J. Zhu, P. Wu, and J. Zhang, “Convolutional neural networks for human activity recognition using mobile sensors,” in 6th International Conference on Mobile Computing, Applications and Services. IEEE, 2014, pp. 197–205.
- [19] F. Ordóñez and D. Roggen, “Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition,” Sensors, vol. 16, p. 115, 01 2016.
- [20] K. Wang, J. He, and L. Zhang, “Attention-based convolutional neural network for weakly labeled human activities’ recognition with wearable sensors,” IEEE Sensors Journal, vol. 19, no. 17, pp. 7598–7604, 2019.
- [21] A. Ignatov, “Real-time human activity recognition from accelerometer data using convolutional neural networks,” Applied Soft Computing, vol. 62, pp. 915–922, 2018.
- [22] Q. Teng, K. Wang, L. Zhang, and J. He, “The layer-wise training convolutional neural networks using local loss for sensor based human activity recognition,” IEEE Sensors Journal, vol. PP, pp. 1–1, 03 2020.
- [23] Z. Wu, T. Nagarajan, A. Kumar, S. Rennie, L. S. Davis, K. Grauman, and R. Feris, “Blockdrop: Dynamic inference paths in residual networks,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [24] R. Teja Mullapudi, W. R. Mark, N. Shazeer, and K. Fatahalian, “Hydranets: Specialized dynamic architectures for efficient inference,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8080–8089.
- [25] N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” arXiv preprint arXiv:1701.06538, 2017.
- [26] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” arXiv preprint arXiv:1502.03167, 2015.
- [27] X. Glorot, A. Bordes, and Y. Bengio, “Deep sparse rectifier neural networks,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics, 2011, pp. 315–323.
- [28] X. Li, S. Chen, X. Hu, and J. Yang, “Understanding the disharmony between dropout and batch normalization by variance shift,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 2682–2690.
- [29] D. Ravi, C. Wong, B. Lo, and G.-Z. Yang, “Deep learning for human activity recognition: A resource efficient implementation on low-power devices,” in 2016 IEEE 13th international conference on wearable and implantable body sensor networks (BSN). IEEE, 2016, pp. 71–76.
- [30] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [31] Z. Yang, O. I. Raymond, C. Zhang, Y. Wan, and J. Long, “Dfternet: Towards 2-bit dynamic fusion networks for accurate human activity recognition,” IEEE Access, vol. 6, pp. 56 750–56 764, 2018.
- [32] M. Zeng, H. Gao, T. Yu, O. J. Mengshoel, H. Langseth, I. Lane, and X. Liu, “Understanding and improving recurrent networks for human activity recognition by continuous attention,” in Proceedings of the 2018 ACM International Symposium on Wearable Computers, 2018, pp. 56–63.
- [33] A. Khan, N. Hammerla, S. Mellor, and T. Plötz, “Optimising sampling rates for accelerometer-based human activity recognition,” Pattern Recognition Letters, vol. 73, pp. 33–40, 2016.
- [34] F. Li, K. Shirahama, M. A. Nisar, L. Köping, and M. Grzegorzek, “Comparison of feature learning methods for human activity recognition using wearable sensors,” Sensors, vol. 18, no. 2, p. 679, 2018.
- [35] J. Long, W. Sun, Z. Yang, O. I. Raymond, and B. Li, “Dual residual network for accurate human activity recognition,” arXiv preprint arXiv:1903.05359, 2019.
- [36] N. Y. Hammerla, S. Halloran, and T. Plötz, “Deep, convolutional, and recurrent models for human activity recognition using wearables,” arXiv preprint arXiv:1604.08880, 2016.
- [37] D. Singh, E. Merdivan, I. Psychoula, J. Kropf, S. Hanke, M. Geist, and A. Holzinger, “Human activity recognition using recurrent neural networks,” in International Cross-Domain Conference for Machine Learning and Knowledge Extraction. Springer, 2017, pp. 267–274.