Real-time 3D object proposal generation and classification under limited processing resources
Abstract
The task of detecting 3D objects is important to various robotic applications. The existing deep learning-based detection techniques have achieved impressive performance. However, these techniques are limited to run with a graphics processing unit (GPU) in a real-time environment. To achieve real-time 3D object detection with limited computational resources for robots, we propose an efficient detection method consisting of 3D proposal generation and classification. The proposal generation is mainly based on point segmentation, while the proposal classification is performed by a lightweight convolution neural network (CNN) model. To validate our method, KITTI datasets are utilized. The experimental results demonstrate the capability of proposed real-time 3D object detection method from the point cloud with a competitive performance of object recall and classification.
Index Terms:
Point cloud segmentation, object detection, OptimizationI INTRODUCTION
Robots are gradually undertaking more and more tasks in our daily lives, such as driving [1] and providing service for hospitals [2]. Introducing fully autonomous robots into our daily lives implies that robots share the spatial world with people. Due to this situation, it is imperative for robots to recognize all objects in the surrounding environments and understand the scenes they visualize [3]. Over the past ten years, approaches based on deep learning have achieved remarkable progress in vision-based object detection [4, 5], and 3D object recognition from the point cloud [6], which makes the perception systems in robots more reliable and accurate than ever before. However, the deep learning model requires that a robot be equipped with energy-intensive processing capabilities, such as a GPU, for detecting 3D objects in real-time. Furthermore, a large number of small mobile robots are not able to dedicate those energy resources due to limitations in power supply and energy storage. Fortunately, certain relevant parts of the processing can be saved if proper hybrid approaches are exploited, which implies that power requirements can be reduced. In this work, we propose an efficient 3D object proposal generation and classification approach, which is capable of detecting objects in real-time with limited processing resources.
Three-dimensional object detection can provide accurate spatial location and geometrical shapes of targets, benefiting a robot’s perception system. The traditional approach has been to segment out objects of interest (OOIs) and then apply some simple classifiers for further classification, such as a naive Bayes classifier [7] or support vector machine (SVM) classifier [8]. With the prevalence of deep learning, many methods based on CNN have been proposed for 3D object detection [9, 10, 11]. Despite their high detection accuracy, the deep learning-based methods require a large amount of annotated data for training purposes, and powerful processors for both training and real-time detection. However, many robots do not usually have powerful processing capabilities, especially small and medium-sized robots. When using these methods, a relevant part of the processing effort is dedicated to extracting point features, and generating 3D proposals. However, unlike 2D proposals in the image, 3D proposals are usually well scattered in 3D space. Taking advantage of this characteristic, we propose an efficient segmentation method for searching for 3D proposals, which reduces the computation effort significantly without sacrificing the quality of the estimated proposals. In addition, an efficient and lightweight deep learning model is developed for learning pointwise features for the classification task. Hence, our detection framework consists of two main parts: proposal generation and proposal classification.
The proposal generation firstly involves a pruning step for the removal of points estimated to be part of the ground. Because it is assumed that the OOIs are not part of the ground, the segmentation process can ignore all those points assumed to belong to that surface. The majority of the approaches used for estimating a road or ground surface assume that the surface is flat or possesses a similarly simple shape; consequently, these approaches attempting to approximate the surface with a plane. However, this assumption is not consistent with the real-world scenario, in which the ground/road contains several slopes within an area. Consequently, to achieve better estimation, the ground/road surface is assumed to be piece-wise multi-linear (PWML) [12], or at least piece-wise constant (PWC). In these cases, the area is divided into smaller but sufficiently large regions, in which dominant almost-horizontal, piece-wise approximating patches are assumed to be part of the ground/road surface in that region of the PWML or PWC partition. A dominant patch takes on the role of a local ground/road reference for classifying points as being part of saliences, depressions in the terrain, or the ground/road.
The segmentation process is based on the continuity of the surfaces. Each inferred segment is considered as a potential proposal, except for some improper segments, which are too large or too small. There are several parameters involved in the proposal generation step; these parameters are tuned once through a process based on particle swarm optimization (PSO) [13]. The efficient PointNet [24, 25] used to perform the classification task consists mainly of multi-layer perceptron (MLP) on each point, which is equivalent to a 1 x1 x1 convolutional kernel in 3D, and it can perform the real-time classification on a standard CPU. Moreover, every proposal defines its own size; consequently, no bounding box regression task is required. Hence, the model is simpler and faster. In addition, it requires smaller training datasets than those needed for end-to-end CNN-based detection methods [10, 14]. It is even possible to train the model with limited processing resources, such as those available in a common CPU.
The performance of the proposed method is evaluated using well-known KITTI datasets [29] via the consideration of three metrics: recall of proposals, the accuracy of the classification, and the processing time. Experimental results show that the method can attain high recall and accuracy in a real-time fashion and under the limited processing resources, typically found in small and medium-sized robots. This work makes two main contributions. The first contribution is the approach for inferring the ground, which is approximated via a PWC representation. Compared with other ground extraction method [17, 18, 19] in the traffic context, this representation does not require the assumption that ground in the point cloud is one even plane, and is able to deal efficiently with uneven terrains. The second contribution is the proposed framework for detection, which can achieve real-time performance, e.g. by offering processing times of less than 0.1 seconds per massive point cloud, without utilizing a GPU. Consequently, this approach can be exploited by small robots equipped with simple CPUs with 1 or 2 cores, or by low-scale GPUs.
The rest of the paper is organized as follows. Section II introduces the related work, and Section III illustrates how to build an efficient 3D object detection method. Additional procedures for model optimization are presented in Section IV, while experiments involving the proposed method are described in Section V. Section VI concludes our work and summarizes its contributions.
II RELATED WORK
The proposed 3D object detection framework can be split roughly into two parts: point cloud segmentation, and proposal classification. Related work concerning the point cloud segmentation will be firstly reviewed. Then a literature review of 3D object detection will be undertaken, to compare the proposed 3D object detection framework with those approaches.
II-A Point cloud segmentation
Point cloud segmentation is used to infer objects of interest (OOIs) from a point cloud and is based on the assumption that 3D objects are sufficiently separated and there are no relevant intersections between adjacent objects. There are usually two main procedures involved: ground removal, and the clustering of the remaining set of points. Himmelsbach et al. [15] represented the terrain with a circle of infinite radius, centered around the robot itself, and split this circle into a number of circular sectors with fixed interval angles; Then the ground is searched by extracting horizontal lines at a low altitude, from the point sets of every segment. The remaining non-ground points are mapped into a 2D occupancy grid image, and clustering is done efficiently by finding connected components of occupied grid cells. Moosmann et al. [16] constructed an undirected graph in which every point is treated as a node. The normal of the local surface is estimated for every node against its neighbouring points, and the similar local surfaces, which either form local convexities or are approximately vertical normal vectors, are merged together to grow the ground plane or obstacle area.
Douillard et al. [17] formulated the ground surface detection as non-ground outlier rejection and proposed a Gaussian Process Incremental Sample Consensus, based on the variance of the height of an outlier from the mean of a Gaussian distribution, to propagate the ground surface labels in an iterative manner to eventually include all ground points, while the remaining non-ground points are subsequently segmented into different clusters. Point segmentation approaches, after the removal of all ground points, often bring about issues of under-segmentation or over-segmentation. To alleviate segmentation errors, Held et al. [18] built a probabilistic model to combine the spatial, temporal, and semantic cues for every segment. The probabilistic model iterates through every individual segment when conducting splitting and through all pairs of segments when merging. Zermas et al. [19] started with an approximate coarse ground plane based on a deterministically extracted set of seed points with low height values, and iteratively refined the ground plane fitting by selecting seed points belonging to previously estimated ground surface. After removing the ground points, line segments are found efficiently for every scan and subsequently merged across neighbouring scans. One of the drawbacks in all these methods is that they include the assumption that one even plane should be able to fit the ground in the point cloud, but this assumption may fail in various real-life situations. In contrast, our ground removal approach adopts multiple small planes to fit the ground surface, resulting in a more robust approach.
II-B 3D object detection
The conventional pipeline in 3D object detection involves segmenting a point cloud, then classifying the clusters into objects. After point cloud segmentation, Teichman et al. [20] adopted two classifiers, i.e., the segment and holistic classifiers, to classify feature vectors. The results were then combined with a discrete Bayes filter in a boosting framework. Wang et al. [21] proposed a feature-centric voting algorithm which convolutes the 3D point space in a sliding window with a voting scheme in a manner similar to feature transformation, enabling it to find new features describing object locations and orientations. An SVM classifier was subsequently applied to classify 3D candidates into different categories. As CNN-based approaches have become more and more dominant in computer vision tasks, a number of related 3D object detection approaches have been proposed. Chen et al. [22] proposed multi-view 3D object detection and converted the point cloud into bird-view representations, consisting of multiple height maps, one density map, and one intensity map. The mature 2D CNN framework used for object detection in images was applied to these bird-view images to generate 3D object candidates.
Ku et al. [14] designed AVOD-FPN, which generates 3D proposals on the bird-view images of the point cloud with a 2D CNN, then crops the corresponding features from RGB and bird-view images for each proposal and predicts the 3D bounding boxes based on fused features. Zhou et la. [23] adopted PointNet to extract features from the low resolution raw point cloud for each voxel, then employed a shallow 3D CNN network to convert 3D feature maps into 2D feature maps for 3D object detection. Other methods [26, 10] use sparse CNN [27, 28] to learn 3D feature maps from sparse 3D data, then compress them into 2D feature maps for object detection. Even though a large part of the computation for the sparse CNN is shifted to a CPU, these methods still require a GPU to achieve real-time performance. Although they can achieve desirable detection performance, these deep-learning-based approaches require a large training dataset and powerful processor, and cannot run in real-time without a GPU. To maintain both efficiency and accuracy, our framework employs point cloud segmentation to generate proposals and design an efficient classification model based on a CNN.
III Object detection methodology
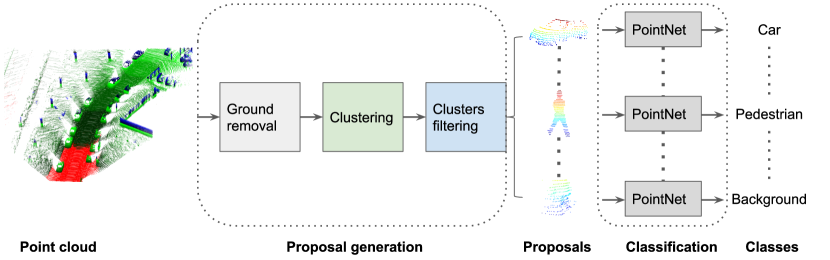
The framework of the proposed detection approach can be seen in Fig. 1. It consists mainly of two parts: proposal generation and proposal classification. The proposal generation consists of ground removal, clustering, and cluster filtering. All of these steps are described in the following sections.
III-A Ground removal
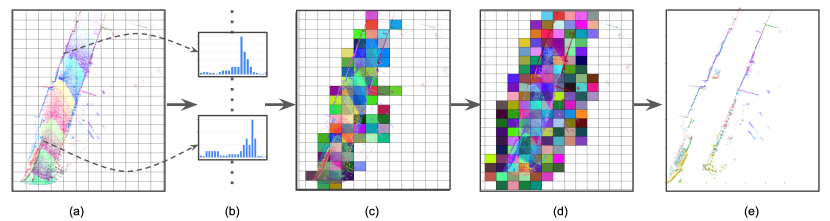
Pre-processing the data by removing points that belong to the ground has been shown empirically to improve segmentation performance significantly. The typical method employed in urban ground detection is to estimate an approximate 3D plane via model-fitting techniques, such as Random Sample Consensus (RANSAC). However, a simple plane is usually not sufficient for approximating the ground surface. A more powerful representation involves using a PWML approximation, such as in [12], or even more constrained cases, such as PWC with fixed partitions. The PWC assumes that in each region of the partition, the ’altitude’ of the nominal ground is constant (i.e. the nominal surface of the terrain is flat and horizontal). In order to infer the altitude of the nominal surface in a subregion, a histogram of the altitudes of the points whose XY coordinates belong to this subregion can be generated. Additional basic rules, which consider the continuity of the properties of adjacent subregions, enable this process to avoid being misled by plateaus. The PWC requires very low processing effort, and performs better than the more sophisticated RANSAC.
Fig. 2 summarizes ground modelling based on a fixed-size PWC approximation. The coverage in XY () of the entire point cloud, is partitioned into multiple sub-regions, . For each subregion, a histogram of points’ heights (given simply by the points Z coordinates) is built. It is assumed that the ratio between the number of ground points and the number of non-ground points in every sub-region is larger than a certain user-defined threshold. According to this rule, the minimum bin value, whose frequency in the histogram is over this threshold, is assumed to be ground height. This operation can be implemented efficiently in parallel. The pseudo-code of the algorithm can be found in A. Since the assumption may fail when a sub-region contains the flat plane belonging to an object, such as the roof of a car, we design the post-processing step to amend such false detections. The post-processing will compare the height of every sub-region with those of its adjacent regions, and its ground height value will be updated with the lowest height found in the neighbourhood. Once the ground planes are inferred, points can be classified as either being part of the ground (’close enough’) or not. Based on this classification, only the points of interest (those above the ground) are kept for the posterior proposal generation of OOIs.
III-B Point cloud clustering
The remaining points, i.e. the points ’over the ground’, belong mostly to the OOIs, such as vehicles, cyclists, pedestrians, and background objects (buildings and plants). These objects are usually well separated when the ground points are removed. Therefore, we can perform clustering on these remaining points to find the potential 3D proposals.
Two methods are used to do point cloud clustering: distance-based and scan-based clustering. For the distance-based clustering method, the only criterion used to decide whether two points belong to the same cluster or not is their Euclidean distance. Hence, the distances between all point pairs are calculated and compared with a pre-defined distance threshold . A random point is first selected and put into a separate list . Then, the distances of other points from are calculated; Those points with distances from less than , are removed and added to the same list . Similar operations are performed repeatedly between points in and the rest of the points until no more points are added to list , and is treated as a cluster. After this first cluster is complete, a new list will be created to search for the next cluster and so on until no more points are left. The algorithm details are shown in B. Distance-based clustering, which does not require the ordering information among points, can be generalized to any point cloud dataset. However, processing a large number of point clouds takes a considerable amount of time, since every point is sequentially required to do a comparison against the rest of the points.
The 3D point cloud, generated by the LiDAR, has a multi-layer structure and every layer, also called a scan, produced from the same LiDAR ring includes contiguous points. Based on this characteristic, the scan-based clustering method is proposed to speed up processing. The points in every scan, or single layer, are first segmented into line segments, then these line segments are compared with their vertical neighbouring segments. Finally, the line segments which are close together are merged into one segment.
It is assumed that points traverse in a raster in a counterclockwise fashion, starting from the top scan-line. is used to decide whether two points in the same scan belongs to the same segment or not, and is set to distinguish two points in neighbouring scans. We save all clusters, called , in the form of dictionary variables, in which the key and value are label number and corresponding points, respectively. All line segments begin with the first scan and are saved into a dictionary with the label as the key and the point group as the value, called .
The first is appended to . Then line segments are extracted from the second scan and saved in another dictionary, . Next, every line segment in is compared with all segments in . If has no segment whose distance from is smaller than . Then, the key for in is assigned a new label number, and this new key and its points are added to . If includes one connection with , no new key is generated, and the key for is the same as the one in ; all points in are appended to the point group with the same key in the and . If includes more than two connections with , the minimum key for the connected segments in is selected as the unique key for these connected clusters.
Merging operations are implemented in the and . After processing a current scan, the becomes the and the algorithm starts to process the next scan. The pseudo-code of scan-based clustering can be found in C. The author in [19] designed a complicated label management system to handle label conflict and merge issues, while this paper employs the dictionary to save the points in all clusters directly, making our algorithm easier to implement.
In contrast to the distance-based clustering method, the scan-based approach takes the advantage of the ordering of the points along the LIDAR scan-lines and covert clustering problem in 3D space into the line segmentation, and only the Euclidean distance between one point and its neighbouring points along the scan line is required, resulting in much lower algorithm complexity. Therefore, it can achieve a real-time running performance. But the scan-based approach is only applicable to point cloud which is generated by the Lidar or other sensors with fixed multi-layer scanning structure, and is not as generalized as the distance-based method.
III-C Proposals filtering
Three-dimensional proposals, generated by the clustering method, could also be for some background objects, such as super-large and tiny objects, which could be the buildings or leaves, respectively. To remove some improper background proposals and reduce the number of proposals, we set up two criteria to filter background proposals: 1) the size of the desired proposal should be within a certain range, and 2) the number of points in the non-occluded proposals should have a minimum. For the first criterion, we choose the maximum values for length and width to filter out very large objects, and the minimum value for height is defined to remove objects which are too flat, since objects of interest, such as pedestrians, cars, and cyclists, have certain height value.
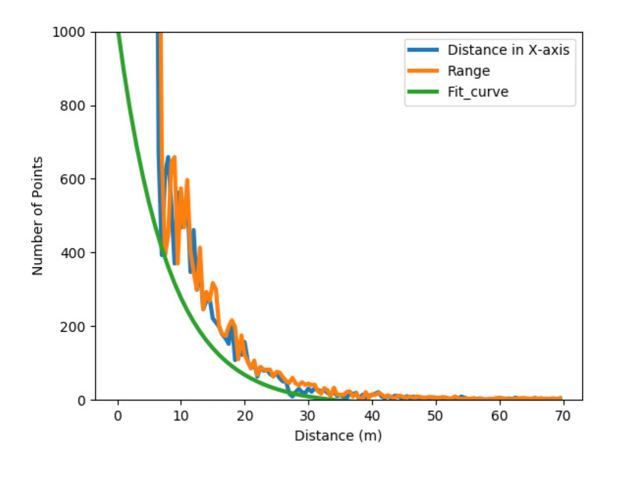
As for the second criterion, the occlusion should be inferred first. The horizontal angle span of every 3D proposal is calculated against the location of the LiDAR and is compared with the angle spans of other proposals. A proposal is labelled as a non-occlusion proposal if it satisfies one of the following cases: 1) its angle scan does not overlap those of other proposals, and 2) its angle scan has overlapped with those of other proposals, but it is closer to the LiDAR than the other proposals. The details of this occlusion labelling algorithm are presented in D. To estimate the minimum number of points in non-occluded proposals, we investigate the relationship between the number of points and the distance from proposals to LiDAR, as shown in Fig. 3. The number of points and the distance to LiDAR are collected from all the ground truth bounding boxes in the training dataset provided by the KITTI benchmark [29]. The distance, which can be represented as either the range or the distance along X-axis to LiDAR, is sampled with an interval of , and its corresponding number of points is the minimum number of points in all the ground truth bounding boxes, whose centre points are located in the distance interval. The exponential function is used to fit these sample points, see the green line in Fig. 3. Three-dimensional proposals with fewer than the minimum number of points are discarded.
III-D Proposals classification
The PointNet-based, efficient, and lightweight classification model is designed to identify the class of 3D region proposals [24]. There are numerous techniques available in the existing literature for processing raw point clouds in every proposal for classification, such as 3D CNN on a 3D voxelization grid [26], or a 2D CNN for bird-view images [22]. In contrast to these methods, the PointNet can consume the raw points directly without altering the data representation, and it also employs an efficient and shared MLP to process the features on each point independently (i.e. pointwise CNN) and max-pooling operation, which can achieve real-time performances under constrained processing resources. Therefore, we choose the PointNet to build our proposal classification network, as shown in Fig. 4.
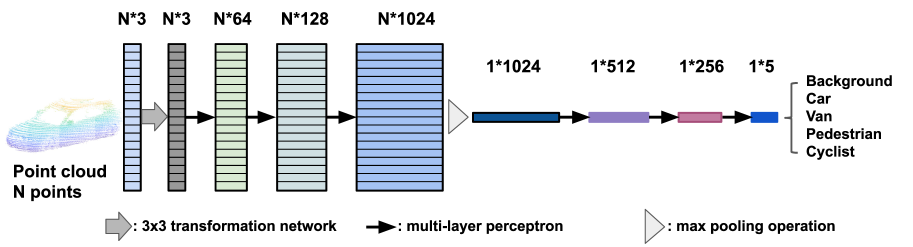
In terms of the classification model, the input consists of 3D coordinates along with points for one proposal. The raw point-cloud can be encapsulated int an matrix. The affine transformation on the point set (such as rotation) should not change the classification results for a geometric object. Therefore, a transformation matrix generated by a spatial transformer network is first learned to transform the input points in order to make the model invariant to certain transformations. This type of transformation matrix is known as input ’TNet’ [24]. The PointNet in [24] also include an feature transformation matrix to align the features, but this matrix and corresponding feature ’TNet’ is omitted in our classification model, as it increase a lot of computation with limited accuracy gain. To increase the channel features from to , three layers of MLP are applied with weights shared among all the point features. A max-pooling network is used to aggregate point features in order to generate global feature vector, and three layers of MLP are applied in order to decrease the channel features from to , then outputs the classification scores for classes: background, car, pedestrian, van, and cyclist. In addition, batch normalization [30] is applied to all layers via ReLU [31] and dropout layers [32] are used for the fully-connected neural network.
IV Parameters learning
The proposed method consists of two sets of parameters: the parameters () in the proposal segmentation model, and the weights () in the classification model. To learn , the PSO is applied, while gradient descent is employed to optimize . This section will cover the optimization of these parameters.
IV-A Proposal segmentation optimization
The parameters in the proposal segmentation model include the distance threshold for the line segmentation done in one scan, merging threshold between adjacent scans, and filtering distance to the ground plane. The objective of the proposed segmentation method is to achieve the highest possible recall of objects via using PSO to optimize parameters. The PSO searches the space of an objective function by adjusting the trajectories of individual agents, called particles. Every particle, , represents a solution, namely, in our case, and the objective function is the recall of objects, as shown in Equation (1).
| (1) |
where is the number of true positives, i.e. the correctly segmented objects, and is the number of false negatives, i.e. the missed objects.
The movement of a swarming particle consists of two components: the stochastic and deterministic movements. Each particle is attracted towards the position of a current global best and its own best location in history, while, at the same time, it tends to move randomly. For each iteration, the particle is updated by Equations (2) and (3). The pseudo-code of PSO can be found in E.
| (2) |
| (3) |
where , and are acceleration constants for different terms, and and are the random number used to simulate diversity in the quality solutions.
IV-B Classification model learning
Considering that the number of labels in the different categories is balanced, we define a naive classification loss function, i.e. negative log-likelihood loss, with the following equation:
| (4) |
where is the number of training samples in one batch, and is the predicted probability of belonging to the labelled class.
Since there exists a differentiable equation between the loss function (4) and parameters , the gradient-based optimization method can be used to optimize the parameters . The gradient descent method, i.e. AdamOptimizer [33], is applied to do the optimization in our classification model with an initial learning rate of 0.0002 and an exponential decay factor of 0.8 for every 18570 steps.
V Experimental results
V-A Implementation details
V-A1 Dataset
The KITTI benchmark dataset is adopted to validate our proposed method. It includes 7481 training pairs for the 3D LIDAR point cloud, RGB image, ground truth annotation, and calibration parameters. The optimization of the PSO and classification model training are conducted on this training dataset using different split ratios between the training and validation datasets.
V-A2 Detection method details
The offset distance to the detected ground plane for removing ground points is set to . For the task of clustering the point cloud, the in Euclidean-based clustering is assigned the value , and the and in the scan-based method are also specified as and , respectively. These parameters are optimized by the PSO. When calculating the objective fitness, i.e. recall value, the intersection over union (IoU) threshold for true positives is set to 0.25. For the ground removal, the user-defined ground ratio threshold for finding the ground height in every subregion is , and the width of bin in histogram is .
For the classification task, the number of points in one proposal is randomly sampled to 100 points, and all points are normalized by subtracting the central point from each other and then dividing this difference by the furthest distance from the center. All convolutional kernel sizes are in classification model, layers of CNNs are used to increase the channel number of features, and the corresponding feature maps sizes are , and . After the max-pooling operation, layers of fully connected networks compress the feature ( to ) through two middle features ( and ).
V-A3 Hardware platform
The processors in our hardware platform are 8 Intel(R) X-
eon(R) CPU E5-1620 v3 @ 3.50GHz, and every core has 2 threads. The memory capacity is 16 Gigabyte. The GPU card is a NVIDIA TITAN Xp with a 12 Gigabyte memory. Because this efficient detection method is proposed for robots with limited processing capabilities, we set an affinity mask to restrict our code to one core when generating the experimental data to make sure that our method can run well on small or medium robot platforms.
V-B Ground removal
In order to compare our ground removal approach with R-
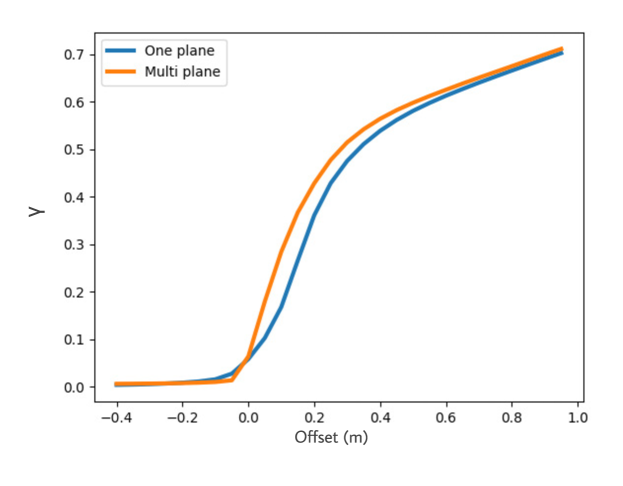
ANSAC qualitatively, we set up a criterion , i.e. the ratio between the number of removed points and the number of all points , see Equation (5). The majority of points can be removed if the plane fits the real landscape of the ground plane. Therefore, given the same offset distance to the detected ground plane, the higher is, the more effective the method is at removing the ground points. The qualitative experimental results and visualization of the ground removal performance can be found in Fig. 5 and 6.
| (5) |
The is calculated by averaging all the ratio values of point clouds randomly selected from the training dataset. From Fig. 5, we can see that, when the offset distance is small, such as , the ratio for the proposed method is higher than that for RANSAC. This finding validates the effectiveness of the proposed method, as it can effectively remove more points on the ground surface and match the detected ground planes of the real landscape. In the case of a larger offset, it does not matter whether the detected plane fits the landscape closely or not. Thus, the ratios of the two methods converge towards each other.
V-C Proposal generation
| Method modality | Recall(%) | Number | Time (s) |
| Clustering_1+Filtering | 92.9 | 55 | 0.038 |
| Clustering_1 | 94.0 | 146 | 0.032 |
| Clustering_2+Filtering | 93.3 | 78 | 2.351 |
| Clustering_2 | 94.5 | 212 | 2.344 |
| Clustering_1 uses the scan-based clustering method, and clustering_2 uses the distance-based approach (the time spent removing the ground is also included in clustering), the second column indicates the average recall value for each combination, and the third column lists the average number of proposals produced by each combination. | |||
In order to make experimental data, which is meaningful for robots with limited processing capabilities, we force our code into one core when running the experiments. Proposal generation consists of three steps: ground removal, clustering, and proposal filtering. For the scan-based clustering method, the processing times for these steps are , , and , respectively. More experimental data is presented in Table I, which shows that the scan-based method is much faster than the distance-based one. The distance-based method is slower because it calculates the distances from one point to all available points and searches a large number of adjacent points in each iteration. The performance of the proposal generation is very similar to that of the distance-based method, since both of them employ distance as the discriminative criterion regardless of the clustering mechanism used.

The proposal generation method with clustering has a higher recall (%) and three times the number of proposals compared to the combination of clustering and filtering, since the filtering procedure can filter out a number of false positives and reduce the number of proposals. However, it also removes some true positives and leads to a decrease in the recall value. In terms of the processing time, the clustering takes up to , while the filtering only consumes and can decrease the number of proposals greatly. A large number of proposals will require a long processing time for the next classification task. Therefore, for a task involving limited computational resources, the filtering procedure is very important for achieving a real-time performance.
| Method | Modality | Recall(%) | Number of proposal | Processing time (s) | |
| GPU | CPU | ||||
| Clustering+Filtering+Classification | Lidar | 92.9 | 55 | 0.041 | |
| Clustering+Classification | Lidar | 94.0 | 146 | 0.035 | |
| AVOD-FPN [14] | Lidar+Camera | 95.2 | 100 | 0.1 | 3.6 |
| Voxelnet [23] | Lidar | – | – | 0.23 | 5.9 |
| SECOND [10] | Lidar+Camera | – | – | 0.05 | 4.8 |
| MV3D [22] | Lidar+Camera | 94.4 | 50 | 0.36 | 11.6 |
| The third column lists the average recall values at IoU threshold of 0.25 and the fourth column contains the average number of proposals produced by the method; the times spent on the GPU and CPU are the average times spent processing one point cloud; the time with ∗ is generated with only one core of CPU, otherwise, the 8 cores of CPU are used to report the time. The clustering method used is scan-based clustering. indicates unavailable data. | |||||
To enhance the performance of the proposal generation me-
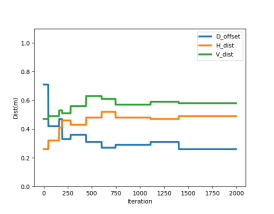
thod, , , and , are optimized using the PSO algorithm. For every generation in the PSO, the recall value is calculated by running the proposal generation algorithm through training samples randomly selected from the entire training dataset. A total of 1000 generation and 50 particles are set for optimization. The convergences of the recall value and all parameters are illustrated in Fig. 7. All parameters are randomly initialized between and . From Fig. 7 (b), we can see that the parameters fluctuate at the beginning, then slowly converge to their optimal values. Since these parameters are constrained by each other, the combination of parameter values will decide the final fitness value. All parameter convergences fluctuate instead of moving in one direction. The convergence graph shows that the best values for , , and are , , and , respectively.
V-D Classification model
To reduce the overfitting and generalize the model, two basic techniques for data augmentation are introduced:
Rotation
Every point cloud in the entire block is rotated along the Z-axis and about the origin [0,0,0] by , where is drawn from the uniform distribution [-/4, /4].
Scaling
Similar to the global scaling operation used in image-based data augmentation, the whole point cloud block is zoomed in or out. The coordinates of the points in the whole block are multiplied by a random variable drawn from the uniform distribution [, ].
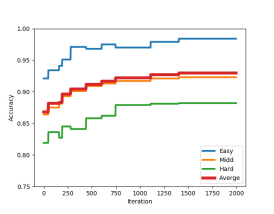
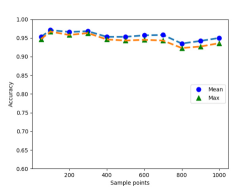
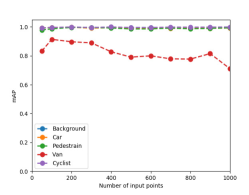
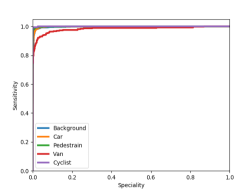
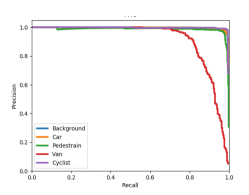
We have investigated how the number of sample points in a proposal affects the classification accuracy and demonstrate their relationship in Fig. 8 (a). It can be observed that the best accuracies of 0.971 (Maximum) and 0.967 (Mean) are achieved when 100 for one proposal. The classification performance could deteriorate if more points (such as 1000 or more) are added to a proposal. The training samples contains 18000 background objects, i.e. 14357 cars, 1297 vans, 734 cyclists, and 2207 pedestrians, and Fig. 8 (b), (d), and, (e) show the mean Average Precision (mAP) curve, the Receiver Operating Characteristic (ROC) curve, and the Precision-Recall Curve (PRC), respectively, for these samples. These curves demonstrate the detailed classification performance of our model for every class. It can be seen that the classification performance for vans is worse than those for other classes. Furthermore, the scores for the background, car, pedestrian, and cyclist are similar. The shape of the van is similar to that of the car, while the number of vans in the training sample is much smaller than the number of the car. Therefore, the classification model for identifying the van cannot be well-trained, leading to the poor classification performance for the van class. As for the cyclist class, even though the number of cyclists in the training sample is small, the shape of this class is distinct from those of other classes, which makes it easy for the classification model to capture its features. Thus, the model achieves a good classification performance for the cyclist class.
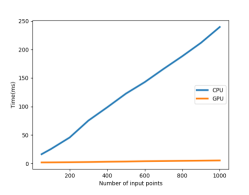
The running time for processing proposals versus different numbers of input points can be found in Fig 8 (c). The implementation time for the CPU increases almost linearly with the number of sample points, while the GPU time is almost constant around due to the parallel computations. We find that it takes to process proposals with points, making it feasible to run our classification model on the CPU-only hardware platform in real-time.
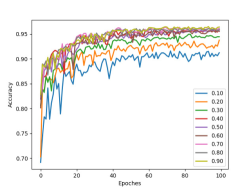
To capture how many data points are needed to train our model, we split the dataset into training and testing sets using different ratios, and the results can be found in Fig. 8 (f). For this experiment, the number of points per proposal is 100, and we find that the classification performances are similar when the split ratio is larger than 0.3. Other end-to-end training detection methods, such as SECOND [10] and 3DBN [26], require a minimum 0.5 split ratio to guarantee consistent performance. In comparison, our framework for detection required less training data and had better capability in generalization because most of the background is removed by the segmentation algorithm, and most of the noise is peeled off, making it easier for this classification model to learn different classes.
V-E Overall performance
To evaluate the performance, we assemble two sub-modules, i.e. proposal generation and classification, together into an object detection method. In Fig. 9, the overall detection performance is presented111More visuliazaiton results can be found in vedios: https://youtu.be/poSbDQ1LCR0, https://youtu.be/7C4kOnLrtig, https://youtu.be/QhXHMC4wsMc, https://youtu.be/LrXg3J_4FKY. It can be observed that we can find bounding boxes which fit nearby objects well, but the bounding boxes are much smaller than the real sizes of the objects that are far away from the Lidar. For instance, in the top middle image, the 2D bounding boxes for cars, which are far away, only cover the bottom halves of these cars because the density of points on the surface of the object is inversely proportional to the distance between the object and Lidar. The proposal of a nearby object includes a number of points and these points can represent its real shape, while, for a far object, there are only a small number of points and only a part of the object can be captured.
The comparison of the computational efficiency of our met-
hod with other 3D detection methods is provided in Table II, which shows that the proposed method is much faster than other existing methods and can achieve a real-time performance on either a GPU ( ) or CPU ( ) hardware platform. As for the performance of the object proposal, AVOD-FPN [14] and MV3D [22] can obtain better recall value than ours, but their efficiency is very low, especially on the CPU platform, since they employ the CNN backbone networks to extract features images for generating proposals.
VI Conclusion
In this paper, we have designed an efficient 3D object detection approach for robots with limited computational resources consisting of proposal generation and a lightweight classification model. The existing deep learning-based 3D object detection methods can achieve the desired detection performance but require the robots to equipped with a powerful processing unit, which is impossible in many small robots. In comparison to existing deep-learning techniques, the proposed method can achieve competitive recall values and classification accuracies. Most conspicuously, the proposed method has the capability of detection in real-time with either a GPU or CPU. In future work, we intend to fuse our work with a semantic segmentation task and combine the information from different resources for some complicated tasks, such as instance segmentation.
VII Acknowledgment
The presented research was supported by the China Scholarship Council (Grant No. 201606950019).
References
- [1] C. Urmson, J. Anhalt, D. Bagnell, C. Baker, R. Bittner, M. Clark, J. Dolan, D. Duggins, T. Galatali, C. Geyer et al., “Autonomous driving in urban environments: Boss and the urban challenge,” Journal of Field Robotics, vol. 25, no. 8, pp. 425–466, 2008.
- [2] A. G. Ozkil, Z. B. Fan, S. Dawids, H. Aanes, J. K. Kristensen, and K. H. Christensen, “Service robots for hospitals: A case study of transportation tasks in a hospital,” IEEE International Conference on Automation and Logistics, pp. 289–294, 2009.
- [3] A. Geiger, M. Lauer, C. Wojek, C. Stiller, and R. Urtasun, “3D traffic scene understanding from movable platforms,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, pp. 1012–1025, 2014.
- [4] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in IEEE conference on computer vision and pattern recognition. IEEE, 2009, pp. 248–255.
- [5] X. Li., N. Kwok., J. E. Guivant., K. Narula., R. Li., and H. Wu., “Detection of imaged objects with estimated scales,” in Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications - Volume 5: VISAPP,, INSTICC. SciTePress, 2019, pp. 39–47.
- [6] A. Dai, A. X. Chang, M. Savva, M. Halber, T. A. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3D reconstructions of indoor scenes,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2432–2443, 2017.
- [7] I. Rish, “An empirical study of the naïve Bayes classifier,” IJCAI 2001 Work Empir Methods Artif Intell, vol. 3, 01 2001.
- [8] M. A. Hearst, “Support vector machines,” IEEE Intelligent Systems, vol. 13, no. 4, pp. 18–28, Jul. 1998.
- [9] B. Graham, M. Engelcke, and L. van der Maaten, “3D semantic segmentation with submanifold sparse convolutional networks,” IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9224–9232, 2017.
- [10] Y. Yan, Y. Mao, and B. Li, “SECOND: Sparsely embedded convolutional detection,” Journal of Sensors, vol. 18, no. 10, 2018.
- [11] B. Li, T. Zhang, and T. Xia, “Vehicle detection from 3D Lidar using fully convolutional network,” arXiv preprint arXiv:1608.07916, 2017.
- [12] A. Robledo, S. Cossell, and J. Guivant, “Outdoor ride: Data fusion of a 3D kinect camera installed in a bicycle,” in Proceedings of Australasian Conference on Robotics and Automation, Australia, 05 2011.
- [13] N. M. Kwok, Q. P. Ha, D. Liu, G. Fang, and K. C. Tan, “Efficient particle swarm optimization: a termination condition based on the decision-making approach,” IEEE Congress on Evolutionary Computation, pp. 3353–3360, 2007.
- [14] J. Ku, M. Mozifian, J. Lee, A. Harakeh, and S. L. Waslander, “Joint 3D proposal generation and object detection from view aggregation,” IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1–8, 2017.
- [15] M. Himmelsbach, F. von Hundelshausen, and H.-J. Wünsche, “Fast segmentation of 3D point clouds for ground vehicles,” IEEE Intelligent Vehicles Symposium, pp. 560–565, 2010.
- [16] F. Moosmann, O. Pink, and C. Stiller, “Segmentation of 3D Lidar data in non-flat urban environments using a local convexity criterion,” IEEE Intelligent Vehicles Symposium, pp. 215–220, 2009.
- [17] B. Douillard, J. Underwood, N. Kuntz, V. Vlaskine, A. Quadros, P. Morton, and A. Frenkel, “On the segmentation of 3D Lidar point clouds,” in IEEE International Conference on Robotics and Automation, May 2011, pp. 2798–2805.
- [18] D. Held, D. Guillory, B. Rebsamen, S. Thrun, and S. Savarese, “A probabilistic framework for real-time 3D segmentation using spatial, temporal, and semantic cues,” in Robotics: Science and Systems (RSS), June 2016.
- [19] D. Zermas, I. Izzat, and N. Papanikolopoulos, “Fast segmentation of 3D point clouds: A paradigm on Lidar data for autonomous vehicle applications,” in IEEE International Conference on Robotics and Automation (ICRA), May 2017, pp. 5067–5073.
- [20] A. Teichman, J. Levinson, and S. Thrun, “Towards 3D object recognition via classification of arbitrary object tracks,” IEEE International Conference on Robotics and Automation, pp. 4034–4041, 2011.
- [21] D. Z. Wang and I. Posner, “Voting for voting in online point cloud object detection.” in Robotics: Science and Systems, 2015.
- [22] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3D object detection network for autonomous driving,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6526–6534, 2016.
- [23] Y. Zhou and O. Tuzel, “Voxelnet: End-to-end learning for point cloud based 3D object detection,” IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4490–4499, 2017.
- [24] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3D classification and segmentation,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 77–85, 2016.
- [25] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” arXiv preprint arXiv:1706.02413, 2017.
- [26] X. Li, J. Guivant, N. Kwok, Y. Xu, R. Li, and H. Wu, “Three-dimensional backbone network for 3D object detection in traffic scenes,” CoRR, vol. abs/1901.08373, 2019.
- [27] B. Graham and L. van der Maaten, “Submanifold sparse convolutional networks,” arXiv preprint arXiv:1706.01307, 2017.
- [28] B. Graham, “Sparse 3D convolutional neural networks,” in Proceedings of Conference on the British Machine Vision Association (BMVA), 2015, pp. 150.1–150.9.
- [29] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the KITTI vision benchmark suite,” in Computer Vision and Pattern Recognition (CVPR). IEEE, 2012, pp. 3354–3361.
- [30] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37, 2015, pp. 448–456.
- [31] V. Nair and G. E. Hinton, “Rectified linear units improve restricted Boltzmann machines,” in Proceedings of the 27th International Conference on International Conference on Machine Learning, ser. ICML’10. USA: Omnipress, 2010, pp. 807–814.
- [32] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,” J. Mach. Learn. Res., vol. 15, no. 1, pp. 1929–1958, Jan. 2014.
- [33] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” International Conference on Learning Representations, vol. abs/1412.6980, 12 2014.
Appendix A Ground removal algorithm
| : | the width of whole region; |
| : | the length of whole region; |
| : | the width of sub region; |
| : | the height of sub region; |
| : | all points in the format [x, y, z] with the size ; |
| : | |
| the minimum number of points in ground bin; | |
| : | |
| the width of bin in the histogram; | |
| : | |
| the function of getting all points in given sub_region; | |
| : | |
| the function to build histogram; | |
| : | |
| the function to compare the height in neighbourhood and return the lowest height value; |
Appendix B 3D point cloud clustering based on Euclidean distance
| : | the minimum distance threshold; |
| : | all the point cloud, ; |
| : | distance calculation, ; |
Appendix C 3D point cloud clustering based on scan order
| : | minimum distance threshold insider one scan; |
| : | minimum distance threshold between two scans; |
| : | all the point cloud, ; |
| : | |
| minimum number of connected points between two segments; | |
| : | |
| find all segments in one scan with the distance threshold ; | |
| : | |
| distance calculation between two segments; |
Appendix D Occlusion labelling algorithm
| : | angle difference threshold to decide whether two adjacent clusters are occluded or not; |
| : | all the clusters which are used to be labeled with occlusion or not; |
| : | |
| function to calculate all the angle with respective to original point; | |
| : | |
| function to calculate the mean range of one cluster; | |
| : | |
| function to build the symmetric matrix about angle overlap; | |
| : | |
| function to build the symmetric matrix about range difference; |
Appendix E Particle swarm optimization
| : | number of iterations; |
| : | number of particles; |
| : | domain of particle search |
| : | recall calculation function; |
| : | initialization function for all particles; |
| : | |
| proposal generation function; |