webOnline Artefacts
Ranking Computer Vision Service Issues using Emotion
Abstract.
Software developers are increasingly using machine learning APIs to implement ‘intelligent’ features. Studies show that incorporating machine learning into an application increases technical debt, creates data dependencies, and introduces uncertainty due to non-deterministic behaviour. However, we know very little about the emotional state of software developers who deal with such issues. In this paper, we do a landscape analysis of emotion found in 1,245 Stack Overflow posts about computer vision APIs. We investigate the application of an existing emotion classifier EmoTxt and manually verify our results. We found that the emotion profile varies for different question categories.
1. Introduction
Recent advances in artificial intelligence have provided software engineers with new opportunities to incorporate complex machine learning capabilities, such as computer vision, through cloud based ‘intelligent’ web services. These new set of services, typically offered as API calls are marketed as a way to reduce the complexity involved in integrating AI-components. However, recent work shows that software engineers struggle to use these intelligent services (Cummaudo et al., 2019a). Furthermore, the accompanying documentation fails to address common issues experienced by software engineers and, often, engineers resort to online communication channels, such as, JIRA and Stack Overflow (SO) to seek advice from their peers (Cummaudo et al., 2019a). While seeking advice on the issues, software engineers tend to express their emotions (such as frustration or confusion) within the questions. Recognising the value of considering emotions, other researchers have investigated emotions expressed by software developers within communication channels (Ortu et al., 2016) including Stack Overflow (SO) (Novielli et al., 2018; Calefato et al., 2018); the broad motivation of these works is to generally understand the emotional landscape and improve developer productivity (Murgia et al., 2014; Ortu et al., 2016; Gachechiladze et al., 2017). However, previous works have not directly focused on the nature of emotions expressed in questions related to intelligent web services. We also do not know if certain types of questions express stronger emotions. The machine-learnt behaviour of these cloud intelligent services is typically non-deterministic and, given the dimensions of data used, their internal inference process is hard to reason about (Cummaudo et al., 2019b). Compounding the issue, documentation of these cloud systems does not explain the limits, nor how they were created (esp. data sets used to train them). This lack of transparency makes it difficult for even senior developers to properly reason about these systems, so their prior experience and anchors do not offer sufficient support (Cummaudo et al., 2019a). In addition, adding machine learned behaviour to a system incurs ongoing maintenance concerns (Sculley et al., 2015). There is a need to better understand emotions expressed by developers to inform cloud vendors and help them improve their documentation and error messages provided by their services. This work builds on top of recent work that explored what pain-points developers face when using intelligent services through a general analysis of 1,425 SO posts (questions) (Cummaudo et al., 2019a) using an existing SO issue classification taxonomy (Beyer et al., 2018). In this work, we consider the emotional state expressed within these pain-points, using the same data set of 1,425 SO posts. We identify the emotions in each SO question, and investigate if the distribution of these emotions is similar across the various types of questions. In order to classify emotions from SO posts, we use EmoTxt, a recently proposed toolkit for emotion recognition from text (Novielli et al., 2018; Calefato et al., 2017; Calefato et al., 2018). EmoTxt has been trained and built on SO posts using the emotion classification model proposed by Shaver et al. (1987). The category of issue was manually determined in our prior work.
The key findings of our study are:
-
•
The distribution of emotions is different across the taxonomy of issues.
-
•
A deeper analysis of the results, obtained from the EmoTxt classifier, suggests that the classification model needs further refinement. Love and joy, the least expected emotions when discussing API issues, are visible across all categories.
In order to promote future research and permit replication, we make our data set publicly available.111See http://bit.ly/2RiULgW. The paper structure is as follows: section 2 provides an overview on prior work surrounding the classification of emotions from text; section 3 describes our research methodology; section 4 presents the results from the EmoTxt classifier; section 5 provides a discussion of the results obtained; section 6 outlines the threats to validity; section 7 presents the concluding remarks.
2. Emotion Mining from Text
Several studies have investigated the role of emotions generally in software development (Wrobel, 2013; Shaw, 2003; Ortu et al., 2016; Gachechiladze et al., 2017). Work in the area of behavioural software engineering established the link between software developer’s happiness and productivity (Graziotin et al., 2017). Wrobel (Wrobel, 2013) investigated the impact that software developers’ emotion has on the development process and found that frustration and anger were amongst the emotions that posed the highest risk to developer’s productivity. Recent studies focused on emotion mining from text within communication channels used by software engineers to communicate with their peers (Murgia et al., 2014; Ortu et al., 2016; Gachechiladze et al., 2017; Novielli et al., 2018). Murgia et al. (2014) and Ortu et al. (2016) investigated the emotions expressed by developers within an issue tracking system, such as JIRA, by labelling issue comments and sentences written by developers using Parrott’s framework. Gachechiladze et al. (2017) applied the Shaver framework to detect anger expressed in comments written by developers in JIRA. The Collab team (Calefato et al., 2017; Novielli et al., 2018) extended the work done by Ortu et al. (2016) and developed a gold standard data set collected from SO posts consisting of questions, comments and feedback. This data set was manually annotated using the Shaver’s emotion model. The Shaver’s model consists of a tree-structured, three level, hierarchical classification of emotions. The top level consists of six basic emotions namely, love, joy, anger, sadness, fear and surprise (Shaver et al., 1987). The subsequent levels further refines the granularity of the previous level. One of their recent work (Novielli et al., 2018) involved 12 raters to manually annotate 4,800 posts (where each post included the question, answer and comments) from SO. The same question was assigned to three raters to reduce bias and subjectivity. Each coder was requested to indicate the presence/absence of each of the six basic emotions from the Shaver framework. As part of their work they developed an emotion mining toolkit, EmoTxt (Calefato et al., 2017). The work conducted by the Collab team is most relevant to our study since their focus is on identifying emotion from SO posts and their toolkit is trained on a large data set of SO posts.
3. Methodology
As mentioned in our introduction, this paper uses the data set reported in Cummaudo et al.’s ICSE 2020 paper (Cummaudo et al., 2019a). As this paper is in press, we reproduce a summary of the methodology used in constructing this data set methodology below. For full details, we refer to the original paper. Supplementary materials used for this work are provided for replication.11footnotemark: 1 Our research methodology consisted of the following steps: (i) data extraction from Stack Overflow resulting in 1,425 questions about intelligent computer vision services; (ii) question classification using the taxonomy presented by Beyer et al. (2018); (iii) automatic emotion classification using EmoTxt based on Shaver et al.’s emotion taxonomy (Shaver et al., 1987); and (iv) manual classification of 25 posts to better understand developers emotion. We calculated the inter-rater reliability between EmoTxt and our manually classified questions in two ways: (i) to see the overall agreement between the three raters in applying the Shaver et al. emotions taxonomy, and (ii) to see the overall agreement with EmoTxt’s classifications. Further details are provided below.
3.1. Data Set Extraction from SO
3.1.1. Intelligent Service Selection
We contextualise this work within popular computer vision service providers: Google Cloud \citepwebGoogleCloud:Home, AWS \citepwebAWS:Home, Azure \citepwebAzure:Home and IBM Cloud \citepwebIBM:Home. We chose these four providers given their prominence and ubiquity as cloud service vendors, especially in enterprise applications (RightScale Inc., 2018). We acknowledge other services beyond the four analysed which provide similar capabilities \citepwebPixlab:Home,Clarifai:Home,Cloudsight:Home,DeepAI:Home,Imagaa:Home,Talkwaler:Home. Additionally, only English-speaking services have been selected, excluding popular computer vision services from Asia (e.g., \citepwebMegvii:Home,TupuTech:Home,YiTuTech:Home,SenseTime:Home,DeepGlint:Home).
3.1.2. Developing a search query
To understand the various ways developers refer to these services, we needed to find search terms that are commonplace in question titles and bodies that discuss the service names. One approach is to use the Tags feature in SO. To discover which tags may be relevant, we ran a search222The query was run on January 2019. within SO against the various brand names of these computer vision services, reviewed the first three result pages, and recorded each tag assigned per question.333Up to five tags can be assigned per question. However, searching using tags alone on SO is ineffective (see (Tahir et al., 2018; Barua et al., 2014)). To overcome this limitation, we ran a second query within the Stack Exchange Data Explorer444http://data.stackexchange.com/stackoverflow (SEDE) using these tags, we sampled 100 questions (per service), and noted the permutations in how developers refer to each service555E.g., misspellings, misunderstanding of brand names, hyphenation, UK vs. US English, and varied uses of apostrophes, plurals, and abbreviations.. We noted 229 permutations.
3.1.3. Executing our search query
Next, we needed to extract questions that make reference to any of these 229 permutations. SEDE has a 50,000 row limit and does not support case-insensitivity, however Google’s BigQuery does not. Therefore, we queried Google’s SO dataset on each of the 229 terms that may occur within the title or body of question posts,666See http://bit.ly/2LrN7OA. which resulted in 21,226 questions.
3.1.4. Refining our inclusion/exclusion criteria
To assess the suitability of these questions, we filtered the 50 most recent posts as sorted by their CreationDate values. This helped further refine the inclusion and exclusion criteria: for example, certain abbreviations in our search terms (e.g., ‘GCV’, ‘WCS’777Watson Cognitive Services) allowed for false positive questions to be included, which were removed. Furthermore, we consolidated all overlapping terms (e.g., ‘Google Vision API’ was collapsed into ‘Google Vision’) to enhance the query. Additionally, we reduced our 221 search terms to just 27 search terms by focusing on computer vision services only888Our original data set aimed at extracting posts relevant to all intelligent services, and not just computer vision services. However, 21,226 questions were too many to assess without automated analysis, which was beyond the scope of our work. which resulted in 1,425 questions. No duplicates were recorded as determined by the unique ID, title and timestamp of each question.
3.1.5. Manual filtering
The next step was to assess the suitability and nature of the 1,425 questions extracted. The second author ran a manual check on a random sample of 50 posts, which were parsed through a templating engine script999We make this available for future use at: http://bit.ly/2NqBB70. in which the ID, title, body, tags, created date, and view, answer and comment counts were rendered for each post. Any match against the 27 search terms in the title or body of the post were highlighted, in which three false positives were identified as either library imports or stack traces, such as aws-java-sdk-rekognition:jar. In addition, we noted that there were false positive hits related to non-computer vision services. We flagged posts of such nature as ‘noise’ and removed them from further classification.
| Dimension | Our Interpretation |
|---|---|
| API usage | Issue on how to implement something using a specific component provided by the API |
| Discrepancy | The questioner’s expected behaviour of the API does not reflect the API’s actual behaviour |
| Errors | Issue regarding an error when using the API, and provides an exception and/or stack trace to help understand why it is occurring |
| Review | The questioner is seeking insight from the developer community on what the best practices are using a specific API or decisions they should make given their specific situation |
| Conceptual | The questioner is trying to ascertain limitations of the API and its behaviour and rectify issues in their conceptual understanding on the background of the API’s functionality |
| API change | Issue regarding changes in the API from a previous version |
| Learning | The questioner is seeking for learning resources to self-learn further functionality in the API, and unlike discrepancy, there is no specific problem they are seeking a solution for |
3.2. Question Type & Emotion Classification
3.2.1. Manual classification of question category
We classify our 1,425 posts using Beyer et al.’s taxonomy (Beyer et al., 2018) as it was comprehensive and validated (Cummaudo et al., 2019a). We split the posts into 4 additional random samples, in addition to the random sample of 50 above. 475 posts were classified by the second author and three other research assistants101010Software engineers in our research group with at least 2 years industry experience classified the remaining 900 (i.e., a total of 1,375 classifications). An additional 450 classifications were assigned due to reliability analysis, in which the remaining 50 posts were classified nine times by various researchers in our group.111111Due to space limitations, reliability analysis is omitted and is reported in (Cummaudo et al., 2019a). Due to the nature of reliability analysis, multiple classifications (450) existed for these 50 posts. Therefore, we applied a ‘majority rule’ technique to each post allowing for a single classification assignment and therefore analysis within our results. When there was a majority then we used the majority classification; when there was a tie, then we used the classification that was assigned the most out of the entire 450 classifications. As an example, 3 raters classified a post as API Usage, 1 rater classified the same post as a Review question and 5 raters classified the post as Conceptual, resulting in the post being classified as a Conceptual question. For another post, three raters assigned API Usage, Discrepancy and Learning (respectively), while 3 raters assigned Review and 3 raters assigned Conceptual. In this case, Review and Conceptual were tied, but was resolved down to Conceptual as this classification received 147 more votes than Review across all classifications made in the sample of 50 posts. However, where a post was extracted from our original 1,425 posts but was either a false positive, not applicable to intelligent services (see section 3.1.5), or not applicable to a taxonomy dimension/category, then the post was flagged for removal in further analysis. This was done 180 times, leaving a total of 1,245 posts.
3.2.2. Emotion classification using ML techniques
After extracting and classifying all posts, we then piped in the body of each question into a script developed to remove all HTML tags, code snippets, blockquotes and hyperlinks, as suggested by Novielli et al. (2018). We replicated and extended the study conducted by Novielli et al. (2018) on our data set derived from 1,425 SO posts, consisting of questions only. Our study consisted of three main steps, namely, (1) automatic emotion classification using EmoTxt, (2) manual annotation process and, (3) comparison of the automatic classification result with the manually annotated data set.
3.2.3. Emotion classification using EmoTxt
We started with a file containing 1,245 non-noise SO questions, each with an associated question type as classified using the strategy discussed in section 3.2.1. We pre-processed this file by extracting the question ID and body text to meet the format requirements of the EmoTxt classifier (Calefato et al., 2017). This classifier was used as it was trained on SO posts as discussed in Section 2. We ran the classifier for each emotion as this was required by EmoTxt model. This resulted in 6 output prediction files (one file for each emotion: Love, Joy, Surprise, Sadness, Fear, Anger). Each question within these files referenced the question ID and a predicted classification (YES or NO) of the emotion. We then merged the emotion prediction files into an aggregate file with question text and Beyer et al.’s taxonomy classifications. This resulted in 796 emotion classifications. We further analysed the classifications and generated an additional classification of No Emotion for the 622 questions where EmoTxt predicted NO for all the emotion classification runs. Of the 796 questions with emotion detected, 143 questions had 2 or more emotions predicted: 1 question121212See http://stackoverflow.com/q/55464541. had up to 4 emotions detected (Surprise, Sadness, Joy and Fear), 28 questions had up to 3 emotions detected, and the remaining 114 had up to two emotions detected.
3.2.4. Manual Annotation Process
In order to evaluate and also better understand the process used by EmoTxt to classify emotions, we manually annotated a small sample of 25 SO posts, randomly selected from our data set. Each of these 25 posts were assigned to three raters who carried out the following three steps: (i) identify the presence of an emotion; (ii) if an emotion(s) exists, classify the emotion(s) under one of the six basic emotions proposed by the Shaver framework (Shaver et al., 1987); (iii) if no emotion is identified, annotate as neutral. We then collated all rater’s results and calculated Light’s Kappa () (Light, 1971) to measure the overall agreement between raters to measure the similarity in which independent raters classify emotions to SO posts. As does not support multi-class classification (i.e., multiple emotions) per subjects (i.e., per SO post), we binarised the results each emotion and rater as TRUE or FALSE to indicate presence, calculated the per emotion against the three raters, and averaged the result across all emotions to get an overall strength of agreement.
3.2.5. Comparing EmoTxt results with the results from Manual Classification
The next step involved comparing the ratings of the 25 SO posts that were manually annotated by the three raters with the results obtained for the same set of 25 SO posts from the EmoTxt classifier. Similar to section 3.2.4, we used Cohen’s Kappa () (Cohen, 1960) to measure the consistency of classifications of EmoTxt’s classifications versus the manual classifications of each rater. We separated the classifications per emotion and calculated for each rater against EmoTxt and averaged these values for all emotions. After noticing poor results, the three raters involved in section 3.2.4 were asked to compare and discuss the ratings from the EmoTxt classifier against the manual ratings. The findings from this process are presented and discussed in the next two sections.
4. Findings

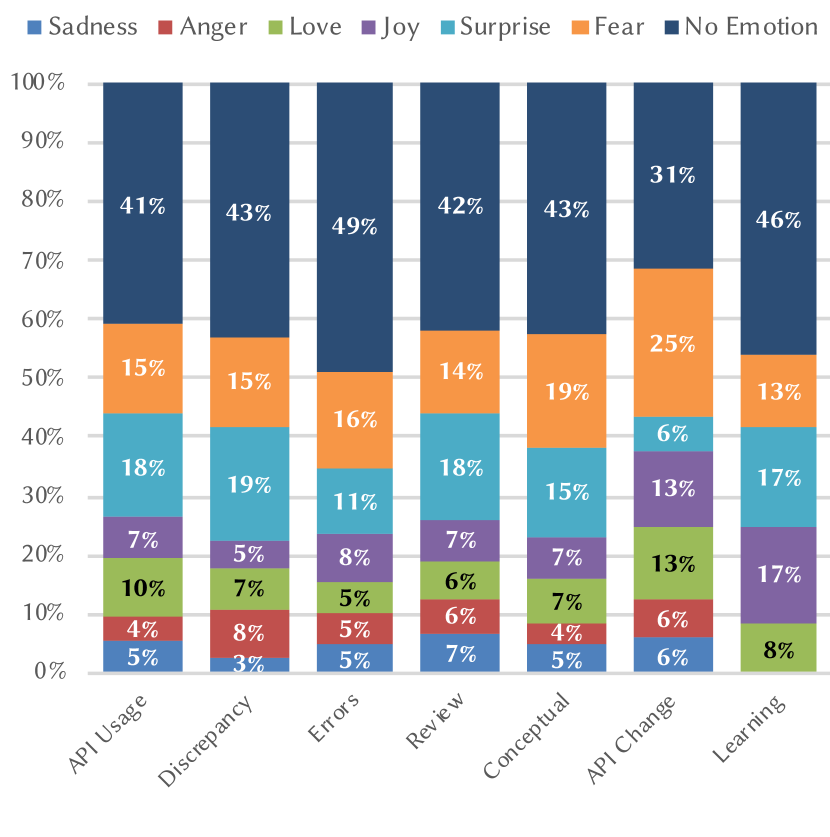
Figure 1 displays the overall distribution of question types from the 1,245 posts classified in (Cummaudo et al., 2019a), when adjusted for majority ruling as per section 3.2.1. It is evident that developers ask issues predominantly related to API errors when using computer vision services and, additionally, how they can use the API to implement specific functionality. There are few questions related to version issues or self-learning.
| Question Type | Fear | Joy | Love | Sadness | Surprise | Anger | No Emotion | Total |
|---|---|---|---|---|---|---|---|---|
| API Usage | 50 | 22 | 34 | 18 | 59 | 13 | 135 | 331 |
| Discrepancy | 38 | 12 | 18 | 7 | 48 | 20 | 108 | 251 |
| Errors | 69 | 34 | 22 | 21 | 48 | 23 | 206 | 423 |
| Review | 34 | 16 | 15 | 16 | 42 | 14 | 98 | 235 |
| Conceptual | 26 | 10 | 10 | 7 | 21 | 5 | 59 | 138 |
| API Change | 4 | 2 | 2 | 1 | 1 | 1 | 5 | 16 |
| Learning | 3 | 4 | 2 | 0 | 4 | 0 | 11 | 24 |
| Total | 224 | 100 | 103 | 70 | 223 | 76 | 622 | 1418 |
Table 2 displays the frequency of questions that were classified by EmoTxt when compared to our assignment of question types, while fig. 2 presents the emotion data proportionally across each type of question. No Emotion was the most prevalent across all question types, which is consistent with the findings of the Collab group during the training of the EmoTxt classifier. Interestingly, API Change questions had a distinct distribution of emotions, where 31.25% of questions had No Emotion compared to the average of 42.01%. This is likely due to the low sample size of API Change questions, with only 12 assignments, however the next highest set of emotive questions are found in the second largest sample (API Usage, at 59.21%) and so greater emotion detected is not necessarily proportional to sample size. Unsurprisingly, Discrepancy questions had the highest proportion of the Anger emotion, at 7.97%, compared to the mean of 4.74%, which is indicative of the frustrations developers face when the API does something unexpected. Love, an emotion which we expected least by software developers when encountering issues, was present across the different question types. The two highest emotions, by average, were Fear (16.67%) and Surprise (14.90%), while the two lowest emotions were Sadness (4.47%) and Anger (4.74%). Joy and Love were roughly the same and fell in between the two proportion ends, with means of 8.96% and 8.16%, respectively. Results from our reliability analysis showed largely poor results. Guidelines of indicative strengths of agreement are provided by Landis and Koch (1977), where is poor agreement, is slight agreement and is fair agreement. Our readings were indicative of poor agreement between raters () and slight agreement with EmoTxt (). The strongest agreements found were for No Emotion both between each of our three raters () and each rater and EmoTxt (), with fair and slight agreement respectively.
| ID | Quote | Classification | Emotion |
|---|---|---|---|
| 53249139 | “I’m trying to integrate my project with Google Vision API… I’m wondering if there is a way to set the credentials explicitly in code as that is more convenient than setting environment variables in each and every environment we are running our project on… I know for a former client version 1.22 that was possible… but for the new client API I was not able to find the way and documentation doesn’t say anything in that regards.” | API Usage | Fear |
| 40013910 | “I want to say something more about Google Vision API Text Detection, maybe any Google Expert here and can read this. As Google announced, their TEXT_DETECTION was fantastic… But for some of my pics, what happened was really funny… There must be something wrong with the text detection algorithm.” | Discrepancy | Anger |
| 50500341 | “I just started using PYTHON and now i want to run a google vision cloud app on the server but I’m not sure how to start. Any help would be greatly appreciated.” | API Usage | Sadness |
| 49466041 | “I am getting the following error when trying to access my s3 bucket… my hunch is it has something to do with the region…I have given almost all the permissions to the user I can think of…. Also the region for the s3 bucket appears to be in a place that can work with rekognition. What can I do?” | Errors | Surprise |
| 55113529 | ”Following a tutorial, doing everything exactly as in the video… Hoping to figure this out as it is a very interesting concept…Thanks for the help… I’m getting this error:…” | Errors | Joy |
| 39797164 | “Seems that the Google Vision API has moved on and the open Sourced version has not….In my experiments this ‘finds’ barcodes much faster than using the processor that the examples show. Am I missing something somewhere?” | API Change | Love |
5. Discussion
Our findings from the comparison between the manually annotated SO posts and the automatic classification revealed substantial discrepancies. Table 3 provide some sample questions from our data set and the emotion identified by EmoTxt within the text. A subset of questions analysed by our three raters do not indicate the automatic (EmoTxt) emotion, and upon manual inspection of the text after poor results from our reliability analysis, an introspection of the data set sheds some light to the discrepancy. For example, question 55113529 shows no indication of Joy, rather the developer is expressing a state of confusion. The phrase “Thanks for your help” could be the reason why the miss-classification occurred if words like “thanks” were associated with joy. However, in this case, it seems unlikely that the developer is expressing joy as the developer has followed a tutorial but is still encountering an error. Similarly, question 39797164, classified as Love and question 50500341, classified as Sadness express a state of confusion and the urge to know more about the product; upon inspecting the entire question in context, it is difficult to consistently agree with the emotions as determined by EmoTxt, and further exploration into the behaviour and limitations of the model is necessary. Our results indicate further work is needed to refine the ML classifiers that mine emotions in the SO context. The question that arises is whether the classification model is truly reflective of real-world emotions expressed by software developers. As highlighted by Curumsing (2017), the divergence of opinions with regards to the emotion classification model proposed by theorists raises doubts to the foundations of basic emotions. Most of the studies conducted in the area of emotion mining from text is based on an existing general purpose emotion framework from psychology (Bruna et al., 2016; Ortu et al., 2016; Novielli et al., 2018) – none of which are tuned for software engineering domain. In our our study, we note the emotions expressed by software developers within SO posts are quite narrow and specific. In particular, emotions such as frustration and confusion would be more appropriate over love and joy.
6. Threats to Validity
Internal validity:
The API Change and Learning question types were few in sample size (only 12 and 22 questions, respectively). The emotion proportion distribution of these question types are quite different to the others. Given the low number of questions, the sample is too small to make confident assessments. Furthermore, our assignment of Beyer et al.’s question type taxonomy was single-label; a multi-labelled approach may work better, however analysis of results would become more complex. A multi-labelled approach would be indicative for future work.
External validity:
EmoTxt was trained on questions, answers and comments, however our data set contained questions only. It is likely that our results may differ if we included other discussion items, however we wished to understand the emotion within developers’ questions and classify the question based on the question classification framework by Beyer et al. (2018). Moreover, this study has only assessed frustrations within the context of a concrete domain; intelligent computer vision services. The generalisability of this study to other intelligent services, such as natural language processing services, or conventional web services, may be different. Furthermore, we only assessed four popular computer vision services; expanding the data set to include more services, including non-English ones, would be insightful. We leave this to future work.
Construct validity:
Some posts extracted from SO were false positives. Whilst flagged for removal (section 3.1.5), we cannot guarantee that all false positives were removed. Furthermore, SO is known to have questions that are either poorly worded or poorly detailed, and developers sometimes ask questions without doing any preliminary investigation. This often results in down-voted questions. We did not remove such questions from our data set, which may influence the measurement of our results.
7. Conclusion
In this paper we analysed SO posts for emotions using an automated tool and cross-checked it manually. We found that the distribution of emotion differs across the taxonomy of issues, and that the current emotion model typically used in recent works is not appropriate for emotions expressed within SO questions. Consistent with prior work (Lin et al., 2018), our results demonstrate that machine learning classifiers for emotion are insufficient; human assessment is required.
References
- (1)
- Barua et al. (2014) Anton Barua, Stephen W Thomas, and Ahmed E Hassan. 2014. What are developers talking about? An analysis of topics and trends in Stack Overflow. Empirical Software Engineering 19, 3 (2014), 619–654.
- Beyer et al. (2018) Stefanie Beyer, Christian Macho, Martin Pinzger, and Massimiliano Di Penta. 2018. Automatically classifying posts into question categories on stack overflow. In the 26th Conference. ACM, Gothenburg, Sweden, 211–221.
- Bruna et al. (2016) Ondřej Bruna, Hakob Avetisyan, and Jan Holub. 2016. Emotion models for textual emotion classification. Journal of Physics: Conference Series 772 (11 2016), 012063. https://doi.org/10.1088/1742-6596/772/1/012063
- Calefato et al. (2018) Fabio Calefato, Filippo Lanubile, Federico Maiorano, and Nicole Novielli. 2018. Sentiment polarity detection for software development. Empirical Software Engineering 23, 3 (2018), 1352–1382.
- Calefato et al. (2017) Fabio Calefato, Filippo Lanubile, and Nicole Novielli. 2017. EmoTxt: a toolkit for emotion recognition from text. In 2017 Seventh International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW). IEEE, 79–80.
- Cohen (1960) Jacob Cohen. 1960. A coefficient of agreement for nominal scales. Educational and Psychological Measurement 20, 1 (1960), 37–46.
- Cummaudo et al. (2019a) Alex Cummaudo, Rajesh Vasa, Scott Barnett, John Grundy, and Mohamed Abdelrazek. 2019a. Interpreting Cloud Computer Vision Pain-Points: A Mining Study of Stack Overflow. In 42nd International Conference on Software Engineering (ICSE). Seoul, South Korea. (In Press).
- Cummaudo et al. (2019b) Alex Cummaudo, Rajesh Vasa, John Grundy, Mohamed Abdelrazek, and Andrew Cain. 2019b. Losing Confidence in Quality: Unspoken Evolution of Computer Vision Services. In 2019 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, Cleveland, OH, USA, 333–342.
- Curumsing (2017) Maheswaree Kissoon Curumsing. 2017. Emotion-Oriented Requirements Engineering. Ph.D. Dissertation. PhD dissertation. Swinburne University of Technology.
- Gachechiladze et al. (2017) Daviti Gachechiladze, Filippo Lanubile, Nicole Novielli, and Alexander Serebrenik. 2017. Anger and its direction in collaborative software development. In 2017 IEEE/ACM 39th International Conference on Software Engineering: New Ideas and Emerging Technologies Results Track (ICSE-NIER). IEEE, 11–14.
- Graziotin et al. (2017) Daniel Graziotin, Fabian Fagerholm, Xiaofeng Wang, and Pekka Abrahamsson. 2017. What happens when software developers are (un)happy. Journal of Systems and Software 140 (07 2017). https://doi.org/10.1016/j.jss.2018.02.041
- Landis and Koch (1977) J Richard Landis and Gary G Koch. 1977. The Measurement of Observer Agreement for Categorical Data. Biometrics 33, 1 (March 1977), 159–17.
- Light (1971) Richard J Light. 1971. Measures of response agreement for qualitative data: Some generalizations and alternatives. Psychological Bulletin 76, 5 (1971), 365–377.
- Lin et al. (2018) Bin Lin, Fiorella Zampetti, Gabriele Bavota, Massimiliano Di Penta, Michele Lanza, and Rocco Oliveto. 2018. Sentiment analysis for software engineering: How far can we go?. In Proceedings of the 40th International Conference on Software Engineering. 94–104.
- Murgia et al. (2014) Alessandro Murgia, Parastou Tourani, Bram Adams, and Marco Ortu. 2014. Do developers feel emotions? an exploratory analysis of emotions in software artifacts. In Proceedings of the 11th working conference on mining software repositories. ACM, 262–271.
- Novielli et al. (2018) Nicole Novielli, Fabio Calefato, and Filippo Lanubile. 2018. A gold standard for emotion annotation in stack overflow. In 2018 IEEE/ACM 15th International Conference on Mining Software Repositories (MSR). IEEE, 14–17.
- Ortu et al. (2016) Marco Ortu, Alessandro Murgia, Giuseppe Destefanis, Parastou Tourani, Roberto Tonelli, Michele Marchesi, and Bram Adams. 2016. The emotional side of software developers in JIRA. In Proceedings of the 13th International Conference on Mining Software Repositories. ACM, 480–483.
- RightScale Inc. (2018) RightScale Inc. 2018. RightScale 2018 State of the Cloud Report. Technical Report.
- Sculley et al. (2015) David Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, and Dan Dennison. 2015. Hidden technical debt in machine learning systems. In Advances in neural information processing systems. 2503–2511.
- Shaver et al. (1987) Phillip Shaver, Judith Schwartz, Donald Kirson, and Cary O’connor. 1987. Emotion knowledge: further exploration of a prototype approach. Journal of personality and social psychology 52, 6 (1987), 1061.
- Shaw (2003) Mary Shaw. 2003. Writing good software engineering research papers. In 25th International Conference on Software Engineering, 2003. Proceedings. IEEE, 726–736.
- Tahir et al. (2018) Amjed Tahir, Aiko Yamashita, Sherlock Licorish, Jens Dietrich, and Steve Counsell. 2018. Can you tell me if it smells?: A study on how developers discuss code smells and anti-patterns in Stack Overflow. In 22nd International Conference on Evaluation and Assessment in Software Engineering (EASE). ACM, Christchurch, New Zealand, 68–78.
- Wrobel (2013) Michal R Wrobel. 2013. Emotions in the software development process. In 2013 6th International Conference on Human System Interactions (HSI). IEEE, 518–523.
IEEEtran \bibliographywebweb