Randomized Subspace Derivative-Free Optimization with Quadratic Models and Second-Order Convergence
Abstract
We consider model-based derivative-free optimization (DFO) for large-scale problems, based on iterative minimization in random subspaces. We provide the first worst-case complexity bound for such methods for convergence to approximate second-order critical points, and show that these bounds have significantly improved dimension dependence compared to standard full-space methods, provided low accuracy solutions are desired and/or the problem has low effective rank. We also introduce a practical subspace model-based method suitable for general objective minimization, based on iterative quadratic interpolation in subspaces, and show that it can solve significantly larger problems than state-of-the-art full-space methods, while also having comparable performance on medium-scale problems when allowed to use full-dimension subspaces.
keywords:
Derivative-free optimization; Large-scale optimization; Worst case complexity1 Introduction
In this work, we consider the problem of smooth nonlinear optimization where derivatives of the objective are unavailable, so-called derivative-free optimization (DFO) [13, 2, 24]. DFO methods are widely used across many fields [1], but in this work we focus on large-scale derivative-free problems, such as those arising from bilevel learning of variational models in imaging [17], fine-tuning large language models [25], adversarial example generation for neural networks [32], and as a possible proxy for global optimization methods in the high-dimensional setting [10]. Here we focus on the widely used class of model-based DFO methods, which are based on iteratively constructing local (interpolating) models for the objective.
Standard model-based methods [13, 24] suffer from a lack of scalability with respect to the problem dimension, coming from dimension-dependent interpolation error bounds affecting worst-case complexity, and significant per-iteration linear algebra costs; thus, they have traditionally been limited to small- or medium-scale problems. More recently, starting with [9], model-based DFO methods based on iterative minimization in random subspaces has proven to be a promising approach for tackling large-scale DFO problems in theory and practice. Theoretically, for example, using linear models in random subspaces improves the worst-case complexity of such methods from to evaluations to find an -approximate stationary point, for a problem with decision variables. This aligns with similar results for derivative-based optimization [5, 31] and other DFO approaches, such as direct search methods with random models [21, 30] and for gradient sampling in randomly drawn subspaces [23]. This model-based framework has been extended to handle stochastic objective values [16] and specialized to exploit structured quadratic model construction approaches [12]. The case of direct search methods in random subspaces has also been extended to the stochastic and nonsmooth case, and to show convergence to second-order optimal points [15].
There are alternative approaches for large-scale DFO where iterations are performed in subspaces that are deterministically generated from information from previous iterations, such as [36, 22, 33], where the method from [36, Chapter 5.3] alternates between iterations in two-dimensional subspaces and full-dimensional finite differencing. The method from [35] uses partially random subspaces, similar to [12], but is specialized to two-dimensional subspaces. We also note [26], where a full-dimensional model is updated at each iteration only inside a randomly generated subspace.
1.1 Contributions
Existing random subspace methods for model-based DFO have theoretical convergence to approximate first-order optimal points, but there is currently no theory handling second-order optimality in random subspace model-based DFO (with only [15] handling the direct search case). Although [12] does provide a mechanism for constructing fully quadratic interpolation models in random subspaces, which is a necessary component of second-order convergence theory, only first-order convergence theory is given. We also note the related work [3], which proves convergence to second-order optimal points for a trust-region method with probabilistic models and function values, which uses similar ideas but with different sources of uncertainty (instead of the approach here which uses randomly drawn subspaces with deterministic models and function values).
There are two main contributions in this work:
-
•
First, we show how the random subspace model-based method in [9] can be extended to allow convergence to second-order stationary points (similar to full space methods [13, 19]), and prove a high probability worst-case complexity bound for this method. Our approach is based on adapting a recent approach for second-order convergence of (derivative-based) subspace adaptive regularization with cubics [31, 11]. We show a worst-case complexity bound111The notation is the same as but hiding logarithmic factors as well as constants. of iterations and evaluations to achieve second-order optimality level for an -dimensional problem, a significant improvement on the iterations and evaluations for full space methods. For this theory to hold, we need to consider either low accuracy solutions or problems with low effective rank (i.e. low rank Hessians, such as fine-tuning large language models [25]). We note that the numerical evidence from [9] suggests that subspace methods are indeed most practical for finding low accuracy solutions.
-
•
We present a new practical algorithm for random subspace model-based DFO based on quadratic interpolation models. In [9], a practical approach based on linear interpolation models was built for nonlinear least-squares problems (a special case where linear models provide good practical performance [8]). Here, we extend this approach to handle general quadratic interpolation approaches, focusing in particular on underdetermined quadratic interpolation [28] in subspaces. Compared to state-of-the-art full-space methods using similar model constructions [4], our approach has comparable performance when set to use full-dimensional subspaces, but when using low-dimensional subspaces is able to solve larger problems (of dimension ) where existing approaches fail due to the significant linear algebra costs at this scale.
Structure
Firstly, in Section 2 we recall the random subspace model-based approach from [9] and its associated first-order complexity results. In Section 3 we extend this approach to find second-order critical points, stating the theoretical algorithm and proving the associated worst-case complexity bounds. Then, in Section 4 we outline our practical subspace method based on quadratic model construction in subspaces, which we test numerically in Section 5.
Notation
We use to denote the Euclidean norm of vectors in and operator 2-norm of matrices, and is the closed ball of radius centered at . We use to denote with both logarithmic and constant factors omitted.
2 Background
In this work we consider the problem
| (1) |
where is continuously differentiable and nonconvex, but is not available. In standard model-based DFO, at iteration , we construct a local quadratic approximation for that we hope to be accurate near the current iterate :
| (2) |
for some and (symmetric) . This is typically achieved by finding and to interpolate the value of at a collection of points near . We then use this model inside a trust-region framework to ensure a globally convergent algorithm, where—compared to derivative-based trust-region methods—special care has to be taken to ensure that is sufficiently accurate and is not too small relative to , see e.g. [13] for details.
In the large-scale case, which would typically be for DFO, the linear algebra cost of model construction and management becomes significant, and the model error (relative to the true objective value) can grow rapidly. To avoid this issue, in [9] it was proposed to perform each iteration within a randomly drawn, low-dimensional subspace. Specifically, for some , at each iteration we generate a random , defining an affine space . We then construct a low-dimensional model to approximate only on ,
| (3) |
for some and (symmetric) . We will adopt the convention where variables with hats are in the low-dimensional space and those without hats are in the full space. The trust-region framework is easily adapted to this situation: the model is minimized subject to a ball constraint to get a tentative low-dimensional step , which in turn defines a new potential iterate , which may be accepted or rejected via a sufficient decrease test.
To achieve first-order convergence, the model (3) must be sufficiently accurate in the following sense, [9, Definition 1].
Definition 2.1.
Given , and , a model is -fully linear in if
| (4a) | ||||
| (4b) | ||||
for all with , where the constants are independent of , , and .
| (5) |
| (6) |
A prototypical random subspace algorithm is presented in Algorithm 1. It is a simplification of the original algorithm [9, Algorithm 1], which includes a more sophisticated trust-region management procedure based on [29] and allows the model to not be -fully linear at all iterations. The version presented here is based on [16, Algorithm 2.1] and has the same first-order convergence guarantees.
In order to prove convergence of Algorithm 1, we need the following standard assumptions on the objective function, model and trust-region subproblem calculation (5).
Assumption 2.2.
The objective function in (1) is bounded below by and is continuously differentiable, where is -Lipschitz continuous for some .
Assumption 2.3.
The model Hessians are uniformly bounded, for all , for some .
Assumption 2.4.
While the above assumptions are common for trust-region methods, we need an additional assumption on the random matrices defining the subspace at each iteration.
Assumption 2.5.
The matrices are uniformly bounded, for all , and at each iteration is well-aligned, i.e.
| (8) |
for some and independent of and all previous iterations .
Although condition (8) depends on , which is not available, Assumption 2.5 can still be satisfied using Johnson-Lindenstrauss transforms [34]. For example, may have independent entries or be the first columns of a random orthogonal matrix scaled by . More details on how Assumption 2.5 may be satisfied can be found in [31, Chapter 4], [5, Section 3.2], [9, Section 2.6], [16, Section 3.1], [30, Section 3.3], or [12, Section 2.5], for example. Most crucially, for such constructions, (8) can be satisfied for independent of .
Under these assumptions, Algorithm 1 has a first-order worst-case complexity bound of the following form (e.g. [9, Corollary 1] or [12, Theorem 9]).
Theorem 2.6.
This result implies that is driven below for the first time after iterations and objective evaluations (with high probability), assuming interpolation points are used to construct . Assuming linear interpolation models, we have and , so in the full-space case and we get a worst-case complexity of iterations and objective evaluations. However, using a Johnson-Lindenstrauss transform we may use and , giving the same iteration complexity but an improved complexity of evaluations.
3 Convergence to Second-Order Stationary Points
We now consider the extension of the framework in Section 2 to a second-order convergent algorithm. Our basic framework is the same, namely at each iteration we select a random and build a low-dimensional model (3) to approximate in the corresponding affine space .
Now, we are interested in the second-order criticality measure
| (10) |
(see [13, Chapter 10], for example). Restricting the objective to the space we get the corresponding subspace criticality measure
| (11) |
and our interpolation model defines its own approximate (subspace) criticality measure
| (12) |
To achieve (i.e. convergence to second-order critical points), we need a more restrictive notion of model accuracy.
Definition 3.1.
The subspace model in (3) is -fully quadratic if there exist constants independent of such that
| (13a) | ||||
| (13b) | ||||
| (13c) | ||||
for all .
This notion is discussed in [12, Section 2.4], and a specific sampling mechanism for achieving this is described there.
In addition, we need the following assumptions on the objective and computed trust-region step which are standard for second-order convergence (e.g. [13, Chapter 10]).
Assumption 3.2.
The objective is bounded below by , and is twice continuously differentiable and is -Lipschitz continuous. Additionally, the Hessian at all iterates is uniformly bounded, for some independent of .
Assumption 3.3.
The step satisfies
| (14) |
for some independent of .
We also require Assumption 2.3 (bounded model Hessians) holds here.
Lemma 3.4 (Lemma 10.15, [13]).
Suppose Assumption 3.2 holds and is -fully quadratic on . Then , where .
Proof.
This argument is based on [13, Lemma 10.17]. First, since , we immediately have ; it remains to show . By definition of , we either have or . From Assumptions 3.3 and 2.3, we have
| (16) |
First, if , then implies
| (17) |
Then we have
| (18) | ||||
| (19) | ||||
| (20) |
and so (by definition of ), and hence as required. Alternatively, if , then
| (21) |
In this case, we get
| (22) |
and so again by definition of , and . ∎
Now, we need to specify our requirements for a well-aligned subspace. This is based on the approach in [11], originally from the PhD thesis [31, Chapter 5.6]. At iteration , suppose has eigendecomposition , where and , and are orthonormal. Define , and so the (true) subspace Hessian is .
Definition 3.6.
A subspace is well-aligned if
| (23a) | ||||
| (23b) | ||||
| (23c) | ||||
| (23d) | ||||
for some and independent of .
In practice, a well-aligned subspace can be achieved by generating randomly (see Section 3.1 below). Hence, we use the following assumption.
Assumption 3.7.
At any iteration , the matrix is well-aligned in the sense of Definition 3.6 with probability at least , for some , independent of all previous iterations .
The first two well-aligned properties (23a) and (23b) match the first-order case (Assumption 2.5); i.e. the subspace sees a sizeable fraction of the true gradient. The third condition (23c) says the subspace sees a sizeable fraction of the left-most eigenvector (since ), and the last condition (23d) says the first eigenvectors remain approximately orthogonal to the last eigenvector in the subspace.
Lemma 3.8.
Proof.
This argument is based on [11, Lemma 6.10], originally from [31, Lemma 5.6.6]. First, suppose that . Then
| (26) |
using from and we are done. Instead, suppose that . Using Rayleigh quotients, we have
| (27) |
Since , we have and , and so
| (28) |
If then the second term is non-negative, and so
| (29) |
and so with . Instead, if then and so we have
| (30) |
and so again yielding and the result follows. ∎
Lemma 3.9.
Proof.
We are now ready to prove the worst-case complexity of Algorithm 2 to (approximate) second-order stationary points. The below closely follows the argument from [9], used to prove Theorem 2.6. For a fixed , define the following sets of iterations:
-
•
is the set of iterations in for which is well-aligned.
-
•
is the set of iterations in for which is not well-aligned.
-
•
(resp. ) is the set of iterations in which are successful (resp. unsuccessful).
-
•
is the set of iterations in for which .
-
•
is the set of iterations in for which .
Hence, for any and , we have the partitions , as well as if .
We first use standard trust-region arguments to bound (by considering the four cases separately), provided remains large. We can then bound (to high probability) the total number of iterations for which is large by noting that occurs with small probability (Assumption 3.7).
Lemma 3.10.
Proof.
Lemma 3.11.
Proof.
Lemma 3.12.
Proof.
This follows the same argument as in [9, Lemmas 6 & 7], which we include here for completeness. In both cases, we consider the movement of , which is increased by at most if and decreased by if .
To show (41), we note:
-
•
Since , the value is below the starting value .
-
•
If , then increases by at most , and is only possible if .
-
•
If , then is decreased by and if .
Hence the total decrease in from must be fully matched by the initial gap plus the maximum possible amount that can be increased above ; that is,
| (44) |
and we get (41).
We can now bound the total number of well-aligned iterations.
Lemma 3.13.
Proof.
This follows the proof of [9, Lemma 9]. Since , we bound these terms individually.
First, we use Lemma 3.10 to get
| (50) | ||||
| (51) | ||||
| (52) | ||||
| (53) |
where the second inequality follows from Lemma 3.12 (specifically (41) after noting ) and Lemma 3.11 (with ), and the last inequality comes from using Lemma 3.10 a second time.
To get a total complexity bound, it suffices to note that is not well-aligned (i.e. ) for only a small fraction of all iterations, which comes from the following Chernoff-type bound.
Lemma 3.14.
Proof.
This is [9, Eq. (66)]. ∎
Lastly, we follow the argument from [9, Theorem 1] to get our main worst-case complexity bound.
Theorem 3.15.
Proof.
Fix some iteration , and let and be the number of well-aligned iterations in . If , from Lemma 3.13 we have
| (66) |
If we choose such that , then
| (67) | ||||
| (68) |
from Lemma 3.14. Now define
| (69) |
which gives
| (70) |
using from our assumption on . Then (68) gives
| (71) |
If we have , then since , we again get (71) since the left-hand side of (71) is zero.
Summary of complexity
Our main result Theorem 3.15 gives a worst-case complexity to achieve of iterations, with high probability (and where that probability converges to 1 as ).
For convenience, define . Then for sufficiently small222Specifically, we need to get and to ensure , which is required for . We also need in order to ignore the term in . we have , and , with .
Hence, our overall (high probability) complexity bound is iterations. If we assume evaluations per iteration, which is required for fully quadratic models, we get an alternative (high probability) complexity of objective evaluations. This matches the existing (full space) complexity bound for model-based DFO from [19, Chapter 4.2].
Remark 1.
Following the arguments from [9, Section 2.5], the above high-probability complexity bound can be used to derive alternative results, such as complexity bounds that hold in expectation, and almost-sure convergence of a subsequence of to zero, for example.
3.1 Generating Well-Aligned Subspaces
We now turn our attention to satisfying Assumption 3.7, that is, the matrix is well-aligned with high probability. We can achieve this by choosing to be a Johnson-Lindenstrauss Transform (JLT) (e.g. [34, Section 2.1]). This is a random matrix ensemble that approximately preserves norms of finite collections of vectors, the most common example being where the entries of are chosen to be i.i.d. distributed, although other constructions exist. See [31, Chapter 4] and [9, Section 2.6] for more details.
To satisfy Assumption 3.7, we choose to be a JLT such that (with high probability) (based on ideas from [31, Chapter 5] and [11])
| (78a) | ||||
| (78b) | ||||
| (78c) | ||||
| (78d) | ||||
all hold, where . This requires (approximately) preserving the norm of vectors, and so can be achieved with subspace dimension . The additional requirement can also be achieved with high probability without any modification to , with typical, e.g. [30, Table 2].
The above immediately gives the first three conditions for a well-aligned subspace, (23a), (23b) and (23c). For the last condition (23d), we use the polarization identity333That is, for any . to compute
| (79) | ||||
| (80) | ||||
| (81) | ||||
| (82) |
where the last equality uses the fact that and are orthonormal. Similar reasoning yields and so (23d) is achieved.
In terms of the subspace fully quadratic constants, we note that has -Lipschitz continuous Hessian under Assumption 3.2. Recalling the definition , for models built using -poised fully quadratic interpolation, we have [13, Theorems 3.14 & 3.16], where is the number of interpolation points needed. So, using full space methods we have the standard values .
For our subspace models, we have and , and so we have . So, using JLTs as above with and we get .
That is, full space methods use with and subspace methods require with , a significant improvement for large . Specifically, using a complexity of from above, the dependency on decreases from iterations for full-space methods to for subspace methods. This is summarized in Table 1.
| Method | Iteration WCC | Evaluation WCC | |||
|---|---|---|---|---|---|
| Full space | |||||
| Subspace |
Remark 2.
A limitation of the above theory is the requirement (24). If we pick and assume , then we get . To apply the JLT, we actually need , which gives . Hence for to hold, we need to seek low accuracy solutions, or have a situation where , i.e. the problem has low effective rank. This structure does arise in practice, see [7, Section 1], [6, Section 1] and references therein for examples, with a notable example being finetuning of large language models, where scalable DFO methods are practically useful [25].
In the case where is generated using scaled Gaussians (i.e. each entry of is i.i.d. ), then this can be improved (see [11, Lemma 6.6] or [31, Lemma 5.6.2]). Then, we compute
| (83) |
since is a -distributed random variable for any unit vector . In this case, we can get a different expression for , namely
| (84) |
and so for we still require either low accuracy solutions or low effective rank, via , but without the stringent requirement on (and hence on ).
4 Practical Implementation
In [9, Section 4] the algorithm DFBGN, a practical implementation of Algorithm 1 for nonlinear least-squares problems was presented, based on linear interpolation models (for each residual in the least-squares sum). DFBGN was designed to efficiently use objective evaluations, a key principle of DFO methods (which are often used when objective evaluations are slow/expensive to obtain). In this section, we outline a RSDFO-Q (random subspace DFO with quadratic models), a practical implementation of the ideas in Algorithms 1 and 2, for general objectives (1), based on quadratic interpolation models.
At the core of DFBGN is the maintenance of an interpolation set comprising points including the current iterate, say for some linearly independent set . Points that are added to this set are either from a trust-region step (5) or of the form for random (mutually orthogonal) unit vectors , orthogonal to all current (which is optimal in a specific sense, see [12, Theorem 4]). Points are removed from this set using geometric considerations to ensure the full linearity of the resulting model, following the approach in [29, 8]. Given this interpolation set, the subspace in Algorithm 2 is effectively defined by .
For a general objective problem (1), quadratic interpolation models, with at least interpolation points (including ), are typically preferred to linear interpolation models. However, in this situation we lose the important feature of DFBGN, namely that every interpolation point (except ) defines a direction in the subspace. In this section, we give a practical approach to avoiding this issue, and provide a subspace method for solving the general problem (1) based on (underdetermined) quadratic interpolation models.
As with DFBGN, the design of RSDFO-Q is based on the principles:
-
•
Low linear algebra cost: the per-iteration linear algebra cost should be linear in (but may be higher in , since the algorithm is designed for )
-
•
Efficient use of objective evaluations: objective evaluations should be re-used where possible, while restricting exploration at each iteration to a -dimensional subspace. In particular, the algorithm with should have broadly comparable performance to state-of-the-art (full-space) DFO methods.444Given the added flexibility of the subspace method to set , and their resulting ability to handle problems with much larger , it is unlikely that a subspace method with will match/outperform state-of-the-art full-space methods.
The key idea to extend the DFBGN approach to quadratic models is to maintain two sets of interpolation points. To work in a -dimensional subspace with at most interpolation points, we maintain a ‘primary’ set of interpolation points , which define the current subspace just as in DFBGN. We separately maintain a ‘secondary’ set of at most interpolation points, which is disjoint from the primary set. Points in the secondary set are only used for model construction, whereas points in the primary set are used for model construction as well as defining the subspace and geometry management. Whenever points are removed from the primary set, which is based on similar principles to DFBGN, those points are added to the secondary set (and the oldest points from the secondary set are deleted). We note that the case in general can yield fully quadratic (subspace) models, as required for Algorithm 2, and smaller values of can yield fully linear (subspace) models, as required for Algorithm 1; see [13, Chapters 3& 5] for details.
Given the subspace defined by , we work with an orthonormal basis for the same space for convenience. By construction of , all the primary interpolation points are in the subspace, but the secondary points likely will not be. Hence, before building an interpolation model, we project all secondary interpolation points into the subspace via
| (85) |
For notational convenience, we have for all . Given these perturbed points, the subspace model construction for (3) is based on minimum Frobenius norm quadratic interpolation [28]. That is, we solve the equality-constrained QP
| (86) |
where for any we have the associated defined above, and is the projection of into the current subspace (with ).
| (87) |
A complete description of RSDFO-Q is given in Algorithm 3. Aside from the more complex model construction in (86), it closely follows the overall structure of DFBGN [9]. The trust-region updating mechanism is more complex than DFBGN, as it employs a lower bound , where is only periodically reduced, and does not evaluate the objective at the tentative trust-region step if the step is too short. Both these complications are drawn from BOBYQA [29].
There are two situations where points are to be removed from the primary interpolation set . The first is where a single point is removed (lines 12 and 21), and the second is where potentially multiple points are removed (lines 19 and 22). In the case where a single point is removed, Algorithm 4 gives details on how this is done. In the case where multiple points are removed, [9, Algorithm 4] is used to select the points to remove. These two approaches are very similar, differing only in whether the tentative trust-region step is used in the Lagrange polynomial evaluation: they try to remove points which are far from the current iterate and/or degrade the geometry of the primary interpolation set. In both cases, the points removed from are added to (with the oldest points removed from if it grows too large). Following the heuristic for DFBGN [9, Section 4.5], the number of points to remove in lines 19 and 22 is for unsuccessful steps () and 1 otherwise.
Remark 3.
The default parameter choices in Algorithm 3 are , , , , , , , , , and .
| (88) |
5 Numerical Results
We now demonstrate the numerical performance of RSDFO-Q in light of the underlying principles described in Section 4. In particular, we benchmark against Py-BOBYQA [4] as a state-of-the-art full space DFO method based on the same minimum Frobenius norm quadratic interpolation mechanism. It also shares many of the complexities in the trust-region updating mechanism that are present in Algorithm 3.
5.1 Testing Framework
We test our solvers on two collections of problems from the CUTEst set [20, 18]:
-
•
The medium-scale collection ‘CFMR’ of 90 problems with (with most common) from [4, Section 7].
-
•
The large-scale collection ‘CR-large’ of 28 problems with (with most common) from [9, Appendix C].
We terminate all solvers after objective evaluations and 12 hours (wall) runtime, whichever occurs first555All solvers are implemented in Python with key linear algebra routines implemented in NumPy. The objective evaluation time for all problems was negligible., and run each randomized solver 10 times on each problem (from the same starting point) to get a good assessment of the average-case behavior. All solvers had the same starting point and initial trust-region radius.
For each problem instance and solver, we measure the total objective evaluations required to find a point with , where is the true minimum listed in [4, 9] and is an accuracy measure (smaller values mean higher accuracy solutions). In our results, we show accuracy levels , as it was observed in [9, Section 5] that subspace methods are most suited to finding lower-accuracy solutions. If a solver terminates on budget or runtime before a sufficiently accurate point was found, the total objective evaluations is considered to be .
Solvers are compared using data profiles [27], showing the proportion of problem instances solved within a given number of evaluations in units of for problems in (i.e. the cost of estimating a full gradient using finite differencing), and performance profiles [14], which plot the proportion of problem instances solved within a given ratio of the minimum evaluations required by any instance of any solver.
5.2 Medium-Scale Results
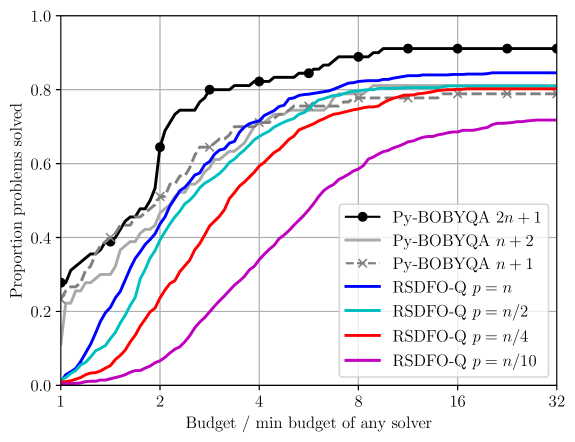
We first show results for medium-scale problems based on the ‘CFMR’ problem collection ().666The 12hr runtime limit was not reached for any of these problem instances. In Figure 1, we compare Py-BOBYQA with interpolation points (i.e. linear or underdetermined quadratic interpolation models) against RSDFO-Q with interpolation points, with subspace dimension .
We see that the full-space method Py-BOBYQA is the best-performing algorithm, with larger numbers of interpolation points giving the best performance. Among the subspace methods, those with larger choices of achieve the best performance, aligning with the results in [9]. In particular (c.f. principles in Section 4), we see that RSDFO-Q with full blocks (and interpolation points) achieves broadly comparable performance to Py-BOBYQA (worse than Py-BOBYQA with points but better than points), while having the significant additional flexibility of working in a subspace of arbitrary dimension .



5.3 Large-Scale results
In Figure 2 we show the same results (based on total objective evaluations) as Figure 1, but for the large-scale test set ‘CR-large’ (). Here, we observe that Py-BOBYQA with quadratic models ( and ) fail to solve any problems, as their significant per-iteration linear algebra costs777e.g. Model construction in each iteration of Py-BOBYQA with requires the solution of a linear system. mean they hit the runtime limit quickly. The only Py-BOBYQA variant able to make progress uses linear models with . However, this method is outperformed by all variants of the subspace method RSDFO-Q (including with ). We find that medium-dimensional subspaces (i.e. and ) are the best-performing variants.
For comparison, in Figure 3, we show data and performance profiles based on runtime to find a point with sufficient decrease. Among the variants of RSDFO-Q, we find that the low-dimensional variants are the best-performing, at least initially. However, the increased robustness of the variant (accompanied by an increase in the per-iteration linear algebra cost) means it ultimately outperforms the variant.








6 Conclusion
We have provided the first second-order convergence result for a random subspace model-based DFO method, and shown that, compared to full space model-based DFO, these approaches can achieve a significant improvement in dimension dependence of the complexity bound, from evaluations to evaluations to find an -approximate second-order critical point for an -dimensional problem. This theory is relevant particularly when seeking low accuracy solutions or if the objective has low effective rank (i.e. low rank Hessians).
We then introduce a practical algorithm (RSDFO-Q) for general unconstrained model-based DFO in subspaces based on iterative construction of quadratic models in subspaces. This extends the practical method from [9], which was limited to linear models (and specialized to nonlinear least-squares problems). Numerical results compared to the state-of-the-art method Py-BOBYQA show that RSDFO-Q can solve problems of significantly higher dimension (), exploiting a significantly reduced per-iteration linear algebra cost, while RSDFO-Q with full-dimensional subspaces achieves comparable performance to Py-BOBYQA on medium-scale problems ().
Acknowledgement(s)
We acknowledge the use of the University of Oxford Advanced Research Computing (ARC) facility888http://dx.doi.org/10.5281/zenodo.22558 in carrying out this work.
Funding
LR was supported by the Australian Research Council Discovery Early Career Award DE240100006. CC was supported by the Hong Kong Innovation and Technology Commission (InnoHK CIMDA Project).
References
- [1] S. Alarie, C. Audet, A.E. Gheribi, M. Kokkolaras, and S. Le Digabel, Two decades of blackbox optimization applications, EURO Journal on Computational Optimization 9 (2021), p. 100011.
- [2] C. Audet and W. Hare, Derivative-Free and Blackbox Optimization, Springer Series in Operations Research and Financial Engineering, Springer, Cham, Switzerland, 2017.
- [3] J. Blanchet, C. Cartis, M. Menickelly, and K. Scheinberg, Convergence rate analysis of a stochastic trust-region method via supermartingales, INFORMS Journal on Optimization 1 (2019), pp. 92–119.
- [4] C. Cartis, J. Fiala, B. Marteau, and L. Roberts, Improving the flexibility and robustness of model-based derivative-free optimization solvers, ACM Transactions on Mathematical Software 45 (2019), pp. 1–41.
- [5] C. Cartis, J. Fowkes, and Z. Shao, Randomised subspace methods for non-convex optimization, with applications to nonlinear least-squares, arXiv preprint arXiv:2211.09873 (2022).
- [6] C. Cartis, X. Liang, E. Massart, and A. Otemissov, Learning the subspace of variation for global optimization of functions with low effective dimension, arXiv preprint arXiv:2401.17825 (2024).
- [7] C. Cartis and A. Otemissov, A dimensionality reduction technique for unconstrained global optimization of functions with low effective dimensionality, Information and Inference: A Journal of the IMA 11 (2022), pp. 167–201.
- [8] C. Cartis and L. Roberts, A derivative-free Gauss–Newton method, Mathematical Programming Computation 11 (2019), pp. 631–674.
- [9] C. Cartis and L. Roberts, Scalable subspace methods for derivative-free nonlinear least-squares optimization, Mathematical Programming 199 (2023), pp. 461–524.
- [10] C. Cartis, L. Roberts, and O. Sheridan-Methven, Escaping local minima with local derivative-free methods: A numerical investigation, Optimization 71 (2022), pp. 2343–2373.
- [11] C. Cartis, Z. Shao, and E. Tansley, Random subspace cubic regularization methods, December (2024).
- [12] Y. Chen, W. Hare, and A. Wiebe, Q-fully quadratic modeling and its application in a random subspace derivative-free method, Computational Optimization and Applications (2024).
- [13] A.R. Conn, K. Scheinberg, and L.N. Vicente, Introduction to Derivative-Free Optimization, MPS-SIAM Series on Optimization, Society for Industrial and Applied Mathematics, Philadelphia, 2009.
- [14] E.D. Dolan and J.J. Moré, Benchmarking optimization software with performance profiles, Mathematical Programming 91 (2002), pp. 201–213.
- [15] K.J. Dzahini and S.M. Wild, Direct search for stochastic optimization in random subspaces with zeroth-, first-, and second-order convergence and expected complexity, arXiv preprint arXiv:2403.13320 (2024).
- [16] K.J. Dzahini and S.M. Wild, Stochastic trust-region algorithm in random subspaces with convergence and expected complexity analyses, SIAM Journal on Optimization 34 (2024), pp. 2671–2699.
- [17] M.J. Ehrhardt and L. Roberts, Inexact derivative-free optimization for bilevel learning, Journal of Mathematical Imaging and Vision 63 (2021), pp. 580–600.
- [18] J. Fowkes, L. Roberts, and Á. Bűrmen, PyCUTEst: An open source Python package of optimization test problems, Journal of Open Source Software 7 (2022), p. 4377.
- [19] R. Garmanjani, Trust-region methods without using derivatives: Worst case complexity and the nonsmooth case, Ph.D. diss., Universidade de Coimbra, 2015.
- [20] N.I.M. Gould, D. Orban, and P.L. Toint, CUTEst: A constrained and unconstrained testing environment with safe threads for mathematical optimization, Computational Optimization and Applications 60 (2015), pp. 545–557.
- [21] S. Gratton, C.W. Royer, L.N. Vicente, and Z. Zhang, Direct search based on probabilistic descent, SIAM Journal on Optimization 25 (2015), pp. 1515–1541.
- [22] M. Kimiaei, A. Neumaier, and P. Faramarzi, New subspace method for unconstrained derivative-free optimization, ACM Transactions on Mathematical Software 49 (2023), pp. 1–28.
- [23] D. Kozak, S. Becker, A. Doostan, and L. Tenorio, A stochastic subspace approach to gradient-free optimization in high dimensions, Computational Optimization and Applications 79 (2021), pp. 339–368.
- [24] J. Larson, M. Menickelly, and S.M. Wild, Derivative-free optimization methods, Acta Numerica 28 (2019), pp. 287–404.
- [25] S. Malladi, T. Gao, E. Nichani, A. Damian, J.D. Lee, D. Chen, and S. Arora, Fine-Tuning Language Models with Just Forward Passes, in 37th Conference on Neural Information Processing Systems (NeurIPS 2023). 2023.
- [26] M. Menickelly, Avoiding geometry improvement in derivative-free model-based methods via randomization, arXiv preprint arXiv:2305.17336 (2023).
- [27] J.J. Moré and S.M. Wild, Benchmarking derivative-free optimization algorithms, SIAM Journal on Optimization 20 (2009), pp. 172–191.
- [28] M.J.D. Powell, Least Frobenius norm updating of quadratic models that satisfy interpolation conditions, Mathematical Programming 100 (2004), pp. 183–215.
- [29] M.J.D. Powell, The BOBYQA algorithm for bound constrained optimization without derivatives, Tech. Rep. DAMTP 2009/NA06, University of Cambridge, 2009.
- [30] L. Roberts and C.W. Royer, Direct search based on probabilistic descent in reduced spaces, SIAM Journal on Optimization 33 (2023).
- [31] Z. Shao, On random embeddings and their application to optimisation, Ph.D. diss., University of Oxford, 2021.
- [32] G. Ughi, V. Abrol, and J. Tanner, An empirical study of derivative-free-optimization algorithms for targeted black-box attacks in deep neural networks, Optimization and Engineering 23 (2022), pp. 1319–1346.
- [33] D. van de Berg, N. Shan, and A. del Rio-Chanona, High-dimensional derivative-free optimization via trust region surrogates in linear subspaces, in Proceedings of the 34th European Symposium on Computer Aided Process Engineering / 15th International Symposium on Process Systems Engineering (ESCAPE34/PSE24). 2024.
- [34] D.P. Woodruff, Sketching as a tool for numerical linear algebra, Foundations and Trends® in Theoretical Computer Science 10 (2014), pp. 1–157.
- [35] P. Xie and Y.x. Yuan, A new two-dimensional model-based subspace method for large-scale unconstrained derivative-free optimization: 2D-MoSub, arXiv preprint arXiv:2309.14855 (2024).
- [36] Z. Zhang, On derivative-free optimization methods, Ph.D. diss., Chinese Academy of Sciences, 2012.