Randomised benchmarking for characterizing and forecasting correlated processes
Abstract
The development of fault-tolerant quantum processors relies on the ability to control noise. A particularly insidious form of noise is temporally correlated or non-Markovian noise. By combining randomized benchmarking with supervised machine learning algorithms, we develop a method to learn the details of temporally correlated noise. In particular, we can learn the time-independent evolution operator of system plus bath and this leads to (i) the ability to characterize the degree of non-Markovianity of the dynamics and (ii) the ability to predict the dynamics of the system even beyond the times we have used to train our model. We exemplify this by implementing our method on a superconducting quantum processor. Our experimental results show a drastic change between the Markovian and non-Markovian regimes for the learning accuracies.
pacs:
03.65.Ud, 03.67.Mn, 42.50.Dv, 42.50.XaA major challenge in building near-term quantum computers is noise [1, 2, 3]. As the number of qubits and the depths of quantum circuits scale up, the fidelity of the output quantum state decreases rapidly, restricting current experiments to low depths [4, 5, 6], or few qubits [7]. A quantum device can be affected by both spatially and temporally correlated noise. Correlated noise can be more harmful then uncorrelated one for scalable quantum error mitigation [8, 9], and can lower the threshold of error correcting codes [10, 11]. Efficient tools to characterize correlated noise are essential for the development of scalable quantum computing technologies.
A variety of techniques have been developed for characterizing Markovian noises, including spatially correlated ones, such as quantum process tomography (QPT) [12, 13], gate set tomography [14, 15] and randomized benchmarking (RB) [16, 17, 18, 19, 20]. RB is a highly economical method that consists of averaging over random sequences of gates to estimate the error rates within a given device.
The process tensor framework was recently introduced to expand the applicability of the above tools to time-correlated or non-Markovian noise [21, 22]. A process tensor is a complete positive mapping from any sequence of quantum operations to a final state of the system. Similar to QPT, the process tensor can be systematically reconstructed with process tensor tomography (PTT), where one applies all the possible sequences of linearly independent quantum operations and performs quantum state tomography [23]. Unlike RB, PTT yields detailed information about the noise, which can be used to improve the performance of the quantum device [24]. However, the detailed characterization of complex noise is far more expensive than RB. PTT requires a number of measurements that grows exponentially with . Meanwhile, it is possible to get around this exponential scaling by exploiting the process tensor’s natural form as a matrix product density operator with a finite bond dimension [22, 25, 26], which motivates efficient heuristic PTT schemes based on one-dimensional tensor network states [27, 28, 29]. Alternatively, one may apply recently-developed shadow-based schemes [30].
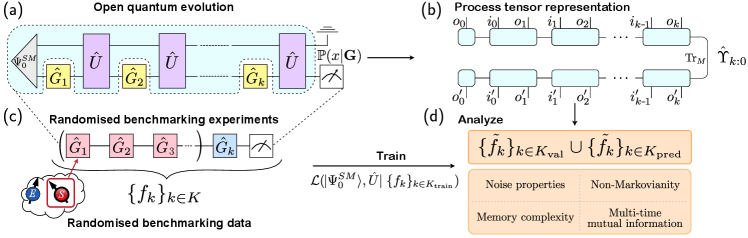
In this work, we develop a method to reconstruct the process tensors by applying supervised machine learning methods to RB data. Our scheme thus inherits the simplicity of RB while capturing the complexity of multi-time non-Markovian system dynamics. It enables one to characterize the process, including concrete measures of non-Markovianity, while its computational cost is related to the memory size of the process, which is often small for real quantum hardware [24].
As a proof of principle, we demonstrate our scheme on a superconducting quantum processor, where we couple a “system” qubit to an “environment” qubit with tunable coupling strength, going from weak to strong, resulting in system dynamics from nearly Markovian to highly non-Markovian. We observe a sharp change in learning accuracy between these two regimes; very high learning accuracy in the Markovian regime, and generally lower accuracy in the highly non-Markovian regime, although this can be systematically improved by using larger memory models. In both cases, we can predict future dynamics beyond the times used for training.
Open quantum evolution model and the process tensor framework. Stationary classical non-Markovian processes can always be written as hidden Markov models [31, 32]. Similarly, for quantum processes with time-independent noise, one could reconstruct a quantum version of the hidden Markov model, referred to as the open quantum evolution (OQE) model, which describes the overall unitary dynamics of the system coupled to a minimal environment [33], which we call memory . Once obtained, the OQE model contains all the information of the system dynamics, which can be used to compute process tensors of any steps and predict all the future dynamics.
Without loss of generality, we assume a pure system-memory () initial state . We consider the discretized dynamics from time steps to (), and denote the unitary evolutionary operator from to as . At each step we apply a quantum operation (unitary operation or measurement) on . The overall dynamics can be written as
| (1) |
which is shown in Fig. 1(a). Eq. (1) also defines the process tensor as a mapping from initial state of the system , together with , into the final state , as shown in Fig. 1(b) (See Supplementary for detailed construction of from OQE [34]). contains all the observable information of the -step system dynamics and is uniquely defined (in contrast OQE is not unique [33]). In the next, we focus on time-independent noise with for any . In this case, the open quantum dynamics is completely determined by and , and our goal is to determine them by performing RB on the system only.
Reconstructing the OQE model with RB. For RB one first randomly generates sequences, denoted as , where in each sequence the last operation is understood as the undo gate used to isolate the noise effects. Then the RB protocol proceeds as follows: (1) Preparing an initial state of the system; (2) Applying each onto to obtain the final state and measuring for a positive operator-valued measure element ; (3) Computing the average and repeating (1) and (2) for different . For Markovian noise that is also gate-independent, can be well approximated by an exponential decay where , and are constants [19, 20]. For non-Markovian noise, instead, non-exponential behavior of is expected in general [35]. The RB protocol can be naturally understood in the process tensor framework, which is demonstrated in Fig. 1(c) in correspondence with Fig. 1(a).
Based on the RB data, we propose a variational scheme to reconstruct the hidden OQE model by minimizing the mean square loss between the predicted outcomes and the experiment outcomes :
| (2) |
where is the set of used for training. We use the BFGS optimizer [36], with parameterized as in Ref. [37] and randomly initialized with a predefined memory size . The gradient is computed by automatic differentiation [38]. Once an optimal OQE model has been obtained, one can use it to predict the output quantum state of the system for any sequence ( may not be in ) as shown in Fig. 1(d).
Experimental setup. To demonstrate our method, we apply it to reconstruct temporally correlated noise on a superconducting quantum processor. We use two capacitive-coupled transmon qubits, one as system () and the other as environment (). Note that we have differentiated between the physical environment of the quantum processor and memory that goes into the OQE, where includes the qubit and can include other effects that we cannot directly control. The Hamiltonian is , where is the coupling strength, is the local energy for the system or environment qubit. Once again, we highlight the fact that a one qubit memory is sufficient for modelling realistic quantum computers [23, 25, 24].
We apply the standard RB protocol on as depicted in Fig. 1(c). The initial state is chosen as . While it is not necessary for our algorithm, for a more straightforward implementation we consider that the initial state is separable: , and we can simplify Eq. (2) by fixing without loss of generality (one can change the environment basis without any observable effects). As a result, only remains to be determined. To tune the system dynamics from Markovian to non-Markovian, one needs to tune the coupling between and . In our experiment, is kept as a constant, but we tune the effective coupling strength by changing the imbalance via the voltage bias , as shown in Fig. 2(a).

The reconstruction accuracy. In our experiment, each gate operation takes about ns, with depending on the number of native gates obtained through Epstein decomposition [39]. The idle time between gates is set to be ns. In this way, the duration between successive time steps in OQE could be slightly different, which would break our assumption of time-independent . Nevertheless, our results later show that our reconstructed models are still accurate. For each in Fig. 2(a), we independently prepare two datasets with and respectively, and for each we prepare data pairs. We take (for each ) of the first dataset for training (), and the rest of the first dataset (denoted as instead) as well as the whole second dataset () for testing. For training, we ramp up (dimension of ) from to such that our model becomes increasingly more expressive. For each , we use the BFGS optimizer with at most iterations to find an optimal as a unitary matrix. We run the optimization for each instance for times and choose the one with the lowest loss value as our final result.
In Fig. 2(c,d), we show the loss values for the two testing datasets and respectively. In both cases, we can see that for we can obtain very low loss with a small , while for one needs larger to reach lower loss. Importantly, the model trained for can be well generalized to , which shows that our method is capable of predicting future dynamics. In addition, the OQE trained with works better for than , especially for , which is a sign of overfitting in the near Markovian regime for large .
To better visualize the power of our trained OQE model, in Fig. 2(b) we directly plot the average predicted measurement outcomes from the OQE reconstructed with , compared to obtained from experiment for . We can see that in the near-Markovian regime with , there is a very good matching between them, while in the non-Markovian regime, the discrepancy becomes larger, especially for larger . There is a constant bias between the predicted values and the experimental results for large , which indicates a measurement bias from the experiment that has not been taken into account in our method.
Quantifying the properties of multi-time processes. The process tensor, obtained from the OQE model, is a Hermitian, positive, unit-trace multipartite matrix. In other words, it is a multi-time density matrix whose correlations quantify non-Markovianity. Here, we consider three different properties of the process tensor: 1) its entropy; 2) its multipartite non-Markovianity; and 3) non-Markovianity across two times. As such, we need to define von Neumann entropy and mutual information .

For the first measure, we compute the entropy of the whole process tensor , which quantifies the level of noise in the process. For OQE, is the same as the final entropy of the space, thus it is sometimes referred to as memory complexity [33] and it resembles statistical complexity of classical stochastic process [40]. The second measure quantifies the multi-time correlation between the past and the future of the process. To do so, we first vectorise the process tensor, i.e., , with the normalisation. The entropy of a subpart of this pure state vanishes iff the process is Markovian [41]. We take to be times to and denote the entropy as , which captures the correlations between the past and the future. Finally, we compute the mutual information between marginals of the process tensor; from , we obtain a bipartite process tensor by contracting all with , i.e., inserting the identity gates at all time slots . Indices are traced out and a is inserted at . The mutual information of quantifies four time correlation which vanishes for all Markovian processes.
The three quantities above capture different aspects of the non-Markovian process and are plotted in Fig. 3. Panels (a,b) display and , respectively to show a sharp transition from the Markovian regime for to the non-Markovian regime for . Neither measure converges with for , which means that a larger (and more training data) may be required for the hidden OQE. Interestingly, for , is much larger than . This could mean that the underlying quantum dynamics can be well approximated by a Markovian but non-unitary process. To further examine this, we compute the mutual information for and respectively in panels (c,d). In the first case, the mutual information is small and gradually increases with , indicating an evolution of short-range memory with the dynamics. Owing to the lower coupling, more time is needed to generate the required interaction to accumulate temporal correlations. Moreover, as one would expect, these correlations reduce with temporal separation . Nevertheless, one can see that even in a low-coupling regime a coherent system can eventually develop non-Markovian features. Meanwhile, in the second case, the mutual information starts very high and quickly saturates (note the y-axis scale difference between c/d). Because we have fixed interaction with a small environment, the quantity decays exponentially. But the closer-in-time correlations maintain a large steady state with until they are slowly reduced by dissipation. Using our tools, we see that the dynamics of memory can be studied in company with the usual information provided by RB curves.
Summary. We have proposed an experimentally friendly scheme to characterize temporally correlated noise in open quantum dynamics based on data from randomized benchmarking experiments. We demonstrated our method on a superconducting quantum processor, where we tune the quantum dynamic of the system qubit from Markovian to highly non-Markovian by tuning the effective coupling strength to an environment qubit. Our results show that, close to the Markovian regime, we can reconstruct an OQE model with a very small memory size and with high prediction accuracy on the testing datasets. In the highly non-Markovian regime, the reconstruction accuracy is generally lower but can be systematically improved by using a larger memory size. In both cases the reconstructed OQE model can well predict the observed and even unobserved system dynamics. We computed three different measures of non-Markovianity using the process tensor obtained from reconstructed OQE and we find that they indeed have a close correspondence with the Markovian or non-Markovian behaviors of the system dynamics. Our method thus opens up the possibility of quantifying temporally correlated noise in quantum devices based on existing RB data.
Acknowledgements.
This work was supported by the Open Research Fund from State Key Laboratory of High Performance Computing of China (Grant No. 202201-00), the Hunan Provincial Science Fund for Distinguished Young Scholars (Grant No. 2021JJ10043), and the Innovation Program for Quantum Science and Technology (Grant No. 2021ZD030240). D.P. acknowledges support from the National Research Foundation, Singapore under its QEP2.0 programme (NRF2021-QEP2-02-P03).References
- Zhao et al. [2022] Y. Zhao, Y. Ye, H.-L. Huang, Y. Zhang, D. Wu, H. Guan, Q. Zhu, Z. Wei, T. He, and S. o. Cao, Phys. Rev. Lett. 129, 030501 (2022).
- Krinner et al. [2022] S. Krinner, N. Lacroix, A. Remm, A. Di Paolo, E. Genois, C. Leroux, C. Hellings, S. Lazar, F. Swiadek, J. Herrmann, et al., Nature 605, 669 (2022).
- AI [2023] G. Q. AI, Nature 614, 676 (2023).
- Arute et al. [2019] F. Arute, K. Arya, R. Babbush, D. Bacon, J. C. Bardin, R. Barends, R. Biswas, S. Boixo, F. G. S. L. Brandao, Buell, et al., Nature 574, 505 (2019).
- Wu et al. [2021] Y. Wu, W.-S. Bao, S. Cao, F. Chen, M.-C. Chen, X. Chen, T.-H. Chung, H. Deng, Y. Du, D. Fan, et al., Phys. Rev. Lett. 127, 180501 (2021).
- Zhu et al. [2022] Q. Zhu, S. Cao, F. Chen, M.-C. Chen, X. Chen, et al., Science Bulletin 67, 240 (2022).
- Arute et al. [2020] F. Arute, K. Arya, R. Babbush, D. Bacon, J. C. Bardin, R. Barends, S. Boixo, M. Broughton, B. B. Buckley, et al., Science 369, 1084 (2020).
- Endo et al. [2018] S. Endo, S. C. Benjamin, and Y. Li, Phys. Rev. X 8, 031027 (2018).
- Endo et al. [2021] S. Endo, Z. Cai, S. C. Benjamin, and X. Yuan, Journal of the Physical Society of Japan 90, 032001 (2021).
- Nickerson and Brown [2019] N. H. Nickerson and B. J. Brown, Quantum 3, 131 (2019).
- Maskara et al. [2019] N. Maskara, A. Kubica, and T. Jochym-O’Connor, Phys. Rev. A 99, 052351 (2019).
- Chuang and Nielsen [1997] I. L. Chuang and M. A. Nielsen, Journal of Modern Optics 44, 2455 (1997).
- D’Ariano and Lo Presti [2001] G. M. D’Ariano and P. Lo Presti, Phys. Rev. Lett. 86, 4195 (2001).
- Blume-Kohout et al. [2017] R. Blume-Kohout, J. K. Gamble, E. Nielsen, K. Rudinger, J. Mizrahi, K. Fortier, and P. Maunz, Nature Communications 8, 14485 (2017).
- Nielsen et al. [2021] E. Nielsen, J. K. Gamble, K. Rudinger, T. Scholten, K. Young, and R. Blume-Kohout, Quantum 5, 557 (2021).
- Emerson et al. [2005] J. Emerson, R. Alicki, and K. Życzkowski, Journal of Optics B: Quantum and Semiclassical Optics 7, S347 (2005).
- Lévi et al. [2007] B. Lévi, C. C. López, J. Emerson, and D. G. Cory, Phys. Rev. A 75, 022314 (2007).
- Knill et al. [2008] E. Knill, D. Leibfried, R. Reichle, J. Britton, R. B. Blakestad, J. D. Jost, C. Langer, R. Ozeri, S. Seidelin, and D. J. Wineland, Phys. Rev. A 77, 012307 (2008).
- Magesan et al. [2011] E. Magesan, J. M. Gambetta, and J. Emerson, Phys. Rev. Lett. 106, 180504 (2011).
- Magesan et al. [2012] E. Magesan, J. M. Gambetta, and J. Emerson, Phys. Rev. A 85, 042311 (2012).
- Costa and Shrapnel [2016] F. Costa and S. Shrapnel, New Journal of Physics 18, 063032 (2016).
- Pollock et al. [2018] F. A. Pollock, C. Rodríguez-Rosario, T. Frauenheim, M. Paternostro, and K. Modi, Phys. Rev. A 97, 012127 (2018).
- White et al. [2020] G. A. White, C. D. Hill, F. A. Pollock, L. C. Hollenberg, and K. Modi, Nature Communications 11, 6301 (2020).
- White et al. [2022] G. White, F. Pollock, L. Hollenberg, K. Modi, and C. Hill, PRX Quantum 3, 020344 (2022).
- White et al. [2021] G. A. L. White, F. A. Pollock, L. C. L. Hollenberg, C. D. Hill, and K. Modi, arXiv:2107.13934 (2021).
- Luchnikov et al. [2019] I. A. Luchnikov, S. V. Vintskevich, H. Ouerdane, and S. N. Filippov, Phys. Rev. Lett. 122, 160401 (2019).
- Guo et al. [2018] C. Guo, Z. Jie, W. Lu, and D. Poletti, Phys. Rev. E 98, 042114 (2018).
- Guo et al. [2020] C. Guo, K. Modi, and D. Poletti, Phys. Rev. A 102, 062414 (2020).
- Luchnikov et al. [2020] I. A. Luchnikov, S. V. Vintskevich, D. A. Grigoriev, and S. N. Filippov, Phys. Rev. Lett. 124, 140502 (2020).
- White et al. [2023] G. A. L. White, K. Modi, and C. D. Hill, Phys. Rev. Lett. 130, 160401 (2023).
- Crutchfield and Young [1989] J. P. Crutchfield and K. Young, Phys. Rev. Lett. 63, 105 (1989).
- Shalizi and Crutchfield [2001] C. R. Shalizi and J. P. Crutchfield, Journal of Statistical Physics 104, 817 (2001).
- Guo [2022a] C. Guo, Phys. Rev. A 106, 022411 (2022a).
- [34] “See supplementary material.” .
- Figueroa-Romero et al. [2021] P. Figueroa-Romero, K. Modi, R. J. Harris, T. M. Stace, and M.-H. Hsieh, PRX Quantum 2, 040351 (2021).
- Fletcher [2000] R. Fletcher, “Newton-like methods,” in Practical Methods of Optimization (John Wiley & Sons, Ltd, 2000) Chap. 3, pp. 44–79.
- Reck et al. [1994] M. Reck, A. Zeilinger, H. J. Bernstein, and P. Bertani, Phys. Rev. Lett. 73, 58 (1994).
- Guo and Poletti [2021] C. Guo and D. Poletti, Phys. Rev. E 103, 013309 (2021).
- Epstein et al. [2014] J. M. Epstein, A. W. Cross, E. Magesan, and J. M. Gambetta, Phys. Rev. A 89, 062321 (2014).
- Yang et al. [2018] C. Yang, F. C. Binder, V. Narasimhachar, and M. Gu, Phys. Rev. Lett. 121, 260602 (2018).
- Guo [2022b] C. Guo, SciPost Phys. 13, 028 (2022b).