Random Simplicial Complexes:
Models and Phenomena
Abstract
We review a collection of models of random simplicial complexes together with some of the most exciting phenomena related to them. We do not attempt to cover all existing models, but try to focus on those for which many important results have been recently established rigorously in mathematics, especially in the context of algebraic topology. In application to real-world systems, the reviewed models are typically used as null models, so that we take a statistical stance, emphasizing, where applicable, the entropic properties of the reviewed models. We also review a collection of phenomena and features observed in these models, and split the presented results into two classes: phase transitions and distributional limits. We conclude with an outline of interesting future research directions.
1 Introduction
Simplicial complexes serve as a powerful tool in algebraic topology, a field of mathematics fathered by Poincaré at the end of the 19th century. This tool was built—or discovered, depending on one’s philosophical view—by topologists in order to study topology. Much more recently, over the past decade or so, this tool was also discovered by network and data scientists who study complex real-world systems in which interactions are not necessarily diadic. The complexity of interactions in these systems is amplified by their stochasticity, making them difficult or impossible to predict, and suggesting that these intricate systems should be modeled by random objects. In other words, the combination of stochasticity and high-order interactions in real-world complex systems suggests that models of random simplicial complexes may be useful models of these systems.
From the mathematical perspective, the study of random simplicial complexes combines combinatorics and probability with geometry and topology. As a consequence, the history of random simplicial complexes is quite dramatic. The drama is that this history is super-short, compared to the histories of probability and topology taken separately. For example, the first and simplest model of random simplicial complexes, the Linial-Meshulam model [1], appeared only in 2006. The main reason behind this dramatic delay is that probability and topology had been historically at nearly opposite extremes in terms of methods, skills, intuition, and esthetic (dis)likes among mathematicians. Fortunately, the wall is now dismantled, and over the last 15 years or so, the field of random topology has been growing explosively, as our review attempts to convey through the lens of random simplicial complexes.
We do not attempt to review all existing models and results related to random simplicial complexes, which is a mission impossible. Instead, we try to focus on those models for which some exciting phenomena—which we review as well—have been rigorously established in mathematics, especially in topology. It is not entirely coincidental that a majority of these models are particulary attractive not only from the topological and probabilistic perspectives, but also from the statistical and information-theoretic perspectives. This is because these models tend to be statistically unbiased, in the sense that they are canonical models satisfying the maximum entropy principle. As a consequence, they can be used as the correct null models of real-world complexes exhibiting certain structural features.
We take this statistical stance in our review of models in Section 2. This review is then followed by the review of some of the most exciting phenomena related to these models, which we split between phase transitions (Section 3) and distributional limit theorems (Section 4). Many of the presented results are higher-dimensional analogues of the well-known phenomena in random graphs related to connectivity, giant component, cycles, etc., therefore we preamble, where possible, the higher-dimensional statements with brief recollections of their one-dimensional counterparts. The focus on mathematics taken in this review precludes us unfortunately from covering many exciting subjects, such as models of growing complexes [2, 3, 4, 5, 6, 7], their applications, and phenomena in them including percolation [8, 9, 10, 11, 12, 13]. Yet in the concluding Section 6 that outlines our view on interesting future directions, we also comment briefly on some applications and their implications for different models of random simplicial complexes.
2 Review of models
In application to real-world systems, the models of random simplicial complexes reviewed here are typically used as null models reproducing a particular property of interest. In other words, these models are not intended to be “correct models” of real-world systems, but they are intended to be correct null models of these systems. By “correct” we mean here a model that is statistically unbiased, and by “statistically unbiased” we mean a model that maximizes entropy across all models that have a desired property. Therefore, we begin this section with a brief recollection of basic facts behind the maximum entropy principle and canonical ensembles, which we call canonical models in this review. We then observe that, with a few exceptions, the reviewed models are higher-dimensional generalizations of -dimensional random simplicial complexes, which are random graphs. Therefore, we preamble, where possible, the definition of a higher-dimensional model with its -dimensional counterpart. We finish the section with a short summary of the maximum entropy properties of the reviewed models.
2.1 Maximum entropy principle and canonical models
The maximum entropy principle [14] formalizes the concept of statistical unbiasedness of a null model. Indeed, Shannon entropy is the unique measure of information satisfying the basic axioms of continuity, monotonicity, and system and subset independence [15], and the maximum entropy principle follows directly from these axioms coupled with the additional consistency axioms of uniqueness and representation invariance [16, 17, 18]. For these reasons, a maximum-entropy model is the unique model that contains all the information that the model is asked to model, and, more importantly, that does not contain any other junk information.
Formally, let be a space of graphs or simplicial complexes, and a probability distribution on corresponding to a model of : is the probability with which the model generates . The Shannon entropy of is . Let , , be a finite collection of functions that we call properties of , and let be a set of numbers that we will associate with values of properties . In general, properties can take values in spaces that are more sophisticated than , but suffices for us here. Denote , , and let be a probability distribution on .
Given a pair of properties and their values , the microcanonical model is then the one that maximizes entropy under the sharp constraints that the values of the properties of must be equal to exactly: . This means that is the uniform distribution over all such s:
where .
The canonical model is the one that maximizes entropy under the soft constraints that the values of the properties are equal to in expectation: . If the properties are sufficiently nice (e.g., satisfy certain convexity assumptions [19, 20]), then the measure is a Gibbs measure
where and the parameters solve the system of equations . The solution exists and is unique under the same niceness assumptions [19, 20]. Since Gibbs measures are known as exponential families in statistics, canonical models of random graphs are called exponential random graph models there. Consequently, canonical models of simplicial complexes are exponential random simplicial complexes [21].
Finally, the hypercanonical model is the canonical model with random . The measure is thus the -mixture of the Gibbs measures,
reproducing a desired distribution of the values of the properties of .
It is important to notice that depends on only via . For this reason, the properties are called sufficient statistics [22]: it suffices to know to know ; no further details about are needed. It follows that all ’s with the same value of are equally likely in the canonical model, so that it is a probabilistic mixture of the corresponding microcanonical models, while the hypercanonical model is a probabilistic mixture of the canonical models.
Canonical models of random graphs and simplicial complexes tend to be more tractable than their microcanonical counterparts, explaining why the best-studied models of random simplicial complexes are based on canonical models of random graphs, versus microcanonical ones. We begin with the simplest models based on the Erdős-Rényi graphs.
2.2 Complexes based on homogeneous random graphs
The Erdős-Rényi graphs and .
Perhaps the best-studied random graph model is the model of random graphs with nodes and edges. All such graphs are equiprobable in the model, so that the model is microcanonical. It was introduced in 1951 by Solomonoff and Rapoport [23], and then studied by Erdős and Rényi in 1959 [24]. Its canonical counterpart, introduced by Gilbert in 1959 [25], is the ensemble of random graphs in which every possible edge between the pairs of nodes exists independently with probability . The sufficient statistic in this canonical model is the number of edges . If in the large graph limit , then the microcanonical and canonical models are asymptotically equivalent according to all definitions of such equivalence [26, 27, 28].
The Linial-Meshulam complex .
The constructive definition of the model can be rephrased as follows: take a complete -complex, which is a set of vertices, and then add -simplexes (edges) to it at all possible locations independently with probability . The result is a random -dimensional complex .
The Linial-Meshulam model [1] is a straightforward -dimensional analogy of : take a complete -complex, which is the complete graph of size , and then add -simplexes (filled triangles) to it at all possible locations independently with probability . The result is a random -dimensional complex .
The -dimensional Linial-Meshulam complexes and .
The Linial-Meshulam complex admits the natural generalization to any dimension [29] in the following way. Take a complete -complex, and then add -simplexes to it at all possible locations independently with probability . We denote this random complex by .
The microcanonical version of canonical is also well defined. Here, we can take a complete -complex, add exactly -simplexes to it chosen uniformly at random out of all the possibilities. Note that . The microcanonical model gained less consideration than the canonical one, but some of its aspects were studied in [30, 31]. It should be easy to show that is asymptotically equivalent to , but this has not been done.
The random flag complexes and .
The Linial-Meshulam complexes are just one way to generalize the Erdős-Rényi graphs to higher dimensions. Another straightforward generalization is to extend into a random flag complex [32, 33]. Recall that the flag complex of a graph is the simplicial complex obtained by filling all the -cliques in with -simplexes, for all . We can similarly define as the flag complex of . To the best of our knowledge, the model has not been considered in the past.
The multi-parameter complexes and .
A further generalization of , subsuming both the Linial-Meshulam and flag complexes, is the multi-parameter complex considered in [34, 35, 36, 37]. Let where , , is the probability of the existence of simplexes of dimension in . Given this vector of probabilities, the complex is then defined as follows. First, take vertices and add edges to them independently with probability , i.e., generate a graph. Second, considering this graph as a -skeleton of a -complex, go over all the triangles (i.e. -cliques) in it, and fill each of them with a -simplex independently with probability . Do not stop here, but continue in this fashion—given the -skeleton, go over all the -cliques in it, and fill each of them with a -simplex independently with probability —until .
Among the -based complexes discussed thus far, the complex is the most general since it subsumes both the flag complex,
and the Linial-Meshulam complex,
The model is canonical, and to specify its sufficient statistics, we define a -shell to be the complete -dimensional boundary of a (potential) -simplex in a complex . That is, may or may not contain ( can be filled or empty), but if is a -shell, then all its simplexes are filled, so that can be thought of as a “pre--simplex”, in the sense that it is ready to be filled with , but might eventually be left empty.
As shown in [21] (see also Section 2.6), the sufficient statistics in are not only the numbers of -simplexes of each dimension , but also the numbers of -shells. Therefore, the microcanonical counterpart of is , where , , and . This model has not been considered in the past, but it is another natural higher-dimensional generalization of , while and are special cases of .
All other relationships between the discussed complexes are shown in Fig. 1.

2.3 Complexes based on inhomogeneous random graphs
2.3.1 General complexes
The inhomogeneous random graph .
The edge existence probability in the random Erdős-Rényi graph does definitely not have to be the same for all edges. Each edge can have a different existence probability , . Such random graphs are known as inhomogeneous or generalized random graphs [38, 39, 40, 41]. We denote them by , where is the matrix of edge existence probabilities, .
The multi-parameter complex .
A straightforward generalization of to higher dimensions was introduced in [21]. It is also a generalization of , and it is defined as follows. Let be a vector of simplex existence probabilities for all possible simplexes of all possible dimensions : , , and collects the existence probabilities for all possible simplexes of dimension . Given such a vector of tensors , the random complex is then generated similarly to : starting with an inhomogeneous random graph , go over all the -cliques (-shells) in this graph, and fill them with -simplexes independently with probability . Proceed to higher dimensions in a similar fashion, filling -shells with -simplexes independently with probabilities . The complex is a special case of —the one with .
2.3.2 Configuration models
The configuration models and .
The inhomogeneous random graphs are quite general, subsuming many other important models of random graphs. In particular, they encompass the soft configuration model [38, 39, 40, 41, 42, 43, 44], which is the canonical model of random graphs with a given sequence of expected degrees , , . The model is the with given by
| (2.1) |
where the parameters ’s (known as Lagrange multipliers) solve the system of equations given by
| (2.2) |
This equation guarantees the expected degree of node to be .
The sufficient statistics in are the degrees of all nodes in a graph. Therefore, ’s microcanonical counterpart, the configuration model [45, 46], is the uniform distribution over all the graphs with the degree sequence . Note that can be any sequence of nonnegative real numbers in , but in , is a graphical sequence of nonnegative integers. A sequence is called graphical, if there exists a graph whose degree sequence is . The necessary and sufficient conditions for to be graphical are the Erdős-Gallai conditions [47].
An important special case of is the random -regular graph .
The -dimensional configuration models and .
Recall that the degree of a vertex (-simplex) is the number of edges (-simplexes) that contain . In a similar vein, the degree of -simplex is defined to be the number of -simplices that contain .
The -dimensional soft configuration model is a generalization of , where now is a sequence of expected degrees of all -simplexes . To construct we take the complete -skeleton on vertices, and add all possible -simplexes independently with probability
| (2.3) |
where the summation is over all -faces of (as implied by the standard notation), and the parameters solve the system of equations
| (2.4) |
Note that is a special case of :
where is given by (2.3). If , then Eqs. (2.3,2.4) reduce to Eqs. (2.1,2.2), respectively, and we have .
The is the canonical model of random complexes whose sufficient statistics are the degrees of all the -simplexes in a complex. Therefore, ’s microcanonical counterpart, the configuration model , is the uniform distribution over complexes with the complete -skeleton and the degree sequence of -simplexes equal to . In , is a realizable sequence of nonnegative integers, versus any sequence of nonnegative real numbers in . The conditions for to be realizable, analogous to the Erdős-Gallai graphicality conditions in the case, are at present unknown.
2.4 Complexes based on inhomogeneous random graphs with random connection probabilities
2.4.1 General complexes
The inhomogeneous random graph with random connection probabilities .
Note that the edge probabilities in inhomogeneous random graphs can themselves be random [52, 53, 40, 41]. In that case, we replace with which is a random matrix with entries in , and the corresponding inhomogeneous random graph is denoted . This class of random graphs is extremely general and subsumes a great variety of many important random graph models, for example .
Of a particular interest is the case where
where is a set of random variables in some measure space , and is a fixed function called the connection probability function. This class of models is quite general and subsumes, for instance, the stochastic block models [54], hidden variable models [52, 53], latent space models [55, 56, 57], random geometric graphs [58, 59], and many other popular models. If the ’s are independent random variables uniformly distributed in , and is a symmetric integrable function, then is also known as a graphon in the theory of graph limits [60, 61].
The multi-parameter complex .
The most general class of models considered in this chapter is a version of the multi-parameter complex with random simplex existence probabilities . To emphasize their randomness, we denote this complex by , where is random . For maximum generality, the probabilities of existence of different simplexes, including simplexes of different dimensions, do not have to be independent random variables, so that the space of is parameterized by joint probability distributions over the vector of tensors , equivalent to all nonempty subsets of . As evident from Fig. 1, all other models of random complexes and graphs are special cases of . In particular, is a special degenerate case of . At this level of generality, the complex has not been considered or defined before, yet it is simply a higher-dimensional version of the well-studied .
2.4.2 Hypersoft configuration model
The hypersoft configuration model .
The hypersoft configuration model is the hypercanonical model of random graphs with a given expected degree distribution [52, 53, 40, 41, 44, 62]. It is defined as the in which the expected degree sequence is not fixed but random: the expected degree of every vertex is an independent random variable with distribution , . In other words, to generate an graph, one first samples s independently from the distribution , then solves the system of equations (2.2) to find all s, and finally creates edges with probabilities (2.1). The is thus a probabilistic mixture of ’s with random . The degree distribution in is the mixed Poisson distribution with mixing [40, 41].
An equivalent definition of is based on the observation that the distribution defines the joint distribution of via (2.2). This means that an equivalent procedure to generate an graph is to sample directly from first, and then create edges with probabilities (2.1). This definition makes it explicit that the is a special case of .
For a given , it may difficult to find the explicit form of the distribution . However, in many cases with important applications—including the Pareto with a finite mean, for instance—it has been shown that the canonical connection probability (2.1) and its classical limit approximation
| (2.5) |
where is the mean of , lead to asymptotically equivalent random graphs [28]. In such cases, the random Lagrange multipliers ’s are asymptotically independent, , , with the distribution defined by the distribution via the change of variables where . Generating such a graph is extremely simple: first sample either the ’s or ’s independently from the distribution or , respectively, and then generate edges with probabilities (2.5).
The -dimensional hypersoft configuration model .
A straightforward generalization of to dimension is achieved by defining the as the probabilistic mixture of with random : the expected degree of every -simplex is an independent random variable with distribution . In other words, to generate a random complex, one first prepares the complete -complex of size , then samples the expected degrees of all the -simplexes independently from the distribution , then solves the system of equations (2.4) to find all the ’s, and finally creates the -simplexes independently with probability (2.3). For the same reasons as in the case, the model is a special case of for any . The model has not been previously considered, except the case.
2.4.3 Geometric complexes
An important class of random complexes are geometric complexes, which are a special case of whose -skeletons are random geometric graphs. Their randomness comes from random locations of vertices in a space, and this randomness is often modeled by either binomial or Poisson point processes whose definitions we recall next.
Let be a metric space with a probability distribution on it. The definitions below apply to any sufficiently nice pair of and . However, for the sake of simplicity, in the subsequent sections of this chapter, the space will always be a flat -dimensional torus , while will be its Lebesgue measure , i.e., , where is the Euclidean volume of .
The binomial point process
is simply a set of random points sampled independently from . In the simplest case , we simply sample ’s from the uniform distribution, , viewed as a circle. The distribution of the number of points in any measurable subset is binomial with mean , giving the process its name.
The Poisson point process
is the binomial process with a random number of points sampled from the Poisson distribution with mean , i.e. , where . The distribution of the number of points in any measurable is Poisson with mean , where is the rate of the process. Another key property of the Poisson process is spatial independence: the numbers of points in any pair of disjoint subsets of are independent random variables. This property, absent in the binomial process, makes the Poisson process favorable in probabilistic analysis.
In the limit, the two process are asymptotically identical—the binomial process converges to the Poisson process in a proper sense [63]. For this reason, and given that the Poisson process is easier to deal with, we will restrict ourselves in this chapter to the Poisson process on the torus . These setting turn out to provide the most elegant results, while not losing much in terms of generality.
The random geometric graph .
We start with , which is a special case of , in which
where is the distance between in , and is the connectivity radius parameter [58, 59]. In other words, the vertices of this random graph are a realization of the binomial process, and two vertices are connected if the distance between them in is at most . To generate the random geometric graph we first sample , and then generate as described above.
The random Vietoris-Rips complex .
This is the flag complex over the random geometric graph . It is thus a straightforward higher-dimensional generalization of . Note that we can consider for the binomial process as well, which is a special case of . Then with .
The random Čech complex .
This is a different higher-dimensional generalization of . The rule is: draw balls of radius around each of the points , then look for all the intersections of these balls, and for every -fold intersection of the balls, add the corresponding -simplex to the complex. Note that the binomial version can still be considered as a special case of with a different rule for the creation of higher-dimensional simplexes, compared to .
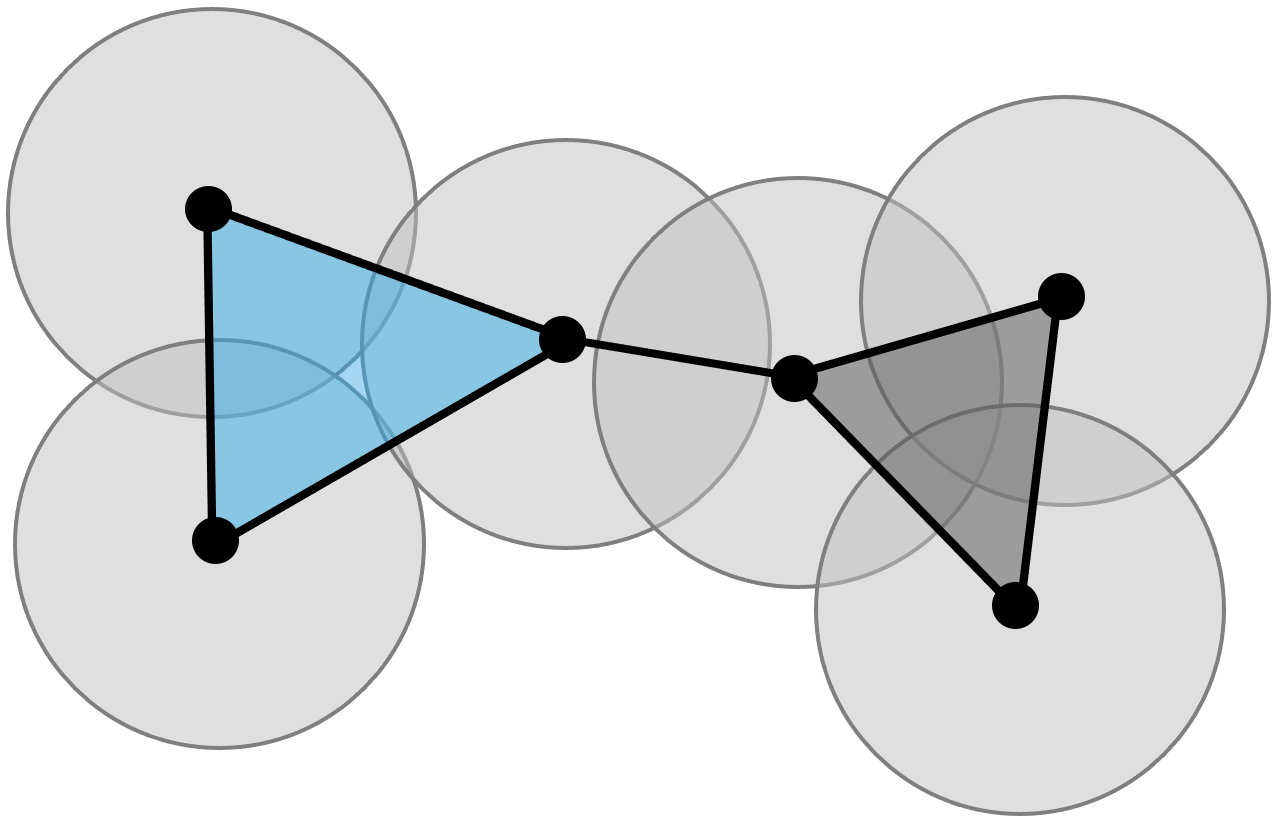
While the -skeleton of both and is the same random geometric graph , higher-dimensional simplexes in these complexes are in general different, as illustrated in Fig. 2. The following useful relation was proved in [64] for any :
A powerful property of the Čech complex is due to the Nerve Lemma [65] stating that under mild conditions we have the following isomorphism between the homology groups :
where . This property, absent in the Rips complex, is very useful in the probabilistic analysis of the Čech complex, allowing one to switch back-and-forth between combinatorics and stochastic geometry.
2.5 Complexes based on random hypergraphs
2.5.1 General complexes
The main reason why the Linial-Meshulam model is defined on top of the complete -skeleton, is simplicity. The complete -complex underlying the -complex simplifies its topological analysis drastically. Much less simple, but also much more general, is the complex in which the probability of existence of simplexes of different dimensions are all different, but this complex is still relatively simple from the probabilistic perspective, since simplexes of higher dimensions are created in a conditionally independent manner, with the conditions being the existence of required simplexes of lower dimensions. Very recently, this simplicity was sacrificed even further for the sake of even greater generality in a class of models based on random hypergraphs [66, 67], which we briefly review next.
The inhomogeneous random hypergraph .
This is a straightforward generalization of the inhomogeneous random graph to hypergraphs: every possible hyperedge (which is a nonempty subset of ) in exists independently with probability . Note that is not a simplicial complex with high probability, unless is specially designed for to be a complex.
The lower and upper complexes and .
Introduced in [68, 66], these are both based on the . The lower complex is the largest simplicial complex that the random contains, while the upper complex is the smallest simplicial complex that contains the random , so that . In other words, a simplex is included in the lower complex if and only if and also all its faces are hyperedges of . The other way around, every hyperedge is included in the upper complex as a simplex together with all its faces, even if some of these faces do not happen to be in .
Compared to the graph-based models reviewed in the previous sections, the hypergraph-based models are much more difficult to analyze, primarily because the distributions of the skeletons are highly nontrivial and carry intricate dependency structure. However, an exciting fact about these two models is that they are dual in some strict topological sense (Alexander duality), and therefore statements about one of the models can be translated with ease to corresponding statements about the other [66, 67].
At this point, it may be tempting to proceed similarity to the previous -sections, and let the hyperedge existence probabilities be random , leading to , , and . However, nothing new is gained by doing so, since the model is already general enough as it includes any possible joint distribution of simplex existence probabilities, including the distributions describing and . That is, the lower and upper models and with nonrandom are special cases of the more general model with the joint distribution of set equal to the joint distribution of simplex existence probabilities in and , while the lower and upper models and with random are equivalent to with matching joint distributions of .
2.5.2 -configuration models
One interesting special case of the -complexes from the previous section is the -version of the -dimensional (soft) configuration model considered in [50].
The -configuration models - and -.
The -degree of a -simplex is defined to be the number of simplexes of dimension that contain [2], and the -configuration models are defined by a vector of a given sequence of (expected) -degrees of vertices , as opposed to the vector of (expected) -degrees of -simplexes in the in Section 2.3.2. No low-dimensional skeleton is formed in the Z-, while the probability of -simplex is
| (2.6) |
where the parameters of vertices solve the system of equations
| (2.7) |
If simplex is added to the complex, then so are all its lower-dimensional faces. The Z- is a special case of the with and given by (2.6).
The model is canonical with the -degree of all vertices being its sufficient statistics, so that the corresponding microcanonical model Z- is the uniform distribution over all the -complexes with the -degree sequence of the vertices equal to . Note that these complexes satisfy the additional constraint: they do not contain any simplex of dimension that is not a face of a -simplex. The hypercanonical model Z- is the Z- with random .
2.6 Random simplicial complexes as canonical models
Table 1 summarizes what is known concerning the reviewed complexes as canonical models. To convey this knowledge succinctly, it suffices to focus only on the canonical models per se, since their microcanonical constituents and hypercanonical mixtures are coupled to them as discussed in Section 2.1.
| Models | Spaces | Properties | Refs | Comments |
|---|---|---|---|---|
| , | [39] | (1) | ||
| , | [21] | (1) | ||
| , | [21] | (1) | ||
| , | [21] | (1,2) | ||
| , | [39] | (1) | ||
| , | [21] | (1,2) | ||
| [39] | (3) | |||
| here | (4) | |||
| Z- | [50] | (5) |
To define a canonical model, one needs to specify not only the sufficient statistics (whose expectations can take any admissible values in a particular canonical model), but also the space of allowed complexes over which the entropy of a canonical model is maximized. Table 1 uses the following notations for such spaces of labeled graphs and complexes:
-
•
: all graphs of size ;
-
•
: flag complexes of size ;
-
•
: all complexes of size ;
-
•
: -complexes of size with a complete -skeleton;
-
•
: -complexes of size whose all -simplexes, for all , are faces of -simplexes.
For the sufficient statistics, Table 1 uses the following notations that rely on the definition of a -shell, which can be found at the end of Section 2.2:
-
•
and : numbers of -shells and -simplexes (, the number of edges);
-
•
and : -shell and -simplex (, a vertex; , an edge);
-
•
and : -degree and generalized -degree of ().
Finally, the comments referred to in Table 1 are as follows:
-
1.
The values of properties are not shown, but they are assumed to match properly the model parameters. That is, in a general canonical model we have that , so that the model, for example, is the canonical model with and . Similarly, the model is the canonical model with and , giving the expected values of the sufficient statistics as functions of the model parameters .
-
2.
The presence of the constraints on the existence of the boundaries of -simplexes, their -shells, in addition to the constraints on the existence of -simplexes themselves, may appear surprising at first. These stem from the conditional nature of the definition of these complexes. The models with these additional constraints removed, e.g. the canonical model over with , are still entirely unknown. This is not surprising, since such models appear to be combinatorially intractable [21].
-
3.
Note that the constraints under which entropy is maximized in a hypercanonical model are generally intractable. The proofs that these constraints are the degree distributions in the dense and sparse HSCM graphs appear in [44] and [62], respectively. That is, the HSCM is the unbiased maximum-entropy model of random graphs with a given degree distribution, versus an (expected) degree sequence in the (S)CM.
-
4.
The -dimensional ((H)S)CM models have not been considered before. The proof that maximizes entropy subject to the expected -degree sequence constraints is a straightforward adjustment of notations in the corresponding proof for a general canonical model [14], so that it is omitted here for brevity.
-
5.
The hypercanonical version of the model (Z-) has not been considered before. Efficient algorithms to sample from a generalized version of Z- are considered in [51].
3 Phase transitions
Phase transitions are very interesting and important phenomena occurring in random structures in statistical physics. In this section we briefly recall the most fundamental types of phase transitions that have been studied in random graphs, and then describe their higher dimensional analogues in simplicial complexes.
3.1 Homological Connectivity
The very first theorem proved for random graphs in [24] was the phase transition when the random graph becomes connected. The following is the equivalent result for the random graph.
Theorem 3.1.
Let . Then
where is any function satisfying . In addition, if for , and denoting by the number of connected components in , then
where denotes convergence in distribution. This convergence implies that
The main idea behind the proof of Theorem 3.1 is to show that around , the random graph consists only of a giant connected component and isolated vertices. In that case, the phase transition for connectivity can be achieved by analysing the number of isolated vertices.
Note that in the language of homology, the event ‘ is connected’ can be phrased as ‘the th homology group is trivial’, and that is equal to the th Betti number . Thus, it is tempting to try to generalize this phase transition for higher degrees of homology, and search for the point (value of or ) where the th homology group becomes trivial.
3.1.1 The random -complex
We start with the Linial-Meshulam random -complex . Recall that , and that Theorem 3.1 studies . Similarly, the following results studies in .
Theorem 3.2.
Let . Then
where .
In addition, if , , then
which implies that
Note that taking in Theorem 3.2, nicely recovers the graph result in Theorem 3.1. Thus, Linial and Meshulam named this phase transition ‘homological connectivity’. The phase transition itself was proved first for and for homology in coefficients in [1], and then for any and homology in coefficients in [29]. The Poisson limit was proved a decade later [30].
Aside from the analogy between the statements of Theorems 3.2 and 3.1, the general idea behind the proof also shares some similarity. To prove Theorem 3.2 one can show that around , the only possible cycles in 111More accurately, the proof actually looks at cocycles in . are those generated by isolated -simplexes. An ‘isolated’ -simplex is such that it is not included in any -dimensional simplex. The fact that isolated -simplexes yield nontrivial is relatively easy to prove. The much harder part here is to show that these are the only possible cycles.
3.1.2 The random flag complex
The random flag complex differs from the random -complex in two important ways. Firstly, has random homology in all possible degrees , rather than just and as in . Secondly, note that in both and are monotone – is decreasing in , while is increasing. This is not the case for the flag complex, where except for , none of the homology groups is monotone. The following result was proved by Kahle [33].
Theorem 3.3.
Let . Then,
Note that here as well, taking agrees with the phase transition in Theorem 3.1. The phase transition here is also a consequence of the vanishing of the isolated -simplexes. However, as oppose to the proofs in [1, 29] which mainly consist of combinatorial arguments, the proof in [33] goes in a different way, employing Garland’s method. Briefly, Garland’s method [69] is a powerful tool that allows “breaking” the computation of homology into local pieces (the links of the faces), and to invoke spectral graph arguments.
3.1.3 The multi-parameter random complex
Phase transitions are usually described as a rapid change of system behavior, in response to a small change in a system parameter value (e.g. or above). Since the multi-parameter complex has an infinite sequence of parameters, we cannot describe a suitable phase transition per se. Nevertheless, interesting results were presented in [70], showing that there are different regions within this high-dimensional parameter space, where in each region there is a single dominant homology group .
To describe the result we need a few definitions. Let and let . Define
These functions are then used to define different domains
for , and where . We also define . Finally, define
Theorem 3.4 ([70]).
Let , be such that , where may be a function of , and . Let , and suppose that . Then, with high probability
and for all we have
In other words, in each the -th Betti numbers is quite large, and all other Betti numbers are negligible compared to it. One can think of this results as a “multi-parameter phase transition” so that the system behavior changes as one moves from one region to another. The proofs in [37] relies mainly on counting faces and using Morse inequalities.
3.1.4 Random geometric complexes
With respect to connectivity, the random geometric graph behaves quite similarly to the random graph. Denoting by the expected degree equal to the expected number of points in a ball of radius , with standing for the volume of the unit-ball in , the following was shown in [71].
Theorem 3.5.
Let . Then
where is any function satisfying .
In other words, in both models connectivity is achieved once the expected degree is larger than .
Moving to higher dimensions, the geometric models start to exhibit different behavior than the combinatorial ones. The main difference is the following. In and , when , homological connectivity describes the stage where homology becomes trivial. This is due to the fact that there is no structure underlying the complex. In the geometric complexes, the vertices are sampled over a metric space , which might has its own intrinsic homology. Thus, for large enough, one should expect the homology of the random complex ( or ) to “converge” to the homology of , rather than to vanish. To account for this, the event we will refer to as the -th homological connectivity here, is defined in [72] as
for the Čech complex, and similarly for the Rips complex, with ‘’ replaced by ‘’. Note that is a monotone event (i.e. for all ).
In the Čech complex, the phase transition in is by now fully understood. The following was proved in [72].
Theorem 3.6.
Let , then for ,
for any . In addition,
While the proof there considers only the flat torus case, the results in [73] indicate that similar results could be achieved for any compact Riemannian manifold. The key idea behind the proof of Theorem 3.6 was to consider the evolution of complex as is increased, and to look for critical faces. By that we mean simplexes that facilitate changes in when they first enter the complex. The analysis of critical faces employs Morse theory [74, 75]. The proof then consists of the following arguments:
-
1.
If is large enough (), we have coverage, i.e. . Then, by the Nerve Lemma [65] we have that .
-
2.
If we can show that w.h.p. no more critical faces that modify enter the complex. In other words, has reached its limit. From the previous argument the limit is , and thus we conclude that holds.
-
3.
If , critical faces still enter the complex and make chances in . Thus does not hold (w.h.p.).
Similarly to Theorems 3.1 and 3.2, the results in [72] also include a Poisson limit for the counting of the critical faces, when . This result is the analogue of the isolated vertices in the random graph, since: (a) Critical faces are the ‘obstructions’ to homological connectivity, in the same way that isolated vertices are for connectivity. (b) It can be shown that critical faces are indeed isolated when they first enter the complex. Since the exact definition of the critical faces require more details, we will not present the exact theorem here, but refer the reader to [72, 76].
Homological connectivity for the Rips complex is still an open problem to date. The most recent result in this direction appeared in [77]. By using Discrete Morse Theory [78], Kahle was able to prove the following.
Theorem 3.7.
Let be a compact and convex subset of . Then
In particular, if then (w.h.p.).
Note that this result is for compact and convex sets , for which for all . While this result is a significant step, it is still incomplete since: (a) It does not provide a sharp phase transition. In particular, there is no reason to believe that the constant provided by the proof, is the optimal one. (b) It does not apply to general manifolds.
3.2 Emergence of homology
Another fundamental result proved from random graph concerns the appearance of cycles. The following was proved in [47] (for the model, but the statement for is equivalent).
Theorem 3.8.
Let , then
where .
Note that the event ‘ contains cycles’ can be phrased as . In other words, Theorem 3.8 describes a phase transition for the emergence of in .
In the following, we will review the results known to date about the emergence of -cycles for the various random simplicial complex models.
3.2.1 The random -complex
For the random -complex, the following is an aggregate of a collection of works.
Theorem 3.9.
Let . There exists such that
where . In addition, the only -cycles in are generated by empty -shells.
The first case was proved in [79], the middle case was proved in [80], and the last case was proved in [81]. An equation defining the critical values can be found in [79], while numerical approximations [80] yield , . So roughly, it looks like .
Another closely related phase transition is for collapsibility. Briefly, a -complex is collapsible, if we can iteratively erase pairs of simplexes in dimension and , without changing the topology of the complex. In [82] a phase transition for collapsibility was shown at critical values .
3.2.2 The random flag complex
Recall that the homology is non-monotone (in ). In Section 3.1.2 we saw that the largest value of such that is non-trivial is when . In this section we look for the smallest possible value of .
Theorem 3.10.
Let , and suppose that . Then,
for any .
3.2.3 Random geometric complexes
The behavior of random geometric complexes is similar in many ways to that of the random flag complex. In particular, for each we have two phase transitions – one for the emergence of the first -cycles, and another for homological connectivity (Section 3.1.4). Here we present the former phase transition.
Theorem 3.11.
For ,
where , for some constant .
Note that the transition occurs when . In other words, the first cycles appear in a sparse regime where the expected degree is small. Consequently, it was shown in [77] that in this regime the only -cycles that appear are the smallest possible ones – i.e., -shells, which consist of vertices. The phase transition in Theorem 3.11 then essentially describes the appearance of these empty -shells.
A similar result was proved for the Rips complex.
Theorem 3.12.
For any ,
where , for some constant .
There are two main differences between Theorems 3.11 and 3.12. Firstly, due to the Nerve Lemma [65], the Čech complex on (as well as any subset of ) cannot have any -cycles for . The Rips complex, on the other hand, may have -cycles for any . Secondly, the transition here occurs when , as opposed to in Theorem 3.11. This difference stems from the fact that empty shells cannot appear in the Rips complex. Thus, it can be shown that the smallest possible -cycle is achieved by generating an empty cross-polytope, which consists of vertices.
3.3 Percolation-related phenomena
Percolation theory studies the emergence of infinite or “giant” connected component in various random media. The study of higher-dimensional analogues is at a preliminary stage, and we describe here the most recent results.
In the case of random graphs, giant components are commonly defined in terms of the number of vertices. Specifically, for both the and models, by a “giant component” we refer to a component that consists of many vertices. As opposed to connectivity which we discussed earlier, this notion does not have a simple analogue in higher dimensions. In this section we present two different notions – one of the random -complex and another for the random Čech complex.
3.3.1 Random -complex
Starting with the graph, the following was proved in [47].
Theorem 3.13.
Let , and . Denote by the largest connected component in . Then with high probability
In other words, a giant component appears for . Further, it can be shown that in this case, the giant component is unique.
In order to generalize the emergence of the giant component to higher dimension, the notion of shadow was introduced in [84]. Suppose that is a -dimensional simplicial complex with a complete -skeleton. The shadow of , denoted , is the set of all -dimensional faces such that (a) , and (b) adding to generates a new -cycle.
In the case of the graph (i.e., ) the shadow are all the edges not in the graph, such that adding them generates a new cycle. In that case, it is easy to show that when we have , so that the shadow has a positive density, and we say that the graph has a giant shadow. In [80], this phenomenon was generalized for higher dimensions.
Theorem 3.14.
In other words, when a giant shadow emerges in the random -complex, similarly to what happens in the graph case.
3.3.2 Random geometric complexes
Similarly to the model, the random geometric graph exhibits a phase transition for the emergence of a giant component. This phase transition occurs when the expected degree is constant, and the corresponding critical value is denoted as .
In the context of geometric complexes, a different generalization for percolation was studied recently [85, 86]. Consider the random Čech complex defined in Section 2, where is a homogeneous Poisson process on the -torus . One of the nice facts about the torus, is that it has non-trivial homology for all , and in particular . In [85] the notion of a “giant -cycle” was introduced, by which we mean any -cycle in that corresponds to any of the nontrivial cycles in .
To define this more rigorously, we consider the union of balls , and the fact that . We then take the inclusion map , and its induced map . By a giant -cycle we refer to all nontrivial elements in the image . Finally, we define the events
In other words, is the event that some giant cycles exist, while is the event that all of them are present in (and correspondingly in ). The following was proved in [85].
Theorem 3.15.
Suppose that .
-
1.
There exist , such that if then,
for some .
-
2.
There exist , such that if then,
for some .
In addition, we have for all , and .
In other words, Theorem 3.15 suggests that there is a phase transition describing the emergence of the giant -cycles. However in order to complete the proof, one needs to show that for all .
At this stage the giant shadow and the giant cycle phenomena are incomparable. However, it should be noted that both occur in the regime where the expected degree ( or ) is finite, similarly to the giant component. It is an interesting question whether these are merely two ways to view the same phenomenon, or they describe completely different structures. Finally, we should note that other ideas for extending percolation-type phenomena to higher dimension exist in the literature.
3.4 The fundamental group
Given a space , the fundamental group represents the space of equivalence classes of loops in , where the equivalence is based on homotopy (a continuous transformation of one loop into the other). The space is simply connected if and only if is trivial.
Note that the first homology group also represents loops, but under a different equivalence relation (being a boundary). In fact, it can be shown that is an abelianization of . Thus, it is possible that is trivial while is not. Consequently, the vanishing threshold for is larger than the threshold for as the following statements show.
We start with the random -complex. Here the only relevant dimension is , since otherwise the fundamental group is trivial. The following was proved in [87, 88].
Theorem 3.16.
Let . Then,
where is any constant bigger than .
Further, when it is shown in [87] that the fundamental group is hyperbolic. It is also conjectured in [88] that in fact is the exact sharp threshold for simple connectivity.
For the random flag complex, the existing results [89] are even less sharp.
Theorem 3.17.
Let , then for any
with high probability is nontrivial and hyperbolic.
4 Limit theorems
The results in the previous section focused on a rather qualitative analysis of phase transitions. Another direction of study is to consider some numerical marginals of homology (e.g., the Betti numbers) and find their limiting distribution. In this section we will briefly review some of the results in this direction.
We will not discuss the proofs here, however we note that in most cases they rely on Stein’s method [93, 94]. Briefly, this method allows one to prove central limit theorems and convergence to the normal and Poisson distributions in cases that involve sums of random variables that are not independent.
Notation.
In this section we will use to denote that as , and to denote that . In addition, stands for convergence in distribution, and for the normal distribution with mean and variance .
4.1 Betti numbers
As we have seen in Section 3.2, the -th homology of is nontrivial roughly when is between and (up to constants). It was shown in [32] that when then
In addition, the following central limit theorem was proved in [83].
Theorem 4.1.
Let , and let . Then
In the geometric complexes case, the results usually split according to the expected degree . In the case where (sometimes called the sparse regime), the homology is dominated by empty shells, and thus it is relatively easy to compute the Betti numbers. For example, it was proved in [77] that
where is a known constant [77]. Note that the limit of the right hand side can be zero, finite, or infinite. Consequently we have three possible limits. The following was proved in [83].
Theorem 4.2.
Let , and suppose that .
-
1.
If then with high probability.
-
2.
If then .
-
3.
If then .
Similar results hold for the Rips complex as well, just with replacing [83].
The regime where is finite and non-vanishing is sometimes referred to as the thermodynamic limit. It can be shown that most of the cycles in either the Čech or Rips complexes are generated in this regime. However, exact counting here is much more difficult. It was shown in [77] that (and the same for the Rips). However the exact expectation is not known.
Nevertheless, one can prove laws of large numbers as well as central limit theorems for the Betti number functionals. This type of results was first introduced in [95], and have been improved over the years [96, 97, 98]. The main tools used are stabilization methods for random point processes (e.g. [99]). The result is as follows.
Theorem 4.3.
Let , and suppose that . Then
for some .
A similar result applies to the Rips complex as well. In addition in [98, 100] the binomial process was studied as well, and similar limiting theorems were proved.
In the dense regime, i.e., there are very few results. In particular, even the scale of the expected Betti numbers is not known. The only case analyzed is the Poisson limit when described earlier, as part of the homological connectivity phenomenon.
4.2 Topological types
In [101] a completely different type of limit theorem was proved. There, the goal was to study the distribution of the different topological types that may appear in a random Čech complex. Let be a simplicial complex, and let be the set of all connected components of (so that ). Define the empirical measure
where stands for the Dirac delta measure, and stands for the equivalence class of all components homotopy equivalent to (i.e. so that one component can be “continuously transformed” into the other, see [102]).
Theorem 4.4.
Let , and denote . Then the random measure converges in probability to a universal probability measure. The support of the distribution is the set of all connected (finite) Čech complexes in .
Note that universality here means that the limit is the same regardless of the underlying manifold .
4.3 Persistent homology
In the context of Topological Data Analysis (TDA), one is often more interested in studying persistent homology rather than just the (static) homology. In this section we consider the persistent homology over filtrations of either Čech or Rips complexes, namely or , respectively.
4.3.1 Limit theorems
One useful quantity that can be extracted from persistent homology are the persistent Betti numbers. Briefly, for any , we denote by the number of cycles born before radius and die after radius (see [96] for a formal definition). In [96] the following central limit theorem was proved.
Theorem 4.5.
Let , and suppose that and , for some . Then
for some .
Note that this theorem describes the persistent Betti numbers in the thermodynamic limit, where most cycles are born and die. A similar theorem applies for , and in fact [96] present this central limit theorem for an even larger general class of geometric complexes. In [97] Theorem 4.5 was further extended to a multidimensional central limit theorem (i.e. for a sequence ). Finally, note that Theorem 4.3 is in fact a special case of Theorem 4.5 in the case where .
Recall that a common representation for persistent homology is via a persistence diagram, which is essentially a finite subset of , where the coordinates of each point correspond to the birth and death times of a persistence interval. Thus, persistence diagrams attached to random finite simplicial complexes, can be thought of as a random subset of , or equivalently a random discrete measure on . One can then employ the theory of random sets and random measures to study the limit of such diagrams.
Consider the random Čech filtration , and let be the discrete measure representing the persistence diagram in degree . The main result in [96] shows that there exists a limiting Radon measure on ,
The same is true for the Rips filtration as well. This statement is essentially a law of large numbers for the persistence diagram as a Radon measure in .
A different approach was taken in [103], where persistence diagrams were studied from the point of view of set-topology. In that case it was shown that each persistence diagram can be roughly split into three different areas. The limit of the persistence diagram in the sparse region is empty. In the intermediate region it has a limiting Poisson process distribution. Finally, in the dense region, the persistence diagram converges to a solid (nonrandom) 2d region.
4.3.2 Maximal cycles
Another interesting and significant type of limit for persistence diagrams was presented in [104]. There, it was assumed that is a unit box (though the results should not depend on that). The quantity considered was the maximal death/birth ratio among all persistent cycles of degree , denoted .
Theorem 4.6.
Let be the maximally persistent cycle for either the Rips or Čech complex. Then there exist such that with high probability
Theorem 4.6 provides the scaling for the multiplicative persistence value in a random geometric complex. Since the unit box has no intrinsic homology, this result can be thought of as describing the homology of noisy cycles, i.e., cycles that are not part of the underlying topology. It can be shown that the same result applies for other compact spaces , as long as we do not count cycle that belong to . Recalling Section 3.3.2, such “signal” cycles (those in ) are born when is constant, implying that the birth time is . On the other hand, the signal cycles die when is a constant (depends on and not on ). Therefore, for the signal cycles we have . In other words, taking death/birth as a measure of persistence, Theorem 4.6 shows that asymptotically noisy cycles are significantly less persistent than the signal ones, and one should be able to differentiate between them, assuming a large enough sample.
5 Other directions
In Sections 3 and 4 we presented some of the most fundamental results proved in the mathematical literature on random simplicial complexes. There are numerous important studies that we omit for space reasons, but would like to mention them briefly here.
- •
-
•
Functional limit theorems: One can examine functionals such as the Betti numbers and the Euler characteristic in a dynamic setting, and seek a limit in the form of a stochastic (Gaussian) process. In [103, 108], geometric complexes were studied, and the dynamics was the growing connectivity radius in the complex. The results show that the limiting process is indeed Gaussian. In [109], the random flag complex was studied. Here, the set of edges used to construct the complex turns on and off, following stationary Markov dynamics. The limiting processes are shown to be Ornstein-Uhlenbeck (Gaussian) processes. These results were further extended to the multiparameter complex [110].
-
•
Spanning acycles: Similarly to the study of spanning trees in graphs, one can consider spanning acycles in simplicial complex. Suppose that is a complete -skeleton on vertices. A set of -faces is considered a spanning acycle if . In other words, adding to kills all the existing -cycles (hence “spanning”), while not generating any new -cycles (hence “acycle”). This definition invites the study of spanning acycles in the random -complex. In [111, 112] the weights of faces in the minimal spanning acycle and their connection to the persistence diagram were studied.
6 Future directions
We hope our review illustrates well that the recent progress in the fundamental study of random simplicial complexes in mathematics has been extremely rapid. As far as applications to real-world systems in network/data science are concerned, the progress has been as rapid, but the field is definitely less mature that its -dimensional counterpart dealing with applications of random graph models. There, a collection of important and ubiquitous properties of real-world networks abstracted as graphs have been long identified and well studied. Such properties include sparsity, scale-free degree distributions, degree correlations, clustering, small-worldness, community structure, self-similarity, and so on [113, 114]. Consequently, there have been an impressive body of work on null models that reproduce these properties in the statistically unbiased manner, and on growing network models that attempt to shed light on possible mechanisms that might lead to the formation of these properties in real-world systems [113, 114].
When the same systems are modeled as simplicial complexes or hypergraphs, the list of important properties one should be looking at, is much less understood. Consequently, the world of models dealing with such properties is much less explored, as it is not entirely clear what properties one should be most concerned with in the first place.
In addition to its relative infancy, the other reason why the world of random complex models has not yet been navigated as much, is that models of even simplest higher-dimensional properties tend to be much more complicated, not necessarily at the technical level as much as at the conceptual level.
Consider the null models of the degree distribution, i.e. the configuration models, for example. Since, as opposed to graphs, there is not one but notions of degree in a simplicial complex of size (-degrees of -simplexes for any pair of dimensions , ), it may not be immediately clear what degrees to focus on. The degrees that the and Z- models reproduce in Sections 2.3.2 and 2.5.2, are the -degrees of - and -dimensional simplexes, respectively, with very different constraints imposed on the underlying simplicial structure.
In that regard, these two models are the two simplest extremal versions of a great variety of configuration models we can think of. Such models can reproduce sequences of -degrees of -simplexes for any pair of dimensions , in which case the defining equations (2.3, 2.4) remain the same, except that simplexes in those equations are now understood to be of dimension . We may also want to jointly reproduce different combinations of degree sequences of different dimensions satisfying structural constraints. Such models, based on generalized degree sequences observed in real data, could serve as more adequate and more realistic null models of the data. The first step in this direction has been made in [51].
Another example is homology, which we discussed at length in this chapter. Homology is known to be a powerful tool to capture information about the qualitative structure of simplicial complexes, and its theory in the random setting is constantly growing. However, as a tool to analyze high-dimensional networks, it is not yet as clear what part of the information provided by homology is useful and for what purposes. For example, while (connected components) and (cycles) are quite intuitive, the role of as a network descriptor is not as clear. Neither is it entirely clear what useful information is contained in the number of -cycles, their physical size, their persistent lifetime, etc. So while the theoretical homological analysis is fruitful and highly interesting, it tends to be a challenge to see how and when to use it in application to real-world networks.
The degree distribution and homology are certainly just two out of many properties that the future work may find interesting and important to model in more realistic models of random simplicial complexes. For now, the list of such models is quite rudimentary for the reasons above, so that it is not surprising that rigorous mathematical results are available only for very basic models. Yet we have seen that even for these simplest models, the spectrum of available results is extremely rich and complex.
We have also seen that these results mostly address direct problems, whereas in dealing with real-world data one often faces inverse problems. For example, the results presented in Section 4.3 tell us facts about the persistence diagrams in “laboratory-controlled” settings, i.e. for given complexes in given spaces with known topology—a direct problem. An inverse problem would be to make any statistical inferences about the space topology from a persistence diagram coming from real-world data. Some progress in this direction has been made over the past decade [115, 116, 117, 118, 119], but this is still an active and important area of research to pursue.
Finally, we comment on one potentially very interesting direction of future research in mathematics of random complexes. One of the most fundamentally important recent achievements in mathematics of random graphs is the development and essential completion of the theory of limits of dense graphs known as graphons [60, 61]. One of the main results in that theory is that, even though there are many very different notions of graph convergence, they all are equivalent for dense graphs, and if a family of dense graphs converge, they converge to a (random) graphon [120]. As mentioned in Section 2.4.1, a graphon is an integrable connection probability function modulo a certain equivalence relation, and a graphon-based random graph of size —known as a -random graph in the graphon theory—is , where and . Can an analogous theory be constructed—or discovered, depending on one’s philosophical view—for the limits of dense complexes, e.g. complexons? Complexons may probably be related to hypergraphons [121, 122, 123, 124], the limits of dense hypergraphs, via the lower and upper complexes and discussed in Section 2.5.1.
References
- Linial and Meshulam [2006] N. Linial and R. Meshulam, Homological connectivity of random 2-complexes, Combinatorica 26, 475 (2006).
- Bianconi and Rahmede [2015] G. Bianconi and C. Rahmede, Complex Quantum Network Manifolds in Dimension are Scale-Free, Sci Rep 5, 13979 (2015).
- Bianconi et al. [2015] G. Bianconi, C. Rahmede, and Z. Wu, Complex quantum network geometries: Evolution and phase transitions, Phys Rev E 92, 022815 (2015).
- Bianconi and Rahmede [2016] G. Bianconi and C. Rahmede, Network geometry with flavor: From complexity to quantum geometry, Phys Rev E 93, 53 (2016).
- Courtney and Bianconi [2017] O. T. Courtney and G. Bianconi, Weighted growing simplicial complexes, Phys Rev E 95, 062301 (2017).
- Fountoulakis et al. [2019] N. Fountoulakis, T. Iyer, C. Mailler, and H. Sulzbach, Dynamical Models for Random Simplicial Complexes, (2019), arXiv:1910.12715 .
- Kovalenko et al. [2021] K. Kovalenko, I. Sendiña-Nadal, N. Khalil, A. Dainiak, D. Musatov, A. M. Raigorodskii, K. Alfaro-Bittner, B. Barzel, and S. Boccaletti, Growing scale-free simplices, Commun Phys 4, 43 (2021).
- Bianconi et al. [2019] G. Bianconi, I. Kryven, and R. M. Ziff, Percolation on branching simplicial and cell complexes and its relation to interdependent percolation, Phys Rev E 100, 062311 (2019).
- Iacopini et al. [2019] I. Iacopini, G. Petri, A. Barrat, and V. Latora, Simplicial models of social contagion, Nat Commun 10, 2485 (2019).
- Schaub et al. [2020] M. T. Schaub, A. R. Benson, P. Horn, G. Lippner, and A. Jadbabaie, Random Walks on Simplicial Complexes and the Normalized Hodge 1-Laplacian, SIAM Rev 62, 353 (2020).
- Gambuzza et al. [2021] L. V. Gambuzza, F. Di Patti, L. Gallo, S. Lepri, M. Romance, R. Criado, M. Frasca, V. Latora, and S. Boccaletti, Stability of synchronization in simplicial complexes, Nat Commun 12, 1255 (2021).
- Lee et al. [2021] Y. Lee, J. Lee, S. M. Oh, D. Lee, and B. Kahng, Homological percolation transitions in growing simplicial complexes, Chaos An Interdiscip J Nonlinear Sci 31, 041102 (2021).
- Battiston et al. [2020] F. Battiston, G. Cencetti, I. Iacopini, V. Latora, M. Lucas, A. Patania, J.-g. Young, and G. Petri, Networks beyond pairwise interactions: Structure and dynamics, Phys Rep 874, 1 (2020).
- Jaynes [1957] E. T. Jaynes, Information Theory and Statistical Mechanics, Phys Rev 106, 620 (1957).
- Shannon [1948] C. E. Shannon, A Mathematical Theory of Communication, Bell Syst Tech J 27, 379 (1948).
- Shore and Johnson [1980] J. Shore and R. Johnson, Axiomatic derivation of the principle of maximum entropy and the principle of minimum cross-entropy, IEEE Trans Inf Theory 26, 26 (1980).
- Tikochinsky et al. [1984] Y. Tikochinsky, N. Z. Tishby, and R. D. Levine, Consistent Inference of Probabilities for Reproducible Experiments, Phys Rev Lett 52, 1357 (1984).
- Skilling [1988] J. Skilling, The Axioms of Maximum Entropy, in Maximum-Entropy and Bayesian Methods in Science and Engineering (Springer Netherlands, Dordrecht, 1988) pp. 173–187.
- Rassoul-Agha and Seppäläinen [2015] F. Rassoul-Agha and T. Seppäläinen, A Course on Large Deviations with an Introduction to Gibbs Measures, Graduate Studies in Mathematics, Vol. 162 (American Mathematical Society, Providence, Rhode Island, 2015).
- Chatterjee [2017] S. Chatterjee, Large Deviations for Random Graphs, Lecture Notes in Mathematics, Vol. 2197 (Springer International Publishing, Cham, 2017).
- Zuev et al. [2015] K. Zuev, O. Eisenberg, and D. Krioukov, Exponential random simplicial complexes, Journal of Physics A: Mathematical and Theoretical 48, 465002 (2015).
- Cover and Thomas [2005] T. M. Cover and J. A. Thomas, Elements of Information Theory (Wiley, Hoboken, NJ, 2005).
- Solomonoff and Rapoport [1951] R. Solomonoff and A. Rapoport, Connectivity of random nets, B Math Biophys 13, 107 (1951).
- Erdős and Rényi [1959] P. Erdős and A. Rényi, On Random Graphs, Publ Math 6, 290 (1959).
- Gilbert [1959] E. N. Gilbert, Random Graphs, Ann Math Stat 30, 1141 (1959).
- Anand and Bianconi [2009] K. Anand and G. Bianconi, Entropy measures for networks: Toward an information theory of complex topologies, Phys Rev E 80, 045102 (2009).
- Squartini et al. [2015] T. Squartini, J. de Mol, F. den Hollander, and D. Garlaschelli, Breaking of Ensemble Equivalence in Networks, Phys Rev Lett 115, 268701 (2015).
- Janson [2010] S. Janson, Asymptotic equivalence and contiguity of some random graphs, Random Struct Algor 36, 26 (2010).
- Meshulam and Wallach [2009] R. Meshulam and N. Wallach, Homological connectivity of random k-dimensional complexes, Random Structures & Algorithms 34, 408 (2009).
- Kahle and Pittel [2016] M. Kahle and B. Pittel, Inside the critical window for cohomology of random k-complexes, Random Structures & Algorithms 48, 102 (2016).
- Luczak and Peled [2018] T. Luczak and Y. Peled, Integral homology of random simplicial complexes, Discrete & Computational Geometry 59, 131 (2018).
- Kahle [2009] M. Kahle, Topology of random clique complexes, Discrete Mathematics 309, 1658 (2009).
- Kahle [2014a] M. Kahle, Sharp vanishing thresholds for cohomology of random flag complexes, Annals of Mathematics 179, 1085 (2014a).
- Kahle [2014b] M. Kahle, Topology of random simplicial complexes: a survey, in AMS Contemp Vol Math, Vol. 620 (2014) pp. 201–221.
- Costa and Farber [2015a] A. Costa and M. Farber, in Proc IMA Conf Math Robot, September (Institute of Mathematics and its Applications, 2015) pp. 1–8.
- Costa and Farber [2016a] A. Costa and M. Farber, Random Simplicial Complexes, in Config Spaces Geom Topol Represent Theory (2016) pp. 129–153.
- Costa and Farber [2016b] A. Costa and M. Farber, Large random simplicial complexes, I, J Topol Anal 08, 399 (2016b).
- Söderberg [2002] B. Söderberg, General formalism for inhomogeneous random graphs, Phys Rev E 66, 066121 (2002).
- Park and Newman [2004] J. Park and M. E. J. Newman, Statistical mechanics of networks, Phys Rev E 70, 066117 (2004).
- Britton et al. [2006] T. Britton, M. Deijfen, and A. Martin-Löf, Generating Simple Random Graphs with Prescribed Degree Distribution, J Stat Phys 124, 1377 (2006).
- Bollobás et al. [2007] B. Bollobás, S. Janson, and O. Riordan, The phase transition in inhomogeneous random graphs, Random Struct Algor 31, 3 (2007).
- Bianconi [2008] G. Bianconi, The entropy of randomized network ensembles, EPL 81, 28005 (2008).
- Garlaschelli and Loffredo [2008] D. Garlaschelli and M. Loffredo, Maximum likelihood: Extracting unbiased information from complex networks, Phys Rev E 78, 015101 (2008).
- Chatterjee et al. [2011] S. Chatterjee, P. Diaconis, and A. Sly, Random graphs with a given degree sequence, Ann Appl Probab 21, 1400 (2011).
- Bender and Canfield [1978] E. A. Bender and E. R. Canfield, The asymptotic number of labeled graphs with given degree sequences, J Comb Theory, Ser A 24, 296 (1978).
- Molloy and Reed [1995] M. Molloy and B. Reed, A critical point for random graphs with a given degree sequence, Random Struct Algor 6, 161 (1995).
- Erdős and Rényi [1960] P. Erdős and A. Rényi, On the evolution of random graphs, Publ. Math. Inst. Hung. Acad. Sci 5, 17 (1960).
- Lubotzky et al. [2019] A. Lubotzky, Z. Luria, and R. Rosenthal, Random Steiner systems and bounded degree coboundary expanders of every dimension, Discrete & Computational Geometry 62, 813 (2019), publisher: Springer.
- Keevash [2014] P. Keevash, The existence of designs, arXiv preprint arXiv:1401.3665 (2014).
- Courtney and Bianconi [2016] O. T. Courtney and G. Bianconi, Generalized network structures: The configuration model and the canonical ensemble of simplicial complexes, Phys Rev E 93, 062311 (2016).
- Young et al. [2017] J.-G. Young, G. Petri, F. Vaccarino, and A. Patania, Construction of and efficient sampling from the simplicial configuration model, Phys Rev E 96, 032312 (2017).
- Caldarelli et al. [2002] G. Caldarelli, A. Capocci, P. De Los Rios, and M. A. Muñoz, Scale-Free Networks from Varying Vertex Intrinsic Fitness, Phys Rev Lett 89, 258702 (2002).
- Boguñá and Pastor-Satorras [2003] M. Boguñá and R. Pastor-Satorras, Class of correlated random networks with hidden variables, Phys Rev E 68, 036112 (2003).
- Holland et al. [1983] P. W. Holland, K. B. Laskey, and S. Leinhardt, Stochastic blockmodels: First steps, Soc Networks 5, 109 (1983).
- Sorokin [1927] A. P. Sorokin, Social Mobility (Harper, New York, 1927).
- McFarland and Brown [1973] D. D. McFarland and D. J. Brown, Social distance as a metric: A systematic introduction to smallest space analysis, in Bonds of Pluralism: The Form and Substance of Urban Social Networks (John Wiley, New York, 1973) pp. 213–252.
- Hoff et al. [2002] P. D. Hoff, A. E. Raftery, and M. S. Handcock, Latent Space Approaches to Social Network Analysis, J Am Stat Assoc 97, 1090 (2002).
- Gilbert [1961] E. N. Gilbert, Random Plane Networks, J Soc Ind Appl Math 9, 533 (1961).
- Penrose [2003] M. Penrose, Random Geometric Graphs (Oxford University Press, Oxford, 2003).
- Lovász [2012] L. Lovász, Large Networks and Graph Limits (American Mathematical Society, Providence, RI, 2012).
- Janson [2013] S. Janson, Graphons, cut norm and distance, couplings and rearrangements, NYJM Monogr 4 (2013).
- van der Hoorn et al. [2018] P. van der Hoorn, G. Lippner, and D. Krioukov, Sparse Maximum-Entropy Random Graphs with a Given Power-Law Degree Distribution, J Stat Phys 173, 806 (2018).
- Last and Penrose [2017] G. Last and M. Penrose, Lectures on the Poisson Process, October (Cambridge University Press, Cambridge, 2017).
- De Silva and Ghrist [2007] V. De Silva and R. Ghrist, Coverage in sensor networks via persistent homology, Algebraic & Geometric Topology 7, 339 (2007).
- Borsuk [1948] K. Borsuk, On the imbedding of systems of compacta in simplicial complexes, Fundamenta Mathematicae 35, 217 (1948).
- Farber et al. [2019] M. Farber, L. Mead, and T. Nowik, Random simplicial complexes, duality and the critical dimension, J Topol Anal , 1 (2019).
- Farber and Mead [2020] M. Farber and L. Mead, Random simplicial complexes in the medial regime, Topol Appl 272, 107065 (2020).
- Cooley et al. [2020] O. Cooley, N. D. Giudice, M. Kang, and P. Sprüssel, Vanishing of cohomology groups of random simplicial complexes, Random Structures & Algorithms 56, 461 (2020).
- Garland [1973] H. Garland, p-adic curvature and the cohomology of discrete subgroups of p-adic groups, Annals of Mathematics , 375 (1973).
- Costa and Farber [2017] A. Costa and M. Farber, Large random simplicial complexes, III; the critical dimension, J Knot Theory Its Ramifications 26, 1740010 (2017).
- Penrose [1997] M. D. Penrose, The longest edge of the random minimal spanning tree, The Annals of Applied Probability , 340 (1997).
- Bobrowski [2019] O. Bobrowski, Homological Connectivity in Random Čech Complexes, arXiv:1906.04861 [math] (2019), arXiv: 1906.04861.
- Bobrowski and Oliveira [2019] O. Bobrowski and G. Oliveira, Random Čech Complexes on Riemannian Manifolds, Random Structures & Algorithms 54, 373 (2019).
- Milnor [1963] J. W. Milnor, Morse theory (Princeton university press, 1963).
- Gershkovich and Rubinstein [1997] V. Gershkovich and H. Rubinstein, Morse theory for Min-type functions, The Asian Journal of Mathematics 1, 696 (1997).
- Bobrowski et al. [2021] O. Bobrowski, M. Schulte, and D. Yogeshwaran, Poisson process approximation under stabilization and Palm coupling, arXiv preprint arXiv:2104.13261 (2021).
- Kahle [2011] M. Kahle, Random geometric complexes, Discrete & Computational Geometry 45, 553 (2011).
- Forman [2002] R. Forman, A user’s guide to discrete Morse theory, Sém. Lothar. Combin 48, 35pp (2002).
- Aronshtam et al. [2013] L. Aronshtam, N. Linial, T. Luczak, and R. Meshulam, Collapsibility and vanishing of top homology in random simplicial complexes, Discrete & Computational Geometry 49, 317 (2013).
- Linial and Peled [2016] N. Linial and Y. Peled, On the phase transition in random simplicial complexes, Annals of Mathematics. Second Series 184, 745 (2016).
- Kozlov [2010] D. Kozlov, The threshold function for vanishing of the top homology group of random d-complexes, Proceedings of the American Mathematical Society 138, 4517 (2010).
- Aronshtam and Linial [2015] L. Aronshtam and N. Linial, The threshold for d-collapsibility in random complexes*, Random Structures & Algorithms (2015).
- Kahle and Meckes [2013] M. Kahle and E. Meckes, Limit the theorems for Betti numbers of random simplicial complexes, Homology, Homotopy and Applications 15, 343 (2013).
- Linial et al. [2019] N. Linial, I. Newman, Y. Peled, and Y. Rabinovich, Extremal hypercuts and shadows of simplicial complexes, Israel Journal of Mathematics 229, 133 (2019).
- Bobrowski and Skraba [2020a] O. Bobrowski and P. Skraba, Homological Percolation: The Formation of Giant k-Cycles, International Mathematics Research Notices (2020a).
- Bobrowski and Skraba [2020b] O. Bobrowski and P. Skraba, Homological percolation and the Euler characteristic, Physical Review E 101, 032304 (2020b).
- Babson et al. [2011] E. Babson, C. Hoffman, and M. Kahle, The fundamental group of random 2-complexes, Journal of the American Mathematical Society 24, 1 (2011).
- Luria and Peled [2018] Z. Luria and Y. Peled, On simple connectivity of random 2-complexes, arXiv preprint arXiv:1806.03351 (2018).
- Babson [2012] E. Babson, Fundamental groups of random clique complexes, arXiv preprint arXiv:1207.5028 (2012).
- Costa et al. [2015] A. Costa, M. Farber, and D. Horak, Fundamental groups of clique complexes of random graphs, Trans London Math Soc 2, 1 (2015).
- Costa and Farber [2015b] A. E. Costa and M. Farber, Geometry and topology of random 2-complexes, Isr J Math 209, 883 (2015b).
- Newman [2020] A. Newman, Freeness of the random fundamental group, Journal of Topology and Analysis 12, 29 (2020).
- Stein [1986] C. Stein (IMS, 1986).
- Ross et al. [2011] N. Ross et al., Fundamentals of Stein’s method, Probability Surveys 8, 210 (2011).
- Yogeshwaran et al. [2016] D. Yogeshwaran, E. Subag, and R. J. Adler, Random geometric complexes in the thermodynamic regime, Probability Theory and Related Fields , 1 (2016).
- Hiraoka et al. [2018] Y. Hiraoka, T. Shirai, and K. D. Trinh, Limit theorems for persistence diagrams, The Annals of Applied Probability 28, 2740 (2018).
- Krebs and Polonik [2019] J. T. Krebs and W. Polonik, On the asymptotic normality of persistent Betti numbers, arXiv preprint arXiv:1903.03280 (2019).
- Trinh et al. [2019] K. D. Trinh et al., On central limit theorems in stochastic geometry for add-one cost stabilizing functionals, Electronic Communications in Probability 24 (2019).
- Penrose and Yukich [2001] M. D. Penrose and J. E. Yukich, Central limit theorems for some graphs in computational geometry, Annals of Applied probability , 1005 (2001).
- Goel et al. [2019] A. Goel, K. D. Trinh, and K. Tsunoda, Strong law of large numbers for Betti numbers in the thermodynamic regime, Journal of Statistical Physics 174, 865 (2019).
- Auffinger et al. [2020] A. Auffinger, A. Lerario, and E. Lundberg, Topologies of Random Geometric Complexes on Riemannian Manifolds in the Thermodynamic Limit, International Mathematics Research Notices (2020).
- Hatcher [2002] A. Hatcher, Algebraic topology (Cambridge University Press, Cambridge, 2002).
- Owada et al. [2020] T. Owada, O. Bobrowski, et al., Convergence of persistence diagrams for topological crackle, Bernoulli 26, 2275 (2020).
- Bobrowski et al. [2017a] O. Bobrowski, M. Kahle, and P. Skraba, Maximally persistent cycles in random geometric complexes, The Annals of Applied Probability 27, 2032 (2017a).
- Gundert and Wagner [2016] A. Gundert and U. Wagner, On eigenvalues of random complexes, Israel Journal of Mathematics 216, 545 (2016).
- Dotterrer and Kahle [2012] D. Dotterrer and M. Kahle, Coboundary expanders, Journal of Topology and Analysis 4, 499 (2012).
- Knowles and Rosenthal [2017] A. Knowles and R. Rosenthal, Eigenvalue confinement and spectral gap for random simplicial complexes, Random Structures & Algorithms 51, 506 (2017).
- Thomas and Owada [2021] A. M. Thomas and T. Owada, Functional limit theorems for the Euler characteristic process in the critical regime, Advances in Applied Probability 53, 57 (2021).
- Thoppe et al. [2016] G. C. Thoppe, D. Yogeshwaran, R. J. Adler, et al., On the evolution of topology in dynamic clique complexes, Advances in Applied Probability 48, 989 (2016).
- Owada et al. [2021] T. Owada, G. Samorodnitsky, and G. Thoppe, Limit theorems for topological invariants of the dynamic multi-parameter simplicial complex, Stochastic Processes and their Applications (2021).
- Skraba et al. [2017] P. Skraba, G. Thoppe, and D. Yogeshwaran, Randomly Weighted -complexes: Minimal Spanning Acycles and Persistence Diagrams, arXiv:1701.00239 [math] (2017), arXiv: 1701.00239.
- Hiraoka and Shirai [2017] Y. Hiraoka and T. Shirai, Minimum spanning acycle and lifetime of persistent homology in the Linial–Meshulam process, Random Structures & Algorithms 51, 315 (2017).
- Barabási [2016] A.-L. Barabási, Network science (Cambridge University Press, Cambridge, UK, 2016).
- Newman [2018] M. E. J. Newman, Networks (Oxford University Press, Oxford, 2018).
- Niyogi et al. [2011] P. Niyogi, S. Smale, and S. Weinberger, A topological view of unsupervised learning from noisy data, SIAM Journal on Computing 40, 646 (2011).
- Fasy et al. [2014] B. T. Fasy, F. Lecci, A. Rinaldo, L. Wasserman, S. Balakrishnan, and A. Singh, Confidence sets for persistence diagrams, Annals of Statistics 42, 2301 (2014).
- Chazal et al. [2017] F. Chazal, B. Fasy, F. Lecci, B. Michel, A. Rinaldo, and L. Wasserman, Robust topological inference: Distance to a measure and kernel distance, The Journal of Machine Learning Research 18, 5845 (2017).
- Bobrowski et al. [2017b] O. Bobrowski, S. Mukherjee, and J. E. Taylor, Topological consistency via kernel estimation, Bernoulli 23, 288 (2017b).
- Reani and Bobrowski [2021] Y. Reani and O. Bobrowski, Cycle Registration in Persistent Homology with Applications in Topological Bootstrap, arXiv preprint arXiv:2101.00698 (2021).
- Diaconis and Janson [2008] P. Diaconis and S. Janson, Graph Limits and Exhcangeable Random Graphs, Rend di Matemtica 28, 33 (2008).
- Gowers [2007] W. Gowers, Hypergraph regularity and the multidimensional Szemerédi theorem, Ann Math 166, 897 (2007).
- Elek and Szegedy [2012] G. Elek and B. Szegedy, A measure-theoretic approach to the theory of dense hypergraphs, Adv Math 231, 1731 (2012).
- Zhao [2015] Y. Zhao, Hypergraph limits: A regularity approach, Random Struct Algor 47, 205 (2015).
- Balasubramanian et al. [2021] K. Balasubramanian, D. Gitelman, and H. Liu, Nonparametric Modeling of Higher-Order Interactions via Hypergraphons, J Mach Learn Res 22, 1 (2021).