Random Network Distillation Based Deep Reinforcement Learning for AGV Path Planning
Abstract
With the flourishing development of intelligent warehousing systems, the technology of Automated Guided Vehicle (AGV) has experienced rapid growth. Within intelligent warehousing environments, AGV is required to safely and rapidly plan an optimal path in complex and dynamic environments. Most research has studied deep reinforcement learning to address this challenge. However, in the environments with sparse extrinsic rewards, these algorithms often converge slowly, learn inefficiently or fail to reach the target. Random Network Distillation (RND), as an exploration enhancement, can effectively improve the performance of proximal policy optimization, especially enhancing the additional intrinsic rewards of the AGV agent which is in sparse reward environments. Moreover, most of the current research continues to use 2D grid mazes as experimental environments. These environments have insufficient complexity and limited action sets. To solve this limitation, we present simulation environments of AGV path planning with continuous actions and positions for AGVs, so that it can be close to realistic physical scenarios. Based on our experiments and comprehensive analysis of the proposed method, the results demonstrate that our proposed method enables AGV to more rapidly complete path planning tasks with continuous actions in our environments. A video of part of our experiments can be found at https://youtu.be/lwrY9YesGmw.
I INTRODUCTION
With the development of the industrial digitalisation, intelligent warehousing systems [1] have become an important part of industrial production. Nowadays, Automated Guided Vehicle (AGV) [2] plays a crucial role in intelligent warehousing systems and its path planning has become the focus of research. The path planning algorithms [3, 4, 5] of AGVs develop rapidly. Researchers have proposed many classical path planning algorithms such as A* algorithm [6, 7], Rapidly-Exploring Random Tree (RRT) [8], Dynamic Window Approach [9] and Particle Swarm Optimization [10], which have been widely used in simple environments. However, in realistic scenarios, most of these remain in simulation due to the computational complexity as well as the limitations of the real environment.
At this time, Reinforcement Learning (RL) [11] has been studied to solve the path planning problem. NAIR et al. [13] proposed a path planning and obstacle avoidance method Modified Temporal Difference Learning for environment where static obstacles are known. On the basis of Temporal-Difference (TD) algorithm, WATKINS et al. [14] proposed Q-Learning algorithm that is widely used in discrete path planning environments. With the increasing complexity of the environments that agents need to process, Google’s AI team DeepMind proposed the innovative concept of combining deep learning, which is the processing of perceptual signals, with RL to form Deep Reinforcement Learning (DRL) [15]. The DeepMind team proposed a new approach to DRL, Deep Q-Learning (DQN) [16]. With the successful application of DRL, much research has begun to explore DRL methods to solve problems of AGV path planning. Yang et al. [17] combined a priori knowledge and the DQN algorithm to solve the problem of slow convergence of AGVs in a warehouse environment. Panov et al. [18] studied the DQN algorithm to static grid maps and proved that the algorithm can obtain effective path planning. However, most of the related research on AGV path planning problems use 2D grid maps for experiments, which are still far from the actual physical environment. Real path planning environments are usually complex and thus current researches haven’t solved the problem of slow searching of agents in sparse reward environments. In order to solve the above problems, we will propose a method that can improve intrinsic rewards and conduct experiments in simulation environments that approximate the real physical environment.
As the Proximal Policy Optimisation (PPO) algorithm [19] has been proven to be widely applicable in complex environments, we use PPO as a deep reinforcement learning method in this paper. Xiao et al. [20] introduced distributed sample collection training policy and Beta policy for action sampling, which exhibits stronger robustness in the PPO algorithm. Our team [21] use a curiosity-driven model to enhance the exploration of the AGV agent. Shi et al. [22] studied a dynamic hybrid reward mechanism based on the PPO algorithm to solve the RL problem with sparse rewards. In DRL, reward shaping [23] can solve the problem of sparse reward environment, but constructing suitable reward functions is not easy, and in most cases, reward shaping limits the performance of algorithms such as PPO. In order to solve the sparse reward problem, we propose to introduce an exploratory method for the deep reinforcement learning algorithm PPO. The basic method of Random Network Distillation (RND) [24, 25, 26] is to increase the intrinsic rewards of agents and assist the extrinsic rewards to enable agents to better explore the environment. This has not been studied for path planning yet. Combining the PPO algorithm with the intrinsic reward measurements from RND, we augment the extrinsic reward in the environment during AGV path planning. In addition, in order to be able to simulate the path planning in real intelligent warehouses, we set up experimental environments for AGVs, and the experimental results show that by enhancing the extrinsic rewards through the intrinsic rewards of RND, our proposed method is able to explore several sparsely rewarded AGV path-planning environments more efficiently and stable. In summary, our contributions of this paper include the following two aspects.
-
•
We propose a novel AGV path planning method RND-PPO, which combines the random network distillation mechanism with the PPO algorithm. Extrinsic rewards from environmental feedback are enhanced by additional intrinsic rewards, to solve the problem of AGVs that learn hard in sparsely rewarded path planning environments.
-
•
We design simulation AGV agent path planning environments with physical rigid body properties and continuous motion space. The environments have both fixed and randomly generated target objects to simulate the real environment.
The rest of this paper is organized as follows. Section II describes the AGV path planning environment model. In Section III, the framework of our proposed RND-PPO method is presented and related algorithms are given in detail. The experiments and results are demonstrated in Section IV. Finally, Section V presents the conclusion and future work.
II AGV Path Planning Environment Model
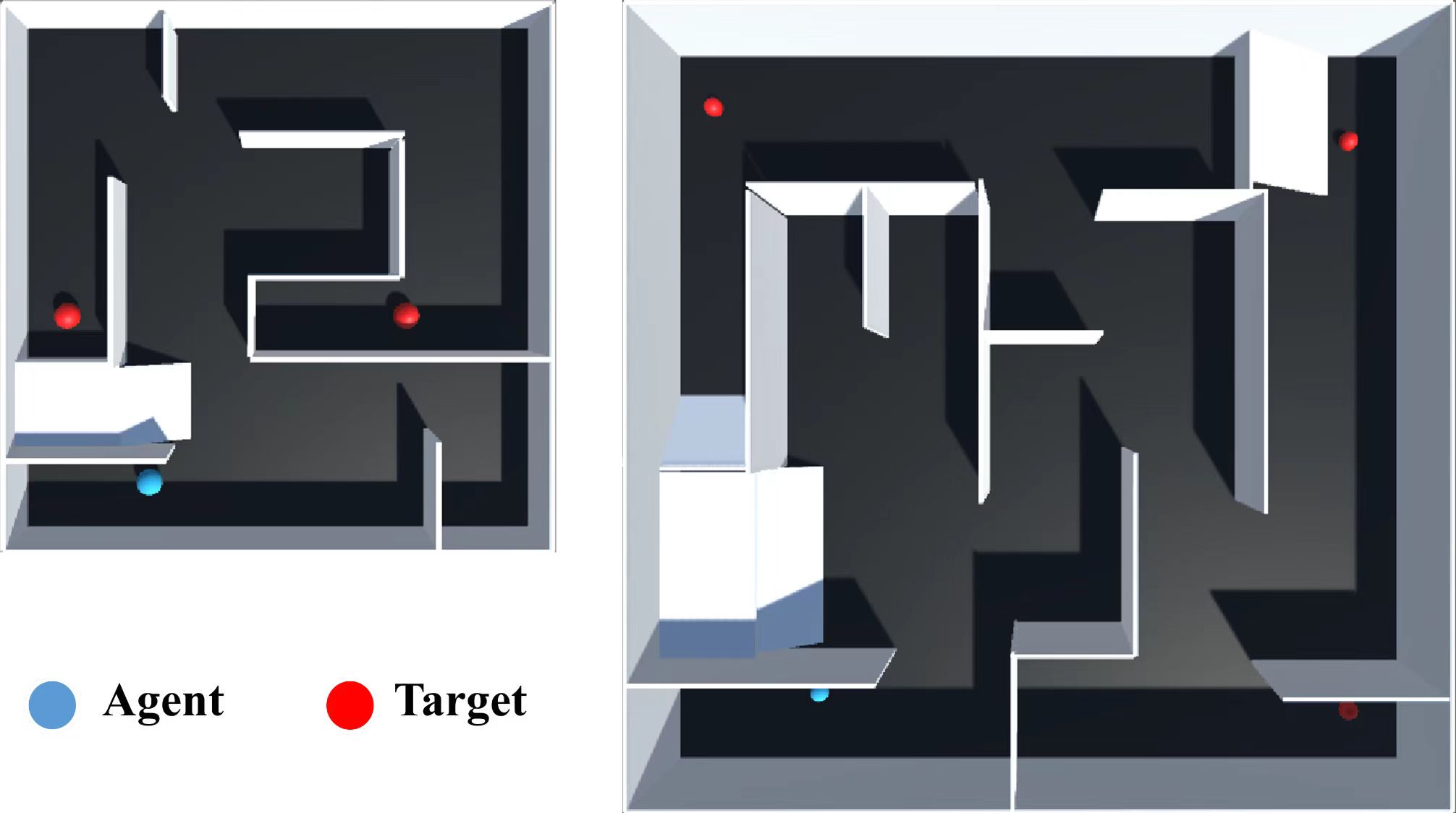
We design AGV path planning environment model with real physical body and action. For the situations that AGV agents need to face in real physical environments, we design multiple sets of models based on a simple scene and a complex scene, both of which consist of a closed square space, an AGV agent body, multiple static obstacles and a target object. The complex scene is four times the size of the simple scene. Most of the research is based on studies of static environments. In order to better test the performance of RND-PPO in different environments, we added dynamic target objects to these scenes. The simulation scenes are shown in Fig. 1. The simple scene on the left has two randomly generated targets and the complex scene on the right has three. Target objects are represented by red blobs and the agent is a blue blob.
The AGV agent is described by a set of state variables and interacts with the environment by performing actions to change its state variables. To replace the discrete actions used in most research, we build the agent as rigid body and create a continuous action space for it. The continuous actions are generated from a neural network and then passed to the action function, which processes the received action vectors. In this paper, the environment contains two consecutive vectors representing the control forces in the -axis and -axis, which are transmitted to the physical force to make agent move.
During training, the sensors provide state information to the agent, such as the position, velocity, colour of other objects in the environment and so on. In our model, the internal observation space dimension of the agent is 8, which records the 3D position of agent, the 3D position of target object, and the -axis component and -axis component of the speed of the agent are observed respectively. In addition, the AGV agent is equipped with two 3D ray perception sensors, one for detecting the information around the agent with 10 rays and horizontal field of view of 360 degrees. The other one intensively detects information in the forward direction of agent, with 7 rays and horizontal field of view of 120 degrees. Each ray can detect 2 targets including wall and target object, and each ray has two dimensions to detect collision or not, so the total observation dimensions are .
The computation of reward function within each learning episode is divided into two parts. One for the extrinsic reward obtained from the interaction of agent with environment, and the other for the intrinsic reward given to agent by our proposed RND-PPO model, which will be introduced in the next section. Thus the total reward is written as
| (1) |
When the agent collids with the target object, the extrinsic reward is set to 5. This value is an empirical value obtained from several experiments. In order to make the agent find the target as soon as possible, we design a tiny single-step negative reward. The extrinsic reward function is defined as
| (2) |
The MaxStep is the maximum number of steps an agent can explore in a learning episode.
III AGV PATH PLANNING BASED ON RND-PPO
It is often impractical to design dense reward functions for tasks of RL agents, so agents need to explore the environment in a targeted manner. RND [24] was introduced as an exploration method for DRL methods, and it has the flexibility to combine intrinsic and extrinsic rewards.

III-A Framework of AGV Path Planning with RND-PPO
The key to solving the AGV path planning problem using RL is how the AGV agent updates its own action policy based on the received rewards to obtain the maximum cumulative reward value. In the real AGV path planning environments, the rewards are sparse, in this case we need to use intrinsic rewards to guide the AGV agent to fully explore the state space and action space in the environment, so we design a new exploration mechanism RND-PPO to motivate the agent to explore the environment.
The structure of our proposed RND-PPO is shown in Fig. 2. The AGV agent training process is divided into two stages. The yellow box is the RND stage and the other part connected to it is PPO training stage. RND defines a new training stage and the RND training alternates with the training of the agent. The model obtained from the RND training is input to PPO and used to generate the corresponding intrinsic rewards. The next stage is the agent training stage, which is a stage of using the trained RND model, combining the intrinsic rewards predicted by the RND model with the RL algorithm PPO. In the end, the agent completes the learning of the optimal policy by using the obtained extrinsic rewards , intrinsic rewards and environment state .
III-B Random Network Distillation Model
To address the lack of exploration of PPO in sparse reward environments, among the intrinsic reward methods used for exploration, we invoke Random Network Distillation (RND) which is a technique based on prediction error. The model is presented in the yellow part of Fig. 2. In RND, the agent first constructs a randomly-fixed target neural network , where fixed means that it will not be updated throughout the learning process, and constructs a prediction network , whose goal is to predict the output of the randomly-set target network . The target network and the prediction network map the observations to the reward . The target network defined as: , network parameter is denoted as and remain fixed after random initialisation. The prediction network defined as: , network parameter is denoted as which is trained to minimise the prediction error. The parameter is updated by minimising the expected value of the mean square error through gradient descent algorithm. The agent will input the observation obtained from the environment into the target network , at which time serves as the prediction target of the prediction network . When the prediction network is input with a novel state, due to the large discrepancy between this distribution and inputs it has ever received, the agent will receive a large intrinsic reward as
| (3) |

III-C AGV agent path planning with RND-PPO
In the sparse reward environment, we propose an exploration mechanism that uses RND based PPO to motivate the agent to find more novel state . First, we give the concept of state novelty which can be measured by the prediction error. For AGV agent observing the state at the current moment, the fewer the number of states similar to state among all previously visited states, the more novel state is.
The PPO algorithm is essentially a model-free algorithm, and its core architecture remains an Actor-Critic algorithm. The critic network fits the state value function and action value function through the environmental state information observed by an agent, and updates critic network parameters by calculating advantage function and using the mean square error as critic loss function. The advantage function is shown as
| (4) |
where is a tunable coefficient. Different estimates can be obtained by adjusting . When updating the actor network, PPO uses two networks with the same structure to preserve the old and new policy. The policy ratio is used to measure the ratio of the probability of taking a certain state-action pair under the new policy to the probability of taking the same state-action pair under the old policy. The policy ratio is defined as
| (5) |
PPO introduces a new clip mechanism, which can effectively reduce the number of computation steps while limiting the magnitude of policy update, and it is defined as follows
| (6) |
where is a hyperparameter, is an estimate of the advantage function at time step . The purpose of setting is to specify the magnitude of the policy update to prevent the update from being too large and causing the training to be unsmooth.

In our proposed method shown in Algorithm 1, the first three lines initialise various parameters of the RND-PPO. After that, the training process of the RND model starts to indicate lines in Algorithm 1. The parameters of the target network are fixed, and according to the stochastic gradient descent method, the expected value of the mean square error is minimised, and prediction network parameters are optimised. This RND process can be regarded as doing distillation between the target network, which is randomly generated with fixed parameters, and the prediction network, whose parameters are to be updated, so that the prediction network is constantly close to the target network. Then the training process of the agent using the PPO algorithm based on intrinsic and extrinsic rewards starts to indicate lines in Algorithm 1. These rewards are first normalised separately to compute the final set of training trajectories. In the last stages, it combines intrinsic motivations with extrinsic rewards to calculate the advantage function and value function, subsequently refining PPO by updating the policy parameters .
IV Experiments
In this section, we evaluate our method RND-PPO, for learning AGV agent path planning policy in two groups of experiments. First, we introduce details of our implementation, including the hyperparameters. Then, we compare our proposed method with the baseline PPO in both static and dynamic scenarios. Static and dynamic environments also include simple and complex scenarios, respectively. Experiments show that using RND can improve the efficiency and stability of AGV agent learning path planning policy.

IV-A Experimental Settings
The AGV agent body and the target object are spheres with a radiuis of per unit length, the size of the simple scene is , the size of the complex scene is . The maximum number of steps for each learning episode of the static and dynamic experiments in the simple scene is 2000, and the maximum number of steps for the complex static and dynamic scenes is 3000 and 4000, respectively. The number of learning episodes in each experiment is . The reward function of AGV agent is shown in Eq. (1). All the experiments are carried out on an AMD Ryzen 7 5800H 3.20 GHz PC with 16GB memory.
IV-B Simple Scene Experiments
The simple scene is a map: is the start location of agent, and is the location of target object in static experiment. In dynamic experiment, the target object will be randomly generated in and .
We test our method in the simple scene and choose three metrics including training episodes, environment cumulative reward and episode length, to evaluate our experimental results. First, we test our proposed method in the simple static environment. In the simple static environment, after episodes of training, our proposed method RND-PPO is able to obtain the environmental cumulative reward of within steps of an episode. In contrast, as shown in Fig. 3, the PPO algorithm without RND performs poorly, and the agent is able to obtain the same environmental reward value within steps over episodes of training. However, performance of PPO is worse in the simple dynamic environment where there are two randomly generated target objects, and since there is no intrinsic reward for exploration of the environment. It is difficult for PPO to explore the location of the other target object that would earn a reward as shown in Fig. 4. Although PPO relies on search by chance to find the first target object faster than RND-PPO, it needs to spend a large number of training episodes in searching the second target object. PPO can find the target object with an average of steps after requiring training episodes and get an environmental cumulative reward of . In contrast, our proposed RND-PPO method only requires training episodes to get same environmental cumulative reward with an average of steps.
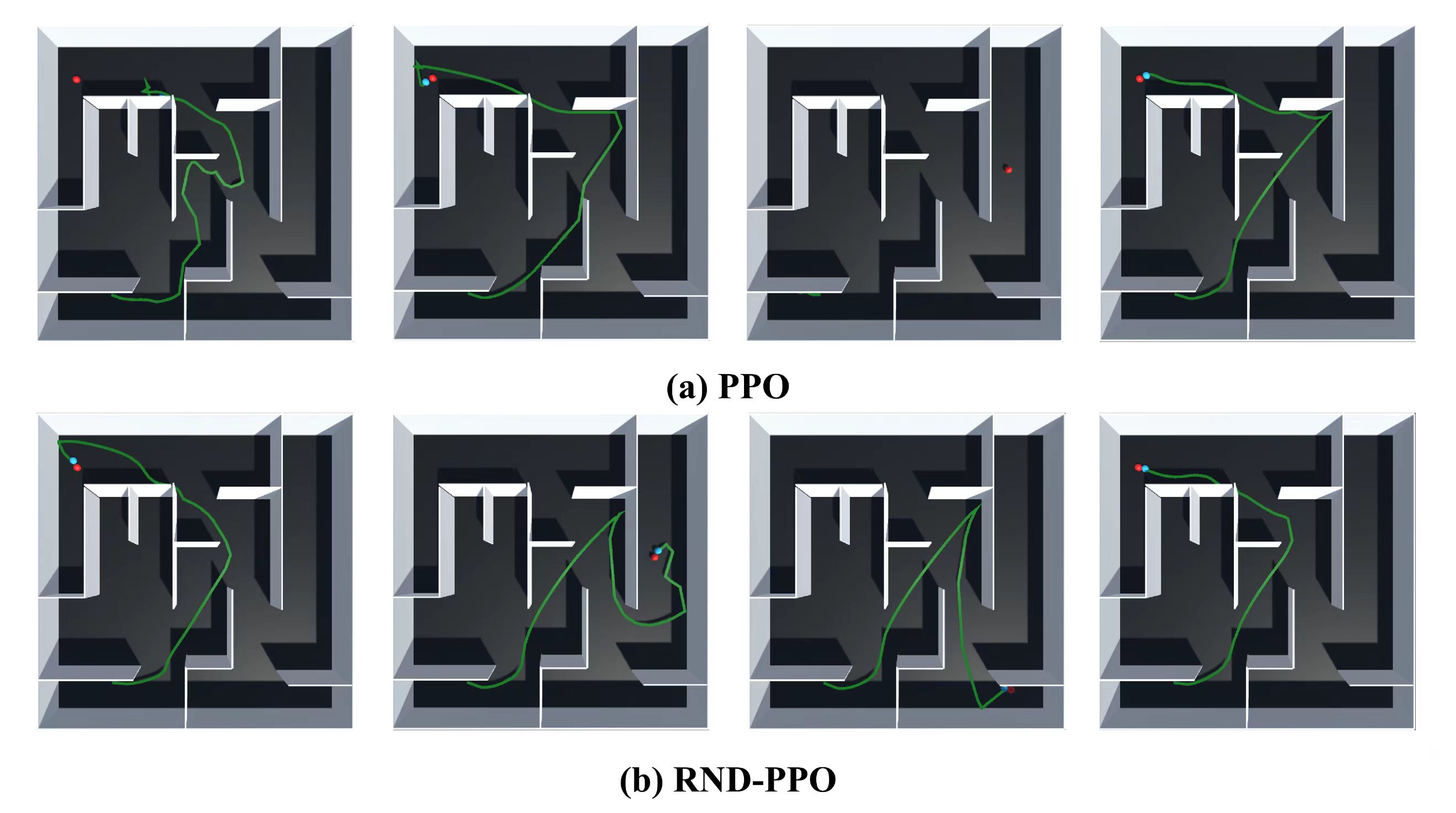
IV-C Complex Scene Experiments
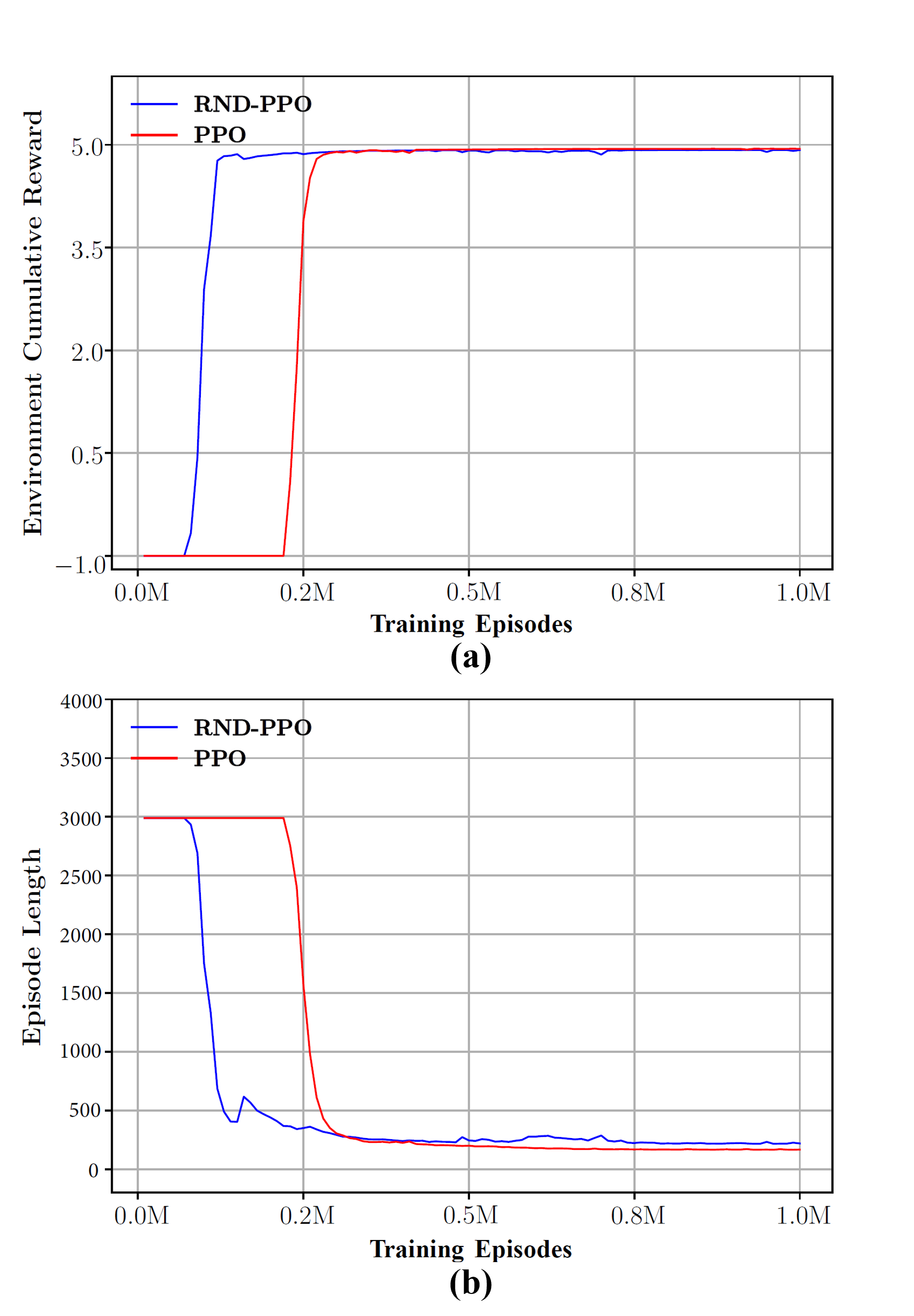
The complex scene is a map: is the start location of agent, and is the location of target object in the static experiment. In the dynamic experiment, the target object will be randomly generated in , and . Fig. 5 and Fig. 6 show the trajectory of the AGV agent after training , , and episodes in the complex static and dynamic environment respectively. The AGV agent trained using RND-PPO has found the path to reach the target object after episodes, while the agent trained only by PPO is still exploring the space around the starting position. The two metrics used for evaluation can be found in Fig. 7, and our proposed method is the better performer on both data. In the static environment, after the same training of episodes, our proposed method is already able to obtain an environmental cumulative reward of in steps of an episode, while the PPO can hardly get an environmental reward value of , which means it still expores the environment. The agent trained by PPO is able to reach the same environmental reward value of only after beeing trained for at least episodes.
In the dynamic experiment, Fig. 6 shows the experimental results of the AGV agent after being trained by PPO and RND-PPO. It can be seen that our proposed method RND-PPO can find the optimal path quickly and accurately when the target object randomly appears in three positions. However, the agent trained only by using PPO can only find the target object located in the upper left corner due to the fact that there is no intrinsic reward that can motivate the AGV agent to explore the whole environment. The relationship between the three metrics is shown in Fig. 8. The agent trained by RND-PPO found the first target object after episodes of training, while PPO did not complete this goal until around episodes. During the episodes of training, the curve of RND-PPO fluctuated due to the presence of dynamic objects, and fell into a short struggle in exploring the new environment. But soon with the help of the intrinsic rewards of RND, the agent learnt the paths to reach the three target objects. The agent under RND-PPO training is able to reach more than 4.8 environment cumulative reward after episodes with steps per episode. The PPO, on the other hand, still failed to complete the entire path planning task until the end of training. In conclusion, our proposed method explore static and dynamic environment faster in both simple or complex scene than the agent trained with PPO only.
V CONCLUSIONS
In this paper, we propose a novel method RND-PPO for AGV path planning, which introduces random network distillation mechanism to give intrinsic rewards to the AGV agent to address the effect of sparse reward environments and to improve the speed of training. In addition, we have developed simulated environments with realistic physical states containing the location of static obstacles and dynamic targets. We evaluate our approach with different scenarios. Both qualitative and quantitative experiments show that our approach is efficient with good performance. The RND-PPO agent makes use of intrinsic rewards, avoids limiting itself to a single rewarded target object, and adapts quickly to changes in the external environment. We adopt the widely used PPO algorithm as the basic implementation, which can in principle be extended to other RL algorithms (e.g., SAC). Our future work will focus on statistical analysis of RND-PPO in more complex dynamic environments to optimise the use of intrinsic rewards.

ACKNOWLEDGMENT
This work was supported by the National Natural Science Foundation of China under Grant No. 62133011 and the Special Funds of the Tongji University for ”Sino-German Cooperation 2.0 Strategy” No. ZD2023001. The authors would like to thank TÜV SÜD for the kind and generous support. We are also grateful for the efforts from our colleagues in Sino German Center of Intelligent Systems in Tongji University.
References
- [1] Zhang, Wenbo, et al. ”Real-Time Conflict-Free Task Assignment and Path Planning of Multi-AGV System in Intelligent Warehousing.” 2018 37th Chinese Control Conference (CCC), 2018.
- [2] Ryck, M. De, M. Versteyhe, and F. Debrouwere. ”Automated Guided Vehicle Systems, State-of-the-art Control Algorithms and Techniques.” Journal of Manufacturing Systems, Vol.54, No.1, 2020: 152-173.
- [3] Chun-Ying, Wang, L. Ping, and Q. Hong-Zheng. ”Review on Intelligent Path Planning Algorithm of Mobile Robots.” Transducer and Microsystem Technologies, 2024.
- [4] Guo, H. L., Hao, Y. Y. ”Warehouse AGV path planning based on Improved A* algorithm.” Eighth International Conference on Electromechanical Control Technology and Transportation (ICECTT), 2023.
- [5] Wen, Tao, and Li Sun. ”Research on Optimization Algorithm of AGV Path Planning.” 2021 4th International Conference on Information Systems and Computer Aided Education, 2021.
- [6] Guruji, Akshay Kumar, H. Agarwal, and D. K. Parsediya. ”Time-efficient A* Algorithm for Robot Path Planning.” International Conference on Innovations in Automation and Mechatronics Engineering, 2017.
- [7] Song, Yuanchang Bucknall, Richard. ”Smoothed A* Algorithm for Practical Unmanned Surface Vehicle Path Planning.” Applied Ocean Research, Vol.83, 2019: 9-20.
- [8] Wang, Wei, H. Deng, and X. Wu. ”Path Planning of Loaded Pin-jointed bar Mechanisms Using Rapidly-exploring Random Tree Method.” Computers & Structures, Vol.209, 2018: 65-73.
- [9] Lee, Dhong Hun, et al. ”Finite Distribution Estimation-Based Dynamic Window Approach to Reliable Obstacle Avoidance of Mobile Robot.” IEEE Transactions on Industrial Electronics, Vol.68, No.10, 2021: 998-1006.
- [10] Song, Zidong Zou, Lei. ”An Improved PSO Algorithm for Smooth Path Planning of Mobile Robots Using Continuous High-degree Bezier Curve.” Applied Soft Computing, Vol.100, 2021.
- [11] Sutton, Richard S., and A. G. Barto. ”Reinforcement Learning: An Introduction.” AI Magazine, Vol.21, No.1, 2000: 103.
- [12] Silver, David, et al. ”Mastering the Game of Go with Deep Neural Networks and Tree Search.” Nature 529, 2016: 484–489.
- [13] Nair, Devika S., and P. Supriya. ”Comparison of Temporal Difference Learning Algorithm and Dijkstra’s Algorithm for Robotic Path Planning.” 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), 2018: 1619-1624.
- [14] Christopher, J. ”Q-learning. Machine Learning.” Machine Learning, Vol.8, 1992: 279-292.
- [15] Arulkumaran, Kai, et al. ”A Brief Survey of Deep Reinforcement Learning.” IEEE Signal Processing Magazine, Vol.34, No.6, 2017: 26-38.
- [16] Mnih, Volodymyr, et al. ”Playing Atari with Deep Reinforcement Learning.” Computer Science, 2013.
- [17] Yang, L. Juntao, and P. Lingling. ”Multi-robot Path Planning Based on a Deep Reinforcement Learning DQN Algorithm.” CAAI Transactions on Intelligence Technology, Vol.5, No.3, 2020: 177-183.
- [18] Panov, Aleksandr I., K. S. Yakovlev, and R. Suvorov. ”Grid Path Planning with Deep Reinforcement Learning: Preliminary Results.” Procedia Computer Science, Vol.123, 2018:347-353.
- [19] Schulman, John, et al. ”Proximal Policy Optimization Algorithms.” arXiv preprint arXiv:1707.06347, 2017.
- [20] Xiao, Qianhao, et al. ”An Improved Distributed Sampling PPO Algorithm Based on Beta Policy for Continuous Global Path Planning Scheme.” Sensors, Vol.23, No.13, 2023: 6101.
- [21] Yin H, Lin Y, Yan J, et al. ”AGV Path Planning Using Curiosity-Driven Deep Reinforcement Learning.” 2023 IEEE 19th International Conference on Automation Science and Engineering (CASE), 2023: 1-6.
- [22] Shi J, Zhang T, , et al. ”Efficient Lane-changing Behavior Planning via Reinforcement Learning with Imitation Learning Initialization,” 2023 IEEE Intelligent Vehicles Symposium (IV), 2023.
- [23] Ng, Andrew Y., Daishi Harada, and Stuart Russell. ”Policy Invariance under Reward Transformations: Theory and Application to Reward Shaping.” International Conference on Machine Learning, Vol.99, 1999.
- [24] Rao J, et al. ”A Modified Random Network Distillation Algorithm and Its Application in USVs Naval Battle Simulation.” Ocean Engineering, Vol.261, 2022: 112147.
- [25] Sovrano, Francesco. ”Combining Experience Replay with Exploration by Random Network Distillation.” 2019 IEEE conference on games (CoG), 2019: 1-8.
- [26] Pan, Lifan, et al. ”Learning Navigation Policies for Mobile Robots in Deep Reinforcement Learning with Random Network Distillation.” 2021 the 5th International Conference on Innovation in Artificial Intelligence, 2021: 151-157.