RACER: An LLM-powered Methodology for Scalable Analysis of
Semi-structured Mental Health Interviews
Abstract
Semi-structured interviews (SSIs) are a commonly employed data-collection method in healthcare research, offering in-depth qualitative insights into subject experiences. Despite their value, the manual analysis of SSIs is notoriously time-consuming and labor-intensive, in part due to the difficulty of extracting and categorizing emotional responses, and challenges in scaling human evaluation for large populations. In this study, we develop RACER, a Large Language Model (LLM) based expert-guided automated pipeline that efficiently converts raw interview transcripts into insightful domain-relevant themes and sub-themes. We used RACER to analyze SSIs conducted with 93 healthcare professionals and trainees to assess the broad personal and professional mental health impacts of the COVID-19 crisis. RACER achieves moderately high agreement with two human evaluators (72%), which approaches the human inter-rater agreement (77%). Interestingly, LLMs and humans struggle with similar content involving nuanced emotional, ambivalent/dialectical, and psychological statements. Our study highlights the opportunities and challenges in using LLMs to improve research efficiency and opens new avenues for scalable analysis of SSIs in healthcare research.
keywords:
Semi-structured interviews , Large language models , Healthcare NLP , Burnout , COVID-191 Introduction
Semi-structured interviews (SSIs) are a widely used qualitative research method in healthcare research, that provide an in-depth understanding of subjects’ experiences in their own words [1]. SSIs require interviewers to ask prespecified ‘root’ questions, along with the option to ask follow-up questions to gain clarity on the interviewee’s responses. This flexibility is a key characteristic of SSIs, allowing for a more dynamic and responsive data collection process, especially in areas where exploratory forays are needed. The adaptability of SSIs is particularly beneficial in exploring complex or sensitive topics such as mental health. SSIs allow rapport building between interviewer and subject, and facilitate candid responses on sensitive matters. The open-ended nature of follow-up questions gives subjects the freedom to reflect on experiences and articulate thoughts without judgement. This helps reveal the nuances, contradictions, and diversity of perspectives that traditional fixed quantitative surveys may overlook. However, the traditional manual analysis of these interviews is a time-consuming and resource-intensive process. The advent of Large Language Models (LLMs), such as GPT-4 [2, 3, 4], offers a novel and efficient method to extract and interpret data from such text corpora. Yet, the validity of LLMs in analyzing emotional states may be limited in circumstances where participants express multiple emotions or conflicting (dialectical) states.
As a case-study, we leveraged data from SSIs, conducted during the peak of the COVID-19 crisis in 2020, to understand the mental well-being of 93 healthcare professionals and trainees. The COVID-19 pandemic brought to the forefront profound personal and professional challenges experienced by healthcare workers. Fear of infecting family members, grief over patient deaths, moral dilemmas in resource allocation, and anxieties about professional preparedness collectively introduced a heightened level of psychological complexity and stress in the lives of healthcare professionals. The stigma surrounding the pursuit of mental health support exacerbated these challenges, leaving healthcare workers hesitant to openly discuss their difficulties or seek assistance.
In this paper, we developed RACER, an expert-guided automated pipeline that Retrieved responses to about 40 questions per SSI, Aggregated responses to each question across all subjects, Clustered these responses for each question into insightful domain-relevant Expert-guided themes [5], and finally Re-clustered responses to produce a robust result. Human evaluation on a subset of the total population revealed moderately high agreement [6] between humans and RACER outputs, and similarities between inter-human disagreement and human-machine disagreement. We summarize our findings from applying RACER to our SSI-survey on the experiences of healthcare professionals and trainees during COVID-19, to reveal the power of this approach. Our results demonstrate both the capabilities and the limitations leveraging LLMs to efficiently process and extract insights from a large corpus of SSIs.
2 Results
| Characteristic | Percentage |
|---|---|
| Gender | |
| Male | 54.84% |
| Female | 45.16% |
| Age Group | |
| 22-33 years | 39.78% |
| 34-45 years | 32.26% |
| 46-60 years | 16.13% |
| 61+ years | 5.38% |
| Unclear/Excluded | 6.45% |
| Healthcare Professional/Student Type | |
| Physicians | 54.84% |
| Medical Students | 21.51% |
| Nurses | 8.60% |
| Residents | 7.53% |
| Other Professionals | 12.90% |
| Unclear/Excluded | 1.08% |
| Location | |
| Houston, Texas | 44.09% |
| Other Texas | 21.50% |
| Florida | 10.75% |
| Mid-West US | 13.98% |
| Other US | 5.38% |
| Unclear/Excluded | 2.15% |
| Marital Status | |
| Not married | 41.94% |
| Married | 52.69% |
| Unclear/Excluded | 5.38% |
| Have Kids? | |
| Yes | 51.61% |
| No | 45.16% |
| Unclear/Excluded | 3.23% |
| Specialty Area | |
| Emergency Medicine | 26.88% |
| Psychiatry | 16.13% |
| Pulmonary Critical Care | 16.13% |
| Internal Medicine | 11.83% |
| Neurology/Neurocritical Care | 5.38% |
| Surgery/ER | 5.38% |
| Pediatrics | 5.38% |
| Other Specialties | 17.22% |
| Unclear/Excluded | 2.15% |
| Years of Practice | |
| Under 15 Years | 71.23% |
| 15-30 Years | 20.55% |
| Over 30 Years | 5.48% |
| Unclear/Excluded | 1.37% |

2.1 Recruitment and interview of a diverse sample of healthcare professionals and trainees
Healthcare professionals and trainees across different specialties and career stages were recruited via snowball sampling method [7], described as follows. The investigators asked colleagues if they knew of anyone willing to participate in interviews about their COVID-19 experiences. Announcements were also posted online and through professional networks. Participation was voluntary with no compensation provided. Approval was obtained from the Baylor College of Medicine (Houston, TX) Institutional Review Board. The interviews were performed by a team of two research coordinators with healthcare backgrounds, and a third-year medical student, under the supervision of the investigators.
The study population of healthcare professionals and trainees consisted of 93 subjects (51 male, 42 female) with diverse demographics (Table 1). Subjects were from 22 years to over 61 years in age, and were located predominantly in Texas. Over half were married and had children. Most (75%) had no care-taking responsibilities in addition to child-care. Professionally, the sample included physicians (54.8%), medical students (21.5%), nurses (8.6%), residents (7.5%) and other healthcare professionals. Subjects trained at multiple institutions, with prominent representation from Baylor College of Medicine and University of Texas systems. Various specialties were represented in the cohort, with emergency medicine, psychiatry and pulmonary/critical care among the most common.
SSIs were conducted over videoconferencing using a standard template consisting of a total of 41 questions, including four questions that were only asked to students, and seven questions that were asked to only non-students. Questions were either factual, concerning demographics and personal and professional background, or open ended, where interviewees were asked to talk about their experiences during the COVID-19 pandemic, focusing on their exposure to the virus, work impacts, emotional responses, future outlooks, and coping strategies. Interviewees discussed how they had practiced in high-risk areas, their concerns for personal and family safety, and modifications made to their routines. They also reflected on the physical toll the crisis had taken. The impact on their work included changes in working hours, shifts in patient care quality, and altered management approaches. Emotional and psychological questions revealed how the crisis affected them emotionally, the level of support they received, family dynamics, and changes in burnout levels. Looking ahead, they pondered the crisis’s short-term and long-term impacts on their careers and specialty choices. Finally, they shared their openness to seeking help for burnout or mental overwhelm and identified potential obstacles in obtaining this help. Students were not asked clinical-practice related questions, and were instead asked about how their training was being affected by pandemic-related changes. Interviews lasted on average 26.7 +/- 8.9 s.d. minutes. When transcribed from raw interview audio into text transcripts (using Otter.AI[8]), were on average 4044.30 +/- 1348.34 s.d. words long.

2.2 RACER extracts relevant interviewee responses and robustly clusters them
We developed an LLM-based automated pipeline called RACER (Figure 1) that converts a corpus of text SSI transcripts into insightful themes per interview question. RACER, consists of four stages, Retrieve, Aggregate, Cluster with Expert guidance, and Recluster:
Retrieve: We first structured interview transcripts by using an LLM (OpenAI’s GPT-4[2]) to retrieve relevant SSI text in response to each of the questions in the interview template. (See Methods LLM prompt details) To avoid LLM ‘hallucinations’ [9], we asked the LLM to provide ‘evidence’ in the form of text quoted verbatim from the transcript, to back up its response to each question. LLM outputs missing either answers or backing evidence to any question were automatically detected and rerun.
Aggregate: For each question, we then aggregated the retrieved responses across all subjects who were asked that question.
Cluster with Expert guidance: We then asked the LLM to semantically cluster the responses into primary and secondary clusters (‘themes’ and ‘sub-themes’). For most questions, we provided the LLM expert-guidance in the form of primary-cluster definitions. The LLM discovered secondary clusters (or sub-themes) automatically. Expert-provided cluster definitions were always mutually exclusive and collectively exhaustive, while those discovered by the LLM were not constrained to be so. Similar to before, invalid LLM responses, e.g. those missing cluster assignments for any subjects, were automatically re-run.
Re-Cluster: Leveraging the probabilistic nature of LLMs, we assessed the robustness of the clustering process by re-running it four more times, employing the same cluster definitions and validation criteria as in the initial step. We used a majority vote over 5 runs to assign subjects to clusters, to get robust cluster assignments for all downstream processing. The number of votes (3, 4 or 5 out of total 5 LLM calls) additionally provided a synthetic measure of LLM confidence [10, 11]. Only a very small fraction of subject-question pairs (12 out of 3342, 0.36%) had no ‘robust’ cluster assignments after applying the majority voting process.
All together, we found that RACER was able to take unstructured transcriptions and extract relevant and insightful, clustered responses in a robust manner for downstream human analysis.
2.3 Human-machine disagreement approaches inter-human disagreement
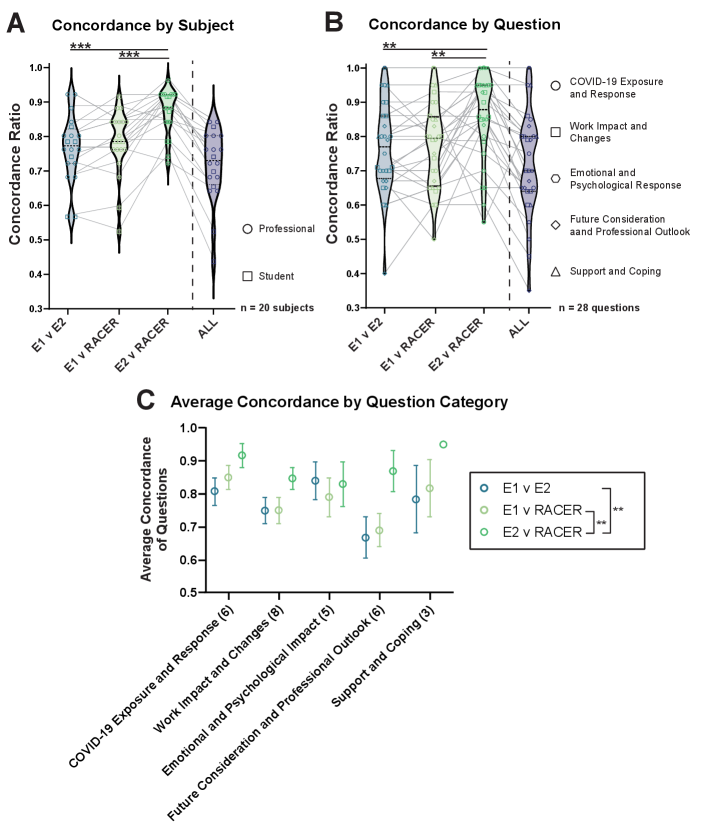
To validate the output of running RACER on our SSI dataset, two human evaluators cross-checked the resulting cluster assignments for 20 randomly-selected subjects across 28 open ended questions. Using the same cluster definitions as were previously used by RACER, each human evaluator (E1 and E2) independently read the raw transcript file and assigned each subject’s answers to the primary clusters. Evaluator cluster assignments were then compared to RACER’s robust cluster assignments. To quantify agreement, we defined a concordance score and a concordance ratio as follows: If the clusters for a given subject-question pair matched exactly (for mutually exclusive clusters), or were sub-sets or super-sets of each other (for mutually non-exclusive clusters) they were assigned a concordance score of 1. Conversely, mismatch was assigned a concordance score of 0. The overall concordance ratio is the proportion of matched subject-question pairs between evaluators.
We observed a concordance of 78% (E1) and 87% (E2) between human evaluators and RACER, and a 77% (E1-E2) inter-rater concordance (Figure 2B). When all three evaluators were compared simultaneously, there was a little decrease in the concordance (72%), indicating that across the majority of subject-question pairings, cluster assignments produced by humans and RACER were all in agreement. See Methods for additional details.
2.4 Machine ”confusion” resembles human confusion

We examined the confidence score produced by RACER per subject-question pair to see how it might affect the subject-question pair’s concordance with human evaluators (Figure 3). Amongst the 443 subject-question pair sample evaluated by humans, 392 (87.7%) were entirely robust (5 of 5 repeat clusters). This was similar to the population confidence score distribution 88.2% (1852 of 2099 subject-question pairs). RACER’s average confidence across all subjects for a given question showed significant and positive correlations with Human-RACER concordance of the 20 subjects evaluated for those same questions. Additionally, we observed that the confidence scores of subject-question pairs that were concordant between human evaluators and RACER, were higher than for non-concordant subject-question pairs. This was due to significant differences in the proportion of lower confidence subject-question pairs between concordant and non-concordant groups. Interestingly, when we juxtaposed RACER confidence scores against human-human concordance, we observed that RACER confidence was lower when humans were non-concordant. This suggests that areas where RACER was less confident or ‘confused’ were also areas where human evaluators tended to disagree. Thus the RACER confidence generated via repeated clustering could also serve as an indicator of SSI ambiguity or difficulty.
2.5 Insights using RACER on healthcare worker experience during COVID-19
We now summarize the insights gleaned from analyzing SSIs with 93 subjects using our automated processing pipeline.
2.5.1 COVID-19 exposure, response, work impact and work changes
The vast majority of practicing healthcare professionals reported having professional contact with COVID-19 patients in the past two months. Most subjects expressed safety concerns for themselves and loved ones, especially regarding viral exposure risks. Common protective measures adopted included heightened hygiene practices, using personal protective equipment, limiting travel and social interactions, and modifying routines at work and home to minimize transmission risks. Over half of the subjects reported physical tolls from the crisis, frequently citing exhaustion, disturbed sleep, and dietary changes (Figure 4).
Most subjects felt personally prepared to handle the pandemic, attributing this largely to their medical knowledge, experience, and ability to adapt. Assessment of institutional preparedness was more varied, with around 60% expressing their hospital/unit was prepared, but around 25% felt improvements were still needed.
Working hours markedly increased for most subjects during the pandemic, with over 80% reporting working more than 40 hours per week compared to pre-COVID times. For many, this resulted from escalations in patient load and administrative duties. Approaches to patient management also evolved, with the vast majority of practicing healthcare professionals stating their methods differed from usual practices. This included increased reliance on technology, more precautions with patients, and adjustments to treatments due to COVID-19. Most still felt capable of handling the situation professionally, though some desired more protections and support systems.
Among students and trainees, the majority believed they adhered closely to the Hippocratic oath during the pandemic. Their views on their educational institution’s policies regarding medical students’ roles during that time were divided, with half in agreement and others expressing mixed or negative sentiments, reflecting a spectrum of perspectives on the adequacy and effectiveness of institutional responses to the crisis.
2.5.2 Emotional and psychological impact, and support and coping strategies
The COVID-19 crisis negatively affected the emotional state of most subjects, with many reporting feelings of anxiety, stress, sadness, or anger. However, around 25% indicated a mix of both positive emotions like gratitude as well as negative feelings. Despite those challenges, the overwhelming majority felt supported by peers and family, suggesting strong social networks within and outside the workplace. Family dynamics had been affected for some, with around a quarter reporting increased family problems during the pandemic. This data underscored the profound emotional and psychological effects of the crisis on healthcare professionals, juxtaposed with the resilience and support systems that helped them navigate these challenges.
In regards to burnout, over 60% of subjects assessed their pre-pandemic burnout as low or mild. When asked about current burnout, around 40% still reported mild or no burnout, but the percentage reporting severe burnout rose from around 15% pre-pandemic to 20% during the crisis. If feeling burned out, nearly 90% stated they would seek help, with most mentioning professional resources like counseling. Over 60% also reported they would seek professional help if feeling mentally overwhelmed, with therapists and workplace programs being commonly cited options. However, around 45% still anticipated obstacles in getting help, including logistical barriers and stigma concerns (Figure 5).
2.5.3 Future considerations and professional outlook
When asked about near-term impacts, over 50% expressed concerns about anticipated difficulties, health risks, economic instability, and significant lifestyle changes. However, around 15% hoped for new opportunities and growth resulting from the crisis. Looking 5 years ahead, around 20% expected advancements in healthcare practices and systems due to learned lessons. Though nearly 10% feared lingering personal and professional impact. Among non-students considering job changes, around 15% expressed an immediate willingness to switch fields while around 18% would change contingent on worsening conditions.
Regarding effects on career plans, 35% of students reported the crisis has impacted their specialty choices or work preferences. Specifically, around 20% described reconsidering their specialty choice due to the pandemic. Another 15% mentioned shifting their preferences regarding research involvement, practice locations, and other factors. However, 50% of students stated the crisis has not affected their professional plans or specialty decisions. Over 50% of students explicitly stated adherence to their Hippocratic oath obligations, while 10% conveyed adherence through descriptions of their clinical actions and interventions. Of students agreeing with their school’s pandemic policies, 40% expressed unqualified agreement and 10% provided positive justifications. However, around 15% agreed tentatively due to concerns over student safety and curriculum changes (Figure 6).
3 Discussion
3.1 Summary
Our study demonstrates the utility of RACER for efficiently analyzing semi-structured interviews (SSIs), particularly those exploring complex mental health topics within the healthcare domain. We introduce a novel approach by employing RACER to analyze emotions and psychological behaviors, opening new possibilities for exploration in mental health. By providing expert-guided constraints and using automated response validation steps, RACER accurately extracts and robustly clusters relevant responses from interview transcripts. Automating these laborious manual tasks significantly enhances the scalability of SSI analysis. The inter-rater agreement between LLM-assigned clusters and human expert clusters further bolsters our claims. The automated pipeline achieved moderately high concordance compared with manual evaluation by human annotators. The overall concordance ratio of 0.72 for RACER versus both human evaluators approaches the 0.77 concordance ratio between the two human evaluators.
3.2 Limitations and tradeoffs
Our findings reveal both the promises and current pitfalls of LLMs for SSI analysis. We found that when the RACER struggled with robust clustering, both humans and machine were more likely to be non-concordant which could suggest shared limitations in handling complex emotions or psychologically nuanced statements [12] or ambiguity of the underlying SSI. This underscores the indispensable role of human expertise in reviewing and interpreting LLM outputs, where RACER’s confidence levels can guide expert scrutiny.
While RACER provided evidence in the form of quoting relevant interview text to support its response in the Retrieval step, the underlying methodology remains opaque. In contrast, human evaluators were able to describe their techniques, even if subjective. For instance, humans considered different amounts of contextual information outside the question scope, and inferred subject intentions to varying degrees, i.e. whether the subject needed to explicitly say certain phrases, or if they could be inferred from previous statements or knowledge of the subject matter. An LLM’s ability to consider large amount of contextual information can be a double-edged sword; beneficial if relevant information appears elsewhere in the transcript, but misleading if the research is indeed directed towards a narrow window of text around the question.
We demonstrated that LLMs can help discover knowledge by automatically extracting themes and topics from subject responses. However, good performance requires clear, mutually exclusive category definitions. We found it highly useful to involve domain experts early to precisely define mutually exclusive thematic clusters. For certain questions, where succinct mutually exclusive categorization was not possible, we chose to use LLM-discovered clusters. However, validation of such non-exclusive categorization is challenging. Our results showed higher LLM accuracy and inter-rater agreement for questions with non-overlapping expert-defined clusters versus those allowing multiple clusters.
Additionally, human evaluators exhibited biases, such as default cluster tendencies requiring countering evidence (e.g. starting from a default of ‘no’ and requiring evidence to switch to a ‘yes’, or vice versa). Thus, expert human analysis also demonstrates cognitive variability and individual biases. Rather than definitive classifications, both human and machine outputs should be considered informed yet inherently biased perspectives on complex qualitative responses [13]. Thus, in the future, clearly delineating the parameters of evaluations with humans and RACER may improve concordance.
While RACER’s cluster assignments may deviate slightly from human reviewers, RACER was internally consistent and demonstrated high clustering repeatability for most questions. Furthermore, unlike humans, RACER was able to efficiently process an extensive dataset of 93 subjects and can scale to significantly larger data set sizes that would otherwise be infeasible for human evaluators to handle.
3.3 Future work
For researchers undertaking projects in this emerging domain, both optimism and caution are warranted [14, 15, 16, 17, 18, 19]. With appropriate constraints and validation, LLMs can accelerate knowledge extraction from SSIs. We implemented safeguards against hallucination risks like requiring verbatim textual evidence for an answer, which constrained the LLM to mostly avoid fabricating content. While this is already an area of active research, the possibility of a few false positives remains and needs to be accounted for in downstream use.
While evaluation of LLM outputs through comparison to multiple human raters was helpful through comparison to multiple human raters, inter-rater agreement must also be looked at to assess inherent ambiguity. To further improve performance, we recommend specialized training for both SSI interviewers and human evaluators.
We found it useful to generate an ensemble of LLM clustering outputs from repeated runs, and used it to extract robust cluster assignments and to get a measure of model uncertainty. Future work exploring this direction could produce useful methods that help build trust in LLM-assisted analyses and inform human-in-the-loop processes for high-stakes applications [20].
4 Methods
4.1 Semi-structured interviews
Interviewers were provided with a standard template to guide their discussions. The subjects were all healthcare professionals or trainees, including physicians, nurses, and medical students. The interviews followed a semi-structured format, where the interviewers were instructed to cover a previously decided list of questions, and were allowed to ask exploration questions if the ‘root’ question was not answered. The questions covered in the SSIs are listed in A. Raw audio / video interview files were transcribed into text format using the Otter.AI transcription service [8]. Out of 100 interviews conducted, 7 were compromised due to data-corruption/loss issues, providing a total of 93 transcriptions for further processing. Voice to text transcription was carried out using Otter.AI[8], which attempts to perform automated speaker diarization, but does not do so perfectly. To the best of our knowledge, this shortcoming did not seem to influence the subsequent processing steps.
4.2 RACER
We used the OpenAI GPT-4 LLM for all our work, except for prompts which exceeded GPT-4’s limits, where we used GPT-4-32k.
4.2.1 Retrieval
In this step, the model was tasked with retrieving relevant responses for each question from a predefined list of questions (listed in A) from the transcript. The prompt for the LLM consisted of instructions and a template consisting of the aforementioned list of questions and what format each question’s response should be in, followed by the entire SSI transcript. The full prompt is detailed in A.
LLM Response Validation: By asking the LLM to respond in a structured format, we could partially automate the process of verifying the LLM’s response. The LLM is called once for each subject, and then the response is parsed using the Python Pandas library. The LLM’s response is marked invalid if it is ill-formatted (not parsable in tab-separated-values format) or incomplete (wrong number of rows, i.e. questions, or columns, i.e. incomplete response). The LLM is called again on invalid responses till the LLM returns a valid response. We found that at most 4-5 (5%-6%) subjects would have invalid responses in the first attempt, and in total, we were making about 10% additional calls to get valid responses for all subjects. The most common issues were that the LLM would sometimes be incomplete (skip questions, end output before final question) and sometimes use the specified tab-delimiter incorrectly.
4.2.2 Cluster with Expert guidance
In this step, we employed a semantic clustering approach which grouped responses based on the underlying themes or sentiments (”semantic clusters”) they conveyed. In preliminary explorations, we found that the LLM is able to automatically generate interesting semantic clusters from a list of the subjects’ responses without additional human guidance. However, in many cases (21 out of 40 questions), we felt like it was important to exercise more control over the LLM’s response to facilitate human consumption of the results. So, we provided expert guidance in the form of a list of primary clusters or ”themes” (defined on a per-question basis), which were included in the prompt using a template (detailed in B). Secondary clusters or ”sub-themes” were discovered automatically by the LLM. Each subject’s response was mapped exclusively to one primary cluster and could furthermore be associated with one or more secondary clusters.
LLM Response Validation: The LLM returned two lists in its response: one of the cluster labels and their definitions, and the other of the cluster-labels (single or two-level clustering) assigned to each subject. The LLM was called once for each of 40 questions, and these responses were parsed using the Python Pandas library. A LLM response is marked invalid if it was ill-formatted or incomplete. The LLM was called again on invalid responses till the LLM returned a valid response. We found that almost 20 questions would have invalid responses in the first attempt, and in total, we were making almost 80% additional calls to get valid responses for all questions. We suspect that the rate of invalid responses in this step is higher than in the previous step due to the added complexity of the task i.e. the response needs to first produce a valid clustering-schema, and then additionally assign each of 93 subjects to the clusters according to the clustering schema.
4.2.3 Recluster
We repeated the above clustering step four additional times using a similar prompt (detailed in C) with previously defined cluster-definitions. As in the original clustering, any invalid LLM responses were automatically detected and re-processed until a valid response was obtained. For the final cluster assignments used in downstream analysis, we applied a majority vote rule based on the 5 clustering repetitions. In a few cases ( of all subject-question pairs), this process failed to find any cluster assignments that passed the majority-vote.
4.3 Human evaluation of LLM responses
Our study employed human evaluation to verify the alignment between RACER-generated clusters and human interpretation, utilizing two independent evaluators who analyzed the responses of 20 randomly selected subjects from a pool of 93. Each evaluator individually reviewed the raw interview transcript files for the selected 20 subjects and used the same cluster definitions as RACER to assign subjects to clusters. Human evaluators spent approximately 30 minutes per subject on average for a comprehensive review and categorization of the responses. This time investment reflects the thoroughness and attention to detail applied by the evaluators in their analysis, and also highlights the limits of this process to scale to large study populations. To validate the semantic clustering results produced by the LLM, each human evaluator compared their assigned scores with those generated by the LLM. An inter-rater comparison was also conducted, involving a detailed examination of the scores and evaluations independently made by both human evaluators (E1 and E2) for the same set of subjects. Concordance scores of 1 were assigned to clusters that precisely matched or were sub- or super-sets of each other, while discrepancies received a concordance score of 0. The overall concordance ratio represented the proportion of clusters aligning between the evaluators.
Additionally, the evaluators’ findings were juxtaposed with RACER’s cluster assignments to gauge both inter-evaluator consistency and the degree of correspondence with the LLM’s outcomes. We also compared the use of Cohen’s kappa coefficient with our concordance score and found them to be similar (Appendix 8). Due to the nature of the comparison across questions which varied in the number of possible clusters as well as probability of different cluster assignment across questions, the concordance scores were used as they better described the intended comparisons. Instances where RACER did not produce any robust cluster assignments were categorized as ’mismatch’ during the evaluation process.
Acknowledgements
We thank the involved research staff and consenting subjects for supporting this research.
Author Contributions Statement
SHS, NM, AS and AP conceived of the study/analysis. NM supervised the collection of interviews. SHS designed and coded the automated interview transcription, LLM processing, data-analysis, and visualization pipelines. SHS and NM evaluated early LLM performance and designed the expert-guided clustering criteria. KJ and KB performed the human evaluation, data interpretation and writing related to human evaluation. KJ visualized and analyzed the human evaluation data. AP funded the transcription and large-language model accounts. SHS wrote the first draft of the manuscript, excluding text related to human evaluation. All authors interpreted the results and reviewed and edited the manuscript.
Competing Interests Statement
All authors declare no financial or non-financial competing interests.
Code Availability Statement
Code used to generate our results can be found at
https://github.com/satpreetsingh/RACER
Data Availability Statement
Aggregated cluster assignment data required to reproduce figures has been made publicly available on the accompanying code repository. Human evaluation statistical analyses and visualizations were performed with Prism 10 (GraphPad Software). Data from earlier stages of the pipeline contain Personally identifiable information (PII) and therefore has not been released.
References
- [1] Eike Adams. The joys and challenges of semi-structured interviewing. Community Practitioner, 83(7):18–22, 2010.
- [2] Peter Lee, Carey Goldberg, and Isaac Kohane. The AI revolution in medicine: GPT-4 and beyond. Pearson, 2023.
- [3] Peter Lee, Sebastien Bubeck, and Joseph Petro. Benefits, limits, and risks of gpt-4 as an ai chatbot for medicine. New England Journal of Medicine, 388(13):1233–1239, 2023.
- [4] V Vien Lee, Stephanie CC van der Lubbe, Lay Hoon Goh, and Jose M Valderas. Harnessing chatgpt for thematic analysis: Are we ready? arXiv preprint arXiv:2310.14545, 2023.
- [5] V. Vien Lee, Stephanie C. C. van der Lubbe, Lay Hoon Goh, and Jose M. Valderas. Harnessing ChatGPT for thematic analysis: Are we ready?, October 2023. arXiv:2310.14545 [cs].
- [6] Mary L McHugh. Interrater reliability: the kappa statistic. Biochemia medica, 22(3):276–282, 2012.
- [7] Leo A Goodman. Snowball sampling. The annals of mathematical statistics, pages 148–170, 1961.
- [8] Otter.ai. Otter.ai: Voice meeting notes transcription service, 2023. Accessed: 2023-12-10.
- [9] SM Tonmoy, SM Zaman, Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha, and Amitava Das. A comprehensive survey of hallucination mitigation techniques in large language models. arXiv preprint arXiv:2401.01313, 2024.
- [10] Benjamin Kompa, Jasper Snoek, and Andrew L Beam. Second opinion needed: communicating uncertainty in medical machine learning. NPJ Digital Medicine, 4(1):4, 2021.
- [11] Sree Harsha Tanneru, Chirag Agarwal, and Himabindu Lakkaraju. Quantifying uncertainty in natural language explanations of large language models. arXiv preprint arXiv:2311.03533, 2023.
- [12] William Boag, Olga Kovaleva, Thomas H. McCoy, Anna Rumshisky, Peter Szolovits, and Roy H. Perlis. Hard for humans, hard for machines: predicting readmission after psychiatric hospitalization using narrative notes. Translational Psychiatry, 11(1):1–6, January 2021. Number: 1 Publisher: Nature Publishing Group.
- [13] Mohammad Atari, Mona J. Xue, Peter S. Park, Damián Blasi, and Joseph Henrich. Which Humans? January 2024. Publisher: OSF.
- [14] Kimberly Badal, Carmen M. Lee, and Laura J. Esserman. Guiding principles for the responsible development of artificial intelligence tools for healthcare. Communications Medicine, 3(1):47, April 2023.
- [15] Debadutta Dash, Rahul Thapa, Juan M Banda, Akshay Swaminathan, Mehr Kashyap, Nikesh Kotecha, Jonathan H Chen, Saurabh Gombar, Lance Downing, Rachel Pedreira, Ethan Goh, Angel Arnaout, Garret K Morris, Matthew P Lungren, Eric Horvitz, and Nigam H Shah. Evaluation of GPT-3.5 and GPT-4 for supporting real-world information needs in healthcare delivery.
- [16] Yu Ying Chiu, Ashish Sharma, Inna Wanyin Lin, and Tim Althoff. A Computational Framework for Behavioral Assessment of LLM Therapists, January 2024. arXiv:2401.00820 [cs].
- [17] Liyan Tang, Zhaoyi Sun, Betina Idnay, Jordan G. Nestor, Ali Soroush, Pierre A. Elias, Ziyang Xu, Ying Ding, Greg Durrett, Justin F. Rousseau, Chunhua Weng, and Yifan Peng. Evaluating large language models on medical evidence summarization. npj Digital Medicine, 6(1):158, August 2023.
- [18] Michael Wornow, Yizhe Xu, Rahul Thapa, Birju Patel, Ethan Steinberg, Scott Fleming, Michael A. Pfeffer, Jason Fries, and Nigam H. Shah. The shaky foundations of large language models and foundation models for electronic health records. npj Digital Medicine, 6(1):135, July 2023.
- [19] Nigam H. Shah, David Entwistle, and Michael A. Pfeffer. Creation and Adoption of Large Language Models in Medicine. JAMA, 330(9):866, September 2023.
- [20] Nadine Bienefeld, Jens Michael Boss, Rahel Lüthy, Dominique Brodbeck, Jan Azzati, Mirco Blaser, Jan Willms, and Emanuela Keller. Solving the explainable AI conundrum by bridging clinicians’ needs and developers’ goals. npj Digital Medicine, 6(1):94, May 2023.
APPENDICES
Appendix A LLM prompt for retrieving relevant responses from interview transcripts
[Interview Transcript Appended]
Appendix B LLM prompt template for semantic Clustering of responses aggregated across all subjects
Out of 40 questions in our template in A, 21 questions had expert-provided templates that defined the primary clusters but left secondary-cluster definitions to the LLM. 4 questions (Q13, Q15, Q17, Q19) used LLM-discovered single-level clustering. The following Python code shows the template used for generating the prompt associated with each question:
Appendix C LLM prompt for Re-Clustering using previously defined clusters
Appendix D Concordance analysis
Appendix E Concordance vs Cohen’s Kappa
