Raccoons vs Demons:
multiclass labeled P300 dataset
Abstract
We publish dataset of visual P300 BCI performed in Virtual Reality (VR) game Raccoons versus Demons (RvD). Data contains reach labels incorporating information about stimulus chosen enabling us to estimate model’s confidence at each stimulus prediction stage.
Data and experiments code are available at https://gitlab.com/impulse-neiry_public/raccoons-vs-demons
Keywords P300, EEG, BCI, Transfer learning
1 Introduction
Firstly Brain-Computer Interfaces (BCI) were developed mostly with disabled patients in mind (e.g. [Bla+04], [Ric+13], [Hof+08]). Nowadays there are numerous attempts to employ BCI solutions for healthy people using noninvasive electrodes (see [Mar+12], ).
Another crucial thing for further BCI development is processing and visualization instruments. At the beginning every laboratory used own programming environments and data format, some even used proprietary platforms. Happily at the moment we have fully open sourced systems based on Python programming language like MNE [Gra+13], PyRiemann [CBA13] and MOABB [JB18], also EDF data format [KO03] to store EEG/MEG data specifically.
2 Materials and methods
2.1 Participants
61 healthy participants (23 males) naive to BCI with mean age 28 years from 19 to 45 y.o. took part in the study.
All subject signed informed consent (see appendix) and passed primary prerequisites on their health and condition.
2.2 Stimulation and EEG recording
The EEG was recorded with NVX-52 encephalograph (MCS, Zelenograd, Russia) at 500 Hz. We used 8 sponge electrodes (Cz, P3, P4, PO3, POz, PO4, O1, O2), see 1. Stimuli were presented with HTC Vive Pro VR headset with TTL hardware sync.

2.3 Experimental procedure
Participants were asked to play the P300 BCI game in virtual reality. BCI was embedded into a game plot with the player posing as a forest warden. The player was supposed to feed animals and protect them from demons.
We have used an oddball paradigm. At the learning stage, 5 numbered animated raccoons (see 2) were presented to the participant. The stimulation consisted of raccoon jumps in a random order to prevent activation anticipation (for animation timeline see fig. 2B). Participants were instructed to count jumps of a specific raccoon for 5 sessions. Each session consisted of all targets activating 10 times, after which the animal received food. This produced 50 target and 450 non-target evoked potentials that were used for classification.
During BCI feedback scene, stimuli were presented as animated demons, which were jumping. The instruction for each participant was essentially the same as for the learning session (counting jumps of the target stimuli). Before each session the participants called out the number of demon they would be counting during the session. This was done to get rid of the usual copy-spell scheme, and to preserve interactivity (participant choose target himself). Selected demon was destroyed at the end of the scene (10 activations of all stimuli). Then demons came closer to the participant, eventually grabbing one of the raccoons and running away. When the target was removed from the screen one way or another, the new demon was spawned to the initial position, so the number of stimuli remained constant.
Data was recorded for later offline analysis. The game was accompanied with spoken instruction and background music.

3 Data structure and terms
Essentially in an oddball paradigm we have to solve 2 different but connected classification tasks:
-
1.
Binary
Classification of a single epoch to contain P300 or not (in other words to be target or empty). In this case each epoch is classified independently. It is suitable for online (calibration then test on the same person) training because only 250 epochs are enough to train such a model. Another noticeable trait of this type of problem is imbalanced training and testing sets because each stimulus is activated the same number of times while only one of them is target. So we end up with to class ratio where is the number of stimuli. For this task accuracy metric is not sufficient because of class imbalance so we track precision, recall, f1 and ROC AUC in all experiments.
-
2.
Multiclass
Classification of the stimulus chosen by user. As long as we have several stimuli (usually 5 to 7) it’s a multiclass problem. Here we consider several epochs at a time (usually equal number from each stimulus) and have prior knowledge that only one stimulus could be the target thus others are empty. In this case classification is more balanced because the participant chooses different stimuli each time (in fact it depends on visualization setup). Usually this problem is solved by summation of probabilities of binary problem by stimulus and choosing the one with highest sum. Regarding metrics this task is well described by accuracy.

Let’s introduce some terminology helpful in further narration (for illustration see 3:
-
•
Round - sequence of epochs with one target where each stimulus was activated once (and produced one epoch), so this is quantum of multiclass prediction. Usually stimuli are activated in random order.
-
•
Act - sequence of rounds with one target after which decision on target stimulus is made. Usually the number of sessions is from 5 to 10 in our experiments.
-
•
(Game) Record - sequence of acts obtained from one person during one recording session (one game).
-
•
Dataset - collection of records sharing the same visual activation and hardware setup.
4 Preprocessing and Classification
As a main metrics we use multiclass accuracy because in a final gaming environment this is how user measures performance. Binary task metrics are measured in all experiments as well and in many cases higher binary metrics means higher multiclass accuracy.
We divide EEG signal handling to two principal steps:
-
1.
Preprocessing - which includes signal processing stuff and some non-statistical permutations e.g. clipping, epochs slicing, etc. At the end of this step we obtain epochs with labels (either binary or multiclass).
-
2.
Classification - applying statistical classifiers to predict labels having epoch data
For preprocessing step we search for optimal hyperparameter values by cross-validation. The reason for this seemingly trivial step is lack of motivation in choosing such parameters. Although many researches report similar filtering (e.g. [Con+11], [BC14], [Gug+09], [RG08], [Kay+18]) they don’t describe motivation for choosing one or another downsampling factor, filtering band, clipping as well as epoch duration. Below we report results of classification pipeline with varying parameters and choose ones that minimize final epoch representation without metrics degradation.
For this step we use predefined set
Binary epochs classification is a common task for BCI and main approaches are well described in [Lot+18]. In recent years Deep Learning emerged in all fields, so EEG analysis is not an exception and we have beautiful overviews of [CHC19] and [Roy+19].
Our preprocessing is quite standard:
-
1.
Decimation with an anti-aliasing filter from SciPy package [Vir+20]
-
2.
Bandpass filtering with Butterworth IIR
-
3.
Clipping off scale samples
-
4.
Channelwise standard scaling (subtracting mean and dividing by std for all values of each channel)

Each test were conducted with other parameters fixed at some sane level (such that qualitative result persisted)
4.1 Decimation
First we need to determine which minimal signal frequency we will operate on in all later stages. On 5 we see that classification degrades for decimation more than 35 times resulting in a rate of about 15Hz. So this is the upper value of frequency on which P300 occurs. Different lines correspond to different final classifiers and transparent zones of corresponding colour refer standard deviation by persons.

4.2 Filtering
Since we optimized decimation and chose minimal available frequency then we only need to filter low frequencies with Butterworth filter. On 6 we see that filtering very low frequencies (below 0.2Hz) is crucial for classification and band from 0.2 to 1 doesn’t affect final classification quality.

4.3 Epoch duration
The same operation was held over epoch durations. First we tested right bounds and found quality degradation on 600ms (see 8).

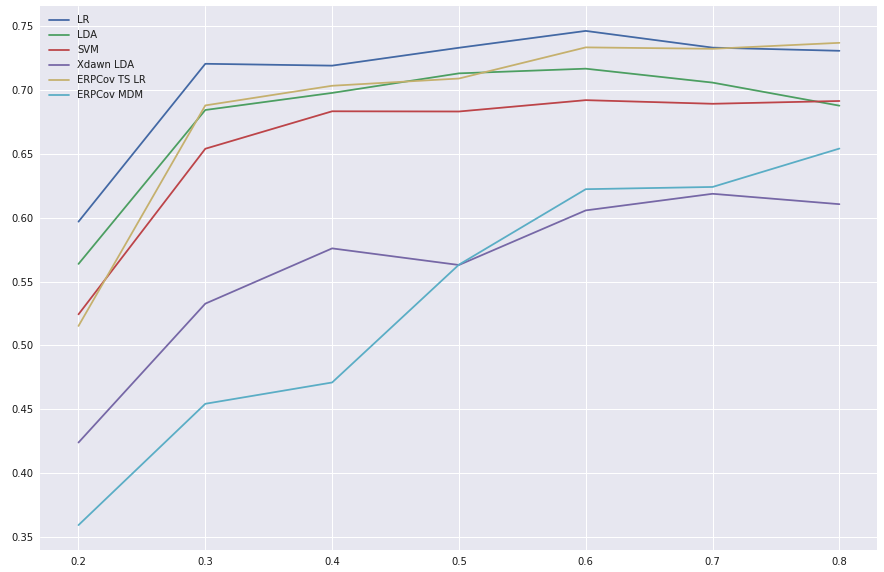
5 Multiclass confidence level
Having robust binary target-empty epoch classifier (trained for each person separately) we may proceed to aggregating these predictions to a final multiclass problem solution.
As a standard approach we consider taking epochs grouped by activated stimulus, predicting their probabilities to be target and sum these probabilities. This way we obtain "activation score" for each stimulus. Then multiclass prediction consists in choosing the stimulus with the highest activation score. We call it baseline multiclass classification.
In gaming environment (which is our case) misclassification cost is high because person feels frustrated and snatched. So we have decided to introduce some confidence score by which we could reject potentially wrong predictions. In case of rejection "misfire" animation is played and we ask the user to repeat the choice procedure.
Some attempts to fix classification errors were taken. For example in [Mar+12] competition EEG signal itself used to predict if SVM classifier were right or not.
5.1 Heuristics
This score could be based on prior knowledge that one act has only one target. Having activation scores of each stimulus we expect a good binary classifier to give low scores to all but one stimulus. And distribution of sorted activation scores confirms this statement.

When there isn’t one obvious leader it’s a motive to suspect lower probability to give the right answer. So our task is to find some criterion (which we call confidence score) that separate wrongly classified acts. During experiments we have considered different confidence scores based on activation scores:
-
•
sum of activations
-
•
max activation
-
•
mean activation
-
•
median activation
-
•
min activation
-
•
max - mean
-
•
max - median
-
•
second max
-
•
max - second max
-
•
max - mean of all but max
-
•
max - median of all but max
-
•
max - sum of activations
To estimate the threshold value we plot criterion distribution for correctly classified acts and for misclassified ones.

On average confidence scores are lower for misclassified acts, so we are able to pick those acts among which the rate of correctly classified (precision) is high. But considering the game setup we couldn’t afford to trigger "misfire" action too frequently because it would be too disturbing for a user. We have stated the rejection rate couldn’t be more than 30%, precisely 10% to 20% would be optimal because the user encounters misfire at some point but doesn’t get overwhelmed by this mechanics.
Finally we can see that ’max-mean’ and ’max-median’ performs best at 5 - 50% of rejected acts which is the region of interest for us (see 11). For the best heuristic ’max-median’ we could increase accuracy by 5% sacrificing only 12% of all acts on average. However this misfiers is concentrated in a few participants which is evidenced by a median accuracy of 90% in this case.
5.2 Stacking
In fact we perform some kind of stacking, so we may apply a model to predict if this act could be misclassified.
Curve of negative rate vs precision in 5-fold cross-validation is shown on plot for Logistic Regression, Random Forest and our Heuristics Threshold classifiers.

This plot shows that in range 10 to 25 % our heuristics work the same as trained classifiers and provides 4 to 9 % increase in precision of predictions (see 11).
6 Discussion
Introduction of multiclass labels allows us to incorporate prior knowledge of choosing only one stimulus per session. This could efficiently be used in Neural Networks architecture development as well as in Bayesian methods based approaches.
References
- [KO03] Bob Kemp and Jesus Olivan “European data format ’plus’ (EDF+), an EDF alike standard format for the exchange of physiological data” In Clinical neurophysiology : official journal of the International Federation of Clinical Neurophysiology 114, 2003, pp. 1755–61 DOI: 10.1016/S1388-2457(03)00123-8
- [Bla+04] Benjamin Blankertz et al. “The BCI competition 2003: Progress and perspectives in detection and discrimination of EEG single trials” In IEEE TRANS. BIOMED. ENG, 2004
- [Hof+08] Ulrich Hoffmann, Jean-Marc Vesin, Touradj Ebrahimi and Karin Diserens “An efficient P300-based brain-computer interface for disabled subjects” Datasets and MATLAB-Code are available at http://bci.epfl.ch In Journal of Neuroscience Methods 167.1, 2008, pp. 115–125 DOI: 10.1016/j.jneumeth.2007.03.005
- [RG08] Alain Rakotomamonjy and Vincent Guigue “BCI competition III: dataset II- ensemble of SVMs for BCI P300 speller” In Biomedical Engineering, IEEE Transactions on 55, 2008, pp. 1147–1154 DOI: 10.1109/TBME.2008.915728
- [Gug+09] Christoph Guger et al. “How many people are able to control a P300-based brain-computer interface (BCI)?” In Neuroscience Letters 462, 2009, pp. 94–8 DOI: 10.1016/j.neulet.2009.06.045
- [Con+11] Marco Congedo et al. “”Brain Invaders”: a prototype of an open-source P300- based video game working with the OpenViBE platform” In 5th International Brain-Computer Interface Conference 2011 (BCI 2011), 2011, pp. 280–283 URL: https://hal.archives-ouvertes.fr/hal-00641412
- [Mar+12] Perrin Margaux et al. “Objective and Subjective Evaluation of Online Error Correction during P300-Based Spelling” In Adv. in Hum.-Comp. Int. 2012 London, GBR: Hindawi Limited, 2012 DOI: 10.1155/2012/578295
- [CBA13] Marco Congedo, Alexandre Barachant and Anton Andreev “A New Generation of Brain-Computer Interface Based on Riemannian Geometry” In CoRR abs/1310.8115, 2013 arXiv: http://arxiv.org/abs/1310.8115
- [Gra+13] Alexandre Gramfort et al. “MEG and EEG data analysis with MNE-Python” In Frontiers in Neuroscience 7, 2013, pp. 267 DOI: 10.3389/fnins.2013.00267
- [Kap+13] A.. Kaplan et al. “Adapting the P300-Based Brain–Computer Interface for Gaming: A Review” In IEEE Transactions on Computational Intelligence and AI in Games 5.2, 2013, pp. 141–149
- [Ric+13] Angela Riccio et al. “Attention and P300-based BCI performance in people with amyotrophic lateral sclerosis” In Frontiers in Human Neuroscience 7, 2013, pp. 732 DOI: 10.3389/fnhum.2013.00732
- [BC14] Alexandre Barachant and Marco Congedo “A Plug&Play P300 BCI Using Information Geometry” In CoRR abs/1409.0107, 2014 arXiv: http://arxiv.org/abs/1409.0107
- [And+16] Anton Andreev, Alexandre Barachant, Fabien Lotte and Marco Congedo “Recreational Applications of OpenViBE: Brain Invaders and Use-the-Force” In Brain-Computer Interfaces 2: Technology and Applications chap. 14 John Wiley, 2016, pp. 241–257 URL: https://hal.archives-ouvertes.fr/hal-01366873
- [JB18] Vinay Jayaram and Alexandre Barachant “MOABB: trustworthy algorithm benchmarking for BCIs” In Journal of Neural Engineering 15.6 IOP Publishing, 2018, pp. 066011 DOI: 10.1088/1741-2552/aadea0
- [Kay+18] Murat Kaya et al. “A large electroencephalographic motor imagery dataset for electroencephalographic brain computer interfaces” In Scientific Data 5, 2018, pp. 180211 DOI: 10.1038/sdata.2018.211
- [Lot+18] F Lotte et al. “A review of classification algorithms for EEG-based brain–computer interfaces: a 10 year update” In Journal of Neural Engineering 15.3 IOP Publishing, 2018, pp. 031005 DOI: 10.1088/1741-2552/aab2f2
- [CHC19] Alexander Craik, Yongtian He and Jose L Contreras-Vidal “Deep learning for electroencephalogram (EEG) classification tasks: a review” In Journal of Neural Engineering 16.3 IOP Publishing, 2019, pp. 031001 DOI: 10.1088/1741-2552/ab0ab5
- [Roy+19] Yannick Roy et al. “Deep learning-based electroencephalography analysis: a systematic review” In Journal of Neural Engineering 16.5 IOP Publishing, 2019, pp. 051001 DOI: 10.1088/1741-2552/ab260c
- [Vir+20] Pauli Virtanen et al. “SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python” In Nature Methods 17, 2020, pp. 261–272 DOI: https://doi.org/10.1038/s41592-019-0686-2