Quantum algorithm for time-dependent Hamiltonian simulation
by permutation expansion
Abstract
We present a quantum algorithm for the dynamical simulation of time-dependent Hamiltonians. Our method involves expanding the interaction-picture Hamiltonian as a sum of generalized permutations, which leads to an integral-free Dyson series of the time-evolution operator. Under this representation, we perform a quantum simulation for the time-evolution operator by means of the linear combination of unitaries technique. We optimize the time steps of the evolution based on the Hamiltonian’s dynamical characteristics, leading to a gate count that scales with an -norm-like scaling with respect only to the norm of the interaction Hamiltonian, rather than that of the total Hamiltonian. We demonstrate that the cost of the algorithm is independent of the Hamiltonian’s frequencies, implying its advantage for systems with highly oscillating components, and for time-decaying systems the cost does not scale with the total evolution time asymptotically. In addition, our algorithm retains the near optimal scaling with simulation error .
I Introduction
The problem of simulating quantum systems, whether it is to study their dynamics, or to infer their salient equilibrium properties, was the original motivation for quantum computers Feynman (1982) and remains one of their major potential applications Reiher et al. (2017); Babbush et al. (2018). Classical algorithms for this problem are known to be grossly inefficient. Nonetheless, a significant fraction of the world’s computing power today is spent on solving instances of this problem — a reflection on their importance Gioiosa (2017); Sterling et al. (2018); Lee (2014).
An important class of quantum simulations that is known to be particularly challenging, and is the focus of this work, is that of time-dependent quantum processes, which are at the heart of many important quantum phenomena. These include for example quantum control schemes Pang and Jordan (2017), transition states of chemical reactions Butler (1998) analog quantum computers such as quantum annealers Farhi et al. (2001) and the quantum approximate optimization algorithm Farhi et al. (2014). Devising state-of-the-art resource efficient quantum algorithms to simulate these types of processes on quantum circuits is therefore a very worthy cause: it will allow for the studying of said phenomena in a controllable and vastly more illuminating manner.
In the literature, a number of quantum algorithms designed to simulate the dynamics of time-dependent quantum many-body Hamiltonians already exist. However, most of them are variants of algorithms that suit time-independent Hamiltonians but lack optimizations for dynamical ones. For example, Hamiltonians based on the Lie-Trotter-Suzuki decomposition were developed in Refs. Wiebe et al. (2011); Poulin et al. (2011), where the complexity scales polynomially with error. More recent advances Berry et al. (2014, 2015) improve it to a logarithmic error scaling, which directly lead to applications in time-dependent Hamiltonian simulations Low and Wiebe (2019); Kieferová et al. (2019). A recent study by Berry et al. Berry et al. (2020) improves the Hamiltonian scaling to norm, by considering the dynamical properties of the time-dependent Hamiltonian. However, these mostly comprise of slicing the dynamics into a sequence of ‘quasi-static’ steps, each of which implementing a static quantum simulation module. In addition, all the above-mentioned algorithms assume a time-dependent oracle — a straightforward but not necessarily practical assumption that can obscure the true complexity of the simulation when physical models are considered.
The sub-optimality that characterizes existing quantum algorithms can be attributed mainly to the fact that the time-evolution operator for time-dependent Hamiltonians is a more intricate entity than its time-independent counterpart (this matter is discussed in more detail below): While in the time-independent case the Schrödinger equation can be formally integrated, the time-evolution unitary operator for time-dependent systems is given in terms a Dyson series Dyson (1949) — a perturbative expansion, wherein each summand is a multi-dimensional integral over a time-ordered product of the (usually interaction-picture) Hamiltonian at different points in time. These time-ordered integrals pose multiple algorithmic and implementation challenges.
In this paper, we provide a quantum algorithm for simulating a time-dependent Hamiltonian dynamics. This algorithm invokes a separation of the Hamiltonian into a sum of a static diagonal part and a dynamical part , i.e., , and switches to the interaction-picture with respect to . The target evolution operator becomes a product of an interaction-picture unitary followed by a diagonal unitary that can be simulated efficiently. The interaction Hamiltonian is expanded as a sum of generalized permutations, and the resulting Dyson series of the evolution operator becomes an integral-free representation Kalev and Hen (2020) with the notion of divided differences, which is a well-studied quantity de Boor (2005); Davis (1975); Mccurdy (1980); Gupta et al. (2020a); McCurdy et al. (1984); Zivcovich (2019). The divided differences have an intuition of discretized derivatives and is closely related to polynomial interpolations de Boor (2005). We refer the reader to Appendix A for a short summary of the notion of the divided differences. Under this representation, we use the LCU method Berry et al. (2015) to simulate with a truncated Dyson series. We find a partitioning scheme that determines the duration of the time steps along the simulation. Following this procedure, in general, each time interval has a different duration which is determined form the Hamiltonian’s dynamical characteristics and can lead to substantially fewer number of steps as compared to using identical-length simulation segments, typically used in quantum simulation algorithms. We analyze the implementation gate and qubit costs and discuss the circumstances under which our simulation algorithm provides improvements over the state-of-the-art. Specifically, our algorithm is independent of the oscillation frequencies of the Hamiltonian. This is in stark contrast to existing algorithms which have dependence on , which grows with oscillation rates. Another class of Hamiltonians for which our algorithm is preferred over others is those with exponential decays. We show that for these systems, our algorithms requires asymptotically a finite number of steps which does not scale with the evolution time, leading in turn to an exponential saving comparing to the linear scaling in existing approaches. Moreover, the cost with Hamiltonian norm only mainly depends on the interaction Hamiltonian and not the total Hamiltonian Berry et al. (2020). This also indicates an advantage of the algorithm when the time-dependent Hamiltonian is dominant by a static part.
The paper is organized as follows. In Sec. II, we review the permutation expansion method that leads to an integral-free representation for the Dyson series, as introduced in Ref. Kalev and Hen (2020). In Sec. III, we present in detail the simulation algorithm that combines the integral-free expression of the evolution operator with the LCU method, and analyze the circuit costs. We highlight the main advantages of our algorithm in Sec. III.4.3. In Sec. III.5, we address the cases when the exponential-sum expansion of the time-dependence is not exact and estimate the error that stems from a finite sum approximation. Finally, we give a brief summary for our methods and results in Sec. V.
II Permutation expansion method for time-dependent Hamiltonians
In this section, we briefly describe the integral-free Dyson series expression of the evolution operator, derived from a permutation expansion of the time-dependent Hamiltonian Kalev and Hen (2020). Without loss of generality Gupta et al. (2020b), we expand a general time-dependent Hamiltonian in terms of products of time-dependent diagonal matrices, , and permutation operators, , i.e.,
| (1) |
where . This decomposition can be done efficiently as long as scales polynomially with , where is the dimension of the Hamiltonian. We decompose each diagonal matrix into a finite sum of exponential functions, i.e.,
| (2) |
where and are complex diagonal matrices with diagonal elements being
| (3) | |||
| (4) |
in some basis (the basis in which is diagonal) and indicates the number of terms in the exponential decomposition for . This can be done for many cases when the time dependencies are simple combinations of exponential terms. For simplicity we assume here that the ’s are finite, and address the most general time dependence in detail in Sec. III.5 and refer to various algorithms Beylkin and Monzón (2005, 2010); Braess and Hackbusch (2009); Wiscombe and Evans (1977); Norvidas (2010) for efficiently finding an exponential sum approximation of a function.
For a lighter notation, we set for all . We can evaluate the time-evolution operator corresponding to as
| (5) | ||||
| (6) |
where and are multi-indices. The action of on a basis vector is
| (7) | ||||
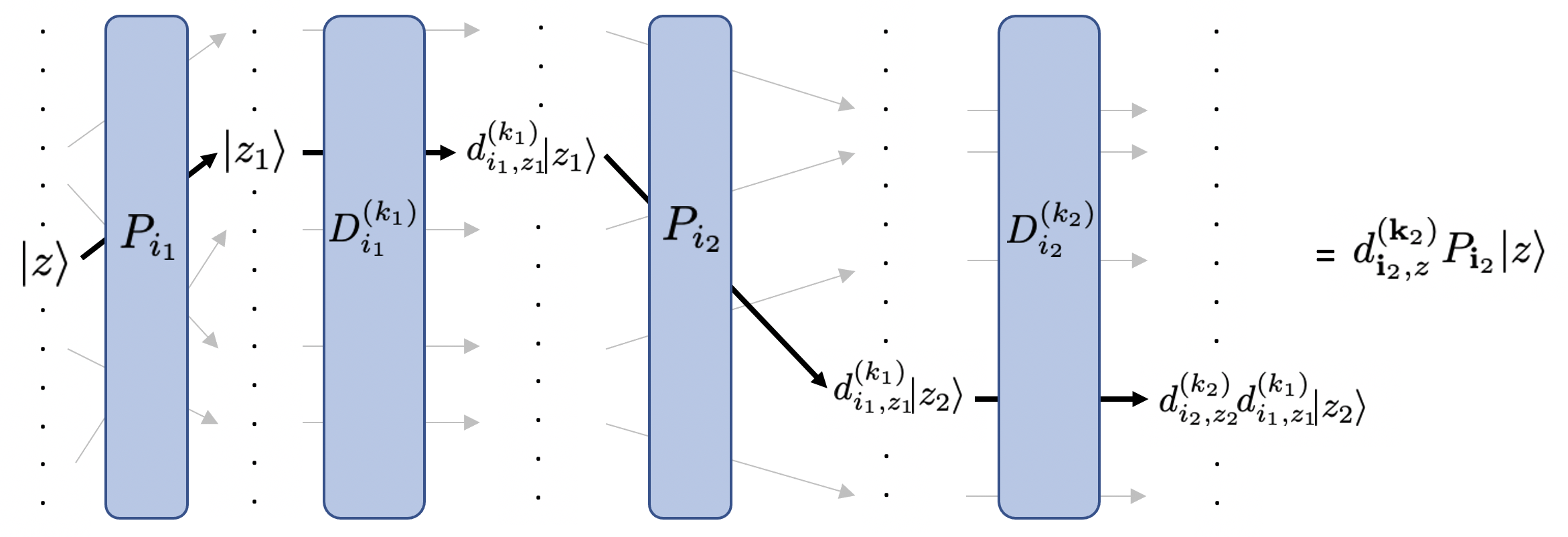
where with ranging from 1 to , and is the th diagonal element of . is a shorthand of , and similarly . Figure 1 illustrates the accumulative actions of on a basis vector .
To proceed, we use the following identity to simplify the expression in terms of divided differences. It is a variant of Hermite-Genocchi formula de Boor (2005) applying to the exponential function.
Identity 1.
For ,
| (8) |
where and is the divided difference of the exponential function with inputs . (The case with can be shown by explicit integration, and the identity follows by induction. For more details, see Ref. Kalev and Hen (2020).)
With this property, the multi-dimensional integration in the time-evolution operator can be simplified as
| (9) |
where . The second equality uses the change of variable , and the last equality follows from Identity 1 and the identity of . By completing the basis, we get
| (10) |
This is an integral-free expression for the unitary time-evolution operator of the time-dependent Hamiltonian . We will later approximate the unitary by truncating the series at some order that scales as Berry et al. (2015), where is the required accuracy.
III Time-dependent Hamiltonian simulation algorithm
A time-dependent Hamiltonian can be expressed as a sum of two Hamiltonians—a time-independent and a dynamical , i.e.,
| (11) |
In many practical models, represents a static and simple Hamiltonian that is often diagonal in a known basis (which we will identify with the computational basis). Hence, hereafter, we assume that is a diagonal operator with real diagonal elements. The component represents the nontrivial interactions between subsystems. Assume111For the most general cases, one can set . is diagonal in the computational basis . We switch to the interaction picture, i.e.,
| (12) |
where
| (13) |
The Schrödinger-picture unitary operator , satisfying , is equivalent to a time-ordered matrix exponential followed by a diagonal unitary, i.e.,
| (14) |
Hence, the simulation of consists of two parts—a complicated and a simple diagonal unitary The simulation of can be achieved with a gate cost that scales only linearly with the locality of . When we write , where each is some tensor product of (single-qubit) Pauli- operators acting on at most qubits, it can be shown that the gate cost scales as Nielsen and Chuang (2011); Kalev and Hen (2021). Therefore, the main focus of our simulation is on .
We next provide an overview of the simulation algorithm in Sec. III.1. In Sec. III.2, we incorporate the LCU framework with the permutation expansion method. Sec. III.3.2 provides the state preparation operation and Sec. III.4 evaluates the simulation cost for the whole procedure.
III.1 An overview of the algorithm
Our proposed simulation algorithm consists of a permutation expansion procedure for and the LCU method for the quantum simulation. In Sec. III.2, we explain in detail the essential ingredients for merging these two approaches. Before delving into technical details, we provide an overview of the algorithm in this section.
Given a time-dependent Hamiltonian , we first decompose into a sum of a static diagonal term (if exists) and a dynamical term . We switch to an interaction picture so that the target unitary evolution over a period becomes
| (15) |
Therefore, the simulation of is equivalent to applying followed by . Since the diagonal unitary can be efficiently simulated, we focus on hereafter.
Let us expand as a sum of permutations as
| (16) |
where are permutations () and are some diagonal matrices that are expressed as exponential sums, i.e.,
| (17) |
and are some complex diagonal matrices. Partition into segments , whose respective durations , are determined by the partitioning scheme given in Sec. III.2 and the time markers , are defined as . The total number of steps is denoted as . The evolution operator from to is expressed as
| (18) |
where we denote
| (19) |
where the max norm, the maximum real part of and . Here, are some diagonal unitaries as derived later in Eq. (38) and each is a unique product of permutations. Note that the above evolution operators are given as a linear combination of unitaries (LCU). We provide a review for the LCU method in Appendix C. We set the truncation order to be222An exact truncation order that guarantees the accuracy is , where is the Lambert W-function.
| (20) |
where is the overall simulation accuracy.
To implement the LCU routine for each , we require preparing a state
| (21) |
where represents quantum registers that each has dimension and represents quantum registers that each has dimension , and is the normalization factor. Following the same notation in Sec. C, let us denote the state preparation unitary as , i.e., (B is explicitly given in Sec. III.3.2). Let us denote the control unitary such that
| (22) |
The Oblivious Amplitude Amplification (OAA) involves interleaving the operator as
| (23) |
where . For each piece of the unitary, we implement on the extended system . By construction, we have
| (24) |
This means that applying effectively performs the unitary on the main system , with error . Combining pieces of the procedure, it effectively simulates with overall error , i.e.,
| (25) |
where are the OAA operators for the corresponding piece of evolution. This implies that applying the sequence of s followed by the circuit for can approach the action of to an arbitrary accuracy.
III.2 Permutation expansion for
In this section, we give a thorough introduction of the permutation expansion in the Dyson series and the conditions arisen from implementing the LCU method. We focus on addressing the interaction-picture unitary , i.e., the time-ordered operator in Eq. (14). Using the expansions introduced in Eqs. (16) and (17), we get
| (26) |
We denote the basis in which is diagonal by and its diagonal elements by . The action of on a basis vector becomes
| (27) | |||
where is the th diagonal element of , i.e., , and with . By Identity 1, this can be further simplified as
| (28) |
where
| (29) |
III.3 The LCU routine
To implement the LCU method for a quantum simulation of , we first decompose the overall simulation duration into pieces in sequence, i.e.,
| (30) |
where the operators in the product of the last equation are understood to be ordered, and and . The number of steps, , and the step size, , are to be determined. When acting on a computational basis state, each piece in the decomposition can be written as
| (31) |
which has the same form as Eq. (28) except that the integration intervals are shifted (with ). We can denote
which leads to
| (32) |
To formulate the above expression in terms of a linear combination of unitaries, we need to evaluate the norms of and . The norm of is bounded by
| (33) |
The norm of the can be bounded by using the following identity.
Identity 2.
For any complex values ,
| (34) |
where denotes the real part of an input and .
The proof can be found in Appendix A. From Identity 2, we show in Appendix B that
| (35) |
where we denoted the quantity
| (36) |
With these bounds, the factors in the expansion form in Eq. (32) can be written as
| (37) | ||||
where
and
The evolution operator from to becomes
| (38) |
where are diagonal unitaries with diagonal elements being .
To implement the LCU method for simulating , we require a preparation of the state
| (39) |
where represents quantum registers that each has dimension and represents quantum registers that each has dimension . The normalization constant is
| (40) |
where we define the as
| (41) |
and we note that is an upper bound on the max-norm of the interaction Hamiltonian at time , . The quantity is related to the energy strength in a typical LCU setup Berry et al. (2015). In Appendix D, we provide an alternative way that uses a larger bound , which leads to an exponential saving for the state preparation. We proceed with hereafter.
The OAA step in the LCU method requires . This leads to
| (42) |
and Eq. (40) becomes a truncated Taylor expansion of 2 up to order , i.e., . If we require , where is the total number of steps and is some positive number, then the simulation error for each is also within . The required truncation order with this accuracy scales as
| (43) |
III.3.1 Time partitioning and number of time steps
The condition in Eq. (42) imposes a constraint on the next step size given the current time ,
| (44) |
Remembering that is a function of , this condition determines the schedule, as every is determined by the preceding time steps.
Special care should be given when setting the last time step, as can become too large that exceeds the total desired evolution time . Whenever is found to be greater than (or if the argument inside the is found to be negative), one should replace the bound with a larger bound and set the final step .
Let us now examine the dependence of on in order to determine a bound on the number of time steps (equivalently, number of repetitions) required for the execution of the entire time evolution. We distinguish between three cases. (i) When , we have , similar to the time-independent case though we note that a vanishing maximal could imply time-dependent oscillations as well. This can be seen by taking the limit of Eq. (44). (ii) In the case where , i.e., a system with a decaying , we have , i.e., the time steps are longer than . Furthermore, the total number of steps is finite even for an arbitrarily large evolution time . Note that since approaches zero asymptotically, for a large enough time , we have , i.e., the argument inside the logarithm above becomes negative. This indicates it reaches the final step, i.e., the bound should be modified as and becomes the final step. (iii) In the case where (an amplified ), we have at large simulation times, . From Eq. (44), we have in this limit.
We see that (for large enough simulation times) the time step is inversely proportional to which upper-bounds the max-norm of the interaction Hamiltonian at time . Therefore, we have , which implies .
It would be instructive to compare the above scaling with that of Ref. Berry et al. (2020) in which the simulation algorithm is said to have an -norm scaling, i.e., an algorithm cost scaling linearly with up to logarithmic factors. Under a similar intuition, our algorithm has a discretized -norm-like scaling with . However in our case, is related to the norm of the interaction Hamiltonian.
III.3.2 State preparation
In this subsection, we provide a procedure to prepare the state given in Eq. (39). First, we initialize a state , where each of the first registers has dimension (responsible for part), each of the later registers has dimension (responsible for part), and the last register is a qubit (for the cosine decomposition). For simplicity, we can perform a Hadamard gate on the last qubit and then omit its dependence for the following discussion. The next step is to create a state in following the form,
| (45) |
where . For each from the first registers (the part) and the corresponding in the later registers (the part), we make
| (46) |
Then Eq. (45) becomes
| (47) |
which is the required in Eq. (39), when combined with .
Next, we provide a process that produces the state in Eq. (45). First, we perform a rotation that takes the first register in the part to
| (48) |
and perform a control gate from the first register to the second (both in the part) such that
| (49) |
Continuing this procedure for the rest of the registers in the part, the state becomes
| (50) |
At this step, we perform CNOT operations333Strictly speaking, they are not standard CNOTs but higher-dimensional operations that act like a CNOT on the first two levels. from the first registers ( part) to the last registers ( part) correspondingly, e.g., perform a CNOT from the first register in the part to the first register in the part, and so on and so forth. Finally, we have
| (51) |
which gives Eq. (45) as required. The estimated gate cost for the preparation of is . More detail regarding the cost is provided in Sec. III.4.1.
III.3.3 Implementation of the controlled unitaries
The second ingredient of the LCU routine is the construction of the controlled operation
| (52) |
Taking an approach similar to that taken in Ref. Kalev and Hen (2021), we first note that Eq. (52) indicates that can be carried out in two steps: a controlled-phase operation () followed by a controlled-permutation operation ().
The controlled-phase operation requires a somewhat intricate calculation of non-trivial phases. We therefore carry out the required algebra with the help of additional ancillary registers and then ‘push’ the results into phases. The latter step is done by employing the unitary
| (53) |
whose implementation cost depends only on the precision with which we specify and is independent of Hamiltonian parameters Nielsen and Chuang (2011) (see Ref. Kalev and Hen (2021) for a complete derivation). With the help of the (controlled) unitary transformation
| (54) |
we can write , so that
| (55) |
Note that sends computational basis states to computational basis states. We provide an explicit construction of in Ref. Kalev and Hen (2021). We find that its gate cost is and qubit cost is Addiitonal details are provided in Sec. III.4.1.
The construction of is carried out by a repeated execution of the simpler unitary transformation . Recall that are the off-diagonal permutation operators that appear in the Hamiltonian. The gate cost of is therefore . Additional details may be found in Ref. Kalev and Hen (2021).
III.4 Algorithm cost
We next analyze the circuit costs for the permutation expansion algorithm. Recall that the simulation of consists of two operations— and . The diagonal unitary can be implemented efficiently with a gate cost that scales linearly with the system size. To observe this, note that is a diagonal matrix with real diagonal elements and can be written as , where each is a tensor product of Pauli-’s () acting on at most qubits (weight- operators). Hence, we can write . Each can be simulated using at most CNOT gates with a single ancillary qubit. For example, let be a weight- () operator, then can be implemented as
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/efbba610-91b4-4b14-9952-dcfb8dedcab0/expZgate.png)
where are the qubits acts on and is an ancillary qubit for extracting the phase. There are total such implementations for . Therefore, the total gate cost is and the qubit cost is . Since usually grows linearly with the system size, the gate cost also scales linearly.
III.4.1 The cost for the state preparation and the controlled unitaries
The cost of implementing resembles those in Ref. Kalev and Hen (2021). The first ingredient is the preparation of state . Recall from Sec. III.3.2, the operation that takes to has gate cost . The operation for costs Shende et al. (2006). The total gate cost for the preparation of (i.e., ) is (Lemma 8 in Childs et al. (2017)). In Appendix D, we provide an alternative procedure that leads to a scaling for implementing . The qubit cost in the state preparation is
The next component is the implementation of the control unitary . As shown in Kalev and Hen (2021), the gate cost of performing the control permutation is , where is the “locality,” i.e., each permutation is a tensor product of at most Pauli- operators. The implementation of the control phase involves the calculation of (the product of diagonal elements in the permutation expansion) and the divided differences (with ’s being the inputs). The cost of the former is , where is the cost of obtaining an element of . The cost of later is , where is the cost of obtaining energy differences of (elements of ) [therefore, is the cost for obtaining the inputs ’s as defined in Eq. (29)]. The additional cost for the reversibility of the process scales as . A detailed discussion of the costs of and may be found in Ref. Kalev and Hen (2021). Combining these, we estimate the total cost for is
| (56) |
III.4.2 Overall cost of the algorithm
The full simulation for is a product of segments , where each segment is simulated by interleaving and . The total number of segments, , is determined by , where each is determined by partitioning scheme described in Sec. III.3.1.
As discussed above, the number of LCU applications can be upper-bounded by (in the long simulation time limit), which can be viewed as a discretized -norm-like scaling with the norm of the non-static component of the Hamiltonian .
Combining with the cost for simulating and the cost for each step (56), we conclude that at worst, the total gate cost scales as
| (57) |
and the qubit cost scales as
| (58) |
where scales as . For convenience, we provide a glossary of symbols in Table 1. A summary of the gate and qubit costs of the simulation circuit and the various sub-routines used to construct it is given in Table 2.
| Symbol | Meaning |
|---|---|
| the number of permutation expansion terms of the non-static Hamitonain, c.f., Eq. (16) | |
| the length of exponential sum expansion, c.f., Eq. (17) | |
| the number partitions, c.f., Sec. III.3.1 | |
| the series expansion truncation order, | |
| the upper bound on the locality of | |
| the cost of obtaining an element of | |
| the cost of obtaining energy differences of | |
| the cost of obtaining an element of | |
| the number of terms in the static Hamiltonian, i.e., | |
| the locality of |
| Unitary | Gate cost | Qubit cost |
|---|---|---|
III.4.3 Example advantages of the algorithm
To illustrate how our simulation algorithm can provide speedups over existing algorithms, we focus in this subsection on two types of Hamiltonian systems: highly oscillating systems and decaying systems.
The cost of our algorithm is independent of the oscillation rates of the dynamics, whereas the cost of any simulation algorithm (e.g., Berry et al. (2020); Kieferová et al. (2019); Low and Wiebe (2019); Poulin et al. (2011)) that depends on would depend on oscillation rates of the system. To illustrate this advantage, consider a two-level system with a Hamiltonian
| (59) |
where , and . In this case, we have and . The gate cost of simulating scales as
| (60) |
which is independent of . This means the simulation cost remains the same even if becomes arbitrarily large. One can realize the absence of owing to the fact that phases are explicitly integrated out into an integral-free expansion series, where the bound of each term does not depend on the oscillations (due to Identity 2). Therefore, our simulation can be significantly more effective when the time dependence of the Hamiltonian has very high frequencies. Note that while the example above was given for a simple qubit system with pure oscillation, the frequency-independence in cost holds for any system.
Another class of systems for which our algorithm can provide seedup are Hamiltonians with exponential decays, i.e., . For concreteness, consider the Hamiltonian
| (61) |
where and and and . In this case, and .
The -norm defined in Ref. Berry et al. (2020) is , which has a linear scaling with the simulation duration , whereas our discretized -norm tends to a constant in the long time limit. This can be seen from the fact that the partition terminates at a large enough time (), where becomes the final simulation step, as described in Sec. III.3.1. The above results also hold for any combination of exponential decays (even when these are multiplied by oscillatory terms) with which different time decay dependencies may be constructed.
III.5 Hamiltonians with arbitrary time dependence
The simulation algorithm invokes a switch to the interaction picture, by dividing the Hamiltonian into a static diagonal part and a time-dependent Hermitian operator . The is expanded using permutations and exponential sums as presented in Eq. (17). There, we assume that the time dependence can be expressed as exponential sums with a finite number of terms, . Although this assumption holds for many models (e.g., when the time dependencies are some combinations of trigonometric functions and exponential decays), the exponential series generally requires an infinite sum (e.g., a Fourier series). A straightforward procedure to obtain a finite sum approximation is via a truncated Fourier series. As an example, let us consider a polynomial function of time, i.e., . Using the proof of Theorem 8.14 in Ref. Rudin (1976), it can be shown that a truncated Fourier series of is close to when the truncation order is . We also note that, other than Fourier series, there have been numerous studies Norvidas (2010); Beylkin and Monzón (2005, 2010); Braess and Hackbusch (2009); Wiscombe and Evans (1977) regarding finding an exponential-sum approximation of a function. Some of them, e.g., Beylkin and Monzón (2005), provide efficient algorithms with logarithmically scaling terms (with respect to the inverse of a required accuracy). These results suggest that efficient methods for finding the exponential-sum decompositions of the time dependences of can exist in many cases.
Suppose that is approximated by a finite series of exponential sum. The resulting error of the unitary evolution, due to the Hamiltonian approximation, scales only at most linearly with the evolution duration. This can be shown using the following property. Given two time-dependent Hamiltonians and such that
| (62) |
then
| (63) |
This holds true for any norm . Before proving this, we first note a property of the so-called Subadditivity of error in implementing unitaries Nielsen and Chuang (2011). It says that for unitaries and , we have
| (64) |
This can be easily shown by
| (65) |
where the basic operator norm inequalities are used. Now we prove the bound in Eq. (63). We divide into segments such that each segment has width . We can rewrite the time evolution operators as
Repeatedly using the subadditivity of error, we have
| (66) |
Since this inequality holds for any , we can take and it yields Eq. (63) as claimed.
Now we apply this property to the simulation of . Suppose that we have an accurate approximation of , i.e., for all , where is the finite exponential-sum approximation of . The accumulative error from this approximation is bounded by and the overall error is , where is the error from LCU implementation. Recall that is closely related to (the number of terms). Although it is intuitive that a larger can allow for a smaller , the explicit relation between the two largely depends on the model and the expansion method. Nonetheless, we can expect to scale at least linearly with for many cases, e.g., aforementioned truncated Fourier series for a polynomial.
The simulation cost also depends on , the number of terms in the permutation expansion. This quantity usually scales linearly with the system size and can be easily determined. For example, a typical spin model usually involves a sum of tensor products of Pauli-’s (or ’s) and Pauli-’s. Each tensor product represents an interaction between qubits on certain lattice sites. Due to the common locality constraint that prevents a qubit interacting with the ones arbitrarily far apart, the number of interacting terms, , scales at most linearly with the number of qubits. In addition, a tensor product of Pauli operators can be easily separated into a product of diagonal matrix and a permutation, e.g., . We conclude that will have modest linear scaling for most practical models.
IV Alternative scheme and reduction to the time-independent case
In this section, we provide an alternative yet equivalent scheme for the dynamical simulation, one that will allow us to establish an immediate connection to the time-independent Hamiltonian simulation formalism (specifically to the scheme presented in Ref. Kalev and Hen (2021)), in which is assumed constant in time.
In previous sections, we have chosen to partition the interaction-picture unitary into short time segments and then follow its execution by the application of a diagonal bringing it back to the Schrödinger picture. Here, we show that the Schrödinger picture can be partitioned similarly.
Recalling the expansion of in Eq. (32), we have
with
Breaking the phase, we get:
| (67) |
We find that
| (68) |
where
| (69) |
Inspecting the full unitary evolution, we observe
| (70) |
The evolution operator can be simplifies as
| (71) |
eliminating the diagonal piece. Each can be rewritten as:
| (72) |
The factor can be absorbed into the divided difference:
| (73) |
with
| (74) |
which simplifies to
| (75) |
By inserting additional phases into the divided differences, we can rewrite
| (76) |
with
| (77) |
Now, we can write as alternating off-diagonal and diagonal unitaries:
| (78) |
When becomes time-independent, and . To synchronize the notation with Kalev and Hen (2021), we identify and . The evolution operator becomes , which coincides with Kalev and Hen (2021).
V Conclusions
We presented a quantum algorithm for simulating the evolution operator generated from a time-dependent Hamiltonian. The algorithm involves a permutation expansion for the interaction Hamiltonian, a switch to the interaction-picture, and the incorporation of the LCU technique. Combining the permutation expansion with the Dyson series has led to an integral-free representation for the interaction-picture unitary with coefficients involving the notion of divided differences with complex inputs.
We found that our expansion allowed us to adjust the time steps based on the dynamical characteristics of the Hamiltonian, providing a resource saving as compared to the equal-size partition with the largest bound. This further resulted in a gate resource that scales with an -norm-like scaling with respect only to the ‘non-static’ norm of the Hamiltonian.
Specifically, we demonstrated that for systems with a decaying non-static component, the resources do not scale with the total evolution time asymptotically. Furthermore, the simulation cost is independent of the frequencies, implying a significant advantage for systems with highly oscillating components.
Acknowledgements.
This work is supported by the U.S. Department of Energy (DOE), Office of Science, Basic Energy Sciences (BES) under Award No. DE-SC0020280.References
- Feynman (1982) R. P. Feynman, International Journal of Theoretical Physics, 21, 467 (1982).
- Reiher et al. (2017) M. Reiher, N. Wiebe, K. M. Svore, D. Wecker, and M. Troyer, Proceedings of the National Academy of Sciences 114, 7555 (2017), http://www.pnas.org/content/114/29/7555.full.pdf .
- Babbush et al. (2018) R. Babbush, N. Wiebe, J. McClean, J. McClain, H. Neven, and G. K.-L. Chan, Phys. Rev. X 8, 011044 (2018).
- Gioiosa (2017) R. Gioiosa, in Rugged Embedded Systems, edited by A. Vega, P. Bose, and A. Buyuktosunoglu (Morgan Kaufmann, Boston, 2017) pp. 123–148.
- Sterling et al. (2018) T. Sterling, M. Anderson, and M. Brodowicz, in High Performance Computing, edited by T. Sterling, M. Anderson, and M. Brodowicz (Morgan Kaufmann, Boston, 2018) pp. 285–311.
- Lee (2014) G. Lee, in Cloud Networking, edited by G. Lee (Morgan Kaufmann, Boston, 2014) pp. 179–189.
- Pang and Jordan (2017) S. Pang and A. N. Jordan, Nature Communications 8, 14695 (2017).
- Butler (1998) L. J. Butler, Annual Review of Physical Chemistry 49, 125 (1998), pMID: 15012427, https://doi.org/10.1146/annurev.physchem.49.1.125 .
- Farhi et al. (2001) E. Farhi, J. Goldstone, S. Gutmann, J. Lapan, A. Lundgren, and D. Preda, Science 292, 472 (2001).
- Farhi et al. (2014) E. Farhi, J. Goldstone, and S. Gutmann, arXiv e-prints , arXiv:1411.4028 (2014), arXiv:1411.4028 [quant-ph] .
- Wiebe et al. (2011) N. Wiebe, D. W. Berry, P. Høyer, and B. C. Sanders, Journal of Physics A: Mathematical and Theoretical 44, 445308 (2011).
- Poulin et al. (2011) D. Poulin, A. Qarry, R. Somma, and F. Verstraete, Phys. Rev. Lett. 106, 170501 (2011).
- Berry et al. (2014) D. W. Berry, A. M. Childs, R. Cleve, R. Kothari, and R. D. Somma, in Proceedings of the Forty-Sixth Annual ACM Symposium on Theory of Computing, STOC ’14 (Association for Computing Machinery, New York, NY, USA, 2014) p. 283–292.
- Berry et al. (2015) D. W. Berry, A. M. Childs, R. Cleve, R. Kothari, and R. D. Somma, Phys. Rev. Lett. 114, 090502 (2015).
- Low and Wiebe (2019) G. H. Low and N. Wiebe, “Hamiltonian simulation in the interaction picture,” (2019), arXiv:1805.00675 [quant-ph] .
- Kieferová et al. (2019) M. Kieferová, A. Scherer, and D. W. Berry, Phys. Rev. A 99, 042314 (2019).
- Berry et al. (2020) D. W. Berry, A. M. Childs, Y. Su, X. Wang, and N. Wiebe, Quantum 4, 254 (2020).
- Dyson (1949) F. J. Dyson, Phys. Rev. 75, 486 (1949).
- Kalev and Hen (2020) A. Kalev and I. Hen, “An integral-free representation of the dyson series using divided differences,” (2020), arXiv:2010.09888 [quant-ph] .
- de Boor (2005) C. de Boor, Surveys in Approximation Theory 1, 46 (2005).
- Davis (1975) P. Davis, Interpolation and Approximation, Dover Books on Mathematics (Dover Publications, 1975).
- Mccurdy (1980) A. C. Mccurdy, Accurate Computation of Divided Differences, Ph.D. thesis, University of California, Berkeley (1980), aAI8029490.
- Gupta et al. (2020a) L. Gupta, L. Barash, and I. Hen, Computer Physics Communications 254, 107385 (2020a).
- McCurdy et al. (1984) A. McCurdy, K. C. Ng, and B. N. Parlett, Mathematics of computation 43, 501 (1984).
- Zivcovich (2019) F. Zivcovich, Dolomites Research Notes on Approximation 12, 28 (2019).
- Gupta et al. (2020b) L. Gupta, T. Albash, and I. Hen, Journal of Statistical Mechanics: Theory and Experiment 2020, 073105 (2020b).
- Beylkin and Monzón (2005) G. Beylkin and L. Monzón, Applied and Computational Harmonic Analysis 19, 17 (2005).
- Beylkin and Monzón (2010) G. Beylkin and L. Monzón, Applied and Computational Harmonic Analysis 28, 131 (2010), special Issue on Continuous Wavelet Transform in Memory of Jean Morlet, Part I.
- Braess and Hackbusch (2009) D. Braess and W. Hackbusch, “On the efficient computation of high-dimensional integrals and the approximation by exponential sums,” (2009) pp. 39–74.
- Wiscombe and Evans (1977) W. Wiscombe and J. Evans, Journal of Computational Physics 24, 416 (1977).
- Norvidas (2010) S. Norvidas, Acta Mathematica Hungarica 128, 26 (2010).
- Nielsen and Chuang (2011) M. A. Nielsen and I. L. Chuang, Quantum Computation and Quantum Information: 10th Anniversary Edition, 10th ed. (Cambridge University Press, USA, 2011).
- Kalev and Hen (2021) A. Kalev and I. Hen, Quantum 5, 426 (2021).
- Shende et al. (2006) V. V. Shende, S. S. Bullock, and I. L. Markov, IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 25, 1000 (2006).
- Childs et al. (2017) A. M. Childs, R. Kothari, and R. D. Somma, SIAM Journal on Computing 46, 1920 (2017), https://doi.org/10.1137/16M1087072 .
- Rudin (1976) W. Rudin, Principles of Mathematical Analysis, 3rd ed. (McGraw-Hill Education, 1976).
Appendix
Appendix A Properties of divided difference
We begin with a formal definition of divided difference for complex-valued functions and follow with some properties that will be of use to us when deriving the new bound. The main results are derived for the exponential functions.
Definition 1.
Let be an open subset of , and is analytic in . For any non-negative integer and , the divided difference of is denoted as . If , . Suppose has distinct elements. Let be a sorted set of , i.e., there exists a permutation such that the first elements of are equal and the following elements of are equal and so on and so forth. There are same-element clusters and . The divided difference of is defined as
where denotes the th derivative of .
Although the above sorting procedure is not unique, it can be shown that any choice of the permutation gives the same result, and hence the definition is well-defined.
The divided difference involves a recursive relation that connects a input case to two cases. For ,
| (79) |
For , and suppose , and are all distinct,
| (80) |
In fact, it can be shown that for distinct ,
| (81) |
Remark.
Since any analytic function admits a Taylor expansion representation and the divided difference is a linear functional, the divided difference of an analytic function has a series expansion form, i.e., for and in ’s analytic domain,
| (82) |
where . Because for all , the non-vanishing term of the series starts from the th order.
For simplicity, we denote the divided difference for the exponential function as , i.e.,
| (83) |
Property 1.
For any non-negative integer and ,
| (84) |
This property and the fact that divided differences are permutation symmetric among inputs imply that any input can be factored out of the divided difference by subtracting it from every entry.
Property 2.
For any non-negative integer and ,
| (85) |
An equivalent definition of divided difference for an analytic function is via its Taylor expansion. It amounts to apply divided difference on every order of the series. Since any polynomial of order less than is annihilated, the series starts from the order . 2 is derived from the Taylor expansion of with respect to the origin.
Lemma 1.
For any non-negative integer and ,
| (86) |
Proof.
This can be observed from the series expansion of the divided difference for the exponential function, i.e., from 2,
| (87) |
Performing term-by-term integration over on both side, we have
| (88) |
where the last equality follows from the series expansion representation of . This completes the proof. ∎
Corrolary 1.
Let , where and . We denote , where . For any ,
| (89) |
This can be verified by evaluating the series expansion form on both side, by a similar manner in the proof of Lemma 1 .
With these properties, we are ready to prove the bound in Identity 2 in the main context.
Theorem 1.
For any non-negative integer and ,
| (90) |
where gives the real part of the input.
Proof.
We proceed by induction. Eq. (90) is trivially satisfied with the equality when . For the case , we have
| (91) |
where Lemma 1 is used. Assume that we have
| (92) |
which it is true for . It follows that
| (93) |
where the second and the third equalities use Lemma 1 and the second inequality uses (92). This proves that the inequality holds for any number of complex inputs. ∎
Appendix B Bounding
For , we use the following theorem,
Theorem 1.
For any complex values ,
| (94) |
where denotes the real part of an input and .
This is proved in Appendix A. From this, we have
| (95) |
From the definition of , we have
| (96) |
Based on the property that increasing any input in will only increase its value (can be proved by taking derivatives in the Hermite-Genocchi form), we have
| (97) |
Using the permutation symmetric property and Property 1, we have
| (98) |
Therefore, we have
| (99) |
Appendix C LCU method review
We give a brief introduction to the LCU method in this section, and we adapt the original paper Berry et al. (2015)’s notations for a more convenient reference to readers. Suppose we have a unitary , which is an infinite sum of unitaries, i.e.,
| (100) |
where and are some unitaries. A truncated series, up to order , yields an operator
| (101) |
which approaches as increases. We perform the following procedure to effectively implement on a state embedded in a larger system. Prepare an -dimensional ancilla and implement a unitary such that
| (102) |
where . Suppose we have access to a control unitary such that for each ,
| (103) |
Consider the following combination of the above operations
| (104) |
We have
| (105) |
where ’s ancillary part is orthogonal to . Let us denote the orthogonal projection onto that subspace and the reflection operator with respect to . It is shown that the sequence of operations , acting on the total system is when is unitary and . This procedure is the so-called Oblivious Amplitude Amplification (OAA). However, is in general not unitary because it is a truncated series of . This nonunitarity can be accounted for when and . More specifically, it is shown that if and , then
| (106) |
This means when is -close to and is -close to 2, the effect of the operator on the whole system is -close to only acting on .
Note that the condition can be satisfied when the truncation order is high enough. However, the condition is satisfied only when are specifically chosen. By construction, we require . If we choose , then
| (107) |
becomes a truncated Taylor expansion of 2, i.e., . In fact, it can be shown that the required truncation order such that scales like . With this , it also guarantees that , because
| (108) |
In summary, performing on an extended system , with and , effectively performs on with accuracy.
Appendix D An alternative approach for the LCU setup
We provide an alternative procedure for the LCU routine that leads to an exponential saving for the state preparation. Let us define
| (109) |
Re-evaluate the coefficients in Eq. (32) using the above, we have
| (110) |
The evolution operator from to becomes
| (111) |
The required state for LCU becomes
| (112) |
where is the normalization factor, i.e.,
| (113) |
To prepare the state (112), we first prepare a state in the following form,
| (114) |
Subsequently, for each in the first registers ( part), we transform it to , and for each in the later registers ( part), we transform it to . The state (114) becomes
| (115) |
which is the required in (112), when combined with . Note that since the transformations and are mappings to the equally distributed state, they can be done with a column of parallel Hadamard gates, which has a gate cost . This provides an exponential saving comparing to given in the main context. This saving can be apparent when becomes large. However, this can create an overhead in the required number of repetitions. Indeed, we have here comparing to in the main context, and the overall simulation cost monotonically increases with this quantity. If only a few is much larger than the others such that , then the method provided in the main context is preferred. Depending on the models, one may favors one over the other.