Quantifying VIO Uncertainty
Abstract
We compute the uncertainty of XIVO, a monocular visual-inertial odometry system based on the Extended Kalman Filter, in the presence of Gaussian noise, drift, and attribution errors in the feature tracks in addition to Gaussian noise and drift in the IMU. Uncertainty is computed using Monte-Carlo simulations of a sufficiently exciting trajectory in the midst of a point cloud that bypass the typical image processing and feature tracking steps. We find that attribution errors have the largest detrimental effect on performance. Even with just small amounts of Gaussian noise and/or drift, however, the probability that XIVO’s performance resembles the mean performance when noise and/or drift is artificially high is greater than 1 in 100.
1 Introduction
Our companion paper [12] observed that the feature tracks commonly used in visual inertial odometry algorithms are affected by drift, noise, and attribution errors. This manuscript follows up on the companion and investigates the effect of drift, noise, and attribution errors on state estimation performance and uncertainty of XIVO, our in-house visual-inertial odometry system previously known as Corvis [3, 2], in simulation.111https://github.com/ucla-vision/xivo Using a simulation rather than a benchmark dataset of real-world data allows us to quantify the individual effects of each rather than a mixture of all three. It also enables Monte-Carlo trials to calculate uncertainty without using the ergodicity assumption in [13]. Since our previous work in [13] has shown that covariance matrices estimated by XIVO are not accurate, all mentions of “uncertainty” or “covariance” refers to sample covariances calculated using Monte-Carlo trials.
Most existing works on visual-inertial odometry benchmark performance on a real-world dataset of motion sequences consisting of IMU data and RGB images. When using current real-world datasets, there is little opportunity to benchmark uncertainty, as each motion sequence is only collected once.222If the ergodicity assumption holds, the methods in [13] can be used to compute uncertainty using real data. Simulated cause-and-effect on our in-house monocular visual-inertial system allows us to study the effects of Gaussian noise, drift, and attribution errors individually on a general implementation. In real-world data, all these effects are tangled together.
2 Preliminaries
Our notation is consistent with [6] and past works describing the algorithm implemented in XIVO [3], [2]. A detailed description of XIVO and its equations are given in [11].
Let denote the length of a trajectory in timesteps. Timestamps are denoted with the variable . The state contains a rotation vector, translation vector, and velocity. Let denote the estimated state and denote the error state.
Our Monte-Carlo trials contain runs each, indexed by . are the state and error state at time in run . The sample covariance at each timestep is given by
| (1) |
The mean sample covariance over an entire trajectory is
| (2) |
Although not a part of standard metrics for evaluating SLAM systems [9], errors in scale are the most sensitive to small perturbations in the input data. In other words, the error in translation and linear velocity are state-dependent and well-aligned with the ground-truth translation vector. This magnitude of these errors will vary widely depending on the exact imperfections in the input data. The scale factor of an estimated trajectory is the mean value of the ratio of the norms of the estimated translation and ground-truth translation , after both trajectories are centered around their centroids:
| (3) |
where
| (4) | ||||
When , the estimated trajectory is “smaller” than the ground-truth trajectory. When , the estimated trajectory is “larger” than the ground-truth trajectory. To avoid division-by-zero errors when is close to the origin, we only include timesteps when when computing . For a set of Monte-Carlo trials indexed by , we can compute a set of scale factors using equation (3) and plot their distribution.
2.1 On Observability and Identifiability for Monocular VIO
Observability is a property of a model that is assumed to contain a dynamic state, inputs, and outputs. Informally, a model is observable if given the inputs and outputs, the trajectory of the dynamic state can be exactly determined. A model is unknown-input observable if the state of the model can be exactly determined even if a subset of the inputs are not known. If the model contains calibration parameters to be estimated online, then the model is identifiable if the value of the calibration parameters and the trajectory of the dynamic state can be determined from the inputs and outputs. Parameter identifiability requires a sufficiently exciting input, i.e. if the input is not varied enough then it is possible that multiple values of the calibration parameters can satisfy the model dyanmics and output equations. What makes an input sufficiently exciting depends on the model.
For linear time-invariant systems, the definition of a sufficiently exciting input is well-known. The condition is called persistent excitation. Various equivalent definitions can be found in [17], [8], and [15].
The exact conditions for sufficient excitation of nonlinear systems is not well understood and is still an active area of study. An early result states that nonlinear systems are locally identifiable if their linearization about an equilibrium point is identifiable [1] — then the requirement for parameter identifiability is the same as for a linear time-invariant system, persistent excitation. Examples of recent papers on the topic are [7, 14, 10]. In texts on systems identification and adaptive control, the requirements for sufficient excitation can be derived from LaSalle’s invariance theorem and Barbalat’s Lemma [4]. Texts on system identification and adaptive control typically focus on linear-in-parameters nonlinear systems, or other assumed relationships between the dynamics and the parameters.
VIO models are not covered by the literature on systems identification and adaptive control. There are many previous works about the observability and identifiability of VIO models; each paper uses a slightly different model. The definition of sufficient excitation therefore varies from work to work. For example in [3], IMU measurements are outputs and the inputs to the model, linear jerk and angular acceleration, are modeled as noise independent of the state. IMU biases are Brownian motion. In [16], the IMU measurements are modeled as inputs, rather than outputs, and the state contains an extra time-calibration parameter. IMU input noise is independent of the state. In [2], IMU measurements are inputs to the model, IMU input noise is not independent of the state, there is no extra time-calibration parameter, and IMU biases are slowly-varying unknown inputs rather than noise. The model implemented in XIVO and used in these experiments is the one examined in [2].
[2] proves that the VIO model under examination is identifiable if and only if IMU bias rates are zero or exactly known. Otherwise, there exist multiple trajectories that can satisfy the output equations. The multiple trajectories are, however, a bounded set; the size of the bounded set is proportional to the IMU bias rates and inversely proportional to the minimum excitation of the angular velocity, angular acceleration, angular jerk, and linear jerk. The minimum excitation of a 3D signal over a time interval is defined as:
| (5) |
In other words, the minimum excitation of is determined by the (arbitrary) direction in 3D space with the smallest maximum value. If there is a direction that is not covered at all (e.g. no angular jerk in the -direction), then the minimum excitation is zero, and the bounded set of possible trajectories in [2] is actually unbounded. Sufficient excitation therefore means that angular velocity, angular acceleration, angular jerk, and linear jerk each cover 3-DOF. A randomly generated 3D trajectory will almost surely meet the requirement.
Of course, the model and the state estimation algorithm are different. A state estimation algorithm may fail to find the correct state of an observable model with a sufficiently exciting input. Conversely, it is also possible for a state estimation algorithm to produce the original state even if the model is not observable or the input is not sufficiently exciting.
3 Experiment
We simulate IMU and visual inputs to our in-house VIO system, XIVO. Inputs are perturbed with Gaussian noise, drift, and random attribution errors so that we may measure the effect of each on Absolute Trajectory Error (ATE), Relative Pose Error (RPE), sample covariance (1), and scale factor (3).
3.1 The Trajectory Studied
Our experiment focuses on a randomly generated trajectory that is guaranteed to be sufficiently exciting and pictured in Figure 1. In the randomly generated trajectory, linear acceleration and angular velocity in the spatial frame are modeled as Brownian motion with acceleration drift m and angular velocity drift rad/s. A random amount of drift is added to and with every IMU measurement, at 400Hz. and are then transformed into the body-frame inputs, and . Boundary conditions on linear velocity are set to m/s and m/s. Boundary conditions on translation are set to m and m. If the simulated ground-truth state in the spatial frame hits either boundary, the sign of that component of linear acceleration is flipped. Boundary conditions on all components of rotation vector are set to and . The total length of the trajectory is 127.76m over 80 seconds.
Although randomly generated Brownian motion curves, such as the trajectory in Figure 1, are guaranteed to be sufficiently exciting, the frequent and non-smooth changes in rotation and acceleration make convergence of an EKF and feature depth initialization (see [11]) difficult due to lack of parallax for triangulation.


3.2 Configuration
The configuration of XIVO in Monte-Carlo experiments is given in Figure 2. More details about the configuration are given in the paragraphs below.

IMU Simulation.
We simulate an IMU with similar specifications to the Intel RealSense d435i, a low-cost device. The accelerometer and gyroscope produce measurements at 400 Hz. IMU noise levels are held constant with accelerometer noise m/s and gyroscope noise radians/s/. IMU bias is initially zero, but drifts with parameters m/s and radians/s/.
Vision Simulation.
So that we may have complete control over feature position errors and attribution, we skip the typical image processing step and instead directly feed pixel measurements of an attributed point cloud into XIVO at a rate of 25Hz. The point cloud consists of 1000 randomly generated points uniformly located in a box; all Monte-Carlo trials use the same set of generated features. At each vision timestep Visibility is calculated using a camera with no distortion and the following intrinsics:
| (6) |
Observed features fall in and out of view during motion.
Extrinsics.
Due to the development of specialized visual-inertial calibration, such as Kalibr, we assume that camera intrinsics, camera-IMU timestamp alignment, camera-IMU extrinsics, and accelerometer-gyroscope alignment are known. As in [3], we “remove” camera-IMU extrinsics from the state by setting the initial covariance of that portion of the state to a value . All other calibration quantities are removed from the state through compile-time switches.
XIVO Configuration.
A bare-bones “feature tracker” is configured to “track” and initialize depth estimates of 250 - 500 visible features. If there are more than 500 features, they will be ignored. Feature depths are initialized with a combination of triangulation minimizing angular reprojection errors [5] and subfiltering. There is no loop closure in these experiments. The EKF in XIVO uses 60 tracked features in its state. The features selected for state estimation are those with the most confident estimate of depth (see [11] for more details).
3.3 Experiment Parameters
Gaussian Noise.
Let be the standard deviation of noise added to feature tracks and let be the standard deviation of noise used by the EKF when creating state estimates. We test values of pixels and set .
Drift.
To simulate drift, we associate with each feature a bias , with unit of pixels. When feature is first detected, is initialized to . With each frame, evolves as where . At time , the XIVO receives a simulated tracker measurement of , where is the location of feature in the camera frame at time . We test and two different values for the assumed Gaussian noise uncertainty in the EKF, and . Over 25 frames (one simulated second), this corresponds to an average drift of zero pixels for all values of , with standard deviations of pixels.
Attribution Errors.
To create attribution errors, we swap the measurements of percent of uniformly randomly selected visible features each frame before passing feature tracks to XIVO. The features assigned attribution errors are always those that are “tracked” by the bare-bones feature tracker, but may or may not be used in state estimation by the EKF. XIVO is configured to use Mahalanobis Gating to reject outlier measurements, such as those caused by misattributions. Since measurement errors caused by randomly swapping visible features are catastrophic, Mahalanobis Gating prevents the outlier measurements from becoming part of the EKF’s measurement update. Therefore, the real effect of our random misattributions is that the lifetime of feature tracks are prematurely cut short. We test with percent.
3.4 Results
The outputs of our Monte-Carlo experiments are the box-and-whisker plots of distributions of ATE, RPE, mean sample covariance, and scale factor, shown in Figures 3 - 14. As expected, increasing Gaussian noise, drift, and attribution errors increase ATE, RPE, mean sample covariance, and scale errors. The degradation with respect to Gaussian noise and drift is graceful. However, the degradation with respect to attribution errors is exponential. Cutting the lifetime of feature tracks causes the largest performance errors, mean sample covariance, scale bias, and scale variance. Next, Gaussian noise causes larger performance errors, mean sample covariance, and scale uncertainty than drift. Drift, however, causes larger scale bias than Gaussian noise.
More particular details are noted in the paragraphs below. All plots for the same quantity (e.g. distribution of ) use the same vertical-axis scale for the Gaussian noise and drift experiments. The plots containing results of the attribution experiments require a different vertical-axis scale because of the exponential degradation.
Gaussian Noise.
Results are shown in Figures 3, 4, 5. The general trend is that performance errors and state uncertainty, and variations of performance error and state uncertainty, increase with . The variation in generally increases with , but mean and median of hover around .
Next, we note that for performance error and scale errors for are larger than performance error and scale errors for . We hypothesize that the combination of frequent changes in motion that make the dynamics less linear and poor feature initialization add measurement errors that are not adequately captured when we set . When we instead set a little bit higher, to , performance error and scale errors when become lower than when . Results when are shown in Figures 6, 7, and 8.








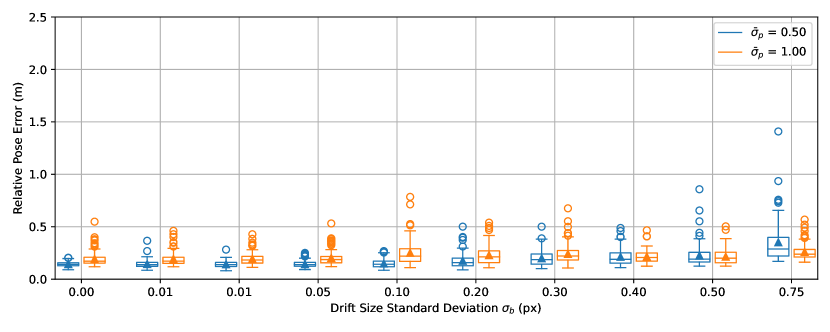
Drift.
Distributions of performance error, state covariance, and scale error in the drift experiment are shown in Figures 9, 10, 11. Performance error, state covariance, and scale errors increase monotonically with for both and ; their variations also widen as increases. Values of performance error, state covariance, and are closer to their ideal values when than when for smaller quantities of drift. Once is high enough, values of performance error, state covariance, and are closer to their ideal values with .



Attribution Errors.
Distributions of performance error, state covariance, and scale error are shown in Figures 12, 13, 14. Results are simple: performance error, state covariance, and scale factor increase exponentially as is increased. Variation in all three increase uniformly with . Figures 12, 13, and 14 only display values of up to , so that distributions of performance error, state covariance, and scale error at lower values are not dwarfed. Mean values of performance error, state covariance, and scale factor are shown for all tested values of in Figure 15.
We note that is a rather low percentage of outliers and that SLAM systems commonly encounter higher outlier ratios, as illustrated by the previous chapter. This indicates that outliers in real-world data are not random, like our simulated attribution errors, and that algorithms used to select features for state estimation are functioning as intended.








4 Summary and Discussion
There are at least two limitations to our results. The first is that we used theoretically correct values of in the Gaussian noise experiment rather than treating as a tuning parameter. An ideal experiment with infinite resources would find the very best333The notion of “best” also needs to be defined. value of for every possible value of every disturbance and then compare the distribution of performance errors, mean sample covariance, and scales. The second limitation is that we studied a randomly generated trajectory to eliminate the possibility that the number of trajectories that could produce the same measurements could be unbounded. Many realistic trajectories, such as driving a car on a flat road or flying a drone at a constant velocity, are not sufficiently exciting.
Nevertheless, we have systematically quantified and characterized the performance and uncertainty of an well-known monocular-VIO state estimation algorithm based on the Extended Kalman Filter. Our results largely confirm what is anecdotally known by practitioners: monocular VIO is “finicky”. Whenever possible, a practitioner will always choose RGB-D SLAM, Lidar-Inertial Odometry, or Stereo Visual-Inertial Odometry if the platform allows it. The fliers in Figures 3, 5, 9, and 11 indicate that the right combination of noise and/or drift in the IMU and visual measurements has more than a 1 in 100 chance of creating a state estimate with a performance error more than twice the mean error and far above the lowest possible error. This highlights the need for more Monte-Carlo studies of SLAM, rather than reliance on benchmark datasets with individual trajectories.
References
- [1] M. Grewal and K. Glover. Identifiability of linear and nonlinear dynamical systems. IEEE Transactions on Automatic Control, 21(6):833–837, December 1976. Conference Name: IEEE Transactions on Automatic Control.
- [2] J. Hernandez, K. Tsotsos, and S. Soatto. Observability, identifiability and sensitivity of vision-aided inertial navigation. In 2015 IEEE International Conference on Robotics and Automation (ICRA), pages 2319–2325, May 2015.
- [3] E. Jones and S. Soatto. Visual-inertial navigation, mapping and localization: A scalable real-time causal approach. The International Journal of Robotics Research, 30(4):407–430, April 2011.
- [4] Eugene Lavretsky and Kevin Wise. Robust and Adaptive Control: With Aerospace Applications. Springer Science & Business Media, November 2012. Google-Books-ID: a2128lhlWfQC.
- [5] Seong Hun Lee and Javier Civera. Closed-form optimal two-view triangulation based on angular errors. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019.
- [6] Richard M. Murray, Zexiang Li, and S. Shankar Sastry. A Mathematical Introduction to Robotic Manipulation. Routledge, Boca Raton, 1 edition edition, March 1994.
- [7] Alberto Padoan, Giordano Scarciotti, and Alessandro Astolfi. A Geometric Characterization of the Persistence of Excitation Condition for the Solutions of Autonomous Systems. IEEE Transactions on Automatic Control, 62(11):5666–5677, November 2017. Conference Name: IEEE Transactions on Automatic Control.
- [8] T. Soderstrom, L. Ljung, and I. Gustavsson. Identifiability conditions for linear multivariable systems operating under feedback. IEEE Transactions on Automatic Control, 21(6):837–840, December 1976. Conference Name: IEEE Transactions on Automatic Control.
- [9] Jürgen Sturm, Nikolas Engelhard, Felix Endres, Wolfram Burgard, and Daniel Cremers. A benchmark for the evaluation of RGB-D SLAM systems. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 573–580, October 2012.
- [10] Patrizio Tomei and Riccardo Marino. An Enhanced Feedback Adaptive Observer for Nonlinear Systems with Lack of Persistency of Excitation. IEEE Transactions on Automatic Control, pages 1–6, 2022. Conference Name: IEEE Transactions on Automatic Control.
- [11] Stephanie Tsuei and Xiaohan Fei. xivo/doc.pdf at devel · ucla-vision/xivo. https://github.com/ucla-vision/xivo/blob/devel/doc/doc.pdf, February 2023.
- [12] Stephanie Tsuei, Wenjie Mo, and Stefano Soatto. Feature Tracks are not Zero-Mean Gaussian, March 2023. arXiv:2303.14315 [cs].
- [13] Stephanie Tsuei, Stefano Soatto, Paulo Tabuada, and Mark B. Milam. Learned uncertainty calibration for visual inertial localization. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 5311–5317, 2021.
- [14] Cristiano Maria Verrelli and Patrizio Tomei. Nonanticipating Lyapunov Functions for Persistently Excited Nonlinear Systems. IEEE Transactions on Automatic Control, 65(6):2634–2639, June 2020. Conference Name: IEEE Transactions on Automatic Control.
- [15] Jan C. Willems, Paolo Rapisarda, Ivan Markovsky, and Bart L.M. De Moor. A note on persistency of excitation. Systems & Control Letters, 54(4):325–329, April 2005.
- [16] Yulin Yang, Patrick Geneva, Kevin Eckenhoff, and Guoquan Huang. Degenerate Motion Analysis for Aided INS With Online Spatial and Temporal Sensor Calibration. IEEE Robotics and Automation Letters, 4(2):2070–2077, April 2019. Conference Name: IEEE Robotics and Automation Letters.
- [17] Karl-Johan Åström and Bohlin Torsten. Numerical Identification of Linear Dynamic Systems from Normal Operating Records. IFAC Proceedings Volumes, 2(2):96–111, September 1965.