Quantifying Atomic Knowledge in Self-Diagnosis
for Chinese Medical LLMs
Abstract
The booming development of medical large-scale language models (LLMs) enables users to complete preliminary medical consultations (self-diagnosis) in their daily lives. Recent evaluations of medical LLMs mainly focus on their ability to complete medical tasks, pass medical examinations, or obtain a favorable GPT-4 rating. There are still challenges in using them to provide directions for improving medical LLMs, including misalignment with practical use, lack of depth in exploration, and over-reliance on GPT-4. To address the above issues, we construct a fact-checking style Self-Diagnostic Atomic Knowledge (SDAK) benchmark. Through atomic knowledge that is close to real usage scenarios, it can more accurately, reliably, and fundamentally evaluate the memorization ability of medical LLMs for medical knowledge. The experimental results show that Chinese medical LLMs still have much room for improvement in self-diagnostic atomic knowledge. We further explore different types of data commonly adopted for fine-tuning medical LLMs and find that distilled data enhances medical knowledge retention more effectively than real-world doctor-patient conversations.
Quantifying Atomic Knowledge in Self-Diagnosis
for Chinese Medical LLMs
Yaxin Fan1, Feng Jiang2,3,4††thanks: Corresponding author, Benyou Wang2,3, Peifeng Li1 and Haizhou Li2,3 1School of Computer Science and Technology, Soochow University, Suzhou, China 2School of Data Science, The Chinese University of Hong Kong, Shenzhen, China 3Shenzhen Research Institute of Big Data, Shenzhen, China 4 University of Science and Technology of China, Hefei, China [email protected] {jeffreyjiang,wangbenyou,haizhouli}@cuhk.edu.cn [email protected]
1 Introduction
In the digital age, seeking health information from the Internet for self-diagnosis has become a common practice of patients (White and Horvitz, 2009; Demner-Fushman et al., 2019; Farnood et al., 2020). During the self-diagnosis, the searched health information can assist users in making necessary medical decisions, such as self-treatment or going to the hospital for professional treatment. With the development of generative models (Ouyang et al., 2022; Sun et al., 2021; OpenAI, 2023), Large-scale Language Models (LLMs) hold the promise of revolutionizing the retrieval paradigm that seeks health suggestions via a search engine because they can provide more efficient suggestions through natural conversations.

To enhance the medical capabilities of open-source LLMs in Chinese, recent studies Wang et al. (2023a); Zhang et al. (2023); Zhu and Wang (2023); Yang et al. (2023) attempt to fine-tune the foundation models on medical instruction or conversation data. As for the methods for evaluating their performance, the existing work is mainly divided into three categories: medical NLP-related tasks Zhu et al. (2023), medical exams Umapathi et al. (2023); Wang et al. (2023d), and evaluating medical dialogue evaluations through GPT-4 Zhang et al. (2023); Yang et al. (2023), as shown in Figure 1.
Challenges.
Despite the progress of evaluation, there are still some challenges in using them to provide directions for improving medical LLMs: (1) Misalignment with practical use. Most current Chinese medical LLMs are patient-centric, typically addressing questions related to medical consultations rather than complex and professional queries, such as ”What should I take for a cold?”(感冒应该吃什么药?). The results from these evaluations, such as NLP tasks or medical exams, do not match the actual needs of users. (2) Lack of depth in exploration. Since most evaluations simply judge whether the model’s responses to complex questions are correct or incorrect, it is challenging to determine whether errors stem from basic memorization failures or a lack of advanced reasoning abilities in LLMs Zheng et al. (2023). (3) Over-reliance on GPT-4 for evaluation. Evaluation by GPT-4 is not satisfactory because of its evaluation bias Wang et al. (2023c) and its insufficient medical knowledge (seen in Figure 4).
Solutions.
To address the above limitations, we propose a fact-checking style medical benchmark named the Self-Diagnostic Atomic Knowledge Benchmark (SDAK) to assess Chinese medical LLMs. Inspired by atomic fact-checking Chern et al. (2023), we utilize atomic knowledge Min et al. (2023), an indivisible unit of information, for a more precise, reliable, and fundamental evaluation of an LLM’s proficiency in medical knowledge (examples are shown in Table 2). To ensure that the evaluation is closer to the real usage scenario of medical LLMs, we adopt thematic analysis Braun and Clarke (2012); Zheng et al. (2023) to extract the most commonly used atomic knowledge types from self-diagnostic queries. Then, we create atomic knowledge items for each type according to structured medical contents from public medical websites, each item consists of a pair of factual and counterfactual claims. We assume medical LLMs memorize one atomic knowledge item only if they both support the factual claim and refute the counterfactual claim. To reduce reliance on GPT-4, we designed two necessary automation indicators (instruction following rate, factual accuracy) and an optional manual metric (accuracy reliability). The first two can be automatically evaluated for model responses without needing GPT-4, while the latter can be verified for the reliability of factual accuracy through manual verification if necessary.
Results.
The experimental results show that: (a) the instruction following ability of most medical LLMs fine-tuned with domain data decreased to varying degrees compared to general LLMs, and the memorization ability of LLMs in the medical domain was not significantly improved; (b) the reliability of the answers after manual verifying mostly exceed 95% indicating our metric is reliable to measure the memorization ability of LLMs.
Findings.
After an in-depth analysis of error types, knowledge types, and data sources for fine-tuning, we find the following three points: (1) Sycophancy is the primary cause of errors, whether it is in general or medical LLMs. (2) There is still a huge gap between the existing Chinese medical LLMs and GPT-4, although GPT-4 performs poorly in some more specialized medical knowledge. (3) Compared to real doctor-patient conversation data, distilled data from the advanced LLMs can better help open-source LLMs memorize more atomic knowledge. We believe that this is due to the fact that doctors are less likely to explain medical knowledge and diagnosis to patients in real doctor-patient conversations. The above insights could provide future research directions for the Chinese medical LLMs community. Our data, code, and model will be released in ¡AnonymousURL¿.
2 Related Work

2.1 Medical Evaluation Methods
The existing efforts put into the evaluation of the medical abilities of LLMs are mainly divided into three types: medical NLP-related tasks Zhu et al. (2023), medical exams Umapathi et al. (2023); Wang et al. (2023d), and conducting medical dialogue evaluations through GPT-4 Zhang et al. (2023); Yang et al. (2023). However, inconsistent scenarios, lack of depth exploration, and insufficient medical ability of GPT-4 pose new challenges to evaluating medical LLMs in Chinese. In this paper, we aim to address the above limitations and explore the memorization ability of LLMs in the self-diagnostic scenario.
2.2 Fact-checking
The fact-checking task Thorne et al. (2018); Guo et al. (2022); Wadden et al. (2020); Saakyan et al. (2021); Sarrouti et al. (2021); Mohr et al. (2022) aims to determine whether the claims are supported by the evidence provided, which has been an active area of research in NLP. Recently, some researchers Min et al. (2023); Chern et al. (2023) have paid more attention to automatically evaluating the factuality of atomic knowledge contained in the long-form model-generated text. They utilized GPT-4 to automatically decompose atomic facts in complex texts and verify the overall factual accuracy. However, this method is not applicable in the medical domain due to the insufficient mastery of medical knowledge in GPT-4, which cannot extract critical facts in user queries like extracting common sense.
2.3 Chinese Medical LLMs
To enhance the medical capability of open-source LLMs Du et al. (2022); Touvron et al. (2023a, b); Baichuan (2023), previous work has attempted to adopt real-world medical data or the mixture of real-world and distilled/semi-distilled from ChatGPT conversations Wang et al. (2023e, b) for fine-tuning. The former Xu (2023); Wang et al. (2023a, b) mainly learn the medical capabilities of doctors from doctor-patient conversations, while the latter Zhu and Wang (2023); Yang et al. (2023); Zhang et al. (2023) further additionally added distilled conversations from advanced LLMs such as ChatGPT. Despite there being much progress in medical LLMs in Chinese, how to better evaluate their performance is still an area that needs to be studied, such as the extent of self-diagnostic medical knowledge stored in these LLMs.
3 Construction of Self-diagnostic Atomic Knowledge Benchmark
Motivation. Despite the robust growth of Chinese medical LLMs, various evaluations for them have yet to be significantly helpful in improving them. On the one hand, some existing evaluations focus on medical NLP tasks Zhu et al. (2023) or medical exams Umapathi et al. (2023); Wang et al. (2023d), which do not align with real usage scenarios (self-diagnosis). Moreover, due to the complexity of the testing questions, it is challenging to determine whether the model’s errors stem from issues in memory, or reasoning, which are crucial for improving LLMs’ performance. On the other hand, some efforts Zhang et al. (2023); Yang et al. (2023) have attempted to use GPT-4 in a conversational format for evaluation. However, due to GPT-4’s inherent evaluation biases, its imperfect grasp of medical knowledge, and limitations in accessibility, this method is also not suitable. Therefore, inspired by atomic fact-checking evaluation studies, we build a fact-checking style medical benchmark named the Self-Diagnostic Atomic Knowledge Benchmark (SDAK) to more accurately, reliably, and fundamentally evaluate the memorization ability of medical LLMs for medical knowledge, as shown in Figure 2.
3.1 Thematic Analysis of Atomic Types
To obtain the most common types of atomic knowledge for queries of real users in the self-diagnostic scenario, we select the KUAKE-QIC Zhang et al. (2022) dataset as the source data. It mainly contains user queries from search engines with ten intent types, and examples are shown in Appendix A.
Then, we conducted thematic analysis Braun and Clarke (2012); Zheng et al. (2023) of 200 samples randomly selected from each intent type in KUAKE-QIC to identify the atomic knowledge types. Specifically, we first conduct the induction by initiating the preliminary type of atomic knowledge for each selected sample, where we mainly focus on medical-related knowledge, specializing in Disease-Symptom, Medicine-Effect, etc. Then, we deduce the most common type of atomic knowledge by aggregating the type into a broader atomic type if more samples fall into this type. Take the query with Diagnosis intent in Figure 2 as an example. Since both breast pain and breast cancer in this query are the symptom and disease, respectively, the atomic type involved in this query is Disease-Symptom.
Table 1 shows the atomic types and percentages contained in the queries with various intents we constructed. We find that over 80% of queries in each intent fall into different atomic types we deduced, indicating that atomic knowledge is a more fine-grained basic unit. Besides, the queries with different intents tend to involve the same type of atomic knowledge, e.g., queries with both Diagnosis and Cause intents involve the same atomic type of Disease-Symptom, which demonstrates the necessity and efficiency of evaluating LLMs in terms of atomic knowledge. After removing the non-objective intent related to specific user locations, such as Price and Advice, we collect 17 most common types of atomic knowledge from real-world self-diagnostic queries, as shown in Table 1.
| Intent | Atomic Type | Percentage | |
| Diagnosis | Disease-Symptom | 81% | |
| Disease-Examination | 10% | ||
| Cause | Disease-Cause | 64% | |
| Disease-Symptom | 25% | ||
| Method | Disease-Medicine | 55% | |
| Disease-Method | 34% | ||
| Advice | Disease-Hospital | 80% | |
| Disease-Department | 8% | ||
| Disease-Examination | 11% | ||
| Metric_explain | Examination-Range | 63% | |
| Metric-Effect | 37% | ||
| Disease_express | Disease-Symptom | 62% | |
| Disease-Infectivity | 15% | ||
| Diseases-Complication | 15% | ||
| Result | Disease-Symptom | 36% | |
| Western Medicine-SideEffect | 14% | ||
| Chinese Medicine-SideEffect | 19% | ||
| Food-Effect | 17% | ||
| Attention | Disease-Food | 59% | |
| Disease-Prevention | 21% | ||
| Effect | Western Medicine-Effect | 20% | |
| Chinese Medicine-Effect | 27% | ||
| Food-Effect | 44% | ||
|
Treatment-Price | 97% |
3.2 Construction of Atomic Knowledge Items
After obtaining the most common atomic types, we construct pairs of factual and counterfactual claims for each atomic type to convey atomic knowledge items.
To avoid data contamination, we do not construct atomic claims based on existing Chinese medical knowledge graphs, e.g., CMeKG Odmaa et al. (2019) has been utilized by some Chinese medical LLMs Wang et al. (2023a, b). Instead, we manually build atomic knowledge items according to the structured medical content from the public medical websites111https://www.xiaohe.cn/medical
and https://www.120ask.com/disease for the following two reasons. On the one hand, the medical content from these websites is reliable because it is edited and verified by professional medical teams. On the other hand, these websites are also the main source of medical knowledge for self-diagnostic queries.
| Atomic Type | Example of factual (Counterfactual) atomic claim | ||
|---|---|---|---|
| Disease-Symptom |
|
||
| Disease-Infectivity |
|
||
| Disease-Department |
|
||
| Disease-Method |
|
||
|
|
||
| Disease-Medicine |
|
As shown in Figure 2, we first extract the atomic knowledge from the structured medical content according to the atomic types we build. For example, we extract the disease Tail pancreatic cancer (尾胰癌) and symptom abdominal pain (腹痛) for the Disease-Symptom atomic type. Then, we heuristically construct a factual claim in the form of implication relation, as shown in Table 2.
Given that LLMs may exhibit a sycophantic bias Wei et al. (2023); Du et al. (2023), e.g., it always supports the user’s claims, it is unreliable to explore the amount of self-diagnostic knowledge stored in LLMs’ memory merely by whether or not LLMs supports factual claims. To avoid this, we propose using contrastive evaluation based on constructing a counterfactual claim for each factual claim by converting the implication into a non-implication relation, as shown in Table 2. LLMs are considered to possess one atomic knowledge item only if they both support the factual claim and refute the counterfactual claim. For each atomic type, we randomly selected at most 1,000 structured medical content to build atomic knowledge items and the statistics are shown in Appendix B.

3.3 Manual Verification
To verify the reliability of atomic claims, we conducted the manual verification based on the evidence retrieved through a search engine. We first randomly selected 50 factual claims for each atomic type. Then, we verify the correction of the claims. Follow the previous work Chern et al. (2023) and retrieve evidence by feeding factual claims into a search engine 222The search engine we adopted is Baidu, which is one of the most popular Chinese search engines.. The top 10 items retrieved by the search engine as evidence and manually judge whether the evidence supports the factual claims.
| Atomic Type | Number | ||
| Support | Neural | Refute | |
| Metric-Effect | 43 | 6 | 1 |
| Disease-Infectivity | 42 | 5 | 3 |
| Disease-Department | 48 | 0 | 2 |
| Disease-Method | 45 | 5 | 0 |
| Disease-Cause | 46 | 4 | 0 |
| Chinese Medicine-Effect | 48 | 1 | 1 |
| Chinese Medicine-SideEffect | 46 | 1 | 3 |
| Western Medicine-Effect | 50 | 0 | 0 |
| Western Medicine-SideEffect | 44 | 3 | 3 |
| Food-Effect | 43 | 5 | 2 |
| Disease-Examination | 45 | 0 | 5 |
| Disease-Prevention | 33 | 11 | 6 |
| Diseases-Complication | 42 | 7 | 1 |
| Disease-Symptom | 48 | 2 | 0 |
| Examination-Range | 32 | 12 | 6 |
| Disease-Food | 47 | 3 | 0 |
| Disease-Medicine | 46 | 1 | 3 |
| Total | 748 | 66 | 36 |
| Percentage | 88.00% | 7.76% | 4.24% |
Table 3 shows the results of manual verification, where Support, Neural, and Refute indicate that evidence supports claims, insufficient evidence, and evidence refutes claims, respectively. 88% of claims can be fully supported by the evidence 333We also asked a professional doctor to verify 170 factual claims (each atomic type contains 10) and found there are 87% of claims that can be supported. and only 4% are refuted, which shows the reliability of the atomic claims we constructed. In addition, the reliability of about 8% of factual claims cannot be verified due to insufficient evidence. We attribute it to the fact that these pieces of atomic knowledge are relatively low-frequency, leading to search engines failing to retrieve the related evidence.
4 Experiments
4.1 General and Medical LLMs for Evaluation
We select the following popular general LLMs and Chinese medical LLMs for evaluation on our SDAK. In addition to the closed-sourced ChatGPT and GPT-4 OpenAI (2023) models, we select representative open-source Chinese LLMs such as Baichuan2 Baichuan (2023), Qwen Bai et al. (2023), and ChatGLM2 Du et al. (2022) for evaluation. As for the Chinese medical LLMs, we select two types of models:
Fine-tuned merely on real-world data: BenTsao Wang et al. (2023a), ChatGLM-Med Wang et al. (2023b), MedicalGPT Xu (2023).
4.2 Fact-checking Style Evaluation Method
To comprehensively evaluate the performance of LLM on the SDAK benchmark, we propose the fact-checking style evaluation method, as shown in Figure 3.
4.2.1 Evaluation Prompt
Firstly, for a pair of claims for each atomic knowledge in SDAK, we designed an appropriate prompt to instruct LLMs to output as we specified to evaluate the performance of LLMs. The prompt is as follows: If the following claim is correct, please reply ”correct” first, and then give the reason. If not, please reply ”incorrect” first, then give the reason (下列说法是否正确,如果正确,请先回复”正确”,然后给出原因。如果错误,请先回复“错误”,然后给出原因。). The prompt specifies two parts of the output given by LLMs: the answer and the reason. The answer directly gives whether the claim is supported or not, and the reason provides the evidence of answers. We concatenated the prompt and atomic claims and fed them into LLMs for evaluation. Refer to Appendix C for the exploration of different prompts.
| Domain | Data | LLMs | Zero-shot | Few-shot | ||||
| IFR(%) | FactAcc(%) | AccR(%) | IFR(%) | FactAcc(%) | AccR(%) | |||
| General | - | GPT-4 | 100 | 100 | ||||
| Qwen-14b-Chat | 98 | 100 | ||||||
| ChatGPT | 97 | 99 | ||||||
| Qwen-7b-Chat | 98 | 100 | ||||||
| Baichuan2-13b-Chat | 96 | 99 | ||||||
| ChatGLM2 | 97 | 100 | ||||||
| Baichua2-7b-Chat | 95 | 98 | ||||||
| Medical | Mixed | Zhongjing | 97 | 100 | ||||
| Chatmed-Consult | 98 | 99 | ||||||
| HuatuoGPT | 98 | 100 | ||||||
| Real | MedicalGPT | 100 | 100 | |||||
| ChatGLM-Med | 75 | 93 | ||||||
| BenTsao | 70 | 96 | ||||||
4.2.2 Evaluation Metrics
To evaluate the performance of LLMs in processing atomic knowledge, we developed two necessary automatic metrics: Instruction Following Rate (IFR) and Factual Accuracy (FactAcc), and an optional manual metric: Accuracy Reliability (AccR). These metrics collectively assess an LLM’s ability to process and respond to medical information accurately and reliably. Instruction Following Rate (IFR) assesses whether LLMs can adhere to the given instructions. An LLM is considered to follow instructions if it provides answers (be it correct or incorrect) to both factual and counterfactual atomic claims at the start of its response. Factual Accuracy (FactAcc) measures the abilities of LLMs on self-diagnostic atomic knowledge. LLMs are considered to memorize the atomic knowledge if they give the answer ’correct’ to the factual claim and ’incorrect’ to the counterfactual claim of an item. Accuracy Reliability (AccR) evaluates the reliability of factual accuracy. We randomly selected 100 atomic knowledge items and manually checked the model’s responses. If the reason given by LLMs can support the answer ’correct’ to a factual claim and the answer ’incorrect’ to a counterfactual claim, we believe that the answers given by LLMs are reliable.
4.3 Evaluation Results
The performance of each model on SDAK is shown in Table 4. A key finding is that while general LLMs maintain an instruction-following rate above 99% in zero-shot and few-shot settings, most medical LLMs show a 5%-15% decline in zero-shot setting. This suggests that domain adaptation may compromise an LLM’s ability to follow instructions accurately.
In terms of factual accuracy (FactAcc) in the zero-shot setting, GPT-4 unsurprisingly achieves the best performance of 65.42% among all LLMs. Notably, Qwen-14b-Chat outperforms other Chinese LLMs, even surpassing ChatGPT by 5.57%. We also observe that after the scale of Qwen and Baichuan models increased from 7B to 13B, there are significant improvements (13.61% and 25.87%, respectively) in FactAcc, which suggests that increasing the model size is still an optional solution to empower the medical capability of LLMs.
Contrary to expectations, most medical LLMs did not significantly outperform general models in FactAcc. Where Zhongjing, Chatmed-Consult, and HuatuoGPT surpass the Baichuan2-7b-chat, and their best performance (Zhongjing) in the FactAcc only reaches 24.78% in the zero-shot setting. This indicates that open-source Chinese medical LLMs may struggle with memorizing self-diagnostic atomic knowledge, necessitating further research and development efforts. The significant differences in medical models with different training data prompted us to conduct an in-depth analysis of the impact of different training data, as shown in Section 5.3.
| Domain | LLMs | Error Type | |||
|---|---|---|---|---|---|
| NotFollow | Sycophancy | Safety | Misinterpretation | ||
| General | GPT4 | 0 | 68 | 26 | 6 |
| Qwen-14b-Chat | 0 | 68 | 24 | 8 | |
| ChatGPT | 0 | 79 | 17 | 4 | |
| Qwen-7b-Chat | 0 | 74 | 20 | 6 | |
| Baichuan2-13b-Chat | 0 | 72 | 24 | 4 | |
| ChatGLM2-6b | 0 | 70 | 25 | 5 | |
| Baichuan2-7b-Chat | 0 | 74 | 21 | 5 | |
| Medical | Chatmed-Consult | 20 | 48 | 18 | 14 |
| Zhongjing | 8 | 62 | 18 | 12 | |
| HuatuoGPT | 0 | 64 | 22 | 14 | |
| MedicalGPT | 23 | 62 | 2 | 13 | |
| ChatGLM-med | 5 | 54 | 1 | 40 | |
| BenTsao | 5 | 90 | 5 | 0 | |
In addition, in the few-shot setting, the performance of most models on all metrics is improved significantly, indicating that in-context learning can effectively improve the abilities of models on instruction-following and self-diagnostic atomic knowledge.
Finally, after manually checking the answers provided by various models, we find that both the general LLMs and the medical LLMs can provide a good basis for the answers, with most of them achieving over 95% performance in Accuracy Reliability (AccR). It also proves that FactAcc can reliably reflect the LLMs’ memorization ability of self-diagnostic atomic knowledge.
5 Analysis
The analysis is conducted in the zero-shot setting.
5.1 Error Analysis on Atomic Knowledge
We conducted a detailed analysis of errors to gain insights into the challenges LLMs face in memorizing medical atomic knowledge. We randomly selected 100 atomic knowledge items where various models provided incorrect responses, as shown in Table 5. This analysis revealed four primary error categories: NotFollow, where LLMs either evade directly answering (’correct’ or ’incorrect’) or provide irrelevant information; Sycophancy, characterized by LLMs indiscriminately supporting both factual and counterfactual claims, distinct from mere bias or agreeability; Safety, LLMs argue that claims are not strictly expressed and provide a more cautious answer; and Misinterpretation, where LLMs erroneously treat counterfactual claims as factual. Appendix F shows the examples of each type.
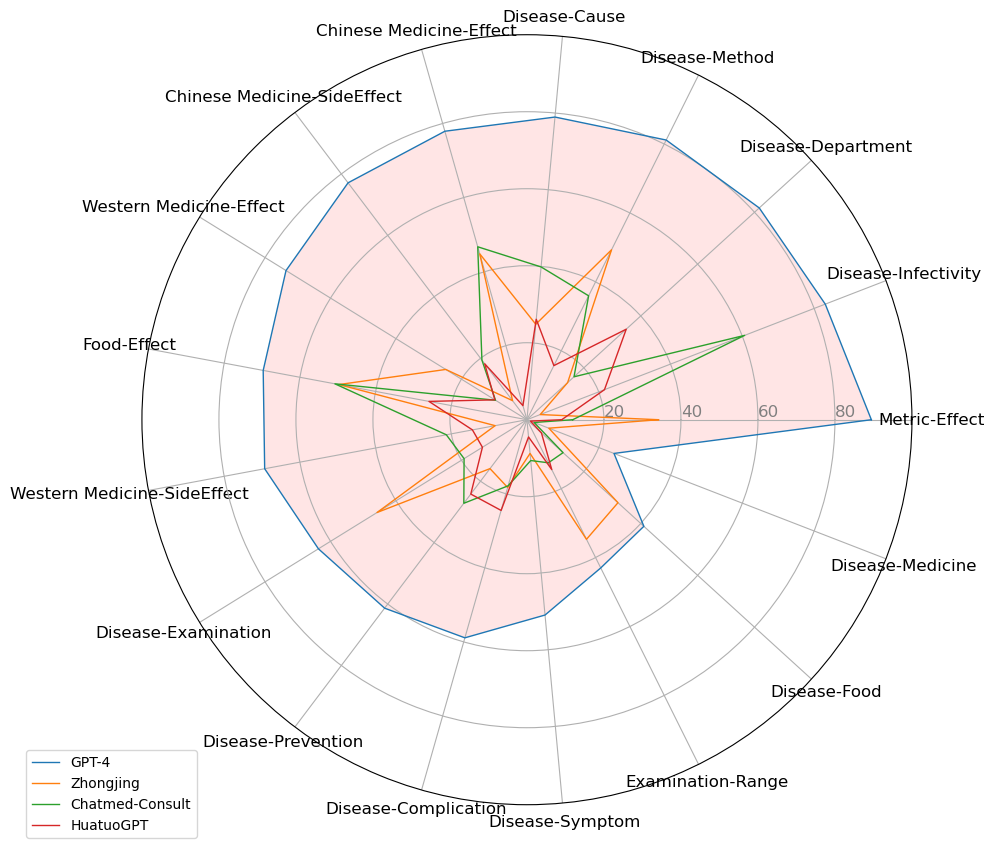
Table 5 shows that the proportion of ’NotFollow’ responses aligns with the Instruction Following Rate (IFR) in Table 4, underscoring the effectiveness of this metric in our evaluation. Notably, in the samples where LLMs followed instructions, ’Sycophancy’ emerged as the predominant error type. This finding echoes previous research Sharma et al. (2023) and underscores the need for contrastive evaluation to verify LLMs’ grasp of medical atom knowledge: Simply measuring an LLM supporting a factual claim correctly does not necessarily indicate that it has mastered the knowledge, but may be caused by sycophancy. Our results also highlight a tendency for general LLMs to adopt more cautious stances in responses, a pattern especially pronounced in models like Chatmed-Consult, Zhongjing, and HuatuoGPT, which were trained on mixed datasets, including distilled data from ChatGPT. In contrast, domain-specific medical LLMs displayed a higher rate of ’Misinterpretation’, suggesting an increased internal inconsistency post domain adaptation training.
5.2 Performance of LLMs on Various Types of Atomic Knowledge
We further plotted the FactAcc of various models on different types of atomic knowledge through a radar graph in Figure 4. It reveals that GPT-4 demonstrates robust performance in medical common sense types, as indicated in the upper half of Figure 4, with achievements surpassing or closing to 80%. In contrast, GPT-4’s performance declines in more specialized atomic knowledge areas, such as Disease-Medicine and Disease-Food interactions, located in the lower right part of Figure 4. We also observed that Chinese medical LLMs, despite their advancements, still lag behind GPT-4 in all atomic knowledge types. Additionally, we noticed that various models exhibit similar performance levels on certain atomic knowledge items due to sharing part of datasets. Therefore, we suggest that Chinese medical LLM needs more differentiated development in the future.
5.3 Effect of Different Types of Training Data
In the above experiments, we observed a notable performance enhancement in models trained with a mix of data types compared to those relying solely on real-world doctor-patient conversations. This led us to explore further the influence of different data sources on both the IFR and FactAcc, as shown in Figure LABEL:different_accuracy. For a controlled comparison, we fine-tuned models using distilled, semi-distilled, and real-world data sets on the same base model, Baichuan-7b-base. Specifically, we utilized 69,768 real-world and 61,400 distilled single-turn conversations from HuatuoGPT and 549,326 semi-distilled single-turn conversations from Chatmed-Consult. The experimental setting can be seen in Appendix G.
In the upper segment of Figure LABEL:different_accuracy, we illustrate how different training datasets impact the IFR. The base model, trained exclusively on general conversation data, exhibited a high instruction following rate (98.94%). However, introducing medical datasets (10K conversations) initially led to a significant decline in IFR due to the cost of domain adaptation. Notably, when the training data exceeded 20K samples, the IFR progressively improved, signifying successful domain adaptation via sufficient domain data. Intriguingly, models trained on distilled data outperformed those trained on real-world conversation data in terms of IFR. This could be attributed to the nature of real doctor-patient interactions, which are more dialogic and less instructional, thus less effective for training models in instruction following.
The lower part of Figure LABEL:different_accuracy examines the impact of these data types on FactAcc. Training with increased proportions of distilled data from ChatGPT led to a consistent enhancement in FactAcc (from 7.65% with no medical data to 39.41% with full medical data). In contrast, models trained solely on real-world data struggled to assimilate medical knowledge effectively. We believe this is because ChatGPT often adds additional explanations to its answers in order to better serve humans, while in real doctor-patient conversations, doctors rarely explain the basis and approach of their diagnosis to patients. Furthermore, the performance of models trained on semi-distilled data displayed notable fluctuations. Initially, with 20K training samples, these models achieved a peak FactAcc of 39.29%, even surpassing those trained on 549K samples from Chatmed Consult. However, further increasing the training sample size resulted in a decrease in FactAcc. This decline could be linked to the presence of more low-quality real-user queries in the semi-distilled data.
6 Conclusion
In this paper, we build the Self-Diagnostic Atomic Knowledge (SDAK) benchmark to evaluate atomic knowledge in open-source Chinese medical LLMs. It contains 14,048 atomic knowledge items across 17 types from user queries, each comprising a pair of factual and counterfactual claims. Then, we designed two necessary automatic evaluation metrics (instruction following rate and factual accuracy) and an optional manual evaluation metric (accuracy reliability) to evaluate the Chinese medical LLMs comprehensively. Experimental results revealed that while these LLMs show promise, they are not yet on par with GPT-4, particularly in some more professional medical scenarios. We also found that these models’ errors often stem from sycophantic tendencies and that distilled data enhances medical knowledge retention more effectively than real doctor-patient conversations. We hope the SDAK benchmark and our findings can prompt the development of Chinese medical LLMs.
Limitations
The main limitation is the limited size of the SDAK benchmark. Since the application of LLMs is extremely time-consuming and resource-intensive, we have to limit the size of the benchmark, leading it to hardly cover all atomic medical knowledge comprehensively in self-diagnosis scenario. However, it is worth noting that our method can easily expand the size of SDAK benchmark if computing resources are no longer a problem impeding LLMs in the future. We also acknowledge that the quality of our dataset is not perfect, although only 4% of the samples do not match objective facts. We will try to make up for this deficiency in future research. In addition, the SDAK benchmark we have built serves as a medical LLMs evaluation for Chinese, but its paradigm is language-independent and can be easily transferred to other languages such as English, French, Japanese, etc. Furthermore, although we have taken measures to avoid creating test data from existing data as much as possible, we acknowledge that it is still impossible to completely avoid the possibility of data leakage.
Ethics Statement
The main contribution of this paper is establishing the SDAK benchmark to quantify the self-diagnostic atomic knowledge in Chinese Medical Large Language Models. This benchmark is built using heuristic rules based on medical knowledge publicly available on the Internet. The data sources are all ethical. Firstly, the atomic knowledge types utilized in our study were sourced from KUAKE-QIC, which is a public dataset that can be accessed freely. Secondly, we only extract the related medical terms (such as medication name and disease name) from medical encyclopedia entries on the third-party medical website, which are public medical knowledge and can be found in many medical resources like Wikipedia or Baidu Baike and do not contain any information that uniquely identifies individuals. Therefore, it does not violate dataset copyright and privacy information.
References
- Bai et al. (2023) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. 2023. Qwen technical report.
- Baichuan (2023) Baichuan. 2023. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305.
- Braun and Clarke (2012) Virginia Braun and Victoria Clarke. 2012. Thematic analysis. American Psychological Association.
- Chern et al. (2023) I-Chun Chern, Steffi Chern, Shiqi Chen, Weizhe Yuan, Kehua Feng, Chunting Zhou, Junxian He, Graham Neubig, and Pengfei Liu. 2023. Factool: Factuality detection in generative ai – a tool augmented framework for multi-task and multi-domain scenarios.
- Demner-Fushman et al. (2019) Dina Demner-Fushman, Yassine Mrabet, and Asma Ben Abacha. 2019. Consumer health information and question answering: helping consumers find answers to their health-related information needs. Journal of the American Medical Informatics Association, 27(2):194–201.
- Du et al. (2023) Yanrui Du, Sendong Zhao, Muzhen Cai, Jianyu Chen, Haochun Wang, Yuhan Chen, Haoqiang Guo, and Bing Qin. 2023. The calla dataset: Probing llms’ interactive knowledge acquisition from chinese medical literature.
- Du et al. (2022) Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. 2022. Glm: General language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 320–335.
- Farnood et al. (2020) Annabel Farnood, Bridget Johnston, and Frances S Mair. 2020. A mixed methods systematic review of the effects of patient online self-diagnosing in the ‘smart-phone society’on the healthcare professional-patient relationship and medical authority. BMC Medical Informatics and Decision Making, 20:1–14.
- Guo et al. (2022) Zhijiang Guo, Michael Schlichtkrull, and Andreas Vlachos. 2022. A Survey on Automated Fact-Checking. Transactions of the Association for Computational Linguistics, 10:178–206.
- Min et al. (2023) Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation.
- Mohr et al. (2022) Isabelle Mohr, Amelie Wührl, and Roman Klinger. 2022. CoVERT: A corpus of fact-checked biomedical COVID-19 tweets. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 244–257, Marseille, France. European Language Resources Association.
- Odmaa et al. (2019) BYAMBASUREN Odmaa, Yunfei YANG, Zhifang SUI, Damai DAI, Baobao CHANG, Sujian LI, and Hongying ZAN. 2019. Preliminary study on the construction of chinese medical knowledge graph. Journal of Chinese Information Processing, 33(10):1–7.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Saakyan et al. (2021) Arkadiy Saakyan, Tuhin Chakrabarty, and Smaranda Muresan. 2021. COVID-fact: Fact extraction and verification of real-world claims on COVID-19 pandemic. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 2116–2129, Online. Association for Computational Linguistics.
- Sarrouti et al. (2021) Mourad Sarrouti, Asma Ben Abacha, Yassine Mrabet, and Dina Demner-Fushman. 2021. Evidence-based fact-checking of health-related claims. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3499–3512, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Sharma et al. (2023) Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. 2023. Towards understanding sycophancy in language models.
- Sun et al. (2021) Yu Sun, Shuohuan Wang, Shikun Feng, Siyu Ding, Chao Pang, Junyuan Shang, Jiaxiang Liu, Xuyi Chen, Yanbin Zhao, Yuxiang Lu, et al. 2021. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv preprint arXiv:2107.02137.
- Thorne et al. (2018) James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: a large-scale dataset for fact extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 809–819, New Orleans, Louisiana. Association for Computational Linguistics.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023a. Llama: Open and efficient foundation language models.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Umapathi et al. (2023) Logesh Kumar Umapathi, Ankit Pal, and Malaikannan Sankarasubbu. 2023. Med-halt: Medical domain hallucination test for large language models.
- Wadden et al. (2020) David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. 2020. Fact or fiction: Verifying scientific claims. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7534–7550, Online. Association for Computational Linguistics.
- Wang et al. (2023a) Haochun Wang, Chi Liu, Nuwa Xi, Zewen Qiang, Sendong Zhao, Bing Qin, and Ting Liu. 2023a. Huatuo: Tuning llama model with chinese medical knowledge.
- Wang et al. (2023b) Haochun Wang, Chi Liu, Sendong Zhao, Bing Qin, and Ting Liu. 2023b. Chatglm-med: 基于中文医学知识的chatglm模型微调. https://github.com/SCIR-HI/Med-ChatGLM.
- Wang et al. (2023c) Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. 2023c. Large language models are not fair evaluators.
- Wang et al. (2023d) Xidong Wang, Guiming Hardy Chen, Dingjie Song, Zhiyi Zhang, Zhihong Chen, Qingying Xiao, Feng Jiang, Jianquan Li, Xiang Wan, Benyou Wang, and Haizhou Li. 2023d. Cmb: A comprehensive medical benchmark in chinese.
- Wang et al. (2023e) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023e. Self-instruct: Aligning language models with self-generated instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13484–13508, Toronto, Canada. Association for Computational Linguistics.
- Wei et al. (2023) Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, and Quoc V. Le. 2023. Simple synthetic data reduces sycophancy in large language models.
- White and Horvitz (2009) Ryen W White and Eric Horvitz. 2009. Experiences with web search on medical concerns and self diagnosis. In AMIA annual symposium proceedings, volume 2009, page 696. American Medical Informatics Association.
- Xu (2023) Ming Xu. 2023. Medicalgpt: Training medical gpt model. https://github.com/shibing624/MedicalGPT.
- Yang et al. (2023) Songhua Yang, Hanjie Zhao, Senbin Zhu, Guangyu Zhou, Hongfei Xu, Yuxiang Jia, and Hongying Zan. 2023. Zhongjing: Enhancing the chinese medical capabilities of large language model through expert feedback and real-world multi-turn dialogue.
- Zhang et al. (2023) Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhihong Chen, Jianquan Li, Guiming Chen, Xiangbo Wu, Zhiyi Zhang, Qingying Xiao, Xiang Wan, Benyou Wang, and Haizhou Li. 2023. Huatuogpt, towards taming language model to be a doctor.
- Zhang et al. (2022) Ningyu Zhang, Mosha Chen, Zhen Bi, Xiaozhuan Liang, Lei Li, Xin Shang, Kangping Yin, Chuanqi Tan, Jian Xu, Fei Huang, Luo Si, Yuan Ni, Guotong Xie, Zhifang Sui, Baobao Chang, Hui Zong, Zheng Yuan, Linfeng Li, Jun Yan, Hongying Zan, Kunli Zhang, Buzhou Tang, and Qingcai Chen. 2022. CBLUE: A Chinese biomedical language understanding evaluation benchmark. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7888–7915, Dublin, Ireland. Association for Computational Linguistics.
- Zheng et al. (2023) Shen Zheng, Jie Huang, and Kevin Chen-Chuan Chang. 2023. Why does chatgpt fall short in providing truthful answers?
- Zhu and Wang (2023) Wei Zhu and Xiaoling Wang. 2023. Chatmed: A chinese medical large language model. https://github.com/michael-wzhu/ChatMed.
- Zhu et al. (2023) Wei Zhu, Xiaoling Wang, Huanran Zheng, Mosha Chen, and Buzhou Tang. 2023. Promptcblue: A chinese prompt tuning benchmark for the medical domain.
| Intent | Query | Atomic Type | ||
|---|---|---|---|---|
| Diagnosis |
|
Disease-Symptom | ||
|
Disease-Examination | |||
| Cause |
|
Disease-Cause | ||
| Method |
|
Disease-Medicine | ||
|
Disease-Method | |||
| Advice |
|
Disease-Hospital | ||
|
Disease-Department | |||
| Metric_explain |
|
Examination-Range | ||
|
Metric-Effect | |||
| Diseases_express |
|
Disease-Infectivity | ||
|
Disease-Complication | |||
| Result |
|
Western Medicine-SideEffect | ||
|
Chinese Medicine-SideEffect | |||
|
Food-Effect | |||
| Attention |
|
Disease-Food | ||
|
Disease-Prevention | |||
| Effect |
|
Western Medicine-Effect | ||
|
Chinese Medicine-Effect | |||
| Price |
|
Disease-Price | ||
|
Examination-Price |
Appendix A Examples of Different Types of Query
Table 6 shows the self-diagnostic queries with different intents.
Appendix B Statistics of the SDAK Benchmark
Table 7 shows the statistics of our SDAK Benchmark.
| Atomic Type | Example of factual(counterfactual) atomic claim | Number | ||
|---|---|---|---|---|
| Metric-Effect |
|
840 | ||
| Disease-Infectivity |
|
1000 | ||
| Disease-Department |
|
1000 | ||
| Disease-Method |
|
1000 | ||
| Disease-Cause |
|
1000 | ||
| Chinese Medicine-Effect |
|
500 | ||
| Chinese Medicine-SideEffect |
|
500 | ||
| Western Medicine-Effect |
|
500 | ||
| Food-Effect |
|
815 | ||
| Western Medicine-SideEffect |
|
500 | ||
| Disease-Examination |
|
1000 | ||
| Disease-Prevention |
|
785 | ||
| Diseases-Complication |
|
1000 | ||
| Disease-Symptom |
|
1000 | ||
| Examination-Range |
|
608 | ||
| Disease-Food |
|
1000 | ||
| Disease-Medicine |
|
1000 |
Appendix C Performance of ChatGPT with Different Prompts
Although we did not conduct prompt engineering in depth, we study the effect of simple prompts that provide the same instruction on ChatGPT’s performance of self-diagnostic atomic knowledge, as shown in Figure 6. The detail of prompt1 is shown in Section 4.2 and the prompt2 is as follows: If the following statements about medical knowledge are correct, please first output ”correct” or ”incorrect” and then give the corresponding reasons on a separate line.(下列关于医学知识的说法是否正确,请先输出“正确”或“错误”,然后另起一行给出相应的原因。). From Figure 6, we can see that there is no significant performance difference between prompt1 and prompt2 on various types of atomic knowledge. This indicates that LLMs are not sensitive to simple prompts that provide the same instruction.

Appendix D Few-shot Experiments
For few-shot learning, we follow the previous work Wang et al. (2023d) and provide three demonstrations. We first constructed a validation set as the source of few-shot examples. Specifically, we randomly constructed another 10 atomic knowledge items for each of the 17 atomic types, with each item comprising a pair of factual and counterfactual claims. This process resulted in a comprehensive validation dataset of 340 claims. Subsequently, we randomly selected three claims and got responses from GPT4 with our evaluation prompt. To ensure the reliability of GPT-4’s outputs, we engaged a professional medical doctor for the verification and correction of any erroneous responses. Then, we conducted three-time experiments, each with three claims randomly selected from the validation dataset as few-shot examples.
The forms of the few-shot prompt are as follows:
If the following claim is correct, please reply "correct" first, and then give the reason. If not, please reply "incorrect" first, then give the reason. Input:<ex. 1> Output: <response 1> Input: <ex. 2> Output: <response 2> Input: <ex. 3> Output: <response 3> Input: <testing> Output:
Appendix E Hyper-parameters
For ChatGPT and GPT-4, we adopted the GPT-3.5-turbo-0301 and GPT-4-0314 version, respectively, and the generation settings are set by default. For other open-source generic LLMs and medical LLMs, we adopted the same generation settings as Baichuan2 Baichuan (2023) for a fair comparison. The temperature, top_k, top_p, and repetition_penalty are set to 0.3, 5, 0.85, and 1.05, respectively, and other parameters are set by default. All experiments for each LLM are conducted three times, and we report the mean and standard deviation values.
Appendix F Error Types of LLMs on Atomic Knowledge
Examples of each error type are shown in Table 8- 11. Table 8 shows the example of the NotFollow error type in that LLMs do not follow the instruction we specify to give the correct or incorrect answer at the beginning of the response. For the type of Sycophancy, the responses provided by LLMs always support both the factual and counterfactual claims. From Table 9, we can observe that LLMs given the correct (gray font) answer to both factual and counterfactual claims and the reasons (orange font) always support their answers. This indicates that LLMs have no relevant knowledge in their memory and always cater to the opinion of users. Table 10 shows the example of the Safety error type. We can observe that LLMs given the incorrect (gray font) answer to both factual and counterfactual claims and the reasons (orange font) argue that claims are not strictly expressed, e.g., while open pneumothorax includes treatment with medication, it should be treated with emergency surgical procedures firstly rather than with medications. Table 11 shows the example of the Misinterpretation error type. We can see that LLMs misinterpret the counterfactual claim as a factual claim and give a similar response to that of the factual claim.
Appendix G Experimental Setting for Analysis
To give the base model initial dialogue ability, each set was supplemented with 48,818 general single-turn conversations, following HuatuoGPT. We adopt the ZeRO strategy to distribute the model across 4 A100 GPUs for training. The epoch, learning rate, batch_size, and maximum context length are set to 2, , 128, 64, and 2048, respectively.
| NotFollow | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
|||||||||||
|
|||||||||||
|
|||||||||||
|
| Sycophancy | |||||||
|---|---|---|---|---|---|---|---|
|
|||||||
|
|||||||
|
|||||||
|
| Safety | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
|
||||||||
|
||||||||
|
| Misinterpretation | |||||||
|---|---|---|---|---|---|---|---|
|
|||||||
|
|||||||
|
|||||||
|