QNCD: Quantization Noise Correction for Diffusion Models
Abstract.
Diffusion models have revolutionized image synthesis, setting new benchmarks in quality and creativity. However, their widespread adoption is hindered by the intensive computation required during the iterative denoising process. Post-training quantization (PTQ) presents a solution to accelerate sampling, aibeit at the expense of sample quality, extremely in low-bit settings. Addressing this, our study introduces a unified Quantization Noise Correction Scheme (QNCD), aimed at minishing quantization noise throughout the sampling process. We identify two primary quantization challenges: intra and inter quantization noise. Intra quantization noise, mainly exacerbated by embeddings in the resblock module, extends activation quantization ranges, increasing disturbances in each single denosing step. Besides, inter quantization noise stems from cumulative quantization deviations across the entire denoising process, altering data distributions step-by-step. QNCD combats these through embedding-derived feature smoothing for eliminating intra quantization noise and an effective runtime noise estimation module for dynamiclly filtering inter quantization noise. Extensive experiments demonstrate that our method outperforms previous quantization methods for diffusion models, achieving lossless results in W4A8 and W8A8 quantization settings on ImageNet (LDM-4). Code is available at: https://github.com/huanpengchu/QNCD.
1. Introduction

Recently, diffusion models have achieved remarkable progress in various synthesizing tasks, such as image generating (ho2020denoising, ), super-resolution (saharia2021image, ), image editing and in-panting (song2020score, ), image translation (sasaki2021unitddpm, ) etc. Compared to traditional SOTA generative adversarial networks (GANs (goodfellow2020generative, )), diffusion models do not suffer from the problem of model collapse and posterior collapse, exhibit higher stability.
However, this comes at the cost of the high computational resources and a large number of parameters required to run these models, which are only available on cloud-based devices. For example, Stable Diffusion (rombach2021high, ) requires 16 GB of running memory and GPU and more than 10 GB of VRAM, which is not feasible for most consumer-grade PCs, let alone resource-limited edge devices.
Our work employs post-training quantization (PTQ) to speed up the sampling process in all time steps, while avoiding the high cost of retraining diffusion models. PTQ, having been well-studied in traditional deep learning tasks like classification and segmentation (bhalgat2020lsq+, ; cai2020zeroq, ; guo2022squant, ), stands out as a preferred compression method due to the minimal requirements on training data and the convenience of direct deployment on hardware devices. Despite the many attractive benefits of PTQ, its implementation in diffusion models remains challenging. The main reason for this is that the framework of diffusion models is quite different from previous PTQ implementations (e.g., CNN and ViT (dosovitskiy2020image, ; liu2021post, ) for image recognition). Specifically, diffusion models commonly use UNet structures, which incorporate embedding. In addition, diffusion models iteratively invoke the same UNet model during sampling. In recent work, PTQ4DM (shang2023post, ) and Q-Diffusion (li2023q, ) first apply PTQ to diffusion models and attribute the challenge to the fact that the activation distribution is constantly changing with time steps. PTQD (PTQD, ) integrates partial quantization noise into diffusion perturbed noise and proposes a mixed-precision scheme.
In contrast, we analyze in detail the sources of quantization noise and its negative impact on sampling direction, image quality. Specifically, we propose QNCD, a novel post-training quantization noise correction scheme dedicated for diffusion models. First, we identify embeddings in resblock modules as the primary source of intra quantization noise, as embeddings amplifies the outliers of original features, making quantization challenging. We compute smoothing factors from embeddings, making features easy for quantization, thus reducing intra quantization noise. Besides, for inter quantization noise accumulated among sampling steps, we propose a run-time noise estimation module based on the diffusion and denoising theory of diffusion model. By filtering out the estimated quantization noise, our QNCD can dynamically correct deviations in output distribution throughout the sampling steps.
As shown in Fig. 1, with a smaller LPIPS Distance (dosovitskiy2016generating, ) and a higher CLIP Score (radford2021learning, ), the sampling direction of our QNCD more closely aligns with that of full-precision (FP) model. In addition, our method’s FID (heusel2017gans, ) metric consistently outperforms Q-Diffusion, with a final FID reduction of 2.23, reaching 27.33. Overall, our contributions are shown as follows:
-
•
We propose QNCD, a novel post-training quantization scheme for diffusion models to filter out quantization noise.
-
•
We find that a new challenge in quantizing diffusion models is the ongoing emergence and accumulation of quantization noise, which alters sampling direction and image quality.
-
•
We introduce a feature smooth approach to reduce intra quantization noise when combining features with embeddings. Simultaneously, we utilize a run-time noise estimation module to correct inter quantization noise
-
•
Our extensive experiments show that our method achieves new state-of-the-art performance for post-training quantization of diffusion models, especially in low-bit cases. Additionally, our methodology aligns more closely with the full-precision models in both objective metrics and subjective evaluations.
2. Related Work
Model quantization is a method that transitions from floating-point computations to low-precision fixed-point operations. This shift can effectively diminish the model’s computational burden, reduce parameter size and memory usage, and expedite computational processes.It can be divided into two main categories: quantization-aware training (QAT) (jacob2018quantization, ) and post-quantization training (PTQ). QAT often yields superior outcomes with significantly fewer bits, but comes with the cost of substantial training overhead and a need for the raw dataset. In constract, PTQ bypasses the need for extensive data retraining, leveraging just a fraction of unlabeled data for calibration, making it a more cost-effective and deployment-friendly alternative. Given that retraining for diffusion has an unaffordable cost (e.g the training of Stable Diffusion (rombach2021high, ) requires a cluster of over 4000 NVIDIA A100 GPUs), current works have pivoted towards PTQ to obtain low-bit diffusion models.
Until now, only a handful of current studies have focused on post-training quantization of diffusion models. Among them, PTQ4DM (shang2023post, ) devised a time-step aware sampling strategy for calibration dataset, but its experiments are limited to small datasets and low resolutions. Q-Diffusion (li2023q, ) employs a state-of-the-art PTQ method (BRECQ (li2021brecq, )) to obtain the performance, which imposes an additional training burden. PTQD (PTQD, ) integrates partial quantization noise into diffusion perturbed noise and proposes a mixed-precision scheme. TDQ (TDQ, ) dynamically adjusts the quantization interval based on time step information.
Our method analyze in detail the sources of quantization noise and propose corresponding correction modules. In addition, we employ the most primitive PTQ methods, inherently attributing the performance improvement to our approach.
3. Method
In Section 3.1, we provide an introduction to the sampling process of the diffusion model and present a unified formula for quantization noise. Following this, in Section 3.2, we analyze the sources of quantization noise and its impact on the sampling direction. In Section 3.3, we present the entire workflow of QNCD.

3.1. Preliminaries
Diffusion models are a family of probabilistic generative models that progressively destruct real data by injecting noise, then learn to reverse this process for generation, represented notably by denosing diffusion probabilistic models (DDPMs (ho2020denoising, )). DDPM is composed of two chains: a forward chain that perturbs data to noise, and a reverse chain that converts noise back to data. The former is usually designed by hand and its goal is to convert any data distribution into a simple prior distribution (e.g., a standard Gaussian distribution). Given a data distribution , the forward process generates a sequence of random variables with transition kernel :
| (1) |
where and are hyper parameters and .
In the denoising process, with a Gaussian noise , the diffusion model can generate samples by iterative sampling from until obtaining , where the Gaussian distribution is a simulation of the unavailable real distribution . The mean value of is calculated from the noise prediction network (usually the UNet model):
| (2) |
where . Therefore, the sampling process of is shown as follows:
| (3) |
The diffusion model continuously evokes the noise prediction network to acquire the noise and filter it out. The huge number of iterative time steps (sometimes =4000) and the complexity of the noise prediction network make the sampling of diffusion models expensive. Post-training quantization for diffusion models is performed on the noise prediction network , which inevitably introduces quantization noise.
| (4) |
The noise prediction network UNet is constructed from multiple Resblocks, where parameterized operations (such as convolutions, fully connected layers, etc.) will generate intra quantization noise within the single-step sampling. From the perspective of complete sampling process, these intra quantization noises accumulate to form inter quantization noise which further accumulates in the current output , thus affecting subsequent sampling processes.
3.2. Quantization noise analysis
3.2.1. Intra Quantization Noise introduced by embedding
We consider the quantization noise within the denoising network UNet in a single sampling step as intra quantization noise, which is strongly affected by embedding. As shown in Fig. 2(a), intra quantization noise of the diffusion model exhibits periodic changes during a single step. It escalates when embedding is incorporated into features but then decreases during the fusion of UNet’s low-level and high-level features. This cyclical behavior underscores that the primary culprit of quantization noise is the embedding integration phase. Take the embedding fusion stage of DDIM as an example:
| (5) |
Where stands for activation and is the corresponding embedding. imparts an utterly different distribution to activation . In Fig. 2(b), the distribution of feature generally stabilizes within a quantization-friendly range after processing through a normalization layer. However, the emergence of outliers within the activated correlation channel may pose a challenge.
These outliers are several magnitudes larger than the majority of the data, leading to a skew in the maximum magnitude measurement during quantization. This dominance by outliers could possibly result in reduced precision for the majority of non-outlier values. Further complications arise with the incorporation of embedding, as shown in the middle part of Fig. 2(b). Embedding separates a dimensional scale vector which scales the feature on a channel-by-channel basis. This channel-specific scaling alters the distribution of the activation in a manner that certain channels, especially those with problematic outliers, experience amplification. Since activations are typically per-tensor quantized, the combined effect of embedding magnification and existing outliers makes the quantization of activations less efficient.
In summary, after normalization, feature is easily quantifiable, but with the introduction of , it becomes challenging to quantify , indicating an increase in intra quantization noise.

3.2.2. Inter Quantization Noise
Diffusion models attain their final outputs through iterative denoising network calls. During this procedure, the inter quantization noise, expressed as in Eq. 4, assimilates into and advances to the subsequent denoising step, exerting an influence over the entire sampling process.
As shown in Fig. 3, we plot the variation curves of the output Mean and Std during sampling steps. The accumulated inter quantization noise changes the distribution of synthesized data. With continuous sampling, the data distribution of the quantization model further deviates from that of the full-precision model.
3.3. Effect of Quantization Noise
Quantization noise reduces the sampling efficiency of the diffusion model, changes the sampling direction, and ultimately reduces the quality of the synthesized image.
First, the introduction of quantization noise gives rise to new noise sources that necessitate denoising, substantially impairing the sampling efficiency of diffusion models. As depicted in Fig. 1, we compare LPIPS distance and FID metrics at each step between the full-precision model and the quantized model. The quantized diffusion model has a FID metric of 194.11 after 30 steps, which is still much larger than the result of the full-precision (FP) model after only 10 steps (FID = 140.76).
Besides, quantization noise also alters the iteration direction of diffusion models. In Fig. 1, we visualize the changing trend of CLIP Score for different methods to provide a more intuitive representation of the iteration direction. At the beginning of the iteration, all methods start with relatively low CLIP Scores, while full-precision model’s score continues to rise, indicating correct iteration direction. By step 25, quantized diffusion model shows a 3.16% difference in CLIP Score compared to full-precision model (26.09% vs. 29.25%).
In conclusion, quantization noise presents challenges in maintaining performance following model quantization. This not only calls for minimizing intra quantization noise as much as possible at all steps but also necessitates estimating and filtering out the remaining accumulated inter quantization noise.
3.4. Qunantization Noise Correction for Diffusion Models
We propose two techniques: intra quantization correction techniques and inter quantization correction techniques to address the challenges identified in the previous section.

3.4.1. Intra Quantization Correction
As shown in Fig.2, during the single-step sampling process, embedding amplifies outliers of activation, leading to an imbalance among channels. Ultimately, this induces a periodic increase in intra quantization noise. For reducing intra quantization noise, we propose the utilization of a channel-specific smoothing factor . By dividing activation with their respective values, channels are balanced out and more adaptable to quantization. We then incorporate the filtered factor into weights, thus maintaining mathematical equivalence of the convolution, as follows:
| (6) |
Ultimately, we can transfer the quantization challenges presented by embedding from activations to weights, which are more robust to quantization.
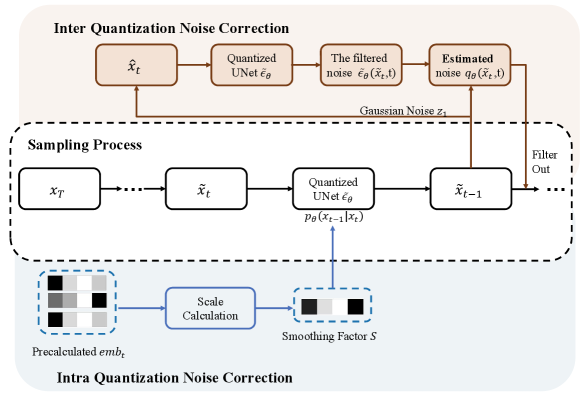
Since embedding operates on a channel-by-channel basis, our goal is to derive a factor for each channel from the embedding, making easier to quantize. As evident from Eq. 5, the term , derived from the separation from embedding, accentuates the discrepancies among the activation channels. However, is dynamic and fluctuates based on the time step . Consequently, we examine the embedding across all scenarios to ascertain the mean value of and employ it as a static factor :
| (7) |
As shown in Fig. 2(b), The static factor we obtained serves to calibrate these unbalanced channels, harmonizing the distribution across each one, rendering the eventual activations more conducive to per-tensor quantization. Different and are highly similar, with only minor amplitude differences present on some channels.
In addition, in LDM-type diffusion models, embedding is incorporated differently than in Eq. 5:
| (8) |
where and are pretrained affine transform parameters in the Group-Norm operation. At this point, the distribution of the final activation is jointly determined by and the coefficients of group norms. Thus, our smoothing factor is calculated as follows:
| (9) |
In Fig. 4, we present a visualization of within across various modules, time steps, and categories. The key observation is that the distribution of exhibits imbalance, unevenly scaling the input activations by channel, which renders the activations less suitable for quantization. Despite this, the aggregate distribution of different remains relatively stable, with only minor amplitude discrepancies across certain channels.
Our smoothing factor is thus capable of effectively representing the encountered during the sampling phase. By filtering through , our QNCD method mitigates the enhancing impact of on activation outliers, leading to a reduction in intra quantization noise. Crucially, is pre-computed prior to the formal inference stage for each Resblock, ensuring no additional computational load during the actual inference.
3.4.2. Inter Quantization Noise Correction
Eq. 4 shows the process of a single-step sampling in diffusion models, where UNet outputs the filtered noise . It consists of two parts, the de-noising noise , and inter quantization noise , which keeps accumulating in . Ideally, we filter out , thus avoiding the accumulation of quantization noise, but it is impractical to separate from .
The training stage of the diffusion model gives us a possibility to separate :
| (10) |
Eq. 10 does a single-step diffusion operation, where a Gaussian noise is added to to get .
| (11) |
The training process of the diffusion model (Eq. 11) drives the denoising network to learn the distribution of Gaussian noise , which means is satisfied in the pre-trained diffusion model.
This property is still guaranteed in the quantized pre-trained diffusion model:
| (12) |
As shown in Fig. 5 and Eq. 12, we add the standard Gaussian noise to to get , and feed it into the quantized model . The output of the quantized model contains both the Gaussian noise to be filtered out and the newly introduced quantization noise . is obtained by a single-step denoising and diffusion process on , thus their distributions remain highly similar as well as the corresponding quantization noise:
| (13) |
Finally, the quantization noise can be determined, as the Gaussian noise is manually designed and is the output of the noise predicting network, both of which are ascertainable.
Based on the above analysis, we can estimate the quantization noise by simulating the diffusion model training process. We first add the deterministic noise to , which can be filtered out in the diffusion sample process, and then the rest of the indeterministic noise is the quantization noise . Besides, the quantization noise is obtained through estimation and doesn’t align perfectly with the actual noise in terms of pixel dimension, whereas it is identical at the level of the overall distribution. Thus we get the distribution of the quantization noise at stage and correct the output sample in Eq. 4.
The above procedure is for single-step quantization noise estimation. In the diffusion model, the distributions of samples from neighboring steps are very similar, as well as the corresponding quantization noise distribution (). Therefore, in actual sampling process, we divide entire sampling steps into multiple stages, estimating the distribution of quantization noise one time per stage. For example our method run only 4 times to estimate the quantization noise during a sampling process of 100 time steps, which brings a negligible increase in sampling duration. As shown in Fig. 3, our QNCD periodically estimates the distribution of inter quantization noise and corrects distribution deviations caused by this noise. This noise correction enables the distribution of sample outputs to closely align with the full-precision models.
3.5. Summary of methods
As shown in Fig. 5, our method contains two major blocks: intra quantization noise correction module and inter quantization noise correction module. Firstly, we determine the smoothing factor on a channel-by-channel basis, thereby transitioning the distribution disparities induced by embedding to the weights, which makes the activation easier for quantization. Secondly, we discern the distribution of quantization noise via our run-time noise estimation module, enabling its exclusion in subsequent sampling steps.
4. Experiments
4.1. Implementation Details
Datasets and quantization settings: Consistent with the experimental details of PTQ4DM (shang2023post, ), Q-Diffusion (li2023q, ), we conduct image synthesis experiments using pre-trained diffusion models (DDIM (song2020denoising, )) , latent diffusion models (LDM (rombach2021high, )) and Stable Diffusion on four standard benchmarks: CIFAR(3232) (krizhevsky2009learning, ), ImageNet (256256) (deng2009imagenet, ), LSUN-Bedrooms(256256) (yu2015lsun, ), MS-COCO (512512) (cocodataset, ). All experimental configurations, including the number of steps and variance, follow the official implementation. To facilitate method validation and comparison, we use the naive PTQ method (MSE-based range setting) for 8-bit quantization due to its simplicity and speed. For 4-bit weight quantization, we adopt BRECQ (li2021brecq, ) and Adaround (nagel2020adaptive, ) to ensure model performance. We uniformly sample from all time steps to create the PTQ calibration dataset, using 5120 samples for all datasets.
Evaluation Details: For each experiment we report the widely adopted Frechet Inception Distance (FID) (heusel2017gans, ) and sFID (salimans2016improved, ) to evaluate performance. For ImageNet and CIFAR experiments, we additionally report Inception Score (IS) (barratt2018note, ) for reference to ensure consistency of reported results. For MS-COCO, we introduce CLIP Score to ensure the correspondence between the synthesized images and prompts.
In line with Q-Diffusion, we generated 50,000 samples for evaluation. Due to the time-consuming nature of sampling high-resolution images like MS-COCO, we produced only 10,000 samples with Stable Diffusion to speed up the comparison process.
4.2. Unconditional Generation
| Method | Bitwidth | DDIM(Steps=100) | DDIM(Steps=250) | ||||
| (W/A) | IS | FID | sFID | IS | FID | sFID | |
| FP | 32/32 | 9.04 | 4.19 | 4.41 | 9.06 | 4.00 | 4.35 |
| TDQ | 8/8 | 8.85 | 5.99 | - | - | - | - |
| Q-Diffusion | 8/8 | 9.17 | 3.93 | 4.34 | 9.38 | 3.84 | 4.27 |
| Ours | 8/8 | 9.24 | 3.36 | 4.24 | 9.41 | 3.46 | 4.21 |
| Q-Diffusion | 4/8 | 9.41 | 4.92 | 5.13 | 9.64 | 4.37 | 4.59 |
| Ours | 4/8 | 9.53 | 4.85 | 5.06 | 9.78 | 4.43 | 4.51 |
| Q-Diffusion | 4/6 | 7.53 | 39.07 | 43.36 | 7.81 | 34.65 | 37.29 |
| Ours | 4/6 | 8.86 | 12.26 | 14.83 | 9.01 | 11.09 | 13.46 |
| Method | ImageNet(FID / IS ) | LSUN-Bed(FID / SFID ) | ||
|---|---|---|---|---|
| (FP:11.42/245.39) | (FP:3.16/7.84) | |||
| W8A8 | W4A8 | W4A6 | W8A8 | |
| 11.94/153.92 | 10.40/214.73 | - | 3.75/9.89 | |
| - | - | 41.23/- | - | |
| Q-Diffusion | 10.92/229.31 | 9.56/219.64 | 41.25/89.82 | 4.03/10.15 |
| QNCD | 10.57/231.85 | 9.48/221.62 | 20.14/136.49 | 3.82/9.65 |
Results on CIFAR: The results are displayed in Tab 1. Note that WA means -bit quantization for weights and -bit for activations. At W8A8 bitwidth, our method achieves FIDs and sFIDs close to the full-precision model, with FID reductions of 0.57 (steps=100) and 0.38 (steps=250) compared to Q-Diffusion. Previous methods struggled with low-bit quantization noise, leading to high FIDs and sFIDs, such as 39.07 and 43.36 for W4A6 at 100 steps with Q-Diffusion. Our method effectively eliminates this noise, achieving a much lower FID of 12.26, proving its effectiveness. Our method enables 6-bit activation quantization on diffusion models without performance collapse, unlike previous methods limited to 8-bit.
Results on LSUN-Bedrooms: At the W8A8 bitwidth, our method reduces the FID by 0.21 compared to Q-Diffusion as shown in Tab. 2, proving the effectiveness of our method on the task of high-resolution image synthesis.
4.3. Class-conditional Generation



Results on ImageNet: we carry out complex experiments on the generation of conditional ImageNet datasets to demonstrate the effectiveness of our method. To facilitate the validation, we adopt the LDM-4 model with 20 steps. As shown in the Tab. 2, our method consistently narrows the performance gap between quantized and full-precision diffusion models. Specifically, under the settings of W8A8 and W4A8, our QNCD can approach lossless performance. It is worth noting that at the W4A6 bidwidth setting, the IS of Q-Diffusion drops to 89.82, which is 156.1 lower than that of the full-precision model (245.39). Our method well handles the low-bit quantization of the activation. Compared to the FID of Q-Diffusion which is as high as 41.25, the FID of our method is 20.14, indicating the effectiveness of our method. The visualizations are available in the Appendix.

4.4. Text-guided Image Generation
We assess the performance of QNCD through Stable Diffusion for text-guided image generation, using text prompts derived from the MS-COCO dataset. As demonstrated in Tab. 7, our method surpasses Q-Diffusion in both FID metrics and CLIP Scores.
In addition, we visualize the final generated image in Fig. 6. For all three methods (FP, Q-Diffusion, and ours), we have given the same content conditions as input to facilitate comparison. It can be noticed that the accumulated quantization noise changes the content space of the image, causing the final synthesized image to be shifted. As shown in the red box in Fig.6, the synthesized image shows the importation of abnormal content , such as abnormal faces, incomplete bowls and floating cows. Compared with Q-Diffusion, our method provides a higher quality image, which is closer to the full-precision model synthesized image and has more realistic details, colors, and richer semantic information. In conclusion, our method effectively mitigates the quantization noise, and is closer to the full-precision model not only in terms of statistical metrics, but also in terms of visualization. More visualization results are shown in Appendix.
| Method | Bitwidth | Stable Diffusion(Steps=50) | |
| (W/A) | FID | CLIP Score | |
| FP | 32/32 | 23.80 | 30.54 |
| Q-Diffusion | 8/8 | 27.84 | 30.23 |
| Intra-QNCD | 8/8 | 27.41 | 30.25 |
| Inter-QNCD | 8/8 | 27.60 | 30.29 |
| QNCD | 8/8 | 27.33 | 30.32 |

4.5. Ablation Study
4.5.1. Comparison of SNR and Cosine Similarity.
Given the output of the floating-point noise prediction network and the corresponding quantization noise, we plot the change curve of the signal-to-noise ratio (SNR) of the quantized diffusion model, as shown in Fig. 8, as well as the cosine similarity between the corresponding output and the FP output. We can find that: 1, with the increase of denoising steps, the cosine similarity between the quantized model output and the FP output is continuously decreasing, which also means that the overall quantization noise is continuously accumulating, and the corresponding SNR is continuously decreasing. 2, our method can estimate and filter out the quantization noise on a global scale, resulting in a better SNR, and a sampling process closer to that of the floating-point model.
4.5.2. Effects of each module
As shown in Tab. 3, we conducted ablation experiments on Stable Diffusion (step=50) with MS-COCO 512×512 dataset to demonstrate the effectiveness of our QNCD, which includes intra quantization noise correction (Intra-QNCD) and inter quantization noise correction (Inter-QNCD). Intra-QNCD reduces FID by 0.43 compared to Q-Diffusion, while Inter-QNCD reduces FID by 0.24 and improves the CLIP Score by 0.06. Combining both blocks, QNCD achieves a 0.51 reduction in FID, showing their collaborative effectiveness in improving performance. These results validate our noise correction techniques in post-training quantization of diffusion models.
| FP16 | Original PTQ(W8A8) | Q-Diffusion(W8A8) | QNCD(W8A8) | |
|---|---|---|---|---|
| Inference Time | 959.5ms | 601.8ms | 628.3ms | 631.2ms |
| IQA Score(0 1) | 0.847 | 0.728 | 0.775 | 0.793 |
4.5.3. Comparison of real inference efficiency
For fair comparison, we provide end-to-end inference times in Tab. 4. Inference times are based on the UNet of Stable Diffusion V1.4, which denote whole denoising process of diffusion models. The experimental background is A100, TensorRT-8.6 and CUDA-11.7. Similarly to our QNCD, Q-Diffusion introduces the Short-Cut split operation in pursuit of better model performance, which also imposes an additional inference burden (26.5ms compared to original PTQ). Our method runs at a similar speed to Q-Diffusion, but with higher image quality.
4.5.4. Comparison through Image Quality Assessment
As shown in Tab. 2, the FID metrics of PTQD and Q-Diffusion on ImageNet dataset are 11.94 and 10.92, superior to the FP’s score of 12.45 under the W8A8 setting. This same pattern extends to the LSUN-Bedrooms and CIFAR datasets, which is unexpected and implies that the FID metric may not be an optimal indicator of image quality. This is because FID focuses more on the overall distribution similarity rather than the specific quality of each image. For a more comprehensive comparison, we further refer to objective Image Quality Assessment(IQA) metrics proposed in CLIP-IQA (clipiqa, ) to evaluate 5000 synthesized images. Our method achieves an IQA metric of 0.793, which is better than Q-Diffusion (0.775), but still falls short compared to FP (0.847).
5. Conclusion
In this paper, we propose QNCD, a unified quantization noise correction scheme for diffusion models. To start with, we do a detailed analysis of the sources and effects of quantization noise in terms of visualization and actual metrics, and find that the periodic increase in intra quantization noise comes from embedding’s alteration of feature distributions. Thus, we calculate a smoothing factor for features to reduce quantization noise. Besides, a run-time noise estimation module is proposed to estimate the distribution of inter quantization noise, which is further filtered out in the sampling process of the diffusion model. Leveraging these techniques, our QNCD surpasses existing state-of-the-art post-training quantized diffusion models, especially at low-bit activation quantization (W4A6). Our approach achieves the current SOTA on multiple diffusion modeling frameworks (DDIM , LDM and Stable Diffusion) and multiple datasets, demonstrating the broad applicability of QNCD.
Acknowledgements
We want to extend our heartfelt thanks to everyone who has provided their suggestions regarding our manuscript. Their insightful comments and constructive feedback have significantly contributed to the improvement of this paper.
References
- (1) Barratt, S., Sharma, R.: A note on the inception score. arXiv preprint arXiv:1801.01973 (2018)
- (2) Bhalgat, Y., Lee, J., Nagel, M., Blankevoort, T., Kwak, N.: Lsq+: Improving low-bit quantization through learnable offsets and better initialization. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 2978–2985 (2020)
- (3) Cai, Y., Yao, Z., Dong, Z., Gholami, A., Mahoney, M.W., Keutzer, K.: Zeroq: A novel zero shot quantization framework. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13166–13175 (2020)
- (4) Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
- (5) Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
- (6) Dosovitskiy, A., Brox, T.: Generating images with perceptual similarity metrics based on deep networks. Advances in neural information processing systems 29 (2016)
- (7) Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Communications of the ACM 63(11), 139–144 (2020)
- (8) Guo, C., Qiu, Y., Leng, J., Gao, X., Zhang, C., Liu, Y., Yang, F., Zhu, Y., Guo, M.: Squant: On-the-fly data-free quantization via diagonal hessian approximation. ArXiv (abs/2202.07471), 1–14 (2022)
- (9) He, Y., Liu, L., Liu, J., Wu, W., Zhou, H., Zhuang, B.: Ptqd: Accurate post-training quantization for diffusion models. Advances in Neural Information Processing Systems 36 (2024)
- (10) Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. In: Advances in Neural Information Processing Systems. vol. 30, pp. 12–21 (2017)
- (11) Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems 33(6), 6840–6851 (2020)
- (12) Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., Kalenichenko, D.: Quantization and training of neural networks for efficient integer-arithmetic-only inference. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2704–2713 (2018)
- (13) Krizhevsky, A., et al.: Learning multiple layers of features from tiny images (2009), 4, 6
- (14) Li, X., Lian, L., Liu, Y., Yang, H., Dong, Z., Kang, D., Zhang, S., Keutzer, K.: Q-diffusion: Quantizing diffusion models. arXiv preprint arXiv:2302.04304 (2023)
- (15) Li, Y., Gong, R., Tan, X., Yang, Y., Hu, P., Zhang, Q., Yu, F., Wang, W., Gu, S.: Brecq: Pushing the limit of post-training quantization by block reconstruction. In: International Conference on Learning Representations (2021)
- (16) Lin, T., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: Common Objects in Context. arXiv preprint arXiv:1405.0312 (2014)
- (17) Liu, Z., Wang, Y., Han, K., Zhang, W., Ma, S., Gao, W.: Post-training quantization for vision transformer. Advances in Neural Information Processing Systems 34, 28092–28103 (2021)
- (18) Nagel, M., Amjad, R.A., Baalen, M.v., Louizos, C., Blankevoort, T.: Up or down? adaptive rounding for post-training quantization. arXiv preprint arXiv:2004.10568 (2020)
- (19) Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
- (20) Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10674–10685 (2021)
- (21) Saharia, C., Ho, J., Chan, W., Salimans, T., Fleet, D.J., Norouzi, M.: Image superresolution via iterative refinement. IEEE Transactions on Pattern Analysis and Machine Intelligence PP (2021)
- (22) Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X.: Improved techniques for training gans. In: Advances in neural information processing systems. vol. 29 (2016)
- (23) Sasaki, H., Willcocks, C.G., Breckon, T.: Unitddpm: Unpaired image translation with denoising diffusion probabilistic models. arXiv preprint arXiv:2104.05358 (2021)
- (24) Shang, Y., Yuan, Z., Xie, B., Wu, B., Yan, Y.: Post-training quantization on diffusion models. In: CVPR (2023)
- (25) So, J., Lee, J., Ahn, D., Kim, H., Park, E.: Temporal dynamic quantization for diffusion models. Advances in Neural Information Processing Systems 36 (2024)
- (26) Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
- (27) Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
- (28) Wang, J., Chan, K.C., Loy, C.C.: Exploring clip for assessing the look and feel of images. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 2555–2563 (2023)
- (29) Yu, F., Seff, A., Zhang, Y., Song, S., Funkhouser, T., Xiao, J.: Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365 (2015)