Pushing Boundaries:
Mixup’s Influence on Neural Collapse
Abstract
Mixup is a data augmentation strategy that employs convex combinations of training instances and their respective labels to augment the robustness and calibration of deep neural networks. Despite its widespread adoption, the nuanced mechanisms that underpin its success are not entirely understood. The observed phenomenon of Neural Collapse, where the last-layer activations and classifier of deep networks converge to a simplex equiangular tight frame (ETF), provides a compelling motivation to explore whether mixup induces alternative geometric configurations and whether those could explain its success. In this study, we delve into the last-layer activations of training data for deep networks subjected to mixup, aiming to uncover insights into its operational efficacy. Our investigation (code), spanning various architectures and dataset pairs, reveals that mixup’s last-layer activations predominantly converge to a distinctive configuration different than one might expect. In this configuration, activations from mixed-up examples of identical classes align with the classifier, while those from different classes delineate channels along the decision boundary. Moreover, activations in earlier layers exhibit patterns, as if trained with manifold mixup. These findings are unexpected, as mixed-up features are not simple convex combinations of feature class means (as one might get, for example, by training mixup with the mean squared error loss). By analyzing this distinctive geometric configuration, we elucidate the mechanisms by which mixup enhances model calibration. To further validate our empirical observations, we conduct a theoretical analysis under the assumption of an unconstrained features model, utilizing the mixup loss. Through this, we characterize and derive the optimal last-layer features under the assumption that the classifier forms a simplex ETF.
1 Introduction
Consider a classification problem characterized by an input space and an output space . Given a training set , with denoting the -th input data point and representing the corresponding label, the goal is to train a model by finding parameters that minimize the cross-entropy loss incurred by the model’s prediction relative to the true target , averaged over the training set, .
Papyan, Han, and Donoho (2020) observed that optimizing this loss leads to a phenomenon called Neural Collapse, where the last-layer activations and classifiers of the network converge to the geometric configuration of a simplex equiangular tight frame (ETF). This phenomenon reflects the natural tendency of the networks to organize the representations of different classes such that each class’s representations and classifiers become aligned, equinorm, and equiangularly spaced, providing optimal separation in the feature space. Understanding Neural Collapse is challenging due to the complex structure and inherent non-linearity of neural networks. Motivated by the expressivity of overparametrized models, the unconstrained features model (Mixon et al., 2020) and the layer-peeled model (Fang et al., 2021) have been introduced to study Neural Collapse theoretically. These mathematical models treat the last-layer features as free optimization variables along with the classifier weights, abstracting away the intricacies of the deep neural network.
1.1 Mixup
Mixup, a data augmentation strategy proposed by Zhang et al. (2017), generates new training examples through convex combinations of existing data points and labels:
where is a randomly sampled value from a predetermined distribution . Conventionally, this distribution is a symmetric distribution, with frequently set as the default. The loss associated with mixup can be mathematically represented as:
| (1) |
A specific mixup data point, represented as , is categorized as a same-class mixup point when , and classified as different-class when .
1.2 Problem Statement
Despite the widespread use and demonstrated efficacy of the mixup data augmentation strategy in enhancing the generalization and calibration of deep neural networks, its underlying operational mechanisms remain not well understood. The emergence of Neural Collapse prompts the following question:
Does mixup induce its own distinct configurations in last-layer activations, differing from traditional Neural Collapse? If so, does the configuration contribute to the method’s success?
This study aims to uncover the potential geometric configurations in the last-layer activations resulting from mixup and to determine whether these configurations can offer insights into its success.
1.3 Contributions
Our contributions in this paper are twofold.
Empirical Study and Discovery
We conduct an extensive empirical study focusing on the last-layer activations of mixup training data. Our study reveals that mixup induces a geometric configuration of last-layer activations across various datasets and models. This configuration is characterized by distinct behaviours:
-
•
Same-Class Activations: These form a simplex ETF, aligning with their respective classifier.
-
•
Different-Class Activations: These form channels along the decision boundary of the classifiers, exhibiting interesting behaviors: Data points with a mixup coefficient, , closer to 0.5 are located nearer to the middle of the channels. The density of different-class mixup points increases as approaches 0.5, indicating a collapsing behaviour towards the channels.
We investigate how this configuration varies under different training settings and the layer-wise trajectory the features take to arrive at the configuration. Additionally, the configuration offers insight into mixup’s success. Specifically, we measure the calibration induced by mixup and present an explanation for why the configuration leads to increased calibration.
Motivated by our theoretical analysis, we also examine the configuration of the last-layer activations obtained through training with mixup while fixing the classifier as a simplex ETF.
Theoretical Analysis
We provide a theoretical analysis of the discovered phenomenon, utilizing an adapted unconstrained features model tailored for the mixup training objective. Assuming the classifier forms a simplex ETF under optimality, we theoretically characterize the optimal last-layer activations for all class pairs and for every .
1.4 Results Summary
The results of our extensive empirical investigation are presented in Figures 1, 3, 5, 10, and 12. These figures collectively illustrate a consistent identification of a unique last-layer configuration induced by mixup, observed across a diverse range of:
- Architectures:
- Datasets:
- Optimizers:
The networks trained showed good generalization performance and calibration, as substantiated by the data presented in Tables 1 and 2. That is, the values are comparable to those found in other papers (Zhang et al., 2017; Thulasidasan et al., 2020).
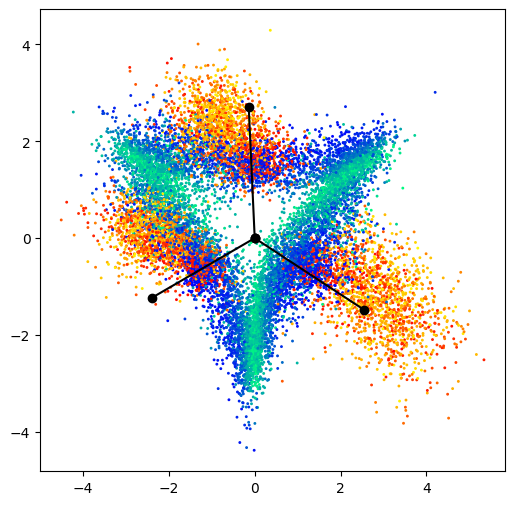
Beyond our principal observations, we conducted a counterfactual experiment, the results of which are depicted in Figures 2 and 8. These reveal a notable divergence in the configuration of the last-layer features when mixup is not employed. They also show that for MSE loss, the last-layer activations are convex combinations of the classifiers, which one may expect.
Furthermore, we juxtaposed the findings from our empirical investigation with theoretically optimal features, which were derived from an unconstrained features model and are showcased in Figure 6.
| Network | Dataset | Baseline | Mixup |
|---|---|---|---|
| FashionMNIST | 95.10 | 94.21 | |
| WideResNet-40-10 | CIFAR10 | 96.2 | 97.30 |
| CIFAR100 | 80.03 | 81.42 | |
| FashionMNIST | 93.71 | 94.24 | |
| ViT-B/4 | CIFAR10 | 86.92 | 92.56 |
| CIFAR100 | 59.95 | 69.83 |
To complement these results, we train models using mixup while fixing the classifier as a simplex ETF, and we plot the last-layer features in Figure 7. This yields last-layer features that align more closely with the theoretical features.








2 Experiments
2.1 Model Training
We consider FashionMNIST (Xiao et al., 2017), CIFAR10, and CIFAR100 (Krizhevsky & Hinton, 2009) datasets. Unless otherwise indicated, for all experiments using mixup augmentation, was used, meaning was sampled uniformly between 0 and 1. Each dataset is trained on both a Vision Transformer (Dosovitskiy et al., 2021), and a wide residual network (Zagoruyko & Komodakis, 2017). For each network and dataset combination, the experiment with the highest test accuracy is repeated without mixup and is referred to as the “baseline” result. No dropout was used in any experiments. Hyperparameter details are outlined in Appendix B.1.
2.2 Visualizations of last-layer activations
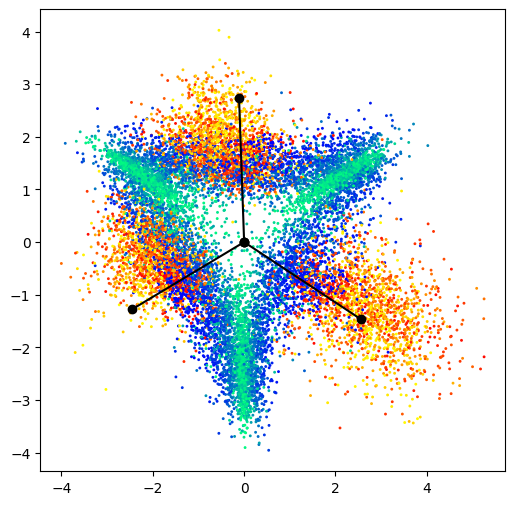
For each dataset and network pair, we visualize the last-layer activations for a subset of the training dataset consisting of three randomly selected classes. After obtaining the last-layer activations, they undergo a two-step projection: first onto the classifier for the subset of three classes, then onto a two-dimensional representation of a three-dimensional simplex ETF. A more detailed explanation of the projection can be found in Appendix B.2. The results of this experiment can be seen in Figure 1. Notably, activations from mixed-up examples of the same classes closely align with a simplex ETF structure, whereas those from different classes delineate channels along the decision boundary. Additionally, in certain plots, activations from mixed-up examples of different classes become increasingly sparse as approaches 0 and 1. This suggests a clustering of activations towards the channels. When generating plots, we keep the network in train mode 111We choose to have the network in evaluation mode for the WideResNet-40-10 CIFAR100 combination because the batch statistics are highly skewed due to the high number of classes.. Since ViT does not have batch normalization layers, this difference is not applicable.
2.3 Comparison of different loss functions
As part of our empirical investigation, we have conducted experiments utilizing Mean Squared Error (MSE) loss instead of cross-entropy, through which we observed in Figure 2 that features of mixed up examples are derived from simple convex combinations of same-class features. Initially, we anticipated a similar uninteresting configuration for cross-entropy; however, our measurements reveal that the resulting geometric configurations are markedly more interesting and complex. Additionally, we compare results in Figure 1 to the baseline (trained without mixup) cross-entropy loss in Figure 2. For the baseline networks, mixup data is loosely aligned with the classifier, regardless of same-class or different-class. The area in between classifiers is noisy and filled with examples where is close to 0.5. Additional baseline last-layer activations can be found in Figure 8.


2.4 Layer-wise trajectory of CLS token
Using the same projection method as in Figure 1, we investigate the trajectory of the CLS token for ViT models. First, we randomly select two CIFAR10 training images. Then, we create a selection of mixed up examples using the respective images. For each mixed up example, we project the path of the CLS token at each layer of the ViT-B/4 network.
Figure 3 presents the results for two images of the same class, and two images of a different class. For different-class mixup, the plot shows that for very small , the network first classifies the image as class 1 and only in deeper layers it realizes the image is also partially class 2.
The results in Figure 1 suggest that applying mixup to input data enforces a particularly rigid geometric structure on the last-layer activations. Manifold mixup (Verma et al., 2019), a subsequent technique, proposes the mixing of features across various layers of a network. The results in Figure 3 suggest that using regular mixup promotes manifold mixup-like behaviour in previous layers.


2.5 Calibration
Thulasidasan et al. (2020) demonstrated that mixup improves calibration for networks. That is, training with mixup causes the softmax probabilities to be in closer alignment with the true probabilities of misclassification. To measure a network’s calibration, we use the expected calibration error (ECE) as proposed by Pakdaman Naeini et al. (2015). The exact definition of ECE can be found in Appendix C. Results for ECE can be found in Table 2. Last-layer activation plots for are available in Figure 9 in Appendix D.
| Network | Baseline | Mixup () | Mixup () |
|---|---|---|---|
| WideResnet-40-10 | 0.024 | 0.077 | 0.013 |
| ViT-B/4 | 0.122 | 0.014 | 0.019 |
The configuration presented in Figure 1 sheds light on why mixup improves calibration. Recall, mixup promotes alignment of the model’s softmax probabilities for the training example with its label . Here, acts as a gauge for these softmax probabilities, essentially reflecting the model’s confidence in its predictions. Turning to Figure 4, it becomes therefore evident that as nears 0.5, the model’s certainty in its predictions diminishes. This reduction in confidence is manifested geometrically through the spatial distribution of features along the channel. This, in turn, causes an increase in misclassification rates, due to a greater chance of activations erroneously crossing the decision boundary. This simultaneous reduction in confidence and classification accuracy leads to enhanced calibration in the model and is purely attributed to the geometric structure to which the model converged. The above logic holds as we traverse the train mixed up features but we expect some test features to be noisy perturbations of train mixed up features.
3 Unconstrained features model for mixup
3.1 Theoretical characterization of optimal last-layer leatures
To study the resulting last-layer features under mixup, we consider an adaptation of the unconstrained features model to mixup training. Let be the dimension of the last-layer features, be the one-hot vector in entry , be the classifier, and be the last-layer feature associated with target . Then, adapting Equation 1 to the unconstrained features setting, we consider the optimization problem given by
| (2) |
where are the weight decay parameters. It is reasonable to consider decay on the features , a practice that is frequently observed in prior work (Zhu et al., 2021; Zhou et al., 2022), due to the implicit decay to the last-layer features from the inclusion of decay in the previous layers’ parameters.
The following theorem characterizes the optimal last-layer features under the assumption that the optimal classifier is a simplex ETF, ie.
| (3) |
where is the identity, is the ones vector, is a partial orthogonal matrix (satisfying ), and is its multiplier.
Note that we make this assumption as it holds in practice based on our empirical measurements illustrated in Figure 5.
Theorem 3.1.
Assume that at optimality, is a simplex ETF with multiplier , and denote the -th row of by . Then, any minimizer of equation 2 satisfies:
1) Same-Class: For all and ,
where is the unique solution to the equation
2) Different-Class: For all and ,
where is of the form
and satisfies
Interpretation of Theorem.
Theorem 3.1 establishes that, within the framework of our model’s assumptions, the optimal same-class features are independent of and align with the classifier as a simplex ETF. In contrast, the optimal features for different classes are linear combinations (depending on ) of the classifier rows corresponding to the mixed-up targets. This is consistent with the observations in Figure 1, where the same-class features consistently cluster at simplex vertices, regardless of the value of , while the different-class features dynamically flow between these vertices as varies.




In Figure 6, we plot the last-layer features obtained from Theorem 3.1, numerically solving for the values of and that satisfy their respective equations.


Similar to the empirical results in Figure 1, the density of different-class mixup points decreases as lambda approaches 0 and 1. However, the theoretically optimal features exhibit channels arranged in a hexagonal pattern, differing from the empirical features observed in the FashionMNIST and CIFAR10 datasets. In particular, in the empirical representations, there is a more pronounced elongation of different-class features as the mixup parameter approaches . In attempt to understand these differences, we introduce an amplification of these same features in the directions of the classifier rows not corresponding to the mixed-up targets, with increasing amplifications as gets closer to 0.5 (details of the amplification function is outlined in Appendix A.2). This results in the plot on the right that behaves more similarly to the other empirical outcomes, while achieving a very close (though marginally larger) loss when compared to the true optimal configuration (the loss values are indicated below each plot in Figure 6). This demonstrates that the features have some degree of flexibility while remaining in close proximity to the minimum loss.
3.2 Training with fixed simplex ETF classifier
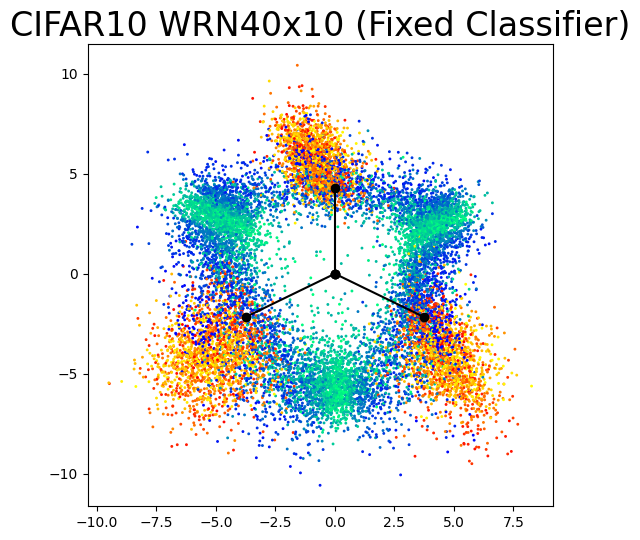
To enhance our comprehension of the differences between theoretical features (depicted in Figure 6) and empirical features (illustrated in Figure 1), we performed an experiment employing mixup within the training framework detailed in Section 2, but fixing the classifier as a simplex ETF. The resulting last-layer features are visualized in Figure 7. Prior work (Zhu et al., 2021; Yang et al., 2022; Pernici et al., 2022) have explored the effects of fixing the classifier, but not in the context of mixup. Our observations reveal that when the classifier is fixed as a simplex ETF, the empirical features tend to exhibit a more hexagonal shape in its different-class mixup features, aligning more closely with the theoretically optimal features. Moreover, comparable generalization performance is achieved when compared to training with a learnable classifier under the same setting.
Based on these results, a possible explanation for the variation in configuration is that during the training process, the classifier is still being learned and requires several epochs to converge to a simplex ETF, as depicted in Figure 5. During this period, the features may traverse regions that lead to slightly suboptimal loss, as there is flexibility in the features’ structures without much degradation to the loss performance (depicted in Figure 6).
4 Related work
The success of mixup has prompted many mixup variants, each successful in their own right (Guo et al., 2018; Verma et al., 2019; Yun et al., 2019; Kim et al., 2020). Additionally, various works have been devoted to better understanding the effects and success of the method.
Guo et al. (2018) identified manifold intrusion as a potential limitation of mixup, stemming from discrepancies between the mixed-up label of a mixed-up example and its true label, and they propose a method for overcoming this.
In addition to the work by Thulasidasan et al. (2020) on calibration for networks trained with mixup, Zhang et al. (2022) posits that this improvement in calibration due to mixup is correlated with the capacity of the network. Zhang et al. (2021) theoretically demonstrates that training with mixup corresponds to minimizing an upper bound of the adversarial loss.
Chaudhry et al. (2022) delved into the linearity of various representations of a deep network trained with mixup. They observed that representations nearer to the input and output layer exhibit greater linearity compared to those situated in the middle.
Carratino et al. (2022) interprets mixup as an empirical risk minimization estimator employing transformed data, leading to a process that notably enhances both model accuracy and calibration. Continuing on the same path, Park et al. (2022) offers a unified theoretical analysis that integrates various aspects of mixup methods.
Furthermore, Chidambaram et al. (2021) conducted a detailed examination of the classifier optimal to mixup, comparing it with the classifier obtained through standard training.
Recent work has also been devoted to studying the benefits of mixup with feature-learning based analysis by Chidambaram et al. (2023) and Zou et al. (2023). The former considering two features generated from a symmetric distribution for each class and the latter considering a data model with two features of different frequencies, feature noise, and random noise.
The discovery of Neural Collapse by Papyan et al. (2020) has spurred investigations of this phenomenon. Recent theoretical inquiries by Mixon et al. (2020); Fang et al. (2021); Lu & Steinerberger (2020); E & Wojtowytsch (2020); Poggio & Liao (2020); Zhu et al. (2021); Han et al. (2021); Tirer & Bruna (2022); Wang et al. ; Kothapalli et al. (2022) have delved into the analysis of Neural Collapse employing both the unconstrained features model (Mixon et al., 2020) and the layer-peeled model (Fang et al., 2021). Liu et al. (2023) removes the assumption on the feature dimension and the number of classes in Neural Collapse and presents a Generalized Neural Collapse which is characterized by minimizing intra-class variability and maximizing inter-class separability.
To our knowledge, there has not been any investigation into the geometric configuration induced by mixup in the last layer.
5 Conclusion
In conclusion, through an extensive empirical investigation across various architectures and datasets, we have uncovered a distinctive geometric configuration of last-layer activations induced by mixup. This configuration exhibits intriguing behaviors, such as same-class activations forming a simplex equiangular tight frame (ETF) aligned with their respective classifiers, and different-class activations delineating channels along the decision boundary, with varying densities depending on the mixup coefficient. We also examine the layer-wise trajectory that features follow to reach this configuration in the last-layer, and measure the calibration induced by mixup to provide an explanation for why this particular configuration in beneficial for calibration.
Furthermore, we have complemented our empirical findings with a theoretical analysis, adapting the unconstrained features model to mixup. Theoretical results indicate that the optimal same-class features are independent of the mixup coefficient and align with the classifier, while different-class features are dynamic linear combinations of the classifier rows corresponding to mixed-up targets, influenced by the mixup coefficient. Motivated by our theoretical analysis, we also conduct experiments investigating the configuration of the last-layer activations from training with mixup while keeping the classifier fixed as a simplex ETF and see that it aligns more closely with the theoretically optimal features, without degrading test-performance.
These findings collectively shed light on the intricate workings of mixup in training deep networks, emphasizing its role in organizing last-layer activations for improved calibration. Understanding these geometric configurations induced by mixup opens up avenues for further research into the design of data augmentation strategies and their impact on neural network training.
6 Acknowledgements
We acknowledge the support of the Natural Sciences and Engineering Research Council of Canada (NSERC). This research was enabled in part by support provided by Compute Ontario (http://www.computeontario.ca/) and Compute Canada (http://www.computecanada.ca/).
References
- Carratino et al. (2022) Luigi Carratino, Moustapha Cissé, Rodolphe Jenatton, and Jean-Philippe Vert. On mixup regularization, 2022.
- Chaudhry et al. (2022) Arslan Chaudhry, Aditya Krishna Menon, Andreas Veit, Sadeep Jayasumana, Srikumar Ramalingam, and Sanjiv Kumar. When does mixup promote local linearity in learned representations?, 2022.
- Chidambaram et al. (2021) Muthu Chidambaram, Xiang Wang, Yuzheng Hu, Chenwei Wu, and Rong Ge. Towards understanding the data dependency of mixup-style training. CoRR, abs/2110.07647, 2021. URL https://arxiv.org/abs/2110.07647.
- Chidambaram et al. (2023) Muthu Chidambaram, Xiang Wang, Chenwei Wu, and Rong Ge. Provably learning diverse features in multi-view data with midpoint mixup, 2023.
- Dosovitskiy et al. (2021) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021.
- E & Wojtowytsch (2020) Weinan E and Stephan Wojtowytsch. On the emergence of tetrahedral symmetry in the final and penultimate layers of neural network classifiers. arXiv preprint arXiv:2012.05420, 2020.
- Fang et al. (2021) Cong Fang, Hangfeng He, Qi Long, and Weijie J Su. Exploring deep neural networks via layer-peeled model: Minority collapse in imbalanced training. Proceedings of the National Academy of Sciences, 118(43):e2103091118, 2021.
- Guo et al. (2018) Hongyu Guo, Yongyi Mao, and Richong Zhang. Mixup as locally linear out-of-manifold regularization, 2018.
- Han et al. (2021) XY Han, Vardan Papyan, and David L Donoho. Neural collapse under mse loss: Proximity to and dynamics on the central path. In International Conference on Learning Representations, 2021.
- Kim et al. (2020) Jang-Hyun Kim, Wonho Choo, and Hyun Oh Song. Puzzle mix: Exploiting saliency and local statistics for optimal mixup, 2020.
- Kingma & Ba (2017) Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017.
- Kothapalli et al. (2022) Vignesh Kothapalli, Ebrahim Rasromani, and Vasudev Awatramani. Neural collapse: A review on modelling principles and generalization. arXiv preprint arXiv:2206.04041, 2022.
- Krizhevsky & Hinton (2009) Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical Report 0, University of Toronto, Toronto, Ontario, 2009. URL https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf.
- Liu et al. (2023) Weiyang Liu, Longhui Yu, Adrian Weller, and Bernhard Schölkopf. Generalizing and decoupling neural collapse via hyperspherical uniformity gap, 2023.
- Loshchilov & Hutter (2017) Ilya Loshchilov and Frank Hutter. Fixing weight decay regularization in adam. CoRR, abs/1711.05101, 2017. URL http://arxiv.org/abs/1711.05101.
- Lu & Steinerberger (2020) Jianfeng Lu and Stefan Steinerberger. Neural collapse with cross-entropy loss. arXiv preprint arXiv:2012.08465, 2020.
- Mixon et al. (2020) Dustin G Mixon, Hans Parshall, and Jianzong Pi. Neural collapse with unconstrained features. arXiv preprint arXiv:2011.11619, 2020.
- Pakdaman Naeini et al. (2015) Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. Proceedings of the AAAI Conference on Artificial Intelligence, 29(1), Feb. 2015. doi: 10.1609/aaai.v29i1.9602. URL https://ojs.aaai.org/index.php/AAAI/article/view/9602.
- Papyan et al. (2020) Vardan Papyan, X. Y. Han, and David L. Donoho. Prevalence of neural collapse during the terminal phase of deep learning training. Proceedings of the National Academy of Sciences, 117(40):24652–24663, sep 2020. doi: 10.1073/pnas.2015509117. URL https://doi.org/10.1073%2Fpnas.2015509117.
- Park et al. (2022) Chanwoo Park, Sangdoo Yun, and Sanghyuk Chun. A unified analysis of mixed sample data augmentation: A loss function perspective, 2022.
- Pernici et al. (2022) Federico Pernici, Matteo Bruni, Claudio Baecchi, and Alberto Del Bimbo. Regular polytope networks. IEEE Transactions on Neural Networks and Learning Systems, 33(9):4373–4387, September 2022. ISSN 2162-2388. doi: 10.1109/tnnls.2021.3056762. URL http://dx.doi.org/10.1109/TNNLS.2021.3056762.
- Poggio & Liao (2020) Tomaso Poggio and Qianli Liao. Explicit regularization and implicit bias in deep network classifiers trained with the square loss. arXiv preprint arXiv:2101.00072, 2020.
- Thulasidasan et al. (2020) Sunil Thulasidasan, Gopinath Chennupati, Jeff Bilmes, Tanmoy Bhattacharya, and Sarah Michalak. On mixup training: Improved calibration and predictive uncertainty for deep neural networks, 2020.
- Tirer & Bruna (2022) Tom Tirer and Joan Bruna. Extended unconstrained features model for exploring deep neural collapse. In international conference on machine learning (ICML), 2022.
- Verma et al. (2019) Vikas Verma, Alex Lamb, Christopher Beckham, Amir Najafi, Ioannis Mitliagkas, Aaron Courville, David Lopez-Paz, and Yoshua Bengio. Manifold mixup: Better representations by interpolating hidden states, 2019.
- (26) Peng Wang, Huikang Liu, Can Yaras, Laura Balzano, and Qing Qu. Linear convergence analysis of neural collapse with unconstrained features. In OPT 2022: Optimization for Machine Learning (NeurIPS 2022 Workshop).
- Xiao et al. (2017) Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. CoRR, abs/1708.07747, 2017. URL http://arxiv.org/abs/1708.07747.
- Yang et al. (2022) Yibo Yang, Shixiang Chen, Xiangtai Li, Liang Xie, Zhouchen Lin, and Dacheng Tao. Inducing neural collapse in imbalanced learning: Do we really need a learnable classifier at the end of deep neural network?, 2022.
- Yun et al. (2019) Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regularization strategy to train strong classifiers with localizable features, 2019.
- Zagoruyko & Komodakis (2017) Sergey Zagoruyko and Nikos Komodakis. Wide residual networks, 2017.
- Zhang et al. (2017) Hongyi Zhang, Moustapha Cissé, Yann N. Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. CoRR, abs/1710.09412, 2017. URL http://arxiv.org/abs/1710.09412.
- Zhang et al. (2021) Linjun Zhang, Zhun Deng, Kenji Kawaguchi, Amirata Ghorbani, and James Zou. How does mixup help with robustness and generalization? In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=8yKEo06dKNo.
- Zhang et al. (2022) Linjun Zhang, Zhun Deng, Kenji Kawaguchi, and James Zou. When and how mixup improves calibration, 2022.
- Zhou et al. (2022) Jinxin Zhou, Chong You, Xiao Li, Kangning Liu, Sheng Liu, Qing Qu, and Zhihui Zhu. Are all losses created equal: A neural collapse perspective, 2022.
- Zhu et al. (2021) Zhihui Zhu, Tianyu Ding, Jinxin Zhou, Xiao Li, Chong You, Jeremias Sulam, and Qing Qu. A geometric analysis of neural collapse with unconstrained features, 2021.
- Zou et al. (2023) Difan Zou, Yuan Cao, Yuanzhi Li, and Quanquan Gu. The benefits of mixup for feature learning, 2023.
Appendix A Theoretical Model
A.1 Proof of Theorem 3.1
Our proof uses similar techniques as Yang et al. (2022), but we extend these ideas to the more intricate last-layer features that arise from mixup.
Proof.
Assuming that is a simplex ETF with multiplier , our unconstrained features optimization problem in equation 2 becomes separable across and , and so it suffices to minimize
over each individually.
| () | ||||
| ( j-th entry of ) | ||||
Setting gives
| (4) |
Case:
In this case, equation 4 reduces to
| (5) |
Taking inner product with in equation 5 gives
Since , , , are all positive, it follows that .
For all , we have
Since is strictly decreasing on , in particular it is injective on , so
for some and for all , where
By our definition of as the softmax applied on , needs to satisfy
ie.
So, must satisfy , where is defined by
(note that we only consider the domain since we’ve shown that ). We will show that there exists a unique satisfying these properties.
since and (since all terms in the product are positive except ) for all . So is strictly decreasing, and thus it is injective.
and , so by continuity of , there exists such that , and is unique by injectivity of .
Case:
Taking inner product with in equation 4 and using properties of as a simplex ETF gives
By the same argument as in the previous case, we get that for all ,
for some (we will omit the subscript for brevity as we are optimizing over each individually). Thus for all , where
So,
| (8) |
We then solve the quadratic equation in to get
So, is of the form
By our definition of as the softmax applied on , must satisfy
We have
| (since ) | |||
Substituting this in equation 4, we get
and that concludes our proof. ∎
A.2 Amplification of Theoretical features
In this section we provide additional details of function used to generate the amplified features in Figure 6.
We define . Then for the different class features (), define the amplified features as .
The motivation for the function form of is to ensure that it is symmetric about , increasing when and decreasing when with its maximum at . These properties correspond to a larger amplification as approaches , while preserving symmetry in the amplifications. Note that the exact function is not important, but rather that it yields last-layer features that are closer to the empirical results (with elongations, while resulting in just a minor increase in loss. As mentioned in the main text, this implies that the features can have some deviation from the theoretical optimum without much change in the value of the loss.
Appendix B Experimental details
B.1 Hyperparameter settings
For the WideResNet experiments, we minimize the mixup loss using stochastic gradient descent (SGD) with momentum 0.9 and weight decay . All datasets are trained on a WideResNet-40-10 for 500 epochs with a batch size of 128. We sweep over 10 logarithmically spaced learning rates between and , picking whichever results in the highest test accuracy. The learning rate is annealed by a factor of 10 at 30%, 50%, and 90% of the total training time.
For the ViT experiments, we minimize the mixup loss using Adam optimization (Kingma & Ba, 2017). For each dataset we train a ViT-B with a patch size of 4 for 1000 epochs with a batch size of 128. We sweep over 10 logarithmically spaced learning rates from to and weight decay values from to , selecting whichever yields the highest test accuracy. The learning rate is warmed up for 10 epochs and is annealed using cosine annealing as a function of total epochs.
B.2 Projection Method
For all of the last-layer activation plots, the same projection method is used. First, we randomly select three classes. We denote the centred last-layer activations for said classes by a matrix and the classifier of the network for said classes as . The projection method is then as follows:
-
1.
Calculate where is the normalized classifier.
-
2.
Define
-
3.
Let be a two dimensional representation of a three dimensional simplex.
-
4.
Compute and plot.
Appendix C Expected calibration error
To calculate the expected calibration error, first gather the predictions into bins of equal interval size. Let be the set of predictions whose confidence is in bin . We can define the accuracy and confidence of a given bin as
where is the confidence of example . The expected calibration (ECE) is then calculated as
Appendix D Additional Last-Layer Plots
Here we provide additional plots of last-layer activations. Namely, Figure 8 provides additional baseline last-layer activation plots for mixup data for every architecture and dataset combination in Figure 1. Figure 9 provides last-layer activations for the additional value in Table 2. Figure 10 shows the evolution of the last-layer activations throughout training. Figure 11 shows last-layer activations for multiple random subsets of three classes. Finally, Figure 12 shows the last-layer activations for a ViT-B/4 trained on CIFAR10 using the AdamW optimizer.