Pruning’s Effect on Generalization Through the Lens of Training and Regularization
Abstract
Practitioners frequently observe that pruning improves model generalization. A long-standing hypothesis based on bias-variance trade-off attributes this generalization improvement to model size reduction. However, recent studies on over-parameterization characterize a new model size regime, in which larger models achieve better generalization. Pruning models in this over-parameterized regime leads to a contradiction – while theory predicts that reducing model size harms generalization, pruning to a range of sparsities nonetheless improves it. Motivated by this contradiction, we re-examine pruning’s effect on generalization empirically.
We show that size reduction cannot fully account for the generalization-improving effect of standard pruning algorithms. Instead, we find that pruning leads to better training at specific sparsities, improving the training loss over the dense model. We find that pruning also leads to additional regularization at other sparsities, reducing the accuracy degradation due to noisy examples over the dense model. Pruning extends model training time and reduces model size. These two factors improve training and add regularization respectively. We empirically demonstrate that both factors are essential to fully explaining pruning’s impact on generalization.
1 Introduction
Neural network pruning techniques remove unnecessary weights to reduce the memory and computational requirements of a model. Practitioners can remove a large fraction (often 80-90%) of weights without harming generalization, measured by test error [31, 19, 13]. While recent pruning research [19, 13, 52, 7, 30, 43, 11, 66, 4, 34, 64, 53, 35, 37, 56, 54, 9, 67, 59] focuses on reducing model footprint, improving generalization has been a core design objective for earlier work on pruning [31, 22]; recent pruning literature also frequently notes that it improves generalization [19, 13].
How does pruning affect generalization? An enduring hypothesis claims that pruning may benefit generalization by reducing model size, defined as the number of weights in a model.111 This hypothesis traces back to seminal work in pruning, such as Optimal Brain Surgeon [22]: \saywithout such weight elimination, overfitting problems and thus poor generalization will result. And again in pioneering work [19] applying pruning to deep neural network models: \saywe believe this accuracy improvement is due to pruning finding the right capacity of the network and hence reducing overfitting. Because the latter hypothesis leaves the definition of network capacity unspecified, we examine an instantiation of it, measuring network capacity with model size. We refer to this as the size-reduction hypothesis. However, algorithms for pruning neural networks and our understanding of the impact of model size on generalization have changed.
First, pruning algorithms have grown increasingly complex. Learning rate rewinding [52], a state-of-the-art algorithm prunes weights iteratively. An iteration consists of weight removal, where the algorithm removes a subset of remaining weights, followed by retraining, where the algorithm continues to train the model, replaying the original learning rate schedule. Across iterations, this retraining scheme effectively adopts a cyclic learning rate schedule [57], which may benefit generalization.
Second, emerging empirical and theoretical findings challenge our understanding of generalization for deep neural network models with an ever-increasing number of weights [47, 12, 45, 68]. In particular, the size-reduction hypothesis builds on the classical generalization theory on bias-variance trade-off, which predicts that reducing model size improves the generalization of an overfitted model [23]. However, recent work [5, 46] reveals that beyond this classical bias-variance trade-off regime lies an over-parameterized regime where models are large enough to achieve near-zero training error. In this regime, bigger models often achieve better generalization [5, 46, 29, 27, 58]. Practitioners routinely apply modern pruning algorithms to models in this over-parameterized regime. While our renewed understanding of generalization predicts that reducing the size of an over-parameterized model should harm generalization, pruning to a range of sparsities nevertheless improves it. The size-reduction hypothesis is therefore inconsistent with our empirical observation about pruning.


A new direction.
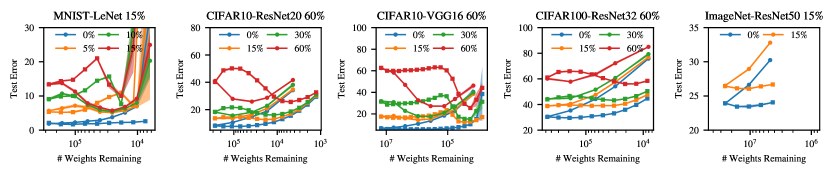
We first confirm that the size-reduction hypothesis does not fully explain pruning’s effect on generalization. Figure 1a compares the generalization of a family of sparse models of different sizes generated by a state-of-the-art pruning algorithm [52], and the generalization of a family of models generated by the same algorithm, except modified to no longer remove weights. This algorithm, which we refer to as the augmented training algorithm, differs from standard training in two ways: (1) the number of training epochs is larger; (2) the learning rate schedule is cyclic.
The results show that for any sparse VGG-16 model generated by the pruning algorithm with more than 1% of its original weights, its generalization is indistinguishable from that of the model generated by the augmented training algorithm that does not remove weights but trains the model for the same number of epochs and with the same learning rate schedule as the pruning algorithm.222In Appendix C we show this phenomenon for 4 additional benchmarks, and other pruning algorithms. For a range of sparsities, pruning’s effect on generalization remains unchanged in the absence of weight removal, illustrating that the size-reduction hypothesis cannot fully explain pruning’s effect on generalization.
Our approach.
We instead develop an explanation for pruning’s impact on generalization through an analysis of its effect on each training example’s loss – the difference in the example’s training loss between the sparse model produced by pruning and the dense model produced by standard training.
We then interpret pruning’s effect on each example in relation to the example’s influence on generalization. In particular, an example’s influence on generalization is the absolute change to generalization due to leaving this example out, which Paul et al. [50] propose to approximate with the L2 distance between the predicted probabilities and one-hot labels early in training, called the EL2N (Error L2 Norm) score. Paul et al. [50] show that an example with a high EL2N score may cause a large weight update, thereby substantially changing the predictions and loss of other examples. We thus refer to high EL2N examples as influential examples. Our analysis shows the following results.
Better training.
We prune a VGG-16 model on the CIFAR-10 dataset to the optimal sparsity, the sparsity with the best validation error. At this sparsity, we find that the pruned model achieves better training loss than the dense model. In the left plot in Figure 1b, we present the change in training loss due to pruning for the training examples grouped by their EL2N score percentiles. We observe that influential examples show the greatest training loss improvement. Pruning may therefore lead to better training, improving the training loss of the sparse model over the dense model, particularly on examples with a large influence on generalization.
Additional regularization.
We prune the same VGG-16 model on CIFAR-10 dataset with the pruning algorithm configured to produce the sparsest model that still improves generalization over the dense model. At this sparsity, we find that the pruned model achieves worse training loss than the dense model. In the right plot in Figure 1b, we present the change in training loss due to pruning for the training examples grouped by their EL2N score percentiles. The results show that pruning may also improve generalization while increasing the training loss of the sparse model over the dense model, particularly on examples with a large influence on generalization.
While it is perhaps counter-intuitive that increasing training loss, particularly on the most influential examples may improve generalization, examining these pruning-affected examples leads us to hypothesize that it is due to an observation that Paul et al. [50] made: in image classification datasets, a small fraction of influential training examples have ambiguous or erroneous labels, training on which impairs generalization. Therefore, it is instead better for the model to not fit them.
We examine this hypothesis by introducing random label noise into the training dataset. We find that on such datasets, pruning may improve generalization by increasing the training loss on the noisy examples, while still preserving the training loss of examples from the original training dataset. The result is an overall generalization improvement for the sparse model. Notably, reducing model width has a similar effect on training loss and generalization, suggesting a reduced number of weights in the model as the underlying cause for generalization improvement in the presence of noisy examples. We refer to the effect of removing weights as additional regularization, which reduces the accuracy degradation due to noisy examples over the original dense model.
Implications.
It has been a long-standing hypothesis that pruning improves generalization by reducing the number of weights (via the Minimum Description Length principle [18] or Vapnik–Chervonenkis theory [62]). Our empirical observations suggest that the theory and practice of pruning should instead focus on the two effects of modern pruning algorithms: better training and additional regularization, both of which are indispensable to explaining pruning’s benefits to generalization fully. Our results also suggest that quantifying pruning’s heterogenous effect across training examples is key to understanding pruning’s influence on generalization.
Contributions.
We present the following contributions:
-
1.
We find that pruning may lead to better training, improving the training loss, as well as the generalization over the dense model at optimal sparsity.
-
2.
We find that pruning may also lead to additional regularization, reducing the accuracy degradation due to noisy examples, and improving the generalization over the dense model at optimal sparsity.
-
3.
We demonstrate that our deconstruction of pruning’s effect into training and regularization cannot be further simplified — alternative explanations such as extended training time and reduced model size only partially explain the effects of pruning on generalization.
2 Preliminaries
We study Iterative Magnitude Pruning (IMP) with learning-rate rewinding [52]. This algorithm consists of four steps: (1) Train a neural network to completion. (2) Remove a specified fraction of the smallest-magnitude remaining weights. (3) Reset the learning rate to its value in an earlier epoch and (4) Repeat steps 1-3 iteratively until the model reaches the desired overall sparsity.
Terminology. Dense models refer to models without any removed weights. Sparse models refer to models with removed weights as a result of pruning. The optimally sparse model is the model pruned to the sparsity at which it achieves the best validation error. The optimal sparsity is the sparsity of the optimally sparse model. Generalization refers to the classification error on the test set.
Experimental methodology. We use standard architectures: LeNet [32], VGG-16 [55], ResNet-20, ResNet-32 and ResNet-50 [24], and train on benchmarks (MNIST, CIFAR-10, CIFAR-100, ImageNet) using standard hyperparameter settings and standard cross-entropy loss function [13, 14, 65]. Following Frankle and Carbin [13], Frankle et al. [14], we set the in IMP to for MNIST-LeNet benchmark and for the others. Appendix B shows further details.
We report all results by running the same experiment 3 times with distinct random seeds. We conclude that any real-valued results of two experiments differ if and only if the mean difference between three independent runs of respective experiments is at least one standard deviation away from zero, otherwise we say that the results match. We use PyTorch [49] on TPUs with OpenLTH library [13].
Limitations. Our work is empirical in nature. Though we validate each of our claims with extensive experimental results on benchmarks with different architectures and datasets, we recognize that our claims may still not generalize due to the empirical nature of our study.
3 Generalization Improvement from Better Training
Not all training examples have the same effect on training and generalization [61, 50, 8, 21, 25]. In this section, we measure pruning’s effect on each training example by examining the difference in its training loss between the dense model produced by standard training and the sparse model produced by pruning. Our results show that pruning most significantly affects training examples that are most influential to model generalization.
Method. Paul et al. [50] propose to estimate an example’s influence on model generalization with the EL2N (Error L2 Norm) score – the L2 distance between the predicted probability and the one hot label of the example early in training. Details for computing the EL2N score is available in Section B.3. They show that an example with a high EL2N score may cause a large weight update, thereby substantially changing the predictions and loss of other examples. Paul et al. [50] rely on this relationship between EL2N score and generalization to remove examples with little influence on generalization from the dataset to accelerate training without affecting model generalization. We similarly use the EL2N score to assess the impact of pruning on generalization.
To measure the difference in training loss on examples due to pruning, we partition the training set into subgroups, each with a different range of EL2N score percentiles. We then compute the average training loss difference on examples in each subgroup. We compute this difference by subtracting the training loss of the dense model produced by standard training from that of the sparse model produced by pruning. A negative value indicates that the sparse model has better training loss than the dense model. We pick because it is the largest value of that enables us to clearly present the per-subgroup training loss difference.
We measure training loss at two sparsities of interest: the sparsity that achieves the best generalization, and the highest sparsity that still attains better generalization than the dense model. In Appendix L, we present pruning’s effect on subgroup training loss at a wider range of sparsities.


Results. Figure 2a presents pruning’s effect on subgroup training loss. Our results show that at the sparsity that achieves the best generalization, for all subgroups, the average training loss of the pruned model either matches or improves over the dense model, indicating better training.
Figure 2a also shows that pruning’s effect on training example subgroups is nonuniform. Pruning most significantly affects the most influential examples – the ones with the highest range of EL2N scores. Specifically, the average magnitude of pruning’s effect on examples with the top 20% EL2N scores is 3.5-71x that on examples with the bottom 80% EL2N scores. Pruning to the said sparsity thus improves generalization while improving the training loss of example subgroups nonuniformly, with an emphasis on influential examples. In Appendix D, we validate the effect of pruning-improved examples on generalization: excluding 20% of pruning-improved examples hurts generalization more than excluding a random subset of the same size.
Conclusion. On standard datasets, pruning to the sparsity that achieves the best generalization leads to better training – the training loss of most example subgroups improves over the dense model. The subgroup with the most influence on generalization sees the largest training loss improvement.
4 Generalization Improvement from Additional Regularization
Pruning to the highest sparsity that improves generalization (Figure 2b) displays a similar effect as pruning to the sparsity that attains the best generalization (Figure 2a) – generalization improves with an overall improved training loss over the dense model, except for CIFAR-10, where pruning improves generalization while worsening training loss on most subgroups of examples. Specifically, for ResNet20 on CIFAR-10 at 83.22% sparsity (Figure 2b, second from left) and VGG-16 on CIFAR-10 at 99.08% sparsity (Figure 2b, third from left), the training loss of the sparse model is worse than the dense model. While pruning always increases training loss when it removes a large enough fraction of weights, the accompanied generalization improvement does not always occur in general.
The second and third plots of Figure 2b show that the loss increase is especially pronounced on particular subgroups of influential examples. Examining these pruning-affected training examples in Section K.1 leads us to hypothesize that the generalization improvement is due to an observation Paul et al. [50] made: although influential examples are predominately beneficial for generalization, there exist a small fraction of noisy examples, such as ones with ambiguous or erroneous labels, that exert a significant influence on generalization, albeit in a harmful way.333We present leave-subgroup-out retraining experiments for these examples in Appendix K.
To precisely characterize pruning’s effect on noisy examples, we inject random label noise into the training dataset. Doing so enables a comparison of pruning’s effect on noisy data and original data.
Method. We inject random label noise by selecting examples uniformly at random and changing the label of each example to one of the other labels in the dataset sampled uniformly at random. We refer to the data that is not affected as original data. We sample and fix the random labels before each independent run of an experiment.
We report the following results for models trained on datasets with and without random label noise: (1) pruning’s impact on generalization versus sparsity (Figure 3); (2) pruning’s impact on training loss for the original data and random label data versus sparsity (Figure 4);444Numerical results available in Table 11 in Appendix M (3) pruning’s impact on training loss for subgroups of examples, each with a different range of EL2N scores (Figure 5).

Generalization results. Figure 3 shows that, in the presence of random label noise, the generalization of the optimally sparse models is better than that of the dense models on 11 out of 13 benchmarks and matches that of the dense models on the rest of the benchmarks. Our results provide evidence that pruning to the optimal sparsity improves generalization in the presence of random label noise.
The extent of pruning’s generalization improvement at the optimal sparsity grows as the portion of label noise increases. For example, for VGG-16 on CIFAR-10 benchmark, pruning to the optimal sparsity improves generalization by 5.2%, 16.1% and 34.6% on 15%, 30% and 60% label noise.

Original versus noisy data. Figure 4 shows that pruning initially reduces the average training loss on noisy examples: for instance, training loss on noisy examples is slightly lower for the sparse ResNet20 models on CIFAR-10 with many weights remaining (i.e., more than 10% ) than for the dense model. Since noisy examples are influential examples [50], these results indicate better training, which improves model training loss with a particular emphasis on influential examples.
As the fraction of weights remaining drops further, the loss of the sparse model on noisy data grows. For instance, the training loss on noisy examples increases for the sparse ResNet20 models on CIFAR-10 with few weights remaining (i.e., less than 10%). Moreover, the gap between the average training loss of the sparse model on original versus noisy examples widens beyond the dense model, indicating that pruning leads to additional regularization. In particular, for a range of sparsities where generalization improves over the dense model, the sparse model fits original examples significantly better than those with randomized labels. Taking the dense VGG-16 model trained on the CIFAR-10 dataset with 15% – 60% random label noise as an example, we observe that this model incurs 0.03 – 0.13 higher training loss on the partition with injected random label noise than on the partition without. Pruning to the optimal sparsity widens this training loss gap to 1.38 – 2.97. Furthermore, the gap between the average training loss of the sparse models on original versus noisy examples eventually diminishes as the sparsity increases even further.

Difference in loss by subgroups. Figure 5 shows the difference between the loss of the dense and optimally sparse model on subgroups of examples with different EL2N scores, but this time in the presence of random label noise. The results show that pruning to the optimal sparsity often increases the loss of influential examples, contrary to what Figure 2 shows when training on original data only where pruning decreases the training loss of influential examples.
As random label examples are influential and harm generalization [50], increasing the training loss on influential examples may therefore improve generalization. In Appendix E, we validate that excluding examples misclassified by the optimally sparse models improves generalization similar to pruning.
Conclusion. We study pruning’s effects on training and regularization by connecting them to noisy examples. By introducing random label noise, we show the two effects of pruning more clearly. At relatively low sparsities, we observe better training because the training loss of sparse models is lower than the dense model, especially on influential examples highly influential to generalization. As sparsity increases, regularization effects dominate, because the sparse models see a larger gap between training loss on the noisy versus original data than the dense model. We note that across all sparsities, pruning has a highly nonuniform effect across example subgroups with different influences on generalization (EL2N scores) on both standard datasets and datasets with random label noise.
Crucially, the effect of pruning at the optimal sparsity – be it better training or additional regularization – depends on the noise levels in the dataset. On datasets with few noisy examples, Figure 2 shows that at the optimal sparsity, better training is the key to good generalization, because training loss reduces. On datasets with injected random label noise, Figure 5 shows that the optimal sparsity is the one at which pruning-induced regularization effects increase noisy data loss.
5 Isolating the Effects of Extending Training Time and Reducing Model Size
We identified two effects of pruning on generalization: better training and additional regularization. They intersect with two components of the pruning algorithm: extended training time and model size reduction, respectively. In this section, we study these two effects in isolation by extending dense model training time and reducing the dense model size by scaling down its width.555To isolate other effects of pruning, we also evaluate the contribution of design choices of pruning algorithms, such as the heuristic selecting which weights to prune, to generalization via ablation studies in Appendix J. We confirm that both effects of pruning are necessary to fully explain pruning’s impact on generalization. Thus our deconstruction of pruning’s effect in terms of training and regularization cannot be further simplified.
5.1 Extended Training Time
What happens to generalization if the weight removal part is removed from pruning, and only the retraining part remains? To answer, we train dense models exactly as done in the pruning algorithm, for the same number of gradient steps and learning rate schedule, but without removing weights.
Method. We study the effect of training dense models for extra gradient steps on generalization, without removing any weights. When training the dense models, we use the same learning rate schedule as pruning, replaying the original learning rate schedule designed for the dense model multiple times, effectively adopting a cyclic learning rate schedule. We refer to this training algorithm as extended dense training. We report and compare the generalization of models that pruning and extended dense training algorithm produce.

Results. Figure 6 shows test errors of models that extended dense training and pruning produce as a function of training epochs.666Numerical results available in Table 5 in Appendix M. The two algorithms produce models with similar generalization on standard datasets without random label noise, where pruning improves training at optimal sparsity, as shown in Section 3. Indeed, in Appendix L, we show that longer training time similarly leads to better training. However, on benchmarks with random label noise, extended dense training underperforms pruning on 9 out of the 13 benchmarks. On LeNet, ResNet20, VGG-16, ResNet32 and ResNet50 benchmarks with noise, extended dense training achieves test errors that are worse than pruning by 0 (matching) to 2.6%, 0.4 to 14.5%, 3.6 to 34.2%, 0 (matching) to 4.8% and -0.3%, respectively.
Conclusion. On standard datasets without random label noise, the extended dense training algorithm produces models with generalization that matches or exceeds the optimally sparse model. However, with random label noise, the extended dense training algorithm can no longer produce models that match the generalization of the optimally sparse model.
5.2 Size Reduction
What happens to generalization if the retraining part is removed from pruning, and only the weight removal part remains? To answer, we compare pruning with model width down-scaling, since both techniques reduce the number of weights in a model.
At optimal sparsity, we show that size reduction is not necessary to replicate generalization improvements with dense models in Section 1; in this section, we show that size reduction is also not sufficient to replicate generalization improvement with dense models.
Method. We reduce the model size by down-scaling the width of a dense model: we train a sequence of dense models using the standard number of training epochs, where the next model in the sequence has 80% of the width of the model preceding it. This width scaling ratio mimics our sparsity schedule, where the pruned model always has 80% of the remaining weights in the previous iteration. We then compare the generalization of models that pruning and width down-scaling produce.
Results. Figure 7 presents the test errors of models that pruning and width down-scaling produce, using square and circle markers respectively. Width down-scaling under-performs pruning on 4 out of 5 benchmarks on datasets without random label noise. When training with random label noise, width down-scaling has notable regularization effects and significantly improves generalization, similar to pruning. In Appendix I, we show that the regularization effects of both algorithms manifest similarly across example subgroups, suggesting that pruning’s regularization effect is a consequence of model size reduction in general. However, despite this improvement, a gap remains between the minimum test error of models that pruning and width down-scaling produce achieve: pruning does better on LeNet, ResNet20, VGG-16, ResNet32 and ResNet50 benchmarks by -4 (pruning does worse) to 0.4%, 0% (matching), 1.5 to 1.8%, 0 (matching) to 2.1%, and 0.36% in test error, respectively.
Conclusion. On standard datasets with random label noise, width down-scaling produces models with similar generalization (no worse by more than 2.1%) as the optimally sparse models. However, without random label noise, width down-scaling under-performs pruning.
5.3 Conclusion
By removing the weight removal part from pruning in Section 5.1, we show the importance of pruning-induced additional regularization for achieving good generalization in the presence of label noise more clearly than Section 4. Similarly, by removing the retraining part from pruning in Section 5.2, we show the importance of pruning-induced better training for achieving good generalization using the original dataset without random label noise more clearly than Section 3.
We confirm that both effects of pruning are required to fully account for its impact on generalization. Our deconstruction of pruning’s effect in terms of training and regularization is therefore minimal.
6 Related Work
Pruning has an extended history: early work starting from the 1980s found that pruning enhances model interpretability and generalization [44, 31, 22]. More recently, the advent of deep neural network models motivates the adoption of pruning to reduce the storage and computational demand of deep models [19, 20, 30, 39, 7, 43, 11, 66, 4, 34, 64, 53, 35, 37, 56, 54, 9, 67, 59]. In this section, we describe several branches of pruning research pertinent to our work.
Pruning algorithm design. Recent pruning research often focuses on improving pruning algorithm design. An extended line of research studies the heuristics that determine which weights to remove [43, 11, 33] – the simplest heuristic is to remove weights with the smallest magnitude. For example, Molchanov et al. [42], Louizos et al. [41] propose to learn which weights to prune as part of the optimization process. Another line of research concerns the structure of the weights to remove to achieve computational speedup without significantly hurting model generalization. For example, Li et al. [36], Liu et al. [40] propose to prune weights in groups or to prune neurons, convolutional filters and channels. Our work does not produce a new pruning algorithm design. Rather, we study the existing pruning algorithms to understand their effect on model generalization.
Pruning’s effect on generalization. There are many reported instances in which pruning benefits model generalization [31, 19, 13]. This effect has sparked interest in examining pruning as a technique to gain additional generalization benefits beyond common regularization techniques. Weight decay is a typical regularization technique that encourages model weights to have a small norm as part of the training objective. Giles and Omlin [16] demonstrated that pruning can improve the generalization of recurrent neural network models better than weight decay. Thimm and Fiesler [60], Augasta and Kathirvalavakumar [1] compared the effect on the generalization of several contemporary pruning techniques. Bartoldson et al. [3] discovered a positive correlation between pruning instability, defined as the drop in test accuracy immediately following weights removal, and model generalization. The authors found that higher pruning-induced instability leads to increased flatness of minima, which in turn improves generalization. Our work differs from prior work as we study pruning’s effects on generalization through a novel perspective, examining pruning’s impact on training examples.
Pruning’s effect beyond generalization. Our work contributes to a growing line of work [25, 38] investigating pruning’s effect on examples beyond test error. Hooker et al. [25] discovered that model compression can have a disproportionately large impact on predicting the under-represented long-tail of the data distribution. Liebenwein et al. [38] studied the performance of pruning using metrics such as out-of-distribution generalization and resilience to noise, and found that pruning may not preserve these alternative performance metrics even when it preserves test accuracy. To the best of our knowledge, our work is the first to examine pruning’s impact on examples in the training set.
7 Closing Discussion
Importance of training improvement. Our work sheds light on an overlooked and underestimated effect of pruning that boosts generalization – training improvement. Seminal work on pruning [22, 19] focuses on its regularization effect and attributes pruning’s beneficial influence on generalization to regularization that comes with model size reduction. Instead, our work discovers that, on standard image classification benchmarks, the state-of-the-art pruning algorithm attains the optimal generalization consistently by improving model training.
How does model size reduction impact generalization? The relationship between model complexity and generalization has long been a subject of immense interest [51, 23, 5, 46]. Informally, model complexity refers to the model’s ability to fit a wide variety of functions [17]. For example, model size [5] and the norm of model weights [48] both provide meaningful measures of model complexity for the study of generalization. Classical theories (e.g., on VC dimension [63] and Rademacher complexity [2]) show that reducing model complexity decreases the likelihood for the learning algorithm to produce trained models with a large gap between training and test loss, and may therefore improve generalization, We instead focus on learning dynamics of training example subgroups and show that reducing model size improves generalization by mitigating the accuracy degradation due to noisy examples. Therefore, our work contributes a complementary perspective to the understanding of the relationship between model complexity and generalization.
Societal impact. Our work examines pruning’s effect on generalization. While we measure generalization using test error, Hooker et al. [25] show that test error may be an imperfect characterization of model prediction quality due to a lack of consideration of fairness and equity. Concretely, our work does not address the potential disproportionate impact of model pruning on label categories. Our work must therefore be interpreted within the context of the community’s current and future understanding of pruning’s potential contribution to systemic bias, especially against minority groups that may be underrepresented in existing training datasets.
Implication for fairness. A growing line of work concerns the adverse impact of pruning on model fairness [25, 26, 6, 6] – they show that pruning disproportionately worsens the prediction accuracy on a small subgroup of examples. However, our results show that their work does not completely characterize pruning’s effects pertinent to fairness: (1) We show that only at relatively high sparsities can pruning harm the prediction accuracy of any example subgroup, where pruning’s regularization effects dominate. (2) We show that size reduction in general, rather than pruning in particular, underpins the disproportionately worse accuracy of the pruned model on certain subgroups of examples. Our results call for further assessment and discussion of pruning’s risk to model fairness.
Conclusion. We show that the long-standing size-reduction hypothesis attributing pruning’s beneficial effect on generalization to its reduction of model size does not fully explain pruning’s impact on generalization. Inspired by studies [61, 50] that show nonuniform effects of training examples on generalization, we develop an analysis to study pruning’s impact on generalization by interpreting its effect on an example’s training loss in relation to the example’s influence on generalization.
With this novel analysis, we find that, at the optimal sparsity, pruning leads to either better training or additional regularization, which improves training loss over the dense model, and reduces the accuracy degradation due to noisy examples over the dense model, respectively. Both effects contribute to improving model generalization.
Our novel analysis adds to our empirical toolkit for studying the effect of a learning algorithm on generalization through its effect on the loss of training examples. Using our novel analysis, we derive findings that advance our empirical understanding of pruning as a learning algorithm.
References
- Augasta and Kathirvalavakumar [2013] M. Augasta and T. Kathirvalavakumar. Pruning algorithms of neural networks — a comparative study. Central European Journal of Computer Science, 3, 2013.
- Bartlett and Mendelson [2003] P. L. Bartlett and S. Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results. The Journal of Machine Learning Research, 3, 2003.
- Bartoldson et al. [2020] B. Bartoldson, A. Morcos, A. Barbu, and G. Erlebacher. The generalization-stability tradeoff in neural network pruning. In Advances in Neural Information Processing Systems, 2020.
- Baykal et al. [2019] C. Baykal, L. Liebenwein, I. Gilitschenski, D. Feldman, and D. Rus. Data-dependent coresets for compressing neural networks with applications to generalization bounds. In International Conference on Learning Representations, 2019.
- Belkin et al. [2019] M. Belkin, D. Hsu, S. Ma, and S. Mandal. Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proceedings of the National Academy of Sciences, 116(32), 2019.
- Blakeney et al. [2021] C. Blakeney, N. Huish, Y. Yan, and Z. Zong. Simon says: Evaluating and mitigating bias in pruned neural networks with knowledge distillation. arXiv preprint arXiv:2106.07849, 2021.
- Blalock et al. [2020] D. Blalock, J. J. Gonzalez Ortiz, J. Frankle, and J. Guttag. What is the state of neural network pruning? In Conference on Machine Learning and Systems, 2020.
- Calders et al. [2009] T. Calders, F. Kamiran, and M. Pechenizkiy. Building classifiers with independency constraints. In IEEE International Conference on Data Mining Workshops, 2009.
- Chen et al. [2021] T. Chen, B. Ji, T. Ding, B. Fang, G. Wang, Z. Zhu, L. Liang, Y. Shi, S. Yi, and X. Tu. Only train once: A one-shot neural network training and pruning framework. In Advances in Neural Information Processing Systems, 2021.
- Deng et al. [2009] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In IEEE conference on computer vision and pattern recognition, 2009.
- Dong et al. [2017] X. Dong, S. Chen, and S. Pan. Learning to prune deep neural networks via layer-wise optimal brain surgeon. In Advances in Neural Information Processing Systems, 2017.
- Dziugaite and Roy [2016] G. K. Dziugaite and D. M. Roy. Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data. In Conference on Uncertainty in Artificial Intelligence, 2016.
- Frankle and Carbin [2019] J. Frankle and M. Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations, 2019.
- Frankle et al. [2020] J. Frankle, G. K. Dziugaite, D. M. Roy, and M. Carbin. Linear mode connectivity and the lottery ticket hypothesis. In Proceedings of the 37th International Conference on Machine Learning, 2020.
- Frankle et al. [2021] J. Frankle, G. K. Dziugaite, D. Roy, and M. Carbin. Pruning neural networks at initialization: Why are we missing the mark? In International Conference on Learning Representations, 2021.
- Giles and Omlin [1994] C. Giles and C. Omlin. Pruning recurrent neural networks for improved generalization performance. IEEE Transactions on Neural Networks, 5(5), 1994.
- Goodfellow et al. [2016] I. Goodfellow, Y. Bengio, and A. Courville. Deep Learning. MIT Press, 2016.
- Grünwald [2007] P. D. Grünwald. The minimum description length principle. MIT press, 2007.
- Han et al. [2015] S. Han, J. Pool, J. Tran, and W. J. Dally. Learning both weights and connections for efficient neural networks. In Conference on Neural Information Processing Systems, 2015.
- Han et al. [2016] S. Han, H. Mao, and W. J. Dally. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. In International Conference on Learning Representations, 2016.
- Hardt et al. [2016] M. Hardt, E. Price, E. Price, and N. Srebro. Equality of opportunity in supervised learning. In Conference on Neural Information Processing Systems, 2016.
- Hassibi et al. [1993] B. Hassibi, D. Stork, and G. Wolff. Optimal brain surgeon and general network pruning. In IEEE International Conference on Neural Networks, 1993.
- Hastie et al. [2017] T. Hastie, J. Friedman, and R. Tisbshirani. 2.9 Model Selection and Bias-Variance Tradeoff, page 37–38. 2017.
- He et al. [2016] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Conference on Computer Vision and Pattern Recognition, 2016.
- Hooker et al. [2019] S. Hooker, A. C. Courville, Y. N. Dauphin, and A. Frome. What do compressed deep neural networks forget? arXiv preprint arXiv:1911.05248, 2019.
- Hooker et al. [2020] S. Hooker, N. Moorosi, G. Clark, S. Bengio, and E. Denton. Characterising bias in compressed models. arXiv preprint arXiv:2010.03058, 2020.
- Huang et al. [2019] Y. Huang, Y. Cheng, A. Bapna, O. Firat, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V. Le, Y. Wu, and z. Chen. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In Conference on Neural Information Processing Systems, 2019.
- Krizhevsky and Hinton [2009] A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images. Master’s thesis, Department of Computer Science, University of Toronto, 2009.
- Krizhevsky et al. [2012] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Conference on Neural Information Processing Systems, 2012.
- Lebedev and Lempitsky [2016] V. Lebedev and V. Lempitsky. Fast convnets using group-wise brain damage. In IEEE Conference on Computer Vision and Pattern Recognition, 2016.
- LeCun et al. [1990] Y. LeCun, J. Denker, and S. Solla. Optimal brain damage. In Conference on Neural Information Processing Systems, 1990.
- Lecun et al. [1998] Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 1998.
- Lee et al. [2021] J. Lee, S. Park, S. Mo, S. Ahn, and J. Shin. Layer-adaptive sparsity for the magnitude-based pruning. In International Conference on Learning Representations, 2021.
- Lee et al. [2019] N. Lee, T. Ajanthan, and P. Torr. Snip: Single-shot network pruning based on connection sensitivity. In International Conference on Learning Representations, 2019.
- Lee et al. [2020] N. Lee, T. Ajanthan, S. Gould, and P. H. S. Torr. A signal propagation perspective for pruning neural networks at initialization. In International Conference on Learning Representations, 2020.
- Li et al. [2017] H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf. Pruning filters for efficient convnets. In International Conference on Learning Representations, 2017.
- Liebenwein et al. [2020] L. Liebenwein, C. Baykal, H. Lang, D. Feldman, and D. Rus. Provable filter pruning for efficient neural networks. In International Conference on Learning Representations, 2020.
- Liebenwein et al. [2021] L. Liebenwein, C. Baykal, B. Carter, D. Gifford, and D. Rus. Lost in pruning: The effects of pruning neural networks beyond test accuracy. In Conference on Machine Learning and Systems, 2021.
- Liu et al. [2017] Z. Liu, J. Li, Z. Shen, G. Huang, S. Yan, and C. Zhang. Learning efficient convolutional networks through network slimming. In IEEE International Conference on Computer Vision, 2017.
- Liu et al. [2019] Z. Liu, M. Sun, T. Zhou, G. Huang, and T. Darrell. Rethinking the value of network pruning. In International Conference on Learning Representations, 2019.
- Louizos et al. [2018] C. Louizos, M. Welling, and D. P. Kingma. Learning sparse neural networks through l0 regularization. In International Conference on Learning Representations, 2018.
- Molchanov et al. [2017a] D. Molchanov, A. Ashukha, and D. Vetrov. Variational dropout sparsifies deep neural networks. In International Conference on Machine Learning, 2017a.
- Molchanov et al. [2017b] P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz. Pruning convolutional neural networks for resource efficient inference. In International Conference on Learning Representations, 2017b.
- Mozer and Smolensky [1988] M. C. Mozer and P. Smolensky. Skeletonization: A technique for trimming the fat from a network via relevance assessment. In Conference on Neural Information Processing Systems, 1988.
- Nagarajan and Kolter [2019] V. Nagarajan and J. Z. Kolter. Uniform convergence may be unable to explain generalization in deep learning. In Conference on Neural Information Processing Systems, 2019.
- Nakkiran et al. [2020] P. Nakkiran, G. Kaplun, Y. Bansal, T. Yang, B. Barak, and I. Sutskever. Deep double descent: Where bigger models and more data hurt. In International Conference on Learning Representations, 2020.
- Neyshabur et al. [2014] B. Neyshabur, R. Tomioka, and N. Srebro. In search of the real inductive bias: On the role of implicit regularization in deep learning. arXiv preprint arXiv:1412.6614, 2014.
- Neyshabur et al. [2015] B. Neyshabur, R. Tomioka, and N. Srebro. Norm-based capacity control in neural networks. In Conference on Learning Theory, 2015.
- Paszke et al. [2019] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. Pytorch: An imperative style, high-performance deep learning library. In Conference on Neural Information Processing Systems, 2019.
- Paul et al. [2021] M. Paul, S. Ganguli, and G. K. Dziugaite. Deep learning on a data diet: Finding important examples early in training. In Conference on Neural Information Processing Systems, 2021.
- Rasmussen and Ghahramani [2000] C. Rasmussen and Z. Ghahramani. Occam's razor. In Conference on Neural Information Processing Systems, 2000.
- Renda et al. [2020] A. Renda, J. Frankle, and M. Carbin. Comparing rewinding and fine-tuning in neural network pruning. In International Conference on Learning Representations, 2020.
- Serra et al. [2020] T. Serra, A. Kumar, and S. Ramalingam. Lossless compression of deep neural networks. In International Conference on the Integration of Constraint Programming, Artificial Intelligence, and Operations Research, 2020.
- Serra et al. [2021] T. Serra, X. Yu, A. Kumar, and S. Ramalingam. Scaling up exact neural network compression by relu stability. In Conference on Neural Information Processing Systems, 2021.
- Simonyan and Zisserman [2015] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations, 2015.
- Singh and Alistarh [2020] S. P. Singh and D. Alistarh. Woodfisher: Efficient second-order approximation for neural network compression. In Conference on Neural Information Processing Systems, 2020.
- Smith [2017] L. N. Smith. Cyclical learning rates for training neural networks. In IEEE Winter Conference on Applications of Computer Vision, 2017.
- Szegedy et al. [2015] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In IEEE Conference on Computer Vision and Pattern Recognition, 2015.
- Tanaka et al. [2020] H. Tanaka, D. Kunin, D. L. Yamins, and S. Ganguli. Pruning neural networks without any data by iteratively conserving synaptic flow. In Conference on Neural Information Processing Systems, 2020.
- Thimm and Fiesler [1995] G. Thimm and E. Fiesler. Evaluating pruning methods. In International Symposium on Artificial Neural Networks, 1995.
- Toneva et al. [2019] M. Toneva, A. Sordoni, R. T. des Combes, A. Trischler, Y. Bengio, and G. J. Gordon. An empirical study of example forgetting during deep neural network learning. In International Conference on Learning Representations, 2019.
- Vapnik [1999] V. Vapnik. The nature of statistical learning theory. Springer science & business media, 1999.
- Vapnik and Chervonenkis [1971] V. N. Vapnik and A. Y. Chervonenkis. On the uniform convergence of relative frequencies of events to their probabilities. Theory of Probability and its Applications, 16, 1971.
- Wang et al. [2019] C. Wang, R. Grosse, S. Fidler, and G. Zhang. EigenDamage: Structured pruning in the Kronecker-factored eigenbasis. In International Conference on Machine Learning, 2019.
- Wang et al. [2020] C. Wang, G. Zhang, and R. Grosse. Picking winning tickets before training by preserving gradient flow. In International Conference on Learning Representations, 2020.
- Yu et al. [2017] R. Yu, A. Li, C. Chen, J. Lai, V. I. Morariu, X. Han, M. Gao, C. Lin, and L. S. Davis. NISP: pruning networks using neuron importance score propagation. arXiv preprint arXiv:1711.05908, 2017.
- Yu et al. [2022] X. Yu, T. Serra, S. Ramalingam, and S. Zhe. The combinatorial brain surgeon: Pruning weights that cancel one another in neural networks. In International Conference on Machine Learning, 2022.
- Zhang et al. [2021] C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals. Understanding deep learning (still) requires rethinking generalization. Communications of the ACM, 64(3), 2021.
Checklist
The checklist follows the references. Please read the checklist guidelines carefully for information on how to answer these questions. For each question, change the default [TODO] to [Yes] , [No] , or [N/A] . You are strongly encouraged to include a justification to your answer, either by referencing the appropriate section of your paper or providing a brief inline description. For example:
-
•
Did you include the license to the code and datasets? [Yes] See Section.
-
•
Did you include the license to the code and datasets? [No] The code and the data are proprietary.
-
•
Did you include the license to the code and datasets? [N/A]
Please do not modify the questions and only use the provided macros for your answers. Note that the Checklist section does not count towards the page limit. In your paper, please delete this instructions block and only keep the Checklist section heading above along with the questions/answers below.
-
1.
For all authors…
-
(a)
Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? [Yes]
-
(b)
Did you describe the limitations of your work? [Yes] Section 7
-
(c)
Did you discuss any potential negative societal impacts of your work? [Yes] Section 7
-
(d)
Have you read the ethics review guidelines and ensured that your paper conforms to them? [Yes]
-
(a)
-
2.
If you are including theoretical results…
-
(a)
Did you state the full set of assumptions of all theoretical results? [N/A]
-
(b)
Did you include complete proofs of all theoretical results? [N/A]
-
(a)
-
3.
If you ran experiments…
-
(a)
Did you include the code, data, and instructions needed to reproduce the main experimental results (either in the supplemental material or as a URL)? [No]
-
(b)
Did you specify all the training details (e.g., data splits, hyperparameters, how they were chosen)? [Yes] Appendix B
-
(c)
Did you report error bars (e.g., with respect to the random seed after running experiments multiple times)? [Yes] Section 2
-
(d)
Did you include the total amount of compute and the type of resources used (e.g., type of GPUs, internal cluster, or cloud provider)? [Yes] Appendix B
-
(a)
-
4.
If you are using existing assets (e.g., code, data, models) or curating/releasing new assets…
-
(a)
If your work uses existing assets, did you cite the creators? [Yes] Section 2
-
(b)
Did you mention the license of the assets? [N/A]
-
(c)
Did you include any new assets either in the supplemental material or as a URL? [No]
-
(d)
Did you discuss whether and how consent was obtained from people whose data you’re using/curating? [N/A]
-
(e)
Did you discuss whether the data you are using/curating contains personally identifiable information or offensive content? [N/A]
-
(a)
-
5.
If you used crowdsourcing or conducted research with human subjects…
-
(a)
Did you include the full text of instructions given to participants and screenshots, if applicable? [N/A]
-
(b)
Did you describe any potential participant risks, with links to Institutional Review Board (IRB) approvals, if applicable? [N/A]
-
(c)
Did you include the estimated hourly wage paid to participants and the total amount spent on participant compensation? [N/A]
-
(a)
Appendix A Acknowledgement.
We thank Zack Ankner, Xin Dong, Zhun Liu, Jesse Michel, Alex Renda, Cambridge Yang, and Charles Yuan for their helpful discussion and feedback to this project. This work was supported in part by a Facebook Research Award, the MIT-IBM Watson AI-LAB, Google’s Tensorflow Research Cloud, and the Office of Naval Research (ONR N00014-17-1-2699). Daniel M. Roy is supported in part by an NSERC Discovery Grant and Canada CIFAR AI Chair funding through the Vector Institute. Part of this work was done while Gintare Karolina Dziugaite and Daniel M. Roy were visiting the Simons Institute for the Theory of Computing.
Appendix B Additional Experimental Details
We complement the description of experimental methods in Section 2 with additional details.
B.1 Models and Datasets
We study pruning’s effect on generalization using LeNet [32], VGG-16 [55], ResNet-20, ResNet-32 and ResNet-50 [24]. We use the MNIST dataset, consisting of 60,000 images of handwritten digits whose labels correspond to 10 integers between 0 and 9. We also use the CIFAR-10 and -100 [28] datasets, which consists of 60,000 images in 10 and 100 classes. For both datasets, we draw 2,000 of the original training images randomly as validation set; we continue to use the remaining 48,000 of the training images as training set. We use all 10,000 original test images as our test set. We use the ImageNet dataset [10] as well, which contains 1,281,167 images in 1,000 classes. We again randomly draw 50,000 images as validation set and use the remaining 1,231,167 training images as our training set. We use all 50,000 original test images as our test set.
B.2 Training Hyperparameters
Our training hyper-parameter configuration follows the precedent of Frankle and Carbin [13], Frankle et al. [14], Wang et al. [65]: details are available in Table 1.
| Model | Dataset | Epochs | Batch | Opt. | LR | LR Drop | Weight Decay | Initialization | Rewind Epoch | |||
| LeNet | MNIST | 60 | 128 |
|
1.2e-3 | - | - | Kaiming Normal | 0 | |||
| ResNet20 | CIFAR-10 | 160 | 128 | SGD() | 0.1 | 10x at epoch 80, 120 | 1e-4 | Kaiming Normal | 10 | |||
| VGG-16 | CIFAR-10 | 160 | 128 | SGD() | 0.1 | 10x at epoch 80, 120 | 1e-4 | Kaiming Normal | 10 | |||
| ResNet32 | CIFAR-100 | 160 | 128 | SGD() | 0.1 | 10x at epoch 80, 120 | 1e-4 | Kaiming Normal | 10 | |||
| ResNet50 | ImageNet | 90 | 768 | SGD() | 0.3 | 10x at epoch 30, 60, 80 | 1e-4 | Kaiming Normal | 10 |
B.3 EL2N Score Calculation
We follow the method that Paul et al. [50] describes to compute the EL2N scores of examples in the training dataset. For a model architecture and dataset , we first train of a model for of the total training time to obtain partially trained weights for each model. Subsequently, we compute the EL2N score for each image-label pair , as , where is one-hot label, and is the softmax output of the model. Following the precedent of [50], we take and . There is no precedent for choosing the appropriate value for for the ImageNet benchmark, and we find setting , which corresponds to measuring EL2N scores at the th epoch of training, and to be a reasonable choice.
Appendix C Size-Reduction Does Not Explain Pruning’s Benefits to Generalization
In Section 1, we develop an augmented version of the pruning algorithm, by modifying the pruning algorithm to no longer remove weights. This augmented training algorithm corresponds to extended dense training with a cyclic learning rate schedule (EDT) we examine in Section 5.1 – it trains the model for the same number of epochs and with the same cyclic learning rate schedule as pruning.
In Section 1, we highlight the similarity between the generalization of models that this EDT algorithm and pruning produce. This similarity shows that the size-reduction hypothesis does not fully explain pruning’s effect on the generalization of VGG-16 model. In this section, we demonstrate that, with the exception of LeNet on MNIST, this phenomenon generalizes to other model architectures and pruning algorithms, thereby showing that size-reduction does not fully explain pruning’s benefits to generalization in general.
Method.
For 5 model architecture and dataset combinations, we generate a family of models with different sparsities (or training epochs, in the case of the augmented training algorithm), using the following algorithms including 5 variants of pruning algorithms and the EDT algorithm:
-
1.
Learning rate rewinding, as described in Section 2.
- 2.
-
3.
Learning rate rewinding, but modified to remove weights according to a gradient-based weight selection criterion called SynFlow [59, 15]. This pruning algorithm uses the following heuristic to remove weights: the pruning algorithm first replaces each weight in the model with ; then, it feeds an input tensor filled with all 1’s to this instrumented model, and the sum of the output logits is computed as . This pruning algorithm then assigns an importance score to each weight, and remove the weights receiving the lowest such scores. Tanaka et al. [59] designed SynFlow to mitigate layer collapse, a phenomenon associated with ordinary magnitude-based pruning algorithm where weight removal concentrates on certain layers, effectively disconnecting the sparse model.
-
4.
Learning rate rewinding, but modified to remove weights according to a gradient-based selection criterion called SNIP [34]. This pruning algorithm computes gradient for each layer using samples of training data. It then assigns an importance score to each weight, and removes the weights receiving the lowest such scores. The intuition behind this importance score is that it prevents pruning weights with the highest "effect on the loss (either positive or negative)" [15, 34].
-
5.
Iterative random pruning, where a random set of weights are removed at each pruning iteration. The algorithm otherwise behaves like learning rate rewinding.
-
6.
The augmented algorithm, which trains the model for the same number of epochs and with the same cyclic learning rate schedule as pruning, without removing weights.
In Table 2, for each benchmark and algorithm, we tabulate the test error of the model with the best validation error, selected from the family of models that each aforementioned algorithm generates. In Figure 8, we plot generalization of all models within the family of models each aforementioned algorithm generates as a function of sparsities and training time.
| M-LeNet | C10-ResNet20 | C10-VGG-16 | C100-ResNet32 | I-ResNet50 | |||
|
1.8±0.1 | 7.7±0.1 | 5.9±0.1 | 29.9±0.3 | 23.4±0.1 | ||
|
1.5±0.1 | 8.1±0.3 | 6.2±0.1 | 30.6±0.4 | 23.5±0.1 | ||
| SynFlow | 1.7±0.1 | 7.8±0.3 | 6.1±0.1 | 30.2±0.2 | 23.9±0.1 | ||
| SNIP | 1.9±0.1 | 7.7±0.1 | 6.1±0.1 | 29.6±0.2 | 23.4±0.0 | ||
|
1.9±0.2 | 8.1±0.3 | 6.4±0.2 | 30.2±0.1 | 23.9±0.1 | ||
| EDT | 1.8±0.1 | 7.6±0.3 | 6.0±0.1 | 29.0±0.1 | 23.4±0.3 |

Results.
In Table 2, for each benchmark and algorithm, we select, from the family of models that each aforementioned algorithm generates, the model with the best validation error and tabulate its test error. In Figure 8, we plot the generalization of the family of models each aforementioned algorithm generates as a function of sparsities and training time in epochs. We observe that with the exception of LeNet on MNIST, the generalization of dense models that the augmented training algorithm produces matches or exceeds the generalization of sparse models that pruning algorithms produce. For LeNet on MNIST, however, the augmented training algorithm under-performs weight rewinding. We conjecture, without testing, that for this benchmark, the lack of any explicit form of regularization in the training process makes pruning’s regularization effect uniquely important for generalization.
Conclusion.
In Section 1, We show that the augmented training algorithm produces VGG-16 models with generalization that is indistinguishable from that of models that pruning with learning rate rewinding produces. In this section, We further show that this phenomenon shows up even if we apply other iterative pruning algorithms to additional model-dataset combinations. We therefore conclude that in general, size reduction does not fully account for pruning’s benefits to generalization.
Appendix D Effects of Leaving Out Pruning-Affected Examples
In this section, we focus on the subgroups of examples whose training loss improves when pruning to a range of generalization-improving sparsities. By excluding them from the training dataset, we empirically examine their influence on the generalization of the dense models.
Method.
We refer to the top of training examples whose training loss improves the most during pruning as the top-improved examples. To examine the influence of these top-improved examples on generalization, for each sparsity pruning reaches, we train two dense models on two datasets respectively: a). the original training dataset excluding the top-improved examples at the specified sparsity, which we denote as TIE (Top-Improved Examples); b). a dataset of the same size as a)., but consisting of randomly drawn examples, which we denote as RND. We then compare their resulting generalization. If the top-improved examples are indeed the ones with the largest influence on generalization, excluding them from the training dataset should affect generalization more so than excluding a random subset of the same size. We set in our experiments, we also tried setting , but the resulting generalization difference between models we train on two datasets is negligible.

Result.
We show in Figure 9 the generalization of dense models on the dataset excluding top-improved examples (TIE) and randomly drawn dataset of the same size (denoted RND) as a function of the sparsity at which the top-improved examples are selected. Figure 9 shows that, averaging within the sparsities where generalization improves (the range of sparsities in green), excluding top-improved examples hurts generalization more than excluding a random subset of examples of the same size by 0.78%, 0.77%, 0.34%, 0.69% for LeNet on MNIST, ResNet20 on CIFAR-10, VGG-16 on CIFAR-10, ResNet50 on ImageNet benchmarks. For ResNet32 on CIFAR-100 benchmark, we do not observe a significant difference between them. However, increasing the width of the ResNet32 model on CIFAR-100 from 16 to 128, we find that excluding the top-improved examples hurts generalization more than excluding a random subset of examples of the same size by 0.44% (c.f. the 1st image from the right on the 2nd row), similar to our finding on the remaining benchmarks.
Conclusion
The top-improved examples affect generalization to a greater extent than a randomly chosen set of examples of the same size. Moreover, on standard image classification benchmarks, they are more beneficial to generalization than randomly chosen examples.
Appendix E Leaving Out Noisy Examples Improves Generalization
Section 4 demonstrates that, when pruning to the optimal sparsity in the presence of random label noise, its effect is to increase training loss on noisy examples. In this section, we show that increasing training loss on the same set of noisy examples improves the generalization of dense models to the same, if not larger, extent as pruning. Our results validate the connection between increased training loss on noisy examples to generalization improvement.
Method.
Pruning to the optimal sparsity increases the training loss especially on a particular subgroup of examples consisting primarily of noisy examples. A simple and hyperparameter-free method to increase training loss of dense models on the same set of examples is to exclude from the training dataset the set of examples that the sparse models misclassify. Since training only on a dataset subset changes the number of gradient steps an epoch takes, we increase the total number of epochs so that the total number of gradient steps taken remains the same as training on the original dataset. We compare pruning and training dense models exclusively on the subset of examples that the sparse models correctly predict; we refer to such dense models as dense-subset models. In Figure 10, plot the test errors of the dense-subset models as a function of the sparsity of the pruned model whose prediction determines which examples to exclude when training the said dense-subset model. For comparison, we also plot the test errors of sparse models as a function of its sparsity. We summarize the numerical results in Table 8.

Results.
Variations in the generalization of the dense-subset models track variations in the generalization of the sparse models with respect to the fractions of weights remaining. Moreover, the generalization of the optimal dense-subset models matches or exceeds the generalization of the optimally sparse models.
Conclusion.
Section 4 shows that, in the presence of random label noise, pruning to the optimal sparsity has regularization effects: pruning increases the loss on a select subgroup of training examples consisting predominantly of noisy examples. In this section, we demonstrate that increasing training loss on the same set of examples benefits dense model generalization as well. Our results establish a connection between pruning’s regularization effect and generalization improvement.
Appendix F Comparing Pruning with Width Down-scaling
In this section, we present a less-cluttered version of the images we show in Section 5.2.

Appendix I Similarities between Pruning and Width Down-scaling
In Section 5.2, we observe that the pruned models and width down-scaled models attain similar generalization at the optimal sparsity and model width on benchmarks with random label noise, where pruning’s effect at the optimal sparsity is to improve generalization by strengthening regularization (Section 4). Their similarity is surprising because pruning and down-scaling model width are two distinct methods to reduce model size. In this section, we further compare pruning and width down-scaling with equalized training time and quantify the similarities between their effects on training examples.
Method.
Width down-scaling differs from pruning because a pruned model receives extra training, due to the retraining step. To compare fairly, we modify the pruning and width down-scaling algorithms as such to equalize the amount of training:777Alternatively, one can equalize training by increasing the amount of training of width down-scaled models. However this increases the amount of compute required by an order of magnitude, and beyond reasonable budget. This is because unlike iterative pruning, a trained model with a larger width does not become the starting point for training a model with a smaller width, and therefore no amount of training is shared between models with different sizes.
-
1.
For pruning, we adopt a variant of the magnitude pruning algorithm, called one-shot pruning [52]. While iterative pruning (the pruning algorithm we introduce in Section 2) removes a fixed fraction of the remaining weights per iteration until achieving the desired sparsity, one-shot pruning removes all weights at once to reach the desired sparsity. Like iterative pruning, one-shot pruning retrains the model after weights removal.
-
2.
For width down-scaling, we equalize the amount of training with one-shot pruning by training the width down-scaled model for the same number of gradient steps and using the same learning rate schedule as one-shot pruning.
We then quantify the similarities between two algorithms by comparing (1). the generalization of their produced models; (2). average loss change, relative to the standard dense model, on training example subgroups with distinct EL2N percentile ranges due to respective algorithms; (3). overlap of the 10% examples whose training loss changes the most due to two algorithms, relative to the training loss of the original dense model, measured in terms of Jiccard similarity index. The Jiccard similarity index measures the similarity between the content of two sets and , with the following formula:

Generalization.
Figure 12 shows that generalization of models that both algorithms produce are qualitatively similar on benchmarks with injected random label noise – generalization of models that both algorithms generate improves when they only remove a relatively small fraction of weights. As both algorithms remove more weights, generalization of produced models begins to suffer.

Change in loss by subgroups.
Figure 13 shows that on benchmarks with random label noise, pruning and width down-scaling has similar effects on example subgroups with distinct EL2N score percentile ranges at optimal sparsity and model width respectively – training loss increase for both algorithms tends to concentrate on examples with high EL2N score percentile ranges.
| Model | Noise Level | Jaccard Similarity |
| M-LeNet | 0%/5%/10%/15% | 0.60 / 0.11 / 0.74 / 0.62 |
| C10-ResNet20 | 0%/15%/30%/60% | 0.20 / 0.37 / 0.35 / 0.42 |
| C10-VGG-16 | 0%/15%/30%/60% | 0.14 / 0.57 / 0.27 / 0.12 |
| C100-ResNet32 | 0%/15%/30%/60% | 0.17 / 0.23 / 0.27 / 0.28 |
| I-ResNet50 | 0%/15%/ | 0.26 / 0.26 |
Affected examples overlap.
Table 3 shows that the 10% of training examples whose training loss changes the most due to pruning and width down-scaling overlap significantly more than random baseline.
Conclusion.
Pruning and width down-scaling have similar regularization effects: they nonuniformly increase the average training loss of example subgroups, which we show is key to improving generalization in the presence of random label noise (Section 4). Therefore, the regularization effect of pruning may be a consequence of model size reduction in general.
Appendix J Ablation Studies
Pruning algorithms are complex aggregation of individual design choices. In this section, we examine whether specific design choices of pruning algorithms including weight resetting and weight selection heuristics contributes to the generalization-improving effect of pruning.
J.1 Rewinding Weights
The pruning algorithm we use in this study, namely, learning rate rewinding, rewinds learning rate to their value early in training after each pruning iteration. Its predecessor, an iterative pruning algorithm called weight rewinding rewinds not just learning rate, but also weights to their values early in training after each pruning iteration. Frankle and Carbin [13] proposed weight rewinding and later, Renda et al. [52] found that rewinding weight is unnecessary if one’s goal is to produce a family of models achieving the optimal parameter count - generalization trade-off. In this section, we expand the comparison weight rewinding [13] and learning rate rewinding [52] to datasets with random label noise, and show that rewinding weights is actually necessary for achieving optimal generalization on benchmarks with random label noise.
Method.
To examine whether rewinding weights contributes to the generalization-improving effect of pruning, we compare the generalization of models that weight rewinding produces with generalization of models that learning rate rewinding produces. The former pruning algorithm rewinds weights and the latter does not.

Results.
We plot our results in Figure 14. Numerical results are available in Table 9 in Appendix M. We observe that across 18 model, dataset, noise level combinations, weight rewinding out-performs learning rate rewinding on 10 benchmarks, whereas learning rate rewinding only out-performs weight rewinding on 2. For the remaining 6 benchmarks, two algorithms produce models with matching generalization. Notably, weight rewinding is better at mitigating random label noise than learning rate rewinding. Across all model architectures, on datasets with and without random label noise, the optimal test error of models that weight rewinding produces is lower than the optimal test error of models that learning rate rewinding produces by -0.7% to 0.3%, 0% (matching) to 5.5%.
Conclusion.
Weight resetting contributes to the generalization-improving effect of pruning.
J.2 Weight Selection Heuristics
The pruning algorithm we study, namely learning rate rewinding [52], removes weights based on the simple heuristic that weights with low magnitude are less important for the given task. We study whether pruning’s generalization improving effect is affected by the choice of weight selection heuristic.
Method.
We modify learning rate rewinding to adopt the following alternative weight selection heuristics, and compare the generalization of models that each modified pruning algorithm generates.
-
1.
Random selection. Weights are removed at random without considering their values.
-
2.
Synaptic flow preserving weight selection [59]. This weight selection heuristic works as follow. The heuristic algorithm first replaces each weight in the model with ; then, the algorithm feed an input tensor filled with all 1’s to this instrumented model, and the sum of the output logits is computed as . The heuristic algorithm then assigns an importance score to each weight, and the weights receiving the lowest such scores are removed. Tanaka et al. [59] designed SynFlow to mitigate layer collapse, a phenomenon associated with ordinary magnitude-based pruning method where weight removal concentrates on certain layers, effectively disconnecting the sparse model.

Results.
We plot and tabulate the result of comparison in Figure 15 and Table 10. We observe that SynFlow-based weight selection heuristic beats magnitude-based one on 6 out of 18 benchmarks. We also observe that random pruning is particularly effective at mitigating random label noise – on 9 out of 13 benchmarks with random label noise, random pruning out-performs magnitude-based weight selection heuristic.
Conclusion.
The choice of weight selection heuristic plays a significant role in determining pruning’s generalization-improving effect.
Appendix K Closer Look at Examples with Training Loss Most Worsened by Pruning
In this section, we take a closer look at the examples in the standard image classification training datasets whose training loss is increased the most by pruning to a range of generalization-improving and generalization-preserving sparsities.
K.1 Example Images and Labels
When pruning to sparsities that improve or preserve (causing <2% error increase) generalization, what is the nature of examples whose training loss increases or decreases the most? Here, we present examples whose training loss is affected the most by pruning to the aforementioned sparsities. We show that while the majority of these examples are atypical representations of their labels, a fraction of these examples contain incorrect or ambiguous labels.
|
|
|
|
|
|||||||||||
| Most-worsened | 1.4% | 16.7-13.4% | 2.3-0.7% | 16.7-8.6% | 13.4% | ||||||||||
| Most-improved | 80-5.5% | 80-21% | 80-2.3% | 80-21% | 80-16.8% | ||||||||||
| Least-affected | 100-1.4% | 100-5.5% | 100-0.19% | 100-8.6% | 100-13.4% |
Method.
We select three subsets of training examples: the most-worsened examples, the most-improved examples and the least-affected examples as follow.
-
1.
The most-worsened examples: we first measure the per-example training loss after pruning to the following sparsities. For ResNet20 on CIFAR-10 and VGG-16 on CIFAR-10 benchmarks, a range of sparsities with an increased overall training loss but improved generalization exist. We measure per-example training loss after pruning to these sparsities. For LeNet on MNIST, ResNet32 on CIFAR-100 and ResNet50 on ImageNet benchmarks, however, no such sparsities exist. We therefore choose to measure per-example training loss after pruning to sparsities with an increased overall training loss and generalization that is no worse than that of the dense models by 2%. We then rank examples in the training dataset based on the geometric average of their training loss increase after pruning to aforementioned sparsities, relative to their training loss before pruning.888Since we are concerned with examples whose training loss increases due to pruning, and in general, one cannot compute geometric average of arrays with negative numbers, we set negative training loss increase due to pruning to a small number , effectively ignoring them. We select examples with the most training loss increase as the most-worsened examples.
-
2.
The most-improved examples: we first measure the per-example training loss after pruning to sparsities with improved generalization and decreased training loss. We then rank examples in the training dataset based on the geometric average of their training loss decrease after pruning to aforementioned sparsities, relative to their training loss before pruning.999Similar to how we select most-worsened examples, since we are concerned with examples whose training loss decreases due to pruning, and in general, one cannot compute geometric average of arrays with negative numbers, we set negative training loss decrease due to pruning to a small number , effectively ignoring them. We select examples with the most training loss decrease as the most-improved examples.
-
3.
The least-affected examples: we first measure the per-example training loss after pruning to sparsities that attains generalization no worse than that of the dense models by 2%. We then rank examples in the training dataset based on geometric average of the absolute value of their training loss change after pruning to aforementioned sparsities, relative to their training loss before pruning. We select examples with the least absolute value of training loss change as the least-affected examples.
For each type of training example subset, we tabulate the sparsities at which we measure per-example training loss after pruning in Table 4. We average the per-example training loss across selected sparsities and across independent runs of the same experiment with distinct random seeds.
On each benchmark, we present the 20 examples from each category Figure 16. Notably, the set of 20 least-affected examples are not unique, as many examples are practically unaffected by pruning.
Results.
We describe our observations in the captions of Figure 16.
Conclusion.
When pruning to sparsities that improves or preserves generalization (<2% error increase), the set of examples whose training loss is most affected (i.e., either most worsened or most improved) are examples that are atypical representations of their labels. A fraction of them have ambiguous or erroneous labels. In contrast, the least affected examples are mostly unambiguous and canonical representations of the labels.














K.2 Empirical Analysis
We refer to the set of examples whose training loss is increased the most by pruning as top-worsened examples. In this subsection, we empirically evaluate the effect of the top-worsened examples on generalization. We focus on two benchmarks – CIFAR-10-ResNet20 and CIFAR-10-VGG-16, since we only observe generalization improvement with an overall increase in training loss on the two aforementioned benchmarks.
Method.
For each benchmark and model with sparsity that the pruning algorithm generates, we create two dataset subsamples of size to evaluate the effect of top-worsened examples on generalization, where : a). start with a randomly drawn examples, and add additional examples whose training loss is increased the most by pruning to sparsity (i.e., the top-worsened examples); we denote this dataset subsample as ; b). start with the same examples, but add additional examples drawn randomly from the rest of the dataset; we denote this dataset subsample as . We then train dense models on two subsamples and to obtain the corresponding generalization , . If our hypothesis is correct – that pruning improves generalization by increasing training loss, essentially ignoring, a small fraction of noisy examples detrimental to generalization – for a range of sparsities where pruning improves generalization, we should observe that the generalization of dense models we train on the subsample containing top-worsened examples () to be worse than the one we train on a randomly drawn subsample (). Following the precedent of Paul et al. [50], we choose to be the size equivalent to of the training dataset and to be of the training dataset.
Notably, subsampling the dataset is necessary to reveal the effect of the small fraction of noisy examples empirically. Their relatively rare occurrence makes their harmful effect on generalization difficult to detect empirically. This is consistent with with observation and experimental setup used in Paul et al. [50], characterizing the harmful effect of a small fraction of training examples with high EL2N scores. We similarly demonstrate the harmful effect of examples avoided by the sparse models.
Results.
We visualize the generalization difference - of dense models we train on the two dataset subsamples as a function of sparsities in Figure 17. Indeed, dense models we train on the subsample containing the top-worsened examples achieve worse generalization compared with dense models we train on a random subsample, most notably near and beyond the highest sparsity that still improves generalization. Within the range of sparsity levels where pruning improves generalization, the test errors of dense ResNet20, VGG-16 models we train on the dataset subsample containing the top-worsened examples is worse than the models trained on a random subsample by 0 (matching) to 0.35% and 0 (matching) to 0.54% respectively. We thus confirm that pruning improves generalization while avoiding fitting a small fraction of examples harmful to generalization.

Appendix L Effects of Learning Algorithms on Subgroup Training Loss
In Section 3, we partition the training set into subgroups, each with a distinct EL2N score percentile range and present pruning’s effect on the average training loss of example subgroups at two sparsities of interests. In this section, we present pruning’s effect on the average training loss of example subgroups at more sparsities. We similarly present the effect of two other learning algorithms, extended dense training (Section 5.1) and width downscaling (Section 5.2), on subgroup training loss.
Method.
Similar to Section 3, to measure the change in training loss due to a particular learning algorithm, we partition the training set into subgroups, each with a different range of EL2N scores. For each subgroup, we then compute the average change in training loss after we apply the learning algorithm, relative to the resulting training loss after training the dense model with standard hyperparameters as specified in Section B.2, on examples in the subgroup. A negative value indicates that the learning algorithm improves the subgroup training loss relative to training the dense model with standard hyperparameters. We present the effect of pruning on subgroup training loss across a sequence of evenly spaced 5 sparsities in Figure 18. We present the effect of extended dense training and width downscaling on subgroup training loss across a sequence of 5 evenly spaced training time milestones and model downscaling factors in Figure 19 and Figure 20, respectively. Consistent with Section 3, we pick because it is the largest value of that enables us to clearly present per-subgroup training loss change.





Pruning results.
Figure 18 shows that, at low sparsities, pruning’s effect is to improve training loss on almost all example subgroups. For example, on CIFAR-10-ResNet20 benchmark with 0% random label noise, pruning to 80% to 26.21% weights remaining reduces the average training loss on example subgroups. At these sparsities, pruning’s effect is to improve training. Pruning to higher sparsities, pruning’s regularization effect dominates – pruning increases training loss across all example subgroups. For example, on CIFAR-10-ResNet20 benchmark with 8.59% to 0.92% weights remaining, pruning’s effect is to increase the average training loss on almost all example subgroups.
Extended dense training results.
Figure 19 shows that the effect of extended dense training is to improve training loss on almost all example subgroups. This effect is similar to pruning to low sparsities (e.g., 80% to 26.21% weights remaining for CIFAR-10-ResNet20), as shown in Figure 18. However, unlike pruning to high sparsities (e.g, 8.59% to 0.92% weights remaining for CIFAR-10-ResNet20), we do not observe any regularization effect of extended dense training.





Width downscaling results.
Figure 20 shows that width downscaling has a regularization effect, as it increases training loss on almost all example subgroups. This effect is similar to pruning to high sparsities (e.g., 8.59% to 0.92% weights remaining for CIFAR-10-ResNet20), as shown in Figure 18. However, unlike pruning to low sparsities (e.g, 80% to 26.21% weights remaining for CIFAR-10-ResNet20), we do not observe any training loss improvement at any model width we test.



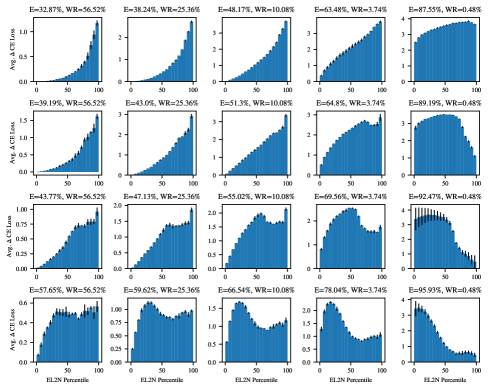

Appendix M Data for Experiments in Paper
| Models | Method | Noise Level | Test Errors |
| M-LeNet | LR | 5%/10%/15% | 5.21±0.08%/7.57±0.35%/9.96±0.62% |
| EDT | 5%/10%/15% | 4.84±0.33%/8.96±0.13%/13.04±0.71% | |
| C10-ResNet20 | LR | 15%/30%/60% | 13.04±0.43%/16.03±0.13%/25.39±0.11% |
| EDT | 15%/30%/60% | 13.45±0.16%/18.40±0.24%/39.87±0.58% | |
| C10-VGG-16 | LR | 15%/30%/60% | 12.47±0.29%/15.47±0.13%/25.29±0.49% |
| EDT | 15%/30%/60% | 16.04±0.22%/28.22±0.37%/59.46±0.53% | |
| C100-ResNet32 | LR | 15%/30%/60% | 38.81±0.70%/43.86±0.29%/55.83±0.45% |
| EDT | 15%/30%/60% | 39.51±0.40%/44.10±0.49%/60.62±0.74% | |
| I-ResNet50 | LR | 15% | 26.15±0.09% |
| EDT | 15% | 25.95±0.06% |
| Model | Noise Level | Rewind | Type | Test Error |
| M-LeNet | 0%/5%/10%/15% | Weight | Sparse | 1.5±0.1%/3.7±0.3%/4.2±0.1%/4.4±0.2% |
| LR | Sparse | 1.8±0.1%/5.2±0.1%/7.6±0.3%/10.0±0.6% | ||
| N/A | Dense | 2.1±0.2%/5.3±0.2%/9.1±0.2%/13.4±0.3% | ||
| C10-ResNet20 | 0%/15%/30%/60% | Weight | Sparse | 8.1±0.3%/13.1±0.2%/15.4±0.2%/24.5±0.5% |
| LR | Sparse | 7.7±0.1%/13.0±0.4%/16.0±0.1%/25.4±0.1% | ||
| N/A | Dense | 8.2±0.1%/13.6±0.3%/18.4±0.4%/40.3±0.4% | ||
| C10-VGG-16 | 0%/15%/30%/60% | Weight | Sparse | 6.2±0.1%/12.0±0.3%/14.8±0.4%/23.8±0.2% |
| LR | Sparse | 5.9±0.1%/12.5±0.3%/15.5±0.1%/25.5±0.3% | ||
| N/A | Dense | 6.6±0.0%/17.5±0.2%/31.5±0.6%/62.7±0.6% | ||
| C100-ResNet32 | 0%/15%/30%/60% | Weight | Sparse | 30.6±0.4%/38.7±0.6%/42.9±0.1%/54.7±0.5% |
| LR | Sparse | 29.9±0.3%/38.8±0.7%/43.9±0.3%/55.8±0.5% | ||
| N/A | Dense | 30.3±0.2%/38.9±0.3%/44.0±0.6%/61.0±0.4% |
| Model | Method | Noise Level | Test Error |
| M-LeNet | WD | 0%/5%/10%/15% | 1.90±0.09%/5.63±0.18%/5.45±0.38%/6.08±0.33% |
| LR | 0%/5%/10%/15% | 1.82±0.11%/5.21±0.08%/7.57±0.35%/9.96±0.62% | |
| C10-ResNet20 | WD | 0%/15%/30%/60% | 8.42±0.11%/13.06±0.16%/16.01±0.55%/25.29±0.59% |
| LR | 0%/15%/30%/60% | 7.71±0.09%/13.04±0.43%/16.03±0.13%/25.39±0.11% | |
| C10-VGG-16 | WD | 0%/15%/30%/60% | 6.67±0.04%/14.32±0.24%/17.43±0.10%/26.76±0.37% |
| LR | 0%/15%/30%/60% | 5.86±0.08%/12.47±0.29%/15.47±0.13%/25.29±0.49% | |
| C100-ResNet32 | WD | 0%/15%/30%/60% | 30.43±0.25%/38.88±0.13%/44.41±0.16%/57.92±0.29% |
| LR | 0%/15%/30%/60% | 29.93±0.34%/38.81±0.70%/43.86±0.29%/55.83±0.45% | |
| I-ResNet50 | WD | 0%/15% | 23.89±0.10%/24.75±0.18% |
| LR | 0%/15% | 23.42±0.14%/26.15±0.09% |
| Model | Method | Noise Level | Test Error (Optimal) | Test Error (0% Sparsity) |
| MNIST LeNet | LR | 5%/10%/15% | 5.22±0.06%/7.57±0.35%/10.03±0.60% | 5.35±0.18%/9.08±0.21%/13.40±0.32% |
| DS | 5%/10%/15% | 2.55±0.12%/2.74±0.13%/3.30±0.11% | 5.23±0.35%/9.11±0.09%/12.03±0.93% | |
| CIFAR-10 ResNet20 | LR | 15%/30%/60% | 12.63±0.12%/15.88±0.26%/25.39±0.11% | 13.57±0.26%/18.35±0.42%/40.26±0.43% |
| DS | 15%/30%/60% | 9.76±0.11%/11.38±0.10%/18.66±0.26% | 11.20±0.29%/14.51±0.40%/32.77±0.48% | |
| CIFAR-10 VGG-16 | LR | 15%/30%/60% | 12.39±0.27%/15.19±0.26%/25.49±0.29% | 17.51±0.18%/31.46±0.60%/62.68±0.63% |
| DS | 15%/30%/60% | 8.84±0.08%/10.09±0.09%/17.80±0.37% | 18.07±0.57%/32.25±0.40%/61.21±0.88% | |
| C100 ResNet32 | LR | 15%/30%/60% | 38.81±0.70%/43.29±0.40%/55.81±0.46% | 38.85±0.29%/43.97±0.61%/61.03±0.36% |
| DS | 15%/30%/60% | 34.24±0.25%/37.17±0.23%/47.38±1.10% | 34.35±0.26%/37.89±0.33%/52.66±0.42% | |
| ImageNet ResNet50 | LR | 15% | 26.12±0.08% | 26.44±0.06% |
| DS | 15% | 24.75±0.09% | 24.77±0.07% |
| Model | Method | Noise Level | Test Error |
| M-LeNet | WR | 0%/5%/10%/15% | 1.50±0.08%/3.74±0.30%/4.16±0.07%/4.41±0.16% |
| LR | 0%/5%/10%/15% | 1.82±0.11%/5.21±0.08%/7.57±0.35%/9.96±0.62% | |
| C10-ResNet20 | WR | 0%/15%/30%/60% | 8.07±0.29%/13.09±0.24%/15.43±0.25%/24.47±0.49% |
| LR | 0%/15%/30%/60% | 7.71±0.09%/13.04±0.43%/16.03±0.13%/25.39±0.11% | |
| C10-VGG-16 | WR | 0%/15%/30%/60% | 6.19±0.10%/11.97±0.33%/14.81±0.39%/23.80±0.15% |
| LR | 0%/15%/30%/60% | 5.86±0.08%/12.47±0.29%/15.47±0.13%/27.90±1.41% | |
| C100-ResNet32 | WR | 0%/15%/30%/60% | 30.58±0.36%/38.74±0.59%/42.89±0.09%/54.67±0.50% |
| LR | 0%/15%/30%/60% | 29.93±0.34%/38.81±0.70%/43.86±0.29%/55.83±0.45% | |
| I-ResNet50 | WR | 0%/15% | 23.51±0.08%/26.14±0.23% |
| LR | 0%/15% | 23.42±0.14%/26.15±0.09% |
| Model | Method | Noise Level | Test Error |
| M-LeNet | Magnitude | 0%/5%/10%/15% | 1.82±0.11%/5.21±0.08%/7.57±0.35%/9.96±0.62% |
| SynFlow | 0%/5%/10%/15% | 1.65±0.05%/5.20±0.15%/9.59±0.20%/11.72±0.64% | |
| Random | 0%/5%/10%/15% | 1.86±0.19%/5.11±0.27%/6.88±0.23%/7.50±0.07% | |
| C10-ResNet20 | Magnitude | 0%/15%/30%/60% | 7.71±0.09%/13.04±0.43%/16.03±0.13%/25.39±0.11% |
| SynFlow | 0%/15%/30%/60% | 7.83±0.28%/12.61±0.41%/15.27±0.02%/25.09±0.20% | |
| Random | 0%/15%/30%/60% | 8.14±0.29%/12.09±0.08%/14.53±0.09%/24.52±0.42% | |
| C10-VGG-16 | Magnitude | 0%/15%/30%/60% | 5.86±0.08%/12.47±0.29%/15.47±0.13%/25.29±0.49% |
| SynFlow | 0%/15%/30%/60% | 6.14±0.09%/12.35±0.18%/15.04±0.21%/30.67±10.03% | |
| Random | 0%/15%/30%/60% | 6.40±0.17%/14.65±0.39%/17.77±0.42%/27.30±0.49% | |
| C100-ResNet32 | Magnitude | 0%/15%/30%/60% | 29.93±0.34%/38.81±0.70%/43.86±0.29%/55.83±0.45% |
| SynFlow | 0%/15%/30%/60% | 30.24±0.24%/38.13±0.33%/43.12±0.57%/55.55±0.17% | |
| Random | 0%/15%/30%/60% | 30.15±0.14%/37.18±0.32%/41.44±0.30%/53.60±0.07% | |
| I-ResNet50 | Magnitude | 0%/15% | 23.42±0.14%/26.15±0.09% |
| SynFlow | 0%/15% | 23.90±0.08%/26.37±0.10% | |
| Random | 0%/15% | 23.86±0.10%/26.49±0.10% |
| Benchmark | Noise Level | Partition | Dense/Sparse (Diff) CE Loss |
| M-LeNet | 5% | Noisy | 0.46±0.06/0.2±0.13(-0.26) |
| Original | 0.02±0.0/0.01±0.0(-0.01) | ||
| 10% | Noisy | 0.53±0.04/3.83±0.06(+3.3) | |
| Original | 0.03±0.01/0.24±0.01(+0.21) | ||
| 15% | Noisy | 0.59±0.0/3.5±0.17(+2.91) | |
| Original | 0.05±0.01/0.36±0.04(+0.31) | ||
| C10-ResNet20 | 15% | Noisy | 2.63±0.06/3.18±0.27(+0.55) |
| Original | 0.18±0.0/0.26±0.03(+0.08) | ||
| 30% | Noisy | 2.52±0.01/3.1±0.03(+0.58) | |
| Original | 0.34±0.0/0.55±0.02(+0.21) | ||
| 60% | Noisy | 2.21±0.01/2.61±0.0(+0.4) | |
| Original | 0.77±0.01/1.16±0.0(+0.39) | ||
| C10-VGG-16 | 15% | Noisy | 0.06±0.01/3.28±0.39(+3.22) |
| Original | 0.03±0.01/0.31±0.02(+0.28) | ||
| 30% | Noisy | 0.12±0.01/2.99±0.1(+2.87) | |
| Original | 0.07±0.0/0.53±0.01(+0.46) | ||
| 60% | Noisy | 0.27±0.01/2.55±0.01(+2.28) | |
| Original | 0.14±0.01/1.17±0.04(+1.03) | ||
| C100-ResNet32 | 15% | Noisy | 4.19±0.03/5.71±0.04(+1.52) |
| Original | 0.43±0.0/0.81±0.01(+0.38) | ||
| 30% | Noisy | 4.25±0.04/5.13±0.34(+0.88) | |
| Original | 0.66±0.01/1.05±0.16(+0.39) | ||
| 60% | Noisy | 4.02±0.02/4.94±0.04(+0.92) | |
| Original | 1.24±0.02/2.13±0.03(+0.89) | ||
| I-ResNet50 | 15% | Noisy | 7.53±0.03/7.34±0.04(-0.19) |
| Original | 0.56±0.0/0.53±0.0(-0.03) |