Pruning Randomly Initialized Neural Networks
with Iterative Randomization
Abstract
Pruning the weights of randomly initialized neural networks plays an important role in the context of lottery ticket hypothesis. Ramanujan et al. [26] empirically showed that only pruning the weights can achieve remarkable performance instead of optimizing the weight values. However, to achieve the same level of performance as the weight optimization, the pruning approach requires more parameters in the networks before pruning and thus more memory space. To overcome this parameter inefficiency, we introduce a novel framework to prune randomly initialized neural networks with iteratively randomizing weight values (IteRand). Theoretically, we prove an approximation theorem in our framework, which indicates that the randomizing operations are provably effective to reduce the required number of the parameters. We also empirically demonstrate the parameter efficiency in multiple experiments on CIFAR-10 and ImageNet. The code is available at https://github.com/dchiji-ntt/iterand.
1 Introduction
The lottery ticket hypothesis, which was originally proposed by Frankle and Carbin [6], has been an important topic in the research of deep neural networks (DNNs). The hypothesis claims that an over-parameterized DNN has a sparse subnetwork (called a winning ticket) that can achieve almost the same accuracy as the fully-trained entire network when trained independently. If the hypothesis holds for a given network, then we can reduce the computational cost by using the sparse subnetwork instead of the entire network while maintaining the accuracy [15, 22]. In addition to the practical benefit, the hypothesis also suggests that the over-parametrization of DNNs is no longer necessary and their subnetworks alone are sufficient to achieve full accuracy.
Ramanujan et al. [26] went one step further. They proposed and empirically demonstrated a conjecture related to the above hypothesis, called the strong lottery ticket hypothesis, which informally states that there exists a subnetwork in a randomly initialized neural network such that it already achieves almost the same accuracy as a fully trained network, without any optimization of the weights of the network. A remarkable consequence of this hypothesis is that neural networks could be trained by solving a discrete optimization problem. That is, we may train a randomly initialized neural network by finding an optimal subnetwork (which we call weight-pruning optimization), instead of optimizing the network weights continuously (which we call weight-optimization) with stochastic gradient descent (SGD).
However, the weight-pruning optimization requires a problematic amount of parameters in the random network before pruning. Pensia et al. [25] theoretically showed that the required network width for the weight-pruning optimization needs to be logarithmically wider than the weight-optimization at least in the case of shallow networks. Therefore, the weight-pruning optimization requires more parameters, and thus more memory space, than the weight-optimization to achieve the same accuracy. In other words, under a given memory constraint, the weight-pruning optimization can have lower final accuracy than the weight-optimization in practice.
In this paper, we propose a novel optimization method for neural networks called weight-pruning with iterative randomization (IteRand), which extends the weight-pruning optimization to overcome the parameter inefficiency. The key idea is to virtually increase the network width by randomizing pruned weights at each iteration of the weight-pruning optimization, without any additional memory consumption. Indeed, we theoretically show that the required network width can be reduced by the randomizing operations. More precisely, our theoretical result indicates that, if the number of randomizing operations is large enough, we can reduce the required network width for weight-pruning to the same as that for a network fully trained by the weight-optimization up to constant factors, in contrast to the logarithmic factors of the previous results [25, 24]. We also empirically demonstrate that, under a given amount of network parameters, IteRand boosts the accuracy of the weight-pruning optimization in multiple vision experiments.
2 Background
In this section, we review the prior works on pruning randomly initialized neural networks.
Notation and setup.
Let . Let be an -layered ReLU neural network with an input and parameters , where each weight is randomly sampled from a distribution over . A subnetwork of is written as where is a binary mask and "" represents an element-wise multiplication.
Ramanujan et al. [26] empirically observed that we can train the randomly initialized neural network by solving the following discrete optimization problem, which we call weight-pruning optimization:
| (1) |
where is a distribution on a set of labeled data and is a loss function. To solve this optimization problem, Ramanujan et al. [26] proposed an optimization algorithm, called edge-popup (Algorithm 1).
The TrainMask (Algorithm 2) is the key process in Algorithm 1. It has a latent variable , where each element represents an importance score of the corresponding weight , and optimizes instead of directly optimizing the discrete variable . Given the score , the corresponding is computed by the function , which returns defined as follows: if is top in , otherwise , where is a hyperparameter representing a sparsity rate of the pruned network. In the line 3 of Algorithm 2, returns the updated value of by stochastic gradient descent with a learning rate , weight decay , momentum coefficient , and gradient vector .
On the theoretical side, Malach et al. [19] first provided a mathematical justification of the above empirical observation. They formulated it as an approximation theorem with some assumptions on the network width as follows.
Theorem 2.1 (informal statement of Theorem 2.1 in [19])
Let be an -layered network with bounded weight matrices, and be a randomly initialized -layered neural network. If the width of is larger than by the factor of a polynomial term, then there probably exists a subnetwork of that approximates .
By considering a well-trained network as , Theorem 2.1 indicates that pruning a sufficiently wide may reveal a subnetwork which achieves good test accuracy as , in principle.
In the follow-up works [25, 24], the assumption on the network width was improved by reducing the factor of the required width to a logarithmic term. However, Pensia et al. [25] showed that the logarithmic order is unavoidable at least in the case of . While their results imply the optimality of the logarithmic bound, it also means that we cannot further relax the assumption on the network width as long as we work in the same setting. This indicates a limitation of the weight-pruning optimization, i.e. the weight-pruning optimization can train only less expressive models than ones trained with the conventional weight-optimization like SGD, under a given amount of memory or network parameters.
3 Method
In this section, we present a novel method called weight-pruning with iterative randomization (IteRand) for randomly initialized neural networks.
As discussed in Section 2, although the original weight-pruning optimization (Algorithm 1) can achieve good accuracy, it still has a limitation in the expressive power under a fixed amount of memory or network parameters. Our method is designed to overcome this limitation. The main idea is to randomize pruned weights at each iteration of the weight-pruning optimization. As we prove in Section 4, this reduces the required size of an entire network to be pruned.
We use the same notation and setup as Section 2. In addition, we assume that each weight of the network can be re-sampled from at each iteration of the weight-pruning optimization.
3.1 Algorithm
Algorithm 3 describes our proposed method, IteRand, which extends Algorithm 1. The differences from Algorithm 1 are lines 5-7. IteRand has a hyperparameter (line 5). At the -th iteration, whenever can be divided by , pruned weights are randomized by function (line 6). There are multiple possible designs for , which will be discussed in the next subsection.
Note that controls how frequently the algorithm randomizes the pruned weights. Indeed the total number of the randomizing operations is . If is too small, the algorithm is likely to be unstable because it may randomize even the important weights before their scores are well-optimized, and also the overhead of the randomizing operations cannot be ignored. In contrast, if is too large, the algorithm becomes almost same as the original weight-pruning Algorithm 1, and thus the effect of the randomization disappears. We fix on CIFAR-10 (about ) and on ImageNet (about ) in our experiments (Section 5).
3.2 Designs of
Here, we discuss how to define function. There are several possible ways to randomize a subset of the parameters .
Naive randomization.
For any distribution , a naive definition of the randomization function (which we call naive randomization) can be given as follows.
where we denote the -th component of as , and each is a random variable with the distribution . Also this can be written in another form as
| (2) |
where is a random variable with the distribution .
Partial randomization.
The naive randomization (Eq. (2)) is likely to be unstable because it entirely replaces all pruned weights with random values every iteration. To increase the stability, we modify the definition of the naive randomization as it replaces a randomly chosen subset of the pruned weights as follows (which we call partial randomization):
| (3) |

where is the same as in Eq. (2), is a hyperparameter and is a binary vector whose each element is sampled from the Bernoulli distribution , i.e. with probability and with probability .
4 Theoretical justification
In this section, we present a theoretical justification for our iterative randomization approach on the weight-pruning of randomly initialized neural networks.
4.1 Setup
We consider a target neural network of depth , which is described as follows.
| (4) |
where is a -dimensional real vector, is the ReLU activation, and is a matrix. Our objective is to approximate the target network by pruning a randomly initialized neural network , which tends to be larger than the target network.
Similar to the previous works [19, 25], we assume that is twice as deep as the target network . Thus, can be described as
| (5) |
where is a matrix () with . Each element of the matrix is assumed to be drawn from the uniform distribution . Since there is a one-to-one correspondence between pruned networks of and sequences of binary matrices with , every pruned network of can be described as
| (6) |
Under these setups, we recall that the previous works showed that, with high probability, there exists a subnetwork of that approximates when the width of is larger than by polynomial factors [19] or logarithmic factors [25, 24].
4.2 Formulation and main results
Now we attempt to mathematically formulate our proposed method, IteRand, as an approximation problem. As described in Algorithm 3, the method consists of two steps: optimizing binary variables and randomizing pruned weights in . The first step can be formulated as the approximation problem of by some as described above. Corresponding to the second step, we introduce an idealized assumption on for a given number : each element of the weight matrix can be re-sampled with replacement from the uniform distribution up to times, for all . (re-sampling assumption for )
Under this re-sampling assumption, we obtain the following theorem.
Theorem 4.1 (Main Theorem)
Fix , and we assume that . Let , and assume that satisfies the re-sampling assumption for .
If holds for all , then with probability at least , there exist binary matrices such that
| (7) |
In particular, if is larger than , then is enough.
Theorem 4.1 shows that the iterative randomization is provably helpful to approximate wider networks in the weight-pruning optimization of a random network. In fact, the required width for in Theorem 4.1 is reduced to even twice as wide as when the number of re-sampling is sufficiently large, in contrast to the prior results without re-sampling assumption where the required width is logarithmically wider than [25, 24]. This means that, under a fixed amount of parameters of , we can achieve a higher accuracy by weight-pruning of with iterative randomization since a wider target network has a higher model capacity.
4.3 Proof ideas for Theorem 4.1
Let us consider the case of . Then the target network can be written as , where , and can be written as where . Also, subnetworks of can be written as for some .
There are two technical points in our proof. The first point is the following splitting of :
| (8) |
for any . This splitting is very similar to the one used in the previous works [19, 25, 24]:
| (9) |
However, if we use the latter splitting Eq. (9), it turns out that we cannot obtain the lower bound of in Theorem 4.1 when . (Here we do not treat this case, but the proof for is given in Appendix A.) Thus we need to use our splitting Eq. (8) instead.
Using Eq. (8), we can give another proof of the following approximation result without iterative randomization, which was already shown in the previous work [19].
Lemma 4.2
Fix . Let be uniformly random weights of a -layered neural network . If holds, then with probability at least ,
| (10) |
where for some .
Proof (sketch):
We assume that is an even number as so that we can split an index set of hidden neurons of into and . Then we have the corresponding subnetworks and given by , which satisfy the equation .
By the splitting Eq. (8), it is enough to consider the probabilities for approximating by a subnetwork of and for approximating by a subnetwork of . Now we have
| (11) | |||
| (12) |
for , by a standard argument of the uniform distribution and the inequality for . By the union bound, with probability at least , we have and such that
Combining these inequalities, we finish the proof.
The second point of our proof is introducing projection maps to leverage the re-sampling assumption, as follows. As in the proof of Lemma 4.2, we assume that for some and let . Now we define a projection map
| (13) |
where , and denotes the floor function. Similarly for , we can define and the corresponding projection map. Using these projection maps, we can extend Lemma 4.2 to the one with the re-sampling assumption, which is the special case of Theorem 4.1:
Proposition 4.3 (Theorem 4.1 with )
Fix . Let be uniformly random weights of a -layered neural network . Let and we assume that each element of and can be re-sampled with replacement up to times. If holds, then with probability at least ,
| (14) |
where for some .
Proof (sketch):
Similarly to the proof of Lemma 4.2, we utilize the splitting Eq. (8). We mainly argue on the approximation of since the argument for approximating is parallel.
By the assumption that each element of and can be re-sampled up to times, we can replace the probability in Eq. (11) in the proof of Lemma 4.2, using the projection map , by
| (15) |
where . Indeed, since we have
| (16) |
we can evaluate the probability Eq. (15) as
| (17) |
for . Eq. (17) can play the same role as Eq. (11) in the proof of Lemma 4.2.
Parallel argument can be applied for the approximation of by replacing with . The rest of the proof is the same as Lemma 4.2.
5 Experiments
In this section, we perform several experiments to evaluate our proposed method, IteRand (Algorithm 3). Our main aim is to empirically verify the parameter efficiency of IteRand, compared with edge-popup [26] (Algorithm 1) on which IteRand is based. Specifically, we demonstrate that IteRand can achieve better accuracy than edge-popup under a given amount of network parameters. In all experiments, we used the partial randomization with (Eq. (3)) for Randomize in Algorithm 3.
Setup.
We used two vision datasets: CIFAR-10 [13] and ImageNet [28]. CIFAR-10 is a small-scale dataset of images with class labels. It has k images for training and k for testing. We randomly split the k training images into k for actual training and k for validation. ImageNet is a dataset of images with class labels. It has the train set of million images and the validation set of k images. We randomly split the training images into , and used the former for actual training and the latter for validating models. When testing models, we used the validation set of ImageNet (which we refer to as the test set). For network architectures, we used multiple convolutional neural networks (CNNs): Conv6 [6] as a shallow network and ResNets [11] as deep networks. Conv6 is a 6-layered VGG-like CNN, which is also used in the prior work [26]. ResNets are more practical CNNs with skip connections and batch normalization layers. Following the settings in Ramanujan et al. [26], we used non-affine batch normalization layers, which are layers that only normalize their inputs and do not apply any affine transform, when training ResNets with edge-popup and IteRand. All of our experiments were performed with 1 GPU (NVIDIA GTX 1080 Ti, 11GB) for CIFAR-10 and 2 GPUs (NVIDIA V100, 16GB) for ImageNet. The details of the network architectures and hyperparameters for training are given in Appendix B.
Parameter distributions.
With the same notation as Section 2, both IteRand and edge-popup requires two distributions: and . In our experiments, we consider Kaiming uniform (KU) and signed Kaiming constant (SC) distribution. The KU distribution is the uniform distribution over the interval where is the constant defined for each layer of ReLU neural networks [1][10]. The SC distribution is the uniform distribution over the two-valued set , which is introduced by Ramanujan et al. [26]. We fix to the KU distribution, and use the KU or SC distribution for .
5.1 Varying the network width
To demonstrate the parameter efficiency, we introduce a hyperparameter of the width factor for Conv6, ResNet18 and ResNet34. The details of this modification are given in Appendix B. We train and test these networks on CIFAR-10 using IteRand, edge-popup and SGD, varying the width factor in for each network (Figure 2). In the experiments for IteRand and edge-popup, we used the sparsity rate of for Conv6 and for ResNet18 and ResNet34. Our method outperforms the baseline method for various widths. The difference in accuracy is large both when the width is small (), and when is the KU distribution where edge-popup struggles.

5.2 ImageNet experiments
The parameter efficiency of our method is also confirmed on ImageNet (Figure 3(a)). ImageNet is more difficult than CIFAR-10, and thus more complexity is required for networks to achieve competitive performance. Since our method can increase the network complexity as shown in Section 4, the effect is significant in ImageNet especially when the complexity is limited such as ResNet34.
In addition to the parameter efficiency, we also observe the effect of iterative randomization on the behavior of optimization process, by plotting training curves (Figure 3(b)). Surprisingly, IteRand achieves significantly better performance than edge-popup at the early stage of the optimization, which indicates that the iterative randomization accelerates the optimization process especially when the number of iterations is limited.



6 Related work
Lottery ticket hypothesis
Frankle and Carbin [6] originally proposed the lottery ticket hypothesis. Many properties and applications have been studied in subsequent works, such as transferability of winning subnetworks [22], sparsification before training [15, 31, 29] and further ablation studies on the hypothesis [34].
Zhou et al [34] surprisingly showed that only pruning randomly initialized networks without any optimization on their weights can be a training method surprisingly. Ramanujan et al. [26] went further by proposing an effective pruning algorithm on random networks, called edge-popup, and achieved competitive accuracy compared with standard training algorithms by weight-optimization [27]. Malach et al. [19] mathematically formalized their pruning-only approach as an approximation problem for a target network and proved it with lower bound condition on the width of random networks to be pruned. Subsequent works [25, 24] successfully relaxed the lower bound to the logarithmic factor wider than the width of a target network. Our work can be seen as an extension of their works to allow re-sampling of the weights of the random networks for finite times, and we showed that the logarithmic factor can be reduced to a constant one when is large enough. (See Section 4.)
Neural network pruning and regrowth
Studies of finding sparse structures of neural networks date back to the late 1980s [9, 14]. There are many approaches to sparsify networks, such as magnitude-based pruning [8], regularization [17] and variational dropout [21]. Although these methods only focus on pruning unnecessary weights from the networks, there are several studies on re-adding new weights during sparsification [12] to maintain the model complexity of the sparse networks. Han et al. [7] proposed a dense-sparse-dense (DSD) training algorithm consisting of three stages: dense training, pruning, and recovering the pruned weights as zeros followed by dense training. Mocanu et al. [20] proposed sparse evolutionary training (SET), which repeats pruning and regrowth with random values at the end of each training epoch. Pruning algorithms proposed in other works [2, 23, 4] are designed to recover pruned weights by zero-initialization instead of random values, so that the recovered weights do not affect the outputs of the networks. While these methods are similar to our iterative randomization method in terms of the re-adding processes, all of them use weight-optimization to train networks including re-added weights, in contrast to our pruning-only approach.
7 Limitations
There are several limitations in our theoretical results. (1) Theorem 4.1 indicates only the existence of subnetworks that approximate a given neural network, not whether our method works well empirically. (2) The theorem focused on the case when the parameter distribution is the uniform distribution over the interval . Thus, generalizing our theorem to other distributions, such as the uniform distribution over binary values [3], is left for future work. (3) The required width given in the theorem may not be optimal. Indeed, prior work [25] showed that we can reduce the polynomial factors in the required width to logarithmic ones in the case when the number of re-sampling operations . Whether we can reduce the required width for remains an open question.
Also our algorithm (IteRand) and its empirical results have several limitations. (1) Pruning randomly-initialized networks without any randomization can reduce the storage cost by saving only a single random seed and the binary mask representing the optimal subnetwork. However, if we save the network pruned with IteRand in the same way, it requires more storage cost: random seeds and binary masks, where is the number of re-samplings. (2) Although our method can be applied with any score-based pruning algorithms (e.g. Zhou et al [34] and Wang et al [32]), we evaluated our method only combined with edge-popup [26], which is the state-of-the-art algorithm for pruning random networks. Since our theoretical results do not depend on any pruning algorithms, we expect that our method can be effectively combined with better pruning algorithms that emerge in the future. (3) We performed experiments mainly on the tasks of image classification. An intriguing question is how effectively our method works on other tasks such as language understanding, audio recognition, and deep reinforcement learning with various network architectures.
8 Conclusion
In this paper, we proposed a novel framework of iterative randomization (IteRand) for pruning randomly initialized neural networks. IteRand can virtually increase the network widths without any additional memory consumption, by randomizing pruned weights of the networks iteratively during the pruning procedure. We verified its parameter efficiency both theoretically and empirically.
Our results indicate that the weight-pruning of random networks may become a practical approach to train the networks when we apply the randomizing operations enough times. This opens up the possibility that the weight-pruning can be used instead of the standard weight-optimization within the same memory budget.
Acknowledgement
The authors thank Kyosuke Nishida and Hengjin Tang for valuable discussions in the early phase of our study. We also thank Osamu Saisho for helpful comments on the manuscript. We appreciate CCI team in NTT for building and maintaining their computational cluster on which most of our experiments were computed.
References
- [1] torch.nn.init – PyTorch 1.8.1 documentation. https://pytorch.org/docs/stable/nn.init.html. Accessed: 2021-10-21.
- [2] Guillaume Bellec, David Kappel, Wolfgang Maass, and Robert Legenstein. Deep rewiring: Training very sparse deep networks. International Conference on Learning Representations, 2018.
- [3] James Diffenderfer and Bhavya Kailkhura. Multi-prize lottery ticket hypothesis: Finding accurate binary neural networks by pruning a randomly weighted network. In International Conference on Learning Representations, 2021.
- [4] Utku Evci, Trevor Gale, Jacob Menick, Pablo Samuel Castro, and Erich Elsen. Rigging the lottery: Making all tickets winners. In International Conference on Machine Learning, pages 2943–2952. PMLR, 2020.
- [5] Facebook. facebookresearch/open_lth. https://github.com/facebookresearch/open_lth. Accessed: 2021-10-21.
- [6] Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations, 2019.
- [7] Song Han, Jeff Pool, Sharan Narang, Huizi Mao, Enhao Gong, Shijian Tang, Erich Elsen, Peter Vajda, Manohar Paluri, John Tran, et al. Dsd: Dense-sparse-dense training for deep neural networks. International Conference on Learning Representations, 2017.
- [8] Song Han, Jeff Pool, John Tran, and William J Dally. Learning both weights and connections for efficient neural networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems-Volume 1, pages 1135–1143, 2015.
- [9] Stephen Hanson and Lorien Pratt. Comparing biases for minimal network construction with back-propagation. Advances in Neural Information Processing Systems, 1:177–185, 1988.
- [10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In 2015 IEEE International Conference on Computer Vision (ICCV), pages 1026–1034. IEEE Computer Society, 2015.
- [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778. IEEE Computer Society, 2016.
- [12] Torsten Hoefler, Dan Alistarh, Tal Ben-Nun, Nikoli Dryden, and Alexandra Peste. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks. arXiv preprint arXiv:2102.00554, 2021.
- [13] Alex Krizhevsky. Learning multiple layers of features from tiny images. 2009.
- [14] Yann LeCun, John S Denker, and Sara A Solla. Optimal brain damage. In Advances in Neural Information Processing Systems, pages 598–605, 1990.
- [15] Namhoon Lee, Thalaiyasingam Ajanthan, and Philip Torr. Snip: Single-shot network pruning based on connection sensitivity. In International Conference on Learning Representations, 2018.
- [16] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations, 2017.
- [17] Christos Louizos, Max Welling, and Diederik P Kingma. Learning sparse neural networks through l_0 regularization. In International Conference on Learning Representations, 2018.
- [18] Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA, June 2011. Association for Computational Linguistics.
- [19] Eran Malach, Gilad Yehudai, Shai Shalev-Schwartz, and Ohad Shamir. Proving the lottery ticket hypothesis: Pruning is all you need. In International Conference on Machine Learning, pages 6682–6691. PMLR, 2020.
- [20] Decebal Constantin Mocanu, Elena Mocanu, Peter Stone, Phuong H Nguyen, Madeleine Gibescu, and Antonio Liotta. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science. Nature communications, 9(1):1–12, 2018.
- [21] Dmitry Molchanov, Arsenii Ashukha, and Dmitry Vetrov. Variational dropout sparsifies deep neural networks. In International Conference on Machine Learning, pages 2498–2507. PMLR, 2017.
- [22] Ari Morcos, Haonan Yu, Michela Paganini, and Yuandong Tian. One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- [23] Hesham Mostafa and Xin Wang. Parameter efficient training of deep convolutional neural networks by dynamic sparse reparameterization. In International Conference on Machine Learning, pages 4646–4655. PMLR, 2019.
- [24] Laurent Orseau, Marcus Hutter, and Omar Rivasplata. Logarithmic pruning is all you need. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 2925–2934. Curran Associates, Inc., 2020.
- [25] Ankit Pensia, Shashank Rajput, Alliot Nagle, Harit Vishwakarma, and Dimitris Papailiopoulos. Optimal lottery tickets via subset sum: Logarithmic over-parameterization is sufficient. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 2599–2610. Curran Associates, Inc., 2020.
- [26] Vivek Ramanujan, Mitchell Wortsman, Aniruddha Kembhavi, Ali Farhadi, and Mohammad Rastegari. What’s hidden in a randomly weighted neural network? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11893–11902, 2020.
- [27] David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors. Nature, 323(6088):533–536, 1986.
- [28] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, 2015.
- [29] Hidenori Tanaka, Daniel Kunin, Daniel L Yamins, and Surya Ganguli. Pruning neural networks without any data by iteratively conserving synaptic flow. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 6377–6389. Curran Associates, Inc., 2020.
- [30] Ben Trevett. bentrevett/pytorch-sentiment-analysis. https://github.com/bentrevett/pytorch-sentiment-analysis. Accessed: 2021-10-21.
- [31] Chaoqi Wang, Guodong Zhang, and Roger Grosse. Picking winning tickets before training by preserving gradient flow. In International Conference on Learning Representations, 2020.
- [32] Yulong Wang, Xiaolu Zhang, Lingxi Xie, Jun Zhou, Hang Su, Bo Zhang, and Xiaolin Hu. Pruning from scratch. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 12273–12280, 2020.
- [33] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. In Edwin R. Hancock Richard C. Wilson and William A. P. Smith, editors, Proceedings of the British Machine Vision Conference (BMVC), pages 87.1–87.12. BMVA Press, September 2016.
- [34] Hattie Zhou, Janice Lan, Rosanne Liu, and Jason Yosinski. Deconstructing lottery tickets: Zeros, signs, and the supermask. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
Appendix A Proof of main theorem (Theorem 4.1)
A.1 Settings and main theorem
Let . We consider a target neural network of depth , which is described as follows.
| (18) |
where is a -dimensional real vector, is the ReLU activation, and is a matrix. Our objective is to approximate the target network by pruning a randomly initialized neural network , which tends to be larger than the target network.
Similar to the previous works [19, 25], we assume that is twice as deep as the target network . Thus, can be described as
| (19) |
where is a matrix () with . Each element of the matrix is assumed to be drawn from the uniform distribution . Since there is a one-to-one correspondence between pruned networks of and sequences of binary matrices with , every pruned network of can be described as
| (20) |
We introduce an idealized assumption on for a given number : each element of the weight matrix can be re-sampled with replacement from the uniform distribution up to times, for all (re-sampling assumption for ). Here, re-sampling with replacement means that we sample a new value for an element of and replace the old value of the element by the new one.
Under this re-sampling assumption, we describe our main theorem as follows.
Theorem A.1 (Main Theorem)
Fix , and we assume that . Let and we assume that each element of can be re-sampled with replacement from the uniform distribution up to times.
If holds for all , then with probability at least , there exist binary matrices such that
| (21) |
In particular, if is larger than , then is enough.
A.2 Proof of Theorem A.1
Our proof is based on the following simple observation, similar to the arguments in Malach et al. [19].
Lemma A.2
Fix some , and . Let . If holds, then with probability at least , we have
| (22) |
for some .
Proof:
We can assume without loss of generality. By considering half -ball of , we have
Thus it follows that
First, we consider to approximate a single variable linear function by some subnetwork of -layered neural network with hidden neurons, without the re-sampling assumption. Note that this is the same setting as in Malach et al. [19], but we give another proof so that we can later extend it to the one with the resumpling assumption.
Lemma A.3
Fix . Let be uniformly random weights of a -layered neural network . If holds, then with probability at least ,
| (23) |
where for some .
Proof:
The core idea is to decompose as
| (24) |
We assume that is an even number as so that we can split an index set of hidden neurons of into and . Then we have the corresponding subnetworks and given by , which satisfy the equation .
From Eq. (24), it is enough to consider the probabilities for approximating by a subnetwork of and for approximating by a subnetwork of . Now we have
| (25) | |||
| (26) |
for as well as in the proof of Lemma A.2. By using the union bound, with probability at least , we have and such that
Combining these inequalities and Eq. (24), we finish the proof.
Now we extend Lemma A.3 to the one with the re-sampling assumption.
Lemma A.4
Fix . Let be uniformly random weights of a -layered neural network . Let and we assume that each elements of and can be re-sampled with replacement up to times. If holds, then with probability at least ,
| (27) |
where for some .
Proof:
As in the proof of Lemma A.3, we assume that and let . Now we consider and a projection defined by . Since we assumed that each elements of and can be re-sampled up to times, we can replace the probability Eq. (25) in the proof of Lemma A.3 by
| (28) |
where . Since we have
| (29) |
we can evaluate the probability as
for . The rest of the proof is same as Lemma A.3.
Then, we generalize the above lemma to the case which the target function is a single-variable linear map with higher output dimensions.
Lemma A.5
Fix . Let be uniformly random weights of a -layered neural network . Let and we assume that each elements of and can be re-sampled with replacement up to times.
If holds, then with probability at least ,
| (30) |
where for some .
Proof:
We denote . As in the proof of Lemma A.3, we assume and split the index set into , . Also we consider the corresponding subnetworks of :
Similar as the proof of Lemma A.3 and Lemma A.4, it is enough to show that there probably exists a subnetwork of which approximates , and also that there simultaneously exists a subnetwork of which approximates .
For simplicity, we focus on in the following argument, but same conclusion holds for as well. Fix . Then we consider the following probability,
| (31) |
where for . By using Eq. (29), if , we have
Therefore, by the union bound over , we have for each such that , , , with probability at least , and thus
| (32) |
if we substitute for , and for . We note that the choice of and may not be unique, but Eq. (32) does not depend on these choice.
Therefore, by taking appropriately, we have
for all with .
Subsequently, we can generalize Lemma A.5 to multiple variables version:
Lemma A.6
Fix , , . Let be uniformly random weights of a -layered neural network . Let and we assume that each elements of and can be re-sampled with replacement up to times.
If holds, then with probability at least ,
| (33) |
where for some , .
Proof:
Let , and we assume . We take as the following binary matrix:
By the decomposition , where each is a -matrix, we have
| (34) |
Here, we denote as follows:
where each is a -matrix with binary coefficients. Then we have
| (35) |
By combining Eq. (34) and Eq. (35), we have
| (36) |
Applying Lemma A.5 to each independent summands in Eq. (36), with probability at least , there exists for fixed such that
| (37) |
where is the -th column vector of .
Proof of Theorem A.1:
By Lemma A.6, for each fixed , we know that there exists binary matrices such that
| (38) |
for all with , with probability at least . Taking the union bound, we can get satisfying Eq. (38) for all with probability at least .
For the above and any with , we define sequences and as
where and are given by
By induction on , we can show that
| (39) |
For , this is trivial by definition. Consider the case. First of all, we remark that the following inequality is obtained by Eq. (38) and the -Lipschitz property of ReLU function :
By scaling , the above inequality can be rewritten as follows:
Then, we have
and .
Appendix B Details for our experiments
B.1 Network architectures
In our experiments on CIFAR-10 and ImageNet, we used the following network architectures: Conv6, ResNet18, ResNet34, ResNet50, and ResNet101. In Table 1 (for CIFAR-10) and Table 2 (for ImageNet), we describe their configurations with a width factor . When , the architectures are standard ones.
For each ResNet network, the bracket represents the basic block for ResNet18 and ResNet34, and the bottleneck block for ResNet50 and ResNet101, following the original settings by He et al. [11]. We have a batch normalization layer right after each convolution operation as well. Note that, when we train and evaluate these networks with IteRand or edge-popup [26], we replace the batch normalization to the non-affine one, which fixes its all learnable multipliers to and all learnable bias terms to following the design by Ramanujan et al. [26].
| Conv6 | ResNet18 | ResNet34 | |
|---|---|---|---|
| Convolution | , , max-pool | , | , |
| & Pooling Layers | , , max-pool | ||
| , , max-pool | |||
| avg-pool | avg-pool | ||
| Linear Layers | , , |
| ResNet18 | ResNet34 | ResNet50 | ResNet101 | |
| Convolution | ||||
| Pooling | ||||
| Convolution | ||||
| Blocks | ||||
| Pooling | ||||
| Linear | ||||
B.2 Hyperparameters
In our experiments, we trained several neural networks by three methods (SGD, edge-popup [26], and IteRand) on two datasets (CIFAR-10 and ImageNet). For each dataset, we adopted different hyperparameters as follows.
CIFAR-10 experiments.
-
•
SGD: We used SGD with momentum for the optimization. It has the following hyperparameters: a total epoch number , batch size , learning rate , weight decay , momentum coefficient . For all network architectures, we used common values except for the learning rate and weight decay: , , and . For the learning rate and weight decay, we used for Conv6, for ResNet18 and ResNet34, following Ramanujan et al. [26]. Moreover, we decayed the learning rate by cosine annealing [16].
-
•
edge-popup: With the same notation in Section 2, edge-popup has the same hyperparameters as SGD and an additional one, a sparsity rate . We used the same values as SGD for each network except for the learning rate and the sparsity rate. For the learning rate, we used for Conv6, and for ResNet18 and ResNet34. We decayed the learning rate by cosine annealing, same as SGD. For the sparsity rate, we used for Conv6, and for ResNet18 and ResNet34.
-
•
IteRand: With the notation in Section 3, IteRand has the same hypeparameters as edge-popup and the following additional ones: a randomization period and a sampling rate for partial randomization. We used the same values as edge-popup for the former hyperparameters, and for the latter ones.
ImageNet experiments.
-
•
SGD: For all network architectures, we used the following hyperparameters (except for the learning rate): , and . For the first epochs, we gradually increased the learning rate as for each -th epoch (). For the next epochs, we decayed the learning rate by cosine annealing starting from . For the final epochs, we set the learning rate to ensure the optimization converges.
-
•
edge-popup: For all network architectures, we used the same hyperparameters as SGD and the sparsity rate .
-
•
IteRand: For all network architectures, we used the same hyperparameters as edge-popup and .
B.3 Experimental results in table forms
Appendix C Additional experiments
C.1 Ablation study on hyperparameters: and
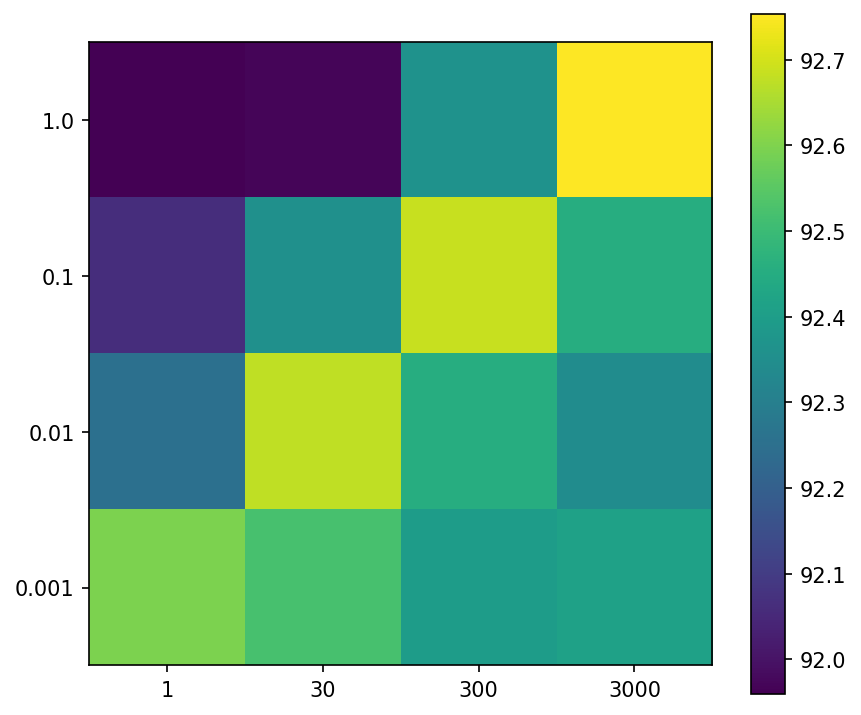
controls the frequency of randomizing operations during the optimization. Note that, in our experiments in Section 5, we fixed it to on CIFAR-10, which is nearly epoch (= iterations) when the batch size is . As we discussed in Section 3, too small may degrade the performance because it may randomize even the important weights before their scores are well-optimized. In contrast, too large makes IteRand almost same as edge-popup, and thus the effect of the randomization disappears. Figure 4 shows this phenomenon with varying in . In relation to our theoretical results (Theorem A.1), we note that the expected number (here we denote ) of randomizing operations for each weight is in inverse proportion to . The theoretical results imply that greater leads to better approximation ability of IteRand. We observe that the results in Figure 4 are consistent with this implication, in the region where is not too small ().



Also, we investigate the relationship between and . Figure 5 shows how test accuracy changes when both and vary. From this result, we find that the accuracies seem to depend on . This may be because each pruned parameter in the neural network is randomized times in expectation during the optimization. On the other hand, when we use larger , we have to explore in longer period (e.g. iterations when ). Thus appropriately choosing leads to shrink the search space of .
C.2 Computational overhead of iterative randomization
IteRand introduces additional computational cost to the base method, edge-popup, by iterative randomization. However, the additional computational cost is negligibly small in all our experiments. We measured the average overhead of a single randomizing operation, which is the only difference from edge-popup, as follows: ms for ResNet18 (M params), ms for ResNet50 (M params). Thus, the total additional cost should be about seconds in the whole training ( hours) for ResNet18 on CIFAR-10 and seconds in the whole training (one week) for ResNet50 on ImageNet.
Also, we measured the total training times of our expriments for ResNet-18 on CIFAR-10 (Table 5). The additional computational cost of IteRand over edge-popup is tens of seconds, which is quite consistent with the above estimates.
| IteRand | (secs) |
|---|---|
| edge-popup | (secs) |
| SGD | (secs) |
C.3 Experiments with varying sparsity
Table 6 shows the comparison of IteRand and edge-popup when varying the sparsity parameter . We can see that IteRand is effective for almost all the sparsities .
| Networks | Methods | |||||||
|---|---|---|---|---|---|---|---|---|
| Conv6 | IteRand (SC) | |||||||
| edge-popup (SC) | ||||||||
| ResNet18 | IteRand (SC) | |||||||
| edge-popup (SC) |
Moreover, we compared the pruning-only approach (IteRand and edge-popup) and the iterative magnitude pruning (IMP) approach [6] with various sparsity rates. We employed the OpenLTH framework [5], which contains the implementation of IMP, as a codebase for this experiment and implemented both edge-popup and IteRand in this framework. The results are shown in Table 7. Overall, the IMP outperforms the pruning-only methods. However, there is still room for improvement in the pruning-only approach such as introducing scheduled sparsities or an adaptive threshold, which is left to future work.
C.4 Detailed empirical analysis on the parameter efficiency
We conducted experiments to see how much more network width edge-popup requires than IteRand to achieve the same accuracy (Table 8). Here we use ResNet18 with various width factors . We first computed the test accuracies of IteRand with as target values. Next we explored the width factors for which edge-popup achieves the same accuracy as the target values. Table 8 shows that edge-popup requires times wider networks than IteRand in this specific setting.
| IteRand (KU) | - | - | ||
|---|---|---|---|---|
| edge-popup (KU) |
C.5 Experiments with large-scale networks
In addition to the experiments in Section 5, we conducted experiments to see the effectiveness of IteRand with large-scale networks: WideResNet-50-2 [33] and ResNet50 with the width factor . Table 9 shows that the iterative randomization is still effective for these networks to improve the performance of weight-pruning optimization.
| IteRand (SC) | edge-popup (SC) | # of parameters | |
|---|---|---|---|
| WideResNet-50-2 | M | ||
| ResNet50 () | M |
C.6 Experiments with a text classification task
Although our main theorem (Theorem 4.1) indicates that the effectiveness of IteRand does not depend on any specific tasks, we only presented the results on image classification datasets in the body of this paper. In Table 10, we present experimental results on a text classification dataset, IMDB [18], with recurrent neural networks (see Table 11 for the network architectures). For this experiment, we implemented both edge-popup and IteRand on the Jupyter notebook originally written by Trevett [30]. All models are trained for epochs and the learning rate we used is for SGD and for edge-popup and IteRand. Note that the learning rate does not work well for SGD, thus we employed the different value from the one for edge-popup and IteRand. Also we set the hyperparameters for IteRand as , ( epochs) and .
| IteRand (SC) | edge-popup (SC) | SGD | |
|---|---|---|---|
| LSTM | |||
| BiLSTM |
| (Bi)LSTM | |
|---|---|
| Embedding Layer | |
| LSTM Layer | |
| ( for BiLSTM) | |
| Dropout Layer | |
| Linear Layer | |
| Output Layer | sigmoid |