Providence: a Flexible Round-by-Round Risk-Limiting Audit
Abstract
A Risk-Limiting Audit (RLA) is a statistical election tabulation audit with a rigorous error guarantee. We present ballot polling RLA Providence, an audit with the efficiency of Minerva and flexibility of Bravo. We prove that Providence is risk-limiting in the presence of an adversary who can choose subsequent round sizes given knowledge of previous samples. We describe a measure of audit workload as a function of the number of rounds, precincts touched, and ballots drawn. We quantify the problem of obtaining a misleading audit sample when rounds are too small, demonstrating the importance of the resulting constraint on audit planning. We present simulation results demonstrating the superiority of Providence using these measures and describing an approach to planning audit round schedules.
We describe the use of Providence by the Rhode Island Board of Elections in a tabulation audit of the 2021 election. Our implementation of Providence and audit planning tools in the open source R2B2 library should be useful to the states of Georgia and Pennsylvania, which are planning pre-certification ballot polling RLAs for the 2022 general election.
1 Introduction
It is well-known that electronic voting systems are vulnerable to software errors and manipulation which may be undetected. Errors and/or manipulation may not always change an election outcome, but we would want to know when they do. Software independent voting systems [14, 13] are ones where an undetected change in the software cannot lead to an undetected change in the election outcome. Evidence-based elections [16] use software independent systems to produce trustworthy evidence of outcome correctness; incorrect outcomes are detected with high probability when the evidence is examined. One approach to evidence-based elections is to use voter-verified paper ballots, store them securely, and perform public audits—a compliance audit to determine whether the ballots were stored securely; and a rigorous tabulation audit, known as a risk-limiting audit (RLA) [7], to determine whether the outcome is correctly computed from the stored ballots. Many US states have had pilot RLA programs. Additionally, some states allow RLAs to be used towards audit requirements, and some states require RLAs before elections can be certified.
We propose the Providence audit, a new approach to the ballot polling RLA, and propose a new model for the work load of an election. We show that Providence is superior to the popular ballot polling RLA Bravo for real elections, and describe the use of our open source implementation by the Rhode Island Board of Elections for an audit of their 2021 elections. Our open-source implementations of Providence and our audit planning tools are likely to be useful later this year; ballot polling audits are expected to be used as pre-certification RLAs in at least one statewide contest in both Georgia and Pennsylvania for the 2022 general elections in the US.
1.1 Background
Ballot comparison RLAs require the fewest ballots of all known RLA approaches. On the other hand, they require the use of special election technology and are not always feasible. Ballot polling RLAs require a larger number of ballots, but are more feasible because they do not require any additional functionality of the voting system. What is needed is a complete ballot manifest (a list of ballot storage containers and the number of ballots in each) which enables the creation of a well defined list of the ballots and their locations (the fifth ballot in box number 20, for example).
A ballot polling audit begins when a round [22] of multiple randomly-chosen ballots is drawn. A risk measure is then computed to determine whether (a) the audit ends in success (the election outcome is declared correct) or (b) another round should be drawn. Election officials would typically decide to perform a full manual hand count if the audit does not stop in spite of drawing a large number of ballots, typically over multiple rounds. Ballot polling audits have been used in a number of US state pilots (California, Georgia, Indiana, Michigan, Ohio, Pennsylvania, Virginia and elsewhere) and in real statewide audits (Georgia, Virgina) [18] as well as in audits of smaller jurisdictions, such as Montgomery County, Ohio [22].
A round-by-round (R2) audit is one where the decision of whether to draw more ballots or not is taken after drawing a round of ballots; typically hundreds or thousands or tens of thousands of ballots in statewide elections. A ballot-by-ballot (B2) audit is the special case of round size one—when the decision is made after each ballot is drawn. The popular Bravo audit requires the smallest expected number of ballots when the announced tally of the election is correct, and stopping decisions are taken a ballot at a time (that is, when it is used as a B2 audit). Election officials typically draw ballots in large round sizes, and Bravo needs to be modified for use in this manner. For use as an R2 audit, the Bravo stopping condition can be applied once at the end of each round (End-of Round (EoR)), or retroactively after each ballot drawn if ballot order is retained (Selection-Ordered (SO)). SO Bravo is closer to the original B2 Bravo, and requires fewer ballots on average than EoR Bravo. But it requires the additional effort of tracking the order of ballots.
Zagórski et al. propose ballot polling RLA Minerva [22], which does not need ballot order and relies only on sample and round tallies. They prove that it requires fewer ballots than EoR Bravo when both audits have the same pre-determined round schedule and the true tally is as announced. They also present first-round simulations demonstrating that Minerva draws fewer ballots than SO Bravo in the first round for large first round sizes when the true tally is as announced. Broadrick et al. provide further simulations that show Minerva requires fewer ballots over multiple rounds and for lower stopping probability [4], though the improvement from using Minerva over either version of Bravo decreases with round size.
1.2 Open Questions in the Literature
A major limitation of Minerva is that one needs to determine the round schedule before the audit begins because Minerva has not been shown to be risk-limiting if an adversary can choose subsequent round sizes after knowing the sample drawn. Bravo, on the other hand, is not limited in this manner. This allows Bravo audits the flexibility of choosing smaller subsequent round sizes if the sample drawn so far is a “good” sample. An open question is whether a ballot polling RLA exists with the efficiency of Minerva and this flexibility of Bravo.
A major limitation of our understanding of the ballot polling problem as a community is that we use the number of ballots drawn or values proportional to this number [10, 1, 5] as measures of the workload of an audit. If this were a correct measure of the workload of an audit, we would want to use B2 audits (round size is one) and make decisions about stopping the audit after drawing each ballot, because this leads to the smallest expected number of ballots. Election officials, on the other hand, greatly prefer drawing many ballots at once. This preference is likely due to the following.
-
Firstly, each round has an overhead workload as well, including setting up the round and communicating among the various localities involved in conducting the audit (for example, audits of statewide contests involve the drawing of ballots at county offices where the ballots are stored).
-
Secondly, there is an overhead to finding a storage box and unsealing it. For large round sizes, multiple ballots may be drawn at once from a box, and the number of boxes retrieved is smaller than the number of ballots (storage boxes commonly contain many hundreds of ballots each). For smaller round sizes, the number of times a box is retrieved would be roughly identical to the number of ballots drawn, as it is unlikely that a single box will hold multiple ballots from the sample.
-
Finally, in the current environment of misinformation, election officials would want to ensure that the probability of a misleading audit sample (falsely indicating that the loser won) is very small, which implies that round sizes should be large.
Thus the workload of an audit is not simply a linear (or affine) function of the number of ballots drawn. Relatedly, an optimal round schedule is not completely determined by the expected number of ballots drawn. It depends on other variables as well. The consideration of all these variables is necessary while planning an audit.
1.3 Our Contributions
We present Providence, and provide the following:
-
1.
Proof that Providence is an RLA and resistant to an adversary who can choose subsequent round sizes with knowledge of previous samples.
-
2.
Simulations of Providence, Minerva, SO Bravo, and EoR Bravo which show that Providence uses number of ballots similar to those of Minerva, both fewer than either version of Bravo.
-
3.
Results and analysis from the use of Providence in a pilot audit in Rhode Island.
-
4.
A model of workload that includes the overhead effort of each round and the overhead effort of retrieving a storage unit of ballots; simulations that illustrate the use of this model to compare the different types of ballot polling audits and to plan an audit with minimal workload.
-
5.
An analysis of round size as a function of the maximum acceptable probability of a misleading audit sample.
-
6.
Open source implementation of Providence and audit planning tools.
Our results demonstrate the superiority of Providence over the other audits. Our work may be used by election officials to plan ballot polling audits, including in Georgia and Pennsylvania in 2022.
1.4 Organization
Section 2 describes related work. Section 3 describes the Providence audit, section 4 the simulations comparing the number of ballots drawn using various ballot polling audits and section 5 the use of Providence in an audit carried out by the Board of Elections of Rhode Island. Section 6 presents our workload model and describes its use for a ballot polling audit using details of the 2020 US Presidential election in the state of Virginia. Our conclusions, the availability of an audit implementation and acknowledgements may be found in sections 7, 8 and 9 respectively.
2 Related work
Bernhard provides a good description of the RLA and its assumptions, and also describes the process on the ground [2].
The Bravo audit [8] is the most popular ballot polling audit. When ballots are sampled one at a time, it is the audit with the smallest expected number of ballots drawn.
The Minerva audit [22, 21] was developed for use with large first round sizes, and has been proven to be risk limiting when the round schedule for the audit is fixed before any ballots are drawn. First-round sizes for a stopping probability of when the announced tally is correct have been shown to be smaller than those for EoR and SO Bravo for a wide range of margins; simulations [21] support these observations. Additional simulations [4] have shown that Minerva requires fewer ballots than EoR and SO Bravo over multiple rounds and for smaller stopping probability. As expected, the advantage of Minerva decreases for smaller stopping probability (smaller round sizes) as such round schedules approach the B2 round schedule (1,1,1,…) for which Bravo is known to be most efficient.
Ballot polling audit simulations provide a means of educating the public and election officials [15] and to understand audit properties [10, 9, 3, 6]. There is work measuring the amount of time taken to examine a single ballot [5]. Simple workload estimates may be obtained by using the number of ballots drawn [12], a more thorough workload estimation model includes the time taken to access individual ballots[1].
We now summarize the model drawing largely from the notation and terminology of [22, 21, 4, 8]. The model is related work and not claimed to be original to this work.
An audit is a function that takes as input the sample of ballots and outputs either (1) Correct: stop the audit or (2) Undetermined: sample more ballots. Bravo and Minerva are modeled as binary hypothesis tests where the null hypothesis corresponds to a tied election and the alternative hypothesis to an election tally as announced. (When the number of ballots is odd, corresponds to the announced loser winning by one ballot.) Thus the null hypothesis is the outcome distinct from the announced one which is most difficult to detect; the probability of failing to detect it, given that the null hypothesis is true, is the worst case such probability and should be below the risk limit [17].
Definition 1 (Risk Limiting Audit (-RLA)).
An audit is a Risk Limiting Audit with risk limit iff for sample
The stopping conditions of Bravo and Minerva rely on the following ratios.
Definition 2 (Bravo Ratio).
The Bravo audit uses the ratio . Consider a sample size of ballots with for the reported winner. The proportion of ballots for the reported winner under the alternative hypothesis and null hypothesis are and respectively.
| (1) |
In Bravo, . A Bravo audit outputs correct if and only if
It is easy to see that the ratio is the likelihood ratio:
Where Bravo uses the ratio of the values of the probability distribution functions, Minerva uses the ratio of their tails. Now it becomes useful to have shorthand for a sequence of cumulative round sizes and the corresponding sequence of cumulative winner ballot tallies. We use:
Definition 3 (Minerva Ratio).
The R2 Minerva audit uses the ratio . We use cumulative round sizes , with corresponding ballots for the reported winner in each round. The proportion of ballots for the reported winner under the alternative hypothesis and null hypothesis are and respectively.
| (2) | |||
3 Providence
In this section we introduce the stopping condition of Providence and prove some properties.
Recall that the proof that the Minerva audit is risk-limiting assumes that the round schedule of Minerva is predetermined and that, in particular, an adversarial auditor cannot determine the next round size after drawing a sample. This presents difficulties because a non-adversarial election official might want to draw a small next round if the current sample comes close to satisfying the risk limit. Because the Minerva round size is predetermined, however, the election official would be required to draw a larger round size than necessary for the sample. Conversely, if the current sample is not at all close to satisfying the risk limit, it would be advantageous to draw a larger round than the predetermined round size.
The Providence audit is risk-limiting even if an adversarial auditor determines round sizes after drawing the sample, and next round size computations may use knowledge of the current sample.
3.1 Definition
Definition 4 (-Providence).
For cumulative round size for round and a cumulative ballots for the reported winner found in round , the R2 Providence stopping rule for the round is:
where and for , we define as follows:
| (3) | |||
Notice that Providence requires the computation of for and no other values of . The value of is simply the ratio of the the tails of the binomial distributions for the two hypotheses and can be fairly efficiently computed. The computation of for , as required in Minerva, relies on the convolution of two probability distribution functions and is hence computationally considerably more expensive.
Notice also that Providence and Minerva are identical for .
3.2 Risk-Limiting Property: Proof
We now prove that Providence is risk-limiting using lemmas from basic algebra in Appendix A.
Theorem 1.
An -Providence audit is an -RLA.
Proof.
Let -Providence. Let be the cumulative round sizes used in this audit, with corresponding cumulative tallies of ballots for the reported winner . For round , by Definitions 4 and 3, we see that the (the audit stops) only when
By Lemma 7, we see that this is equivalent to the following:
For any round , by Definition 4 and Lemma 7, (the audit stops) if and only if
By Lemma 8 and Definition 3, this is equivalent to
By Lemma 7 and Definition 4, we see that there exists a for which
The above may be rewritten as
The left hand side above is the probability of stopping in the round and , given the null hypothesis, which is smaller than times the same probability given the alternate hypothesis. Summing both sides over all values of gives us a similar relationship between the probabilities of stopping in round (given the null and alternate hypotheses respectively). Note here that the relationship holds even if the values of depend on . When both sides of the inequality are further summed over all rounds, we get:
Finally, because the total probability of stopping the audit under the alternative hypothesis is not greater than 1, we get
∎
3.3 Resistance to an adversary choosing round sizes
Minerva was proven to be a risk-limiting audit for a predetermined round schedule. As explained earlier, it is not clear that Minerva is risk-limiting if an adversary can adaptively select the round schedule as the audit proceeds. In this section we prove that Providence does not have this problem, and is risk-limiting even when the adversary can choose next round sizes based on knowledge of the current sample.
Definition 5 (Strategy-Proof RLA).
An audit is a Strategy-Proof Risk Limiting Audit with risk limit iff for all strategies of selecting round schedule and for sample
Lemma 1.
Providence is a Strategy-Proof RLA.
Proof.
To illustrate the practical implication of this property, we consider a toy example: an RLA of a two-candidate contest with margin and risk limit . Suppose we wish to achieve a conditional stopping probability in each round of the audit. For Providence, we can compute a new round size for each round based on the previous samples. For Minerva, however, we would have a predetermined round schedule. We use the default Minerva round schedule of audit software Arlo [19] (used by many states performing an RLA), which is is ; that is, the next marginal round size is times the current one. This multiplier of is known to give, over a wide range of margins, a probability of stopping roughly in the second round if the first round size has probability of stopping .
Both the audits of our toy example therefore begin with a first round size of with a probability of stopping, and both will stop in the first round if the sample contains at least ballots for the winner. We now consider two cases for which the audit proceeds to a second round.
-
In one case there are votes for the winner in the sample, just one fewer than the minimum needed to meet the risk limit. In the Minerva audit, we are already committed to a second round size of which, given the nearly-passing sample of the first round is higher than necessary, achieving a stopping probability in the second round of . The Providence audit samples more than fewer ballots with a round size of , achieving the desired probability of stopping.
-
In a less lucky sample, the winner recieves ballots, few more than the loser recieves. In the Minerva audit, we again have to use a second round size of , but now this round size only achieves a probability of stopping, significantly less than the desired . Again, the Providence audit can scale up the second round size according to the first sample and achieve the desired probability of stopping with ballots.
3.4 Efficiency
Lemma 2.
For any risk-limit , for any margin and for any round schedule , the Providence RLA is more efficient than EoR Bravo.
Proof.
Appendix A∎
4 Providence Audit Simulations
We use simulations to provide additional evidence for our theoretical claims regarding Providence and to gain insight into audit behavior. As done in [4], we use margins from the 2020 US Presidential election—state-wide pairwise margins of or larger between the two leading candidates. Narrower margins are computationally expensive, especially for the simulations of tied elections, which, by design, have a low probability of stopping and hence quickly increase in sample size. We use the simulator in the R2B2 software library[11]. For each margin, we perform Providence audit trials each on a tied election (hypothesis , the null hypothesis) and the election as reported (hypothesis , the alternate hypothesis). All trials have risk limit , a maximum of rounds, and a conditional stopping probability of in each round. That is, each next round size is selected to be large enough to give a conditional probability of stopping in that round, assuming the announced tally is correct and given the tally of previous rounds. We use a maximum of five rounds because virtually no audits would progress beyond five rounds given the large conditional probability of stopping.
In the simulations of Providence audits of a tied election, the fraction of audits that stop, as shown in Figure 1, is an estimate of maximum risk. For all margins, this estimated maximum risk is less than the risk limit, supporting the claim that Providence is risk-limiting.

Simulations of audits of the election as reported provide insight into stopping probability and number of ballots drawn when the election is as reported. Figure 2 shows that the stopping probabilities over the first rounds are near and slightly above as expected, since our software chose round sizes to give at least a conditional stopping probability. The values are not as tight around for later rounds because fewer audit trials make it to later rounds, and our experimental probability estimates are not as accurate.

We now investigate the efficiency of Providence compared to Minerva, SO Bravo, and EoR Bravo by taking a single margin as an example: the 2020 US Presidential election in the state of Texas, with margin . We run an additional simulations for each of the three other audits on the same underlying election and on a tied election. Both Bravo implementations use a conditional stopping probability of for each round, while Minerva uses a first round size with stopping probability and a multiplier of to obtain subsequent round sizes.

Figure 3 shows the probability of stopping as a function of the number of ballots sampled, a plot similar to those presented in [4]. Points above (higher probability of stopping) and to the left (fewer ballots) represent more efficient audits. As shown, Providence has comparable efficiency to Minerva, while both are significantly more efficient than either implementation of Bravo. In a contest with a narrow margin (in the 2020 US Presidential election, eight states had margins smaller than ) the difference in number of ballots sampled could correspond to many days of work which would need to be completed before a certification deadline.
5 Pilot use
The Rhode Island Board of Elections performed a pilot audit in Providence in February 2022. The contest audited was a single yes-or-no question in the November 2021 election: Portsmouth’s Issue 1, "School Construction and Renovation Projects". The question had a reported margin of and the audit used a risk-limit of .
A first round size of ballots with large probability of stopping () was selected. Selection order was tracked for the sake of analysis. As expected, the audit concluded in the first round. The Providence risk was . Table 1 shows risk measures for the drawn sample using Providence, Minerva and Bravo (both EoR and SO).
| ballots |
Providence |
Minerva |
SO Bravo |
EoR Bravo |
|---|---|---|---|---|
| 140 | 0.0418 | 0.0418 | 0.0541 | 0.366 |
Note that the risk measures shown in Table 1 imply that, for the sample obtained in the pilot audit, an EoR Bravo audit would not have stopped in the first round, despite the large round size. Further, if the risk limit had been instead of , SO Bravo also would have required moving on to a second round.
We can use simulations to better understand typical audit behavior for the margin of this pilot audit and contextualize the results we obtained in the pilot. We run trial audits for several stopping probabilities . Each round size is chosen to give a probability of stopping assuming the announced tally and given the results of previous rounds. We use the same risk limit and margin of .
Figure 4 shows the average number of ballots sampled for each value of in the simulations. The vertical line denotes the stopping probability of the first round size actually chosen in the pilot ( ballots). The large value of corresponds to a large first round size and a corresponding large value of average number of ballots. In later sections we show why average number of ballots is not the only metric to optimize, and how large round sizes can be beneficial from the perspective of other important metrics.

For this pilot audit, extensive planning of the round schedule was not necessary because the margin was large enough that relatively few ballots were needed to achieve the high probability of stopping. In Section 6 we consider a larger state-wide contest in Virginia, where selecting the round schedule has more significant implications. Virginia also currently uses ballot polling RLAs, whereas Rhode Island primarily uses batch comparison RLAs. Some of the ideas introduced in Section 6 provide a context for this pilot case as well.
For the sake of analysis, the selection order of the ballots sampled during the pilot was also recorded. Figure 5 shows the cumulative tally of winner ballots after each new ballot in the selection order is added to the sample. We observe two interesting phenomena in this particular sample’s selection order.
-
First, an SO Bravo audit of this sample stops because the Bravo condition is met when the sample (orange line) surpasses the minimum number of winner ballots (blue line) earlier in the sample.111Such cases also provide insight into how Providence is a tighter test in expectation because SO Bravo ignores information from the rest of the sample after the Bravo condition is met at some point earlier in the selection order. EoR Bravo, however, does not stop. It might be difficult to explain to the public why SO Bravo stops in more extreme cases like this, where the condition is met early in the sample, but poor evidence for the alternative hypothesis in the rest of the sample is ignored.
-
Second, only of the first ballots were for the announced winner. A first round of size would have resulted in a smaller average total number of ballots drawn, but would have provided a misleading sample (suggesting that the winner was incorrectly reported) due to a too-small sample size.
Both these ideas are addressed more thoroughly in Section 6.

6 Audit workload
Some election audits have benefited from a one-and-done approach: draw a large sample with high probability of stopping in the first round and usually avoid a second round altogether. This is appealing for two reasons. Firstly, rounds have some overhead in both time and effort. Thus the time and person-hours of an audit grows not just with the number of ballots sampled but also with the number of rounds. Secondly, smaller first round sizes are not large enough to accurately capture the distribution of votes. There is a higher probability that the true winner has fewer votes in the audit sample than some other candidate. On the other hand, a one-and-done audit may draw more ballots than are necessary; a more efficient round schedule could require less effort and time pre-certification. To evaluate the quality of various round schedules, we construct a simple workload model. Using this model we show how optimal round schedules can be chosen. We provide software that can be used by election officials to choose round schedules based on estimates of the model parameters like maximum allowed probability of a misleading audit sample.
As an example, we consider the US Presidential contest in the 2016 Virginia statewide general election. This contest had a margin of between the two candidates with the most votes. Analytical approximation of the expected audit behavior (quantities like expected total number of ballots sampled or total number of rounds) is challenging because the number of possible sequences of samples grows exponentially with the number of rounds. Therefore we use the typical approach of simulations, again with risk limit .
We simulate audits considering each candidate with a column in the results available at the Virginia Department of Elections website, including irrelevant ballots. We consider a simple round schedule, in which each round is selected to give the same probability of stopping, . That is, if the audit does not stop in the first round, we select a second round size which, given the sample drawn in the first round, will again have a probability of stopping in the second round. Note that since there are multiple candidates, we compute the minimum round size to achieve stopping probability for each pairwise contest between the winner and one of the losers, and we then select the largest such minimum round size and scale it up according to the proportion of the total ballots that are relevant to that pairwise contest. For this round schedule scheme, a one-and-done audit is achieved by choosing large , say or . We run trial audits for each value of , assuming the reported results are correct222For this particular round schedule scheme, computing the expected number of rounds is straightforward analytically, but the expected number of ballots is still difficult, and so we use simulations..
Note that simulations of audits of tied elections are not necessary, as all the audits we are considering are risk-limiting and hence we already know the performance to expect when auditing a tied election, even one not reported as such.
6.1 Person-hours
6.1.1 Average total ballots.
The simplest workload models are a function of just the total number of a ballots sampled.333Sometimes total distinct ballots sampled is used, but for the margins we use in our examples in this section, the difference between total distinct ballots and total ballots is insignificant[21]. It is straightforward to modify the model we discuss here to account for total distinct ballots. Figure 6 shows the average total number of ballots sampled as a function of .

Figure 7 provides the same number as a fraction of the Providence values. It is straightforward to show that Providence and both forms of Bravo collapse to the same test when each round corresponds to a single ballot. Figures 6 and 7 show that for larger stopping probabilities (i.e. larger rounds), Providence requires fewer ballots on average. In particular, the savings of Providence become larger as increases; for , EoR Bravo and SO Bravo require more than and times as many ballots as Providence respectively.

6.1.2 Round overhead.
It is clear that average number of ballots alone is an inadequate workload measure. (Consider a state conducting its audit by selecting a single ballot at random, notifying just the county where the ballot is located, and then waiting to hear back for the manual interpretation of the ballot before moving on to the next one. This of course is inefficient and is why audits are actually performed in rounds.)
In a US state-wide RLA, the state organizes the audit by determining the random sample and communicating with the counties, but election officials at the county level physically sample and inspect the ballots after drawing them from secure storage boxes stored in county locations. Therefore each audit round requires some number of person-hours for set up and communication between state and county. This overhead for a round includes choosing the round size, generating the random sample, and communicating that random sample to the counties, as well as the communication of the results back to the state afterwards.
Consequently, we now consider a model with a constant per-ballot workload and a constant per-round workload . So for an audit with expected number of ballots and expected number of rounds , we estimate that the workload of the audit is
| (4) |
Note there is also some constant overhead of workload for the whole audit, namely in Equation 4, which we take to be zero in our examples but could be used by election officials to represent, for example, the effort of constructing a ballot manifest. For simplicity, (and without loss of generality), we measure in multiples of the per ballot workload; that is, we assume it is one unit, . A per round workload of corresponds to a per round workload which is times the per ballot workload. We use as a conservative example. That is, we set the overhead of a round equal to the workload of sampling ballots. Based on available data[5], the time retrieving and analyzing each individual ballot is on the order of seconds which means that is equivalent to roughly person-hours of workload. This corresponds to about minutes being spent, on average, per round in each of the counties of Virginia, a clearly conservative workload estimate.
As shown in Figure 8, average workloads first reduce as stopping probability increases; this is likely due to a decrease in the number of rounds. After hitting a sweet spot, average workloads again increase with stopping probability; this time, likely because the average number of rounds does not increase much and the cost changes because of number of ballots drawn, which increases with round size. Providence achieves the lowest minimum average workload at roughly for our example choice of .

Importantly, this gives us a way to estimate the minimum expected workload, as well as which round schedule value achieves it, for arbitrary round workload. For each round workload , we produce a dataset analagous to that of Figure 8 and then find the minimum average workload achieved for each of the audits and its corresponding stopping probability .
Figure 9 shows the optimal achievable workload for a wide range of per round workloads. For very low round workloads, the workload function approaches just the total number of ballots, and so workload is minimized by minimizing the number of ballots drawn, which corresponds to small round sizes, and we would expect all three audits to behave similarly, as ballot-by-ballot audits, with the smallest workload. On the other hand, for extremely large values of round workload, the average number of ballots has little impact on the workload function, and so the three audits again have similar values, all corresponding to large round sizes in order to minimize the number of rounds. We know that there is variation in the number of ballots used by each type of audit for large round sizes (a factor of two for ), but these values would be small in comparison to . We observe this behaviour in Figure 9 for extremely small and large workload values. For more reasonable values of the round workload , SO Bravo and EoR Bravo achieve minimum workload roughly and times greater than that of Providence.
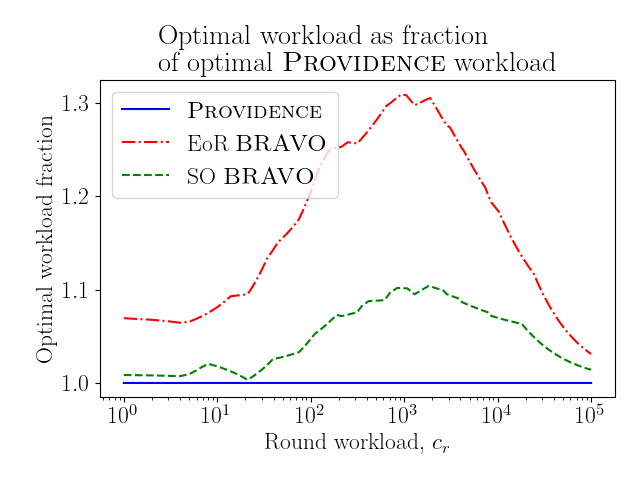
Figure 10 shows the corresponding round schedule parameters that achieve these minimal workloads. As expected, an overhead for each round means that larger round sizes are needed to achieve an optimal audit, and so for all three audits increases as a function of . Notice that Providence is generally above and to the left of SO Bravo, and SO Bravo is generally above and to the left of EoR Bravo. This relationship reflects the fact that for the same round workload, Providence can get away with a larger stopping probability because it requires fewer ballots.

6.1.3 Precinct overhead.
For a more complete model, we can also introduce container-level workload. If. around requires multiple ballots from a single container, the container need only be unsealed once. Based on a Rhode Island pilot RLA report[5], this may mean that a ballot from a new container requires roughly twice the time as a ballot from an already-opened container. Typically available election results give per-precinct granularity of vote tallies, rather than individual container information. In Virginia, however, most precincts have a single ballot scanner whose one box has sufficient capacity for all the ballots cast in that precinct anyways, and so we model the per-container workload as a per-precinct workload, . In this model, the workload estimate incurs an additional workload of every time a precinct is sampled from for the first time in a round. That is, let be the expected number of distinct precincts sampled from in round , and let . Then the new model is
| (5) |
We can again explore the minimum achievable workloads under this model, as shown in Figure 11.

6.2 Real time
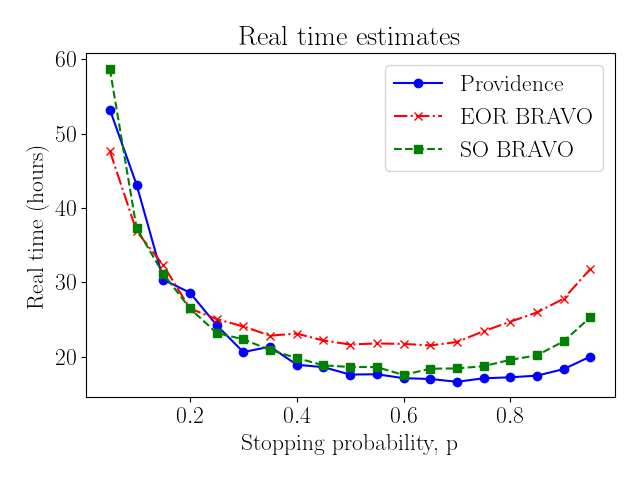
Given tight certification deadlines444Virginia recently passed legislation requiring pre-certification RLAs., the total real time to conduct the RLA is also an important factor to consider when planning audits. Because each county can sample ballots for the same round concurrently, the total real time for a round depends only on the slowest county. In Virginia, Fairfax County typically has the most votes cast by a significant difference; in the contest we consider, Fairfax County had 551 thousand votes cast, more than double the 203 thousand of second-highest Virginia Beach City. Consequently, we model the expected total real time of an audit using just the largest county, and we define analagous variables for the expected values in just the largest county. For the largest county, let the expected total ballots sampled be , the expected number of rounds , and the expected number of distinct precinct samples summed over all rounds be . Similarly, we use real time per-ballot, per-round, and per-precinct workload variables, , , and . So the real time of the audit is estimated by
| (6) |
As before, we can use our simulations to estimate , , and using the corresponding averages over the trials. Available data to estimate values for , , and is limited, and so we take as an example the values seconds, hours, and seconds.555The value seconds corresponds to a serial retrieval and interpretation of the ballots based on the [5] timing, seconds corresponds to the approximate doubling in time for new-box ballots as reported in [5] in the ballot-level comparison timing data, and hours is just a guess at an approximate order for this variable. In practice, election officials could use our software and their own estimates of these values to explore choices for round schedules. Figure 12 shows how the estimated real time for these values differs as a function of . It should be noted that real values of , , and will vary greatly based on the number of parallel teams retrieving and checking ballots, the distribution of ballots and containers both in number and physical space, and other factors. We provide Figure 12 only as an example of the general shape and behavior of this function. Use of this optimal scheduling tool would depend on parameter estimates tailored to each case.
6.3 Misleading samples
Unfortunately, efficiency alone is not sufficient for planning audits. In the US today, election officials have a legitimate need to include personal safety as a consideration. In a random sample, a true loser may receive more votes than the true winner. This happens more often when the sample sizes are small, like for a hypothetical first round size of in the pilot audit, as seen in Figure 5. In the abstract, a misleading sample in an early round is dealt with by drawing more ballots (moving on to another round), but in practice the implications of this approach may be dangerous.
Imagine that Alice beats Bob in an election contest both truly and in the reported results, but Bob’s supporters are insistent he really won. When election officials carry out the RLA, they choose a small first round size in the hopes of achieving an efficient audit by getting to stop sooner (and drawing fewer ballots on average). After the first round, by chance, there are more votes for Bob than for Alice in the sample. Bob’s supporters celebrate their victory that the audit has in fact revealed that Bob really won, but the election officials have to explain that they are moving on to a second round. After the second round, there are more votes in the sample for Alice and sufficiently many that the risk limit is met and the audit now ends confirming the announced result that Alice won. This is an undesirable situation, as it can appear to Alice’s supporters that election officials are simply drawing ballots till a chosen outcome is obtained.
We introduce the notion of a misleading sample, any cumulative sample which, assuming the announced outcome is correct, contains more ballots for a loser than for the winner. We can again use our simulations to gain insight into the frequency of misleading samples. For each stopping probability , Figure 13 gives the proportion of simulated audits that had a misleading sample at any point. Notably, this proportion is as high as 1 in 5 for the smaller stopping probability round schedules. Accordingly, we introduce a new parameter to our audit-planning tool, the maximum acceptable probability that the audit is misleading, the misleading limit.
In Figure 13, horizontal lines are included to show misleading limits of , , and . To achieve a probability of a misleading sample of at most , a round schedule with at least roughly is needed. To achieve a probability of misleading of roughly , a round schedule with is needed, and to achieve a probability of misleading of roughly , a round schedule with is needed. It is not unreasonable to think that election officials might choose a misleading limit of , or smaller, given the state of public perception of election security in the US and the associated threats of violence. Consequently, the desired misleading limit may be a deciding constraint in the choice of round schedule.

We observe a similar behavior in our simulations of audits on the contest from the pilot audit. Figure 14 shows the proportion of the pilot simulations which contained a misleading sample in any round. Despite the large difference in margin ( in Virginia and in the pilot) we still observe that a misleading limit of is first achieved at roughly and at .

If election officials wish to enforce a misleading limit for all the rounds, our simulation analysis could help. On the other hand, for a given round, it is straightforward to compute analytically the probability that a loser has more votes than the winner in the sample. Table 2 shows for various margins the minimum first round size that guarantees a probability of a misleading sample at most . For all values of and all margins, Providence achieves a higher probability of stopping than either EoR Bravo or SO Bravo. As seen in the Table 2, to enforce requires minimum round sizes with at least roughly a probability of stopping in the first round. Even if the most efficient audit schedule (by either workload or real time measures) would use a lower stopping probability to choose the first round size, the election officials may opt to use this constraint on the probability of a misleading sample as the deciding factor in planning their audits.
6.3.1 Misleading SO Bravo sequences.
As we consider the idea of misleading samples, it is noteworthy that SO Bravo suffers from a different and unique type of misleading result.
After drawing a cumulative ballots in a round, some number of them are votes for the announced winner. There are possible sequences of ballots which can lead to such a sample. Given a value of , however, the particular sequence of the sample that led to that value of contains no additional information about whether the sample is more likely under the alternative or null hypotheses. That is to say, and have the same value regardless of the sequence. Despite this, the SO Bravo RLA stopping condition is not just a function of and but also a function of the sequence, the selection order. In particular, if the sequence of ballots is such that the standard Bravo stopping condition was met for some and corresponding , the audit will stop, even if by the end of the sequence the values and no longer meet the Bravo condition. We refer to such sequences which stop under SO Bravo, but not under EoR Bravo, as misleading sequences. To be clear, this is not a mathematical issue; stopping in such cases is still a correct application of Wald’s SPRT result[20]. The misleading nature of such stoppages is the note we are making. This is another case where election officials might have difficulty explaining the misleading situation to the public.
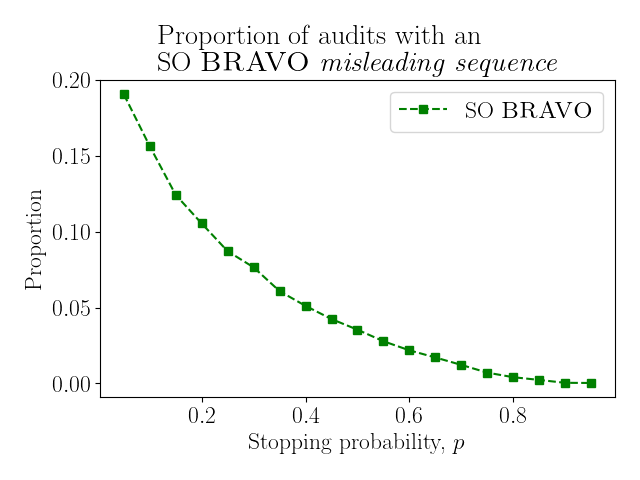
Recall from Section 5 that the pilot Providence RLA performed in Providence, Rhode Island had an SO Bravo misleading sequence. In particular, the audit passed with an SO Bravo risk measure of but the final cumulative tally of the sample gives a Bravo risk measure of .
It is easy to use our simulations to see how often SO Bravo misleading sequences occur by checking whether the final cumulative sample of each SO Bravo trial meets the EoR Bravo stopping condition and counting those which do not. Figure 15 shows the proportion of simulated SO Bravo audits that stopped with a misleading sequence. Unlike the more general misleading sample discussed so far, these misleading sequences are unique to SO Bravo audits, and Figure 15 only shows the proportion of audits that stopped with a misleading sequence; additional SO Bravo audits also contained misleading samples.
7 Conclusion
A rigorous tabulation audit is an important part of a secure election. We present Providence and demonstrate that it is as efficient as Minerva and as flexible as Bravo. We present proofs and simulation results to verify the claimed properties of Providence, and we provide an open source implementation of the stopping condition and useful related functionality for planning audits. We define the constraint of an acceptable probability of a misleading audit sample, and describe its importance to the planning process.
| margin | Prov | SO | EoR | ||
|---|---|---|---|---|---|
| 0.1 | 0.25 | 25 | 0.221 | 0.152 | 0.115 |
| 0.15 | 73 | 0.202 | 0.186 | 0.141 | |
| 0.05 | 657 | 0.227 | 0.192 | 0.127 | |
| 0.03 | 1825 | 0.246 | 0.194 | 0.124 | |
| 0.01 | 16423 | 0.246 | 0.196 | 0.124 | |
| 0.01 | 0.25 | 85 | 0.792 | 0.707 | 0.559 |
| 0.15 | 239 | 0.817 | 0.712 | 0.549 | |
| 0.05 | 2163 | 0.817 | 0.721 | 0.569 | |
| 0.03 | 6011 | 0.824 | 0.723 | 0.573 | |
| 0.01 | 54117 | 0.824 | 0.724 | 0.57 | |
| 0.001 | 0.25 | 149 | 0.962 | 0.889 | 0.783 |
| 0.15 | 421 | 0.958 | 0.894 | 0.801 | |
| 0.05 | 3815 | 0.96 | 0.896 | 0.785 | |
| 0.03 | 10607 | 0.961 | 0.897 | 0.787 | |
| 0.01 | 95491 | 0.962 | 0.897 | 0.787 |
8 Availability
Providence is implemented in the open source R2B2 software library for R2 and B2 audits [11] We provide software to test stopping conditions, find round sizes to achieve a given probability of stopping, and find round sizes that have acceptable probabilities of a misleading sample. The software also includes the simulator for all these audits and the functionality to perform the workload and real time analysis we present in this paper.
9 Acknowledgements
The authors are grateful to the Rhode Island Board of Elections for conducting a pilot Providence RLA, and to Georgina Cannan, Liz Howard, Mark Lindeman, and John Marion for their support of the pilot. The authors thank Audrey Malagon for useful information on audits.
References
- [1] Matthew Bernhard. Election Security Is Harder Than You Think. PhD thesis, University of Michigan, 2020.
- [2] Matthew Bernhard. Risk-limiting Audits: A practical systematization of knowledge. In In Proceedings, Seventh International Joint Conference on Electronic Voting (E-Vote-ID’21), October 2021, 2021.
- [3] Michelle L. Blom, Peter J. Stuckey, and Vanessa J. Teague. Ballot-polling risk limiting audits for IRV elections. In Robert Krimmer, Melanie Volkamer, Véronique Cortier, Rajeev Goré, Manik Hapsara, Uwe Serdült, and David Duenas-Cid, editors, Electronic Voting - Third International Joint Conference, E-Vote-ID 2018, Bregenz, Austria, October 2-5, 2018, Proceedings, volume 11143 of Lecture Notes in Computer Science, pages 17–34. Springer, 2018.
- [4] Oliver Broadrick, Sarah Morin, Grant McClearn, Neal McBurnett, Poorvi L. Vora, and Filip Zagórski. Simulations of ballot polling risk-limiting audits. In Seventh Workshop on Advances in Secure Electronic Voting, in Association with Financial Crypto, 2022.
- [5] Common Cause, VerifiedVoting, and Brennan Center. Pilot implementation study of risk-limiting audit methods in the state of rhode island. https://www.brennancenter.org/sites/default/files/2019-09/Report-RI-Design-FINAL-WEB4.pdf.
- [6] Zhuoqun Huang, Ronald L. Rivest, Philip B. Stark, Vanessa J. Teague, and Damjan Vukcevic. A unified evaluation of two-candidate ballot-polling election auditing methods. In Robert Krimmer, Melanie Volkamer, Bernhard Beckert, Ralf Küsters, Oksana Kulyk, David Duenas-Cid, and Mikhel Solvak, editors, Electronic Voting - 5th International Joint Conference, E-Vote-ID 2020, Bregenz, Austria, October 6-9, 2020, Proceedings, volume 12455 of Lecture Notes in Computer Science, pages 112–128. Springer, 2020.
- [7] Mark Lindeman and Philip B Stark. A gentle introduction to risk-limiting audits. IEEE Security & Privacy, 10(5):42–49, 2012.
- [8] Mark Lindeman, Philip B Stark, and Vincent S Yates. BRAVO: Ballot-polling risk-limiting audits to verify outcomes. In EVT/WOTE, 2012.
- [9] Katherine McLaughlin and Philip B. Stark. Simulations of risk-limiting audit techniques and the effects of reducing batch size on the 2008 California House of Representatives elections. NSF report, 2010.
- [10] Katherine McLaughlin and Philip B. Stark. Workload estimates for risk-limiting audits of large contests. Honors Thesis, University of California, Berkeley, 2011.
- [11] Sarah Morin and Grant McClearn. The R2B2 (Round-by-Round, Ballot-by-Ballot) library, https://github.com/gwexploratoryaudits/r2b2.
- [12] Kellie Ottoboni, Matthew Bernhard, J. Alex Halderman, Ronald L Rivest, and Philip B. Stark. Bernoulli ballot polling: A manifest improvement for risk-limiting audits. International Conference on Financial Cryptography and Data Security, pages 226–241, 2019.
- [13] Ronald L Rivest. On the notion of "software independence" in voting systems. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 366(1881):3759–3767, 2008.
- [14] Ronald L. Rivest and John P. Wack. On the notion of “software independence” in voting systems. Prepared for the TGDC, and posted by NIST at the given url.
- [15] Philip B. Stark. Simulating a ballot-polling audit with cards and dice. In Multidisciplinary Conference on Election Auditing, MIT, december 2018.
- [16] Philip B. Stark and David A. Wagner. Evidence-based elections. IEEE Secur. Priv., 10(5):33–41, 2012.
- [17] Poorvi L. Vora. Risk-limiting Bayesian polling audits for two candidate elections. CoRR, abs/1902.00999, 2019.
- [18] Verified Voting. Audit law database, https://verifiedvoting.org/auditlaws/.
- [19] VotingWorks. Arlo, https://voting.works/risk-limiting-audits/.
- [20] Abraham Wald. Sequential tests of statistical hypotheses. The Annals of Mathematical Statistics, 16(2):117–186, 1945.
- [21] Filip Zagórski, Grant McClearn, Sarah Morin, Neal McBurnett, and Poorvi L. Vora. The Athena class of risk-limiting ballot polling audits. CoRR, abs/2008.02315, 2020.
- [22] Filip Zagórski, Grant McClearn, Sarah Morin, Neal McBurnett, and Poorvi L. Vora. Minerva– an efficient risk-limiting ballot polling audit. In 30th USENIX Security Symposium (USENIX Security 21), pages 3059–3076. USENIX Association, August 2021.
Appendix A Proofs
Lemma 2. For any risk-limit , for any margin and for any round schedule , the Providence RLA is more efficient than EoR Bravo.
Proof.
Let be a round schedule, and assume that an EoR Bravo audit stops in round , after observing ballots for the announced winner in each round respectively. That is, the EoR Bravo stopping condition is true:
To see the Providence stopping condition is fulfilled, we rewrite as
Where inequality follows from [21, Theorem 6]. Note that we apply this result on for just .
∎
Lemma 3.
For and , the ratio is strictly increasing as a function of for .
Proof.
See [22, Lemma 4]. ∎
Lemma 4.
Given a monotone increasing sequence: , for , the sequence:
is also monotone increasing.
Proof.
See [22, Lemma 2]. ∎
Lemma 5.
For and , the ratio is strictly increasing as a function of for .
Lemma 6.
Given a strictly monotone increasing sequence: and some constant ,
unless , in which case .
Proof.
Evident. ∎
Lemma 7.
For -Providence, there exists
a
such that
Proof.
Lemma 8.
For ,
Proof.
We induct on the number of rounds. For , we have
Suppose the lemma is true for round with history . Observe that
by the induction hypothesis. Then this is simply equal to
∎
Definition 6.
Let be the round schedule of an audit that has not stopped by the round . Let us define
| (7) |
As we have seen in Lemma 7, such a value of exists and if and only if the result of the audit is Correct, (i.e., the stopping condition in Definition 4 holds).
The following lemma shows a Markov-like property of Providence audit (i.e., for an audit that has not stopped in the first rounds, only cumulative results of the round matter: cumulative sample size and the number of ballots for the winner ).
Lemma 9.
Let be a round schedule for an execution of Providence audit that has not stopped in any of its first rounds (i.e., for every : ), then:
Proof.
Let denote the number of ballots drawn for the declared winner up to the round (out of sampled ballots). The stopping decision for the round is made as follows:
∎
That is, the stopping condition is equivalent to that of a two round audit with the same cumulative votes for the winner and cumulative round sizes: the first round is of size and has votes for the winner, and the second (cumulative) round size is with (cumulative) votes for the winner. Compare this to the similar property for the Bravo stopping condition.