Provably Correct Training of Neural Network
Controllers Using Reachability Analysis
Abstract
In this paper, we consider the problem of training neural network (NN) controllers for nonlinear dynamical systems that are guaranteed to satisfy safety and liveness (e.g., reach-avoid) properties. Our approach is to combine model-based design methodologies for dynamical systems with data-driven approaches to achieve this target. We confine our attention to NNs with Rectifier Linear Unit (ReLU) nonlinearity which are known to represent Continuous Piece-Wise Affine (CPWA) functions. Given a mathematical model of the dynamical system, we compute a finite-state abstract model that captures the closed-loop behavior under all possible CPWA controllers. Using this finite-state abstract model, our framework identifies a family of CPWA functions guaranteed to satisfy the safety requirements. We augment the learning algorithm with a NN weight projection operator during training that enforces the resulting NN to represent a CPWA function from the provably safe family of CPWA functions. Moreover, the proposed framework uses the finite-state abstract model to identify candidate CPWA functions that may satisfy the liveness properties. Using such candidate CPWA functions, the proposed framework biases the NN training to achieve the liveness specification. We show the efficacy of the proposed framework both in simulation and on an actual robotic vehicle.
keywords:
Neural networks; Formal methods; Reachability analysisThis paper was not presented at any conference.
, ,
1 Introduction
The last decade has witnessed tremendous success in using machine learning (ML) in a multitude of safety-critical cyber-physical systems domains, such as autonomous vehicles, drones, and smart cities. Indeed, end-to-end learning is attractive for the realization of feedback controllers for such complex cyber-physical systems, thanks to the appeal of designing control systems based on purely data-driven architectures. However, regardless of the explosion in the use of machine learning to design data-driven feedback controllers, providing formal safety and reliability guarantees of these ML-based controllers is in question. It is then unsurprising the recent focus in the literature on the problem of safe and trustworthy autonomy in general, and safe reinforcement learning, in particular.
The literature on the safe design of ML-based controllers for dynamical and hybrid systems can be classified according to three broad approaches, namely (i) incorporating safety in the training of ML-based controllers, (ii) post-training verification of ML-based controllers, and (iii) online validation of safety and control intervention. Representative examples of the first approach include reward-shaping (Jiang et al.,, 2020; Saunders et al.,, 2018), Bayesian and robust regression (Berkenkamp et al.,, 2016; Liu et al., 2019a, ; Pauli et al.,, 2020), and policy optimization with constraints (Achiam et al.,, 2017; Turchetta et al.,, 2016; Wen et al.,, 2020). Unfortunately, these approaches do not provide provable guarantees on the safety of the trained controller.
To provide strong safety and reliability guarantees, several works in the literature focus on applying formal verification techniques (e.g., model checking) to verify pre-trained ML-based controllers’ formal safety properties. Representative examples of this approach are the use of SMT-like solvers (Dutta et al.,, 2018; Liu et al., 2019b, ; Sun et al.,, 2019) and hybrid-system verification (Fazlyab et al.,, 2019; Ivanov et al.,, 2019; Xiang et al.,, 2019). However, these techniques only assess a given ML-based controller’s safety rather than design or train a safe agent.
Due to the lack of safety guarantees on the resulting ML-based controllers, researchers proposed several techniques to restrict the output of the ML-based controller to a set of safe control actions. Such a set of safe actions can be obtained through Hamilton-Jacobi analysis (Fisac et al.,, 2018; Hsu et al.,, 2021), and barrier certificates (Abate et al.,, 2021; Chen et al.,, 2021; Cheng et al.,, 2019; Ferlez et al.,, 2020; Li and Belta,, 2019; Robey et al.,, 2020; Taylor et al.,, 2020; Wabersich and Zeilinger, 2018b, ; Wang et al.,, 2018; Xiao et al.,, 2020). Unfortunately, methods of this type suffer from being computationally expensive, specific to certain controller structures or else employ training algorithms that require certain assumptions on the system model. Other techniques in this domain include synthesizing a safety layer or shield based on safe model predictive control with the assumption of existing a terminal safe set (Bastani et al.,, 2021; Wabersich and Zeilinger, 2018a, ; Wabersich and Zeilinger,, 2021), and Lyapunov methods (Berkenkamp et al.,, 2017; Chow et al.,, 2018, 2019) which focus mainly on providing stability guarantees rather than general safety and liveness guarantees.
This paper proposes a principled framework combining model-based control and data-driven neural network training to achieve enhanced reliability and verifiability. Our framework bridges ideas from reachability analysis to guide and bias the neural network controller’s training and provides strong reliability guarantees. Our starting point is the fact that Neural Networks (NNs) with Rectifier Linear Unit (ReLU) nonlinearity represent Continuous Piece-Wise Affine (CPWA) functions. Given a nonlinear model of the system, we compute a finite-state abstract model capable of capturing the closed-loop behavior under all possible CPWA controllers. Such a finite-state abstract model can be computed using a direct extension of existing reachability tools. Next, our framework uses this abstract model to search for a family of safe CPWA controllers such that the system controlled by any controller from this family is guaranteed to satisfy the safety properties. During the neural network training, we use a novel projection operator that projects the trained neural network weights to ensure that the resulting NN represents a CPWA function from the identified family of safe CPWA functions.
Unlike the safety property, satisfying the liveness property can not be enforced by projecting the trained neural network weights. Therefore, to account for the liveness properties, our framework utilizes the abstract model further to refine the family of safe CPWA functions to find candidate CPWA functions that may satisfy the liveness properties. The framework then ranks these candidates and biases the NN training accordingly until a NN that satisfies the liveness property is obtained. In conclusion, the contributions of this paper can be summarized as follows:
-
1.
An abstraction-based framework that captures the behavior of all neural network controllers.
-
2.
A novel projected training algorithm to train provably safe NN controllers.
-
3.
A procedure to bias the NN training to satisfy the liveness properties.
2 Problem Formulation
Notation: The symbols and denote the set of real and natural numbers, respectively. The symbols and denote the logical AND and logical IMPLIES, respectively. We denote by the interior of a set and by the the set of all vertices of a polytope . We use to denote a Continuous and Piece-Wise Affine (CPWA) function of the form:
| (1) |
where the collection of polytopic subsets is a partition of the set such that and if . We call each polytopic subset a linear region, and denote by the set of linear regions associated to , i.e.:
| (2) |
2.1 Dynamical Model, NN Controller, and Specification
Consider discrete-time nonlinear dynamical systems of the form:
| (3) |
where the state vector , the control vector , and . Given a feedback control law , we use to denote the closed-loop trajectory of (3) that starts from the state and evolves under the control law .
In this paper, our primary focus is on controlling the nonlinear system (3) with a state-feedback neural network controller . An -layer Rectified Linear Unit (ReLU) NN is specified by composing layer functions (or just layers). A layer with inputs and outputs is specified by a weight matrix and a bias vector as follows:
| (4) |
where the function is taken element-wise, and for brevity. Thus, an -layer ReLU NN is specified by layer functions whose input and output dimensions are composable: that is they satisfy . Specifically:
| (5) |
where we index a ReLU NN function by a list of matrices . Also, it is common to allow the final layer function to omit the function altogether, and we will be explicit about this when it is the case.
As a typical control task, this paper considers a reach-avoid specification , which combines a safety property for avoiding a set of obstacles with , and a liveness property for reaching a goal region in a bounded time horizon . We use and to denote a trajectory satisfies the safety and liveness specifications, respectively, i.e.:
Given a set of initial states , a control law satisfies the specification (denoted by ) if all trajectories starting from the set satisfy the specification, i.e., , .
2.2 Main Problem
Given the dynamical model (3) and a reach-avoid specification , we consider the problem of designing a NN controller with provable guarantees as described in the next problem.
Problem 1.
Given the nonlinear dynamical system (3) and a reach-avoid specification , compute an assignment of neural network weights and a set of initial states such that .
While it is desirable to find the largest possible set of safe initial states , our algorithm will instead focus on finding an sub-optimal . For space considerations, the quantification of the sub-optimality in the computations of is omitted.
3 Overview of the Proposed Formal Training Framework
Before describing our approach to solve Problems 1, we start by recalling the connection between ReLU neural networks and Continuous Piece-Wise Affine (CPWA) functions as follows (Pascanu et al.,, 2013):
Proposition 2.
Every ReLU NN represents a continuous piece-wise affine function.
In this paper, we confine our attention to CPWA controllers (and hence neural network controllers) that are selected from a bounded polytopic set , i.e., we assume that and .
Our solution to Problem 1 is to use the mathematical model of the dynamical system (3) to guide the training of neural networks. In particular, our approach is split into two components, one to address the safety specifications while the other one addresses the liveness specifications as described in the next two subsections.

3.1 Addressing Safety Specification
Our approach to address the safety specification is as follows:
-
•
Step 1: Capture the closed-loop behavior of the system under all CPWA controllers using a finite-state abstract model. Such abstract model can be obtained by extending current results on reachability analysis for polytopic systems (Yordanov et al.,, 2012).
-
•
Step 2: Identify a family of CPWA controllers that lead to correct behavior on the abstract model.
-
•
Step 3: Enforce the training of the NN to pick from the identified family of the CPWA controllers.
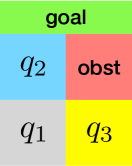
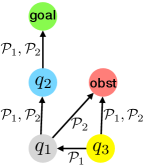
Figure 1 conceptualizes our framework. To start with, we construct an abstract model by partitioning both the state space and the set of all allowed CPWA functions . In Figure 1 (a), the state space is partitioned into a set of abstract states such that . Similarly, the controller space is partitioned into a set of controller partitions such that (each controller partition represents a subset of CPWA functions). The resulting abstract model is a non-deterministic finite transition system with nodes represent abstract states in and transitions are labeled by controller partitions in . Transitions between the abstract states are computed based on the reachable sets of the nonlinear system (3) from each abstract state and under every controller partition .
Based on the abstract model, we compute a function that maps each abstract state to a subset of the controller partitions that are considered to be safe at the abstract state , denoted by . For example, in Figure 1 (b), since the transition from labeled by leads to the obstacle, the controller partition is unsafe at , and hence . Similarly, . For the abstract state , since both and can lead to the obstacle, is empty, and hence is considered an unsafe abstract state. The set of initial states that can provide safety guarantee is the union of the safe abstract states, i.e., .
Using the set of safe controllers captured by , it is direct to show that if a neural network gives rise to CPWA functions in at every abstract state , then the NN satisfies the safety specifications. Therefore, to ensure the safety of the resulting trained neural network, we propose a NN weight “projection” operator to enforce that the trained NN only gives rise to the CPWA functions indicated by .
3.2 Addressing Liveness Specification
Our approach to addressing the liveness specification (reaching the goal) can be summarized as follows:
-
•
Step 1: Use the abstract model to identify candidate controller partitions that can lead to satisfaction of the liveness properties.
-
•
Step 2: Train one local neural network for each of the abstract states using either imitation learning or reinforcement learning. We take into account the knowledge of as constraints during training, and use the NN weight projection operator to ensure that the resulting NN still enjoys the safety specifications.
-
•
Step 3: Combine all the local neural networks into a single global NN.
In the context of the example in Figure 1 (c), the controller partition is assigned to both and as the candidate controller partition that may lead to the satisfaction of the liveness properties.
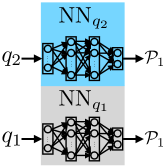
Next, we train one local neural network for each abstract state, or a subset of abstract states assigned with the same controller partition as shown in Figure 1 (d). During training of the local neural networks, we project their weights to enforce that the resulting NNs only give rise to the CPWA functions belong to the assigned controller partitions . Since the controller partition is chosen from the subset at every , the resulting NN enjoys the same safety guarantees.
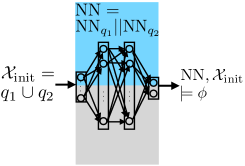
Finally, in Figure 1 (e), we combine the local networks trained for each abstract state into a single NN controller, with layers of fixed weights to decide which part of the NN should be activated.
3.3 Formal Guarantees
We highlight that the proposed framework above always guarantees that the resulting NN satisfies the safety specification thanks to the NN weight projection operator. This is reflected in Theorem 10 in Section 5.2.
On the other hand, achieving the liveness specification depends on the effort of neural network training and the quality of training data, and hence needs an extra step of formally verifying the resulting neural networks and iteratively changing the candidate controller partitions if needed. However, we argue that the resulting NN architecture is modular and is composed of a set of local networks that are more amenable to verification. The proposed architecture leads to a direct divide-and-conquer approach in which only some of the local networks may need to be re-trained whenever the liveness properties are not met.
4 Provably Safe Training of NN Controllers
In this section, we provide details on how to construct the abstract model that captures the behavior of all CPWA controllers along with how to choose the controller partitions that satisfy the safety specifications and train the corresponding NN controllers.
4.1 Step 1: Constructing the Abstract Model
In order to capture the behavior of the system (3) under all possible CPWA controllers in the form of (1), we construct a finite-state abstract model by discretizing both the state space and the set of all allowed CPWA functions. In particular, we partition the state space into a collection of abstract states, denoted by . The goal region is represented by a single abstract state , and the set of obstacles represents each obstacle by an abstract state , . Other abstract states represent infinity-norm balls in the state space , and the partitioning of the state space satisfies and if . For the interest of this paper, we consider the size of abstract states is pre-specified, by noticing that discretization techniques such as adaptive partitioning (e.g., Hsu et al., (2018)) can be directly applied in our framework. In experiments, we show results with both uniform and non-uniform partitioning of the state space.
Similarly, we partition the controller space into polytopic subsets. For simplicity of notation, we define the set of parameters be a polytope that combines and , and with some abuse of notation, we use with a single parameter to denote with the pair . The controller space is discretized into a collection of polytopic subsets in , denoted by , such that and if . We call each of the subsets a controller partition. Each controller partition represents a subset of CPWA functions, by restricting parameters in a CPWA function to take values from .
In order to reason about the safety property , we introduce a posterior operator based on the dynamical model (3). The posterior of an abstract state under a controller partition is the set of states that can be reached in one step from states by using affine state feedback controllers with parameters , i.e.:
| (6) |
Calculating the exact posterior of a nonlinear system is computationally daunting. Therefore, we rely on over-approximations of the posterior set denoted by .
Our abstract model is defined by using the set of abstract states , the set of controller partitions , and the posterior operator . Intuitively, an abstract state has a transition to under a controller partition if the intersection between and is non-empty.
Definition 3.
(Posterior Graph) A posterior graph is a finite transition system , where:
-
•
;
-
•
;
-
•
;
-
•
, if and .
The computation of the posterior operator can be done by borrowing existing techniques in reachability analysis of polytopic systems (Yordanov et al.,, 2012), with the subtle difference due to the need to consider polytopic partitions of the parameter space instead of the well-studied problem of considering polytopic partitions of the input space . We refer to the Posterior Graph as the finite-state abstract model of (3).
4.2 Step 2: Computing the Function
Once the abstract model is computed, our framework identifies a set of safe controller partitions at each abstract state . It is possible that the set is empty at some state , in which case, the state is considered to be unsafe.
We first introduce the operator as follows:
| (7) |
We identify the set of unsafe abstract states in a recursive manner by backtracking from the set of obstacles in the posterior graph :
The backtracking stops at iteration when it cannot find new unsafe states, i.e., . This backtracking process ensures that the set includes all the abstract states that inevitably lead to the obstacles (either directly or over multiple transitions).
Then, we define the set of safe abstract states as . The following proposition guarantees that there exists a controller partition assignment for each safe abstract state such that collision-free can be satisfied for all times in the future.
Proposition 4.
The set of safe abstract states is control positive invariant, i.e.:
| (8) |
Assume for the sake of contradiction that , s.t. , . Then, by the backtracking process, which contradicts the assumption that . Correspondingly, the function maps each abstract state to the subset of controller partitions that can be used to force the invariance of the set :
| (9) |
The following theorem summarizes the safety property.
Theorem 5.
Let be a state feedback CPWA controller defined at an abstract state . Assume that the parameters of the affine functions in are chosen such that and . Consider the set of initial states and define a controller as:
| (10) |
where is the number of safe abstract states. Then, it holds that
It is sufficient to show that the set is positive invariant under the controller in the form of (10). In other words, for any state , let be the abstract state contains , i.e., , then by applying any controller with any , it holds that .
The definitions of the posterior operator (6) and the operator (7) directly yield and , and hence:
| (11) |
where , , , and are arbitrarily chosen. Now consider an arbitrary safe abstract state , by Proposition 4 and the definition of as (9), the set , and for any , it holds that:
| (12) |
where it uses the definition . Therefore, by (11) and (12), for any and any .
By Theorem 5, the system is guaranteed to satisfy the safety specification by applying any CPWA controller at each abstract sate , as long as the controller parameters are chosen from the safe controller partitions . This allows us to conclude the safety guarantee provided by a NN controller if the CPWA function represented by the NN is chosen from the safe controller partitions, as we show in detail in the next subsection.
4.3 Step 3: Safe Training Using NN Weight Projection
As described in Section 3, the final NN consists of several local networks that will be trained to account for the liveness property. Nevertheless, to ensure that the safety property is met by each of the local networks , we propose a NN weight projection operator that can be incorporated in the training of these local NNs. Given a controller partition , this operator projects the weights of to ensure that the network represents a CPWA function belongs to .
Consider a local network of layers, including hidden layers and an output layer. The NN weight projection operator updates the weight matrix and the bias vector of the output layer to and , respectively, such that the CPWA function represented by the updated local network belongs to the selected controller partition at linear regions intersecting . To be specific, let the CPWA functions represented by the local network before and after the weight projection be and , respectively. Then, we formulate the NN weight projection operator as an optimization problem:
| (13) | |||
| (14) |
where by the notation (2), is the set of linear regions of the CPWA function . Consider the CPWA function is in the form of (1), where affine functions parametrized by are associated to linear regions , . Then, the constraints (14) require that whenever the corresponding linear region intersects the abstract state . As a common practice, we consider there is no ReLU activation function in the output layer. Then, the projection operator does not change the set of linear regions, i.e., , since the linear regions of a neural network only depend on the hidden layers, while the projection operator updates the output layer weights.
The optimization problem (13)-(14) tries to minimize the change of NN outputs due to the projection, which is measured by the largest 1-norm difference between the control signals and across the abstract state , i.e., . The relation between this objective function and the change of output layer weights is captured in the following proposition.
Proposition 6.
Consider an -layer local network whose output layer weights change from , to , . Then, the largest change of the NN’s outputs across the abstract state is bounded as follows:
| (15) | |||
where and are the -th and the -th entry of and , respectively.
In the above proposition, by following the notation of layer functions (4), we use a single function to represent all the hidden layers:
| (16) |
where is the number of neurons in the -layer (the last hidden layer). We denote by the intersected regions between the linear regions in and the abstract state , i.e.:
| (17) |
and denote by the set of all vertices of regions in , i.e., . {pf} The function can be written as , and after the change of output layer weights, . Then,
| (18) | |||
| (19) | |||
| (20) | |||
| (21) |
where (19) directly follows the form of and , (20) takes the absolute value of each term before summation and uses the fact that the hidden layer outputs . We notice that when is restricted to each linear region of , (20) is a linear program whose optimal solution is attained at extreme points. Therefore, in (21), the maximum can be taken over a finite set of all the vertices of linear regions in .
Proposition 6 proposes a direct way to design the intended projection operator. It implies that minimizing the right hand side of the inequality (15) will minimize the upper bound on the change in the control signal due to the projection operator. To that end, given a controller partition , let be the NN weight projection operator that updates the output layer weights of as . In order to minimize the change of NN outputs due to the projection, we minimize its upper bound in (15). Accordingly, we write the NN weight projection operator as the following optimization problem:
| (22) | |||
| (23) |
A direct question is related to the computational complexity of the proposed projection operator . This is addressed in the following proposition.
Proposition 7.
Using the epigraph form of the problem (22)-(23), we can write it in the equivalent form:
| (24) | |||
| (25) | |||
| (26) | |||
| (27) |
The inequality (24) is affine since the hidden layer function is known and does not depend on the optimization variables. The number of inequalities in (24) is finite since the set of vertices is finite. To see the constraint (27) is affine, consider the CPWA function , which is represented by the NN with the output layer weights , , and the hidden layer function . Since restricted to each linear region is a known affine function, the parameter (coefficients of restricted to ) affinely depends on and .
Finally, the following result shows the safety guarantee provided by applying the projection operator during training of the neural network controller.
Theorem 8.
4.4 Safety-biased Training to Reduce the Effect of Projection
As a practical issue, it is often desirable to have the trained NNs be safe or close to safe even before the weight projection, and thus the projection operator does not or only slightly modifies the NN weights without compromising performance. To reduce the effect of projection, our algorithm alternates the training and projection, and uses the safe controller partitions as constraints to bias the training.
We show the provably safe training of each local network in Algorithm 1. Similar to a projected gradient algorithm, Algorithm 1 alternates the training (Line 3 in Algorithm 1) and the NN weight projection (Line 5 in Algorithm 1) up to a pre-specified maximum iteration max_iter. The training approach Constrained-Train (Line 3 in Algorithm 1) can be any imitation learning or reinforcement learning algorithm, with some extra constraints required by the safe controller partition . In the imitation learning setting, we use to denote the collection of training data generated by an expert, where each state is associated with an input label . The approach Constrained-Train requires that all the training data satisfy and . Similarly, in the reinforcement learning setting, we assign high reward to the explored state-action pairs that satisfy and .
To guarantee that the trained neural networks are safe, Algorithm 1 identifies the set of linear regions (Line 4 in Algorithm 1) and projects the neural network weights by solving the linear program (22)-(23) (Line 5 in Algorithm 1). The solved weights , are then used to replace the currently trained output layer weights , (Line 6 in Algorithm 1), and the largest possible change of the NN’s outputs is bounded by (15). Thanks to the training approach Constrained-Train takes the constraints required by into consideration, and the problem (22)-(23) tries to minimize the change of NN outputs due to the projection, we observe in our experiments that the projection operator usually does not change the trained NN weights much. Indeed, in the result section, we show that the trained NNs perform well even with just a single projection at the end (i.e., ).
5 Extension to Liveness Property
5.1 Controller Partition Assignment
Among all the safe controller partitions in , we assign one of them to each abstract state , by taking into account the liveness specification . The liveness property requires that the nonlinear system (3) can reach the goal by using the trained NN controller. Unlike the safety property which can be enforced using the projection operator , achieving the liveness property depends on practical issues, such as the amount of training data and the effort spent on training the NNs. To that end, we show that the safety guarantee provided by our algorithm does not impede training NNs to satisfy the liveness property by using standard learning techniques.
Since the posterior graph over-approximates the behavior of the system, a transition from the abstract state to in does not guarantee that every state can reach in one step. Therefore, we introduce a predecessor operator to capture the liveness property. The predecessor of an abstract state under a controller partition is defined as the set of states that can reach in one step by using an affine state feedback controller with some parameter :
The predecessor operator can be computed using backward reachability analysis of polytopic systems (Yordanov et al.,, 2012). We then introduce the predecessor graph:
Definition 9.
(Predecessor Graph) A predecessor graph is a finite transition system , where:
-
•
;
-
•
;
-
•
;
-
•
, if and .
Notice that in the construction of , we restrict transition labels to the safe controller partitions at each state . Let be the set of all trajectories over the predecessor graph , then we use to denote the map from a trajectory to the abstract state at time step in , and use to denote the map from to the label associated to the transition from to . By extending the formulation of specification to the abstract state space, a trajectory in satisfies the reach-avoid specification , denoted by , if reaches the goal state in steps. Similar to the notation introduced in the posterior graph, we define a operator in the predecessor graph:
At each abstract state , our objective is to choose the candidate controller partition that can lead most of the states to the goal. To that end, we restrict our attention to the trajectories in that progress towards the goal. That is, let be the length of a trajectory , and map a state to the length of the shortest trajectory from the state to the goal in the predecessor graph . Then, we use to denote the subset of trajectories that lead to the goal:
| (28) |
Now we can define the subset of abstract states that progress towards the goal from abstract state under controller partition , denoted by , as the set of abstract states along trajectories that satisfy the given specification:
| (29) |
Then, the intersection between the abstract state and the predecessors of abstract states under the controller partition , i.e.:
| (30) |
measures the portion of states that progress towards the goal by applying input with at the current step. Then, our algorithm assigns each abstract state with the controller partition corresponding to the maximum volume of , i.e. , where is the Lebesgue measure of . Indeed, and as mentioned in Section 3.3, such procedure only ranks the available choices of controller partitions and one may need to iterate over the remaining choices using the same heuristic above.
5.2 Combined NN Controller
The final step of our framework is to combine all the local networks into one global NN controller. Figure 2 (a) shows the overall structure of the global NN controller obtained by combining modules corresponding to the local networks . As input to the NN controller, the state is fed into all the local networks, and the output of the NN controller is the summation of all the local network outputs. In the figures, we show a single output for simplicity, but it can be easily extended to multiple outputs (indeed, even in the figures, and can be thought as vectors in , and the summation and product operations correspond to vector addition and scalar multiplication, respectively).
Each module consists of two parts: logic and ReLU NN. The logic component decides whether the current state is in the abstract state associated with , and outputs if the answer is affirmative, otherwise. The ReLU network is trained for this abstract state using Algorithm 1. By multiplying the outputs of the logic and the ReLU NN, output of the module is identical to the output of the ReLU NN if , and zero otherwise. Figure 2 (b) is an example of the module for an arbitrary abstract state given by and .
The logic component in each module can be implemented as a single layer NN with fixed weights. Given the -representation of the abstract state , the weight matrix and the bias vector of the single layer NN are and , respectively. Essentially, this choice of weights encodes each hyperplane inequality in the -representation to each neuron in the single layer. To represent whether an inequality holds, we use a step function as the nonlinear activation function for the single layer: , otherwise. The product of the outputs of all the neurons in the single layer is computed at the end (by the product operator ), and hence the logic component returns if and only if all the hyperplane inequalities are satisfied.
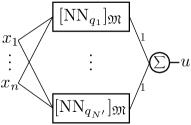
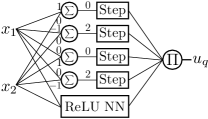
We refer to the single layer NN for the logic component as , along with the ReLU network , each module can be written as , where denotes the parallel composition. Using the same notation, we can write the global NN controller as:
| (31) |
where is the number of safe abstract states. We summarize the guarantees on the global NN controller in Theorem 10, whose proof follows directly from the discussion above along with Theorem 5 and Theorem 8. Let be defined as (5.1) and be the set of states that can be reached in one step from abstract state using local network :
| (32) |
Theorem 10.
Consider the nonlinear system (3) and the reach-avoid specification . Let the controller partition assignment and the local neural networks satisfy (i) and (ii) the neural network weights of is projected on using the projection operator (22)-(23). Then, the global neural network controller NN given by (31) is guaranteed to be safe, i.e., with . Moreover, if all the local networks satisfy , then NN satisfies the liveness property, i.e., .
In words, Theorem 10 guarantees that the global NN composed from provably safe local networks is still safe (i.e., satisfies ). This reflects the fact that the composition of the global network respects the linear regions on which the local networks are defined. Moreover, if the local networks satisfy the local reachability requirements, then the global NN satisfies the liveness property , which reflects the fact that the set in (5.1) is defined to guarantee progress towards the goal.
In practice, by combining the local networks into a single NN controller, it allows one to repair the NN controller in a systematic way when it fails to meet the liveness property. For example, if a local network fails to satisfy the local reachability requirement , then only need to be improved, such as by further training with augmented data collected at the state , without affecting local networks that satisfy the specification at other abstract states.
6 Experimental Results
We evaluated the proposed framework both in simulation and on an actual robotic vehicle. All experiments were executed on an Intel Core i9 2.4-GHz processor with 32 GB of memory.
6.1 Controller Performance Comparison in Simulation
We first present simulation results of a wheeled robot under the control of NN controllers trained by our algorithm. Let the state vector of the system be , where , denote the coordinates of the robot, and is the heading direction. The discrete-time dynamics of the robot is given by:
| (33) | ||||
where the control input is determined by a neural network controller, i.e., , with the controller space considered to be a hyperrectangle. We choose discrete time step size .
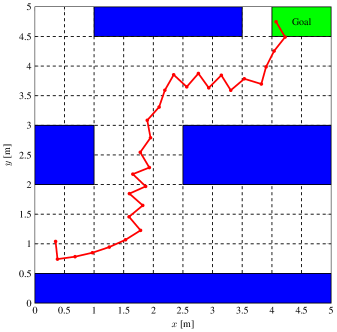
We considered two different workspaces indexed by and as shown in the upper and lower row of Figure 3, respectively. As the first step of our algorithm, we discretized the state space and the controller space as described in Section 4.1. To illustrate the flexibility in the choice of partition strategies, we partitioned the state space corresponding to workspace uniformly into abstract states, while partitioning the state space corresponding to workspace non-uniformly into abstract states. In both cases, the range of heading direction is uniformly partitioned into intervals, and the partitions of the , dimensions are shown as the dashed lines in the workspaces in Figure 3. We uniformly partitioned into hyperrectangles. By computing the reachable sets using the reachability tool TIRA (Meyer et al.,, 2019), we constructed the posterior graph , which is then used to find the set of safe abstract states and the function . The execution time to compute the posterior graph and to identify the set of safe states can be found in Table 1.
We used the nonlinear MPC solver FORCES (Domahidi and Jerez,, 2019; Zanelli et al.,, 2017) as an expert to collect training data, and used Keras (Chollet et al.,, 2015) to train a shallow NN (one hidden layer) with hidden layer neurons for each abstract state . At the end of training, we projected the trained NN weights only once as mentioned in Section 4.3. For workspace , it takes seconds to collect all the training data, and seconds to train all the local NNs including the projection of the NN weights. For workspace , the execution time for collecting data is seconds, and the total time for training and projection is seconds.
In Figure 3, we show some trajectories under NN controllers trained by our algorithm in both workspaces. Despite we choose trajectories with initial states in the set to be close to the obstacles or initially heading towards the obstacles, all the trajectories are collision-free as guaranteed by our algorithm. Moreover, by assigning controller partitions based on strategies in Section 5.1, all trajectories satisfy the liveness specification .
|
Workspace 1 |



|
|
Workspace 2 |



|
|
Standard Imitation Learning |



|
|
Provably Safe Training |


|
Next, we compare NN controllers trained by our algorithm with those trained by standard imitation learning, which minimizes the regression loss without taking into account the safety guarantee. All NN controllers are trained using the same set of the training data. We vary the NN architectures for the NNs trained by standard imitation learning to achieve better performance, and train them using enough episodes for the loss to be low enough. Nevertheless, as shown in Figure 4, for all the NN controllers trained by standard imitation learning, we are able to find initial states starting from which the trajectories are not safe. However, with the same initial states, trajectories under NN controllers trained by our algorithm are collision-free as the framework guarantees.
6.2 Actual Robotic Vehicle
We tested the proposed framework on a small robotic vehicle called PiCar, which carries a Raspberry Pi that runs the NN controller trained by our algorithm. We used the motion capture system Vicon to measure states of the PiCar in real time. Figure 5 (a) shows the PiCar and our experimental setup. We modeled the PiCar dynamics by the rear-wheel bicycle drive (Klančar et al.,, 2017), and took model-error into consideration by adding a bounded disturbance when computing the reachable sets. We trained the local networks using Proximal Policy Optimization (PPO) (Schulman et al.,, 2017). Figure 5 (b) shows the PiCar’s trajectory under the NN controller trained by our framework. The PiCar runs on the race track for multiple loops and satisfies the safety property .


6.3 Scalability Study
1- Scalability with respect to Partition Granularity: We first show scalability of our algorithm with respect to the choice of partition parameters. Using the two workspaces in Figure 3, we increase the number of abstract states and controller partitions by decreasing the partition grid size and report the execution time for each part of our framework in Table 1. We notice that the execution time grows linearly with the number of abstract states and the number of controller partitions.
Although we conducted all the experiments on a single CPU core, we note that our algorithm can be highly parallelized. For example, computing reachable sets of the abstract states, checking intersection between the posteriors and the abstract states when constructing the posterior graph, and training local neural networks can all be done in parallel. After training the NN controller, the execution time of the controller is almost instantaneous, which is a major advantage of NN controllers.
| Workspace | Number of | Number of | Number of | Compute | Construct | Compute | Assign |
|---|---|---|---|---|---|---|---|
| Index | Abstract | Controller | Safe & Reachable | Reachable | Posterior | Function | Controller |
| States | Partitions | Abstract States | Sets [s] | Graph [s] | [s] | Partitions [s] | |
| 1 | 552 | 160 | 400 | 52.6 | 82.3 | 0.06 | 0.7 |
| 1 | 552 | 320 | 400 | 107.5 | 160.3 | 0.1 | 0.9 |
| 1 | 552 | 640 | 400 | 223.1 | 329.6 | 0.2 | 1.7 |
| 1 | 1104 | 160 | 800 | 108.2 | 333.0 | 0.2 | 2.3 |
| 1 | 1104 | 320 | 800 | 219.6 | 684.2 | 0.4 | 2.7 |
| 1 | 1104 | 640 | 800 | 451.5 | 1297.4 | 0.6 | 4.2 |
| 2 | 904 | 160 | 632 | 88.1 | 159.1 | 0.1 | 1.0 |
| 2 | 904 | 320 | 632 | 203.6 | 313.2 | 0.2 | 1.1 |
| 2 | 904 | 640 | 632 | 393.2 | 660.8 | 0.3 | 1.7 |
| 2 | 1808 | 160 | 1264 | 202.1 | 634.6 | 0.3 | 3.4 |
| 2 | 1808 | 320 | 1264 | 388.6 | 1298.1 | 0.6 | 4.0 |
| 2 | 1808 | 640 | 1264 | 778.2 | 2564.4 | 0.9 | 5.9 |
2- Scalability with respect to System Dimension: Abstraction-based controller design is known to be computational expensive for high-dimensional systems due to the curse of dimensionality. In Table 2, we show scalability of our algorithm with respect to the system dimension. To conveniently increase the system dimension, we consider a chain of integrators represented as the linear system , where is the identity matrix, and . With the fixed number of controller partitions, Table 2 shows that the number of abstract states and execution time grow exponentially with the system dimension . Nevertheless, our algorithm can handle a high-dimensional system in a reasonable amount of time.
| System | Number of | Compute Reachable | Construct Posterior |
|---|---|---|---|
| Dimension | Abstract States | Sets [s] | Graph [s] |
| 2 | 69 | 0.6 | 0.7 |
| 4 | 276 | 2.7 | 2.6 |
| 6 | 1104 | 11.7 | 34.2 |
| 8 | 4416 | 57.1 | 521.0 |
| 10 | 17664 | 258.1 | 9840.4 |
7 Conclusion
In this paper, we proposed a framework for training neural network controllers for nonlinear dynamical systems with rigorous safety and liveness guarantees. Our framework computes a finite-state abstract model that captures the behavior of all possible CPWA controllers, and enforces the correct behavior during training through a NN weight projection operator, which can be applied on top of any existing training algorithm. We implemented our framework on an actual robotic vehicle that shows the capability of our approach in real-world applications. Compared to existing techniques, our framework results in provably correct neural network controllers removing the need for online monitoring, predictive filters, barrier functions, or post-training formal verification. Future research directions include extending the framework to multiple agents in unknown environment, and using the proposed abstract model to generalize learning for different tasks in meta-learning setting.
References
- Abate et al., (2021) Abate, A., Ahmed, D., Edwards, A., Giacobbe, M., and Peruffo, A. (2021). Fossil: A software tool for the formal synthesis of lyapunov functions and barrier certificates using neural networks. In Proceedings of the 24th ACM International Conference on Hybrid Systems: Computation and Control.
- Achiam et al., (2017) Achiam, J., Held, D., Tamar, A., and Abbeel, P. (2017). Constrained policy optimization. In Proceedings of the 34th International Conference on Machine Learning, pages 22–31.
- Bastani et al., (2021) Bastani, O., Li, S., and Xu, A. (2021). Safe reinforcement learning via statistical model predictive shielding. In Robotics: Science and Systems.
- Berkenkamp et al., (2016) Berkenkamp, F., Krause, A., and Schoellig, A. P. (2016). Bayesian optimization with safety constraints: safe and automatic parameter tuning in robotics. arXiv preprint arXiv:1602.04450.
- Berkenkamp et al., (2017) Berkenkamp, F., Turchetta, M., Schoellig, A., and Krause, A. (2017). Safe model-based reinforcement learning with stability guarantees. In Advances in neural information processing systems.
- Chen et al., (2021) Chen, S., Fazlyab, M., Morari, M., Pappas, G. J., and Preciado, V. M. (2021). Learning lyapunov functions for hybrid systems. In Proceedings of the 24th ACM International Conference on Hybrid Systems: Computation and Control.
- Cheng et al., (2019) Cheng, R., Orosz, G., Murray, R. M., and Burdick, J. W. (2019). End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 3387–3395.
- Chollet et al., (2015) Chollet, F. et al. (2015). Keras. url=https://keras.io.
- Chow et al., (2018) Chow, Y., Nachum, O., Duenez-Guzman, E., and Ghavamzadeh, M. (2018). A lyapunov-based approach to safe reinforcement learning. In Advances in neural information processing systems, pages 8092–8101.
- Chow et al., (2019) Chow, Y., Nachum, O., Faust, A., Duenez-Guzman, E., and Ghavamzadeh, M. (2019). Lyapunov-based safe policy optimization for continuous control. arXiv preprint arXiv:1901.10031.
- Domahidi and Jerez, (2019) Domahidi, A. and Jerez, J. (2014–2019). Forces professional. Embotech AG, url=https://embotech.com/FORCES-Pro.
- Dutta et al., (2018) Dutta, S., Jha, S., Sankaranarayanan, S., and Tiwari, A. (2018). Output range analysis for deep feedforward neural networks. In NASA Formal Methods Symposium. Springer.
- Fazlyab et al., (2019) Fazlyab, M., Robey, A., Hassani, H., Morari, M., and Pappas, G. (2019). Efficient and accurate estimation of lipschitz constants for deep neural networks. In Advances in Neural Information Processing Systems, pages 11423–11434.
- Ferlez et al., (2020) Ferlez, J., Elnaggar, M., Shoukry, Y., and Fleming, C. (2020). Shieldnn: A provably safe nn filter for unsafe nn controllers. arXiv preprint arXiv:2006.09564.
- Fisac et al., (2018) Fisac, J. F., Akametalu, A. K., Zeilinger, M. N., Kaynama, S., Gillula, J., and Tomlin, C. J. (2018). A general safety framework for learning-based control in uncertain robotic systems. IEEE Transactions on Automatic Control, 64(7):2737–2752.
- Hsu et al., (2018) Hsu, K., Majumdar, R., Mallik, K., and Schmuck, A.-K. (2018). Multi-layered abstraction-based controller synthesis for continuous-time systems. In Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, pages 120–129.
- Hsu et al., (2021) Hsu, K.-C., Rubies-Royo, V., Tomlin, C. J., and Fisac, J. F. (2021). Safety and liveness guarantees through reach-avoid reinforcement learning. In Robotics: Science and Systems.
- Ivanov et al., (2019) Ivanov, R., Weimer, J., Alur, R., Pappas, G. J., and Lee, I. (2019). Verisig: verifying safety properties of hybrid systems with neural network controllers. In Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, pages 169–178.
- Jiang et al., (2020) Jiang, Y., Bharadwaj, S., Wu, B., Shah, R., Topcu, U., and Stone, P. (2020). Temporal-logic-based reward shaping for continuing learning tasks. arXiv:2007.01498.
- Klančar et al., (2017) Klančar, G., Zdešar, A., Blažič, S., and Škrjanc, I. (2017). Wheeled mobile robotics.
- Li and Belta, (2019) Li, X. and Belta, C. (2019). Temporal logic guided safe reinforcement learning using control barrier functions. arXiv preprint arXiv:1903.09885.
- (22) Liu, A., Shi, G., Chung, S.-J., Anandkumar, A., and Yue, Y. (2019a). Robust regression for safe exploration in control. arXiv preprint arXiv:1906.05819.
- (23) Liu, C., Arnon, T., Lazarus, C., Barrett, C., and Kochenderfer, M. J. (2019b). Algorithms for verifying deep neural networks. arXiv preprint arXiv:1903.06758.
- Meyer et al., (2019) Meyer, P.-J., Devonport, A., and Arcak, M. (2019). Tira: toolbox for interval reachability analysis. In Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, pages 224–229.
- Pascanu et al., (2013) Pascanu, R., Montufar, G., and Bengio, Y. (2013). On the number of response regions of deep feed forward networks with piece-wise linear activations. arXiv preprint arXiv:1312.6098.
- Pauli et al., (2020) Pauli, P., Koch, A., Berberich, J., and Allgöwer, F. (2020). Training robust neural networks using lipschitz bounds. arXiv preprint arXiv:2005.02929.
- Robey et al., (2020) Robey, A., Hu, H., Lindemann, L., Zhang, H., Dimarogonas, D. V., Tu, S., and Matni, N. (2020). Learning control barrier functions from expert demonstrations. In 59th IEEE Conference on Decision and Control.
- Saunders et al., (2018) Saunders, W., Sastry, G., Stuhlmueller, A., and Evans, O. (2018). Trial without error: Towards safe reinforcement learning via human intervention. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, pages 2067–2069.
- Schulman et al., (2017) Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017). Proximal policy optimization algorithms. arXiv:1707.06347.
- Sun et al., (2019) Sun, X., Khedr, H., and Shoukry, Y. (2019). Formal verification of neural network controlled autonomous systems. In Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, pages 147–156.
- Taylor et al., (2020) Taylor, A. J., Singletary, A., Yue, Y., and Ames, A. D. (2020). A control barrier perspective on episodic learning via projection-to-state safety. arXiv preprint arXiv:2003.08028.
- Turchetta et al., (2016) Turchetta, M., Berkenkamp, F., and Krause, A. (2016). Safe exploration in finite markov decision processes with gaussian processes. In Advances in Neural Information Processing Systems, pages 4312–4320.
- (33) Wabersich, K. P. and Zeilinger, M. N. (2018a). Linear model predictive safety certification for learning-based control. In 57th IEEE Conference on Decision and Control.
- (34) Wabersich, K. P. and Zeilinger, M. N. (2018b). Scalable synthesis of safety certificates from data with application to learning-based control. In 2018 European Control Conference (ECC), pages 1691–1697. IEEE.
- Wabersich and Zeilinger, (2021) Wabersich, K. P. and Zeilinger, M. N. (2021). A predictive safety filter for learning-based control of constrained nonlinear dynamical systems. arXiv:1812.05506.
- Wang et al., (2018) Wang, L., Theodorou, E. A., and Egerstedt, M. (2018). Safe learning of quadrotor dynamics using barrier certificates. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 2460–2465. IEEE.
- Wen et al., (2020) Wen, L., Duan, J., Li, S. E., Xu, S., and Peng, H. (2020). Safe reinforcement learning for autonomous vehicles through parallel constrained policy optimization. arXiv preprint arXiv:2003.01303.
- Xiang et al., (2019) Xiang, W., Lopez, D. M., Musau, P., and Johnson, T. T. (2019). Reachable set estimation and verification for neural network models of nonlinear dynamic systems. In Safe, Autonomous and Intelligent Vehicles, pages 123–144. Springer.
- Xiao et al., (2020) Xiao, W., Belta, C., and Cassandras, C. G. (2020). Adaptive control barrier functions for safety-critical systems. arXiv:2002.04577.
- Yordanov et al., (2012) Yordanov, B., Tumova, J., Cerna, I., Barnat, J., and Belta, C. (2012). Temporal logic control of discrete-time piecewise affine systems. IEEE Transactions on Automatic Control, 57(6):1491–1504.
- Zanelli et al., (2017) Zanelli, A., Domahidi, A., Jerez, J., and Morari, M. (2017). Forces nlp: an efficient implementation of interior-point methods for multistage nonlinear nonconvex programs. International Journal of Control, pages 1–17.