Provably Convergent Learned Inexact Descent Algorithm for Low-Dose CT Reconstruction
Abstract
We propose a provably convergent method, called Efficient Learned Descent Algorithm (ELDA), for low-dose CT (LDCT) reconstruction. ELDA is a highly interpretable neural network architecture with learned parameters and meanwhile retains convergence guarantee as classical optimization algorithms. To improve reconstruction quality, the proposed ELDA also employs a new non-local feature mapping and an associated regularizer. We compare ELDA with several state-of-the-art deep image methods, such as RED-CNN and Learned Primal-Dual, on a set of LDCT reconstruction problems. Numerical experiments demonstrate improvement of reconstruction quality using ELDA with merely 19 layers, suggesting promising performance of ELDA in solution accuracy and parameter efficiency.
Key words: Low-dose CT, deep learning, inverse problems, learned descent algorithm, optimization.
1 Introduction
Computed Tomography (CT) is one of the most widely used imaging technologies for medical diagnosis. CT employs X-ray measurements from different angles to generate cross-sectional images of the human body [1, 2]. As high dosage X-rays can be harmful to human body [3, 4, 5], substantial efforts have been devoted to image reconstruction using low-dose CT measurements [6, 7, 8]. There are two main strategies for dose reduction in CT scans: one is to reduce the number of views, and the other is to reduce the exposure time and the current of X-ray tube [9], both of which will introduce various degrees of noise and artifacts and then compromise the subsequent diagnosis. Here we focus on the second type however our method is not specific to a particular scanning mode. We formulate the problem as an optimization problem which will be solved with our Efficient Learned Descent Algorithm (ELDA).
The classic analytical method to reconstruct CT images from projection data, Filtered Back-Projection (FBP), leads to heavy noise and artifacts in the low dose scenario. The remedy for this problem have been sought from three different perspectives: pre-processing the sinograms [10, 11, 12], post-processing the images [13], or the hybrid approach with iterative reconstructions that encode prior information into the process [14, 15, 16].
The advent of machine learning methods and its success on various image processing applications, have naturally led to incorporation of deep models into all of the above approaches and produced a better performance than analytical methods [17]. For instance, CNN methods[18, 19, 20, 21], that have been applied to sparse view [22, 23, 24, 21, 25] and low dose [18, 19, 20, 26, 27] data. It is also applied in projection domain synthesis [25, 28], post processing [29, 24, 20, 30, 21], and for prior learning in iterative methods [31, 32, 33].
Recently, a number of learned optimization methods have been proposed and are proven very effective in CT reconstruction problem, as they are able to learn adaptive regularizer which leads to more accurate image reconstruction in a variety of medical imaging applications. However, existing works model regularizers using convolutional neural networks (CNNs) which only explore local image features. This limits the representation power of deep neural networks and is not suitable for medical imaging applications which demand high image qualities. Moreover, most of existing deep networks for image reconstruction are cast as black-boxes and can be difficult to interpret. Last but not least, deep neural networks for image reconstruction are also criticized for lacking mathematical justifications and convergence guarantee.
In this work, we leverage the framework developed in [34] and propose an improved learned descent algorithm ELDA. It further boosts image reconstruction quality using an adaptive non-local feature regularizer. More importantly, compared to [34], ELDA is more computationally efficient since the safeguard iterate is only computed when a descent condition fails to hold, which happens rarely due to allowance of inexact gradient computation in our algorithmic design. As a result, our model retains convergence guarantee and meanwhile also improves reconstruction quality over existing methods. The main contributions of this work are summarized as follows.
-
•
We propose an efficient learned descent algorithm with inexact gradients, called ELDA, to solve the non-smooth non-convex optimization problem in low-dose CT reconstruction. We provide comprehensive convergence and iteration complexity analysis of ELDA.
-
•
ELDA adopts efficient update scheme which only computes safeguard iterate when the desired descent condition fails to hold, and hence is more computationally economical than LDA developed in [34]. Moreover, ELDA employs sparsity enhancing and non-local smoothing regularization which further improve imaging quality.
-
•
We conduct comprehensive experimental analysis of ELDA and compare it to several state-of-the-art deep-learning based methods for LDCT reconstruction.
In section 2, we present the related works in the literature that associate with our problem. Then in section 3, we present our method by first defining our model and each of its components, and then stating the algorithm and details of network training. After that in section 4, we state our lemma and theorem regarding the output of the network. Section 5 presents the numerical results including parameter study, ablation study and comparison with other competing algorithms.
2 Related Works
A natural application of neural networks in CT reconstruction, has been in noise removal in either the projection domain [25, 28] or the image domain [29, 24, 20, 30, 21]. In particular, Residual Encoder-Decoder Convolutional Neural Network (RED-CNN) proposed by Chen et al [29], is an end-to-end mapping from low-dose CT images to normal dose which uses FBP to get low-dose CT images from projections and restrict the problem to denoising in the image domain. And yet another attempt is FBPConvNet by Jin et al [24] which is inspired by U-net [35] and further explores CNN architectures while noting the parallels with the general form of an iterative proximal update.
Model Based Image Reconstruction (MBIR) methods attempt to model CT physics, measurement noise, and image priors in order to achieve higher reconstruction quality in LDCT. Such methods learn the regularizer and are able to improve LDCT reconstruction significantly [14, 16, 36, 31], however their convergence speed is not optimal [37]. Later, researchers adopted NNs in other aspects of the algorithm and formed a new class of methods called Iterative Neural Networks (INN). INNs seek to enjoy the best of both world of MBIR and denoising deep neural networks, by employing moderate complexity denoisers for image refining and learning better regularizers [38, 39, 40, 41].
INNs have network architectures that are inspired by the optimization model and algorithm and this learning capacity enables them to outperform the classical iterative solutions by learning better regularizer while also being more time efficient. For example, recently BCD-Net [39] improved the reconstruction accuracy compared to MBIR methods and NN denoisers. It showed that it generalizes better than denoisers such as FBPConvNet which lack MBIR modules, and also its learned transforms help to outperform state-of-the-art MBIR methods. Further research in this area has been devoted to improving time efficiency of the algorithm with the image quality. Recently,[40] proposed Momentum-Net, as the first fast and convergent INN architecture inspired by Block Proximal Extrapolated Gradient method using a Majorizer. It also guarantees convergence to a fixed-point while improving MBIR speed, accuracy, and reconstruction quality. Momentum-Net is a general framework for inverse problems and its recent application to LDCT [41] showed it improves image reconstruction accuracy compared to a state-of-the-art noniterative image denoising NN. Convergence guarantee is one of the main challenges in the design of INNs and beside its theoretical value, it is highly desirable in medical applications. LEARN[32] is another model that unrolls an iterative reconstruction scheme while modeling the regularization by a field-of-experts. And yet another similar attempt is Learned Primal-Dual [42] which unfolds a proximal primal-dual optimization method where the proximal operator is replaced with a CNN. Their choice of iterative scheme is primal dual hybrid gradient (PDHG) which is further modified to benefit from the learning capacity of NNs and then used to solve the TV regularized CT reconstruction problem.
In all of the previous works, the architecture is only inspired by the optimization model, and in order to improve their performance they introduce components in the network that does not correspond to steps of the algorithm. Also, the choice of regularization limits the network to only learn local features and as we will empirically demonstrate, it limits the performance of these networks. One model that attempts to learn non-local features is MAGIC [43]. It is also a deep neural network inspired by a simple iterative reconstruction method, i.e. gradient descent. However MAGIC breaks the correspondence between architecture and algorithm in order to extract non-local features. They manually add a non-local corrector in iteration steps which is only intuitively justified, and does not directly correspond to a modified regularizer in the optimization model.
In [34], a Learned Descent Algorithm (LDA) is developed. The LDA architecture is fully determined by the algorithm and thus the network is fully interpretable. As interpretability and convergence guarantee is highly desirable in medical imaging, this framework is a promising method for inverse problems such as LDCT reconstruction. Compared to [34], the present work proposes a more efficient numerical scheme of LDA, leading to comparable network parameters, lower computational cost, and more stable convergence behavior. We achieve this by developing an efficient learned inexact descent algorithm which only computes the safeguard iterate when a prescribed descent condition fails to hold and thus substantially reduces computational cost in practice. Additionaly, we propose a novel non-local smoothing regularizer that further confirms the heuristics in optimization inspired networks such as MAGIC [43] but leads to a fully interpretable network and allows us to provide convergence guarantee of the network.
3 Method
In this section, we introduce the proposed inexact learned descent algorithm for solving the following low-dose CT reconstruction model:
| (1) |
where is the data fidelity term that measures the consistency between the reconstructed image and the sinogram measurements , and is the regularization that may incorporate prior information of . The regularization is realized as a highly structured DNN with parameter to be learned. The optimal parameter of is then obtained by minimizing the loss function , where measures the (averaged) difference between -the minimizer of , and the given ground truth for every , where is the number of training data pairs. For notation simplicity, we write and instead of and respectively hereafter. We choose as the data-fidelity term, where is the system matrix for CT scanner. However, our proposed method can be readily extended to any smooth but (possibly) nonconvex .
3.1 Regularization Term in Model (1)
The regularization term in (1) consists of two parts. One of them enhances the sparsity of the solution under a learned transform and the other one smooths the feature maps non-locally:
| (2) |
where is a coefficient to balance these two terms which can be learned.
3.1.1 The sparsity-enhancing regularizer
To enhance the sparsity of under a learned transform , we propose to minimize the norm of . If is a differential operator, then the norm of reduces to the total variation of . That is,
| (3) |
where each can be viewed as a feature descriptor vector at the position , as depicted in Fig. 1 (up). In our experiments, we simply set the feature extraction operator to a vanilla -layer CNN with nonlinear activation function but no bias, as follows:
| (4) |
where denote the convolution weights consisting of kernels with identical spatial kernel size (), and denotes the convolution operation. Here, the componentwise activation function is constructed to be the smoothed rectified linear unit as defined below
| (5) |
where the prefixed parameter is set to be in our experiment. Besides the smooth , each convolution operation of in (4) can be viewed as matrix multiplication, which enable to be differentiable, and can be easily obtained by Chain Rule where each can be implemented as transposed convolutional operation [44].
As defined in (3) is nonsmooth and nonconvex, we apply the Nesterov’s smoothing technique [45] to get the smooth approximation and the detail is given in [34]:
| (6) |
where Here the parameter controls how close the smoothed is to the original function , and one can readily show that for all in . From (6) we can also derive to be
where is the Jacobian of at .


3.1.2 The nonlocal smoothing regularizer
Since convolution operations only extract the local information, each feature descriptor vector can only encode the local features of a small patch of the input (i.e. receptive field) [46]. So here we seek to incorporate an additional non-local smoothing regularizer that enables capturing of the underlying long-range dependencies between the patches of the feature descriptor vectors. To this end we form the folded feature descriptor vectors as described in Fig. 1 (bottom) by folding the adjacent feature descriptors together, and define by:
| (7) |
where the similarity matrix is defined by and is the standard deviation, which is estimated by the median of the Euclidean distances between the folded feature descriptor vectors in the model.
Additionally, can also be written in the quadratic form [47] as where is the trace operator, , and is the diagonal matrix with , and is positive semidefinite. And its gradient is computed by
where is the Jacobian of . And , and . Each represents the -th row of the folded feature matrix as illustrated in Fig. 1.
3.2 Inexact Learned Descent Algorithm
Now we present an inexact smoothing gradient descent type algorithm to solve the nonconvex and nonsmooth problem (1) with the smooth approximation of defined by The proposed algorithm is shown in Algorithm 1. In each iteration , we solve the following smoothed problem (9) with fixed in Line 3-14. And Line 15 is aimed to check and update by a reduction principle.
| (9) |
As the regularization term is learned via a deep neural network (DNN), some common issues of the DNN have to be taken into consideration when designing the algorithm, such as gradient exploding and vanishing problem during training [48]. Substantial improvement in performance has been achieved by ResNet [49] which introduces residual connections to alleviate these issues. As in (9) only the second term is learned, we desire to have individual residual updates for this term in our algorithm. To this end, we use the first order proximal method to solve the smoothed problem (9) by iterating the following steps
| (10a) | ||||
| (10b) | ||||
where .
From our construction of , it is hard to get the close-form solution to subproblem in (10b). Here we propose to linearize the “nonsimple” term by
| (11) |
With this approximation, instead of solving (10b) directly, we update by the following step
| (12) |
which has a closed-form solution giving the residual update
| (13) |
where and .
From the optimization perspective, with the approximation in (11), if we update then the algorithm can not be guaranteed to converge. In order to ensure convergence, we check whether satisfies
| (14) |
where and are prefixed constant numbers. If the condition (14) holds, we take ; otherwise, we take the standard gradient descent coming from
| (15) |
which has the exact solution
| (16) |
To ensure convergence, we need to find through line search such that satisfies
| (17) |
where is a prefixed constant. Lemma 4.2 proves the convergence of lines 3–14 Algorithm 1, including the termination of its line search (lines 9–13) in finitely many steps.
Our algorithm is inspired by [34] but modified to become more efficient and suitable for deep neural network. The first contrast is the number of computations of the two candidates and . While [34] computes both candidates at every iteration and then chooses the one that achieves a smaller function value, we propose the criteria above in (14) for updating , which potentially saves extra computational time for calculating the candidate . In addition, the descending condition in Line 5 of Algorithm 1 mitigates the frequent alternations between the candidates and with the algorithm proceeding, as details shown in Section 5.2.
The learned inexact gradient
To further increase the capacity of the network, we employ the learned transposed convolution operator, i.e. we replace by a transposed convolution with relearned weights, where denotes the index of convolution in (4). To approximately achieve , we add the constraint term to the loss function in training to produce the data-driven transposed convolutions. Here is the number of parameters in learned transposed convolutions and is the Frobenius norm. In effect, the consequence of this modification is only to substitute by the inexact gradient equipped with learned transpose at Line 4 in Algorithm 1. This can further increase the capacity of the unrolled network while maintaining the convergence property.
3.3 Network Training:
We allow the step sizes and to vary in different phases. Moreover, all and initial threshold are designed to be learned parameters fitted by data. Here let stand for the set of all learned parameters of ELDA which consists of the weights of the convolutions and approximated transposed convolutions, step sizes and threshold , parameter . Given training data pairs of the ground truth data and its corresponding measurement , the loss function is defined to be the sum of the discrepancy loss and the constraint loss :
| (18) |
where measures the discrepancy between the ground truth and which is the output of the -phase network. Here, the constraint coefficient is set to in our experiment.
4 Convergence Analysis
According to the problem we are solving, we make a few assumptions on and throughout this section.
(A1): is differentiable and (possibly) nonconvex, and is -Lipschitz continuous.
(A2): Every component of is differentiable and (possibly) nonconvex, is -Lipschitz continuous, and for some constant .
(A3): is coercive, and .
With the smoothly differentiable activation defined in (5) and boundedness of as well as the fixed convolution weights in (4) after training, we can immediately verify that the first two assumptions hold, and typically in image reconstruction is assumed to be coercive [34].
As the objective function in (1) is nonsmooth and nonconvex, we utilize the Clarke subdifferential[50] to characterize the optimality of solutions. We denote .
Definition 4.1 (Clarke subdifferential).
Suppose that is locally Lipschitz, the Clarke subdifferential of at is defined as
Definition 4.2 (Clarke stationary point).
For a locally Lipschitz function , a point is called a Clarke stationary point of if .
Lemma 4.1.
The gradient of is Lipschitz continuous.
Proof.
From equation 6 in the paper, it follows that
We only need to show one of the terms under the sum is Lipschitz, i.e. we need to be Lipschitz, where . We show is Lipschitz by showing its derivative is bounded:
Note that is Lipschitz in since , therefore . Also since is Lipschitz, we get . Also, a polynomial in times is bounded so we get:
| (19) |
where is some constant that bounds all the instances of polynomial in times occurring above. Therefore is Lipschitz with constant . ∎
The following Lemma 4.2 considers the case where is a positive constant, which corresponds to an iterative scheme that only executes Lines 3–14 of Algorithm 1.
Lemma 4.2.
Let , and arbitrary initial . Suppose is the sequence generated by repeating Lines 3–14 of Algorithm 1 with fixed , and . Then as .
Proof.
In each iteration we compute by , and put only if the condition is satisfied. In this case, we will have .
Otherwise we compute where is found through line search until the criteria
| (20) |
is satisfied and then put . In this case, from Lemma 3.2 in [34] we know that the gradient is Lipschitz continuous with constant . And is also Lipschitz continuous with constant . Furthermore, in (A1) we assumed is -Lipschitz continuous. Hence putting , we get that is -Lipschitz continuous, which implies
| (21) |
Also by the optimality condition of we have:
| (22) |
From above (21) and (22), we can get
| (23) |
Therefore it is enough for so that the criteria (20) is satisfied. This implies that there is a finite so that and the line search stops successfully and we can get . Hence in both cases (i) and (ii), we can conclude that .
Now from we have
| (24) |
which by rearranging gives
| (25) |
And From and , we can get
| (26) |
Because equals either or depending on the condition on Line 5 and 9 in the Algorithm, from (25) and (26), we have
| (27) |
where .
Summing up (27) for , we have
| (28) |
Combining with the fact , we have
| (29) |
The right hand side is finite, and thus by letting we conclude , which proves the lemma. ∎
Note that Lemma 4.2 does not rely on the term in (13) and Line 5 in Algorithm 1. Thus it will still hold if we change the to a generalized learned inexact when updating as described in Section 3.2. Next we consider the case where varies in Theorem 4.4. More precisely, we focus on the subsequence which selects the iterates when the reduction criterion in Line 15 is satisfied for and is reduced.
Lemma 4.3.
Suppose that the sequence is generated by Algorithm 1 and any initial . Then for any we have
| (30) |
Proof.
The proof of this lemma is similar to Lemma 3.4 of [34]. The second inequality is immediate from (27). So we focus on the first inequality. For any and , denote
| (31) |
Since , to prove the first inequality it suffices to show that
| (32) |
If , then the two quantities above are identical and the first inequality holds. Now suppose . We then consider the relation between , and in three cases:
Theorem 4.4.
Proof.
By the Lemma 4.2 and the definition of Clarke subdifferential, this theorem can be easily proved in the similar way to Theorem 3.6 in [34].
Due to Lemma 4.3 and for all and , we know that
Since is coercive, we know that is bounded. Hence is also bounded and has at least one accumulation point.
Note that satisfies the reduction criterion in Line 15 of Algorithm 1, i.e., as . For notation simplicity, let denote any convergent subsequence of and the corresponding used in the iteration to generate . Then there exists such that , , and as .
Note that the Clarke subdifferential of at is given by :
| (33) |
where and . Then we know that there exists sufficiently large, such that
where we used the facts that and in the first inequality, and and the continuity of for all in the last inequality. Furthermore, we denote
Then we have
| (34) |
Comparing (33) and (34), we can see that the last two terms on the right hand side of (34) converge to those of (33), respectively, due to the facts that and the the continuity of . Moreover, noting that , we can see that the first term on the right hand side of (34) also converges to the set formed by the first term of (33) due to the continuity of and . Hence we know that
as . Since and is closed, we conclude that . ∎
5 Experiments and Results
Here we present our experiments on LDCT image reconstruction problems with various dose levels and compare with existing state-of-the-art algorithms in terms of image quality, run time and the number of parameters etc. We adopt a warm start training strategy which imitates the iterating of optimization algorithm. More precisely, first we train the network with phases, where each phase in the network corresponds to an iteration in optimization algorithm. After it converges, we add more phases and we continue training the -phase network until it converges. We continue adding 2 more phases until there is no noticeable improvement.
As computing the similarity weight matrix is high-cost in time and memory, we also experiment with approximation of computed on the initial reconstruction without updating in each iteration, i.e. Thus can be differentiated as In the approximation scenario we compute once and use it for all the phases, but in the other case we have an extra computation in each phase, every time we compute . As shown in the Section 5.2, this approximation does not exacerbate the network performance much but can increase the running speed.
All the experiments are performed on a computer with Intel i7-6700K CPU at 3.40 GHz, 16 GB of memory, and a Nvidia GTX-1080Ti GPU of 11GB graphics card memory, and implemented with the PyTorch toolbox [51] in Python. The initial is obtained by FBP algorithm. The spatial kernel size of the convolution and transposed convolution is set to be and the channel number is set to with layer number as default. The learned weights of convolutions and transposed convolutions are initialized by Xavier Initializer [52] and the starting is initialized to be . All the learnable parameters are trained by the Adam Optimizer with and . The network is trained with learning rate 1e-4 for epochs when phase number , followed by epochs when adding more phases.
We test the performance of ELDA on the “2016 NIH-AAPM-Mayo Clinic Low-Dose CT Grand Challenge” [53] which contains 5936 full-dose CT (FDCT) data from 10 patients, from which we randomly select images and resize them to the size . Then we randomly divide the dataset into images for training and for testing. Distance-driven algorithm [54, 55] is applied to simulate the projections in fan-beam geometry. The source-to-rotation center and detector-to-rotation center distances are both set to 250 mm. The physical image region covers 170 mm 170 mm. On detector there are 512 detector elements each with width 0.72 mm. There are 1024 projection views in total with the projection angles are evenly distributed over a full scan range. Similar to [56], the simulated noisy transmission measurement is generated by adding Poisson and electronic noise as
| (35) |
where is the incident X-ray intensity and is the variance the background electronic noise. And represents the noise-free projection. In this simulation, is set to for normal dose and is prefixed to be 10 for all dose cases. Then the noisy projection is calculated by taking the logarithm transformation on . In low dose case, in order to investigate the robustness of all compared algorithms, we generated three sets of different low dose projections with and which correspond to , and of the full dose incident accordingly. We use peak signal to noise ratio (PSNR) and structureal similarity index measure (SSIM) to evaluate the quality of the reconstructed images.
5.1 Parameter Study
The regularization term of our model is learned from training samples, yet there are still a few key network hyperparameters need to be set manually. Specifically, we investigate the impacts of some parameters of the architecture, which includes the number of convolutions (), the depth of the convolution kernels () and the phase number (). The influence of each hyperparameter is sensed by perturbing it with others fixed at , and . The setting includes all factors/components listed in Table. 2 and all following results are trained and tested with dose level .
Depth of the convolution kernels: We evaluate the instances of and . The results are listed in Table. 1. It is evident that the PSNR score raises with growing depth of the kernels, but the profit gradually reduces. On the contrary, the number of parameters and running time grow greatly in the meantime.
| Depth of conv. kernels | 16 | 32 | 48 | 64 |
|---|---|---|---|---|
| PSNR (dB) | 47.11 | 47.51 | 47.73 | 47.75 |
| Number of parameters | 14,152 | 55,912 | 125,320 | 222,376 |
| Average testing time (s) | 1.139 | 1.231 | 1.411 | 1.539 |
| Number of convolutions | 2 | 3 | 4 | 5 |
| PSNR (dB) | 47.27 | 47.60 | 47.73 | 47.77 |
| Number of parameters | 42,376 | 83,848 | 125,320 | 167,656 |
| Average testing time (s) | 1.117 | 1.258 | 1.411 | 1.530 |

| Algorithms | Plain-GD | AGD | LDA | ELDA |
|---|---|---|---|---|
| PSNR (dB) | 45.47 | 45.95 | 46.29 | 46.35 |
| Average testing time (s) | 0.602 | 0.605 | 1.338 | 1.239 |
| ELDA Factors / Components | ||||
| Inexact Transpose? | ✘ | ✔ | ✔ | ✔ |
| Non-local regularizer? | ✘ | ✘ | ✔ | ✔ |
| Approximated Matrix ? | ✘ | ✘ | ✘ | ✔ |
| PSNR (dB) | 46.35 | 46.74 | 47.75 | 47.73 |
| Average testing time (s) | 1.239 | 1.247 | 3.703 | 1.411 |
Number of convolutions: We evaluate the cases of different number of convolutions and . The corresponding results are reported in Table. 1. We can observe that more convolutions contribute to better reconstructed image quality. But the increase of PSNR score is insignificant from convolutions to while the parameter number and the test time rise significantly.
Phase number : As shown in Fig. 2, the PSNR increases with the phase number . And the plot approaches nearly flat after 19 phases.
To balance the trade-off between reconstruction performance and network complexity, we take , , when comparing with other methods.
| Dose Level | Run Time | Parameters | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | SSIM | PSNR (dB) | SSIM | PSNR (dB) | SSIM | |||
| FBP [57] | 38.030.68 | 0.90840.0128 | 35.250.74 | 0.84590.0209 | 32.350.77 | 0.75560.0295 | 1.0 | N/A |
| TGV [58] | 43.600.50 | 0.98450.0020 | 42.800.52 | 0.98120.0027 | 41.100.62 | 0.96980.0055 | N/A | |
| FBPConvNet [24] | 42.490.47 | 0.97640.0029 | 41.140.49 | 0.96980.0041 | 39.620.48 | 0.95890.0052 | ||
| RED-CNN [29] | 44.580.58 | 0.98480.0026 | 43.250.60 | 0.98080.0033 | 41.610.63 | 0.97370.0048 | ||
| Learned PD [42] | 44.810.59 | 0.98630.0025 | 43.280.61 | 0.98130.0034 | 41.740.62 | 0.97450.0048 | 1.8 | |
| LEARN [32] | 45.190.60 | 0.98680.0023 | 43.860.61 | 0.98400.0027 | 42.060.61 | 0.97760.0037 | 4.8 | |
| LDA [34] | 46.290.60 | 0.98960.0019 | 44.640.61 | 0.98580.0025 | 42.970.64 | 0.98020.0035 | 1.3 | |
| MAGIC [43] | 47.540.66 | 0.99190.0017 | 45.830.64 | 0.98880.0022 | 44.370.63 | 0.98530.0027 | 5.3 | |
| ELDA (Ours) | 47.730.69 | 0.99230.0017 | 46.400.64 | 0.98990.0021 | 44.860.65 | 0.98590.0031 | 1.4 | |









5.2 Ablation Study
In this section, we first investigate the effectiveness of the proposed algorithm in ELDA. To this end, we compare ELDA with unrolling the standard gradient descent iteration of (1), and an accelerated inertial version by setting where is also learned. Here these two algorithms are named as Plain-GD and AGD, respectively. In addition, to show the superiority of the new descending condition (14)&(17) over the competition strategy in LDA [34], we compare the result with LDA here as well. The comparison of different algorithms are shown in Table. 2 (up), where the experiments follow the default parameter configuration as Section 5.1 without the additional components listed in Table. 2 (bottom). It is quite obvious that all AGD, LDA and ELDA achieve higher PNSRs than Plain-GD, where ELDA achieves the best. With the new descending condition it achieves average 0.06 dB PSNR better than LDA and about 0.1 seconds faster. Furthermore, we have also computed the ratios that the candidate is taken instead of , and found it to be for LDA and for ELDA respectively. That indicates that the proposed descending condition (14) can effectively avoid the frequent candidate alternating compared to the competition strategy used in LDA.
Moreover, we check the influence of some essential factors/components of our ELDA model, i.e. the inexact transpose, the nonlocal smoothing regularizer and the approximated weight matrix . The results are summarized in Table. 2 (bottom). It is remarkable that the inexact transpose and the nonlocal smoothing regularizer can effectively increase the network performance by a large margin. And with the approximated weight matrix there is no significant decreasing of the PSNR. As the initial obtained by FBP is not far from in each iteration, the approximated by can provide a good estimation to the true one. Thus, in the following sections we will keep all these features in Table 2 (bottom) when comparing ELDA with other methods.








5.3 Comparison with the State-of-the-art
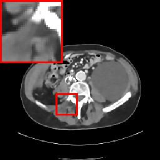
In this section, we compare our reconstruction results on the 100 AAPM-Mayo testing images with several existing algorithms: two classic reconstruction methods, i.e., FBP [57] and TGV [58] and six approaches based on deep learning, i.e., FBPConvNet [24], RED-CNN [29], Learned Primal-Dual [42], LDA [34], LEARN [32] and MAGIC [43]. For fair comparison, all deep learning algorithms compared here are trained and evaluated on the same dataset, dose levels and evaluation metrics. The experimental results on various dose levels are summarized in Table. 4 and the representative qualitative results on dose level are shown in Fig. 3. These results show that ELDA reconstructs more accurate images using relatively much fewer network parameters and decent running time.
5.4 Validation with NBIA Data
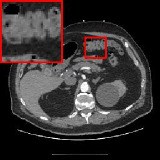
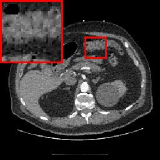
To demonstrate the generalizability of the proposed method, we validate our model on another dataset of the National Biomedical Imaging Archive (NBIA). We randomly sampled 80 images from the NBIA dataset with various parts of the human body for diversity. For fair comparison, all deep learning based reconstruction models compared here are trained on the same dataset identical to Section 5.3. Fig. 4 visualizes the reconstructed images obtained by different methods under dose level 2.5%. It can be seen that ELDA preserves the details well, avoids over-smoothing and reduces artifacts, which gives the promising reconstruction quality in Fig. 4. The quantitative results are provided in Table. 4.
| Dose Level | ||||||
|---|---|---|---|---|---|---|
| PSNR (dB) | SSIM | PSNR (dB) | SSIM | PSNR (dB) | SSIM | |
| FBP | 37.360.43 | 0.91250.0145 | 34.610.51 | 0.85330.0240 | 31.740.55 | 0.76820.0339 |
| FBPConvNet | 40.860.25 | 0.96930.0026 | 39.270.29 | 0.95870.0033 | 37.690.38 | 0.94490.0036 |
| RED-CNN | 41.740.32 | 0.97510.0022 | 40.320.38 | 0.96830.0026 | 38.760.46 | 0.95780.0029 |
| Learned PD | 41.860.31 | 0.97600.0025 | 40.390.39 | 0.96870.0031 | 38.890.43 | 0.95940.0033 |
| LEARN | 42.440.35 | 0.97800.0021 | 41.060.42 | 0.97380.0021 | 39.330.48 | 0.96380.0024 |
| TGV | 42.530.52 | 0.98180.0017 | 41.440.32 | 0.97620.0032 | 39.600.22 | 0.96010.0080 |
| LDA | 43.370.38 | 0.98290.0017 | 41.640.47 | 0.97630.0023 | 39.990.55 | 0.96780.0021 |
| MAGIC | 44.580.37 | 0.98660.0017 | 43.100.28 | 0.98210.0024 | 41.120.20 | 0.97070.0058 |
| ELDA (Proposed) | 44.650.53 | 0.98670.0016 | 43.330.45 | 0.98260.0017 | 41.610.55 | 0.97630.0017 |
6 Conclusion
In brief, we propose an efficient inexact learned descent algorithm for low-dose CT reconstruction. With incorporating the sparsity enhancing and non-local smoothing modules in the regularizer, the proposed ELDA outperforms several existing state-of-the-art reconstruction methods in accuracy and efficiency on two widely known datasets and retains convergence property.
References
- [1] G. N. Hounsfield, “Computerized transverse axial scanning (tomography): Part 1. description of system,” The British Journal of Radiology, vol. 46, no. 552, pp. 1016–1022, 1973.
- [2] A. M. Cormack, “Representation of a function by its line integrals, with some radiological applications. ii,” Journal of Applied Physics, vol. 35, no. 10, pp. 2908–2913, 1964.
- [3] D. J. Brenner, C. D. Elliston, E. J. Hall, and W. E. Berdon, “Estimated risks of radiation-induced fatal cancer from pediatric ct,” American journal of roentgenology, vol. 176, no. 2, pp. 289–296, 2001.
- [4] A. S. Brody, D. P. Frush, W. Huda, R. L. Brent et al., “Radiation risk to children from computed tomography,” Pediatrics, vol. 120, no. 3, pp. 677–682, 2007.
- [5] N. Saltybaeva, K. Martini, T. Frauenfelder, and H. Alkadhi, “Organ dose and attributable cancer risk in lung cancer screening with low-dose computed tomography,” PloS one, vol. 11, no. 5, p. e0155722, 2016.
- [6] A. M. den Harder et al., “Radiation dose reduction in pediatric great vessel stent computed tomography using iterative reconstruction: A phantom study,” PloS one, vol. 12, no. 4, p. e0175714, 2017.
- [7] A. Sauter et al., “Ultra low dose ct pulmonary angiography with iterative reconstruction,” PLoS One, vol. 11, no. 9, p. e0162716, 2016.
- [8] E. J. Keller et al., “Reinforcing the importance and feasibility of implementing a low-dose protocol for ct-guided biopsies,” Academic radiology, vol. 25, no. 9, pp. 1146–1151, 2018.
- [9] C.-J. Hsieh, S.-C. Jin, J.-C. Chen, C.-W. Kuo, R.-T. Wang, and W.-C. Chu, “Performance of sparse-view ct reconstruction with multi-directional gradient operators,” PloS one, vol. 14, no. 1, p. e0209674, 2019.
- [10] H. Lu, T. li, and Z. Liang, “Sinogram noise reduction for low-dose ct by statistics-based nonlinear filters,” Proceedings of SPIE - The International Society for Optical Engineering, vol. 5747, 04 2005.
- [11] A. Manduca et al., “Projection space denoising with bilateral filtering and ct noise modeling for dose reduction in ct,” Medical Physics, vol. 36, no. 11, pp. 4911–4919, 2009.
- [12] Jing Wang, Tianfang Li, Hongbing Lu, and Zhengrong Liang, “Penalized weighted least-squares approach to sinogram noise reduction and image reconstruction for low-dose x-ray computed tomography,” IEEE Transactions on Medical Imaging, vol. 25, no. 10, pp. 1272–1283, 2006.
- [13] S. Tipnis et al., “Iterative reconstruction in image space (iris) and lesion detection in abdominal ct,” in Medical Imaging 2010: Physics of Medical Imaging, vol. 7622. International Society for Optics and Photonics, 2010, p. 76222K.
- [14] L. L. Geyer et al., “State of the art: iterative ct reconstruction techniques,” Radiology, vol. 276, no. 2, pp. 339–357, 2015.
- [15] M. J. Willemink et al., “Iterative reconstruction techniques for computed tomography part 2: initial results in dose reduction and image quality,” European radiology, vol. 23, no. 6, pp. 1632–1642, 2013.
- [16] X. Zheng, S. Ravishankar, Y. Long, and J. A. Fessler, “Pwls-ultra: An efficient clustering and learning-based approach for low-dose 3d ct image reconstruction,” IEEE transactions on medical imaging, vol. 37, no. 6, pp. 1498–1510, 2018.
- [17] H. Shan et al., “Competitive performance of a modularized deep neural network compared to commercial algorithms for low-dose ct image reconstruction,” Nature Machine Intelligence, vol. 1, no. 6, pp. 269–276, 2019.
- [18] K. Liang, H. Yang, K. Kang, and Y. Xing, “Improve angular resolution for sparse-view ct with residual convolutional neural network,” in Medical Imaging 2018: Physics of Medical Imaging, vol. 10573. International Society for Optics and Photonics, 2018, p. 105731K.
- [19] Y. Han and J. C. Ye, “Framing u-net via deep convolutional framelets: Application to sparse-view ct,” IEEE transactions on medical imaging, vol. 37, no. 6, pp. 1418–1429, 2018.
- [20] H. Chen et al., “Low-dose ct via convolutional neural network,” Biomedical optics express, vol. 8, no. 2, pp. 679–694, 2017.
- [21] S. Xie and T. Yang, “Artifact removal in sparse-angle ct based on feature fusion residual network,” IEEE Transactions on Radiation and Plasma Medical Sciences, vol. 5, no. 2, pp. 261–271, 2021.
- [22] Z. Zhang, X. Liang, X. Dong, Y. Xie, and G. Cao, “A sparse-view ct reconstruction method based on combination of densenet and deconvolution,” IEEE transactions on medical imaging, vol. 37, no. 6, pp. 1407–1417, 2018.
- [23] D. Hu et al., “Hybrid-domain neural network processing for sparse-view ct reconstruction,” IEEE Transactions on Radiation and Plasma Medical Sciences, vol. 5, no. 1, pp. 88–98, 2021.
- [24] K. H. Jin, M. T. McCann, E. Froustey, and M. Unser, “Deep convolutional neural network for inverse problems in imaging,” IEEE Transactions on Image Processing, vol. 26, no. 9, pp. 4509–4522, 2017.
- [25] H. Lee, J. Lee, H. Kim, B. Cho, and S. Cho, “Deep-neural-network-based sinogram synthesis for sparse-view ct image reconstruction,” IEEE Transactions on Radiation and Plasma Medical Sciences, vol. 3, no. 2, pp. 109–119, 2018.
- [26] E. Kang, W. Chang, J. Yoo, and J. C. Ye, “Deep convolutional framelet denosing for low-dose ct via wavelet residual network,” IEEE transactions on medical imaging, vol. 37, no. 6, pp. 1358–1369, 2018.
- [27] Q. Yang et al., “Low-dose ct image denoising using a generative adversarial network with wasserstein distance and perceptual loss,” IEEE transactions on medical imaging, vol. 37, no. 6, pp. 1348–1357, 2018.
- [28] H. Lee, J. Lee, and S. Cho, “View-interpolation of sparsely sampled sinogram using convolutional neural network,” in Medical Imaging 2017: Image Processing, vol. 10133. International Society for Optics and Photonics, 2017, p. 1013328.
- [29] H. Chen et al., “Low-dose ct with a residual encoder-decoder convolutional neural network,” IEEE transactions on medical imaging, vol. 36, no. 12, pp. 2524–2535, 2017.
- [30] E. Kang, J. Min, and J. C. Ye, “A deep convolutional neural network using directional wavelets for low-dose x-ray ct reconstruction,” Medical physics, vol. 44, no. 10, pp. e360–e375, 2017.
- [31] S. Ye, S. Ravishankar, Y. Long, and J. A. Fessler, “Spultra: Low-dose ct image reconstruction with joint statistical and learned image models,” IEEE Transactions on Medical Imaging, vol. 39, no. 3, pp. 729–741, 2019.
- [32] H. Chen et al., “Learn: Learned experts’ assessment-based reconstruction network for sparse-data ct,” IEEE transactions on medical imaging, vol. 37, no. 6, pp. 1333–1347, 2018.
- [33] D. Wu, K. Kim, G. El Fakhri, and Q. Li, “Iterative low-dose ct reconstruction with priors trained by artificial neural network,” IEEE transactions on medical imaging, vol. 36, no. 12, pp. 2479–2486, 2017.
- [34] Y. Chen, H. Liu, X. Ye, and Q. Zhang, “Learnable descent algorithm for nonsmooth nonconvex image reconstruction,” arXiv preprint arXiv:2007.11245, 2020.
- [35] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241.
- [36] I. Y. Chun and J. A. Fessler, “Convolutional dictionary learning: Acceleration and convergence,” IEEE Transactions on Image Processing, vol. 27, no. 4, pp. 1697–1712, 2017.
- [37] ——, “Convolutional analysis operator learning: Acceleration and convergence,” IEEE Transactions on Image Processing, vol. 29, no. 1, pp. 2108–2122, 2019.
- [38] J. Sun, H. Li, Z. Xu et al., “Deep admm-net for compressive sensing mri,” in Advances in neural information processing systems, 2016, pp. 10–18.
- [39] I. Y. Chun, X. Zheng, Y. Long, and J. A. Fessler, “Bcd-net for low-dose ct reconstruction: Acceleration, convergence, and generalization,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2019, pp. 31–40.
- [40] I. Y. Chun, Z. Huang, H. Lim, and J. Fessler, “Momentum-net: Fast and convergent iterative neural network for inverse problems,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, pp. DOI: 10.1109/tpami.2020.3012955.
- [41] S. Ye, Y. Long, and I. Y. Chun, “Momentum-net for low-dose ct image reconstruction,” arXiv preprint arXiv:2002.12018, 2020.
- [42] J. Adler and O. Öktem, “Learned primal-dual reconstruction,” IEEE transactions on medical imaging, vol. 37, no. 6, pp. 1322–1332, 2018.
- [43] W. Xia et al., “Magic: Manifold and graph integrative convolutional network for low-dose ct reconstruction,” arXiv preprint arXiv:2008.00406, 2020.
- [44] V. Dumoulin and F. Visin, “A guide to convolution arithmetic for deep learning,” arXiv preprint arXiv:1603.07285, 2016.
- [45] Y. Nesterov, “Smooth minimization of non-smooth functions,” Mathematical programming, vol. 103, no. 1, pp. 127–152, 2005.
- [46] H. Le and A. Borji, “What are the receptive, effective receptive, and projective fields of neurons in convolutional neural networks?” CoRR, vol. abs/1705.07049, 2017.
- [47] M. Belkin and P. Niyogi, “Laplacian eigenmaps for dimensionality reduction and data representation,” Neural Computation, vol. 15, no. 6, pp. 1373–1396, 2003.
- [48] K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,” in European Conference on Computer Vision. Springer International Publishing, 2016, pp. 630–645.
- [49] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
- [50] F. H. Clarke, Optimization and nonsmooth analysis. Siam, 1990, vol. 5.
- [51] A. Paszke et al., “Pytorch: An imperative style, high-performance deep learning library,” in Advances in Neural Information Processing Systems 32. Curran Associates, Inc., 2019, pp. 8024–8035.
- [52] X. Glorot and Y. Bengio, “Understanding the difficulty of training deep feedforward neural networks,” in In Proceedings of the International Conference on Artificial Intelligence and Statistics. Society for Artificial Intelligence and Statistics, 2010.
- [53] C. McCollough, “Tu-fg-207a-04: Overview of the low dose ct grand challenge,” Medical Physics, vol. 43, pp. 3759–3760, 06 2016.
- [54] B. De Man and S. Basu, “Distance-driven projection and backprojection,” in 2002 IEEE Nuclear Science Symposium Conference Record, vol. 3. IEEE, 2002, pp. 1477–1480.
- [55] ——, “Distance-driven projection and backprojection in three dimensions,” Physics in Medicine & Biology, vol. 49, no. 11, p. 2463, 2004.
- [56] T. li, H. Lu, and Z. Liang, “Penalized weighted least-squares approach to sinogram noise reduction and image reconstruction for low-dose x-ray computed tomography,” IEEE transactions on medical imaging, vol. 25, pp. 1272–83, 11 2006.
- [57] A. C. Kak, M. Slaney, and G. Wang, “Principles of computerized tomographic imaging,” Medical Physics, vol. 29, no. 1, p. 107, 2002.
- [58] S. Niu et al., “Sparse-view x-ray ct reconstruction via total generalized variation regularization,” Physics in Medicine & Biology, vol. 59, no. 12, p. 2997, 2014.