Provable Hierarchical Imitation Learning via EM
Abstract
Due to recent empirical successes, the options framework for hierarchical reinforcement learning is gaining increasing popularity. Rather than learning from rewards, we consider learning an options-type hierarchical policy from expert demonstrations. Such a problem is referred to as hierarchical imitation learning. Converting this problem to parameter inference in a latent variable model, we develop convergence guarantees for the EM approach proposed by [10]. The population level algorithm is analyzed as an intermediate step, which is nontrivial due to the samples being correlated. If the expert policy can be parameterized by a variant of the options framework, then, under regularity conditions, we prove that the proposed algorithm converges with high probability to a norm ball around the true parameter. To our knowledge, this is the first performance guarantee for an hierarchical imitation learning algorithm that only observes primitive state-action pairs.
1 Introduction
Recent empirical studies [25, 31, 36, 38] have shown that the scalability of Reinforcement Learning (RL) algorithms can be improved by incorporating hierarchical structures. As an example, consider the options framework [35] representing a two-level hierarchical policy: with a set of multi-step low level procedures (options), the high level policy selects an option, which, in turn, decides the primitive action applied at each time step until the option terminates. Learning such a hierarchical policy from environmental feedback effectively breaks the overall task into sub-tasks, each easier to solve.
Researchers have investigated the hierarchical RL problem under various settings. Existing theoretical analyses [6, 18, 19, 28] typically assume that the options are given. As a result, only the high-level policy needs to be learned. Recent advances in deep hierarchical RL (e.g., [2]) focus on concurrently learning the full options framework, but still the initialization of the options is critical. A promising practical approach is to learn an initial hierarchical policy from expert demonstrations. Then, deep hierarchical RL algorithms can be applied for policy improvement. The former step is named as Hierarchical Imitation Learning (HIL).
Due to its practicality, HIL has been extensively studied within the deep learning and robotics communities. However, existing works typically suffer from the following limitations. First, the considered HIL formulations often lack rigor and clarity. Second, existing works are mostly empirical, only testing on a few specific benchmarks. Without theoretical justification, it remains unclear whether the proposed methods can be generalized beyond their experimental settings.
In this paper, we investigate HIL from a theoretical perspective. Our problem formulation is concise while retaining the essential difficulty of HIL: we need to learn a complete hierarchical policy from an unsegmented sequence of state-action pairs. Under this setting, HIL becomes an inference problem in a latent variable model. Such a transformation was first proposed by [10], where the Expectation-Maximization (EM) algorithm [14] was applied for policy learning. Empirical results for this algorithm and its gradient variants [17, 24] demonstrate good performance, but the theoretical analysis remains open. By bridging this gap, we aim to solidify the foundation of HIL and provide some high level guidance for its practice.
1.1 Related work
Due to its intrinsic difficulty, existing works on HIL typically consider its easier variants for practicality. If the expert options are observed, standard imitation learning algorithms can be applied to learn the high and low level policies separately [26]. If those are not available, a popular idea [7, 29, 32, 33] is to first divide the expert demonstration into segments using domain knowledge or heuristics, learn the individual option corresponding to each segment, and finally learn the high level policy. With additional supervision, these steps can be unified [34]. In this regard, the EM approach [10, 17, 24] is this particular idea pushed to an extreme: without any other forms of supervision, we simultaneously segment the demonstration and learn from it, by exploiting the latent variable structure.
From the theoretical perspective, inference in parametric latent variable models is a long-standing problem in statistics. For many years the EM algorithm has been considered the standard approach, but performance guarantees [30, 40] were generally weak, only characterizing the convergence of parameter estimates to stationary points of the finite sample likelihood function. Under additional local assumptions, convergence to the Maximum Likelihood Estimate (MLE) can be further established. However, due to the randomness in sampling, the finite sample likelihood function is usually highly non-concave, leading to stringent requirements on initialization. Another weakness is that converging to the finite sample MLE does not directly characterize the distance to the maximizer of the population likelihood function which is the true parameter.
Recent ideas on EM algorithms [3, 39, 42, 43] focus on the convergence to the true parameter directly, relying on an instrumental object named as the population EM algorithm. It has the same two-stage iterative procedure as the standard EM algorithm, but its -function, the maximization objective in the M-step, is defined as the infinite sample limit of the finite sample -function. Under regularity conditions, the population EM algorithm converges to the true parameter. The standard EM algorithm is then analyzed as its perturbed version, converging with high probability to a norm ball around the true parameter. The main advantage of this approach is that the true parameter usually has a large basin of attraction in the population EM algorithm. Therefore, the requirement on initialization is less stringent. See [42, Figure 1] for an illustration.
The -function adopted in the population EM algorithm is named as the population -function. To properly define such a quantity, the stochastic convergence of the finite sample -function needs to be constructed. When the samples are i.i.d., such as in Gaussian Mixture Models (GMMs) [3, 11, 41], the required convergence follows directly from the law of large numbers. However, this argument is less straightforward in time-series models such as Hidden Markov Models (HMMs) and the model considered in HIL. For HMMs, [42] showed that the expectation of the -function converges, but both the stochastic convergence analysis and the analytical expression of the population -function are not provided. The missing techniques could be borrowed from a body of work [8, 13, 27, 37] analyzing the asymptotic behavior of HMMs. Most notably, [27] provided a rigorous treatment of the population EM algorithm via sufficient statistics, assuming the HMM is parameterized by an exponential family.
Finally, apart from the EM algorithm, a separate line of research [1, 21] applies spectral methods for tractable inference in latent variable models. However, such methods are mainly complementary to the EM algorithm since better performance can usually be obtained by initializing the EM algorithm with the solution of the spectral methods [23].
1.2 Our contributions
In this paper, we establish the first known performance guarantee for a HIL algorithm that only observes primitive state-action pairs. Specifically, we first fix and reformulate the original EM approach by [10] in a rigorous manner. The lack of mixing is identified as a technical difficulty in learning the standard options framework, and a novel options with failure framework is proposed to circumvent this issue.
Inspired by [3] and [42], the population version of our algorithm is analyzed as an intermediate step. We prove that if the expert policy can be parameterized by the options with failure framework, then, under regularity conditions, the population version algorithm converges to the true parameter, and the finite sample version converges with high probability to a norm ball around the true parameter. Our analysis directly constructs the stochastic convergence of the finite sample -function, and an analytical expression of the resulting population -function is provided. Finally, we qualitatively validate our theoretical results using a numerical example.
2 Problem settings
Notation.
Throughout this paper, we use uppercase letters (e.g., ) for random variables and lowercase letters (e.g., ) for values of random variables. Let be the set of integers such that . When used in the subscript, the brackets are removed (e.g., ).
2.1 Definition of the hierarchical policy

In this section, we first introduce the options framework for hierarchical reinforcement learning [4, 35], captured by the probabilistic graphical model shown in Figure 1. The index represents the time; respectively represent the state, the action, the option and the termination indicator. For all , , and are defined on the finite state space , the finite action space and the finite option space ; is a binary random variable. Define the parameter where , , and . The parameter space is a convex and compact subset of a Euclidean space.
For any , if we fix and consider a given , the joint distribution on the rest of the graphical model is determined by the following components: an unknown environment transition probability , a high level policy parameterized by , a low level policy parameterized by and a termination policy parameterized by . Sampling a tuple from such a joint distribution, or equivalently, implementing the hierarchical decision process, follows the following procedure. Starting from the first time step, the decision making agent first determines whether or not to terminate the current option . The decision is encoded in a termination indicator sampled from . indicates that the option terminates and the next option is sampled from ; indicates that the option continues and . Next, the primitive action is sampled from , applying the low level policy associated with the option . Using the environment, the next state is sampled from . The rest of the samples are generated analogously.
The options framework corresponds to the above hierarchical policy structure and the policy triple . However, due to a technicality identified at the end of this subsection, we consider a novel options with failure framework for the remainder of this paper, which adds an extra failure mechanism to the graphical model in the case of . Specifically, there exists a constant such that when the termination indicator , with probability the next option is assigned to , whereas with probability the next option is sampled uniformly from the set of options . Notice that if , we recover the standard options framework.
To simplify the notation, we define as the combination of and the failure mechanism. For any , with any other input arguments,
Formally, the options with failure framework is defined as the class of policy triples parameterized by and . With and a given , let be the joint distribution of . With any input arguments,
On the policy framework.
The options with failure framework is adopted to simplify the construction of the mixing condition (Lemma D.1). It is possible that our analysis could be extended to learn the standard options framework. In that case, instead of constructing the usual one step mixing condition, one could target the multi-step mixing condition similar to [8, Chap. 4.3].
2.2 The imitation learning problem
Suppose an expert uses an options with failure policy with true parameters and ; its initial condition is sampled from a distribution . A finite length observation sequence with is observed from the expert. and the parametric structure of the expert policy are known, but is unknown. Our objective is to estimate from .
On the practicality of our setting.
Two comments need to made here. First, it is common in practice to observe not one, but a set of independent observation sequences. In that case, the problem essentially becomes easier. Second, the cardinality of the option space and the parameterization of the expert policy are usually unknown. A popular solution is to assume an expressive parameterization (e.g., a neural network) in the algorithm and select through cross-validation. Theoretical analysis of EM under this setting is challenging, even when samples are i.i.d. [15, 16]. Therefore, we only consider the domain of correct-specification.
Throughout this paper, the following assumptions are imposed for simplicity.
Assumption 1 (Non-degeneracy).
With any other input arguments, the domain of , and as functions of can be extended to an open set that contains . Moreover, for all , , and parameterized by are strictly positive.
Assumption 2 (Differentiability).
With any other input arguments, , and as functions of are continuously differentiable on .
Next, consider the stochastic process induced by and the expert policy. Based on the graphical model, it is a Markov chain with finite state space . Let be its set of stationary distributions, which is nonempty and convex.
Assumption 3 (Stationary initial distribution).
is an extreme point of . That is, , and it cannot be written as the convex combination of two elements of .
On the assumptions.
The first two assumptions are generally mild and therefore hold for many policy parameterizations. The third assumption is a bit more restrictive, but it is essential for our theoretical analysis. In Appendix A, we provide further justification of this assumption in a particular class of environments: , there exists such that . In such environments, contains a unique element which is also the limiting distribution. If we start sampling the observation sequence late enough, Assumption 3 is approximately satisfied.
3 A Baum-Welch type algorithm
Adopting the EM approach, we present Algorithm 1 for the estimation of . It reformulates the algorithm by [10] in a rigorous manner, and an error in the latter is fixed: when defining the posterior distribution of latent variables, at any time , the original algorithm neglects the dependency of future states on the current option . A detailed discussion is provided in Appendix B.1.
Since our graphical model resembles an HMM, Algorithm 1 is intuitively similar to the classical Baum-Welch algorithm [5] for HMM parameter inference. Analogously, it iterates between forward-backward smoothing and parameter update. In each iteration, the algorithm first estimates certain marginal distributions of the latent variables conditioned on the observation sequence , assuming the current estimate of is correct. Such conditional distributions are named as smoothing distributions, and they are used to compute the -function, which is a surrogate of the likelihood function. The next estimate of is assigned as one of the maximizing arguments of the -function.
From the structure of our graphical model, a prior distribution of is required to compute the smoothing distributions. Since the true prior distribution is unknown, , defined next, is used as its approximation: , ; , . Theorem 2 shows that the additional estimation error introduced by this approximation vanishes as , regardless of the choice of . Let be the set of allowed by Algorithm 1.
3.1 Latent variable estimation
In the following, we define the forward message, the backward message and the smoothing distribution for all , and all . All of these quantities are probability mass functions over , and normalizing constants , and are adopted to enforce this. With any input arguments and , the forward message is defined as
On the LHS, the dependency on is omitted for a cleaner notation. By convention, is equivalent to
The backward message is defined as
where the value of on the RHS is arbitrary. By convention, the boundary condition is
| (1) |
The smoothing distribution is defined as
It can be easily verified that the normalizing constant does not depend on .
Finally, for all , and , with any input arguments and , we define the two-step smoothing distribution as
where is the same normalizing constant as the one for the smoothing distribution .
The quantities above can be computed using the forward-backward recursion. For simplicity, we omit normalizing constants by using the proportional symbol . The proof is deferred to Appendix B.2.
Theorem 1 (Forward-backward smoothing).
For all and , with any input arguments on the LHS,
-
1.
(Forward recursion) ,
(2) When ,
(3) -
2.
(Backward recursion) ,
(4) -
3.
(Smoothing) ,
(5) -
4.
(Two-step smoothing) ,
(6)
3.2 Parameter update
For all and , the (finite sample) -function is defined as
| (7) |
The parameter update is performed as , which may not be unique. Since is compact and is continuous with respect to , the maximization is well-posed. Note that our definition of is an approximation of the standard definition of -function in the EM literature. See Appendix B.3 for a detailed discussion.
3.3 Generalization to continuous spaces
Although we require finite state and action space for our theoretical analysis, Algorithm 1 can be readily generalized to continuous and : we only need to replace by a density function. However, generalization to continuous option space requires a substantially different algorithm. The forward-backward smoothing procedure in Theorem 1 involves integrals rather than sums, and Sequential Monte Carlo (SMC) techniques need to be applied. Fortunately, it is widely accepted that a finite option space is reasonable in the options framework, since the options need to be distinct and separate [9].
4 Performance guarantee
Our analysis of Algorithm 1 has the following structure. We first prove the stochastic convergence of the -function to a population -function , leading to a well-posed definition of the population version algorithm. This step is our major theoretical contribution. With additional assumptions, the first-order stability condition is constructed, and techniques in [3] can be applied to show the convergence of the population version algorithm. The remaining step is to analyze Algorithm 1 as a perturbed form of its population version, which requires a high probability bound on the distance between their parameter updates. We can establish the strong consistency of the parameter update of Algorithm 1 as an estimator of the parameter update of the population version algorithm. Therefore, the existence of such a high probability bound can be proved for large enough . However, the analytical expression of this bound requires knowledge of the specific parameterization of , which is not available in this general context of discussion.
Concretely, we first analyze the asymptotic behavior of the -function as . From Assumption 3, the observation sequence is generated from a stationary Markov chain . Let be its state space. Using Kolmogorov’s extension theorem, we can extend this one-sided Markov chain to the index set and define a unique probability measure over the sample space . Any observation sequence can be regarded as a segment of an infinite length sample path . Therefore, if the observation sequence is not specified, is a random variable with underlying probability measure .
One caveat is that the definition of from Section 3 fails for some . To fix this issue, define the set of proper sample paths as
| (8) |
Note that ; therefore, working on is probabilistically equivalent to working on . For all , follows the definition from Section 3; for other sample paths, is defined arbitrarily. In this way, becomes a well-defined random variable. Its stochastic convergence is characterized in the following theorem.
Theorem 2 (The stochastic convergence of the -function).
We name as the population -function. The analytical expressions of and are provided in Appendix C.2, where the complete version of the above theorem (Theorem 7) is proved. In the following, we provide a high level sketch of the main idea.
Proof Sketch.
The main difficulty of the proof is that, defined in (7) is (roughly) the average of terms, with each term dependent on the entire observation sequence; as , all the terms keep changing such that the law of large numbers cannot be applied directly. As a solution, we approximate and with smoothing distributions in an infinitely extended graphical model independent of , resulting in an approximated -function (still depends on ). The techniques adopted in this step are analogous to Markovian decomposition and uniform forgetting in the HMM literature [8, 37]. The limiting behavior of the approximated -function is the same as that of , since their difference vanishes as . For the approximated -function, we can apply the ergodic theorem since the smoothing distributions no longer depend on . ∎
The population version of Algorithm 1 has parameter updates . To characterize the local convergence of Algorithm 1 and its population version, we impose the following assumptions for the remainder of Section 4.
Assumption 4 (Strong concavity).
There exists such that for all ,
For any , let .
Assumption 5 (Additional local assumptions).
There exists such that
-
1.
(Identifiability) For all , the set has a unique element . Moreover, for all , with the convention that , we have
-
2.
(Uniqueness of finite sample parameter updates) For all , and , -almost surely, the set has a unique element .
On the additional assumptions.
In Assumption 4, we require the strong concavity of over the entire parameter space since the maximization step in our algorithm is global. Such a requirement could be avoided: if the maximization step is replaced by a gradient update (Gradient EM), then only needs to be strongly concave in a small region around . The price to pay is to assume knowledge on structural constants of (Lipschitz constant and strong concavity constant). See [3] for an analysis of the gradient EM algorithm.
Nonetheless, we expect the following to hold in certain cases of tabular parameterization: for all , the function is strongly concave over (see the end of Appendix C.2). From this condition, Assumption 4 and 5.1 directly follow. Assumption 5.2 holds as well; in fact, it is a quite mild assumption due to the sample-based nature of .
The next step is to characterize the convergence of the population version algorithm.
Theorem 3 (Convergence of the population version algorithm).
With all the assumptions,
-
1.
(First-order stability) There exists such that for all ,
-
2.
(Contraction) Let . For all ,
If , the population version algorithm converges linearly to the true parameter .
The proof is given in Appendix C.3, where we also show an upper bound on . The idea mirrors that of [3, Theorem 4] with problem-specific modifications. Algorithm 1 can be regarded as a perturbed form of this population version algorithm, with convergence characterized in the following theorem.
Theorem 4 (Performance guarantee for Algorithm 1).
With all the assumptions, if we have
-
1.
For all and , there exists such that the following statement is true. If the observation length , then with probability at least ,
-
2.
If , Algorithm 1 with any has the following performance guarantee. If , then with probability at least , for all ,
The proof is provided in Appendix C.4. Essentially, we use Theorem 2 to show the uniform (in and ) strong consistency of as an estimator of , following the standard analysis of M-estimators. A direct corollary of this argument is the high probability bound on the difference between and , as shown in the first part of the theorem. Combining this high probability bound with Theorem 3 and [3, Theorem 5] yields the final performance guarantee.
Theorem 4 has two practical implications. First, under regularity conditions, with large enough , Algorithm 1 can converge with arbitrarily high probability to an arbitrarily small norm ball around the true parameter. In other words, with enough samples, the EM approach can recover the true parameter of the expert policy arbitrarily well. Second, the estimation error (upper bound) decreases exponentially in the initial phase of the algorithm. In this regard, a practitioner can allocate his computational budget accordingly.
One limitation of our analysis is that the condition is hard to verify for a practical parameterization of the expert policy. This is typical in the theory of EM algorithms: even in the case of i.i.d. samples, characterizing the contraction coefficient is intractable except for a few simple parametric models. Nonetheless, such a condition strengthens our intuition on when the EM approach to HIL works: should have a large curvature with respect to , and the function should not change much with respect to around . In the next section, we present a numerical example to qualitatively demonstrate our result.
5 Numerical example
In this section, we qualitatively demonstrate our theoretical result through an example. Here, we value clarity over completeness, therefore large-scale experiments are deferred to future works.

Consider the Markov Decision Process (MDP) illustrated in Figure 2. There are four states, numbered from left to right as 1 to 4. At any state , there are two allowable actions: LEFT and RIGHT. If , then the next state is sampled uniformly from the states on the right of state (including itself). Symmetrically, if , then the next state is sampled uniformly from the states on the left of state (including ).
Suppose an expert applies the following options with failure policy with parameters and . The option space has two elements: LEFTEND and RIGHTEND. equals if , and if . For all , . equals if , and otherwise. Symmetrically, equals if , and otherwise. Intuitively, the high level policy directs the agent to states 1 and 4, and the option terminates with high probability when the corresponding target state is reached.
In our experiment, the parameter spaces , and are all equal to the interval . The initial parameter estimate . For all , .
We investigate the behavior of as a random variable dependent on and . 50 sample paths of length are sampled from (approximately) the stationary Markov chain induced by the expert policy, with . After running Algorithm 1 with any sample path and any , we obtain a sequence . Let be the average of for fixed and , over the 50 sample paths. The result is shown in Figure 3.

Assumption 1, 2, 3 and 5.2 hold in this example, and we speculate that Assumption 4 and 5.1 hold as well. The condition cannot be verified, but the empirical result exhibits patterns consistent with the performance guarantee, even though rigorously Theorem 4 is not applicable. First, decreases exponentially in the early phase of the algorithm. Second, as increases, Algorithm 1 achieves better performance.
An observation is worth mentioning as a separate note: for , first slightly increases, then levels off. This is due to the parameter estimate on some sample paths converging to bad stationary points of the finite sample likelihood function, which suggests that early stopping could be helpful in practice. Omitted details and additional experiments are provided in Appendix E, where we also investigate, for example, the effect of and random initialization on the performance of Algorithm 1.
6 Conclusions
In this paper, we investigate the EM approach to HIL from a theoretical perspective. We prove that under regularity conditions, the proposed algorithm converges with high probability to a norm ball around the true parameter. To our knowledge, this is the first performance guarantee for an HIL algorithm that only observes primitive state-action pairs. Future works could further investigate the practical performance of this approach, especially its scalability in complicated environments.
Acknowledgements
We thank the anonymous reviewers for their constructive comments. Z.Z. thanks Tianrui Chen for helpful discussions. The research was partially supported by the NSF under grants DMS-1664644, CNS-1645681, and IIS-1914792, by the ONR under grant N00014-19-1-2571, by the NIH under grants R01 GM135930 and UL54 TR004130, and by the DOE under grant DE-AR-0001282.
References
- Anandkumar et al. [2014] A. Anandkumar, R. Ge, D. Hsu, S. M. Kakade, and M. Telgarsky. Tensor decompositions for learning latent variable models. Journal of Machine Learning Research, 15(80):2773–2832, 2014.
- Bacon et al. [2017] P.-L. Bacon, J. Harb, and D. Precup. The option-critic architecture. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, pages 1726–1734, 2017.
- Balakrishnan et al. [2017] S. Balakrishnan, M. J. Wainwright, and B. Yu. Statistical guarantees for the EM algorithm: From population to sample-based analysis. The Annals of Statistics, 45(1):77–120, 2017.
- Barto and Mahadevan [2003] A. G. Barto and S. Mahadevan. Recent advances in hierarchical reinforcement learning. Discrete event dynamic systems, 13(1-2):41–77, 2003.
- Baum et al. [1970] L. E. Baum, T. Petrie, G. Soules, and N. Weiss. A maximization technique occurring in the statistical analysis of probabilistic functions of Markov chains. The annals of mathematical statistics, 41(1):164–171, 1970.
- Brunskill and Li [2014] E. Brunskill and L. Li. PAC-inspired option discovery in lifelong reinforcement learning. In Proceedings of the 31st International Conference on Machine Learning, pages 316–324, 2014.
- Butterfield et al. [2010] J. Butterfield, S. Osentoski, G. Jay, and O. C. Jenkins. Learning from demonstration using a multi-valued function regressor for time-series data. In 2010 10th IEEE-RAS International Conference on Humanoid Robots, pages 328–333. IEEE, 2010.
- Cappé et al. [2006] O. Cappé, E. Moulines, and T. Rydén. Inference in hidden Markov models. Springer Science & Business Media, 2006.
- Daniel et al. [2016a] C. Daniel, G. Neumann, O. Kroemer, and J. Peters. Hierarchical relative entropy policy search. Journal of Machine Learning Research, 17(1):3190–3239, 2016a.
- Daniel et al. [2016b] C. Daniel, H. Van Hoof, J. Peters, and G. Neumann. Probabilistic inference for determining options in reinforcement learning. Machine Learning, 104(2-3):337–357, 2016b.
- Daskalakis et al. [2017] C. Daskalakis, C. Tzamos, and M. Zampetakis. Ten steps of EM suffice for mixtures of two Gaussians. In Conference on Learning Theory, pages 704–710, 2017.
- Davidson [1994] J. Davidson. Stochastic limit theory: An introduction for econometricians. OUP Oxford, 1994.
- De Castro et al. [2017] Y. De Castro, E. Gassiat, and S. Le Corff. Consistent estimation of the filtering and marginal smoothing distributions in nonparametric hidden Markov models. IEEE Transactions on Information Theory, 63(8):4758–4777, 2017.
- Dempster et al. [1977] A. P. Dempster, N. M. Laird, and D. B. Rubin. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological), 39(1):1–22, 1977.
- Dwivedi et al. [2018a] R. Dwivedi, N. Ho, K. Khamaru, M. I. Jordan, M. J. Wainwright, and B. Yu. Singularity, misspecification, and the convergence rate of EM. arXiv preprint arXiv:1810.00828, 2018a.
- Dwivedi et al. [2018b] R. Dwivedi, N. Ho, K. Khamaru, M. J. Wainwright, and M. I. Jordan. Theoretical guarantees for EM under mis-specified gaussian mixture models. In Advances in Neural Information Processing Systems 31, pages 9681–9689, 2018b.
- Fox et al. [2017] R. Fox, S. Krishnan, I. Stoica, and K. Goldberg. Multi-level discovery of deep options. arXiv preprint arXiv:1703.08294, 2017.
- Fruit and Lazaric [2017] R. Fruit and A. Lazaric. Exploration–exploitation in MDPs with options. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, pages 576–584, 2017.
- Fruit et al. [2017] R. Fruit, M. Pirotta, A. Lazaric, and E. Brunskill. Regret minimization in MDPs with options without prior knowledge. In Advances in Neural Information Processing Systems 30, pages 3166–3176, 2017.
- Hairer [2006] M. Hairer. Ergodic properties of Markov processes. Unpublished lecture notes, 2006. URL http://www.hairer.org/notes/Markov.pdf.
- Hsu et al. [2012] D. Hsu, S. M. Kakade, and T. Zhang. A spectral algorithm for learning hidden Markov models. Journal of Computer and System Sciences, 78(5):1460–1480, 2012.
- Jain and Kar [2017] P. Jain and P. Kar. Non-convex optimization for machine learning. Foundations and Trends® in Machine Learning, 10(3-4):142–336, 2017.
- Kontorovich et al. [2013] A. Kontorovich, B. Nadler, and R. Weiss. On learning parametric-output HMMs. In Proceedings of the 30th International Conference on Machine Learning, pages 702–710, 2013.
- Krishnan et al. [2017] S. Krishnan, R. Fox, I. Stoica, and K. Goldberg. DDCO: Discovery of deep continuous options for robot learning from demonstrations. In Conference on Robot Learning, pages 418–437, 2017.
- Kulkarni et al. [2016] T. D. Kulkarni, K. Narasimhan, A. Saeedi, and J. Tenenbaum. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In Advances in neural information processing systems 29, pages 3675–3683, 2016.
- Le et al. [2018] H. Le, N. Jiang, A. Agarwal, M. Dudik, Y. Yue, and H. Daumé. Hierarchical imitation and reinforcement learning. In Proceedings of the 35th International Conference on Machine Learning, pages 2917–2926, 2018.
- Le Corff and Fort [2013] S. Le Corff and G. Fort. Online expectation maximization based algorithms for inference in hidden Markov models. Electronic Journal of Statistics, 7:763–792, 2013.
- Mann and Mannor [2014] T. Mann and S. Mannor. Scaling up approximate value iteration with options: Better policies with fewer iterations. In Proceedings of the 31th International Conference on Machine Learning, pages 127–135, 2014.
- Manschitz et al. [2014] S. Manschitz, J. Kober, M. Gienger, and J. Peters. Learning to sequence movement primitives from demonstrations. In 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 4414–4421. IEEE, 2014.
- McLachlan and Krishnan [2007] G. J. McLachlan and T. Krishnan. The EM algorithm and extensions, volume 382. John Wiley & Sons, 2007.
- Nachum et al. [2018] O. Nachum, S. S. Gu, H. Lee, and S. Levine. Data-efficient hierarchical reinforcement learning. In Advances in Neural Information Processing Systems 31, pages 3303–3313, 2018.
- Niekum et al. [2012] S. Niekum, S. Osentoski, G. Konidaris, and A. G. Barto. Learning and generalization of complex tasks from unstructured demonstrations. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5239–5246. IEEE, 2012.
- Niekum et al. [2015] S. Niekum, S. Osentoski, G. Konidaris, S. Chitta, B. Marthi, and A. G. Barto. Learning grounded finite-state representations from unstructured demonstrations. The International Journal of Robotics Research, 34(2):131–157, 2015.
- Shiarlis et al. [2018] K. Shiarlis, M. Wulfmeier, S. Salter, S. Whiteson, and I. Posner. TACO: Learning task decomposition via temporal alignment for control. In Proceedings of the 35th International Conference on Machine Learning, pages 4654–4663, 2018.
- Sutton et al. [1999] R. S. Sutton, D. Precup, and S. Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artificial intelligence, 112(1-2):181–211, 1999.
- Tessler et al. [2017] C. Tessler, S. Givony, T. Zahavy, D. J. Mankowitz, and S. Mannor. A deep hierarchical approach to lifelong learning in minecraft. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, pages 1553–1561, 2017.
- van Handel [2008] R. van Handel. Hidden Markov models. Unpublished lecture notes, 2008. URL https://web.math.princeton.edu/~rvan/orf557/hmm080728.pdf.
- Vezhnevets et al. [2017] A. S. Vezhnevets, S. Osindero, T. Schaul, N. Heess, M. Jaderberg, D. Silver, and K. Kavukcuoglu. Feudal networks for hierarchical reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning, pages 3540–3549, 2017.
- Wang et al. [2015] Z. Wang, Q. Gu, Y. Ning, and H. Liu. High dimensional EM algorithm: Statistical optimization and asymptotic normality. In Advances in Neural Information Processing Systems 28, pages 2521–2529, 2015.
- Wu [1983] C. J. Wu. On the convergence properties of the EM algorithm. The Annals of statistics, 11(1):95–103, 1983.
- Xu et al. [2016] J. Xu, D. J. Hsu, and A. Maleki. Global analysis of expectation maximization for mixtures of two Gaussians. In Advances in Neural Information Processing Systems 29, pages 2676–2684, 2016.
- Yang et al. [2017] F. Yang, S. Balakrishnan, and M. J. Wainwright. Statistical and computational guarantees for the Baum-Welch algorithm. Journal of Machine Learning Research, 18(1):4528–4580, 2017.
- Yi and Caramanis [2015] X. Yi and C. Caramanis. Regularized EM algorithms: A unified framework and statistical guarantees. In Advances in Neural Information Processing Systems 28, pages 1567–1575, 2015.
Appendix
Organization.
Appendix A presents discussions that motivate Assumption 3. In particular, we show that Assumption 3 approximately holds in a particular class of environment. Appendix B provides details on Algorithm 1, including the comparison with the existing algorithm from [10], the forward-backward implementation and the derivation of the -function from (7). In Appendix C, we prove our theoretical results from Section 4. Technical lemmas involved in the proofs are deferred to Appendix D. Finally, Appendix E presents details of our numerical example omitted from Section 5.
Appendix A Discussion on Assumption 3
In this section we justify Assumption 3 in a particular class of environment. Consider the stochastic process generated by any and an options with failure hierarchical policy with parameter . It is a Markov chain with its transition kernel parameterized by , and its state space is finite. Denote its one step transition kernel as and its step transition kernel as . In the following, we show that is uniformly ergodic when the environment meets the reachability assumption: , there exists such that .
Proposition 5 (Ergodicity).
Proof of Proposition 5.
We start by analyzing the irreducibility of the Markov chain with any . Denote the probability measure on the natural filtered space as . The dependency on is dropped for a cleaner notation, since the following proof holds for all . For any , let and . For any time ,
From Assumption 1, there exists a state such that , . Consider the first factor in the sum,
From Assumption 1, the second term on the RHS is positive for all and . From the reachability assumption, for any there exists an action such that . As a result, for any , , and the considered Markov chain is irreducible.
As shown above, for all , where is the two step transition kernel of the Markov chain . Due to Assumption 2, is continuous with respect to . Moreover, since is compact, if we let we have . The classical Doeblin-type condition can be constructed as follows. For all and , with any probability measure over the finite sample space ,
| (9) |
A Markov chain convergence result is restated in the following lemma, tailored to our need.
Lemma A.1 ([8], Theorem 4.3.16 restated).
With the Doeblin-type condition in (9), the Markov chain with any has a unique stationary distribution . Moreover, for all , and ,
Letting and , we have
Proposition 5 shows that in , the initial distribution (of ) is not very important since the distribution of converges to uniformly with respect to and . As a result, also converges to the unique limiting distribution, regardless of the initial distribution. When sampling the observation sequence from the expert, we can always start sampling late enough such that Assumption 3 is approximately satisfied. Note that the proof of Proposition 5 does not use the failure mechanism imposed on the hierarchical policy, implying that the result also holds for the standard options framework.
Appendix B Details of the algorithm
B.1 An error in the existing algorithm
First, we point out a technicality when comparing Algorithm 1 to the algorithm from [10]. The algorithm from [10] learns a hierarchical policy following the standard options framework, not the options with failure framework considered in Algorithm 1. To draw direct comparison, we need to let in Algorithm 1. However, an error in the existing algorithm can be demonstrated without referring to .
For simplicity, consider fixed to ; let . Then, according to the definitions in [10], the (unnormalized) forward message is defined as
The (unnormalized) backward message is defined as
The smoothing distribution is defined as
We use the proportional symbol to represent normalizing constants independent of and . [10] claims that, for any and ,
However, applying Bayes’ formula, it follows that
Using the Markov property,
Therefore,
Applying Bayes’ formula again, it follows that
For the claim in [10] to be true, should not depend on and . Clearly this requirement does not hold in most cases, since the likelihood of the future observation sequence should depend on the currently applied option.
B.2 Proof of Theorem 1
We drop the dependency on , since the following proof holds for all . The proportional symbol is used to replace a multiplier term that depends on the context.
1. (Forward recursion)
First consider any fixed . For a cleaner notation, we use as an abbreviation of . Let , be any two subsets of , and let , be the sets of values generated from and , respectively, such that the uppercase symbols are replaced by the lowercase symbols. ( and are two sets of random variables; and are two sets of values of random variables.) Then, for all , is defined as
If the RHS does not depend on and , we can omit it on the LHS by using . ,
Furthermore,
where replaces a multiplier that does not depend on . Taking expectation with respect to gives the desirable forward recursion result. For the case of , the proof is analogous.
2. (Backward recursion)
For any , ,
where the multipliers replaced by are independent of and . Moreover,
Plugging in the structure of the policy gives the desirable result.
3. (Smoothing)
Consider any fixed . For any ,
Taking expectation with respect to on both sides yields the desirable result. Notice that the second term on the RHS does not depend on , therefore is not involved in the expectation. For the case of the proof is analogous.
4. (Two-step smoothing)
For any , consider any fixed ,
Take expectation with respect to on both sides. Notice that only the first term on the RHS depends on . We have
where the multipliers replaced by are independent of and . For the case of the proof is analogous. ∎
B.3 Discussion on the -function
In our algorithm, as motivated by Section 3, we effectively consider the following joint distribution on the graphical model shown in Figure 1: the prior distribution of is , and the distribution of the rest of the graphical model is determined by an options with failure policy with parameters and . From the EM literature [3, 22], the complete likelihood function is
The marginal likelihood function is
where the superscript means marginal. From the definition of smoothing distributions, we can verify that .
The standard MLE approach maximizes the logarithm of the marginal likelihood function (marginal log-likelihood) with respect to . However, such an optimization objective is hard to evaluate for time series models (e.g., HMMs and our graphical model). As an alternative, the marginal log-likelihood can be lower bounded [22, Chap. 5.4] as
where on the RHS is arbitrary. The RHS is usually called the (unnormalized) -function. For our graphical model, it is denoted as .
The RHS is well-defined from the non-degeneracy assumption. From the classical monotonicity property of EM updates [22, Chap. 5.7], maximizing the (unnormalized) -function with respect to guarantees non-negative improvement on the marginal log-likelihood. Therefore, improvements on parameter inference can be achieved via iteratively maximizing the (unnormalized) -function.
Using the structure of the hierarchical policy, can be rewritten as
where contains terms unrelated to . Consider the first term on the last line, which partially captures the effect of assuming on the parameter inference. Since this term is upper bounded by , when is large enough this term becomes negligible. The precise argument is similar to the proof of Lemma C.2. Therefore, after dropping the last line and normalizing, we arrive at our definition of the (normalized) -function in (7).
Appendix C Details of the performance guarantee
C.1 Smoothing in an extended graphical model
Before providing the proofs, we first introduce a few definitions. Consider the extended graphical model shown in Figure 4 with a parameter ; .

Let the joint distribution of be . Define the distribution of the rest of the graphical model using an options with failure hierarchical policy with parameters and , analogous to our settings so far. With these two components, the joint distribution on the graphical model is determined. Let be such a joint distribution; is omitted for conciseness.
We emphasize the comparison between and . The sample space of is the domain of , whereas the sample space of is the domain of since is fixed to .
Consider the infinite length observation sequence corresponding to any , where is defined in (8). Analogous to the non-extended model (Figure 1), we can define smoothing distributions for the extended model with any parameter . For all and , with any input arguments and , the forward message is defined as
The backward message is defined as
The smoothing distribution is defined as
The two-step smoothing distribution is defined as
The quantities , and are normalizing constants such that the LHS of the expressions above are probability mass functions. In particular, since , we can define for in the same way as . The dependency on in the smoothing distributions is dropped for a cleaner notation.
Recursive results similar to Theorem 1 can be established; the proof is analogous and therefore omitted. As in Theorem 1, we make extensive use of the proportional symbol which stands for, the LHS equals the RHS multiplied by a normalizing constant. Moreover, the normalizing constant does not depend on the input arguments of the LHS.
Corollary 6 (Forward-backward smoothing for the extended model).
For all and , with any input arguments,
-
1.
(Forward recursion) ,
(10) -
2.
(Backward recursion) ,
(11) -
3.
(Smoothing) ,
(12) -
4.
(Two-step smoothing) ,
(13)
The following lemma characterizes the limiting behavior of and as .
Lemma C.1 (Limits of smoothing distributions).
The proof is given in Appendix D.4. The dependency of and on is omitted for a cleaner notation.
C.2 The stochastic convergence of the -function
In this subsection, we present the proof of Theorem 2.
First, consider and defined in Lemma C.1. Using the arguments from Section 4, they can also be analyzed in the infinitely extended probability space , where denotes the power set. We only define and for ; for other sample paths, they are defined arbitrarily. Since , such a restriction from to does not change our probabilistic results.
For any sample path , let and be the values of and corresponding to . With a slight overload of notation, let , which is the set of components in corresponding to time .
For all , , and , define
where the dependency of the RHS on is shown explicitly for clarity. is upper bounded by a constant that does not depend on , , and , due to Assumption 1 and 2. Moreover, for all , and , is continuously differentiable with respect to ; for all , and , is Lipschitz continuous with respect to , due to Lemma C.1.
Next, define
| (14) |
The subscripts and in denote that the expectation is taken with respect to the probability measure .
With the above definitions, we state the complete version of Theorem 2. The -function defined in (7) is written as , showing its dependency on the sample path.
Theorem 7 (The complete version of Theorem 2).
Before proving Theorem 7, we state the following definition and an auxiliary lemma required for the proof. For all , and , the sample-path-based population -function is defined as
| (15) |
The superscript s in stands for sample-path-based. If the sample path is not specified, is a random variable associated with probability measure . Note that due to stationarity, for any , and , .
The difference between and is bounded in the following lemma.
Lemma C.2 (Bounding the difference between the -function and the sample-path-based population -function).
The proof is provided in Appendix D.5. Now we are ready to present the proof of Theorem 7 step-by-step. The structure of this proof is similar to the standard analysis of HMM maximum likelihood estimators [8, Chap. 12].
Proof of Theorem 7.
We prove the two parts of the theorem separately.
1. For all , there exists such that the set . For all and , due to the differentiability of with respect to , there exists a gradient at any such that
We need to transform the above almost surely (in ) convergence to the convergence of expectation, using the dominated convergence theorem. As a requirement, the quantity inside the limit on the LHS needs to be upper-bounded. For all , , and ,
| (16) |
Since continuously differentiable functions are Lipschitz continuous on convex and compact subsets, , and as functions of are Lipschitz continuous on , with any other input arguments. From the expression of , we can verify that for any fixed and , as a function of is Lipschitz continuous on , and the Lipschitz constant only depends on and . Consequently, the RHS of (16) can be upper-bounded for all . Applying the dominated convergence theorem, we have
| (17) |
On the other hand, notice that for all , and ,
Combining with (17) proves the differentiability of with respect to for any fixed . The gradient is
Analogously, using the dominated convergence theorem we can also show that the gradient is continuous with respect to . Details are omitted due to the similarity with the above procedure. It is worth noting that we let instead of . In this way, the gradient can be naturally defined when is not an interior point of .
From differentiability and , is also continuous with respect to . Since is compact, the set of maximizing arguments is nonempty.
2. We need to prove the uniform (in and ) almost sure convergence of the -function to the population -function . The proof is separated into three steps. First, we show the almost sure convergence of to for all using the ergodic theorem. Second, we extend this pointwise convergence to uniform (in ) convergence using a version of the Arzelà-Ascoli theorem [12, Chap. 21]. Finally, from Lemma C.2, the difference between and vanishes uniformly in as .
Concretely, for the pointwise (in ) almost sure convergence of as , we apply Birkhoff’s ergodic theorem. Let be the standard shift operator. That is, for any , . Due to stationarity, is a measure-preserving map, i.e., for all . Therefore, the quadruple defines a dynamical system.
Here, we need some clarification on some concepts and notations. Consider the Markov chain induced by the expert policy, let be its set of all stationary distributions. Comparing to from Assumption 3, they both depend on the true parameter ; the former corresponds to the chain , while the latter corresponds to the chain . From the structure of our graphical model, they are equivalent by some transformation.
From Section 4, is defined from an element of that depends on . Denote this stationary distribution as . Since is an extreme point of (Assumption 3), is also an extreme point of . Then, we can apply a standard Markov chain ergodicity result. From [20, Theorem 5.7], the dynamical system is ergodic. For our case, Birkhoff’s ergodic theorem is restated as follows.
Lemma C.3 ([20], Corollary 5.3 restated).
If a dynamical system is ergodic and satisfies , then as ,
For our purpose, observe that for any , . Therefore, applying the ergodic theorem to , as ,
| (18) |
To extend the pointwise convergence in (18) to uniform (in ) convergence, the following concept is required. The sequence indexed by as functions of and is strongly stochastically equicontinuous [12, Equation 21.43] if for any there exists such that
| (19) |
Indeed this property holds for , as shown in Appendix D.6. The version of the Arzelà-Ascoli theorem we use is restated as follows, tailored to our need.
On the concavity of .
As discussed after introducing Assumption 4, we expect the following to hold in certain cases of tabular parameterization: for all , the function is strongly concave over . Details are presented below.
Consider for example, we need to provide sufficient conditions such that the following function is strongly concave with respect to , given any .
Let the marginal distribution of on be . If is strictly positive on , then we rewrite as
In the case of tabular parameterization, is an entry of indexed as ; its logarithm is 1-strongly concave on the interval . is strongly concave with respect to if is strictly positive for all and . We speculate that this requirement is mild, but a rigorous characterization is quite challenging.
C.3 The convergence of the population version algorithm
We first present the complete version of Theorem 3, where an upper bound on is also shown. Notice that we assume all the assumptions, including Assumption 4 and 5.
Theorem 8 (The complete version of Theorem 3).
With all the assumptions,
- 1.
-
2.
(Contraction) Let . For all ,
If , the population version algorithm converges linearly to the true parameter .
Proof of Theorem 8.
We prove the two parts separately in the following.
1. For convenience of notation, let such that, for example, is the gradient of with respect to . Using the expressions of from Theorem 7, we have
Consider the first term,
We use the triangle inequality and the Jensen’s inequality in the third and the fourth line respectively. The fifth line is finite due to being compact and the continuity of the gradient (Assumption 2). The last line is due to the limit form of Lemma D.7, similar to the argument in Appendix D.4. Notice that the coefficient of on the last line does not depend on .
Analogously, we have
Combining everything, we have the upper bound on .
2. The proof of the second part mirrors the proof of [3, Theorem 4]. The main difference is the construction of the following self-consistency (a.k.a. fixed-point) condition.
Lemma C.5 (Self-consistency).
With all the assumptions, .
The proof of this lemma is presented in Appendix D.7. Such a condition is used without proof in [3] since it only considers i.i.d. samples, and the self-consistency condition for EM with i.i.d. samples is a well-known result. However, for the case of dependent samples like our graphical model, such a condition results from the stochastic convergence of the -function which is not immediate.
For the rest of the proof, we present a brief sketch here for completeness. Due to concavity, we have the first order optimality conditions: for all , and . Using , we can combine the two optimality conditions together and obtain the following. For all ,
From Assumption 4, . From Cauchy-Schwarz and the first part of this theorem, . Canceling on both sides completes the proof. ∎
C.4 Proof of Theorem 4
1. We first show the strong consistency of , the parameter update of Algorithm 1, as an estimator of . This follows from standard techniques in the analysis of M-estimators. In particular, consider the set of sample paths such that and has a unique element . Such a set of sample paths has probability measure 1.
For all , and , with one of the above sample path ,
From Theorem 7, -almost surely, as . Therefore,
An equivalent argument is the following. -almost surely, for any there exists such that for all , . In particular, for any , let
From the identifiability assumption (Assumption 5), the RHS is positive. Therefore, such an assignment of is valid. Consequently, for all , and ,
which means that . Taking supremum over and , we summarize the argument as the following. -almost surely, for any there exists such that for all ,
Such a result is equivalent to the uniform (in and ) strong consistency of as an estimator of . As ,
This result is insufficient for Part 1, since is sample path dependent. To get rid of this sample path dependency, we use the dominated convergence theorem. Notice that -almost surely, for all , is bounded due to the compactness of . Therefore we have
For any , there exists such that for all ,
Applying Markov’s inequality, for any ,
Scaling yields the desirable result.
2. The proof of Part 2 is the same as [3, Theorem 5]. We present a sketch for completeness. For all , condition the following proof on the high probability event that .
Appendix D Proofs of auxiliary lemmas
In particular, the first three subsections develop a few essential lemmas required for the proofs in later subsections. In Appendix D.1, we show an important mixing property of the options with failure framework. In Appendix D.2, such a mixing property is used to prove a general contraction result of our forward-backward smoothing procedure (Theorem 1 and Corollary 6), similar to the concept of filtering stability in the HMM literature. At a high level, considering the forward-backward recursion in the extended graphical model (Corollary 6), this result characterizes the effect of changing and the boundary conditions and on the smoothing distribution , given any observation sequence . Due to this high level reasoning, we name this result as the smoothing stability lemma. Appendix D.3 provides concrete applications of this lemma to quantities defined in earlier sections.
D.1 Mixing
Recall that is the auxiliary parameter in the options with failure framework.
Lemma D.1 (Mixing).
There exists a constant and a conditional distribution parameterized by such that for all , with any input arguments , , and ,
Proof of Lemma D.1.
The proof is separated into two parts.
1. We first show an intermediate result: there exists a constant and a conditional distribution parameterized by such that for all , with any input arguments , and ,
This can be proved as follows. Let . Similar to the procedure in Appendix A, from the non-degeneracy assumption, the differentiabiilty assumption and being compact, we have . For any , with any input arguments and , let . Observe that . Let and
Clearly . Moreover, for any , .
On the other hand, with any input arguments,
which completes the proof of the first part.
2. Define as follows. With any input arguments, let
Clearly . Omit the dependency on for a cleaner notation since every term is parameterized by . When , with any other input arguments,
Similarly, when and ,
Finally, when and ,
Combining the above cases and the definition of completes the proof. ∎
D.2 Smoothing stability
Before stating the smoothing stability lemma, we introduce a few definitions. The quantities defined in this subsection depend on an observation sequence , but such a dependency is usually omitted to simplify the notation, unless specified otherwise. Consistent with our notations so far, in the following we make extensive use of the proportional symbol .
D.2.1 Forward and backward recursion operators
With any given observation sequence and any , define the filtering operator as the following. For any probability measure over , is also a probability measure such that with any input arguments and ,
| (21) |
The RHS has exactly the form of the forward recursion, therefore the recursion on both in (2) and in (10) can be expressed using . For generality, let and be any two indexed sets of probability measures such that and . We restrict and to be strictly positive. Due to Assumption 1, such a restriction is valid. Notice that and here can be equal. We use the seemingly more complicated notation because even if , and are still different; in this case they are just two different sets of probability measures satisfying the same recursion .
Similarly, we define the backward recursion operator as follows. For any probability measure over , is also a probability measure such that with any input arguments and ,
| (22) |
The recursion on both in (4) and in (11) can be expressed using . Let and be any two indexed sets of probability measures such that and . We restrict and to be strictly positive.
The operation is defined as follows: is an indexed set of probability measures such that for any input arguments and ,
| (23) |
D.2.2 Forward and backward smoothing operators
For any and any , with any observation sequence and any input arguments and , observe that
and
To simplify notation, let
| (24) |
Then,
| (25) |
where is a normalizing constant such that
From (25), we define the forward smoothing operator on the probability measure such that as probability measures,
The subscript in stands for forward. depends on the the parameters and , the observation and the specific choice of . In the general case of , is a nonlinear operator which requires rather sophisticated analysis. However, when , it is straightforward to verify that the normalizing constant , and becomes a linear operator.
In fact, the linear operator can be regarded as the standard operation of a Markov transition kernel on probability measures. With a slight overload of notation, define such a Markov transition kernel on , entry-wise, as the following. For any and in ,
| (26) |
We name this Markov transition kernel as the forward smoothing kernel. Such a definition is analogous to Markovian decomposition in the HMM literature [8]. The only caveat here is that we also allow perturbations on the parameter. The resulting operator is nonlinear and no longer corresponds to a Markov transition kernel.
To proceed, we characterize the difference between operators and when and are close. First, we show a version of Lipschitz continuity for the options with failure framework.
Lemma D.2 (Lipschitz continuity).
For all and , there exists a real number such that with any input arguments , , , and , the function defined in (24) is -Lipschitz with respect to on the set . Moreover, is upper bounded by a constant that does not depend on and .
Proof of Lemma D.2.
Due to Assumption 2, with any input arguments , , , and , is continuously differentiable with respect to . As continuously differentiable functions are Lipschitz continuous on convex and compact subsets, is Lipschitz continuous on , hence also on . The Lipschitz constants depend on the choice of input arguments , , , and .
We can let be the smallest Lipschitz constant on that holds for all input arguments , , , and . Clearly is upper bounded by any Lipschitz constant on that holds for all input arguments, which does not depend on and . ∎
Next, we bound the difference between operators and .
Lemma D.3 (Perturbation on the forward smoothing kernel).
Let be any probability measure on . Let and be defined with the same observation sequence and the same choice of . Their difference is only in the first entry of the superscript ( in ; in ). Then, for all , , , , and ,
Proof of Lemma D.3.
From the definitions, for any , , , , and ,
From the definition of the normalizing constant , we have
Therefore,
and
As a result, for any given , and ,
Combining everything together,
On the other hand, we can formulate a backward smoothing recursion as
| (27) |
where is a normalizing constant such that
The subscript in stands for backward. Similar to the forward smoothing operator , we can define the backward smoothing operator from (27) such that as probability measures,
Analogous to , in the general case of , is a nonlinear operator. However, if , becomes a linear operator and induces a Markov transition kernel. The following lemma is similar to Lemma D.3. We state it without proof.
Lemma D.4 (Perturbation on the backward smoothing kernel).
Let be any probability measure on . Let and be defined with the same observation sequence and the same choice of . Then, for any , , , , and ,
D.2.3 A perturbed contraction result for smoothing stability
For any with , let . Remember the following definition from Appendix D.2.1, with the index set restricted to : for any , and are two indexed sets of probability measures defined on such that, for all , (1) if , and ; (2) and are strictly positive on their domains. and are two indexed sets of probability measures defined on such that for all , (1) if , and ; (2) and are strictly positive on their domains. and are allowed to be equal.
The smoothing stability lemma is stated as follows.
Lemma D.5 (Smoothing stability).
With , , and defined above,
where is a positive real number dependent only on and . Specifically,
Intuitively, if , Lemma D.5 has the form of an exact contraction, which is similar to the standard filtering stability result for HMMs. Indeed, our proof uses the classical techniques of uniform forgetting from the HMM literature [8]. If is different from , such a contraction is perturbed. For HMMs, similar results are provided in [13, Proposition 2.2, Theorem 2.3].
Proof of Lemma D.5.
Consider the first bound. It holds trivially when . Now consider only . Using the forward smoothing operators, for any ,
Therefore,
where the first term is due to being a linear operator.
From Lemma D.3, the second term on the RHS is upper bounded by . As for the first term, we can construct the classical Doeblin-type minorization condition [8, Chap. 4.3]. Applying Lemma D.1 in the definition of the Markov transition kernel (26), we have
| (28) |
Observe that just defined is a probability measure. Further define entry-wise as
We can verify that is also a Markov transition kernel. Moreover,
To proceed, the standard approach is to use the fact that the Dobrushin coefficient of is upper bounded by one. For clarity, we avoid such definitions and take a more direct approach here, which requires the extension of the total variation distance for two probability measures to the total variation norm for a finite signed measure. For a finite signed measure over a finite set , let the total variation norm of be
When is the difference between two probability measures , the total variation norm of coincides with the total variation distance between and . Therefore, the same notation is adopted here.
Let be the set of finite signed measures over the finite set . From [8, Chap. 4.3.1], is a Banach space. Define an operator norm for as
Since is a Markov transition kernel, [8, Lemma 4.3.6]. Therefore,
The second inequality is due to the sub-multiplicativity of the operator norm. Finally, the desirable result follows from unrolling the summation and identifying the geometric series.
The proof of the second bound is analogous, using the backward smoothing operators instead of the forward smoothing operators. Details are omitted. ∎
Note that Lemma D.5 only holds when considering the options with failure framework. For the standard options framework, the one-step Doeblin-type minorization condition (28) we construct in the proof does not hold anymore, due to the failure of Lemma D.1. Instead, one could target the two-step minorization condition: define a two step smoothing kernel similar to and lower bound it similar to (28). Notations are much more complicated. For simplicity, this extension is not considered in this paper.
D.3 The approximation lemmas
This subsection applies Lemma D.5 to quantities defined in earlier sections.
First, we bound the difference of smoothing distributions in the non-extended graphical model (as in Theorem 1) and the extended one with parameter (as in Corollary 6). The parameter in the two models can be different. The bounds use quantities defined in Appendix D.1 and Appendix D.2. Recall the definition of from 8.
Lemma D.6 (Bounding the difference of smoothing distributions, Part I).
For all , and , with the observation sequence corresponding to any , we have
-
1.
,
-
2.
,
Similarly, we can bound the difference of smoothing distributions in two extended graphical models with different and different parameter .
Lemma D.7 (Bounding the difference of smoothing distributions, Part II).
For all and , with any two integers and the observation sequence corresponding to any , we have
It can be easily verified that in Lemma D.6 and Lemma D.7, the bounds still hold if and on the LHS are interchanged. We only present the proof of Lemma D.6. As for Lemma D.7, the proof is analogous therefore omitted. Our proof essentially relies on the smoothing stability lemma (Lemma D.5).
Proof of Lemma D.6.
Consider the first bound. For a cleaner notation, let
Apply Lemma D.5 as follows: , let and ; let and . Due to Assumption 1, the strictly positive requirement is satisfied. Then, we have
where denotes element-wise product and denotes Euclidean inner product. Therefore,
Next, we bound the difference of two-step smoothing distributions . Although the idea is straightforward, the details are tedious. For any , from (6) we have
The denominators are all positive due to the non-degeneracy assumption. It can be easily verified that the normalizing constants involved in the second and the third line cancel each other. As abbreviations, define
Then,
| (29) |
Now, we bound the two terms on the RHS separately. Consider the first term in (29),
| (30) |
Denote the two terms on the RHS of (30) as and respectively. To bound , we can apply Lemma D.5 on the index set as follows, assuming . For any , let and . For any , let , where is a normalizing constant. For , let . Then,
Such a bound holds trivially if .
Next, we bound as follows. Straightforward computation yields the following result.
where we use the definition of in (24).
D.4 Proof of Lemma C.1
Based on Lemma D.7, for all , and , with any observation sequence, both the sequences and are Cauchy sequences associated with the total variation distance. Moreover, the set of probability measures over the finite sample space is complete. Therefore, the limits of both and as exist with respect to the total variation distance. From the definitions of and in Appendix C.1, it is clear that their limits as do not depend on .
The Lipschitz continuity of also follows from Lemma D.7. Specifically, for all and , with any observation sequence,
The coefficient of on the RHS can be upper bounded by a constant that does not depend on and . The same argument holds for . ∎
D.5 Proof of Lemma C.2
For a cleaner notation, we omit the dependency on in the following analysis. From the definitions, for all and ,
where the last term is a small error term associated with such that,
The maximum on the RHS is finite due to the non-degeneracy assumption. Furthermore,
Since the bounds in Lemma D.6 hold for any , they also hold in the limit as . Therefore, for any , and any ,
For any , and any ,
Combining everything above,
where is a positive real number that only depends on and the structural constants , and . Due to Assumption 2, is continuous with respect to . Since is compact, . Therefore,
Taking supremum with respect to , and completes the proof. ∎
D.6 Proof of the strong stochastic equicontinuity condition (19)
First, for all and ,
Due to the boundedness of from Appendix C.2, we can apply the ergodic theorem (Lemma C.3). almost surely,
Notice that for all , , and ,
The RHS does not depend on . Due to Assumption 2, , and as functions of the parameter are uniformly continuous on , with any other input arguments. Therefore it is straightforward to verify that, for any ,
Applying the dominated convergence theorem,
D.7 Proof of Lemma C.5
Consider the following joint distribution on the graphical model shown in Figure 1: the prior distribution of is , and the joint distribution of the rest of the graphical model is determined by an options with failure policy with parameters and . Notice that this is the correct graphical model for the inference of the true parameter , since the assumed prior distribution of coincides with the correct one.
For clarity, we use the same notations as in Appendix B.3 for the complete likelihood function, the marginal likelihood function and the (unnormalized) -function. Specifically, such quantities used in this proof have the same symbols as those defined in Appendix B.3, but mathematically they are not the same.
Parallel to Appendix B.3, the complete likelihood function is
The marginal likelihood function is
Let be the conditional distribution of given . For any ,
Therefore, for the inference of considered in this proof, the (unnormalized) -function can be expressed as
We can rewrite using the structure of the options with failure framework, drop the terms irrelevant to and normalize using . The result is the following definition of the (normalized) -function:
We draw a comparison between and defined in (7): their difference is in the first term of . Maximizing with respect to is equivalent to maximizing the (unnormalized) -function . In Algorithm 1, since is unavailable, we use as its approximation.
depends on the observation sequence, therefore it is a function of a sample path . In the following we explicitly show this dependency by writing . Clearly, for all , and ,
Combining this with the stochastic convergence of as shown in Theorem 2, we have, that for any , as ,
Using the dominated convergence theorem, such a convergence holds in expectation as well. For any ,
Since maximizing with respect to is equivalent to maximizing the (unnormalized) -function , the standard monotonicity property of the EM update holds as well. For all , and ,
Taking expectation on both sides, we have
due to the non-negativity of the Kullback-Leibler divergence. Therefore, , and in the limit we have for all . Applying the identifiability assumption for the uniqueness of completes the proof. ∎
Appendix E Additional experiments and details omitted in Section 5
E.1 Generation of the observation sequences
We first introduce the method to sample observation sequences from the stationary Markov chain induced by the expert policy. Using the expert policy and a fixed pair, we generate 50 sample paths of length 20,000. Then, the first 10,000 time steps in each sample path are discarded, and the rest state-action pairs are saved as the observation sequences used in the algorithm. For different , we just take the first time steps in each observation sequence.
Such a procedure is motivated by Proposition 5: it can be easily verified that Assumption 1 and 2 hold in our numerical example. Therefore, from Proposition 5, the distribution of approaches the unique stationary distribution regardless of the initial pair. In this way, Assumption 3 is approximately satisfied.
E.2 Analytical expression of the parameter update
For our numerical example, the parameter update of Algorithm 1 has a unique analytical solution. For all , , and , we first derive the analytical expression of which is the updated parameter for based on the previous parameter . Such a notation for parameter updates is borrowed from Assumption 5. Using the expression of the -function (7), we have
where on the RHS is the state value from the sample path . We omit on the RHS for a cleaner notation. Let denote the sum inside the argmax. Then,
Taking the derivative of , we can verify that is strongly concave. Therefore, the parameter update for is unique.
where is the unconstrained parameter update given as
Similarly, the unconstrained parameter updates for and are the following:
where the . The parameter updates and are the projections of and onto , respectively.
E.3 Supplementary results to Figure 3
In this subsection we present supplementary results to Figure 3. In Figure 3, is defined as the average of over all the 50 sample paths. Here, we divide the set of sample paths into smaller sets and evaluate the average of over these smaller sets separately. The settings for the computation of parameter estimates are the same as in Section 5. The following procedure serves as the post-processing step of the obtained parameter estimates.
Concretely, as defined in Section 5, we obtain a sequence after running Algorithm 1 with any sample path and any . After fixing and letting , is a function of only. With a given threshold interval , we define a smaller set of sample paths as the set of with greater than the -th percentile and less than the -th percentile. Let be the average of over this smaller set of sample path specified by interval . For , the values of with specific choices of are plotted below. If , is equivalent to investigated in Section 5.
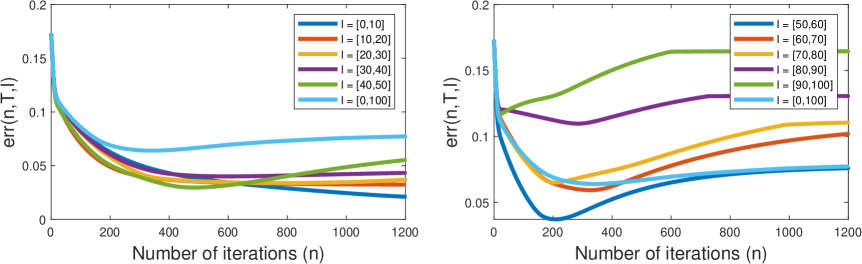
Figure 5 suggests that with probability around 0.6, our algorithm with the particular choice of and achieves decent performance, decreasing the original estimation error by at least a half. A worth-noting observation is that, for all the choices of (including representing the failed sample paths), roughly follows the same exponential decay in the early stage of the algorithm (roughly the first 10 iterations). The same behavior can be observed for and as well. It is not clear whether this behavior is general or specific to our numerical example. Detailed investigation is required in future work.
E.4 Varying
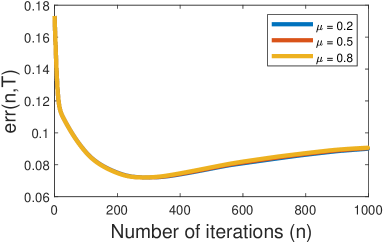
In this subsection we investigate the effect of on the performance of Algorithm 1. Intuitively, from the uniform forgetting analysis throughout this paper, it is reasonable to expect that at each iteration, the effect of on the parameter update is negligible if is large. However, such a negligible error could accumulate if is large. The effect of on the final parameter estimate is not clear without experiments.
We use the same observation sequences as in Section 5. is fixed as 5000. , and the parameter space for all the three parameters remains the same as . For all , . The performance of the algorithm is evaluated by defined in Section 5. The result is presented in Figure 6, which shows that indeed, the effect of on the final performance of the algorithm is negligible. For , is higher than .
E.5 Random initialization
Up to this point, all the empirical results use the same initial parameter estimate on all the 50 sample paths. In this subsection, we evaluate the effect of the initial estimation error on the performance of the algorithm, by applying random . Such a randomization is not considered in Section 5 since more explanations are required.
In this experiment, we use the same observation sequences as in Section 5. is fixed to 8000. For all , . The parameter space for all the three parameters remains the same as . For each observation sequence, we first generate three independent samples , and uniformly from the interval . Then, is generated as follows: with a scale factor , let , and . As a result, dependent on is different for different observation sequences. The choices of are not symmetrical with respect to due to the restriction of the bounded parameter space. For the parameter estimates obtained from the computation, is defined as in Section 5. The result is shown in Figure 7.

From Figure 7, the curves corresponding to and qualitatively match the performance guarantee in Theorem 4. The algorithm achieves decent performance when is intermediate (the case of ), where the average estimation error is reduced by at least a half. If is small (the case of ), the parameter estimates cannot improve much from . If is large (the case of ), the algorithm cannot converge to the vicinity of the true parameter, which is consistent with our local convergence analysis.