PROV-IO+: A Cross-Platform Provenance Framework for Scientific Data on HPC Systems
Abstract
Data provenance, or data lineage, describes the life cycle of data. In scientific workflows on HPC systems, scientists often seek diverse provenance (e.g., origins of data products, usage patterns of datasets). Unfortunately, existing provenance solutions cannot address the challenges due to their incompatible provenance models and/or system implementations.
In this paper, we analyze four representative scientific workflows in collaboration with the domain scientists to identify concrete provenance needs. Based on the first-hand analysis, we propose a provenance framework called PROV-IO+, which includes an I/O-centric provenance model for describing scientific data and the associated I/O operations and environments precisely. Moreover, we build a prototype of PROV-IO+ to enable end-to-end provenance support on real HPC systems with little manual effort. The PROV-IO+ framework can support both containerized and non-containerized workflows on different HPC platforms with flexibility in selecting various classes of provenance. Our experiments with realistic workflows show that PROV-IO+ can address the provenance needs of the domain scientists effectively with reasonable performance (e.g., less than 3.5% tracking overhead for most experiments). Moreover, PROV-IO+ outperforms a state-of-the-art system (i.e., ProvLake) in our experiments.
Index Terms:
Data provenance, high performance computing (HPC), workflows, HPC I/O libraries, scientific data management.1 Introduction
1.1 Motivation
Data-driven scientific discovery has been well acknowledged as a new fourth paradigm of scientific innovation [1]. The shift toward the data-driven paradigm imposes new challenges in data findability, accessibility, interoperability, reusability (i.e., FAIR principles [2, 3]) and trustworthiness [4], all of which demand innovative solutions for modeling and capturing provenance, i.e., the lineage of data life cycle.

As an example, Figure 1 shows a simplified scientific workflow which analyzes geophysical sensing data on high performance computing (HPC) systems (i.e., DASSA [5]) . The workflow takes geophysical data as input, which are often stored in different file formats (e.g., “.tdms”, “.h5”). It then converts non-HDF5 files into a uniform HDF5 format (i.e., “.h5”). Depending on the analysis goals, the workflow further applies a set of analysis programs (e.g., “Decimate”, “X-Correlation-Stacking”) to process the files, the results of which are stored as data products in HDF5 format.
Based on our survey, the domain scientists using DASSA need the fine-grained origin of the data products (i.e., backward data lineage). For example, User A applies the “Decimate” program with a number of HDF5 files as input and generates a set of data products. Another User B may query the origin of the datasets in the final data products to understand which datasets in the input files contributed to which portions of the final data products, or who initiated the “Decimate” application to generate the data products and when. Such provenance information is important for ensuring the reproducibility, explainability, and security of the DASSA data.
Nevertheless, the DASSA workflow involves multiple programs accessing multiple files using different I/O interfaces and operations (e.g., HDF5 and POSIX), which makes tracking and deriving the data provenance non-trivial. Moreover, as we will elaborate in Section §3, there are other diverse needs of provenance for different scientific workflows and data (e.g., I/O statistics, configuration lineage). Such diversity, complexity, as well as the stringent performance requirement in HPC environments call for a practical solution beyond the state of the art.
1.2 Limitations of State-of-the-art Tools
Unfortunately, to the best of our knowledge, existing provenance tools cannot address the grand challenge above sufficiently due to a number of limitations:
First, while the importance of provenance has been well recognized across communities in general (e.g., databases [6, 7, 8, 9, 10], operating systems (OS) [11, 12], eScience [13, 14, 15, 16, 17]), there is a lack of concrete understanding of the exact provenance needs of domain scientists, largely due to the variety of data and metadata that could be generated from HPC systems. As a result, existing solutions are often too coarse-grained (e.g., whole file tracking without understanding HPC data formats [11]) to help domain scientists effectively, or too specific for one use case (e.g., Machine Learning [18]) to support general needs.
Second, in terms of provenance modeling, we find that existing standards (e.g., W3C PROV [19]) are too vague to describe the characteristics of scientific data provenance precisely. Scientists often seek a variety of information from scientific workflows on HPC systems, including the origins of data products, the configurations used for deriving results, the usage patterns of datasets, and so on, which cannot be described effectively using any existing provenance models. Such ambiguity limits the capability of existing provenance solutions for describing scientific data.
Third, in terms of usability, existing approaches often require the users to identify the critical code sites in the workflow software (e.g., loop structure [20]) and manually insert API calls to track the desired information accordingly. Moreover, they often rely on many external packages to work properly, which make it difficult to deploy and use them on different HPC platforms. The labor-intensive and error-prone approaches, together with the portability and compatibility issues, hinder the wide adoption of provenance products and diminishes the potential benefits.
Note that the limitations highlighted above are correlated. For example, the lack of understanding of provenance needs and the ambiguity of the provenance model are contributing to each other, which fundamentally limits the usability of existing solutions in terms of granularity, expressibility, etc., which in turn makes clarifying the ambiguity and real needs difficult.
1.3 Key Insights & Contributions
We tackle the grand challenge of provenance support for scientific data on HPC systems in this paper.
First, we observe that for a provenance framework to be practical and useful, inputs from the end users (i.e., domain scientists) is essential. Therefore, we collaborate with domain scientists to analyze four representative scientific workflows in depth. In doing so, we identify the unique characteristics of the workflows studied (e.g., I/O interfaces, data formats, access patterns) as well as the specific needs for scientific data provenance (e.g., lineage at file, dataset, or attribute granularity).
Second, we observe that I/O operations are critically important in affecting the state of data that form the lineage needed by the domain scientists. Therefore, different from existing solutions [20, 21, 22], we introduce an I/O-centric provenance model dedicated for the HPC environments. The model enriches the W3C PROV standard [19] with a variety of concrete sub-classes, which can describe both the data and the associated I/O operations and execution environments precisely with extensibility. Moreover, it enables us to decouple the data provenance from specific executions of a workflow and support the integration of provenance from multiple runs naturally, which is important as workflows may evolve over time.
Third, based on the fine-grained provenance model, we find that the rich I/O middleware already used by the scientists provide an ideal vehicle for capturing the desired provenance transparently. Therefore, we create a configurable and extensible library and integrate it with existing I/O code paths (e.g., HDF5 I/O and POSIX syscalls) to capture necessary information without requiring the scientists to modify the source code of their workflows. Moreover, to further improve the usability, we persist the captured provenance as standard RDF triples [23] and enable provenance query and visualization.
Forth, through the communication with domain scientists in the industry, we notice the increasing importance of supporting containerization [24]. By wrapping the HPC workflows together with their dependencies in containers, the containerization techniques can effectively reduce the burden of software maintenance and thus enable more desired features including reproducibility, reusability, interoperability, etc. Therefore, a provenance framework should be generic enough to handle provenance in both containerized and non-containerized scenarios.
Based on the key ideas above, we build a framework called PROV-IO+, which can provide end-to-end provenance support for domain scientists with little manual effort across platforms. We deploy PROV-IO+ on representative supercomputers and evaluate it with realistic workflows. Our experiments show that PROV-IO+ incurs reasonable performance overhead and outperforms a state-of-the-art provenance product (i.e., IBM ProvLake [20]) for the use cases evaluated. More importantly, through the query and visualization support, PROV-IO+ can address the provenance needs of the scientists effectively.
In summary, we have made the following contributions:
-
•
Identifying concrete provenance needs of domain scientists based on four representative scientific workflows;
-
•
Designing a comprehensive PROV-IO+ model to describe the provenance of scientific data precisely and extensibly;
-
•
Building a practical prototype of PROV-IO+ which can support different HPC workflows with little human efforts in both containerized and non-containerized scenarios;
-
•
Measuring the PROV-IO+ prototype in HPC environments and demonstrating the efficiency and effectiveness;
-
•
Releasing PROV-IO+ as an open-source tool to facilitate follow-up research on provenance in general.
1.4 Experimental Methodology & Artifact Availability
Experiments were performed on three state-of-the art platforms, including LBNL Cori Supercomputer [25], Samsung SAIT Supercomputer (SuperCom) [26], and Google Cloud Platform (GCP) [27]. First, in terms of non-containerized scenario, we applied PROV-IO+ to three scientific workflows (i.e., DASSA [5], Top Reco [28], and an I/O-intensive application based on H5bench [29]) on the Cori supercomputer. Second, in terms of containerized scenario, we applied PROV-IO+ to analyze one deep learning workflow (i.e., Megatron-LM [30]) on SuperCom. As will be discussed in §3, these use cases cover diverse characteristics (e.g., various languages, file formats, I/O interfaces, metadata) and provenance needs (e.g., file/dataset/attribute lineage, metadata versioning, I/O statistics). We varied the critical parameters of the workflows to measure the run-time performance and storage requirements under a wide range of scenarios. Third, we examined container’s impact on provenance tracking with Megatron-LM [30] on the Google Cloud Platform where we can schedule both containerized and non-containerized workflows and perform a fair comparision. In addition, we compared PROV-IO+ with ProvLake [20] using the Python-based Top Reco workflow as ProvLake only supports Python at the time of this writing. The PROV-IO+ prototype is open-source at https://github.com/hpc-io/prov-io.
2 Background
2.1 W3C Provenance Standard
The PROV family of specifications, published by the World Wide Web Consortium (W3C), is a set of provenance standard to promote provenance publication on the Web with interoperability across diverse provenance management systems [31]. One key specification is PROV-DM, an extensible relational model which describes provenance information with a graph representation. As shown in Figure 2, a W3C provenance graph abstracts information into classes of Entity, Activity, Agent, and Relation between the first three classes. Another critical specification is PROV-O which describes the mapping of PROV-DM classes to RDF triples. In PROV-O, Entity, Activity and Agent are mapped to subjects and objects, while Relation is mapped to predicates. We follow the W3C PROV standard in the PROV-IO+ design.

2.2 HPC I/O Libraries
I/O libraries (e.g., ADIOS [32], HDF5 [33], and NetCDF [34]) play an essential role in scientific computations. Many workflows leverage the library I/O to manipulate data files. For example, HDF5 (i.e., Hierarchical Data Format version 5) is one of the the most wildly used I/O libraries for scientific data [35]. It is developed to be a parallel data management middleware to bridge the gap between HPC applications and the complicated, low-level details of underlying file systems, and has grown to a popular data format and management system.
In this work, we integrate our solution with the HDF5 library besides the classic POSIX I/O operations. This is based on the observation that HDF5 has evolved with a Virtual Object Layer (VOL) which can intercepts object-level API operations to functional plugins, called VOL Connectors [36]. VOL connectors allow third-party developers to add desired storage functionalities, which can be loaded dynamically at runtime. We leverage such extensibility for tracking the provenance of HDF5 I/O data.
3 Case Studies
Use Case Description I/O Interface Provenance Need Top Reco training GNN models for top quark reconstruction; multi-program, multi-file; POSIX metadata version control & mapping DASSA parallel processing of acoustic sensing data; multi-program, multi-file; HDF5 & POSIX backward lineage of data products H5bench simulating typical I/O patterns of HDF5 app; multi-program, single-file; HDF5 I/O statistics & bottleneck Megatron-LM parallel transformer model for NLP; multi-program, multi-file; POSIX Checkpoint-configuration consistency
In this section, we discuss four real-world use cases to motivate the I/O-centric provenance further. For each case, we describe its semantics and characteristics, the provenance need of the domain scientists, and the associated challenges.
3.1 Top Reco - Lineage of configurations
Workflow Description. Top Reco [28] is a Machine Learning (ML) workflow in high-energy physics data analysis, which uses Graph Neural Network (GNN) models for top quark reconstruction. Top quarks are the elementary particles with the most mass that may decay quickly and are not detectable directly due to their mass. By representing particles and their relationships as graphs, the GNN-based workflow can help reconstruct top quarks more accurately and efficiently, which is important for physics discoveries.
In Figure 3, we show the key steps of the Top Reco workflow. First, the workflow takes two types of files as input, including the “.root” file for input event and the “.ini” file for configuration. Second, it generates “.tfrecord” files which stores the training dataset and test dataset based on the input events. Third, it trains a GNN model with the training dataset and tests the model with the test dataset by accessing the “.tfrecord” files. Fourth, a range of scores of edge and nodes are generated as the output of the model. Finally, a reconstructor component runs a simulation of reconstructing the top quarks based on highest scores. As summarized in Table I, the Top Reco workflow uses the POSIX I/O interface, and involves multiple programs accessing multiple files.

Provenance Need. In the Top Reco case, the domain scientists are interested in the impact of GNN configurations on the model performance. Specifically, they would like to know which combination of model hyperparameters and dataset preselections result in the best training accuracy. In other words, they would like to have fine-grained version control of the metadata (e.g., hyperparameters, preselections) as well as the correlation between the metadata and the result to ensure the explainability and reproducibility.
Challenges. Essentially, the Top Reco case requires automatic version control management on the machine learning model. However, a typical version control system (e.g., Git) cannot meet the requirements because it cannot automatically track the model performance and maps the performance to the model configuration. In practice, the scientists may need to execute the workflow for multiple times with different configurations, and each execution may take multiple hours or more. Due to lack of provenance support, the scientists have to manually make a new copy of configuration when they start a new run, and record the corresponding result later. Such common practice is time-consuming and not scalable. In other words, a new provenance framework is urgently needed.
3.2 DASSA - Lineage of Data Products
Workflow Description. As mentioned in Section §1.1, DASSA [5] is a parallel storage and analysis framework for distributed acoustic sensing (DAS). It uses a hybrid (i.e., MPI and OpenMP) data analysis execution engine to support efficient and automated parallel processing of geophysical data in HPC environments, which has been applied for accelerating a variety of scientific computations including earthquake detection, environmental characterization, and so on. The overall workflow is described in Figure 1.
Provenance Need. As discussed in Section §1.1, the domain scientists need the backward data lineage to understand the origin of the data products and to ensure the data reproducibility, explainability, and security, among others.
Challenges. The DASSA workflow may involve multiple different programs, file formats, I/O interfaces, and end users, which is representative for large-scale scientific workflows in HPC environments. Moreover, both the file level and the sub-file level (e.g., inner hierarchies of the HDF5 format) information is needed. To the best of our knowledge, none of the existing provenance models or systems can handle the complexity to meet the comprehensive needs.
3.3 H5bench - Data usage and I/O performance
Workflow Description. H5bench [29] is a parallel I/O benchmark suite for HDF5 [37] that is representative of various large-scale workflows. It includes a default set of read and write workloads with typical I/O patterns in HDF5 applications on HPC systems, which enables creating synthetic workflows to simulate diverse HDF5 I/O operations in HPC environments. The benchmark also contains ‘overwrite’ and ‘append’ operations that allow modifying data or metadata of existing files and appending new data, respectively. We collect an H5bench-based workflow which contains a combination of ‘write’, ‘overwrite’, ’append’ and ‘read’ workloads operating on HDF5 files via MPI. This workflow simulates the typical scenarios where a single file may be accessed concurrently by HPC applications and multiple versions of a dataset may be generated accordingly. As shown in Table I, the H5bench-based workflow mainly uses the HDF5 I/O interface, and involves multiple programs accessing a single file.
Provenance Need. Understanding frequently accessed data in large datasets leads to optimizing I/O performance by improved data placement and layout. Scientists typically use the H5bench-based workflow to collect I/O statistics and identify potential bottlenecks on HPC systems. While I/O profiling tools, such as Darshan [38] and Recorder [39] collect coarse-grained statistics of I/O performance, there are no tools to extract data access information and the cost of those operations. Fine-grained information such as the total number of each type of HDF5 I/O operations incurred during the workflow, the accumulated time cost for each type of operations, the distribution of operations and time overhead, the HDF5 APIs invoked at a specific time point, etc. would be critically important for understanding the system behavior and fine-tuning the performance.
Challenges. The H5bench use case involves handling HDF5 datasets concurrently and measuring diverse fine-grained metrics at the HDF5 API level, which requires deep understanding of the semantics and internals of HDF5. Since existing solutions are largely incompatible with HDF5, they are fundamentally inapplicable for this important category of use cases.
3.4 Megatron-LM - Checkpoint Consistency
Workflow Description. Megatron-LM is based on Megatron, which is a powerful transformer (i.e., a type of deep learning models) developed by NVIDIA [30, 40, 41]. Megatron supports training large transformer language models at scale, which is achieved by providing efficient, model-parallel (tensor, sequence, and pipeline), and multi-node pre-training of transformer-based models (e.g., GPT [42], BERT [43], and T5 [44]) using mixed precision. Megatron-LM scales the transformer training by supporting data parallelism and model parallelism further. Specifically, the data parallelism is achieved by splitting the input dataset across specified devices (e.g., GPUs); on the other hand, the model parallelism is implemented by splitting the execution of a single transformer module over multiple GPUs working on the same dataset. Both data parallelism and model parallelism features can be optionally configured in the workflow, and they are both enabled in this study for completeness. Figure 4 shows a simplified overview of the Megatron-LM workflow. First, a training corpus (“.json”) is preprocessed by the data processing module, which generates a binary file (“.bin”) and an index file (“.idx”). The preprocessed data become the input of the pretraining transformer models. A trained model (i.e., checkpoint) will be generated at the end of pretraining, and it can be used in the follow-up evaluation or text generation. Users may also skip the pretraining step if they already have a trained model available.
Provenance Need. In the Megatron-LM workflow, the consistency between pretraining models’s checkpoint and the corresponding configuration is important. The checkpoint mainly records the metadata of the previous pretraining process, such as micro/global batch size and state of optimizer/scheduler, which are dependent on the configuration parameters. Blindly modifying configuration parameters in the next pretraining could easily result in various types of errors (e.g., network errors, test code errors). Moreover, many configuration parameters are tightly correlated with each other, changing configuration parameters without preserving the correlation may also lead to failures. In addition, adjusting pretraining hyperparameters incautiously may affect the model quality negatively (e.g., result in overfitting). Therefore, in the Megatron-LM use case, the domain scientists want to track the checkpoint and configuration provenance to ensure the checkpoint-configuration consistency.
Challenges. The challenge for the Megatron-LM workflow is two-fold. First of all, the workflow involves hundreds of configuration entries and checkpointed statuses which are difficult to track or reason by human. Due to the lack of tool support, the domain scientists cannot manage checkpoints generated by multiple training processes conveniently and identify a qualified checkpoint and the associated configurations consistent with new training processes.
Moreover, with the growing popularity of container technologies [45, 46], HPC systems have started to be integrated with container-based job runtime tools [24]. In such HPC systems, large-scaled parallel pretraining models are executed in a containerized environment, which largely avoids tedious efforts in resolving installation or runtime dependencies (e.g, PyTorch [47] and nccl [48]). Besides the challenge of the Megatron-LM workflow itself, the domain scientists using the workflow would like to execute the workflow in a containerized HPC environment. Since a container is an isolated environment by design where application cannot directly interactive with the host system, how to containerized Megatron-LM and track provenance information of the containerized workflow at scale on HPC systems is another major challenge in this use case.

Note that both Megatron-LM and Top Reco ( §3.1) belong to deep learning provenance use cases. However, Megatron-LM has two major differences compared to Top Reco. First, in Megatron-LM, the provenance need is checkpoint-configuration consistency, while Top Reco’s provenance need is configuration version control. Second, Top Reco is a traditional single thread workflow, while Megatron-LM is a containerized parallel workflow, which introduces more challenges in terms of both provenance tracking and provenance storage.
3.5 Summary
By analyzing the four cases in depth and consulting with the domain scientists, we find that there is a big gap between the provenance needs and existing solutions. The variety of the workflow characteristics (e.g., different I/O interfaces and file formats) as well as the diversity of scientists’ needs motivates us to design a comprehensive provenance framework to address the challenge, which we elaborate in the following sections.
4 PROV-IO+ Design
In this section, we introduce the design of PROV-IO+. We focus on the provenance model (§4.1) and its system architecture (§4.2), which are two fundamental pillars of PROV-IO+. We defer additional implementation details to the next section (§5).


4.1 PROV-IO+ Model
Figure 5(a) shows an overview of the PROV-IO+ model, which is derived based on the W3C standard (§2.1) as well as the characteristics of typical workflows and the provenance needs of domain scientists (§3).
Following the W3C specification, we classify information into five PROV-IO+ super-classes: Entity (yellow boxes in Figure 5(a)), Activity (purple boxes), Agent (orange boxes), Extensible Class (green boxes) and Relation (text on arrows). Moreover, we introduce a variety of concrete sub-classes to enrich the model, which can capture the data with different granularity as well as the associated I/O operations and execution environments for deriving the data. We summarize the definitions of the sub-classes in Table II and highlight the main concepts added to each super-class as follows:
| Super-class | Sub-class | Description |
|---|---|---|
|
Data Object
Directory |
POSIX file system directory. | |
| Data Object File | POSIX file system file. | |
| Data Object Group | I/O library interior group structure (e.g., HDF5 group). | |
| Entity | Data Object Dataset | I/O library interior dataset structure (e.g. , HDF5 dataset). |
| Data Object Attribute | POSIX Inode extended attribute and I/O library interior attribute structure (e.g., HDF5 attribute). | |
| Data Object Datatype | I/O library interior datatype structure (e.g., HDF5 datatype). | |
| Data Object Link | POSIX file system hard/soft link. | |
| I/O API Create | POSIX syscall “open” and I/O library “Create” APIs (e.g., H5Acreate). | |
| I/O API Open | I/O library “Open” APIs (e.g., H5Aopen). | |
| I/O API Read | POSIX syscall “read” (and variants) and I/O library “Read” APIs (e.g., H5Aread). | |
| Activity | I/O API Write | POSIX syscall “write” (and variants) and I/O library “Write” APIs (e.g., H5Awrite). |
| I/O API Fsync | POSIX syscall “fsync” (and variants) and I/O library “Flush” APIs (e.g., H5Flush). | |
|
I/O API
Rename |
POSIX syscall “rename” (and variants) and I/O library “Rename” APIs. | |
| User | Workflow user. | |
| Agent | Rank | Individual MPI rank. |
| Program | Program instance. | |
| Thread | A thread of a program. | |
| Checkpoint | Checkpoint information of a program/workflow (e,g, checkpoint path, checkpoint status). | |
| Extensible Class | Type | Type of a program/workflow (e.g., Machine Learning (Top Reco), Acoustic Sensing (DASSA)). |
| Configuration | Workflow configurations (e.g., hyperparameter in Top Reco). | |
| Metrics | Evaluation metrics of the workflow. E.g., model accuracy in Top Reco. | |
|
provio:
wasCreatedBy |
The relation between a I/O API Create and a Data Object. | |
|
provio:
wasOpenedBy |
The relation between a I/O API Open and a Data Object. | |
| Relation |
provio:
wasReadBy |
The relation between a I/O API Read and a Data Object. |
|
provio:
wasWrittenBy |
The relation between a I/O API Write and a Data Object. | |
|
provio:
wasFlushedBy |
The relation between a I/O API Fsync and a Data Object. | |
|
provio:
wasModifiedBy |
The relation between a I/O API Rename and a Data Object. |
4.1.1 Entity
This PROV-IO+ super-class includes seven specific Data Object sub-classes (i.e., Directory, File, Group, Dataset, Attribute, Datatype, Link). Together, these sub-classes cover common I/O structures and file formats. For example, Attribute is a combined sub-class that can map to both the HDF5 attributes and the extended attributes of an inode in a POSIX-compliant Ext4 file system [49].
4.1.2 Activity
This super-class includes six specific I/O API sub-classes (i.e., Create, Open, Read, Write, Fsync, Rename). These sub-classes cover a wide range of commonly used I/O operations in HPC environments. For example, Read can map to HDF5 read-family operations (e.g., “H5Gread”, “H5Dread”, “H5Aread”, “H5Tread”) and POSIX system call “read” and its variants. Note that these operations are applicable to other I/O libraries too (e.g., NetCDF [34]).
4.1.3 Agent
This super-class includes a set of sub-classes representing the operator of a series of activities, such as Thread, User, Rank, and Program. This fine-grained representation is necessary because HPC applications are typically multi-threaded and are executed in parallel (e.g., a group of MPI processes with different ranks running on a cluter of nodes).
4.1.4 Extensible class
This super-class contains properties pertained by entities, activities and agents. It is designed to be extensible because valuable information is often workflow-specific. In the current prototype, we define four generic sub-classes (i.e., Checkpoint, Type, Configuration, Metrics) to cover a variety of valuable information that cannot be described precisely in the native W3C specification (e.g., hyperparameters of ML models, checkpoints of AI model training).
4.1.5 Relation
This super-class describes the diverse relations among other classes. We inherit the basic W3C provenance relations between entity & entity (prov:wasDerivedFrom), entity & agent (prov:wasAttributedTo), activity & agent (prov:AssociatedWith), agent & agent (prov:actedOnBehalfOf). Moreover, we introduce new relations between entity & activity to precisely describe the relations between various I/O API and Data Object sub-classes (e.g., provio:wasCreatedBy, provio:wasReadBy, provio:wasWrittenBy, provio:wasModifiedBy).
To make the description more concrete, we show an example snippet of provenance captured by PROV-IO+ in Figure 5(b). The provenance snippet contains five records pertained by different subjects. Each subject can be an Agent (e.g., “Bob”, “MPI_rank_0”), an Activity (e.g., “H5Dcreate2–b1”), or an Entity (e.g., “/Timestep_0/x”). Each record is a series of triples starting with a unique subject, where the triples describe provenance information of a subject. Note that the record length may vary depending on the provenance information associated with the subject. Given this snippet, we can derive complex provenance information (e.g., dataset “/Timestep_0/x” was created by I/O API “H5Dcreate2–b1” associated with program “vpicio_un_h5.exe–a1” on thread “MPI_rank_0”, which was started by user “Bob”).
4.2 PROV-IO+ Architecture
Figure 6 shows the architecture of the PROV-IO+ framework, which supports two usage modes: Mode #1 (Figure 6a) provides provenance support for traditional non-containerized workflows on HPC systems; Mode #2 (Figure 6b) supports containerized workflows. There are five components in total, including: (1) the PROV-IO+ model (yellow) to specify the provenance information §4.1; (2) a provenance tracking engine (blue modules) which captures I/O operations from multiple I/O interfaces; (3) a provenance store (green) which persists captured provenance into RDF triples; (4) a user engine (red) for users to query and visualize provenance information; (5) a containerizer engine (purple) to support other components in containerized environments.
Among the five components, the PROV-IO+ model (yellow) has been discussed in details in §4.1. We introduce the other three common components used in both modes (i.e., provenance tracking, provenance store, and user engine) one by one in §4.2.1, and then discuss the containerizer engine for supporting containerized workflows in §4.2.2.


4.2.1 Mode #1: Support for Classic Workflows
To provide provenance support for the classic, non-containerized workflows (i.e., Mode #1), PROV-IO+ leverages three major components based on its provenance model (§4.1) as follows:
Provenance Tracking. As shown in Figure 6a, a scientific workflow is typically started on compute nodes. The workflow may consist of several parallel applications with multiple threads running concurrently. During the workflow execution, all I/O operations (e.g., POSIX and HDF5) are monitored by PROV-IO+ for provenance collection.
Specifically, the Provenance Tracking component contains two thin modules (i.e., PROV-IO+ Lib Connector and PROV-IO+ Syscall Wrapper) for monitoring the library I/O and POSIX I/O operations respectively. In case of the HDF5 library, the PROV-IO+ Lib Connector monitors the I/O requests within the HDF5 Virtual Object Layer (VOL). In case of POSIX, the I/O syscalls are monitored through the PROV-IO+ Syscall Wrapper which is configurable via environmental variables. In both cases, PROV-IO+ let the native I/O requests pass through and invoke the core PROV-IO+ Library for collecting the provenance defined by the PROV-IO+ model without changing the original I/O semantics.
Note that both the library I/O and POSIX I/O operations can be tracked in a transparent and non-intrusive way from the workflow’s perspective, which is important for usability.
In addition, to achieve extensibility, we provide a set of PROV-IO+ APIs which enables users to convey user/workflow-specific semantics and requirements to PROV-IO+ (i.e., Extensible Class in PROV-IO+ model). Similar to ProvLake [20], users can instrument their workflows with PROV-IO+ APIs as needed (e.g., tracking a specific hyperparameter of a ML workflow). By providing such flexibility, additional provenance needs can be satisfied by PROV-IO+ conveniently.
Provenance Store. The Provenance Store component maintains the provenance information as RDF graphs durably on the underlying parallel file system to enable future queries. We choose an RDF triplestore instead of a traditional SQL database for two main reasons: (1) W3C PROV-DM already has a well-defined ontology (i.e., PROV-O[19]) to map the model to RDF, so using RDF makes PROV-IO+ compatible with other W3C-compliant solutions; (2) To answer path queries in provenance use cases, SQL queries with repeated self-joins are necessary to compute the transitive closure, which often leads to worse performance when the provenance grows [50].
More specifically, the Provenance Store component provides an interface for the PROV-IO+ Library to manipulate provenance records and maintain provenance graphs efficiently, which includes creating a new provenance RDF graph in memory, loading an existing graph, inserting new records to an existing graph, etc. To minimize the performance impact on the workflow, the in-memory provenance graph is serialized to the Provenance Store asynchronously. And depending on the need of the user, the serialization operation may be triggered either periodically or by the end of the workflow.
PROV-IO+ User Engine. The provenance information could be enormous due to the complexity of scientific workflows. To avoid distraction and help users derive insights, the PROV-IO+ User Engine component allows users to enable/disable individual sub-classes defined in the PROV-IO+ model, which also enables flexible tradeoffs between completeness and overhead.
Moreover, the engine provides a query interface to allow the user to issue queries on the provenance generated by PROV-IO+. Moreover, it includes a visualization module to visualize the provenance (sub)graphs requested by the user. Note that both the query and the visualization need to follow the PROV-IO+ model, which enforces a uniform way to represent the rich provenance information.
Note that in the preliminary version of the prototype [51], the user engine only provides a basic query interface to users. As a result, users have to issue query preimitives one by one to achieve a complicated provenance query. In the current prototype, PROV-IO+ is further equipped with a set of high-level integrated query APIs for answering typical provenance needs, which can simplify the query complexity and improve the usability for end users further. For example, in the DASSA use case, to track the backward lineage of an output file, an user only needs to provide the name of the file and the level of predecessor through the integrated query APIs, which will retrieve the provenance information conveniently.
4.2.2 Mode #2: Support for Containerized Workflows
To provide provenance support for containerized workflows, PROV-IO+ includes an additional component called containerizer besides the components discussed above.
The containerizer engine provides two main functionalities. First, it assembles the target workflows (including their dependencies) as well as the PROV-IO+ common modules (§4.2.1) into container images to be executed on container platforms. For example, on an HPC system using Singularity/Apptainer [24], the containerizer engine first creates the Docker image for the workflow and then converts the Docker image into a Singularity/Apptainer image for execution on compute nodes.
Second, the containerizer engine establishes the mapping between the directory namespace within the container and the namespace outside the container on the HPC storage nodes, and re-directs the relevant provenance I/O activities to the provenance store for persistency, as shown in the “Directory Mapping Layer” and the purple dash lines in Figure 6b). In this way, PROV-IO+ can support containerized workflows on HPC systems automatically with little additional efforts. More implementation details will be discussed in the next section.
5 PROV-IO+ Implementation
In this section, we discuss additional implementation details of the major components in the PROV-IO+ framework.
Provenance Tracking. To support HDF5 I/O, we implement the PROV-IO+ Lib Connector in C and integrate it with the native HDF5 VOL-provenance connector, which follows a homomorphic design in which each HDF5 native I/O API has a counterpart API [36]. Upon each invocation of an HDF5 native API, the counterpart API adds the corresponding virtual data object to a linked list. PROV-IO+ Lib Connector leverages the linked list with locking support to achieve concurrency control on I/O operations on the same data object. To collect provenance, the PROV-IO+ Library APIs are invoked. We collect Agent information at the initialization stage of the native HDF5 VOL-provenance connector. Entity and Activity classes are tracked at each homomorphic API during the workflow runtime.
Similarly, to support POSIX I/O, we use GOTCHA [52] to build a C wrapper layer for POSIX syscall and invokes the PROV-IO+ Library internally. Additionally, the current PROV-IO+ APIs support invoking the PROV-IO+ Library from workflows written in multiple languages including Python, C/C++, and Java.
Moreover, to support large-scale ML/AI workflows, we further instrument PyTorch, one of the most popular machine learning framework, with the PROV-IO+ library. This enables PROV-IO+ to provide more transparency in supporting ML/AI workflows by capturing specific provenance information needed by this category of workflows (e.g., checkpointing information).
Provenance Store. The Provenance Store is implemented based on Redland librdf [53] to serve as the durable backend of the PROV-IO+ Library. We choose Redland because based on our experiences, many other existing RDF solutions are not directly usable in our HPC environments due to compatibility issues in dependent packages and/or operating system (OS) kernels [54, 55, 56, 57, 58].
We utilize Redland’s in-memory graph representation and its support for serializing in-memory graph to multiple on-disk RDF formats (e.g., Turtle [59], ntriples [60], etc.). Redland librdf also supports the integration of multiple databases as the storage backend (e.g., BerkeleyDB, MySQL, SQLite). In the current prototype, we store provenance information in the Turtle format directly for simplicity.
To avoid potential data races when serializing from multiple processes to the Provenance Store, PROV-IO+ maintains an in-memory sub-graph for each process and lets the process serialize its own sub-graph to a unique RDF file on disk. The sub-graph files are then parsed and merged into a complete provenance graph. Since every node in the graph has a globally unique ID (GUID), merging the sub-graphs does not cause unnecessary duplication. Note that this strategy also help performance because no extra inter-process communication or synchronization is needed during workflow execution, and the merging can be performed after workflow execution.
PROV-IO+ User Engine. The user engine supports querying RDF triples with SPARQL, which is a semantic query language to retrieve and manipulate data stored in RDF [61]. We use Python scripts as the SPARQL endpoint. Note that depending on different use case scenarios, the query can vary a lot, as will be demonstrated in Section §6.7. Note that PROV-IO+ provides highly integrated query APIs for scientists to conveniently retrieve provenance based on their needs. For instance, in DASSA workflow, to query the backward data lineage, the scientists only need to specify the output data object and the level of its predecessor (i.e., how many steps back) to the query API, and the user engine will return the target information if applicable. Similarly, highly integrated and customized query APIs are developed for remaining workflows based on their provenance use cases. In the current prototype, we utilize Graphviz [62] for RDF graph visualization.
Containerizer Engine. The Containerizer Engine is implemented as a set of scripts to enable the provenance support in the containerized environment conveniently. For example, to support containrized Megatron-LM workflow on the Singularity/Apptainer platform, the Containerizer Engine first creates a Docker image by using the NGC’s PyTorch 21.07 as the parent image. Besides the Megatron-LM workflow itself, the image also contains the PROV-IO+ library and related dependencies. After the Docker image is created, it is further converted to a Singularity/Apptainer image in order to run it in the containerized HPC environment. Moreover, the directory namespace in the container image is mapped to the PROV-IO+ provenance store on the storage nodes for for data persistence.
Also, since Singularity/Apptainer provides three running modes (i.e., ”run”, ”exec” and ”shell”) for different execution scenarios (e.g., interactive jobs and batch jobs), the Containerizer Engine includes different sets of scripts to support different modes. For example, to support running containerized workflows in the batch mode with the IBM Spectrum LSF [63] job scheduler, the Containerizer Engine includes scripts to ensure that the configuration parameters of the PROV-IO+ supported containers are consistent with the LSF batch scripts.
6 Evaluation
In this section, we evaluate the prototype of the PROV-IO+ framework in representative HPC environments.
First of all, we introduce the experimental methodology and HPC platforms for non-containerized and containerized workflows, respectively (§6.1). Next, we evaluate PROV-IO+ with three non-containerized workflows (i.e., Top Reco, DASSA and H5Bench) from two perspectives including the tracking performance (§6.2) and the storage requirement (§6.3). Similarly, we evaluate PROV-IO+ with one containerized workflow (i.e., Megatron-LM) and measure both the tracking performance and the storage requirement (§6.4). Moreover, we analyze the impact of containerization on provenance tracking by comparing the tracking overhead in two versions (i.e., with and without containerization) of Megatron-LM (§6.5).
| Cori | SAIT SuperCom | |
|---|---|---|
| Processor | Intel Xeon Phi | AMD EPYC |
| Cores | 622,336 | 204,160 |
| OS | Cray Linux | Redhat 8 |
| PFS | Lustre | Lustre |
| Scheduler | Slurm | LSF |
| Container Runtime | – | Singularity/Apptainer |
In addition, we compare PROV-IO+ with a state-of-the-art provenance product (i.e., ProvLake [20]) (§6.6), and evaluate the query effectiveness of PRVO-IO for all workflows from the end user’s perspective (§6.7).
Overall, our experimental results shows that PROV-IO+ can support both non-containerized and containerized workflows effectively. Its tracking overhead is less than 3.5% in more than 95% of our experiments, and it outperforms ProvLake in terms of both tracking and storage overhead.
| Workflow | Provenance Need | Information Tracked | Komadu? | ProvLake? | PROV-IO+? |
| Top Reco (Python) | metadata ver. control & mapping | hyperparameter, preselection, training accuracy | No | Yes | Yes |
| file lineage | program, I/O API, file | ||||
| DASSA | dataset lineage | program, I/O API, dataset | No | No | Yes |
| (C++) | attribute lineage | program, I/O API, attr | |||
| scenario-1 | I/O API | ||||
| H5bench | scenario-2 | I/O API, duration | No | No | Yes |
| (C) | scenario-3 | user, thread, program, file | |||
| Megatron-LM (Python) | ckpt-config consistency | checkpoint info, loss, model configuration | No | Yes | Yes |
6.1 Experimental Methodology
Non-Containerized Workflows. We have evaluated the PROV-IO+ framework for non-containerized workflows on a state-of-the-art supercomputer named Cori, which is a Cray XC40 supercomputer deployed at the National Energy Research Scientific Computing Center (NERSC) with a peak performance of about 30 petaflops. As shown in Table III, Cori uses the Slurm job scheduler and do not use container runtime by default. We conduct experiments on Cori using 64 Intel Xeon “Haswell” processor nodes and up to 4096 cores, unless otherwise specified. The storage backend is a Lustre parallel file system (PFS) with stripe count of 128 and stripe size of 16MB.




We apply PROV-IO+ to three representative non-containerized workflows including Top Reco [28], DASSA [5], and an H5bench-based workflow [29]. As mentioned in §3, the three use cases exhibit diverse characteristics (e.g., various file formats, I/O interfaces, metadata) and provenance needs (e.g., file/dataset/attribute lineage, I/O statistics, metadata versioning). We summarize the information tracked by PROV-IO+ in the experiments to meet the provenance needs in Table IV and elaborate them in detail in the following subsections.
Containerized Workflow. Besides experimenting with the classic workflows, we have evaluated the PROV-IO+ framework for one containerized workflow on a supercomputer deployed at Samsung Advanced Institute of Technology (SAIT), which is an HPE Apollo 6500 Gen10 Plus System. For simplicity, we call the system SuperCom in the rest of the paper. Similar to Cori, SuperCom uses Lustre as the parallel file system. Different from Cori, SuperCom’s job management is based on a combination of IBM LSF scheduler and Singularity/Apptainer, which is a container runtime designed for HPC environments [24]. A detailed comparison between the two platforms (i.e., Cori and SuperCom ) is summarized in Table III.
We apply PROV-IO+ to the representative deep learning workflow Megatron-LM [30], which exhibits unique characteristics and provenance needs as discussed in §3.4 and summarized in Table IV. We containerize the workflow through the PROV-IO+ containerizer engine and leverage eight NVIDIA A100 GPUs on SAIT SuperCom to accelerate the training. For clarity, we present the evaluation results on SAIT SuperCom in §6.4.
Containerization Impact Analysis. In addition to experimenting on Cori and SuperCom, we have used Google Cloud Platform (GCP) to study the impact of containerization on provenance tracking. We use GCP because Cori and SuperCom are customized for supporting LBNL’s and Samsung’s missions respectively, and we cannot modify their runtime environment (e.g., adding or removing Singularity/Apptainer) conveniently. By leveraging GCP, we can build the necessary system environments for running both non-containerized and containerized workflows and conduct a fair comparison on the same infrastructure.
More specifically, we use the GCP Deep Learning virtual machines (VMs) with 32 vCPUs, 120 GB DRAM, and 4 NVIDIA T4 GPUs for the comparison experiments. And we apply PROV-IO+ in two different modes for provenance tracking on two versions of Megatron-LM (i.e., non-containerized and containerized) respectively. We discuss the comparison results in §6.5.
6.2 Performance of Provenance Tracking
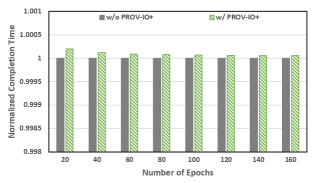
In case of Top Reco, the scientists need the mapping between configurations and the training performance. Therefore, PROV-IO+ tracks three domain-specific items (e.g., model hyperparameters, dataset preselections, and training accuracy) based on the extensible class defined in the PROV-IO+ model. To track the mapping between workflow configuration and training accuracy, we instrument the workflow’s training loop with PROV-IO+ APIs and record the training accuracy at the end of each epoch, and add the training accuracy to the provenance graph as a property of configurations. In addition, we vary the number of training epochs to see how the performance scales. Note that Top Reco is a single process workflow.
Figure 7(a) shows the performance for Top Reco. The y-axis is the normalized completion time (starting with 0.998), while the x-axis is the number of training epoch (roughly equivalent to training time). The grey bars are the baseline without provenance, and the green bars show the performance with PROV-IO+ enabled. We can see that the tracking overhead is negligible overall with a maximum of 0.02%. The overhead with a shorter training time is relatively high, which is mostly caused by the latency of Redland. As the number of training epoch increases, the overhead of PROV-IO+ decreases almost linearly because PROV-IO+ tracks a constant amount of information.
In case of DASSA, the scientists need the backward lineage of data products in different granularity. As shown in the second column of Table IV, PROV-IO+ tracks the information of user, program, file, dataset, or attribute for different lineage needs based on the PROV-IO+ model (§4.1). We follow a similar configuration as the domain scientists’ by using 32 compute nodes and up to 2048 input files (1.35TB in total).
Figure 7(b) shows the tracking performance for DASSA. The x-axis means the number of input files; the y-axis on the left and right sides show the normalized completion time and the raw completion time (in second), respectively. The grey bars represent the normalized baseline without PROV-IO+, and the red, green and blue bars represent the normalized completion time under three usage scenarios (i.e., “File Lineage”, “Dataset Lineage” and “Attribute Lineage”) where different provenance granularity are enabled (e.g., for “File Lineage” we enable “program”, “I/O API” and “file” tracking). The solid grey line means the average baseline completion time (in second) without provenance tracking, while the dashed blue line represents the worst case raw completion time with PROV-IO+ under all scenarios.
We can see the max overhead occurred when tracking the attribute lineage of the entire 2048 files, which is about 11%. This is because DASSA heavily relies on HDF5 attributes. To access an attribute, the program first needs to open the file and the dataset containing it, which incurs more I/O operations to track. But overall, PROV-IO+ incurs reasonable overhead in DASSA (from 1.8% to 11%). This is expected because DASSA does not require heavy I/O API tracking. In other words, PROV-IO+ is efficient for tracking the backward lineage in file, dataset, and attribute granularity.





In the H5bench based workflow, the scientists need the data usage and I/O statistics in general. We consider three different usage scenarios with different needs. As summarized in Table IV, scenario-1 tracks the total number of I/O APIs; scenario-2 tracks both the I/O API count and their duration for bottleneck analysis; scenario-3 tracks the users and threads that modify the file. Moreover, for each scenario, we consider three different I/O patterns including: write-read, write-overwrite-read, and write-append-read. In (c) and (d), we run the workflow with 128 to 4096 MPI processes. In (e), since the append operations from a large amount of MPI processes can easily overwhelm the memory buffer for appending and lead to out-of-memory (OOM) errors, we reduce the number of MPI processes ( 2 to 64). Also, based on the observation that the computation time of many HPC applications may vary from dozens to thousands of seconds per I/O operation, we introduce a relatively modest computation time of 25 seconds per step in the experiments.
Figure 7 (c) (d) (e) show the tracking performance under three different I/O patterns (i.e., “write+read”, “write+overwrite+read”, “write+append+read”). The x-axis stands for the number of MPI ranks. The left y-axis is the normalized completion time and the right y-axis is the raw completion time in second. The grey bars represent the baseline while the three types of colored bars stand for the performance of different provenance usage scenarios mentioned in Table IV(red for “scenario 1”, green for “scenario 2”, blue for “scenario 3”). The grey solid line is the average baseline completion time, while the blue dash line is the worst-case raw completion time with PROV-IO+ enabled.
Overall, we find that PROV-IO+ incurs reasonable amount of overhead (i.e., ranging from 0.5% to 4%) even under heavy I/O operations (3.9TB data with 4096 MPI ranks). In particular, the PROV-IO+ overhead under the “write-append-read” I/O pattern (Figure 7 (c)) is minimal (around 0.5%). This is because the HDF5 I/O operation under this pattern takes more computation time than under the other two patterns to determine the append offset and memory range, which makes the PROV-IO+ overhead more negligible. Also, by comparing scenario-1 and scenario-2, we find that tracking the I/O API duration introduce little additional overhead. This is reasonable because the timing information can be piggybacked with the I/O API tracking which dominates the overall tracking time.
6.3 Storage Requirements
The storage requirement of PROV-IO+ is directly related to the amount and the class of information tracked. Specifically, the storage overhead may increase in two ways: (1) the size of a single provenance record may increase (e.g., adding timing information will increase size of an I/O API record); (2) the total number of records in a provenance file may increase (e.g., tracking thread information will create a number of thread records). We summarize the storage performance of PROV-IO+ for the three workflows in Figure 8.
Figure 8(a) shows the Top Reco case. The x-axis represents the number of epochs and the y-axis is the provenance size (KB). We can see that the provenance size is negligible. This is because PROV-IO+ allows users to specify the target provenance precisely without incurring unnecessary overhead. It also scales linearly since the number of new nodes added to provenance graph is the same as the increment in training epochs.
Figure 8(b) shows the DASSA case. The x-axis is the number of input files while the y-axis represents the provenance size (MB). Lines in three different colors represent File Lineage, Dataset Lineage and Attribute Lineage, respectively. We can see that the storage requirement varies from 40 MBs (with 128 input files) to about 800 MBs (with 2048 files) with linear scalability (note that the x-axis increases by a multiple of 2). Although DASSA heavily relies on attributes, the storage overhead in the three usage scenarios is similar. This is because I/O API is still the dominant part in all scenarios. Even though the number of file and dataset is far less than attribute in DASSA input data, when compared to number of APIs involved in the workflow, their contribution to storage overhead is insignificant.
Figure 8 (c)(d)(e) shows the H5bench-based workflow with three different I/O patterns. The x-axis represents number of MPI ranks and the y-axis stands for provenance size in MBs. Note that x-axis also increases by a multiple of 2. Lines in three different colors represents three different provenance usage scenarios (Table IV). We can see the provenance size varies from a few KBs to 168 MBs. Among the three I/O patterns, “write+overwrite+read” has the highest storage overhead under usage scenario 2. This is because the pattern includes one more I/O application (i.e., overwrite) than “write+read” and has much more MPI processes contributing to provenance graph than “write+append+read”. Moreover, scenario 2 also has the largest amount of tracked information (I/O API and their duration). Note that the storage overhead in this workflow also scales linearly.
In summary, because of the flexibility of the fine-grained PROV-IO+ model, PROV-IO+’s storage overhead is reasonable for all the use cases evaluated.
6.4 Experiments with Containerized Workflow
In this section, we introduce our experiments with a containerized workflow (i.e., Megatron-LM [30]) on the Samsung supercomputer (SuperCom).
Megatron-LM supports multiple pretraining models (§3.4), and we configure Megatron-LM to use GPT-2 as the pretraining model in this set of experiments based on the need of the domain scientists. The training dataset is WikiText103 [64] which is provided by the Megatron-LM authors [30]. We enable both model parallelism and data parallelism (§3.4) in the workflow for experiments.
As mentioned in §3.4, the major provenance need in the Megatron-LM use case is to ensure the consistency between the checkpoint and the workflow configurations. Therefore, we track detailed checkpoint information pertaining to a pretraining process (e.g., the path of the checkpoint file) as well as a variety of relevant configuration parameters (e.g., the number of GPUs, the batch size). The configuration information is tracked once at the beginning of workflow execution as the information remains invariant throughout the workflow execution, while the checkpoint information is tracked transparently by instrumenting PyTorch at the end of the workflow execution. In addition, we record the GPT-2 training loss at the end of each training iteration. We change the number of training iterations in the experiments to measure how the tracking performance and storage requirement scales. We report the measurement results as follows.
Figure 9a shows the provenance tracking performance. The y-axis is the normalized workflow completion time, and the x-axis is the number of training iteration. We use the grey bar to represent the baseline without provenance tracking, and the blue bar stands for workflow completion time with provenance enabled. For each experiment, we repeat it five times and calculate the average performance value. The result shows that the maximum tracking overhead is about 0.6% when the training iteration is set to 50. When the number of iteration increases, PROV-IO+’s tracking overhead tends to be negligible, which implies that PROV-IO+ is scalable in terms of tracking performance.
Figure 9b shows the storage requirement of tracking Megatron-LM with PROV-IO+. The y-axis is the provenance size (KB), and the x-axis is the number of training iteration. The result shows that, to track the checkpoint-configuration consistency information, the provenance size is negligible in general (e.g., less than 15 KB in all experiments). The size of the provenance information scales almost linearly as the number of training iterations increases, mainly because the training loss is recorded at the end of each training iteration.
In summary, to track the necessary provenance for maintaining the checkpoint-configuration consistency in containerized Megatron-LM, PROV-IO+ introduces small tracking and negligible storage consumption.


6.5 Impact of Containerziation on Provenance Tracking
In this section, we analyze the impact of containerization on PROV-IO+’s provenance collection. As mentioned in §6.1, we leverage the GCP platform for the comparison experiments because we can setup different runtime environments for both containerized and non-containarized workflows on GCP. We apply PROV-IO+ in two different modes for tracking two versions of Megatron-LM (i.e., non-containerized and containerized) on GCP respectively.
To validate the impact of containerization, we execute the non-containerized version of Megatron-LM workflow and the containerized version separately on different GCP VMs. This is to ensure that there is no interference between the executions of the two versions. The provenance information tracked is the same as described in §6.4. We reduce the scale of the workflow to meet the VM’s resource constraints (e.g., vCPUs and memory).
The performance of PROV-IO+ on non-containerized Megatron-LM and containerized Megatron-LM are shown in Figure 10a and Figure 10b, respectively. In both cases, the y-axis is the normalized workflow completion time, and the x- axis is the number of training iteration. By comparing Figure 10a and Figure 10b, we can see that in both cases PROV-IO+ incurs little overhead, especially when the number of iterations is large. This suggests that containerization has little impact on PROV-IO+, and both modes of PROV-IO+ can support provenance tracking efficiently.
In conclusion, our experiments on three different platforms (i.e., Cori in §6.2, SuperCom in §6.4, and GCP §6.5) shows that PROV-IO+’s provenance tracking performance has little dependence on the platforms, and the overhead is consistently low across different execution platforms.







6.6 Comparison with Other Frameworks
In this section, we compare PROV-IO+ to state-of-the-art provenance systems. Table V shows the basic characteristics of Komadu [65], ProvLake [20], and PROV-IO+. We can see that all three frameworks are derived from the base PROV-DM model, which makes the comparison fair. On the other hand, Komadu only supports Java programs and ProvLake only supports Python, which makes them incompatible with many C/C++ based scientific workflows (e.g., DASSA and H5bench). Note that PROV-IO+’s C/C++ interface is designed for integration with major HPC I/O libraries. Once the I/O library is integrated with PROV-IO+ (e.g., HDF5), the provenance support is mostly transparent to the workflow users, i.e., users can control the rich provenance features through a configuration file without manually modifying their source code with APIs. Neither Komadu nor ProvLake support such capability or transparency.
| Komadu | ProvLake | PROV-IO+ | |
|---|---|---|---|
| Base model | PROV-DM | PROV-DM | PROV-DM |
| Language | Java | Python | C/C++,Python,Java |
| Transparency | No | No | Hybrid |
Since ProvLake has outperformed Komadu based on a previous study [17], we focus on the comparison with ProvLake. Because ProvLake does not support C/C++ workflows, we cannot apply it to DASSA and H5bench. Therefore, we compare the two provenance tools using Python-based Top Reco in the rest of this section.
Different from PROV-IO+ which is I/O-centric, ProvLake is ’process-oriented’. Specifically, ProvLake creates records based on the execution steps of a workflow, and the provenance data are maintained as attribute or property of individual steps. On the contrary, PROV-IO+ is not limited to the execution steps of the workflow. For example, it can track a task in the workflow, an I/O operation invoked by a task, a data object involved in the I/O operation, etc., all of which are further correlated via the relations defined by the PROV-IO+ model (§4.1). Such flexibility and richness is not available in ProvLake.
To make the comparison with ProvLake fair, we use the same instrument points in the Top Reco workflow for both tools. Specifically, we instrument Top Reco at its GNN training loop and track the training accuracy at the end of each epoch to corresponding provenance records. Since the workflow configuration is never changed during the entire workflow, we only add it to ProvLake’s record once at the beginning of the workflow. In addition, to be representative, we track three different numbers of configurations (i.e., 20, 40, and 80).
| Workflow | Provenance Need | Query Statement (SPARQL) | of Statements in Query |
| 1: data_object_a prov:wasAttributedTo ?program. | 3*N | ||
| DASSA | file/dataset/attribute lineage | 2: ?data_object prov:wasAttributedTo ?program; | (where N is backward |
| 3: provio:wasReadBy ?IO_API. | propagation steps) | ||
| scenario-1 | 4: ?IO_API prov:wasMemberOf prov:Activity; | 1 | |
| scenario-2 | 5: ?IO_API prov:wasMemberOf prov:Activity; | 2 | |
| H5bench | 6: provio:elapsed ?duration. | ||
| 7: file_a prov:wasAttributedTo ?program. | |||
| scenario-3 | 8: ?program prov:actedOnBehalfOf ?thread. | 3 | |
| 9: ?thread prov:actedOnBehalfOf ?user. | |||
| Top Reco | metadata version control & mapping | 10: ?configuration ns1:Version ?version; | 2 |
| 11: provio:hasAccuracy ?accuracy. | |||
| Megatron-LM | ckpt-config consistency | 12: ?batch_size ns1:hasValue 256; | 2 |
| 13: prov:influenced ?checkpoint_path |
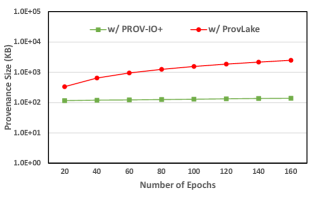
Figure 11(a),(b),(c) compares the provenance tracking performance of the two systems where y-axis is normalized completion time. Figure 11 (d),(e),(f) shows the storage overhead where y-axis is size in KB. In all figures x-axis is the number of configurations. In (a)(b)(c), grey bars stand for the baseline without provenance tracking, green bars show the normalized performance with PROV-IO+, and red bars show the performance with ProvLake. In (d)(e)(f), green lines stand for PROV-IO+ provenance file size and red lines stand for ProvLake provenance file size.
As shown in Figure11(a)(b)(c), both frameworks incur negligible tracking overhead (e.g., less than 0.025%) and the PROV-IO+ overhead is even lower than ProvLake for most cases. Similarly, as shown in Figure11(d)(e)(f), PROV-IO+ always incurs less storage overhead, regardless of the number of configuration fields tracked. This is mainly because ProvLake has to track more irrelevant workflow information not needed in the use case.
6.7 Query Effectiveness
As mentioned in §5, PROV-IO+ supports provenance query with visualization. Table VI summarizes the queries used to answer the diverse provenance needs of the three workflow cases. We can see that the provenance can be queried effectively and efficiently using a few simple SPARQL statements in general. Since the number of queries involved is small, the query time overhead is negligible in our experiments. We discuss each case in more details below.
In DASSA, to get the backward lineage of a data product, we can start with the program which generated the data product and look for its input data. The same procedure can be repeated as needed. For example, DASSA may convert “WestSac.tdms” into “WestSac.h5” with program “tdms2h5”, and then use “decimate” to process “WestSac.h5” into data product “decimate.h5”. To get the backward lineage of “decimate.h5”, in the query, we first retrieve with keywords “decimate.h5 prov:wasAttributedTo ?program” to locate program “decimate”. Next, in the same query, we add statement “?file wasAttributedTo ?program” to retrieve that program’s input file “WestSac.h5” which is the first level predecessor of “decimate.h5”. We can further expand the query by adding similar statements to locate “decimate.h5”’s earlier predecessors (e.g., “WestSac.tdms”).
As summarized in Table VI, for each backward step, we only need three query statements. Figure 12 shows the visualization of this example, which follows the PROV-IO+ provenance model (§4.1) and highlights the queried data lineage in blue. Other types of lineages (e.g., dataset and attribute) can be queried and visualized in the same way.

Similarly, in H5bench, we have three types of provenance needs (i.e., the scenarios described in §6.2) which can be answered using 1, 2, 3 SPARQL statements respectively. In Top Reco, the metadata versioning and mapping information can be queried in 2 statements. Note that the provenance needs are diverse across the real use cases, but the number of queries needed is consistently small. This elegant result suggests that PROVI-IO+ is effective for scientific data on HPC systems.
In case of Megatron-LM, users want to identify the checkpoint which is consistent with the configuration for the follow-up training process. Figure 13 shows a scenario where there are two different batch sizes used during the previous pretraining (i.e., “Batch_Size_A” is 128, and “Batch_Size_B” is 256), and there are three checkpoints generated based on the two batch sizes (i.e., “Checkpoint_1”, “Checkpoint_2”, “Checkpoint_3”). Assume the user wants to continue a GPT pretraining process which has a batch size of 256 with one of the existing checkpoints (i.e., “Checkpoint_3”), s/he can query the provenance with as few as 2 lines of SPARQL statements, as shown in the last row of Table VI. Moreover, the user can also add advanced conditions to the query to filter out the feasible checkpoint with the best quality (e.g., a checkpoint with certain training loss).

7 Discussion
The design of the PROV-IO+ tool is driven by the needs of the domain scientists using four scientific workflows. Given the diversity of science, it is likely that the prototype cannot directly address the unique provenance queries of all scientists. We plan to collaborate with more domain scientists to identify additional needs and refine PROV-IO+ accordingly. For example, researchers from INRIA [66] are interested in porting PROV-IO+ on their edge devices with limited hardware resource. Similarly, HPE [67] researchers are interested in integrating PROV-IO+ to their provenance solutions. We are in communication with the researchers to extend the real-world impact of PROV-IO+ further.
Similarly, while the current prototype supports POSIX and HDF5 I/O transparently and is extensible by design, there are other popular I/O systems in HPC (e.g., ADIOS [32]) which we have not integrated yet. We leave the integration with other I/O libraries as future work.
In addition, there are other important aspects of provenance (e.g., security [68]) which cannot be ignored in practice. We hope that our efforts and the resulting open-source tool can facilitate follow-up research in the communities and help address the grand challenge of provenance support for scientific data in general.
8 Related Work
Database Provenance. Historically, provenance has been well studied in databases to understand the causal relationship between materialized views and table updates [69, 6]. The concept has also been extended to other usages [70, 8]. In general, database provenance may leverage the well-defined relational model and the relatively strict transformations to capture precise provenance within the system [71], which is not applicable for general software. On the other hand, some query optimizations (e.g., provenance reduction [72]) could potentially be applied to PROV-IO+. Therefore, PROV-IO+ and these tools are complementary.
OS-Level Provenance. Great efforts have also been made to capture provenance at the operating system (OS) level [11, 12, 50]. For example, PASS [11, 12] intercepts system calls via custom kernel modules for inferring data dependencies. Similarly to these efforts, PROV-IO+ recognizes the importance of I/O syscalls. But different from PASS, PROV-IO+ is non-intrusive to the OS kernel. Moreover, PROV-IO+ leverages the unique characteristics of HPC workflows and systems to meet the needs of domain scientists, while PASS is largely inapplicable in this context. More specifically, we elaborate on five key differences as follows:
(1) Provenance Model: PROV-IO+ follows the W3C specifications to represent rich provenance information in a relational model (§4.1). In contrast, PASS follows the conventional logging mechanism without a general relational model, which limits its capability of capturing and describing complex provenance. For example, PASS has to establish the dependencies among events via a kernel-level logger (i.e., ‘Observer’ [12]) which cannot interpret the semantics or relations of HPC I/O library events. Consequently, PASS can only answer relatively limited queries (e.g., ancestor of a node [12]) instead of the rich lineage defined in W3C.
(2) System Architecture: PROV-IO+ is a user-level solution designed for the HPC environment (§4.2). In contrast, PASS heavily relies on customized kernel modules to achieve its core functionalities. This kernel-based architecture makes PASS incompatible with modern HPC systems. For example, neither the PASTA file system (in PASS [11]) nor the Lasagna file system (in PASSv2 [12]) is compatible with the Lustre PFS dominant in HPC. In other words, translating the core functionalities of PASS to HPC systems would require substantial efforts (if possible at all), and the implications on performance and scalability is unclear.
(3) Granularity: PROV-IO+ can handle fine-grained I/O provenance which is critical for understanding HPC workflows (e.g., the lineage of an attribute of an HDF5 file), while PASS collects relatively coarse-grained events (e.g., access to an entire file).
(4) Tracking APIs: By embedding in popular HPC I/O libraries, PROV-IO+ does not require modifying the source code to track I/O provenance. In contrast, to use PASS, users must consider how to apply six low-level calls (e.g., pass_read, pass_mkobj [12]) to the target applications.
(5) Storage & Query: Based on the well-defined model, PROV-IO+ stores provenance as RDF triples backed by the parallel file system. In contrast, PASS relies on its own local file system to generate provenance as local logs. The storage representation directly affects the user query capability. For example, PROV-IO+ supports querying RDF triples via SPARQL [61], while PASS only supports a special Path Query Language which is much less popular today.
In summary, while PROV-IO+ is partially inspired by the seminal PASS designed more than a decade ago, the two works are different due to the different goals and contexts. Therefore, we view PASS and PROV-IO+ as complementary.
Workflow & Application Provenance. Provenance models or systems for workflows and/or applications have also been explored [21, 18, 20, 73]. For example, Karma [21] describes a model with a hierarchy of ‘workflow-service-application-data’. However, the model is designed for the cloud environment and cannot cover diverse HPC needs (e.g., HDF5 attributes, MPI ranks). PROV-ML [18] is a series of well-defined specifications for machine learning workflows. Different from PROV-ML, PROV-IO+ is designed for general HPC workflows. IBM ProvLake [20] is a lineage data management system capable of capturing data provenance across programs. Unlike PROV-IO+, ProvLake always require users to modify the source code using its special APIs, which severely limits its usage and scalability for complicated HPC workflows.Similar to PROV-IO+, there are a few provenance capturing tools using DBMS to store queriable provenance data, but they do not follow any widely used provenance models [74, 75, 76].
Other Usage of Provenance. Provenance has been applied to other venues. For example, MOLLY uses lineage-driven fault injection to expose bugs in fault-tolerant protocols [77]. There have been a multitude of domain-specific or application-specific provenance and ontology management implementations. However, they do not capture the I/O access information that PROV-IO+ manages. We believe the comprehensive provenance information enabled by PROV-IO+ can also be leveraged to stimulate several data quality and storage optimizations, which we leave as future work.
Non-Provenance Tools. In addition, great efforts have been made to manage workflows [78, 79] or log I/O events for various purposes [38, 39, 88, 89, 90, 91, 92, 93, 94, 80, 81, 82, 83, 84, 85, 86, 87]. While they are effective for their original goals, they are insufficient to address provenance needs in general due to a number of reasons: (1) no relational model to support tracking or querying rich provenance (e.g., various relations defined in W3C PROV-DM [31]); (2) agnostic to the fine-grained semantics in HPC I/O libraries (e.g., HDF5 attributes); (3) little portability across different I/O libraries or workflow environments; (4) no programmable interface to specify customized provenance needs.
9 Conclusion & Future Work
We have introduced a provenance tool called PROV-IO+ for scientific data on HPC systems. Experiments with representative HPC workflows show that PROV-IO+ can address diverse provenance needs with reasonable overhead. We believe that PROV-IO+ represents a promising direction toward ensuring the rigorousness and trustworthiness of scientific data management. In the future, we will address the limitations mentioned in §7. Moreover, in the Top Reco case studied in this paper, the domain scientists would like to identify the best configurations across multiple runs of the workflow. In other words, there is a need of provenance across multiple executions of the same workflow. Similar cross-workflow provenance may be needed when multiple different workflows cooperate to process shared datasets, which requires additional modeling and interface to bridge the semantic gap between workflows. We would like to investigate such complex multi-workflow scenario as well. In addition, we observe that diagnosing the correctness and performance anomalies in HPC systems is increasingly challenging due to the complexity (e.g., a single SSD failure may cause the “blast radius” problem due to system dependencies), and we will apply PROV-IO+ to address such open challenges in the future. Overall, we believe that PROV-IO+ represents a promising direction toward ensuring the rigorousness and trustworthiness of scientific data management.
10 Acknowledgments
The authors would like to thank the anonymous reviewers for the constructive feedback. We also thank Xiangyang Ju for providing the Top Reco workflow, and James Loo, Jim Wayda for the help on Samsung systems. This work was supported in part by NSF under grants CNS-1855565, CCF-1853714, CCF-1910747 and CNS-1943204. Any opinions, findings, and conclusions expressed in this material are those of the authors and do not necessarily reflect the views of the sponsors. This manuscript has been authored by an author at Lawrence Berkeley National Laboratory under Contract No. DE-AC02-05CH11231 with the U.S. Department of Energy. The U.S. Government retains, and the publisher, by accepting the article for publication, acknowledges, that the U.S. Government retains a non-exclusive, paid-up, irrevocable, world-wide license to publish or reproduce the published form of this manuscript, or allow others to do so, for U.S. Government purposes.
References
- [1] Kristin M. Tolle, D. W. Tansley and Anthony J.. Hey “The Fourth Paradigm: Data-Intensive Scientific Discovery” In Proceedings of the IEEE, 2011
- [2] Mark D Wilkinson et al. “The FAIR Guiding Principles for scientific data management and stewardship” In Scientific Data, 2016
- [3] “FAIR Principles” URL: https://www.go-fair.org/fair-principles/
- [4] Martin Milton and Antonio Possolo “Trustworthy data underpin reproducible research” In Nature Physics, 2020
- [5] B. Dong et al. “DASSA: Parallel DAS Data Storage and Analysis for Subsurface Event Detection” In 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS’20), 2020
- [6] Peter Buneman, Sanjeev Khanna and Wang Chiew Tan “Why and Where: A Characterization of Data Provenance” In Proceedings of the 8th International Conference on Database Theory (ICDT’01), 2001
- [7] Xing Niu et al. “Interoperability for Provenance-aware Databases using PROV and JSON” In 7th USENIX Workshop on the Theory and Practice of Provenance (TaPP’15), 2015
- [8] Pierre Senellart “Provenance and Probabilities in Relational Databases” In SIGMOD Rec. 46.4 New York, NY, USA: Association for Computing Machinery, 2018, pp. 5–15 DOI: 10.1145/3186549.3186551
- [9] Zhengjie Miao, Qitian Zeng, Boris Glavic and Sudeepa Roy “Going Beyond Provenance: Explaining Query Answers with Pattern-Based Counterbalances” In Proceedings of the 2019 International Conference on Management of Data (SIGMOD’19), 2019
- [10] Zhuo Wang et al. “A Provenance Storage Method Based on Parallel Database” In 2015 2nd International Conference on Information Science and Control Engineering (ICISCE’15), 2015
- [11] Kiran-Kumar Muniswamy-Reddy, David A. Holland, Uri Braun and Margo Seltzer “Provenance-Aware Storage Systems” In Proceedings of the Annual Conference on USENIX ’06 Annual Technical Conference (ATC’06), 2006
- [12] Kiran-Kumar Muniswamy-Reddy et al. “Layering in Provenance Systems” In Proceedings of the 2009 Conference on USENIX Annual Technical Conference (ATC’09), 2009
- [13] Eduardo Jandre, Bruna Diirr and Vanessa Braganholo “Provenance in Collaborative in Silico Scientific Research: A Survey” In SIGMOD Rec. 49.2 New York, NY, USA: Association for Computing Machinery, 2020, pp. 36–51 DOI: 10.1145/3442322.3442329
- [14] Yogesh L. Simmhan, Beth Plale and Dennis Gannon “A Survey of Data Provenance in E-Science” In SIGMOD Rec. 34.3 New York, NY, USA: Association for Computing Machinery, 2005, pp. 31–36 DOI: 10.1145/1084805.1084812
- [15] Susan B. Davidson and Juliana Freire “Provenance and Scientific Workflows: Challenges and Opportunities” In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data (SIGMOD’08), 2008
- [16] Isuru Suriarachchi, Sachith Withana and Beth Plale “Big Provenance Stream Processing for Data Intensive Computations” In 2018 IEEE 14th International Conference on eScience (eScience’18), 2018
- [17] Renan Souza et al. “Efficient Runtime Capture of Multiworkflow Data Using Provenance” In 2019 15th International Conference on eScience (eScience’19), 2019
- [18] Renan Souza et al. “Provenance Data in the Machine Learning Lifecycle in Computational Science and Engineering” In 2019 IEEE/ACM Workflows in Support of Large-Scale Science (WORKS’19), 2019
- [19] “The PROV Data Model - W3C” URL: https://www.w3.org/TR/prov-overview/
- [20] Leonardo Azevedo et al. “Experiencing ProvLake to Manage the Data Lineage of AI Workflows” In Meeting in Innovation in Information Systems (EISI) in Brazilian Symposium in Information Systems (SBSI’20), 2020
- [21] Yogesh L. Simmhan, Beth Plale and Dennis Gannon “A Framework for Collecting Provenance in Data-Centric Scientific Workflows” In 2006 IEEE International Conference on Web Services (ICWS’06), 2006
- [22] Bill Howe et al. “End-to-End eScience: Integrating Workflow, Query, Visualization, and Provenance at an Ocean Observatory” In 2008 IEEE Fourth International Conference on eScience (eScience’08), 2008
- [23] “Resource Description Framework” URL: https://www.w3.org/RDF/
- [24] “Apptainer/Singularity” URL: https://apptainer.org
- [25] “Cori at LBNL” URL: https://www.nersc.gov/systems/cori/
- [26] “Samsung Advanced Institute of Technology” URL: https://www.sait.samsung.co.kr/saithome/main/main.do
- [27] “Google Cloud Platform” URL: https://cloud.google.com
- [28] Xu Allison, Wang Haichen and Ju Xiangyang “A Graph Neural Network-based Top Quark Reconstruction Package” URL: https://indico.cern.ch/event/932415/contributions/3918265/attachments/2086561/3505362/GNN_Top_Reco_-_Allison_Xu.pdf
- [29] “h5bench” URL: https://www.hdfgroup.org/solutions/hdf5/
- [30] Mohammad Shoeybi et al. “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism” arXiv, 2019 DOI: 10.48550/ARXIV.1909.08053
- [31] Paolo Missier, Khalid Belhajjame and James Cheney “The W3C PROV Family of Specifications for Modelling Provenance Metadata” In Proceedings of the 16th International Conference on Extending Database Technology (EDBT’13), 2013
- [32] “ADIOS” URL: https://www.olcf.ornl.gov/center-projects/adios/
- [33] “HDF5” URL: https://https://www.hdfgroup.org/solutions/hdf5/
- [34] “NetCDF” URL: https://www.unidata.ucar.edu/software/netcdf/
- [35] “Automatic Library Tracking Database at NERSC” URL: https://www.nersc.gov/assets/altdatNERSC.pdf
- [36] Tonglin Li et al. “H5Prov: I/O Performance Analysis of Science Applications Using HDF5 File-level Provenance” In Cray User Group (CUG’19), 2019
- [37] Mike Folk et al. “An Overview of the HDF5 Technology Suite and Its Applications” In Proceedings of the EDBT/ICDT 2011 Workshop on Array Databases (AD’11), 2011
- [38] “Darshan, HPC I/O Characterization Tool” URL: https://www.mcs.anl.gov/research/projects/darshan/
- [39] Sushma Yellapragada, Chen Wang and Marc Snir “Verifying IO Synchronization from MPI Traces” In 2021 IEEE/ACM Sixth International Parallel Data Systems Workshop (PDSW’21), 2021
- [40] Deepak Narayanan et al. “Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM” In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC’21, 2021
- [41] Vijay Korthikanti et al. “Reducing Activation Recomputation in Large Transformer Models” arXiv, 2022 DOI: 10.48550/ARXIV.2205.05198
- [42] Alec Radford and Karthik Narasimhan “Improving Language Understanding by Generative Pre-Training”, 2018
- [43] Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” arXiv, 2018 DOI: 10.48550/ARXIV.1810.04805
- [44] Colin Raffel et al. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer” arXiv, 2019 DOI: 10.48550/ARXIV.1910.10683
- [45] “Docker” URL: https://www.docker.com
- [46] “Kubernetes” URL: https://kubernetes.io
- [47] “pytorch” URL: https://pytorch.org
- [48] “nccl” URL: https://developer.nvidia.com/nccl
- [49] “Ext4” URL: https://ext4.wiki.kernel.org/index.php/Main_Page
- [50] Ashish Gehani and Dawood Tariq “SPADE: Support for Provenance Auditing in Distributed Environments” In Proceedings of the 13th International Middleware Conference (Middleware’12), 2012
- [51] Runzhou Han et al. “PROV-IO: An I/O-Centric Provenance Framework for Scientific Data on HPC Systems” In Proceedings of the 31st International Symposium on High-Performance Parallel and Distributed Computing (HPDC’22), 2022
- [52] “GOTCHA v1.0.2” URL: https://github.com/LLNL/GOTCHA
- [53] “Redland RDF” URL: https://librdf.org
- [54] “Apache Jena” URL: https://jena.apache.org
- [55] “NEO4J” URL: https://neo4j.com
- [56] “Blazegraph” URL: https://blazegraph.com
- [57] “Apache Rya” URL: https://rya.apache.org
- [58] “AnzoGraphDB” URL: https://cambridgesemantics.com/anzograph/
- [59] “Terse RDF Triple Language” URL: https://www.w3.org/TR/turtle/
- [60] “N-Triples” URL: https://www.w3.org/TR/n-triples/
- [61] “SPARQL Query Language for RDF” URL: https://www.w3.org/TR/rdf-sparql-query/
- [62] “Graphviz” URL: https://graphviz.org
- [63] “IBM Spectrum LSF Session Scheduler” URL: https://www.ibm.com/docs/en/spectrum-lsf/10.1.0?topic=lsf-session-scheduler
- [64] Stephen Merity, Caiming Xiong, James Bradbury and Richard Socher “Pointer Sentinel Mixture Models” In CoRR, 2016 URL: http://arxiv.org/abs/1609.07843
- [65] Isuru Suriarachchi, Quan Zhou and Beth Plale “Komadu: A Capture and Visualization System for Scientific Data Provenance” In Journal of Open Research Software 3, 2015 DOI: 10.5334/jors.bq
- [66] “Inria KerData Team” URL: https://team.inria.fr/kerdata/
- [67] “HPE AI Research Lab” URL: https://www.hpe.com/us/en/hewlett-packard-labs.html
- [68] Adam Bates, Dave Tian, Kevin R.. Butler and Thomas Moyer “Trustworthy Whole-System Provenance for the Linux Kernel” In Proceedings of the 24th USENIX Conference on Security Symposium (Security’15), 2015
- [69] Yingwei Cui, Jennifer Widom and Janet L. Wiener “Tracing the Lineage of View Data in a Warehousing Environment” In ACM Trans. Database Syst., 2000
- [70] Jennifer Widom “Trio: A System for Integrated Management of Data, Accuracy, and Lineage” In 2nd Biennial Conference on Innovative Data Systems Research (CIDR’05), 2005
- [71] Lucian Carata et al. “A Primer on Provenance”, 2014
- [72] Daniel Deutch, Yuval Moskovitch and Noam Rinetzky “Hypothetical Reasoning via Provenance Abstraction” In Proceedings of the 2019 International Conference on Management of Data (SIGMOD’19), 2019
- [73] Quan Zhou, Devarshi Ghoshal and Beth Plale “Study in Usefulness of Middleware-Only Provenance” In 2014 IEEE 10th International Conference on eScience (eScience’14), 2014
- [74] “Braid-DB” URL: https://github.com/ANL-Braid/DB/
- [75] “Chimbuko” URL: https://github.com/CODARcode/Chimbuko
- [76] Jeremy Logan et al. “A Vision for Managing Extreme-Scale Data Hoards” In IEEE 39th International Conference on Distributed Computing Systems (ICDCS’19), 2019
- [77] Peter Alvaro, Joshua Rosen and Joseph M. Hellerstein “Lineage-Driven Fault Injection” In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (SIGMOD’15), 2015
- [78] “Apache Taverna” URL: https://incubator.apache.org/projects/taverna.html
- [79] “EFFIS” URL: https://github.com/wdmapp/effis
- [80] Di Zhang, Dong Dai, Runzhou Han and Mai Zheng “SentiLog: Anomaly Detecting on Parallel File Systems via Log-based Sentiment Analysis” In Proceedings of the 13th ACM Workshop on Hot Topics in Storage and File Systems (HotStorage), 2021
- [81] Dong Dai, Om Rameshwar Gatla and Mai Zheng “A performance study of lustre file system checker: Bottlenecks and potentials” In 2019 35th Symposium on Mass Storage Systems and Technologies (MSST), 2019
- [82] Erci Xu et al. “Understanding SSD reliability in large-scale cloud systems” In 2018 IEEE/ACM 3rd International Workshop on Parallel Data Storage & Data Intensive Scalable Computing Systems (PDSW-DISCS), 2018
- [83] Erci Xu et al. “Lessons and Actions: What We Learned from 10K SSD-Related Storage System Failures” In 2019 USENIX Annual Technical Conference (USENIX ATC), 2019
- [84] Yiliang Shi et al. “A Command-Level Study of Linux Kernel Bugs” In 2017 International Conference on Computing, Networking and Communications (ICNC), 2017
- [85] Mai Zheng et al. “GMProf: A low-overhead, fine-grained profiling approach for GPU programs” In 19th International Conference on High Performance Computing (HiPC), 2012
- [86] Dachuan Huang et al. “LiU: Hiding disk access latency for HPC applications with a new SSD-enabled data layout” In 2013 IEEE 21st International Symposium on Modelling, Analysis and Simulation of Computer and Telecommunication Systems (MASCOTS), 2013
- [87] Duo Zhang and Mai Zheng “Benchmarking for Observability: The Case of Diagnosing Storage Failures” In BenchCouncil Transactions on Benchmarks, Standards and Evaluations (TBench), 2021
- [88] Mai Zheng et al. “Torturing Databases for Fun and Profit” In 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2014
- [89] Jinrui Cao et al. “A generic framework for testing parallel file systems” In 2016 1st Joint International Workshop on Parallel Data Storage and data Intensive Scalable Computing Systems (PDSW-DISCS), 2016
- [90] Jinrui Cao et al. “PFault: A general framework for analyzing the reliability of high-performance parallel file systems” In Proceedings of the 2018 International Conference on Supercomputing (ICS), 2018
- [91] Runzhou Han et al. “A study of failure recovery and logging of high-performance parallel file systems” In ACM Transactions on Storage (TOS), 2021
- [92] Om Rameshwar Gatla and Mai Zheng “Understanding the fault resilience of file system checkers” In 9th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage), 2017
- [93] Om Rameshwar Gatla et al. “Towards Robust File System Checkers” In 16th USENIX Conference on File and Storage Technologies (FAST), 2018
- [94] Om Rameshwar Gatla et al. “Towards robust file system checkers” In ACM Transactions on Storage (TOS), 2018