Progressive Multi-modal Conditional Prompt Tuning
Abstract.
Pre-trained vision-language models (VLMs) have shown remarkable generalization capabilities via prompting, which leverages VLMs as knowledge bases to extract information beneficial for downstream tasks. However, existing methods primarily employ uni-modal prompting, which only engages a uni-modal branch, failing to simultaneously adjust vision-language (V-L) features. Additionally, the one-pass forward pipeline in VLM encoding struggles to align V-L features that have a huge gap. Confronting these challenges, we propose a novel method, Progressive Multi-modal conditional Prompt Tuning (ProMPT). ProMPT exploits a recurrent structure, optimizing and aligning V-L features by iteratively utilizing image and current encoding information. It comprises an initialization and a multi-modal iterative evolution (MIE) module. Initialization is responsible for encoding images and text using a VLM, followed by a feature filter that selects text features similar to image. MIE then facilitates multi-modal prompting through class-conditional vision prompting, instance-conditional text prompting, and feature filtering. In each MIE iteration, vision prompts are obtained from filtered text features via a vision generator, promoting image features to focus more on target object during vision prompting. The encoded image features are fed into a text generator to produce text prompts that are more robust to class shifts. Thus, V-L features are progressively aligned, enabling advance from coarse to exact prediction. Extensive experiments are conducted in three settings to evaluate the efficacy of ProMPT. The results indicate that ProMPT outperforms existing methods on average across all settings, demonstrating its superior generalization and robustness. Code is available at https://github.com/qiuxiaoyu9954/ProMPT.
1. Introduction
In recent years, the advent of pre-trained vision-language models (VLMs), such as CLIP (Radford et al., 2021) and ALIGN (Jia et al., 2021), has marked a significant leap in the field of computer vision (CV), particularly in terms of their generalizability in downstream tasks. VLMs are trained on large-scale aligned text-image pairs, enabling them to learn open-set visual concepts from natural language during pre-training. This approach significantly enhances their zero-shot generalization abilities. A typical vision-language model architecture consists of a text encoder and an image encoder. During inference, a hand-crafted template prompt is combined with all category inputs to produce text features through the text encoder. These features are then compared with image features, extracted by the image encoder, to calculate similarity and thereby determine the predicted category.
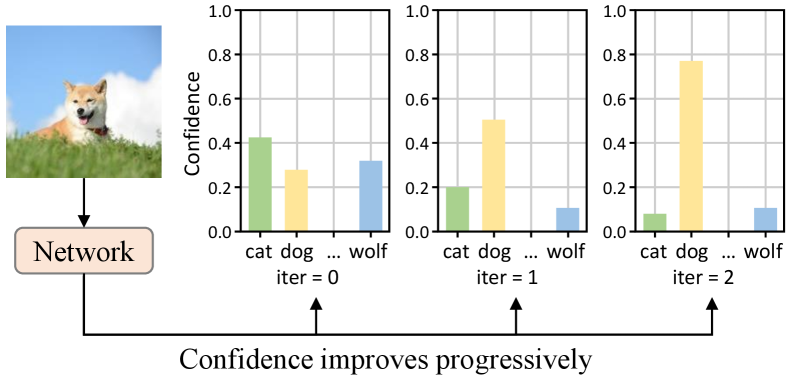
While VLMs exhibit impressive performance in generalizing to new classes, significant challenges arise when fine-tuning them for downstream tasks. Firstly, fine-tuning the whole model demands massive data, since insufficient data results in over-fitting. Secondly, fine-tuning large-scale models requires considerable computational resources and risks the catastrophic forgetting of previously acquired knowledge. Addressing the aforementioned concerns, extensive research (Radford et al., 2021; Jin et al., 2022; Zhou et al., 2022b, a) has highlighted prompt learning as an effective paradigm. It originates in the field of natural language processing (NLP) (Shin et al., 2020; Petroni et al., 2019; Lester et al., 2021; Li and Liang, 2021), encompassing hard prompts and soft prompts. Hard prompts are artificially crafted sentence templates designed to restructure the input to resemble the format in pre-training. However, designing templates requires careful verification with intensive labor as minor wording changes can significantly affect performance (Zhou et al., 2022b). Recently, a series of works (Shu et al., 2022; Zhu et al., 2023; Yao et al., 2023; Khattak et al., 2023) have explored soft prompts for VLMs. Concretely, soft prompts are learnable vectors that are injected into the model to stimulate information beneficial for downstream tasks. A representative method is CoOp (Zhou et al., 2022b), which trains learnable parameters in an end-to-end manner while keeping the entire pre-trained parameters fixed.
Taking into account the studies mentioned, we summarize the following considerations. First, image classification relying on VLMs is a multi-modal task that contends with a significant domain gap between V-L modalities, as well as challenges of data acquisition and annotation. Existing methods typically utilize a one-pass forward pipeline, where text and image encoders separately process input text and images once. The prediction is inferred by the similarity between V-L features. However, owing to the vast gap between image and text, aligning their features effectively is non-trivial. Second, existing prompting methods for VLMs predominantly concentrate on adapting the language branch, leaving the vision branch unchanged. Since the primary objective of VLMs is to harmonize the embeddings in the V-L branches, a single text prompting may hinder modeling of the correlation between the output embeddings in both branches, thus leading to sub-optimal solutions.
Regarding the issues, we propose Progressive Multi-modal conditional Prompt Tuning (ProMPT), a simple yet efficient approach. ProMPT draws inspiration from the work of Feng et al. (Feng et al., 2021, 2024) and discovers that in the human process of recognizing images, images can be repeatedly and deeply understood. Repetitive digestion of image aids in enhancing classification accuracy. Rather than making a direct prediction, ProMPT revisits the original image multiple times to check answers, incrementally refining the prediction from coarse to precise. In Figure 1, when an image is input into our network for classification, the confidence of the correct category progressively rises with each iteration. This process enables the prediction to be corrected from initial wrong “cat” to eventual correct “dog”.
Specifically, we implement a recurrent architecture that employs an iterative evolution strategy to align V-L features for accurate prediction. ProMPT comprises two main modules: an initialization module and a multi-modal iterative evolution (MIE) module. In initialization, for a given image, we utilize the original CLIP to encode text and image, generating V-L features. The cosine similarity is then calculated to select the text features of the top- categories, which serve as the initial input for MIE. Following that, the V-L features are updated progressively through MIE, containing three steps: class-conditional vision prompting, instance-conditional text prompting, and feature filtering. On one hand, to make vision encoding more focused on the relevant target objects, vision prompts are derived from the top- text features through a vision generator. On the other hand, inspired by CoCoOp (Zhou et al., 2022a), we convert image features into instance-conditional text prompts via a text generator to foster generalization. Feature filtering is intended to select the most image-relevant top- text features. Unlike most uni-modal methods, we introduce prompts in both V-L branches to facilitate the alignment of V-L features. Throughout the iterative process, vision and text prompts are continuously optimized, stimulating useful knowledge of VLMs, and promoting better alignment of V-L features. ProMPT evolves results, from rough to accurate prediction.
To evaluate the efficacy of our proposed ProMPT, we conduct comprehensive experiments across three representative settings: generalization from base-to-novel classes, cross-dataset evaluation, and domain generalization. The experimental results demonstrate the superiority of ProMPT over established baselines. Notably, in the generalization from base-to-novel classes setting, our method surpasses the baseline CoCoOp (Zhou et al., 2022a) in 10 out of 11 datasets, achieving absolute performance improvements of 3.2% in new classes and 1.97% in harmonic mean (HM). Additionally, in the cross-dataset evaluation and domain generalization settings, ProMPT exhibits valid generalizability and robustness with optimal average accuracy.
2. RELATED WORKS
In this section, we provide an overview of the related works, focusing on vision-language models and prompt learning.
Vision-Language Models. Recently, the field of CV has witnessed the advent and growing application of VLMs, like CLIP (Radford et al., 2021), ALIGN (Jia et al., 2021), and Florence (Yuan et al., 2021), particularly in few-shot or zero-shot learning scenarios. Vision-language models are trained on corpora of enormous noisy image-text pairs from the web based on contrastive learning by pulling the representations of matching image-text pairs close while pushing those of mismatching pairs far away to learn aligned vision-language representations. Under the supervision of natural language, VLMs exhibit impressive efficacy across a broad spectrum of downstream tasks. However, despite their ability to learn generalized representations, direct application to specific downstream tasks often leads to notable performance drops, posing a substantial challenge. Numerous studies have demonstrated that performance can be enhanced by tailoring VLMs with customized methods for downstream tasks, such as visual recognition (Zhou et al., 2022b, a; Gao et al., 2023; Zhang et al., 2021), video understanding (Ju et al., 2022; Fang et al., 2022; Amato et al., 2023; Li et al., 2022; Zhuo et al., 2022), and object detection (Gu et al., 2021; Shi et al., 2022; Du et al., 2022). In this work, we present progressive multi-modal conditional prompt tuning for vision-language models to promote image classification tasks under few-shot settings.
Prompt Learning. Prompt learning, originating from the NLP field, is generally classified into hard prompts and soft prompts. Hard prompts (Jin et al., 2022; Petroni et al., 2019; Wallace et al., 2019; Mishra et al., 2022; Le Scao and Rush, 2021) refer to hand-crafted sentence templates. By inserting input sentences into the templates, pre-trained models mimic the pre-training form in downstream tasks, thereby better eliciting the knowledge learned by the models. In addition, a series of works have employed learnable vectors as pseudo tokens injected into the input or hidden layers of models to participate in the attention computation of Transformer, known as soft prompts (Lester et al., 2021; Li and Liang, 2021; Liu et al., 2021, 2023; Han et al., 2022). These can more effectively extract information useful for downstream tasks from the pre-trained models.

In light of the prominent advantages of prompt learning in NLP, numerous approaches (Bahng et al., 2022; Rao et al., 2022; Zhu et al., 2023; Lee et al., 2023; Lu et al., 2022) have been adopted in the vision and vision-language domains, where the original parameters of the pre-trained model remain unchanged, and only some additional learnable prompt parameters are updated. VPT (Jia et al., 2022) has achieved substantial performance boosts by incorporating a few trainable parameters in the input space while keeping the model backbone frozen. CoOp (Zhou et al., 2022b) adapts CLIP-like VLMs for downstream image recognition tasks by modeling word templates as learnable vectors in language branch. CoCoOp (Zhou et al., 2022a) further evolves CoOp (Zhou et al., 2022b) by introducing input-conditional prompts for each image, thus enhancing the generalization capabilities of CoOp. TPT (Shu et al., 2022) dynamically learns adaptive prompts with a single test sample. DetPro (Du et al., 2022) learns soft prompt representations for open-vocabulary object detection based on VLMs. The above approaches primarily engage with uni-modal prompts either in vision or language branch, restricting VLMs to be optimized in only a single modality and ignoring multi-modal feature interactions. In contrast, we introduce optimizable soft prompts simultaneously in both V-L branches, aiming to advance the alignment between V-L representations.
3. METHODOLOGY
In this section, we commence by reviewing the architecture of the pre-trained CLIP. Following this, we briefly outline the overall framework of the proposed method ProMPT. Subsequently, we elaborate on the two main component modules of ProMPT, namely initialization and multi-modal iterative evolution (MIE). Lastly, we detail the design of the training objective tailored for ProMPT.
3.1. Review of CLIP
Our model is constructed upon the foundation of a pre-trained CLIP, which is composed of a text encoder and an image encoder. The text encoder adopts a Transformer (Vaswani et al., 2017) to encode text as vectorized representations, whereas the image encoder proceeds images into feature vectors based on a vision transformer (ViT) (Dosovitskiy et al., 2020) or a ResNet (He et al., 2016). During the pre-training, Radford et al. (Radford et al., 2021) collect a large number of image-text pairs to implement contrastive learning for CLIP, thus enabling CLIP to learn joint V-L representations. As a result, CLIP is adept at performing zero-shot visual recognition tasks with its parameters entirely frozen. Following existing approaches (Zhou et al., 2022b, a), our work employs a ViT-based CLIP model. We introduce the encoding process for both vision and text inputs in detail below.
Encoding image. The image encoder comprises transformer layers firstly embeds an image into latent embeddings . A learnable class token in image encoder is successively fed into along with to produce ,
| (1) |
To derive the final image representation , an image projector layer transforms from into a shared V-L latent embedding space,
| (2) |
Encoding text. Given the input text, the text encoder with transformer layers tokenizes and embeds it into word embeddings . At each layer, the embedding is input into the -th transformer layer as:
| (3) |
In a manner analogous to the image branch, the text representation is derived from the last token of the last transformer layer through a text projector layer, in the same embedding space as ,
| (4) |
Zero-shot inference. During zero-shot inference, the text inputs consist of hand-crafted prompts (e.g., ‘A photo of a [CLASS]’), where [CLASS] is substituted with the class name of label . The score for the -th class is quantified by computing the cosine similarity between the outputs of the text encoder and the image encoder. This calculation employs a similarity function with a temperature parameter , expressed as:
| (5) |
3.2. Framework Overview
To effectively transfer VLMs to image classification tasks, we explore the performance of multi-modal prompting, an advancement over the majority of existing uni-modal prompting approaches. In previous methods (Zhou et al., 2022b, a), learnable prompts are introduced into the language branch, solely adjusting the text encoding of this branch. However, we hypothesize that limiting prompting to the text encoder alone is sub-optimal. To better align V-L features, we advocate for multi-modal prompt tuning. Drawing inspiration from VPT (Jia et al., 2022), our method integrates learnable soft prompts into deep layers of ViT in CLIP. Figure 2 shows the overall architecture of our proposed ProMPT (Progressive Multi-modal conditional Prompt Tuning) framework. In the vision branch, vision prompts are generated by the text features most relevant to the image, encouraging image features to concentrate more on the target objects in the image. Concurrently, in the language branch, we apply image features to generate language prompts. These dynamic prompts have been demonstrated to improve generalizability by Zhou et al (Zhou et al., 2022a).
Moreover, we mimic the human process of distinguishing images, where an image can be analyzed repeatedly until accurate recognition is achieved. Specifically, we divide ProMPT into two principal phases: initialization () and multi-modal iterative evolution (), where represents the number of iterations. The strategy is designed to incrementally optimize more relevant prompts in each iteration, fostering the alignment of V-L features.
3.3. Initialization
For an image classification task with an image and a set of labels , the initialization phase leverages the original structure of CLIP to encode the input image and text.
ViT splits into fixed-size patches which are projected into patch embeddings . Unless otherwise stated, the superscript in the formulas uniformly denotes the iteration number. Subsequently, the process of image encoding in initialization is as follows, similar to Equation 1 and Equation 2,
| (6) |
In the language branch, the set is filled into the template prompt to generate . Each category is tokenized and embedded into word embeddings , where is the embeddings of the hand-crafted template “a photo of a” and represents the embeddings of the category . Subsequent to this step, is encoded through each layer of to obtain at the last layer . The feature , at the last position of , is mapped into text representation via the text projector layer .
| (7) |
Notably, we incorporate a feature filter to extract valuable text information based on and the text representations of the label set . As depicted in Figure 3, we first calculate the prediction probability for all classes according to Equation 5. Afterwards, the text features corresponding to the top- highest probability values are selected. Later on, is applied for the generation of conditional prompts during MIE.

3.4. Multi-modal Iterative Evolution
CLIP has shown remarkable effectiveness across various tasks, especially in zero-shot scenarios. Therefore, the features of categories we obtained in initialization are approximately valid. We input together with image into the multi-modal iterative evolution (MIE) module, which aims to preserve and enhance the alignment between image and text features. In this way, the V-L features in initialization eventually converge to a precisely aligned state. MIE contains three sub-processes: class-conditional vision prompting, instance-conditional text prompting, and feature filtering, each contributing to the iterative refinement of feature alignment.
Class-conditional vision prompting. To force image features to pay more attention to category-related information during encoding, we implement class-conditional vision prompting. As shown in the left part of Figure 4, we introduce prompts at up to a specific depth in the -th iteration. Specifically, a set of vision generators are designed to map into corresponding vision prompts for application in . In addition, an Add module is inserted to fully integrate and fuse the class-conditional vision prompts of the -th iteration process,
| (8) |
where is realized through a two-layer MLP (Linear-ReLU-Linear) responsible for mapping text features to image embedding space. The dimensional transformation process is expressed as . Considering that constructing separate would considerably increase the training parameters, we share weight matrix across and set layer-specific bias terms, which is aimed at balancing the training parameters with model performance.
Formally speaking, input embeddings are denoted as . Other vision prompts are further injected in corresponding layers of the image encoder to participate in self-attention computation and the final image representation is computed as follows,
| (9) |
Instance-conditional text prompting. Inspired by CoCoOp (Zhou et al., 2022a), we apply features from the image branch to generate instance-conditional text prompts via a text generator . As illustrated in the right part of Figure 4, the architecture of is the same as that of . Instead, we employ a single generator to create text prompts for insertion at the input layer , thereby setting . The specific process for dimensional transformation follows: . With the Add operation, image features pass through to yield text prompts ,
| (10) |
Once text prompts are obtained, they are concatenated with and subsequently fed into in turn for computing the text features of the label set during the -th iteration.
| (11) |

Feature filtering. In analogy to initialization, the feature filtering of MIE, as depicted in Figure 3, selects the top- text features that exhibit the highest relevance to according to prediction probabilities in a similar manner to Equation 5. Subsequently, these filtered features are utilized as inputs for the next iteration process, continuing the cycle of evolution.
| (12) |
3.5. Training Objective
To optimize ProMPT, we adopt a cross-entropy loss function aimed at minimizing the distance between ground-truth labels and prediction probabilities during the -th iteration derived from Equation 12,
| (13) |
where symbolizes the one-hot vector for the ground-truth label. Throughout the training phase, the advanced ProMPT maintains the whole parameters of CLIP fixed, while concurrently engaging in the optimization of prompts and generators. To this end, we apply for the output of all iterations in the MIE, excluding initialization. Overall, the final loss function of our model is formulated as:
| (14) |
where acts as a constant weighting factor for modulating the significance of each iterative evolution. The aggregation of serves to guide the model towards accurate predictions at each iteration, thereby progressively fostering multi-modal learning.

4. EXPERIMENTS
4.1. Experimental Setup
In this section, we elaborate on the experimental setup: benchmark setting, datasets, implementation details, and compared methods.
Benchmark setting. Our approach is primarily evaluated in three different experimental settings:
-
Generalization from base-to-novel classes. To demonstrate the generalizability of ProMPT, we partition datasets into base and novel classes to assess method in a zero-shot setting. The model is first trained on base classes in a few-shot setting and then evaluated on base and novel classes.
-
Cross-dataset evaluation. To verify the ability of ProMPT in cross-dataset transfer, we train our model on ImageNet in a few-shot manner and directly test it on other datasets.
-
Domain generalization. To validate the robustness of method on out-of-distribution datasets. Similarly, we deploy our ImageNet-trained model directly on four distinct ImageNet datasets that contain various types of domain shifts.
Datasets. In our study on generalization from base-to-novel classes setting and cross-dataset evaluation setting, we adopt 11 datasets following Zhou et al. (Zhou et al., 2022b). These include ImageNet (Deng et al., 2009), Caltech101 (Fei-Fei, 2004), OxfordPets (Parkhi et al., 2012), StanfordCars (Krause et al., 2013), Flowers102 (Nilsback and Zisserman, 2008), Food101 (Bossard et al., 2014), FGVCAircraft (Maji et al., 2013), SUN397 (Xiao et al., 2010), UCF101 (Soomro et al., 2012), DTD (Cimpoi et al., 2014) and EuroSAT (Helber et al., 2019). These datasets cover a wide range of image classification tasks involving generic objects, fine-grained categories, scene understanding, action recognition, texture classification, and satellite imagery recognition. For assessing domain generalization, we utilize ImageNet as source dataset and its four variants as target datasets, namely ImageNetV2 (Recht et al., 2019), ImageNet-Sketch (Wang et al., 2019), ImageNet-A (Hendrycks et al., 2021b) and ImageNet-R (Hendrycks et al., 2021a).
Implementation details. Our implementation leverages the open-source CLIP with the ViT-B/16 architecture, where , and . The text prompt length is fixed to 5, with the prompts initialized with the pre-trained CLIP word embeddings of “a photo of a”. The vision prompt length and depth are configured to 8 and 9, respectively. We utilize hyperparameters and set iteration numbers to 2. Experiments are executed on a single GeForce GTX 3090Ti GPU with a batch size of 4 and a learning rate of 0.008 via SGD optimizer for 5 epochs. To streamline the implementation, we uniformly utilize 16 shots for each class. In base-to-novel generalization, we report the accuracies for base and novel classes, alongside their harmonic mean (HM), averaging the outcomes over 3 runs. For cross-dataset evaluation and domain generalization, the model is trained on ImageNet for 2 epochs at a learning rate of 0.0024, with the vision prompt depth adjusted to 3.
Compared methods. We evaluate ProMPT and compare it with several notable prompt learning methods for VLMs, including:
-
CLIP (Radford et al., 2021) exploits hand-crafted text prompts (“a photo of a [CLASS]”), achieving excellent zero-shot generalization.
-
CoOp (Zhou et al., 2022b) replaces the hand-crafted prompts with learnable soft prompts that are optimized by the downstream datasets.
-
CoCoOp (Zhou et al., 2022a) introduces Meta-Net on the basis of CoOp, which combines image features with soft prompts of CoOp to generate instance-conditional prompts.
| Source | Target | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ImageNet | Caltech101 | O-Pets | S-Cars | Flowers102 | Food101 | Aircraft | SUN397 | DTD | EuroSAT | UCF101 | Average | |
| CoOp | 71.51 | 93.70 | 89.14 | 64.51 | 68.71 | 85.30 | 18.47 | 64.15 | 41.92 | 46.39 | 66.55 | 63.88 |
| CoCoOp | 71.02 | 94.43 | 90.14 | 65.32 | 71.88 | 86.06 | 22.94 | 67.36 | 45.73 | 45.37 | 68.21 | 65.74 |
| ProMPT | 70.47 | 93.73 | 90.20 | 65.83 | 71.20 | 86.30 | 24.57 | 67.33 | 44.27 | 51.13 | 67.93 | 66.25 |
| Prompts | Source | Target | |||||
|---|---|---|---|---|---|---|---|
| ImageNet | ImageNetV2 | ImageNet-Sketch | ImageNet-A | ImageNet-R | Average | ||
| CLIP | hand-crafted | 66.73 | 60.83 | 46.15 | 47.77 | 73.96 | 57.18 |
| CoOp | tp | 71.51 | 64.20 | 47.99 | 49.71 | 75.21 | 59.28 |
| CoCoOp | tp | 71.02 | 64.07 | 48.75 | 50.63 | 76.18 | 59.91 |
| ProMPT | vp+tp | 70.47 | 63.97 | 48.90 | 50.97 | 77.17 | 60.25 |
| N | Average | ImageNet | OxfordPets | Food101 | FGVCAircraft | EuroSAT | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base | New | H | Base | New | H | Base | New | H | Base | New | H | Base | New | H | Base | New | H | |
| 0 | 69.34 | 74.77 | 71.95 | 72.43 | 68.14 | 70.22 | 91.17 | 97.26 | 94.12 | 90.10 | 91.22 | 90.66 | 27.19 | 36.29 | 31.09 | 56.48 | 64.05 | 60.03 |
| 1 | 79.69 | 74.01 | 76.74 | 76.17 | 70.50 | 73.22 | 94.60 | 97.53 | 96.04 | 90.70 | 91.83 | 91.26 | 30.50 | 24.87 | 27.40 | 88.57 | 78.67 | 83.32 |
| 2 | 80.94 | 74.89 | 77.80 | 76.03 | 70.37 | 73.09 | 95.20 | 97.80 | 96.48 | 90.93 | 91.80 | 91.36 | 35.33 | 33.83 | 34.57 | 92.47 | 76.03 | 83.45 |
4.2. Generalization from Base-to-Novel Classes
We compare the proposed ProMPT with the aforementioned methods on the 11 datasets, and the experimental results are shown in Table 3.5. In all tables, the scale of the accuracy is in percentage. See Table 3.5 (a), ProMPT achieves a performance enhancement of 0.47% on base classes and a significant 3.20% on new classes respectively over the superior CoCoOp from an average performance perspective. This improvement demonstrates that ProMPT is equipped with solid generalization while ensuring basic performance. We attribute this phenomenon to the proposed MIE module, which gradually optimizes the prediction results in an iterative manner. During each iteration of the MIE module, class-conditional vision prompting promotes image features to focus more intently on the target objects during encoding, thus achieving a better alignment with text features; secondly, instance-conditional text prompting learns text prompts for each image rather than specific to some certain classes. These dynamic prompts are more robust to class shifts. In comparison to CoOp, although ProMPT is slightly inferior by 1.75% on base classes, its generalization on new classes surges from 63.22% to 74.89%. Besides, HM boosts from 71.66% to 77.80%, further evidencing the excellent capabilities of ProMPT.
More specifically, ProMPT surpasses CoCoOp on roughly all datasets when transferred to new classes, especially on EuroSAT and FGVCAircraft with satisfactory improvements of 15.99% and 10.12%, separately, as visualized in Figure 5. This makes sense because, for fine-grained tasks (FGVCAircraft) or specific tasks (EuroSAT), multi-modal conditional prompting that adapts the model from vision-language modality jointly is more dominant than uni-modal ones. On the other hand, minor performance degradations of ProMPT are observed on 4 out of 11 datasets in the base classes. Nevertheless, these reductions only remain within a mere 0.9%, which is considered trivial in comparison to the substantial gains afforded by ProMPT. In conclusion, with the aim of striking a balance between accuracy and generalization, we inspect the harmonic mean across all datasets depicted in Table 3.5. This comprehensive analysis reveals that ProMPT consistently demonstrates outstanding capability.
4.3. Cross-dataset Evaluation
We assess the cross-dataset generalization ability of ProMPT by learning multi-modal prompts on all the 1000 ImageNet classes and then transferring it directly to the remaining 10 datasets. As shown in Table 2, we compare the performance of ProMPT with that of CoOp and CoCoOp. On the source dataset, ImageNet, ProMPT achieves comparable performance. On the majority of target datasets, ProMPT exhibits superior performance, outperforming CoOp in all 10 datasets and surpassing CoCoOp in 5 out of 10 datasets. Overall, ProMPT stands out among the comparative methods with the highest average accuracy of 66.25%. This indicates the effectiveness of our proposed conditional multi-modal prompting and iterative evolution strategy in enhancing generalizability.
4.4. Domain Generalization
To verify the domain generalization of ProMPT, we train our model on the source ImageNet dataset and directly evaluate it on four out-of-distribution datasets. As depicted in Table 3, our method consistently outperforms all other methods on variant data and achieves the best average performance across the target data sets. These results highlight that the multi-modal conditional prompts markedly augment the robustness of our model.


4.5. Ablation Study
In this section, we put forward several ablation studies to delve deeper into the impact of various factors on ProMPT. We sequentially ablate the number of iterations, model structure, prompt length, vision prompt layer, and loss weighting factor. Unless otherwise specified, the reported results are the average performance of all datasets in the generalization from base-to-novel classes setting.
| Method | ProMPT | - | - | - | - | - |
|---|---|---|---|---|---|---|
| Base | 80.94 | 69.34 | 80.47 | 79.20 | 78.92 | 78.70 |
| New | 74.89 | 74.22 | 73.12 | 70.68 | 70.93 | 72.52 |
| H | 77.80 | 71.70 | 76.62 | 74.70 | 74.71 | 75.48 |
Effect of iterative optimization. We select several representative datasets, including generic-objects ImageNet and fine-grained OxfordPets, etc., to explore the impact of iteration numbers on ProMPT by increasing successively. Table 4 lists the results delivered by setting different , suggesting that the average capability improves as iteration continues in training, and reaches a culmination when . Furthermore, we visualize the iterative classification process. As illustrated in Figure 7, it can be observed that with the progression of iterations, ProMPT not only maintains but also gradually raises the confidence for already correctly identified category. Notably, Figure 7 underscores the correction capability of ProMPT. It can rectify category initially misclassified by the basic CLIP to the correct ones, eventually converging to a relatively stable state, thereby achieving stable prediction performance.
Effect of main components. We explore the efficacy of each component by removing it from ProMPT. The results are summarized in the Table 5. Discarding the iterative module (-) means only the initialization phase (i.e. CLIP), where the accuracy degrades by 11.6%, 0.67%, and 6.1% on Base, New, and H respectively. Afterwards, we execute three ablation settings: removing vision generator (-), removing text generator (-), and removing both (-). All settings consistently suffer greater losses in the new classes than the base classes, which suggests that conditional prompts are vital in improving generalization. Finally, we abolish feature filter , which results in considerable damage. Without , all text features are indiscriminately used to generate vision prompts. In this way, image features are equally concerned with some information of mismatched classes during encoding. Hence, is essential owing to the function of choosing the beneficial information reasonably.

Effect of prompt length. In Figure 8 (a), we display the effect of vision prompt length on ProMPT. determines the number of text features selected in and reflects the extent of class-related information included. Additionally, we conduct ablation on text prompt length . Figure 8 (b) presents the results. In brief, the performance initially improves and then decreases with an increase in . Accordingly, we set and for optimal efficiency.
Effect of vision prompt layer. We further investigate the impact of varying the number of layers for inserting vision prompts into the vision transformer on ProMPT. It can be intuitively seen from Figure 8 (c) that the more layers of vision prompt are implanted, the better model performance, achieving a peak at 9 layers.
Effect of loss weighting factor. We perform ablation for by varying it. The influence can be inferred from Figure 8 (d) that the effectiveness of ProMPT is positively correlated with . The optimal outcome is observed when .
5. CONCLUSION
In this work, we introduce an innovative framework named Progressive Multi-modal Conditional Prompt Tuning (ProMPT) for VLMs in image classification. To effectively refine and align image and text representations, ProMPT employs a recurrent architecture to leverage the original image and the current encoded information. Further, the presented multi-modal conditional prompt tuning can not only generate class-related vision prompts that make image features concentrate more on the target category, but also yield more robust text prompts suitable for class shifts. In this way, classification results progressively converge from coarse to fine through the multi-modal iterative evolution strategy. Extensive experimental results on three representative settings illustrate the effectiveness of our proposed approach, showcasing better generalization and robustness compared to baselines with a large margin.
References
- (1)
- Amato et al. (2023) Giuseppe Amato, Paolo Bolettieri, Fabio Carrara, Fabrizio Falchi, Claudio Gennaro, Nicola Messina, Lucia Vadicamo, and Claudio Vairo. 2023. VISIONE: a large-scale video retrieval system with advanced search functionalities. In ICMR. 649–653.
- Bahng et al. (2022) Hyojin Bahng, Ali Jahanian, Swami Sankaranarayanan, and Phillip Isola. 2022. Exploring visual prompts for adapting large-scale models. arXiv preprint arXiv:2203.17274 (2022).
- Bossard et al. (2014) Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. 2014. Food-101–mining discriminative components with random forests. In ECCV. 446–461.
- Cimpoi et al. (2014) Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. 2014. Describing textures in the wild. In CVPR. 3606–3613.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. ImageNet: A large-scale hierarchical image database. In CVPR. 248–255.
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
- Du et al. (2022) Yu Du, Fangyun Wei, Zihe Zhang, Miaojing Shi, Yue Gao, and Guoqi Li. 2022. Learning to prompt for open-vocabulary object detection with vision-language model. In CVPR. 14084–14093.
- Fang et al. (2022) Han Fang, Pengfei Xiong, Luhui Xu, and Wenhan Luo. 2022. Transferring image-CLIP to video-text retrieval via temporal relations. TMM (2022).
- Fei-Fei (2004) Li Fei-Fei. 2004. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In CVPRW. IEEE, 178–178.
- Feng et al. (2024) Hao Feng, Keyi Zhou, Wengang Zhou, Yufei Yin, Jiajun Deng, Qi Sun, and Houqiang Li. 2024. Recurrent Generic Contour-based Instance Segmentation with Progressive Learning. TCSVT (2024).
- Feng et al. (2021) Hao Feng, Wengang Zhou, Jiajun Deng, Qi Tian, and Houqiang Li. 2021. DocScanner: Robust document image rectification with progressive learning. arXiv preprint arXiv:2110.14968 (2021).
- Gao et al. (2023) Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. 2023. CLIP-Adapter: Better vision-language models with feature adapters. IJCV (2023), 1–15.
- Gu et al. (2021) Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. 2021. Open-vocabulary object detection via vision and language knowledge distillation. In ICLR.
- Han et al. (2022) Xu Han, Weilin Zhao, Ning Ding, Zhiyuan Liu, and Maosong Sun. 2022. PTR: Prompt tuning with rules for text classification. AI Open (2022), 182–192.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In CVPR. 770–778.
- Helber et al. (2019) Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. 2019. EuroSAT: A novel dataset and deep learning benchmark for land use and land cover classification. JSTARS (2019), 2217–2226.
- Hendrycks et al. (2021a) Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. 2021a. The many faces of robustness: A critical analysis of out-of-distribution generalization. In ICCV. 8340–8349.
- Hendrycks et al. (2021b) Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. 2021b. Natural adversarial examples. In CVPR. 15262–15271.
- Jia et al. (2021) Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision-language representation learning with noisy text supervision. In ICML. 4904–4916.
- Jia et al. (2022) Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. 2022. Visual prompt tuning. In ECCV. 709–727.
- Jin et al. (2022) Woojeong Jin, Yu Cheng, Yelong Shen, Weizhu Chen, and Xiang Ren. 2022. A good prompt is worth millions of parameters: low-resource prompt-based learning for vision-language models. In ACL. 2763–2775.
- Ju et al. (2022) Chen Ju, Tengda Han, Kunhao Zheng, Ya Zhang, and Weidi Xie. 2022. Prompting visual-language models for efficient video understanding. In ECCV. 105–124.
- Khattak et al. (2023) Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. 2023. MaPLe: Multi-modal prompt learning. In CVPR. 19113–19122.
- Krause et al. (2013) Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 2013. 3D object representations for fine-grained categorization. In ICCVW. 554–561.
- Le Scao and Rush (2021) Teven Le Scao and Alexander M Rush. 2021. How many data points is a prompt worth?. In NAACL. 2627–2636.
- Lee et al. (2023) Yi-Lun Lee, Yi-Hsuan Tsai, Wei-Chen Chiu, and Chen-Yu Lee. 2023. Multimodal prompting with missing modalities for visual recognition. In CVPR. 14943–14952.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In EMNLP. 3045–3059.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: optimizing continuous prompts for generation. In ACL. 4582–4597.
- Li et al. (2022) Yikang Li, Jenhao Hsiao, and Chiuman Ho. 2022. VideoCLIP: A cross-attention model for fast video-text retrieval task with image clip. In ICMR. 29–33.
- Liu et al. (2021) Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Lam Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. 2021. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv:2110.07602 (2021).
- Liu et al. (2023) Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2023. GPT understands, too. AI Open (2023).
- Lu et al. (2022) Yuning Lu, Jianzhuang Liu, Yonggang Zhang, Yajing Liu, and Xinmei Tian. 2022. Prompt distribution learning. In CVPR. 5206–5215.
- Maji et al. (2013) Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. 2013. Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151 (2013).
- Mishra et al. (2022) Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. 2022. Cross-task generalization via natural language crowdsourcing instructions. In AC. 3470–3487.
- Nilsback and Zisserman (2008) Maria-Elena Nilsback and Andrew Zisserman. 2008. Automated flower classification over a large number of classes. In ICVGIP. 722–729.
- Parkhi et al. (2012) Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. 2012. Cats and dogs. In CVPR. 3498–3505.
- Petroni et al. (2019) Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. Language models as knowledge bases?. In EMNLP-IJCNLP. 2463–2473.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In ICML. 8748–8763.
- Rao et al. (2022) Yongming Rao, Wenliang Zhao, Guangyi Chen, Yansong Tang, Zheng Zhu, Guan Huang, Jie Zhou, and Jiwen Lu. 2022. DenseCLIP: Language-guided dense prediction with context-aware prompting. In CVPR. 18082–18091.
- Recht et al. (2019) Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. 2019. Do ImageNet classifiers generalize to ImageNet?. In ICML. 5389–5400.
- Shi et al. (2022) Hengcan Shi, Munawar Hayat, Yicheng Wu, and Jianfei Cai. 2022. ProposalCLIP: Unsupervised open-category object proposal generation via exploiting CLIP cues. In CVPR. 9611–9620.
- Shin et al. (2020) Taylor Shin, Yasaman Razeghi, Robert L Logan IV, Eric Wallace, and Sameer Singh. 2020. AutoPrompt: Eliciting knowledge from language models with automatically generated prompts. In EMNLP. 4222–4235.
- Shu et al. (2022) Manli Shu, Weili Nie, De-An Huang, Zhiding Yu, Tom Goldstein, Anima Anandkumar, and Chaowei Xiao. 2022. Test-time prompt tuning for zero-Shot generalization in vision-language models. In NeurIPS.
- Soomro et al. (2012) Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. 2012. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402 (2012).
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In NeurIPS. 6000–6010.
- Wallace et al. (2019) Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. 2019. Universal adversarial triggers for attacking and analyzing NLP. In EMNLP-IJCNLP. 2153–2162.
- Wang et al. (2019) Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. 2019. Learning robust global representations by penalizing local predictive power. NeurIPS.
- Xiao et al. (2010) Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. 2010. Sun database: Large-scale scene recognition from abbey to zoo. In CVPR. 3485–3492.
- Yao et al. (2023) Hantao Yao, Rui Zhang, and Changsheng Xu. 2023. Visual-language prompt tuning with knowledge-guided context optimization. In CVPR. 6757–6767.
- Yuan et al. (2021) Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, et al. 2021. Florence: A new foundation model for computer vision. arXiv preprint arXiv:2111.11432 (2021).
- Zhang et al. (2021) Renrui Zhang, Rongyao Fang, Wei Zhang, Peng Gao, Kunchang Li, Jifeng Dai, Yu Qiao, and Hongsheng Li. 2021. Tip-Adapter: Training-free clip-adapter for better vision-language modeling. arXiv preprint arXiv:2111.03930 (2021).
- Zhou et al. (2022a) Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022a. Conditional prompt learning for vision-language models. In CVPR. 16816–16825.
- Zhou et al. (2022b) Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022b. Learning to prompt for vision-language models. IJCV (2022), 2337–2348.
- Zhu et al. (2023) Beier Zhu, Yulei Niu, Yucheng Han, Yue Wu, and Hanwang Zhang. 2023. Prompt-aligned gradient for prompt tuning. In ICCV. 15659–15669.
- Zhuo et al. (2022) Yaoxin Zhuo, Yikang Li, Jenhao Hsiao, Chiuman Ho, and Baoxin Li. 2022. CLIP4Hashing: unsupervised deep hashing for cross-modal video-text retrieval. In ICMR. 158–166.