Private Inputs for Leader-Follower Game with Feedback Stackelberg Strategy
Abstract
In this paper, the two-player leader-follower game with private inputs for feedback Stackelberg strategy is considered. In particular, the follower shares its measurement information with the leader except its historical control inputs while the leader shares none of the historical control inputs and the measurement information with the follower. The private inputs of the leader and the follower lead to the main obstacle, which causes the fact that the estimation gain and the control gain are related with each other, resulting that the forward and backward Riccati equations are coupled and making the calculation complicated. By introducing a kind of novel observers through the information structure for the follower and the leader, respectively, a kind of new observer-feedback Stacklberg strategy is designed. Accordingly, the above-mentioned obstacle is also avoided. Moreover, it is found that the cost functions under the presented observer-feedback Stackelberg strategy are asymptotically optimal to the cost functions under the optimal feedback Stackelberg strategy with the feedback form of the state. Finally, a numerical example is given to show the efficiency of this paper.
Index Terms:
feedback Stackelberg strategy, private inputs, observers, asymptotic optimality.I Introduction
In the traditional control model, centralized control is a basic concept and has been extensively studied from time-invariant system to time-variant system and system with time-delay [1, 2, 3]. However, with the development of wireless sensor network and artificial intelligence, the centralized control will no longer be applicable due to the fact that the achievable bandwidth would be limited by long delays induced by the communication between the centralized controller [4]. The task of effectively controlling multiple decision-makers systems in the absence of communication channels is increasingly an interesting and challenging control problem. Correspondingly, the decentralized control of large-scale systems arises accordingly, which has widespread implementation in electrical power distribution networks, cloud environments, multi-agent systems, reinforcement learning and so on [5, 6, 7, 8], where decisions are made by multiple different decision-makers who have access to different information.
Decentralized control can be traced back to 1970s [9, 10, 11]. The optimization of decentralized control can be divided into two categories. The first category is the decentralized control for multi-controllers with one associated cost function [12, 13, 14]. Nayyar studied decentralized stochastic control with partial history observations and control inputs sharing in [15] by using the common information approach and the -step delayed sharing information structure was investigated in [16]. [17] focused on decentralized control in networked control system with asymmetric information by solving the forward and backward coupled Riccati equations through forward iteration, where the historical control inputs was shared unilaterally compared with the information structure shared with each other in [15, 16]. [18] designed decentralized strategies for mean-field system, which was further shown to have asymptotic robust social optimality. The other category is the decentralized control for game theory [23, 24, 25]. Two-criteria LQG decision problems with one-step delay observation sharing pattern for stochastic discrete-time system in Stackelberg strategy and Nash equilibrium strategy were considered in [19] and [20], respectively. Necessary conditions for an optimal Stackelberg strategy with output feedback form were given in [21] with incomplete information of the controllers. [22] investigated feedback risk-sensitive Nash equilibrium solutions for two-player nonzero-sum games with complete state observation and shared historical control inputs. Static output feedback incentive Stackelberg game with markov jump for linear stochastic systems was taken into consideration in [26] and a numerical algorithm was further proposed which guaranteed local convergence.
Noting that the information structure in the decentralized control systems mentioned above has the following feature, that is, all or part of historical control inputs of the controllers are shared with the other controllers. However, the case, where the controllers have its own private control inputs, has not been addressed in decentralized control system, which has applications in a personalized healthcare setting, in the states of a virtual keyboard user (e.g., Google GBoard users) and in the social robot for second language education of children [27]. It should be noted that the information structure where the control information are unavailable to the other decision makers will cause the estimation gain depends on the control gain and vice versa, which means the forward and backward Riccati equations are coupled, and make the calculation more complicated. Motivated by [28], which focused on the LQ optimal control problem of linear systems with private input and measurement information by using a kind of novel observers to overcome the obstacle, in this paper, we are concerned with the feedback Stackelberg strategy for two-player game with private control inputs. In particular, the follower shares its measurement information to the leader, while the leader doesn’t share any information to the follower due to the hierarchical relationship and the historical control inputs for the follower and the leader are both private, which is the main obstacle in this paper. To overcome the problem, firstly, the novel observers based on the information structure of each controller are proposed. Accordingly, a new kind of observer-feedback Stackelberg strategy for the follower and the leader is designed. Finally, it proved that the associated cost functions for the follower and the leader under the proposed observer-feedback Stackelberg strategy are asymptotically optimal as compared with the cost functions under the optimal feedback Stackelberg strategy with the feedback form of the state obtained in [29].
The outline of this paper is given as follows. The problem formulation is given in Section II. The observers and the observer-feedback Stackelberg strategy with private inputs are designed in Section III. The asymptotical optimal analysis is shown in Section IV. Numerical examples are presented in Section V. Conclusion is given in Section VI.
Notations: represents the space of all real -dimensional vectors. means the transpose of the matrix . A symmetric matrix (or ) represents that the matrix is positive definite (or positive semi-definite). denotes the Euclidean norm of vector , i.e., . denotes the Euclidean norm of matrix , i.e., . represents the eigenvalues of the matrix and represents the largest eigenvalues of the matrix . is an identity matrix with compatible dimension. in block matrix represents a zero matrix with appropriate dimensions.
II Problem Formulation
Consider a two-player leader-follower game described as:
| (1) | |||||
| (2) | |||||
| (3) |
where is the state with initial value . and are the two control inputs of the follower and the leader, respectively. is the measurement information. , and () are constant matrices with compatible dimensions.
The associated cost functions for the follower and the leader are given by
| (4) | |||||
| (5) | |||||
where the weight matrices are such that , () and () with compatible dimensions.
Feedback Stackelberg strategy with different information structure for controllers had been considered since 1970s in [29], where the information structure satisfied that the controller shared all or part of historical inputs to the other. To the best of our knowledge, there has been no efficiency technique to deal with the case of private inputs for controllers. The difficultly lies in the unavailability of other controllers’ historical control inputs, which leads to the fact that the estimation gain depends on the control gain and makes the forward and backward Riccati equations coupled. In this paper, our goal is that by designing the novel observers based on the measurements and private inputs for the follower and the leader, respectively, we will show the proposed observer-feedback Stackelberg strategy is asymptotic optimal to the deterministic case in [29]. Mathematically, by denoting
| (6) | |||||
| (7) |
we will design the observer-feedback Stackelberg strategy based on the information , where is -casual for in this paper. The following assumptions will be used in this paper.
Assumption 1
System is stabilizable with and system () is observable.
By denoting the admissible controls sets (i=1, 2) for the feedback Stackelberg strategy of the follower and the leader:
| (8) |
where and represent the strategy for the follower and the leader, respectively, the definition of the feedback Stackelberg strategy [30] is given.
Definition 1
is the optimal feedback Stackelberg strategy, if there holds that:
Firstly, the optimal feedback Stackelberg strategy in deterministic case with perfect information structure is given, that is, the information structure of the follower and the leader both satisfy
Lemma 1
Under Assumption 1, the optimal feedback Stackelberg strategy with the information structure for the follower and the leader satisfying , is given by
| (9) | |||||
| (10) |
where the feedback gain matrices and satisfy
| (11) | |||||
| (12) |
with
where and satisfy the following two-coupled algebraic Riccati equations:
| (13) | |||||
| (14) | |||||
The optimal cost functions for feedback Stackelberg strategy are such that
| (15) | |||||
| (16) |
Proof 1
The optimal feedback Stackelberg strategy for deterministic case with perfect information structure for the follower and the leader in finite-time horizon has been shown in (18)-(28) with in [29]. By using the results in Theorem 2 in [3], the results obtained in [29] can be extended into infinite horizon, i.e., (18)-(28) in [29] are convergent to the algebraic equations obtained in (11)-(12) and (13)-(14) in Lemma 1 of this paper by using the monotonic boundedness theorem. This completes the proof.
Remark 1
Remark 2
Compared with [29], where the historical control inputs of the follower and the leader are shared with each other, the historical control inputs of this paper are private, leading to the main obstacle.
III The observer-feedback Stackelberg strategy
Based on the discussion above, we are in position to consider the leader-follower game with private inputs, i.e., is -casual.
Remark 3
As pointed out in [17], the information structure in decentralized control, where one of the controllers (C1) doesn’t share the historical control inputs to the other controller (C2) while C2 shares its historical control inputs with C1, is a challenge problem due to the control gain and estimator gain are coupled. The difficulty with private inputs for the follower and the leader is even more complicated due to the unavailability of the historical control inputs of each controller.
Considering the private inputs of the follower and the leader, the observers () are designed as follows:
| (17) | |||||
| (18) | |||||
where the observer gain matrices and are chosen to make the observers stable. Accordingly, the observer-feedback Stackelberg strategy is designed as follows:
| (19) | |||||
| (20) |
For convenience of future discussion, some symbols will be given beforehand.
| (23) | |||||
| (25) | |||||
| (27) | |||||
| (30) | |||||
| (32) | |||||
Subsequently, the stability of the observers () and the stability of the closed-loop system (1) under the designed observer-feedback Stackelberg strategy (19)-(20) are shown, respectively.
Theorem 1
Proof 2
By substituting the observer-feedback controllers (19)-(20) into (1), then is recalculated as:
| (34) | |||||
Accordingly, by adding (19)-(20) into the observers (17)-(18) and combining with (34), the derivation of for are given as
that is
| (35) |
Subsequently, if there exist matrices and making stable, then, the stability of the matrix means that
i.e., (33) is established. That is to say, the observers are stable under (19)-(20). The proof is completed.
Remark 4
Noting that in Theorem 1 the key point lies in that how to select () so that the eigenvalues of the matrix are within the unit circle. The following analysis gives an method to find .
According to the Lyapunov stability criterion, i.e., is stable if and only if for any positive definite matrix , admits a solution such that . Thus, if there exists a such that
| (36) |
then is stable. Following from the elementary row transformation, one has
that is, is equivalent to the following matrix inequality
| (41) |
Noting that is related with , in order to use the linear matrix inequality (LMI) Toolbox in Matlab to find , (41) will be transmit into a LMI form. Let
and rewrite in (23) as , where
To this end, we have
with . Based on the discussion above, it concludes that is stable if there exists a such that the following LMI:
| (47) |
In this way, by using the LMI Toolbox in Matlab, can be found according, which stabilizes where .
Theorem 2
Proof 3
According to (34), the closed-loop system (1) is reformulated as
| (48) |
Together with (35), we have
| (53) |
The stability of is guaranteed by the stabilizability of and the observability of for . Following from Theorem 1, is stabilized by selecting appropriate gain matrices and . Subsequently, the stability of the closed-loop system (1) is derived. This completes the proof.
IV The asymptotical optimal analysis
The stability of the state and the observers, i.e., and for has been shown in Theorem 1 and Theorem 2 under the observer-feedback controllers (19)-(20). To shown the rationality of the design of the observer-feedback controllers (19)-(20), the asymptotical optimal analysis relating with the cost functions under (19)-(20) is given. To this end, denote the cost functions for the follower and the leader satisfying
| (54) | |||||
| (55) | |||||
Now, we are in position to show that the observer-feedback Stackelberg strategy (19)-(20) is asymptotical optimal to the optimal feedback Stackelberg strategy presented in Lemma 1.
Theorem 3
Under Assumption 1, the corresponding cost functions (54)-(55) under the observer-feedback Stackelberg strategy (19)-(20) with () selected from Theorem 1 are given by
| (62) | |||||
| (69) | |||||
where
Moreover, the differences, which are denoted as and , between (62)-(69) and the optimal cost functions (15)-(16) obtained in Lemma 1 under the optimal feedback Stackelberg strategy are such that
| (78) | |||||
| (85) | |||||
Proof 4
The proof will be divided into two parts. The first part is to consider the cost function of the follower under the observer-feedback controllers (19)-(20). Following from (34), system (1) it can be rewritten as
| (86) | |||||
where in (11) have been used in the derivation of the last equality.
Firstly, we will prove satisfies (62). Combing (86) with (13), one has
| (87) | |||||
Substituting (4) from to on both sides, we have
| (97) | |||||
According to Theorem 2, the stability of (1) means that
Thus, following from (4) and letting , (62) can be obtained exactly.
The second part is to consider the cost function of the leader under the observer-feedback controllers (19)-(20), that is, we will show that satisfies (69). Following from (86), it derives
| (98) | |||||
where the algebraic Riccati equation (14) has been used in the derivation of the last equality. For further optimization, we make the following derivation:
| (99) | |||||
Substituting (4) from to on both sides, one has
| (109) | |||||
Due to , (69) can be immediately obtained by letting in (4).
Finally, we will show the asymptotical optimal property under the observer-feedback Stackelberg strategy (19)-(20).
Theorem 4
Under the condition of Theorem 2, the optimal cost functions (62)-(69) under the observer-feedback Stackelberg strategy (19)-(20) are asymptotical optimal to the optimal cost functions (110)-(111) under the optimal feedback Stackelberg strategy (9)-(10), that is to say, for any , there exists a sufficiency large integer for such that
| (112) |
Proof 5
Following from Theorem 2, there exists a stable matrix . Thus, by [2], there exist constants and such that
| (117) |
In this way, one has
| (124) | |||||
| (129) | |||||
| (134) | |||||
| (139) | |||||
| (140) |
Since , thus there exists a sufficiency large integer such that for any , satisfying
Combing with (124), one has
| (141) |
That is to say, the cost functions (62)-(69) under the observer-feedback Stackelberg strategy (19)-(20) are asymptotical optimal to the cost functions (110)-(111) under the optimal feedback Stackelberg strategy (9)-(10) when the integer is large enough. The proof is now completed.
V Numerical Examples
To show the validity of the results in Theorem 1 to Theorem 4, the following example is presented. Consider system (1)-(3) with
and the associated cost functions (4)-(5) with
By decoupled solving the algebraic Riccati equations (13)-(14), the feedback gains in (11)-(12) are respectively calculated as
By using the LMI Toolbox in Matlab, () are calculated as
while the four eigenvalues of matrix are calculated as:
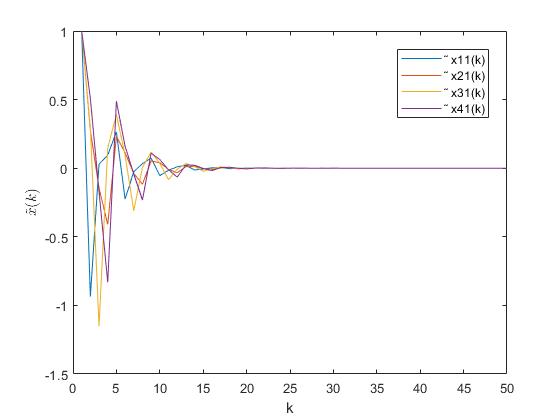
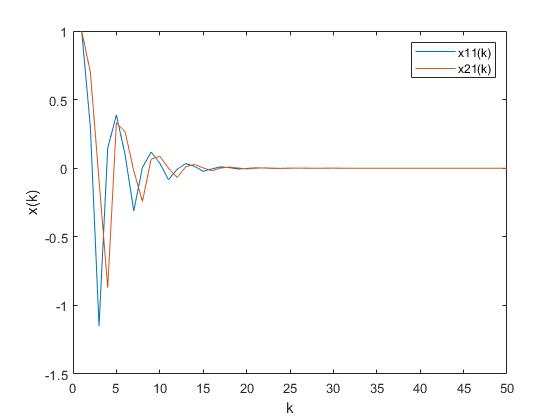
which means that in (23) is sable. In this way, following from Theorem 1, the state error estimation in (35) is stable, which is shown in Fig. 1, where data 1 to data 4 represent the four components of vector . Moreover, under the observer-feedback Stackelberg strategy (19)-(20), the state in (1) is also stable which can be seen in Fig. 2, where data 1 and data 2 represent the two components of . Finally, by analyzing Fig. 1 and Fig. 2 and selecting in Theorem 4, the asymptotical optimal property of the cost functions (62)-(69) under the observer-feedback Stackelberg strategy (19)-(20) is guaranteed.
VI Conclusion
In this paper, we have considered the feedback Stackelberg strategy for two-player leader-follower game with private inputs, where the follower only shares its measurement informaiton with the leader, while none of the historical control inputs and measurement information of the leader are shared with the follower due to the hierarchical relationship. The unavaliable access of the historical inputs for both controllers causes the main difficulty. The obstacle is overcome by designing the observers based on the informaiton structure and the observer-feedback Stackelberg strategy. Moreover, we have shown that the cost functions under the proposed observer-feedback Stackelberg strategy are asymptotical optimal to the cost functions under the optimal feedback Stackelberg strategy.
References
- [1] D. Anderson and B. Moore, “Linear optimal control”, Prentice-Hall, Englewood Cliffs, NJ, 1971.
- [2] M. Rami, X. Chen, J. Moore and X. Zhou. “Solvability and asymptotic behavior of generalized Riccati equations arising in indefinite stochastic LQ Controls”, IEEE Transactions on Automatic, 46(3): 428-440, 2001.
- [3] H. S. Zhang, L. Li, J. J. Xu and M. Y. Fu, “Linear quadratic regulation and stabilization of discrete-time systems with delay and multiplicative noise”, IEEE Transactions on Automatic Control, 60(10): 2599-2613, 2015.
- [4] N. W. Bauer, M. Donkers, N. van de Wouw and W. Heemels, “Decentralized observer-based control via networked communication”, Automatica, 49: 2074-2086, 2013.
- [5] F. Blaabjerg, R. Teodorescu, M. Liserre and A. V. Timbus, “Overview of control and grid synchronization for distributed power generation systems”, IEEE Transactions on Industrial Electronics, 53: 1398-1409, 2006.
- [6] B. Hoogenkamp, S. Farshidi, R. Y. Xin, Z. Shi, P. Chen and Z. M. Zhao, “A decentralized service control framework for decentralized applications in cloud environments”, Service-Oriented and Cloud Computation, 13226: 65-73, 2022.
- [7] Q. P. Ha, and H. Trinh, “Observer-based control of multi-agent systems under decentralized information structure”, International Journal of Systems Science, 35(12): 719-728, 2004.
- [8] D. Görges, “Distributed adaptive linear quadratic control using distributed reinforcement learning”, IFAC-PapersOnLine, 52(11): 218-223, 2019.
- [9] H. Witsenhausen, “A counterexample in stochastic optimum control”, SIAM Journal on Control and Optimization, 6(1): 131-147, 1968.
- [10] E. Davison, N. Rau and F. Palmay, “The optimal decentralized control of a power system consisting of a number of interconnected synchronous machines”, International Journal of Control, 18(6): 1313-1328, 1973.
- [11] E. Davison, “The robust decentralized control of a general servomechanism problem”, IEEE Transactions on Automatic Control, AC-21: 14-24, 1976.
- [12] T. Yoshikawa, “Dynamic programming approach to decentralized stochastic control problem”, IEEE Transactions on Automatic Control, 20(6): 796-797, 1975.
- [13] J. Swigart and S. Lall, “An explicit state-space solution for a deffcentralized two-player optimal linear-quadratic regulator”, American Control Conference, 6385-6390, 2010.
- [14] X. Liang, J. J Xu, H. X. Wang and H. S. Zhang, “Decentralized output-feedback control with asymmetric one-step delayed information”, IEEE Transactions on Automatic Control, doi: 10.1109/TAC.2023.3250161, 2023.
- [15] A. Nayyar, A. Mahajan and T. Teneketzis, “Decentralized stochastic control with partial history sharing: A common information approach”, IEEE Transactions on Automatic Control, 58(7): 1644-1658, 2013.
- [16] A. Nayyar, A. Mahajan and T. Teneketzis, “Optimal control strategies in delayed sharing information structures”, IEEE Transactions on Automatic Control, 56(7): 1606-1620, 2011.
- [17] X. Liang, Q. Q. Qi, H. S. Zhang and L. H. Xie, “Decentralized control for networked control systems with asymmetric information”, IEEE Transactions on Automatic Control, 67(4): 2067-2083, 2021.
- [18] B. C. Wang, X. Yu and H. L. Dong, “Social optima in linear quadratic mean field control withunmodeled dynamics and multiplicative noise” Aisan Journal of Control, 23(3): 1572-1582, 2019.
- [19] T. Başar, “Two-criteria LQG decision problems with one-step delay observation sharing pattern”, Information and Control, 38: 21-50, 1978.
- [20] P. George, “On the linear-quadratic-gaussian Nash game with one-step delay observation sharing pattern”, IEEE Transactions on Automatic Control, 27: 1065-1071, 1982.
- [21] F. Suzumura and K. Mizukami, “Closed-loop strategy for Stackelberg game problem with incomplete information structures” IFAC 12th Triennial World Congress, Australia, 413-418, 1993.
- [22] M. B. Klompstra, “Nash equilibria in risk-sensitive dynamic games”, IEEE Transactions on Automatic Control, 45(7): 1397-1401, 2000.
- [23] M. Pachter, “LQG dynamic games with a control-sharing information pattern”, Dynamic Games and Applications, 7: 289-322, 2017.
- [24] Y. Sun, J. J. Xu and H. S. Zhang, “Feedback Nash equilibrium with packet dropouts in networked control systems”, IEEE Transactions on Circuits and Systems II: Express Briefs, 70(3): 1024-1028, 2022.
- [25] Z. P. Li, M. Y. Fu, H. S. Zhang and Z. Z. Wu, “Mean field stochastic linear quadratic games for continuum-parameterized multi-agent systems”, Journal of the Franklin Institute, 355: 5240-5255, 2018.
- [26] H. Mukaidani, H. Xu and V. Dragan, “Static output-feedback incentive Stackelberg game for discrete-time markov jump linear stochastic systems with external disturbance”, IEEE Control Systems Letters, 2(4): 701-706, 2016.
- [27] S. R. Chowdhury, X. Y. Zhou and N. Shroff, “Adaptive control of differentially private linear quadratic systems”, IEEE International Symposium on Information Theory, 485-490, 2021.
- [28] J. J. Xu and H. S. Zhang, “Decentralized control of linear systems with private input and measurement information”, arXiv:2305.14921, 1-6, 2023.
- [29] D. Castanon and M. Athans, “On stochastic dynamic Stackelberg strategies”, Automatica, 12: 177-183, 1976.
- [30] A. Bensoussan, S. Chen and S. P. Sethi, “The maximum principle for global solutions of stochastic Stackelberg differential games”, SIAM Journal of Control and Optimization, 53(4): 1965-1981, 2015.