∗11email: {xliu7788, bgao9725, hyou8279, zima9310, yliu8248}@uni.sydney.edu.au
†11email: {basem.suleiman, ali.anaissi}@sydney.edu.au
Privacy-Preserving Personalized Fitness Recommender System : A Multi-level Deep Learning Approach
Abstract
Recommender systems have been successfully used in many domains with the help of machine learning algorithms. However, such applications tend to use multi-dimensional user data, which has raised widespread concerns about the breach of users’ privacy. Meanwhile, wearable technologies have enabled users to collect fitness-related data through embedded sensors to monitor their conditions or achieve personalized fitness goals. In this paper, we propose a novel privacy-aware personalized fitness recommender system. We introduce a multi-level deep learning framework that learns important features from a large-scale real fitness dataset that is collected from wearable IoT devices to derive intelligent fitness recommendations. Unlike most existing approaches, our approach achieves personalization by inferring the fitness characteristics of users from sensory data and thus minimizing the need for explicitly collecting user identity or biometric information, such as name, age, height, weight. In particular, our proposed models and algorithms predict (a) personalized exercise distance recommendations to help users to achieve target calories, (b) personalized speed sequence recommendations to adjust exercise speed given the nature of the exercise and the chosen route, and (c) personalized heart rate sequence to guide the user of the potential health status for future exercises. Our experimental evaluation on a real-world Fitbit dataset demonstrated high accuracy in predicting exercise distance, speed sequence, and heart rate sequence compared to similar studies. Furthermore, our approach is novel compared to existing studies as it does not require collecting and using users’ sensitive information, and thus it preserves the users’ privacy.
Keywords:
Personalization Fitness Recommender system Deep learning Sensors.1 Introduction
With the advent of artificial intelligence, many innovative enterprises have provided various personalized products and services to individuals. Personalization is generally made possible by mining multidimensional data from individuals so that the products and services can be custom-made to people’s inclinations. In particular, the research of personalization on improving individuals’ well-being has attracted a lot of attention. For instance, smartphones and smartwatches can sense the dynamic changes of users, such as heart rate, blood pressure, sleep patterns, etc., to realize real-time and non-invasive monitoring of human health [16]. A study found that smartwatches can effectively monitor the instantaneous changes in the user’s heart rate, and can accurately help diagnose atrial fibrillation associated with ischemic stroke (asymptomatic or paroxysmal) [25]. On the other hand, other products focus on providing personalized suggestions to users, such as customizing exercise plans for users, understanding their reactions to the plans, and analyzing exercise results to continuously improve user experiences. For example, a framework named PRO-Fit (Personalized Recommender and Organizer Fitness assistant) was introduced, which uses collaborative filtering on user profile and activity data to generate personalized fitness schedules according to user availability and fitness goals [11]. Traditionally, people can achieve comparative goals by hiring a human trainer, but machine learning-based applications have certain advantages in terms of quality and affordability. More specifically, machine learning algorithms can integrate various information sources from thousands or even millions of users to develop products or services, which is far beyond the knowledge range of a human trainer. In addition, recommender systems as software products usually have a lower marginal cost to provide services to new users. However, despite the convenience brought by technology, societies are paying more attention to the security and privacy issues in data mining and prediction. In 2018, the European Union issued General Data Protection Regulation (GDPR) to regulate the protection of citizens’ personal data and privacy. In this sense, Tan et al. [31] and Bouhenguel et al. [7] discussed the Bluetooth security threats of wearable devices, and share their knowledge and insights on how to prevent devices and the networks they are connected to from being attacked. Other researchers such as Cyr et al. [10] analyzed the potential security problems of Fitbit devices when collecting and utilizing users’ data, such as unnecessarily collecting information from nearby devices, or withholding all collected data to the device owners. Unfortunately, most service or product providers are inherently motivated to collect as much data as possible, especially personal data, from users to cultivate machine or deep learning models to enhance user experience.
Although most of the existing work in the literature focuses on building accurate artificial intelligence models to make personalized fitness recommendations, little consideration is given to protecting the privacy of users. For instance, Dharia et al. [11] proposed a PRO-Fit framework to proactively push notifications recommending fitness-related activities to users, which is based on their multivariate data, including their fitness preferences, calendar data, and social network data. Although the model has achieved good performance, the framework inevitably collects an intensive amount of sensitive data from users. Likewise, the “TweetFit” framework which was proposed in [13] profiles people’s wellness by taking advantage of data from sensors such as speed or heart rate measurements during exercises and multiple social media sources such as Twitter tweets and Instagram image captions and comments. On the other hand, with specific attention to GDPR compliance, Sanchez et al. [26] presented a fitness data privacy model that learns people’s privacy preferences for fitness data sharing and processing collected by the Internet of things (IoT) devices. They studied user privacy permission settings of fitness trackers such as Fitbit and smartwatches with the supplement of a questionnaire to learn users’ privacy profiles by applying machine learning modeling. They further developed a rule-based personal data manager (PDM) framework to provide privacy advice to users based on their machine learning models. However, this work mainly focuses on the general privacy settings of IoT devices, not their product functions. Loepp et al.[21] proposed a prototypical smartphone app that recommends personalized running routes based on analyzing multivariate data of the workout routes users have run, e.g., length of the route, uniqueness of the route, the shape of the route, the light of the route, and so on. The framework makes personalized recommendations based on running routes following a rule-based approach and users’ preferences which were manually set by users. Compared with the rule-based approach, machine or deep learning-based recommender systems have the advantage of learning user attributes intelligently and require minimum manual input from the users.
In this paper, we address the above challenges by proposing a novel privacy-aware personalized fitness recommender system. In our proposed approach, we introduce a multi-level deep learning framework that learns important features from a large-scale real fitness dataset collected from wearable IoT devices to derive intelligent fitness recommendations. Unlike most existing approaches, our approach achieves personalization by inferring the fitness characteristics of users from sensory data and thus minimizing the need for explicitly collecting user identity or biometric information, such as name, age, height, and weight.
Our proposed approach consists of two key components. We first build a model that learns user embedding and workout route embedding from a real-world Fitbit dataset. The user and workout route embeddings are then fed as input features to our proposed deep learning models to create personalized recommendations. Second, we develop a workout profile prediction model that suggests personalized workout recommendations that can guide the user based on their choice of workout distance, route and speed sequence, sport type, and target calories to consume. The goal of our exercise distance prediction is to provide personalized guidance for users to achieve the target exercise calorie. Similarly, our predicted speed sequence aims to guide the user to adjust the exercise speed according to the conditions of the selected target exercise calories and the selected exercise route. Meanwhile, our predicted heart rate sequence aims to provide the user with an important indicator of the expected health status in the upcoming exercise.
In our approach, we also propose a three-dimensional tensor of ”users – workout routes – contextual features” based on the historical workout data. The goal of this tensor is to capture the underlying structures inherited in users and workout routes using the Tensor Decomposition method CANDECOMP/PARAFAC (CP) [20]. The two resultant matrices related to the latent characteristics of the users and workout routes are then combined with other contextual features (choice of sport, target calories, etc.) as input to two models. The first model is a Multi-Layer Perceptron (MLP) which is used to predict the total distance of a future workout. The second model is a Long Short-Term Memory (LSTM) which is used to predict the speed sequence and heart rate sequence of a future workout.
The main contributions of our proposed approach are threefold:
-
1.
An approach to building privacy-aware personalized fitness recommendation systems, by inferring the fitness characteristics of users from sensory data instead of collecting multidimensional private data from users. This is complementary to the personalized fitness recommendation systems that do not consider privacy preservation, and the privacy preservation approaches running on independent encryption protocols.
-
2.
A model that learns user embedding and workout route embedding from real workout datasets collected from Fitbit devices. This includes gender, sport type, calories, workout duration, workout distance, workout speed, workout heart rate, and workout route geographical data. Our user and workout route embeddings are further utilized as the input features for our proposed privacy-aware and personalized fitness recommender.
-
3.
A workout profile prediction model that suggests personalized recommendation of the necessary workout distance, the rhythm of speed, the change of heart rate of a future exercise based on the user’s choice of workout route, sport type, and target calories to consume.
The rest of this paper is structured as follows. In section 2, we present background information relevant to the topics of our proposed approach. We also, discuss various related studies in the literature and practice. The details of our proposed approach, including our methods and algorithms, are introduced in section 3. The experimental evaluation and result analysis are discussed in section 4. In section 5, we discuss the results in the context of our research goals and contributions. We draw key conclusions and future work in section 6.
2 Related Work
In this section, we first briefly review the technologies for sequential data modeling and technologies used in building recommender systems. Then we discuss related studies on different fitness recommendation topics, e.g., Fitness Activity Detection and Recommendation, Sequential Fitness Profile Recommendation, and Privacy Preservation in Fitness Recommendation.
Recurrent Neural Networks (RNNs). In recent years, RNNs and particularly LSTM networks have been widely used in processing time-series data for sequential modeling tasks, for example, speech recognition [15], machine translation [30], image captioning [9], etc. Ilya Sutskever et al. proposed an end-to-end approach to address sequence to sequence mapping problem by constructing a multi-layer LSTM network, which maps the input sequence to a fixed-dimensional vector through LSTM, and then uses another LSTM to output the target sequence [30]. They put forward several innovative techniques to improve the model, such as using stacked LSTM structure and reversing input vectors, etc. In English-French translation tasks, their model shows better performance over single forward LSTM models. Moreover, Bi-directional LSTM is an extension of traditional LSTMs that improves model performance on many sequential modeling tasks. This is because a unidirectional LSTM network only propagates information from past to future, while a Bi-directional LSTM network manages inputs in two ways, one from past to future and one from future to past [28]. Therefore, it consolidates the context of each step in the input sequence. Similarly, in our work, we consider a Bi-directional stacked LSTM architecture to solve the sequence-to-sequence modeling task.
Technologies of Recommender Systems. Recommender systems generally follow two basic approaches: collaborative filtering or content-filtering [1]. Collaborative filtering holds the belief that people would continue the same experience in the future if they liked something in the past. The K-nearest Neighboring (KNN) method is often used to be the most favored approach to conducting collaborative filtering, which conducts finding similar users’ profiles to one certain user to compute likeness and dislikes for an item [27]. In contrast, content-based filtering methods are useful in situations where user information is sufficient but not item information. It works as a classifier to model the likes and dislikes of the users to evaluate an item [27]. In collaborative filtering-based recommender systems, a two-dimensional data matrix associated with users and items is usually constructed. The 2-D matrix can be factorized into two matrices, namely a user matrix and an item matrix that contain the latent characteristics describing the user preferences and item profiles [17]. One disadvantage of the matrix factorization approach is that the context is only a scalar, representing the user’s rating of the item. To overcome this shortcoming, Karatzoglou et al. discussed a multidimensional equivalent method to the 2-D matrix factorization approach named Tensor Decomposition [17]. Contrary to the single rating feature in the matrix decomposition method, a multidimensional contextual feature vector is established between each user and item. This method allows flexible integration of context information when learning entity embeddings to provide context-aware recommendations. In our work, we consider establishing a rich context feature vector between each user and workout route to derive user embeddings and workout route embeddings.
Fitness Activity Detection & Recommendation. Guo et al. proposed FitCoach, which is a virtual fitness coach built upon data sensed by IoT devices [14]. It aims at detecting people’s workout statistics such as exercise types with a lightweight support vector machine (SVM) classifier and providing fine-grained feedback on exercise form scores, i.e., motion strength and performing period, to assist users to maintain proper exercise postures and avoid injuries. Similarly, Zhao et al. introduced a fitness recommender system designed to generate personalized and gamified content to promote daily physical activities [36]. They collected various types of user data and built separate sub-models for user profile prediction with a non-machine learning approach. The sub-models work individually, but their results are jointly input into a decision tree-based recommendation engine to create personalized recommendations, such as extending an existing exercise or suggesting a different type of activity. Yong et al. proposed an IoT-based intelligent fitness system that monitors people’s health with data collected by IoT devices, recognizes people’s actions using a convolutional neural network (CNN) based model, and provides fitness-related recommendations, such as reminding users to attend fitness courses or going to gyms based on user predefined exercise plans [34]. They explicitly collected users’ scores on the exercise items to build a collaborative filtering based recommender system to realize personalization. Similarly, Saumil Dharia et al. presented the PRO-Fit framework that collects users’ multivariate data, including fitness preferences, calendar data, and social network data [11]. It applies machine learning algorithms to classify users’ activities into specific types, which are then used to establish user profiles reflecting their current lifestyle (sedentary vs. active). These user profiles are further fed into a collaborative filtering-based recommender system for personalized fitness activity or fitness partner recommendations. Unlike most studies that target the general public, Mogaveera et al. introduced a health monitoring and fitness recommendation system using machine learning targeting patients [23]. The system collects data from both patients (body details, disease & health records) and doctors (disease categories) to monitor patients’ condition based on some predefined rules and to provide personalized recommendations of diet and exercise plans through a decision tree based machine learning model.
Compared with the existing research, our focus is on recommending dynamic changes of workout speed and heart rate of an exercise, which are complementary dimensions in the field of fitness recommendation. In addition, the construction of these exercise activity recommendation systems usually boils down to recommending some predefined fitness categories. In contrast, we propose a deep learning framework to solve a rarely studied sequence-to-sequence regression task to model workout speed and heart rate. Moreover, as discussed above, most researchers have achieved personalization with rule-based or collaborative filtering-based methods. In contrast, we propose learning user profiles based on tensor decomposition. Compared with the rule-based method, this method is considered to be more scalable and compared with the collaborative filtering method, it can realize context-aware user profiles [17].
Sequential Fitness Profile Recommendation. Berndsen et al. proposed a recommender system that predicts the target finish time of Marathon with an XGBoost model, followed by a collaborative filtering & K-Nearest-Neighbours (KNN) based framework to generate pacing recommendations for runners to achieve the target finish time [6]. More specifically, historical training data of athletes, such as GPS data, completion time, and pacing information, are used to predict the target completion time. Meanwhile, a runner’s user profile can be inferred by applying collaborative filtering and further used to find the successful marathon finishers with the most similar user profiles applying K-Nearest-Neighbours (KNN) algorithm. Finally, pacing strategy recommendation is achieved by using the pacing strategies from these successful marathon finishers with similar user profiles. Compared with their work, the exercises we focus on are less competitive than Marathon, such as jogging, biking, etc. However, our task of predicting workout distance is similar to the prediction of target finish time in [6], except that we propose a multi-layer perceptron model to solve this task. In addition, their approach to workout pacing recommendation is through looking up historical exercises and following existing pacing records. We propose an LSTM based model to generate personalized new pacing sequences.
Jianmo et al. proposed a personalized fitness recommendation system named FitRec to solve two tasks: predicting the heart rate and speed at all time steps of a future workout, and short-term prediction of heart rate and speed at a specific time step during an ongoing workout [24]. The former predicts a future workout profile to show users the anticipated performances in terms of heart rate and speed while the latter predicts transient heart rate and speed during an ongoing exercise, so as to facilitate tasks like anomaly detection or real-time decision-making. FitRec was primarily designed based on LSTM modules. More specifically, they used LSTMs to project the sequence of the most recent workout measurements of the user into a dense vector, which forms the user embedding vector. Then, the user embedding vector is concatenated with other input attributes of the new workout sequence as the combined contextual sequence input for two different LSTM networks corresponding to the two tasks and adopt a 2-layer stacked LSTM architecture and an LSTM-based encoder-decoder architecture respectively.
Compared with FitRec, our work differs in many ways, although we study the same dataset as FitRec, and its task of predicting a future workout profile has a similar purpose to ours. First, we suggest adding caloric expenditure to the input features, so that our system can provide different recommendations according to users’ inputs of target caloric expenditure, which enhances the practical value of our research. Furthermore, FitRec predicts the speed of a workout using distance and time as inputs, which arguably may be seen as a trivial issue solvable by simple math. Therefore, we propose removing the time sequence feature from the inputs to avoid potential information leakage. Besides, we improve the derivation of entity embeddings by learning them from all historical workout records of the users, instead of learning only from the latest one. Our tensor decomposition method for learning entity embedding is also different from theirs.
Privacy Preservation in Fitness Recommendation. In privacy-aware recommendation systems, privacy preservation is usually achieved through some independent encryption protocols in the process of data collection or data exchange [26]. [5] proposed a reversible data transform algorithm based privacy-preserving data collection protocol for mobile app recommendation systems. According to this protocol, a user’s data is sent through a user group with encryption, which avoids direct communication between a user and a data collector. Likewise, Arijit Ukil addresses the privacy preservation problem through a random security key pre-distribution method [32]. According to the proposed scheme, private data can be collected from various sources and aggregated by the service provider or the server securely. [35] studies the challenge of privacy preservation in a more specific scenario when the recommendation systems of two independent business entities are merged. In this scenario, both a homomorphic encryption approach and a scalar product approach are proposed to encrypt raw data before data exchange takes place between the two systems. Badsha et al. also proposed a homomorphic encryption approach to enforce privacy preservation in building a recommender system [3]. More specifically, they collected encrypted ratings on items from users and sent ciphertexts to recommender servers to calculate the similarity among the rated items homomorphically. The similarity scores were subsequently decrypted by the users without revealing any private information and then used to build a recommender system by using content-based filtering and collaborative filtering methods.
In contrast, our work focuses on developing the recommendation algorithm itself with minimum private data, which is complementary to the data encryption approach discussed above. Sanchez et al. conducted a study on users’ preferences on privacy permission in the fitness domain and recommended a series of strategies for users to set permissions according to the collected and shared data [26]. They found that users have the highest acceptance rates of privacy permissions in terms of gender and fitness types, while the users are reluctant to share their height, weight, age, and social network information. The results of this study confirm our hypothesis about privacy protection and are consistent with our attempt to construct a personalized fitness recommendation system by using minimum private information from the users. To the best of our knowledge, most existing work in the fitness recommendation domain attempted to collect multidimensional demographic parameters from the users to improve the performances of their recommendation algorithms. In this paper, we demonstrate that a recommendation algorithm can be developed using minimum private data from users.
3 Methodology -
In this section, we first introduce an overview of our proposed framework (), and then we introduce the details of each component of the proposed framework.
Our is composed of three-dimensional tensor data analysis and two deep learning models (MLP and multi-layer Bi-LSTM), which are used to predict the total workout distance, and the speed and heart rate sequences respectively. The main inputs of the framework are Target Caloric Expenditure, Sport Type, User ID, and Workout Route ID. Based on the User ID, User Embedding can be found by looking up the pre-trained user embedding tensor using the Tensor Decomposition method. Similarly, based on the Workout Route ID, Workout Route Embedding can be found by looking up the pre-trained workout route embedding tensor, as well as the Total Workout Route Distance, Altitude Sequence and Distance Sequence associated with the chosen route. In summary, the contextual input features consist of Target Caloric Expenditure, Sport Type, User Embedding, Workout Route Embedding, and Total Workout Route Distance. The sequential input features encompass Altitude Sequence and Distance Sequence.
3.1 Model Structure

Firstly, the MLP model takes the input of the contextual features to predict the required Total Workout Distance. Subsequently, the predicted Total Workout Distance is then concatenated with other contextual input features and sequential input features to form the input at each time step of the Multi-layer Bi-LSTM model. The Multi-layer Bi-LSTM model predicts the Heart Rate Sequence through a fully connected layer at the output of the first LSTM layer and predicts the Speed Sequence through another fully connected layer at the output of the second LSTM layer.
3.2 Entity Embedding with Tensor Decomposition
One of the main objectives of this study is to learn the latent characteristics of users from historical workout records without using their private data. We propose using a collaborative filtering method based on Tensor Decomposition to achieve this goal, which is a generalization of the conventional matrix decomposition method in higher-dimensional space.
For tensor analysis, a three-dimensional ”user-workout route-contexts” tensor of size is constructed based on historical workout records. However, each workout record in the dataset contains a unique workout route because it has a unique sequence of altitudes, longitudes, and latitudes. To reduce the dimension of the three-dimensional tensor, we first cluster the workout routes into a smaller number of categories where to represent the workout routes in the three-dimensional tensor. In the third dimension, the contexts encompass several computed features like user’s gender, sport type, user’s workout frequency, user’s average workout duration, user’s average workout distance, user’s average workout speed, user’s average workout heart rate, etc.

Several methods have been proposed in the literature for learning tensors known as tensor decomposition among which two typical approaches are mostly used in the literature known as CANDECOMP/ PARAFAC (CP) and Tucker decomposition [20]. This paper implements tensor decomposition using the CP approach since it has gained much popularity over tucker decomposition, and it is the most widely used algorithm due to its ease of interpretation.
Given a tensor , the main goal of CP decomposition is to decrease the sum square error between the model and a given tensor :
| (1) |
where ”” is a vector outer product. is the latent element, and are r-th columns of component matrices , and , and is the weight used to normalize the columns of and .
In this sense, CP method decomposes into three matrices , and as shown in Fig. 2. Matrix represents the user mode, represents the workout route mode, and represents the context mode. This can be solved by minimizing the sum square error of
| (2) |
At first, the function given in Equation 2 seems to be a non-convex problem, because its goal is to optimize the sum of squares of three matrices. However, by fixing two factor matrices and solving only the third one, this problem can be simplified to a linear least squares problem. Following this approach, the ALS technique can be employed here, which solves every component matrix repeatedly by locking all other components until it converges [2].
| (3) |
Assume we have completed CP Decomposition with a selected rank and learned matrices , , and . Then we fit the full Tucker3 model to the data using the CP Decomposition matrices , , and by minimizing
| (4) |
where denotes Kronecker product.
The optimal in equation 4 can be determined as
| (5) |
when the residual decomposition error is minimized.
The underlying idea is to find the similarity between and where is a super diagonal core tensor that all its super diagonal values are 1 and all its off-superdiagonal values are 0. To compare the similarity, we can have a look at the distribution of the elements in the superdiagonal and off-super diagonal of . If the superdiagonal elements of are all close to the corresponding elements of , which is 1, and the off-superdiagonal elements of are all close to the corresponding elements of , which is 0, then we say the CP Decomposition result is appropriate. Formally, the similarity between the two tensors, or core consistency can be written as
| (6) |
where the closer the cc score is to 100 the better.
3.3 Workout Distance Prediction
Our distance prediction model is based on MLP architecture, which refers to a fully connected neural network containing one or more hidden layers. As MLP is the basic form of neural network that can be used to solve classification and regression tasks, we adopt the MLP architecture to build a model that predicts workout distance using the contextual input features .
For the MLP model shown in Fig. 3, we feed the contextual input features into the network, and the output at the hidden layer can be calculated by by
| (7) |
The output of hidden layer after activation is where
| (8) |
Similarly, we can compute the output at the output layer by
| (9) |
And finally the model predicts a normalized workout distance by
| (10) |
where
| (11) |

3.4 Speed and Heart Rate Sequence Prediction
We propose a Multi-layer Bi-LSTM Model to predict speed and heart rate sequences due to inputs and outputs being in sequential format. LSTM-based models are an extension for RNNs that implement memory states to store information and gate mechanisms to control information flow for the purpose of alleviating vanishing gradient problems [29]. More specifically, they use cell state and hidden state to carry information. A forget gate is used to control the preservation and removal of information passed from the last time step. Meanwhile, an input gate is used to decide what new information we’re going to store, while an output gate is used to specify what information contributes to the output at the current time step.
Firstly, the output through the forget gate is computed as:
| (12) |
where
-
, are the hidden states of the LSTM at time step and respectively
-
is the input at time step
-
denotes sigmoid activation function
Then the output through the input gate is computed as:
| (13) |
where denotes hyperbolic tangent activation function. Meanwhile, the cell state from the previous time step is updated by:
| (14) |
Lastly, the output at the current time step is computed as:
| (15) |
Fig. 4 shows the detailed structure of the 2-layer Bi-LSTM model. At step , with input , heart rate is predicted through the hidden state of the first Bi-LSTM layer and speed is predicted through the hidden state of the second Bi-LSTM layer. We propose predicting the heart rate and speed at two different stages instead of predicting them both at the second stage or just using a single LSTM stage.

When training the models, we find that the predicted heart rate sequence is always positively correlated with the input calories. However, in some cases, the predicted speed might be negatively correlated to the calorie input during inference, which is counter-intuitive. Therefore, we design the model structure by predicting the heart rate at the first layer and then using its hidden states as the input to the second LSTM layer to predict the speed. This approach reinforces the model to learn the correct correlation between speed and input calories to alleviate the counter-intuitive problem.
Formally, if we denote the output of LSTM as where refers to layer, the predicted heart rate and speed are computed as:
| (16) |
where SELU denotes scaled exponential linear unit activation function. Inspired by [19] and [24], our sequence model adopts SELU as the activation function, because it induces self-normalizing properties like variance stabilization, which can solve vanishing and exploding gradient problems.
Furthermore, the use of the bidirectional mechanism helps the model more effectively learn the underlying context by traversing the sequential input features twice, i.e., both forward and backward [29]. For instance, understanding whether the workout route is going uphill or downhill facilitates a better prediction of speed and heart rate.
4 Experiments and Results
4.1 Dataset
We use the open-source Endomondo dataset [24] of 167,373 workout records from 956 users. Each workout record consists of both sequential data (i.e., heart rate, speed, time elapsed, distance, altitude, latitude, longitude) and contextual data (i.e., gender, sport, userID, URL). For each workout record, the sequential data contains 500 data points, with sampling intervals ranging from seconds to minutes. In addition, the total caloric expenditure of each workout record can be queried on endomondo.com, if the user is not deactivated.
We have conducted data cleaning prior to the experiments. For instance, the original dataset has a high rate of abnormal measurements such as running speeds exceeding 50 km/h or abnormal average altitudes over 8000 meters. Moreover, 97 of the workout records belong to the types of running, cycling, and mountain biking, while there are fewer than 50 records for most other sport types in the dataset. Hence, we decide to only focus on running, cycling, and mountain biking in our study to ensure there is enough data for each sport type. About 65,500 workout records are retained after cleaning up and deleting the records that no longer provide caloric expenditure due to users’ discontinuation.
Data augmentation is done to facilitate the modeling of workout distance according to different input variables. For instance, we expect our model outputs a shorter distance given a smaller caloric input. Specifically, we extend a workout route by appending a small random sub-sequence extracted from the start of the sequence to the end of the sequence if the user has returned to the starting location at the end of the exercise. Given a sequence that returns to the starting location , the extended sequence can be represented as where . For the workout distance prediction model, the original workout distance is used as the ground truth while the caloric expenditure, the extended workout distance , the entity embeddings, and the other contextual features are model inputs. The resulted dataset after the our pre-processing will be made available from the project repository for further experimentation and reproducibility. 111https://github.com/BasemSuleiman/Personalized_Intelligent_Fitness_Recommender.
4.2 Training Procedure
We first perform CP tensor decomposition to obtain user embeddings and workout route embeddings. Core consistency scores of ranks 2 to 20 are computed to choose the most appropriate rank of the decomposed tensors. Then we pick the entity embeddings of high scores to train the workout distance prediction model and the speed & heart rate sequences prediction model respectively. The workout distance prediction model is trained using Adam [18] with weight decay of and the speed & heart rate prediction model is trained using Adagrad [12]. For both models, we perform hyperparameter tuning with random search and/or grid search on the validation set. The best parameters are shown in table 1.
| Workout Distance Model | Speed & HeartRate Model | ||||||||||
| 2 Layer MLP |
|
1 Layer LSTM |
|
||||||||
| 3 Layer MLP |
|
2 Layer (Bi) LSTM |
|
4.3 Evaluation Metrics
We report the results of our experiments through Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) for the workout distance prediction task and speed & heart rate sequences prediction task respectively.
| (17) |
| (18) |
where is the number of workout records in the test set and is the number of time steps in each workout record.
4.4 Entity Embedding with Tensor Decomposition
As discussed in section 3, we adopt the CP tensor decomposition method to generate entity embeddings and perform core consistency diagnostic to find the best rank of the decomposed tensors. Using formula 6 to compute core consistency, the closer the value is to 100, the more appropriate the rank is. Generally speaking, with the increase of the number of ranks, the core consistency score tends to decrease monotonically due to the increase of decomposition noise and other non-trilinear variations [8].
As Figure 5 illustrates, the core consistency score is relatively high starting at CP Decomposition rank of 2. With the increase of CP Decomposition ranks, the score fluctuates and peaks at the rank of 13, after which a downward trend can be observed.
Core consistency diagnostic provides an intrinsic evaluation of the CP Decomposition rank. However, it does not necessarily guarantee that the rank selected with this method will perform best at the final regression task. Therefore, we select the decomposed entity embedding tensors of rank 2, 11, and 13, respectively, and use the final models to further evaluate them. The rank 13 tensors have the highest core consistency score, and they are relatively high in dimension, which may increase challenges to the convergence of the final models. In contrast, the rank 2 tensors have a relatively high core consistency score and low dimension. We also pick rank 11 to balance the core consistency score and complexity.
Inspired by word2vec [22], we evaluate the trained entity embeddings with cosine similarity: . Taking user embeddings of size 13 as an example, the cosine similarity between randomly picked user A (192 running records) and user B (129 running records) is 0.78660, while that between user A and user C (132 mountain biking and 1 biking records) is -0.00489. Similarly, the cosine similarity between user D (104 biking and 70 running records) and user A is 0.57067, and that between user D and user C is 0.18126. The findings suggest that sport type has a large impact on the trained user embeddings, that is, users playing similar sports may have closer embeddings.
In addition, we use T-SNE to plot the entity embeddings on a 2D plane, as shown in Fig. 6 and Fig. 7. To compare the results intuitively, 3 user embedding scatterplots are drawn, and color-coded according to the average workout calories, average workout speed, and average workout distance respectively. Similarly, we plot 3 figures for the workout route embeddings, and color code them according to the type of sport. The size of each data point in the figures is proportional to the magnitudes of the average workout calories, average workout speed, and average workout distance respectively. As for the user embeddings, we observe that the users with similar preferences of average workout speeds and average workout distances tend to be clustered together. Although patterns are not as obvious for the workout route embeddings, possibly due to a lack of data points, the points of the same sports seem to be clustered together for running and mountain biking. More T-SNE plots of the entity embeddings of other ranks can be found in APPENDICES: 0.A.

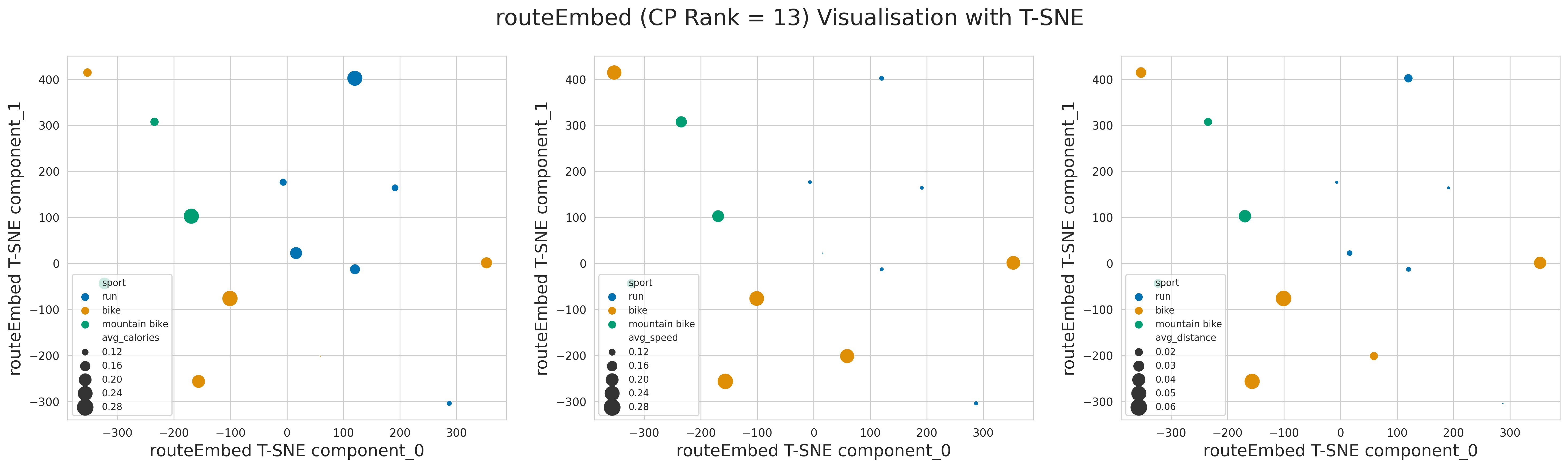
4.5 Workout Distance Prediction Model
For the experiment of the distance prediction sub-model, we ran ablations on training MLP models with different hidden layers and different entity embedding dimensions as input features. The former is to heuristically seek the optimal number of hidden layers for best model performance, while the latter is an extrinsic evaluation of the pre-trained entity embeddings on solving one of our final tasks.
| Models | Distance RMSE (KM) |
| 2 Layer MLP | |
| + Embedding Size 2 | 0.1423 |
| + Embedding Size 11 | 0.1394 |
| + Embedding Size 13 | 0.1387 |
| 3 Layer MLP | |
| + Embedding Size 2 | 0.1422 |
| + Embedding Size 11 | 0.1420 |
| + Embedding Size 13 | 0.1433 |
As shown in Table 2, the model that produces the best performance is 2 Layer MLP (1 hidden layer) with entity embedding of size 13. Since the performances of the 3 Layer MLP models (2 hidden layers) do not exceed those of the 2 Layer MLP models, we choose not to further experiment with more hidden layers. The task of predicting workout distance produces a single scalar, which is relatively simple. Hence, a 2 Layer MLP model is adequate. In contrast, the increase of hidden layers is likely to lead to over-fitting.
Moreover, the result of the extrinsic evaluation of entity embeddings is consistent with the intrinsic evaluation result in section 4.4. Regardless of the number of MLP layers, the best model is achieved with entity embedding of size 13, followed by that of size 2, and then that of size 11. In the intrinsic evaluation of entity embeddings, we found that entity embedding of size 13 has the highest core consistency score, followed by that of size 2, and then that of size 11. This finding validates the hypothesis of core consistency, that is, the higher the core consistency value, the more appropriate the CP decomposition result is.
Although we cannot compare the result of this model with FitRec [24], as it does not have the task of predicting workout distance, our best model achieves an RMSE of 0.1387 (km), which is reasonably good for predicting workout distance in practice.
4.6 Speed & Heart Rate Prediction Model
For the speed & heart rate prediction sub-model, we first ran ablations on different entity embedding inputs based on a 1 Layer LSTM network structure, which is an extrinsic evaluation of the pre-trained entity embeddings. From Table 3, we observe that MAE drops as embedding size increases. The 1 Layer LSTM model with an entity embedding size of 13 is found to yield the best performance, which decreases the MAE of the baseline (1 Layer LSTM without entity embedding) by 5.8 and 12.5 on speed and heart rate respectively. The result of this experiment is consistent with the core consistency diagnostic result in section 4.4 that the embedding size of 13 is most appropriate.
| Speed & HeartRate Model | Speed MAE (KMPH) | Heart Rate MAE (BPM) |
| 1 Layer LSTM | ||
| + No Embedding | 2.92 | 13.01 |
| + Embedding Size 2 | 2.90 | 13.01 |
| + Embedding Size 11 | 2.80 | 11.57 |
| + Embedding Size 13 | 2.75 | 11.38 |
| Embedding Size 13 | ||
| + 2 Layer Stacked LSTM | 2.51 | 11.376 |
| + 2 Layer Stacked Bi-LSTM | 2.4 | 11.304 |
| + 2 Layer Stacked Bi-LSTM + Attention | 3.2 | 13.92 |
Then we ran ablations on different LSTM structures with entity embedding size set to 13. As shown in Table 3, model performances are improved by applying another layer of LSTM and the bidirectional LSTM structure. The best model is the 2 Layer Stacked Bi-LSTM with embedding size 13, whose MAEs on speed and heart rate are 2.4 km/h and 11.3 beats/minute respectively. Compared with the baseline model (1 Layer LSTM without entity embedding), its MAEs are 17.8% and 13.1% less for speed and heart rate predictions respectively. However, the addition of the attention mechanism does not improve model performance. It is likely that speed and heart rate mostly depend on neighboring steps rather than distant steps in the sequence. In this case, the attention mechanism has little help since it primarily addresses information loss problems for long sequences [4].
4.7 Comparison with FitRec
To further evaluate our result, we compare our with FitRec [24]. As shown in Table 4, our and FitRec use the same dataset, and both aim to provide fitness recommendations by predicting speed and heart rate sequences. The comparison is conducted in the following aspects. First, in pre-processing, FitRec keeps all sports while we only keep running, cycling, and mountain biking, which account for 97% of the total workouts, considering each sport needs sufficient samples to train a decent deep learning model. In addition, for each workout, FitRec only extracts the first 450 out of the 500 timestamps to reduce noise in the dataset, while we recommend keeping the entire 500 timestamps so that the model is more practical in real life. Furthermore, both studies share similar input features, including historical user information, route information, sport type, and gender. However, FitRec uses the time sequence and distance sequence as their inputs to predict speed sequence, while we remove the time sequence to avoid data leakage (), which adds a significant challenge to the regression task. Considering the practical application of the model, we also add target caloric consumption to be one of the input features.
Moreover, both systems derive user embeddings to extract the latent characteristics of the users from historical workout data. However, FitRec only uses a user’s latest exercise record to derive user embeddings through an LSTM network. In contrast, we train user embeddings and workout route embeddings through tensor decomposition with all historical workout records. Using more records enables us to realize more abundant information from the entities.
| FitRec | ||||||||||
| Pre-processing | • 3 sport types (Account for 97% of data) • Entire sequence of each workout | • All sport types • First 450 of 500 timestamps for each workout | ||||||||
| Input and Output |
|
|
||||||||
| Embedding method | • Trained on all historical records • Tensor decomposition | • Trained on the user’s most recent record • LSTM | ||||||||
| Best Model |
|
|
||||||||
| Results |
|
|
Next, our speed and heart rate prediction model has a bidirectional LSTM structure while FitRec implements a unidirectional LSTM.
Finally, FitRec and our model have achieved similar performance in predicting speed and heart rate. More specifically, FitRec performs a little better in speed prediction, while our result in heart rate prediction is better. This does not mean our model is inferior in predicting speed. FitRec uses distance and elapsed time as inputs to predict speed, which might lead to data leakage to a certain extent. The removal of the elapsed time feature in our implementation adds challenges to the speed prediction task.
Moreover, we also add target caloric expenditure as an input feature to our model to influence the magnitudes of the predicted speed sequence, which potentially further elevates the difficulty of the task. Despite these challenges, we still achieve a comparative result in speed prediction and a superior result in heart rate prediction. Furthermore, the implementation of tensor decomposition provides a more flexible and lighter method for extracting user and route information. The overall better result can be due to many factors, such as a better strategy of training entity embeddings, different model design, and less variance of sport types in the dataset, etc.
The proposed models, datasets and experimental data will be made available at the project repository for further extension and reproducibility studies. 222https://github.com/BasemSuleiman/Personalized_Intelligent_Fitness_Recommender..
5 Discussion
Our can provide personalized fitness recommendations by applying the models mentioned in section 3. The system allows users to specify the type of sport (run, bike, or mountain bike) and select a specific route, and then input target caloric expenditure. According to these inputs, our will provide various recommendations in the aspects of distance as well as speed and heart rate at each time step. Table 5 shows a typical running workout from the dataset, whose original record has 6.2 km of distance, 592 kcal of caloric consumption, and average speed and heart rate of 8.8 km/h and 149 beats per minute respectively. Given the same caloric input, our predicts similar distance, speed, and heart rate. Furthermore, for higher target caloric inputs, we observe the greater distance, speed, and heart rate are predicted, and vice versa. Moreover, Fig. 8 shows the change in speed and heart rate with respect to time stamps. The blue line represents the original workout record, while the dotted lines represent the recommended speed and heart rate according to various input target caloric expenditures. We observe that the model can properly predict the fluctuation of speed and heart rate with relatively low MAE. By comparing three different predicted workout speed and heart rate sequences, the system can properly predict the correlation between distance, calories, and heart rate.
| Original workout record | |||
| Calories | Distance | Speed AVG. | Heart Rate AVG. |
| 592kcal | 6.2km | 8.8km/h | 149bpm |
| Recommended workout | |||
| Calories | Distance | Speed AVG. | Heart Rate AVG. |
| 474 kcal | 5.97km | 8.46km/h | 136 bpm |
| 592 kcal | 6.18km | 8.64km/h | 142 bpm |
| 651 kcal | 6.28km | 8.69km/h | 145bpm |
Our has a high degree of freedom in choosing sport type, route, and target calories, and the personalized recommendations of speed and heart rate change dynamically according to the workout route. Therefore, the system provides users with greater flexibility to plan and predict exercises, and to modify the speed and pace during exercises.
The proposed models, datasets and experimental data will be made available at the project repository for further extension and reproducibility studies. 333https://github.com/BasemSuleiman/Personalized_Intelligent_Fitness_Recommender..

6 Conclusion and Future Work
In this paper, we propose , a Multi-layer MLP and Multi-layer Bi-LSTM based framework that provides personalized fitness recommendations with privacy preservation. Our employs Tensor Decomposition to infer entity embeddings from historical workout data and has achieved satisfactory results on predicting workout distance, workout speed sequence, and workout heart rate sequence. We demonstrate that personalized fitness recommendations can be achieved using minimum identity information from the users.
For further studies, we propose extending the work in three aspects. First, the cold-start problem is an interesting topic in building recommender systems, for which in our case is on new sport types and new users. Users playing new sports will have to exercise without personalized recommendation and contribute an adequate amount of workout data before a model can be trained to cover these sport types. Likewise, for new users who have absolutely no workout history, it is a challenge to learn user embeddings using the Tensor Decomposition method. Moreover, our is built on a two-model pipeline, instead of an end-to-end model structure to realize the two related tasks respectively. Though the models share the same contextual input features and the prediction of the first model feeds into the second model, one can argue that the accuracy of the application can be further improved if an end-to-end structure is applied, such as an encoder-decoder structure. Lastly, the Transformer architecture [33] has become dominant in sequence prediction tasks, especially in the field of natural language processing. Although our experiment on the attention mechanism shows little performance enhancement, it is possible to improve the performance by trying the Transformer architecture.
References
- [1] Amatriain, X.: Mining large streams of user data for personalized recommendations. SIGKDD Explor. Newsl. 14(2), 37–48 (Apr 2013). https://doi.org/10.1145/2481244.2481250, https://doi.org/10.1145/2481244.2481250
- [2] Anaissi, A., Lee, Y., Naji, M.: Regularized tensor learning with adaptive one-class support vector machines. In: International Conference on Neural Information Processing. pp. 612–624. Springer, Springer International Publishing, Cham (2018)
- [3] Badsha, S., Yi, X., Khalil, I.: A practical privacy-preserving recommender system. Data Science and Engineering 1(3), 161–177 (Sep 2016). https://doi.org/10.1007/s41019-016-0020-2, https://doi.org/10.1007/s41019-016-0020-2
- [4] Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. ArXiv 1409 (09 2014)
- [5] Beg, S., Anjum, A., Ahmad, M., Hussain, S., Ahmad, G., Khan, S., Choo, K.K.R.: A privacy-preserving protocol for continuous and dynamic data collection in iot enabled mobile app recommendation system (mars). Journal of Network and Computer Applications 174, 102874 (2021). https://doi.org/https://doi.org/10.1016/j.jnca.2020.102874, https://www.sciencedirect.com/science/article/pii/S1084804520303386
- [6] Berndsen, J., Smyth, B., Lawlor, A.: A collaborative filtering approach to successfully completing the marathon. In: 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA). pp. 653–658. IEEE, Miami, FL, USA (2020). https://doi.org/10.1109/ICMLA51294.2020.00108
- [7] Bouhenguel, R., Mahgoub, I., Ilyas, M.: Bluetooth security in wearable computing applications. In: 2008 International Symposium on High Capacity Optical Networks and Enabling Technologies. pp. 182–186. IEEE, Penang, Malaysia (2008). https://doi.org/10.1109/HONET.2008.4810232
- [8] Bro, R., Kiers, H.: A new efficient method for determining the number of components in parafac models. Journal of Chemometrics 17(5), 274–286 (May 2003). https://doi.org/10.1002/cem.801
- [9] Chu, Y., Yue, X., Yu, L., Sergei, M., Wang, Z.: Automatic image captioning based on resnet50 and lstm with soft attention. Wireless Communications and Mobile Computing 2020, 8909458 (Oct 2020). https://doi.org/10.1155/2020/8909458, https://doi.org/10.1155/2020/8909458
- [10] Cyr, B., Horn, W., Miao, D., Specter, M.A.: Security analysis of wearable fitness devices (fitbit) (2014)
- [11] Dharia, S., Eirinaki, M., Jain, V., Patel, J., Varlamis, I., Vora, J., Yamauchi, R.: Social recommendations for personalized fitness assistance. Personal Ubiquitous Comput. 22(2), 245–257 (Apr 2018). https://doi.org/10.1007/s00779-017-1039-8, https://doi.org/10.1007/s00779-017-1039-8
- [12] Duchi, J., Hazan, E., Singer, Y.: Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research 12, 2121–2159 (07 2011)
- [13] Farseev, A., Chua, T.S.: Tweetfit: Fusing multiple social media and sensor data for wellness profile learning. In: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. p. 95–101. AAAI’17, AAAI Press, San Francisco, California, USA (2017)
- [14] Guo, X., Liu, J., Chen, Y.: Fitcoach: Virtual fitness coach empowered by wearable mobile devices. In: IEEE INFOCOM 2017 - IEEE Conference on Computer Communications. pp. 1–9. IEEE, Atlanta, GA, USA (2017). https://doi.org/10.1109/INFOCOM.2017.8057208
- [15] Jorge, J., Giménez, A., Iranzo-Sánchez, J., Civera, J., Sanchís, A., Juan, A.: Real-time one-pass decoder for speech recognition using LSTM language models. In: Kubin, G., Kacic, Z. (eds.) Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15-19 September 2019. pp. 3820–3824. ISCA, Graz, Austria (2019). https://doi.org/10.21437/Interspeech.2019-2798, https://doi.org/10.21437/Interspeech.2019-2798
- [16] Kamišalić, A., Fister, I., Turkanović, M., Karakatič, S.: Sensors and functionalities of non-invasive wrist-wearable devices: A review (2018). https://doi.org/10.3390/s18061714, https://www.mdpi.com/1424-8220/18/6/1714
- [17] Karatzoglou, A., Amatriain, X., Baltrunas, L., Oliver, N.: Multiverse recommendation: N-dimensional tensor factorization for context-aware collaborative filtering. In: Proceedings of the Fourth ACM Conference on Recommender Systems. p. 79–86. RecSys ’10, Association for Computing Machinery, New York, NY, USA (2010). https://doi.org/10.1145/1864708.1864727, https://doi.org/10.1145/1864708.1864727
- [18] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: Bengio, Y., LeCun, Y. (eds.) 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. ICLR, San Diego, CA, USA (2015), http://arxiv.org/abs/1412.6980
- [19] Klambauer, G., Unterthiner, T., Mayr, A., Hochreiter, S.: Self-normalizing neural networks. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc., Long Beach, CA, USA (2017), https://proceedings.neurips.cc/paper/2017/file/5d44ee6f2c3f71b73125876103c8f6c4-Paper.pdf
- [20] Kolda, T.G., Bader, B.W.: Tensor decompositions and applications. SIAM review 51(3), 455–500 (2009)
- [21] Loepp, B., Ziegler, J.: Recommending running routes: Framework and demonstrator. In: Proceedings of the 2nd Second Workshop on Recommendation in Complex Scenarios (ComplexRec ’18). p. 26–29. Association for Computing Machinery, New York, NY, USA (2018), http://toinebogers.com/workshops/complexrec2018/resources/proceedings.pdf#page=26
- [22] Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space (2013)
- [23] Mogaveera, D., Mathur, V., Waghela, S.: e-health monitoring system with diet and fitness recommendation using machine learning. In: 2021 6th International Conference on Inventive Computation Technologies (ICICT). pp. 694–700. IEEE, Coimbatore, India (2021). https://doi.org/10.1109/ICICT50816.2021.9358605
- [24] Ni, J., Muhlstein, L., McAuley, J.: Modeling heart rate and activity data for personalized fitness recommendation. In: The World Wide Web Conference. p. 1343–1353. WWW ’19, Association for Computing Machinery, New York, NY, USA (2019). https://doi.org/10.1145/3308558.3313643, https://doi.org/10.1145/3308558.3313643
- [25] Raja, J.M., Elsakr, C., Roman, S., Cave, B., Pour-Ghaz, I., Nanda, A., Maturana, M., Khouzam, R.N.: Apple watch, wearables, and heart rhythm: where do we stand? Annals of translational medicine 7(17) (2019)
- [26] Sanchez, O.R., Torre, I., He, Y., Knijnenburg, B.P.: A recommendation approach for user privacy preferences in the fitness domain. User Modeling and User-Adapted Interaction 30(3), 513–565 (Jul 2020). https://doi.org/10.1007/s11257-019-09246-3, https://doi.org/10.1007/s11257-019-09246-3
- [27] Sarwar, B., Karypis, G., Konstan, J., Riedl, J.: Item-based collaborative filtering recommendation algorithms. In: Proceedings of the 10th International Conference on World Wide Web. p. 285–295. WWW ’01, Association for Computing Machinery, New York, NY, USA (2001). https://doi.org/10.1145/371920.372071, https://doi.org/10.1145/371920.372071
- [28] Schuster, M., Paliwal, K.K.: Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing 45(11), 2673–2681 (1997). https://doi.org/10.1109/78.650093
- [29] Siami-Namini, S., Tavakoli, N., Namin, A.S.: The performance of lstm and bilstm in forecasting time series. In: 2019 IEEE International Conference on Big Data (Big Data). pp. 3285–3292. IEEE, Los Angeles, CA, USA (2019). https://doi.org/10.1109/BigData47090.2019.9005997
- [30] Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2. p. 3104–3112. NIPS’14, MIT Press, Cambridge, MA, USA (2014)
- [31] Tan, M., Masagca, K.A.: An investigation of bluetooth security threats. In: 2011 International Conference on Information Science and Applications. pp. 1–7. IEEE, Jeju, Korea (South) (2011). https://doi.org/10.1109/ICISA.2011.5772388
- [32] Ukil, A.: Privacy preserving data aggregation in wireless sensor networks. In: 2010 6th International Conference on Wireless and Mobile Communications. pp. 435–440. IEEE, Valencia, Spain (2010). https://doi.org/10.1109/ICWMC.2010.77
- [33] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L.u., Polosukhin, I.: Attention is all you need. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc., Long Beach, CA, USA (2017), https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
- [34] Yong, B., Xu, Z., Wang, X., Cheng, L., Li, X., Wu, X., Zhou, Q.: Iot-based intelligent fitness system. J. Parallel Distrib. Comput. 118(P1), 14–21 (Aug 2018). https://doi.org/10.1016/j.jpdc.2017.05.006, https://doi.org/10.1016/j.jpdc.2017.05.006
- [35] Zhan, J., Wang, I.C., Hsieh, C.L., Hsu, T.S., Liau, C.J., Wang, D.W.: Towards efficient privacy-preserving collaborative recommender systems. In: 2008 IEEE International Conference on Granular Computing. pp. 778–783. IEEE, Hangzhou, China (2008). https://doi.org/10.1109/GRC.2008.4664769
- [36] Zhao, Z., Arya, A., Orji, R., Chan, G.: Effects of a Personalized Fitness Recommender System Using Gamification and Continuous Player Modeling: System Design and Long-Term Validation Study. JMIR Serious Games 8(4), e19968 (Nov 2020)
Appendix 0.A Appendices
Entity Embedding T-SNE plot





