Privacy-Aware Data Cleaning-as-a-Service
Abstract
Data cleaning is a pervasive problem for organizations as they try to reap value from their data. Recent advances in networking and cloud computing technology have fueled a new computing paradigm called Database-as-a-Service, where data management tasks are outsourced to large service providers. In this paper, we consider a Data Cleaning-as-a-Service model that allows a client to interact with a data cleaning provider who hosts curated, and sensitive data. We present PACAS: a Privacy-Aware data Cleaning-As-a-Service model that facilitates interaction between the parties with client query requests for data, and a service provider using a data pricing scheme that computes prices according to data sensitivity. We propose new extensions to the model to define generalized data repairs that obfuscate sensitive data to allow data sharing between the client and service provider. We present a new semantic distance measure to quantify the utility of such repairs, and we re-define the notion of consistency in the presence of generalized values. The PACAS model uses (X,Y,L)-anonymity that extends existing data publishing techniques to consider the semantics in the data while protecting sensitive values. Our evaluation over real data show that PACAS safeguards semantically related sensitive values, and provides lower repair errors compared to existing privacy-aware cleaning techniques.
1 Introduction
Data cleaning is a pervasive problem motivated by the fact that real data is rarely error free. Organizations continue to be hindered by poor data quality as they wrangle with their data to extract value. Recent studies estimate that up to 80% of the data analysis pipeline is consumed by data preparation tasks such as data cleaning [1]. A wealth of data cleaning solutions have been proposed to reduce this effort: constraint based cleaning that use dependencies as a benchmark to repair data values such that the data and dependencies are consistent [2], statistical based cleaning, which propose updates to the data according to expected statistical distributions [3], and leveraging master data as a source of ground truth [4].
Recent advances in networking and cloud infrastructure have motivated a new computing paradigm called Database-as-a-Service that lowers the cost and increases access to a suite of data management services. A service provider provides the necessary hardware and software platforms to support a variety of data management tasks to a client. Companies such as Amazon, Microsoft, and Google each provide storage platforms, accelerated computational capacity, and advanced data analytics services. However, the adoption of data cleaning services has been limited due to privacy restrictions that limit data sharing. Recent data cleaning efforts that use a curated, master data source share a similar service model to provide high quality data cleaning services to a client with inconsistent data [4, 5]. However, these techniques largely assume the master data is widely available, without differentiating information sensitivity among the attribute values.


| ID | GEN | AGE | ZIP | DIAG | MED |
| male | 51 | P0T2T0 | osteoarthritis | ibuprofen | |
| female | 45 | P2Y9L8 | tendinitis | addaprin | |
| female | 32 | P8R2S8 | migraine | naproxen | |
| female | 67 | V8D1S3 | ulcer | tylenol | |
| male | 61 | V1A4G1 | migraine | dolex | |
| male | 79 | V5H1K9 | osteoarthritis | ibuprofen |
| ID | GEN | AGE | DIAG | MED |
| male | 51 | osteoarthritis | ibuprofen | |
| male | 79 | osteoarthritis | intropes | |
| male | 45 | osteoarthritis | addaprin | |
| female | 32 | ulcer | naproxen | |
| female | 67 | ulcer | tylenol | |
| male | 61 | migrane | dolex | |
| female | 32 | pylorospasm | appaprtin | |
| male | 37 | hypertension | dolex |
| ID | GEN | AGE | ZIP | DIAG | MED |
| * | [31,60] | P* | osteoarthritis | ibuprofen | |
| * | [31,60] | P* | tendinitis | addaprin | |
| * | [31,60] | P* | migraine | naproxen | |
| * | [61,90] | V* | ulcer | tylenol | |
| * | [61,90] | V* | migraine | dolex | |
| * | [61,90] | V* | osteoarthritis | ibuprofen |
Example 1.1
A data broker gathers longitudinal data from hospital and doctors’ records, prescription and insurance claims. Aggregating and curating these disparate datasets lead to a valuable commodity that clients are willing to pay for gleaned insights, and to enrich and clean their individual databases. Table 3 shows the curated data containing patient demographic, diagnosis and medication information. The schema consists of patient gender (GEN), age (AGE), zip code (ZIP), diagnosed illness (DIAG), and prescribed medication (MED).
A client such as a pharmaceutical firm, owns a stale and inconsistent subset of this data as shown in Table 3. For example, given a functional dependency (FD) on Table 3, it states that a person’s gender and diagnosed condition determine a prescribed medication. That is, for any two tuples in Table 3, if they share equal values in the [GEN, DIAG] attributes, then they should also have equal values in the MED attribute. We see that tuples - falsify . Error cells that violate are highlighted in light and dark gray, and values in bold are inaccurate according to Table 3.
If the client wishes to clean her data with the help of a data cleaning service provider (i.e., the data broker and its data), she must first match the inconsistent records in Table 3 against the curated records in Table 3. This generates possible fixes (also known as repairs) to the data in Table 3. The preferred repair is to update , to ibuprofen (from ), and migraine (from ). However, this repair discloses sensitive patient information about diagnosed illness and medication from the service provider. It may be preferable to disclose a more general value that is semantically similar to the true value to protect individual privacy. For example, instead of disclosing the medication ibuprofen, the service provider discloses Non-steroid anti-inflammatory drug (NSAID), which is the family of drugs containing ibuprofen. In this paper, we explore how to compute such generalized repairs in an interactive model between a service provider and a client to protect sensitive data and to improve accuracy and consistency in client data.
State-of-the-Art. Existing work in data privacy and data cleaning have been limited to imputation of missing values using decision trees [6], or information theoretic techniques [7], and studying trade-offs between privacy bounds and query accuracy over differentially private relations [8]. In the data cleaning-as-a-service setting, which we consider in this paper, using differential privacy poses the following limitations: (i) differential privacy provides guarantees assuming a limited number of interactions between the client and service provider; (ii) queries are limited to aggregation queries; and (iii) data randomization decreases data utility.
Given the above limitations, we explore the use of Privacy Preserving Data Publishing (PPDP) techniques, that even though do not provide the same provable privacy guarantees as differential privacy, do restrict the disclosure of sensitive values without limiting the types of queries nor the number of interactions between the client and service provider. PPDP models prevent re-identification and break attribute linkages in a published dataset by hiding an individual record among a group of other individuals. This is done by removing identifiers and generalizing quasi-identifier (QI) attributes (e.g., GEN, AGE, ZIP) that together can re-identify an individual. Well-known PPDP methods such as -anonymity require the group size to be at least such that an individual cannot be identified from other individuals [9, 10]. Extensions include (X,Y)-anonymity that break the linkage between the set of QI attributes, and the set of sensitive attributes by requiring at least distinct sensitive values for each unique [11]. For example, Table 3 is -anonymous for by generalizing values in the QI attributes. It is also (X,Y)-anonymous for sensitive attribute MED for since there are three distinct medications for each value in the QI attributes , e.g., values of co-occur with ibuprofen, addaprin, and naproxen of .
To apply PPDP models in data cleaning, we must also address the highly contextualized nature of data cleaning, where domain expertise is often needed to interpret the data to achieve correct results. It is vital to incorporate these domain semantics during the cleaning process, and into a privacy model during privacy preservation. Unfortunately existing PPDP models only consider syntactic forms of privacy via generalization and suppression of values, largely ignoring the data semantics. For example, upon closer inspection of Table 3, the values in the QI attributes in records are associated with the same family of medication, since ibuprofen, addaprin, and naproxen all belong to the the NSAID class, which are analgesic drugs. In past work, we introduced a privacy-preserving framework that uses an extension of (X,Y)-anonymity to incorporate a generalization hierarchy, which capture the semantics of an attribute domain111-anonymity and extensions, e.g., -diversity and -closeness also do not consider the underlying data semantics. [12]. In Table 3, the medications in are modeled as synonyms in such a hierarchy. In this paper, we extend our earlier work [12] to define a semantic distance metric between values in a generalization hierarchy, and to incorporate generalized values as part of the data repair process.
Example 1.2
To clean Table 3, a client requests the correct value(s) in tuples from the data cleaning service provider. The service provider returns ibuprofen to the client to update and to ibuprofen. However, disclosing the specific ibuprofen medication violates the requirements of the underlying privacy model. Hence, the service provider must determine when such cases arise, and offer a revised solution to disclose a less informative, generalized value, such as NSAID or analgesic. The model must provide a mechanism for the client and service provider to negotiate such a trade-off between data utility and data privacy.
Technical Challenges.
-
1.
Data cleaning with functional dependencies (FDs), and record matching (between the service provider and client) is an NP-complete problem. In addition, it is approximation-hard, i.e., the problem cannot be approximately solved with a polynomial-time algorithm and a constant approximation ratio [4]. We extend this data cleaning problem with privacy restrictions on the service provider, making it as hard as the initial problem. In our earlier work, we analyzed the complexity of this problem, and proposed a data cleaning framework realizable in practice [12]. In this paper, we extend this framework to consider a new type of repair with generalized values that further protects sensitive data values.
-
2.
Given a generalization hierarchy as shown in Figures 1 and 2, proposed repairs from a service provider may contain general values that subsume a set of specific values at the leaf level. In such cases, we study and propose a new (repair) semantics for data consistency with respect to (w.r.t.) an FD involving general values.
-
3.
By proposing generalized values as repair values, we lose specificity in the client data instance. We study the trade-off between generalized versus specific repair values. Resolving inconsistencies w.r.t. a set of FDs requires traversing the space of possible fixes (which may now include general values). Quantifying the individual utility of a generalized value as a repair value, while respecting data cleaning budgets from the client is our third challenge.
Our Approach and Contributions. We build upon our earlier work that introduced PACAS, a rivacy-ware data leaning-s-a-ervice framework that facilitates data cleaning between a client and a service provider [12]. The interaction is done via a data pricing scheme where the service provider charges the client for each disclosed value, according to its adherence to the privacy model. PACAS includes a new privacy model that extends (X,Y)-anonymity to consider the data semantics, while providing stronger privacy protection than existing PPDP methods. In this work, we present extensions to PACAS to resolve errors (FD violations) by permitting updates to the data that are generalizations of the true value to avoid disclosing details about sensitive values. Our goal is to provide repair recommendations that are semantically equivalent to the true value in the service provider data. We make the following contributions:
-
1.
We extend PACAS the existing privacy-preserving, data cleaning framework that identifies FD errors in client data, and allows the client to purchase clean, curated data from a service provider [12]. We extend the repair semantics to introduce generalized repairs that update values in the client instance to generalized values.
-
2.
We re-define the notion of consistency between a relational instance (with generalized values) and a set of FDs. We propose an entropy-based measure that quantifies the semantic distance between two values to evaluate the utility of repair candidates.
-
3.
We extend our SafeClean algorithm that resolves FD errors by using external data purchased from a service provider. SafeClean proposes repairs to the data by balancing its data privacy requirements against satisfying query purchase requests for its data at a computed price [12]. Given a cleaning budget, we present a new budget allocation algorithm that improves upon previous, fixed allocations, to consider allocations according to the number of errors in which a database value participates.
-
4.
We evaluate the effectiveness of SafePrice and SafeClean over real data showing that by controlling data disclosure via data pricing, we can effectively repair FD violations while guaranteeing (X,Y,L)-anonymity. We also show that our SafeClean achieves lower repair error than comparative baseline techniques.
We provide notation and preliminaries in Section 2. In Section 3, we define generalized relations, and their consistency w.r.t. a set of FDs, and present a new semantic distance function. We present our problem definition, and review the PACAS system in Section 4. We discuss how data privacy is enforced via data pricing in Section 5, and describe new extensions to our data cleaning algorithm that consider generalized values in Section 6. We present our experimental results in Section 7, related work in Section 8, and conclude in Section 9.
2 Preliminaries
2.1 Relations and Dependencies
A relation (table) with a schema is a finite set of -ary tuples . A database (instance) is a finite set of relations with schema . We denote by small letters as variables. Let refer to single attributes and as sets of attributes. A cell is the -th position in tuple with its value denoted by . We use to refer to the value if it is clear from the context. A functional dependency (FD) over a relation with set of attributes is denoted by , in which and are subsets of . We say holds over , , if for every pair of tuples , , implies . Table 4 summarizes our symbols and notations.
A matching dependency (MD) over two relations and with schemata and is an expression of the following form:
| (1) |
where and are comparable pairs of attributes in and . The MD states that for a pair of tuples with and , if values are similar to values according to the similarity function , the values of and are identical [5].
| Symbol | Description |
| relation and relational schema | |
| relational attributes | |
| sets of relational attributes | |
| database instance and database schema | |
| functional dependency and matching dependency | |
| domain of attribute | |
| sub-domain of attribute in level | |
| , | domain and value generalization hierarchies |
| generalization relation for levels | |
| generalization relation for values, tuples, and relations | |
| Simple query and generalized query (GQ) | |
| level and sequence of levels | |
| support set, and conflict set | |
| total and the budget for the i-th iteration | |
| generalization level | |
| database cell and error cell | |
| distance function for values, tuples and relations |
2.2 Generalization
Generalization replaces values in a private table with less specific, but semantically consistent values according to a generalization hierarchy. To generalize attribute , we assume a set of levels and a partial order , called a generalization relation on . Levels are assigned with disjoint domain-sets . In , each level has at most one parent. The domain-set is the maximal domain set and it is a singleton, and is the ground domain set. The definition of implies the existence of a totally ordered hierarchy, called the domain generalization hierarchy, . The domain set generalizes iff . We use to refer to the number of levels in . Figures 1(a) and 2(a) show the DGH s for the medication and age attributes, resp. A value generalization relationship for , is a partial order on . It specifies a value generalization hierarchy, , that is a tree whose leaves are values of the ground domain-set and whose root is the single value in the maximal domain-set in . For two values and in , means is more specific than according to the VGH. We use rather than when the attribute is clear from the context. The VGH for the MED and AGE attributes are shown in Figures 1(b) and 2(b), respectively. According to VGH of MED, ibuprofen NSAID.
A value is ground if there is no value more specific than it, and it is general if it is not ground. In Figure 1, ibuprofen is ground and analgesic is general. For a value , its base denoted by is the set of ground values such that . We use to refer to the level of according to .
A general relation (table) is a relation with some general values and a ground relation has only ground values. A general database is a database with some general relations and a ground database has only ground relations. The generalization relation trivially extends to tuples. We give an extension of the generalization relation to general relations and databases in Section 3.
The generalization hierarchies (DGH and VGH) are either created by the data owners with help from domain experts or generated automatically based on data characteristics [13]. The automatic generation of hierarchies for categorical attributes [14] and numerical attributes [15, 16, 17] apply techniques such as histogram construction, binning, numeric clustering, and entropy-based discretization [13].
2.3 Generalized Queries
We review generalized queries (GQs) to access values at different levels of the DGH [12].
Definition 1 (Generalized Queries)
A generalized query (GQ) with schema is a pair , where is an -ary select-projection-join query over , and is a set of levels for each of the values in according to the DGHs in . The set of answers to over , denoted as , contains -ary tuples with values at levels in , such that and generalizes , i.e. .
Intuitively, answering a GQ involves finding the answers of , and then generalizing these values to levels that match . For a fixed size DGH, the complexity of answering is the same as answering .
Example 2.1
Consider a GQ with level , and query posed on relation is Table 3. The query requests the gender and medication of patients with a migraine. The answers to are {(female, naproxen), (male, dolex)}. The GQ asks for the same answers but at the levels specified by . Therefore the answers to are {(female, NSAID), (male, acetaminophen)}, which are generalized according to and Figure 1.
2.4 Privacy-Preserving Data Publishing
The most well-known PPDP privacy model is -anonymity that prevents re-identification of a single individual in an anonymized data set [9, 10].
Definition 2 (-group and -anonymity)
A relation is -anonymous if every QI-group has at least tuples. An -group is a set of tuples with the same values in .
As an example, Table 3 has two QI-groups, and , and it is -anonymous with . -anonymity is known to be prone to attribute linkage attacks where an adversary can infer sensitive values given QI values. Techniques such as (X,Y)-anonymity aim to address this weakness by ensuring that for each QI value in , there are at least different values of sensitive values in attribute(s) in the published (public) data [18].
Definition 3 ((X,Y)-anonymity)
A table with schema and attributes is (X,Y)-anonymous with value if for every , there are at least values in , , where .
The query in Definition 3 returns distinct values of attributes that appear in with the values . Therefore, if the size of is greater than for every tuple , that means every values of are linked with at least values of . Note that -anonymity is a special case of (X,Y)-anonyity when is the set of QI attributes and is the set of sensitive attributes that are also a key in [18].
Example 2.2
For , with , Table 3 is (X,Y)-anonymous since each , is either {ibuprofen, addaprin, naproxen} or {tylenol, dolex, ibuprofen}, which means the values of in each tuple are linked to distinct values of ( represents the set of distinct values of that are linked to the values of in ). Table 3 is not (X,Y)-anonymous with and , since for , ibuprofen with size .
The (X,Y)-anonymity model extends -anonymity; if is a key for and are QI and sensitive attributes, respectively, then (X,Y)-anonymity reduces to -anonymity.
The -diversity privacy model extends -anonymity with a stronger restriction over the -groups [19]. A relation is considered -diverse if each -group contains at least “well-represented” values in the sensitive attributes . Well-representation is normally defined according to the application semantics, e.g., entropy -diversity requires the entropy of sensitive values in each -group to satisfy a given threshold [19]. When well-representation requires sensitive values in each attribute, (X,Y)-anonymity reduces to -diversity.
2.4.1 (X,Y,L)-anonymity.
In earlier work, we introduced (X,Y,L)-anonymity, which extends (X,Y)-anonymity to consider the semantic closeness of values [12]. Consider the following example showing the limitations of (X,Y)-anonymity.
Example 2.3
(X,Y)-anonymity prevents the linkage between sets of attributes and in a relation by making sure that every values of appears with at least distinct values of in . For example, Table 3 is (X,Y)-anonymous with , , and because the values of appear with three different values; co-occurs with ibuprofen, addaprin, naproxen and appears with tylenol, dolex, ibuprofen.
(X,Y)-anonymity ignores how close the values of are according to their VGHs. For example, although ibuprofen, addaprin, naproxen are distinct values, they are similar medications with the same parent NSAID according to the VGH in Figure 1. This means the value of attributes is linked to NSAID which defies the purpose of (X,Y)-anonymity.
(X,Y,L)-anonymity resolves this issue by adding a new parameter for levels of . In (X,Y,L)-anonymity, every values of has to appear with at least values of in the levels of . For example, Table 3 is not (X,Y,L)-anonymous if because appears with values that all roll up to NSAID at level . Thus, to achieve (X,Y,L)-anonymity we need to further suppress values in Table 3 to prevent the linkage between and NSAID.
Definition 4 ((X,Y,L)-anonymity)
Consider a table with schema and attributes , and a set of levels corresponding to attribute DGHs from . is (X,Y,L)-anonymous with value if for every , there are at least values in , where is a GQ with .
2.5 Data Pricing
High quality data is a valuable commodity that has lead to increased purchasing and selling of data online. Data market services provide data across different domains such as geographic and locational (e.g., AggData [20]), advertising (e.g., Oracle [21], Acxiom [22]), social networking (e.g., Facebook [23], Twitter [24]), and people search (e.g. Spokeo [25]). These vendors have become popular in recent years, and query pricing has been proposed as a fine-grained and user-centric technique to support the exchange and marketing of data [26].
Given a database instance and query , a pricing function returns a non-negative real number representing the price to answer [26]. A pricing function should have the desirable property of being arbitrage-free [26]. Arbitrage is defined using the concept of query determinacy [27]. Intuitively, determines if for every database , the answers to over can be computed from the answers to over . Arbitrage occurs when the price of is less than that of , which means someone interested in purchasing can purchase the cheaper instead, and compute the answer to from . For example, determines because the user can apply over to obtain . Arbitrage occurs if is cheaper than which means a user looking for can buy and compute answers to . An arbitrage-free pricing function denies any form of arbitrage and returns consistent pricing without inadvertent data leakage [26]. A pricing scheme should also be history-aware [26]. A user should not be charged multiple times for the same data purchased through different queries. In such a pricing scheme, the data seller must track the history of queries purchased by each buyer and price future queries according to historical data.
3 Generalized Relations
Using general values as repair values in data cleaning requires us to re-consider the definition of consistency between a relational instance and a set of FDs. In this section, we introduce an entropy-based measure that allows us to quantify the utility of a generalized value as a repair value, and present a revised definition of consistency that has not been considered in past work [12].
3.1 Measuring Semantic Distance
By replacing a value in a relation with a generalized value , there is necessarily some information loss. We present an entropy-based penalty function that quantifies this loss [28]. We then use this measure as a basis to define a distance function between two general values.
Definition 5 (Entropy-based Penalty [28])
Consider an attribute in a ground relation . Let be a random variable to randomly select a value from attribute in . Let be the value generalization hierarchy of the attribute (the values of in are ground values from ). The entropy-based penalty of a value in denoted by is defined as follows:
where is the probability that the value of is a ground value and a descendant of , . The value is the entropy of conditional to .
Intuitively, the entropy measures the uncertainty of using the general value . measures the information loss of replacing values in with . Note that if is ground because , and is maximum if is the root value in . is monotonic whereby if , then . Note that the conditional entropy is not a monotonic measure [28].
Example 3.1
Definition 6 (Semantic Distance Function, )
The semantic distance between and in is defined as follows:
in which is the least common ancestor of and .
Intuitively, if is a descendant of or vice versa, i.e. or , their distance is the the difference between their entropy-based penalties, i.e., . This is the information loss incurred by replacing a more informative child value with its ancestor when . If and do not align along the same branch in the VGH, i.e. and , is the total distance between and as we travel through their least common ancestor , i.e. .
Example 3.2
The distance captures the semantic closeness between values in the VGH. We extend the definition of to tuples by summing the distances between corresponding values in the two tuples. The function naturally extends to sets of tuples and relations. We use the distance measure to define repair error in our evaluation in Section 7.
3.2 Consistency in Generalized Relations
A (generalized) relation may contain generalized values that are syntactically equal but are semantically different and represent different ground values. For example, and in Table 3 are syntactically equal (containing [31,60]), but their true values in Table 3 are different, and , respectively. In contrast, two syntactically different general values may represent the same ground value. For example, although analgesic and NSAID are different general values, they may both represent ibuprofen. The consistency between traditional FDs and a relation is based on syntactic equality between values. We present a revised definition of consistency with the presence of generalized values in .
Given a generalized relation with schema , and FD with attributes in , satisfies (), if for every pair of tuples in , if and are equal ground values then is an ancestor of or vice-versa, i.e. or . Since a general value encapsulates a set of distinct ground values in , relying on syntactic equality between two (general) values, and is not required to determine consistency, since they may be syntactically different but represent the same ground value. Our definition requires that be an ancestor of (or vice-versa), which means they represent the same ground value. This definition extends to FDs with a set of attributes in . The definition reduces to the classical FD consistency when is ground. Assuming VGHs have fixed size, consistency checking in the presence of generalized values is in quadratic time according to .
Example 3.3
Consider an FD that states two patients of the same gender that are diagnosed with the same disease should be prescribed the same medication. According to the classic definition of FD consistency, and in Table 3 are inconsistent as and are males with osteoarthritis, i.e. {male, osteoarthritis}, but are prescribed different medications, i.e. ibuprofen intropes . Under our revised definition of consistency for a generalized relation, if we update to NSAID, which is the ancestor of ibuprofen, then and are now consistent. In our revised consistency definition, ibuprofen NSAID , indicating that the general value NSAID may represent the ground value ibuprofen. However, if we were to update to vasodilators, which is not the ancestor of ibuprofen, then and remain inconsistent under the generalized consistency definition, since the general value vasodilators cannot represent ibuprofen.
4 PACAS Overview
We formally define our problem, and then review the PACAS framework [12], including extensions for generalized repairs.
4.1 Problem Statement
Consider a client, CL, and a service provider, SP, with databases containing single relations , respectively. Our discussion easily extends to databases with multiples relations. We assume a set of FDs defined over that is falsified. We use FDs as the benchmark for error detection, but our framework is amenable to other error detection methods. The shared generalization hierarchies are generated by the service provider (applying the techniques mentioned in Section 2.2). The problem of privacy-preserving data cleaning is twofold, defined separately for CL and SP. We assume a generalization level , which indicates the maximum level that values in our repaired database can take from the generalization hierarchy.
Client-side: For every cell with value , let be the corresponding accurate value in . A cell is considered dirty if . We assume the client can initiate a set of requests to in which each request is of the form , that seeks the clean value of database cell at level in . We assume for a fixed cleaning budget . Let be the clean version of where for each cell, . The problem is to generate a set of requests , where the answers (possibly containing generalized values) are used to compute a relation such that: (i) , (ii) is minimal, and (iii) for each , its level .
In our implementation, we check consistency using the consistency definition in Section 3.2, and measure the distance using the semantic distance function (Defn. 6).
Service-side: The problem is to compute a pricing function that assigns a price to each request such that preserves (X,Y,L)-anonymity.

4.2 Solution Overview
Figure 3 shows the PACAS system architecture consisting of two main units that execute functions for CL and SP. Figure 3(a) shows the CL unit containing four modules. The first module finds equivalence classes in . An equivalence class (eq) is a set of cells in with equal values in order for to satisfy [2]. The next three modules apply an iterative repair for the eqs. These modules select an eq, purchase accurate value(s) of dirty cell(s) in the class, and then repair the cells using the purchased value. If the repairs contain generalized values, the CL unit must verify consistency of the generalized relation against the defined FDs. The cleaning iterations continue until is exhausted or all the eqs are repaired. We preferentially allocated the budget to cells in an eq based on the proportion of errors in which the cells (in an eq) participate. Figure 3(b) shows the SP unit. The Record Matching module receives a request from CL, identifies a matching tuple in , and returns at the level according to the VGH. The Data Pricing and Validate Privacy module computes prices for these requests, and checks whether answering these requests will violate (X,Y,L)-anonymity in . If so, the request is not safe to be answered. The Query Answering module accepts payment for requests, and returns the corresponding answers to CL.
5 Limiting Disclosure of Sensitive Data
The SP must carefully control disclosure of its curated and sensitive data to the CL. In this section, we describe how the SP services an incoming client request for data, validates whether answering this request is safe (in terms of violating (X,Y,L)-anonymity), and the data pricing mechanism that facilitates this interaction.
5.1 Record Matching and Query Generation
Given an incoming CL request , the SP must translate to a query that identifies a matching (clean) tuple in , and returns at level . To answer each request, the SP charges the CL a price that is determined by the level of data disclosure and the adherence of to the privacy model. To translate a request to a GQ , we assume a schema mapping exists between and , with similarity operators to compare the attribute values. This can be modeled via matching dependencies (MDs) in SP [5].
Example 5.1
Consider a request that requests the medication of the patient in tuple at level . To translate into a generalized query , we use the values of the QI attributes GEN and AGE in tuple . We define a query requesting the medications of patients in with the same gender and age as the patient in tuple . The GQ level is equal to the level of the request, i.e. . The query is generated from an assumed matching dependency (MD) that states if the gender and age of two records in SP and CL are equal, then the two records refer to patients with the same prescribed medication.
5.2 Enforcing Privacy
Recall from Section 2.4.1 that (X,Y,L)-anonymity extends (X,Y)-anonymity to consider the attribute domain semantics. Given a GQ, the SP must determine whether it is safe to answer this query, i.e., decide whether disclosing the value requested in violates (X,Y,L)-anonymity (defined in Defn. 4). In this section, we formalize the privacy guarantees of (X,Y,L)-anonymity, and in the next section, review the SafePrice data pricing algorithm that assigns prices to GQs to guarantee (X,Y,L)-anonymity.
(X,Y,L)-anonymity applies tighter privacy restrictions compared to (X,Y)-anonymity by tuning the parameter (determined by the data owner). At higher levels of , it becomes increasingly more difficult to satisfy the (X,Y,L)-anonymity condition, while (X,Y,L)-anonymity reduces to (X,Y)-anonymity at for every . We formally state this in Theorem 5.1. (X,Y,L)-anonymity is a semantic extension of (X,Y)-anonymity. Similar extensions can be defined for PPDP models such as (X,Y)-privacy, -diversity, -closeness. Unfortunately, all these models do not consider the data semantics in the attribute DGHs and VGHs [11].
Theorem 5.1
Consider a relation and let and be two subsets of attributes in . Let and be levels of the attributes in with , i.e. every level of is lower than or equal to its corresponding level in . The following holds for relation with a fixed :
-
1.
If is -anonymous it is also -anonymous, but not vice versa (i.e. can be -anonymous but not -anonymous).
-
2.
For any levels of attributes in , if is (X,Y,L)-anonymous, it is also (X,Y)-anonymous.
Proof of Theorem 5.1. In the first item, if is -anonymous, then for every , in which . Considering , we can claim , which proves is also -anonymous. The claim holds because if has answers in levels of , it will have fewer or equal number of answers in the higher level since different values in levels of may be replaced with the same ancestors in the levels of . The second item holds because if is (X,Y,L)-anonymous it is also -anonymous where contains the bottom levels of attributes in ; due to and item 1. If is -anonymous, then every value of appears with ground values and we can conclude it is (X,Y)-anonymous.
5.3 Pricing Generalized Queries.
PPDP models have traditionally been used in non-interactive settings where a privacy-preserving table is published once. We take a user-centric approach and let users dictate the data they would like published. We apply PPDP in an interactive setting where values from relation are published incrementally according to (user) CL requests, while verifying that the disclosed data satisfies (X,Y,L)-anonymity [12]. We adopt a data pricing scheme that assigns prices to GQs by extending the baseline data pricing algorithm defined in [29] to guarantee (X,Y,L)-anonymity. We review this baseline pricing algorithm next.
Baseline Data Pricing. The baseline pricing model computes a price for a query over relation according to the amount of information revealed about when answering [29].
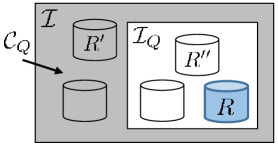
Given a query over a relation (a database with single relation ), the baseline pricing model determines the price of based on the amount of information revealed about by answering . Let be a set of possible relations that the buyer believes to be , representing his initial knowledge of . As the buyer receives answers to , he gains new knowledge, allowing him to eliminate relations from , which provide a different answer . This set of eliminated instances is called the conflict set of denoted as , and intuitively represents the amount of information that is revealed by answering (Figure 4). As more queries are answered, the size of is reduced. We can apply a set function that uses to compute a price for . We can use the weighted cover set function with predefined weights assigned to the relations in . Query prices are computed by summing the weights for relations in , which has been shown to give arbitrage-free prices [29]. In practice, the set is usually infinite making it infeasible to implement. To circumvent this problem, a smaller, finite subset called the support set is used to generate arbitrage-free prices [29]. The support set is defined as the neighbors of , generated from via tuple updates, insertions, and deletions. The values that are used to generate the support set are from the same domain of the original relation .
Several optimizations are applied to the baseline pricing, and its effectiveness is experimentally justified [29]. Most importantly, the relations in the support set can be modeled by update operations. That is, we generate each relation in from by applying its corresponding update operation and use the resulting relation to compute the value of the weighted function as the final price. We roll-back the update to restore , and continue this process to compute the weighted function using other relations in . We avoid storing all databases in to enable more efficient price computations.
Algorithm 1 provides pseudocode of the baseline algorithm. The algorithm takes query , database , a support set , and a weight function , and computes the price to answer over . The baseline algorithm is history-aware as input excludes databases that were already considered by past queries.
SafePrice Algorithm. We describe the SafePrice algorithm (originally introduced in [12]) that enforces (X,Y,L)-anonymity over (equivalently in our framework). We first present the definition of a safe query, i.e., criteria for a GQ to preserve (X,Y,L)-anonymity.
Definition 7
(Safe Query) Consider a GQ over a relation with schema , , and levels corresponding to attributes in . Let be the set of relations such that . is safe (or preserves (X,Y,L)-anonymity of ) with value , if for every tuple , there are at least tuples in the set of answers where is a GQ with .
In Definition 7, represents the set of relations that the buyer believes is drawn from after observing the answer . If there are at least tuples in the answer set of over , this indicates that the buyer does not have enough information to associate the values in to less than values of at level , thus preserving (X,Y,L)-anonymity. If the SP determines that a GQ is safe, he will assign a finite price relative to the amount of disclosed information about .
Algorithm 2 presents the SafePrice details. The given support set represents the user’s knowledge about relation after receiving the answer to past purchased queries. We maintain a set that represents all admissible relations after answering and captures the user’s posterior knowledge about after answering . We use to check whether answering is safe. This is done by checking over instances in whether values in are associated with at least values of using the query . The price for a query is computed by summing the weights of the inadmissible relations in the conflict set (Line 2). Similar to the baseline pricing, we use the support set and admissible relations rather than and , respectively. We iterate over tuples (Line 2), and check whether values in are associated with less than values in over relations in . If so, we return an infinite price reflecting that query is not safe (Line 2).
Proposition 1
If the input GQ is not safe, Algorithm 2 preserves (X,Y,L)-anonymity by returning an infinite price.
Proof sketch: According to Definition 7, if violates (X,Y,L)-anonymity then for , there are less than answers to over relations in . Since , there will be less than answers to over relations in , meaning Algorithm 2 assigns infinite price to in Line 2. Note that if Algorithm 2 returns an infinite price, it does not imply is unsafe (this only occurs when ).
Given the interactive setting between the CL and the SP, we must ensure that all (consecutively) disclosed values guarantee (X,Y,L)-anonymity over . We ensure that SafePrice is history-aware by updating the support set after answering each GQ. The SP uses the pricing function in Algorithm 2 to update to reflect the current relations that have been eliminated by answering the latest GQ. The SP implements (cf. Figure 3) by translating to a GQ, and then invoking SafePrice.
We assume that requesting a query price is free. We acknowledge that returning prices might leak information about the data being priced and purchased. This problem is discussed in the data pricing literature, particularly to incentivize data owners to return trustful prices when prices reveal information about the data (cf. [30] for a survey on this issue). We consider this problem as a direction of future work.
5.4 Query Answering
A CL data request is executed via the method, where she purchases the value in at price . The Query Answering module executes via SP accepts payment, translates to a GQ, and returns the answer over to CL. Lastly, SP updates the support set to ensure SafePrice has an accurate history of disclosed data values.
We note that all communication between CL and SP is done via the AskPrice and Pay methods (provided by SP). We assume there is a secure communication protocol between the CL and SP, and that all data transfer is protected and encrypted. The model is limited to a single SP that sells data at non-negotiable prices. We intend to explore general cases involving multiple SP providers and price negotiation as future work.
6 Data Cleaning with Generalized Values
Existing constraint-based data repair algorithms that propose updates to the data to satisfy a set of data dependencies assume an open-access data model with no data privacy restrictions [2, 31, 32, 33, 34]. In these repair models, inadvertent data disclosure can occur as the space of repair candidates is not filtered nor transformed to obscure sensitive values. A privacy-aware data repair algorithm must address the challenge of providing an accurate repair to an error while respecting data generalizations and perturbations to conceal sensitive values.
In earlier work, we introduced SafeClean, a data repair algorithm that resolves errors in a relation using data purchased from a service provider [12]. The key distinctions of SafeClean from past work include: (i) SafeClean interacts with the service provider, SP, to purchase trusted values under a constrained budget . This eliminates the overhead of traversing a large search space of repair candidates; and (ii) SafeClean tries to obtain values with highest utility from SP for repairing CL. However, the existing SafeClean algorithm grounds all purchased values thereby not allowing generalized values in . In this paper, we extend SafeClean to consider generalized values in by re-defining the notion of consistency between a relation and a set of FDs (Section 3.2), and revising the budget allocation algorithm to requests according to the number of errors in which cells in an equivalence participate (Section 6.4). In contrast, the existing SafeClean provides fixed budget allocations. We give an overview of our cleaning algorithm and subsequently describe each component in detail.
6.1 Overview
For a fixed number of FDs , the problem of finding minimal-cost data repairs to such that satisfies is NP-complete [2]. Due to these intractability results, we necessarily take a greedy approach that cleans cell values in that maximally reduce the overall number of errors w.r.t. . This is in similar spirit to existing techniques that have used various weighted cost functions [2, 35] or conflict hypergraphs [33] to model error interactions among data dependencies in .
Given and , we identify a set of error cells that belong to tuples that falsify some . For an error cell , we define eq() as the equivalence class to which belongs. An equivalence class is a set of database cells with the same value such that is satisfied [2]. We use eqs for two reasons: (i) by clustering cells into eqs, we determine a repair value for a group of cells rather than an individual cell, thereby improving performance; and (ii) we utilize every cell value within an eq to find the best repair.
The SafeClean algorithm repairs FD errors by first finding all the eqs in . The algorithm then iteratively selects an eq, and purchases the true value of a cell, and updates all dirty cells in the same class to the purchased value. The SP may decide that returning a generalized value is preferred to protect user sensitive data in . If so, then the CL must validate consistency of its data including these generalized values. At each iteration, we repair the eq class with cells that participate in the largest number of FD errors. At each iteration, SafeClean assigns a portion of the budget that is proportional to the number of errors relative to the total number of errors in (this new extension to SafeClean is discussed in Section 6.4). SafeClean continues until all the eqs are repaired, or the budget is exhausted.
SafeClean Algorithm. Algorithm 3 gives details of SafeClean’s overall execution. The algorithm first generates the set of eqs via GenerateEQs in Line 3. Equivalence classes containing only one value are removed since there is no need for repair. In Line 3, SafeClean selects an equivalence class with cells participating in the largest number of violations for repair (further details in Section 6.3). To repair the error cells in , SafeClean generates a request using GenerateRequest that requests a repair value for a cell in (Line 3). This request is made at the lowest possible level (less than ) at a price allowable within the given budget. The algorithm assigns a fraction of the remaining budget, i.e. ( is the remaining budget) to purchase data at each iteration. This fraction depends on the number of violations in (cf. Section 6.4 for details). If such a request can be satisfied, the value(s) are purchased and applied (Lines 3-3). If there is insufficient budget remaining to purchase a repair value, then the eq cannot be repaired. In either case, SafeClean removes from EQ and continues with the next eq (Line 3). SafeClean terminates when is exhausted, or there are no eqs are remaining. We present details of eq generation, selection, request generation, and data purchase/repair in the following sections.
6.2 Generating Equivalence Classes
The eqs are generated by GenerateEQs in Algorithm 4 that takes as input and , and returns the set of eqs EQ. For every cell , the procedure initializes the eq of as , and adds it to the set of eqs EQ (Line 4). We then iteratively merge the eqs of any pair of cells if there is a FD , , and both and are ground. The procedure stops and returns EQ when no further pair of eqs can be merged.
Example 6.1
Given FD in Table 3, since , and have the same attribute values on GEN and DIAG, we merge , and into the same . Similarly, we cluster and into the same .
6.3 Selecting Equivalence Classes for Repair
In each iteration of Algorithm 3, we repair the cells in an eq that will resolve the most errors in w.r.t. . To achieve this goal, we choose as the eq with cells participating in the largest number of errors. For a cell and an FD , let be the set of errors w.r.t. and . For an eq , let and . The eq returned by Select in Line 3 of Algorithm 3 is the eq with the largest number of errors in . In other words, this is the number of tuple pairs that every cell in participates, summed over all FDs in .
Example 6.2
We continue Example 6.1 with and . According to our error definition, given FD , is involved in three errors with tuples (, and ), while has one error (). Hence, our algorithm will select to repair first.
6.4 Data Request Generation
To repair cells in , we generate a request by GenerateRequest (Algorithm 5) that requests accurate and trusted value of a cell at level from . There are two restrictions on this request: (i) the price must be within the budget , and (ii) the level must be . The value is defined as follows:
In this definition, the allocated budget to each iteration is proportional to the number of FD violations in , and also depends on the total number of errors in . This allocation model improves upon previous work that decreases the budget allocated to the -request by a factor of , and does not adjust the allocation to the number of errors in which a cell participates [12]. Note that if the price paid for (i.e. ) is less than this allocated budget, the remaining budget carries to the next iteration through .
If there is no such request, GenerateRequest returns null, indicating that cannot be repaired with the allocated budget (Line 5). If there are several requests that satisfy (i) and (ii), we follow a greedy approach and select the request at the lowest level with the price to break ties (Line 5). For a cell , LowestAffordableLevel in Line 5 finds the lowest level in which the value of can be purchased from considering the restrictions in (i) and (ii). Our greedy algorithm spends most of the allocated budget in the current iteration. An alternative approach is to select requests with the highest acceptable level () to preserve the budget for future iterations.
6.5 Purchase Data and Repair
To repair the cells in , Algorithm 3 invokes to purchase the trusted value and replaces the value of every cell in with in ApplyRepair. The algorithm then removes the eq from EQ and continues to repair the next eq. The algorithm stops when there is no eq to repair or the budget is exhausted.
Example 6.3
Continuing from Example 6.2, since has the largest number of errors, we purchase the trusted value from to repair first. If the purchased value is general value NSAID, we update all cells in , i.e., , and to NSAID to resolve the inconsistency.
6.6 Complexity Analysis
We analyze the complexity of SafeClean’s modules:
-
•
Identifying errors involves computing equivalence classes, and selecting an equivalence class for repair. In the worst case, this is quadratic in the number of tuples in .
-
•
For each data request to resolve an error, executing SafePrice and rely on , the support set , and the complexity of GQ answering. We assume the size of is linear w.r.t the size of . The complexity of running GQs is the same as running SQL queries. Thus, all procedures run in polynomial time to the size of .
-
•
In applyRepair, for each returned value from SP, we update the error cells in for each equivalence class and each FD, taking time on the order of for attribute domain size . We must update the affected cells in the equivalence class, and their dirty scores; both taking time bounded by the number of cells in . Hence, Algorithm 3 runs in polynomial time to the size of and .
7 Experiments
Our evaluation focuses on the following objectives:
-
1.
We evaluate the impact of generalized values on the repair error, and the runtime performance. In addition, we study the proportion of generalized repair values that are recommended for varying budget levels.
-
2.
The efficiency and effectiveness of SafePrice to generate reasonable prices that allow SafeClean to effectively repair the data.
-
3.
We evaluate the repair error and scalability of SafeClean as we vary the parameters and to study the repair error to runtime tradeoff.
-
4.
We compare SafeClean against PrivateClean, a framework that explores the link between differential privacy and data cleaning [8]. We study the repair error to runtime tradeoff between these two techniques, and show that data randomization in PrivateClean significantly hinders error detection and data repair, leading to increased repair errors.
7.1 Experimental Setup
We implement PACAS using Python 3.6 on a server with 32 Core Intel Xeon 2.2 GHz processor with 64GB RAM. We describe the datasets, baseline comparative algorithm, metrics and parameters. The datasets, their schema, and source code implementation can be found at [36].
| Clinical | Census | Food | |
| 345,000 | 300,000 | 30,000 | |
| 29 | 40 | 11 | |
| 61/73 | 17/250 | 248/70 | |
| 5/5 | 5/6 | 5/5 |
| Sym. | Description | Values |
| budget | 0.2, 0.4, 0.6, 0.8 | |
| support set size | 6, 8, 10, 12, 14 | |
| generalization level | 0, 1, 2, 3, 4 | |
| #tuples in X-group | 1, 2, 3, 4, 5 | |
| error rate | 0.05, 0.1, 0.15, 0.2, 0.25 |
Datasets. We use three real datasets. Table 6 gives the data characteristics, showing a range of data sizes in the number of tuples (), number of attributes (), number of unique values in the sensitive attribute (), and the height of the attribute (). We denote sensitive attributes with an asterisk (*).
Clinical Trials (Clinical). The Linked Clinical Trials database describes patient demographics, diagnosis, prescribed drugs, symptoms, and treatment [37]. We select the country, gender, source and age as QI attributes. We define two FDs: (i) [age, overall_status, gender] [drug_name*]; and (ii) [overall_status, timeframe, measure] [condition*]. We construct attribute value generalization hierarchies (VGH) with five levels on attributes drug name and condition, respectively using external ontologies (Bioprotal Medical Ontology [38], the University of Maryland Disease Ontology [39], and the Libraries of Ontologies from the University of Michigan [40]). The average number of children per node in the VGH is eight.
Census. The U.S. Census Bureau provides population characteristics such as education level, years of schooling, occupation, income, and age [41]. We select sex, age, race, and native country as QI attributes. We define two FDs: (i) [age, education-num] [education*]; and (ii) [age, industry code, occupation] [wage-per-hour*]. We construct VGH on attributes wage-per-hour and education by stratifying wage and education levels according to hierarchies from US statistics [42], and the US Department of Education [43]. The average number of children per node is five.
Food Inspection (Food). This dataset contains violation citations of inspected restaurants in New York City describing the address, borough, zipcode, violation code, violation description, inspection type, score, grade. We define inspection type, borough, grade as QI attributes. We define two FDs: (i) [borough, zipcode] [address*]; and (ii) [violation code, inspection type] [violation description*]. We construct attribute VGH on address and violation description by classifying streets into neighborhoods, districts, etc, and extracting topic keywords from the description and classifying the violation according to the Food Service Establishment Inspection Code [44]. The average number of children per node in the VGH is four.
For each dataset, we manually curate a clean instance according to the defined FDs, verify with external sources and ontologies, and is used as the ground truth. To create a dirty instance , we duplicate to obtain , and use BART, an error generation benchmarking tool for data cleaning applications to inject controlled errors in the FD attributes [45]. We use BART to generate constraint-induced errors and random errors, and define error percentages ranging from 5% to 25%, with respect to the number of tuples in a table. We use BART’s default settings for all other parameters.
Comparative Baseline. The closest comparative baseline is PrivateClean, a framework that explores the link between differential privacy and data cleaning [8]. PrivateClean provides a mechanism to generate -differentially private datasets on numerical and discrete values from which a data analyst can apply data cleaning operations. PrivateClean proposes randomization techniques for discrete and numeric values, called Generalized Randomized Response (GRR), and applies this across all attributes. To guarantee a privatized dataset with discrete attributes is -differentially private at confidence , a sufficient number of distinct records is needed. In our comparison evaluation, we set , and the degree of privacy (applied uniformly across the attributes and equivalent to for discrete attributes [8]). Since PrivateClean does not directly propose a data cleaning algorithm, but rather data cleaning operators, we apply the well-known Greedy-Repair [2] FD repair algorithm to generate a series of updates to correct the FD violations. We use the transform() operation to represent each of these updates in PrivateClean, and use the source code provided by the authors in our implementation. We choose the Greedy-Repair algorithm for its similarity to our repair approach; namely, to repair cells on an equivalence class basis, and to minimize a cost function that considers the number of data updates and the distance between the source and target values.
Metrics. We compute the average runtime over four executions. To measure the quality of the recommended repairs, we define the repair error of a cell as the distance between a cell’s true value and its repair value. We use the semantic distance measure, , in Section 3.1, that quantifies the distance between two values (suppose a true value), and (a repair value) in the attribute value generalization hierarchy, and considers the distribution of and in the relation. We assume a cell’s value, and its repair are both in the generalization hierarchy. The repair error of a relational instance is computed as the sum of the repair errors across all cells in the relation. We use the absolute value of the repair error in our experiments (denoted as ). Similar to other error metrics (such as mean squared error), lower error values are preferred.
Parameters. Unless otherwise stated, Table 6 shows the range of parameter values we use, with default values in bold. We vary the following parameters to evaluate algorithm performance: (i) the budget ; (ii) the size of the support set in the pricing function; (iii) (the lower bound of generalization); (i) , the number of tuples in an -group; and (vi) the error rate in .
7.2 Generalized Values
We measure the proportion of generalized values that are returned for varying levels of the budget . Since a repair value may be returned at any level of the VGH, we compute the semantic distance between the generalized value and the corresponding ground value in the CL. We normalize the distance between () into four ranges: [0-0.25], [0.25-0.5], [0.5-0.75], [0.75-1], where a distance of zero indicates and are both ground values.

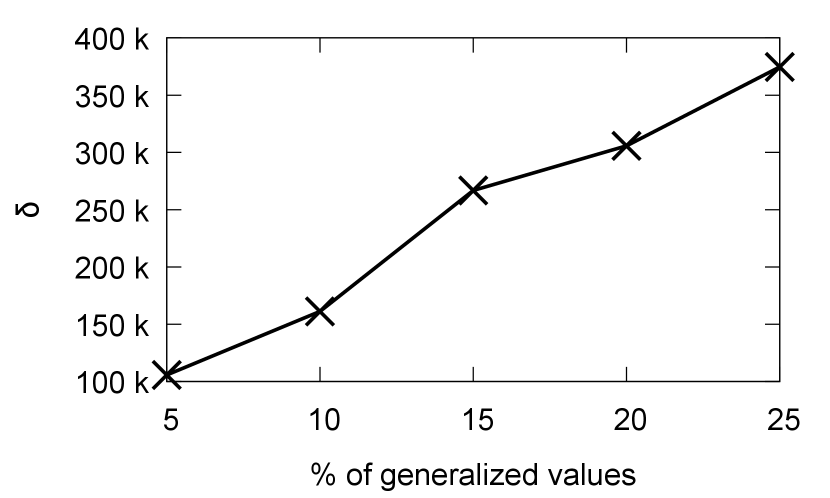

Figure 5 shows the relative proportions for varying values over the clinical dataset. As expected, the results show that the proportion of generalized values at the highest levels of the VGH occur for low values since we can only afford (cheaper) generalized values under a constrained budget. In contrast, for values close to 0.9, close to of the repair values are specific, ground values with a distance range of [0, 0.25], while the remaining are generalized values at the next level. We observe that for approximately 70% of the total repair values are very close to the ground value (where distance is at [0-0.25]), indicating higher quality repairs.
We evaluate the impact on the runtime to repair error tradeoff when an increasing number of generalized values occur in the repaired relation. We control the number of generalized values indirectly via the number of error cells under a constrained budget where it is expected that close to all repair recommendations will be general values. Figure 6 and Figure 7 show the repair error and runtime curves over the clinical data, respectively. As expected, we observe for an increasing number of generalized values, the repair error increases as the constrained budget leads to more values returned at the highest * generalized value, thereby increasing the distance between ground-truth relation and repaired relation. In contrast, the increased number of generalized values leads to lower runtimes due to the increased number of unsatisfied query requests.
7.3 SafePrice Efficiency and Effectiveness

The SafePrice algorithm relies on a support set to determine query prices by summing the weights of discarded instances from the conflict set . These discarded instances represent the knowledge gained by CL. We vary the size of the initial to determine its influence on the repair error (), and the overall runtime. Figure 8 shows a steady decrease in the repair error for increasing . As grows, the SP is less restrictive to answer GQs and fewer requests are declined at lower levels. As more requests are answered at these lower levels, the repair error decreases. Figure 9 shows that the SafePrice runtime scales linearly with increasing , making it feasible to implement in practice. From Figures 8 and 9, we determine that SafePrice achieves an average 6% reduction in the repair error at a cost of 16m runtime. This is expected due to the additional time needed to evaluate the larger space of instances to answer GQs. Comparing across the three datasets, the data sizes affect runtimes as a larger number of records must be evaluated during query pricing. This is reflected in longer runtimes for the larger clinical and census datasets.
7.4 SafePrice Parameter Sensitivity
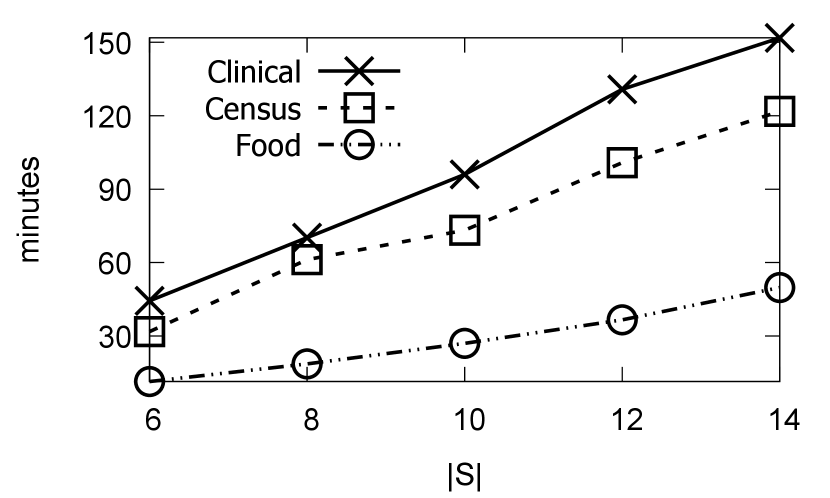







We vary the parameters , GQ level , error rate , budget , and measure their influence on SafeClean repair error and runtime over all three datasets. We expect that enforcing more stringent privacy requirements through larger and values will result in larger repair errors. Figures 10 to 13 do indeed reflect this intuition.
In Figure 10, SafeClean experiences larger repair errors for increasing as generalizations to conceal sensitive values become increasingly dependent on the attribute domain and its VGH i.e., (X,Y,L)-anonymity indicates there must be at least values at a given level in the VGH. Otherwise, the data request is denied. Figure 11 shows that for increasing , runtimes decrease linearly as query requests to satisfy more stringent become more difficult. On average, we observe that an approximate 10% improvement in runtime leads to a 7% increase in the repair error for each increment of . Figures 12 and 13 show the repair error and runtime, respectively, as we vary the query level parameter . The repair error increases, particularly after as more stringent privacy requirements are enforced, i.e., distinct values are required at each generalization level. This makes satisfying query requests more difficult, leading to unrepaired values and lower runtimes, as shown in Figure 13.
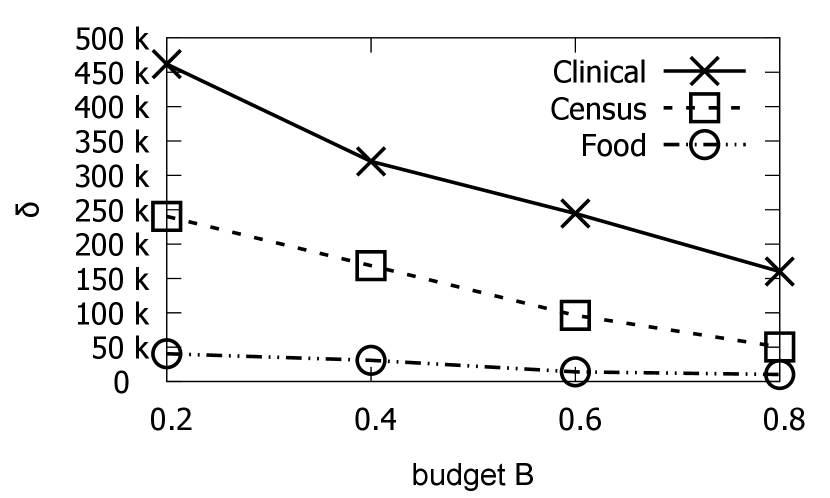
Figure 14 shows the repair error increases as we scale the error rate . For a fixed budget, increasing the number of FD errors leads to a decreasing budget for each FD error. This makes some repairs unaffordable for the CL, leading to unrepaired values and an increased number of generalized repair values. This situation can be mitigated if we increase the budget . As expected, Figure 15 shows that the SafeClean runtime increases for an increasing number of FD violations, due to the larger overhead to compute more equivalance classes, compute prices to answer queries, and to check consistency in the CL.
Figures 16 and 17 show the repair error and runtime, respectively, as we vary the budget . For increasing budget allocations, we expect the SP to recommend more ground (repair) values, and lower repair error values, as shown in Figure 16. Given the larger budget allocations, the SP is able to answer a larger number of query requests, and must compute their query prices, thereby increasing algorithm runtime. We observe that an average 14% reduction in the repair error leads to an approximate 7% increase in runtime.
7.5 Comparative Evaluation
We compare SafeClean to PrivateClean, a framework for data cleaning on locally differentially private relations [8]. Section 7.1 describes the baseline algorithm parameter settings and configuration. Despite the differing privacy models, our evaluation aims to explore the influence of increasing error rates on the repair error , and algorithm runtimes using the Clinical dataset. We hope these results are useful for practitioners to understand qualitative and performance trade-offs between the two privacy models. For SafeClean, we measure total time of the end-to-end process from error detection to applying as many repairs as the budget allows. In PrivateClean, we measure the time to privatize the , error detection, running the Greedy-Repair FD repair algorithm [2], and applying the updates via the Transform operation.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c3010462-382a-4125-b544-f82bf7b3fcec/x18.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c3010462-382a-4125-b544-f82bf7b3fcec/x19.png)
For PrivateClean, we measure the repair error for source value and target (clean) value , as recommended by Greedy-Repair, where both are ground values.
Figure 18 shows the comparative repair error between SafeClean and PrivateClean as we vary the error rate . SafeClean achieves an average lower repair error than PrivateClean. This poor performance by PrivateClean is explained by the underlying data randomization used in differential privacy, which provides strong privacy guarantees, but poor data utility, especially in data cleaning applications. As acknowledged by the authors, identifying and reasoning about errors over randomized response data is hard [8]. This randomization may update rare values to be more frequent, and similarly, common values to be more rare. This leads to more uniform distributions (where stronger privacy guarantees can be provided), but negatively impact error detection and cardinality-minimal data repair techniques that rely on attribute value frequencies to determine repair values [2]. We envision that SafeClean is a compromise towards providing an (X,Y,L)-anonymous instance while preserving data utility.
SafeClean’s lower repair error comes at a runtime cost, as shown in Figure 19. As we scale the error rate, SafeClean’s runtime scales linearly due to the increased overhead of data pricing. Recall the pricing mechanism in Section 5.3, the price of query is determined by the query answer over the relation and its neighbors in the support set . In contrast, PrivateClean does not incur such an overhead due to its inherent data randomization. There are opportunities to explore optimizations to lower SafeClean’s overhead to answer query requests and compute prices to answer each query. In practice, optimizations can be applied to improve overall performance, including decreasing the parameter according to application requirements, and considering distributed (parallel) executions of query processing over partitions of the data. SafeClean aims to provide a balanced approach towards achieving data utility for data cleaning applications while protecting sensitive values via data pricing and (X,Y,L)-anonymity.
8 Related Work
Data Privacy and Data Cleaning. We extend the PACAS framework introduced in [12], which focuses on repairs involving ground values. While the prior PACAS framework prices and returns generalized values, the CL does not allow generalized values in its relation . Instead, the CL instantiates a grounding process to ground any generalized values returned by the SP. In this work, we remove this limitation by re-defining the notion of consistency between and the set of FDs to include generalized values. We have also extended the budget allocation scheme to consider allocations according to the proportion of errors in which cells (in an equivalence class) participate. This improves the PACAS framework to be more adaptive to the changing number of unresolved errors instead of only assigning fixed allocations. Our revised experiments, using repair error as a measure of accuracy, show the influence of generalized repairs along varying parameters towards improved efficiency and effectiveness.
There has been limited work that considers data privacy requirements in data cleaning. Jaganathan and Wright propose a privacy-preserving protocol between two parties that imputes missing data using a lazy decision-tree imputation algorithm [6]. Information-theoretic metrics have been used to quantify the information loss incurred by disclosing sensitive data values [57, 7]. As mentioned previously, PrivateClean provides a framework for data cleaning on local deferentially private relations using a set of generic user-defined cleaning operations showing the trade-off between privacy bounds and query accuracy [8]. While PrivateClean provides stronger privacy bounds than PACAS, these bounds are only applicable under fixed query budgets that limit the number of allowed queries (only aggregation queries), which is difficult to enforce in interactive settings. Our evaluation has shown the significant repair error that PrivateClean incurs due to the inherent randomization needed in local differential privacy.
Ge et. al., introduce APEx, an accuracy-aware, data privacy engine for sensitive data exploration that allow users to pose adaptive queries with a required accuracy bound. APEx returns query answers satisfying the bound and guarantees that the entire data exploration process is differentially private with minimal privacy loss. Similar to PACAS, APEx allows users to interact with private data through declarative queries, albeit specific aggregate queries (PACAS has no such restriction). APEx enable users to perform specific tasks over the privatized data, such as entity resolution. While similar in spirit, APEx uses the given query accuracy bound to tune differential privacy mechanisms to find a privacy level that satisfies the accuracy bound. In contrast, PACAS applies generalization to target predicates in the given query requests, without randomizing the entire dataset, albeit with looser privacy guarantees, but with higher data utility.
Dependency Based Cleaning. Declarative approaches to data cleaning (cf. [46] for a survey) have focused on achieving consistency against a set of dependencies such as FDs and inclusion dependencies and their extensions. Data quality semantics are declaratively specified with the dependencies, and data values that violate the dependencies are identified as errors, and repaired [5, 47, 35, 48, 49, 58]. There are a wide range of cleaning algorithms, based on user/expert feedback [50, 51, 52], master database [4, 5], knowledge bases or crowdsourcing [53], probabilitic inference [54, 55]. Our repair algorithm builds upon these existing techniques to include data disclosure requirements of sensitive data and suggesting generalized values as repair candidates.
Data Privacy. PPDP uses generalization and suppression to limit data disclosure of sensitive values [9, 10]. The generalization problem has been shown to be intractable, where optimization, and approximation algorithms have been proposed (cf. [11] for a survey). Extensions have proposed tighter restrictions to the baseline -anonymity model to protect against similarity and skewness attacks by considering the distribution of the sensitive attributes in the overall population in the table [11]. Our extensions to (X,Y)-anonymity to include semantics via the VGH can be applied to existing PPDP techniques to semantically enrich the generalization process such that semantically equivalent values are not inadvertently disclosed.
In differential privacy, the removal, addition or replacement of a single record in a database should not significantly impact the outcome of any statistical analysis over the database [56]. An underlying assumption requires that the service provider know in advance the set of queries over the released data. This assumption does not hold for the interactive, service-based data cleaning setting considered in this paper. PACAS aims to address this limitation by marrying PPDP and data pricing in interactive settings.
Data Pricing. We use the framework by Deep and Koutris that provides a scalable, arbitrage-free pricing for SQL queries over relational databases [29]. Recent work has considered pricing functions to include additional properties such as being reasonable (differentiated query pricing based on differentiated answers), and predictable, non-disclosive (the inability to infer unpaid query answers from query prices) and regret-free (asking a sequence of queries during multiple interactions is no more costly than asking at once) [26]. We are investigating extensions of SafePrice to include some of these properties.
9 Conclusions
We present PACAS, a data cleaning-as-a-service framework that preserves (X,Y,L)-anonymity in a service provider with sensitive data, while resolving errors in a client data instance. PACAS anonymizes sensitive data values by implementing a data pricing scheme that assigns prices to requested data values while satisfying a given budget. We propose generalized repair values as a mechanism to obfuscate sensitive data values, and present a new definition of consistency with respect to functional dependencies over a relation. To adapt to the changing number of errors in the database during data cleaning, we propose a new budget allocation scheme that adjusts to the current number of unresolved errors. We believe that PACAS provides a new approach to privacy-aware cleaning that protects sensitive data while offering high data cleaning utility, as data markets become increasingly popular. As next steps, we are investigating: (i) optimizations to improve the performance of the data pricing modules; and (ii) extensions to include price negotiation among multiple service providers and clients.
References
- [1] H. Bowne-Anderson, What data scientists really do, Harvard Business Review.
- [2] P. Bohannon, W. Fan, M. Flaster, R. Rastogi, A cost-based model and effective heuristic for repairing constraints by value modification, in: Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD), 2005, p. 143?154.
- [3] T. Dasu, J. M. Loh, Statistical distortion: Consequences of data cleaning, Proceedings of the VLDB Endowment 5 (11) (2012) 1674?1683.
- [4] W. Fan, J. Li, S. Ma, N. Tang, W. Yu, Towards certain fixes with editing rules and master data, The VLDB Journal 21 (2) (2012) 213?238.
- [5] W. Fan, X. Jia, J. Li, S. Ma, Reasoning about record matching rules, Proceedings of the VLDB Endowment 2 (1) (2009) 407?418.
- [6] G. Jagannathan, R. N. Wright, Privacy-preserving imputation of missing data, Data and Knowledge Engineering 65 (1) (2008) 40?56.
- [7] F. Chiang, D. Gairola, Infoclean: Protecting sensitive information in data cleaning, Journal of Data and Information Quality (JDIQ) 9 (4) (2018) 1–26.
- [8] S. Krishnan, J. Wang, M. J. Franklin, K. Goldberg, T. Kraska, Privateclean: Data cleaning and differential privacy, in: Proceedings of the 2016 International Conference on Management of Data (SIGMOD), 2016, p. 937?951.
- [9] L. Sweeney, K-anonymity: A model for protecting privacy, International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 10 (5) (2002) 557–570.
- [10] P. Samarati, Protecting respondents’ identities in microdata release, IEEE Transactions on Knowledge and Data Engineering (TKDE) 13 (6) (2001) 1010–1027.
- [11] B. C. M. Fung, K. Wang, R. Chen, P. S. Yu, Privacy-preserving data publishing: A survey of recent developments, ACM Computing Surveys 42 (4) (2010) 14:1–14:53.
- [12] Y. Huang, M. Milani, F. Chiang, PACAS: Privacy-aware, data cleaning-as-a-service, in: 2018 IEEE International Conference on Big Data (Big Data), 2018, pp. 1023–1030.
- [13] J. Han, M. Kamber, J. Pei, Data Mining: Concepts and Techniques, 3rd Edition, Morgan Kaufmann Publishers Inc., 2011.
- [14] S. Lee, S.-Y. Huh, R. D. McNiel, Automatic generation of concept hierarchies using wordnet, Expert Systems with Applications 35 (3) (2008) 1132–1144.
- [15] U. M. Fayyad, K. B. Irani, Multi-interval discretization of continuous-valued attributes for classification learning, in: International Joint Conference on Artificial Intelligence (IJCAI), 1993, p. 1022?1027.
- [16] R. Kerber, Chimerge: Discretization of numeric attributes, in: Proceedings of the National Conference on Artificial Intelligence (AAAI), 1992, p. 123?128.
- [17] H. Liu, R. Setiono, Feature selection via discretization, IEEE Transactions on Knowledge and Data Engineering (TKDE) 9 (4) (1997) 642–645.
- [18] K. Wang, B. C. M. Fung, Anonymizing sequential releases, in: Conference on Knowledge Discovery and Data Mining (KDD), 2006, p. 414?423.
- [19] A. Machanavajjhala, D. Kifer, J. Gehrke, M. Venkitasubramaniam, -diversity: Privacy beyond -anonymity, ACM Transactions on Knowledge Discovery from Data (TKDD) 1 (1) (2007) 1–52.
- [20] AggData locational data, https://www.aggdata.com/ (2009).
- [21] Oracle Data Marketplace, https://www.oracle.com/ca-en/data-cloud/ (2018).
- [22] Acxiom: Data, Identity Solution, https://www.acxiom.com/ (2018).
- [23] Facebook Consumer Behaviour and Marketing, https://www.facebook.com/business/insights (2018).
- [24] Twitter Social Data, https://developer.twitter.com/en/enterprise (2018).
- [25] Spokeo, https://www.spokeo.com/purchase (2006).
- [26] M. Balazinska, B. Howe, D. Suciu, Data markets in the cloud: An opportunity for the database community, Proceedings of the VLDB Endowment (PVLDB) 4 (12) (2011) 1482–1485.
- [27] A. Nash, L. Segoufin, V. Vianu, Views and queries: Determinacy and rewriting, ACM Transactions on Database Systems (TODS) 35 (3) (2010) 1–41.
- [28] A. Gionis, T. Tassa, k-anonymization with minimal loss of information, IEEE Transactions on Knowledge and Data Engineering (TKDE) 21 (2) (2009) 206–219.
- [29] S. Deep, P. Koutris, QIRANA: A framework for scalable query pricing, in: Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD), 2017, pp. 699–713.
- [30] A. Roth, Buying private data at auction: The sensitive surveyor’s problem, ACM SIGecom Exchanges 11 (1) (2012) 1–8.
- [31] F. Chiang, R. J. Miller, Active repair of data quality rules, in: Proceedings of the International Conference on Information Quality, (ICIQ), 2011, pp. 174–188.
- [32] G. Beskales, I. F. Ilyas, L. Golab, Sampling the repairs of functional dependency violations under hard constraints, in: Proceedings of the VLDB Endowment (PVLDB), 2010, pp. 197–207.
- [33] L. Golab, I. F. Ilyas, G. Beskales, A. Galiullin, On the relative trust between inconsistent data and inaccurate constraints, in: IEEE International Conference on Data Engineering (ICDE), 2013, pp. 541–552.
- [34] M. Dallachiesa, A. Ebaid, A. Eldawy, A. Elmagarmid, I. F. Ilyas, M. Ouzzani, N. Tang, Nadeef: a commodity data cleaning system, in: Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD), 2013, pp. 541–552.
- [35] M. Volkovs, F. Chiang, J. Szlichta, R. J. Miller, Continuous data cleaning, in: IEEE International Conference on Data Engineering (ICDE), 2014, pp. 244–255.
- [36] PACAS: Experimental datasets and source code, https://pacas123.github.io/PACAS/.
- [37] Linked Clinical Trials, https://old.datahub.io/dataset/linkedct (2016).
- [38] Bioportal Medical Ontology, https://bioportal.bioontology.org/ontologies (2018).
- [39] Disease Ontology, http://disease-ontology.org/ (2018).
- [40] University of Michigan Library, Libraries of ontologies, https://guides.lib.umich.edu/ontology/ontologies (2017).
- [41] Census Income Database, https://archive.ics.uci.edu/ml/machine-learning-databases/census-income-mld/census-income.html (2017).
- [42] US Data and Statistics, https://www.usa.gov/statistics (2018).
- [43] US Department of Education, https://www.ed.gov/ (2017).
- [44] New York State Food Services Inspection, https://www.health.ny.gov (2017).
- [45] P. Arocena, B. Glavic, G. Mecca, R. J. Miller, P. Papotti, D. Santoro, Messing up with bart: error generation for evaluating data-cleaning algorithms, Proceedings of the VLDB Endowment (PVLDB) 9 (2) (2015) 36–47.
- [46] L. Bertossi, L. Bravo, Generic and declarative approaches to data quality management, in: S. Sadiq (Ed.), Handbook of Data Quality: Research and Practice, Springer Berlin Heidelberg, 2013, pp. 181–211.
- [47] F. Chiang, R. J. Miller, A unified model for data and constraint repair, in: IEEE International Conference on Data Engineering (ICDE), 2011, pp. 446–457.
- [48] S. Kolahi, L. Lakshmanan, On approximating optimum repairs for functional dependency violations, in: International Conference on Database Theory (ICDT), 2009, pp. 53–62.
- [49] I. F. Ilyas, X. Chu, Trends in cleaning relational data: Consistency and deduplication, Foundations and Trends in Databases 5 (4) (2015) 281–393.
- [50] C. Gokhale, S. Das, A. Doan, J. F. Naughton, N. Rampalli, J. Shavlik, X. Zhu, Corleone: Hands-off crowdsourcing for entity matching, in: Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD), 2014, pp. 601–612.
- [51] J. Wang, T. Kraska, M. J. Franklin, J. Feng, Crowder: Crowdsourcing entity resolution, Proceedings of the VLDB Endowment (PVLDB) 5 (11) (2012) 1483–1494.
- [52] M. Yakout, A. K. Elmagarmid, J. Neville, M. Ouzzani, I. F. Ilyas, Guided data repair, Proceedings of the VLDB Endowment (PVLDB) 4 (5) (2011) 279–289.
- [53] X. Chu, J. Morcos, I. F. Ilyas, M. Ouzzani, P. Papotti, N. Tang, Y. Ye, KATARA: A data cleaning system powered by knowledge bases and crowdsourcing, in: Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD), 2015, pp. 1247–1261.
- [54] T. Rekatsinas, X. Chu, I. F. Ilyas, C. Ré, Holoclean: Holistic data repairs with probabilistic inference, Proceedings of the VLDB Endowment 10 (11) (2017) 1190–1201.
- [55] Z. Yu, X. Chu, Piclean: A probabilistic and interactive data cleaning system, in: Proceedings of the International Conference on Management of Data (SIGMOD), 2019, pp. 2021–2024.
- [56] C. Dwork, Differential privacy, in: International Colloquium on Automata, Languages and Programming (ICALP), 2006, pp. 1–12.
- [57] D. Huang, D. Gairola, Y. Huang, Z. Zheng, F. Chiang, PARC: Privacy-Aware Data Cleaning, Proceedings of the ACM International on Conference on Information and Knowledge Management (CIKM), 2016, pp. 2433–2436.
- [58] S. Baskaran, A. Keller, F. Chiang, L. Golab, J. Szlichta, Efficient Discovery of Ontology Functional Dependencies, in: Proceedings of the ACM International on Conference on Information and Knowledge Management, CIKM, 2017, pp. 1847–1856