Privacy Amplification by Subsampling in Time Domain
Abstract
Aggregate time-series data like traffic flow and site occupancy repeatedly sample statistics from a population across time. Such data can be profoundly useful for understanding trends within a given population, but also pose a significant privacy risk, potentially revealing e.g., who spends time where. Producing a private version of a time-series satisfying the standard definition of Differential Privacy (DP) is challenging due to the large influence a single participant can have on the sequence: if an individual can contribute to each time step, the amount of additive noise needed to satisfy privacy increases linearly with the number of time steps sampled. As such, if a signal spans a long duration or is oversampled, an excessive amount of noise must be added, drowning out underlying trends. However, in many applications an individual realistically cannot participate at every time step. When this is the case, we observe that the influence of a single participant (sensitivity) can be reduced by subsampling and/or filtering in time, while still meeting privacy requirements. Using a novel analysis, we show this significant reduction in sensitivity and propose a corresponding class of privacy mechanisms. We demonstrate the utility benefits of these techniques empirically with real-world and synthetic time-series data.
1 Introduction
Time-series data about people’s behavior can be sensitive, yet may contain information that is highly beneficial for society. As a concrete example, consider highway traffic data that is released by the California Department of Transportation 111https://pems.dot.ca.gov/ (Chen et al.,, 2001). The data contains aggregate statistics (number of cars, average speed, etc.) every five minutes gathered by physical sensors. Just like any other form of sensitive, aggregate data, this traffic data could expose the behavior of a single participant. In an extreme case, if a participant is the only driver on a highway (say, late at night), then an adversary could track their movement through the entire road network. However, such data is absolutely vital for society to manage critical road infrastructure and strategize on where to augment it. To this end, we aim to provide a privacy mechanism that releases a sanitized version of a given time-series while preserving its aggregate trends through time.
We adopt differential privacy (DP) (Dwork et al., 2006b, ), one of the most widely used privacy definitions, as our privacy measure. For data with bounded sensitivity, a first plausible DP mechanism is to add Gaussian (Dwork and Roth,, 2014) or Laplace (Dwork et al., 2006b, ) noise proportional to the sensitivity. Rastogi and Nath, (2010) propose a second algorithm that adds noise to the first discrete Fourier transform (DFT) coefficients and ignores higher frequencies of the signal. In both cases, the problem is that the sensitivity scales with , the number of time steps. If an individual can theoretically participate at each timestep, then the worst-case influence they can have on the time-series grows linearly with . Thus, as becomes larger, the requisite noise variance increases, and the resulting output loses utility. In this paper, we take a new approach to addressing this longstanding problem using subsampling and filtering techniques from the signal processing domain. We find that random subsampling along with filtering can reduce sensitivity without significant losses of utility.
Our starting point is to observe two key properties of real time-series data, which we exploit to design better mechanisms that add significantly less noise for a given . The first is that time-series data is often oversampled. Returning to our example, a transit analyst may be interested in observing how traffic changes on an hourly basis. This being the case, the five-minute sampling period of the sensor system is excessive and contributes very little to their utility. Indeed, with standard mechanisms, this excessive sampling rate may damage their utility since it increases the number of time steps, , many times beyond what is needed. The second property is that a single person almost never contributes to the aggregate statistics at every time step. It is implausible that an individual passes the same sensor on a highway every five minutes for more than a year.
We formalize these two observations into mathematical assumptions, and exploit them as follows. The first property motivates our use of subsampling, which trades these unnecessary extra time steps in exchange for reduced additive noise. The second property enables us to significantly boost this reduction in additive noise: we know that, feasibly, an individual can only participate in a limited number of time steps to begin with. This allows us to show that w.h.p. they will contribute to an even smaller number of timesteps after subsampling, thus allowing us to significantly scale down noise added.
We additionally extend our results to a class of mechanisms that filter and subsample the time-series. For the traffic analyst, the process of subsampling may be high variance if traffic changes significantly during an hour. In essence, which sample is chosen during that hour will have a large effect on the shape of the resulting time series. To mitigate this the analyst may wish to average the time series in time (filter) before subsampling. Unfortunately, this significantly complicates the privacy analysis used on subsampling alone. To address this we employ a novel concentration analysis that accounts for the effects of subsampling and filtering simultaneously.
This paper investigates how and in what circumstances subsampling and filtering enable us to achieve a better privacy-utility tradeoff for publishing aggregate time-series data under differential privacy. Ultimately, by exploiting the two reasonable assumptions listed above, we make nontrivial gains in utility while maintaining a strong -DP guarantee. Using a novel concentration analysis, we propose a class of filter/subsample mechanisms for publishing sanitized time-series data. Our experiments indicate that—by using significantly less additive noise than baseline methods—our mechanisms achieve a better privacy-utility tradeoff in general for oversampled time-series.
1.1 Related Work
With regards to subsampling and Differential Privacy, prior work has shown that subsampling individuals (rows) helps amplify privacy (Kasiviswanathan et al.,, 2011; Beimel et al.,, 2014, 2013; Bassily et al.,, 2014; Abadi et al.,, 2016; Balle et al.,, 2018); our setting is different from these results in that we consider subsampling time steps which are equivalent to columns or features, which has not been considered in prior work.
The most closely related work in terms of publishing time-series data privately is by Rastogi and Nath, (2010). They propose an -DP algorithm that perturbs only the first discrete Fourier transform (DFT) coefficients with the Laplace mechanism and zeros the remaining high frequency coefficients, since adding noise to those results in the sanitized time-series being scattered. However, the sensitivity still scales with and the algorithm perturbs the first coefficient a lot if is large. In comparison, we provide an analysis using subsampling that introduces better scaling with . Fan and Xiong, (2012) utilize the Kalman filter to correct the noisy signal by the Laplace mechanism and adopt adaptive sampling to reduce the published time steps, thereby reducing the number of compositions. Their main focus is real-time data publishing, where we focus on offline data publishing.
Closer to our line of study is differentially private continual observation (Dwork et al.,, 2010; Chan et al.,, 2011), which proposes a method to repeatedly publish aggregates (in particular, count) under the continual observation of the data signal. The main difference from our work is that they protect event-level privacy; namely, they try to hide the event that an individual participates in the time-series at a single time step by perturbation. We hide participation in the entire time-series, assuming that an individual can participate at multiple time steps.
As for DP under filtering, Ny and Pappas, (2014) investigate the DP mechanisms for general dynamic systems. The work relates filters to an input with the sensitivity, but it does not address the issue that the sensitivity depends linearly on .
More broadly, some work proposes new privacy definitions suitable for traffic (more generally, spatio-temporal) data (Xiao and Xiong,, 2015; Cao et al.,, 2017, 2019; Meehan and Chaudhuri,, 2021). Though these definitions are more appropriate for some situations, we believe the classic DP definition is the right choice for our setting, where there is a trusted central authority.
2 Preliminaries and Problem Setting
Among aggregate time-series data, we focus on a count data throughout this paper. More formally, we consider time-series signal of length , where corresponds to the count of individuals’ participation at time . The count signal is an output of a function , where is the input space. We aim to publish the randomized version of , denoting as , with a privacy guarantee.
The appropriate privacy notion for our setting is differential privacy. We say two datasets are neighboring if they differ on at most an individual’s participation.
Definition 1 (-DP (Dwork et al., 2006a, )).
A randomized algorithm satisfies -DP if for any neighboring datasets and for any ,
One of the most famous DP algorithms is the Gaussian mechanism, which adds the Gaussian noise with a variance proportional to the -sensitivity (Dwork et al., 2006b, ). The -sensitivity of a function is the maximum difference between the outputs of from any neighboring datasets in terms of -norm.
Definition 2.
The -sensitivity of a function is
where and are neighboring datasets and is -norm.
Theorem 1 (Gaussian mechanism (Dwork and Roth,, 2014)).
Let be arbitrary and be a function. Then, for , the algorithm :
satisifies -DP, where ’s are drawn i.i.d. from and .
As we see from the Gaussian mechanism, the larger -sensitivity leads to the higher noise variance. Thus, we consider filtering and subsampling the input signal to reduce the sensitivity.
Filtering the signal is a well-used technique in signal processing. In particular, low-pass filters attenuate the effect of high frequencies and make the signal smoother. Let be a filtering vector and be a filtered signal. We express the filtering operation as for all . With a matrix , this can be seen as , where , for all . Note that a matrix is a circular matrix. From now on, we represent the filter with and the filtered signal with . We further assume that the -norm of each row is normalized to , i.e., for all , where is -th row of a matrix .
As opposed to row-wise subsampling in the past DP literature that can completely discard an individual’s participation in a dataset with some probability, we contemplate column-wise subsampling. Formally, we define the subsampling operator as , where is the power set of and is a length of subsampled signal. We define as the random variable of subsampling indices. We consider the Poisson sampling with parameter for , i.e., for all , with probability independently. Therefore, we express the subsampling to with as , where .
3 Privacy Amplification by Subsampling
Recalling the example of the California highway traffic data (Chen et al.,, 2001), the number of cars passed by the physical sensor is sampled once every five minutes. The sensitivity grows exceedingly large with the number of sampled time steps, ; thus, the noise added to satisfy DP becomes too large to convey even daily or weekly trends for baseline mechanisms. However, it is extremely unlikely that a single individual participates at every sensor snapshot in a day. Therefore, by making the mild assumption that an individual participates no more than at time steps in the signal, we can significantly reduce the sensitivity. Without subsampling, this trivially reduces the (-) sensitivity by a factor of . In this section, we demonstrate how we can reduce the sensitivity even further with high probability through subsampling and propose our -DP algorithm that utilizes subsampling.
3.1 Assumption
To make the above assumption precise, we formalize it as follows.
Denote -th individual’s participation to the dataset as .
Thus, .
Without loss of generality, we assume for all and , i.e., an individual can participate at most once at each time step.
It is straightforward to extend our results to the case where participation is at most times.
The formal statement for limited individual’s participation assumption is as follows.
Assumption 1.
, i.e., an individual can participate at most time steps.
| ID | () |
|---|---|
| 1 | 63 |
| 2 | 35 |
| 3 | 39 |
| 4 | 29 |
| 5 | 51 |
| 6 | 39 |
| 7 | 43 |
| 8 | 19 |
| 9 | 27 |
| 10 | 208 |
| 11 | 27 |
| 12 | 34 |
| 13 | 45 |
| 14 | 47 |
| 15 | 75 |
| ID | () |
|---|---|
| 1 | 208 |
| 2 | 127 |
| 3 | 98 |
| 4 | 225 |
| 5 | 265 |
| 6 | 121 |
| 7 | 191 |
| 8 | 78 |
| 9 | 94 |
| 10 | 182 |
| 11 | 170 |
| 12 | 206 |
| 13 | 94 |
| 14 | 82 |
| 15 | 350 |
Assumption 1 formalizes the observation that no individuals participate at all time steps, especially when the signal is oversampled. In most cases, the maximum time steps that an individual can participate at are smaller than ; thus, . This assumption is empirically evident in real time-series data. Table 1 shows the maximum number of check-ins per individual for the top 15 most visited venues for Gowalla (Cho et al.,, 2011) and Foursquare (Yang et al.,, 2015, 2016) datasets. Similar to our highway example, it is implausible that an individual checks into a certain venue every time step. We see that is, at least empirically, much smaller than . Since we do not know the exact value of the maximum individual’s participation a priori, we must set conservatively in practice. However, even if the assumption does not hold strictly, our guarantee is still valid with gentle privacy degradation as discussed in Section 3.3.1. This assumption yields that .
Although the assumption reduces the -sensitivity from to , we will show that random subsampling reduces it further in the following sections.
3.2 Sensitivity Reduction by Subsampling
With the assumption in mind, the naive approach to achieve DP is to apply the Gaussian mechanism with the sensitivity parameter . The dependency on is undesirable as , which tends to be proportional to , becomes larger. Therefore, we propose to apply random subsampling to relax this dependency. The intuition behind it is that the probability that subsampled time steps contain all (or most) of an individual’s participation is very low under Assumption 1; thus, we get the further dependency reduction. Formally, we show that helps reduce the -sensitivity with high probability, where the probability is over the choice of , under Assumption 1.
Throughout the analysis, we assume that , i.e., -th individual is the only one who participates in and does not in . Also, we let , time indices that -th individual participates.
3.2.1 Sensitivity Reduction by Subsampling Only
We start from examining the sensitivity of . Intuitively, under Assumption 1, the probability that contains almost all time steps is small; thus, we obtain the sensitivity reduction with high probability.
Theorem 2.
Fix . Let . Then, with probability , .
The proof follows directly from the tail probability of the binomial distribution with parameters and . By using the tail bound of the binomial distribution, we can explicitly express the upper bound of for fixed with and .
Corollary 1.
Let . Then, with probability , .
The claim is a direct consequence of the Hoeffding’s inequality. We see with high probability that the dependency on is replaced by plus the probably small additional term.
3.2.2 Sensitivity Reduction by Filtering and Subsampling
Next, we consider the case where we filter the signal before subsampling. Some filters have an averaging effect across time steps; thus, filtered signals become smoother and less noisy in general.
Again, we go back to our running example of the CA highway traffic data. The signal is very oversampled for an analyst who is only interested in how traffic trends change every two hours. Changes on the order of five minutes do not contribute to their utility, but magnifies the sensitivity significantly. By filtering, we effectively average in time to smooth the signal, and ultimately reduce the variance after subsampling. As detailed in Section 2 we represent a filter as a matrix , which, after multiplying with the signal, produces the smoother signal.
However, from the DP point of view, filtering spreads the content of -th time step across all time steps; thus, the effects of subsampling are now less obvious. As an extreme example, consider a filter that simply averages across all time points, i.e., for any and . Then, any individual’s contribution scatters equally along all time steps. Thus, the intuition above does not hold here, but still, we can apply a similar way of thinking if is somewhat similar to the identity matrix—there exist time steps that -th individual’s influence is large, and the probability of choosing almost all such time steps is low.
We define the function as . By letting if and otherwise and , we can express . Fix two signals induced by neighboring datasets. Then, it holds that
where the last inequality follows from Assumption 1.
It remains to bound the maximum singular value of to complete bounding the sensitivity.
To bound how large the maximum singular value is likely to be, we use the following simplified version of the theorem by Tropp, (2015).
Theorem 3 (Simplified version, (Tropp,, 2015)).
For ,
where is the stable rank of , the ratio between the squared Frobenius norm of and the squared spectral norm of , and .
As we assume in Section 2 that is a circular matrix and for all , and . Combining this theorem with the sensitivity bound with the maximum singular value, we are able to bound the reduction in sensitivity from both subsampling and filtering simultaneously. Our final sensitivity reduction theorem for filtered and subsampled signals is given below.
Theorem 4.
Fix . Let . Then, with probability at least , .
Note that the theorem above does not fully make use of Assumption 1; thus, the statement holds even if we replace with . Also, we note that by taking to be an identity matrix, the function is exactly the same as , but the bound is looser than Theorem 2 in general. Furthermore, it is hard to obtain the explicit upper bound for in general, but we give the relationship between and in Appendix 3.
3.3 Algorithm
Algorithm 1 gives our -DP algorithm for a filtered and subsampled count signal. The central idea is to utilize the sensitivity analysis in the previous section and add less variance noise than the standard Gaussian mechanism. One note is that the interpolation in the last line of Algorithm 1 does not incur a privacy breach by using as long as the interpolation is bijective given , which is usually the case.
From Theorems 2 and 4, we see that Algorithm 1 satisfies -DP. In short, our privacy guarantee allows smaller in exchange for a little larger under the same noise variance as the standard Gaussian mechanism.
The corollary follows directly from Theorem 4.
We provide the detailed proof in Appendix 1.
The guarantee implicitly requires to be small enough.
In other words, if is smaller or equal to , the compensation for the term is negligible and we obtain the better privacy.
Also, is a monotonously decreasing function with respect to ; thus, one can easily find appropriate to satisfy desired numerically.
When is an identity matrix, i.e., not filtering before subsampling, we have a better privacy guarantee.
The proof is almost identical to the one for Corollary 2. Note that the above guarantee heavily relies on Assumption 1 as opposed to Corollary 2.
3.3.1 Graceful Privacy Degradation When Assumption 1 Fails
Although we succeed in amplifying privacy by subsampling, one would cast doubt on the validity of Assumption 1, i.e., any individual participates at most time steps. Here, we show even if the assumption does not hold precisely, our algorithm still satisfies DP and the privacy level does not degrade abruptly.
Proposition 1.
If for some , then Algorithm 1 satisfies -DP.
In short, the above proposition claims that if the actual participation limit is instead of , privacy parameters increase only slightly; in particular, only increases by a factor of .
4 Experiments
We next investigate how well our algorithm works in practice by empirically evaluating it on real and synthetic data. Specifically, we ask the following questions:
-
1.
How does our algorithm compare with existing baselines such as the Gaussian mechanism and DFT in terms of accuracy?
-
2.
How does filtering before subsampling improve accuracy?
-
3.
How does the sampling frequency of the time-series data affect accuracy?
We answer the first question by experimenting with three real datasets in Section 4.2. We then answer the rest of the questions with a synthetic dataset in Section 4.3.
4.1 Setup
Datasets.
We consider four datasets – three real, and one synthetic.
PeMS () (Chen et al.,, 2001) is a dataset collected by California Transportation Agencies (CalTrans) Performance Measurement System (PeMS). We select a sensor from a highway in the Bay area, California, and sample the flow data, the number of cars that passed the sensor, every five minutes from Jan. 2017. Gowalla () (Cho et al.,, 2011) is a dataset of check-in information from a location-based social networking website called Gowalla. We use the most visited location and aggregate the check-in count every 24 hours from Feb. 2009. Foursquare () (Yang et al.,, 2015, 2016) is a similar dataset with check-in information from the location data platform Foursquare. We pick the most checked-in place and aggregate the count every 6 hours from April 2012. Since raw Gowalla and Foursquare datasets contain user IDs, we use them to calculate the empirical in Table 1. We set as confirmed by Table 1.
Since we do not have the data generating mechanisms for real data, to understand how the sampling frequency affects the accuracy and the conditions under which filtering helps, we also experiment with a synthetic dataset Synth. We generate the signal value given time step as , where we set , and . The resulting signal has two overall trends: periodicity and linear growth. We expect a good algorithm to return a randomized version that maintains both trends. We control the sampling frequency to examine how the extent of oversampling affects the utility. We do this by, given (relative) sampling frequency , generating the signal . Thus, as the relative frequency increases, the signal is oversampled more and the length gets larger. We set for (thus, given ) and for any . We generate several signals with varying ’s (). We provide the reason why we fix for the Synth data in Appendix 2. Furthermore, we consider the case where there is observation noise: unbiased randomness added to each time step that is typical in real-world time-series. To do so, we add mean-zero Gaussian noise to each time step, yielding a more realistic, noisy version of the signal: , where ’s are drawn i.i.d. from and .
Algorithms.
The simplest baseline for our problem is the standard Gaussian mechanism. The Gaussian mechanism for time-series data adds noise corresponding to the sensitivity to each of time steps by considering time-series data as a -dimensional vector. The more involved baseline is the algorithm by Rastogi and Nath, (2010) (DFT). It adds noise to the first discrete Fourier transform coefficients and ignores higher frequency contents of the signal. For DFT, we use the hyperparameters reported as being the best in their paper. While DFT is originally an -DP algorithm, we extend it to be -DP by changing the noise distribution to Gaussian from Laplace for direct comparison with our algorithm. For our algorithm, we consider two variations—with and without filtering.
Experiment Setup.
We set the privacy parameters and so that each mechanism guarantees -DP throughout the experiments. Accuracy is measured by the mean absolute error (MAE) between the raw signal and the output. For the noisy Synth data, we measure the MAE between the true signal (before adding observation noise) and the output. For each time-series, we repeat the algorithms times and report the mean and standard deviation of MAE; this is because the outputs depend heavily on the randomness of the mechanisms. We choose a subsampling parameter for our algorithm to be , i.e., the subsampled signal length would be around for the real datasets. For the synthetic signal, . We present further details of the experiments in Appendix 2.
4.2 Results on Real Data
| PeMS | Gowalla | Foursquare | |
|---|---|---|---|
| Gaussian | 93.0 1.6 | 33.0 1.5 | 57.4 1.5 |
| DFT | 55.7 2.8 | 39.3 3.5 | 42.9 3.4 |
| Ours w/o Filter | 42.8 2.9 | 16.7 2.7 | 29.5 2.4 |
| Ours w/ Filter | 60.9 4.0 | 21.2 3.9 | 39.6 3.6 |
Table 2 summarizes the MAEs on the real datasets. We see that for all the datasets, our algorithm without filtering performs the best, indicating the superiority of this algorithm. Ours with filtering performs better than the baselines on the Gowalla and Foursquare dataset, but slightly worse than DFT on the PeMS dataset. This might be due to the periodic nature of the PeMS signal—DFT is suitable for periodic signals in general. Although the overall performance of our algorithms is better than the baselines, it seems that the variance of MAE is slightly larger than the standard Gaussian mechanism. We anticipate that the main reason is the interpolation in Algorithm 1.
4.3 Results on Synthetic Data


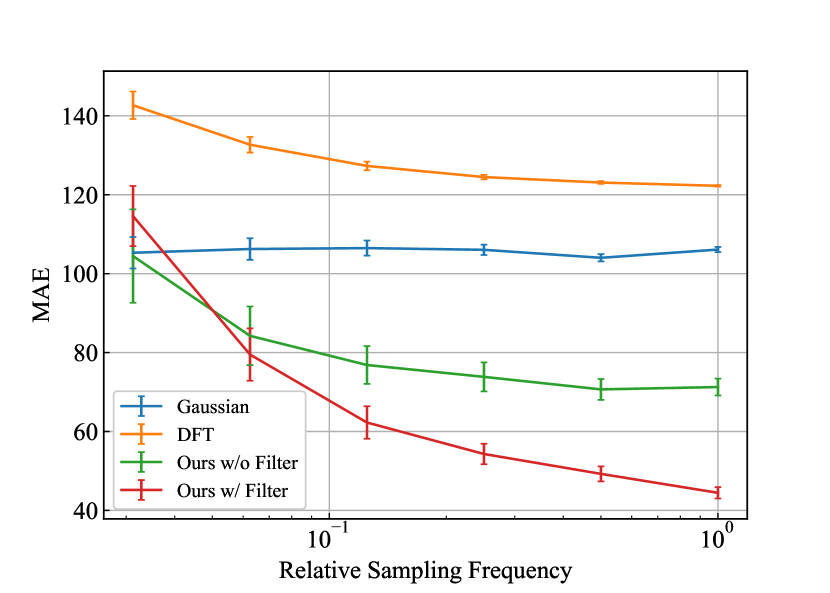
To better understand when filtering works well, we compare the results with and without observation noise. We anticipate that the averaging effect of filtering offers better performance when observation noise is present. Figure 1 shows in orange examples of outputs of four mechanisms: the two baseline mechanisms and our mechanism with and without filtering, each operating on the Synth time-series with observation noise. For reference the Synth signal is plotted in blue (without obs. noise for clarity). We show the outputs operating on the noiseless Synth signal in Appendix 2. Figures 2(a) and 2(b) show the MAEs for Synth dataset with and without observation noise while sweeping relative sampling frequency . We see that our mechanism with filtering generally outperforms the one without filtering when there is observation noise, confirming our hypothesis. Filtering before subsampling has an averaging effect in time, canceling out the observation noise and thus accurately conveying the underlying trends. We can observe this effect directly in Figure 1. The output from our algorithm with filtering concentrates around the raw Synth signal the most, yielding a lower MAE and better capturing underlying trends. On the other hand, when the signal is noiseless, filtering does not help achieve better utility. As seen in Section 3.2, the sensitivity reduction is larger for subsampling without filtering; thus, ours without filtering is more helpful for less noisy signals.
To understand the impact of oversampling, i.e., how sampling frequency matters to utility, we observe the results under several (relative) sampling frequencies (). The larger is, the more oversampled the signal is. For both Figures 2(a) and 2(b), we see a similar trend that MAEs get smaller as becomes larger for our algorithms (with and without filtering). This trend validates the hypothesis that almost no information gets lost by subsampling for oversampled signals. In such a case, we gain utility due to the reduced sensitivity achieved by subsampling. By contrast, for less frequently sampled, fast-moving signals, our algorithms perform worse than the standard Gaussian mechanism. We expect that this is because the error caused by the interpolation dominates the error by adding noise. The linear interpolation does not supplement the information lost by subsampling. Note that MAEs for the Gaussian mechanism and DFT are almost constant because, for experiments on Synth, we fix for all ’s.
4.4 Discussion
Throughout the experiments, we have made the three questions clear.
Our experimental results on real data reveal that our algorithm, especially without filtering, is superior to the baseline mechanisms, the Gaussian mechanism and DFT, in terms of MAE. This is mainly because the sensitivity reduction by subsampling reduces the noise variance and the error incurred by the interpolation is small due to the oversampled nature of real data.
Filtering improves utility when signals contain observation noise as confirmed by the result on the Synth data. It is helpful when we want to capture underlying trends rather than to reproduce original signals because applying a filter has an averaging effect and thus lessens the effect of observation noise. On the contrary, for noiseless signals, we should use our algorithm without filtering since the sensitivity reduction is larger for subsampling but not filtering in general.
The result on the Synth data also indicates that our algorithm works better as data gets oversampled. This result verifies our hypothesis that subsampling preserves overall trends for oversampled signals. The sensitivity reduction is also significant since our algorithm outperforms the baseline mechanisms for such signals.
5 Conclusion and Future Work
This paper investigates how subsampling and filtering help achieve a better privacy-utility tradeoff for the longstanding problem of publishing sanitized aggregate time-series data with a DP guarantee. Using a novel concentration analysis, we show subsampling and filtering reduce the sensitivity with high probability under reasonable assumptions for real time-series data. We then propose a class of DP mechanisms exploiting subsampling and/or filtering, which empirically outperform baselines. Going forward, we plan to develop theoretical utility guarantees for our mechanisms, and explore how alternative interpolation schemes impact utility. Finally, we believe feature-wise subsampling is beneficial beyond time-series data, and are investigating other applications for our techniques.
Acknowledgments
TK, CM, and KC would like to thank ONR under N00014-20-1-2334 and UC Lab Fees under LFR 18-548554 for research support. Also, TK is supported in part by Funai Overseas Fellowship. We would also like to thank our reviewers for their insightful feedback.
References
- Abadi et al., (2016) Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., and Zhang, L. (2016). Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS ’16, pages 308–318, New York, NY, USA. Association for Computing Machinery.
- Balle et al., (2018) Balle, B., Barthe, G., and Gaboardi, M. (2018). Privacy Amplification by Subsampling: Tight Analyses via Couplings and Divergences. In Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc.
- Bassily et al., (2014) Bassily, R., Smith, A., and Thakurta, A. (2014). Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds. In 2014 IEEE 55th Annual Symposium on Foundations of Computer Science, pages 464–473.
- Beimel et al., (2014) Beimel, A., Brenner, H., Kasiviswanathan, S. P., and Nissim, K. (2014). Bounds on the sample complexity for private learning and private data release. Mach Learn, 94(3):401–437.
- Beimel et al., (2013) Beimel, A., Nissim, K., and Stemmer, U. (2013). Characterizing the sample complexity of private learners. In Proceedings of the 4th Conference on Innovations in Theoretical Computer Science, ITCS ’13, pages 97–110, New York, NY, USA. Association for Computing Machinery.
- Cao et al., (2019) Cao, Y., Xiao, Y., Xiong, L., and Bai, L. (2019). PriSTE: From Location Privacy to Spatiotemporal Event Privacy. In 2019 IEEE 35th International Conference on Data Engineering (ICDE), pages 1606–1609, Macao, Macao. IEEE.
- Cao et al., (2017) Cao, Y., Yoshikawa, M., Xiao, Y., and Xiong, L. (2017). Quantifying Differential Privacy under Temporal Correlations. In 2017 IEEE 33rd International Conference on Data Engineering (ICDE), pages 821–832.
- Chan et al., (2011) Chan, T.-H. H., Shi, E., and Song, D. (2011). Private and Continual Release of Statistics. ACM Trans. Inf. Syst. Secur., 14(3):26:1–26:24.
- Chen et al., (2001) Chen, C., Petty, K., Skabardonis, A., Varaiya, P., and Jia, Z. (2001). Freeway Performance Measurement System: Mining Loop Detector Data. Transportation Research Record, 1748(1):96–102.
- Cho et al., (2011) Cho, E., Myers, S. A., and Leskovec, J. (2011). Friendship and mobility: User movement in location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’11, pages 1082–1090, New York, NY, USA. Association for Computing Machinery.
- (11) Dwork, C., Kenthapadi, K., McSherry, F., Mironov, I., and Naor, M. (2006a). Our Data, Ourselves: Privacy Via Distributed Noise Generation. In Vaudenay, S., editor, Advances in Cryptology - EUROCRYPT 2006, Lecture Notes in Computer Science, pages 486–503, Berlin, Heidelberg. Springer.
- (12) Dwork, C., McSherry, F., Nissim, K., and Smith, A. (2006b). Calibrating Noise to Sensitivity in Private Data Analysis. In Halevi, S. and Rabin, T., editors, Theory of Cryptography, Lecture Notes in Computer Science, pages 265–284, Berlin, Heidelberg. Springer.
- Dwork et al., (2010) Dwork, C., Naor, M., Pitassi, T., and Rothblum, G. N. (2010). Differential privacy under continual observation. In Proceedings of the Forty-Second ACM Symposium on Theory of Computing, STOC ’10, pages 715–724, New York, NY, USA. Association for Computing Machinery.
- Dwork and Roth, (2014) Dwork, C. and Roth, A. (2014). The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci., 9(3–4):211–407.
- Fan and Xiong, (2012) Fan, L. and Xiong, L. (2012). Real-time aggregate monitoring with differential privacy. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, CIKM ’12, pages 2169–2173, New York, NY, USA. Association for Computing Machinery.
- Kasiviswanathan et al., (2011) Kasiviswanathan, S. P., Lee, H. K., Nissim, K., Raskhodnikova, S., and Smith, A. (2011). What Can We Learn Privately? SIAM J. Comput., 40(3):793–826.
- Meehan and Chaudhuri, (2021) Meehan, C. and Chaudhuri, K. (2021). Location Trace Privacy Under Conditional Priors. In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, pages 2881–2889. PMLR.
- Ny and Pappas, (2014) Ny, J. L. and Pappas, G. J. (2014). Differentially Private Filtering. IEEE Transactions on Automatic Control, 59(2):341–354.
- Rastogi and Nath, (2010) Rastogi, V. and Nath, S. (2010). Differentially private aggregation of distributed time-series with transformation and encryption. In Proceedings of the 2010 International Conference on Management of Data - SIGMOD ’10, page 735, Indianapolis, Indiana, USA. ACM Press.
- Tropp, (2015) Tropp, J. A. (2015). An Introduction to Matrix Concentration Inequalities. MAL, 8(1-2):1–230.
- Xiao and Xiong, (2015) Xiao, Y. and Xiong, L. (2015). Protecting Locations with Differential Privacy under Temporal Correlations. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, CCS ’15, pages 1298–1309, New York, NY, USA. Association for Computing Machinery.
- Yang et al., (2015) Yang, D., Zhang, D., Chen, L., and Qu, B. (2015). NationTelescope: Monitoring and visualizing large-scale collective behavior in LBSNs. Journal of Network and Computer Applications, 55:170–180.
- Yang et al., (2016) Yang, D., Zhang, D., and Qu, B. (2016). Participatory Cultural Mapping Based on Collective Behavior Data in Location-Based Social Networks. ACM Trans. Intell. Syst. Technol., 7(3):30:1–30:23.