Pretraining in Deep Reinforcement Learning: A Survey
Abstract
The past few years have seen rapid progress in combining reinforcement learning (RL) with deep learning. Various breakthroughs ranging from games to robotics have spurred the interest in designing sophisticated RL algorithms and systems. However, the prevailing workflow in RL is to learn tabula rasa, which may incur computational inefficiency. This precludes continuous deployment of RL algorithms and potentially excludes researchers without large-scale computing resources. In many other areas of machine learning, the pretraining paradigm has shown to be effective in acquiring transferable knowledge, which can be utilized for a variety of downstream tasks. Recently, we saw a surge of interest in Pretraining for Deep RL with promising results. However, much of the research has been based on different experimental settings. Due to the nature of RL, pretraining in this field is faced with unique challenges and hence requires new design principles. In this survey, we seek to systematically review existing works in pretraining for deep reinforcement learning, provide a taxonomy of these methods, discuss each sub-field, and bring attention to open problems and future directions.
1 Introduction
Reinforcement learning (RL) provides a general-purpose mathematical formalism for sequential decision-making (?). By utilizing RL algorithms together with deep neural networks, various milestones in different domains have achieved superhuman performances via optimizing user-specified reward functions in a data-driven manner (?, ?, ?, ?, ?, ?, ?). As such, we have seen a growing interest recently in this research direction.
However, while RL has been proven effective at solving well-specified tasks, the issue of sample efficiency (?) and generalization (?) still hinder its application to real-world problems. In RL research, a standard paradigm is to let the agent learn from its own or others’ collected experience, usually on a single task, and to optimize neural networks tabula rasa with random initializations. For humans, in contrast, prior knowledge about the world contributes greatly to the decision-making process. If the task is related to previously seen tasks, humans tend to reuse what has been learned to quickly adapt to a new task, without learning from exhaustive interactions from scratch. Therefore, as compared to humans, RL agents usually suffer from great data inefficiency (?) and are prone to overfitting (?).
Recent advances in other areas of machine learning, however, actively advocate for leveraging prior knowledge built from large-scale pretraining. By training on broad data at scale, large generic models, also known as foundation models (?), can quickly adapt to various downstream tasks. This pretrain-finetune paradigm has been proven effective in areas like computer vision (?, ?, ?) and natural language processing (?, ?). However, pretraining has not yet had a significant impact on the field of RL. Despite its promise, designing principles for large-scale RL pretraining faces challenges from many sources: 1) the diversity of domains and tasks; 2) the limited data sources; 3) the difficulty of fast adaptation to solve downstream tasks. These factors stem from the nature of RL and are inevitably necessary to be considered.

This survey aims to present a bird’s-eye view of current research on Pretraining in Deep RL. Principled pretraining in RL has a variety of potential benefits. First of all, the substantial computational cost incurred by RL training remains a hurdle for industrial applications. For example, replicating the results of AlphaStar (?) approximately costs millions of dollars (?). Pretraining can ameliorate this issue, either with pretrained world models (?) or pretrained representations (?), by enabling quick adaptation to solve tasks in zero or few-shot manner. Besides, RL is notoriously task- and domain-specific. It has already been shown that pretraining with massive task-agnostic data can enhance these kinds of generalizations (?). Finally, we believe that pretraining with proper architectures can unlock the power of scaling laws (?), as shown by recent success in games (?, ?). By scaling up general-purpose models with increased computation, we are able to further achieve superhuman results, as taught in the “bitter lesson” (?).
Pretraining in deep RL has undergone several breakthroughs in recent years. Naive pretraining with expert demonstrations, using supervised learning to predict the actions taken by experts, has been exhibited with the famed AlphaGo (?). To pursue large-scale pretraining with less supervision, the field of unsupervised RL has been growing rapidly in recent years (?, ?), which allows the agent to learn from interacting with the environment in the absence of reward signals. In accordance with recent advances in offline RL (?), researchers further consider how to leverage unlabeled and sub-optimal offline data for pretraining (?, ?), which we term offline pretraining. The offline paradigm with task-irrelevant data further paves the way towards generalist pretraining, where diverse datasets from different tasks and modalities as well as general-purpose models with great scaling properties are combined to build generalist models (?, ?).
Pretraining has the potential to play a big role for RL and this survey could serve as a starting point for those interested in this direction. In this paper, we seek to provide a systematic review of existing works in pretraining for deep reinforcement learning. To the best of our knowledge, it is one of the pioneering efforts to systematically study pretraining in deep RL.
Following the development trend of pretraining in RL, we organize the paper as follows. After going through the preliminaries of reinforcement learning and pretraining (Section 2), we start with online pretraining in which an agent learns from interacting with the environment without reward signals (Section 3). And then, we consider offline pretraining, the scenario where unlabeled training data is collected once with any policy (Section 4). In Section 5, we discuss recent advances in developing generalist agents for a variety of orthogonal tasks. We further discuss how to adapt to downstream RL tasks (Section 6). Finally, we conclude this survey together with a few prospects (Section 7).
2 Preliminaries
| Notation | Description |
|---|---|
| Markov decision process | |
| State space | |
| Action space | |
| Transition function | |
| Initial state distribution | |
| Reward function | |
| Discount factor | |
| Offline dataset | |
| Trajectory | |
| Q function | |
| Expected total discounted reward function | |
| Neural network parameters | |
| Feature encoder | |
| Skill latent vector | |
| Skill latent space | |
| Entropy | |
| Mutual information | |
2.1 Reinforcement learning
Reinforcement learning considers the problem of finding a policy that interacts with the environment under uncertainty to maximize its collected reward. Mathematically, this problem can be formulated via a Markov Decision Process (MDP) defined by tuple (, , , , , ), with a state space , an action space , a state transition distribution , an initial state distribution , a reward function , and a discount factor . The objective is to find such a policy parameterized by that maximizes
known as the discounted returns. The notation used in the paper is summarized in Table 1.
2.2 Pretraining
Pretraining aims at obtaining transferable knowledge from large-scale training data to facilitate downstream tasks. In the context of RL, transferable knowledge typically includes good representations that facilitate the agent to perceive the world (i.e., a better state space) and reusable skills from which the agent can quickly build complex behaviors given task descriptions (i.e., a better action space). Training data can be one bottleneck for effective RL pretraining. Unlike what we have witnessed in fields like computer vision and natural language processing where a wealth of unlabeled data can be collected with minimal supervision, RL usually requires highly task-specific reward design, which hinders scaling up pretraining for large-scale applications.
Therefore, the focus of this survey is unsupervised pretraining, in which task-specific rewards are unavailable during pretraining but it is still allowed to learn from online interaction, unlabeled logged data, or task-irrelevant data from other modalities. We omit supervised pretraining given that with task-specific rewards this scenario roughly degenerates to existing RL settings (?). Figure 1 demonstrates an overview of the pretraining and adaptation process.
The objective is to acquire useful prior knowledge in various forms like good visual representations, exploratory policies , latent-conditioned policies , or simply logged datasets. Depending on what data is available during pretraining, it requires different considerations to obtain useful knowledge (Section 3-5) and adapt it accordingly to downstream tasks (Section 6).
| Type | Algorithm | Intrinsic Reward | Visual |
| Curiosity-driven Exploration | ICM (?) | ✓ | |
| RND (?) | ✓ | ||
| Disagreement (?) | ✓ | ||
| Plan2Explore (?) | ✓ | ||
| Skill Discovery | VIC (?) | ✓ | |
| VALOR (?) | ✗ | ||
| DIAYN (?) | ✗ | ||
| VISR (?) | ✓ | ||
| DADS (?) | ✗ | ||
| EDL (?) | ✗ | ||
| APS (?) | ✓ | ||
| HIDIO (?) | ✗ | ||
| UPSIDE (?) | ✗ | ||
| LSD (?) | ✗ | ||
| Data Coverage Maximization | CBB (?) | ✗ | |
| MaxEnt (?) | ✗ | ||
| SMM (?) | ✗ | ||
| APT (?) | ✓ | ||
| Proto-RL (?) | ✓ | ||
| RE3 (?) | ✓ | ||
3 Online Pretraining
Most of the previous successes in RL have been achieved given dense and well-designed reward functions. Despite its primacy in providing excel performances for a specific task, the traditional RL paradigm faces two critical challenges when scaling it up to large-scale pretraining. Firstly, it is notoriously easy for an RL agent to overfit (?). As a result, a pretrained agent trained with sophisticated task rewards can hardly generalize to unseen task specifications. Furthermore, it remains a practical challenge to design reward functions which is usually costly and requires expert knowledge.
Online pretraining without these reward signals can potentially be a good solution to learning generic skills and eliminate the supervision requirement. Online pretraining aims at acquiring prior knowledge by interacting with the environment in the absence of human supervision. During the pretraining phase, the agent is allowed to interact with the environment for a long period without access to extrinsic rewards. When the environment is accessible, playing with it facilitates skill learning that will be useful later when a task is assigned to the agent. This solution, also known as unsupervised RL, has been actively studied in recent years (?, ?).
To encourage the agent to build its own knowledge without any supervision, we need principled mechanisms to provide the agent with intrinsic drives. Psychologists found that babies can discover both the tasks to be learned and the solution to those tasks through interacting with the environment (?). With experiences accumulated, they are capable of more difficult tasks later on. This motivates a wealth of research that studies how to build self-taught agents with intrinsic rewards (?, ?, ?). Intrinsic rewards, in contrast to task-specifying extrinsic rewards, refer to general learning signals that encourage the agent either to collect diverse experiences or to develop useful skills. It has been shown that pretraining an agent with intrinsic rewards and standard RL algorithms can lead to fast adaptation once the downstream task is given (?).
Based on how to design intrinsic rewards, we classify existing approaches of unsupervised RL into three categories111This taxonomy of unsupervised RL was originally proposed by ? (?).: curiosity-driven exploration, skill discovery, and maximal data coverage. Table 2 presents a categorization of representative online pretraining algorithms together with their used intrinsic rewards.
3.1 Curiosity-driven Exploration

In the psychology of motivation, curiosity represents motivation to reduce uncertainty about the world (?). Inspired by this line of psychological theory, similar ideas have been studied to build curiosity-driven approaches for online pretraining. Curiosity-driven approaches seek to explore interesting states that can possibly bring knowledge about the environment. Intuitively, if the agent falls short of accurately predicting the environment, it gains knowledge by interacting and then reducing this part of the uncertainty. The defining characteristic of a curiosity-driven agent is how to compute the degree of curiosity to these interesting states, which directly serves as the intrinsic reward for learning. A concrete example is ICM (?), which applies the intrinsic reward proportional to the prediction error as shown in Figure 2:
where and represent the learned forward dynamics model and feature encoder, respectively.
To measure curiosity, a broad class of approaches (?, ?) leverages this kind of learned dynamics models to predict future states in an auxiliary feature space. there are mainly two kinds of estimation: prediction error and prediction uncertainty. Despite that these dynamics-based approaches perform quite well across common scenarios, they usually suffer from action-dependent noisy TVs (?), which will be discussed later in Section 3.1.1. This deficiency encourages the following work to design dynamics-free curiosity estimation (?) and more sophisticated uncertainty estimation methods (?, ?).
Another important design choice is associated with the feature encoder , especially for high-dimensional observations. A proper feature encoder can make the prediction task more tractable and filter out irrelevant aspects so that the agent can only focus on the informative ones. Early studies (?, ?) leverage auto-encoding embeddings to recover the original high-dimensional inputs, but the induced feature space is usually too informative about irrelevant details and hence susceptible to noise. To address this issue, ? (?) utilize an inverse dynamics model for feature encoding to make sure that the agent is unaffected by nuisance factors in the environment. The proposed ICM shows impressive zero-shot performance in playing video games. ? (?) further relax the design burden by simply replacing the feature model with a fixed randomly initialized neural network, which is proven effective by a following large-scale empirical study (?). Despite that random feature encoders are sufficient for good performance at training, learned features (e.g., based on inverse dynamics) generalize better (?). Inspired by recent advances in representation learning, ? (?) directly link curiosity and representation learning loss by formulating a minimax game between a generic representation learning algorithm and a reinforcement learning policy.
3.1.1 Challenges & Future Directions
This kind of approach has several deficiencies. One of the most important issues is how to distinguish epistemic and aleatoric uncertainty. Epistemic uncertainty refers to uncertainty caused by a lack of knowledge. Aleatoric uncertainty, in contrast, refers to the variability in the outcome due to inherently random effects. A concrete phenomenon in RL is the noisy TV problem (?), which refers to the cases where the agent gets trapped by its curiosity in highly stochastic environments. To mitigate this issue, some work attempts to use intrinsic rewards proportional to a reduction in uncertainty (?, ?). However, tractable epistemic uncertainty estimation in high dimension remains challenging (?) due to its sensitivity to imperfect data.
Another issue with the above approaches is that they only receive retrospective signals after the agent has achieved epistemic uncertainty, which might cause inefficiency in exploration. Based on this intuition, ? (?) design a model-based method that can prospectively look for uncertainty in the environment.
3.2 Skill Discovery
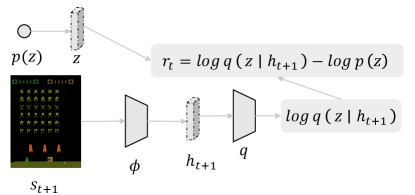
Apart from curiosity-driven approaches that tackle unsupervised RL in a model-based perspective, one can also consider model-free learning of primitive skills222In this work, we use skill, option, and behavior prior interchangeably. that can be composed to solve downstream tasks. This kind of approach is usually referred to as skill discovery approach. The main intuition behind this is that the learned skill should control which states the agent visits, which can be seen as a notion of empowerment.
Generally speaking, the objective for skill discovery can be formalized as maximizing the mutual information (MI) between skill latent variable and state :
| (1) |
where we define skills or options as the policies conditioned on . There are two components for a skill discovery agent to determine: 1) a skill distribution ; 2) a skill policy . Before each episode, skill latent is sampled from distribution , followed by skill to interact with the environment. Learning skills that maximize MI is a challenging optimization problem, upon which a variety of approaches sharing the same spirit have been applied.
Among the existing MI-based skill discovery methods, the majority (?, ?, ?) apply the former form of Equation 1 with the following variational lower bound (?):
In this case, a parametric model is trained together with other variables to estimate the conditional distribution . Maximizing can be achieved by sampling from a learned distribution (?) or directly from a fixed uniform distribution (?). As shown in Figure 3, the intrinsic reward is given by , upon which one can apply standard RL algorithms to learn skills.
Another line of research (?, ?, ?, ?) considers the latter form and similarly derives a lower bound:
In this formulation, maximizing the state entropy encourages exploration while minimizing the conditional entropy results in directed behaviors. The difficulty lies in the density estimation of , especially for high-dimensional state spaces. A common practice is to maximize via maximum entropy estimation (?, ?, ?), which will be elaborated more in Section 3.3.
Although different work uses slightly different approaches to optimize Equation 1, it could be more important to decide other design factors when using skill discovery for online pretraining. For instance, while most studies consider the episodic setting, some efforts have been made to extend MI-based skill discovery to non-episodic settings (?, ?). It is also promising to consider a curriculum with an increasing number of skills to learn (?). Several other factors are also worth mentioning, such as whether skill latent is discrete (?) or continuous (?), whether the reward signals are dense (?) or sparse (?), and whether it works for image-based observations (?).
Skill discovery can be also reinterpreted as goal-conditioned policy learning, where as self-generated and abstract goal is sampled from a distribution instead of provided by the task. One can also consider generating concrete goals in a self-supervised manner (?, ?) and derive a goal-conditioned reward function similarly from MI maximization. DISCERN (?) designs a non-parametric approach for goal sampling, maintaining a buffer of past observations that drifts as the agent collects new experiences. Skew-Fit (?) instead learns a maximum entropy goal distribution by increasing the entropy of a generative model in an iterative manner. ? (?) provide a more formal connection mainly from the perspective of goal-conditioned RL. We refer the interested reader to ? (?) for further discussion.
3.2.1 Challenges & Future Directions
A major issue for MI-based skill discovery approaches is that the objective does not necessarily lead to strong state coverage as one can maximize even with the smallest state variations (?, ?). This lack of coverage can greatly limit their applicability to downstream tasks with complex environments (?). To resolve this issue, some existing work explicitly uses - coordinates as features to enforce state coverage induced by skills (?, ?). It is also explored to separate the learning process to first maximize via maximum entropy estimation, followed by behavior learning (?, ?).
Moreover, it is empirically shown that skill discovery methods underperform other kinds of online pretraining methods, which may be due to restricted skill spaces (?). This calls attention to dissecting what skills are learned. In order to live up to their full potential, the discovered skills must strike a balance between generality (i.e., the applicability to a large variety of downstream tasks) and specificity (i.e., the quality of being useful to induce specific behaviors) (?). It is also desired to avoid learning trivial skills (?, ?).
3.3 Data Coverage Maximization
Previously we have discussed how to obtain knowledge or skills, measured by the agent’s own capability, from unsupervised interaction. Albeit indirectly related to the agent’s ability, data diversity induced by online pretraining plays an essential role in deciding how well the agent obtains prior knowledge. In the field of supervised learning, recent advances have shown that diverse data can enhance out-of-distribution generalization (?) and robustness (?). Another supporting evidence is that most of the famed datasets are large and diverse (?, ?). Motivated by the above considerations, it is desired to use data coverage maximization, usually measured by state visitation, as an objective to stimulate unsupervised learning.
3.3.1 Count-based Exploration
The first category of data coverage maximization is count-based exploration. Count-based exploration methods directly use visit counts to guide the agent towards underexplored states (?, ?). For tabular MDPs, Model-based Interval Estimation with Exploration Bonuses (?) provably turn state-action counts into an exploration bonus reward:
| (2) |
Built on Equation 2, a series of work has studied how to tractably generalize count bonuses to high-dimensional state spaces (?, ?, ?). To approximate these counts in high dimensions, ? (?) introduce pseudo-counts derived from a density model. Specifically, the pseudo-count is defined as:
where is a density model over state space , is the density assigned to after training on a sequence of states , and is the density of if were to be trained on one additional time. Based on similar ideas, it has been shown that a better density model (?) or a hash function (?, ?) for computing state statistics can further improve performance. Besides, a self-supervised inverse dynamics model as discussed in Section 3.1 can also be used to bias the count-based bonuses towards what the agent can control (?).
3.3.2 Entropy Maximization
To encourage novel state visitation, an alternative objective is to directly maximize the entropy of state visitation distribution induced by policy :
where can be Shannon entropy (?, ?, ?), Rényi entropy (?), or geometry-aware entropy (?). The state distribution can either be a discounted distribution (?), a marginal distribution (?), or a stationary distribution (?).
Albeit compelling, the objective relies on maximizing state entropy, which is notoriously hard to estimate and optimize. ? (?) contribute a provably efficient algorithm in the tabular setting using the conditional gradient method (?) to avoid direct optimization. ? (?) propose a similar approach that can be viewed from the perspective of state marginal matching between the state distribution and a given target distribution (e.g., a uniform distribution). Both ? (?) and ? (?) propose to learn a mixture of policies that maximizes the induced state entropy in an iterative manner. While impressive, these parametric approaches struggle to scale up to high dimensional spaces. To address this issue, ? (?) instead optimize a non-parametric, particle-based estimate of state distribution entropy (?), but restrict its use to state-based tasks.
For unsupervised online pretraining with visual observations, entropy maximization becomes more tricky as exploration is now inextricably intertwined with representation learning. This leads to a chicken-and-egg problem (?, ?), where learning useful representations requires diverse data, while effective exploration can only be achieved with good representations. Based on particle-based entropy estimators, several approaches successfully apply entropy maximization in image-based tasks with self-supervised representations learned by inverse dynamics prediction (?), contrastive learning (?, ?), or the information bottleneck (?).
3.3.3 Challenges & Future Directions
Although count-based approaches are shown effective for exploration, it has been shown in previous work (?) that they usually suffer from detachment, in which the agent loses track of interesting areas to explore, and derailment, in which the exploratory mechanism prevents it from returning to previously visited states. Count-based approaches also tend to be short-sighted, driving the agent to get stuck in local minima (?).
When applying state entropy maximization approaches for pretraining, it is worth pointing out that many of them aim at maximizing the entropy of all states visited during the process, and hence the final policy is not necessarily exploratory (?). It has also been shown theoretically that the class of Markovian policies is insufficient for the maximum state entropy objective, while non-Markovian policies are essential to guarantee good exploration.
Instead of learning an exploratory policy, another line of research considers collecting unlabeled records as a prerequisite for offline RL (?, ?), which is an interesting direction for understanding and utilizing task-agnostic agents.
4 Offline Pretraining
| Type | Algorithm | Objective | Visual | Expert Data |
|---|---|---|---|---|
| Skill Extraction | SPiRL (?) | Variational Auto-encoder | ✓ | ✗ |
| OPAL (?) | Variational Auto-encoder | ✗ | ✓ | |
| Parrot (?) | Normalizing Flow | ✓ | ✓ | |
| SkiLD (?) | Variational Auto-encoder | ✗ | ✗ | |
| TRIAL (?) | Energy-based Model | ✗ | ✓ | |
| FIST (?) | Variational Auto-encoder | ✗ | ✓ | |
| Representation Learning | World Model (?) | Reconstruction | ✓ | ✗ |
| ST-DIM (?) | Forward Pixel Prediction | ✓ | ✗ | |
| ATC (?) | Forward Dynamics Modeling | ✓ | ✓ | |
| SGI (?) | Forward Dynamics Modeling | ✓ | ✗ | |
| Markov (?) | Inverse Dynamics Modeling | ✓ | ✗ | |
Despite its attractive effectiveness of learning without human supervision, online pretraining is still limited for large-scale applications. Eventually, it is difficult to reconcile online interaction with the need to train on large and diverse datasets (?). To address this issue, it is desired to decouple data collection and pretraining and directly leverage historical data collected from other agents or humans.
A feasible solution is offline RL (?, ?), which has been gaining attention recently. Offline RL aims to obtain a reward-maximizing policy purely from offline data. A fundamental challenge of offline RL is the distributional shift, which refers to the distribution discrepancy between training data and those seen during testing. Existing offline RL approaches focus on how to address this challenge when using function approximation. For instance, policy constraint approaches (?, ?) explicitly require the learned policy to avoid taking unseen actions in the dataset. Value regularization methods (?) alleviate the overestimation problem of value functions by fitting them to some forms of lower bounds. However, it remains under-explored whether policies trained offline can generalize to new contexts unseen in the offline dataset (?).
Another scenario is offline-to-online RL (?, ?, ?, ?), where offline RL is used for pretraining, followed by online finetuning. It has been shown in this scenario that offline RL can accelerate online RL (?). However, both offline RL and offline-to-online RL require the offline experience to be annotated with rewards, which are challenging to provide for large real-world datasets (?).
A compelling alternative direction for leveraging offline data is to sidestep policy learning, but instead learn prior knowledge that is beneficial for downstream tasks in terms of convergence speed or final performances. What is more intriguing, if our model were able to utilize data without human supervision, it could potentially benefit from web-scale data for decision-making. We refer to this setting as offline pretraining, where the agent can extract important information (e.g., good representations and behavior priors) from offline data. In Table 3, we categorize existing offline pretraining approaches as well as summarize each approach’s key properties.
4.1 Skill Extraction
Learning useful behaviors from offline data has a long history (?, ?). When the offline data comes from expert demonstrations, it is straightforward to pretrain policies via imitation learning (?, ?, ?), which is often used in real-world applications like robotic manipulation (?, ?) and self-driving (?). However, imitation learning approaches often assume that the training data contains complete solutions. They therefore usually fall short of obtaining good policies when demonstrations are collected from a series of sources.
An alternative solution is to learn useful behavior priors from offline data (?, ?, ?), similar to what we have discussed in Section 3.2. Compared with its online counterpart, offline skill extraction assumes a fixed set of trajectories. These approaches learn a spectrum of behavior policies conditioned on latent , which provide a more compact action space for learning high-level policies that can quickly adapt to downstream tasks. Specifically, temporal skill extraction (?) for few-shot imitation (?) and RL (?, ?, ?) considers how to distill offline trajectories into primitive policies , where denotes a skill latent learned via unsupervised learning. By leveraging stochastic latent variable models, we aim at learning a skill latent for a sequence of state-action pairs , where is a fixed horizon or a variable one (?, ?). For example, ? (?) propose the following auto-encoding objective to learn primitive skills:
where encodes the trajectory into skill latent and skill policy serves as a decoder to translate skill latent into action sequences. To transfer skills into downstream tasks, it is feasible to learn a hierarchical policy that generates high-level behaviors with trained on downstream tasks (?), which will be elaborated in Secition 6.2.
Various latent variable models have been used for pretraining behavior priors. For instance, variational auto-encoders (?) are widely considered (?, ?, ?). Following work (?, ?) also explores normalizing flow (?) and energy-based models (?) to learn action priors.
The scenario of pretraining behavior priors also bears resemblance to few-shot imitation learning (?, ?). However, for few-shot imitation learning, it is often assumed that expert data is collected from a single behavior policy. Furthermore, due to error accumulation (?), few-shot imitation learning is often limited to short-horizon problems (?). In this regard, learning behavior priors from diverse and sub-optimal data appears to be a promising direction.
4.1.1 Challenges & Future Directions
Despite its potential to extract useful primitive skills, it is still challenging to pretrain on highly sub-optimal offline data containing random actions (?). Besides, RL with learned skills does not usually generalize to downstream tasks efficiently, requiring millions of online interactions to converge (?). A possible solution is to combine with successor features (?, ?) for fast task inference. However, strategies that directly use the pretrained policies for exploitation may result in sub-optimal solutions in such a scenario (?).
4.2 Representation Learning
| Type | Sufficiency | Compactness |
|---|---|---|
| Reconstruction | ||
| Forward Pixel Prediction | ||
| Forward Dynamics Modeling | ||
| Inverse Dynamics Modeling | ||
While pretraining behavior priors focus on reducing the complexity of the action space, there exists another line of work that aims to pretrain good state representations from offline data to promote transfer. If the agent effectively reduces the representation gap between the learned state representations and the ground-truth endogenous states, it can better focus on factors that are essential for control. Table 4 compares different kinds of representation learning objectives in terms of sufficiency (i.e., whether the representations contain sufficient state information) and compactness (i.e., whether the representations discard irrelevant information).
Learning good state representations for RL is a mature research area with a range of tools (?, ?, ?). Traditionally, the problem is formulated to group states into clusters based on certain properties (?). Existing representation learning approaches generally propose some predictive properties that the desired representations have, with regard to states, actions, and rewards across different time-steps. One of the most representative concepts is bisimulation (?, ?), which originally requires two equivalent states to have the same reward and equivalent distributions over the next bisimilar states. The objective turns out to be very restrictive and is further relaxed by following work (?, ?) with a defined pseudo-metric space to measure behavioral similarity. Despite their recent advances (?, ?, ?) in effective representation learning using deep neural networks, bisimulation methods fail to provide good abstraction when the rewards are sparse or even absent. In this case, solely relying on a forward model can lead to representation collapse (?).
To alleviate representation collapse, one can instead set the targets to pixel observations. This includes reconstruction-based approaches (?, ?) and those based on pixel prediction (?, ?). Reconstruction-based approaches typically train an auto-encoder on image observations to learn a low-dimensional representation, using which a policy is learned subsequently. Approaches based on pixel prediction force the representations to contain sufficient information about future pixel observations. Despite these learned representations preserving sufficient information about the observation, it lacks compactness and does not guarantee to capture of useful information for the control task.
Instead of predicting the future, it is also beneficial to model the inverse dynamics of the system (?, ?). Inverse dynamics modeling learns a representation that is predictive of the action taken between a pair of consecutive states. It has been shown that the learned representation can filter out all uncontrollable aspects of the observations (?). However, it can also wrongly ignore controllable information and cause over-abstraction over the state space (?, ?).
With the rise of self-supervised learning developed for CV and NLP, a natural direction is to adapt these task-agnostic techniques to RL. For instance, a large body of works has explored contrastive learning (?) as an effective framework to learn good representations (?, ?, ?, ?). Contrastive learning typically uses the InfoNCE loss (?) to maximize mutual information between two variables:
where is a bilinear function with learned parameter and is the number of negative samples. These approaches usually incorporate temporal information, aiming to distinguish between sequential and non-sequential states (?, ?). Following works (?, ?) further consider bootstrapped latent representations (?) that get rid of negative samples.
Aside from the above representation learning objectives, some other work considers imposing Lipschitz smoothness (?, ?), kinematic inseparability (?), or the Markov property (?). It has also been shown that a combined objective can also lead to better performance (?).
4.2.1 Challenges & Future Directions
While unsupervised representations have been shown to bring significant improvements to downstream tasks, the absence of reward signals typically leads the pretrained encoder to focus on task-irrelevant features instead of task-relevant ones in visually complex environments (?). To alleviate this issue, one might incorporate additional inductive bias (?) or labeled data that are cheaper to obtain. We will discuss the latter solution in Section 5.
Another challenge for unsupervised representation learning is how to measure its effectiveness without access to downstream tasks. Such evaluation is beneficial because it can provide a proxy metric to predict performance and promote a deeper understanding of the semantic meanings of pretrained representations. To achieve this, it is desired to analyze these representations with probing techniques and determine which properties they encode. Although previous work has made efforts in this direction (?), it remains unclear what properties are most indispensable for pretrained representations.
5 Towards Generalist Agents with RL
So far we have discussed online and offline scenarios that are generally restricted to a single modality and single environment. Recently, there is a surge of interest in building a single generalist model (?, ?, ?) to handle tasks in different environments across different modalities. To enable the agent to learn from and adapt to various open-ended tasks, it is desired to leverage considerable prior knowledge in different forms such as visual perception and language understanding. Intuitively, the aim is to bridge the worlds of RL and other fields of machine learning, combining previous success together to build a large decision-making model capable of a diverse set of tasks. In this section, we look at various considerations for handling data and tasks from different modalities to acquire useful prior knowledge.
5.1 Visual Pretraining
Perception is an unavoidable prerequisite for real-world applications. With an increased number of image-based decision-making tasks, pretrained visual encoders that were exposed to a wide distribution of images can provide RL agents with robust and resilient representations as a basis to learn optimal policies.
The field of computer vision has seen tremendous progress in pretraining visual encoders from large-scale image datasets (?) and video corpora (?). Given that these data are cheap to access, several works have explored the use of pretrained visual encoders on large-scale image datasets as means to improve the generalization and sample efficiency of RL agents. ? (?) equip standard deep RL algorithms with ResNet encoders pretrained on ImageNet and observe that the pretrained representations lead to impressive performances in Adroit (?) but struggle in the DeepMind control suite (?) due to large domain gap. ? (?) further investigate various design choices including datasets, augmentations, and layers, and report positive results on all four considered control tasks. ? (?) conduct a large-scale study on how different properties of pretrained VAE-based embeddings affect out-of-distribution generalization, concluding that some of them (e.g., the GS metric (?)) can be good proxy metrics to predict generalization performance.
Instead of extracting visual information from static image datasets, another intriguing direction is to capture temporal relations from unlabeled videos. ? (?) design a self-supervised approach to learning temporal variance and multi-view invariance on multi-view video data. ? (?) empirically find that, without exploiting temporal information, in-the-wild images collected from YouTube or Egocentric videos lead to better self-supervised representations for manipulation tasks that ImageNet images. ? (?) introduce a two-phase learning framework, which first learns useful representations via generative pretraining on videos and then uses the pretrained model for learning action-conditional world models. ? (?) successfully extract behavioral priors from internet-scale videos with an inverse dynamics model to uncover the underlying actions followed by behavior cloning, finding that the pretrained model exhibits impressive zero-shot capabilities and finetuning results for playing Minecraft. ? (?) also leverage inverse dynamics models to predict action labels from action-free videos, upon which a new contrastive learning framework is proposed to pretrain action-conditioned policies.
5.2 Natural Language Pretraining
Human beings are not only able to perceive the visual world through their eyes, but understand high-level natural language instructions and ground the rich knowledge from texts to complete tasks. In this vein, there has been a long history of how to connect language and actions (?, ?). Especially due to the rapid development of large language models (LLMs) (?, ?) that exhibit great capability of encoding semantic knowledge, it appears to be a promising direction to leverage advanced LLMs as generic computation engines to facilitate decision making (?).
5.2.1 Language-conditioned Policy Learning
To extract and harness the knowledge of well-informed pretrained LLMs, a feasible solution is to condition the policies on text descriptions processed by LLMs. This kind of language-conditioned policy learning could be extremely useful for robotic tasks where high-level language instructions are available. For example, ? (?) use pretrained LLMs to split high-level instructions into sub-tasks via prompt engineering for grounding value functions in real-world robotic tasks. ? (?) further enable grounded closed-loop feedback generated by additional perception models as the source of corrections for LLMs’ predictions. ? (?) instead consider effective exploration in 3D environments, showing that pretrained representations from vision-language models (?) form a semantically meaningful state space for curiosity-driven intrinsic rewards. ? (?) also connect reward specification to vision-language supervision, introducing a framework that leverages text descriptions and pixel observations to produce reward signals.
5.2.2 Policy Initialization
Recent advances bridge the gap between reinforcement learning and sequential modeling (?, ?, ?, ?), opening up opportunities to borrow sequential models to RL tasks. Despite the clear distinction, pretrained LLMs could arguably provide reusable knowledge via weight initialization. ? (?) investigate whether pretrained LLMs can provide good weight initialization for Transformer-based offline RL models, and conclude with very positive results. ? (?) also demonstrate that pretrained LLMs can be used to initialize policies and facilitate behavior cloning as well as online reinforcement learning for embodied tasks. They also suggest using sequential input representations and fintuning the pretrained weights for better generalization.
5.3 Multi-task and Multi-modal Pretraining
With recent advances in building powerful sequence models to handle different modalities and tasks (?, ?, ?), the wave of using large general-propose models (?) has been sweeping through the field of supervised learning. The key ingredient is Transformer (?), a highly capable neural architecture built on the self-attention mechanism (?) that excels at capturing long-range dependencies in sequential data. Due to its strong generality where various tasks in different domains can be formulated as sequence modeling, Transformer is believed to be a unified architecture for developing foundation models (?).
Recently, Transformer-based architectures have also been extended to the field of offline RL (?, ?) and then online RL (?), in which the agent is trained auto-regressively in a supervised manner via likelihood maximization. This opens up the possibility of replicating previous success achieved with Transformer in the field of supervised learning. Specifically, it is expected that by combining large-scale data, open-ended objectives, and Transformer-based architectures, we are ready to build general-purpose decision-making agents that are capable of various downstream tasks in different environments.
Pioneering work in this direction is Gato (?), a generalist agent trained on various tasks from control environments, vision datasets, and language datasets in a supervised manner. To handle multi-task and multi-modal data, Gato uses demonstrations as prompt sequences (?) at inference time. ? (?) extend Decision Transformer (?) to train a generalist agent called Multi-Game DT that can play 41 Atari games simultaneously. Both Gato and Multi-Game DT show impressive scaling law properties. ? (?) make use of large-scale multi-modal data from YouTube videos, Wikipedia pages, and Reddit posts to train an agent able to solve various tasks in Minecraft. To provide dense reward signals, a pretrained vision-language model based on CLIP (?) is introduced as a proxy of human evaluation.
5.4 Challenges & Future Directions
In spite of some promising results, how generalist models benefit from multi-modal and multi-task data remains unclear. More specifically, these models might suffer from detrimental gradient interference (?) between modalities and tasks due to the incurred optimization challenges. To mitigate this issue, it is desired to incorporate more analysis tools for optimization landscapes (?) and gradients (?) to tease out the precise principles.
Another compelling direction is to compose separate pretrained models (e.g., GPT-3 (?) and CLIP (?)) together. By leveraging expert knowledge from different models, this kind of framework can solve complex multi-modal tasks (?).
6 Task Adaptation
While pretraining on unsupervised experiences can result in rich transferable knowledge, it remains challenging to adapt the knowledge to downstream tasks in which reward signals are exposed. In this section, we discuss briefly various considerations for downstream task adaptation. We limit the scope to online adaptation, while adaptation with offline RL or imitation learning is also feasible (?).
In online task adaptation, a pretrained model is given, which can be composed of various components such as policies and representations, together with a target MDP that can interact with. Given that pretraining could result in different forms of knowledge, it brings difficulties to designing principled adaptation techniques. Nevertheless, considerable efforts have been made to study this aspect.
6.1 Representation Transfer
In the field of supervised learning, recent advances (?, ?, ?) have demonstrated that good representations can be pretrained on large-scale unlabeled dataset, as evidenced by their impressive downstream performances. The most common practice is to freeze the weights of the pretrained feature encoder and train a randomly initialized task-specific network on top of that during adaptation. The success of this paradigm is essentially based on the promise that related tasks can usually be solved using similar representations.
For RL, it has been shown that directly reusing pretrained task-agnostic representations can significantly improve sample efficiency on downstream tasks. For instance, ? (?) conduct experiments on the Atari 100K benchmark and find that frozen representations pretrained on exploratory offline data already form a basis of data-efficient RL. This success also extends to the cases where domain discrepancy exists between upstream and downstream tasks (?, ?). However, the issue of negative transfer in the face of domain discrepancy might be exacerbated for RL due to its complexity (?).
When adapting to tasks that have the same environment dynamics as that of the upstream task(s), successor features (?) can be a powerful tool to aid task adaptation. The framework of successor features is based on the following decomposition of reward functions:
| (3) |
where represents features of transition and encodes reward-specifying weights. This leads to a representation of the value function that decouples the dynamics of the environment from the rewards:
where we call the successor features of under . Intuitively, summarizes the dynamics induced by and has been studied within the framework of online pretraining (?, ?) by combining with skill discovery approaches to implicitly learn controllable successor features . Given a learned , the problem of task adaptation reduces to a linear regression derived from Equation 3.
6.2 Policy Transfer
A compelling alternative for task adaptation is to transfer learned behaviors. As discussed in previous sections, existing work has explored how to pretrain primitive skills that can be reused to face new tasks or a single exploratory policy that facilitates exploration at the beginning of task adaptation. The differences in pretrained behaviors result in different adaptation strategies.
To achieve high rewards on the downstream task with skill-conditioned policy , a straightforward strategy is to simply choose the skill with the best outcome and further enhance it with finetuning. However, a single best-performing skill can not fulfill its potential. To better combine diverse skills for task solving, one can view them from the perspective of hierarchical RL (?, ?). In hierarchical RL, the decision-making task is typically decomposed into a two-level hierarchy, where a meta-controller decides which low-level policy to use for task solving, depending on the current state. This hierarchical scheme is agnostic to how the low-level policies are learned. Therefore, it is sufficient to train a meta-controller on top of the discovered skills, which has been proven effective for few-shot adaptation (?) and zero-shot adaptation (?).
Exploratory policies, as another form of prior knowledge, benefit downstream tasks in a different way. Due to the importance of exploration, exploratory policies can provide good initialization for the agent to gather diverse experiences and reach high-rewarding states. For example, ? (?) validate the effectiveness of transferring exploratory policies trained by curiosity-driven approaches, in particular for domains that require structured exploration.
While it is always feasible to finetune pretrained policies, considerations should be taken in order to prevent catastrophic forgetting when learning in the downstream task. Catastrophic forgetting refers to the tendency of neural networks to disregard their previously obtained knowledge when new information is acquired. To mitigate this issue, one might apply knowledge distillation-like regularization together with RL objectives (?):
where is cross entropy and is the teacher policy. We refer the reader to ? (?) for more discussions on catastrophic forgetting in reinforcement learning.
6.3 Challenges & Future Directions
Parameter Efficiency.
Despite that existing pretrained models for RL have much fewer parameters as compared with those in the field of supervised learning, the issue of parameter efficiency is still important with the ever-increasing number of model parameters. More concretely, it is desired to design parameter-efficient transfer learning that updates only a small fraction of parameters while keeping most of the pretrained parameters intact. It has been actively studied in natural language processing (?) with solutions like adding small neural modules as adapters (?) and prepending learnable prefix tokens as soft prompts (?). Built on these techniques, several efforts have been made to enable parameter-efficient transfer with prompting (?, ?), which we believe has a large room to improve with tailored methods.
Domain adaptation.
In this section, we mainly consider task adaptation where unseen tasks are given in the same environment. A more challenging but practical scenario is domain adaptation. In domain adaptation, there exist environmental shifts between the upstream and downstream tasks. Despite that these environmental shifts are commonly seen in real-world applications, it remains a challenging problem to transfer across different domains (?, ?). However, we believe that this direction will rapidly evolve by bringing related techniques from supervised learning to reinforcement learning.
Continually-developed models.
For practical applications, we can take a step forward and consider building large pretrained models continually to support added features (e.g., a modified action space, more powerful architectures, etc). While such consideration was already underway during the development of large-scale RL models (?), it requires a more principled way of combining updates into RL models. We refer the reader to recent work in this direction in the field of supervised learning (?) and reinforcement learning (?, ?).
7 Conclusions and Future Perspectives
In this section, we conclude this survey and highlight several future directions which we believe will be important topics for future work.
This paper introduces pretraining in deep RL by discussing recent trends to obtain general prior knowledge for decision-making. In contrast to its supervised learning counterpart, pretraining faces a variety of challenges unique to RL. In this survey, we present several promising research directions to tackle these challenges and we believe this field will evolve rapidly in the coming years.
There are still several open questions that are important and remain to be addressed.
Benchmarks and evaluation metrics.
Evaluation serves as a means for comparing various methods and driving further improvements. In the field of natural language processing, GLUE (?) is a widely used benchmark to evaluate the performance of models across various natural language understanding tasks. Recently, there has been a surge of research on improving evaluation for RL in terms of evaluation metrics (?) and benchmark datasets (?). To the best of our knowledge, URLB (?) is the only benchmark for pretraining in deep RL. It presents a unified evaluation protocol for online pretraining based on the DeepMind control suite (?). However, a principled evaluation framework for offline pretraining and generalist pretraining is still missing. We expect existing offline RL benchmarks like D4RL (?) and RL Unplugged (?) can serve as the basis for developing pretraining benchmarks, but more challenging tasks should better illustrate the value of pretraining.
Architecture.
As discussed in previous sections, there has been a surge of leveraging large transformers for RL tasks. We expect other recent advances in model architecture can bring more improvements. For example, ? (?) learn large sparse models with a mixture of experts that simultaneously handle images and text with modality-agnostic routing. This has the promise to solve complex tasks at scale. Besides, one can also rethink existing architectures that have the potential to support large-scale pretraining (e.g., Progress Neural Networks (?)).
Multi-agent RL.
Multi-agent RL (?) is an important sub-field of RL. Extending existing pretraining techniques to the multi-agent scenario is non-trivial. Multi-agent RL typically requires socially desirable behaviors (?) and representations (?). To the best of our knowledge, ? (?) present the only effort in pretraining multi-agent RL with supervision. How to enable unsupervised pretraining for multi-agent RL remains unclear, which we believe is a promising research direction.
Theoretical results.
For RL, the significant gap between theory and practice has been a long-standing problem, and bringing large-scale pretraining to RL may exacerbate this even further. Fortunately, recent theoretical studies have made efforts in terms of representation transfer (?) and skill-conditioned policy transfer (?). Increasing focus on theoretical results is likely to have profound effects on the development of more advanced pretraining methods.‘
References
- Abu-El-Haija et al. Abu-El-Haija, S., Kothari, N., Lee, J., Natsev, P., Toderici, G., Varadarajan, B., and Vijayanarasimhan, S. (2016). Youtube-8m: A large-scale video classification benchmark. CoRR, abs/1609.08675. http://arxiv.org/abs/1609.08675.
- Achiam et al. Achiam, J., Edwards, H., Amodei, D., and Abbeel, P. (2018). Variational option discovery algorithms. CoRR, abs/1807.10299. http://arxiv.org/abs/1807.10299.
- Agakov Agakov, D. B. F. (2004). The im algorithm: a variational approach to information maximization. Advances in neural information processing systems, 16(320), 201.
- Agarwal et al. Agarwal, A., Song, Y., Sun, W., Wang, K., Wang, M., and Zhang, X. (2022). Provable benefits of representational transfer in reinforcement learning. CoRR, abs/2205.14571. DOI: 10.48550/arXiv.2205.14571.
- Agarwal et al. Agarwal, R., Machado, M. C., Castro, P. S., and Bellemare, M. G. (2021). Contrastive behavioral similarity embeddings for generalization in reinforcement learning. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=qda7-sVg84.
- Agarwal et al. Agarwal, R., Schwarzer, M., Castro, P. S., Courville, A., and Bellemare, M. G. (2022). Reincarnating reinforcement learning: Reusing prior computation to accelerate progress.. DOI: 10.48550/ARXIV.2206.01626.
- Agarwal et al. Agarwal, R., Schwarzer, M., Castro, P. S., Courville, A. C., and Bellemare, M. (2021). Deep reinforcement learning at the edge of the statistical precipice. In Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., and Vaughan, J. W. (Eds.), Advances in Neural Information Processing Systems, Vol. 34, pp. 29304–29320. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2021/file/f514cec81cb148559cf475e7426eed5e-Paper.pdf.
- Ahn et al. Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., et al. (2022). Do as i can, not as i say: Grounding language in robotic affordances. ArXiv preprint, abs/2204.01691. https://arxiv.org/abs/2204.01691.
- Ajay et al. Ajay, A., Kumar, A., Agrawal, P., Levine, S., and Nachum, O. (2021). OPAL: offline primitive discovery for accelerating offline reinforcement learning. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=V69LGwJ0lIN.
- Akkaya et al. Akkaya, I., Andrychowicz, M., Chociej, M., Litwin, M., McGrew, B., Petron, A., Paino, A., Plappert, M., Powell, G., Ribas, R., et al. (2019). Solving rubik’s cube with a robot hand. ArXiv preprint, abs/1910.07113. https://arxiv.org/abs/1910.07113.
- Allen et al. Allen, C., Parikh, N., Gottesman, O., and Konidaris, G. (2021). Learning markov state abstractions for deep reinforcement learning. Advances in Neural Information Processing Systems, 34, 8229–8241.
- Anand et al. Anand, A., Racah, E., Ozair, S., Bengio, Y., Côté, M., and Hjelm, R. D. (2019). Unsupervised state representation learning in atari. In Wallach, H. M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E. B., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pp. 8766–8779. https://proceedings.neurips.cc/paper/2019/hash/6fb52e71b837628ac16539c1ff911667-Abstract.html.
- Argall et al. Argall, B. D., Chernova, S., Veloso, M., and Browning, B. (2009). A survey of robot learning from demonstration. Robotics and Autonomous Systems, 57(5), 469–483. DOI: https://doi.org/10.1016/j.robot.2008.10.024.
- Badia et al. Badia, A. P., Sprechmann, P., Vitvitskyi, A., Guo, D., Piot, B., Kapturowski, S., Tieleman, O., Arjovsky, M., Pritzel, A., Bolt, A., and Blundell, C. (2020). Never give up: Learning directed exploration strategies. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=Sye57xStvB.
- Bahdanau et al. Bahdanau, D., Cho, K., and Bengio, Y. (2015). Neural machine translation by jointly learning to align and translate. In Bengio, Y., and LeCun, Y. (Eds.), 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. http://arxiv.org/abs/1409.0473.
- Baker et al. Baker, B., Akkaya, I., Zhokhov, P., Huizinga, J., Tang, J., Ecoffet, A., Houghton, B., Sampedro, R., and Clune, J. (2022). Video pretraining (vpt): Learning to act by watching unlabeled online videos. ArXiv preprint, abs/2206.11795. https://arxiv.org/abs/2206.11795.
- Barreto et al. Barreto, A., Dabney, W., Munos, R., Hunt, J. J., Schaul, T., Silver, D., and van Hasselt, H. (2017). Successor features for transfer in reinforcement learning. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V. N., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 4055–4065. https://proceedings.neurips.cc/paper/2017/hash/350db081a661525235354dd3e19b8c05-Abstract.html.
- Barto and Mahadevan Barto, A. G., and Mahadevan, S. (2003). Recent advances in hierarchical reinforcement learning. Discret. Event Dyn. Syst., 13(1-2), 41–77. DOI: 10.1023/A:1022140919877.
- Baumli et al. Baumli, K., Warde-Farley, D., Hansen, S., and Mnih, V. (2021). Relative variational intrinsic control. Proceedings of the AAAI Conference on Artificial Intelligence, 35(8), 6732–6740. DOI: 10.1609/aaai.v35i8.16832.
- Bellemare et al. Bellemare, M. G., Srinivasan, S., Ostrovski, G., Schaul, T., Saxton, D., and Munos, R. (2016). Unifying count-based exploration and intrinsic motivation. In Lee, D. D., Sugiyama, M., von Luxburg, U., Guyon, I., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, pp. 1471–1479. https://proceedings.neurips.cc/paper/2016/hash/afda332245e2af431fb7b672a68b659d-Abstract.html.
- Berner et al. Berner, C., Brockman, G., Chan, B., Cheung, V., Debiak, P., Dennison, C., Farhi, D., Fischer, Q., Hashme, S., Hesse, C., Józefowicz, R., Gray, S., Olsson, C., Pachocki, J., Petrov, M., de Oliveira Pinto, H. P., Raiman, J., Salimans, T., Schlatter, J., Schneider, J., Sidor, S., Sutskever, I., Tang, J., Wolski, F., and Zhang, S. (2019). Dota 2 with large scale deep reinforcement learning. CoRR, abs/1912.06680. http://arxiv.org/abs/1912.06680.
- Bommasani et al. Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., et al. (2021). On the opportunities and risks of foundation models. ArXiv preprint, abs/2108.07258. https://arxiv.org/abs/2108.07258.
- Brown et al. Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. (2020). Language models are few-shot learners. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (Eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
- Burda et al. Burda, Y., Edwards, H., Pathak, D., Storkey, A. J., Darrell, T., and Efros, A. A. (2019a). Large-scale study of curiosity-driven learning. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum?id=rJNwDjAqYX.
- Burda et al. Burda, Y., Edwards, H., Storkey, A. J., and Klimov, O. (2019b). Exploration by random network distillation. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum?id=H1lJJnR5Ym.
- Campos et al. Campos, V., Sprechmann, P., Hansen, S. S., Barreto, A., Kapturowski, S., Vitvitskyi, A., Badia, A. P., and Blundell, C. (2021). Beyond fine-tuning: Transferring behavior in reinforcement learning. In ICML 2021 Workshop on Unsupervised Reinforcement Learning. https://openreview.net/forum?id=4NUhTHom2HZ.
- Campos et al. Campos, V., Trott, A., Xiong, C., Socher, R., Giró-i-Nieto, X., and Torres, J. (2020). Explore, discover and learn: Unsupervised discovery of state-covering skills. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Vol. 119 of Proceedings of Machine Learning Research, pp. 1317–1327. PMLR. http://proceedings.mlr.press/v119/campos20a.html.
- Castro and Precup Castro, P. S., and Precup, D. (2010). Using bisimulation for policy transfer in mdps. In Fox, M., and Poole, D. (Eds.), Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2010, Atlanta, Georgia, USA, July 11-15, 2010. AAAI Press. http://www.aaai.org/ocs/index.php/AAAI/AAAI10/paper/view/1907.
- Chebotar et al. Chebotar, Y., Hausman, K., Lu, Y., Xiao, T., Kalashnikov, D., Varley, J., Irpan, A., Eysenbach, B., Julian, R., Finn, C., and Levine, S. (2021). Actionable models: Unsupervised offline reinforcement learning of robotic skills. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Vol. 139 of Proceedings of Machine Learning Research, pp. 1518–1528. PMLR. http://proceedings.mlr.press/v139/chebotar21a.html.
- Chen et al. Chen, L., Lu, K., Rajeswaran, A., Lee, K., Grover, A., Laskin, M., Abbeel, P., Srinivas, A., and Mordatch, I. (2021a). Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34, 15084–15097.
- Chen et al. Chen, S., Zhu, M., Ye, D., Zhang, W., Fu, Q., and Yang, W. (2021b). Which heroes to pick? learning to draft in moba games with neural networks and tree search. IEEE Transactions on Games, 13(4), 410–421.
- Chen et al. Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. E. (2020). A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Vol. 119 of Proceedings of Machine Learning Research, pp. 1597–1607. PMLR. http://proceedings.mlr.press/v119/chen20j.html.
- Choi et al. Choi, J., Sharma, A., Lee, H., Levine, S., and Gu, S. S. (2021). Variational empowerment as representation learning for goal-conditioned reinforcement learning. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Vol. 139 of Proceedings of Machine Learning Research, pp. 1953–1963. PMLR. http://proceedings.mlr.press/v139/choi21b.html.
- Chowdhery et al. Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., et al. (2022). Palm: Scaling language modeling with pathways. ArXiv preprint, abs/2204.02311. https://arxiv.org/abs/2204.02311.
- Christiano et al. Christiano, P. F., Shah, Z., Mordatch, I., Schneider, J., Blackwell, T., Tobin, J., Abbeel, P., and Zaremba, W. (2016). Transfer from simulation to real world through learning deep inverse dynamics model. CoRR, abs/1610.03518. http://arxiv.org/abs/1610.03518.
- Cobbe et al. Cobbe, K., Hesse, C., Hilton, J., and Schulman, J. (2020). Leveraging procedural generation to benchmark reinforcement learning. In III, H. D., and Singh, A. (Eds.), Proceedings of the 37th International Conference on Machine Learning, Vol. 119 of Proceedings of Machine Learning Research, pp. 2048–2056. PMLR. https://proceedings.mlr.press/v119/cobbe20a.html.
- Codevilla et al. Codevilla, F., Santana, E., Lopez, A. M., and Gaidon, A. (2019). Exploring the limitations of behavior cloning for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
- Colas et al. Colas, C., Karch, T., Sigaud, O., and Oudeyer, P.-Y. (2022). Autotelic agents with intrinsically motivated goal-conditioned reinforcement learning: A short survey. J. Artif. Int. Res., 74. DOI: 10.1613/jair.1.13554.
- Dance et al. Dance, C. R., Perez, J., and Cachet, T. (2021). Demonstration-conditioned reinforcement learning for few-shot imitation. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, Vol. 139 of Proceedings of Machine Learning Research, pp. 2376–2387. PMLR. https://proceedings.mlr.press/v139/dance21a.html.
- Deng et al. Deng, J., Dong, W., Socher, R., Li, L., Li, K., and Li, F. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA, pp. 248–255. IEEE Computer Society. DOI: 10.1109/CVPR.2009.5206848.
- Devlin et al. Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics. DOI: 10.18653/v1/N19-1423.
- Dinh et al. Dinh, L., Sohl-Dickstein, J., and Bengio, S. (2017). Density estimation using real NVP. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net. https://openreview.net/forum?id=HkpbnH9lx.
- Dittadi et al. Dittadi, A., Träuble, F., Locatello, F., Wuthrich, M., Agrawal, V., Winther, O., Bauer, S., and Schölkopf, B. (2021). On the transfer of disentangled representations in realistic settings. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=8VXvj1QNRl1.
- Du et al. Du, Y., Gan, C., and Isola, P. (2021). Curious representation learning for embodied intelligence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10408–10417.
- Ecoffet et al. Ecoffet, A., Huizinga, J., Lehman, J., Stanley, K. O., and Clune, J. (2021). First return, then explore. Nature, 590(7847), 580–586.
- Efroni et al. Efroni, Y., Misra, D., Krishnamurthy, A., Agarwal, A., and Langford, J. (2021). Provable RL with exogenous distractors via multistep inverse dynamics. CoRR, abs/2110.08847. https://arxiv.org/abs/2110.08847.
- Eysenbach et al. Eysenbach, B., Chaudhari, S., Asawa, S., Levine, S., and Salakhutdinov, R. (2021). Off-dynamics reinforcement learning: Training for transfer with domain classifiers. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=eqBwg3AcIAK.
- Eysenbach et al. Eysenbach, B., Gupta, A., Ibarz, J., and Levine, S. (2019). Diversity is all you need: Learning skills without a reward function. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum?id=SJx63jRqFm.
- Eysenbach et al. Eysenbach, B., Salakhutdinov, R., and Levine, S. (2022). The information geometry of unsupervised reinforcement learning. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=3wU2UX0voE.
- Fan et al. Fan, L., Wang, G., Jiang, Y., Mandlekar, A., Yang, Y., Zhu, H., Tang, A., Huang, D.-A., Zhu, Y., and Anandkumar, A. (2022). Minedojo: Building open-ended embodied agents with internet-scale knowledge. ArXiv preprint, abs/2206.08853. https://arxiv.org/abs/2206.08853.
- Ferns et al. Ferns, N., Panangaden, P., and Precup, D. (2004). Metrics for finite markov decision processes.. In UAI, Vol. 4, pp. 162–169.
- Florence et al. Florence, P., Lynch, C., Zeng, A., Ramirez, O. A., Wahid, A., Downs, L., Wong, A., Lee, J., Mordatch, I., and Tompson, J. (2022). Implicit behavioral cloning. In Conference on Robot Learning, pp. 158–168. PMLR.
- Frank and Wolfe Frank, M., and Wolfe, P. (1956). An algorithm for quadratic programming. Naval Research Logistics Quarterly, 3(1-2), 95–110. DOI: https://doi.org/10.1002/nav.3800030109.
- Fu et al. Fu, J., Kumar, A., Nachum, O., Tucker, G., and Levine, S. (2020). D4RL: datasets for deep data-driven reinforcement learning. CoRR, abs/2004.07219. https://arxiv.org/abs/2004.07219.
- Furuta et al. Furuta, H., Matsuo, Y., and Gu, S. S. (2022). Generalized decision transformer for offline hindsight information matching. In International Conference on Learning Representations. https://openreview.net/forum?id=CAjxVodl_v.
- Gehring et al. Gehring, J., Synnaeve, G., Krause, A., and Usunier, N. (2021). Hierarchical skills for efficient exploration. Advances in Neural Information Processing Systems, 34, 11553–11564.
- Gelada et al. Gelada, C., Kumar, S., Buckman, J., Nachum, O., and Bellemare, M. G. (2019). Deepmdp: Learning continuous latent space models for representation learning. In Chaudhuri, K., and Salakhutdinov, R. (Eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, Vol. 97 of Proceedings of Machine Learning Research, pp. 2170–2179. PMLR. http://proceedings.mlr.press/v97/gelada19a.html.
- Givan et al. Givan, R., Dean, T., and Greig, M. (2003). Equivalence notions and model minimization in markov decision processes. Artificial Intelligence, 147(1-2), 163–223.
- Goodfellow and Vinyals Goodfellow, I. J., and Vinyals, O. (2015). Qualitatively characterizing neural network optimization problems. In Bengio, Y., and LeCun, Y. (Eds.), 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. http://arxiv.org/abs/1412.6544.
- Gregor et al. Gregor, K., Rezende, D. J., and Wierstra, D. (2016). Variational intrinsic control. ArXiv preprint, abs/1611.07507. https://arxiv.org/abs/1611.07507.
- Grill et al. Grill, J., Strub, F., Altché, F., Tallec, C., Richemond, P. H., Buchatskaya, E., Doersch, C., Pires, B. Á., Guo, Z., Azar, M. G., Piot, B., Kavukcuoglu, K., Munos, R., and Valko, M. (2020). Bootstrap your own latent - A new approach to self-supervised learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (Eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. https://proceedings.neurips.cc/paper/2020/hash/f3ada80d5c4ee70142b17b8192b2958e-Abstract.html.
- Gulcehre et al. Gulcehre, C., Wang, Z., Novikov, A., Paine, T., Gómez, S., Zolna, K., Agarwal, R., Merel, J. S., Mankowitz, D. J., Paduraru, C., Dulac-Arnold, G., Li, J., Norouzi, M., Hoffman, M., Heess, N., and de Freitas, N. (2020). Rl unplugged: A suite of benchmarks for offline reinforcement learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (Eds.), Advances in Neural Information Processing Systems, Vol. 33, pp. 7248–7259. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2020/file/51200d29d1fc15f5a71c1dab4bb54f7c-Paper.pdf.
- Guo et al. Guo, Z. D., Azar, M. G., Saade, A., Thakoor, S., Piot, B., Pires, B. A., Valko, M., Mesnard, T., Lattimore, T., and Munos, R. (2021). Geometric entropic exploration. ArXiv preprint, abs/2101.02055. https://arxiv.org/abs/2101.02055.
- Gupta et al. Gupta, A., Kumar, V., Lynch, C., Levine, S., and Hausman, K. (2020). Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning. In Kaelbling, L. P., Kragic, D., and Sugiura, K. (Eds.), Proceedings of the Conference on Robot Learning, Vol. 100 of Proceedings of Machine Learning Research, pp. 1025–1037. PMLR. https://proceedings.mlr.press/v100/gupta20a.html.
- Gutmann and Hyvärinen Gutmann, M., and Hyvärinen, A. (2010). Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Teh, Y. W., and Titterington, M. (Eds.), Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Vol. 9 of Proceedings of Machine Learning Research, pp. 297–304, Chia Laguna Resort, Sardinia, Italy. PMLR. https://proceedings.mlr.press/v9/gutmann10a.html.
- Ha and Schmidhuber Ha, D., and Schmidhuber, J. (2018). World models. CoRR, abs/1803.10122. http://arxiv.org/abs/1803.10122.
- Haber et al. Haber, N., Mrowca, D., Wang, S., Li, F., and Yamins, D. L. (2018). Learning to play with intrinsically-motivated, self-aware agents. In Bengio, S., Wallach, H. M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pp. 8398–8409. https://proceedings.neurips.cc/paper/2018/hash/71e63ef5b7249cfc60852f0e0f5bf4c8-Abstract.html.
- Hakhamaneshi et al. Hakhamaneshi, K., Zhao, R., Zhan, A., Abbeel, P., and Laskin, M. (2022). Hierarchical few-shot imitation with skill transition models. In International Conference on Learning Representations. https://openreview.net/forum?id=xKZ4K0lTj_.
- Hansen et al. Hansen, S., Dabney, W., Barreto, A., Warde-Farley, D., de Wiele, T. V., and Mnih, V. (2020). Fast task inference with variational intrinsic successor features. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=BJeAHkrYDS.
- Hazan et al. Hazan, E., Kakade, S. M., Singh, K., and Soest, A. V. (2019). Provably efficient maximum entropy exploration. In Chaudhuri, K., and Salakhutdinov, R. (Eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, Vol. 97 of Proceedings of Machine Learning Research, pp. 2681–2691. PMLR. http://proceedings.mlr.press/v97/hazan19a.html.
- He et al. He, J., Zhou, C., Ma, X., Berg-Kirkpatrick, T., and Neubig, G. (2022). Towards a unified view of parameter-efficient transfer learning. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=0RDcd5Axok.
- He et al. He, K., Fan, H., Wu, Y., Xie, S., and Girshick, R. B. (2020). Momentum contrast for unsupervised visual representation learning. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pp. 9726–9735. IEEE. DOI: 10.1109/CVPR42600.2020.00975.
- Hendrycks et al. Hendrycks, D., Liu, X., Wallace, E., Dziedzic, A., Krishnan, R., and Song, D. (2020a). Pretrained transformers improve out-of-distribution robustness. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 2744–2751, Online. Association for Computational Linguistics. DOI: 10.18653/v1/2020.acl-main.244.
- Hendrycks et al. Hendrycks, D., Mu, N., Cubuk, E. D., Zoph, B., Gilmer, J., and Lakshminarayanan, B. (2020b). Augmix: A simple data processing method to improve robustness and uncertainty. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=S1gmrxHFvB.
- Houlsby et al. Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., Attariyan, M., and Gelly, S. (2019). Parameter-efficient transfer learning for NLP. In Chaudhuri, K., and Salakhutdinov, R. (Eds.), Proceedings of the 36th International Conference on Machine Learning, Vol. 97 of Proceedings of Machine Learning Research, pp. 2790–2799. PMLR. https://proceedings.mlr.press/v97/houlsby19a.html.
- Houthooft et al. Houthooft, R., Chen, X., Duan, Y., Schulman, J., Turck, F. D., and Abbeel, P. (2016). VIME: variational information maximizing exploration. In Lee, D. D., Sugiyama, M., von Luxburg, U., Guyon, I., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, pp. 1109–1117. https://proceedings.neurips.cc/paper/2016/hash/abd815286ba1007abfbb8415b83ae2cf-Abstract.html.
- Huang et al. Huang, B., Feng, F., Lu, C., Magliacane, S., and Zhang, K. (2022a). Adarl: What, where, and how to adapt in transfer reinforcement learning. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=8H5bpVwvt5.
- Huang et al. Huang, W., Xia, F., Xiao, T., Chan, H., Liang, J., Florence, P., Zeng, A., Tompson, J., Mordatch, I., Chebotar, Y., et al. (2022b). Inner monologue: Embodied reasoning through planning with language models. ArXiv preprint, abs/2207.05608. https://arxiv.org/abs/2207.05608.
- Hüllermeier and Waegeman Hüllermeier, E., and Waegeman, W. (2021). Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Machine Learning, 110(3), 457–506.
- Jaegle et al. Jaegle, A., Borgeaud, S., Alayrac, J.-B., Doersch, C., Ionescu, C., Ding, D., Koppula, S., Zoran, D., Brock, A., Shelhamer, E., Henaff, O. J., Botvinick, M., Zisserman, A., Vinyals, O., and Carreira, J. (2022). Perceiver IO: A general architecture for structured inputs & outputs. In International Conference on Learning Representations. https://openreview.net/forum?id=fILj7WpI-g.
- Janner et al. Janner, M., Li, Q., and Levine, S. (2021). Offline reinforcement learning as one big sequence modeling problem. Advances in neural information processing systems, 34, 1273–1286.
- Janny et al. Janny, S., Baradel, F., Neverova, N., Nadri, M., Mori, G., and Wolf, C. (2022). Filtered-cophy: Unsupervised learning of counterfactual physics in pixel space. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=1L0C5ROtFp.
- Jin et al. Jin, C., Liu, Q., and Miryoosefi, S. (2021). Bellman eluder dimension: New rich classes of rl problems, and sample-efficient algorithms. In Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., and Vaughan, J. W. (Eds.), Advances in Neural Information Processing Systems, Vol. 34, pp. 13406–13418. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2021/file/6f5e4e86a87220e5d361ad82f1ebc335-Paper.pdf.
- Kaiser et al. Kaiser, L., Babaeizadeh, M., Milos, P., Osinski, B., Campbell, R. H., Czechowski, K., Erhan, D., Finn, C., Kozakowski, P., Levine, S., Mohiuddin, A., Sepassi, R., Tucker, G., and Michalewski, H. (2020). Model based reinforcement learning for atari. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=S1xCPJHtDB.
- Kamienny et al. Kamienny, P.-A., Tarbouriech, J., Lazaric, A., and Denoyer, L. (2022). Direct then diffuse: Incremental unsupervised skill discovery for state covering and goal reaching. In International Conference on Learning Representations. https://openreview.net/forum?id=25kzAhUB1lz.
- Kaplan et al. Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. (2020). Scaling laws for neural language models. CoRR, abs/2001.08361. https://arxiv.org/abs/2001.08361.
- Kapturowski et al. Kapturowski, S., Campos, V., Jiang, R., Rakićević, N., van Hasselt, H., Blundell, C., and Badia, A. P. (2022). Human-level atari 200x faster.. DOI: 10.48550/ARXIV.2209.07550.
- Khetarpal et al. Khetarpal, K., Riemer, M., Rish, I., and Precup, D. (2020). Towards continual reinforcement learning: A review and perspectives. CoRR, abs/2012.13490. https://arxiv.org/abs/2012.13490.
- Kingma and Welling Kingma, D. P., and Welling, M. (2014). Auto-encoding variational bayes. In Bengio, Y., and LeCun, Y. (Eds.), 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings. http://arxiv.org/abs/1312.6114.
- Kipf et al. Kipf, T., Li, Y., Dai, H., Zambaldi, V. F., Sanchez-Gonzalez, A., Grefenstette, E., Kohli, P., and Battaglia, P. W. (2019). Compile: Compositional imitation learning and execution. In Chaudhuri, K., and Salakhutdinov, R. (Eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, Vol. 97 of Proceedings of Machine Learning Research, pp. 3418–3428. PMLR. http://proceedings.mlr.press/v97/kipf19a.html.
- Kirk et al. Kirk, R., Zhang, A., Grefenstette, E., and Rocktäschel, T. (2021). A survey of generalisation in deep reinforcement learning. CoRR, abs/2111.09794. https://arxiv.org/abs/2111.09794.
- Kollar et al. Kollar, T., Tellex, S., Roy, D., and Roy, N. (2010). Toward understanding natural language directions. In 2010 5th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pp. 259–266. DOI: 10.1109/HRI.2010.5453186.
- Kontoyiannis et al. Kontoyiannis, I., Algoet, P., Suhov, Y., and Wyner, A. (1998). Nonparametric entropy estimation for stationary processes and random fields, with applications to english text. IEEE Transactions on Information Theory, 44(3), 1319–1327. DOI: 10.1109/18.669425.
- Kostrikov et al. Kostrikov, I., Nair, A., and Levine, S. (2022). Offline reinforcement learning with implicit q-learning. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=68n2s9ZJWF8.
- Kulkarni et al. Kulkarni, T. D., Narasimhan, K., Saeedi, A., and Tenenbaum, J. (2016). Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems, Vol. 29. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2016/file/f442d33fa06832082290ad8544a8da27-Paper.pdf.
- Kumar et al. Kumar, A., Fu, J., Soh, M., Tucker, G., and Levine, S. (2019). Stabilizing off-policy q-learning via bootstrapping error reduction. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems, Vol. 32. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2019/file/c2073ffa77b5357a498057413bb09d3a-Paper.pdf.
- Kumar et al. Kumar, A., Zhou, A., Tucker, G., and Levine, S. (2020). Conservative q-learning for offline reinforcement learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (Eds.), Advances in Neural Information Processing Systems, Vol. 33, pp. 1179–1191. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2020/file/0d2b2061826a5df3221116a5085a6052-Paper.pdf.
- Lambert et al. Lambert, N., Wulfmeier, M., Whitney, W., Byravan, A., Bloesch, M., Dasagi, V., Hertweck, T., and Riedmiller, M. (2022). The challenges of exploration for offline reinforcement learning. ArXiv preprint, abs/2201.11861. https://arxiv.org/abs/2201.11861.
- Lange et al. Lange, S., Gabel, T., and Riedmiller, M. (2012). Batch reinforcement learning. In Reinforcement learning, pp. 45–73. Springer.
- Lange and Riedmiller Lange, S., and Riedmiller, M. A. (2010). Deep auto-encoder neural networks in reinforcement learning. In International Joint Conference on Neural Networks, IJCNN 2010, Barcelona, Spain, 18-23 July, 2010, pp. 1–8. IEEE. DOI: 10.1109/IJCNN.2010.5596468.
- Larsen and Skou Larsen, K. G., and Skou, A. (1991). Bisimulation through probabilistic testing. Information and computation, 94(1), 1–28.
- Laskin et al. Laskin, M., Liu, H., Peng, X. B., Yarats, D., Rajeswaran, A., and Abbeel, P. (2022). CIC: contrastive intrinsic control for unsupervised skill discovery. CoRR, abs/2202.00161. https://arxiv.org/abs/2202.00161.
- Laskin et al. Laskin, M., Srinivas, A., and Abbeel, P. (2020). CURL: contrastive unsupervised representations for reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Vol. 119 of Proceedings of Machine Learning Research, pp. 5639–5650. PMLR. http://proceedings.mlr.press/v119/laskin20a.html.
- Laskin et al. Laskin, M., Yarats, D., Liu, H., Lee, K., Zhan, A., Lu, K., Cang, C., Pinto, L., and Abbeel, P. (2021). Urlb: Unsupervised reinforcement learning benchmark. ArXiv preprint, abs/2110.15191. https://arxiv.org/abs/2110.15191.
- LeCun et al. LeCun, Y., Chopra, S., Hadsell, R., Ranzato, M., and Huang, F. (2006). A tutorial on energy-based learning. Predicting structured data, 1(0).
- Lee et al. Lee, K.-H., Nachum, O., Yang, M., Lee, L., Freeman, D., Xu, W., Guadarrama, S., Fischer, I., Jang, E., Michalewski, H., et al. (2022). Multi-game decision transformers. ArXiv preprint, abs/2205.15241. https://arxiv.org/abs/2205.15241.
- Lee et al. Lee, L., Eysenbach, B., Parisotto, E., Xing, E., Levine, S., and Salakhutdinov, R. (2019). Efficient exploration via state marginal matching. ArXiv preprint, abs/1906.05274. https://arxiv.org/abs/1906.05274.
- Lee et al. Lee, S., Seo, Y., Lee, K., Abbeel, P., and Shin, J. (2022). Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble. In Conference on Robot Learning, pp. 1702–1712. PMLR.
- Lester et al. Lester, B., Al-Rfou, R., and Constant, N. (2021). The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics. DOI: 10.18653/v1/2021.emnlp-main.243.
- Levine Levine, S. (2021). Understanding the world through action. In 5th Annual Conference on Robot Learning, Blue Sky Submission Track. https://openreview.net/forum?id=L55-yn1iwrm.
- Levine et al. Levine, S., Kumar, A., Tucker, G., and Fu, J. (2020). Offline reinforcement learning: Tutorial, review, and perspectives on open problems. ArXiv preprint, abs/2005.01643. https://arxiv.org/abs/2005.01643.
- Li et al. Li, C., Wang, T., Wu, C., Zhao, Q., Yang, J., and Zhang, C. (2021). Celebrating diversity in shared multi-agent reinforcement learning. In Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., and Vaughan, J. W. (Eds.), Advances in Neural Information Processing Systems, Vol. 34, pp. 3991–4002. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2021/file/20aee3a5f4643755a79ee5f6a73050ac-Paper.pdf.
- Li et al. Li, L., Walsh, T. J., and Littman, M. L. (2006). Towards a unified theory of state abstraction for mdps.. In AI&M.
- Li et al. Li, S., Du, Y., Tenenbaum, J. B., Torralba, A., and Mordatch, I. (2022a). Composing ensembles of pre-trained models via iterative consensus. CoRR, abs/2210.11522. DOI: 10.48550/arXiv.2210.11522.
- Li et al. Li, S., Puig, X., Du, Y., Wang, C., Akyurek, E., Torralba, A., Andreas, J., and Mordatch, I. (2022b). Pre-trained language models for interactive decision-making. ArXiv preprint, abs/2202.01771. https://arxiv.org/abs/2202.01771.
- Liu and Abbeel Liu, H., and Abbeel, P. (2021a). APS: active pretraining with successor features. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Vol. 139 of Proceedings of Machine Learning Research, pp. 6736–6747. PMLR. http://proceedings.mlr.press/v139/liu21b.html.
- Liu and Abbeel Liu, H., and Abbeel, P. (2021b). Behavior from the void: Unsupervised active pre-training. Advances in Neural Information Processing Systems, 34, 18459–18473.
- Lu et al. Lu, J., Batra, D., Parikh, D., and Lee, S. (2019). Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems, Vol. 32. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2019/file/c74d97b01eae257e44aa9d5bade97baf-Paper.pdf.
- Lu et al. Lu, K., Grover, A., Abbeel, P., and Mordatch, I. (2021a). Pretrained transformers as universal computation engines. ArXiv preprint, abs/2103.05247. https://arxiv.org/abs/2103.05247.
- Lu et al. Lu, K., Grover, A., Abbeel, P., and Mordatch, I. (2021b). Reset-free lifelong learning with skill-space planning. In International Conference on Learning Representations. https://openreview.net/forum?id=HIGSa_3kOx3.
- Lu et al. Lu, Y., Hausman, K., Chebotar, Y., Yan, M., Jang, E., Herzog, A., Xiao, T., Irpan, A., Khansari, M., Kalashnikov, D., and Levine, S. (2022). Aw-opt: Learning robotic skills with imitation and reinforcement at scale. In Faust, A., Hsu, D., and Neumann, G. (Eds.), Proceedings of the 5th Conference on Robot Learning, Vol. 164 of Proceedings of Machine Learning Research, pp. 1078–1088. PMLR. https://proceedings.mlr.press/v164/lu22a.html.
- Lynch et al. Lynch, C., Khansari, M., Xiao, T., Kumar, V., Tompson, J., Levine, S., and Sermanet, P. (2020). Learning latent plans from play. In Conference on robot learning, pp. 1113–1132. PMLR.
- Mahmoudieh et al. Mahmoudieh, P., Pathak, D., and Darrell, T. (2022). Zero-shot reward specification via grounded natural language. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., and Sabato, S. (Eds.), Proceedings of the 39th International Conference on Machine Learning, Vol. 162 of Proceedings of Machine Learning Research, pp. 14743–14752. PMLR. https://proceedings.mlr.press/v162/mahmoudieh22a.html.
- Mavor-Parker et al. Mavor-Parker, A., Young, K., Barry, C., and Griffin, L. (2022). How to stay curious while avoiding noisy tvs using aleatoric uncertainty estimation. In International Conference on Machine Learning, pp. 15220–15240. PMLR.
- Mazoure et al. Mazoure, B., des Combes, R. T., Doan, T., Bachman, P., and Hjelm, R. D. (2020). Deep reinforcement and infomax learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (Eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. https://proceedings.neurips.cc/paper/2020/hash/26588e932c7ccfa1df309280702fe1b5-Abstract.html.
- Meng et al. Meng, L., Wen, M., Yang, Y., Le, C., Li, X., Zhang, W., Wen, Y., Zhang, H., Wang, J., and Xu, B. (2021). Offline pre-trained multi-agent decision transformer: One big sequence model tackles all SMAC tasks. CoRR, abs/2112.02845. https://arxiv.org/abs/2112.02845.
- Misra et al. Misra, D., Henaff, M., Krishnamurthy, A., and Langford, J. (2020). Kinematic state abstraction and provably efficient rich-observation reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Vol. 119 of Proceedings of Machine Learning Research, pp. 6961–6971. PMLR. http://proceedings.mlr.press/v119/misra20a.html.
- Mustafa et al. Mustafa, B., Riquelme, C., Puigcerver, J., Jenatton, R., and Houlsby, N. (2022). Multimodal contrastive learning with limoe: the language-image mixture of experts. CoRR, abs/2206.02770. DOI: 10.48550/arXiv.2206.02770.
- Mutti et al. Mutti, M., Pratissoli, L., and Restelli, M. (2020). A policy gradient method for task-agnostic exploration. In 4th Lifelong Machine Learning Workshop at ICML 2020. https://openreview.net/forum?id=d9j_RNHtQEo.
- Nachum et al. Nachum, O., Gu, S., Lee, H., and Levine, S. (2019). Near-optimal representation learning for hierarchical reinforcement learning. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum?id=H1emus0qF7.
- Nair et al. Nair, A., Dalal, M., Gupta, A., and Levine, S. (2020). Accelerating online reinforcement learning with offline datasets. ArXiv preprint, abs/2006.09359. https://arxiv.org/abs/2006.09359.
- Ndousse et al. Ndousse, K. K., Eck, D., Levine, S., and Jaques, N. (2021). Emergent social learning via multi-agent reinforcement learning. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, Vol. 139 of Proceedings of Machine Learning Research, pp. 7991–8004. PMLR. https://proceedings.mlr.press/v139/ndousse21a.html.
- Ostrovski et al. Ostrovski, G., Bellemare, M. G., van den Oord, A., and Munos, R. (2017). Count-based exploration with neural density models. In Precup, D., and Teh, Y. W. (Eds.), Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, Vol. 70 of Proceedings of Machine Learning Research, pp. 2721–2730. PMLR. http://proceedings.mlr.press/v70/ostrovski17a.html.
- Oudeyer et al. Oudeyer, P.-Y., Kaplan, F., and Hafner, V. V. (2007). Intrinsic motivation systems for autonomous mental development. IEEE transactions on evolutionary computation, 11(2), 265–286.
- Parisi et al. Parisi, S., Rajeswaran, A., Purushwalkam, S., and Gupta, A. (2022). The unsurprising effectiveness of pre-trained vision models for control. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., and Sabato, S. (Eds.), Proceedings of the 39th International Conference on Machine Learning, Vol. 162 of Proceedings of Machine Learning Research, pp. 17359–17371. PMLR. https://proceedings.mlr.press/v162/parisi22a.html.
- Park et al. Park, S., Choi, J., Kim, J., Lee, H., and Kim, G. (2022). Lipschitz-constrained unsupervised skill discovery. In International Conference on Learning Representations. https://openreview.net/forum?id=BGvt0ghNgA.
- Pathak et al. Pathak, D., Agrawal, P., Efros, A. A., and Darrell, T. (2017). Curiosity-driven exploration by self-supervised prediction. In Precup, D., and Teh, Y. W. (Eds.), Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, Vol. 70 of Proceedings of Machine Learning Research, pp. 2778–2787. PMLR. http://proceedings.mlr.press/v70/pathak17a.html.
- Pathak et al. Pathak, D., Gandhi, D., and Gupta, A. (2019). Self-supervised exploration via disagreement. In Chaudhuri, K., and Salakhutdinov, R. (Eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, Vol. 97 of Proceedings of Machine Learning Research, pp. 5062–5071. PMLR. http://proceedings.mlr.press/v97/pathak19a.html.
- Pertsch et al. Pertsch, K., Lee, Y., and Lim, J. (2021a). Accelerating reinforcement learning with learned skill priors. In Kober, J., Ramos, F., and Tomlin, C. (Eds.), Proceedings of the 2020 Conference on Robot Learning, Vol. 155 of Proceedings of Machine Learning Research, pp. 188–204. PMLR. https://proceedings.mlr.press/v155/pertsch21a.html.
- Pertsch et al. Pertsch, K., Lee, Y., Wu, Y., and Lim, J. J. (2021b). Demonstration-guided reinforcement learning with learned skills. In 5th Annual Conference on Robot Learning. https://openreview.net/forum?id=JSC4KMlENqF.
- Pomerleau Pomerleau, D. A. (1988). Alvinn: An autonomous land vehicle in a neural network. Advances in neural information processing systems, 1.
- Pong et al. Pong, V., Dalal, M., Lin, S., Nair, A., Bahl, S., and Levine, S. (2020). Skew-fit: State-covering self-supervised reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Vol. 119 of Proceedings of Machine Learning Research, pp. 7783–7792. PMLR. http://proceedings.mlr.press/v119/pong20a.html.
- Poole et al. Poole, B., Ozair, S., Van Den Oord, A., Alemi, A., and Tucker, G. (2019). On variational bounds of mutual information. In Chaudhuri, K., and Salakhutdinov, R. (Eds.), Proceedings of the 36th International Conference on Machine Learning, Vol. 97 of Proceedings of Machine Learning Research, pp. 5171–5180. PMLR. https://proceedings.mlr.press/v97/poole19a.html.
- Radford et al. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. (2021). Learning transferable visual models from natural language supervision. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Vol. 139 of Proceedings of Machine Learning Research, pp. 8748–8763. PMLR. http://proceedings.mlr.press/v139/radford21a.html.
- Raffel Raffel, C. (2021). A call to build models like we build open-source software.. https://colinraffel.com/blog/a-call-to-build-models-like-we-build-open-source-software.html.
- Rajeswaran et al. Rajeswaran, A., Kumar, V., Gupta, A., Vezzani, G., Schulman, J., Todorov, E., and Levine, S. (2018). Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. In Kress-Gazit, H., Srinivasa, S. S., Howard, T., and Atanasov, N. (Eds.), Robotics: Science and Systems XIV, Carnegie Mellon University, Pittsburgh, Pennsylvania, USA, June 26-30, 2018. DOI: 10.15607/RSS.2018.XIV.049.
- Rakelly et al. Rakelly, K., Gupta, A., Florensa, C., and Levine, S. (2021). Which mutual-information representation learning objectives are sufficient for control?. Advances in Neural Information Processing Systems, 34, 26345–26357.
- Rashid et al. Rashid, T., Peng, B., Boehmer, W., and Whiteson, S. (2020). Optimistic exploration even with a pessimistic initialisation. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=r1xGP6VYwH.
- Reed et al. Reed, S., Zolna, K., Parisotto, E., Colmenarejo, S. G., Novikov, A., Barth-Maron, G., Gimenez, M., Sulsky, Y., Kay, J., Springenberg, J. T., et al. (2022). A generalist agent. ArXiv preprint, abs/2205.06175. https://arxiv.org/abs/2205.06175.
- Reid et al. Reid, M., Yamada, Y., and Gu, S. S. (2022). Can wikipedia help offline reinforcement learning?. ArXiv preprint, abs/2201.12122. https://arxiv.org/abs/2201.12122.
- Ross et al. Ross, S., Gordon, G., and Bagnell, D. (2011). A reduction of imitation learning and structured prediction to no-regret online learning. In Gordon, G., Dunson, D., and Dudík, M. (Eds.), Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Vol. 15 of Proceedings of Machine Learning Research, pp. 627–635, Fort Lauderdale, FL, USA. PMLR. https://proceedings.mlr.press/v15/ross11a.html.
- Rusu et al. Rusu, A. A., Rabinowitz, N. C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., and Hadsell, R. (2016). Progressive neural networks. CoRR, abs/1606.04671. http://arxiv.org/abs/1606.04671.
- Schmidhuber Schmidhuber, J. (1991). Curious model-building control systems. In Proc. international joint conference on neural networks, pp. 1458–1463.
- Schmitt et al. Schmitt, S., Hudson, J. J., Zídek, A., Osindero, S., Doersch, C., Czarnecki, W. M., Leibo, J. Z., Küttler, H., Zisserman, A., Simonyan, K., and Eslami, S. M. A. (2018). Kickstarting deep reinforcement learning. CoRR, abs/1803.03835. http://arxiv.org/abs/1803.03835.
- Schwarzer et al. Schwarzer, M., Anand, A., Goel, R., Hjelm, R. D., Courville, A. C., and Bachman, P. (2021a). Data-efficient reinforcement learning with self-predictive representations. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=uCQfPZwRaUu.
- Schwarzer et al. Schwarzer, M., Rajkumar, N., Noukhovitch, M., Anand, A., Charlin, L., Hjelm, R. D., Bachman, P., and Courville, A. C. (2021b). Pretraining representations for data-efficient reinforcement learning. Advances in Neural Information Processing Systems, 34, 12686–12699.
- Sekar et al. Sekar, R., Rybkin, O., Daniilidis, K., Abbeel, P., Hafner, D., and Pathak, D. (2020). Planning to explore via self-supervised world models. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Vol. 119 of Proceedings of Machine Learning Research, pp. 8583–8592. PMLR. http://proceedings.mlr.press/v119/sekar20a.html.
- Seo et al. Seo, Y., Chen, L., Shin, J., Lee, H., Abbeel, P., and Lee, K. (2021). State entropy maximization with random encoders for efficient exploration. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Vol. 139 of Proceedings of Machine Learning Research, pp. 9443–9454. PMLR. http://proceedings.mlr.press/v139/seo21a.html.
- Seo et al. Seo, Y., Lee, K., James, S., and Abbeel, P. (2022). Reinforcement learning with action-free pre-training from videos. ArXiv preprint, abs/2203.13880. https://arxiv.org/abs/2203.13880.
- Sermanet et al. Sermanet, P., Lynch, C., Chebotar, Y., Hsu, J., Jang, E., Schaal, S., Levine, S., and Brain, G. (2018). Time-contrastive networks: Self-supervised learning from video. In 2018 IEEE international conference on robotics and automation (ICRA), pp. 1134–1141. IEEE.
- Shah and Kumar Shah, R. M., and Kumar, V. (2021). RRL: resnet as representation for reinforcement learning. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Vol. 139 of Proceedings of Machine Learning Research, pp. 9465–9476. PMLR. http://proceedings.mlr.press/v139/shah21a.html.
- Shankar and Gupta Shankar, T., and Gupta, A. (2020). Learning robot skills with temporal variational inference. In III, H. D., and Singh, A. (Eds.), Proceedings of the 37th International Conference on Machine Learning, Vol. 119 of Proceedings of Machine Learning Research, pp. 8624–8633. PMLR. https://proceedings.mlr.press/v119/shankar20b.html.
- Shankar et al. Shankar, T., Tulsiani, S., Pinto, L., and Gupta, A. (2020). Discovering motor programs by recomposing demonstrations. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=rkgHY0NYwr.
- Sharma et al. Sharma, A., Gu, S., Levine, S., Kumar, V., and Hausman, K. (2020). Dynamics-aware unsupervised discovery of skills. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=HJgLZR4KvH.
- Siegel et al. Siegel, N., Springenberg, J. T., Berkenkamp, F., Abdolmaleki, A., Neunert, M., Lampe, T., Hafner, R., Heess, N., and Riedmiller, M. (2020). Keep doing what worked: Behavior modelling priors for offline reinforcement learning. In International Conference on Learning Representations. https://openreview.net/forum?id=rke7geHtwH.
- Silver et al. Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., et al. (2016). Mastering the game of go with deep neural networks and tree search. nature, 529(7587), 484–489.
- Silvia Silvia, P. J. (2012). Curiosity and Motivation. In The Oxford Handbook of Human Motivation. Oxford University Press. DOI: 10.1093/oxfordhb/9780195399820.013.0010.
- Singh et al. Singh, A., Liu, H., Zhou, G., Yu, A., Rhinehart, N., and Levine, S. (2021). Parrot: Data-driven behavioral priors for reinforcement learning. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=Ysuv-WOFeKR.
- Singh et al. Singh, S. P., Barto, A. G., and Chentanez, N. (2004). Intrinsically motivated reinforcement learning. In Advances in Neural Information Processing Systems 17 [Neural Information Processing Systems, NIPS 2004, December 13-18, 2004, Vancouver, British Columbia, Canada], pp. 1281–1288. https://proceedings.neurips.cc/paper/2004/hash/4be5a36cbaca8ab9d2066debfe4e65c1-Abstract.html.
- Smith and Gasser Smith, L., and Gasser, M. (2005). The development of embodied cognition: Six lessons from babies. Artificial life, 11(1-2), 13–29.
- Srinivas and Abbeel Srinivas, A., and Abbeel, P. (2021). Unsupervised learning for reinforcement learning.. https://icml.cc/media/icml-2021/Slides/10843_QHaHBNU.pdf.
- Stadie et al. Stadie, B. C., Levine, S., and Abbeel, P. (2015). Incentivizing exploration in reinforcement learning with deep predictive models. ArXiv preprint, abs/1507.00814. https://arxiv.org/abs/1507.00814.
- Stooke et al. Stooke, A., Lee, K., Abbeel, P., and Laskin, M. (2021). Decoupling representation learning from reinforcement learning. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Vol. 139 of Proceedings of Machine Learning Research, pp. 9870–9879. PMLR. http://proceedings.mlr.press/v139/stooke21a.html.
- Strehl and Littman Strehl, A. L., and Littman, M. L. (2008). An analysis of model-based interval estimation for markov decision processes. Journal of Computer and System Sciences, 74(8), 1309–1331.
- Sutton Sutton, R. (2019). The bitter lesson. Incomplete Ideas (blog), 13, 12.
- Sutton and Barto Sutton, R. S., and Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.
- Tam et al. Tam, A. C., Rabinowitz, N. C., Lampinen, A. K., Roy, N. A., Chan, S. C., Strouse, D., Wang, J. X., Banino, A., and Hill, F. (2022). Semantic exploration from language abstractions and pretrained representations. ArXiv preprint, abs/2204.05080. https://arxiv.org/abs/2204.05080.
- Tang et al. Tang, H., Houthooft, R., Foote, D., Stooke, A., Chen, X., Duan, Y., Schulman, J., Turck, F. D., and Abbeel, P. (2017). #exploration: A study of count-based exploration for deep reinforcement learning. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V. N., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 2753–2762. https://proceedings.neurips.cc/paper/2017/hash/3a20f62a0af1aa152670bab3c602feed-Abstract.html.
- Tao et al. Tao, R. Y., Francois-Lavet, V., and Pineau, J. (2020). Novelty search in representational space for sample efficient exploration. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (Eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. https://proceedings.neurips.cc/paper/2020/hash/5ca41a86596a5ed567d15af0be224952-Abstract.html.
- Tarbouriech and Lazaric Tarbouriech, J., and Lazaric, A. (2019). Active exploration in markov decision processes. In Chaudhuri, K., and Sugiyama, M. (Eds.), The 22nd International Conference on Artificial Intelligence and Statistics, AISTATS 2019, 16-18 April 2019, Naha, Okinawa, Japan, Vol. 89 of Proceedings of Machine Learning Research, pp. 974–982. PMLR. http://proceedings.mlr.press/v89/tarbouriech19a.html.
- Tassa et al. Tassa, Y., Doron, Y., Muldal, A., Erez, T., Li, Y., de Las Casas, D., Budden, D., Abdolmaleki, A., Merel, J., Lefrancq, A., Lillicrap, T. P., and Riedmiller, M. A. (2018). Deepmind control suite. CoRR, abs/1801.00690. http://arxiv.org/abs/1801.00690.
- Tellex et al. Tellex, S., Kollar, T., Dickerson, S., Walter, M., Banerjee, A., Teller, S., and Roy, N. (2011). Understanding natural language commands for robotic navigation and mobile manipulation. Proceedings of the AAAI Conference on Artificial Intelligence, 25(1), 1507–1514. DOI: 10.1609/aaai.v25i1.7979.
- Träuble et al. Träuble, F., Dittadi, A., Wuthrich, M., Widmaier, F., Gehler, P. V., Winther, O., Locatello, F., Bachem, O., Schölkopf, B., and Bauer, S. (2022). The role of pretrained representations for the OOD generalization of RL agents. In International Conference on Learning Representations. https://openreview.net/forum?id=8eb12UQYxrG.
- van den Oord et al. van den Oord, A., Li, Y., and Vinyals, O. (2018). Representation learning with contrastive predictive coding. CoRR, abs/1807.03748. http://arxiv.org/abs/1807.03748.
- Vaswani et al. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. u., and Polosukhin, I. (2017). Attention is all you need. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
- Vinyals et al. Vinyals, O., Babuschkin, I., Czarnecki, W. M., Mathieu, M., Dudzik, A., Chung, J., Choi, D. H., Powell, R., Ewalds, T., Georgiev, P., et al. (2019). Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature, 575(7782), 350–354.
- Wang et al. Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. (2019). GLUE: A multi-task benchmark and analysis platform for natural language understanding. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum?id=rJ4km2R5t7.
- Wang et al. Wang, W., Bao, H., Dong, L., Bjorck, J., Peng, Z., Liu, Q., Aggarwal, K., Mohammed, O. K., Singhal, S., Som, S., and Wei, F. (2022). Image as a foreign language: Beit pretraining for all vision and vision-language tasks. CoRR, abs/2208.10442. DOI: 10.48550/arXiv.2208.10442.
- Warde-Farley et al. Warde-Farley, D., de Wiele, T. V., Kulkarni, T. D., Ionescu, C., Hansen, S., and Mnih, V. (2019). Unsupervised control through non-parametric discriminative rewards. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum?id=r1eVMnA9K7.
- Watter et al. Watter, M., Springenberg, J., Boedecker, J., and Riedmiller, M. (2015). Embed to control: A locally linear latent dynamics model for control from raw images. In Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., and Garnett, R. (Eds.), Advances in Neural Information Processing Systems, Vol. 28. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2015/file/a1afc58c6ca9540d057299ec3016d726-Paper.pdf.
- Wei et al. Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V. (2022). Finetuned language models are zero-shot learners. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=gEZrGCozdqR.
- Xiao et al. Xiao, T., Radosavovic, I., Darrell, T., and Malik, J. (2022). Masked visual pre-training for motor control. ArXiv preprint, abs/2203.06173. https://arxiv.org/abs/2203.06173.
- Xu et al. Xu, K., Verma, S., Finn, C., and Levine, S. (2020). Continual learning of control primitives : Skill discovery via reset-games. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (Eds.), Advances in Neural Information Processing Systems, Vol. 33, pp. 4999–5010. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2020/file/3472ab80b6dff70c54758fd6dfc800c2-Paper.pdf.
- Xu et al. Xu, M., Shen, Y., Zhang, S., Lu, Y., Zhao, D., Tenenbaum, B. J., and Gan, C. (2022). Prompting decision transformer for few-shot policy generalization. In Thirty-ninth International Conference on Machine Learning.
- Yamada et al. Yamada, J., Pertsch, K., Gunjal, A., and Lim, J. J. (2022). Task-induced representation learning. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=OzyXtIZAzFv.
- Yang et al. Yang, M., Levine, S., and Nachum, O. (2022). TRAIL: Near-optimal imitation learning with suboptimal data. In International Conference on Learning Representations. https://openreview.net/forum?id=6q_2b6u0BnJ.
- Yang and Nachum Yang, M., and Nachum, O. (2021). Representation matters: Offline pretraining for sequential decision making. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Vol. 139 of Proceedings of Machine Learning Research, pp. 11784–11794. PMLR. http://proceedings.mlr.press/v139/yang21h.html.
- Yarats et al. Yarats, D., Brandfonbrener, D., Liu, H., Laskin, M., Abbeel, P., Lazaric, A., and Pinto, L. (2022). Don’t change the algorithm, change the data: Exploratory data for offline reinforcement learning. In ICLR 2022 Workshop on Generalizable Policy Learning in Physical World. https://openreview.net/forum?id=Su-zh4a41Z5.
- Yarats et al. Yarats, D., Fergus, R., Lazaric, A., and Pinto, L. (2021). Reinforcement learning with prototypical representations. In Meila, M., and Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Vol. 139 of Proceedings of Machine Learning Research, pp. 11920–11931. PMLR. http://proceedings.mlr.press/v139/yarats21a.html.
- Ye et al. Ye, D., Chen, G., Zhang, W., Chen, S., Yuan, B., Liu, B., Chen, J., Liu, Z., Qiu, F., Yu, H., Yin, Y., Shi, B., Wang, L., Shi, T., Fu, Q., Yang, W., Huang, L., and Liu, W. (2020). Towards playing full MOBA games with deep reinforcement learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (Eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. https://proceedings.neurips.cc/paper/2020/hash/06d5ae105ea1bea4d800bc96491876e9-Abstract.html.
- Ye et al. Ye, D., Chen, G., Zhao, P., Qiu, F., Yuan, B., Zhang, W., Chen, S., Sun, M., Li, X., Li, S., Liang, J., Lian, Z., Shi, B., Wang, L., Shi, T., Fu, Q., Yang, W., and Huang, L. (2022). Supervised learning achieves human-level performance in MOBA games: A case study of honor of kings. IEEE Trans. Neural Networks Learn. Syst., 33(3), 908–918. DOI: 10.1109/TNNLS.2020.3029475.
- Ye et al. Ye, D., Liu, Z., Sun, M., Shi, B., Zhao, P., Wu, H., Yu, H., Yang, S., Wu, X., Guo, Q., Chen, Q., Yin, Y., Zhang, H., Shi, T., Wang, L., Fu, Q., Yang, W., and Huang, L. (2020). Mastering complex control in MOBA games with deep reinforcement learning. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020, pp. 6672–6679. AAAI Press. https://ojs.aaai.org/index.php/AAAI/article/view/6144.
- Yu et al. Yu, T., Kumar, S., Gupta, A., Levine, S., Hausman, K., and Finn, C. (2020). Gradient surgery for multi-task learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (Eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. https://proceedings.neurips.cc/paper/2020/hash/3fe78a8acf5fda99de95303940a2420c-Abstract.html.
- Zhan et al. Zhan, A., Zhao, P., Pinto, L., Abbeel, P., and Laskin, M. (2020). A framework for efficient robotic manipulation. ArXiv preprint, abs/2012.07975. https://arxiv.org/abs/2012.07975.
- Zhang et al. Zhang, A., Ballas, N., and Pineau, J. (2018). A dissection of overfitting and generalization in continuous reinforcement learning. CoRR, abs/1806.07937. http://arxiv.org/abs/1806.07937.
- Zhang et al. Zhang, A., McAllister, R. T., Calandra, R., Gal, Y., and Levine, S. (2021a). Learning invariant representations for reinforcement learning without reconstruction. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=-2FCwDKRREu.
- Zhang et al. Zhang, C., Cai, Y., Huang, L., and Li, J. (2021b). Exploration by maximizing rényi entropy for reward-free rl framework. In Proceedings of the AAAI Conference on Artificial Intelligence, pp. 10859–10867.
- Zhang et al. Zhang, J., Yu, H., and Xu, W. (2021c). Hierarchical reinforcement learning by discovering intrinsic options. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=r-gPPHEjpmw.
- Zhang et al. Zhang, K., Yang, Z., and Basar, T. (2019). Multi-agent reinforcement learning: A selective overview of theories and algorithms. CoRR, abs/1911.10635. http://arxiv.org/abs/1911.10635.
- Zhang et al. Zhang, Q., Peng, Z., and Zhou, B. (2022). Learning to drive by watching youtube videos: Action-conditioned contrastive policy pretraining.. DOI: 10.48550/ARXIV.2204.02393.
- Zhang et al. Zhang, T., McCarthy, Z., Jow, O., Lee, D., Chen, X., Goldberg, K., and Abbeel, P. (2018). Deep imitation learning for complex manipulation tasks from virtual reality teleoperation. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 5628–5635. DOI: 10.1109/ICRA.2018.8461249.
- Zhang et al. Zhang, W., GX-Chen, A., Sobal, V., LeCun, Y., and Carion, N. (2022a). Light-weight probing of unsupervised representations for reinforcement learning. CoRR, abs/2208.12345. DOI: 10.48550/arXiv.2208.12345.
- Zhang et al. Zhang, X., Song, Y., Uehara, M., Wang, M., Agarwal, A., and Sun, W. (2022b). Efficient reinforcement learning in block MDPs: A model-free representation learning approach. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., and Sabato, S. (Eds.), Proceedings of the 39th International Conference on Machine Learning, Vol. 162 of Proceedings of Machine Learning Research, pp. 26517–26547. PMLR. https://proceedings.mlr.press/v162/zhang22aa.html.
- Zheng et al. Zheng, Q., Zhang, A., and Grover, A. (2022). Online decision transformer. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., and Sabato, S. (Eds.), Proceedings of the 39th International Conference on Machine Learning, Vol. 162 of Proceedings of Machine Learning Research, pp. 27042–27059. PMLR. https://proceedings.mlr.press/v162/zheng22c.html.
- Zhu et al. Zhu, Y., Wang, Z., Merel, J., Rusu, A., Erez, T., Cabi, S., Tunyasuvunakool, S., Kramár, J., Hadsell, R., de Freitas, N., and Heess, N. (2018). Reinforcement and imitation learning for diverse visuomotor skills. In Proceedings of Robotics: Science and Systems, Pittsburgh, Pennsylvania. DOI: 10.15607/RSS.2018.XIV.009.