Predictive Modeling through Hyper-Bayesian Optimization
Abstract
Model selection is an integral problem of model based optimization techniques such as Bayesian optimization (BO). Current approaches often treat model selection as an estimation problem, to be periodically updated with observations coming from the optimization iterations. In this paper, we propose an alternative way to achieve both efficiently. Specifically, we propose a novel way of integrating model selection and BO for the single goal of reaching the function optima faster. The algorithm moves back and forth between BO in the model space and BO in the function space, where the goodness of the recommended model is captured by a score function and fed back, capturing how well the model helped convergence in the function space. The score function is derived in such a way that it neutralizes the effect of the moving nature of the BO in the function space, thus keeping the model selection problem stationary. This back and forth leads to quick convergence for both model selection and BO in the function space. In addition to improved sample efficiency, the framework outputs information about the black-box function. Convergence is proved, and experimental results show significant improvement compared to standard BO.
1 Introduction
In cognitive science, “Predictive process modeling” is used as a plausible biological model of the brain Clark2013; Clark2015a. The mind is depicted as a multi-layer prediction machine performing top-down predictions of the world that are met with bottom-up streams of sensory data. The top layers are continuously predicting what is about to be sensed. The model is refined or altered to fit the incoming signals, and this “dance” continues until “equilibrium” is reached.

We draw inspiration from this idea and present the Predictive Modeling Framework, integrating model selection and Bayesian Optimization (BO) to accelerate finding the function optimum (Figure 1). Our framework uses a top level model generator (HyperBO) which is modeled through BO, an efficient method for global optimization of expensive and noisy black-box functions DBLP:journals/corr/abs-1012-2599; Snoek2012; Freitas2015. It searches in the model space, recommending hyperparameters () for the underlying BO modeling the function space. The algorithm moves between BO in the model space and BO in the function space, where the recommended model’s goodness is fed back using a score function that captures how well the model helped convergence in the function space. The score function is a key feature as it is able to offset for the moving nature of BO in the function space. This back and forth leads to quick convergence for both model selection and function optimisation, keeping the stationarity of HyperBO. The framework improves sample efficiency and outputs information about the black-box. Existing convergence analysis of BO algorithms assume an optimal model. We prove convergence w.r.t. a changing model, being optimised alongside the optima search. Our framework is evaluated on five real world regression problems. The model selection involves finding the monotonicity information that best describes the function (Diabetes and Boston Housing), and the kernel parameters that best model the function (Concrete Compression, Fish toxicity, and Power Plant). Our contributions are as follows:
-
•
Development of Predictive Modeling framework for BO incorporating automatic model searching (HyperBO);
-
•
Development of a stationary scoring function to review performance of the model search; and
-
•
Convergence analysis of our framework.
1.1 Related Work
In the space of automating model design, Duvenaud2013 proposes a generative kernel grammar with the ability of defining the space of kernel structures which are built compositionally from a small number of base kernels. malkomes2016bayesian proposes the BOMS method, an automatic framework for exploring the potential space of models using Bayesian Optimization. Building on this work to implement model searching within the optimization search of a black-box function Malkomes:2018:ABO:3327345.3327498 presents ABOMS. This work utilised Bayesian optimization in the model search space to determine the best model hyperparameters, whilst at the same time optimizing the black box function. The fit of the model is measured by the normalized marginal likelihood, allowing comparison of models across iterations. However, this is an indirect measure of the goodness towards the optimization.
1.2 Problem definition
We assume a black-box function with an observation model of where , and . Our goal is to discover , where is a compact subspace of such that:
| (1) |
1.3 Background
1.3.1 Bayesian Optimization
Bayesian optimization is a sample efficient method for the optimization of black box functions. The optimization occurs by constructing a Gaussian Process (GP) model of the function. GP is used as a prior over the space of smooth functions and can be fully described by a mean and covariance function Rasmussen:2005:GPM:1162254. Assuming a mean of zero, the GP is then defined by its covariance function . Given some observations , the posterior is also a GP for which the predictive mean and covariance can be computed via,
| (2) |
| (3) |
with variance , and, is the kernel Gram matrix.
The squared exponential kernel of the form shown in (4) is a popular choice of kernel and will be used in this paper.
| (4) |
where is the signal variance, and is a constant length scale for the -th dimension.
The mean and variance from the GP is used to construct an acquisition function which is then optimized to select the next best sample point.
| (5) |
There are multiple acquisition functions used in Bayesian optimization problems including probability of improvement, GP-UCB, Expected Improvement (EI) and Thompson Sampling DBLP:journals/corr/abs-1012-2599; Basu2017.
2 Proposed Framework
2.1 HyperBO Framework
Our overarching objective is to search for the optima of the black-box function. Whilst conducting the Bayesian optimization search for the function optima, the model search for this BO is guided by another BO in the model space, we call it HyperBO. After every iterations of the inner BO in the function space, a new model, described by a vector of its hyperparameters (), is applied. After iterations with this new model, its performance in progressing the search to the optima is assessed using a scoring function (). This score is then fed back to the GP within HyperBO (). The iterations of the BO in the model space are denoted by . We use Thompson Sampling in order to select the next best model hyperparameter values for the HyperBO. The choice of Thompson sampling as an acquisition function is guided by the need to analyse the convergence of our method, where we use the result of Basu2017. However, we use GP-UCB as an acquisition function for the BO in the function space, as it provides a stricter convergence guarantee. Over time, the HyperBO will converge to the ideal model hyperparameters, accelerating the convergence of the BO in the function space. We note that by using HyperBO for model selection, we use a more active approach of model selection using prediction, rather than the usual passive way of using estimation. Algorithms 1 - 3 describe this Predictive modeling framework.
Mathematically, our optimization problem is defined as:
where score function
Where is the iteration of the BO in the function space, is the scoring function, is the BO algorithm for problem , at ’th iteration, and is the optimization problem in the function space. To maintain the stationarity of the HyperBO optimization problem, i.e. maximizing the scoring function , we should make the scoring function independent of the iteration () of the BO in the function space. In the next we show how to use the convergence results of Bayesian optimization to derive such a scoring function.
Input: black-box function , initial data made of (x,y)
Parameter: number of initial models , number of iteration per model , number of total iterations
Output: and
Input: black-box function , data hyperparameter vector , current optima
Parameter: number of iteration per model
Output:model score , data
2.2 Scoring Function
As mentioned before, a key innovation in our scoring metric is the ability to offset for the moving nature of the BO search, thereby effectively allowing it to function as a black-box that can be analysed independently. In order to maintain this required stationarity, we describe this reduction in progress towards the optima in later iterations via the regret bound of GP-UCB as detailed in Srinivas:2010:GPO:3104322.3104451, utilizing it as a means of describing the average regret.
Regret Bound is of where is of . is the iteration number.
For the score we can ignore as it is a constant. We use the shape of to normalize the gain in performance during any interval of the BO iterations in the function space, making the gain independent of the iteration (). This is what we use as our scoring function.
| (6) |
where is the best observation before BO in the function space with the new hyperparameter, is the best observation after BO with the new hyperparameter.
In practise, it was observed that adding a regularization term to (6) can improve the performance further. This term differs slightly depending on the hyperparameter type being tuned. Some examples will be discussed in the later sections.
2.3 Convergence Analysis
The Predictive Modeling framework with HyperBO can be proven to converge under the Theorem below.
Theorem 1.
Let and . Assuming the kernel functions used in both the BO in the function space and the HyperBO, provides a high probability guarantee on the sample paths of GP derivative to be L’-Lipschitz continuous, and the function is L-Lipschitz continuous. There exists a beyond which is satisfied with probability . Furthermore, the average cumulative regret of the Predictive Modeling framework will converge to .
Proof.
If BO with Thompson Sampling is used Basu2017, then we know that
where , are dependent constants.
This implies we can set any arbitrary and an arbitrary low probability . Then there exists a beyond which happens with high probability ().
Using regret as defined in Srinivas:2010:GPO:3104322.3104451, and recalling that , we can write the cumulative regret as:
where is the actual iterations that the BO in the function space has gone through. Next, we break down by introducing , where .
Because the predictive posterior is smooth w.r.t it makes the acquisition function to be smooth as well w.r.t. . So we can assume that is L-Lipschitz. Hence,
∎
Although the regret does not vanish in our case, it can be made arbitrary small by setting very small. We must also note that the existing convergence analysis assumes that the best model is being used throughout the BO, ignoring the effect of estimation of the model on the convergence. In contrast, we provide the convergence guarantee of our whole approach, including the model selection part, thus making it more useful to look at.
2.4 Application 1 - Length Scale Tuning
It is common for the length scale of the model GP to be tuned periodically with observations during the optimization process. We instead separate the length scale tuning outside of the BO and into the HyperBO framework in order to achieve faster convergence. The length scales for each dimensions, expressed within the vector, are assumed to be anisotropic.
2.4.1 Length Scale Regularization
A regularization is applied to the score function to weight the score towards larger length scale values to prevent over sensitivity to a given input dimension. The overall score function used is given by
| (7) |
where, is the regularization weight.
2.5 Application 2 - Monotonicity Tuning
If a function is monotonic to certain variables, access to monotonicity information can greatly improve the fit of a GP and increase the sample efficiency and convergence during the BO search Wang2018; Golchi2015; Li2018. However it is often the case that this information is not available prior to experimentation. As such, we apply our framework for monotonicity discovery.
2.5.1 Gaussian Process with monotonicity
riihimaki2010gaussian proposed a method of incorporating monotonicity information into a Gaussian process model. The monotonicity is added at some finite locations of the search space through an observation model, via virtual derivative observations. In this method a parameter is used to control the strictness of the monotonicity information. Further details on the theory and implementation of this method can be found at riihimaki2010gaussian.
2.5.2 Searching monotonic models
Unlike riihimaki2010gaussian which requires monotonicity information be incorporated into the GP prior, we work off the assumption that monotonicity information is unknown. Our proposed framework uses HyperBO to search the space of GP models, and in the case of monotonicity, discover the best monotonic GP model to describe the latent function.
riihimaki2010gaussian specified the strictness parameter as a constant. In our work we utilise this parameter instead as a way of discovering monotonicity in a model, by tuning its value to reflect the strength of monotonicity in a given direction and dimension. To do this we assume independent values in each dimension thereby describing the strictness parameter as a vector . In addition we describe monotonicity in both increasing and decreasing directions for each dimension. The reason for having monotonicity directions be described independently is to have the elements of range between - where lower values apply a strong monotonic trend. In order to have an effective search, we conduct the search in the log space, thereby searching for values between -6 to 0, where a lower value (-6) invokes a strong monotonicity. We represent as the in our algorithm.
As an example, for a 2 dimensional function, we construct a vector for the monotonicity directions [-1 1 -2 2] with , where is the strictness parameter for decreasing monotonicity and is for increasing monotonicity in the d-th dimension.





2.5.3 Monotonicity Regularization
Regularization of the form shown in (8) is applied for scoring monotonic models. A low value of indicates the presence of monotonicity, while a high value indicates a lack of monotonicity. As such a weighting is applied to the score in order to prefer large values of and thereby prevent the presence of monotonicity being over emphasised. In our experiments, the values of . The weighting is designed to favour values closer to 0. Below is the form of the score function used with being the regularization weight.
| (8) |
3 Experimental Results
Experimentation was conducted for discovering length scales and monotonicity information of synthetic functions and real world datasets using the Predictive modeling framework. In the experiments presented the framework was used to discover either monotonicity or the length scale values, but the framework can be extended to tune both, if required. Average of 50 trials are reported with error bars indicating standard error. The input ranges of each experiment were normalized.
The results are shown in two cases:
Case 1: HyperBO vs Standard BO;
Case 2: Optimization performance of Best discovered hyperparameter values - re-running experiment with best scoring from HyperBO run. This is used to test the validity of the hyperparameters found by HyperBO. If prior information is available about the true hyperparameter values (gold standard), these are compared against as well.
Code for all Length Scale experiments and synthetic monotonicity experiment can be found at https://bit.ly/2tElQBX.
3.1 Length Scale Experiments
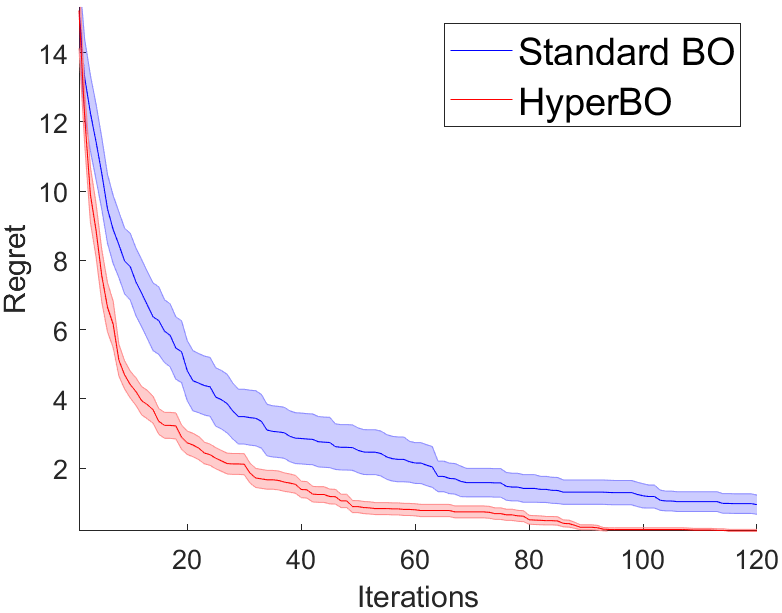
The Predictive modeling framework was applied to 3 real world datasets for tuning length scales, which included Concrete Compressive Strength, Combined Cycle Power Plant and QSAR fish toxicity, whilst searching for the maxima of the dataset. The length scale ranges were discretized between 0.1 and 0.6, with a step size of 0.05. The performance of HyperBO in discovering the appropriate length scales for the models is displayed in Figure 2. For these experiments, the value of in the scoring function (7) was set to in order to normalize the regularization term. In all experiments, tuning of length scale with the framework improves the performance, as shown in Figure 2.
3.1.1 Concrete Compressive Strength
This dataset comprised of 8 variables from 1030 experiments to predict the compressive strength of concrete. The task of BO is to find the maximum compressive strength using the existing data points as a discrete search space.
3.1.2 Combined Cycle Power Plant
This dataset comprised of 4 variables from 9568 data points. The input variables, which include temperature, ambient pressure, relative humidity and exhaust vacuum predict the hourly electrical energy output of a power plant. Here the task is to determine the maximum hourly energy output.
3.1.3 QSAR fish toxicity
This dataset is comprised of 6 molecular descriptors of 908 chemicals predicting toxicity towards the fish species known as Pimephales promelas (fathead minnow). The task here is to determine the maximum toxicity towards the fish.





3.2 Monotonicity Experiments
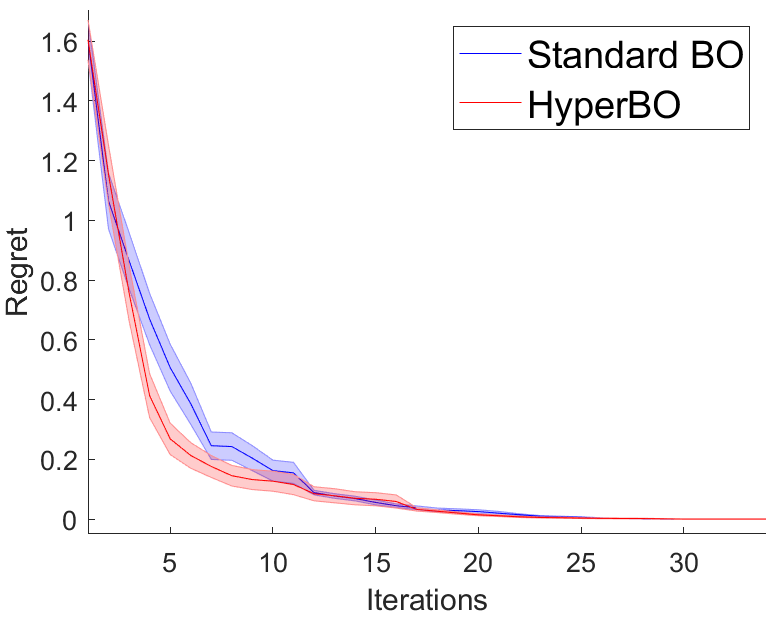
For the monotonicity experiments, the goal is to find the optima quicker and also reveal the existence of monotonicity between variables and the output. The values of were discretized to [-6, 0]. In addition, a constraint was applied such that a value of [-6] could not be applied in both the negative and positive directions of a given dimension. This reduces the search space with the assumption that a given dimension could not be both monotonically increasing and decreasing at the same time. For the following experiments, the value of in the scoring function (8) was set to , to normalize the regularization term. Figure 3a),c),e) shows the performance of the Predictive Modeling framework compared to a Standard BO. Figure 3b),d),f) compares the performance of the best discovered hyperparameters compared to the Standard BO, and where possible, against prior knowledge of monotonicity (synthetic function)(the gold standard).
3.2.1 Virtual Derivatives
The number of virtual derivatives was set to where is the dimension of the data. This was to allow the virtual derivatives to enforce monotonicity strongly in the early iterations (when observations are low), and for observations to control the fit of the GP in later iterations (when observations are higher than virtual derivatives). These points were randomly placed in the search space.
3.2.2 Goldstein-Price Function
The trend towards the maxima of the Goldstein-Price function can be seen to decrease with respect to the first dimension, and increasing with respect to the second dimension (gold standard). When applying HyperBO, the average of the best monotonicity information from the trials returned a value of -3.24 (negative trend) for and 2.64 (positive trend) . The results reflect the expected monotonicity, demonstrating how HyperBO is able to extract monotonicity information for the latent function during the optimization process.
3.2.3 Diabetes
The Diabetes dataset comprises of 10 variables (Age, Sex, BMI, Blood Pressure and 6 blood serum variables), from 443 patients, to predict the diabetes progression 1 year after baseline, and the task is to determine the patient with the highest disease progression. The data of a particular patient was found to be an outlier and removed (the individual had a high disease progression, despite being quite young). Figure 4a) displays the correlation between the input variables and the output. This is used as a metric to assess our findings of monotonicity against. Figure 4b) displays the average direction of monotonicity for each feature. For all but BP, S1, S2 and S5, monotonicity matched the correlation coefficient direction.


3.2.4 Boston Housing
The Boston Housing dataset comprises of 13 features predicting the median house price. The data was scaled with the median house price ranging between -2.5 and 2.5. For our experiment, only per capita crime rate (CRIM), non-retail business portion (INDUS), average number of rooms (RM), weighted distance to employment centres (DIS), pupil-teacher ratio (PTRATIO) portion of black residents (B), and % of lower status (LSTAT) were considered. The task was to discover the maximum median house price, whilst applying monotonic trends within the dataset. As there are multiple maxima in the dataset, the data was filtered to include only 1 maxima which was used in all experiments.
Figure 5a) shows the correlation coefficients between each input feature and the output. Figure 5b) displays the difference in the average monotonicity values for each dimension.


4 Conclusion
This paper presented a novel mean of model selection during Bayesian Optimization search. The Predictive Modeling framework with HyperBO allows searching amongst the model space of GP’s and assesses the performance of a given model in its progression toward the function optima. A scoring function was developed to assess the performance of a selected model at any given iteration. Experimental results applying the framework for monotonicity and length scale tuning have demonstrated its effectiveness in outperforming standard BO. Theoretical analysis proves convergence.