APAdditional References \historyDate of publication xxxx 00, 0000, date of current version xxxx 00, 0000. 10.1109/ACCESS.2017.DOI
This work has been partially funded by the National Science Centre, Poland, grant number 2021/41/B/HS6/02798, and the Commonwealth of Australia (represented by the Defence Science and Technology Group) through a Defence Science Partnerships Agreement. The NetSense study was funded by the U.S. National Science Foundation (CISE) #0968529. The NetHealth study was funded by the U.S. National Institutes of Health (NIH) #R01HL117757.
Corresponding author: Mateusz Nurek (e-mail: [email protected]).
Predicting Relationship Labels and Individual Personality Traits from Telecommunication History in Social Networks using Hawkes Processes
Abstract
Mobile phones contain a wealth of private information, so we try to keep them secure. We provide large-scale evidence that the psychological profiles of individuals and their relations with their peers can be predicted from seemingly anonymous communication traces – calling and texting logs that service providers routinely collect. Based on two extensive longitudinal studies containing more than 900 college students, we use point process modeling to describe communication patterns. We automatically predict the peer relationship type and temporal dynamics, and assess user personality based on the modeling. For some personality traits, the results are comparable to the gold-standard performances obtained from survey self-report data. Findings illustrate how information usually residing outside the control of individuals can be used to reconstruct sensitive information.
Index Terms:
Big5, call series modelling, Hawkes process, inferring personality traits, inferring relation status, relationship dynamic=-15pt
I Introduction
It is a well-known fact that we give away personal information whenever we act and interact online [49]. This has been repeatedly shown for online social media platforms such as Facebook [27, 62], Twitter [33], and even knowledge creation sites like Wikipedia [47]. More specifically, people’s personality profiles can been predicted from the activity traces they leave behind in personal websites [34], blogs [61], Twitter messages [22] or Facebook profiles [27].
Recently, Stachl et al [52] showed that personality profiles could be estimated using information collected from users’ smartphones. This includes digital traces of communication and social behavior, music consumption, app usage, mobility, overall phone activity, and day- and nighttime activity. However, obtaining such data requires access to the user’s social media activity or phones, which might provide specific degrees of safety to the user who controls the privacy settings. In this work, we investigate what can be learned about users using data normally outside their control, e.g., from communication patterns with their peers. We find that even seemingly anonymous information can be used to predicts, with a high level of accuracy both individual characteristics and properties of their social relationships.
This paper addresses three open questions concerning modeling and learning from call and text data traces. The first question relates to modeling the communication patterns between individuals. It is known that human communication is bursty and that it exhibits a long-tail distribution of inter-event times [32, 19, 58]. Hawkes point processes have been successfully applied to model other bursty phenomena, such as information diffusion [37] or neuronal firing patterns in the human brain [21]. The question is can we model the call patterns between individuals using Hawkes point processes? The second question relates to learning about relationships between individuals using call patterns. Hawkes processes fitted on event series have been shown helpful in predicting the final popularity of online items [37], and even differentiating between controversial and authoritative news sources [25]. The question is, therefore, can we differentiate the relationship type between two individuals, given their call and texting timing series fitted using a Hawkes model? The third question relates to inferring users’ personality traits from their call series. While there exist several prior work learning user personality traits using mobile phone data [16, 52, 38], these usually rely on behavioral information collected via sensor and log data from smartphones, which requires access to the users’ phones. The question is can we use the Hawkes model outputs, fitted on the call series involving a given user, to infer their personality traits?
The NetSense and NetHealth Studies. We address the above open questions using two large datasets – NetSense and NetHealth – obtained from the NetSense and NetHealth longitudinal social network studies conducted on a student population at the University of Notre Dame [53, 43]. The datasets contain digital trace timestamped records of the calling and texting information for about 200 and 700 students, respectively, who also filled in periodic surveys administered at the start and end of each semester for two and three years in each respective study. We answer the first question by fitting the parameters of a Hawkes point process to the series of communication events – phone calls or texts – occurring between each pair of students. Using goodness of fit tests, we show that Hawkes with a power-law decaying kernel function generalizes better to unseen data than the exponential kernel.
To answer the second question, we use the student surveys in which they provided labels for their most salient (top-20) contacts in periodic ego-network surveys (e.g., family, friend, significant other and the like). Based on the labels given to relationships by students in subsequent surveys, we first split the pairwise relations in both datasets into six categories: family-relaxing, family-stable, friendship-relaxing, friendship-stable, friendship-strengthening and romantic-relaxing. Next, we characterize each pairwise relationship in our dataset using the Hawkes model’s fitted parameters and secondary quantities. We show that using the Hawkes descriptors, off-the-shelf classifiers significantly outperform autoregressive (ARIMA [31]) baselines, achieving a macro F1-score of for NetSense and for NetHealth), with the best-identified categories being family-stable, friendship-stable, and friendship-relaxing. We obtain the best prediction results when concatenating the autoregressive and Hawkes features (F1-score of and on NetSense and NetHealth, respectively).
We answer the third question by applying a novel joint modeling of Hawkes processes [25] to model jointly the call series of each student participating in the NetSense and NetHealth studies. We describe users using features built on their activity patterns and we use off-the-shelve regressors to predict individual Big5 personality traits [15]. The ground truth is the Big Five Inventory [20], a personality assessment survey filled in by each student. We compare our method with two baselines. The first baseline [38] uses a wide range of complex features (including autoregressive) based on call history. The second baseline uses 145 features (NetSense) and 2212 features (NetHealth) self-reported in the surveys: grades, health, happiness, activity, book reading, and club membership. These are highly personal and sensitive features, and have been shown to be the upper bound of automatic personality traits prediction [40]. We find our method to outperform the first baseline and, surprisingly, very competitive with respect to the prediction upper-bound. This indicates that the Hawkes-modelled call activities embed a surprising amount of personal information.
The main contributions of this paper are as follows:
-
•
We show that a Hawkes point process with a power-law decaying kernel can model the phone call contact series between individuals.
-
•
We use the fitted parameters of a Hawkes model to distinguish between types of relations (such as family, friendship, or romantic).
-
•
We show that the call activity (modeled using Hawkes point processes) might be as predictive of the user’s Big5 psychometric traits as the user filled-in questionnaire.
The ethics of personality profiling. Personality profiling—particularly social media-inferred personality traits—is sometimes seen as Pandora’s box. On the one hand, personality dispositions are associated with happiness, physical and psychological health, the quality of relationships with peers, family, and romantic others, as well as and community involvement [42], criminal activity, and political ideology at a social, institutional level [42]. Personality traits are also predictive of three critical life outcomes: mortality, divorce, and occupational attainment [48]. Such research shows the positive aspects of personality profiling research: one could build systems to prevent and improve individuals’ mental health issues or their relationship with the community. On the other hand, it was also shown that persuasive messaging is more effective when tailored for individuals’ psychological characteristics [36] and that the same processes used to infer personality traits from social data can leak sensitive information such as ethnicity, political and sexual orientation [27]. While social media privacy settings could (at least theoretically) bring some of the data back under the user’s control, our research shows that personality traits can be inferred from data sources entirely outside the user’s control. This work adds to the understanding of what can be achieved with call logs data and advocates creating policy regulating its usage. The latter is increasingly important, as more and more calls are being made using outside the traditional communication networks and onto online messaging platforms such as WhatsApp, which are currently not nationally regulated.
II Prerequisites: Hawkes Processes
In this section, we briefly review the theoretical prerequisites concerning modeling event series using Hawkes point processes.
Event series and point processes. An event is a tuple (timestamp, event features), where the timestamp sits along the non-negative time axis, and the event features are any descriptors related to the event. For example, an event can be the reception of a phone call [56, 44], and the features could be the caller id, length of the call, or whether it was answered or not. An event series is a sequence of events , where are the event timestamps of the of the event, relative to the first event (). For ease of notation, in this paper, we use to denote both the event timestamp and the event itself. A point process is a random process whose realizations consist of event series. We denote an event series observed up to time as .
The Hawkes processes. Hawkes processes [17] are a type of point process with the self-exciting property, i.e., the occurrence of past events increases the likelihood of future events. This results in the cluster property of the Hawkes property [18], which states that events modeled by Hawkes appear to be grouped in time. This latter property makes Hawkes processes desirable to model human interaction activity, which is known to follow a bursty pattern [63]. An alternative approach for modeling interactions are Wold point processes defined through a Markovian transition probability distribution on the inter-event times [11]. The occurrence of events in a Hawkes process is controlled by the event intensity function:
| (1) |
where is the background intensity function and is a kernel function capturing the decaying influence of a past event. is the immigrant intensity (i.e. the volumes of events that come from outside the system). Here, it is constant for each call series, i.e., . Two widely adopted parametric forms for the kernel function include the exponential function and the power-law function .
The branching factor is defined as the expected number of events directly spawned by a single event, i.e., . defines the regime of the Hawkes process: when , each event generates more than one event; the process is expected to generate an infinite number of events. When , the process generates a finite number of events, and it is expected to die out.
Parameter estimation. We estimate the parameters of the Hawkes process by maximizing the log-likelihood function for point processes [9]. In a nutshell, the function quantifies the probability that the model generated the observed data. Higher probabilities indicate better fit models. Formally,
| (2) |
Joint modeling of event series. When analyzing the event series relating to a single entity (say, all the phone call series generated by the same individual), it is desirable to account for the multiple event series simultaneously. Kong et al [25] proposed to jointly model a group of retweet cascades with a shared Hawkes process model by summing the log-likelihood functions of individual series. In Section Inferring Psychometric Traits, we jointly model the call sequences initiated by the same user, and we link the learned models to users’ psychometric traits.
III Data and Methods
In this section, we first introduce NetSense and NetHealth, the two datasets used in this work (Section Datasets). Next, we build the relationship labels (Section Relationships), we profile the datasets (Section Datasets profiling), and we fit Hawkes processes to telecommunication data (Section Analyzing call patterns using Hawkes).
III-A Datasets
This research uses two datasets: NetSense [53] and NetHealth [29]. The NetSense project lasted for two and half years and gathered metadata regarding phone calls, demographic, and networking information about college students enrolled in the study during 2011–2013. The NetSense study was followed by NetHealth, which also recorded metadata on mobile phone activities of Notre Dame University students but over a longer time – four and a half years from 2015 to 2019. Both datasets consist of two parts: the calling and texting activity and the student surveys.
Ethics. All methods were carried out following relevant guidelines and regulations. The Institutional Review Board (IRB) of the University of Notre Dame has reviewed the NetSense study and has approved it - the IRB Number is FWA 00002462. The observational study NetHealth was also approved by the University of Notre Dame’s IRB after a full board review under protocol 17-05-3912. All participants provided written informed consent prior to taking part in both studies.
Calling and texting activity. The NetSense and NetHealth datasets record all calls and texts from the students’ phones enrolled in the study, both outgoing and incoming. The dataset records the caller id, the receiver id, the timestamp, and the call duration for each phone call. For text messages, it records the sender, the receiver, and the timestamp. NetHealth also records metadata about WhatsApp and iMessage communication. Where both the sender (or caller) and the receiver are students enrolled in the program, the call (or text) will be recorded twice – once for the caller and once for the receiver. NetSense and NetHealth also record calls and texts from people outside the study (such as family and friends).
The surveys. The datasets include detailed data on the students since each participating student was surveyed every term about their interests, opinions, or relationships with others. The students have been surveyed six times for NetSense and eight times for NetHealth. This paper leverages two aspects of these surveys: how students describe their relationships with others and how they represent themselves. For the former, participants labeled the relationship with their peers using descriptors such as a friend, family, significant other, co-worker, other, or not labeled at all. For the latter, the students provided information about their hobbies, activities, well-being, grades, weight and height, health condition, and the number of books they read. We use this information in Section Inferring Psychometric Traits to build a baseline for predicting personality traits.
The Big5 psychometric questionnaire. For both datasets and with each survey, students provided answers to forty-four questions from the Big Five Inventory [20]. Students answered the questions on whether they would describe themselves as talkative, curious about many different things, tending to be quiet, among others. Their answers can map each student as a point in the big five personality traits space [15], where each traits (openness, conscientiousness, extraversion, agreeableness, neuroticism) is represented as a numeric value between one and five.
| Previous relation | New relation | Label | NetSense | NetHealth |
| friend | sibling | family- relaxing | 115 | 313 |
| friend | parent | |||
| friend | other family | |||
| parent | parent | family- stable | 363 | 422 |
| sibling | sibling | |||
| friend | coworker | friendship- relaxing | 569 | 1709 |
| friend | other | |||
| friend | acquaintance | |||
| friend | friend | friendship-stable | 675 | 988 |
| other | friend | friendship- strengthening | 41 | 74 |
| coworker | friend | |||
| acquaintance | friend | |||
| significant other | other | romantic- relaxing | 16 | 18 |
| significant other | friend |




III-B Relationships
Research in Sociology, Psychology, Communication, and related fields show that social network relations are inherently dynamic – they change in strength, quality, and character over time [54, 55, 12, 45, 14]. Strong ties can become weak [4], and weak ties can become strong [13]. Contacts may transition from initial acquaintances or workmates to being close friends [12, 60]. In the same way, geographical separation can change the character of ties, with close friends devolving into casual ties. The fundamental message of this previous work is that people’s relations with their peers evolve.
To capture these dynamics, the NetSense and NetHealth projects queried students about their personal relationships with their top-twenty contacts six times during the respective study periods. In particular, each participant was asked to provide a relationship label, characterizing each tie as a friend, family (e.g., parent, sibling, other kin), co-worker, acquaintance, or significant other. We discriminate between three types of temporal dynamics for relationships: stable, strengthening, and relaxing. We denote a relation as stable when the student labels it identically across all surveys. When the relationship transitions between categories, we annotate it with the type and direction of the development, following the rules listed in Table I. We consider a friend as a stronger type of relation than a acquaintance; therefore we label a transition acquaintance friend as “friendship-strengthening”. Similarly, we denote the transition significant other friend as “romantic-relaxing”. One type of transition that might appear peculiar is the “family-relaxing”, where the relation is initially labeled as friend, and later on, it becomes sibling, parent or other family. The reader should remember that the subjects of the studies were college students, for most of whom college is the first time they leave home and live independently. Therefore, it is not inconceivable that the relationship with the family members can go colder over time as they discover friends and college life. Finally, we discard the 13 relationships which have more than one type transition; we consider these as likely input errors by the students (e.g., friend significant other family other). We also discard the relationship classes with less than 15 instances to have enough instances in each class for building classifiers in Section Classify relationship types. Table I shows each relationship type’s final volumes in each dataset.
III-C Datasets profiling
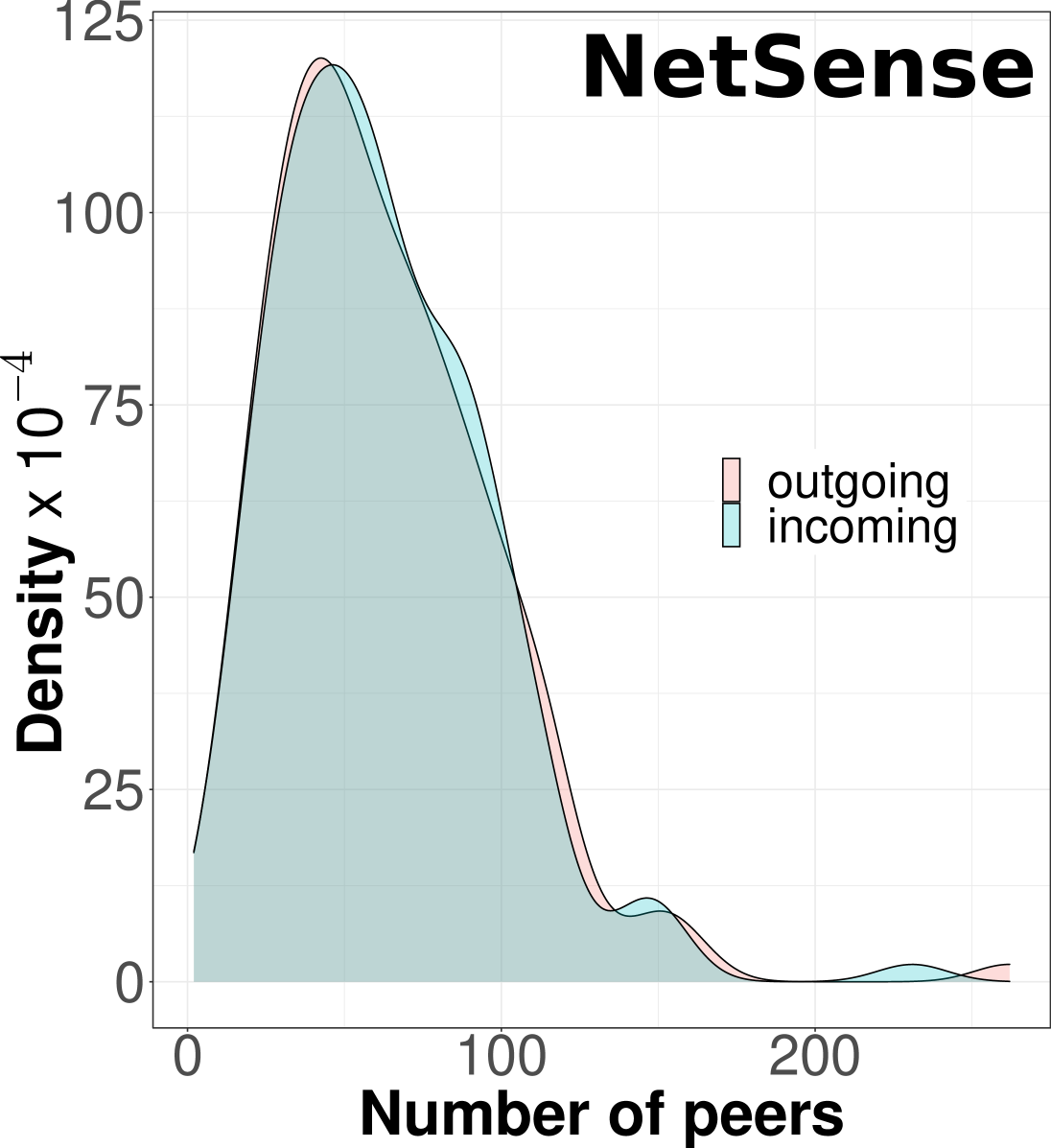
The NetSense dataset covers 178 students who filled out the surveys and whose mobile phone communication is available. NetSense records 7,575,864 phone interactions using the application installed on the students’ mobile phones. The NetHealth study covered 712 students, and it collected information about 60,486,565 phone interactions. In Fig. 1, we present the exploratory analysis of communication datasets. Fig. 1a shows the density of the number of communication events per student. Visibly, the distributions look very similar for both datasets, with most students recording between 5,000 and 20,000 communication events. The distribution is shifted towards higher values for NetHealth as this study lasted longer than NetSense. Fig. 1b shows the density of communication events with respect to the time of day when they were initiated. Most communication starts around noon and continues up to 11 PM. Fig. 1c plots the empirical cumulative distribution of the inter-event times – we observe that these inter-event times are long-tailed distributed, a result already known in literature [19]. Lastly, Fig. 1d and Fig. 1e present for NetSense and NetHealth, respectively, the number of communication peers for each of the students participating in the survey, We distinguish between incoming and outgoing peers and filter out the peers with less than 20 interactions to remove occasional phone calls. Visibly, for NetSense, the two density plots mostly overlap; however, for NetHealth, the students appear to have more incoming peers – probably reflecting the changes in how college students communicate as the conversations involved many short messages on platforms like iMessage. For both studies, most students have less than 130 peers, which is compatible with Dunbar’s number and the theory on cognitive limits of the human brain [10]. For NetSense, out of the 3,159,669 total outgoing communication events, 2,012,816 have been interactions with peers that students labeled in surveys with the type of the relationship. That gives 1,779 relationships to investigate for NetSense. For NetHealth, out of 23,705,245 outgoing events, 15,605,131 were with 3,524 peers that have been categorized – the number of instances for each category is shown in Table I. The following section fits a Hawkes model for each communication relationship.


III-D Analyze call patterns using Hawkes
We model the call series between two individuals as a point process. We assume that future calls are more likely when other calls have recently occurred – in other words, the calling process has the self-exciting property. This hypothesis implies that the future of a sequence of events depends on its entire past and not only the current state. In other words, it does not have the Markov property. Consequently, typical choice modeling tools (such as Markov chains models) are unsuitable for modeling calls. Instead, we fit the call series using Hawkes point processes – which is a well-understood non-Markovian extension of the Poisson process [46]. We leverage a general-purpose point process R library (evently [24]) to produce user-level descriptions based solely on the fitted model parameters of the call series.
Map calls to point processes. In this work, we use phone calls and texts (both denoted hereafter as calls) as point process events (defined in Section Prerequisites: Hawkes Processes). Note that NetHealth includes the WhatsApp and iMessage group messages, which we remove since they are not peer-to-peer communication and are likely to follow other dynamics. An event in our datasets is a tuple (timestamp, sender, receiver). We build event series by grouping incoming and outgoing events between pairs of users. Each timestamp is the time difference (in days) between the recorded timestamp of calls and the timestamp of the first call (). We retain only the series where the sender is a student enrolled in the study. We impose the latter condition so that, in Section Inferring Psychometric Traits, we can match the call series with the surveys filled in by the students. When both the sender and receiver are students in the study, the outgoing series for the sender is identical to the incoming series for the receiver. We filter our call series with fewer than 20 or more than 10,000 recorded calls or texts. We require the former condition to have enough data to fit the Hawkes processes (described next). The latter condition is to avoid computational explosion (considering that Hawkes is quadratic with the number of events). This results in 15,110 call series associated with 178 students, totaling more than 5 million call events for NetSense. For NetHealth, we get 70,752 call series associated with 712 students, totaling more than 33 million events.
Fit Hawkes processes. For each obtained call series, we fit the parameters of a Hawkes model, using the exponential and the power-law kernel functions ( and , respectively, defined in Section Prerequisites: Hawkes Processes). We consider the exogenous intensity function to be constant (), and we fit it from data together with the other parameters using the software package evently [24]. Evently is a R package for modeling events series using Hawkes processes and their variants. Internally, evently leverages IPOPT [59] – the current state of the art in constrained, non-linear optimization – to maximize the log-likelihood function in Eq. 2. By design, it supports a wide array of kernel functions and provides an integrated set of functionalities to conduct event series-level or aggregated-level analyses. For each event series, evently outputs the fitted parameters , , (and for ), and the branching factor .
Interpreting the Hawkes parameters. The Hawkes process is a generative model with interpretable parameters. The branching factor is a crucial quantity for point processes. It indicates the size of the self-exciting effect – when is large, previous calls generate more future calls, and the recent calling history mainly drives the calling relation. The background intensity indicates the size of the exogenous effect – when is large, calls are driven by outside factors. For example, one would expect that the call series between parents and children would exhibit a high , e.g., by calling daily at the same time. The parameter controls the decay rate of the call generation – when is small, the kernel function decays slowly, and new calls are generated endogenously for more extended periods.
Build user representation. We construct user descriptions using the methodology described by Kong et al [26]. We jointly fit all call series involving a given user and describe each user’s activity with a latent mixture of Hawkes models. Due to Hawkes’ quadratic complexity, the joint fitting has significant computation speed advantages over a single large Hawkes model containing all user events. We build the user description by first computing the 5% percentiles bins for every parameter (i.e., , , , and ) for all mixture components and all users. Next, we compute the percentage of mixture parameters within each bin for each user. This results in 20 values (one per 5% percentile bin) for each parameter. In the end, we add a summary of temporal features for user series – the six-point summaries (min, mean, median, max, and percentile) of the call inter-arrival times, the total number of calls in a series and the duration of a series (in days). We also add the total number of call series in which a user is involved. This results in a 99-length vector describing user calling activity.
| KS | ED | LB | KS wins | LL | ||
| NetSense | Exponential | 50.38% | 37.30% | 88.62% | 20.90% | 0.401 |
| Power-Law | 68.12% | 58.63% | 82.49% | 78.10% | 0.665 | |
| NetHealth | Exponential | 39.22% | 31.03% | 89.60% | 22.50% | 0.366 |
| Power-Law | 61.74% | 58.30% | 87.59% | 74.50% | 0.666 |
IV Select a Hawkes process kernel
Here, we select the Hawkes kernel that best describes the time-decaying influence of calls in telecommunication series. We use goodness-of-fit tests and generalization error to compare the two kernels commonly used with human traces data – the exponential and the power-law.
Goodness-of-fit tests. For point processes, the random time change theorem [3] states that the inter-event times transformed using the compensator (i.e., the definite integral of the event intensity) should follow a unit rate exponential distribution (see [28, 26] for more details). We perform three portmanteau statistical tests: the Kolmogorov-Smirnov (KS), Excess Dispersion (ED), and Ljung-Box (LB). For all three tests, to reject the null hypothesis (p-value ¡ 0.05) means failing the test (that is, the sequence does not have the required property). The KS and ED tests assess whether the transformed interevent times are drawn from a unit exponential distribution, whereas LB tests their independence. We also compare the KS statistic for the exponential and power-law kernels to decide which fits better for the passing KS tests.
Generalization error. We test the generalization of each kernel in a temporal holdout setup. We temporally split each call series into two parts. First, the earlier of the call events in each series are used to train model parameters. Next, we compute the holdout log-likelihood on the later of the events. Finally, we normalize the holdout log-likelihood by the number of events in the test set to account for the variable number of calls between series – i.e., we compute the log-likelihood per event.
Results. Table II shows the percentage of call series that pass the statistical tests for each kernel and each dataset. Visibly, power-law exhibits a higher percentage of passing the fitness tests (KS and ED) than exponential. Both kernels show a high passing rate for the independence test (LB). Out of the passing KS tests, power-law wins the highest percentage of pairs when comparing the KS statistic (KS wins)— for NetSense and for NetHealth. Table II also shows the median holdout log-likelihood per event for each kernel and each dataset (we show it summarized as boxplots in the online appendix [1]). The power-law kernel outperforms the exponential kernel for both datasets. Together with the goodness-of-fit tests, this leads us to conclude that the power-law describes the call series better than exponential. Therefore, in the rest of this paper, we only present results for the power-law kernel with all call series refitted using all the available calls.
V Characterize Relationships
In Section Describe relations using Hawkes, we show that the fitted model parameters are descriptive for relationship types. In Section Classify relationship types, we train classifiers to distinguish relationship types.
V-A Describe relations using Hawkes
Here, we use the Hawkes parameters’ interpretability and analyze the fitted Hawkes parameters per relationship type. We concentrate on two quantitites: the branching factor (Fig. 2a) and the background event intensity (Fig. 2b). Fig. 2 shows that the different relations types have specific exogenous and self-excitation patterns. Family relations (shown in dotted lines) have lower branching factors and higher background intensity values. This indicates that outside factors mainly drive the calling dynamics between family members – e.g., students might call their families every day, at the same time, to let them know they are safe. Friendship relations (shown in solid lines) appear to have the opposite pattern. They are mainly driven by self-excitation (high ), and friends are less likely than family to call each other after a period of pause (low ) – linking to the old adage: “out of sight, out of mind”. Finally, romantic relations (dashed lines) have a peculiar mixed behavior. Both and show two modes, one for lower values and one for higher values, indicating a dual nature of romantic relations – some partners call each other because of recent calling activity; in contrast, others use more of a scheduled approach. These patterns are strongly consistent across both datasets and indicate that we can distinguish between types of relationships using a machine learning classifier (see next section).
V-B Classify relationship types
Here, we ask whether the relationships described using fitted Hawkes processes are identifiable one from another.
Predictive setup. We describe each relationship using the fitted Hawkes parameters , , and , and its branching factor . In addition, we train an ARIMA [31] model for each relationship and use the fitted parameters as a baseline to compare with the predictive performance of Hawkes features. Next, we use the Hawkes, ARIMA, and concatenated Hawkes+ARIMA feature sets to train three off-the-shelve classification algorithms: Random Forests [2], Support Vector Machines (SVM) [8], and XGBoost [5]. We compute the prediction performance of each algorithm using two nested cross-validation loops. The outer loop uses five folds to estimate the generalization performance on unseen data. The inner loop tunes hyperparameters using 5-fold cross-validation and random search with 500 combinations. We use the SMOTE algorithm to balance the size of the classes.

Results. Fig. 3 shows the prediction performance for Random Forest, which achieved the best result (see the results for the other two classifiers in the online appendix [1]). The Hawkes features obtain a macro F1-score of for NetSense and for NetHealth, more than double the random classifier and outperforming the ARIMA baseline ( and , respectively). Furthermore, the Hawkes and the ARIMA approaches are complementary, as the concatenated feature set Hawkes+ARIMA yields the best results. Unsurprinsingly, the larger classes (family-stable, friendship-stable and friendship-relaxing) are consistently best predicted. It is perhaps surprising how poorly predicted is the family-relaxing class given its size, which indicates that there are multiple dynamics of how students interact increasingly less with their family. Overall, the results show that relationship types (and their dynamics) can be inferred from the parameter of a Hawkes process fitted on the call series. Additionally, we performed temporal change point detection in the dynamic relations using a paired Wilcoxon signed-rank test (conf. level = 95%) and effect size (Cohen’s d [7]) to compare the log-likelihood before and after the change (more details in the online appendix [1]). We find that statistically significant results (p-value ) were obtained for NetHealth for family-relaxing (effect size = 0.25) and friendship-relaxing (effect size = 0.14).

VI Infer Psychometric Traits
Here, we use call activity to infer the students’ Big5 profiles [15]. First, in Section Baselines and feature sets we detail the baselines and sets of features. Next, in Section Inferring psychometric traits, we present the prediction performance.
VI-A Baselines and feature sets
We set out to predict personality traits using three sets of features, which capture the different aspects of user activity. The first set is the Hawkes-based user representation that we introduced in Section Analyzing call patterns using Hawkes. These features use the call series solely, and we denote them as Hawkes. The second set of features, denoted as Monsted, replicates the work of Monsted et al [38], who use autoregressive models to account for the historical dependency between current and historical volumes of calls in a series. They also build call and text statistics, such as duration, inter-event time, or volume. Unlike the original paper, we do not build features concerning online social network activity (Facebook), proximity (Bluetooth), and geospatial mobility (GPS) – for which the data is not fully available in our studies. The third set of features, denoted as Surveys, builds upon the surveys filled by students. For both NetSense and NetHealth, we extract information that describes the students, such as their grades, perception of their health, number of books they read, or the number of clubs or social organizations they belong to. This results in 145 features for NetSense and 2212 features for NetHealth. Note that Surveys use the information provided by the students, whereas Hawkes and Monsted use only externally observed information (i.e., call series). Note also that Surveys does not contain the forty-four questions related to the Big5 questionnaire (and which serve as ground truth for the predictive exercise). Finally, we also test combinations of feature sets to assess their complementarity.
VI-B Inferring psychometric traits
Predictive setup. We generate the three sets of features for each of the 178 users for NetSense and 712 for NetHealth for whom the Hawkes features exist (see Section Analyzing call patterns using Hawkes). We trialed several off-the-shelf regressors – including SVM, XGBoost, KNN, and Random Forests – out of which Random Forests performed best and is shown in the rest of this section. We tune the hyperparameters and compute prediction performance using 5-fold nested cross-validation and random search with 500 combinations.
Performance of Hawkes features. In line with recent literature [27, 52, 38, 40], we report in Fig. 4 personality traits prediction performances using Pearson’s correlation coefficient. We show the RMSE performances in the online appendix [1]. In their recent survey study, Novikov et al [40] state that the upper limits for correlations between predicted and self-reported personality traits vary between 0.42 and 0.48. Our Hawkes features achieve 0.29 for openness on NetSense, and 0.37 for extraversion on NetHealth– very close to the upper limit range. The other traits are predicted around 0.17 on NetHealth. For NetSense, Hawkes performs poorly for conscientiousness, agreebleness and neuroticism.
NetSense vs NetHealth. We observe a higher variability of performance for NetSense than for NetHealth and a significantly higher variance. We posit this is due to the length of the studies – NetSense it is only two and a half years, while for NetHealth the period is four and a half years – and the amount of data available for each. Since personality traits do not change significantly over the years [40], longer communication periods may contribute to more accurate predictions. We conclude that NetHealth is a better dataset for predicting personality traits from communication data.
Surveys features. Unsurprisingly, the best performing features overall are the Surveys which embed self-reported information – the gold standard in psychology. On NetSense, they achieve around 0.3, and for NetHealth it obtains more than 0.7 on conscientiousness and neuroticism. We make two observations. First, Features outperform the other feature sets given the richness of self-reported information (145 questions for NetSense and 2212 for NetHealth). However, we note that surveying is a very costly process both financially and in time. Second, Hawkes and Surveys appear to capture complementary aspects of personality, as putting them together further increases performances, particularly for openness and extraversion on both datasets.
Hawkes vs Monsted. For NetHealth, the Hawkes features are outperforming the Monsted on four out of the five traits and even come close to the prediction based on the very complex Surveys. The most significant advantage of Hawkes over Monsted is that it does not require complex feature engineering, which may not be easily portable to new datasets.
VII
We structure related works discussion into two sections. First, we discuss work that used Hawkes processes to model contacts and interactions. Second, we explore works that infer personality traits from online data sources.
Modeling interactions in contact networks using point processes. Hawkes processes have been widely used to model social interactions in several applications because they can account for bursts of activity localized in time. Zipkin et al [63] study electronic communications in a dataset of emails pertaining to the US military, where they observe that activity along the edges of the communication network is bursty. They apply a Hawkes model for the email exchange along edges and focus on studying parameter estimation in the presence of missing data. Moore and Davenport [39] learn the topology of a wireless network from limited passive observations of network activity. They use a multi-variate Hawkes process; they show it can detect changes to the existing topology and extract higher-level summaries of information flow in the network. Choudhari et al [6] models simultaneously events and the structure of a social network using a Hidden Markov Hawkes Process that incorporates topical Markov Chains within Hawkes processes to jointly model topical interactions along with the user-user and user-topic patterns. Hawkes processes have also been used to model face-to-face interactions in offices [35] as well as retweet cascades. For the latter task, Kobayashi and Lambiotte [23] propose a Time-Dependent Hawkes process to account for the circadian nature of the users and the aging of information when modeling retweet cascades, whereas Mishra et al [37] leverages a Hawkes process with a power-law relaxation kernel and uses it with the user and timing features to predict the popularity of retweet cascades. Luo et al [30] use company employees’ phone calls to study the alignment method for Hawkes processes based on fused Gromov-Wasserstein discrepancy.
To the best of our knowledge, this is the first work that applies Hawkes modeling to telecom data and uses its outputs to predict users’ relations and personality traits.
Predicting personal traits from social interactions. A fertile area of computational psychology deals with inferring psychometric traits from a range of sources made available by our new interconnected society. For example, Settanni et al [49] show that digital traces from social media can be studied to assess and predict theoretically distant psychosocial characteristics with remarkable accuracy. They also show that when additional user demographics are leveraged as additional digital traces, the accuracy of predictions improves. Some of these works also use social media-inferred personality traits to influence opinions and behavior or infer private traits. For example, Matz et al [36] performed three field experiments that reached over 3.5 million individuals with psychologically tailored advertising and found that matching the content of persuasive appeals to individuals’ psychological characteristics rendered the messaging significantly more effective. Kosinski et al [27] used a public source of social media data (i.e., Facebook likes) to predict the Big5 personality traits of users, alongside a range of highly sensitive personal attributes, including sexual orientation, ethnicity, religious and political views, personality traits, intelligence, happiness, use of addictive substances, parental separation, age, and gender. A follow-up study by Youyou et al [62] even showed that personality traits prediction based on Facebook likes are more accurate than the user’s friends’ estimations based on surveys.
The prior work most relevant to this study relates to learning personality traits from behavioral information collected via smartphones. Such works usually collect data from the onboard sensors and other phone logs [16]. The works closest to ours are by Stachl et al [52], and Monsted et al [38]. Stachl et al [52] predict Big Five personality dimensions using six different classes of behavioral information collected from smartphones: 1) communication and social behavior, 2) music consumption, 3) app usage, 4) mobility, 5) overall phone activity, and 6) day- and night-time activity. They find that the accuracy of these predictions is similar to that of social media platforms. On the contrary, Monsted et al [38] claim that smartphone usage is not as predictive of Big5 personality traits as previously reported, and higher predictabilities in the literature are likely due to overfitting on small datasets.
Our work differs from those mentioned above in two major aspects. First, we use the Hawkes models fitted on the call series to predict user traits. As far as we are aware, no other work has used fitted Hawkes point processes to distill the call interactions between users and predict Big5 traits. Second, the above work requires access to the user’s phone, as most features need to be recorded on the device. Our work shows that personality traits can be accurately predicted solely on call and text logs, which can be obtained outside the user’s device. We also show that our Hawkes descriptors’ prediction accuracy is comparable to that obtained from user-filled surveys.
VIII Conclusion and Future Work
This work investigates whether the Hawkes processes trained on telecommunication metadata predict human sociological traits and aspects. We employ two extensive datasets – NetSense and NetHealth, which contain mobile phone communication metadata and detailed information on surveyed university students. We fit a Hawkes process for each pair (participating student, peer) and use its fitted parameters as descriptors. In a series of experiments, we show that the Hawkes processes can distinguish between types of relationships, predict their temporal dynamics and infer user Big5 psychometric traits. This work is the first to show that Hawkes processes can be used to abstract detailed communication events that carry additional human sociological information. Due to the novelty of our application of the Hawkes process in the described problem, we decided that the right approach would be to start research with a simple model, the vanilla Hawkes process. Our work and results could provide a starting point for future research that will focus on using more complex point process models.
The ethics of using telecom traces to infer private traits. These capabilities raise critical questions concerning user privacy. Our work joins a body of evidence [51, 27, 50] to show how the users’ digital traits can be used to infer the user’s sensitive information (such as the psychological profile). It can be disconcerting that such rich sources of private information lie outside the control of users and in the data warehouses of third parties, and we argue that its usage should be regulated. As Taylor [57] argues, studying human mobility using telecom data is a double-edged sword.
Limitations and future work. For a given pair of individuals (sender, receiver), this work merges outgoing and incoming calls into a single call series. Future work could apply a bivariate Hawkes process to model the intertwining of both aspects of a discussion. In addition, as mentioned earlier, future work may focus on using more complex point process models. For example, call activity may be correlated with time, so it may be essential to use a model that takes into account the daily or weekly seasonality in the background rate [41]. Another direction of research is to use deep learning, however, this will result in a loss of interpretability of the model.
IX Data availability statement
The NetSense dataset is available upon request from Prof. Omar Lizardo, NetHealth data is publicly available for research purposes: https://sites.nd.edu/nethealth/. The code and the data samples are available online at https://github.com/pwr-ai/predicting-relationships-and-big5-using-hawkes.
References
- [1] Online Appendix. Appendix: Predicting Relationship Labels and Individual Personality Traits from Telecommunication History in Social Networks using Hawkes Processes, 2021. https://bit.ly/3fWgsPP.
- [2] Leo Breiman. Random forests. Machine learning, 45(1):5–32, 2001.
- [3] Emery N Brown, Riccardo Barbieri, Valérie Ventura, Robert E Kass, and Loren M Frank. The time-rescaling theorem and its application to neural spike train data analysis. Neural computation, 14(2):325–346, 2002.
- [4] Ronald S Burt. Decay functions. Social Networks, 22(1):1–28, 2000.
- [5] Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In KDD’16, pages 785–794, 2016.
- [6] Jayesh Choudhari, Anirban Dasgupta, Indrajit Bhattacharya, and Srikanta Bedathur. Discovering Topical Interactions in Text-Based Cascades Using Hidden Markov Hawkes Processes. In ICDM’18, volume 2018-Novem, pages 923–928, dec 2018.
- [7] J Cohn. Statistical power analysis for the behavioral sciences. Lawrence Earlbam Associates, Hillsdale, NJ, 1988.
- [8] Corinna Cortes and Vladimir Vapnik. Support-vector networks. Machine learning, 20(3):273–297, 1995.
- [9] Daryl J Daley and David Vere-Jones. Conditional intensities and likelihoods. In An introduction to the theory of point processes, volume I, chapter 7.2. Springer, 2008.
- [10] Robin IM Dunbar. Neocortex size as a constraint on group size in primates. Journal of human evolution, 22(6):469–493, 1992.
- [11] Jalal Etesami, William Trouleau, Negar Kiyavash, Matthias Grossglauser, and Patrick Thiran. A variational inference approach to learning multivariate wold processes. In Int. Conf. on Artificial Intelligence and Statistics, pages 2044–2052, 2021.
- [12] Scott L Feld, J Jill Suitor, and Jordana Gartner Hoegh. Describing changes in personal networks over time. Field methods, 19(2):218–236, 2007.
- [13] James Flamino, Ross DeVito, Boleslaw K Szymanski, and Omar Lizardo. A machine learning approach to predicting continuous tie strengths. arXiv preprint arXiv:2101.09417, 2021.
- [14] Eric Gilbert and Karrie Karahalios. Predicting tie strength with social media. In SIGCHI conference on human factors in computing systems, pages 211–220, 2009.
- [15] Lewis R. Goldberg. An Alternative ”Description of Personality”: The Big-Five Factor Structure. Journal of Personality and Social Psychology, 59(6), 1990.
- [16] Gabriella M. Harari, Sandrine R. Müller, Clemens Stachl, Rui Wang, Weichen Wang, Markus Bühner, Peter J. Rentfrow, Andrew T. Campbell, and Samuel D. Gosling. Sensing Sociability: Individual Differences in Young Adults’ Conversation, Calling, Texting, and App Use Behaviors in Daily Life. Journal of Personality and Social Psychology, 2019.
- [17] Alan G Hawkes. Spectra of some self-exciting and mutually exciting point processes. Biometrika, 1971.
- [18] Alan G. Hawkes and David Oakes. A Cluster Process Representation of a Self-Exciting Process. Journal of Applied Probability, 11(3):493, sep 1974.
- [19] Hang Hyun Jo, Marton Karsai, Janos Kertesz, and Kimmo Kaski. Circadian pattern and burstiness in mobile phone communication. New Journal of Physics, 14, jan 2012.
- [20] Oliver P John, Laura P Naumann, and Christopher J Soto. Paradigm shift to the integrative Big Five trait taxonomy: History, measurement, and conceptual issues. In Handbook of personality: Theory and research, 3rd ed., pages 114–158. Guilford Press, 2008.
- [21] Don H. Johnson. Point process models of single-neuron discharges. Journal of Computational Neuroscience, 3(4):275–299, 1996.
- [22] Margaret L. Kern, Paul X. McCarthy, Deepanjan Chakrabarty, and Marian-Andrei Rizoiu. Social media-predicted personality traits and values can help match people to their ideal jobs. PNAS, 116(52):26459–26464, dec 2019.
- [23] Ryota Kobayashi and Renaud Lambiotte. TiDeH: Time-Dependent Hawkes Process for Predicting Retweet Dynamics. In ICWSM 2016, number ICWSM, 2016.
- [24] Quyu Kong, Rohit Ram, and Marian-Andrei Rizoiu. Evently: Modeling and Analyzing Reshare Cascades with Hawkes Processes. In WSDM’21, pages 1097–1100, 2021.
- [25] Quyu Kong, Marian-Andrei Rizoiu, and Lexing Xie. Describing and Predicting Online Items with Reshare Cascades via Dual Mixture Self-exciting Processes. In CIKM’20, pages 645–654, oct 2020.
- [26] Quyu Kong, Marian-Andrei Rizoiu, and Lexing Xie. Modeling Information Cascades with Self-exciting Processes via Generalized Epidemic Models. In WSDM’20, pages 286–294, jan 2020.
- [27] Michal Kosinski, David Stillwell, and Thore Graepel. Private Traits and Attributes Are Predictable from Digital Records of Human Behavior. PNAS, 110(15):5802–5805, apr 2013.
- [28] Patrick J Laub, Thomas Taimre, and Philip K Pollett. Hawkes processes. arXiv preprint arXiv:1507.02822, 2015.
- [29] Shikang Liu, David Hachen, Omar Lizardo, Christian Poellabauer, Aaron Striegel, and Tijana Milenković. Network analysis of the nethealth data: exploring co-evolution of individuals’ social network positions and physical activities. Applied network science, 3(1):1–26, 2018.
- [30] Dixin Luo, Hongteng Xu, and Lawrence Carin. Fused gromov-wasserstein alignment for hawkes processes. arXiv preprint arXiv:1910.02096, 2019.
- [31] Spyros Makridakis and Michèle Hibon. Arma models and the box-jenkins methodology. Journal of Forecasting, 16(3):147–163, 1997.
- [32] R. Dean Malmgren, Daniel B. Stouffer, Adilson E. Motter, and Luís A.N. Amaral. A Poissonian explanation for heavy tails in e-mail communication. PNAS, 105(47):18153–18158, nov 2008.
- [33] Huina Mao, Xin Shuai, and Apu Kapadia. Loose tweets: An analysis of privacy leaks on twitter. In ACM CCS’11, pages 1–11, 2011.
- [34] Bernd Marcus, Franz MacHilek, and Astrid Schütz. Personality in cyberspace: Personal Web sites as media for personality expressions and impressions. Journal of Personality and Social Psychology, 90(6):1014–1031, jun 2006.
- [35] Naoki Masuda, Taro Takaguchi, Nobuo Sato, and Kazuo Yano. Self-exciting point process modeling of conversation event sequences. In Temporal networks. Springer, 2013.
- [36] S. C. Matz, M. Kosinski, G. Nave, and D. J. Stillwell. Psychological targeting as an effective approach to digital mass persuasion. PNAS, 114(48), nov 2017.
- [37] Swapnil Mishra, Marian-Andrei Rizoiu, and Lexing Xie. Feature driven and point process approaches for popularity prediction. In CIKM, 2016.
- [38] Bjarke Mønsted, Anders Mollgaard, and Joachim Mathiesen. Phone-based metric as a predictor for basic personality traits. Journal of Research in Personality, 74:16–22, jun 2018.
- [39] Michael G Moore and Mark A Davenport. Analysis of wireless networks using Hawkes processes. In Signal Proc. Adv. in Wireless Communications, 2016.
- [40] Pavel Novikov, Larisa Mararitsa, and Victor Nozdrachev. Inferred vs traditional personality assessment: are we predicting the same thing? note, mar 2021.
- [41] Takahiro Omi, Yoshito Hirata, and Kazuyuki Aihara. Hawkes process model with a time-dependent background rate and its application to high-frequency financial data. Physical Review E, 96(1):012303, 2017.
- [42] Daniel J. Ozer and Verónica Benet-Martínez. Personality and the prediction of consequential outcomes. Annual Review of Psychology, 57:401–421, 2006.
- [43] Rachael Purta, Stephen Mattingly, Lixing Song, Omar Lizardo, David Hachen, Christian Poellabauer, and Aaron Striegel. Experiences measuring sleep and physical activity patterns across a large college cohort with fitbits. In Proceedings of the 2016 ACM international symposium on wearable computers, pages 28–35, 2016.
- [44] Troy Raeder, Omar Lizardo, David Hachen, and Nitesh V Chawla. Predictors of short-term decay of cell phone contacts in a large scale communication network. Social Networks, 33(4):245–257, 2011.
- [45] Mark T Rivera, Sara B Soderstrom, and Brian Uzzi. Dynamics of dyads in social networks: Assortative, relational, and proximity mechanisms. Annu. Rev. Sociol., 36(1):91–115, 2010.
- [46] Marian-Andrei Rizoiu, Alexander Soen, Shidi Li, Pio Calderon, Leanne Dong, Aditya Krishna Menon, and Lexing Xie. Interval-censored Hawkes processes. Journal of Machine Learning Research, apr 2022.
- [47] Marian-Andrei Rizoiu, Lexing Xie, Tiberio Caetano, and Manuel Cebrian. Evolution of Privacy Loss in Wikipedia. In WSDM ’16, pages 215–224, 2016.
- [48] Brent W. Roberts, Nathan R. Kuncel, Rebecca Shiner, Avshalom Caspi, and Lewis R. Goldberg. The Power of Personality: The Comparative Validity of Personality Traits, Socioeconomic Status, and Cognitive Ability for Predicting Important Life Outcomes. Perspectives on Psychological Science, 2(4):313–345, 2007.
- [49] Michele Settanni, Danny Azucar, and Davide Marengo. Predicting Individual Characteristics from Digital Traces on Social Media: A Meta-Analysis. Cyberpsychology, Behavior, and Social Networking, 21(4):217–228, apr 2018.
- [50] Christopher Smith-Clarke, Afra Mashhadi, and Licia Capra. Poverty on the cheap: Estimating poverty maps using aggregated mobile communication networks. In CHI’14, pages 511–520. Association for Computing Machinery, 2014.
- [51] Victor Soto, Vanessa Frias-Martinez, Jesus Virseda, and Enrique Frias-Martinez. Prediction of socioeconomic levels using cell phone records. In UMAP’11, 2011.
- [52] Clemens Stachl, Quay Au, Ramona Schoedel, Samuel D. Gosling, Gabriella M. Harari, Daniel Buschek, Sarah Theres Völkel, Tobias Schuwerk, Michelle Oldemeier, Theresa Ullmann, Heinrich Hussmann, Bernd Bischl, and Markus Bühner. Predicting personality from patterns of behavior collected with smartphones. PNAS, 117(30):17680–17687, jul 2020.
- [53] Aaron Striegel, Shu Liu, Lei Meng, Christian Poellabauer, David Hachen, and Omar Lizardo. Lessons learned from the netsense smartphone study. ACM SIGCOMM Computer Communication Review, 43(4):51–56, 2013.
- [54] J Jill Suitor, Barry Wellman, and David L Morgan. It’s about time: How, why, and when networks change. Soc. Networks, 19(1):1–7, 1997.
- [55] Jill Suitor and Shirley Keeton. Once a friend, always a friend? effects of homophily on women’s support networks across a decade. Soc. Networks, 1997.
- [56] Taro Takaguchi, Nobuo Sato, Kazuo Yano, and Naoki Masuda. Importance of individual events in temporal networks. New Journal of Physics, (9):93003, 2012.
- [57] Linnet Taylor. No place to hide? The ethics and analytics of tracking mobility using mobile phone data. Environment and Planning D: Society and Space, 34(2):319–336, apr 2016.
- [58] Javier Ureña-Carrion, Jari Saramäki, and Mikko Kivelä. Estimating tie strength in social networks using temporal communication data. EPJ Data Science, 9(1):37, 2020.
- [59] A Wächter and L T Biegler. On the Implementation of a Primal-Dual Interior Point Filter Line Search Algorithm for Large-Scale Nonlinear Programming. Mathematical Programming, 106(1):25–57, 2006.
- [60] Barry Wellman, Renita Yuk-Lin Wong, David Tindall, and Nancy Nazer. A decade of network change: Turnover, persistence and stability in personal communities. Soc. Networks, 19(1):27–50, January 1997.
- [61] Tal Yarkoni. Personality in 100,000 Words: A large-scale analysis of personality and word use among bloggers. Journal of Research in Personality, 44(3):363–373, jun 2010.
- [62] Wu Youyou, Michal Kosinski, and David Stillwell. Computer-based personality judgments are more accurate than those made by humans. PNAS, (4), 2015.
- [63] Joseph R. Zipkin, Frederic P. Schoenberg, Kathryn Coronges, and Andrea L. Bertozzi. Point-process models of social network interactions: Parameter estimation and missing data recovery. European Journal of Applied Mathematics, 27(3):502–529, 2016.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c88d3d8-57ce-4cd4-8d2e-54ce66b9125a/photo-mateusz-nurek.jpg) |
Mateusz Nurek is a PhD student at the Department of Artificial Intelligence at Wrocław University of Science and Technology in Wrocław, Poland and a member of the Network Science Lab. His research interests include network science and machine learning. He focuses on applying data science techniques in the field of human behavior and social network analysis. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c88d3d8-57ce-4cd4-8d2e-54ce66b9125a/photo-radoslaw-michalski.jpg) |
RADOSŁAW MICHALSKI is an Associate Professor at the Department of Artificial Intelligence at Wrocław University of Science and Technology (Poland). His research areas cover but are not limited to social influence, diffusion processes in complex networks, and machine learning. He has co-authored over 50 publications in these areas. He co-leads the Network Science Lab at Wrocław University of Science and Technology and leads BERG - Blockchain Exploration Research Group. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c88d3d8-57ce-4cd4-8d2e-54ce66b9125a/photo-omar-lizardo.jpeg) |
Omar Lizardo is a Professor and LeRoy Neiman Term Chair at the University of California Los Angeles. He studies culture, cognition, networks, consumption, institutions, organization, and social theory. He currently serves on the editorial board of the social science journals Social Forces, Sociological Theory, Sociological Forum, Journal for the Theory of Social Behaviour, Theory and Society, and Poetics. He is also a member of the Board of Reviewing Editors for the journal Science and an Associate Editor for Discover Data. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c88d3d8-57ce-4cd4-8d2e-54ce66b9125a/photo-ma-rizoiu.png) |
Marian-Andrei Rizoiu is an Assistant Professor with the University of Technology Sydney, where he leads the Behavioral Data Science group. He is a computer scientist interested in addressing research questions where human online behavior and machine learning cross over. His research has made several key contributions to online popularity prediction, real-time tracking and countering disinformation campaigns, and understanding shortages and mismatches in labor markets. Marian-Andrei’s research is funded by Facebook Research and the Commonwealth of Australia, and published in the most selective venues, such as the PNAS, PLOS ONE, PLOS Computations Biology, WWW, NeurIPS, IJCAI, and CIKM. In addition, his work has received significant media attention, including Bloomberg Business Week, Nature Index, BBC, and World Economic Forum. His work has a societal impact for social good, he serves as an expert in legislative initiatives and parliamentary inquiries. See more at www.behavioral-ds.science. |