Predicting Online Item-choice Behavior:
A Shape-restricted Regression Approach
Abstract
This paper examines the relationship between user pageview (PV) histories and their item-choice behavior on an e-commerce website. We focus on PV sequences, which represent time series of the number of PVs for each user–item pair. We propose a shape-restricted optimization model that accurately estimates item-choice probabilities for all possible PV sequences. This model imposes monotonicity constraints on item-choice probabilities by exploiting partial orders for PV sequences, according to the recency and frequency of a user’s previous PVs. To improve the computational efficiency of our optimization model, we devise efficient algorithms for eliminating all redundant constraints according to the transitivity of the partial orders. Experimental results using real-world clickstream data demonstrate that our method achieves higher prediction performance than that of a state-of-the-art optimization model and common machine learning methods.
Index Terms:
Consumer behavior, electronic commerce, graph theory, predictive models, quadratic programmingI Introduction
A growing number of companies are now operating e-commerce websites that allow users to browse and purchase a variety of items [45]. Within this context, there is great potential value in analyzing users’ item-choice behavior from clickstream data, which is a record of user pageview (PV) histories on an e-commerce website. By grasping users’ purchase intention as revealed by PV histories, we can lead users to target pages or design special sales promotions, providing companies with opportunities to build profitable relationships with users [22, 33]. Companies can also use clickstream data to improve the quality of operational forecasting and inventory management [18]. Meanwhile, users often find it difficult to select an appropriate item from among the plethora of choices presented by e-commerce websites [1]. Analyzing item-choice behavior can improve the performance of recommendation systems that help users discover items of interest [20]. For these reasons, a number of prior studies have investigated clickstream data from various perspectives [7]. In this study, we focused on closely examining the relationship between PV histories and item-choice behavior on an e-commerce website.
It has been demonstrated that the recency and frequency of a user’s past purchases are critical indicators for purchase prediction [13, 46] and sequential pattern mining [9]. Accordingly, Iwanaga et al. [19] developed a shape-restricted optimization model for estimating item-choice probabilities from the recency and frequency of a user’s previous PVs. Their method creates a two-dimensional probability table consisting of item-choice probabilities for all recency–frequency combinations in a user’s previous PVs. Nishimura et al. [32] employed latent-class modeling to integrate item heterogeneity into a two-dimensional probability table. These prior studies demonstrated experimentally that higher prediction performance was achieved with the two-dimensional probability table than with common machine learning methods, namely, logistic regression, kernel-based support vector machines, artificial neural networks, and random forests. Notably, however, reducing PV histories to two dimensions (recency and frequency) can markedly decrease the amount of information contained in PV histories reflecting item-choice behavior.
This study focused on PV sequences, which represent time series of the number of PVs for each user–item pair. In contrast to the two-dimensional probability table, PV sequences allow us to retain detailed information contained in the PV history. However, the huge number of possible PV sequences makes it extremely difficult to accurately estimate item-choice probabilities for all of them. To overcome this difficulty, we propose a shape-restricted optimization model that imposes monotonicity constraints on item-choice probabilities based on a partially ordered set (poset) for PV sequences. While this optimization model contains a huge number of constraints, all redundant constraints can be eliminated according to the transitivity of partial order. To accomplish this, we compute a transitivity reduction [2] of a directed graph representing the poset. We demonstrate the effectiveness of our method through experiments using real-world clickstream data.
The main contributions of this paper are as follows:
-
•
We propose a shape-restricted optimization model for estimating item-choice probabilities from a user’s previous PV sequence. This PV sequence model exploits the monotonicity constraints to precisely estimate item-choice probabilities.
-
•
We derive two types of PV sequence posets according to the recency and frequency of a user’s previous PVs. Experimental results show that the monotonicity constraints based on these posets greatly enhances the prediction performance of our PV sequence model.
-
•
We devise constructive algorithms for transitive reduction specific to these posets. The time complexity of our algorithms is much smaller than that of general-purpose algorithms. Experimental results reveal that transitive reduction improves efficiency in terms of both the computation time and memory usage of our PV sequence model.
-
•
We verify experimentally that higher prediction performance is achieved with our method than with the two-dimensional probability table and common machine learning methods, namely, logistic regression, artificial neural networks, and random forests.
The remainder of this paper is organized as follows. Section II gives a brief review of related work. Section III describes the two-dimensional probability table [19], and Section 4 presents our PV sequence model. Section IV describes our constructive algorithms for transitive reduction. Section V evaluates the effectiveness of our method based on experimental results. Section VI concludes with a brief summary of this work and a discussion of future research directions.
II Related work
This section briefly surveys methods for predicting online user behavior and discusses some related work on shape-restricted regression.
II-A Prediction of online user behavior
A number of prior studies have aimed at predicting users’ purchase behavior on e-commerce websites [10]. Mainstream research has applied stochastic or statistical models for predicting purchase sessions [5, 23, 30, 31, 36, 41, 46], but these approaches do not consider which items users choose.
Various machine learning methods have been used to predict online item-choice behavior, including logistic regression [12, 53], association rule mining [37], support vector machines [38, 53], ensemble learning methods [25, 26, 39, 52, 54], and artificial neural networks [21, 47, 50]. Tailored statistical models have also been proposed. For instance, Moe [29] devised a two-stage multinomial logit model that separates the decision-making process into item views and purchase decisions. Yao et al. [51] proposed a joint framework consisting of user-level factor estimation and item-level factor aggregation based on the buyer decision process. Borges and Levener [6] used Markov chain models to estimate the probability of the next link choice of a user.
These prior studies effectively utilized clickstream data in various prediction methods and showed that consideration of time-evolving user behavior is crucial for precise prediction of online item-choice behavior. We therefore focused on user PV sequences to estimate item-choice probabilities on e-commerce websites. Moreover, we evaluated the prediction performance of our method by comparison with machine learning methods that have commonly been used in prior studies.
II-B Shape-restricted regression
In many practical situations, prior information is known about the relationship between explanatory and response variables. For instance, utility functions can be assumed to be increasing and concave according to economic theory [28], and option pricing functions to be monotone and convex according to finance theory [3]. Shape-restricted regression fits a nonparametric function to a set of given observations under shape restrictions such as monotonicity, convexity, concavity, or unimodality [8, 15, 16, 48].
Isotonic regression is the most common method for shape-restricted regression. In general, isotonic regression is the problem of estimating a real-valued monotone (non-decreasing or non-increasing) function with respect to a given partial order of observations [35]. Some regularization techniques [14, 44] and estimation algorithms [17, 35, 43] have been proposed for isotonic regression.
One of the greatest advantages of shape-restricted regression is that it mitigates overfitting, thereby improving prediction performance of regression models [4]. To utilize this advantage, Iwanaga et al. [19] devised a shape-restricted optimization model for estimating item-choice probabilities on e-commerce websites. Along similar lines, we propose a shape-restricted optimization model based on order relations of PV sequences to improve prediction performance.
III Two-dimensional probability table
This section briefly reviews the two-dimensional probability table proposed by Iwanaga et al. [19].
III-A Empirical probability table
| #PVs | Choice | ||||||
|---|---|---|---|---|---|---|---|
| User | Item | Apr 1 | Apr 2 | Apr 3 | Apr 4 | ||
| 1 | 0 | 1 | 0 | ||||
| 0 | 1 | 0 | 1 | ||||
| 3 | 0 | 0 | 0 | ||||
| 0 | 0 | 3 | 1 | ||||
| 1 | 1 | 1 | 0 | ||||
| 2 | 0 | 1 | 0 | ||||
Table I gives an example of a PV history for six user–item pairs. For instance, user viewed the page for item once on each of April 1 and 3. We focus on user choices (e.g., revisit and purchase) on April 4, which we call the base date. For instance, user chose item rather than item on the base date. We suppose for each user–item pair that recency and frequency are characterized by the last PV day and the total number of PVs, respectively. As shown in the table, the PV history can be summarized by the recency–frequency combination , where and are index sets representing recency and frequency, respectively.
Let be the number of user–item pairs having , and set to the number of choices occurring by user–item pairs that have on the base date. In the case of Table I, the empirical probability table is calculated as
| (4) | ||||
| (8) |
where, for reasons of expediency, for with .
III-B Two-dimensional monotonicity model
It is reasonable to assume that the recency and frequency of user–item pairs are positively associated with user item-choice probabilities. To estimate user item-choice probabilities for all recency–frequency combinations , the two-dimensional monotonicity model [19] minimizes the weighted sum of squared errors under monotonicity constraints with respect to recency and frequency.
| (9) | ||||
| subject to | (10) | |||
| (11) | ||||
| (12) |
Note, however, that PV histories are often indistinguishable according to recency and frequency. A typical example is the set of user–item pairs , , and in Table I; although their PV histories are actually different, they have the same value for recency–frequency combinations. As described in the next section, we exploit the PV sequence to distinguish between such PV histories.
IV PV sequence model
This section presents our shape-restricted optimization model for estimating item-choice probabilities from a user’s previous PV sequence.
IV-A PV sequence
The PV sequence for each user–item pair represents a time series of the number of PVs, and is written as
where is the number of PVs periods earlier for (see Table I). Note that sequence terms are arranged in reverse chronological order, so moves into the past as index increases.
Throughout the paper, we express sets of consecutive integers as
where when . The set of possible PV sequences is defined as
where is the maximum number of PVs in each period, and is the number of periods considered.
Our objective is to estimate item-choice probabilities for all PV sequences . However, the huge number of PV sequences makes it extremely difficult to accurately estimate such probabilities. In the case of for instance, the number of different PV sequences is , whereas the number of recency–frequency combinations is only . To avoid this difficulty, we effectively utilize monotonicity constraints on item-choice probabilities as in the optimization model (9)–(12). In the next section, we introduce three operations underlying the development of the monotonicity constraints.
IV-B Operations based on recency and frequency
From the perspective of frequency, it is reasonable to assume that item-choice probability increases as the number of PVs in a particular period increases. To formulate this, we define the following operation:
Definition 1 (Up).
On the domain
the function is defined as
For instance, we have , and . Since this operation increases PV frequencies, the monotonicity constraint should be satisfied by item-choice probabilities.
From the perspective of recency, we assume that more-recent PVs have a larger effect on increasing item-choice probability. To formulate this, we consider the following operation for moving one PV from an old period to a new period:
Definition 2 (Move).
On the domain
the function is defined as
For instance, we have , and . Because this operation increases the number of recent PVs, item-choice probabilities should satisfy the monotonicity constraint .
The PV sequence represents a user’s continued interest in a certain item over three periods. In contrast, the PV sequence implies that a user’s interest decreased over the two most-recent periods. In this sense, the monotonicity constraint may not be validated. Accordingly, we define the following alternative operation, which exchanges numbers of PVs to increase the number of recent PVs:
Definition 3 (Swap).
On the domain
the function is defined as
We thus have because , and because . Since this operation increases the number of recent PVs, item-choice probabilities should satisfy the monotonicity constraint . Note that the monotonicity constraint is not implied by this operation.
IV-C Partially ordered sets
Let be a subset of PV sequences. The image of each operation is then defined as
We define for . The following definition states that the binary relation holds when can be transformed into by repeated application of Up and Move:
Definition 4 ().
Suppose . We write if and only if there exists such that
We also write if or .
Similarly, we define for . Then, the binary relation holds when can be transformed into by repeated application of Up and Swap.
Definition 5 ().
Suppose . We write if and only if there exists such that
We also write if or .
To prove properties of these binary relations, we can use the lexicographic order, which is a well-known linear order [40]:
Definition 6 ().
Suppose . We write if and only if there exists such that and for . We also write if or .
Each application of Up, Move, and Swap makes a PV sequence greater in the lexicographic order. Therefore, we can obtain the following lemma:
Lemma 1.
Suppose . If or , then .
The following theorem states that a partial order of PV sequences is derived by operations Up and Move.
Theorem 1.
The pair is a poset.
Proof.
We can similarly prove the following theorem for operations Up and Swap:
Theorem 2.
The pair is a poset.
IV-D Shape-restricted optimization model
Let be the number of user–item pairs that have the PV sequence . Also, is the number of choices arising from user–item pairs having on the base date. Similarly to Eq. (8), we can calculate empirical item-choice probabilities as
| (13) |
Our shape-restricted optimization model minimizes the weighted sum of squared errors subject to the monotonicity constraint:
| (14) | ||||
| subject to | (15) | |||
| (16) |
where in Eq. (15) is defined by one of the partial orders or .
The monotonicity constraint (15) enhances the estimation accuracy of item-choice probabilities. In addition, our shape-restricted optimization model can be used in a post-processing step to improve prediction performance of other machine learning methods. Specifically, we first compute item-choice probabilities using a machine learning method and then substitute the computed values into to solve the optimization model (14)–(16). Consequently, we can obtain item-choice probabilities corrected by the monotonicity constraint (15). Section VI-D illustrates the usefulness of this approach.
However, since , it follows that the number of constraints in Eq. (15) is , which can be extremely large. When , for instance, we have . The next section describes how we mitigate this difficulty by removing redundant constraints in Eq. (15).
 |
| (a) Operation-based graph |
 |
| (b) Transitive reduction |
 |
| (a) Operation-based graph |
 |
| (b) Transitive reduction |
V Algorithms for transitive reduction
This section describes our constructive algorithms for transitive reduction to decrease the problem size in our shape-restricted optimization model.
V-A Transitive reduction
A poset can be represented by a directed graph , where and are sets of nodes and directed edges, respectively. Each directed edge in this graph corresponds to the order relation , so the number of directed edges coincides with the number of constraints in Eq. (15).
Figs. 1 and 2 show directed graph representations of posets and , respectively. Each edge in Figs. 1(a) and 2(a) corresponds to one of the operations Up, Move, or Swap. Edge is red if and black if or . The directed graphs in Figs. 1(a) and 2(a) can be easily created.
Suppose there are three edges
In this case, edge is implied by the other edges due to the transitivity of partial order
or, equivalently,
As a result, edge is redundant and can be removed from the directed graph.
A transitive reduction, also known as a Hasse diagram, of a directed graph is its subgraph such that all redundant edges are removed using the transitivity of partial order [2]. Figs. 1(b) and 2(b) show transitive reductions of the directed graphs shown in Figs. 1(a) and 2(a), respectively. By computing transitive reductions, the number of edges is reduced from 90 to 42 in Fig. 1, and from 81 to 46 in Fig. 2. This transitive reduction is known to be unique [2].
V-B General-purpose algorithms
The transitive reduction is characterized by the following lemma [40]:
Lemma 2.
Suppose . Then, holds if and only if both of the following conditions are fulfilled:
-
(C1) , and
-
(C2) if satisfies , then .
The basic strategy in general-purpose algorithms for transitive reduction involves the following steps:
-
•
Step 1: An exhaustive directed graph is generated from a given poset .
-
•
Step 2: The transitive reduction is computed from the directed graph using Lemma 2.
Various algorithms for speeding up the computation in Step 2 have been proposed. Recall that in our situation. Warshall’s algorithm [49] has time complexity for completing Step 2 [40]. By using a sophisticated algorithm for fast matrix multiplication, this time complexity can be reduced to [24].
However, such general-purpose algorithms are clearly inefficient, especially when is very large, and Step 1 requires a huge number of computations. To resolve this difficulty, we devised specialized algorithms for directly constructing a transitive reduction.
V-C Constructive algorithms
Let be a transitive reduction of a directed graph representing the poset . Then, the transitive reduction can be characterized by the following theorem:
Theorem 3.
Suppose . Then, holds if and only if any one of the following conditions is fulfilled:
-
(UM1) , or
-
(UM2) such that .
Proof.
See Appendix A-A. ∎
Theorem 3 gives a constructive algorithm that directly computes the transitive reduction without generating an exhaustive directed graph . Our algorithm is based on the breadth-first search [11]. Specifically, we start with a node list . At each iteration of the algorithm, we choose , enumerate such that , and add these nodes to .
Table II shows this enumeration process for with . The operations Up and Move generate
which amounts to searching edges in Fig. 1(a). We next check whether each satisfies conditions (UM1) or (UM2) in Theorem 3. As shown in Table II, we choose
and add them to list ; this amounts to enumerating edges in Fig. 1(b).
| Operation | (UM1) | (UM2) | ||
|---|---|---|---|---|
| — | ||||
| — | ||||
| — | ||||
| — |
Appendix B-A presents pseudocode for our constructive algorithm (Algorithm 1). Recalling the time complexity analysis of the breadth-first search [11], one readily sees that the time complexity of Algorithm 1 is , which is much smaller than as achieved by the general-purpose algorithm [24], especially when is very large.
Next, we focus on the transitive reduction of a directed graph representing the poset . The transitive reduction can then be characterized by the following theorem:
Theorem 4.
Suppose . Then, holds if and only if any one of the following conditions is fulfilled:
-
(US1) such that and for all , or
-
(US2) such that and for all .
Proof.
See Appendix A-B. ∎
Theorem 4 also gives a constructive algorithm for computing the transitive reduction . Let us again consider as an example with . As shown in Table III, operations Up and Swap generate
and we choose
| Operation | (US1) | (US2) | ||
|---|---|---|---|---|
| — | ||||
| — | ||||
| — | ||||
| — |
VI Experiments
The experimental results reported in this section evaluate the effectiveness of our method for estimating item-choice probabilities.
We used real-world clickstream data collected from a Chinese e-commerce website, Tmall111https://tianchi.aliyun.com/dataset/. We used a dataset222https://www.dropbox.com/sh/dbzmtq4zhzbj5o9/AACldzQWbw-igKjcPTBI6ZPAa?dl=0 preprocessed by Ludewig and Jannach [27]. Each record corresponds to one PV and contains information such as user ID, item ID, and a timestamp. The dataset includes 28,316,459 unique user–item pairs composed from 422,282 users and 624,221 items.
VI-A Methods for comparison
| Abbr. | Method |
|---|---|
| 2dimEmp | Empirical probability table (8) [19] |
| 2dimMono | Two-dimensional monotonicity model (9)–(12) [19] |
| SeqEmp | Empirical probabilities (13) for PV sequences |
| SeqUM | Our PV sequence model (14)–(16) using |
| SeqUS | Our PV sequence model (14)–(16) using |
| LR | -regularized logistic regression |
| ANN | Artificial neural networks for regression |
| RF | Random forest of regression trees |
We compared the performance of the methods listed in Table IV. All computations were performed on an Apple MacBook Pro computer with an Intel Core i7-5557U CPU (3.10 GHz) and 16 GB of memory.
The optimization models (9)–(12) and (14)–(16) were solved using OSQP333https://osqp.org/docs/index.html [42], a numerical optimization package for solving convex quadratic optimization problems. As in Table I, daily-PV sequences were calculated for each user–item pair, where is the maximum number of daily PVs and is the number of terms (past days) in the PV sequence. In this process, all PVs from more than days earlier were added to the number of PVs days earlier, and numbers of daily PVs exceeding were rounded down to . Similarly, the recency–frequency combinations were calculated using daily PVs as in Table I, where .
Other machine learning methods (LR, ANN, and RF) were respectively implemented using the LogisticRegressionCV, MLPRegressor, and RandomForestRegressor functions in scikit-learn, a Python library of machine learning tools. Related hyperparameters were tuned through 3-fold cross-validation according to the parameter settings in a benchmark study [34]. These machine learning methods employed the PV sequence as input variables for computing item-choice probabilities. We standardized each input variable and performed undersampling to improve prediction performance.
VI-B Performance evaluation methodology
There are five pairs of training and validation sets of clickstream data in the preprocessed dataset [27]. As shown in Table V, each training period is 90 days, and the next day is the validation period. The first four pairs of training and validation sets, which we call the training set, were used for model estimation, and the fifth pair was used for performance evaluation. To examine how sample size affects prediction performance, we prepared small-sample training sets by randomly choosing user–item pairs from the original training set. Here, the sampling rates are 0.1%, 1%, and 10%, and the original training set is referred to as the full sample. Note that the results were averaged over 10 trials for the sampled training sets.
| Training | |||
|---|---|---|---|
| Pair ID | Start | End | Validation |
| 1 | 21 May 2015 | 18 August 2015 | 19 August 2015 |
| 2 | 31 May 2015 | 28 August 2015 | 29 August 2015 |
| 3 | 10 June 2015 | 7 September 2015 | 8 September 2015 |
| 4 | 20 June 2015 | 17 September 2015 | 18 September 2015 |
| 5 | 30 June 2015 | 27 September 2015 | 28 September 2015 |
| #Cons in Eq. (15) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Enumeration | Operation | Reduction | ||||||
| #Vars | SeqUM | SeqUS | SeqUM | SeqUS | SeqUM | SeqUS | ||
| 5 | 1 | 32 | 430 | 430 | 160 | 160 | 48 | 48 |
| 5 | 2 | 243 | 21,383 | 17,945 | 1,890 | 1,620 | 594 | 634 |
| 5 | 3 | 1,024 | 346,374 | 255,260 | 9,600 | 7,680 | 3,072 | 3,546 |
| 5 | 4 | 3,125 | 3,045,422 | 2,038,236 | 32,500 | 25,000 | 10,500 | 12,898 |
| 5 | 5 | 7,776 | 18,136,645 | 11,282,058 | 86,400 | 64,800 | 28,080 | 36,174 |
| 5 | 6 | 16,807 | 82,390,140 | 48,407,475 | 195,510 | 144,060 | 63,798 | 85,272 |
| 1 | 6 | 7 | 21 | 21 | 6 | 6 | 6 | 6 |
| 2 | 6 | 49 | 1,001 | 861 | 120 | 105 | 78 | 93 |
| 3 | 6 | 343 | 42,903 | 32,067 | 1,638 | 1,323 | 798 | 1,018 |
| 4 | 6 | 2,401 | 1,860,622 | 1,224,030 | 18,816 | 14,406 | 7,350 | 9,675 |
| 5 | 6 | 16,807 | 82,390,140 | 48,407,475 | 195,510 | 144,060 | 63,798 | 85,272 |
We considered the top- selection task to evaluate prediction performance. Specifically, we focused on items that were viewed by a particular user during a training period. From among these items, we selected , a set of top- items for the user according to estimated item-choice probabilities. The most-recently viewed items were selected when two or more items had the same choice probability. Let be the set of items viewed by the user in the validation period. Then, the F1 score is defined by the harmonic average of and as
In the following sections, we examine F1 scores averaged over all users. The percentage of user–item pairs leading to item choices is only 0.16%.
VI-C Effects of the transitive reduction
We generated constraints in Eq. (15) based on the following three directed graphs:
-
•
Case 1 (Enumeration): All edges satisfying were enumerated.
- •
- •
| Time [s] | ||||||||
| Enumeration | Operation | Reduction | ||||||
| #Vars | SeqUM | SeqUS | SeqUM | SeqUS | SeqUM | SeqUS | ||
| 5 | 1 | 32 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 |
| 5 | 2 | 243 | 2.32 | 1.66 | 0.09 | 0.07 | 0.03 | 0.02 |
| 5 | 3 | 1,024 | 558.22 | 64.35 | 3.41 | 0.71 | 0.13 | 0.26 |
| 5 | 4 | 3,125 | OM | OM | 24.07 | 13.86 | 1.72 | 5.80 |
| 5 | 5 | 7,776 | OM | OM | 180.53 | 67.34 | 9.71 | 36.94 |
| 5 | 6 | 16,807 | OM | OM | 906.76 | 522.84 | 86.02 | 286.30 |
| 1 | 6 | 7 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 2 | 6 | 49 | 0.03 | 0.01 | 0.01 | 0.00 | 0.00 | 0.00 |
| 3 | 6 | 343 | 12.80 | 1.68 | 0.20 | 0.03 | 0.05 | 0.02 |
| 4 | 6 | 2,401 | OM | OM | 8.07 | 4.09 | 2.12 | 2.87 |
| 5 | 6 | 16,807 | OM | OM | 906.76 | 522.84 | 86.02 | 286.30 |
| #Cons in Eq. (15) | Time [s] | F1 score [%], | |||||||
|---|---|---|---|---|---|---|---|---|---|
| #Vars | SeqUM | SeqUS | SeqUM | SeqUS | SeqEmp | SeqUM | SeqUS | ||
| 3 | 30 | 29,791 | 84,630 | 118,850 | 86.72 | 241.46 | 12.25 | 12.40 | 12.40 |
| 4 | 12 | 28,561 | 99,372 | 142,800 | 198.82 | 539.76 | 12.68 | 12.93 | 12.95 |
| 5 | 6 | 16,807 | 63,798 | 85,272 | 86.02 | 286.30 | 12.90 | 13.18 | 13.18 |
| 6 | 4 | 15,625 | 62,500 | 76,506 | 62.92 | 209.67 | 13.14 | 13.49 | 13.48 |
| 7 | 3 | 16,384 | 67,584 | 76,818 | 96.08 | 254.31 | 13.23 | 13.52 | 13.53 |
| 8 | 2 | 6,561 | 24,786 | 25,879 | 19.35 | 17.22 | 13.11 | 13.37 | 13.35 |
| 9 | 2 | 19,683 | 83,106 | 86,386 | 244.15 | 256.42 | 13.07 | 13.40 | 13.37 |
Table VI shows the problem size of our PV sequence model (14)–(16) for some settings of the PV sequence. Here, the “#Vars” column shows the number of decision variables (i.e., ), and the subsequent columns show the number of constraints in Eq. (15) for the three cases mentioned above.
The number of constraints grew rapidly as and increased in the enumeration case. In contrast, the number of constraints was always kept smallest by the transitive reduction among the three cases. When , for instance, transitive reductions reduced the number of constraints in the operation case to for SeqUM and for SeqUS.
The number of constraints was larger for SeqUM than for SeqUS in the enumeration and operation cases. In contrast, the number of constraints was often smaller for SeqUM than for SeqUS in the reduction case. Thus, the transitive reduction had a greater impact on SeqUM than on SeqUS in terms of the number of constraints.
Table VII lists the computation times required for solving the optimization problem (14)–(16) for some settings of the PV sequence. Here, “OM” indicates that computation was aborted due to a lack of memory. The enumeration case often caused out-of-memory errors because of the huge number of constraints (see Table VI), but the operation and reduction cases completed the computations for all settings for the PV sequence. Moreover, the transitive reduction made computations faster. A notable example is SeqUM with , for which the computation time in the reduction case (86.02 s) was only one-tenth of that in the operation case (906.76 s). These results demonstrate that transitive reduction improves efficiency in terms of both computation time and memory usage.
Table VIII shows the computational performance of our optimization model (14)–(16) for some settings of PV sequences. Here, for each , the largest was chosen such that the computation finished within 30 min. Both SeqUM and SeqUS always delivered higher F1 scores than SeqEmp did. This indicates that our monotonicity constraint (15) works well for improving prediction performance. The F1 scores provided by SeqUM and SeqUS were very similar and largest with . In light of these results, we use the setting in the following sections.
VI-D Prediction performance of our PV sequence model
 |
 |
 |
| (a) , | (b) , | (c) , |
 |
 |
 |
| (d) , | (e) , | (f) , |
 |
 |
 |
| (a) , | (b) , | (c) , |
 |
 |
 |
| (d) , | (e) , | (f) , |
 |
 |
 |
| (a) SeqEmp, | (b) SeqEmp, | (c) SeqEmp, |
 |
 |
 |
| (d) SeqUM, | (e) SeqUM, | (f) SeqUM, |
 |
 |
 |
| (g) SeqUS, | (h) SeqUS, | (i) SeqUS, |
Fig. 3 shows F1 scores of the two-dimensional probability table and our PV sequence model using the sampled training sets, where the number of selected items is , and the setting of the PV sequence is .
When the full-sample training set was used, SeqUM and SeqUS always delivered better prediction performance than the other methods did. When the 1%- and 10%-sampled training sets were used, the prediction performance of SeqUS decreased slightly, whereas SeqUM still performed best among all the methods. When the 0.1%-sampled training set was used, 2dimMono always performed better than SeqUS did, and 2dimMono also had the best prediction performance in the case . These results suggest that our PV sequence model performs very well, especially when the sample size is sufficiently large.
The prediction performance of SeqEmp deteriorated rapidly as the sampling rate decreased, and this performance was always much worse than that of 2dimEmp. Meanwhile, SeqUM and SeqUS maintained high prediction performance even when the 0.1%-sampled training set was used. This suggests that the monotonicity constraint (15) in our PV sequence model is more effective than the monotonicity constraints (10)–(11) in the two-dimensional monotonicity model.
Fig. 4 shows F1 scores for the machine learning methods (LR, ANN, and RF) and our PV sequence model (SeqUM) using the full-sample training set, where the number of selected items is , and the PV sequence setting is . Note that in this figure, SeqUM( ) represents the optimization model (14)–(16), where the item-choice probabilities computed by each machine learning method were substituted into (see Section 4.4).
Prediction performance was better for SeqUM than for all the machine learning methods, except in the case of Fig. 4(f), where LR showed better prediction performance. Moreover, SeqUM( ) improved the prediction performance of the machine leaning methods, particularly for ANN and RF. This suggests that our monotonicity constraint (15) is also very helpful in correcting prediction values from other machine learning methods.
VI-E Analysis of estimated item-choice probabilities
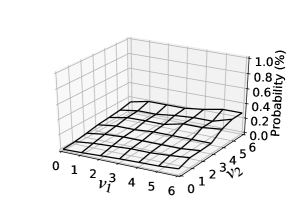
Fig. 5 shows item-choice probabilities estimated by our PV sequence model using the full-sample training set, where the PV sequence setting is . Here, we focus on PV sequences in the form and depict estimates of item-choice probabilities on for each . Note also that the number of associated user–item pairs decreased as the value of increased.
Because SeqEmp does not consider the monotonicity constraint (15), item-choice probabilities estimated by SeqEmp have irregular shapes for . In contrast, item-choice probabilities estimated with the monotonicity constraint (15) are relatively smooth. Because of the Up operation, item-choice probabilities estimated by SeqUM and SeqUS increase as moves from to . Because of the Move operation, item-choice probabilities estimated by SeqUM also increase as moves from to . Item-choice probabilities estimated by SeqUS are relatively high around . This highlights the difference in the monotonicity constraint (15) between posets and .
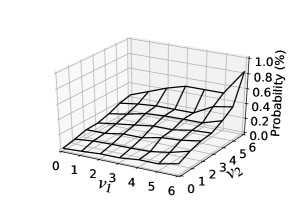
Fig. 6 shows item-choice probabilities estimated by our PV sequence model using the 10%-sampled training set, where the PV sequence setting is . Since the sample size was reduced in this case, item-choice probabilities estimated by SeqEmp are highly unstable. In particular, item-choice probabilities were estimated to be zero for all with in Fig. 6(c), but this is unreasonable from the perspective of frequency. In contrast, SeqUM and SeqUS estimated item-choice probabilities that increase monotonically with respect to .
 |
 |
 |
| (a) SeqEmp, | (b) SeqEmp, | (c) SeqEmp, |
 |
 |
 |
| (d) SeqUM, | (e) SeqUM, | (f) SeqUM, |
 |
 |
 |
| (g) SeqUS, | (h) SeqUS, | (i) SeqUS, |
VII Conclusion
We presented a shape-restricted optimization model for estimating item-choice probabilities on an e-commerce website. Our monotonicity constraints based on tailored order relations could better estimate item-choice probabilities for all possible PV sequences. To improve computational efficiency of our optimization model, we devised constructive algorithms for transitive reduction that remove all redundant constraints from the optimization model.
We assessed the effectiveness of our method through experiments using real-world clickstream data. Experimental results demonstrated that transitive reduction enhanced the efficiency of our optimization model in terms of both computation time and memory usage. In addition, our method delivered better prediction performance than did the two-dimensional monotonicity model [19] and common machine learning methods. Our method was also helpful in correcting prediction values computed by other machine learning methods.
This study made three main contributions. First, we derived two types of posets by exploiting the properties of recency and frequency of a user’s previous PVs. These posets allow us to place appropriate monotonicity constraints on item-choice probabilities. Next, we developed algorithms for transitive reduction of our posets. These algorithms are more efficient than general-purpose algorithms in terms of time complexity for transitive reduction. Finally, our method further expanded the potential of shape-restricted regression for predicting user behavior on e-commerce websites.
Once the optimization model for estimating item-choice probabilities has been solved, the obtained results can easily be put into practical use on e-commerce websites. Accurate estimates of item-choice probabilities will be useful for customizing sales promotions according to the needs of a particular user. In addition, our method can estimate user preferences from clickstream data, therefore aiding creation of high-quality user–item rating matrices for recommendation algorithms [20].
In future studies, we will develop new posets that further improve the prediction performance of our PV sequence model. Another direction of future research will be to incorporate user–item heterogeneity into our optimization model, as in the case of latent class modeling with a two-dimensional probability table [32].
Appendix A Proofs
A-A Proof of Theorem 3
The “only if” part
Suppose . We then have from Definition 4 and Lemma 2. We therefore consider the following two cases:
Case 1: for some
For the sake of contradiction, assume that (i.e., ).
Then there exists an index such that .
If , then and .
If , then and .
This implies that , which contradicts due to condition (C2) of Lemma 2.
Case 2: for some
For the sake of contradiction, assume that (i.e., ).
Then there exists an index such that .
If , then and .
If , then and .
This implies that , which contradicts due to condition (C2) of Lemma 2.
The “if” part
Next, we show that in the following two cases:
Case 1: Condition (UM1) is fulfilled
Condition (C1) of Lemma 2 is clearly satisfied.
To satisfy condition (C2), we consider such that .
From Lemma 1, we have .
Since is next to in the lexicographic order, we have .
Case 2: Condition (UM2) is fulfilled
Condition (C1) of Lemma 2 is clearly satisfied.
To satisfy condition (C2), we consider such that .
From Lemma 1, we have , which implies that for all .
Therefore, we cannot apply any operations to for in the process of transforming from into .
To keep the value of constant, we can apply only the Move operation.
However, once the Move operation is applied to for , the resultant sequence cannot be converted into .
As a result, only can be performed,
and therefore or .
A-B Proof of Theorem 4
The “only if” part
Suppose that . We then have from Definition 5 and Lemma 2. Thus, we consider the following two cases:
Case 1: for some
For the sake of contradiction, assume for some .
If , then and .
If , then and .
This implies that , which contradicts due to condition (C2) of Lemma 2.
Case 2: for some
For the sake of contradiction, assume for some .
If , then , , and .
If , then and .
If , then and .
Each of these results contradicts due to condition (C2) of Lemma 2.
The “if” part
Next, we show that in the following two cases:
Case 1: Condition (US1) is fulfilled
Condition (C1) of Lemma 2 is clearly satisfied.
To satisfy condition (C2), we consider such that .
From Lemma 1, we have , implying that for all .
Therefore, we cannot apply any operations to for in the process of transforming from into .
We must apply the Up operation only once, because the value of remains the same after the Swap operation.
Condition (US1) guarantees that for all , does not coincide with even if is applied.
Therefore, for never leads to .
As a result, must be performed.
Other applicable Swap operations produce a sequence that cannot be converted into .
This means that or .
Case 2: Condition (US2) is fulfilled
Condition (C1) of Lemma 2 is clearly satisfied.
To satisfy condition (C2), we consider such that .
From Lemma 1, we have .
This implies that for all , and that .
Therefore, we cannot apply any operations to for in the process of transforming from into .
To keep the value of constant, we can apply only the Swap operation.
However, once the Swap operation is applied to for , the resultant sequence cannot be converted into .
We cannot adopt for due to condition (US2).
If we adopt for , we have due to condition (US2), so the application of is unavoidable for .
As a result, must be performed.
Other applicable Swap operations produce a sequence that cannot be converted into .
This means that or .
Appendix B Pseudocode
B-A Constructive algorithm for
Input a pair of positive integers
Output transitive reduction
The nodes and directed edges of graph are enumerated in a breadth-first search and are stored in two lists and , respectively. We use , which appends a vertex to the end of . We similarly use .
A queue is used to store nodes of whose successors are under investigation (the “frontier” of ). The nodes in are listed in ascending order of depth, where the depth of is the shortest-path length from to . We use , which returns and deletes the first element in , and , which appends to the end of .
Algorithm 1 summarizes our constructive algorithm for computing the transitive reduction . For a given node in line 6, we find all nodes satisfying condition (UM1) in lines 7–10 and those satisfying condition (UM2) in lines 11–15.
By definition, the membership test for and can be performed in time. Recall that dequeue, enqueue, and append can be performed in time. The FOR loop in lines 11–15 executes in time. Therefore, recalling that , we see that Algorithm 1 runs in time.
B-B Constructive algorithm for
Algorithm 2 summarizes our constructive algorithm for computing the transitive reduction . Here, the difference from Algorithm 1 is the method for finding nodes satisfying conditions (US1) or (US2). For a given node in line 6, we find all nodes satisfying condition (US1) in lines 7–16, and those satisfying condition (US2) in lines 17–26. The following describes the latter part.
Input: a pair of positive integers
Output: the transitive reduction
Let be a directed edge added to in line 22. Let be such that . From line 20, we have . Note that for each in line 19, value gives the smallest value of with for . Also, due to lines 25–26, for . Combining these observations, we see that for ,
Therefore, the pair satisfies condition (US2). It is easy to verify that this process finds all vertices satisfying condition (US2).
Since both of the double FOR loops at lines 7–16 and 17–26 execute in time, Algorithm 2 runs in time.
References
- [1] C. C. Aggarwal, Recommender systems, Cham: Springer International Publishing, 2016
- [2] A. V. Aho, M. R. Garey, and J. D. Ullman, “The transitive reduction of a directed graph,” SIAM J. Comput., vol. 1, no. 2, pp. 131–137, 1972.
- [3] Y. Aıt-Sahalia and J. Duarte, “Nonparametric option pricing under shape restrictions,” J. Econom., vol. 116, no. 1–2, pp. 9–47, 2003.
- [4] E. E. Altendorf, A. C. Restificar, and T. G. Dietterich, “Learning from sparse data by exploiting monotonicity constraints,” in Proc. UAI, 2005, pp. 18–26.
- [5] A. Baumann, J. Haupt, F. Gebert, and S. Lessmann, “Changing perspectives: Using graph metrics to predict purchase probabilities,” Expert Syst. Appl., vol. 94, pp. 137–148, 2018.
- [6] J. Borges and M. Levene, “Evaluating variable-length markov chain models for analysis of user web navigation sessions,” IEEE Trans. Knowl. Data Eng., vol. 19, no. 4, pp. 441–452, 2007.
- [7] R. E. Bucklin and C. Sismeiro, “Click here for Internet insight: Advances in clickstream data analysis in marketing,” J. Interact. Mark., vol. 23, no. 1, pp. 35–48, 2009.
- [8] S. Chatterjee, A. Guntuboyina, and B. Sen, “On risk bounds in isotonic and other shape restricted regression problems,” Ann. Stat., vol. 43, no. 4, pp. 1774–1800, 2015.
- [9] Y. L. Chen, M. H. Kuo, S. Y. Wu, and K. Tang, “Discovering recency, frequency, and monetary (RFM) sequential patterns from customers’ purchasing data,” Electron. Commer. Res. Appl., vol. 8, no. 5, pp. 241–251, 2009.
- [10] D. Cirqueira, M. Hofer, D. Nedbal, M. Helfert, and M. Bezbradica, “Customer Purchase Behavior Prediction in E-commerce: Current Tasks, Applications and Methodologies,” in Inter. Workshop NFMCP, 2019.
- [11] T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein, Introduction to algorithms, MIT press, 2009.
- [12] Y. Dong and W. Jiang, “Brand purchase prediction based on time-evolving user behaviors in e-commerce,” Concurr. Comput., vol. 31, no. 1, pp. e4882, 2019.
- [13] P. S. Fader, B. G. Hardie, and K. L. Lee, “RFM and CLV: Using iso-value curves for customer base analysis,” J. Mark. Res., vol. 42, no. 4, pp. 415–430, 2005.
- [14] B. R. Gaines, J. Kim, and H. Zhou, “Algorithms for fitting the constrained lasso,” J. Comput. Graph. Stat., vol. 27, no. 4, pp. 861–871, 2018.
- [15] P. Groeneboom and G. Jongbloed, Nonparametric estimation under shape constraints (Vol. 38), Cambridge University Press, 2014.
- [16] A. Guntuboyina and B. Sen, “Nonparametric shape-restricted regression,” Stat. Sci., vol. 33, no. 4, pp. 568–594, 2018.
- [17] Q. Han, T. Wang, S. Chatterjee, and R. J. Samworth, “Isotonic regression in general dimensions,” Ann. Stat., vol. 47, no. 5, pp. 2440–2471, 2019.
- [18] T. Huang and J. A. Van Mieghem, “Clickstream data and inventory management: Model and empirical analysis,” Prod. Oper. Manag., vol. 23, no. 3, pp. 333–347, 2014.
- [19] J. Iwanaga, N. Nishimura, N. Sukegawa, and Y. Takano, “Estimating product-choice probabilities from recency and frequency of page views,” Knowl. Based Syst., vol. 99, pp. 157–167, 2016.
- [20] J. Iwanaga, N. Nishimura, N. Sukegawa, and Y. Takano, “Improving collaborative filtering recommendations by estimating user preferences from clickstream data,” Electron. Commer. Res. Appl., vol. 37, 100877, 2019.
- [21] D. Jannach, M. Ludewig, and L. Lerche, “Session-based item recommendation in e-commerce: on short-term intents, reminders, trends and discounts,” User Model. User-adapt. Interact., vol. 27, no. 3–5, pp. 351–392, 2017.
- [22] P. K. Kannan, “Digital marketing: A framework, review and research agenda,” Int. J. Res. Mark., vol. 34, no. 1, pp. 22–45, 2017.
- [23] D. Koehn, S. Lessmann, and M. Schaal, “Predicting online shopping behaviour from clickstream data using deep learning,” Expert Syst. Appl., vol. 150, no. 15, 113342, 2020.
- [24] F. Le Gall, “Powers of tensors and fast matrix multiplication,” in Proc. ISSAC, 2014, pp. 296–303, 2014.
- [25] Q. Li, M. Gu, K. Zhou, and X. Sun, “Multi-Classes Feature Engineering with Sliding Window for Purchase Prediction in Mobile Commerce,” in IEEE ICDM Workshop, 2015, pp. 1048–1054.
- [26] D. Li, G. Zhao, Z. Wang, W. Ma, and Y. Liu, “A method of purchase prediction based on user behavior log,” in IEEE ICDM Workshop, 2015, pp. 1031–1039.
- [27] M. Ludewig and D. Jannach, “Evaluation of session-based recommendation algorithms,” User Model. User-adapt. Interact., vol. 28, no. 4–5, pp. 331–390, 2018.
- [28] R. L. Matzkin, “Semiparametric estimation of monotone and concave utility functions for polychotomous choice models,” Econometrica, vol. 59, no. 5, pp. 1315–1327, 1991.
- [29] W. W. Moe, “An empirical two-stage choice model with varying decision rules applied to internet clickstream data,” J. Mark. Res., vol. 43, no. 4, pp. 680–692, 2006.
- [30] W. W. Moe and P. S. Fader, “Dynamic conversion behavior at e-commerce sites,” Manage. Sci., vol. 50, no. 3, pp. 326–335, 2004.
- [31] A. L. Montgomery, S. Li, K. Srinivasan, and J. C. Liechty, “Modeling online browsing and path analysis using clickstream data,” Mark. Sci., vol. 23, no. 4, pp. 579–595, 2004.
- [32] N. Nishimura, N. Sukegawa, Y. Takano, and J. Iwanaga, “A latent-class model for estimating product-choice probabilities from clickstream data,” Inf. Sci., vol. 429,pp. 406–420, 2018.
- [33] E. W. Ngai, L. Xiu, and D. C. Chau, “Application of data mining techniques in customer relationship management: A literature review and classification,” Expert Syst. Appl., vol. 36, no. 2, pp. 2592–2602, 2009.
- [34] P. Orzechowski, W. La Cava, and J. H. Moore, “Where are we now? A large benchmark study of recent symbolic regression methods,” in Proc. GECCO, 2018, pp. 1183–1190.
- [35] P. M. Pardalos and G. Xue, “Algorithms for a class of isotonic regression problems,” Algorithmica, vol. 23, no. 3, pp. 211–222, 1999.
- [36] C. H. Park and Y. H. Park, “Investigating purchase conversion by uncovering online visit patterns,” Mark. Sci., vol. 35, no. 6, pp. 894–914, 2016.
- [37] A. Pitman and M. Zanker, “Insights from applying sequential pattern mining to e-commerce click stream data,” in IEEE ICDM Workshop, 2010, pp. 967–975.
- [38] J. Qiu, Z. Lin, and Y. Li, “Predicting customer purchase behavior in the e-commerce context,” Electron. Commer. Res., vol. 15, no. 4, pp. 427–452, 2015.
- [39] P. Romov and E. Sokolov, “Recsys challenge 2015: ensemble learning with categorical features,” in Proc. Inter. ACM RecSys Challenge, 2015, pp. 1–4.
- [40] B. Schröder, Ordered Sets: An Introduction with Connections from Combinatorics to Topology, Birkhäuser, 2016.
- [41] C. Sismeiro and R. E. Bucklin, “Modeling purchase behavior at an e-commerce web site: A task-completion approach,” J. Mark. Res., vol. 41, no. 3, pp. 306–323, 2004.
- [42] B. Stellato, G. Banjac, P. Goulart, A. Bemporad, and S. Boyd, “OSQP: An operator splitting solver for quadratic programs,” Math. Program. Comput., in press.
- [43] Q. F. Stout, “Isotonic regression for multiple independent variables,” Algorithmica, vol. 71, no. 2, pp. 450–470, 2015.
- [44] R. J. Tibshirani, H. Hoefling, and R. Tibshirani, “Nearly-isotonic regression,” Technometrics, vol. 53, no. 1, pp. 54–61, 2011.
- [45] E. Turban, J. Outland, D. King, J. K. Lee, T. P. Liang, and D. C. Turban, Electronic Commerce 2018: A Managerial and Social Networks Perspective, Springer, 2017.
- [46] D. Van den Poel and W. Buckinx, “Predicting online-purchasing behaviour,” Eur. J. Oper. Res., vol. 166, no. 2, pp. 557–575, 2005.
- [47] A. Vieira, “Predicting online user behaviour using deep learning algorithms,” arXiv preprint arXiv:1511.06247, 2015.
- [48] J. Wang and S. K. Ghosh, “Shape restricted nonparametric regression with Bernstein polynomials,” Comput. Stat. Data Anal., vol. 56, no. 9, pp. 2729–2741, 2012.
- [49] S. Warshall, “A theorem on boolean matrices,” J. ACM, vol. 9, no. 1, pp. 11–12, 1962.
- [50] Z. Wu, B. H. Tan, R. Duan, Y. Liu, and R. S. Mong Goh, “Neural modeling of buying behaviour for e-commerce from clicking patterns,” in Proc. Inter. ACM RecSys Challenge, 2015, pp. 1–4.
- [51] J. Yeo, S. Kim, E. Koh, S. W. Hwang, and N. Lipka, “Predicting online purchase conversion for retargeting,” in Proc. ACM Inter. Conf. WSDM, 2017, pp. 591–600.
- [52] Z. Yi, D. Wang, K. Hu, and Q. Li, “Purchase behavior prediction in m-commerce with an optimized sampling methods,” in IEEE ICDMW, 2015, pp. 1085–1092.
- [53] Y. Zhang and M. Pennacchiotti, “Predicting purchase behaviors from social media,” in Proc. Inter. Conf. WWW, 2013, pp. 1521–1532.
- [54] Y. Zhao, L. Yao, and Y. Zhang, “Purchase prediction using Tmall-specific features,” Concurr. Comput., vol. 28, no. 14, pp. 3879–3894, 2016.