AABI 20203rd Symposium on Advances in Approximate Bayesian Inference, 2020
Preconditioned training of normalizing flows for variational inference in inverse problems
Abstract
Obtaining samples from the posterior distribution of inverse problems with expensive forward operators is challenging especially when the unknowns involve the strongly heterogeneous Earth. To meet these challenges, we propose a preconditioning scheme involving a conditional normalizing flow (NF) capable of sampling from a low-fidelity posterior distribution directly. This conditional NF is used to speed up the training of the high-fidelity objective involving minimization of the Kullback-Leibler divergence between the predicted and the desired high-fidelity posterior density for indirect measurements at hand. To minimize costs associated with the forward operator, we initialize the high-fidelity NF with the weights of the pretrained low-fidelity NF, which is trained beforehand on available model and data pairs. Our numerical experiments, including a 2D toy and a seismic compressed sensing example, demonstrate that thanks to the preconditioning considerable speed-ups are achievable compared to training NFs from scratch.
1 Introduction
Our aim is to perform approximate Bayesian inference for inverse problems characterized by computationally expensive forward operators, , with a data likelihood, :
| (1) |
where is the unknown model, the observed data, and the measurement noise. Given a prior density, , variational inference (VI, Jordan et al., 1999) based on normalizing flows (NFs, Rezende and Mohamed, 2015) can be used where the Kullback-Leibler (KL) divergence is minimized between the predicted and the target—i.e., high-fidelity, posterior density (Liu and Wang, 2016; Kruse et al., 2019; Rizzuti et al., 2020; Siahkoohi et al., 2020; Sun and Bouman, 2020):
| (2) |
In the above expression, denotes a NF with parameters and a Gaussian latent variable . The above objective consists of the data likelihood term, regularization on the output of the NF, and a log-determinant term that is related to the entropy of the NF output. The last term is necessarily to prevent the output of the NF from collapsing on the maximum a posteriori estimate. For details regarding the derivation of the objective in Equation (2), we refer to Appendix A. During training, we replace the expectation by Monte-Carlo averaging using mini-batches of . After training, samples from the approximated posterior, , can be drawn by evaluating for (Kruse et al., 2019). It is important to note that Equation (2) trains a NF specific to the observed data . While the above VI formulation in principle allows us to train a NF to generate samples from the posterior given a single observation , this variational estimate requires access to a prior density, and the training calls for repeated evaluations of the forward operator, , as well as the adjoint of its Jacobian, . As in multi-fidelity Markov chain Monte Carlo (MCMC) sampling (Peherstorfer and Marzouk, 2019), the costs associated with the forward operator may become prohibitive even though VI-based methods are known to have computational advantages over MCMC (Blei et al., 2017).
Aside from the above computational considerations, reliance on having access to a prior may be problematic especially when dealing with images of the Earth’s subsurface, which are the result of complex geological processes that do not lend themselves to be easily captured by hand-crafted priors. Under these circumstances, data-driven priors—or even better data-driven posteriors obtained by training over model and data pairs sampled from the joint distribution, —are preferable. More specifically, we follow Kruse et al. (2019), Kovachki et al. (2020), and Baptista et al. (2020), and formulate the objective function in terms of a block-triangular conditional NF, , with latent space :
| (3) | ||||
Thanks to the block-triangular structure of , samples of the approximated posterior, can be drawn by evaluating for (Marzouk et al., 2016). Unlike the objective in Equation (2), training does not involve multiple evaluations of and , nor does it require specifying a prior density. However, its success during inference heavily relies on having access to training pairs from the joint distribution, . Unfortunately, unlike medical imaging, where data is abundant and variability among patients is relatively limited, samples from the joint distribution are unavailable in geophysical applications. Attempts have been made to address this lack of training pairs including the generation of simplified artificial geological models (Mosser et al., 2019), but these approaches cannot capture the true heterogeneity exhibited by the Earth’s subsurface. This is illustrated in Figure 1, which shows several true seismic image patches drawn from the Parihaka dataset. Even though samples are drawn from a single data set, they illustrate significant differences between shallow (Figures 1a and 1b) and deeper (Figures 1c and 1d) sections.




To meet the challenges of computational cost, heterogeneity and lack of access to training pairs, we propose a preconditioning scheme where the two described VI methods are combined to:
-
1.
take maximum advantage of available samples from the joint distribution , to pretrain by minimizing Equation (3). We only incur these costs once, by training this NF beforehand. As these samples typically come from a different (neighboring) region, they are considered as low-fidelity;
-
2.
exploit the invertibility of , which gives us access to a low-fidelity posterior density, . For a given , this trained (conditional) prior can be used in Equation (2);
- 3.
2 Related work
In the context of variational inference for inverse problems with expensive forward operators, Herrmann et al. (2019) train a generative model to sample from the posterior distribution, given indirect measurements of the unknown model. This approach is based on an Expectation Maximization technique, which infers the latent representation directly instead of using an inference encoding model. While that approach allows for inclusion of hand-crafted priors, capturing the posterior is not fully developed. Like Kovachki et al. (2020), we also use a block-triangular map between the joint model and data distribution and their respective latent spaces to train a network to generate samples from the conditional posterior. By imposing an additional monotonicity constraint, these authors train a generative adversarial network (GAN, Goodfellow et al., 2014) to directly sample from the posterior distribution. To allow for scalability to large scale problems, we work with NFs instead, because they allow for more memory efficient training (Leemput et al., 2019; Putzky and Welling, 2019; Peters et al., 2020; Peters and Haber, 2020). Our contribution essentially corresponds to a reformulation of Parno and Marzouk (2018) and Peherstorfer and Marzouk (2019). In that work, transport-based maps are used as non-Gaussian proposal distributions during MCMC sampling. As part of the MCMC, this transport map is then tuned to match the target density, which improves the efficiency of the sampling. Peherstorfer and Marzouk (2019) extend this approach by proposing a preconditioned MCMC sampling technique where a transport-map trained to sample from a low-fidelity posterior distribution is used as a preconditioner. This idea of multi-fidelity preconditioned MCMC inspired our work where we setup a VI objective instead. We argue that this formulation can be faster and may be easier to scale to large-scale Bayesian inference problems (Blei et al., 2017).
Finally, there is a conceptional connection between our work and previous contributions on amortized variational inference (Gershman and Goodman, 2014), including an iterative refinement step (Hjelm et al., 2016; Krishnan et al., 2018; Kim et al., 2018; Marino et al., 2018). Although similar in spirit, our approach is different from these attempts because we adapt the weights of our conditional generative model to account for the inference errors instead of correcting the inaccurate latent representation of the out-of-distribution data.
3 Multi-fidelity preconditioning scheme
For an observation , we define a NF as
| (4) |
where we obtain by training through minimizing the objective function in Equation (3). To train , we use available low-fidelity training pairs . We perform this training phase beforehand, similar to the pretraining phase during transfer learning (Yosinski et al., 2014). Thanks to the invertibility of , it provides an expression for the posterior. We refer to this posterior as low-fidelity because the network is trained with often scarce and out-of-distribution training pairs. Because the Earth’s heterogeneity does not lend itself to be easily captured by hand-crafted priors, we argue that this NF can still serve as a (conditional) prior in Equation (2):
| (5) |
To train the high-fidelity NF given observed data , we minimize the KL divergence between the predicted and the high-fidelity posterior density, (Liu and Wang, 2016; Kruse et al., 2019)
| (6) |
where the prior density of Equation (5) is used. Notice that this minimization problem differs from the one stated in Equation (2). Here, the optimization involves “fine-tuning” the low-fidelity network parameters introduced in Equation (3). Moreover, this low-fidelity network is also used as a prior. While other choices exist for the latter—e.g., it could be replaced or combined with a hand-crafted prior in the form of constraints (Peters et al., 2019) or by a separately trained data-driven prior (Mosser et al., 2019), using the low-fidelity posterior as a prior (cf. Equation (5)) has certain distinct advantages. First, it removes the need for training a separate data-driven prior model. Second, use of the low-fidelity posterior may be more informative (Yang and Soatto, 2018) than its unconditional counterpart because it is conditioned by the observed data . In addition, our multi-fidelity approach has strong connections with online variational Bayes (Zeno et al., 2018) where data arrives sequentially and previous posterior approximates are used as priors for subsequent approximations.
In summary, the problem in Equation (6) can be interpreted as an instance of transfer learning (Yosinski et al., 2014) for conditional NFs. This formulation is particularly useful for inverse problems with expensive forward operators, where access to high fidelity training samples, i.e. samples from the target distribution, is limited. In the next section, we present two numerical experiments designed to show the speed-up and accuracy gained with our proposed multi-fidelity formulation.
4 Numerical experiments
We present two synthetic examples aimed at verifying the anticipated speed-up and increase in accuracy of the predicted posterior density via our multi-fidelity preconditioning scheme. The first example is a two-dimensional problem where the posterior density can be accurately and cheaply sampled via MCMC. The second example demonstrates the effect of the preconditioning scheme in a seismic compressed sensing (Candes et al., 2006; Donoho, 2006) problem. Details regarding training hyperparameters and the NF architectures are included in Appendix B. Code to reproduce our results are made available on GitHub. Our implementation relies on InvertibleNetworks.jl (Witte et al., 2020), a recently-developed memory-efficient framework for training invertible networks in the Julia programming language.
4.1 2D toy example
To illustrate, the advantages of working with our multi-fidelity scheme, we consider the 2D Rosenbrock distribution, , plotted in Figure 2a. High-fidelity data are generated via , where and is a forward operator. To control the discrepancy between the low- and high-fidelity samples, we set equal to , where is the spectral radius of , has independent and normally distributed entries, and . By choosing smaller values for , we make more dissimilar to the identity matrix, therefore increasing the discrepancy between the low- and high-fidelity posterior.
Figure 2b depicts the low- (purple) and high-fidelity (red) data densities. The dark star represents the unknown model. Low-fidelity data samples are generated with the identity as the forward operator. During the pretraining phase conducted beforehand, we minimize the objective function in Equation (3) for epochs.





The pretrained low-fidelity posterior is subsequently used to precondition the minimization of (6) given observed data . The resulting low- and high-fidelity estimates for the posterior as plotted in Figure 2c differ significantly. In Figure (2d), the accuracy of the proposed method is verified by comparing the approximated high-fidelity posterior density (orange contours) with the approximation (in green) obtained by minimizing the objective of Equation (2). The overlap between the orange contours and the green shaded area confirms consistency between the two methods. To assess the accuracy of the estimated densities themselves, we also include samples from the posterior (dark circles) obtained via stochastic gradient Langevin dynamics (Welling and Teh, 2011), an MCMC sampling technique. As expected, the estimated posterior densities with and without the preconditioning scheme are in agreement with the MCMC samples.
Finally, to illustrate the performance our multi-fidelity scheme, we consider the convergence plot in Figure 2e where the objective values of Equations (2) and (6) are compared. As explained in Appendix A, the values of the objective functions correspond to the KL divergence (plus a constant) between the posterior given by Equation (2) and the posterior distribution obtained by our multi-fidelity approach (Equation (6)). As expected, the multi-fidelity objective converges much faster because of the “warm start”. In addition, the updates of via Equation (6) succeed in bringing down the KL divergence within only five epochs (see orange curve), whereas it takes epochs via the objective in Equation (2) to reach approximately the same KL divergence. This pattern holds for smaller values of too as indicated in Table 1. According to Table 1, the improvements by our multi-fidelity method become more pronounced if we decrease the . This behavior is to be expected since the samples used for pretraining are more and more out of distribution in that case. We refer to Appendix C for additional figures for different values of .
| Low-fidelity | Without preconditioning | With preconditioning | |
|---|---|---|---|
4.2 Seismic compressed sensing example
This experiment is designed to show challenges with geophysical inverse problems due to the Earth’s strong heterogeneity. We consider the inversion of noisy indirect measurements of image patches sampled from deeper parts of the Parihaka seismic dataset. The observed measurements are given by where . For simplicity, we chose with a compressing sensing matrix with % subsampling. The measurement vector corresponds to a pseudo-recovered model contaminated with noise.
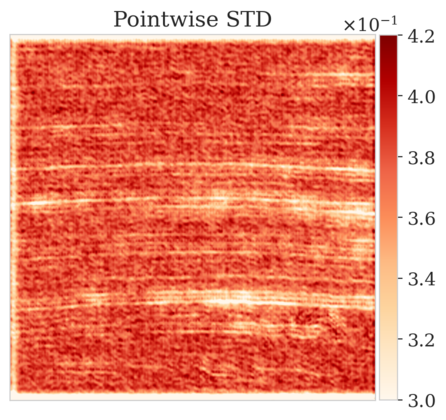
To mimic a realistic situation in practice, we change the likelihood distribution by reducing the standard deviation of the noise to in combination with using image patches sampled from the shallow part of the Parihaka dataset. As we have seen in Figure 1, these patches differ in texture. Given pairs , we pretrain our network by minimizing Equation (3). Figures 3a and 3b contain a pair not used during pretraining. Estimates for the conditional mean and standard deviation obtained by drawing samples from the pretrained conditional NF for the noisy indirect measurement (Figure 3b) are included in Figures 3c and 3d. Both estimates exhibit the expected behavior because the examples in Figure 3a and 3b are within the distribution. As anticipated, this observation no longer holds if we apply this pretrained network to indirect data depicted in Figure 3f, which is sampled from the deeper part. However, these results are significantly improved when the pretrained network is fine-tuned by minimizing Equation (6). After fine tuning, the fine details in the image are recovered (compare Figures 3g and 3h). This improvement is confirmed by the relative errors plotted in Figures 3i and 3j, as well as by the reduced standard deviation (compare Figures 3k and 3l).












5 Conclusions
Inverse problems in fields such as seismology are challenging for several reasons. The forward operators are complex and expensive to evaluate numerically while the Earth is highly heterogeneous. To handle this situation and to quantify uncertainty, we propose a preconditioned scheme for training normalizing flows for Bayesian inference. The proposed scheme is designed to take full advantage of having access to training pairs drawn from a joint distribution, which for the reasons stated above is close but not equal to the actual joint distribution. We use these samples to train a normalizing flow via likelihood maximization leveraging the normalizing property. We use this pretrained low-fidelity estimate for the posterior as a prior and preconditioner for the actual variational inference on the observed data, which minimizes the Kullback-Leibler divergence between the predicted and the desired posterior density. By means of a series of examples, we demonstrate that our preconditioned scheme leads to considerable speed-ups compared to training a normalizing flow from scratch.
References
- Baptista et al. (2020) Ricardo Baptista, Olivier Zahm, and Youssef Marzouk. An adaptive transport framework for joint and conditional density estimation. arXiv preprint arXiv:2009.10303, 2020. URL https://arxiv.org/abs/2009.10303.
- Blei et al. (2017) David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A review for statisticians. Journal of the American statistical Association, 112(518):859–877, 2017.
- Bogachev, V.I. (2006) Bogachev, V.I. Measure Theory. Springer-Verlag Berlin Heidelberg, 2006. ISBN 9783540345138. 10.1007/978-3-540-34514-5. URL https://books.google.com/books?id=4vmOjgEACAAJ.
- Candes et al. (2006) Emmanuel J Candes, Justin K Romberg, and Terence Tao. Stable signal recovery from incomplete and inaccurate measurements. Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, 59(8):1207–1223, 2006.
- Dinh et al. (2016) Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using Real NVP. arXiv preprint arXiv:1605.08803, 2016.
- Donoho (2006) David L Donoho. Compressed sensing. IEEE Transactions on Information Theory, 52(4):1289–1306, 2006. 10.1109/TIT.2006.871582.
- Gershman and Goodman (2014) Samuel Gershman and Noah Goodman. Amortized Inference in Probabilistic Reasoning. In Proceedings of the Annual Meeting of the Cognitive Science Society, volume 36, pages 517–522, 2014.
- Goodfellow et al. (2014) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, NIPS’14, pages 2672–2680, 2014. URL http://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, June 2016. 10.1109/CVPR.2016.90. URL https://ieeexplore.ieee.org/document/7780459.
- Herrmann et al. (2019) Felix J. Herrmann, Ali Siahkoohi, and Gabrio Rizzuti. Learned imaging with constraints and uncertainty quantification. In Neural Information Processing Systems (NeurIPS) 2019 Deep Inverse Workshop, 12 2019. URL https://arxiv.org/pdf/1909.06473.pdf.
- Hjelm et al. (2016) Devon Hjelm, Russ R Salakhutdinov, Kyunghyun Cho, Nebojsa Jojic, Vince Calhoun, and Junyoung Chung. Iterative Refinement of the Approximate Posterior for Directed Belief Networks. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 29, pages 4691–4699. Curran Associates, Inc., 2016. URL https://proceedings.neurips.cc/paper/2016/file/20c9f5700da1088260df60fcc5df2b53-Paper.pdf.
- Jordan et al. (1999) Michael I Jordan, Zoubin Ghahramani, Tommi S Jaakkola, and Lawrence K Saul. An Introduction to Variational Methods for Graphical Models. Machine Learning, 37(2):183–233, 1999. 10.1023/A:1007665907178.
- Kim et al. (2018) Yoon Kim, Sam Wiseman, Andrew Miller, David Sontag, and Alexander Rush. Semi-amortized variational autoencoders. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 2678–2687, Stockholmsmässan, Stockholm Sweden, 10–15 Jul 2018. PMLR. URL http://proceedings.mlr.press/v80/kim18e.html.
- Kingma and Ba (2014) Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. CoRR, abs/1412.6980, 2014.
- Kovachki et al. (2020) Nikola Kovachki, Ricardo Baptista, Bamdad Hosseini, and Youssef Marzouk. Conditional Sampling With Monotone GANs. arXiv preprint arXiv:2006.06755, 2020.
- Krishnan et al. (2018) Rahul Krishnan, Dawen Liang, and Matthew Hoffman. On the challenges of learning with inference networks on sparse, high-dimensional data. In Amos Storkey and Fernando Perez-Cruz, editors, Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 of Proceedings of Machine Learning Research, pages 143–151. PMLR, 09–11 Apr 2018.
- Kruse et al. (2019) Jakob Kruse, Gianluca Detommaso, Robert Scheichl, and Ullrich Köthe. HINT: Hierarchical Invertible Neural Transport for Density Estimation and Bayesian Inference. arXiv preprint arXiv:1905.10687, 2019.
- Leemput et al. (2019) Sil C. van de Leemput, Jonas Teuwen, Bram van Ginneken, and Rashindra Manniesing. MemCNN: A Python/PyTorch package for creating memory-efficient invertible neural networks. Journal of Open Source Software, 4(39):1576, 7 2019. ISSN 2475-9066. 10.21105/joss.01576. URL http://dx.doi.org/10.21105/joss.01576.
- Liu and Wang (2016) Qiang Liu and Dilin Wang. Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm. In Advances in Neural Information Processing Systems, volume 29, pages 2378–2386. Curran Associates, Inc., 2016. URL https://proceedings.neurips.cc/paper/2016/file/b3ba8f1bee1238a2f37603d90b58898d-Paper.pdf.
- Marino et al. (2018) Joseph Marino, Yisong Yue, and Stephan Mandt. Iterative amortized inference. arXiv preprint arXiv:1807.09356, 2018.
- Marzouk et al. (2016) Youssef Marzouk, Tarek Moselhy, Matthew Parno, and Alessio Spantini. Sampling via measure transport: An introduction. Handbook of uncertainty quantification, pages 1–41, 2016.
- Mosser et al. (2019) L. Mosser, O. Dubrule, and M. Blunt. Stochastic Seismic Waveform Inversion Using Generative Adversarial Networks as a Geological Prior. Mathematical Geosciences, 84(1):53–79, 2019. 10.1007/s11004-019-09832-6.
- Parno and Marzouk (2018) Matthew D Parno and Youssef M Marzouk. Transport Map Accelerated Markov Chain Monte Carlo. SIAM/ASA Journal on Uncertainty Quantification, 6(2):645–682, 2018. 10.1137/17M1134640.
- Peherstorfer and Marzouk (2019) Benjamin Peherstorfer and Youssef Marzouk. A transport-based multifidelity preconditioner for Markov chain Monte Carlo. Advances in Computational Mathematics, 45(5-6):2321–2348, 2019.
- Peters and Haber (2020) Bas Peters and Eldad Haber. Fully reversible neural networks for large-scale 3d seismic horizon tracking. In 82nd EAGE Annual Conference & Exhibition, pages 1–5. European Association of Geoscientists & Engineers, 2020.
- Peters et al. (2019) Bas Peters, Brendan R Smithyman, and Felix J Herrmann. Projection methods and applications for seismic nonlinear inverse problems with multiple constraints. Geophysics, 84(2):R251–R269, 2019. 10.1190/geo2018-0192.1.
- Peters et al. (2020) Bas Peters, Eldad Haber, and Keegan Lensink. Fully reversible neural networks for large-scale surface and sub-surface characterization via remote sensing. arXiv preprint arXiv:2003.07474, 2020.
- Putzky and Welling (2019) Patrick Putzky and Max Welling. Invert to Learn to Invert. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32, pages 446–456. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/file/ac1dd209cbcc5e5d1c6e28598e8cbbe8-Paper.pdf.
- Rezende and Mohamed (2015) Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. volume 37 of Proceedings of Machine Learning Research, pages 1530–1538. PMLR, 07–09 Jul 2015. URL http://proceedings.mlr.press/v37/rezende15.html.
- Rizzuti et al. (2020) Gabrio Rizzuti, Ali Siahkoohi, Philipp A. Witte, and Felix J. Herrmann. Parameterizing uncertainty by deep invertible networks, an application to reservoir characterization. arXiv preprint arXiv:2004.07871, 4 2020. URL https://arxiv.org/pdf/2004.07871.pdf.
- Santambrogio (2015) Filippo Santambrogio. Optimal Transport for Applied Mathematicians. Birkäuser, NY, 87, 2015. 10.1007/978-3-319-20828-2.
- Siahkoohi et al. (2020) Ali Siahkoohi, Gabrio Rizzuti, Philipp A. Witte, and Felix J. Herrmann. Faster uncertainty quantification for inverse problems with conditional normalizing flows. Technical Report TR-CSE-2020-2, Georgia Institute of Technology, 07 2020. URL https://arxiv.org/abs/2007.07985.
- Sun and Bouman (2020) He Sun and Katherine L Bouman. Deep probabilistic imaging: Uncertainty quantification and multi-modal solution characterization for computational imaging. arXiv preprint arXiv:2010.14462, 2020.
- Villani (2009) Cédric Villani. Optimal Transport: Old and New, volume 338. Springer-Verlag Berlin Heidelberg, 2009. 10.1007/978-3-540-71050-9.
- Welling and Teh (2011) Max Welling and Yee Whye Teh. Bayesian Learning via Stochastic Gradient Langevin Dynamics. In Proceedings of the 28th International Conference on Machine Learning, ICML’11, pages 681–688, Madison, WI, USA, 2011. Omnipress. ISBN 9781450306195. 10.5555/3104482.3104568. URL https://dl.acm.org/doi/abs/10.5555/3104482.3104568.
- Witte et al. (2020) Philipp Witte, Gabrio Rizzuti, Mathias Louboutin, Ali Siahkoohi, and Felix Herrmann. InvertibleNetworks.jl: A Julia framework for invertible neural networks, November 2020. URL https://doi.org/10.5281/zenodo.4298853.
- Yang and Soatto (2018) Yanchao Yang and Stefano Soatto. Conditional Prior Networks for Optical Flow. In Proceedings of the European Conference on Computer Vision (ECCV), pages 271–287, 2018.
- Yosinski et al. (2014) Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson. How transferable are features in deep neural networks? In Proceedings of the 27th International Conference on Neural Information Processing Systems, NIPS’14, pages 3320–3328, 2014. URL http://dl.acm.org/citation.cfm?id=2969033.2969197.
- Zeno et al. (2018) Chen Zeno, Itay Golan, Elad Hoffer, and Daniel Soudry. Task Agnostic Continual Learning Using Online Variational Bayes. arXiv preprint arXiv:1803.10123, 2018.
Appendix A Mathematical derivations
Let be a bijective transformation that maps a random variable to . We can write the change of variable formula (Villani, 2009) that relates probability density functions and in the following manner:
| (7) |
This relation serves as the basis for the objective functions used throughout this paper.
A.1 Derivation of Equation (2)
In Equation 2, we train a bijective transformation, denoted by , that maps the latent distribution to the high-fidelity posterior density . We optimize the parameters of by minimizing the KL divergence between the push-forward density (Bogachev, V.I., 2006), denoted by , and the posterior density:
| (8) | ||||
In the above expression, we can rewrite the expectation with respect to as the expectation with respect to the latent distribution, followed by a mapping via —i.e.,
| (9) |
The last term in the expectation above can be further simplified via the change of variable formula in Equation (7). If , then:
| (10) |
The last equality in Equation (10) holds due to the invertibility of and the differentiability of its inverse (inverse function theorem). By combining Equations (9) and (10), we arrive at the following objective function for training :
| (11) |
Finally, by ignoring the term, which is constant with respect to , using Bayes’ rule, and inserting our data likelihood model from Equation (1), we derive Equation (2):
| (12) |
Next, based on this equation, we derive the objective function used in the pretraining phase.
A.2 Derivation of Equation (3)
The derivation of objective in Equation (3) follows directly from the change of variable formula in Equation 7, applied to a bijective map, , where and are Gaussian latent spaces. That is to say:
| (13) |
Given (low-fidelity) training pairs, , the maximum likelihood estimate of is obtained via the following objective:
| (14) | ||||
that is the objective function in Equation (3). The NF trained via the objective function, given samples from the latent distribution, draws samples from the low-fidelity joint distribution, .
By construction, is a block-triangular map—i.e.,
| (15) |
Kruse et al. (2019) showed that after solving the optimization problem in Equation (3), approximates the well-known triangular Knothe-Rosenblat map (Santambrogio, 2015). As shown in Marzouk et al. (2016), the triangular structure and ’s invertibility yields the following property,
| (16) |
where denotes the low-fidelity posterior probability density function. The expression above means we can get access to low-fidelity posterior distribution samples by simply evaluating for for a given observed data .
Appendix B Training details and network architectures
For our network architecture, we adapt the recursive coupling blocks proposed by Kruse et al. (2019), which use invertible coupling layers from Dinh et al. (2016) in a hierarchical way. In other words, we recursively divide the incoming state variables and apply an affine coupling layer. The final architecture is obtained by composing several of these hierarchical coupling blocks. The hierarchical structure leads to dense triangular Jacobian, which is essential in representation power of NFs (Kruse et al., 2019).
For all examples in this paper, we use the hierarchical coupling blocks as described in Kruse et al. (2019). The affine coupling layers within each hierarchal block contain a residual block as described in He et al. (2016). Each residual block has the following dimensions: input, hidden, and output channels, except for the first and last coupling layer where we have input and output channels, respectively. We use the Wavelet transform and its transpose before feeding seismic images into the network and after the last layer of the NFs.
Below, we describe the network architectures and training details regarding the two numerical experiments described in the paper. Throughout the experiments, we use the Adam optimization algorithm (Kingma and Ba, 2014).
B.1 2D toy example
We use 8 hierarchal coupling blocks, as described above for both and (Equation (3)). As a result, due to our proposed method in Equation (4), we choose the same architecture for (Equation (2)).
For pretraining according to Equation (3), we use low-fidelity joint training pairs, . We minimize Equation (3) for epochs with a batch size of and a (starting) learning rate of . We decrease the learning rate each epoch by a factor of .
For the preconditioned step—i.e., solving Equation 6, we use latent training samples. We train for epochs with a batch size of and a learning rate . Finally, as a comparison, we solve the objective in Equation 6 for a randomly initialized NF with the same latent training samples for epochs. We decrease the learning rate each epoch by .
B.2 Seismic compressed sensing
We use 12 hierarchal coupling blocks, as described above for both , , and we use the same architecture for as .
For pretraining according to Equation (3), we use low-fidelity joint training pairs, . We minimize Equation (3) for epochs with a batch size of and a starting learning rate of . Once again, we decrease the learning rate each epoch by .
For the preconditioned step—i.e., solving Equation 6, we use latent training samples. We train for epochs with a batch size and a learning rate of , where we decay the step by in every th epoch.
Appendix C 2D toy example—more results
Here we show the effect on our proposed method in the 2D toy experiment. By choosing smaller values for , we make with less close to the identity matrix, hence enhancing the discrepancy between the low- and high-fidelity posterior. The first row of Figure 4 shows the low- (purple) and high-fidelity (red) data densities for decreasing values of from down to . The second row depicts the predicted posterior densities via the preconditioned scheme (orange contours) and the low-fidelity posterior in green along with MCMC samples (dark circles). The third row compares the preconditioned posterior densities to samples obtained via the low-fidelity pretrained NF—i.e., Equation (3). Finally, the last row shows the objective function values during training with (orange) and without (green) preconditioning.

We observe that by decreasing from to , the low-fidelity posterior approximations become worse. As a result, the objective function for the preconditioned approach (orange) at the beginning start from a higher value, indicating more mismatch between low- and high-fidelity posterior densities. Finally, our preconditioning method consistently improves upon low-fidelity posterior by training for epochs.
Appendix D Seismic compressed sensing—more results
Here we show more examples to verify the pretraining phase obtained via solving the objective in Equation (2). Each row in Figure 5 corresponds to a different testing image. The first column shows the different true seismic images used to create low-fidelity compressive sensing data, depicted in the second column. The third and last columns correspond to the conditional mean and pointwise STD estimates, respectively. Clearly, the pretrained network is able to successfully recover the true image, and consistently indicates more uncertainty in areas with low-amplitude events.