Power Grid Behavioral Patterns and Risks of Generalization in Applied Machine Learning
Abstract.
Recent years have seen a rich literature of data-driven approaches designed for power grid applications. However, insufficient consideration of domain knowledge can impose a high risk to the practicality of the methods. Specifically, ignoring the grid-specific spatiotemporal patterns (in load, generation, and topology, etc.) can lead to outputting infeasible, unrealizable, or completely meaningless predictions on new inputs. To address this concern, this paper investigates real-world operational data to provide insights into power grid behavioral patterns, including the time-varying topology, load, and generation, as well as the spatial differences (in peak hours, diverse styles) between individual loads and generations. Then based on these observations, we evaluate the generalization risks in some existing ML works caused by ignoring these grid-specific patterns in model design and training.
1. Introduction
Recent years have seen a rich literature of data-driven approaches designed for the power grid. A wide range of traditional and modern threats (Singer et al., 2022), ranging from natural faults to targeted attacks (Liang et al., 2016) (Case, 2016) (Ospina et al., 2020), have motivated the use of anomaly detection approaches (Li et al., 2021) to safeguard the power grid. The computation burden of solving nonlinear optimization problems in operation and planning has motivated the development of data-driven alternatives to state estimation (SE) (Kundacina et al., 2022) (Yadaiah and Sowmya, 2006), power flow (PF) analysis (Hu et al., 2020)(Mohammadian et al., 2022), optimal power flow (OPF) (Donti et al., 2021) (Li et al., [n. d.])(Kotary et al., 2021), as well as data-driven warm starters to collaborate with physical solvers (Li et al., 2023)(Zamzam and Baker, 2020), etc.
Despite their popularity in recent years, people have long been aware of the risks of machine learning (ML) tools regarding their impracticality(Li et al., 2022) under realistic power grid conditions. The risks come from the ”missing of physics” in general ML methods. Specifically, the transient system dynamics, changing topology, and varying supply and demand are physical reasons behind the temporal grid evolution. In contrast, the physical power flow constraints, operational bounds, and technical limits determine the spatial correlations between different locations. To address the ”missing physics”, recent works insert domain knowledge into their models. Attempts range from creating domain-knowledge-based features (Hooi et al., 2018) and inserting domain knowledge (e.g., adding topology information (Kundacina et al., 2022), steady states (King et al., 2022), or network constraints (Donti et al., 2021) (Li et al., [n. d.])) into the models, to building hybrid approaches that combine machine learning with numerical solvers(Zamzam and Baker, 2020).
To enhance the use of domain knowledge and develop practical models for grid-specific tasks, it is important to gain a clearer understanding of the realistic power grid behaviors, including both temporal and spatial patterns. Yet, limited public access to real-world data can prevent us from gaining insights. This raises the fear of insufficiently considering the power grid reality and training a model on synthetic data that are generated unrealistically. To address these concerns, this paper investigates real-world power grid data to visualize the spatiotemporal behavioral patterns of the following:
-
•
temporal evolution of network topology, total supply and demand
-
•
temporal pattern and spatial differences (including different peak hours, different variation styles, etc.) in individual loads and generations
Unless we have a huge (nearly infinite) amount of data to define all possible scenarios, ignoring these grid-specific behavioral patterns can cause generalization risks, making ML models producing inaccurate, infeasible and even meaningless outcomes. In this paper, we evaluate the following generalization issues:
-
•
ML models ignoring system topology cannot generalize on dynamic graphs: we evaluate this risk by anomaly detection scores in the context of topology change
-
•
ML models trained without consideration of spatial differences in load/generation cannot generalize well on realistic system configurations: we evaluate this risk from anomaly detection scores, as well as solution feasibility of data-driven OPF models
These lessons of generalization risks motivate the consideration of realistic behavioral patterns in the design, and training of data-driven models for power grid applications.
2. Spatiotemporal Behavioral Patterns and Constraints
The power grid has a graphic nature. The nodes which correspond to substation buses and transmission towers are inter-connected by edges that correspond to branches (transmission lines, transformers) and closed switch links. Among the buses, some are injection buses with active generators and/or loads, leading to power supplied or consumed at these locations; others are zero-injection (ZI) buses that have no generators or loads, making the sum of current or power over all associated branches for each ZI bus zero. The connectivity of these buses is identified as the network topology.
This section provides insights into the behavioral patterns of topology, load and generation on real-world large-scale power grids. We analyze the underlying physical reasons behind these patterns to better understand the power system.
All observations are obtained from real data:
Data description: 24-hour data of system model description from a real utility in the Eastern Interconnect of the U.S. The dataset contains a full bus-branch model of the grid based on a 0.5-hour interval.
2.1. Network Topology Patterns
We first investigate how the power grid topology behaves and evolves over time. Two types of changes are observed from the real data described above to reflect topology changes:
-
•
Change in active bus set, characterized by bus split and merge. In the control room, the network topology processor merges any two nodes that are connected by a closed switch. Thus, upon any switch closure, there will be two separate buses merging into one, denoted as a bus-merge in this paper. Any switch opening may cause the previously merged buses to split, denoted as a bus-split.
-
•
Change in branch status, characterized by the opening (disconnection) and closure (connection) of transmission lines and transformers.


Observation: The (bus-branch) topology changes throughout the day. In Figure 1(a), 46 bus-splits and bus-merges are observed in a day on a grid with approximately 20,000 buses in total. In Figure 1(b), 137 transmission line status changes are observed in a day on a grid with approximately 17,000 lines.
Physical reasons: The change in topology can be either a control action or an unexpected event (anomaly). Examples of control actions include opening a transmission line or transformer for scheduled maintenance, reclosing a transmission line after tripping (transmission operation in PJM (a regional transmission organization that coordinates the movement of wholesale electricity in the United States) requires any extra high voltage (EHV) transmission line to be manually reclosed within 5 minutes after tripping, if it does not automatically reclose(PJM, 2022)), opening transmission line for high voltage control (PJM, 2022), closing a transmission line to meet the required transfer capacity, etc. Unexpected events can include sudden and unplanned line tripping (due to overloading, physical damage, etc.), transformer failures, circuit breaker failures, etc.
2.2. Total Generation and Load Pattern
Apart from a dynamic topology, the supply and demand on the power grid are also subject to variation. This section investigates the behavior of total load and generation.
Observation: The total demand and supply on a large grid tend to peak in the morning and early evening. Figure 2 shows that the total daily load and generation vary smoothly within the range of of the mean value, with the generation following the demand throughout the day.

Physical reasons: The total load demand depends highly on the weather conditions. Peak load periods tend to occur in the morning during winter months (when mass heating happens) and in the afternoon during summer months (mass cooling). The major reason for the generation following the demand is the economic operation and optimal control of the power system. Approximately every 5-15 minutes (every 5 minutes in PJM (PJM, 2023)), the operators perform economic dispatch (ED) and security-constrained economic dispatch (SCED) to make the forecasted demand at the lowest possible generation cost (subject to security constraints, if in SCED). The ED solution primarily depends on the generating unit cost function. Approximately every 5 minutes to 1 hour, the operator performs optimal power flow (OPF) to determine the generators’ optimal operating point (power output and voltage set point) that meets the demand with minimal loss or operating cost. Unlike economic dispatch, which is mainly for market purposes, OPF considers power flow constraints of the network and a variety of technical limits.
2.3. Individual Load Patterns
Despite the total load pattern observed, every individual load does not follow the same pattern as above. This section investigates the individual load patterns from the perspective of the peak load time, and the style of variation.


Observation 1: Spatial differences exist in individual load variations. Figure 3(a) shows the distribution of peak time over approximately 10,000 loads. Results show that almost every time slot can witness some loads at their highest. Figure 3(b) further verifies this by showing four loads whose peak times occur at different times of the day.
Physical reasons: We attribute the spatial difference in load peak times to their different types and locations, as well as weather-related factors in different regions. Morning and evening can be peak hours for many residential and transportation loads, whereas depending on the type of consumers, some loads may use electricity during off-peak hours when the time-of-use rate is low and the price is cheaper.
We further dive deeper into the difference in individual load variations.

Observation 2: Diverse styles of load variation exist. These styles include but are not limited to the following: constant load (load remains constant and stable throughout the day), smooth load (load changes smoothly), oscillating load (load changes frequently and noisily), and abrupt load (load changes abruptly at some point). Figure 4 shows four loads of different styles.
Physical reasons: Differences can stem from the different types of loads in the power system. Residential loads consisting of household electrical appliances (lights, refrigerators, heaters, air conditioners, etc) may vary significantly in a day, with peak hours in the morning and evening (when people use more appliances for cooking, heating, air-conditioning, etc). Their off-peak hours are at night (when people sleep). Commercial loads like shopping and office can remain connected for longer durations of time, depending on their work schedule. Some industrial loads may have heavy machinery and systems that operate at all times, resulting in stable loads. Other types of loads can also be subject to unique patterns of variation. Some loads of traffic lighting work all times of day, making them nearly constant and stable. Loads of street lighting only operate at night, leading to abrupt changes at their startup/shutdown times, and stable consumption during their active period. Irrigation loads also work mostly during off-peak or night hours. And some transportation loads (like electric railways) can have peak hours in the morning and evening.
Although a large abrupt change can sometimes occur on an individual load, it is still reasonable to assume that a load changes smoothly most of the time, based on our observations.
Observation 3: Figure 5 plots the distribution of individual load variations within a 0.5-hour interval. Results show that of the loads change by less than of their daily maximal value during any 0.5-hour interval.

2.4. Individual Generation Patterns

This section investigates individual generation patterns.
Observation: The on/off switching of generation units can occur frequently throughout the day. In Figure 6, 300 status changes are observed in a day on a grid with approximately 2,000 generation buses.
Physical reasons: The change in generation status can be caused by either a control action or an unexpected and unplanned loss of generation (contingency). The control signal can be induced by a planned generation shutdown (for maintenance), and unit commitment (UC) operations performed hourly or sub-hourly(Kërçi et al., 2020) in today’s real-time market.

Observation 2: Different styles of generation variation also exist. Examples include constant generation (generation remains constant throughout the day), ramping generation (generation remains active but ramps up and down in a day due to power grid control), and generation with unit commitments (generation is turned on and off by the UC operations, and it can also ramp up and down). Figure 7 plots a few examples.
Physical reasons: The change in generation output can be caused by either: i) the nature of the energy resource, for instance, renewable energy resources have higher uncertainty, while conventional nuclear power plants are usually more stable, or ii) the automatic generation control (AGC) actions on synchronous generators induced by ED, OPF and the power system’s frequency response. Generators’ status changes, if not a contingency, as discussed earlier, is usually decided by the ED and OPF control signals based on their prices (generation cost functions) and technical requirements.
3. Potential Risks of Generalization
Ignoring the grid-specific topology, load, and generation patterns can cause poor generalization performance in data-driven models such that the outputs are inaccurate and even meaningless on unseen data. Specifically, we investigate the following generalization issues:
-
•
ML models ignoring system topology cannot generalize to dynamic graphs
-
•
ML models trained without consideration of spatial differences in load/generation cannot generalize well to realistic system configurations
3.1. Risks of Generalization to Dynamic Graph
Many ML methods are based on non-graphical models. They cannot consider network topology and thus can result in bad estimates on real grids whose topology changes over time. In this section, we evaluate the potential risks of generalization on dynamic graphs, from the perspective of data-driven time series anomaly detection.
We evaluate a variety of outlier detection methods applied to time series grid data. For practical use, we select methods that are 1) unsupervised (anomaly data are unlabeled in reality), and 2) online detection: making decisions upon the arrival of new observations instead of requiring the future data to estimate for the present. The experiment settings are in Appendix A.1. Below shows the different families of ML methods we evaluate:
| Dynamic graph |
|
|||
|
||||
|
||||
|











|
|||
|---|---|---|---|
|
|||
|






Hypothesis testing methods: We evaluate the generalized extreme studentized deviation (GESD) test which is widely used in existing works for smart grid anomaly detection. The classic GESD is an offline algorithm that identifies the anomalous time ticks from the whole time series, based on R-statistics and critical values . For online applications, we implement the method in sliding windows of width , and the upper bound of the number of anomalies in a sliding window is assigned as .
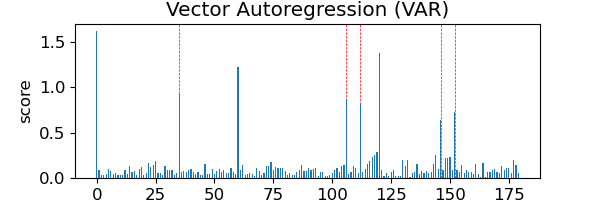
Auto-regressive (AR) models: AR models forecast future data values based on a weighted sum of past observations. We evaluate a univariate method autoregressive integrated moving average (ARIMA) with hyperparameters , and a multivariate method vector auto-regression (VAR) with .
Density/neighborhood-based models: We evaluate both the local outlier factor (LOF) and Parzen window estimator (also known as kernel density estimation) which are two well-known neighborhood-based anomaly detection methods. LOF identifies anomalous data points that have a substantially lower density than their neighbors. The Parzen window estimator learns the probability density of every training data point using a kernel function. In our experiments, LOF has and the Parzen model uses a Gaussian kernel. To obtain good estimators in these approaches, the model needs to fit on a representative data set. So, we fit the models on our training set with 10 topologies and then evaluate them on the validation set which contains data from 3 unseen topologies.
Classification models: We evaluate the one-class support vector machine (One-class SVM) model which is an unsupervised classifier to detect point outliers. It finds a decision boundary that separates high density of points (normal data) from those with small (anomalies). In our experiment, the model is trained with the RBF kernel and the upper bound on the fraction of training errors . Then it is evaluated on the validation set.
Ensemble models: We implement an isolation forest which ensembles 100 trees, each drawing 1 feature from training data. And then, the model is evaluated on our validation set.
Topology-aware methods: We implement the DynWatch model proposed in (Li et al., 2021) which is an unsupervised time series online algorithm to detect point outliers on dynamic graphs. The model considers the impact of topology change using power sensitivity-based graph-distances.
Key findings: Table 1 contains the anomaly scores produced by different families of methods. As results show that on a dynamic graph, the online implementation of the hypothesis test method GESD gives false positive (FP) outcomes. Univariate and multivariate auto-regression models suffer from similar false positive issues when the system shifts to a new topology. Density-based, classification-based, and isolation forests need to be fitted on a set of representative data before they can be used for inference. These methods do not model topology, and thus bad estimates appear when they are used on unseen data drawn from a different topology. And the more the new topology is different from the training data, the worse the estimates are. By contrast, the topology-aware method can detect anomalies on dynamic graphs without generalization issues.
Main conclusion: ML models ignoring topology cannot adapt to dynamic graphs. Potential risks for anomaly detection include producing false positive outcomes upon any normal topology change, as well as producing bad anomaly scores on unseen data from a new topology. For application on dynamic graphs, ML models need to be topology-aware.
3.2. Risks of Generalization to Realistic Load
Due to the limited availability of real data, many ML works are trained and evaluated on synthetic data. The realistic load behaviors have shown the spatial differences among individual loads, characterized by the different peak hours and diverse styles of variation. Such patterns in load variations are neglected in many works, leading to the generation of data in an unrealistic way. As a result, a data-driven model trained and evaluated on unrealistic data can inevitably suffer from a lack of performance guarantees for practical use, raising the fear of making wrong decisions or infeasible predictions. In this section, we evaluate the risk of generalization regarding the nonconsideration of spatial load differences, from the perspective of anomaly detection and data-driven AC-OPF.
Risks on anomaly detection
In this Section, we evaluate how anomaly detection performance can be affected when large load variations and large spatial differences in load occur. Specifically, we compare the anomaly scores using voltage and current measurement data observed from a system with varying topology and different load patterns:
-
•
Small load change and no spatial load difference: At any time, all loads in the system are assumed to have strong correlations such that all loads ramp up and down at the same rate, without differences. The load variation is created from the real load traces in the public Lawrence Berkeley National Laboratory (LBNL) load data. Appendix A.1 describes the data generation.
-
•
Load with large variation, spatial difference, and different styles: This represents a more realistic individual load pattern. The system loads are divided into different groups, each containing a subset of loads with a certain style selected from the 4 observed styles in Figure 4. Then load profiles are generated by interpolating the real-world individual load traces in the utility-provided data described in Section 2. Figure 7(b) shows the time-series data with realistic load patterns. The resulting data have large spatial differences and large load variations.
The experiment settings remain the same as Section 3.1
Key findings: The last column in Table 1 shows the anomaly detection performance of different ML models on dynamic graphs with spatial load differences. By comparison, we can see that when facing large variations and spatial differences in load, anomaly detectors tend to create more false positive outputs. For models that require fitting on some train data, the fitted model cannot generalize well to unseen load configurations, creating bad anomaly scores that make anomalies less detectable.
Main conclusion: ML models for anomaly detection can face generalization risks under large load variations and spatial load differences, producing more false positive outcomes and bad anomaly scores on unseen data. For better generalization, anomaly detection models need to build a tolerance to normal load variations.
Risks on data-driven ACOPF
Considering the computational complexity of obtaining a large amount of labeled data for ACOPF, we evaluate a physics-constrained neural network(Donti et al., 2021)(Li et al., [n. d.]). Unlike a supervised neural network (NN) which directly learns the input-output mapping from labeled data, the constrained neural network enables an unsupervised learning of solutions to nonlinear optimization problems, by enforcing network constraints on the output of NN. And the feasibility can be further enhanced by training with homotopy-based meta-optimization heuristics (Li et al., [n. d.]).
Now, suppose we have a series of realistic system configurations. The realistic data comes from a power grid which can be divided into several sub-networks. Each sub-network contains a group of loads with the same individual load style (e.g., all loads are heavy industrial loads that correspond to a stable constant load style) and no spatial difference between them (all loads ramp up and down at the same rate). Whereas loads from different sub-networks have spatial differences, with different various styles and peak hours. However, suppose that such a small dataset is insufficient, and we deploy data augmentation to create fake data. Specifically, a subset of these realistic data is extracted as test samples, and the remaining data are augmented to create the training and validation set. The training and implementation of the neural network model are the same as that in (Li et al., [n. d.]). Now we compare 3 different ways of data generation (see detailed setting in Appendix A.2:
-
•
naive: At any time moment, all loads are positively correlated and there is no spatial difference between individual load patterns.
-
•
grouped: At any moment, loads are divided into groups. Intra-group loads are correlated and inter-group loads have (random) spatial differences.
-
•
brute-force: every individual load has its own pattern. Random spatial differences exist everywhere.
Figure 8 compares the risk of generalization in different data generation strategies, with different . The risk of generalization is quantified by the infeasibility of NN outputs, characterized by the mean violation of network constraints. We repeat the experiments 10 times with different random seeds in data generation in order to draw reliable conclusions.


Key findings: Results in Figure 8 and Figure 9 show that the naive method which does not consider the spatial difference in data generation, results in models with poorest performance, giving highly infeasible outcomes; the grouped method has resulted in a lower risk of generalization; and the brute-force method which creates the most spatial difference in training data results in the lowest generalization risk on unseen data with realistic load patterns.
Main conclusion: ML models trained and evaluated on unrealistic data ignoring individual load differences cannot generalize well on unseen system configurations with realistic load patterns. Such risk of generalization can result in highly infeasible predictions.
4. Conclusion
This paper provides insights into the spatiotemporal grid patterns regarding the dynamic network topology as well as the temporal variations, spatial differences, and diverse styles in load and generation. Then, we evaluated the risks of generalization in data-driven models caused by ignoring these behavioral patterns. Key findings are that 1) ML models ignoring topology cannot adapt to dynamic graphs. This is verified by anomaly detectors giving false alarms on unseen topology, and 2) models trained on unrealistic load/generation patterns cannot generalize well on realistic power configurations. This is verified by anomaly detectors giving bad anomaly scores and data-driven OPF giving infeasible solutions when used on unseen data where large variations and spatial differences occur.
Acknowledgements.
This research was supported in part by C3.ai Inc., Microsoft Corporation, and the Data Model Convergence (DMC) initiative via the Laboratory Directed Research and Development (LDRD) investments at Pacific Northwest National Laboratory (PNNL). PNNL is a multi-program national laboratory operated for the U.S. Department of Energy (DOE) by Battelle Memorial Institute under Contract No. DE-AC05-76RL0-1830.References
- (1)
- Case (2016) Defense Use Case. 2016. Analysis of the cyber attack on the Ukrainian power grid. Electricity Information Sharing and Analysis Center (E-ISAC) 388 (2016).
- Donti et al. (2021) Priya L Donti, David Rolnick, and J Zico Kolter. 2021. DC3: A learning method for optimization with hard constraints. arXiv preprint arXiv:2104.12225 (2021).
- Hooi et al. (2018) Bryan Hooi, Dhivya Eswaran, Hyun Ah Song, Amritanshu Pandey, Marko Jereminov, Larry Pileggi, and Christos Faloutsos. 2018. GridWatch: Sensor Placement and Anomaly Detection in the Electrical Grid. In ECML-PKDD. Springer, 71–86.
- Hu et al. (2020) Xinyue Hu, Haoji Hu, Saurabh Verma, and Zhi-Li Zhang. 2020. Physics-guided deep neural networks for power flow analysis. IEEE Transactions on Power Systems 36, 3 (2020), 2082–2092.
- King et al. (2022) Ethan King, Ján Drgoňa, Aaron Tuor, Shrirang Abhyankar, Craig Bakker, Arnab Bhattacharya, and Draguna Vrabie. 2022. Koopman-based Differentiable Predictive Control for the Dynamics-Aware Economic Dispatch Problem. In 2022 American Control Conference (ACC). 2194–2201. https://doi.org/10.23919/ACC53348.2022.9867379
- Kotary et al. (2021) James Kotary, Ferdinando Fioretto, Pascal Van Hentenryck, and Bryan Wilder. 2021. End-to-end constrained optimization learning: A survey. arXiv preprint arXiv:2103.16378 (2021).
- Kundacina et al. (2022) Ognjen Kundacina, Mirsad Cosovic, and Dejan Vukobratovic. 2022. State Estimation in Electric Power Systems Leveraging Graph Neural Networks. arXiv preprint arXiv:2201.04056 (2022).
- Kërçi et al. (2020) T. Kërçi, J. Giraldo, and F. Milano. 2020. Analysis of the impact of sub-hourly unit commitment on power system dynamics. International Journal of Electrical Power & Energy Systems 119 (2020), 105819. https://doi.org/10.1016/j.ijepes.2020.105819
- Li et al. ([n. d.]) Shimiao Li, Jan Drgona, Aaron R Tuor, Larry Pileggi, and Draguna L Vrabie. [n. d.]. Homotopy Learning of Parametric Solutions to Constrained Optimization Problems. ([n. d.]).
- Li et al. (2021) Shimiao Li, Amritanshu Pandey, Bryan Hooi, Christos Faloutsos, and Larry Pileggi. 2021. Dynamic graph-based anomaly detection in the electrical grid. IEEE Transactions on Power Systems 37, 5 (2021), 3408–3422.
- Li et al. (2022) Shimiao Li, Amritanshu Pandey, and Larry Pileggi. 2022. GridWarm: Towards Practical Physics-Informed ML Design and Evaluation for Power Grid. arXiv preprint arXiv:2205.03673 (2022).
- Li et al. (2023) Shimiao Li, Amritanshu Pandey, and Larry Pileggi. 2023. Contingency Analyses with Warm Starter using Probabilistic Graphical Model. arXiv:2304.06727 [cs.CR]
- Liang et al. (2016) Gaoqi Liang, Junhua Zhao, Fengji Luo, Steven R Weller, and Zhao Yang Dong. 2016. A review of false data injection attacks against modern power systems. IEEE Transactions on Smart Grid 8, 4 (2016), 1630–1638.
- Mohammadian et al. (2022) Mostafa Mohammadian, Kyri Baker, and Ferdinando Fioretto. 2022. Gradient-enhanced physics-informed neural networks for power systems operational support. arXiv preprint arXiv:2206.10579 (2022).
- Ospina et al. (2020) Juan Ospina, Xiaorui Liu, Charalambos Konstantinou, and Yury Dvorkin. 2020. On the feasibility of load-changing attacks in power systems during the covid-19 pandemic. IEEE Access 9 (2020), 2545–2563.
- PJM (2022) PJM. 2022. PJM Manual 03: Transmission Operations. Revision: 63. uments/manuals/m03.ashx
- PJM (2023) PJM. 2023. PJM Manual 11: Energy and Ancillary Services Market Operations. Revision: 123. https://www.pjm.com/~/media/documents/manuals/m11.ashx
- Singer et al. (2022) Brian Singer, Amritanshu Pandey, Shimiao Li, Lujo Bauer, Craig Miller, Lawrence Pileggi, and Vyas Sekar. 2022. Shedding Light on Inconsistencies in Grid Cybersecurity: Disconnects and Recommendations. In 2023 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 554–571.
- Yadaiah and Sowmya (2006) Narri Yadaiah and G Sowmya. 2006. Neural network based state estimation of dynamical systems. In The 2006 IEEE international joint conference on neural network proceedings. IEEE, 1042–1049.
- Zamzam and Baker (2020) Ahmed S Zamzam and Kyri Baker. 2020. Learning optimal solutions for extremely fast AC optimal power flow. In 2020 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm). IEEE, 1–6.
Appendix A Appendix
A.1. Experiment settings for anomaly detection
In the experiments of anomaly detection, we create time series data with 13 different topologies, the first 10 of which are used as the training set for models that require a pre-fitting, and the last 3 of which are in the test set to evaluate the performance of all methods.
The time series data are generated using the MATLAB tool. Specifically, the main procedures are:
-
(1)
for each individual load on a test case, create time-series load data from real-world load traces
-
(2)
run power flow simulation using the MATPOWER toolbox based on the time-series load configurations
-
(3)
simulate time-series sensor values of voltage, current, and power flow measurements by adding (Gaussian) noise on power flow solutions
Specifically, the first step of creating synthetic time-series load data is necessary for a couple of reasons. In some cases, the real load data (like the real data described in Section 2) are sampled with large time intervals (e.g., half-hourly intervals in the utility-provided case data in Section 2), which are much larger than what we need in the experiment (we expect data sampled at second or less-than-one-minute intervals). Whereas in other cases, we might get load data at one location, or the total energy consumption of a power system, whereas we require time-series load profiles at each individual load locations on a certain power grid.
The main procedures to create a synthetic load trace of length time-ticks, from a real-world load trace of length are as follows. More details are in (Li et al., 2021).
-
(1)
start from the original time-series load data of length (e.g., the 24-hour load profile at one particular load location, sampled at half-hourly interval)
-
(2)
decompose the sequence into three parts: base , variation , and noise with , and learn a Gaussian noise distribution from the noise component
-
(3)
apply interpolation on the variation component to generate a new sequence of length : mathematically, , noise are sampled from the learned distribution and a scaling factor is used to manipulate the magnitude of load variations
In the experiments of Section 3.1, the dashed vertical lines mark the true anomaly moments, and green dashed lines marking the moments of known or expected topology changes.
A.2. Experiment settings for data-driven ACOPF
:
The detailed settings of data generation in the experiments on data-driven ACOPF are as follows:
-
•
naive: At one time moment, all loads in the system are scaled by the same randomly sampled load factor. I.e., for any new synthetic case , randomly sample a load factor , a load is generated by , with denoting the base load obtained by taking the average on the realistic data. This assumes all loads are positively correlated and results in no spatial difference between individual load patterns.
-
•
grouped: loads are divided into groups (in the same way as the realistic data) and each group has a randomly sampled load factor to scale all loads it contains. I.e., for any new synthetic case and a load group , we randomly sample and This results in intra-group spatial correlations and inter-group (random) spatial differences.
-
•
brute-force: every individual load has its own pattern. I.e., for any new case and a load , randomly sample , and . This creates random spatial differences everywhere.