Posterior Inference on Shallow Infinitely Wide Bayesian Neural Networks under Weights with Unbounded Variance
Abstract
From the classical and influential works of Neal (1996), it is known that the infinite width scaling limit of a Bayesian neural network with one hidden layer is a Gaussian process, when the network weights have bounded prior variance. Neal’s result has been extended to networks with multiple hidden layers and to convolutional neural networks, also with Gaussian process scaling limits. The tractable properties of Gaussian processes then allow straightforward posterior inference and uncertainty quantification, considerably simplifying the study of the limit process compared to a network of finite width. Neural network weights with unbounded variance, however, pose unique challenges. In this case, the classical central limit theorem breaks down and it is well known that the scaling limit is an -stable process under suitable conditions. However, current literature is primarily limited to forward simulations under these processes and the problem of posterior inference under such a scaling limit remains largely unaddressed, unlike in the Gaussian process case. To this end, our contribution is an interpretable and computationally feasible procedure for posterior inference, using a conditionally Gaussian representation, that then allows full use of the Gaussian process machinery for tractable posterior inference and uncertainty quantification in the non-Gaussian regime.
1 INTRODUCTION
Gaussian processes (GPs) have been studied as the infinite width limit of Bayesian neural networks with priors on network weights that have finite variance (Neal, 1996; Williams, 1996). This presents some key advantages over Bayesian neural networks with finite widths that usually require computation intensive Markov chain Monte Carlo (MCMC) posterior calculations (Neal, 1996) or variational approximations (Goodfellow et al., 2016, Chapter 19); in contrast to straightforward posterior inference and probabilistic uncertainty quantification afforded by the GP machinery (Williams and Rasmussen, 2006). In this sense, the work of Neal (1996) is foundational. The technical reason for this convergence to a GP is due to an application of the central limit theorem under the bounded second moment condition. More specifically, given an dimensional input and a one-dimensional output , a layer feedforward deep neural network (DNN) with hidden layers is defined by the recursion:
| (1) | ||||
| (2) |
where and is a nonlinear activation function. Thus, the network repeatedly applies a linear transformation to the inputs at each layer, before passing it through a nonlinear activation function. Sometimes a nonlinear transformation is also applied to the final hidden layer to the output layer, but in this paper it is assumed the output is a linear function of the last hidden layer. Neal (1996) considers the case of a Bayesian neural network with a single hidden layer, i.e., . So long as the hidden to output weights are independent and identically distributed Gaussian, or at least, have a common bounded variance given by for some , and is bounded, an application of the classical central limit theorem shows the network converges to a GP as the number of hidden nodes .
1.1 Related Works
The foundational work of Neal (1996) was followed by an explicit computation of some of the kernels obtained from this limiting process (Williams, 1996). Recently, Neal’s result has been extended to prove fully connected multi-layer feedforward networks (Lee et al., 2018; de G. Matthews et al., 2018) and convolutional neural networks (Garriga-Alonso et al., 2019; Novak et al., 2019) also converge to GPs. The Tensor Program of Yang (2019) has successfully extended these results to feedforward and recurrent networks of any architecture. This is useful for uncertainty quantification by designing emulators for deep neural networks (DNNs) based on GPs, since the behavior of finite-dimensional DNNs for direct uncertainty quantification is much harder to characterize. In contrast, once a convergence to GP can be ensured, well established tools from the GP literature (see, e.g., Williams and Rasmussen, 2006) can be brought to the fore to allow straightforward posterior inference. The induced covariance function depends on the choice of the nonlinear activation function , and is in general anisotropic. However, it can be worked out in explicit form under a variety of activation functions for both shallow (Neal, 1996; Williams, 1996; Cho and Saul, 2009) and deep (Lee et al., 2018; de G. Matthews et al., 2018) feedforward neural networks, where for deep networks usually a recursive formula is available that expresses the covariance function of a given layer conditional on the previous layer. The benefit of depth is that it allows a potentially very rich covariance function at the level of the observed data, even if the covariances in each layer conditional on the layer below are simple. Viewing a GP as a prior on the function space, this allows for a rich class of prior structures. However, the process is still Gaussian in all these cases and our intention in this paper is a departure from the Gaussian world.
For finite width neural networks, non-Gaussian weights have recently been considered by Fortuin et al. (2022) and Fortuin (2022). Departures from weights have also recently received attention (Caron et al., 2023; Lee et al., 2023). Theoretical results with infinite variance were hinted at by Neal (1996), and first proved by Der and Lee (2005). Follow-up theoretical results have been obtained in varied architectures for bounded activation functions (Peluchetti et al., 2020; Bracale et al., 2022) and with unbounded activation functions (Bordino et al., 2022). However, posterior inference still remains challenging in the infinite-width limit, due to the reasons made clear in the next sub-section.
1.2 Challenges Posed by Network Weights with Unbounded Prior Variance
Although the GP literature has been immensely influential for uncertainty quantification in DNNs, it is obvious that a DNN does not converge to a GP if the final hidden to output layer weights are allowed to have unbounded variance, e.g., belonging to or others in the stable family, such that the scaling limit distribution is non-Gaussian (Gnedenko and Kolmogorov, 1954). This was already observed by Neal (1996) who admits: “in contrast to the situation for Gaussian process priors, whose properties are captured by their covariance functions, I know of no simple way to characterize the distributions over functions produced by the priors based on non-Gaussian stable distributions.” Faced with this difficulty, Neal (1996) confines himself to forward simulations from DNNs with weights, and yet, observes that the network realizations under these weights demonstrate very different behavior (e.g., large jumps) compared to normal priors on the weights. This is not surprising, since Gaussian processes, with their almost surely continuous sample paths, are not necessarily good candidate models for functions containing sharp jumps, perhaps explaining their lack of popularity in certain application domains, e.g., finance, where jumps and changepoints need to be modeled (see, e.g., Chapter 7 of Cont and Tankov, 2004). Another key benefit of priors with polynomial tails, pointed out by Neal (1996), is that it allows a few hidden nodes to make a large contribution to the output, while drowning out the others, akin to feature selection. In contrast, in the GP limit, the contributions of individual nodes are averaged out. Thus, there are clear motivations for developing computationally feasible posterior inference machinery under these non-Gaussian limits.
Neal (1996) further hints that it may be possible to prove an analogous result using priors that do not have finite variance. Specifically, suppose the network weights are given symmetric -stable priors, which have unbounded variance for all , and the case coincides with a Gaussian random variable. If is an -stable random variable, the density does not in general have a closed form, but the characteristic function is:
where for and , for . Here is called the shift parameter, is the index parameter, is the symmetry parameter, and is the scale parameter (Samorodnitsky and Taqqu, 1994, p. 5). Throughout, we use a zero shift () stable variable, and denote it by . Here corresponds to the symmetric case, and when , the random variable is strictly positive, which we denote by . We refer the reader to Supplementary Material S.1 for some further properties of -stable random variables, as relevant for the present work. Der and Lee (2005) confirm Neal’s conjecture by establishing that the scaling limit of a shallow neural network under -stable priors on the weights is an -stable process. Proceeding further, Peluchetti et al. (2020) show that the limit process for infinitely wide DNNs with infinite-variance priors is also an -stable processes. However, both Der and Lee (2005) and Peluchetti et al. (2020) only consider the forward process and neither considers posterior inference. Inference using -stable densities is not straightforward, and some relevant studies are by Samorodnitsky and Taqqu (1994), Lemke et al. (2015), and more recently by Nolan (2020). The main challenge is that a covariance function is not necessarily defined, precluding posterior inference analogous to the GP case, for example, using the kriging (Stein, 1999) machinery. To this end, our contribution lies in using a representation of the characteristic function of symmetric -stable variables as a normal scale mixture, that then allows a conditionally Gaussian representation. This makes it possible to develop posterior inference and prediction techniques under stable priors on network weights using a latent Gaussian framework.
1.3 Summary of Main Contributions
Our main contributions consist of:
-
1.
An explicit characterization of the posterior predictive density function under infinite width scaling limits for shallow (one hidden layer) Bayesian neural networks under stable priors on the network weights, using a latent Gaussian representation.
-
2.
An MCMC algorithm for posterior inference and prediction, with publicly available code.
-
3.
Numerical experiments in one and two dimensions that validate our procedure by obtaining better posterior predictive properties for functions with jumps and discontinuities, compared to both Gaussian processes and Bayesian neural networks of finite width.
-
4.
A real world application on a benchmark real estate data set from the UCI repository.
2 INFINITE WIDTH LIMITS OF BAYESIAN NEURAL NETWORKS UNDER WEIGHTS WITH UNBOUNDED VARIANCE
Consider the case of a shallow, one hidden layer network, with the weights of the last layer being independent and identically distributed with symmetric -stable priors. Our results are derived under this setting using the following proposition of Der and Lee (2005).
Proposition 1.
(Der and Lee, 2005). Let the network specified by Equations (1) and (2), with a single hidden layer (), have i.i.d. hidden-to-output weights distributed as a symmetric -stable with scale parameter . Then converges in distribution to a symmetric -stable process as for random input-to-hidden weights. The finite dimensional distribution of , denoted as for all , where , is multivariate stable with a characteristic function:
| (3) |
where angle brackets denote the inner product, is the argument of the characteristic function, , and is a random variable with the common distribution (across ) of .
Following Neal (1996), assume for the rest of the paper that the activation function corresponds to the sign function: , if ; , if ; and . For we define , where and are i.i.d. standard Gaussian variables. The next challenge is to compute the expectation within the exponential in Equation (3). To resolve this, we break it into simpler cases. Define as the set of all possible functions . Noting that each can be mapped to two possible options: and , indicates that there are elements in . For each , consider , the event , and the probability . By definition is a set of disjoint events. Next, using the definition of the expectation of discrete disjoint events we obtain:
| (4) |
where the expectation is over input-to-hidden weights. A naïve enumeration sums over an exponential number of terms in , and is impractical. However, details of the computation of and are given in Supplementary Section S.2, where we show how to reduce the enumeration over terms in Equation (4) to terms using the algorithm of Goodman and Pollack (1983), by identifying only those configurations with . This allows circumventing the exponential enumeration in , resulting in a polynomial complexity algorithm, depending on the input dimension . Although this computational complexity still appears rather high at a first glance, especially for high-dimensional inputs, for two or three-dimensional problems (e.g., in spatial or spatio-temporal models), the computation is both manageable and practical, and the complexity is similar to the usual GP regression.
2.1 A Characterization of the Posterior Predictive Density under Stable Network Weights using a Conditionally Gaussian Representation
While the previous section demonstrated the characteristic function in Equation (3) can be computed, the resulting density, obtained via its inverse Fourier transform, does not necessarily have a closed form, apart from specific values of , such as (Gaussian), (Cauchy) or (inverse Gaussian). In this section we show that a conditionally Gaussian characterization of the density function is still possible for the entire domain of , facilitating posterior inference. First, note that the result of Der and Lee (2005) is obtained assuming that there is no intrinsic error in the observation model, i.e., they assume the observations are obtained as , and the only source of randomness is the network weights. We generalize this to more realistic scenarios and consider an additive error term. That is, we consider the observation model , where the error terms are independent identically distributed normal random variables with constant variance . Using the expression for the expectation in the characteristic function from Proposition 1, we derive the full probability density function, as specified in the following theorem, with a proof in Section 7.
Theorem 1.
For real-valued observations under the model where and is as specified in Proposition 1 , denote the matrix . The probability density function of is:
where is the density for a positive -stable random variable, and is a positive definite matrix with probability one that depends on . Specifically, , denoting by the vector with entries .
Theorem 1 is the main machinery we need for posterior inference. We emphasize that is a matrix with random entries, conditional on ; and and are deterministic. Further, the input variables are also deterministic. Theorem 1 implies the hierarchical Gaussian model:
Each of the s defines a level set for the points that lie in the side in contraposition to those that lie in the side. A forward simulation of this model is a weighted sum of the s, with corresponding positive weight for those that lie closer and a negative weight for the points that lie farther. We further present the following corollaries to interpret the distribution of .
Corollary 1.
The matrix in Theorem 1 is stochastic for all and is deterministic when .
Proof.
Recall, . Thus, , w.p. , as , since an variable is a degenerate point mass at . ∎
Noting the case is Gaussian, Corollary 1 indicates is stochastic in the stable limit, but deterministic in the GP limit; a key difference. The lack of representation learning in the GP limit, due to the kernel converging to a degenerate point mass, is a major criticism of the GP limit framework, see for example Aitchison et al. (2021); Yang et al. (2023). A useful implication of Corollary 1 is that the posterior of is non-degenerate in the stable limit. Numerical results supporting this claim are in Supplementary Section S.4. Specifically, when , the limiting process of Proposition 1 is a GP, which has been established to have a deterministic covariance kernel (Cho and Saul, 2009). When , which is our main interest, Corollary 1 ensures that the conditional covariance kernel is stochastic, thereby enabling learning a degenerate posterior of this quantity given the data. This is at a contrast to the degenerate posterior in the Gaussian case, for both shallow and deep infinite-width limits of BNNs, as discussed by Aitchison et al. (2021). We further remark here that although the current work only considers shallow networks, this property of a non-degenerate posterior should still hold for deep networks under -stable weights. However, the challenge of relating the conditional covariance kernel of each layer to the layer below, analogous to the deep GP case (e.g., de G. Matthews et al., 2018), is beyond the scope of the current work.
Corollary 2.
The marginal distribution of the diagonal entries of the matrix is , where the acts as a shift parameter, and the marginal distribution of the entry in the matrix is , where , the probability that and lie on the same side of the hyperplane partition. Further, the entries of are not independent.
Proof.
For , we apply Property 1.2.1 of Samorodnitsky and Taqqu (1994), which we refer as the closure property, to obtain . Next for , we split the summation in two cases: , and . Using the closure property in the separate splits, we obtain . The result follows by applying the closure property once more. The entries of are not independent, as they are obtained from a linear combination of the independent variables . ∎
The value of this corollary does not lie in a numerical or computational speed-up, since the obtained marginals are not independent, but rather in the interpretability that it lends to the model. Explicitly, it indicates that when the points lie closer their conditional covariance is more likely to be positive and when they lie farther apart the covariance is more likely to be negative (see Proposition 1.2.14 of Samorodnitsky and Taqqu, 1994).
Now that the probability model is clear, we proceed to the next problem of interest: prediction. To this end, we present the following proposition, characterizing the posterior predictive density.
Proposition 2.
Consider a vector of real-valued observations , each with respective input variables , under the model and new input variable locations: , with future observations at those locations denoted by . Denote the matrices and . The posterior distribution at these new input variables satisfies the following properties:
-
1.
The conditional posterior of is an -dimensional Gaussian. Specifically:
(5) where , and , using as previously defined for the input variables, and denoting by ‘’ the entries .
-
2.
The posterior predictive density at the new locations conditional on the observations , is given by:
(6) where is the conditional posterior density of , is as previously described for the input variables, and the integral is over the values determined by .
Proof.
The first is an immediate application of Theorem 1 and the conditional density of a multivariate Gaussian. The second part follows from a standard application of marginal probabilities. ∎
3 AN MCMC SAMPLER FOR THE POSTERIOR PREDICTIVE DISTRIBUTION
Dealing with -stable random variables includes the difficulty that the moments of the variables are only finite up to an power. Specifically, for , if , then if , and is finite otherwise (Samorodnitsky and Taqqu, 1994, Property 1.2.16). To circumvent dealing with potentially ill-defined moments, we propose to sample from the full posterior. For fully Bayesian inference, we assign a half-Cauchy prior (Gelman, 2006) and iteratively sample from the posterior predictive distribution by cycling through in an MCMC scheme, as described in Algorithm 1, which has computational complexity of the order of , where is the number of MCMC simulations used. The method of Chambers et al. (1976) is used for simulating the stable variables. An implementation of our algorithms is freely available at https://github.com/loriaJ/alphastableNNet.
There are two hyper-parameters in our model: . We propose to select them by cross validation on a grid of , and selecting the result with smallest mean absolute error (MAE). Another possible way to select is by assigning a prior. The natural choice for is a uniform prior on , however the update rule would need to consider the densities of the such -stable densities , which would be computationally intensive as there is no closed form to this density apart from specific values of . A prior for could be included but a potential issue of identifiability emerges, similar to that identified for the Matérn kernel (Zhang, 2004). We leave these open for future research.
4 NUMERICAL EXPERIMENTS
We compare our method against the predictions obtained from three other methods. The first two are methods for Gaussian processes that correspond to the two main approaches in GP inference: maximum likelihood with a Gaussian covariance kernel (Dancik and Dorman, 2008), and an MCMC based Bayesian procedure using the Matérn kernel (Gramacy and Taddy, 2010); the third method is a two-layer Bayesian neural network (BNN) using a single hidden layer of 100 nodes with Gaussian priors, implemented in pytorch (Paszke et al., 2019), and fitted via a variational approach. The choice of a modest number of hidden nodes is intentional, so that we are away from the infinite width GP limit, and the finite-dimensional behavior can be visualized. The respective implementations are in the R packages mlegp, tgp, and the python libraries pytorch and torchbnn. The estimates used from these methods are respectively the kriging estimate, posterior median and posterior mean. We tune our method by cross-validation over a grid of . We use point-wise posterior median as the estimate, and report the values with smallest mean absolute error (MAE) and the optimal parameters. Results on timing and additional simulations are in Supplementary Section S.4, including the posterior quantiles of , showing the posterior is non-degenerate and stochastic. This suggests learning a non-degenerate posterior is possible, unlike in the GP limit where the kernel is degenerate (Aitchison et al., 2021; Yang et al., 2023). We use a data generating mechanism of the form , where the is the true function. The overall summary is that when has at least one discontinuity, our method performs better at prediction than the competing methods, and when is continuous the proposed method performs just as well as the other methods. This provides empirical support that the assumption of continuity of the true function cannot be disregarded in the universal approximation property of neural networks (Hornik et al., 1989), and the adoption of infinite variance prior weights might be a crucial missing ingredient for successful posterior prediction when the truth is discontinuous.
4.1 Experiments in One Dimension
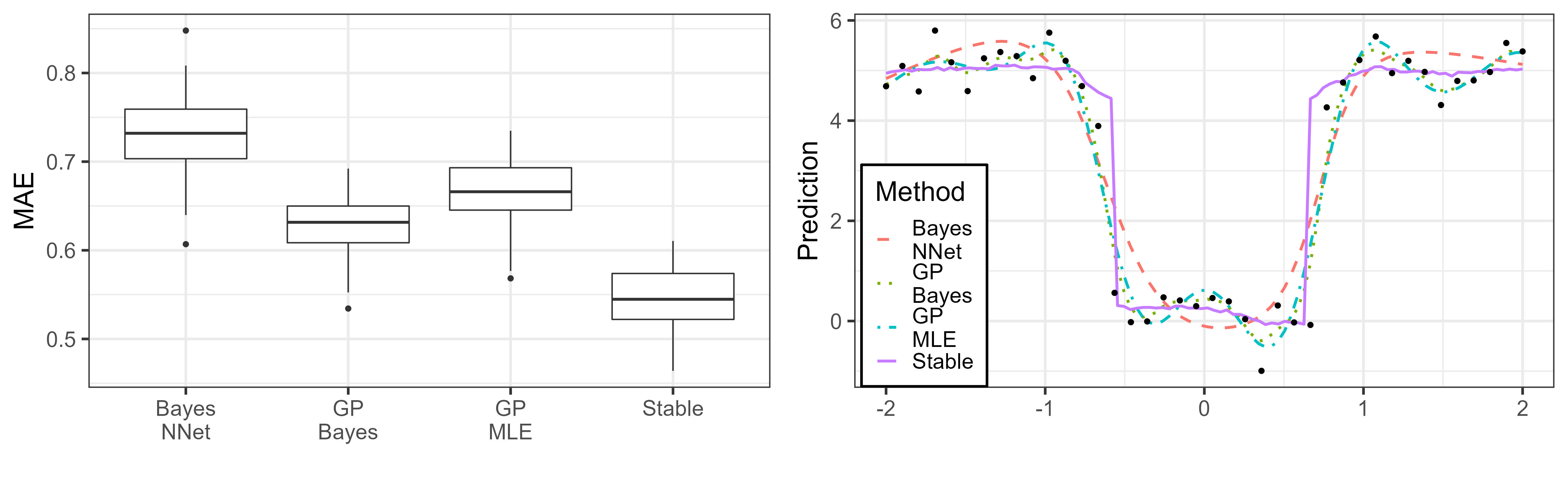
We consider a function with three jumps: , to which we add a Gaussian noise with . We consider with 40 equally spaced points as the training set, and 100 equally spaced points in the testing set. We display the two-panel Figure 1, showing the comparisons between the four methods. The boxplots in the left panel show that the proposed method – which we term “Stable,” has the smallest prediction error. The right panel shows that the BNN, the GP based fully Bayesian, and maximum likelihood methods have much smoother predictions than the Stable method. This indicates the inability of these methods to capture sharp jumps as well as the Stable method, which very clearly captures them. The Stable method obtains the smallest cross validation error for this case with and .

Figure 2 displays the uncertainty of the GP Bayes and Stable methods, for the same setting, using the posterior predictive intervals. In general, the intervals are narrower for the stable case.

4.2 Experiments in Two Dimensions
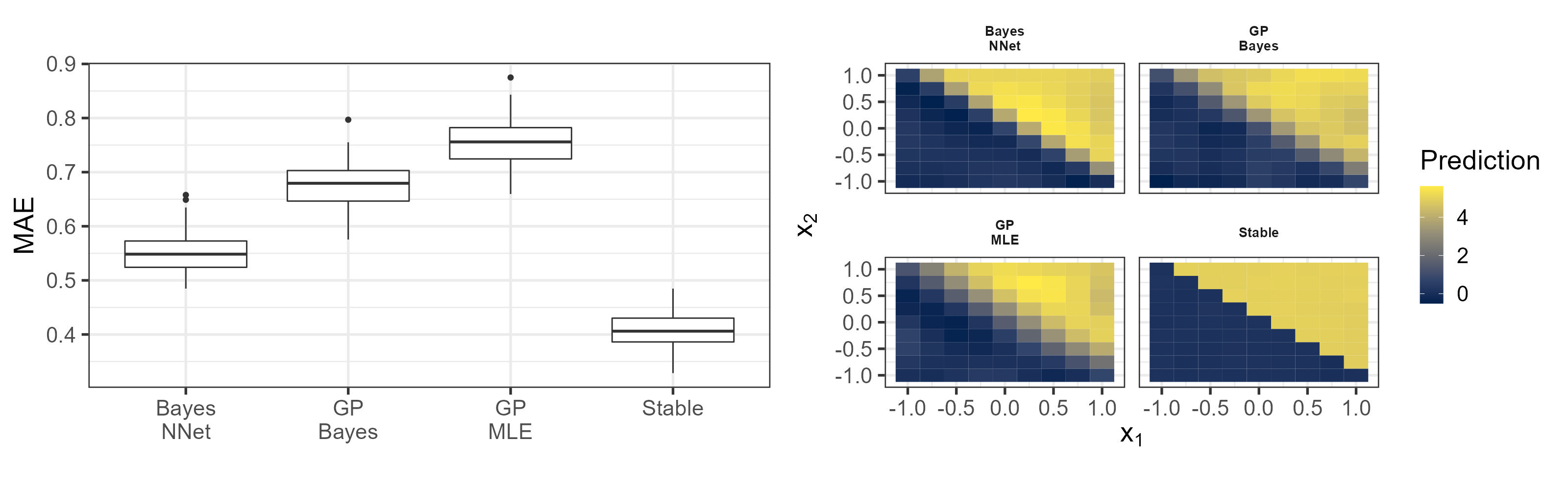
We consider the function: , with additive Gaussian noise with , and observations on an equally-spaced grid of 49 points in the square . In Figure 3 we display the boxplots and contour plots for all methods for out-of-sample prediction on an equally spaced grid of points in the same square. The methods that employ Gaussian processes (GP Bayes and GP MLE) and BNN seem to have smoother transitions between the different quadrants, whereas the Stable method captures the sharp jumps better. This is reinforced by the prediction errors displayed in the left panel. For this example, the Stable method obtains the smallest cross validation error with .

We present quantiles of the posterior predictive distribution for GP Bayes and Stable methods in Figure 4. Our results show sharper jumps using the Stable method, when the true function has jump discontinuities.

5 OUT OF SAMPLE PREDICTION ON REAL ESTATE VALUATION DATA IN TAIPEI
Valuation of real estate properties in Taipei, Taiwan were collected by Yeh and Hsu (2018) in different locations. The data are available from the UCI repository111https://archive.ics.uci.edu/dataset/477/real+estate+valuation+data+set, and is a benchmark dataset. We apply our method to the spatial locations of the properties, to predict the valuations of the real estate dataset. We use 276 locations for training and 138 for testing. We compare the performance of our method to the three methods mentioned in the previous section through the mean absolute error. The results are displayed in Table 1, showing a competitive MAE under the proposed approach. Figure 5 displays the posterior predictive quantiles on the validation set, with narrower intervals under the proposed stable method in most cases.
| Stable | GP MLE | GP Bayes | Bayes NNet | |
|---|---|---|---|---|
| MAE | 0.415 | 0.483 | 0.402 | 0.501 |
| (SE) | (0.07) | (0.07) | (0.05) | (0.07) |
Supplementary Sections S.5 and S.6 present results on ablation experiments and additional data sets with larger sample sizes, including recent data on S&P stock index.

6 CONCLUSIONS
We develop a novel method for posterior inference and prediction for infinite width limits of shallow (one hidden layer) BNNs under weights with infinite prior variance. While the -stable forward scaling limit in this case has been known in the literature (Der and Lee, 2005; Peluchetti et al., 2020), the lack of a covariance function precludes the inverse problem of feasible posterior inference and prediction, which we overcome using a conditionally Gaussian representation. There is a wealth of literature on the universal approximation property of both shallow and deep neural networks, following the pioneering work of Hornik et al. (1989), but they work under the assumption of a continuous true function. Our numerical results demonstrate that when the truth has jump discontinuities, it is possible to obtain much better results with a BNN using weights with unbounded prior variance. The fully Bayesian posterior also allows straightforward probabilistic uncertainty quantification for the infinite width scaling limit under -stable priors on network weights.
Several future directions could naturally follow from the current work. The most immediate is perhaps an extension to posterior inference for deep networks under stable priors, where the width of each layer simultaneously approaches infinity, and we strongly suspect this should be possible. The role of the non-degenerate posterior of on deep generalizations and representation learning merits a thorough investigation and suggests crucial differences from a GP limit (Aitchison et al., 2021; Yang et al., 2023). Developing analogous results under non-i.i.d. or tied weights to perform posterior inference under the scaling limits for Bayesian convolutional neural networks should also be of interest. Finally, one may of course investigate alternative activation functions, such as the hyperbolic tangent, which will lead to a different characteristic function for the scaling limit.
7 Proof of Theorem 1
Our derivations rely on Equation 5.4.6 of Uchaikin and Zolotarev (1999), which states that for and for all positive one has: where is the density function of a positive -stable random variable. Using and and the fact that , we obtain for that:
| (7) |
where is the density function of a positive -stable random variable and . By Equation (4) of Der and Lee (2005), and the characteristic function of independent normally distributed error terms with a common variance , we have that:
where the third equality follows by using Equation (7), and in the last equality we define as the matrix with ones in the diagonal and with the th entry given by . Next, using the fact that the densities are over the independent variables we bring the product inside the integrals and employ the property of the exponential to obtain:
using on the second line the definition of . The required density is now obtained by the use of the inverse Fourier transform on the characteristic function:
where the second line follows by the derived expression for the characteristic function, and the third line follows by Fubini’s theorem since all the integrals are real and finite. We recognize that the term corresponds to a multivariate Gaussian density with covariance matrix , though it is lacking the usual determinant term. We obtain the density using the characteristic function of Gaussian variables to finally obtain the result:
In using freely, we assumed through the previous steps that is positive-definite. We proceed to prove this fact. Note that is obtained from the sum of rank-one matrices and a diagonal matrix, where each of the rank-one matrices is . Let . Then:
implying that is positive-definite with probability 1.
SUPPLEMENTARY MATERIAL
The Supplementary Material contains technical details and numerical results in pdf. Computer code is freely available at: https://github.com/loriaJ/alphastableNNet.
Acknowledgments
Bhadra was supported by U.S. National Science Foundation Grant DMS-2014371.
References
- Aitchison et al. (2021) L. Aitchison, A. Yang, and S. W. Ober. Deep kernel processes. In M. Meila and T. Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 130–140. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/aitchison21a.html.
- Bordino et al. (2022) A. Bordino, S. Favaro, and S. Fortini. Infinitely wide limits for deep stable neural networks: sub-linear, linear and super-linear activation functions. Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openreview.net/forum?id=A5tIluhDW6.
- Bracale et al. (2022) D. Bracale, S. Favaro, S. Fortini, and S. Peluchetti. Infinite-channel deep stable convolutional neural networks, 2022.
- Caron et al. (2023) F. Caron, F. Ayed, P. Jung, H. Lee, J. Lee, and H. Yang. Over-parameterised shallow neural networks with asymmetrical node scaling: Global convergence guarantees and feature learning, 2023.
- Chambers et al. (1976) J. M. Chambers, C. L. Mallows, and B. Stuck. A method for simulating stable random variables. Journal of the American Statistical Association, 71(354):340–344, 1976.
- Cho and Saul (2009) Y. Cho and L. Saul. Kernel methods for deep learning. Advances in Neural Information Processing Systems, 22, 2009.
- Cont and Tankov (2004) R. Cont and P. Tankov. Financial modelling with jump processes. Chapman & Hall/CRC financial mathematics series. Chapman & Hall/CRC, Boca Raton, Fla, 2004. ISBN 1584884134.
- Dancik and Dorman (2008) G. M. Dancik and K. S. Dorman. mlegp: statistical analysis for computer models of biological systems using R. Bioinformatics, 24(17):1966, 2008.
- de G. Matthews et al. (2018) A. G. de G. Matthews, J. Hron, M. Rowland, R. E. Turner, and Z. Ghahramani. Gaussian process behaviour in wide deep neural networks. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=H1-nGgWC-.
- Der and Lee (2005) R. Der and D. Lee. Beyond Gaussian processes: On the distributions of infinite networks. In Proceedings of the 18th International Conference on Neural Information Processing Systems, NIPS’05, page 275–282, Cambridge, MA, USA, 2005. MIT Press.
- Fortuin (2022) V. Fortuin. Priors in bayesian deep learning: A review. International Statistical Review, 90(3):563–591, 2022. https://doi.org/10.1111/insr.12502. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/insr.12502.
- Fortuin et al. (2022) V. Fortuin, A. Garriga-Alonso, S. W. Ober, F. Wenzel, G. Rätsch, R. E. Turner, M. van der Wilk, and L. Aitchison. Bayesian neural network priors revisited. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=xkjqJYqRJy.
- Garriga-Alonso et al. (2019) A. Garriga-Alonso, C. E. Rasmussen, and L. Aitchison. Deep convolutional networks as shallow Gaussian Processes. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bklfsi0cKm.
- Gelman (2006) A. Gelman. Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Analysis, 1:515–534, 2006.
- Genz and Bretz (2002) A. Genz and F. Bretz. Comparison of methods for the computation of multivariate t probabilities. Journal of Computational and Graphical Statistics, 11(4):950–971, 2002. 10.1198/106186002394. URL https://doi.org/10.1198/106186002394.
- Gnedenko and Kolmogorov (1954) B. V. Gnedenko and A. N. Kolmogorov. Limit distributions for sums of independent random variables. Addison-Wesley, Cambridge, Mass. Transl. from Russian by K. L. Chung, 1954.
- Goodfellow et al. (2016) I. Goodfellow, Y. Bengio, and A. Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
- Goodman and Pollack (1983) J. E. Goodman and R. Pollack. Multidimensional sorting. SIAM Journal on Computing, 12(3):484–507, 1983. 10.1137/0212032. URL https://doi.org/10.1137/0212032.
- Gramacy and Taddy (2010) R. B. Gramacy and M. Taddy. Categorical inputs, sensitivity analysis, optimization and importance tempering with tgp version 2, an R package for treed Gaussian process models. Journal of Statistical Software, 33(6):1–48, 2010. 10.18637/jss.v033.i06. URL https://www.jstatsoft.org/v33/i06/.
- Harding (1967) E. F. Harding. The number of partitions of a set of n points in k dimensions induced by hyperplanes. Proceedings of the Edinburgh Mathematical Society, 15(4):285–289, 1967.
- Hornik et al. (1989) K. Hornik, M. Stinchcombe, and H. White. Multilayer feedforward networks are universal approximators. Neural networks, 2(5):359–366, 1989.
- Lee et al. (2023) H. Lee, F. Ayed, P. Jung, J. Lee, H. Yang, and F. Caron. Deep neural networks with dependent weights: Gaussian process mixture limit, heavy tails, sparsity and compressibility, 2023.
- Lee et al. (2018) J. Lee, J. Sohl-dickstein, J. Pennington, R. Novak, S. Schoenholz, and Y. Bahri. Deep neural networks as Gaussian processes. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=B1EA-M-0Z.
- Lemke et al. (2015) T. Lemke, M. Riabiz, and S. Godsill. Fully Bayesian inference for -stable distributions using a poisson series representation. Digital Signal Processing, 47, 10 2015. 10.1016/j.dsp.2015.08.018.
- Neal (1996) R. M. Neal. Priors for infinite networks. In Bayesian Learning for Neural Networks, pages 29–53. Springer, 1996.
- Nolan (2020) J. J. P. Nolan. Univariate stable distributions : models for heavy tailed data. Springer Series in Operations Research and Financial Engineering. Springer, Cham, Switzerland, 1st ed. 2020. edition, 2020. ISBN 3-030-52915-0.
- Novak et al. (2019) R. Novak, L. Xiao, Y. Bahri, J. Lee, G. Yang, D. A. Abolafia, J. Pennington, and J. Sohl-dickstein. Bayesian deep convolutional networks with many channels are gaussian processes. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=B1g30j0qF7.
- Paszke et al. (2019) A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019. URL http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf.
- Peluchetti et al. (2020) S. Peluchetti, S. Favaro, and S. Fortini. Stable behaviour of infinitely wide deep neural networks. In S. Chiappa and R. Calandra, editors, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 of Proceedings of Machine Learning Research, pages 1137–1146. PMLR, 26–28 Aug 2020. URL https://proceedings.mlr.press/v108/peluchetti20b.html.
- Samorodnitsky and Taqqu (1994) G. Samorodnitsky and M. Taqqu. Stable non-Gaussian random processes : stochastic models with infinite variance. Stochastic modeling. Chapman & Hall, New York, 1994. ISBN 0412051710.
- Stein (1999) M. L. Stein. Interpolation of Spatial Data: Some Theory for Kriging. Springer Science & Business Media, July 1999.
- Uchaikin and Zolotarev (1999) V. V. Uchaikin and V. M. Zolotarev. Chance and Stability. De Gruyter, Dec. 1999. URL https://doi.org/10.1515/9783110935974.
- Williams (1996) C. Williams. Computing with infinite networks. In M. Mozer, M. Jordan, and T. Petsche, editors, Advances in Neural Information Processing Systems, volume 9. MIT Press, 1996. URL https://proceedings.neurips.cc/paper_files/paper/1996/file/ae5e3ce40e0404a45ecacaaf05e5f735-Paper.pdf.
- Williams and Rasmussen (2006) C. K. Williams and C. E. Rasmussen. Gaussian processes for machine learning, volume 2. MIT Press, Cambridge, MA, 2006.
- Yang et al. (2023) A. X. Yang, M. Robeyns, E. Milsom, B. Anson, N. Schoots, and L. Aitchison. A theory of representation learning gives a deep generalisation of kernel methods. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 39380–39415. PMLR, 23–29 Jul 2023. URL https://proceedings.mlr.press/v202/yang23k.html.
- Yang (2019) G. Yang. Tensor programs I: Wide feedforward or recurrent neural networks of any architecture are Gaussian processes. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/5e69fda38cda2060819766569fd93aa5-Paper.pdf.
- Yeh and Hsu (2018) I.-C. Yeh and T.-K. Hsu. Building real estate valuation models with comparative approach through case-based reasoning. Applied Soft Computing, 65:260–271, 2018. ISSN 1568-4946. https://doi.org/10.1016/j.asoc.2018.01.029. URL https://www.sciencedirect.com/science/article/pii/S1568494618300358.
- Zhang (2004) H. Zhang. Inconsistent Estimation and Asymptotically Equal Interpolations in Model-Based Geostatistics. Journal of the American Statistical Association, 99(465):250–261, Mar. 2004.
Posterior Inference on Shallow Infinitely Wide Bayesian Neural Networks under Weights with Unbounded Variance
(Supplementary Material)
S.1 Some relevant properties of -stable random variables
One of the most important properties of stable random variables is the closure property (Property 1.2.1, Samorodnitsky and Taqqu, 1994), which states that if independently for , then , where , and . This means that the sum of two -stable variables is again -stable. This is a generalization of the well known property of the closure under convolutions of Cauchy () and Gaussian () random variables. In terms of moments, Samorodnitsky and Taqqu (1994, Property 1.2.16) indicate that for with , we have for and is finite for . Specifically, this implies that -stable random variables have infinite variance, when .
The property of closure under convolutions is easily generalized to the sum of a sequence of i.i.d. -stable variables, which gives rise to a convergence in a non-Gaussian domain, for . Formally, the generalized central limit theorem (Gnedenko and Kolmogorov, 1954) proves that for i.i.d. scaled random variables with infinite variance the convergence is no longer to a Gaussian random variable. Rather the convergence is to an -stable random variable. A statement of the theorem is below.
Theorem S.1.
(Generalized central limit theorem, Uchaikin and Zolotarev, 1999, p. 62) Let be independent and identically distributed random variables with cumulative distribution function satisfying the conditions:
with . Then there exists sequences and , such that the distribution of the centered and normalized sum:
weakly converges to as , where , , and and are as given in Table S1.
| 0 | ||
Finally, the Laplace transforms of positive -stable random variables exist. For and the Laplace transform is given by:
for .
S.2 Computation of and
Since the size of is , indicating an exponential complexity of naïve enumeration, we further simplify Equation (4). When the input points are arranged in a way that is not possible, then must be zero. We can identify the elements in with positive probabilities by considering arbitrary values of . The corresponding function is determined by: , for each . This corresponds to labeling with the points above a hyperplane, and with the points that lie below the hyperplane. When , without loss of generality, let . In this case corresponds to the possible changes in sign that can occur between the input variables, which is equal to . Specifically, the sign change can occur before , between and , …, between and , and after . A similar argument is made in Example 2.1.1 of Der and Lee (2005), suggesting the possibility of considering more than one dimensions.
For , Harding (1967) studies the possible partitions of points in by an -dimensional hyperplane—which corresponds to our problem, and determines that for points in general configuration there are partitions. Goodman and Pollack (1983) give an explicit algorithm for finding the elements of that have non-zero probabilities in any possible configuration. We summarize their algorithm for as Algorithm S.1 in Supplementary Section S.3. This algorithm runs in a computational time of order , which is reasonable for moderate . For the rest of the article, we denote the cardinality of elements in that have positive probability by , with the understanding that will depend on the input vectors that are used and their dimension. This solves the issue of computing deterministically the values of that have positive probability after integrating through input-to-hidden weights.
Next we compute the probability for the determined . For , the s correspond to probabilities obtained from a Cauchy cumulative density function, which we state explicitly in Supplementary Section S.2.1. For general dimension of the input , the value of is given by , where the -dimensional Gaussian vector has -th entry given by . This implies that , where the (possibly singular) variance matrix is . This means we can compute using for example the R package mvtnorm, which implements the method of Genz and Bretz (2002) for evaluating multivariate Gaussian probabilities. Since the s require independent procedures to be computed, this is easily parallelized after obtaining the partitions.
S.2.1 Computation of and in one dimension
Assume, since we are in one dimension, that . In the one-dimensional case consists of the different locations where the change in sign can be located. This corresponds to:
-
1.
Before the first observation, which corresponds to for all , we call this .
-
2.
Between and for some , which corresponds to for and otherwise, we call this .
-
3.
After , for all , and we call this .
Note that the first and last items correspond to linearly dependent vectors as , for all . Now, we compute the probability for the first and last items:
where since are independent standard normal variables.
Next, the change in sign occurring between and , yields:
which corresponds to the desired probability.
S.3 Supporting algorithms
Algorithm S.1 is modified from Goodman and Pollack (1983) for dimensions, which we employ in Algorithm 1, and has a computational complexity of for input points and a general input dimension . We present Algorithm S.2 to sample the latent scales and error standard deviation , which consists of a independent samples Metropolis–Hastings procedure where we sample from the priors, and iteratively update the matrix . For computation of the density functions we use the Woodbury formula, and an application of the matrix-determinant lemma, for an efficient update of and to avoid computationally intensive matrix inversions. Algorithm S.2 has computational complexity of .
-
1.
for those for which , using as key
-
2.
for those for which and
-
3.
for those for which , using as key
-
4.
for those for which , and
S.4 Additional numerical results
We report MCMC convergence diagnostics, run times, and posterior quantiles of . We also include simulation results for a variety of functions in one and two dimensions, where we demonstrate the flexibility of the proposed method.
S.4.1 MCMC diagnostics and computation times

| Stable | GP MLE | GP Bayes | Bayes NNet | ||
|---|---|---|---|---|---|
| Total time (s) | 1-d | 24.047 | 0.067 | 18.073 | 6.91 |
| 2-d | 1339.543 | 0.178 | 22.185 | 7.193 | |
| Per iteration time (ms) | 1-d | 8.016 | 13.400 | 0.602 | 2.303 |
| 2-d | 446.514 | 35.600 | 0.740 | 2.398 |
S.4.2 Posterior quantiles of
We present results showing the posterior is non-degenerate under a stable limit. In the case of a vanilla GP limit the prior on the kernel converges to a point mass, resulting in a degenerate posterior (Aitchison et al., 2021; Yang et al., 2023). However, as shown by our Corollary 1, is stochastic under a stable limit. Figure S2 displays the posterior 25th, 50th, and 75th quantiles of for the examples shown in Sections 4.1 and 4.2, confirming the posterior of is non-degenerate. This is a key feature that distinguishes the current work from prior works on GP limits.

S.4.3 Additional results in one dimension
We show, using a variety of one-dimensional functions, that the Stable procedure results in better performance in presence of discontinuities, while performing similarly to GP-based methods or finite width networks for smooth functions. Posterior uncertainty quantification results are omitted.
One-dimensional one-jump function.
Consider the function with a single jump given by . We use forty equally-spaced observations between and with a Gaussian noise with standard deviation of . We display the obtained results on Figure S3, with optimal hyper-parameters and .

One-dimensional two-jump function.
Consider the function with two jumps given by . We use forty equally-spaced observations between and with a Gaussian noise with standard deviation of . We display the obtained results on Figure S4, with optimal hyper-parameters and .
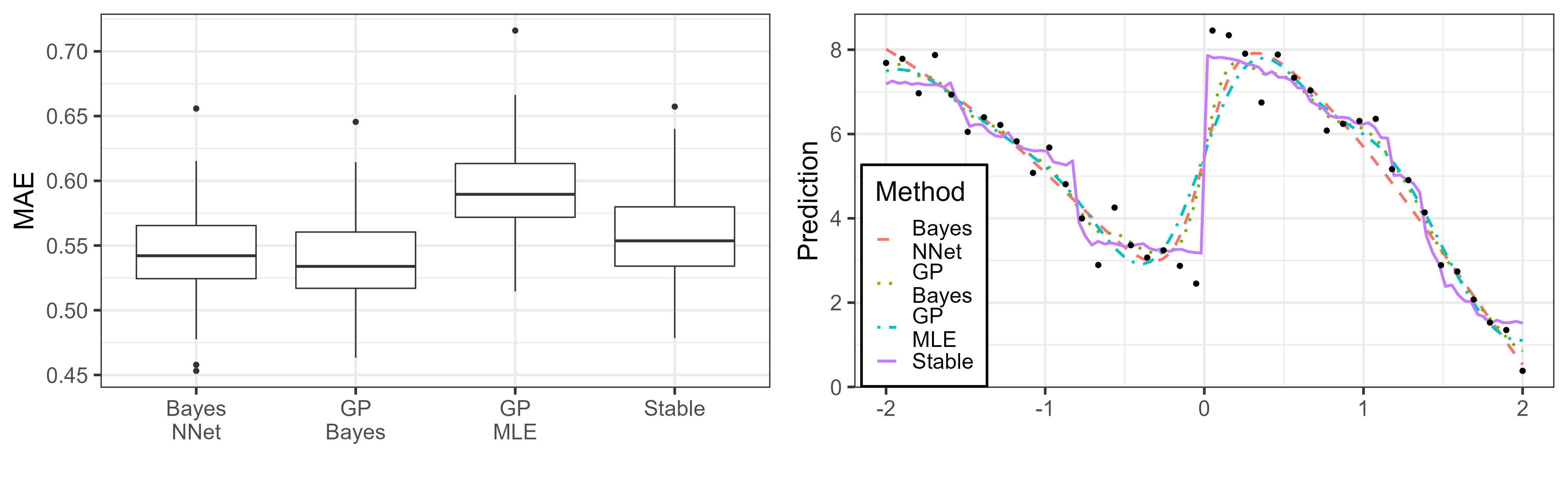
One-dimensional piece-wise smooth.
Consider the piece-wise smooth function with a single jump, given by
We use forty equally-spaced observations between and with a Gaussian noise with standard deviation of , and display the obtained results in Figure S5, using the optimal hyper-parameters and .
One-dimensional smooth function.
Finally, consider the smooth function . We use forty equally-spaced observations between and with a Gaussian noise with standard deviation of . The obtained results are shown in Figure S6. The optimal hyper-parameters are and .

S.4.4 Additional results in two dimensions
We show, using a variety of two-dimensional functions, that the Stable procedure results in better performance in presence of discontinuities, while performing similarly to GP-based methods or finite width networks for smooth functions. Posterior uncertainty quantification results are available, but omitted.
Two-dimensional one-jump function.
Consider the function . Using the grid of points on detailed in Section 4, and additive Gaussian noise with , we obtain the predictions results as shown in Figure S7. Optimal hyper-parameters are and .
Two-dimensional smooth edge.
Consider the function . Note that the jump boundary is determined by a smooth curve. Using the grid of points on detailed in Section 4, and additive Gaussian noise with , we obtain the predictions results as shown in Figure S8. Optimal hyper-parameters are and . The Stable method is able to capture the smoothness of the jump boundary without losing predictive power.

Two-dimensional smooth function.
Consider the smooth function . We use the grid of points on detailed in Section 4, and additive Gaussian noise with . Since this function is continuous, it would be expected that the Stable method would perform similarly as the competing methods. We obtain the predictions results as shown in Figure S9. The optimal hyperparameters are and .

S.5 Ablation study on and
We perform an ablation study on the tuning parameters and for the examples we consider in Section 4. Figure S10 displays the mean absolute error for a grid of the tuning parameters in all two examples. The results show that the smaller s are mostly concentrated close to . These results hint that are good default choices.

S.6 Results on S&P 500
We provide out of sample prediction results for S&P 500 closing prices222Obtained from https://www.nasdaq.com/market-activity/index/spx/historical between July 1, 2019 and June 30, 2021., using and as the training and testing set sizes respectively, with and . Table S3 displays the improved performance from using the Stable method compared to the three competing methods, as measured by the mean absolute error.
| Stable | GP MLE | GP Bayes | Bayes NNet | |
|---|---|---|---|---|
| MAE | 0.054 | 0.071 | 0.054 | 0.210 |
| (SE) | (0.008) | (0.006) | (0.005) | (0.016) |