Pose Estimation from Camera Images for Underwater Inspection
Abstract
High-precision localization is pivotal in underwater reinspection missions. Traditional localization methods like inertial navigation systems, Doppler velocity loggers, and acoustic positioning face significant challenges and are not cost-effective for some applications. Visual localization is a cost-effective alternative in such cases, leveraging the cameras already equipped on inspection vehicles to estimate poses from images of the surrounding scene. Amongst these, machine learning-based pose estimation from images shows promise in underwater environments, performing efficient relocalization using models trained based on previously mapped scenes. We explore the efficacy of learning-based pose estimators in both clear and turbid water inspection missions, assessing the impact of image formats, model architectures and training data diversity. We innovate by employing novel view synthesis models to generate augmented training data, significantly enhancing pose estimation in unexplored regions. Moreover, we enhance localization accuracy by integrating pose estimator outputs with sensor data via an extended Kalman filter, demonstrating improved trajectory smoothness and accuracy.
Index Terms:
underwater, localization, neural networks, novel view synthesis, NeRF, sensor fusion.I Introduction
LOCALIZATION plays a crucial role in underwater reinspection missions [1]. These are tasks carried out by underwater vehicles to examine the health and function of submerged structures like pipelines, offshore platforms, and ship hulls, required to ensure the safety and durability of infrastructure vital to industries like oil and gas, renewable energy, and maritime transport [2, 3]. They stand apart from many underwater navigation tasks in their complexity and the precision required. Unlike general underwater navigation that involves moving from place to place, often prioritizing pathfinding and obstacle avoidance, reinspection missions demand detailed, close-range examination of often complicated underwater structures [3]. As such, reinspection missions require the precise positioning and orientation of underwater vehicles to ensure thorough coverage, accurate data collection and the safety of the vehicles and the structures themselves.
In underwater environments, the use of global positioning systems is hindered due to the rapid dissipation of electromagnetic waves in water [4]. Traditionally, underwater localization has relied on inertial navigation systems (INS), Doppler velocity loggers (DVL) and acoustic positioning systems. However, these methods face significant challenges in the context of inspection missions. Acoustic navigation is often compromised by shadowing effects and multipath interference near marine structures, which can severely distort signal paths and reduce accuracy. Consequently, achieving precise acoustic navigation requires complex and costly setups [5]. Furthermore, INS and DVL, despite their widespread use, suffer from an accumulation of errors over time [5]. This limits their ability to provide the positioning accuracy required for detailed inspection of underwater structures. Although high-grade INS and DVL may be able to provide sufficient accuracy, they, too, come with high costs.
In recent years, advancements in underwater localization have explored the use of optical sensors, such as cameras [6]. Some of these approaches necessitate the deployment of active markers [6, 7] or elaborate setups by divers [8, 9], adding complexity and expense. In contrast, visual localization methods—estimating camera poses from images of the surrounding scene—present a more cost-effective solution. Since inspection vehicles typically come equipped with cameras, visual-based localization can be implemented without the need for extra hardware. Moreover, visual-based localization methods, such as simultaneous localization and mapping (SLAM) [5], visual odometry [10] and visual relocalization [11, 12], have shown promise in navigating terrestrial and underwater environments.
Underwater reinspection missions typically involve the vehicle returning to the same sites for routine monitoring, assessment and/or maintenance. In this sense, these missions have another difference from normal underwater navigation tasks in that they have prior information of the scene or environment available, i.e., the environment is “known” to some degree after the first mission. We can use this available prior information to perform relocalization. This approach can be made effective if in the initial mapping run, we collect positioning information as accurately as possible using precise (and typically expensive and complex) positioning infrastructure such as ultra-short baseline acoustic positioning to characterize the environment. Using these data collected, visual relocalization methods can directly estimate poses from camera images in the following runs, significantly reducing the cost and complexity of reinspection. While SLAM and visual odometry are effective for general navigation, they do not utilize the additional prior information available in reinspection missions. In contrast, visual relocalization uses prior information and thus allows us to use more affordable vehicles and setups for localization in subsequent reinspection missions, significantly simplifying operations.
Visual relocalization techniques are categorized into feature-based methods such as Active Search [13], and deep-learning methods like PoseNet [11]. Active search achieves image-based localization by systematically identifying and matching 2D features in query images with 3D points in a scene model. PoseNet is a deep learning model that utilizes a pretrained convolutional neural network (CNN) to estimate the 6-degree-of-freedom (6-DOF) poses of a camera directly from images. This approach simplifies the camera relocalization problem by bypassing the traditional feature extraction and matching steps, instead relying on the CNN to learn and estimate the camera’s position and orientation within a previously mapped environment directly from the image data.
While Active Search achieves state-of-the-art results in outdoor terrestrial scenes, its effectiveness and robustness are reduced in environments with sparse features or where textures are obscured, conditions common in underwater settings due to limited visibility [11]. Additionally, Active Search is more computationally expensive compared to PoseNet [14]. Hence, we focus on neural-network-based methods inspired by PoseNet to estimate poses from underwater images. Previous research has demonstrated PoseNet’s efficacy in conducting inspection tasks within tanks with toy structures and simulated underwater environments [15, 16, 12]. However, the performance of machine learning-based pose estimators with realistic structures and in at-sea environments has not been thoroughly investigated.
The performance of learning-based pose estimators depends heavily on the diversity of the training data. However, in underwater environments, collecting comprehensive training data is expensive. We propose to use Novel View Synthesis (NVS) models to render augmented training data. Recent advancement in NVS models, such as Neural Radiance Fields (NeRF) [17] and 3D Gaussian Splatting (3DGS) [18], can synthesize photorealistic views of complex 3D scenes from a sparse set of input views by optimizing an underlying continuous volumetric scene function. When provided with a camera pose, NVS models utilize classical volumetric rendering techniques to project synthesized colors and densities into an image [17]. Using a trained NVS model, we can render images from any viewpoint within the boundary, allowing us to bypass the need for extensive physical data collection. We can then use these rendered images to augment our training data.
In this paper, our contributions are as follows:
-
1.
We examine the performance of neural-network based pose estimators with different configurations in inspection missions in confined waters. We investigate the effects of different parameters, such as using RGB information versus grayscale, on the performance. We present the dataset collected, methods employed and results obtained in Section II.
-
2.
We propose a new loss function, -loss, incorporating the geometry of the inspection missions for training the pose estimators. The -loss provides interpretability, and improves computation efficiency and estimation performance. We present the method and results in Section II.
-
3.
We utilize underwater 3D NVS techniques to generate augmented training data. We demonstrate the performance improvement due to this in Section III.
-
4.
We enhance the localization performance by integrating our pose estimation model with data from additional sensors, such as altimeters and compasses. We use an extended Kalman filter (EKF) for tracking and fusion. In Section IV, we present these methods and results showing improved robustness and accuracy of this approach.
-
5.
We evaluate the performance of our proposed methods in at-sea environments. We present these results and discuss the overall performance of the entire pipeline in Section V.
Finally, we conclude this paper in Section VI.
II Pose Estimation
Nielsen et al. [15] evaluated the performance of PoseNet in a small tank, inspecting a subsea connector attached to a metal stick. In our previous work, we assessed the performance of various pretrained CNNs as pose estimators in a simulated underwater environment inspecting a subsea pipe [16]. In this section, we evaluate the performance of visual localization using two neural-network model architectures inspired from PoseNet [11]. The data for training and testing were collected from an artificial ocean basin at the Technology Center for Offshore and Marine, Singapore (TCOMS) [19]. The originally presented PoseNet [11] works on RGB images. Here, we also evaluate the visual localization performance using grayscale images instead of RGB images to determine if similar accuracy can be achieved with higher efficiency, based on the intuition that underwater images typically have limited color information. Finally, we investigate the models’ capability for (1) estimating pose on test images from the same dataset (i.e., capability to interpolate within same dataset), and (2) their capability to generalize to datasets outside that used for training, by using data from different runs for training and testing, which have different paths and conditions during acquisition.
II-A Methods
II-A1 Architecture
The objective of PoseNet is to estimate a 6-DOF pose from a single monocular RGB image given as input to a neural network. The pose consists of the position (in 3D coordinates, --) and the orientation, which is represented in terms of a quaternion. Thus, the model outputs a 7-dimensional (7D) estimated pose vector containing a position vector estimate and an orientation vector estimate , where represents an estimate.
The PoseNet model originally presented by Kendall et al [11] was a CNN, a modified version of the GoogLeNet architecture [20] pretrained on the ImageNet dataset [21], with the softmax classifiers changed to affine regressors, and another fully connected (FC) layer of feature size 2048 inserted before the final regressor. However, regressing a 7D pose vector from a high dimensional output of the FC layer is not optimal [22]. A later work [22] aimed to tackle this by modifying PoseNet by reshaping the FC layer of size 2048 to a 32 64 matrix and applying four long-short-term-memory networks (LSTMs) to perform structured dimensionality reduction. This algorithm, which we refer to as CNN+LSTM, showed a performance improvement compared to PoseNet in terrestrial environments [22], and also in an underwater tank environment [12]. We implement and evaluate both model architectures – the CNN (shown in Fig. 1) and the CNN+LSTM (shown in Fig. 2). Additionally, we assess the performance of these using a pretrained ResNet50 [23] as the backbone.


II-A2 Loss Function
Kendall et al [11] used a composite loss function that is a weighted sum of the (1) L2 loss between the predicted positions and the true positions, and the (2) L2 loss between the predicted quaternions and the true quaternions:
| (1) |
where and , and and represent the true pose. is a free parameter that determines the trade-off between the desired accuracy in translation and orientation. In PoseNet and CNN+LSTM, the value of is fine-tuned using a grid search to ensure the expected value of position and orientation errors are approximately equal, which the authors suggest lead to overall optimal performance. We refer to this loss function as the -loss.
We argue that the -loss is not the optimal approach to our problem, due to three reasons. Firstly, we argue that optimal performance is not necessarily achieved when position and orientation errors are roughly equal. Instead, the performance criteria and loss should incorporate geometry and physics relevant to the inspection task at hand. Secondly, the L2 loss between the predicted and true quaternions does not directly translate to an orientation error interpretable in degrees or radians, and thus, it does not accurately reflect the geometric distance between the predicted and true orientations. Thirdly, searching for the optimal value often involves extensive computational resources. This search can become a significant bottleneck, especially in scenarios where training needs to be done fast.
To overcome these shortcomings, we propose a new loss function more relevant to our problem, the -loss, to improve the training effectiveness, interpretability and efficiency. The -loss is defined as:
| (2) |
Note that we have replaced the quaternion loss in (1) with a loss based on the Eulerian angular difference, , which is calculated as follows. We first determine the rotation between the estimated and ground truth quaternions through quaternion multiplication, , where ∗ denotes the conjugate of the quaternion. is a unit quaternion which can be expressed as where is the scalar part of the quaternion, and is the vector part. is related to a spatial rotation around a fixed point of radians about a unit axis by [24], thus . We approximate , using a Taylor series approximation. The Eulerian angular difference loss provides a more intuitive and direct measure of orientation error.
Additionally, we replace the hyperparameter weight factor in (1) which required tuning, with the average distance between the camera and the object of interest. The intuition here is that this factor translates the rotational error to an equivalent “average” translational error (attributed to the orientation difference). Thus, the overall loss can be interpreted as the “total positional error” in meters, including contributions from translational and orientation error components.
The translation between rotational error and the “average” translational error is described as follows. As illustrated in the example in Fig. 3, if the camera has a pitch orientation error of , the point it observes on the structure remains roughly the same as if the camera had an equivalent translational error of (i.e., moves up by ) for small values of and . Based on the geometry, equivalent translational error can be expressed in terms of orientation error and the average horizontal range between the camera and the structure as:
| (3) |
Assuming the case when the rotational error is small, we approximate . Thus, we obtain:
| (4) |

This modified loss function (Eq. 2) leverages the inherent geometric relationship between positional and rotational errors in inspection missions, reducing computational complexity in finding the optimal as well as provides a more intuitive and interpretable overall loss function which has a physical meaning and represents the pose error in terms of meters.
II-A3 Implementation
To evaluate the effectiveness of deeper backbones, additional LSTM layers, the proposed -loss, and the color information in images, we tested multiple configurations of the two visual localization network architectures. The details of these configurations are summarized in Table I.
| ID | Architecture | Backbone | Loss | Color |
|---|---|---|---|---|
| C1 | CNN | GoogLeNet | -loss | RGB |
| C2 | CNN | GoogLeNet | -loss | Grayscale |
| C3 | CNN | GoogLeNet | -loss | RGB |
| C4 | CNN | ResNet50 | -loss | RGB |
| C5 | CNN+LSTM | GoogLeNet | -loss | RGB |
| C6 | CNN+LSTM | ResNet50 | -loss | RGB |
To adapt the pretrained GoogLeNet architecture to operate on grayscale images, we modified the network’s first convolutional layer by adjusting it to accept single-channel (grayscale) inputs instead of the original three-channel (RGB) inputs. This adjustment was achieved by reducing the number of input channels from three to one. The single-channel input layer was initialized by summing the weights across the RGB channels in the original network to utilize as much prior information as possible. Following this, the layer was fine-tuned via training.
During both training and testing for all configurations, we rescaled input images directly into a 224224 pixels input, deviating from PoseNet’s approach of resizing the images to 256256 before cropping into 224224. This adjustment was made to minimize the loss of image information, a concern particularly acute in underwater images where available information is inherently more limited compared to terrestrial settings. To speed up training, we normalized the images against the ImageNet dataset’s mean and standard deviation. Additionally, poses are normalized to lie within the range [-1, 1].
We used the PyTorch deep learning framework to implement and train the models. The experiments were conducted using an RTX 6000 Ada GPU. For training, we used the stochastic gradient descent optimizer for configurations C1, C2, and C3. For the remaining configurations, we used the Adam optimizer. A batch size of 32 was used. Hyperparameters, including the learning rate, weight decay, and for C1, were tuned using grid search strategy over a predefined set of values. The best set of hyperparameters was selected based on validation performance. Training continued until early stopping was triggered.
II-B Testing in Controlled Environment
The artificial ocean basin at TCOMS is an indoor pool measuring 60 m 48 m 12 m. As illustrated in Fig. 4, a structure was placed in the basin, which consisted of six piles interconnected by metallic pipes, with each pile comprising three metallic oil barrels. The overall dimensions of the structure were approximately 3.9 m 4.6 m 3.0 m. The whole structure was yellow in color. We used a customized remotely operated vehicle (ROV) which is equipped with a monocular camera for collecting RGB image data, a compass for collecting orientation information, and an altimeter for collecting altitude information. We placed a high frequency acoustic modem with four receivers near the operating region (as shown in Fig.5) to estimate the position of the ROV using ultra-short baseline (USBL) positioning. We operated the ROV to inspect the piles in a lawnmower path.


We executed three trials within the environment at different depths to gather data while the ROV surveyed the structure, with each trial featuring a roughly similar trajectory. We refer to these trials as D1, D2 and D3, corresponding to respective average depth levels -1.5 m, -3 m and -4 m. The details of the datasets are described in Table II.
| ID | Dataset Name | Dataset Size |
|---|---|---|
| D1 | Clear Water-Deep | 2165 |
| D2 | Clear Water-Shallow | 2956 |
| D3 | Clear Water-Mid | 933 |
| D4 | Clear Water-NVS | 4193 |
| D5 | Sea Water-1 | 2360 |
| D6 | Sea Water-2 | 735 |
| D7 | Sea Water-NVS | 18918 |
The sensor data from the vehicle was captured using ROS (Robot Operating System), and we sampled the dataset at a frequency of 5 Hz from each recorded data file. We synchronized the sampled data with the USBL position information based on timestamp and interpolate the position data when necessary. For our ground truth, we utilized the x and y coordinates from the USBL position estimates, the z coordinate from the altimeter, and the orientation data from the compass.
We use D1 as the primary dataset to evaluate the models’ capability of interpolation. We randomly select 60% points from the data for training, 20% for validation and 20% for testing. We further assess the models’ ability to generalize to new depths by employing D1 as the training dataset and D3 for validation and testing. Additionally, we investigate the impact of incorporating data from diverse depths on the models’ generalization performance by using D1 and D2 together as the training data and D3 as the validation and test data.
II-C Results & Discussions
II-C1 Model performance
We present the performance of different configurations in Table III. The benchmark for our evaluation is the performance of C1.
| ID | (m) | (m) | (°) | Inference |
|---|---|---|---|---|
| time (ms) | ||||
| C1 | 2.41 | 2.36 | 0.86 | 2.20 |
| C2 | 0.61 | 0.53 | 1.50 | 1.65 |
| C3 | 0.41 | 0.36 | 0.99 | 1.62 |
| C4 | 0.34 | 0.29 | 0.88 | 1.16 |
| C5 | 0.30 | 0.22 | 1.51 | 0.78 |
| C6 | 0.19 | 0.12 | 1.34 | 0.77 |
We observe the following:
1. Comparing the performance of C3 against C1, our results demonstrate that training with our proposed -loss significantly enhances model performance, especially in terms of the overall performance metric .
2. Comparing the performance of C2 against C3, it can be observed that using grayscale images shows significantly worse performance and too little an improvement in inference time, contrary to our initial expectation. The worse performance of grayscale images can be attributed to the fact that since D1 was collected in a non-turbid fresh water environment, the color information in the underwater images is not as limited as one might anticipate in an image taken in a sea environment. As shown in Fig. 6, the underwater RGB images in D1 retain valuable color information that may provide distinguishing features in these environments. Thus, the grayscale images have much less information than RGB images and thus lead to poorer performance. The lack of improvement in inference time is due to the fact that we only reduce the number of channels in the first CNN layer of the pretrained model, resulting in a minimal reduction in computational load. To achieve more substantial computational savings, the entire model architecture would need to be better streamlined for grayscale images, not just the initial layer.
3. Comparing the performance of C6 to C5 and C4 to C3 shows that using ResNet50, a deeper network, as the backbone, improves performance for both CNN and CNN+LSTM.
4. Comparing the performance of C6 to C4 and C5 to C3 shows that the CNN+LSTM architecture consistently outperforms the CNN architecture.
Among all the configurations, C6, which uses the CNN+LSTM architecture with the ResNet50 backbone and is trained using the proposed -loss, performs the best, achieving 0.12 m of positional accuracy and 1.34°of orientation accuracy with an inference time of 0.77 ms.
II-C2 Generalization performance
We test the performance of generalization using the model with the best configuration, C6. We first trained the model on D1 and tested on D3. A significant performance degradation is observed, as shown in the first row of Table IV. This is on expected lines because the test data is sampled from a different distribution than the training data with possibly different paths and conditions, and deep-learning models often fail to extrapolate beyond the bounds of the training data.
To address this issue, we evaluate the use of a larger and more diverse training dataset, by expanding the training data to include both D1 and D2. This augmentation introduces a wider distribution of data, notably enhancing the diversity in depth information. This leads to a 49% improvement in model performance in overall loss, as shown in the second row in Table IV.
These findings underscore the importance of comprehensive baseline mapping to collect sufficiently diverse training data. This is essential for training models that are robust enough to perform accurate localization during reinspection tasks.
| Training Dataset | EKF | Color Jittering | Performance Metrics | ||
| (m) | (m) | (°) | |||
| D1 | 1.45 | 1.34 | 2.09 | ||
| D1+D2 | 0.75 | 0.58 | 3.20 | ||
| D1+D2 | ✓ | 0.47 | 0.47 | 0.00 | |
| D1+D2+D4 | 0.52 | 0.40 | 2.28 | ||
| D1+D2+D4 | ✓ | 0.20 | 0.15 | 0.93 | |
| D1+D2+D4 | ✓ | ✓ | 0.11 | 0.11 | 0.00 |
Camera image Rendered images




III Augmented Training with Novel View Synthesis
The previous section demonstrated the importance of diverse training data with good coverage of the surveyed location. Although it may sometimes be possible to collect such data by extensively covering areas during the baseline mapping run, the practical constraints of cost and labor often limit this approach or render it infeasible. We explore alternative approaches to improve model performance in such data-limited scenarios. We propose to use NVS techniques to create models of the 3D scene, and then use these to generate more images from new aspects to augment the training data. In this section, we present the methods of augmenting training data using NVS models and the results of this approach.
III-A Methods
We first select 540 images from D1 and D2 to train an NVS model for the TCOMS scene. For this, we employ COLMAP [25, 26], an open-source Structure-from-Motion computation software, to compute the camera pose associated with each image within an arbitrary reference coordinate. We use nerfstudio [27] for training the NVS model and rendering images, using the nerfacto approach. To enhance the model’s robustness to dynamic elements in the scene such as lighting changes, we employ the robust loss function proposed by Sabour et al [28]. The details of training the model are presented in our previous work [29].
To render images for new poses that were not sampled during the ROV run, we first synthesize these new camera poses based on the existing poses in the training dataset. This is done by varying the depth and distance to the structure in the existing poses, keeping the orientation the same to ensure the camera is pointing towards the structure in the newly generated poses. In total, we generate 4193 images, and we refer to this dataset as D4. We then use D1, D2, and D4 for training, and D3 for validation and testing to test the improvement provided by using the NVS-based augmentation.
Additionally, it is noted that the images in D4 exhibited different brightness levels and background noise as compared to the original data, introduced during the NVS model reconstruction. To address the potential degradation due to this, we further augment the data by jittering the color of each image during training, thus making the pose estimator robust to minute color and lighting changes. For evaluation, we use the same GPU, framework, and hyperparameter tuning methods as described in the previous section.
III-B Results & Discussion
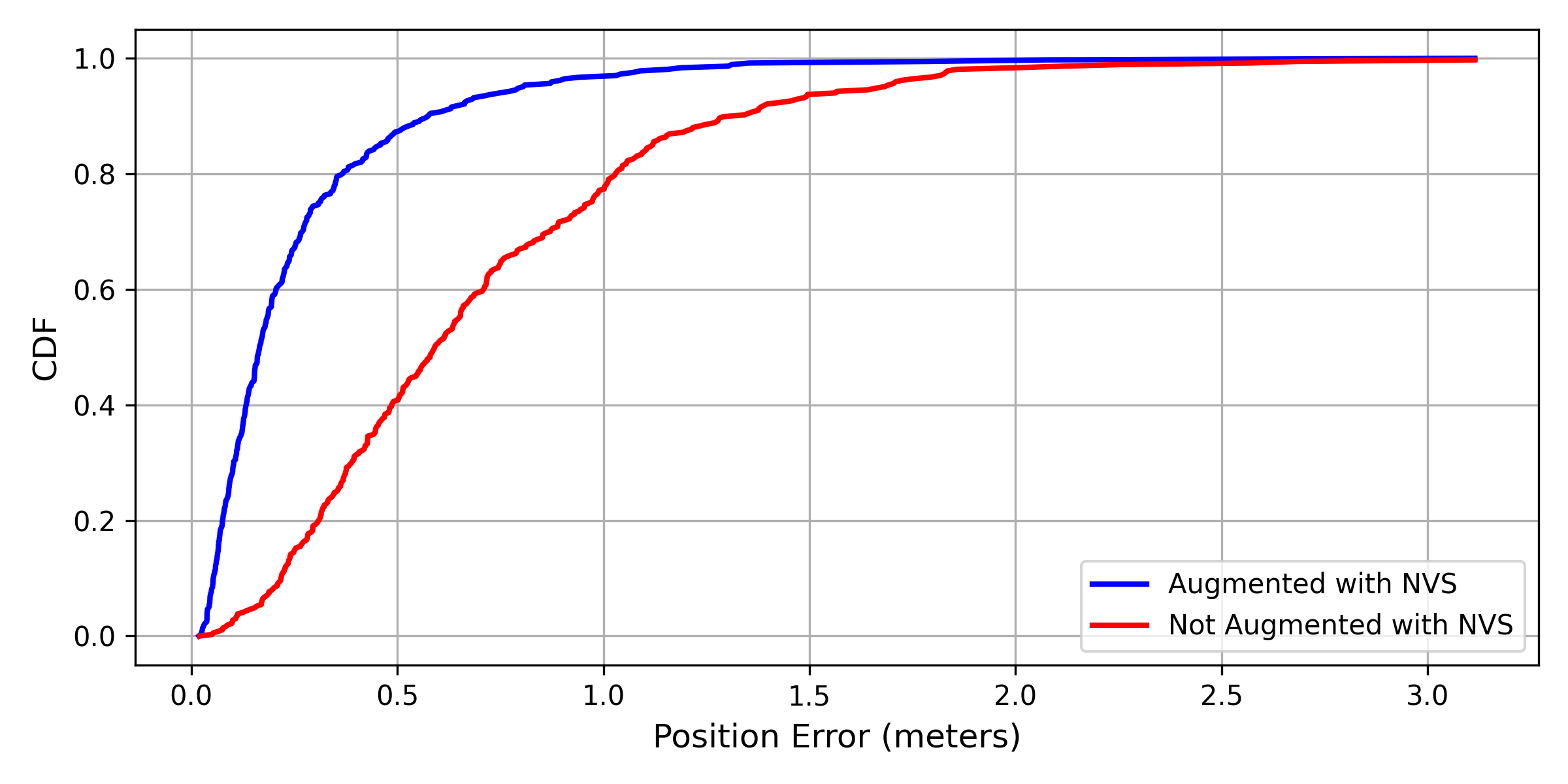
Our results show that utilizing augmented training data generated by a NVS model leads to a significant enhancement in localization accuracy. Comparing row 2 and row 4 in Table IV, we find that by augmenting the training data with D4, the overall localization error can be reduced by 30%.
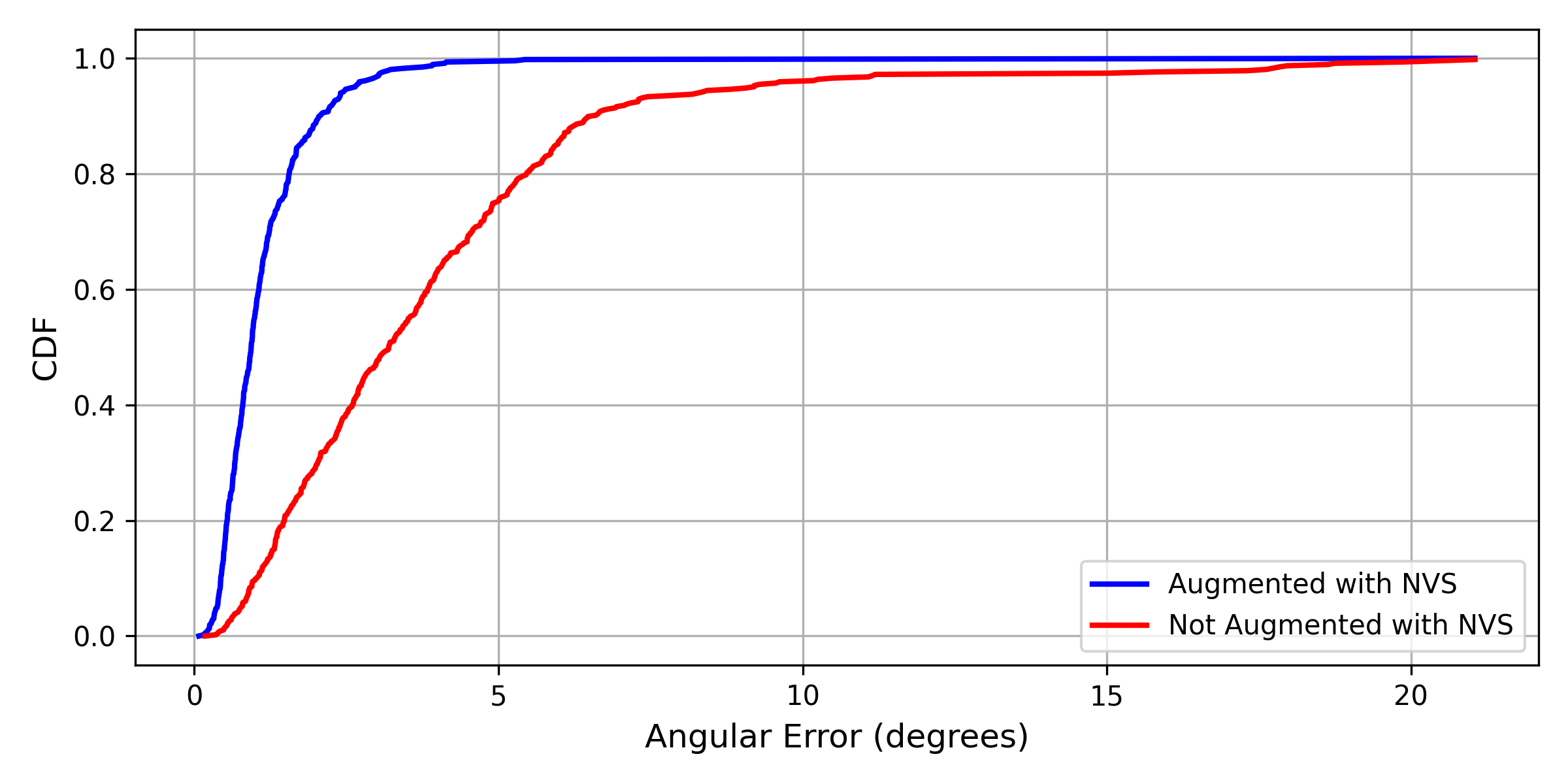
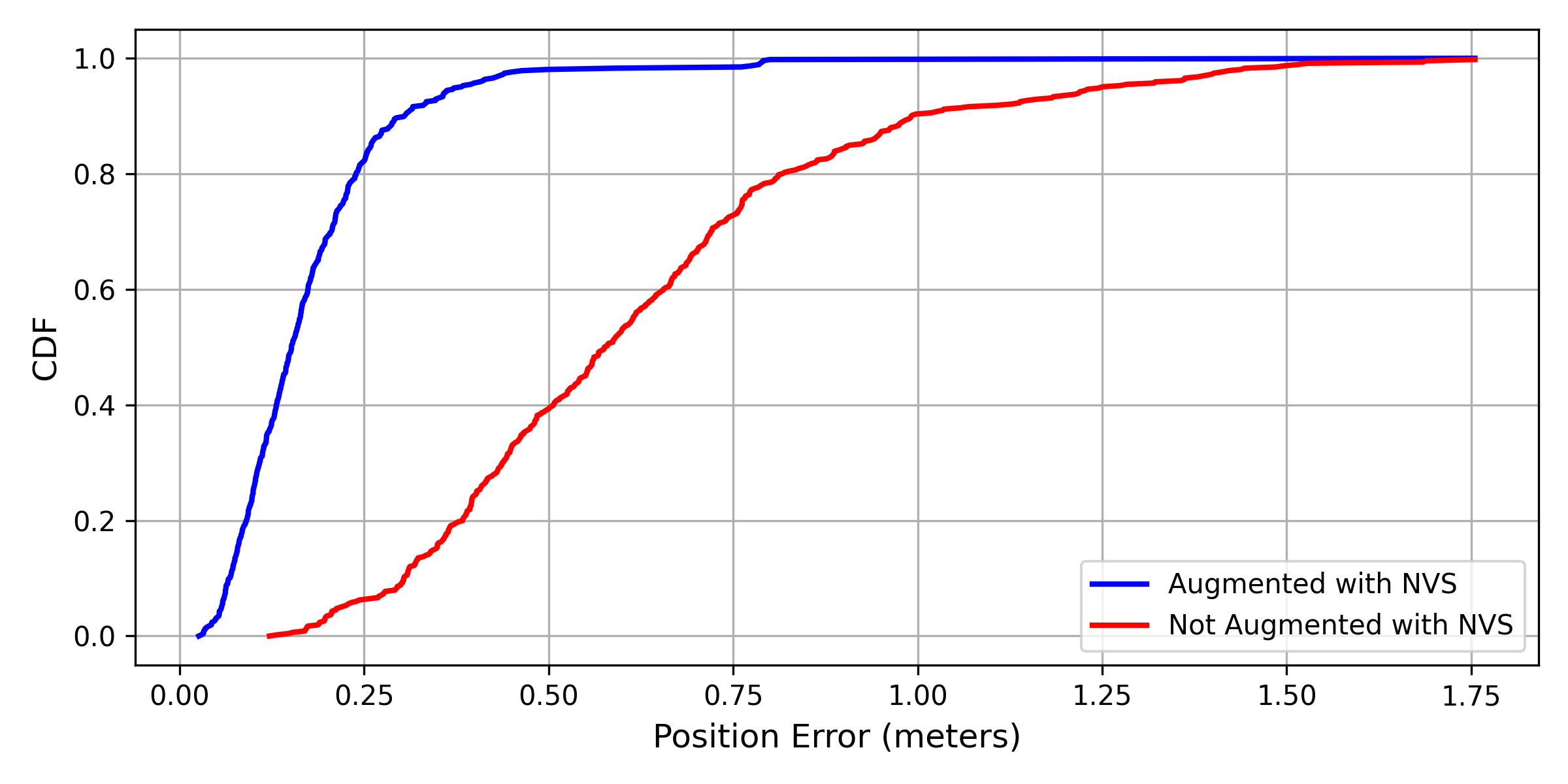
Color jittering augmentation is also highly effective in further improving the model performance, further reducing the error by an additional 61.5%. We compare the performance of the augmented training with color jittering with the performance without augmented training in Fig. 7 and Fig. 8. These plots show that the proposed augmented training with NVS significantly improves the pose estimator’s accuracy and reliability in terms of both position and orientation.
Nonetheless, we observed the presence of outliers. Upon examining the data, we found that these outliers were caused by transient objects, such as the tether shown in Fig. 9(b), which were not present in the training data.


IV Localization enhancement via sensor data fusion
While the trained pose estimators yield small median orientation and position errors, their estimates exhibit some volatility. Our model currently treats each sample independently, ignoring temporal context, and utilizes only the camera inputs during deployment. However, additional information, such as temporal information and other sensor inputs from the ROV, is available. To enhance localization accuracy and achieve a more stable trajectory estimation, we propose sensor fusion using an EKF. This section details the integration of the pose estimator with additional sensor data and presents the results of the sensor fusion.
IV-A Methods
Given the sequential nature of data in reinspection missions and the availability of additional sensors, incorporating temporal information and other sensor data presents a viable strategy for improving the model’s estimation stability and accuracy. Currently, the visual localization model without sensor fusion occasionally results in estimation of poses that are physically implausible or outliers, in context of the dynamics from previous poses. By integrating knowledge of the ROV’s physics model and leveraging previous pose estimates, we can enhance pose accuracy and stability.
Furthermore, during reinspection missions, ROVs are commonly equipped with altimeters and compasses, which have a reasonable accuracy. As such, we could use these reliable depth and orientation measurements during reinspection to further improve the overall localization accuracy.
IV-A1 Model
We assume that the vehicle moves with a constant translational velocity and constant angular velocity since the vehicle normally moves slowly during inspection missions.
We consider the pose estimator outputs, compass data and altimeter data as measurements. The compass yields orientation measurements in the form of a quaternion. The altimeter provides z-coordinate measurements. The pose estimator outputs comprise (1) position in x, y and z coordinates, and (2) orientation in the form of a quaternion. We use an EKF with this model to integrate measurements from the model and these sensor measurements.
IV-A2 Measurement noises
The measurement noise is the other hyperparameter that needs to be carefully selected in the EKF. Nominal values for the measurement noise standard deviations for the compass and altimeter are available from the specifications provided by their manufacturers, and can be set accordingly. However, the noise associated with the pose estimator presents a more complex challenge. Setting a static value for the pose estimator’s measurement noise—such as the standard deviation of localization error derived from validation performance—is inadequate. This is due to the inconsistent nature of the network’s estimations, which can sometimes exhibit substantial errors. To more accurately represent the dynamic noise in pose estimator, we employ dropout techniques at test time for Monte Carlo sampling from the model’s posterior distribution.
Dropout is a technique commonly used as a regularizer in training neural networks to prevent overfitting. Recent works have shown that using dropout during inference can be used to approximate Bayesian inference over the distribution of the network’s weights at test time, without requiring any additional model parameters [30]. We sample 100 Monte Carlo dropout realizations for the inference of each image input sample, and use the standard deviation of these dropout samples as the measurement noise for the inference sample.
IV-B Results & Discussion
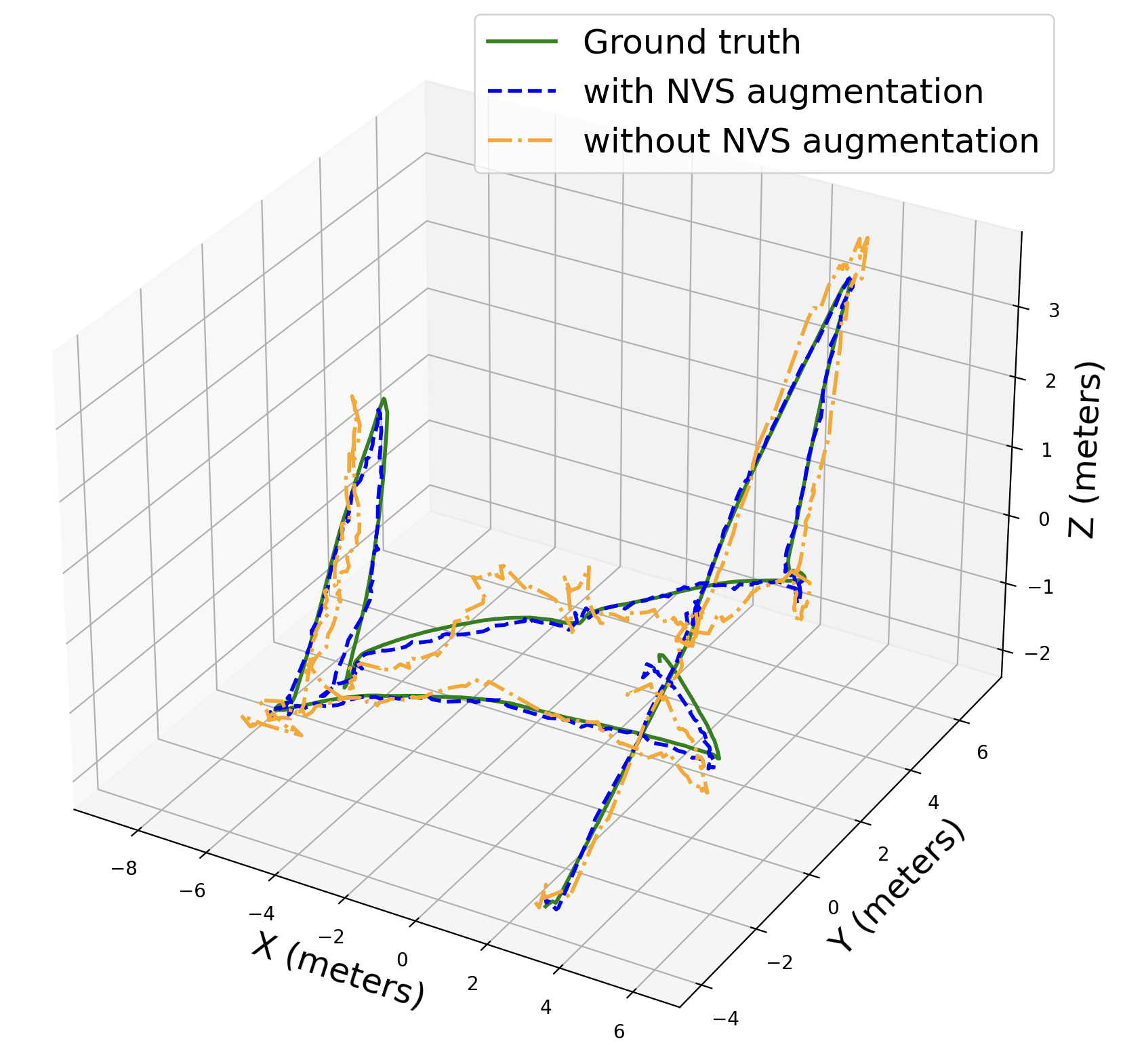
We tune the process noise standard deviation as a hyperparameter to get the best performance. As shown in Table. IV, sensor fusion with the EKF yields more accurate estimated poses. We also find that the predicted trajectory using the EKF is smoother compared to that without using the EKF, as illustrated in Fig. 10. However, the inference time using the EKF is about ten times as long.

V Field trials at sea
To further validate our proposed methods, we conducted field trials in a bay near St. John’s Island, Singapore (SJI). In this section, we present the methods, results and challenges encountered in using our proposed methods from the previous section in a real-world setting.
V-A Methods
We used the ROV to collect data in an at-sea environment, inspecting a submerged pillar. The pillar selected was approximately 5 m tall and 0.5 m in diameter. Although the pillar was a simple black metallic structure, the barnacles and algae growing on its surface provided visual features that could be used for pose estimation. We drove the ROV following a vertical lawnmower path around the pillar, while recording the video from the camera. Due to the high turbidity in the water, we operated the ROV in close proximity to the structure with the average distance being 1 m.
We collected two datasets, named as D5 and D6, on two different days. Samples of images collected in these datasets are shown in Fig. 11.






We use D5 to train an NVS model following the method described in Section II. New camera poses are generated using the same approach. The NVS model is then utilized to create an augmented training dataset, named D7. Samples of images generated at new poses using the NVS model are shown in Fig. 13.
We train the best visual localization architecture configuration, C6, both with augmented training data (datasets D5+D7) and without any augmentation (only D5). Dataset D6 is used for validation and testing. The training methods are similar to those described in Section II.
Camera Image Rendered Images




V-B Results & Discussion
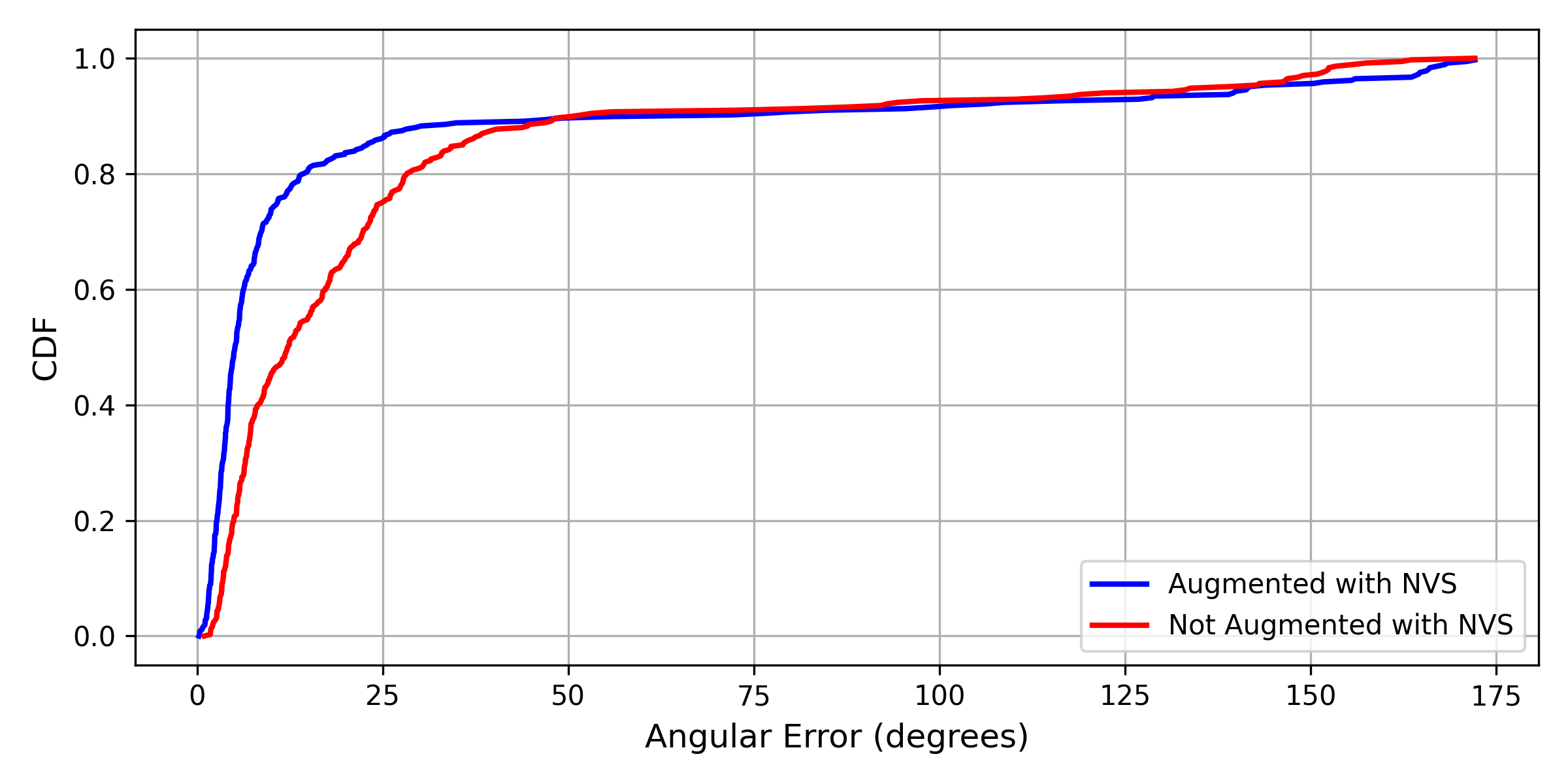
As shown in Fig. 14, augmented training with NVS yields significant improvement in both position and orientation accuracy compared to training without NVS augmentation. With configuration C6 and augmented training, we are able to achieve a position accuracy of 0.17 m and orientation accuracy of 5.09°. We present the performance of C6 on D6 in Table V. While the median accuracy is comparable to the performance in the controlled environment, we note that the standard deviation in the errors are much larger at sea.
Clearly, the real-world setting at sea presents several challenges that are not present in controlled environments. The biggest challenge is the turbidity of the water, which significantly affects the quality of the images. Moreover, lighting is inconsistent at different camera poses and on different days, causing high variablity in the image quality. This introduced three new challenges. First, the noisy images make it challenging to compute camera poses in COLMAP, resulting in a sparse number of registered images. Consequently, the EKF model could not be used for performance improvement since it would not be feasible to assume constant velocity and angular velocity in the vehicle model. Second, the turbidity and inconsistent lighting in the training data introduced artifacts in the NVS model. Thus, the rendered images are more noisy compared to images in clear waters, as shown in Fig. 13. Third, the high variability in image quality can lead to more estimation outliers and large errors during inference. All of these contribute to a decrease in the model’s performance. Nevertheless, we note that the NVS model is still able to produce photorealistic views of the structure.
| Training Dataset | Color Jittering | Performance Metrics | ||
| (m) | (m) | (°) | ||
| D5 | 0.80 | 0.59 | 12.15 | |
| D5+D7 | ✓ | 0.26 | 0.17 | 5.09 |
VI Conclusion
In this paper, we addressed the challenge of localization in underwater inspection missions with a neural-network based pose estimator. We proposed a new loss function to train the pose estimator, and demonstrated that training with -loss significantly improved the model’s performance in pose estimation tasks. This improvement is attributed to the incorporation of domain-specific physics, as the -loss accounts for the relevant geometric considerations in the inspection mission. Furthermore, this loss function also lends more interpretability to the loss. Employing the ResNet50 backbone with a CNN+LSTM architecture allows us to efficiently use the available visual information to estimate the pose, and yielded improvements in the localization performance as compared to benchmark architectures.
In terms of the generalization, using more diverse data with a wider distribution significantly enhances the localization performance on test data that lies outside the training distribution. We additionally investigated the use of NVS techniques to augment training data and showed that this significantly improves the estimator’s performance with previously unsurveyed poses. Thus, this provides a cost-effective and information-efficient method to improve the generalization performance without having to undertake expensive field trials to collect additional data. Further integrating the pose estimator with an EKF allows us to fuse sensor data with the visual-based estimates, and we demonstrated that this further improved the performance and stability. We validated our proposed methods in both controlled environments in a clear water tank and real-world settings at sea.
Overall, our results show that our proposed methods significantly improve the visual localization performance in both controlled underwater environments and real-world settings and achieve good localization accuracy to within desired limits, providing a cost-effective alternative or complement to existing localization solutions. Real-world challenges such as turbidity and noise limit the performance achievable, but the proposed method still performs reasonably, especially when data augmentation using color-based augmentation is used to robustify the technique against color distortion.
Potential improvements to this technique may include utilizing temporal information (i.e., more than one image at a time) to improve the accuracy of pose estimates, fusing more data such as control input information and sonar data, exploring better sensor fusion techniques such as particle filters and using per-pixel loss together with NVS rendered images to fine-tune the model.
The algorithm developed in this work is also utilized as part of a model-based image compression technique for low bandwidth scenarios. The details of this approach and the preliminary results are presented in our previous work [31].
Acknowledgment
This research project is supported by A*STAR under its RIE2020 Advanced Manufacturing and Engineering (AME) Industry Alignment Fund - Pre-Positioning (IAF-PP) Grant No. A20H8a0241.
References
- [1] E. Vargas, R. Scona, J. S. Willners, T. Luczynski, Y. Cao, S. Wang, and Y. R. Petillot, “Robust underwater visual SLAM fusing acoustic sensing,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, pp. 2140–2146. [Online]. Available: https://ieeexplore.ieee.org/document/9561537/
- [2] B. Bingham, B. Foley, H. Singh, R. Camilli, K. Delaporta, R. Eustice, A. Mallios, D. Mindell, C. Roman, and D. Sakellariou, “Robotic tools for deep water archaeology: Surveying an ancient shipwreck with an autonomous underwater vehicle,” vol. 27, no. 6, pp. 702–717. [Online]. Available: https://onlinelibrary.wiley.com/doi/10.1002/rob.20350
- [3] M. Carreras, J. D. Hernandez, E. Vidal, N. Palomeras, and P. Ridao, “Online motion planning for underwater inspection,” in 2016 IEEE/OES Autonomous Underwater Vehicles (AUV). IEEE, pp. 336–341. [Online]. Available: http://ieeexplore.ieee.org/document/7778693/
- [4] H.-P. Tan, R. Diamant, W. K. G. Seah, and M. Waldmeyer, “A survey of techniques and challenges in underwater localization,” vol. 38, no. 14, pp. 1663–1676. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0029801811001624
- [5] S. Zhang, S. Zhao, D. An, J. Liu, H. Wang, Y. Feng, D. Li, and R. Zhao, “Visual SLAM for underwater vehicles: A survey,” vol. 46, p. 100510. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1574013722000442
- [6] S. Kuutti, S. Fallah, K. Katsaros, M. Dianati, F. Mccullough, and A. Mouzakitis, “A survey of the state-of-the-art localization techniques and their potentials for autonomous vehicle applications,” vol. 5, no. 2, pp. 829–846. [Online]. Available: https://ieeexplore.ieee.org/document/8306879/
- [7] A. D. Buchan, E. Solowjow, D.-A. Duecker, and E. Kreuzer, “Low-cost monocular localization with active markers for micro autonomous underwater vehicles,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, pp. 4181–4188. [Online]. Available: http://ieeexplore.ieee.org/document/8206279/
- [8] A. Gomez Chavez, C. Mueller, T. Doernbach, D. Chiarella, and A. Birk, “Robust gesture-based communication for underwater human-robot interaction in the context of search and rescue diver missions.”
- [9] D. Chiarella, M. Bibuli, G. Bruzzone, M. Caccia, A. Ranieri, E. Zereik, L. Marconi, and P. Cutugno, “Gesture-based language for diver-robot underwater interaction,” in OCEANS 2015 - Genova, pp. 1–9. [Online]. Available: https://ieeexplore.ieee.org/document/7271710
- [10] B. Teixeira, H. Silva, A. Matos, and E. Silva, “Deep learning for underwater visual odometry estimation,” vol. 8, pp. 44 687–44 701. [Online]. Available: https://ieeexplore.ieee.org/document/9024043/
- [11] A. Kendall, M. Grimes, and R. Cipolla, “PoseNet: A convolutional network for real-time 6-DOF camera relocalization,” in 2015 IEEE International Conference on Computer Vision (ICCV), pp. 2938–2946, ISSN: 2380-7504.
- [12] L. Peng, H. Vishnu, M. Chitre, Y. M. Too, B. Kalyan, and R. Mishra, “Improved image-based pose regressor models for underwater environments.” [Online]. Available: http://arxiv.org/abs/2403.08360
- [13] T. Sattler, B. Leibe, and L. Kobbelt, “Efficient & effective prioritized matching for large-scale image-based localization,” vol. 39, no. 9, pp. 1744–1756. [Online]. Available: http://ieeexplore.ieee.org/document/7572201/
- [14] Y. Shavit and R. Ferens, “Introduction to camera pose estimation with deep learning.”
- [15] M. C. Nielsen, M. H. Leonhardsen, and I. Schjolberg, “Evaluation of PoseNet for 6-DOF underwater pose estimation,” in OCEANS 2019 MTS/IEEE SEATTLE. IEEE, pp. 1–6. [Online]. Available: https://ieeexplore.ieee.org/document/8962814/
- [16] L. Peng and M. Chitre, “Regressing poses from monocular images in an underwater environment,” in OCEANS 2022 - Chennai, pp. 1–4. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/9775281
- [17] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis.” [Online]. Available: http://arxiv.org/abs/2003.08934
- [18] B. Kerbl, G. Kopanas, T. Leimkuehler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,” vol. 42, no. 4, pp. 1–14. [Online]. Available: https://dl.acm.org/doi/10.1145/3592433
- [19] “TCOMS Research & Development.” [Online]. Available: https://www.tcoms.sg/research-development/
- [20] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions.” [Online]. Available: http://arxiv.org/abs/1409.4842
- [21] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A Large-Scale Hierarchical Image Database,” in CVPR09, 2009.
- [22] F. Walch, C. Hazirbas, L. Leal-Taixe, T. Sattler, S. Hilsenbeck, and D. Cremers, “Image-based localization using LSTMs for structured feature correlation,” p. 11.
- [23] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition.” [Online]. Available: http://arxiv.org/abs/1512.03385
- [24] E. Bernardes and S. Viollet, “Quaternion to Euler angles conversion: A direct, general and computationally efficient method,” vol. 17, no. 11, p. e0276302. [Online]. Available: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9648712/
- [25] J. L. Schönberger, E. Zheng, J.-M. Frahm, and M. Pollefeys, “Pixelwise view selection for unstructured multi-view stereo,” in Computer Vision – ECCV 2016, B. Leibe, J. Matas, N. Sebe, and M. Welling, Eds. Springer International Publishing, pp. 501–518.
- [26] J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp. 4104–4113. [Online]. Available: http://ieeexplore.ieee.org/document/7780814/
- [27] M. Tancik, E. Weber, E. Ng, R. Li, B. Yi, J. Kerr, T. Wang, A. Kristoffersen, J. Austin, K. Salahi, A. Ahuja, D. McAllister, and A. Kanazawa, “Nerfstudio: A modular framework for neural radiance field development,” in ACM SIGGRAPH 2023 Conference Proceedings, ser. SIGGRAPH ’23, 2023.
- [28] S. Sabour, S. Vora, D. Duckworth, I. Krasin, D. J. Fleet, and A. Tagliasacchi, “RobustNeRF: Ignoring distractors with robust losses.” [Online]. Available: http://arxiv.org/abs/2302.00833
- [29] Y. M. Too, H. Vishnu, M. Chitre, B. Kalyan, L. Peng, and R. Mishra, “Feasibility study on novel view synthesis of underwater structures using neural radiance fields,” in OCEANS 2024 MTS/IEEE Singapore. IEEE.
- [30] A. Kendall and R. Cipolla, “Modelling uncertainty in deep learning for camera relocalization.” [Online]. Available: http://arxiv.org/abs/1509.05909
- [31] R. Mishra, M. Chitre, B. Kalyan, Y. M. Too, H. Vishnu, and L. Peng, “An architecture for virtual tethering of ROVs,” in OCEANS 2024 MTS/IEEE Singapore. IEEE.